1. Introduction
In the age of big data, both individuals and businesses need to store large amounts of data. The identification information, preferences, and habits generated by users when using various applications are stored and analyzed. To protect the privacy of users, cloud servers fade in people’s sight. As cloud servers are semi-trusted, unencrypted information being stored in a server can be insecure in two ways: In the first case, some malicious users will access the server. These malicious users will copy the information from the server, which will cause the user’s information to be compromised. In the second scenario, the cloud server is honest but curious. In Chai and Gong [
1], the definition of an honest but curious server in the paper is: (1) storing outsourced data without modifying it; (2) honestly performing all operations such as searching and returning text data separately; and (3) attempting to learn the users’ initial data.
An honest but curious adversary is also defined as a legitimate server that will try to find out all the useful information from the obtained content but will not deviate from the set protocol in the communication channel mentioned by Paverd et al. [
2]. As a result, users need to encrypt their important information and store it on cloud servers; otherwise, their information security will be at risk. For example, threat actors broke into Amazon’s web servers and caused a breach of the sensitive information of 3.7 million users. The stolen data were then posted on various hacking forums for sale. In the same time frame, the FlexBooker cloud server was also compromised and the personal data of up to 19 million users were leaked. The investigation found that the company was using AWS S3 storage buckets to store data but had not implemented any security measures. It is therefore essential that data in cloud servers are kept encrypted.
While encrypting the data keeps them from being compromised, it also prevents the cloud server from being able to manipulate the data. The reality is that users do not want to download data and process them again; they want to be able to add, delete, change, and check their encrypted data directly on the cloud server. As a result, the concept of symmetric searchable encryption (SSE) has been introduced and investigated. SSE enables the execution of keyword searches in ciphertext, one of the most basic data operations [
3].
Users encrypt their private data and outsource them to a semi-trusted server, after which they send a search token to the server to perform a keyword search without revealing sensitive information [
4,
5,
6,
7,
8]. Searchable encryption is divided into symmetric searchable encryption and asymmetric searchable encryption. In earlier research, symmetric searchable encryption was mainly studied in the static case. However, the static case is not applicable to practical work. Dynamic searchable encryption implements dynamic updates on the basis of the former. However, in order to improve the efficiency of the search, each of these options allows some information to be divulged within certain limits. The file injection attack was confirmed by Zhang et al. [
9]. This attack is performed by injecting a relatively small number of files to learn a large portion of the keywords searched by the client. To resist this attack, forward security has received attention.
Bost et al. [
10] proposed a definition of forward security for searchable encryption and proposed a scheme for a type of DSSE based on forward security. Later, Bost et al. [
11] proposed a definition of backward security and gave several schemes. He et al. [
12] propose a searchable solution that satisfies backward and forward security. However, this scheme is only applicable to individual users for searching their own data stored in cloud servers and is not applicable to practical applications.
As most practical application environments are not closed, the implementation of symmetric searchable encryption always falls short of the requirements. We therefore introduce asymmetric searchable encryption.
Our main contributions are summarized as follows.
- (1)
In this paper, a new multi-user dynamic searchable scheme is proposed on the basis of the predecessors. A new validation Bloom filter structure (ABF) based on the existing Bloom filter is proposed. The new ABF not only includes the original features of the Bloom filter but also adds a counter module, which makes the solution easy to implement in dynamic updates and greatly reduces the error rate.
- (2)
In this paper, a new file set encryption scheme is designed, which uses a lightweight algorithm to reduce the overhead of initialization and update. At the same time, the ABF and state op of encrypted files are used to realize dynamic update of data.
- (3)
The scheme satisfies forward and backward safety. Forward security is satisfied by updating the search token, and backward security is realized by a new file set encryption scheme. Compared with other schemes, the scheme in this paper not only has a great advantage in time cost but also fully considers the problem of historical storage, avoiding multiple different storage states for the same file.
2. Related Work
Asymmetric encryption utilizes a pair of keys, known as the public key and private key. The public key is made publicly available and is used for encrypting data, while the private key is kept secret and is used for decrypting data. For asymmetric searchable encryption, it was first proposed by again Boneh et al. [
13] in their article. But this scheme requires a secure communication channel to pass the trapdoor. However, establishing a secure communication channel is very difficult and expensive. Therefore, Beak et al. devised a scheme that does not require a secure communication channel [
14]. Tang and Chen et al. [
15] designed a PKI-based asymmetric searchable encryption scheme. It improves on the flaw that an attacker can obtain the relationship between the trapdoor and the ciphertext, as proposed by Baek et al. Park et al. [
16] propose two structures for link keyword search with public key encryption. However, this solution involves many connections between the user and the server and has a large storage overhead.
Guo et al. [
17] analyze the scheme of Li et al. [
18] and demonstrate that its trapdoor indistinguishability is not satisfied. A security scheme that satisfies the requirements of the test-specified server and provides stronger security guarantees for the confidentiality of keywords is also proposed. However, these two schemes do not address the encryption algorithm for files and only enhance the security of keywords, without much advantage in terms of practical application.
A spatial keyword query satisfying forward–backward security was proposed by Wang et al. [
19]. The article uses Hilbert curves to simplify geometric range queries to range queries and uses prefix encoding to cover range queries. This solution allows other users to search for data, but this solution is not designed to update steps regarding data that already exist on the cloud server. Although this solution proposes a change to the bitmap when updating, the part of the update algorithm and storage file involved is not further described. Chen et al. [
20] proposed a blockchain-based public-key searchable encryption scheme in the paper. The scheme, BSPEFB, not only makes use of smart contracts for searching, which can ensure the correctness and immutability of the returned results, but also satisfies backward and forward security. The solution reduces the number of computationally intensive operations and has a high search efficiency. However, each trapdoor in the scheme corresponds to a separate keyword, which causes a huge inconvenience to the data owner each time the data user requests a search token while giving the data owner an idea of the range of keywords the data user is interested in. If a malicious data owner uses this for analysis, it could easily compromise the data user’s privacy.
4. Proposed Construction
We propose a new chain structure which includes two parts: keyword-security encryption and file-security encryption. Forward–backward security can be satisfied by performing these two parts.
