1. Introduction
As a fine-grained image semantic segmentation problem, fashion parsing aims to predict the label (e.g., T-shirt, bag, face, etc.) for each pixel in a fashion image. It has garnered unprecedented attention due to the fast growth of fashion-related applications, such as virtual try-ons and clothes recommendations [
1,
2]. In particular, models for high-level tasks typically use parsing results as input conditions, which benefit the precision of feature extraction [
3,
4]. However, labeling each pixel is a challenging task because some clothes with similar appearances have different categories in fashion parsing datasets, as shown in
Figure 1. Therefore, the segmentation models cannot reliably forecast classifications due to the presence of confusing semantic information. In addition, the visual variations of targets, such as resolution, deformities, occlusions and background, impose great challenges for segmentation [
5,
6]. Early work on the fashion parsing problem usually adopted the modified image segmentation models, e.g., Grab Cut and the Markov Random Field (MRF). These models always greatly benefit from incorporating shape and texture features, but they can only process limited types of clothing [
7,
8].
Recently, convolutional neural networks (CNNs) have made remarkable progress in image segmentation tasks, primarily due to their strong capabilities of feature capturing [
9,
10,
11,
12]. The prevalent CNN models for fashion parsing were based on some classical end-to-end networks, e.g., fully convolutional networks (FCNs) and U-Net [
13,
14], and they focused on improving the dataset quality to acquire more accurate results. However, dataset imbalance and low annotation quality are very common in human parsing problems in some widely used datasets, such as ModaNet [
15] and LIP [
16]. Therefore, these methods are difficult to adopt in practical applications.
Considering the limitation of the feature representation ability of classical CNN models, Vozarikova et al. [
17] designed extra branches to learn richer features from images and replaced the backbone of U-Net with ResNet-34. Zhu et al. [
18] proposed a progressive cognitive structure to segment human parts, in which the latter layers inherit information from the former layers to improve the recognition ability of small targets. To help the CNN models explicitly learn important information (e.g., edges, poses), some approaches attempted to extract priori knowledge from images and introduce them into models [
19,
20]. Ihsan et al. [
21] injected superpixel features, which were extracted from the Simple Linear Iterative Clustering (SLIC) algorithm, into the decoder path of a modified FCN. However, their method needs post-processing steps to extract the templates of clothing, which means it is not an end-to-end model. Different from manually extracting features, Ruan et al. [
22] designed a side branch for an edge detection task, which aims to improve the continuity of the segmentation results using the features of edges. Liang et al. [
16] proposed to build two networks, where the networks were utilized to learn the mask templates and texture features, respectively. Park et al. [
23] designed a tree structure to help the CNN model infer human parts in the hierarchical representation. For using human poses to provide object-level shape information, Gong et al. [
24] used poses to directly supervise the parsing results and collected more than 50,000 images to build an evaluation dataset. Xia et al. [
25] proposed a human parsing approach that uses human pose location as cues to provide pose-guided segment proposals for semantic parts. Zhang et al. [
26] designed a five-stage model to extract hierarchical features from edges and poses and leverage them to generate parsing results. However, the extracted edges and poses always contain errors, which will be accumulated in the final results.
More recently, researchers found that highlighting relevant features using the self-attention mechanism is another method to improve fashion parsing models [
27,
28]. He et al. [
29] incorporated three attention modules into a CNN, and they found that strengthening the connections between pixels using self-attention modules can increase clothing parsing accuracy. Therefore, one natural question for using a CNN model to solve the problem of fashion parsing is, can we extract priori knowledge and introduce it into a CNN model using an attention mechanism?
