
3L-YOLO: A Lightweight Low-Light Object Detection Algorithm


Abstract
1. Introduction
2. Methods
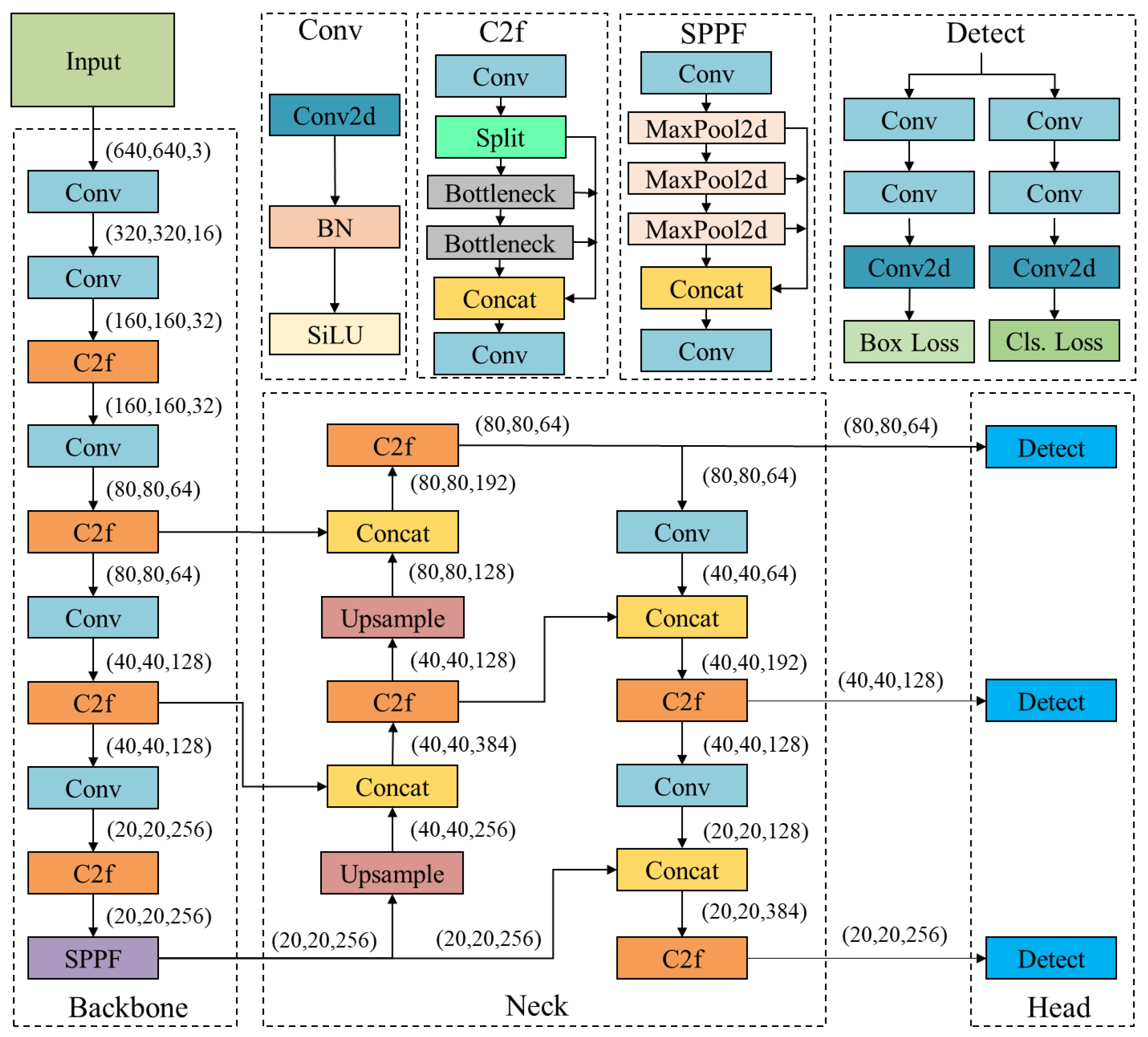
2.1. YOLOv8n Model
2.2. 3L-YOLO Model
2.2.1. Improved C2f Module by Switchable Atrous Convolution
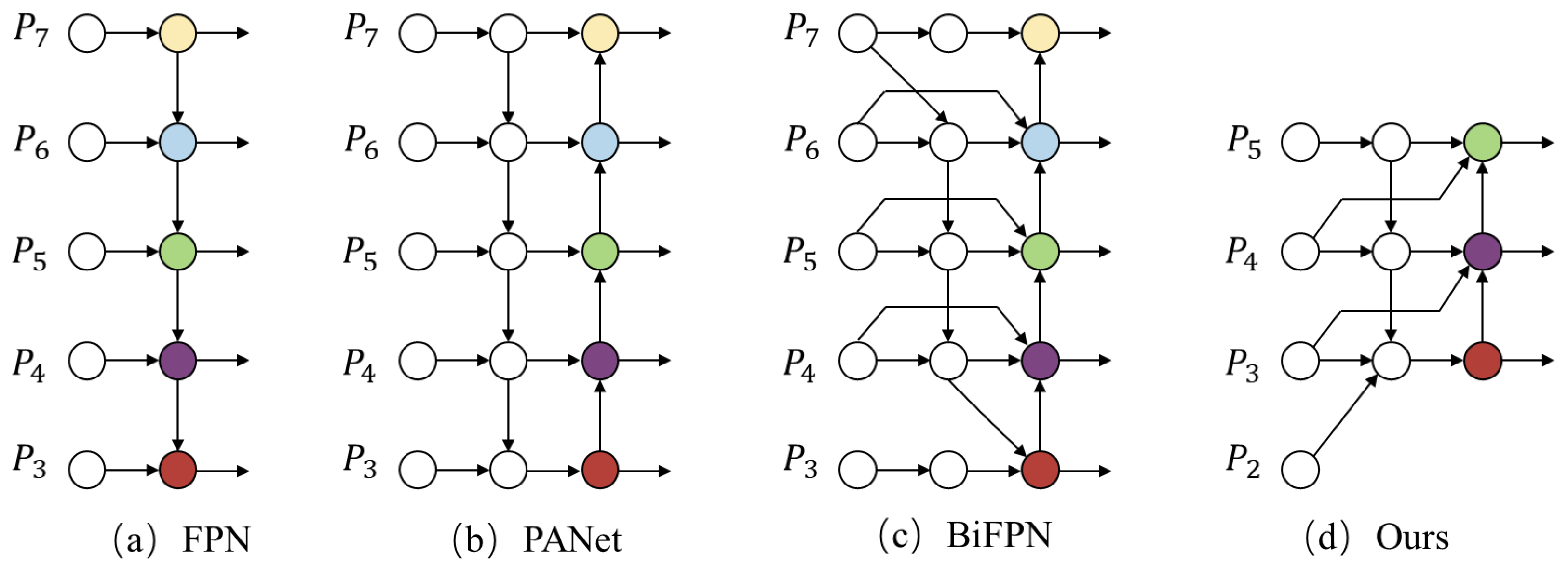
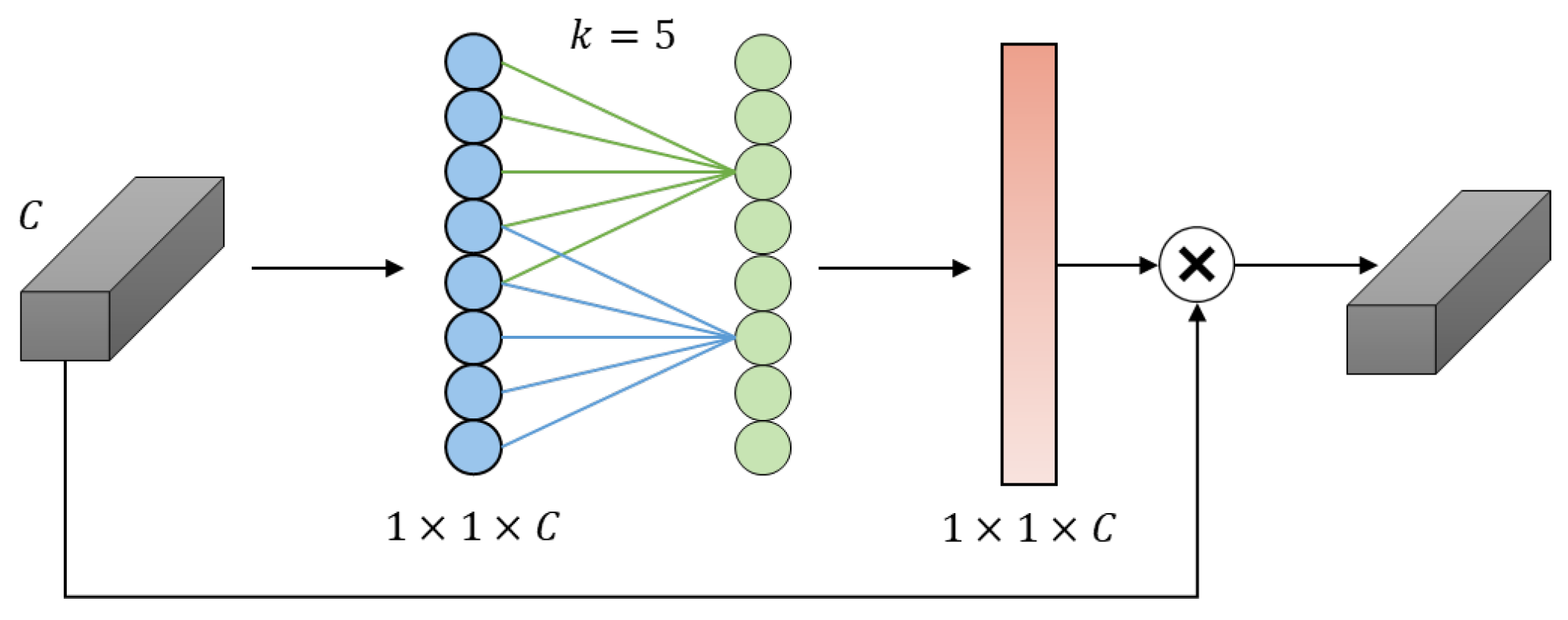
