


Autoencoder-Based DIFAR Sonobuoy Signal Transmission and Reception Method Incorporating Residual Vector Quantization and Compensation Module: Validation Through Air Channel Modeling

Abstract
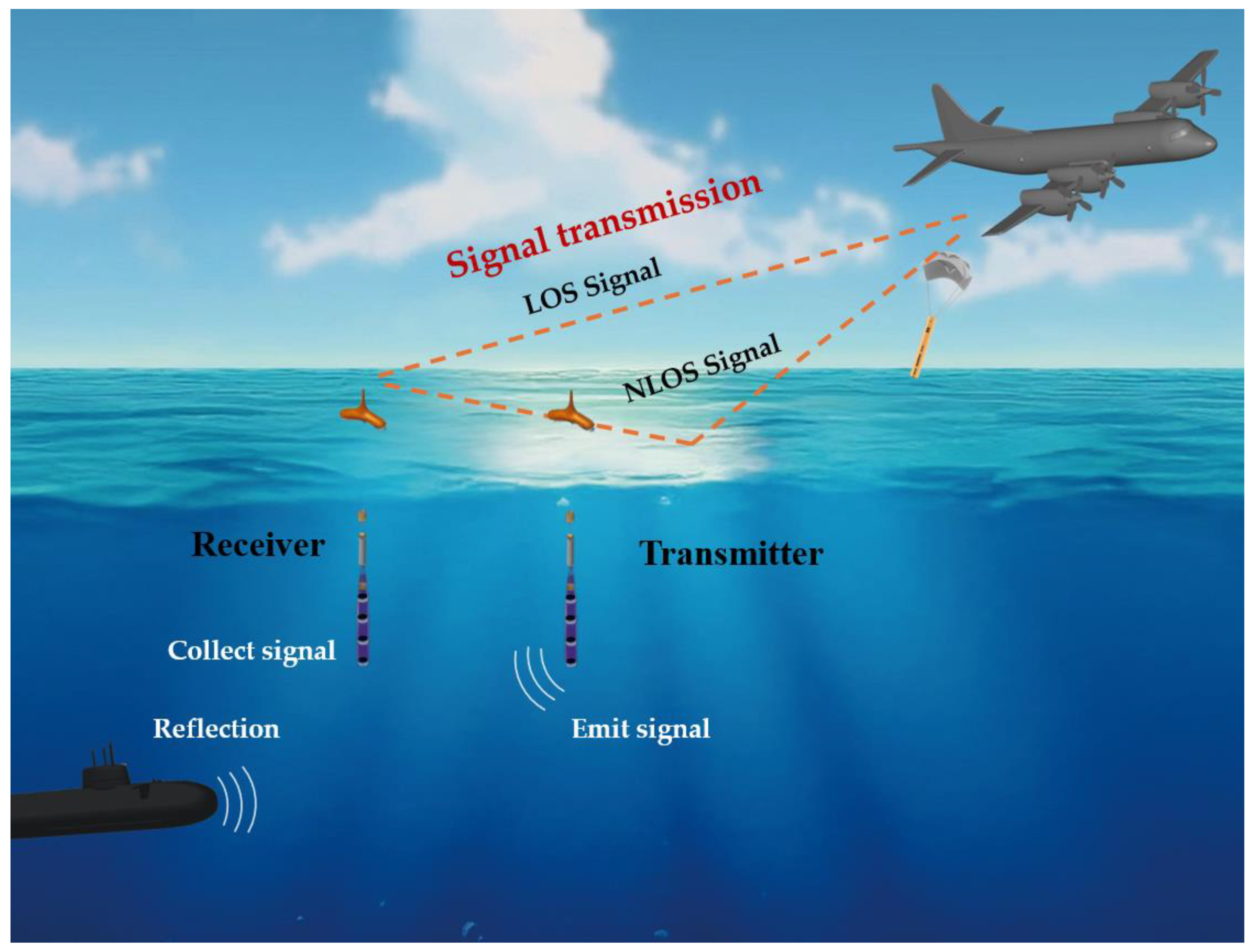
1. Introduction
2. Related Works
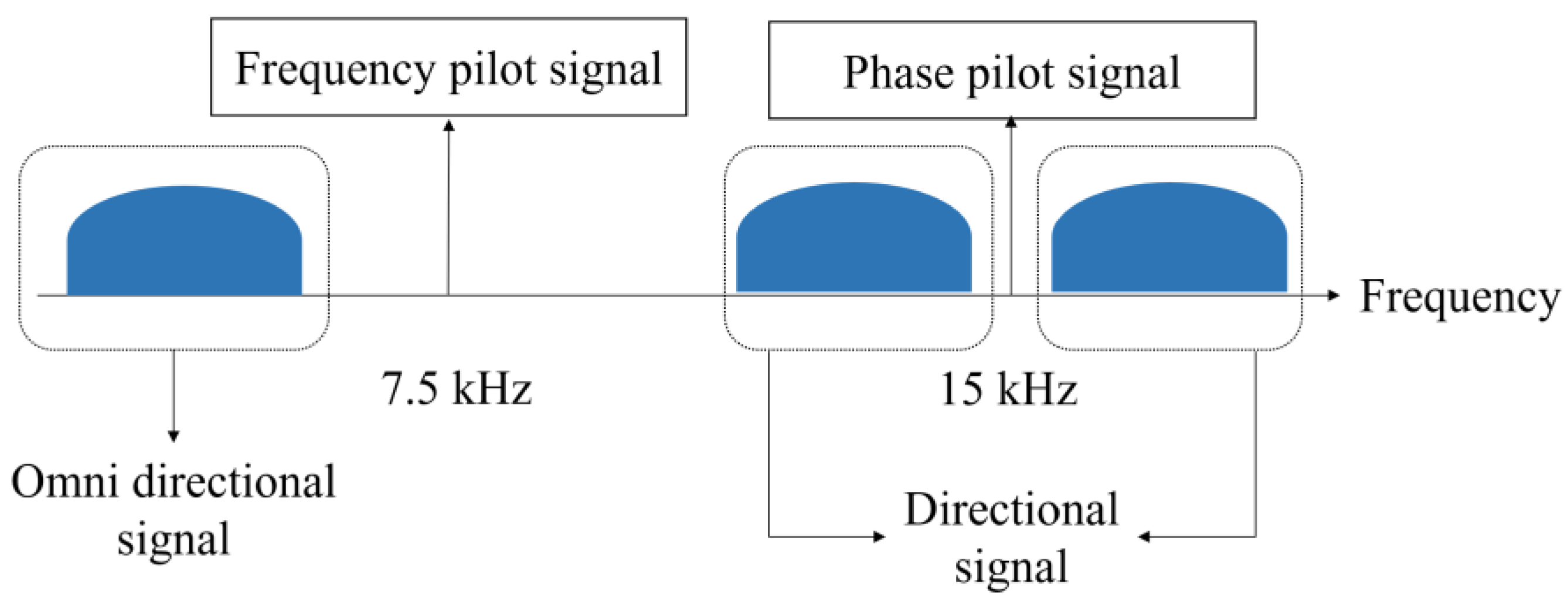
2.1. Traditional DIFAR Sonobuoy Transmission and Reception Technique Based on FDM
