
A Normalization Strategy for Weakly Supervised 3D Hand Pose Estimation


Abstract
:1. Introduction
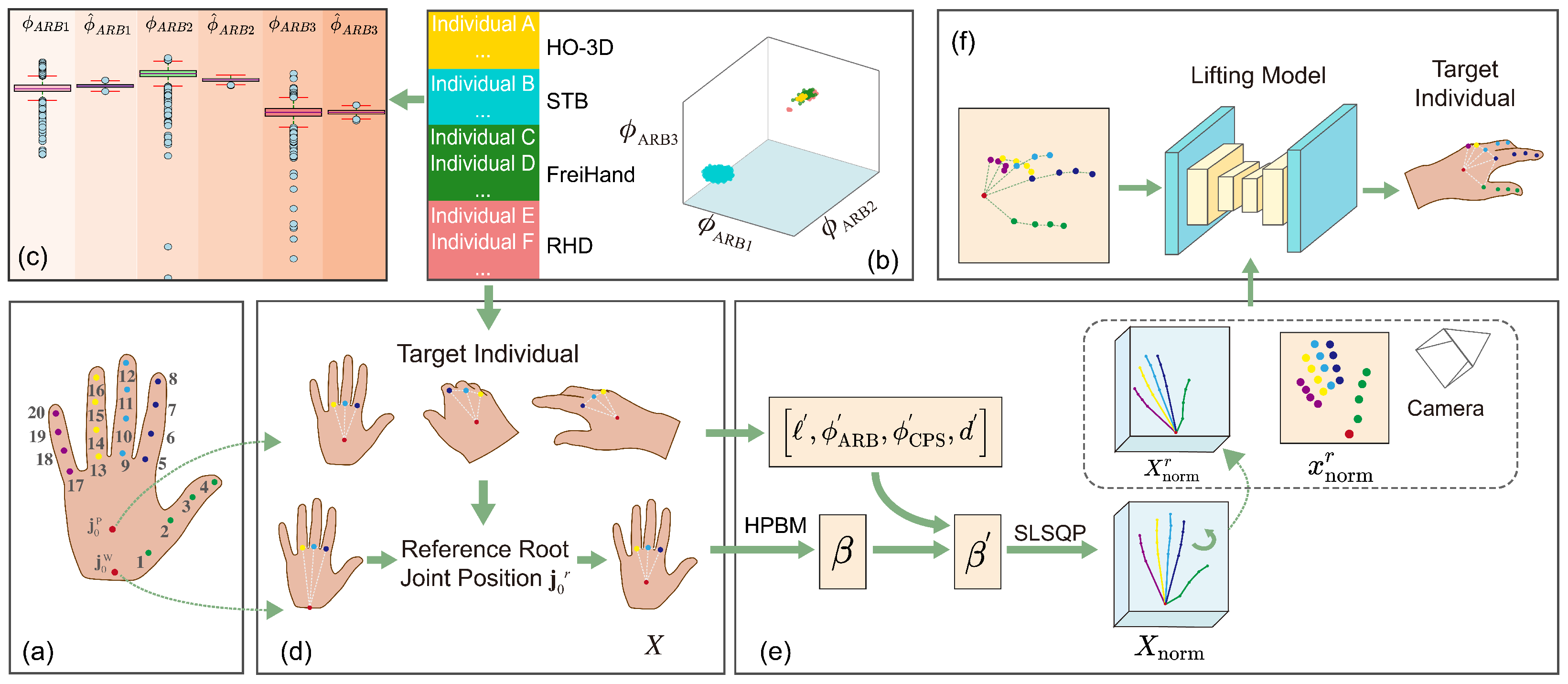
- In consideration of the anatomical characteristics of the hand, a novel HPBM is introduced, specifically crafted to intuitively depict the biomechanical features of hand poses. This model addresses the limitations associated with traditional 3D coordinate-encoded pose representations.
- A universal and effective dataset normalization strategy was explored, utilizing the HPBM to unify biomechanical features and standardize root joint positions within and across datasets. In addition, a weakly supervised training methodology was also introduced, utilizing the HPBM to autonomously generate robust 2D–3D pose pairs without the need for manual annotations.
