

Speaker Anonymization: Disentangling Speaker Features from Pre-Trained Speech Embeddings for Voice Conversion


Abstract
:1. Introduction
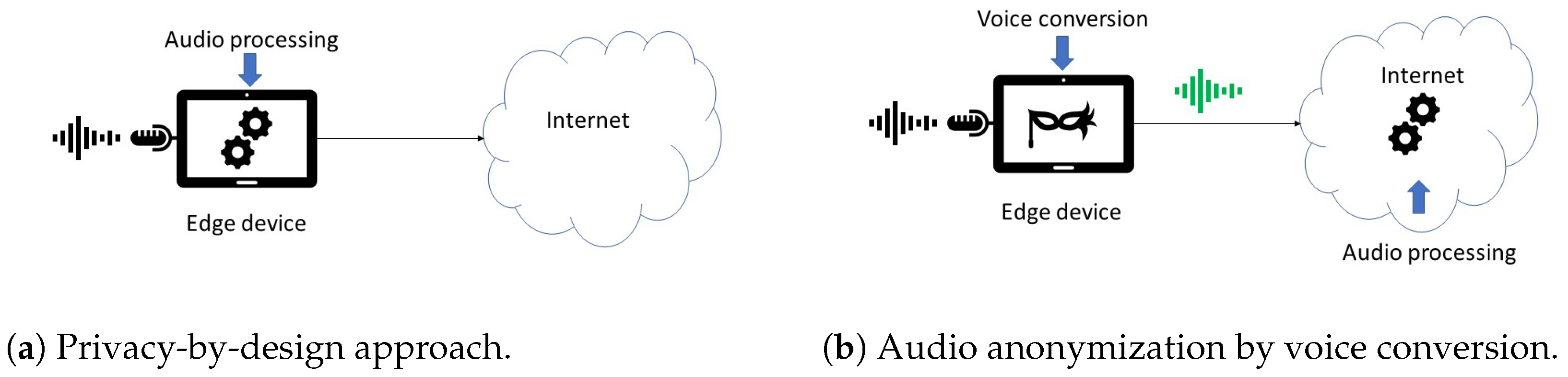
Significance of Speaker Anonymization
- Privacy Protection and Ethical Data Use The preservation of personal privacy is critical in a time when personal data are increasingly being stored digitally. If voice recordings are not sufficiently anonymized, they can be used for malicious activities such as identity theft and spying. Voice anonymization techniques allow voice data to be used while hiding the speaker’s identity.
- Legal Compliance Organizations handling voice data are required to abide by the increasingly strict data protection regulations being introduced by governments and regulatory bodies. In order to guarantee that sensitive voice data are handled in a way that complies with legal requirements, voice anonymization can be a crucial part of compliance strategies.
- Enhanced Security Malicious actors may use exposed voice data to commit fraud or identity theft. The risks of data breaches and unauthorized access are reduced by anonymizing voice recordings.
- Versatile Applications In addition to protecting one’s privacy, voice anonymization makes it possible to use voice data for a variety of purposes without sacrificing the data’s security or confidentiality. This covers everything from enhancing call center and voice assistant functionality to supporting law enforcement organizations in protecting the privacy of their witnesses.