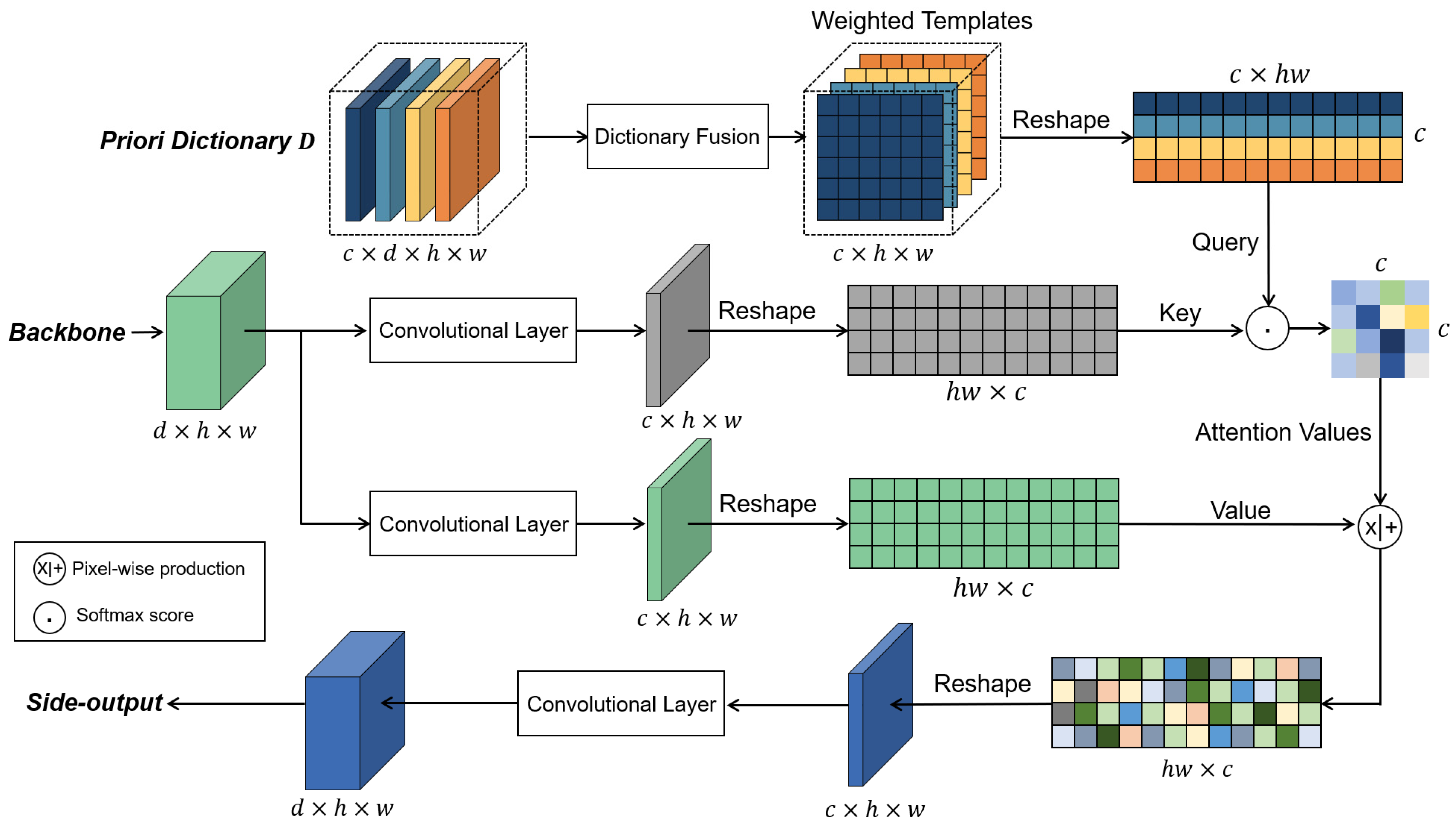
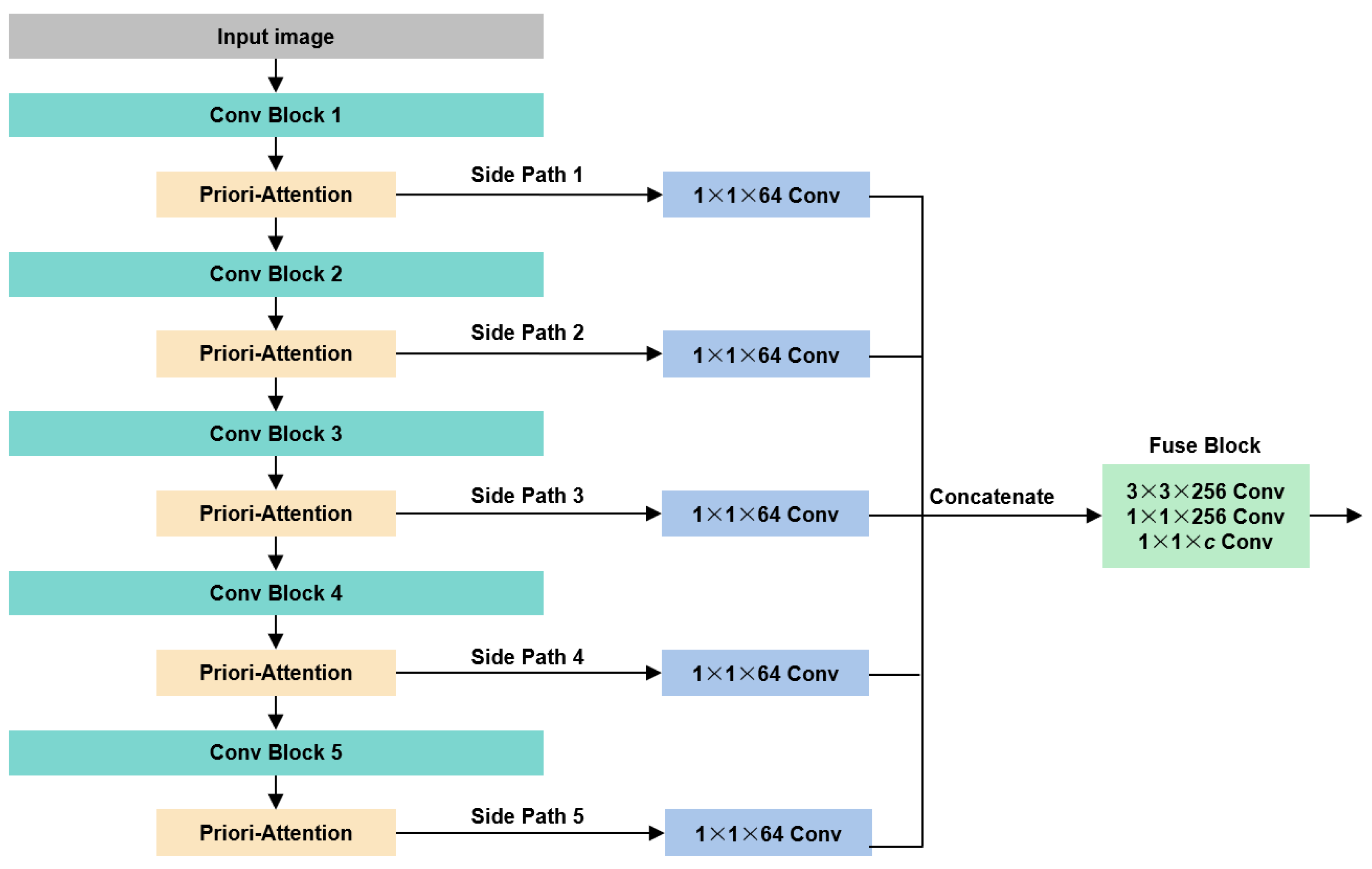
To address these issues, we propose a novel framework aimed at leveraging priori attention with fewer errors to guide the generation of fashion parsing results. Considering that the explicitly extracted priori knowledge (edges and poses) always involves errors, we implicitly extracted latent features for each category using an encoding model. Then, the non-linear combinations of features were utilized to construct a series of category-based templates. We stored these latent space templates in the priori dictionary (PD). To employ the PD in guiding the backbone of a fashion parsing network, a modified attention module is proposed. The entire model is named the Priori Dictionary Network (PDN). The PDN takes advantage of feature templates and an attention mechanism to generate segmentation results, and its contributions are threefold: (1) we put forward a priori dictionary module to help the CNN model capture important features using templates, in which the module combines the advantage of priori information and an attention mechanism; (2) we proposed a joint loss function, L2 loss and cross-entropy loss to supervise the model training, which made the accuracy and IoU increase by 0.45% and 6.01%, respectively; and (3) we developed a multiple path architecture to fuse clothing features on a multi-scale, and the comparison results show that the proposed model outperforms State-of-the-Art methods in public fashion parsing datasets.
4. Conclusions
In this paper, we present a priori attention module-based CNN method for fashion parsing. First, we extracted features from training images and built a priori dictionary to store the features. Then, we attached the priori dictionary to a multi-scale backbone derived from VGG-16 and ResNet. Furthermore, a joint loss function that is composed of L2 loss and cross-entropy loss was proposed to guide the model training. We conducted our model on four public datasets, and the experiment results show that the CNN model can effectively annotate different types of targets by introducing our latent features, with mIOU values of 73.99, 79.91, 69.88 and 45.12 on the four datasets, respectively. Through a fair comparison with other State-of-the-Art models, we demonstrate that the PDN can achieve competitive results for fashion parsing. Additionally, the ablation study shows that the priori attention module and joint loss function improve the performance of the model. Although the PDN model can obtain precise parsing results on high-quality annotated datasets, the feature templates cannot lead to a significant improvement in the performance of predicting pixel labels for small targets. In future work, we will explore the use of priori knowledge introduction to improve parsing accuracy in more complex backbone models.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}