Abstract
(1) Background: Side-channel attacks (SCAs) exploit unintended information leakage to compromise cryptographic security. In cyber-physical systems (CPSs), embedded systems are inherently constrained by limited resources, restricting the implementation of complex countermeasures. Traditional countermeasures, such as hiding techniques, attempt to obscure power consumption patterns; however, their effectiveness has been increasingly challenged. This study evaluates the vulnerability of dummy power traces against deep learning-based SCAs (DL-SCAs). (2) Methods: A power trace dataset was generated using a simulation environment based on Quick Emulator (QEMU) and GNU Debugger (GDB), integrating dummy traces to obfuscate execution signatures. DL models, including a Recurrent Neural Network (RNN), a Bidirectional RNN (Bi-RNN), and a Multi-Layer Perceptron (MLP), were used to evaluate classification performance. (3) Results: The models trained with dummy traces achieved high classification accuracy, with the MLP model reaching 97.81% accuracy and an F1-score of 97.77%. Despite the added complexity, DL models effectively distinguished real and dummy traces, highlighting limitations in existing hiding techniques. (4) Conclusions: These findings highlight the need for adaptive countermeasures against DL-SCAs. Future research should explore dynamic obfuscation techniques, adversarial training, and comprehensive evaluations of broader cryptographic algorithms. This study underscores the urgency of evolving security paradigms to defend against artificial intelligence-powered attacks.
1. Introduction
The increasing integration of embedded systems and Internet of Things (IoT) devices within cyber-physical systems (CPSs) has raised significant cybersecurity concerns. Among these threats, side-channel attacks (SCAs) pose a substantial challenge, as they exploit unintended information leakage, such as power consumption, electromagnetic emissions, and execution timing, to extract sensitive cryptographic information [1,2].
CPS security research has traditionally focused on cyber-layer protections, such as network-level anomaly detection and intrusion detection systems (IDSs). In particular, artificial intelligence (AI) has been widely adopted in these domains, and there is a growing trend toward constructing highly refined datasets to improve detection performance [3,4]. As the field has matured, the focus has shifted from generic network defenses to threats specific to programmable logic controllers (PLCs), which constitute the computational core of most industrial plants. Recent comprehensive surveys have documented that PLC vulnerabilities span firmware, ladder logic, and fieldbus layers and remain a persistent root cause of CPS incidents [5,6]. Complementing these diagnostic efforts, control-theoretic studies have introduced adaptive secure-control schemes that maintain plant safety even when sensor or actuator channels are actively compromised, thereby closing some but not all of the gaps between cyber and physical security domains [7].
Nevertheless, these logic- and control-layer defenses still leave CPSs vulnerable to SCAs that exploit leakages from the underlying hardware. Defense mechanisms such as logic locking have been proposed to counter traditional SCAs [8]. However, with the proliferation of deep learning (DL), empirical evidence indicates that compact convolutional neural network (CNN) architectures can recover AES keys from a single power trace on resource-constrained microcontrollers [9]. Moreover, multi-leak DL pipelines remain effective even when leakage is fragmented across multiple temporal windows, highlighting the robustness of modern SCA methodologies [10]. Even PLCs that do not process cryptographic workloads remain vulnerable. Specifically, cache-based SCAs targeting software-defined PLCs have been shown to reveal control logic and compromise process integrity [11].