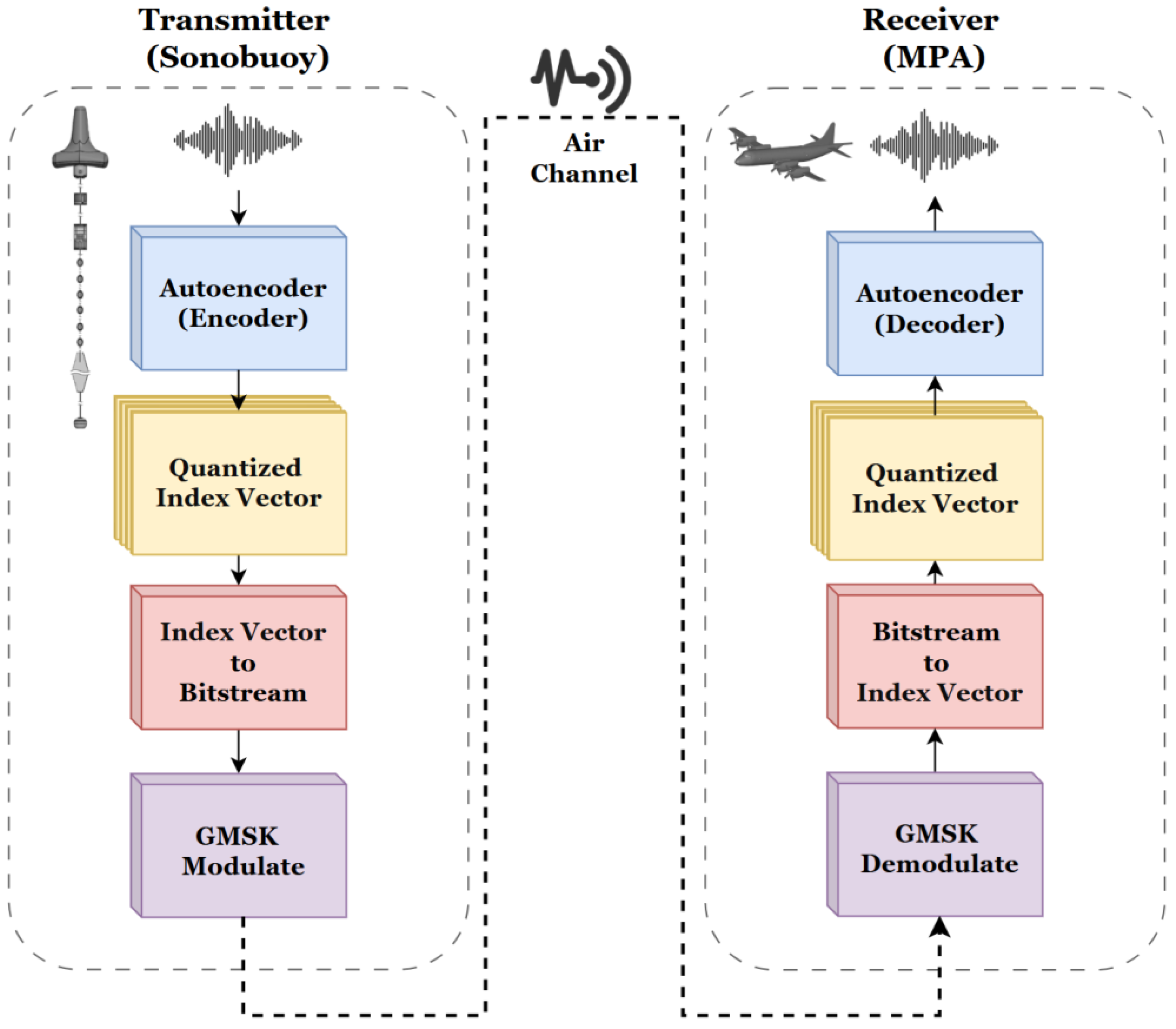
2.2. DIFAR Sonobuoy Transmission and Reception System Based on Autoencoder
- Encoder (Sonobuoy): Maps the collected acoustic signal to a low-dimensional latent space, extracting essential features of the data. The encoder compresses the data, transforming the input into a latent vector that is trained to encapsulate the critical information of the data.