2. State-of-the-Art Techniques
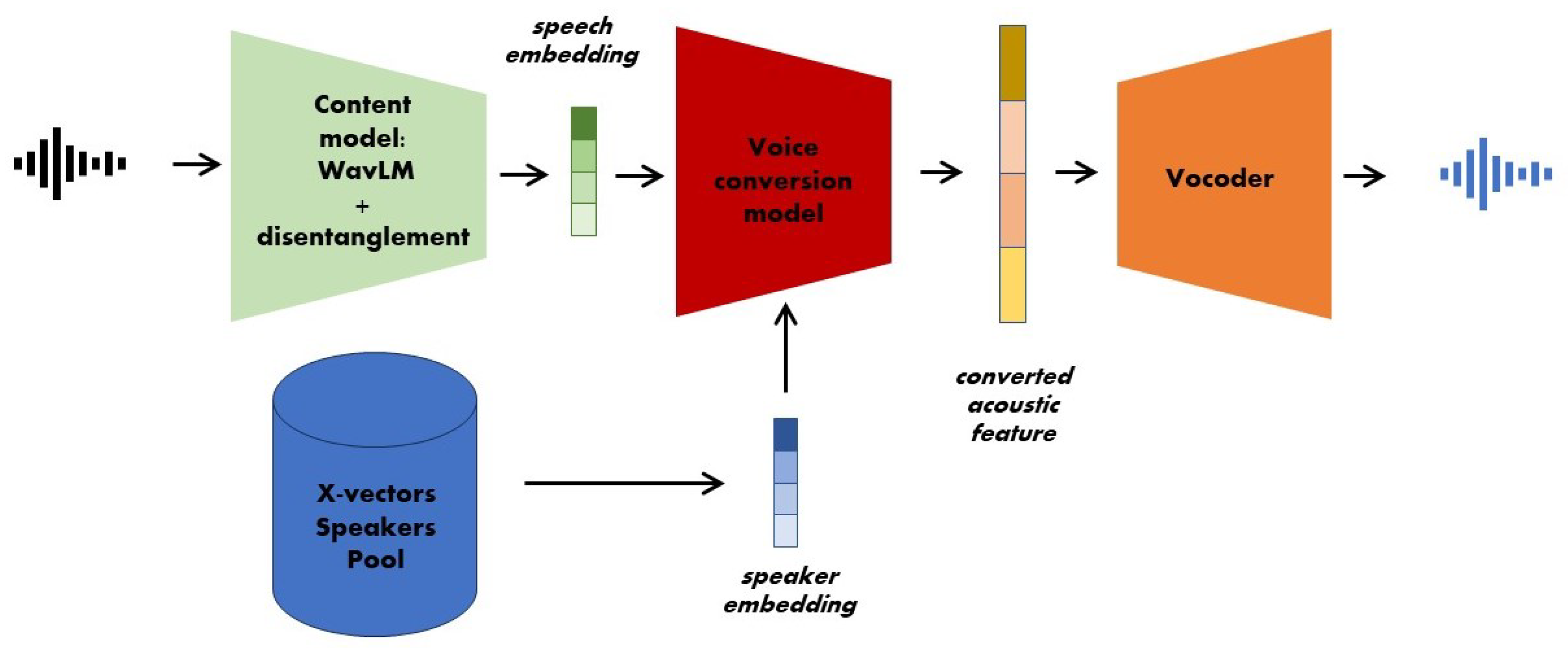
3. The Proposed Approach: Disentanglement of Pre-Trained Speech Embeddings
- 1.
- Instead of using posteriorgrams features, as proposed in the original architecture, pre-trained speech and speaker representations are employed.
- 2.
- We introduce the use of disentanglement techniques, following a similar direction as ContentVec [36], on pre-trained speech representation.
- the pitch is altered by a random shift in range and by a random scale in the range ;
- similarly, the formants are shift by a random value in the range .