2.2.2. Neck Module Based on Multi-Scale Features and Channel Attention Mechanism
2.2.3. Improved Dynamic Detection Head Based on Deformable Convolution
2.2.4. MPDIoU Loss
3. Experimental Results
3.1. Experimental Datasets
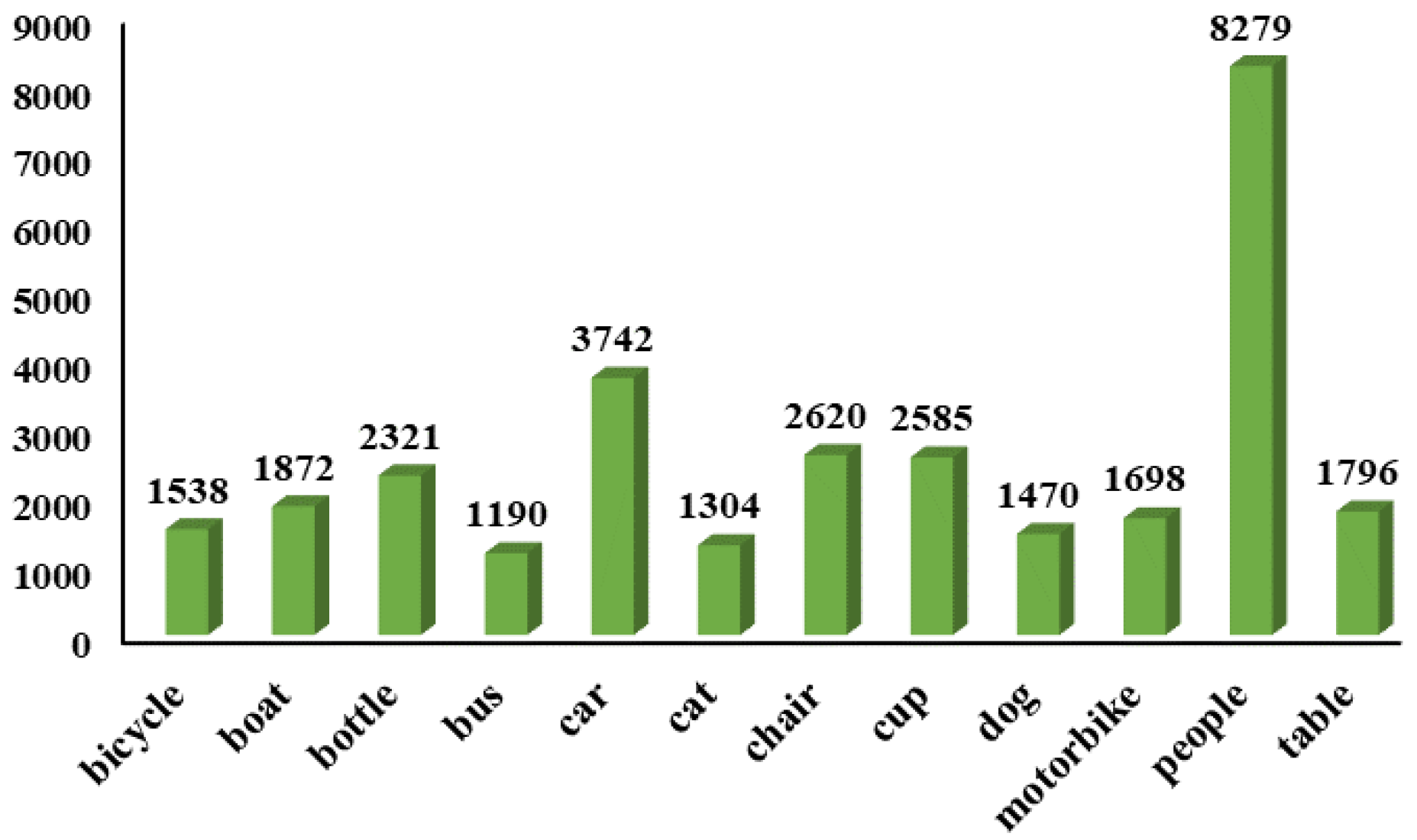
3.1.1. ExDark Dataset
3.1.2. DARK FACE Dataset
3.1.3. Low Light Synthesis Dataset
- Initial Evaluation: Calculate the average gray value of the image and evaluate whether it needs to be darkened. Only process the image whose brightness is higher than the threshold value.
- Brightness Reduction: Randomly decrease the image brightness to 60% to 80% of its original level.
- Gamma Correction: Utilize gamma transformation to simulate the dark light effect, with a random gamma parameter ranging between 2.0 and 5.0.
- Noise Addition: Introduce random Gaussian and Poisson noise. The Gaussian noise has a mean of 0, with a standard deviation randomly varying between 0.1 and 0.3.