4.1. System Model
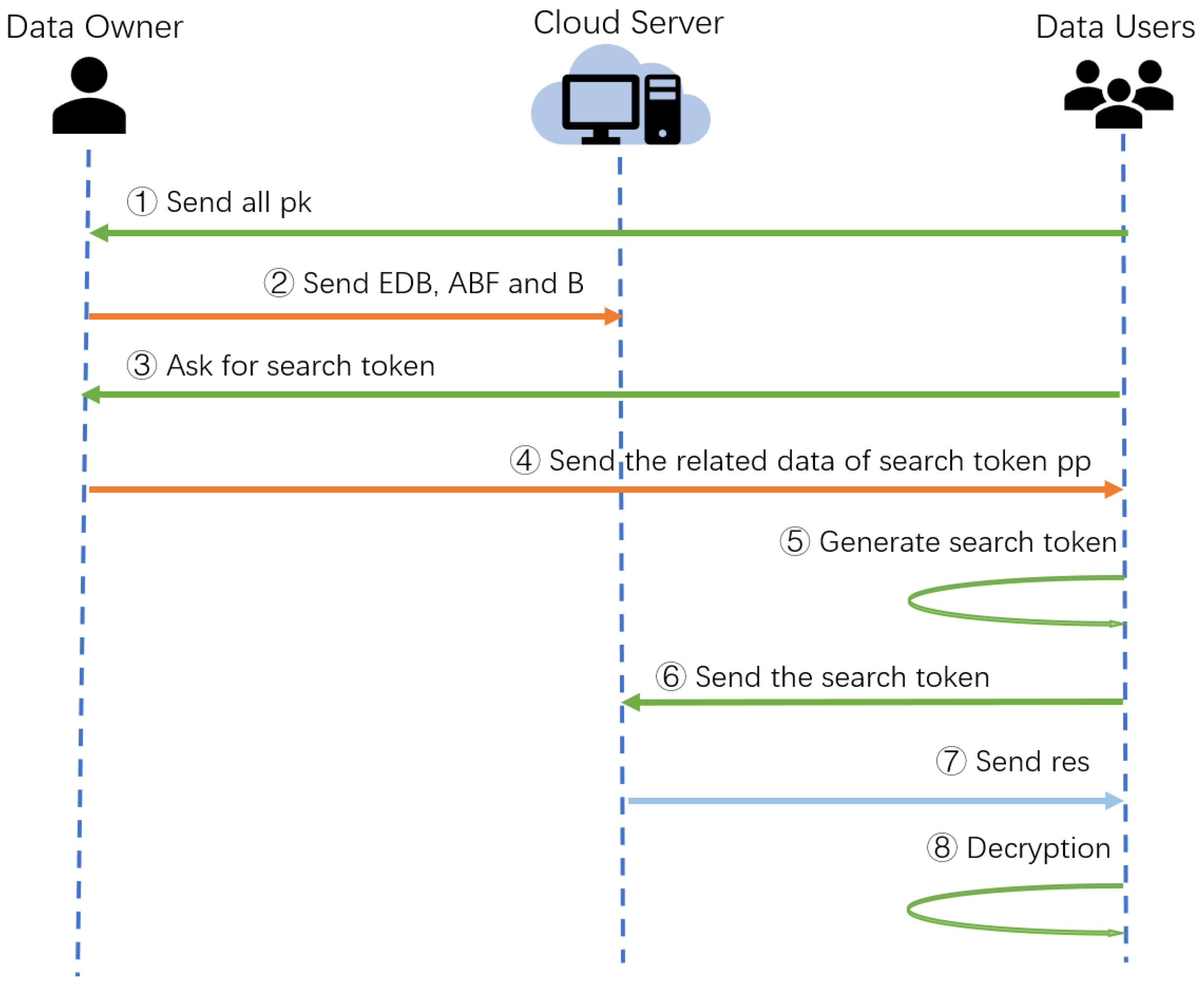
In our design, there are three parts: data owner (DO), data user (DU) and cloud server (CS). The cloud server stores and manages the data owner’s ciphertext set and helps legitimate data users search for the corresponding data. The system model is shown in
Figure 1. First, the data owner collects the public keys of all legitimate users to be used to compute the relevant data pp for the search token. In the second step, the data owner sends the encrypted EDB, ABF, and B to the cloud server for storage. The above is the initialization preparation. Next, if there is a user (legitimate or not), he/she can request the data about the search token from the data owner (Step 3). After that, the data owner sends pp to the data user (Step 4). In step 5, the data user uses the data pp to calculate the corresponding keyword search token. Here, only legitimate users can calculate the correct search token using their private key; otherwise, they will only obtain the wrong data. In the next step, the data user sends the search token to the cloud server to apply for the search. In the seventh step, the cloud server sends a collection of encrypted files from the search to the data user, and finally, in the eighth step, the data user decrypts the data in the res to obtain the plaintext.
The scheme proposed in this paper consists of eight algorithms:
: Input the security parameter and generate the hash function, pseudo-random function, bilinear mapping, and other data required in the next step.
: Each DU generates her/his own public/private keys using its own id.
: data owner initializes the related data. Encrypts (keyword, file set) pairs and sends the encrypted data to cloud server.
: DU runs this algorithm, enters its private key (the data are sent from the DO into the algorithm), calculates the search token, and sends it to the cloud server.
: The data user sends the keyword search token to the cloud server, and the server runs the algorithm to send the corresponding encrypted file set to the data user.
: The algorithm is used to update the data. This algorithm is run by the DO to encrypt the newly stored keywords or files and put them in the corresponding location.
: This algorithm is run by the DO, which updates all keyword search tokens at the end of each update, and then sends all the updated data to the server.
: The data user decrypts the collection from the server to obtain the required file.
4.2. Keyword-Security Encryption
For the encryption of the search token of the keyword, this paper sets the following definition in order to meet the search conditions of multiple users.
Let
be the id set of legitimate search users and the number of users be n. Then, set
to the hashed set of a user’s id, where
. Set
, where
in
is the coefficient of
of the expansion of
, and
is the id of the j-th user. In this article, the data owner sends the following data to the data user:
where
, andr is the random number;
, and
is the data of
;
.
Assuming that a data user with id wants to search for the keyword w, all the data need to be organized into the following form:
As is the root of , and , so that . However, , we can obtain .