4. Experimental Settings
4.1. Implementation Details
4.2. Metrics
4.3. Voice Conversion Baselines
4.4. Vocoder
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometrics recognition using deep learning: A survey. Artif. Intell. Rev. 2023, 56, 8647–8695. [Google Scholar] [CrossRef]
- Mordini, E. Biometric privacy protection: What is this thing called privacy? IET Biom. 2023, 12, 183–193. [Google Scholar] [CrossRef]
- Wells, A.; Usman, A.B. Trust and Voice Biometrics Authentication for Internet of Things. Int. J. Inf. Secur. Priv. 2023, 17, 1–28. [Google Scholar] [CrossRef]
- Chouchane, O.; Panariello, M.; Galdi, C.; Todisco, M.; Evans, N.W.D. Fairness and Privacy in Voice Biometrics: A Study of Gender Influences Using wav2vec 2.0. In Proceedings of the 2023 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 20–22 September 2023; pp. 1–7. [Google Scholar]
- Hacker, P.; Cordes, J.; Rochon, J. Regulating Gatekeeper Artificial Intelligence and Data: Transparency, Access and Fairness under the Digital Markets Act, the General Data Protection Regulation and Beyond. Eur. J. Risk Regul. 2023, 15, 49–86. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep Learning with Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Jiang, Y.; Wang, S.; Ko, B.; Lee, W.H.; Tassiulas, L. Model Pruning Enables Efficient Federated Learning on Edge Devices. IEEE Trans. Neural Networks Learn. Syst. 2019, 34, 10374–10386. [Google Scholar] [CrossRef]
- Cerutti, G.; Prasad, R.; Brutti, A.; Farella, E. Compact recurrent neural networks for acoustic event detection on low-energy low-complexity platforms. IEEE J. Sel. Top. Signal Process. 2020, 14, 654–664. [Google Scholar] [CrossRef]
- Jia, B.; Zhang, X.; Liu, J.; Zhang, Y.; Huang, K.; Liang, Y. Blockchain-Enabled Federated Learning Data Protection Aggregation Scheme with Differential Privacy and Homomorphic Encryption in IIoT. IEEE Trans. Ind. Inform. 2021, 18, 4049–4058. [Google Scholar] [CrossRef]
- Wei, T.; Lv, Z.; Jin, R.; Di, W.; Yang, L.; Yang, X. Homomorphic Encryption Based Privacy Protection Techniques for Cloud Computing. In Proceedings of the 2023 2nd International Conference on Cloud Computing, Big Data Application and Software Engineering (CBASE), Chengdu, China, 3–5 November 2023; pp. 67–71. [Google Scholar]
- Sun, K.; Chen, C.; Zhang, X. “Alexa, stop spying on me!”: Speech privacy protection against voice assistants. In Proceedings of the 18th Conference on Embedded Networked Sensor Systems, Virtual Event, 16–19 November 2020. [Google Scholar]
- Tran, M.; Soleymani, M. A Speech Representation Anonymization Framework via Selective Noise Perturbation. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Han, Y.; Li, S.; Cao, Y.; Ma, Q.; Yoshikawa, M. Voice-Indistinguishability: Protecting Voiceprint In Privacy-Preserving Speech Data Release. In Proceedings of the IEEE International Conference on Multimedia and Expo, London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yoo, I.C.; Lee, K.; Leem, S.; Oh, H.; Ko, B.; Yook, D. Speaker Anonymization for Personal Information Protection Using Voice Conversion Techniques. IEEE Access 2020, 8, 198637–198645. [Google Scholar] [CrossRef]
- Mawalim, C.O.; Galajit, K.; Karnjana, J.; Kidani, S.; Unoki, M. Speaker anonymization by modifying fundamental frequency and x-vector singular value. Comput. Speech Lang. 2022, 73, 101326. [Google Scholar] [CrossRef]
- Noé, P.G.; Nautsch, A.; Evans, N.; Patino, J.; Bonastre, J.F.; Tomashenko, N.; Matrouf, D. Towards a unified assessment framework of speech pseudonymisation. Comput. Speech Lang. 2022, 72, 101299. [Google Scholar] [CrossRef]