3.2. Evaluation Metrics
3.3. Implementation Details
3.4. Results and Analysis
3.4.1. Ablation Experiment
3.4.2. Comparison Experiment on Exdark
3.4.3. Comparison Experiment on Exdark+
3.4.4. Comparison Experiment on DARK FACE
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abba, S.; Bizi, A.M.; Lee, J.-A.; Bakouri, S.; Crespo, M.L. Real-time object detection, tracking, and monitoring framework for security surveillance systems. Heliyon 2024, 10, e34922. [Google Scholar] [CrossRef] [PubMed]
- Akhtar, M.J.; Mahum, R.; Butt, F.S.; Amin, R.; El-Sherbeeny, A.M.; Lee, S.M.; Shaikh, S. A Robust Framework for Object Detection in a Traffic Surveillance System. Electronics 2022, 11, 3425. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, D.; Cao, Y. Visual Navigation Algorithm for Night Landing of Fixed-Wing Unmanned Aerial Vehicle. Aerospace 2022, 9, 615. [Google Scholar] [CrossRef]
- Mujkic, E.; Christiansen, M.P.; Ravn, O. Object Detection for Agricultural Vehicles: Ensemble Method Based on Hierarchy of Classes. Sensors 2023, 23, 7285. [Google Scholar] [CrossRef]
- Wosner, O.; Farjon, G.; Bar-Hillel, A. Object detection in agricultural contexts: A multiple resolution benchmark and comparison to human. Comput. Electron. Agric. 2021, 189, 106404. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Altay, F.; Velipasalar, S. The Use of Thermal Cameras for Pedestrian Detection. IEEE Sens. J. 2022, 22, 11489–11498. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, L.; Yu, X.; Xie, W. Detection Algorithm with Visible Infrared Feature Interaction and Fusion. Control Theory Appl. 2024, 41, 914–922. [Google Scholar]
- Bai, L.; Zhang, W.; Pan, X.; Zhao, C. Underwater Image Enhancement Based on Global and Local Equalization of Histogram and Dual-Image Multi-Scale Fusion. IEEE Access 2020, 8, 128973–128990. [Google Scholar] [CrossRef]
- Li, C.; Tang, S.; Yan, J.; Zhou, T. Low-Light Image Enhancement via Pair of Complementary Gamma Functions by Fusion. IEEE Access 2020, 8, 169887–169896. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.H.; Li, G.; Kwong, S.; Li, C. Underwater Image Enhancement via Minimal Color Loss and Locally Adaptive Contrast Enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. Josa 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Vinoth, K.; Sasikumar, P. Lightweight object detection in low light: Pixel-wise depth refinement and TensorRT optimization. Results Eng. 2024, 23, 102510. [Google Scholar] [CrossRef]
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. You only need 90k parameters to adapt light: A light weight transformer for image enhancement and exposure correction. arXiv 2022, arXiv:2205.14871. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1777–1786. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Wang, C.; Li, J.; Huang, F. DSFD: Dual Shot Face Detector. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5055–5064. [Google Scholar]
- Yin, X.; Yu, Z.; Fei, Z.; Lv, W.; Gao, X. PE-YOLO: Pyramid Enhancement Network for Dark Object Detection. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2023, Heraklion, Greece, 26–29 September 2023; pp. 163–174. [Google Scholar]
- Jiang, C.; He, X.; Xiang, J. LOL-YOLO: Low-Light Object Detection Incorporating Multiple Attention Mechanisms. Comput. Eng. Appl. 2024, 60, 177–187. [Google Scholar] [CrossRef]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Hashmi, K.A.; Kallempudi, G.; Stricker, D.; Afzal, M.Z. FeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 6702–6712. [Google Scholar]
- Xiao, Y.; Jiang, A.; Ye, J.; Wang, M.W. Making of Night Vision: Object Detection Under Low-Illumination. IEEE Access 2020, 8, 123075–123086. [Google Scholar] [CrossRef]
- Hong, Y.; Wei, K.; Chen, L.; Fu, Y. Crafting Object Detection in Very Low Light. In Proceedings of the British Machine Vision Conference, Online, 22–25 November 2021. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 16 November 2024).
