



Identifying Correlated Functional Brain Network Patterns Associated with Touch Discrimination in Survivors of Stroke Using Automated Machine Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Tactile Discrimination
2.3. Design
2.4. Resting State Preprocessing and Analysis
2.5. Identification and Definition of Brain Regions
2.6. Correlation Matrices to ML Dataset Preprocessing
2.7. Auto ML Approach
2.8. Golden Features
2.9. Feature Selection
2.10. Hyperparameter Tuning
2.11. Cross-Validation
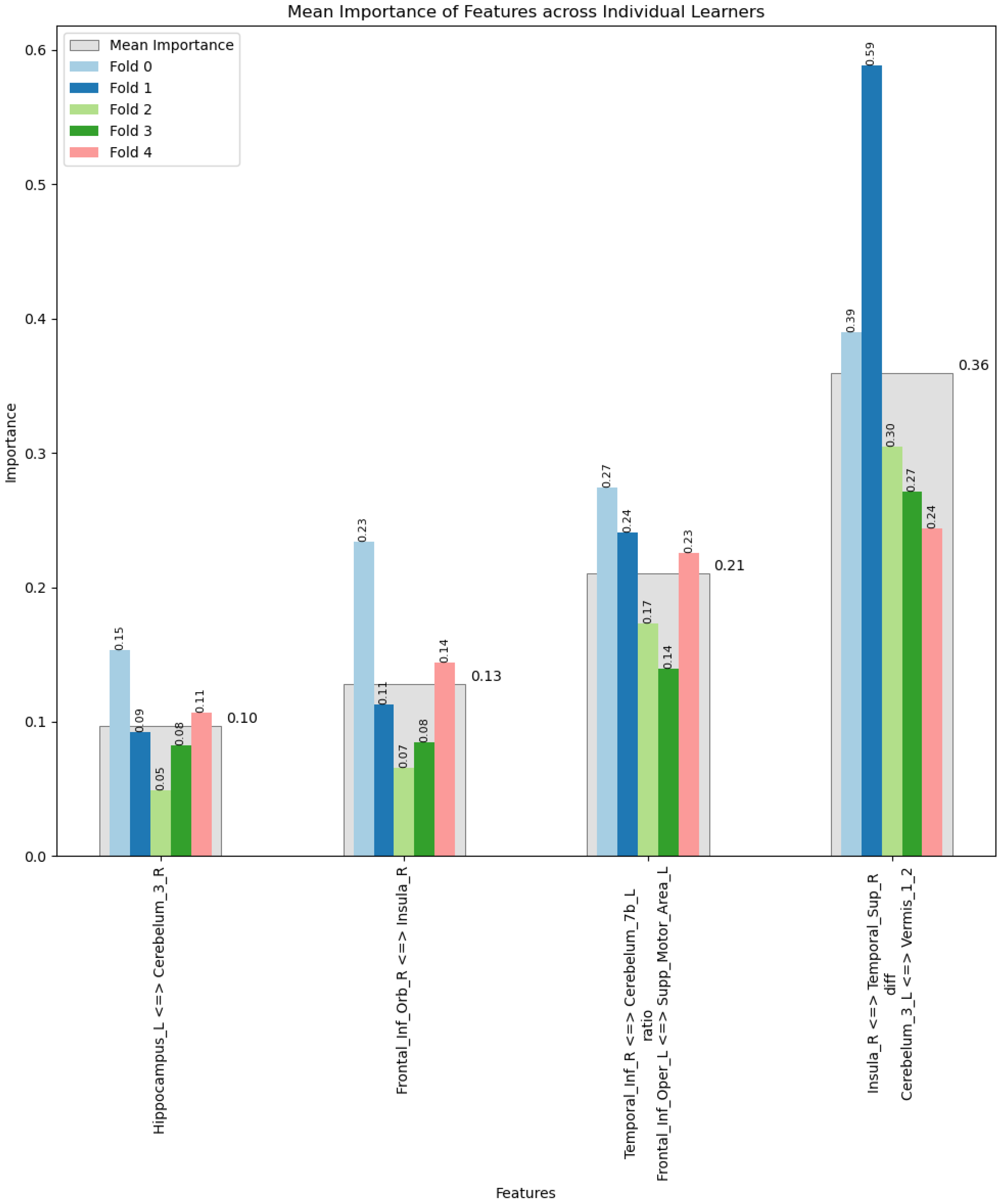
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | in this paper, referred to as artificial neural networks |
| to differentiate them from physical brain networks. | |
| ML | machine learning |
| AI | artificial intelligence |
| AutoML | automated machine learning |
| NIHSS | National Institute of Health Stroke Scale |
| TDT | Tactile Discrimination Test |
| CSF | cerebrospinal fluid |
| BOLD | blood oxygen level-dependent |
| SMA | supplementary motor area |
| GOSS | gradient-based one-side sampling |
Appendix A. Model Hyperparameters
Appendix A.1. Summary of 1_Default_LightGBM
Appendix A.2. Summary of 2_Default_Xgboost
Appendix A.3. Summary of 3_Default_CatBoost
Appendix A.4. Summary of 4_Default_NeuralNetwork
Appendix A.5. Summary of 5_Default_RandomForest
Appendix A.6. Summary of 10_LightGBM
Appendix A.7. Summary of 6_Xgboost
Appendix A.8. Summary of 14_CatBoost
Appendix A.9. Summary of 18_RandomForest
Appendix A.10. Summary of 22_NeuralNetwork
Appendix A.11. Summary of 11_LightGBM
Appendix A.12. Summary of 7_Xgboost
Appendix A.13. Summary of 15_CatBoost
Appendix A.14. Summary of 19_RandomForest
Appendix A.15. Summary of 19_RandomForest_GoldenFeatures
Appendix A.16. Summary of 1_Default_LightGBM_GoldenFeatures
Appendix A.17. Summary of 11_LightGBM_GoldenFeatures
Appendix A.18. Summary of 1_Default_LightGBM_GoldenFeatures_RandomFeature
Appendix A.19. Summary of 1_Default_LightGBM_GoldenFeatures_SelectedFeatures
Appendix A.20. Summary of 19_RandomForest_GoldenFeatures_SelectedFeatures
Appendix A.21. Summary of 6_Xgboost_SelectedFeatures
Appendix A.22. Summary of 4_Default_NeuralNetwork_SelectedFeatures
Appendix A.23. Summary of 23_LightGBM_GoldenFeatures_SelectedFeatures
Appendix A.24. Summary of 24_LightGBM_GoldenFeatures
Appendix A.25. Summary of 25_RandomForest_GoldenFeatures_SelectedFeatures
Appendix A.26. Summary of 26_RandomForest_GoldenFeatures
Appendix A.27. Summary of 27_Xgboost_SelectedFeatures
Appendix A.28. Summary of 28_Xgboost_SelectedFeatures
Appendix A.29. Summary of 29_Xgboost