- Latent Vector (Wireless Communication): The latent vector generated by the encoder is a compressed representation of the original data’s key information. This compressed latent vector, requiring minimal data for transmission, is sent wirelessly from the sonobuoy to the MPA, enabling secure and effective data transfer for further analysis and reconstruction.
- Decoder (MAP): The decoder reconstructs an acoustic signal similar to the original from the latent vector. By performing the inverse process of the encoder, it reconstructs the structure of the input data and restores the original signal based on the received latent vector.
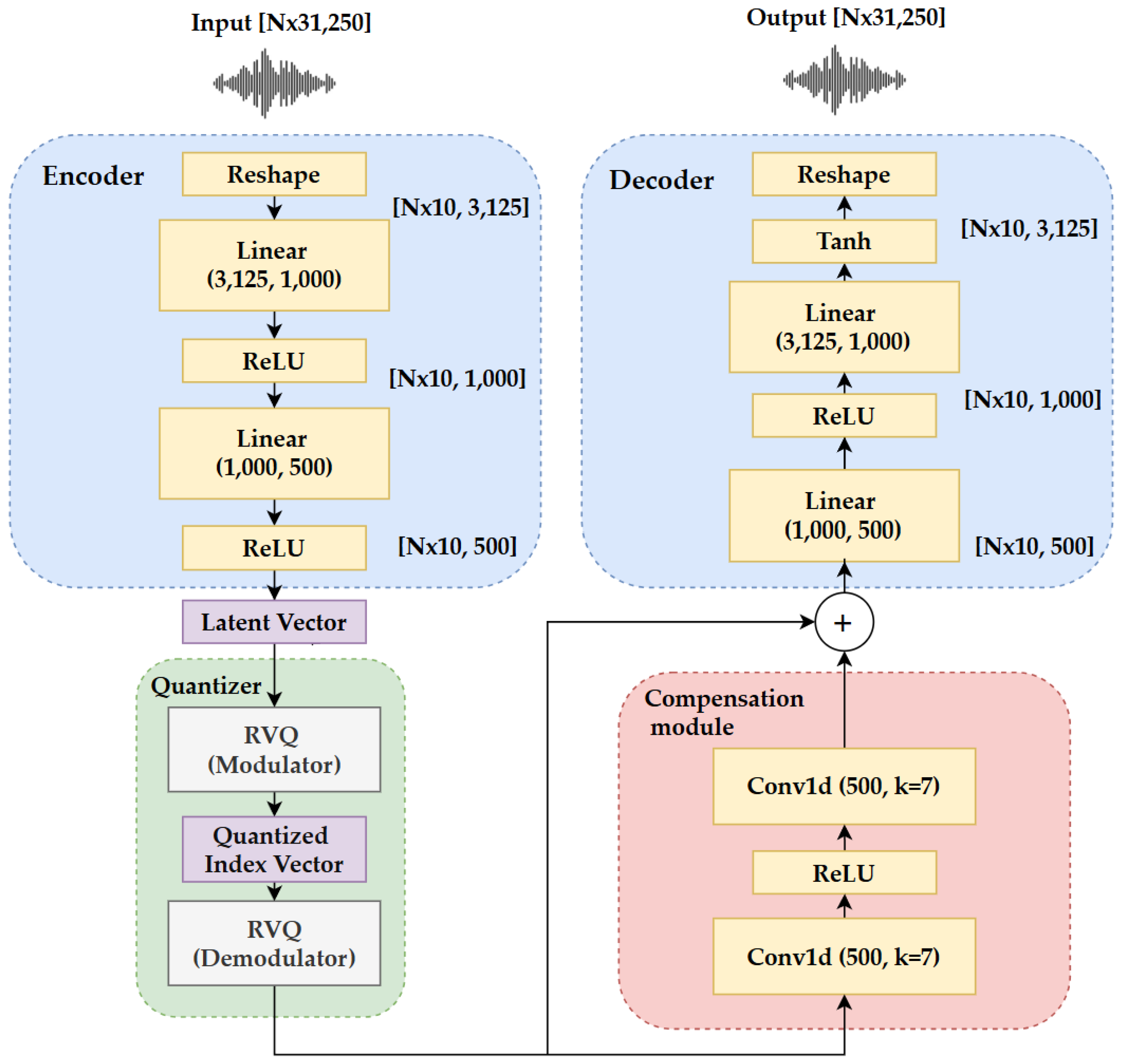
2.3. Residual Vector Quantization (RVQ)
| Algorithm 1: Residual vector quantization (RVQ) |
| 1: RVQ(y, , , …, ) 2: Input: , where is the encoder output vector 3: Input: for (vector quantizers or codebooks) 4: Output: Quantized Vector 5: Initialize: , 6: for = 1 to do 7: 8: 9: return |
2.4. Quantization Compensation Module
2.5. Pruning to Lighten Neural Network Models
2.6. Airchannel Modelling for Realistic Communication Experiments
3. Proposed Method for Autoencoder-Based DIFAR Sonobuoy Signal Transmission and Reception Systems Considering Air Channel Modeling
3.1. Enhanced Autoencoder-Based Neural Network Architecture Combining RVQ and CM
3.2. Description of the Pruning Algorithm
3.2.1. Early Learning Phase
3.2.2. Pruning and Retraining Steps
3.2.3. Pruning Iterations and Performance Evaluation
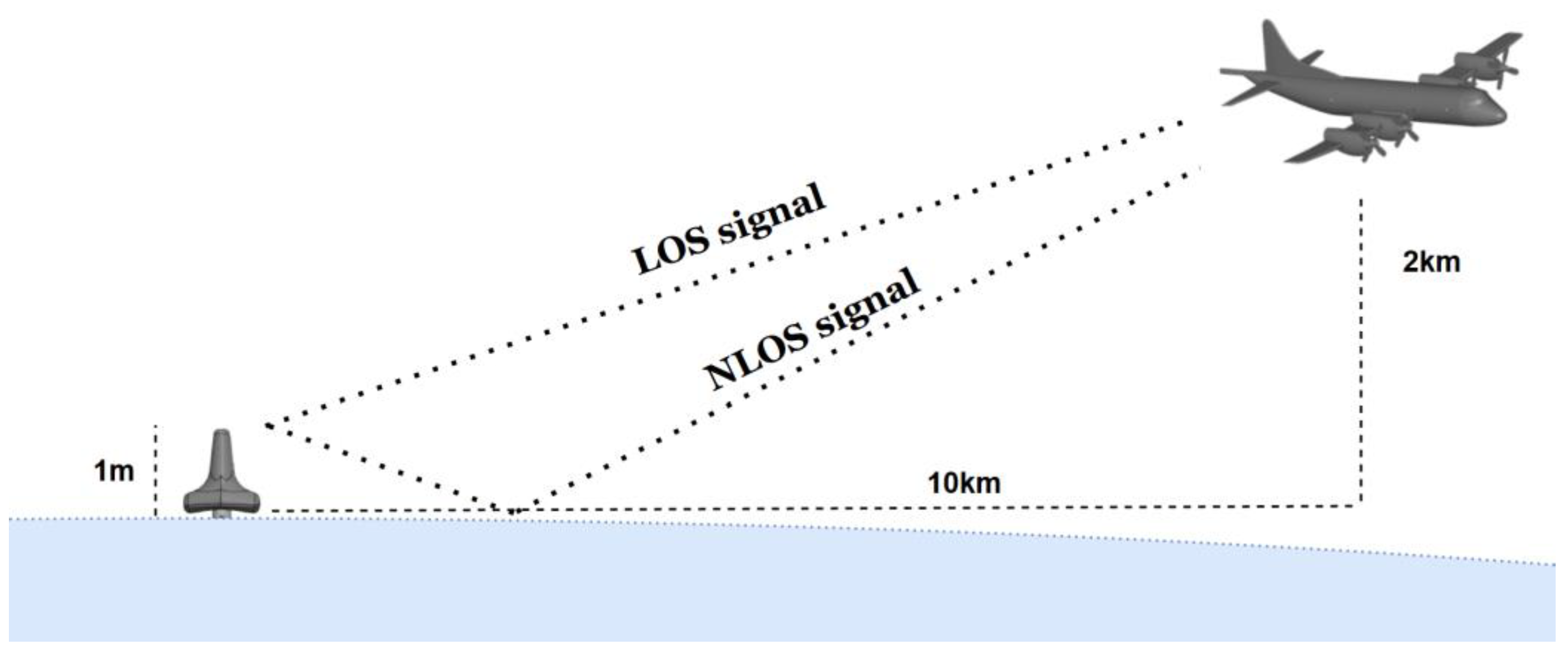
3.3. Air Channel Model Simulating a Maritime Communications Environment
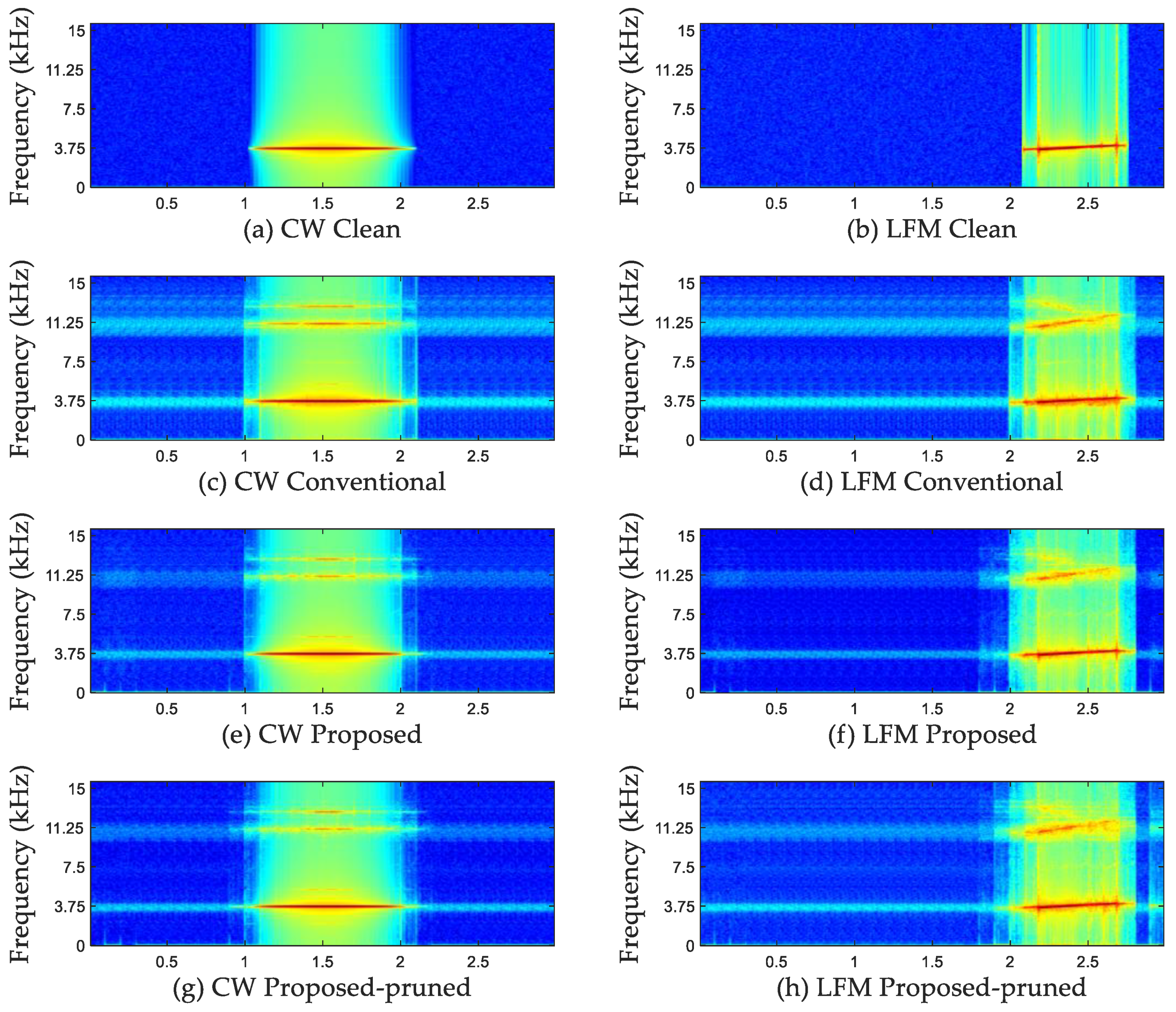
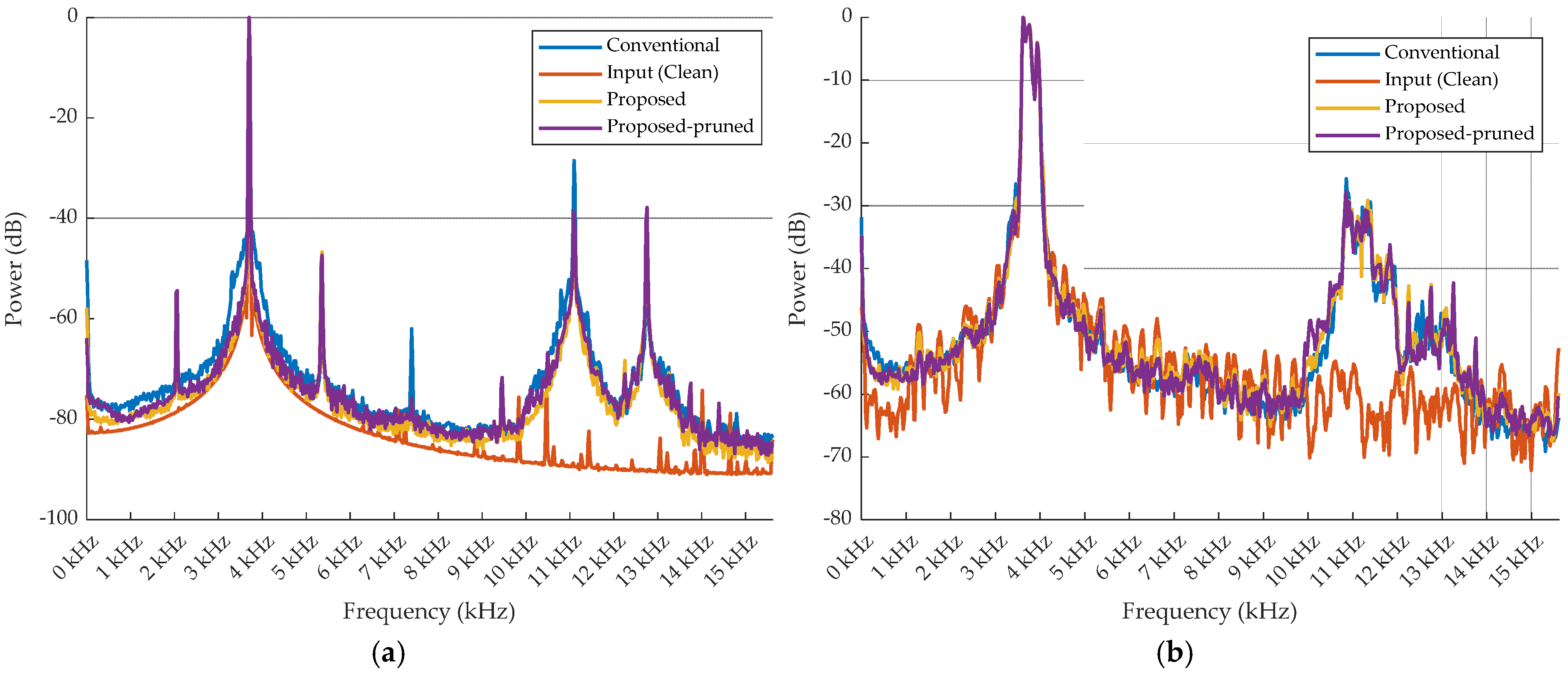
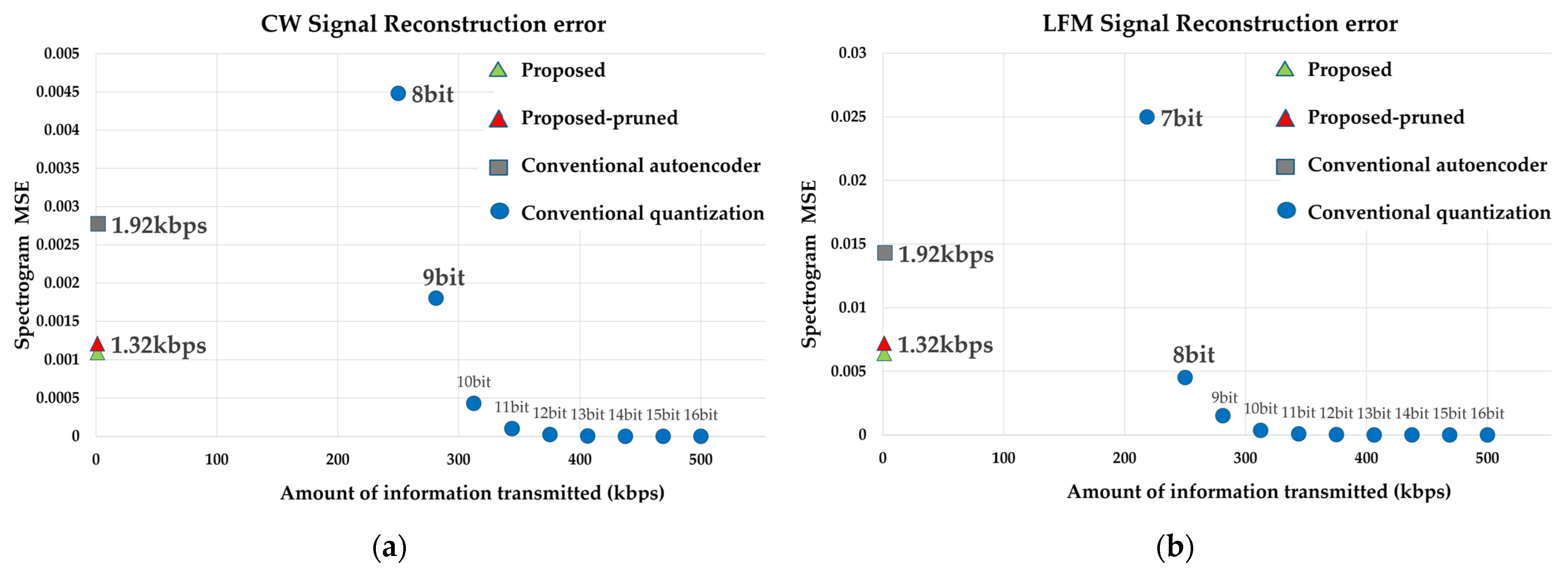
4. Experimental Results
4.1. Training Results of the Proposed Models With or Without Pruning (Techinique)
4.1.1. Experimental Setup for Deep Neural Network Model
- Reconstruction Loss: For signal reconstruction loss, the MSE loss function was utilized. This function is employed to minimize the discrepancy between the final output of the model and the input data. MSE is calculated by averaging the squared differences between the input signal and the reconstructed signal.