- Costante, M.; Matassoni, M.; Brutti, A. Using Seq2seq voice conversion with pre-trained representations for audio anonymization: Experimental insights. In Proceedings of the 2022 IEEE International Smart Cities Conference (ISC2), Pafos, Cyprus, 26–29 September 2022; pp. 1–7. [Google Scholar]
- Tomashenko, N.; Wang, X.; Miao, X.; Nourtel, H.; Champion, P.; Todisco, M.; Vincent, E.; Evans, N.; Yamagishi, J.; Bonastre, J.F. The VoicePrivacy 2022 Challenge Evaluation Plan. arXiv 2022, arXiv:2203.12468. [Google Scholar]
- Liu, S.; Cao, Y.; Wang, D.; Wu, X.; Liu, X.; Meng, H. Any-to-Many Voice Conversion with Location-Relative Sequence-to-Sequence Modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1717–1728. [Google Scholar] [CrossRef]
- Yang, S.; Tantrawenith, M.; Zhuang, H.; Wu, Z.; Sun, A.; Wang, J.; Cheng, N.; Tang, H.; Zhao, X.; Wang, J.; et al. Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion. arXiv 2022, arXiv:2208.08757. [Google Scholar] [CrossRef]
- Kovela, S.; Valle, R.; Dantrey, A.; Catanzaro, B. Any-to-Any Voice Conversion with F0 and Timbre Disentanglement and Novel Timbre Conditioning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Saini, S.; Saxena, N. Speaker Anonymity and Voice Conversion Vulnerability: A Speaker Recognition Analysis. In Proceedings of the 2023 IEEE Conference on Communications and Network Security (CNS), Orlando, FL, USA, 2–5 October 2023; pp. 1–9. [Google Scholar]
- Kang, W.; Hasegawa-Johnson, M.; Roy, D. End-to-End Zero-Shot Voice Conversion with Location-Variable Convolutions. In Proceedings of the INTERSPEECH 2023, Dublin, Ireland, 20–24 August 2023; pp. 2303–2307. [Google Scholar] [CrossRef]
- Li, J.; Tu, W.; Xiao, L. Freevc: Towards High-Quality Text-Free One-Shot Voice Conversion. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, Y.; Kartynnik, Y.; Li, Y.; Tang, J.; Li, X.; Sung, G.; Grundmann, M. StreamVC: Real-Time Low-Latency Voice Conversion. arXiv 2024, arXiv:2401.03078. [Google Scholar]
- Shamsabadi, A.S.; Srivastava, B.M.L.; Bellet, A.; Vauquier, N.; Vincent, E.; Maouche, M.; Tommasi, M.; Papernot, N. Differentially private speaker anonymization. arXiv 2022, arXiv:2202.11823. [Google Scholar] [CrossRef]
- Champion, P.; Jouvet, D.; Larcher, A. Are disentangled representations all you need to build speaker anonymization systems? arXiv 2022, arXiv:2208.10497. [Google Scholar]
- Liu, T.; Lee, K.A.; Wang, Q.; Li, H. Disentangling Voice and Content with Self-Supervision for Speaker Recognition. arXiv 2023, arXiv:2310.01128. [Google Scholar]
- Tomashenko, N.; Wang, X.; Vincent, E.; Patino, J.; Srivastava, B.M.L.; Noé, P.G.; Nautsch, A.; Evans, N.; Yamagishi, J.; O’Brien, B.; et al. The VoicePrivacy 2020 Challenge: Results and findings. Comput. Speech Lang. 2022, 74, 101362. [Google Scholar] [CrossRef]
- Leschanowsky, A.; Gaznepoglu, Ü.E.; Peters, N. Voice Anonymization for All - Bias Evaluation of the Voice Privacy Challenge Baseline System. arXiv 2023, arXiv:2311.15804. [Google Scholar]
- Feng, T.; Hebbar, R.; Mehlman, N.; Shi, X.; Kommineni, A.; Narayanan, S.S. A Review of Speech-centric Trustworthy Machine Learning: Privacy, Safety, and Fairness. arXiv 2022, arXiv:2212.09006. [Google Scholar] [CrossRef]
- Fischer-Hübner, S.; Klakow, D.; Valcke, P.; Vincent, E. Privacy in Speech and Language Technology (Dagstuhl Seminar 22342). Dagstuhl Rep. 2023, 12, 60–102. [Google Scholar] [CrossRef]
- Wu, P.; Liang, P.P.; Shi, J.; Salakhutdinov, R.; Watanabe, S.; Morency, L.P. Understanding the Tradeoffs in Client-side Privacy for Downstream Speech Tasks. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 841–848. [Google Scholar]