Appendix A.30. Summary of 30_Xgboost
Appendix A.31. Summary of 31_CatBoost
Appendix A.32. Summary of 32_LightGBM_GoldenFeatures_SelectedFeatures
Appendix A.33. Summary of 33_LightGBM_GoldenFeatures_SelectedFeatures
Appendix A.34. Summary of 34_LightGBM_GoldenFeatures_SelectedFeatures
Appendix A.35. Summary of 35_LightGBM_GoldenFeatures_SelectedFeatures
Appendix A.36. Summary of 36_RandomForest_GoldenFeatures_SelectedFeatures
Appendix A.37. Summary of 37_RandomForest_GoldenFeatures_SelectedFeatures
Appendix A.38. Summary of 38_RandomForest_GoldenFeatures_SelectedFeatures
Appendix A.39. Summary of 39_RandomForest_GoldenFeatures_SelectedFeatures
Appendix A.40. Summary of 40_Xgboost_SelectedFeatures
Appendix A.41. Summary of 41_Xgboost_SelectedFeatures
Appendix A.42. Summary of 42_Xgboost_SelectedFeatures
Appendix A.43. Summary of 43_Xgboost_SelectedFeatures
Appendix A.44. Summary of 48_NeuralNetwork_SelectedFeatures
Appendix A.45. Summary of 49_NeuralNetwork_SelectedFeatures
Appendix A.46. Summary of 50_NeuralNetwork
Appendix A.47. Summary of 51_NeuralNetwork
References
- Grefkes, C.; Fink, G.R. Recovery from stroke: Current concepts and future perspectives. Neurol. Res. Pract. 2020, 2, 17. [Google Scholar] [CrossRef] [PubMed]
- Dobkin, B.H.; Dorsch, A. New Evidence for Therapies in Stroke Rehabilitation. Curr. Atheroscler. Rep. 2013, 15, 331. [Google Scholar] [CrossRef] [PubMed]
- Shameer, K.; Johnson, K.W.; Glicksberg, B.S.; Dudley, J.T.; Sengupta, P.P. Machine learning in cardiovascular medicine: Are we there yet? Heart 2018, 104, 1156–1164. [Google Scholar] [CrossRef] [PubMed]
- Lin, E.; Tsai, S.J. Machine Learning in Neural Networks. In Frontiers in Psychiatry: Artificial Intelligence, Precision Medicine, and Other Paradigm Shifts; Kim, Y.K., Ed.; Springer: Singapore, 2019; pp. 127–137. [Google Scholar] [CrossRef]
- Carey, L.M.; Crewther, S.; Salvado, O.; Lindén, T.; Connelly, A.; Wilson, W.; Howells, D.W.; Churilov, L.; Ma, H.; Tse, T.; et al. STroke imAging pRevention and Treatment (START): A Longitudinal Stroke Cohort Study: Clinical Trials Protocol. Int. J. Stroke 2013, 10, 636–644. [Google Scholar] [CrossRef] [PubMed]
- Siegel, J.S.; Ramsey, L.E.; Snyder, A.Z.; Metcalf, N.V.; Chacko, R.V.; Weinberger, K.; Baldassarre, A.; Hacker, C.D.; Shulman, G.L.; Corbetta, M. Disruptions of network connectivity predict impairment in multiple behavioral domains after stroke. Proc. Natl. Acad. Sci. USA 2016, 113, E4367–E4376. [Google Scholar] [CrossRef] [PubMed]