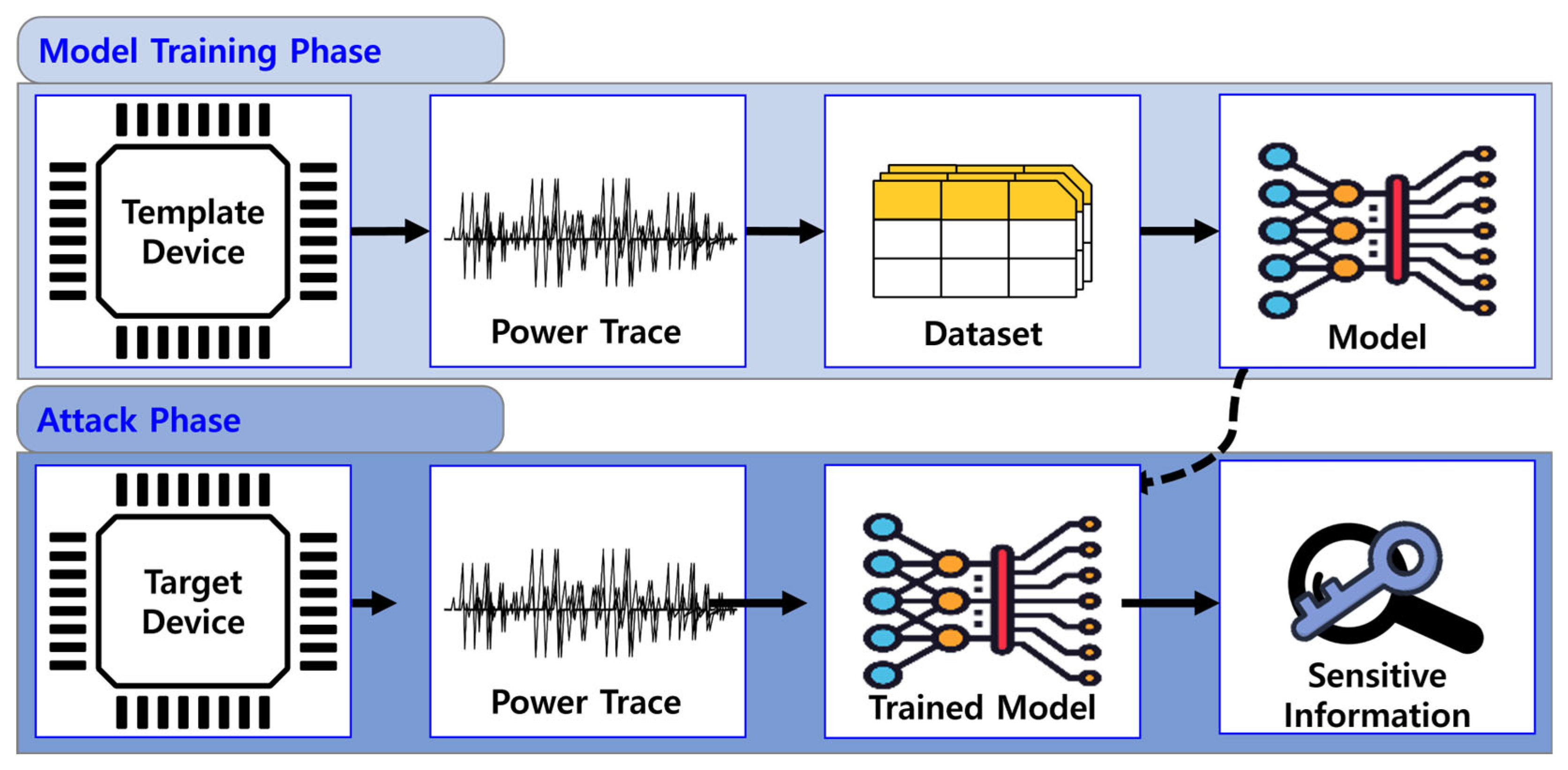
Figure 1 illustrates the workflow of a profiling-based SCA using DL. First, the dataset is constructed using a template device, on which a model is trained. Then, power traces are collected from the target device, and the trained model is exploited to extract sensitive information.
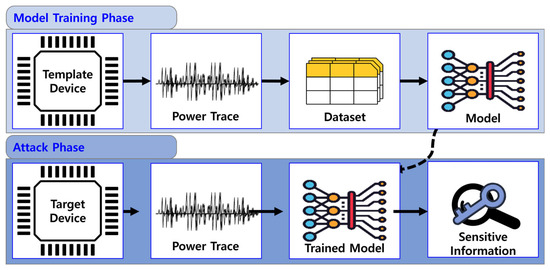
Figure 1.
Workflow of a profiling-based side-channel attack using deep learning.