- Champion, P.; Thebaud, T.; Lan, G.L.; Larcher, A.; Jouvet, D. On the Invertibility of a Voice Privacy System Using Embedding Alignment. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 191–197. [Google Scholar]
- Panariello, M.; Todisco, M.; Evans, N.W.D. Vocoder drift in x-vector–based speaker anonymization. In Proceedings of the Interspeech 2023, Dublin, Ireland, 20–24 August 2023; pp. 2863–2867. [Google Scholar]
- Qian, K.; Zhang, Y.; Gao, H.; Ni, J.; Lai, C.I.; Cox, D.; Hasegawa-Johnson, M.; Chang, S. ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 18003–18017. [Google Scholar]
- Huang, W.C.; Yang, S.W.; Hayashi, T.; Toda, T. A Comparative Study of Self-Supervised Speech Representation Based Voice Conversion. IEEE J. Sel. Top. Signal Process. 2022, 16, 1308–1318. [Google Scholar] [CrossRef]
- Cohen-Hadria, A.; Cartwright, M.; McFee, B.; Bello, J.P. Voice Anonymization in Urban Sound Recordings. In Proceedings of the 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, G.; Dai, H.; Bai, Y. DAFL: Domain adaptation-based federated learning for privacy-preserving biometric recognition. Future Gener. Comput. Syst. 2023, 150, 436–450. [Google Scholar] [CrossRef]
- Tomashenko, N.; Mdhaffar, S.; Tommasi, M.; Estève, Y.; Bonastre, J.F. Privacy attacks for automatic speech recognition acoustic models in a federated learning framework. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6972–6976. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends® Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Byun, K.; Moon, S.; Visser, E. Highly Controllable Diffusion-based Any-to-Any Voice Conversion Model with Frame-level Prosody Feature. arXiv 2023, arXiv:2309.03364. [Google Scholar]
- Tavi, L.; Kinnunen, T.; González Hautamäki, R. Improving speaker de-identification with functional data analysis of f0 trajectories. Speech Commun. 2022, 140, 1–10. [Google Scholar] [CrossRef]
- Patino, J.; Tomashenko, N.A.; Todisco, M.; Nautsch, A.; Evans, N.W.D. Speaker anonymisation using the McAdams coefficient. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Mawalim, C.O.; Okada, S.; Unoki, M. Speaker anonymization by pitch shifting based on time-scale modification. In Proceedings of the 2nd Symposium on Security and Privacy in Speech Communication, Incheon, Republic of Korea, 22–23 September 2022. [Google Scholar]
- Srivastava, B.M.L.; Maouche, M.; Sahidullah, M.; Vincent, E.; Bellet, A.; Tommasi, M.; Tomashenko, N.; Wang, X.; Yamagishi, J. Privacy and Utility of X-Vector Based Speaker Anonymization. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2383–2395. [Google Scholar] [CrossRef]
- Fang, F.; Wang, X.; Yamagishi, J.; Echizen, I.; Todisco, M.; Evans, N.W.D.; Bonastre, J.F. Speaker Anonymization Using X-vector and Neural Waveform Models. arXiv 2019, arXiv:1905.13561. [Google Scholar]
- Panariello, M.; Nespoli, F.; Todisco, M.; Evans, N. Speaker anonymization using neural audio codec language models. arXiv 2023, arXiv:2309.14129. [Google Scholar]
- Borsos, Z.; Marinier, R.; Vincent, D.; Kharitonov, E.; Pietquin, O.; Sharifi, M.; Teboul, O.; Grangier, D.; Tagliasacchi, M.; Zeghidour, N. AudioLM: A Language Modeling Approach to Audio Generation. In IEEE/ACM Transactions on Audio, Speech, and Language Processing; IEEE: Piscataway, NJ, USA, 2023; Volume 31, pp. 2523–2533. [Google Scholar]
- Perero-Codosero, J.M.; Espinoza-Cuadros, F.M.; Hernández-Gómez, L.A. X-vector anonymization using autoencoders and adversarial training for preserving speech privacy. Comput. Speech Lang. 2022, 74, 101351. [Google Scholar] [CrossRef]
- Miao, X.; Wang, X.; Cooper, E.; Yamagishi, J.; Tomashenko, N.A. Speaker Anonymization Using Orthogonal Householder Neural Network. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 3681–3695. [Google Scholar] [CrossRef]