- Carey, L.M.; Seitz, R.J.; Parsons, M.; Levi, C.; Farquharson, S.; Tournier, J.D.; Palmer, S.; Connelly, A. Beyond the lesion: Neuroimaging foundations for post-stroke recovery. Future Neurol. 2013, 8, 507–527. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P.; Chang, M.W.; Devlin, J.; Dragan, A.; Forsyth, D.; Goodfellow, I.; Malik, J.; Mansinghka, V.; Pearl, J.; et al. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson series in artificial intelligence; Pearson: Harlow, UK, 2022; 1166p. [Google Scholar]
- Koza, J.R.; Bennett, F.H.; Andre, D.; Keane, M.A. Automated Design of Both the Topology and Sizing of Analog Electrical Circuits Using Genetic Programming. In Artificial Intelligence in Design ’96; Gero, J.S., Sudweeks, F., Eds.; Springer: Dordrecht, The Netherlands, 1996; pp. 151–170. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Auto-sklearn: Efficient and Robust Automated Machine Learning. In Automated Machine Learning: Methods, Systems, Challenges; The Springer Series on Challenges in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2019; p. 113. [Google Scholar] [CrossRef]
- Rajula, H.S.R.; Verlato, G.; Manchia, M.; Antonucci, N.; Fanos, V. Comparison of Conventional Statistical Methods with Machine Learning in Medicine: Diagnosis, Drug Development, and Treatment. Medicina 2020, 56, 455. [Google Scholar] [CrossRef] [PubMed]
- Choo, Y.J.; Chang, M.C. Use of Machine Learning in Stroke Rehabilitation: A Narrative Review. Brain Neurorehabil. 2022, 15, e26. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.Y.; Chen, C.H.; Tseng, Y.J.; Tsai, Y.T.; Chang, C.Y.; Wang, H.Y.; Chen, C.K. Predicting post-stroke activities of daily living through a machine learning-based approach on initiating rehabilitation. Int. J. Med. Inform. 2018, 111, 159–164. [Google Scholar] [CrossRef] [PubMed]
- Mutke, M.A.; Madai, V.I.; Hilbert, A.; Zihni, E.; Potreck, A.; Weyland, C.S.; Möhlenbruch, M.A.; Heiland, S.; Ringleb, P.A.; Nagel, S.; et al. Comparing Poor and Favorable Outcome Prediction With Machine Learning After Mechanical Thrombectomy in Acute Ischemic Stroke. Front. Neurol. 2022, 13, 737667. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Koh, C.L.; Yeh, C.H.; Goodin, P.; Lamp, G.; Connelly, A.; Carey, L.M. Predicting Post-Stroke Somatosensory Function from Resting-State Functional Connectivity: A Feasibility Study. Brain Sci. 2021, 11, 1388. [Google Scholar] [CrossRef] [PubMed]
- Senadheera, I.; Larssen, B.C.; Mak-Yuen, Y.Y.K.; Steinfort, S.; Carey, L.M.; Alahakoon, D. Profiling Somatosensory Impairment after Stroke: Characterizing Common ‘Fingerprints’ of Impairment Using Unsupervised Machine Learning-Based Cluster Analysis of Quantitative Measures of the Upper Limb. Brain Sci. 2023, 13, 1253. [Google Scholar] [CrossRef]