4.3. Keyword Storage Scheme
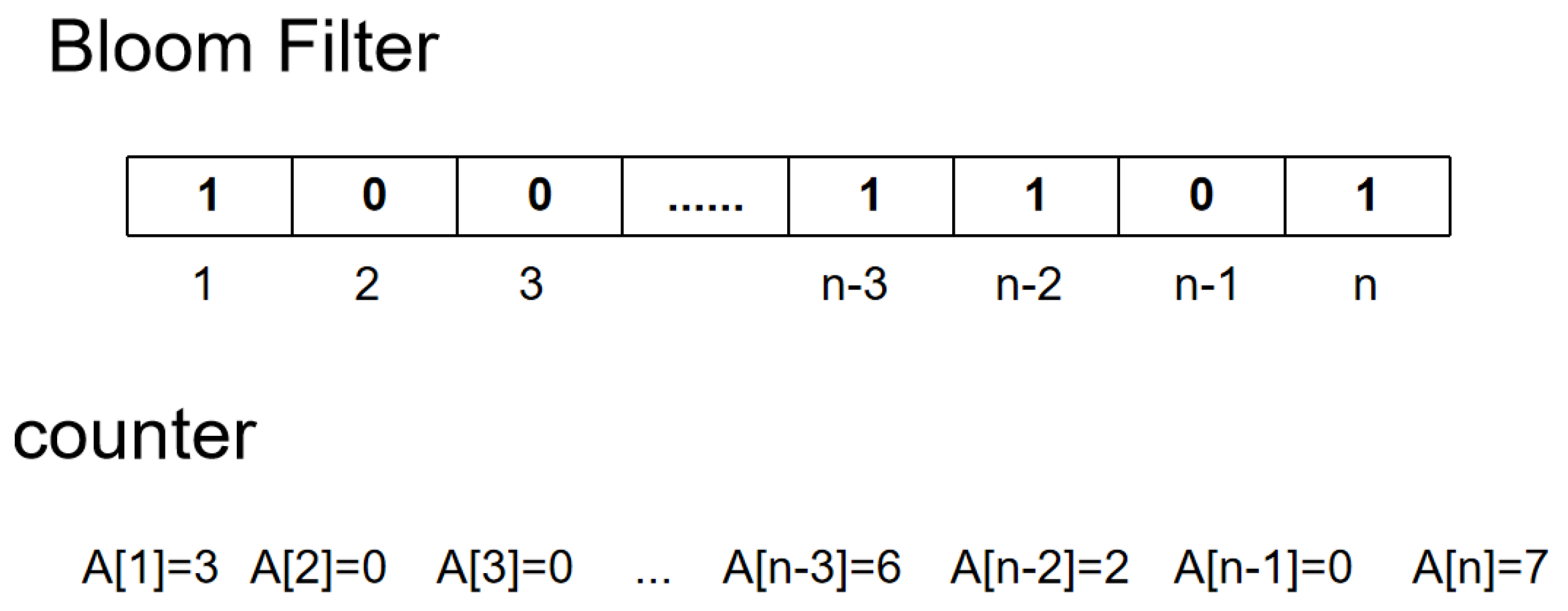
For keyword storage, this paper designs an Authenticator Bloom Filter (ABF). As shown in
Figure 2, the Bloom filter has been modified to add a counting module, and the authenticator is designed to support dynamic updates.
In the ABF structure, for each keyword, the Data Wwner hashes it into the Bloom filter through k unbiased hash functions. For the problem that there may be multiple keywords corresponding to one location, this article adds the counter A[]. Each time A keyword is computed and mapped to the Bloom filter, the count is increased by one for each position A[i]. This means that there is a keyword mapped in the i-th position.
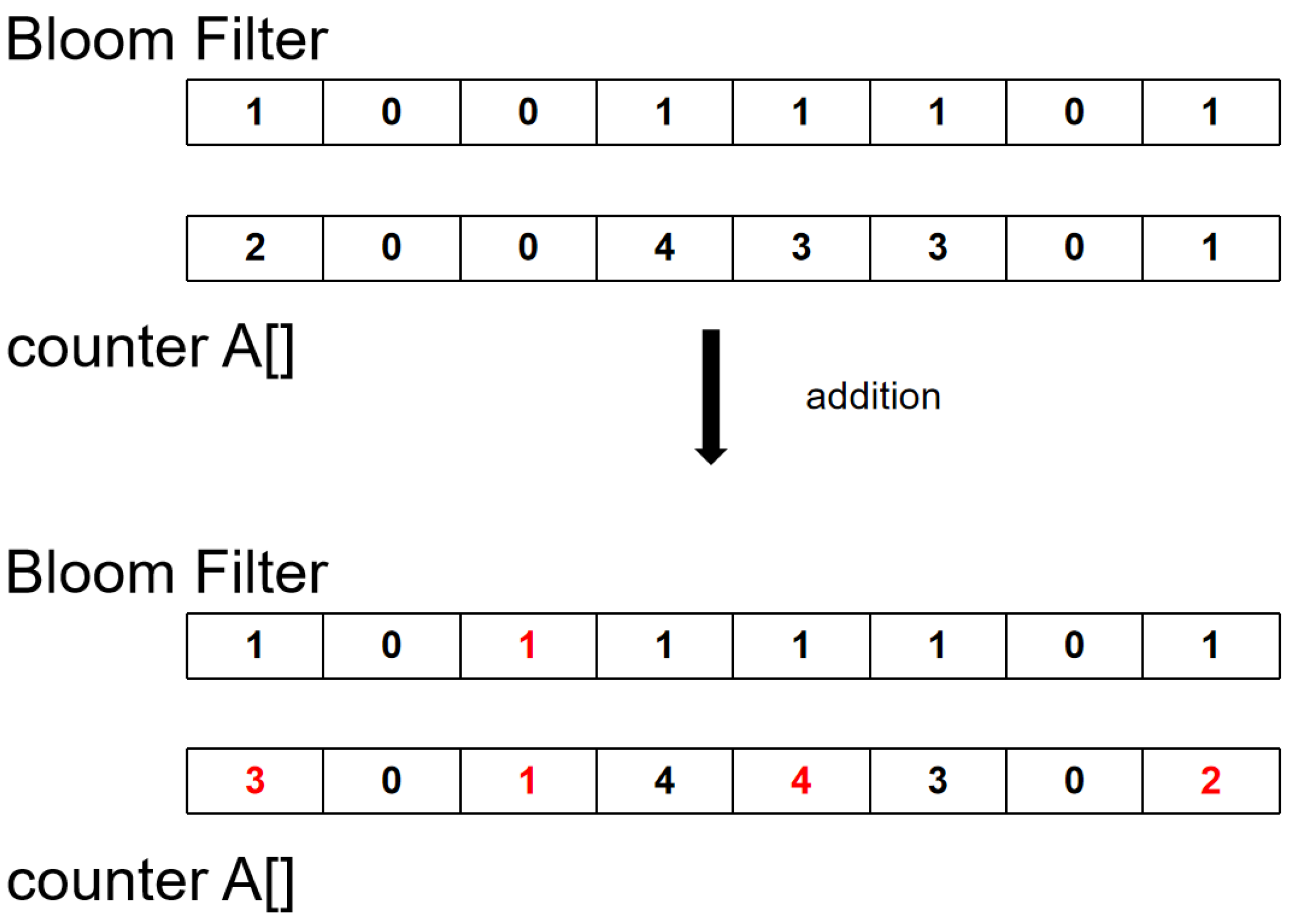
Figure 3 and
Figure 4 show the process of adding and deleting data for the ABF. Add data as shown in
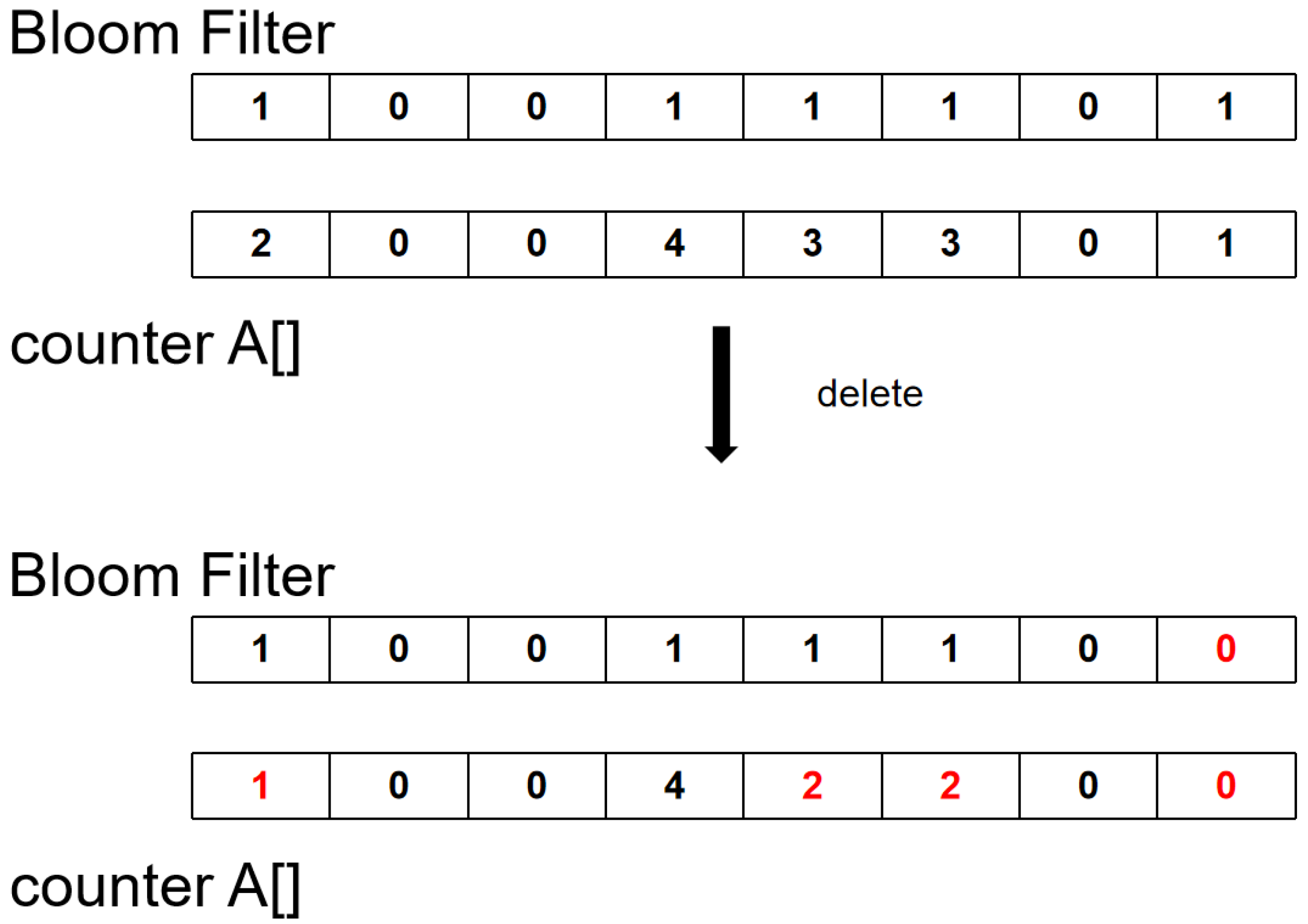
Figure 3. Hash keyword A and map it to bits 1, 3, 5, and 8 in the Bloom filter. Since bits 1, 5, and 8 are already mapped with keywords, only one is added to the counter. On the third bit, not only a one is added to the counter, but also a one is placed on the corresponding bit of the filter. The deletion process is shown in
Figure 4. After keyword B is hashed, it is mapped to the first, fifth, sixth, and eighth bits. First, the corresponding counters are reduced by one, and it is found that the eighth counter is reduced to 0. This means that there are no more keywords mapped to this location, so place 0 in the Bloom filter.
4.4. File-Security Encryption
The ind in this paper’s scheme refers to the address of the file, and the user can find the encrypted file by decrypting to obtain the ind plaintext. This paper uses a symmetric encryption scheme to encrypt the contents of the file, which is not specifically described because it is not very relevant to the scheme of this paper.
The encryption for the document set is as follows:
where
is the state of the file (add/del).