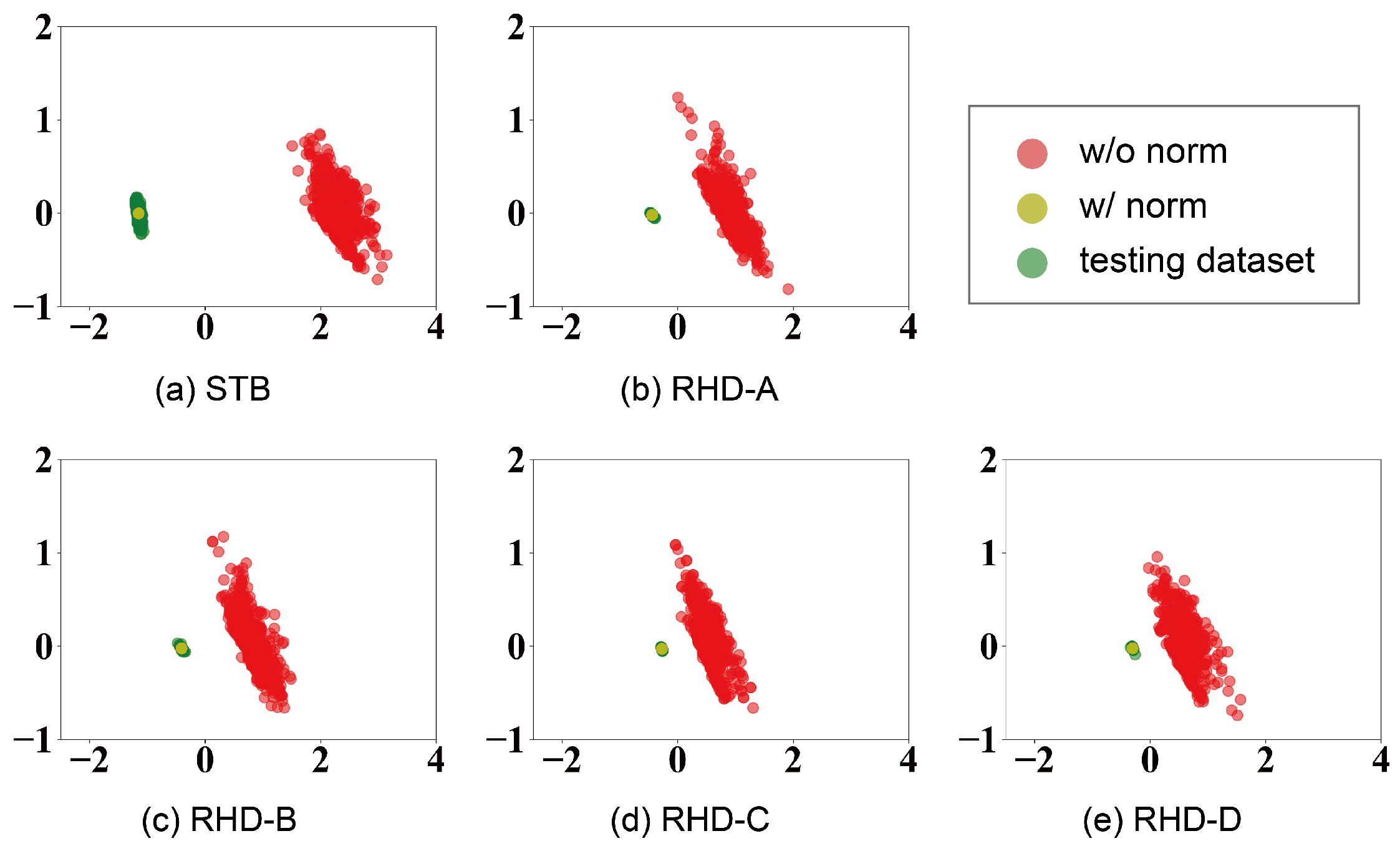
- Compared to training on non-normalized data, models trained on the proposed normalized dataset demonstrated significant improvements. On the RHD and STB datasets, notable reductions of 45.1% and 43.4% in error were observed when the model utilized the ground truth 2D pose. Weakly supervised training further achieved an additional 5.7% reduction. The proposed framework proves effective, delivering advanced estimation performance.