- Lv, Y.; Yao, J.; Chen, P.; Zhou, H.; Lu, H.; Xie, L. Salt: Distinguishable Speaker Anonymization Through Latent Space Transformation. In Proceedings of the 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Taipei, Taiwan, 16–20 December 2023; pp. 1–8. [Google Scholar]
- Baas, M.; van Niekerk, B.; Kamper, H. Voice Conversion with Just Nearest Neighbors. In Proceedings of the INTERSPEECH 2023, Dublin, Ireland, 20–24 August 2023; pp. 2053–2057. [Google Scholar] [CrossRef]
- Chen, X.; Li, S.; Li, J.; Huang, H.; Cao, Y.; He, L. Reprogramming Self-supervised Learning-based Speech Representations for Speaker Anonymization. In Proceedings of the 5th ACM International Conference on Multimedia in Asia, Tainan, Taiwan, 6–8 December 2023. [Google Scholar]
- Deng, J.; Teng, F.; Chen, Y.; Chen, X.; Wang, Z.; Xu, W. V-Cloak: Intelligibility-, Naturalness- & Timbre-Preserving Real-Time Voice Anonymization. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 5181–5198. [Google Scholar]
- Nespoli, F.; Barreda, D.; Bitzer, J.; Naylor, P.A. Two-Stage Voice Anonymization for Enhanced Privacy. arXiv 2023, arXiv:2306.16069. [Google Scholar]
- Lin, J.; Lin, Y.Y.; Chien, C.M.; Lee, H. S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations. In Proceedings of the Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2021; pp. 836–840. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. IEEE J. Sel. Top. Signal Process. 2021, 16, 1505–1518. [Google Scholar] [CrossRef]
- Koluguri, N.R.; Park, T.; Ginsburg, B. TitaNet: Neural Model for speaker representation with 1D Depth-wise separable convolutions and global context. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 23–27 May 2022. [Google Scholar]
- Wei, P.; Yin, X.; Wang, C.; Li, Z.; Qu, X.; Xu, Z.; Ma, Z. S2CD: Self-heuristic Speaker Content Disentanglement for Any-to-Any Voice Conversion. In Proceedings of the INTERSPEECH 2023, Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Deng, Y.; Tang, H.; Zhang, X.; Cheng, N.; Xiao, J.; Wang, J. Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval. arXiv 2024, arXiv:2401.08096. [Google Scholar]
- Pan, Y.; Ma, L.; Zhao, J. PromptCodec: High-Fidelity Neural Speech Codec using Disentangled Representation Learning based Adaptive Feature-aware Prompt Encoders. arXiv 2024, arXiv:2404.02702. [Google Scholar]
- Yang, Z.; Chen, M.; Li, Y.; Hu, W.; Wang, S.; Xiao, J.; Li, Z. ESVC: Combining Adaptive Style Fusion and Multi-Level Feature Disentanglement for Expressive Singing Voice Conversion. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 12161–12165. [Google Scholar] [CrossRef]
- Choi, H.S.; Lee, J.; Kim, W.S.; Lee, J.H.; Heo, H.; Lee, K. Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations. arXiv 2021, arXiv:2110.14513. [Google Scholar]
- Huang, W.C.; Yang, S.W.; Hayashi, T.; Lee, H.Y.; Watanabe, S.; Toda, T. S3PRL-VC: Open-source Voice Conversion Framework with Self-supervised Speech Representations. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 23–27 May 2022. [Google Scholar]
- Yang, S.-W.; Chi, P.H.; Chuang, Y.S.; Lai, C.I.J.; Lakhotia, K.; Lin, Y.Y.; Liu, A.T.; Shi, J.; Chang, X.; Lin, G.T.; et al. SUPERB: Speech Processing Universal PERformance Benchmark. In Proceedings of the Proc. Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 1194–1198. [Google Scholar]