While various countermeasures, such as hiding and masking techniques, have been developed to mitigate these threats, recent advancements in DL have revealed their inherent vulnerabilities [12]. Traditional hiding techniques aim to obfuscate power consumption patterns, making it difficult for attackers to extract meaningful information. However, machine learning (ML) models, particularly DL architectures, have demonstrated a remarkable ability to distinguish between authentic cryptographic executions and those obfuscated with dummy power trace data, potentially rendering conventional hiding methods ineffective [13].
This study systematically investigates the vulnerability of hiding techniques against DL-based SCAs (DL-SCAs). While conventional hiding techniques are designed to obscure power consumption and confound human-crafted analyses or basic statistical models, the findings of this study demonstrate that modern DL models can effectively bypass such defenses. By leveraging their capacity to extract subtle, high-dimensional patterns, DL models can distinguish between original and dummy traces with high accuracy, thereby compromising the intended obfuscation. To evaluate this vulnerability, a reproducible simulation framework was developed to generate realistic side-channel datasets, thereby enabling rigorous assessment of countermeasure robustness. Unlike conventional SCA approaches that focus on key recovery, the proposed method emphasizes the discrimination between obfuscated and genuine operations, introducing a new dimension to the evaluation of side-channel countermeasures. The findings suggest that hiding, in its current form, is insufficient to withstand DL-SCAs.
1.1. Research Contribution
This study makes the following key contributions:
- A novel framework is introduced for generating and evaluating dummy power traces in a virtualized environment. The framework supports diverse instruction sets and hardware configurations, enabling extensibility and architectural generalization while maintaining cost-effectiveness.
- Empirical results demonstrated that obfuscated executions still exhibit distinguishable leakage patterns, which DL models can exploit with high accuracy. This finding challenges the effectiveness of conventional hiding techniques against DL-SCA.
- An experimental evaluation is presented on Recurrent Neural Networks (RNNs), Bidirectional RNNs (Bi-RNNs), and Multi-Layer Perceptrons (MLPs), quantifying their effectiveness in identifying and exploiting residual leakages.
- Insights into the enhancement of cryptographic defenses are provided through the exploration of potential countermeasures, including adversarial machine learning and adaptive obfuscation techniques.
1.2. Paper Structure
The structure of this paper is as follows: Section 2 reviews SCAs and existing cryptographic countermeasures. Section 3 presents the methodology for dataset generation and DL evaluation. Section 4 discusses the experimental results, demonstrating the vulnerabilities of conventional hiding techniques. Section 5 presents an in-depth discussion of the study’s implications, limitations, and ethical considerations. Finally, Section 6 concludes the paper by summarizing key findings and outlining future research directions.
2. Related Works
2.1. Side-Channel Attacks
SCAs exploit unintended information leakage from cryptographic implementations [14,15]. These attacks target physical characteristics of devices, such as power consumption, electromagnetic radiation, and timing variations, to extract cryptographic keys and other sensitive information. Unlike traditional cryptographic attacks, which focus on breaking mathematical structures, SCAs exploit vulnerabilities in the physical execution of cryptographic algorithms.
Among the various SCA techniques, power analysis attacks, including Simple Power Analysis (SPA) and Differential Power Analysis (DPA), have proven to be particularly effective [16]. SPA relies on direct observation of power consumption patterns, while DPA employs statistical analysis to extract information from multiple power traces. Electromagnetic analysis and fault injection attacks further expand the range of SCAs, enabling adversaries to compromise cryptographic implementations with minimal access to the target system [17].
Advancements in ML and DL have further elevated the risk posed by SCAs [18,19]. Modern neural networks can process vast amounts of side-channel data, learning intricate patterns that allow attackers to derive cryptographic keys with higher efficiency than traditional statistical methods. The ability of DL models to generalize across different devices and encryption schemes presents an urgent need for robust and adaptive countermeasures against SCAs.