2. Related works
2.1. The 2D-to-3D Lifting Pipeline
2.2. Techniques for Addressing Limited Annotated 3D Pose Training Data
3. Method
3.1. Overview
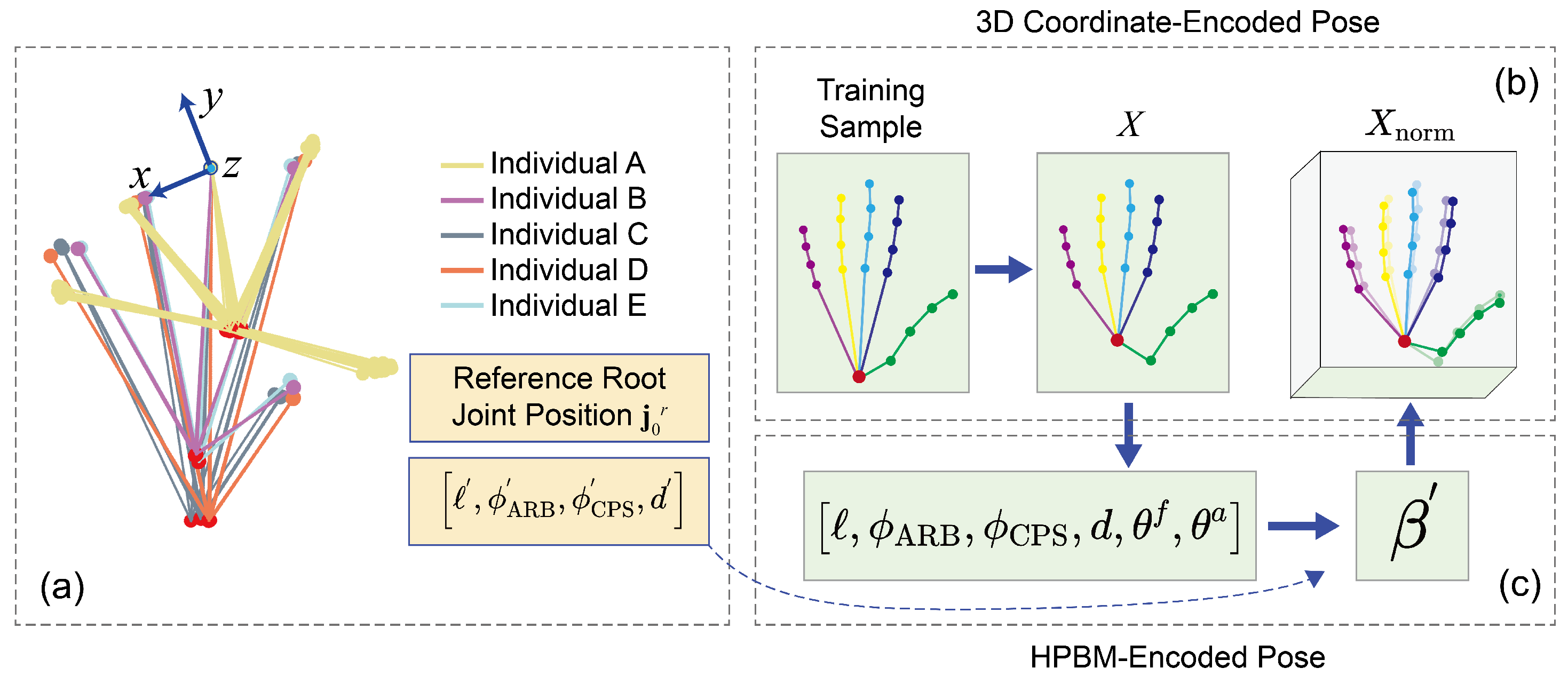
3.2. Hand Pose Biomechanical Model
- The kinematic chain starting from the root joint and extending to the fingertips.
- The parent joint of a given joint is denoted as .
- A bone is defined as the vector pointing from the parent joint to its child joint, computed by .
- The root bones vectors are represented as, as indicated by the solid line in Figure 2a.
- The angular distance between two vectors, and , is denoted by and is calculated using the arccosine function as .
- The normalized vector is defined as .
- The operator is used to project a vector orthogonally onto the plane where , are vectors.