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10208–10219. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads with Attentions. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7369–7378. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14408–14419. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9300–9308. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the Exclusively Dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Yang, W.; Yuan, Y.; Ren, W.; Liu, J.; Scheirer, W.J.; Wang, Z.; Zhang, T.; Zhong, Q.; Xie, D.; Pu, S.; et al. Advancing Image Understanding in Poor Visibility Environments: A Collective Benchmark Study. IEEE Trans. Image Process. 2020, 29, 5737–5752. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar] [CrossRef]
- Wei, K.; Fu, Y.; Yang, J.; Huang, H. A Physics-Based Noise Formation Model for Extreme Low-Light Raw Denoising. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2755–2764. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; p. 721. [Google Scholar]
- Jocher, G. Ultralytics YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 16 November 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Item | Params |
|---|---|---|
| Hardware | CPU | Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30 GHz |
| GPU | NVIDIA GeForce RTX 4090 | |
| Training | Optimizer | SGD |
| Learning rate | ||
| Weight decay | ||
| Momentum coefficient | 0.937 |
| C2f_SAConv | MSFCA_Neck | DCNv3_Dyhead | mAP@0.5 (%) | P (%) | R (%) | Params (M) | GFLOPs |
|---|---|---|---|---|---|---|---|
| 66.1 | 71.3 | 58.8 | 3.01 | 8.1 | |||
| √ | 66.6 | 73.2 | 60 | 3.31 | 7.4 | ||
| √ | 66.6 | 71.4 | 58.3 | 3.24 | 8.5 | ||
| √ | 68.2 | 71.8 | 60.5 | 5.19 | 17.6 | ||
| √ | √ | 68.1 | 68.0 | 63.1 | 3.97 | 12.0 | |
| √ | √ | √ | 68.8 | 76.0 | 59.3 | 5.89 | 16.6 |
| Method | mAP@0.5 (%) | mAP@0.5:0.95 (%) | P (%) | R (%) | Params (M) | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv5n | 65.1 | 38.2 | 68.5 | 58.0 | 2.5 | 7.1 |
| YOLOv7-tiny | 63.5 | 35.5 | 68.8 | 56.6 | 6.04 | 13.3 |
| YOLOv8n | 66.1 | 39.6 | 71.3 | 58.8 | 3.01 | 8.1 |
| Zero_DCE + YOLOv8n | 63.9 | 38.5 | 72.3 | 55.6 | 3.08 | 73.7 |
| LOL-YOLO [30] | 68.1 | 42.3 | 70.9 | 62.5 | 5.66 | 20.6 |
| 3L-YOLO (Ours) | 68.8 | 42.0 | 76.0 | 59.3 | 5.89 | 16.6 |
| Method | mAP@0.5 (%) | P (%) | R (%) |
|---|---|---|---|
| YOLOv5n | 58.0 | 63.3 | 53.9 |
| YOLOv8n | 63.0 | 58.2 | 66.6 |
| YOLOv7-tiny | 63.4 | 66.2 | 59.8 |
| YOLOv5s | 64.5 | 59.5 | 64.5 |
| 3L-YOLO (Ours) | 67.3 | 70.1 | 61.8 |
| Method | mAP@0.5 (%) | P (%) | R (%) |
|---|---|---|---|
| YOLOv8n | 45.6 | 70.5 | 40.2 |
| 3L-YOLO (Ours) | 47.0 | 70.1 | 41.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Z.; Yue, Z.; Liu, L. 3L-YOLO: A Lightweight Low-Light Object Detection Algorithm. Appl. Sci. 2025, 15, 90. https://doi.org/10.3390/app15010090
Han Z, Yue Z, Liu L. 3L-YOLO: A Lightweight Low-Light Object Detection Algorithm. Applied Sciences. 2025; 15(1):90. https://doi.org/10.3390/app15010090
Chicago/Turabian StyleHan, Zhenqi, Zhen Yue, and Lizhuang Liu. 2025. "3L-YOLO: A Lightweight Low-Light Object Detection Algorithm" Applied Sciences 15, no. 1: 90. https://doi.org/10.3390/app15010090
APA StyleHan, Z., Yue, Z., & Liu, L. (2025). 3L-YOLO: A Lightweight Low-Light Object Detection Algorithm. Applied Sciences, 15(1), 90. https://doi.org/10.3390/app15010090