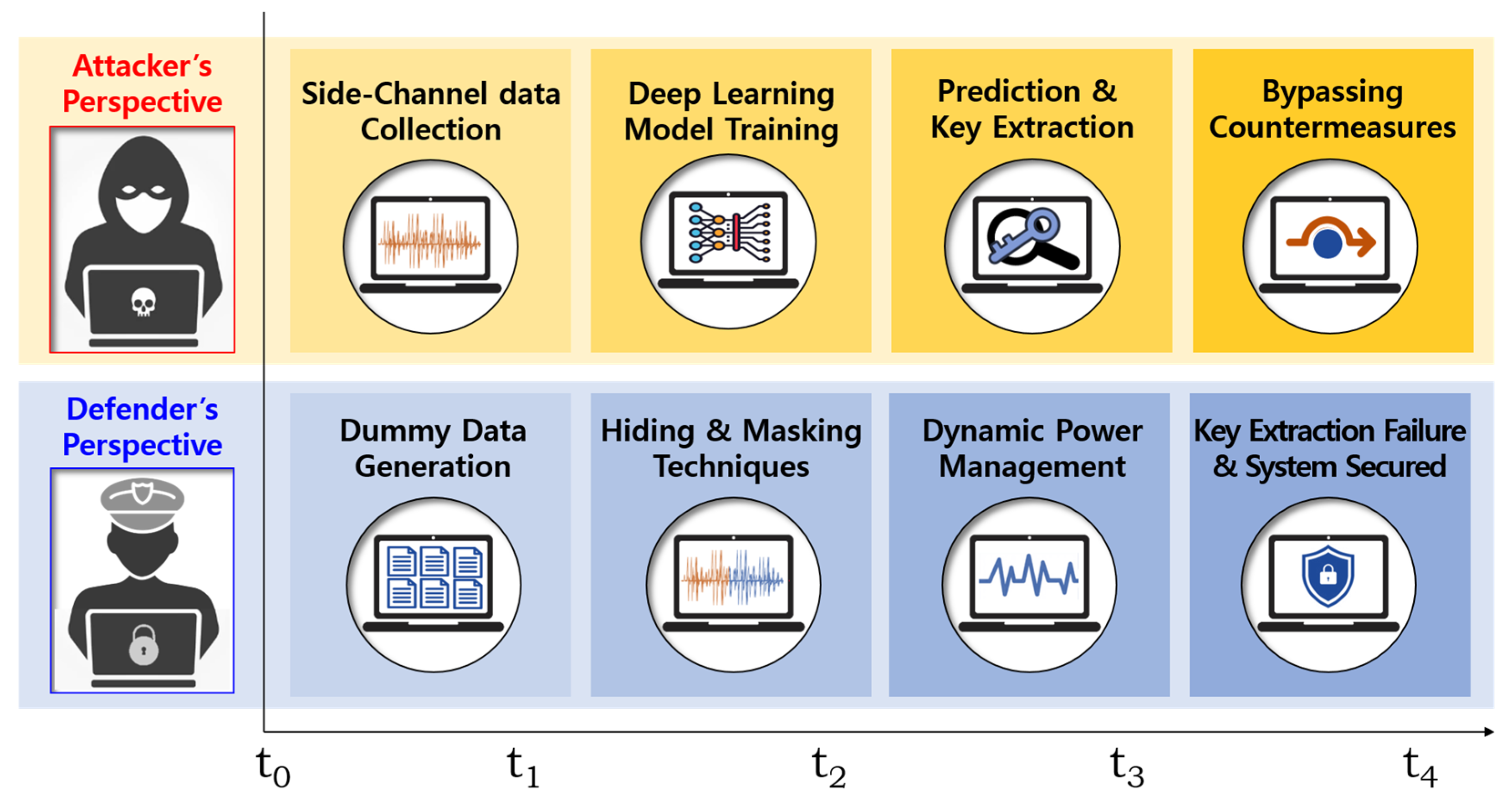
Figure 2 presents the time-sequenced attack and defense perspectives in an SCA scenario. The attacker first collects power traces from cryptographic operations and trains a DL model to extract cryptographic keys. To counteract this, the defender employs a combination of techniques, starting with the generation of dummy data to introduce noise, followed by hiding and masking strategies, and finally, applying dynamic power management to further obfuscate the power consumption patterns. The outcome ensures that key extraction attempts fail, securing the system from DL-SCAs.