3.3. Normalization Strategy
3.4. Weakly Supervised Training
4. Experiments
4.1. Experimental Setup
4.2. Implementation Details
4.3. Evaluation of Normalization Strategy
4.4. Evaluation of Weakly Supervised Approach
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cai, Y.; Ge, L.; Liu, J.; Cai, J.; Cham, T.J.; Yuan, J.; Thalmann, N.M. Exploiting spatial-temporal relationships for 3d pose estimation via graph convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2272–2281. [Google Scholar]
- Jiang, C.; Xiao, Y.; Wu, C.; Zhang, M.; Zheng, J.; Cao, Z.; Zhou, J.T. A2J-Transformer: Anchor-to-Joint Transformer Network for 3D Interacting Hand Pose Estimation from a Single RGB Image. arXiv 2023, arXiv:2304.03635. [Google Scholar]
- Karunratanakul, K.; Prokudin, S.; Hilliges, O.; Tang, S. HARP: Personalized Hand Reconstruction from a Monocular RGB Video. arXiv 2022, arXiv:2212.09530. [Google Scholar]
- Zhang, J.; Tu, Z.; Yang, J.; Chen, Y.; Yuan, J. Mixste: Seq2seq mixed spatio-temporal encoder for 3d human pose estimation in video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13232–13242. [Google Scholar]
- Deng, X.; Zuo, D.; Zhang, Y.; Cui, Z.; Cheng, J.; Tan, P.; Chang, L.; Pollefeys, M.; Fanello, S.; Wang, H. Recurrent 3D Hand Pose Estimation Using Cascaded Pose-guided 3D Alignments. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 932–945. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Kundu, J.N.; Seth, S.; YM, P.; Jampani, V.; Chakraborty, A.; Babu, R.V. Uncertainty-aware adaptation for self-supervised 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20448–20459. [Google Scholar]
- Sharma, S.; Huang, S. An end-to-end framework for unconstrained monocular 3D hand pose estimation. Pattern Recognit. 2021, 115, 107892. [Google Scholar] [CrossRef]
- Li, M.; Wang, J.; Sang, N. Latent distribution-based 3D hand pose estimation from monocular RGB images. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4883–4894. [Google Scholar] [CrossRef]
- Spurr, A.; Iqbal, U.; Molchanov, P.; Hilliges, O.; Kautz, J. Weakly supervised 3d hand pose estimation via biomechanical constraints. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 211–228. [Google Scholar]
- Zimmermann, C.; Brox, T. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4903–4911. [Google Scholar]
- Kulon, D.; Guler, R.A.; Kokkinos, I.; Bronstein, M.M.; Zafeiriou, S. Weakly-supervised mesh-convolutional hand reconstruction in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4990–5000. [Google Scholar]
- Qiu, Z.; Qiu, K.; Fu, J.; Fu, D. Weakly-supervised pre-training for 3D human pose estimation via perspective knowledge. Pattern Recognit. 2023, 139, 109497. [Google Scholar] [CrossRef]
- Yang, C.Y.; Luo, J.; Xia, L.; Sun, Y.; Qiao, N.; Zhang, K.; Jiang, Z.; Hwang, J.N.; Kuo, C.H. CameraPose: Weakly-Supervised Monocular 3D Human Pose Estimation by Leveraging In-the-wild 2D Annotations. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2924–2933. [Google Scholar]
- Guo, S.; Rigall, E.; Qi, L.; Dong, X.; Li, H.; Dong, J. Graph-based CNNs with self-supervised module for 3D hand pose estimation from monocular RGB. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1514–1525. [Google Scholar] [CrossRef]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. A hand pose tracking benchmark from stereo matching. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 982–986. [Google Scholar]
- Ci, H.; Wang, C.; Ma, X.; Wang, Y. Optimizing network structure for 3d human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2262–2271. [Google Scholar]