- Shin, H.; Kim, J.K.; Choo, Y.J.; Choi, G.S.; Chang, M.C. Prediction of Motor Outcome of Stroke Patients Using a Deep Learning Algorithm with Brain MRI as Input Data. Eur. Neurol. 2022, 85, 460–466. [Google Scholar] [CrossRef] [PubMed]
- A Romero, R.A.; Y Deypalan, M.N.; Mehrotra, S.; Jungao, J.T.; Sheils, N.E.; Manduchi, E.; Moore, J.H. Benchmarking AutoML frameworks for disease prediction using medical claims. BioData Min. 2022, 15, 15. [Google Scholar] [CrossRef] [PubMed]
- Carey, L. Review on Somatosensory Loss after Stroke. Crit. Rev. Phys. Rehabil. Med. 2017, 29, 1–41. [Google Scholar] [CrossRef]
- Carey, L.; Macdonell, R.; Matyas, T.A. SENSe: Study of the Effectiveness of Neurorehabilitation on Sensation: A randomized controlled trial. Neurorehabil. Neural Repair 2011, 25, 304–313. [Google Scholar] [CrossRef]
- Goodin, P.; Lamp, G.; Vidyasagar, R.; McArdle, D.; Seitz, R.J.; Carey, L.M. Altered functional connectivity differs in stroke survivors with impaired touch sensation following left and right hemisphere lesions. Neuroimage Clin. 2018, 18, 342–355. [Google Scholar] [CrossRef] [PubMed]
- Spilker, J.; Kongable, G.; Barch, C.; Braimah, J.; Brattina, P.; Daley, S.; Donnarumma, R.; Rapp, K.; Sailor, S. Using the NIH Stroke Scale to assess stroke patients. The NINDS rt-PA Stroke Study Group. J. Neurosci. Nurs. 1997, 29, 384–392. [Google Scholar] [CrossRef] [PubMed]
- Mak-Yuen, Y.Y.K.; Matyas, T.A.; Carey, L.M. Characterizing Touch Discrimination Impairment from Pooled Stroke Samples Using the Tactile Discrimination Test: Updated Criteria for Interpretation and Brief Test Version for Use in Clinical Practice Settings. Brain Sci. 2023, 13, 533. [Google Scholar] [CrossRef] [PubMed]
- Carey, L.M.; Oke, L.E.; Matyas, T.A. Impaired Touch Discrimination After Stroke: A Quantiative Test. J. Neurol. Rehabil. 1997, 11, 219–232. [Google Scholar] [CrossRef]
- Smith, S.M.; Vidaurre, D.; Beckmann, C.F.; Glasser, M.F.; Jenkinson, M.; Miller, K.L.; Nichols, T.E.; Robinson, E.C.; Salimi-Khorshidi, G.; Woolrich, M.W.; et al. Functional connectomics from resting state fMRI. Trends Cogn. Sci. 2013, 17, 666–682. [Google Scholar] [CrossRef]
- Varoquaux, G.; Craddock, R.C. Learning and comparing functional connectomes across subjects. Neuroimage 2013, 80, 405–415. [Google Scholar] [CrossRef] [PubMed]
- Płońska, A.; Płoński, P. MLJAR: State-of-the-Art Automated Machine Learning Framework for Tabular Data. Version 0.10.3, 2021.