- Quantization Penalty: This component aims to minimize the error between the quantized vectors generated by RVQ and the original latent vectors. It is defined as the average of the cumulative errors across each quantization layer.
- CM Loss: To minimize errors arising during the quantization process, the loss is defined by comparing the original latent vectors with the output of the CM using MSE. A specific weight ( = 0.01) is multiplied with the compensation loss and added to the overall loss. This weight was set empirically.
4.1.2. Experimental Results of Deep Neural Network Model
4.2. Assessing the Corruption Impact of QIV in a Wireless Communication Environment
4.2.1. Experimental Setup for Air Channel Model
4.2.2. Experimental Results of Air Channel Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Urick, R.J. Principles of Underwater Sound, 3rd ed.; Peninsula Publishing: Los Altos, CA, USA, 1983. [Google Scholar]
- Swift, M.; Riley, J.L.; Lourey, S.; Booth, L. An overview of the multistatic sonar program in Australia. In Proceedings of the ISSPA ‘99—Fifth International Symposium on Signal Processing and Its Applications (IEEE Cat. No.99EX359), Brisbane, QLD, Australia, 22–25 August 1999; Volume 1, pp. 321–324. [Google Scholar] [CrossRef]
- Lee, J.; Han, S.; Kwon, B. Development of communication device for sound signal receiving and controlling of sonobuoy. J. KIMS Technol. 2021, 24, 317–327. [Google Scholar] [CrossRef]
- Sklar, B. Rayleigh fading channels in mobile digital communication systems. I. Characterization. IEEE Commun. Mag. 1997, 35, 90–100. [Google Scholar] [CrossRef]
- Kuzu, A.; Aksit, M.; Cosar, A.; Guldogan, M.B.; Gunal, E. Calibration and test of DIFAR sonobuoys. In Proceedings of the 2011 IEEE International Symposium on Industrial Electronics (ISIE), Gdansk, Poland, 27–30 June 2011; pp. 1276–1281. [Google Scholar] [CrossRef]
- Park, J.; Seok, J.; Hong, J. Autoencoder-based signal modulation and demodulation methods for sonobuoy signal transmission and reception. Sensors 2022, 22, 6510. [Google Scholar] [CrossRef] [PubMed]
- Spanias, A.S. Speech coding: A tutorial review. Proc. IEEE 1994, 82, 1541–1582. [Google Scholar] [CrossRef]
- Edler, B.; Purnhagen, H. Parametric audio coding. In Proceedings of the WCC 2000—ICCT 2000. 2000 International Conference on Communication Technology, Beijing, China, 21–25 August 2000; Volume 1, pp. 614–617. [Google Scholar] [CrossRef]