- Liu, K.; Ding, R.; Zou, Z.; Wang, L.; Tang, W. A comprehensive study of weight sharing in graph networks for 3d human pose estimation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 318–334. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A simple yet effective baseline for 3d human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2640–2649. [Google Scholar]
- Xu, T.; Takano, W. Graph stacked hourglass networks for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 16105–16114. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7753–7762. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Ma, X.; Rahmani, H.; Fan, Z.; Yang, B.; Chen, J.; Liu, J. Remote: Reinforced motion transformation network for semi-supervised 2d pose estimation in videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1944–1952. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. Mediapipe hands: On-device real-time hand tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Chen, T.; Fang, C.; Shen, X.; Zhu, Y.; Chen, Z.; Luo, J. Anatomy-aware 3d human pose estimation with bone-based pose decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 198–209. [Google Scholar] [CrossRef]
- Lee, S.; Park, H.; Kim, D.U.; Kim, J.; Boboev, M.; Baek, S. Image-free Domain Generalization via CLIP for 3D Hand Pose Estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2934–2944. [Google Scholar]
- Wan, C.; Probst, T.; Gool, L.V.; Yao, A. Self-supervised 3d hand pose estimation through training by fitting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10853–10862. [Google Scholar]
- Spurr, A.; Dahiya, A.; Wang, X.; Zhang, X.; Hilliges, O. Self-supervised 3d hand pose estimation from monocular rgb via contrastive learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 11230–11239. [Google Scholar]
- Chen, Y.; Tu, Z.; Kang, D.; Bao, L.; Zhang, Y.; Zhe, X.; Chen, R.; Yuan, J. Model-based 3d hand reconstruction via self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10451–10460. [Google Scholar]
- Ren, P.; Sun, H.; Hao, J.; Qi, Q.; Wang, J.; Liao, J. A Dual-Branch Self-Boosting Framework for Self-Supervised 3D Hand Pose Estimation. IEEE Trans. Image Process. 2022, 31, 5052–5066. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3d human pose estimation in the wild: A weakly-supervised approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-supervised 3d hand pose estimation from monocular rgb images. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 666–682. [Google Scholar]
- Hua, G.; Liu, H.; Li, W.; Zhang, Q.; Ding, R.; Xu, X. Weakly-supervised 3D human pose estimation with cross-view U-shaped graph convolutional network. IEEE Trans. Multimed. 2022, 25, 1832–1843. [Google Scholar] [CrossRef]
- Cai, Y.; Ge, L.; Cai, J.; Thalmann, N.M.; Yuan, J. 3D hand pose estimation using synthetic data and weakly labeled RGB images. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3739–3753. [Google Scholar] [CrossRef] [PubMed]
- Khaleghi, L.; Sepas-Moghaddam, A.; Marshall, J.; Etemad, A. Multi-view video-based 3D hand pose estimation. IEEE Trans. Artif. Intell. 2022, 4, 896–909. [Google Scholar] [CrossRef]
- Iqbal, U.; Molchanov, P.; Gall, T.B.J.; Kautz, J. Hand pose estimation via latent 2.5 d heatmap regression. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 118–134. [Google Scholar]
- Hampali, S.; Rad, M.; Oberweger, M.; Lepetit, V. Honnotate: A method for 3d annotation of hand and object poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3196–3206. [Google Scholar]
- Zimmermann, C.; Ceylan, D.; Yang, J.; Russell, B.; Argus, M.; Brox, T. Freihand: A dataset for markerless capture of hand pose and shape from single rgb images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 813–822. [Google Scholar]
- Gower, J.C. Generalized procrustes analysis. Psychometrika 1975, 40, 33–51. [Google Scholar] [CrossRef]