- Matyas, T.A.; Mak-Yuen, Y.Y.K.; Boelsen-Robinson, T.P.; Carey, L.M. Calibration of Impairment Severity to Enable Comparison across Somatosensory Domains. Brain Sci. 2023, 13, 654. [Google Scholar] [CrossRef] [PubMed]
- Carey, L.M.; Abbott, D.F.; Egan, G.F.; Donnan, G.A. Reproducible activation in BA2, 1 and 3b associated with texture discrimination in healthy volunteers over time. Neuroimage 2008, 39, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Koh, C.L.; Yeh, C.H.; Liang, X.; Vidyasagar, R.; Seitz, R.J.; Nilsson, M.; Connelly, A.; Carey, L.M. Structural Connectivity Remote From Lesions Correlates With Somatosensory Outcome Poststroke. Stroke 2021, 52, 2910–2920. [Google Scholar] [CrossRef] [PubMed]
- Carey, L.M.; Abbott, D.F.; Harvey, M.R.; Puce, A.; Seitz, R.J.; Donnan, G.A. Relationship between touch impairment and brain activation after lesions of subcortical and cortical somatosensory regions. Neurorehabil. Neural Repair 2011, 25, 443–457. [Google Scholar] [CrossRef] [PubMed]
- Saito, R.; Fujihara, K.; Kasagi, M.; Motegi, T.; Suzuki, Y.; Narita, K.; Ujita, K.; Fukuda, M. Can We Find Any Sustained Neurofunctional Alteration in Remitted Depressive Patients with a History of Modified Electroconvulsive Therapy? Open J. Depress. 2017, 6, 89–99. [Google Scholar] [CrossRef]
- Avants, B.B.; Tustison, N.J.; Song, G.; Cook, P.A.; Klein, A.; Gee, J.C. A reproducible evaluation of ANTs similarity metric performance in brain image registration. Neuroimage 2011, 54, 2033–2044. [Google Scholar] [CrossRef]
- van der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef]
- Oliphant, T.E. Python for Scientific Computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef]
- Gorgolewski, K.; Burns, C.D.; Madison, C.; Clark, D.; Halchenko, Y.O.; Waskom, M.L.; Ghosh, S.S. Nipype: A flexible, lightweight and extensible neuroimaging data processing framework in python. Front. Neuroinform. 2011, 5, 13. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J.; Williams, S.; Howard, R.; Frackowiak, R.S.; Turner, R. Movement-related effects in fMRI time-series. Magn. Reson. Med. 1996, 35, 346–355. [Google Scholar] [CrossRef] [PubMed]
- Behzadi, Y.; Restom, K.; Liau, J.; Liu, T.T. A component based noise correction method (CompCor) for BOLD and perfusion based fMRI. Neuroimage 2007, 37, 90–101. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.G.; Cheung, B.; Kelly, C.; Colcombe, S.; Craddock, R.C.; Di Martino, A.; Li, Q.; Zuo, X.N.; Castellanos, F.X.; Milham, M.P. A comprehensive assessment of regional variation in the impact of head micromovements on functional connectomics. Neuroimage 2013, 76, 183–201. [Google Scholar] [CrossRef] [PubMed]
- Rolls, E.T.; Huang, C.C.; Lin, C.P.; Feng, J.; Joliot, M. Automated anatomical labelling atlas 3. NeuroImage 2020, 206, 116189. [Google Scholar] [CrossRef] [PubMed]
- Kreuzberger, D.; Kuhl, N.; Hirschl, S. Machine Learning Operations (MLOps): Overview, Definition, and Architecture. IEEE Access 2023, 11, 31866–31879. [Google Scholar] [CrossRef]
- Jia, W.; Sun, M.; Lian, J.; Hou, S. Feature dimensionality reduction: A review. Complex Intell. Syst. 2022, 8, 2663–2693. [Google Scholar] [CrossRef]
- Piramuthu, S.; Sikora, R.T. Iterative feature construction for improving inductive learning algorithms. Expert Syst. Appl. 2009, 36, 3401–3406. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Ojala, M.; Garriga, G.C. Permutation Tests for Studying Classifier Performance. J. Mach. Learn. Res. 2010, 11, 1833–1863. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Machlanski, D.; Samothrakis, S.; Clarke, P. Hyperparameter Tuning and Model Evaluation in Causal Effect Estimation. arXiv 2023, arXiv:2303.01412. Available online: http://xxx.lanl.gov/abs/2303.01412 (accessed on 5 August 2023).