- Zeghidour, N.; Luebs, A.; Omran, A.; Skoglund, J.; Tagliasacchi, M. SoundStream: An end-to-end neural audio codec. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 495–507. [Google Scholar] [CrossRef]
- Défossez, A.; Copet, J.; Synnaeve, G.; Adi, Y. High fidelity neural audio compression. arXiv 2022, arXiv:2210.13438. [Google Scholar] [CrossRef]
- Yang, D.; Liu, S.; Huang, R.; Tian, J.; Weng, C.; Zou, Y. HiFi-Codec: Group-residual vector quantization for high fidelity audio codec. arXiv 2023, arXiv:2305.02765. [Google Scholar] [CrossRef]
- Chen, Y.; Guan, T.; Wang, C. Approximate Nearest Neighbor Search by Residual Vector Quantization. Sensors 2010, 10, 11259–11273. [Google Scholar] [CrossRef]
- Ahn, S.; Woo, B.J.; Han, M.H.; Moon, C.; Kim, N.S. HILCodec: High-Fidelity and Lightweight Neural Audio Codec. arXiv 2024, arXiv:2405.04752v2. [Google Scholar] [CrossRef]
- Xu, L.; Wang, J.; Zhang, J.; Xie, X. LightCodec: A high fidelity neural audio codec with low computation complexity. In Proceedings of the ICASSP 2024—IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 586–590. [Google Scholar] [CrossRef]
- Galand, C.; Esteban, D. Design and evaluation of parallel quadrature mirror filters (PQMF). In Proceedings of the ICASSP ‘83—IEEE International Conference on Acoustics, Speech, and Signal Processing, Boston, MA, USA, 14–16 April 1983; pp. 224–227. [Google Scholar] [CrossRef]
- Kumar, K.; Kumar, R.; de Boissiere, T.; Gestin, L.; Teoh, W.Z.; Sotelo, J.; de Brebisson, A.; Bengio, Y.; Courville, A. MelGAN: Generative adversarial networks for conditional waveform synthesis. arXiv 2019, arXiv:1910.06711. [Google Scholar] [CrossRef]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011; Guyon, I., Dror, G., Lemaire, V., Taylor, G., Silver, D., Eds.; PMLR: Bellevue, WA, USA, 2012; Volume 27, pp. 37–49. Available online: https://proceedings.mlr.press/v27/baldi12a.html (accessed on 20 December 2024).