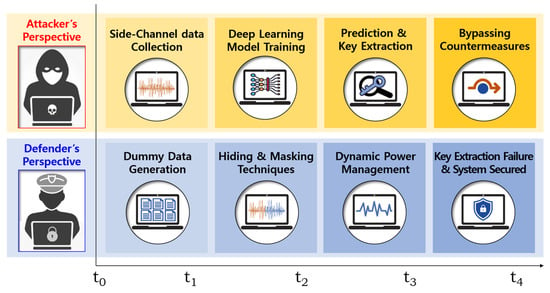
Figure 2.
Time-sequenced side-channel attack and defense process.
One defining characteristic of SCAs in CPS is their non-invasive and non-disruptive nature. This characteristic underpins profiling-based SCAs, which follow a structured attack procedure. In a typical profiling attack scenario, an attacker first acquires a template device that is functionally equivalent to the deployed target, instruments it in a controlled environment, and records realistic side-channel data. A DL model is trained on this template device to learn the statistical mapping between side-channel leakages and secret-dependent internal states [20,21].
After training, the attack transitions from an active data collection phase to a passive exploitation phase. Once the model is trained, only passive power or electromagnetic measurements are required from the operational system. The pre-trained model can recover sensitive information, such as cryptographic keys or executed instructions, without software exploitation or observable process disturbance, rendering conventional monitoring mechanisms ineffective.
This threat model is realistic in CPS, where commercial off-the-shelf microcontrollers and PLCs are widely reused. Furthermore, recent studies have shown that it is possible to analyze the behavior of a microcontroller during execution by using real-time traces [22].
2.2. Countermeasures Against SCAs
To mitigate the risks posed by SCAs, several countermeasures have been developed. Hiding techniques attempt to randomize power consumption patterns by introducing noise or varying execution sequences, making it harder for attackers to extract meaningful information. Blinding methods involve mathematically altering cryptographic computations to obscure correlations between intermediate values and final results. Masking techniques introduce random values during encryption processes to prevent attackers from deriving sensitive data through statistical analysis [23]. Despite their effectiveness, these countermeasures are increasingly challenged by DL-SCA methodologies, which can adapt to and learn from complex data patterns, bypassing traditional security measures [24].
Recent studies have proposed hybrid countermeasures that combine multiple defensive techniques to improve resistance against DL-SCAs [25]. For example, dynamic power management, randomized instruction execution, and noise injection are being explored as complementary approaches to traditional hiding and masking techniques. The effectiveness of these combined countermeasures depends on implementation efficiency, resource overhead, and adaptability to evolving attack methodologies.
Table 1 presents an overview of countermeasures used against SCAs, categorizing them based on their primary defense mechanisms. These methods aim to either obscure power consumption patterns, introduce mathematical transformations, or combine multiple techniques to enhance resistance to DL-based attacks.

Table 1.
Countermeasures against side-channel attacks.
Hiding techniques are a class of side-channel countermeasures designed to make the power consumption of cryptographic devices independent of the data values being processed and the operations being performed. Formally, a hiding countermeasure ensures that the instantaneous power consumption either exhibits random variation or remains constant across different computations, thereby decoupling data-dependent leakage from observable side-channel signals [25]. This is typically achieved by reducing the signal-to-noise ratio (SNR) of the leakage, making it harder to distinguish meaningful patterns [1]. There are two principal approaches to achieving this. The first is to introduce randomization in power consumption per clock cycle, typically by varying the timing or sequence of cryptographic operations. The second is to enforce constant power consumption through uniform switching activity or balanced logic styles, regardless of the input or operation. While achieving perfect randomness or uniformity is infeasible in practice, hiding techniques approximate these conditions to obscure exploitable patterns in power traces, thereby enhancing resistance against power analysis attacks. Table 2 shows the classification of hiding techniques.
Table 2.
Classification of hiding techniques.