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—Volume 2, IJCAI’95, San Francisco, CA, USA, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 1137–1143. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Badrulhisham, F.; Pogatzki-Zahn, E.; Segelcke, D.; Spisak, T.; Vollert, J. Machine learning and artificial intelligence in neuroscience: A primer for researchers. Brain, Behav. Immun. 2024, 115, 470–479. [Google Scholar] [CrossRef] [PubMed]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Glasgow, UK, 2017; Volume 30. [Google Scholar]
- Bullmore, E.; Sporns, O. Complex brain networks: Graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 2009, 10, 186–198. [Google Scholar] [CrossRef] [PubMed]
- Crossley, N.A.; Mechelli, A.; Scott, J.; Carletti, F.; Fox, P.T.; McGuire, P.; Bullmore, E.T. The hubs of the human connectome are generally implicated in the anatomy of brain disorders. Brain 2014, 137, 2382–2395. [Google Scholar] [CrossRef] [PubMed]
- Park, H.J.; Friston, K. Structural and functional brain networks: From connections to cognition. Science 2013, 342, 1238411. [Google Scholar] [CrossRef] [PubMed]
- Friston, K.J. Functional and effective connectivity: A review. Brain Connect. 2011, 1, 13–36. [Google Scholar] [CrossRef] [PubMed]
- Grefkes, C.; Fink, G.R. Connectivity-based approaches in stroke and recovery of function. Lancet Neurol. 2014, 13, 206–216. [Google Scholar] [CrossRef] [PubMed]
- Rehme, A.K.; Grefkes, C. Cerebral network disorders after stroke: Evidence from imaging-based connectivity analyses of active and resting brain states in humans. J. Physiol. 2013, 591, 17–31. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Nachtergaele, P.; Radwan, A.; Swinnen, S.; Decramer, T.; Uytterhoeven, M.; Sunaert, S.; van Loon, J.; Theys, T. The temporoinsular projection system: An anatomical study. J. Neurosurg. JNS 2020, 132, 615–623. [Google Scholar] [CrossRef] [PubMed]
- Gong, D.; He, H.; Liu, D.; Ma, W.; Dong, L.; Luo, C.; Yao, D. Enhanced functional connectivity and increased gray matter volume of insula related to action video game playing. Sci. Rep. 2015, 5, 9763. [Google Scholar] [CrossRef] [PubMed]
- Bodranghien, F.; Bastian, A.; Casali, C.; Hallett, M.; Louis, E.D.; Manto, M.; Mariën, P.; Nowak, D.A.; Schmahmann, J.D.; Serrao, M.; et al. Consensus Paper: Revisiting the Symptoms and Signs of Cerebellar Syndrome. Cerebellum 2016, 15, 369–391. [Google Scholar] [CrossRef] [PubMed]
- Bannister, L.C.; Crewther, S.G.; Gavrilescu, M.; Carey, L.M. Improvement in Touch Sensation after Stroke is Associated with Resting Functional Connectivity Changes. Front. Neurol. 2015, 6, 165. [Google Scholar] [CrossRef] [PubMed]
- Aso, K.; Hanakawa, T.; Aso, T.; Fukuyama, H. Cerebro-cerebellar Interactions Underlying Temporal Information Processing. J. Cogn. Neurosci. 2010, 22, 2913–2925. [Google Scholar] [CrossRef] [PubMed]