- Proakis, J.G.; Salehi, M. Communication Systems Engineering, 2nd ed.; Pearson: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both weights and connections for efficient neural networks. arXiv 2015, arXiv:1506.02626. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Zaman, M.A.; Mamun, S.A.; Gaffar, M.; Alam, M.M.; Momtaz, M.I. Modeling VHF air-to-ground multipath propagation channel and analyzing channel characteristics and BER performance. In Proceedings of the 2010 IEEE Region 8 International Conference on Computational Technologies in Electrical and Electronics Engineering (SIBIRCON), Irkutsk, Russia, 11–15 July 2010; pp. 335–338. [Google Scholar] [CrossRef]
- Matolak, D.W.; Sun, R. Air–ground channel characterization for unmanned aircraft systems—Part I: Methods, measurements, and models for over-water settings. IEEE Trans. Veh. Technol. 2017, 66, 26–44. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Li, X.; Chen, L.; Sun, R. Wireless channel models for maritime communications. IEEE Access 2018, 6, 68070–68088. [Google Scholar] [CrossRef]
- Parsons, J.D. The Mobile Radio Propagation Channel; Wiley: New York, NY, USA, 2000. [Google Scholar]
- International Telecommunication Union. Reflection from the Surface of the Earth. 1986–1990. Available online: http://www.itu.int/pub/R-REP-P.1008-1-1990 (accessed on 20 December 2024).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Ultra Electronics Ltd. AN/SSQ-573 Directional Passive Multi-Mode Sonobuoy. Ultra Maritime. 2021. Available online: https://ultra.group/media/2662/anssq-573-datasheet_final.pdf (accessed on 20 December 2024).
- Anderson, J.B.; Aulin, T.; Sundberg, C.-E. Digital Phase Modulation; Plenum Press: New York, NY, USA, 1986. [Google Scholar]
- International Telecommunication Union. Minimum Performance Objectives for Narrow-Band Digital Channels Using Geostationary Satellites to Serve Transportable and Vehicular Mobile Earth Stations in the 1-3 GHz Range, Not Forming Part of the ISDN. Recommendation ITU-R M.1181. 1995. Available online: https://www.itu.int/dms_pubrec/itu-r/rec/m/R-REC-M.1181-0-199510-I!!PDF-E.pdf (accessed on 20 December 2024).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Encoder (Dim) | Decoder (Dim) |
|---|---|
| Noisy input (3125) | Latent vector (10) |
| Linear (3125–1000) | Linear (10–100) |
| ReLU | ReLU |
| Linear (1000–500) | Linear (100–500) |
| ReLU | ReLU |
| Linear (500–100) | Linear (500–1000) |
| ReLU | ReLU |
| Linear (100–10) | Linear (1000–3125) |
| ReLU | Tanh |