The form of the encrypted file collection is put into the server, but the form of the first key-value pair of each keyword is different from the other; the first set of key-value pairs is as follows:
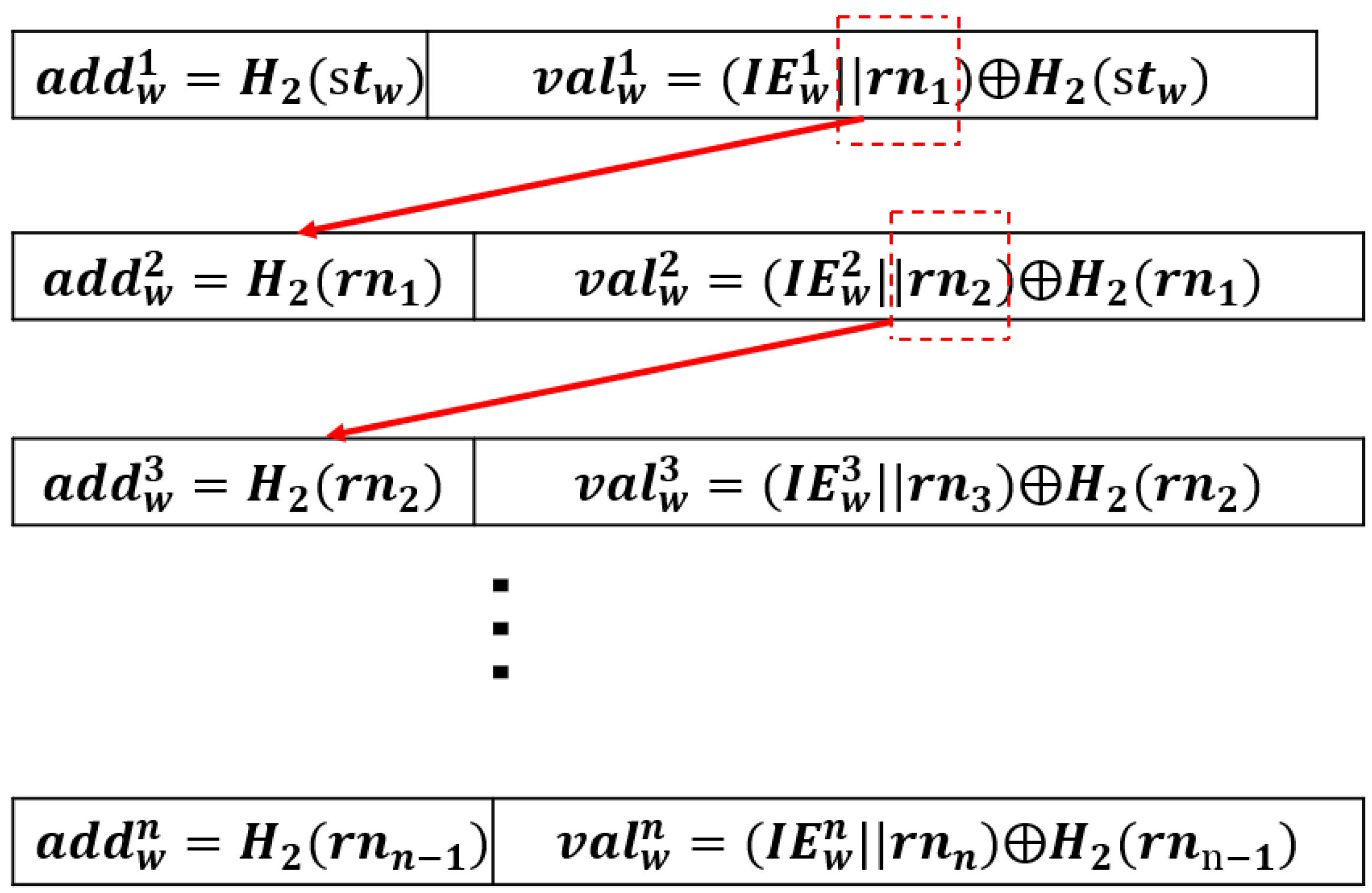
Here the first set of key-value pairs requires a search token and a randomly generated number that is used to search for the next key-value pair, and the rest of the key-value pairs are as follows:
Each key-value pair here is calculated from the previous set of key-value pairs, as shown in
Figure 5.
For document deletion operations, this article does not physically delete an existing document but sets the op state corresponding to the document to delete. When the server runs the search algorithm, it obtains an encrypted file, thus supporting backward security.
5. Construction
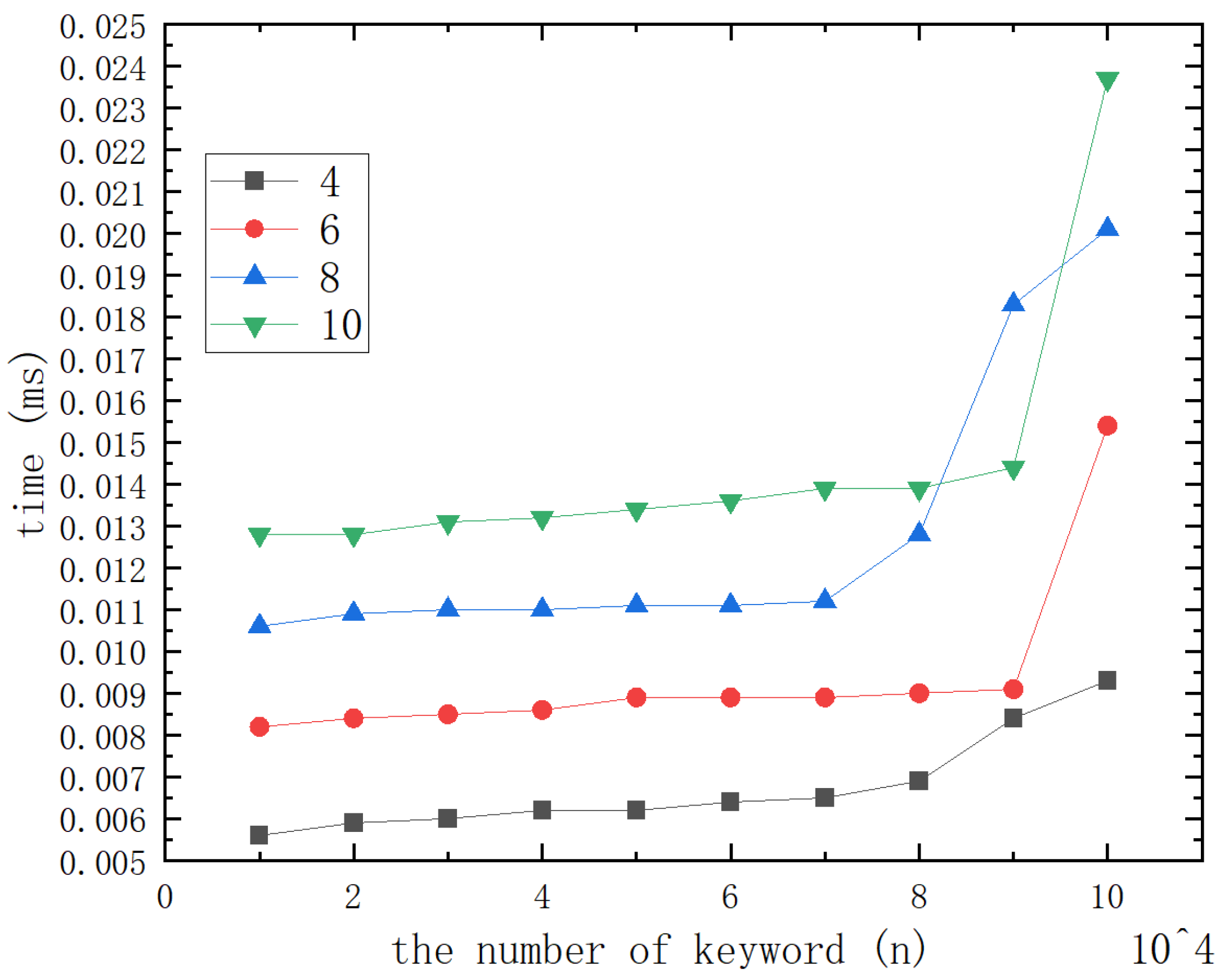
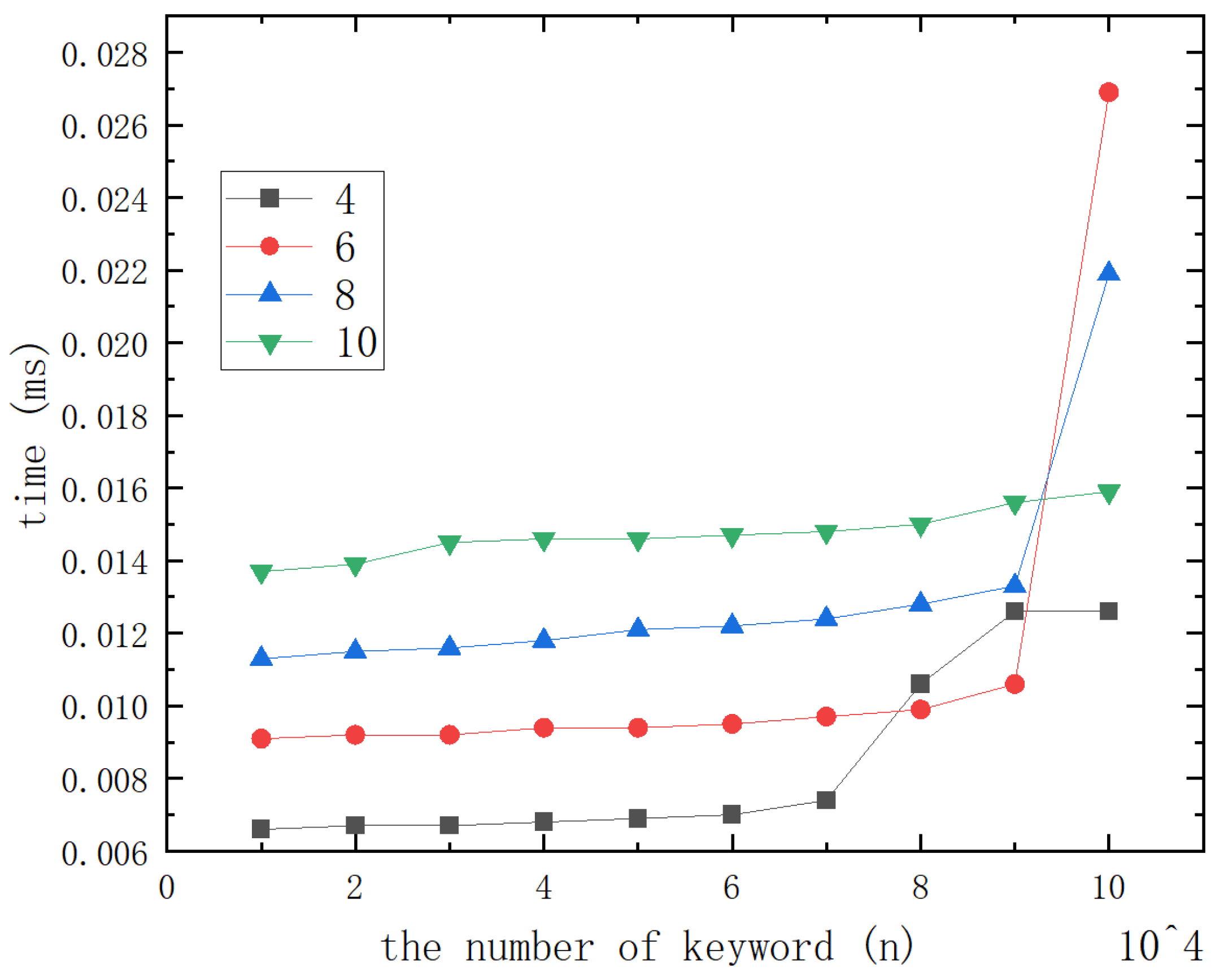
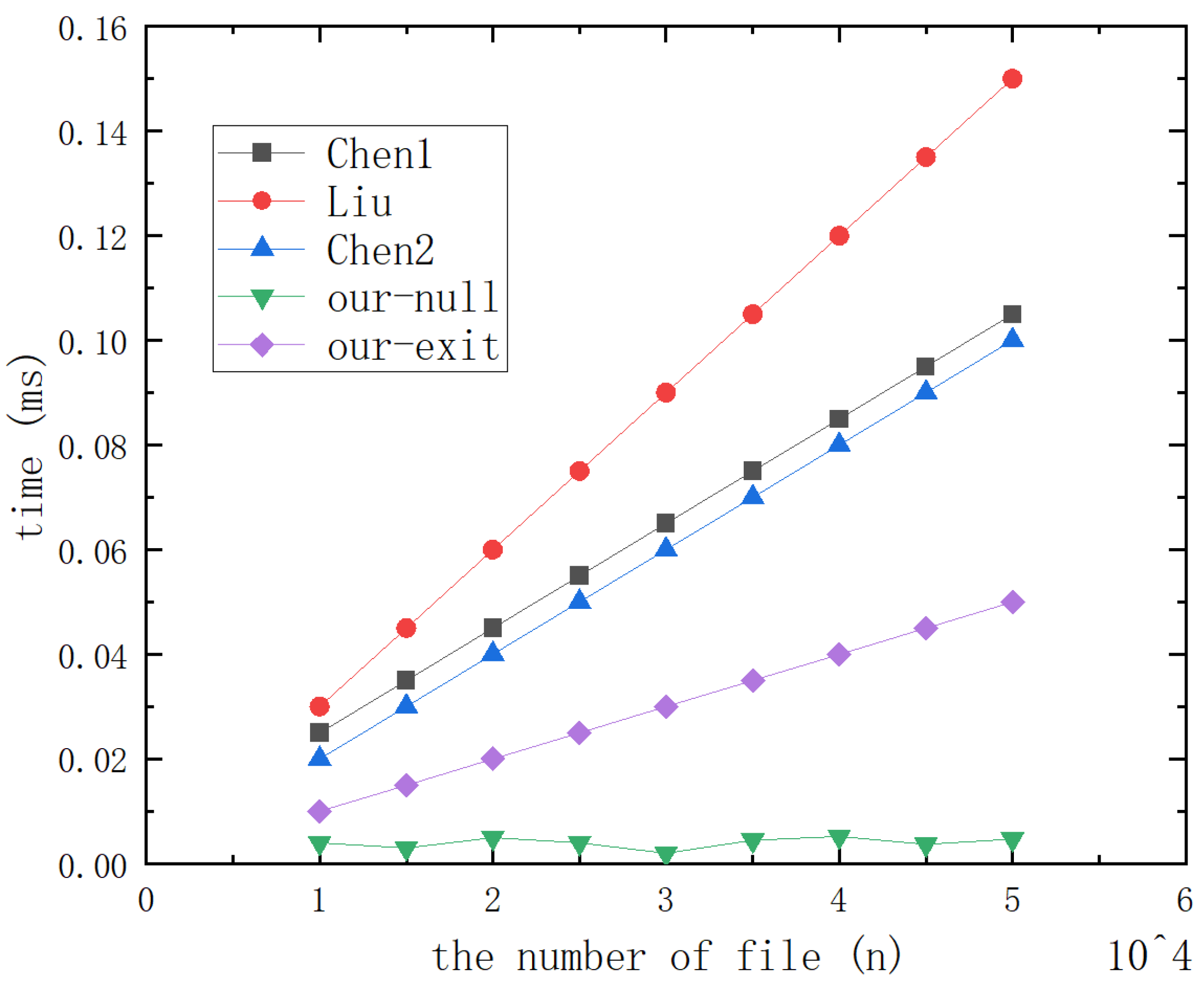
In this section, we introduce our method. This method can be used in many different situations. We will describe and analyze the following Algorithms 1–8.
| Algorithm 1 Setup |