- AU Bozkurt, B.; AU Yagmurlu, K.; AU Middlebrooks, E.H.; AU Cayci, Z.; AU Cevik, O.M.; AU Karadag, A.; AU Moen, S.; AU Tanriover, N.; AU Grande, A.W. Fiber Connections of the Supplementary Motor Area Revisited: Methodology of Fiber Dissection, DTI, and Three Dimensional Documentation. JoVE 2017, 123, e55681. [Google Scholar] [CrossRef]
- Lehéricy, S.; Ducros, M.; Krainik, A.; Francois, C.; Van de Moortele, P.F.; Ugurbil, K.; Kim, D.S. 3-D diffusion tensor axonal tracking shows distinct SMA and pre-SMA projections to the human striatum. Cereb. Cortex 2004, 14, 1302–1309. [Google Scholar] [CrossRef] [PubMed]
- Hagen, M.C.; Zald, D.H.; Thornton, T.A.; Pardo, J. Somatosensory Processing in the Human Inferior Prefrontal Cortex. J. Neurophysiol. 2002, 88, 1400–1406. [Google Scholar] [CrossRef] [PubMed]
- Wiech, K.; Jbabdi, S.; Lin, C.S.; Andersson, J.; Tracey, I. Differential structural and resting state connectivity between insular subdivisions and other pain-related brain regions. Pain 2014, 155, 2047–2055. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Krook-Magnuson, E. Cognitive Collaborations: Bidirectional Functional Connectivity Between the Cerebellum and the Hippocampus. Front. Syst. Neurosci. 2015, 9, 177. [Google Scholar] [CrossRef] [PubMed]
- Kilteni, K.; Ehrsson, H.H. Functional Connectivity between the Cerebellum and Somatosensory Areas Implements the Attenuation of Self-Generated Touch. J. Neurosci. 2020, 40, 894–906. [Google Scholar] [CrossRef] [PubMed]
- de Haan, E.H.F.; Dijkerman, H.C. Somatosensation in the Brain: A Theoretical Re-evaluation and a New Model. Trends Cogn. Sci. 2020, 24, 529–541. [Google Scholar] [CrossRef] [PubMed]
- Cole, D.M.; Smith, S.M.; Beckmann, C.F. Advances and pitfalls in the analysis and interpretation of resting state FMRI data. Front. Syst. Neurosci. 2010, 4, 8. [Google Scholar] [CrossRef] [PubMed]
- Siegel, J.S.; Shulman, G.L.; Corbetta, M. Measuring functional connectivity in stroke: Approaches and considerations. J. Cereb. Blood Flow Metab. 2017, 37, 2665–2678. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age in years | Mean (SD) | 62.71 (13.23) |
| Sex | M/F | 18/42 |
| Lesion Location | left/right/bilateral/unknown | 21/31/1/7 |
| TDT score (AUC, first tested hand) | Mean (SD) | 58.14 (20.33) |
| Strategy | Configuration | Type | RMSE |
|---|---|---|---|
| Default | |||
| 1_Default_LightGBM | LightGBM | 20.88 * | |
| 2_Default_Xgboost | Xgboost | 21.05 | |
| 3_Default_CatBoost | CatBoost | 21.16 | |
| 4_Default_NeuralNetwork | Neural Network | 45.64 | |
| 5_Default_RandomForest | Random Forest | 21.56 | |
| Not_So_Random | |||
| 6_Xgboost_NSR | Xgboost | 21.04 | |
| 7_Xgboost_NSR | Xgboost | 21.23 | |
| 10_LightGBM_NSR | LightGBM | 21.29 | |
| 11_LightGBM_NSR | LightGBM | 20.96 | |
| 14_CatBoost_NSR | CatBoost | 21.19 | |
| 15_CatBoost_NSR | CatBoost | 21.37 | |
| 18_RandomForest_NSR | Random Forest | 21.34 | |
| 19_RandomForest_NSR | Random Forest | 20.86 * | |