| Latent vector (10) | Output (3125) |
| CW | LFM | |
|---|---|---|
| Center frequency (Hz) | 3500, 3600, 3700, 3800 | |
| Bandwidth (Hz) | - | 400 |
| Pulse duration (s) | 0.1, 0.5, 1 | |
| Sampling frequency (Hz) | 31,250 | |
| Total Time (h) | 43 | 43 |
| Model Encoder | Parameter (Encoder) | Parameter (RVQ) | MMACs (Encoder) | MMACs (RVQ) |
|---|---|---|---|---|
| Conventional [6] | 3.68 M | - | 36.82 | - |
| Proposed | 3.63 M | 5.12 M | 36.30 | 51.2 |
| Proposed–Pruned | 1.03 M | 5.12 M | 10.30 | 51.2 |
| Method | Signal Type | Spectrogram MSE | LSD (dB) | SNR (dB) |
|---|---|---|---|---|
| Conventional [6] | CW | 0.00277 | 1.19 | 25.93 |
| LFM | 0.01428 | 1.19 | 17.66 | |
| Proposed | CW | 0.00109 | 1.13 | 29.19 |
| LFM | 0.00639 | 1.10 | 21.56 | |
| Proposed–Pruned | CW | 0.00128 | 1.15 | 28.59 |
| LFM | 0.00719 | 1.12 | 21.08 |
| Method | Signal Type | Spectrogram MSE | LSD (dB) | SNR (dB) |
|---|---|---|---|---|
| Conventional [6] | CW | 0.00418 | 1.26 | 25.94 |
| LFM | 0.02153 | 1.24 | 17.74 | |
| Proposed | CW | 0.00204 | 1.21 | 29.22 |
| LFM | 0.00812 | 1.18 | 21.62 | |
| Proposed–Pruned | CW | 0.00254 | 1.23 | 28.62 |
| LFM | 0.00918 | 1.20 | 21.14 |
| Sonobuoy Characteristics | |
|---|---|
| Telemetry (Digital Mode) | Coherent GMSK at 224 kbps |
| RF Channel | 97 channels (136 MHz~173.5 MHz, 376 kHz spacing) |
| VHF Radiated Power | 1 Watt nominal |
| Method | Signal Type | AWGN SNR | BER (%) | Spectrogram MSE | LSD (dB) | SNR (dB) |
|---|---|---|---|---|---|---|
| Conventional | CW | 0 dB | 0.00006 | 0.00277 | 1.19 | 25.93 |
| LFM | 0.00006 | 0.01428 | 1.19 | 17.66 | ||
| Proposed | CW | 0.00010 | 0.00113 | 1.12 | 29.19 | |
| LFM | 0.00010 | 0.00644 | 1.10 | 21.56 | ||
| Proposed–Pruned | CW | 0 | 0.00120 | 1.15 | 28.59 | |
| LFM | 0 | 0.00719 | 1.12 | 21.08 | ||
| Conventional | CW | −1 dB | 0.00019 | 0.00277 | 1.19 | 25.93 |
| LFM | 0.00012 | 0.00142 | 1.19 | 17.66 | ||
| Proposed | CW | 0.00040 | 0.00129 | 1.13 | 29.03 | |
| LFM | 0.00040 | 0.00649 | 1.10 | 21.54 | ||
| Proposed–Pruned | CW | 0.00020 | 0.00123 | 1.15 | 28.54 | |
| LFM | 0.00040 | 0.00723 | 1.12 | 21.07 | ||
| Conventional | CW | −2 dB | 0.00192 | 0.00277 | 1.19 | 25.93 |
| LFM | 0.00154 | 0.02075 | 1.19 | 21.22 | ||
| Proposed | CW | 0.00215 | 0.00209 | 1.13 | 29.14 | |