- Gong, K.; Zhang, J.; Feng, J. Poseaug: A differentiable pose augmentation framework for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8575–8584. [Google Scholar]
- Yang, L.; Li, S.; Lee, D.; Yao, A. Aligning latent spaces for 3d hand pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2335–2343. [Google Scholar]
- Chen, X.; Liu, Y.; Ma, C.; Chang, J.; Wang, H.; Chen, T.; Guo, X.; Wan, P.; Zheng, W. Camera-space hand mesh recovery via semantic aggregation and adaptive 2d-1d registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13274–13283. [Google Scholar]
- Zhang, B.; Wang, Y.; Deng, X.; Zhang, Y.; Tan, P.; Ma, C.; Wang, H. Interacting two-hand 3d pose and shape reconstruction from single color image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 11–17 October 2021; pp. 11354–11363. [Google Scholar]
- Yang, L.; Li, J.; Xu, W.; Diao, Y.; Lu, C. BiHand: Recovering Hand Mesh with Multi-stage Bisected Hourglass Networks. In Proceedings of the British Machine Vision Conference, Manchester, UK, 7–10 September 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2D Pose | Model | Datasets | w/o norm | w/ norm | ||
|---|---|---|---|---|---|---|
| PJ ↓ | AUC ↑ | PJ ↓ | AUC ↑ | |||
| GT | VPose3D | STB | 12.37 | 0.960 | 6.78 | 0.995 |
| RHD-A | 9.91 | 0.984 | 5.21 | 0.996 | ||
| RHD-B | 9.03 | 0.988 | 5.24 | 0.996 | ||
| RHD-C | 7.87 | 0.992 | 4.70 | 0.997 | ||
| RHD-D | 7.62 | 0.993 | 4.33 | 0.998 | ||
| ST-GCN | STB | 13.52 | 0.958 | 6.77 | 0.995 | |
| RHD-A | 11.18 | 0.970 | 4.48 | 0.995 | ||
| RHD-B | 10.35 | 0.977 | 4.76 | 0.994 | ||
| RHD-C | 7.89 | 0.988 | 4.07 | 0.996 | ||
| RHD-D | 7.47 | 0.990 | 3.71 | 0.998 | ||
| MediaPipe | VPose3D | STB | 11.39 | 0.964 | 10.10 | 0.989 |
| RHD-A | 13.53 | 0.945 | 11.35 | 0.949 | ||
| RHD-B | 13.07 | 0.947 | 11.43 | 0.946 | ||
| RHD-C | 10.83 | 0.971 | 9.18 | 0.971 | ||
| RHD-D | 10.92 | 0.968 | 9.45 | 0.966 | ||
| ST-GCN | STB | 12.42 | 0.963 | 12.33 | 0.951 | |
| RHD-A | 14.70 | 0.929 | 12.23 | 0.931 | ||
| RHD-B | 14.29 | 0.930 | 12.11 | 0.930 | ||
| RHD-C | 11.58 | 0.958 | 9.50 | 0.962 | ||
| RHD-D | 11.54 | 0.957 | 9.66 | 0.959 | ||
| Datasets | w/ norm | w/o norm | ||||
|---|---|---|---|---|---|---|
| STB | 8.43 | 0.0001 | 0.036 | 71.05 | 0.245 | 0.818 |
| RHD-A | 9.89 | 0.0169 | 0.006 | 33.75 | 0.079 | 0.062 |
| RHD-B | 10.10 | 0.0162 | 0.007 | 31.51 | 0.067 | 0.053 |
| RHD-C | 8.69 | 0.0083 | 0.007 | 22.73 | 0.122 | 0.044 |
| RHD-D | 8.08 | 0.0057 | 0.007 | 21.03 | 0.118 | 0.035 |
| Methods | Datasets | |||||
|---|---|---|---|---|---|---|
| RHD-A | RHD-B | RHD-C | RHD-D | RHD | ||
| LDR [11] | - | - | - | - | 11.63 | |
| SS-GCN [17] | - | - | - | - | 13.29 | |
| RC2CHP [44] | - | - | - | - | 13.14 | |
| GT | 5.97 | 6.52 | 7.67 | 8.51 | 7.19 | |
| 4.73 | 4.93 | 4.42 | 4.25 | 4.57 | ||
| MediaPipe | 11.19 | 11.70 | 10.69 | 11.63 | 11.29 | |
| 10.92 | 11.14 | 9.01 | 9.22 | 10.03 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Li, J.; Tan, J. A Normalization Strategy for Weakly Supervised 3D Hand Pose Estimation. Appl. Sci. 2024, 14, 3578. https://doi.org/10.3390/app14093578
Guo Z, Li J, Tan J. A Normalization Strategy for Weakly Supervised 3D Hand Pose Estimation. Applied Sciences. 2024; 14(9):3578. https://doi.org/10.3390/app14093578
Chicago/Turabian StyleGuo, Zizhao, Jinkai Li, and Jiyong Tan. 2024. "A Normalization Strategy for Weakly Supervised 3D Hand Pose Estimation" Applied Sciences 14, no. 9: 3578. https://doi.org/10.3390/app14093578
APA StyleGuo, Z., Li, J., & Tan, J. (2024). A Normalization Strategy for Weakly Supervised 3D Hand Pose Estimation. Applied Sciences, 14(9), 3578. https://doi.org/10.3390/app14093578