| 22_NeuralNetwork_NSR | Neural Network | 65.83 | |
| Golden_Features | |||
| 1_Default_LightGBM_GF | LightGBM | 19.37 * | |
| 11_LightGBM_NSR_GF | LightGBM | 19.59 | |
| 19_RandomForest_NSR_GF | Random Forest | 20.86 | |
| Insert_Random_Feature | |||
| 1_Default_LightGBM_GF_RF | LightGBM | 19.27 | |
| Selected_Features | |||
| 1_Default_LightGBM_GF_SF | LightGBM | 15.86 * | |
| 4_Default_NeuralNetwork_SF | Neural Network | 22.56 | |
| 6_Xgboost_NSR_SF | Xgboost | 21.04 | |
| 19_RandomForest_NSR_GF_SF | Random Forest | 20.09 | |
| Hill_Climbing_1 | |||
| 23_LightGBM_GF_SF_HC1 | LightGBM | 15.65 * | |
| 24_LightGBM_GF_HC1 | LightGBM | 19.15 | |
| 25_RandomForest_GF_SF_HC1 | Random Forest | 20.09 | |
| 26_RandomForest_GF_HC1 | Random Forest | 20.86 | |
| 27_Xgboost_SF_HC1 | Xgboost | 21.04 | |
| 28_Xgboost_SF_HC1 | Xgboost | 21.04 | |
| 29_Xgboost_HC1 | Xgboost | 21.05 | |
| 30_Xgboost_HC1 | Xgboost | 21.05 | |
| 31_CatBoost_HC1 | CatBoost | 21.29 | |
| Hill_Climbing_2 | |||
| 32_LightGBM_GF_SF_HC2 | LightGBM | 15.92 | |
| 33_LightGBM_GF_SF_HC2 | LightGBM | 15.65 * | |
| 34_LightGBM_GF_SF_HC2 | LightGBM | 15.76 | |
| 35_LightGBM_GF_SF_HC2 | LightGBM | 15.86 | |
| 36_RandomForest_GF_SF_HC2 | Random Forest | 20.09 | |
| 37_RandomForest_GF_SF_HC2 | Random Forest | 20.00 | |
| 38_RandomForest_GF_SF_HC2 | Random Forest | 20.09 | |
| 39_RandomForest_GF_SF_HC2 | Random Forest | 20.00 | |
| 40_Xgboost_SF_HC2 | Xgboost | 21.99 | |
| 41_Xgboost_SF_HC2 | Xgboost | 19.62 | |
| 42_Xgboost_SF_HC2 | Xgboost | 21.96 | |
| 43_Xgboost_SF_HC2 | Xgboost | 19.62 | |
| 48_NeuralNetwork_SF_HC2 | Neural Network | 21.58 | |
| 49_NeuralNetwork_SF_HC2 | Neural Network | 21.60 | |
| 50_NeuralNetwork_HC2 | Neural Network | 22.32 | |
| 51_NeuralNetwork_HC2 | Neural Network | 97.35 | |
| Ensemble | |||
| Ensemble | Ensemble | 15.65 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walsh, A.; Goodin, P.; Carey, L.M. Identifying Correlated Functional Brain Network Patterns Associated with Touch Discrimination in Survivors of Stroke Using Automated Machine Learning. Appl. Sci. 2024, 14, 3463. https://doi.org/10.3390/app14083463
Walsh A, Goodin P, Carey LM. Identifying Correlated Functional Brain Network Patterns Associated with Touch Discrimination in Survivors of Stroke Using Automated Machine Learning. Applied Sciences. 2024; 14(8):3463. https://doi.org/10.3390/app14083463
Chicago/Turabian StyleWalsh, Alistair, Peter Goodin, and Leeanne M. Carey. 2024. "Identifying Correlated Functional Brain Network Patterns Associated with Touch Discrimination in Survivors of Stroke Using Automated Machine Learning" Applied Sciences 14, no. 8: 3463. https://doi.org/10.3390/app14083463
APA StyleWalsh, A., Goodin, P., & Carey, L. M. (2024). Identifying Correlated Functional Brain Network Patterns Associated with Touch Discrimination in Survivors of Stroke Using Automated Machine Learning. Applied Sciences, 14(8), 3463. https://doi.org/10.3390/app14083463