- Tsai, H.; Chang, H.; Huang, W.; Huang, Z.; Lakhotia, K.; Yang, S.; Dong, S.; Liu, A.T.; Lai, C.; Shi, J.; et al. SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 8479–8492. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Zen, H.; Clark, R.; Weiss, R.J.; Dang, V.; Jia, Y.; Wu, Y.; Zhang, Y.; Chen, Z. LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Yamagishi, J.; Veaux, C.; MacDonald, K. CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit (Version 0.92); University of Edinburgh, The Centre for Speech Technology Research (CSTR): Edinburgh, UK, 2019. [Google Scholar] [CrossRef]
- Srivastava, B.M.L.; Vauquier, N.; Sahidullah, M.; Bellet, A.; Tommasi, M.; Vincent, E. Evaluating Voice Conversion-Based Privacy Protection against Informed Attackers. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2802–2806. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar] [CrossRef]
- Maouche, M.; Srivastava, B.M.L.; Vauquier, N.; Bellet, A.; Tommasi, M.; Vincent, E. A Comparative Study of Speech Anonymization Metrics. In Proceedings of the Interspeech, Shanhgai, China, 25–29 October 2020; pp. 1708–1712. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Boersma, P.; Weenink, D. Praat, a system for doing phonetics by computer. Glot Int. 2001, 5, 341–345. [Google Scholar]
- Chen, Y.H.; Wu, D.Y.; Wu, T.H.; Lee, H.Y. Again-VC: A One-Shot Voice Conversion Using Activation Guidance and Adaptive Instance Normalization. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 5954–5958. [Google Scholar] [CrossRef]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Kong, J.; Kim, J.; Bae, J. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Meyer, S.; Miao, X.; Vu, N.T. VoicePAT: An Efficient Open-Source Evaluation Toolkit for Voice Privacy Research. IEEE Open J. Signal Process. 2023, 5, 257–265. [Google Scholar] [CrossRef]
- Preiss, J. Automatic Named Entity Obfuscation in Speech. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 10–12 July 2023. [Google Scholar]
- Baril, G.; Cardinal, P.; Koerich, A.L. Named Entity Recognition for Audio De-Identification. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Corpus | LibriTTS | LibriSpeech | VCTK | ||
|---|---|---|---|---|---|
| Set | Train | Dev-Clean | Test-Clean | Test-Other | Train |
| Speakers | 2311 | 40 | 40 | 33 | 109 |
| Utterances | 354,780 | 5736 | 2620 | 2939 | 44,242 |
| Size | 555 h | 9 h | 5.4 h | 5.3 h | 44 h |
| Method | EER ↑ | WER ↓ |
|---|---|---|
| Original | 1.2 | 5.29 |
| Hubert CTC-32 | 44.3 | 9.47 |
| WavLM CTC-31 | 44.6 | 9.39 |
| Hubert HS-1024 | 35.2 | 7.38 |
| WavLM HS-768 | 33.5 | 7.50 |
| Method | EER ↑ | WER ↓ |
|---|---|---|
| Original | 1.2 | 5.29 |
| McAdams [45] | 5.6 | 11.74 |
| Pitch/Formants shift [36] | 35.2 | 10.27 |
| AGAIN-VC [78] | 44.4 | 44.37 |
| PPG-VC [19] | 46.1 | 12.93 |
| WavLM HS-768 [17] | 33.5 | 7.50 |
| S3PRL [66] using WavLM HS-768 | 37.9 | 6.24 |
| +Disentanglement | 49.4 | 6.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matassoni, M.; Fong, S.; Brutti, A. Speaker Anonymization: Disentangling Speaker Features from Pre-Trained Speech Embeddings for Voice Conversion. Appl. Sci. 2024, 14, 3876. https://doi.org/10.3390/app14093876
Matassoni M, Fong S, Brutti A. Speaker Anonymization: Disentangling Speaker Features from Pre-Trained Speech Embeddings for Voice Conversion. Applied Sciences. 2024; 14(9):3876. https://doi.org/10.3390/app14093876
Chicago/Turabian StyleMatassoni, Marco, Seraphina Fong, and Alessio Brutti. 2024. "Speaker Anonymization: Disentangling Speaker Features from Pre-Trained Speech Embeddings for Voice Conversion" Applied Sciences 14, no. 9: 3876. https://doi.org/10.3390/app14093876
APA StyleMatassoni, M., Fong, S., & Brutti, A. (2024). Speaker Anonymization: Disentangling Speaker Features from Pre-Trained Speech Embeddings for Voice Conversion. Applied Sciences, 14(9), 3876. https://doi.org/10.3390/app14093876