Among various hiding techniques, dummy insertion remains one of the most widely adopted approaches, primarily because it does not require hardware or algorithmic modifications [25]. To bypass such dummy-based countermeasures, several prior studies have employed techniques such as feature fusion and data denoising [19], while others have utilized CNNs to identify dummy instructions in IC card environments [26]. Additionally, some efforts have focused on enhancing attack performance by simply increasing the size of neural network models, often without sufficient consideration of architectural efficiency or the risk of overfitting [27,28].
However, these approaches are generally constrained by their reliance on fixed hardware platforms and limited instruction diversity, which significantly restricts their generalizability across varying microarchitectural contexts. Moreover, methods based on passively collected real-world data often lack fine-grained control over instruction distribution and execution behavior, making it difficult to isolate the effects of specific countermeasures.
To address these limitations, the present study introduces a simulation-based methodology that generates intentionally controlled training data and trains DL models within a fully virtualized environment. This design enables precise manipulation of instruction sequences and execution contexts, allowing for the systematic evaluation of dummy insertion schemes under diverse and complex microarchitectural settings.
Experimental results demonstrate that even relatively simple model architectures can reliably distinguish between dummy and genuine instructions, thereby underscoring the inherent vulnerability of conventional hiding techniques to DL-SCAs. Furthermore, the flexibility of the simulation framework facilitates portability and extensibility, making the proposed approach applicable to a wide range of embedded system platforms.
2.3. ELMO
One of the key tools for analyzing SCAs is the Emulator for power Leakages for the M0 (ELMO) [29], an open-source framework designed for power consumption modeling in embedded systems. ELMO enables researchers to simulate the effects of different cryptographic implementations, allowing for precise measurement and evaluation of potential vulnerabilities [15]. By leveraging such tools, researchers can develop and assess novel countermeasures against SCAs in a controlled environment.
Additionally, ELMO uses instruction flow analysis to predict power consumption cycles, providing insights into the power signatures of cryptographic operations. It categorizes assembly instructions into different groups, such as arithmetic logic unit (ALU) operations, load/store operations, and shift operations, which helps refine the accuracy of power analysis predictions.
Recent updates to ELMO have incorporated ML-based analysis, enhancing its ability to simulate real-world attacks [30]. The integration of AI-driven predictive models into SCA research has allowed for more effective assessment of countermeasures and attack techniques. Researchers are now utilizing these advanced simulation tools to refine cryptographic implementations and develop adaptive defenses against evolving threats [31].
Table 3 presents the classification of assembly instructions used in ELMO for power analysis. By categorizing instructions into arithmetic, shift, load/store, and multiplication operations, ELMO enables researchers to analyze the energy consumption patterns of cryptographic implementations more effectively.
Table 3.
Categories of assembly instructions in ELMO.
As DL techniques continue to evolve, they present both challenges and opportunities in the field of cryptographic security. On the one hand, ML models enhance the ability of attackers to conduct sophisticated SCAs; on the other hand, they also provide avenues for developing more resilient countermeasures. Understanding these dynamics is crucial for advancing the security of cryptographic systems and ensuring robust protection against emerging threats.
2.4. Deep Learning Models
To experimentally evaluate the hiding techniques, three representative DL architectures are considered: RNN, Bi-RNN, and MLP [32,33,34]. This subsection describes the architectures of these models.