| LFM | 0.00225 | 0.00751 | 1.10 | 21.53 | ||
| Proposed–Pruned | CW | 0.00225 | 0.00304 | 1.15 | 28.55 | |
| LFM | 0.00266 | 0.00939 | 1.12 | 21.07 | ||
| Conventional | CW | −3 dB | 0.01126 | 0.04241 | 1.19 | 24.48 |
| LFM | 0.01120 | 0.23350 | 1.19 | 16.67 | ||
| Proposed | CW | 0.01207 | 0.01681 | 1.14 | 25.28 | |
| LFM | 0.01125 | 0.01856 | 1.11 | 19.68 | ||
| Proposed–Pruned | CW | 0.01135 | 0.00765 | 1.16 | 27.83 | |
| LFM | 0.01156 | 0.01600 | 1.13 | 19.64 | ||
| Conventional | CW | −4 dB | 0.05318 | 0.20282 | 1.20 | 19.54 |
| LFM | 0.05510 | 0.23350 | 1.24 | 12.70 | ||
| Proposed | CW | 0.05709 | 0.04873 | 1.17 | 20.36 | |
| LFM | 0.05831 | 0.05007 | 1.15 | 15.53 | ||
| Proposed–Pruned | CW | 0.05279 | 0.05013 | 1.18 | 19.82 | |
| LFM | 0.05862 | 0.06266 | 1.17 | 14.66 | ||
| Conventional | CW | −5 dB | 0.19361 | 0.81985 | 1.24 | 7.01 |
| LFM | 0.19355 | 0.82393 | 1.24 | 3.76 | ||
| Proposed | CW | 0.19480 | 0.17122 | 1.26 | 11.75 | |
| LFM | 0.20289 | 0.17099 | 1.27 | 9.94 | ||
| Proposed–Pruned | CW | 0.19061 | 0.16431 | 1.26 | 11.39 | |
| LFM | 0.20401 | 0.16794 | 1.27 | 9.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Hong, J. Autoencoder-Based DIFAR Sonobuoy Signal Transmission and Reception Method Incorporating Residual Vector Quantization and Compensation Module: Validation Through Air Channel Modeling. Appl. Sci. 2025, 15, 92. https://doi.org/10.3390/app15010092
Park Y, Hong J. Autoencoder-Based DIFAR Sonobuoy Signal Transmission and Reception Method Incorporating Residual Vector Quantization and Compensation Module: Validation Through Air Channel Modeling. Applied Sciences. 2025; 15(1):92. https://doi.org/10.3390/app15010092
Chicago/Turabian StylePark, Yeonjin, and Jungpyo Hong. 2025. "Autoencoder-Based DIFAR Sonobuoy Signal Transmission and Reception Method Incorporating Residual Vector Quantization and Compensation Module: Validation Through Air Channel Modeling" Applied Sciences 15, no. 1: 92. https://doi.org/10.3390/app15010092
APA StylePark, Y., & Hong, J. (2025). Autoencoder-Based DIFAR Sonobuoy Signal Transmission and Reception Method Incorporating Residual Vector Quantization and Compensation Module: Validation Through Air Channel Modeling. Applied Sciences, 15(1), 92. https://doi.org/10.3390/app15010092