| Input: |
| Output: |
- 1:
Generates the paramenters about the pairing operation - 2:
Generate the sets - 3:
Select the Hash functions - 4:
|
| Algorithm 2 KeyGen |
| Input: |
| Output: |
- 1:
Generate the sets of user i - 2:
- 3:
|
| Algorithm 3 Initial |
| Input: |
| Output: |
- 1:
whiledo - 2:
- 3:
- 4:
- 5:
- 6:
, - 7:
- 8:
- 9:
- 10:
- 11:
, - 12:
fortodo - 13:
- 14:
, - 15:
- 16:
- 17:
- 18:
, - 19:
- 20:
end for - 21:
end while - 22:
send ,,B and to the cloud server
|
| Algorithm 4 Trapdoor |
| Input: |
| Output: |
- 1:
- 2:
|
| Algorithm 5 Search |
| Input: |
| Output: |
- 1:
- 2:
- 3:
if - 4:
else - 5:
- 6:
- 7:
- 8:
, - 9:
fortodo - 10:
- 11:
- 12:
, - 13:
end for - 14:
send res to DataUser
|
| Algorithm 6 Update |
| Input: |
| Output: |
- 1:
whiledo - 2:
,, - 3:
- 4:
While do - 5:
if not exit - 6:
update ABF - 7:
, - 8:
, - 9:
- 10:
- 11:
, - 12:
- 13:
else - 14:
, - 15:
- 16:
- 17:
- 18:
- 19:
if - 20:
, - 21:
else - 22:
fortodo - 23:
- 24:
- 25:
- 26:
if - 27:
, - 28:
end for - 29:
, - 30:
- 31:
- 32:
, - 33:
end while - 34:
end while
|
| Algorithm 7 UpdateST |
| Input: |
| Output: |
- 1:
- 2:
for each keyword do - 3:
- 4:
- 5:
- 6:
- 7:
- 8:
end for - 9:
|
| Algorithm 8 Dec |
| Input: |
| Output: |
- 1:
- 2:
fortodo - 3:
- 4:
- 5:
if - 6:
- 7:
end for - 8:
return tal
|
: The algorithm is run by the DO and the initialization parameters are defined. First, the data owner inputs the security parameter to the algorithm, then generatea the addition group , whose order is a prime q. Let the multiplicative group have the same order. Let be a map. So, we have g as the generator of group . Then, the Hash function is selected and we also need to generate vector based on the set of public keys of all users.
: Each DU generates her/his own public/private keys using its own id.
: The data owner runs Algorithm 3 to initialize all the data. The data owner encrypts all the data before sending it to the cloud server. The initialization data for each keyword are placed in , where is a document collection of keywords (line 4–5). The search token corresponding to this keyword is evaluated by four hashes and mapped to the Bloom filter, while the counter A[i] at each corresponding position of the filter is increased by one.
The next step is to encrypt the file set. The first document of each keyword is encrypted differently from the other documents, so it needs to be calculated separately. This scheme requires key-value pairs to store encrypted file sets. Key-value pairs are represented in this paper by , and the corresponding value is represented in this paper by . This scheme needs to create an to store the random number generated by the latest keyword file for future updates. Finally, are sent to the cloud server.
: The DU runs this algorithm, enters its private key and the data sent from the DO into the algorithm, and calculates the search token and sends it to the cloud server.
: The CS runs this algorithm, uses the keyword search token to put its corresponding set of encrypted files into the set res, and sends the res to the DU. First, the cloud server needs to map the search token to the vABF to determine whether the token exists (Line 2–3). If the search token exists, the key-value pair of the encrypted file is found through the token. First, the first value is found by searching the token, and then the encrypted file and value are calculated by . Then, the key pair of the next encrypted file is found by the value found in turn, and all the encrypted files are put into the set through calculation. Finally, the cloud server sends the set to the DU.
: This algorithm is run by the DO to encrypt the newly stored keywords or files and put them in the corresponding location.
Updates in this scheme are batch updates (including additions and deletions), and the data owner packages the files that need to be added along with other keywords, update status, and search tokens into a quadruple doc, and puts all the docs into a collection, Doc.
There are four situations that need to be determined during the update:
When the keyword corresponding to the updated document does not exist (line 8–18). At this point, you need to initialize the keyword and its files and update the ABF;
When the keyword exists, and the corresponding first document is the target document (line 20–28). When determining that the first document is the target document, change the status op directly to the target op′;
When the keyword exists, and the target file corresponds to a subsequent known file set (line 30–36). Check whether all the files correspond to the target file at one time, and change the corresponding state of the file op to the target state op′ (add or del state) if found;
If the target file has not been stored (line 38–43). Add the target file to the end of the file set while updating and file counters B and .
: This algorithm is run by the DO, which updates all keyword search tokens at the end of each update and then sends all the updated data to the server. This algorithm is run when the data owner is sure that all the data that need to be updated have been updated. When updating the search token, the data owner needs to randomly select a random number r to replace the original r to achieve the purpose of data update. Since the generation of a key-value pair for the first document of the encrypted document set corresponding to each keyword involves a search token, the EDB needs to be updated after each search token is updated. Finally, the new and are sent to the cloud server.
: The DU runs this algorithm to take the encrypted data from the cloud server and decrypt it one by one. After obtaining the file state , determine whether it is the state , and if it is, put the file into the collection . Finally, send to the DU.
6. Security Analysis
6.1. Forward–Backward Privacy
First, forward security means that an update does not reveal any information about the updated keywords. Since the hash function is one-way, the server cannot decrypt the stored identifier unless the client can generate a previous search token. At the same time, every time the data owner updates, the updated keyword search token is updated, so even if the previous search token is leaked, it will not affect future security. Therefore, the scheme in this paper realizes forward privacy.
Backward security ensures that search queries do not show indexes that were previously added but later removed. In this scenario, the file and its file state are encrypted. Because the search results are still in ciphertext, even if it is stored in a curious server, an attacker cannot learn useful information about the index without knowing exactly what the keyword is. Thus, we support backward privacy.
6.2. Adaptive Security
In order to improve the efficiency of the solution, most existing solutions will leak some information to the cloud server. Therefore, the confidentiality of searchable encryption schemes means that no more information is leaked than is allowed. To demonstrate confidentiality, we follow a true-ideal simulation paradigm similar to the work [
23].
Let be this article’s scheme, S be the simulator, and be the adversary. We defined the following two games:
: Run the algorithm and the algorithm . Then, the game is published and is saved. After that, The attacker then selects a database DB, executes various queries against it, including update queries, search queries, and decryption queries, and returns the answers to these queries by executing the corresponding algorithms or protocols update, search, and dec, respectively. Finally, outputs a bit .
: In an ideal world, the opponent selects A safety parameter, and the simulator selects the leak functions and to generate system parameters and return them to the . The adversary then selects a database, DB, and executes various queries against it, including update queries, search queries, and decryption queries. The experiment returns the answers to these queries by calling the leak function . Finally, outputs a bit .
Theorem 1. Let H be the password hash function. The scheme is adaptively safe in the stochastic prediction model, where the set of leakage functions is defined as follows:where . Proof. Our proof uses a hybrid argument consisting of a series of games. The first game is exactly the same as the game in the real world, while the last game is exactly the same as the game in the ideal world.
G0: This game is the real world SSE security game Real. So, we can obtain:
G1: In this game, we need to randomly select the user’s public key
to replace the original public key
. It is easy to see here that G1 and G0 are indistinguishable.
G2: In this game, we create a table
to store search tokens. Each search token is replaced by a random number. Whenever a keyword search token is called, we call the number in the table
instead of the number in the text. In the case of updates, we will randomly select a string in
to act. Here we have:
G3: In this game, we need to create four tables
to answer the random oracle query, which are used to record the
that needs to be mapped to the ABF. In the game, whenever these four values need to be calculated, they are directly taken at random from
and put into the four
tables. If the opponent can distinguish between game 2 and game 3, then the hash function can be distinguished from the real random function, which is obviously impossible. Thus, we have:
G4: In this game, two tables, H1 and H2, need to be created to answer
’s query.
is to record the response to
and H2 is to record the response to
(). In our game, we only consider the leak function in the algorithms update, so we can define
, which only leaks the number of keyword/document pairs. In game 2, we generate the search token
in the update algorithm as a random string instead of the search token generated in the algorithm. In addition, the
and
during token generation is also replaced by the random strings. If the adversary can distinguish between games 2 and 3, we can distinguish between hashed and truly random functions. Then, we have:
G5: In this game, we maintain a table
to generate the encrypted document. In the update protocol, game 5 uses random numbers instead of encrypted document
. It can be seen that games 4 and 5 are the same.
G6: Simulator S simulates the adversary’s point of view with a leak function L that includes search patterns and add history. From the opponent’s point of view, G4 and G5 are exactly the same. Thus, they are indistinguishable:
Conclusion: To sum up the contributions of G0, G1, G2, G3, G4, G5, and G6 we have:
□
Since the hash function is a one-way function, this scheme is an -adaptively-secure searchable encryption scheme.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}