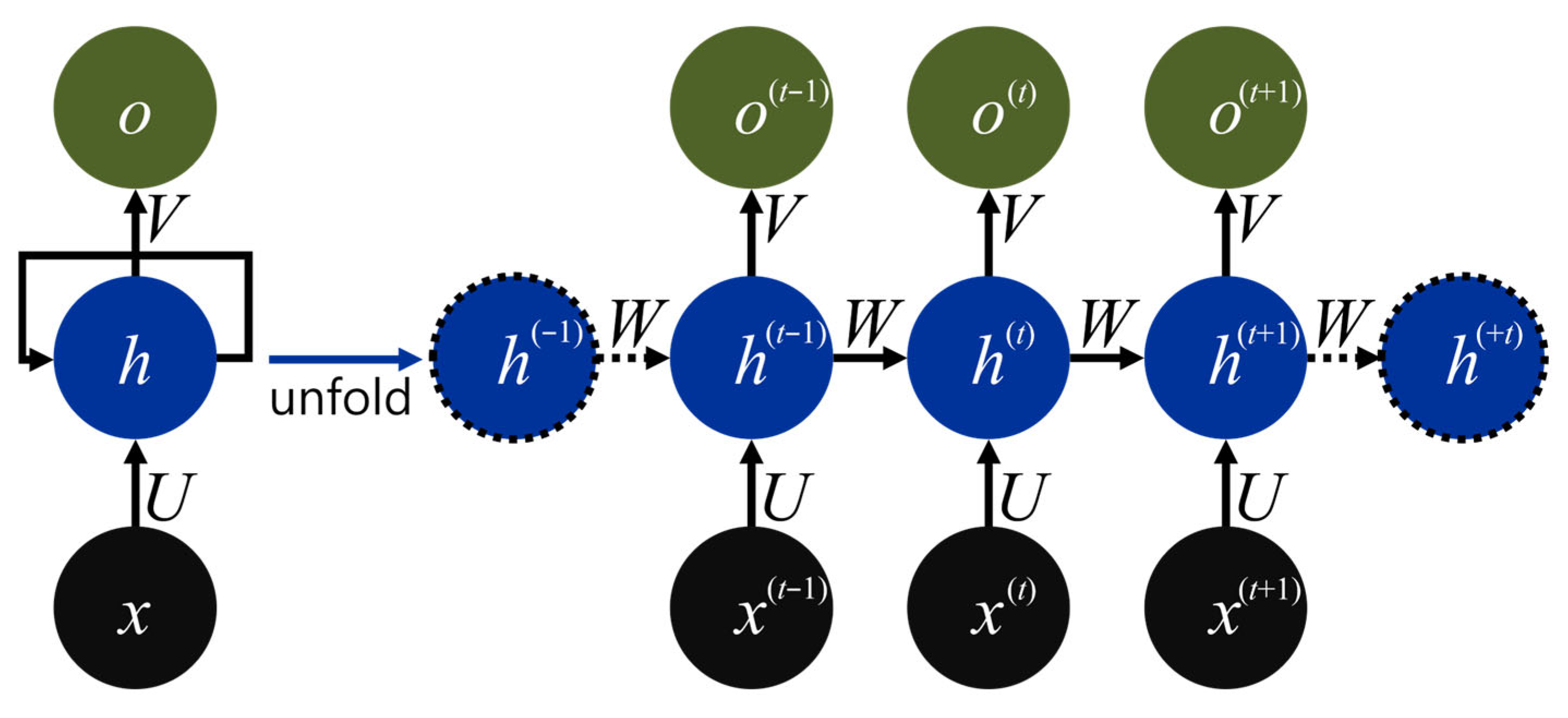
RNNs were initially designed to model sequential dependencies by introducing cyclic connections that propagate hidden states across time steps. Figure 3 schematically illustrates the unfolded recurrent cell used in this study. At each time step, the current input vector x(t) is first projected into the hidden space via the input-to-hidden weight matrix U. This input contribution is combined with the transformed previously hidden state h(t−1) through the recurrent weight matrix W; the result is passed through a nonlinear activation function to yield the new hidden state h(t). The updated hidden state is subsequently mapped to the output o(t) via the hidden-to-output weight matrix V. Since the parameter triplet {U, W, V} is shared across all time steps, the model can capture long-range temporal dependencies while keeping the number of parameters independent of sequence length. The diagram includes the boundary states h(−1) and h(+t), which are handled in a standard manner during implementation.
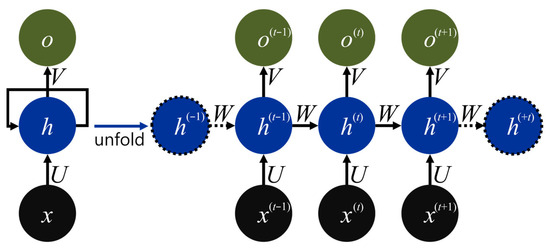
Figure 3.
Architecture of the unfolded RNN cell.
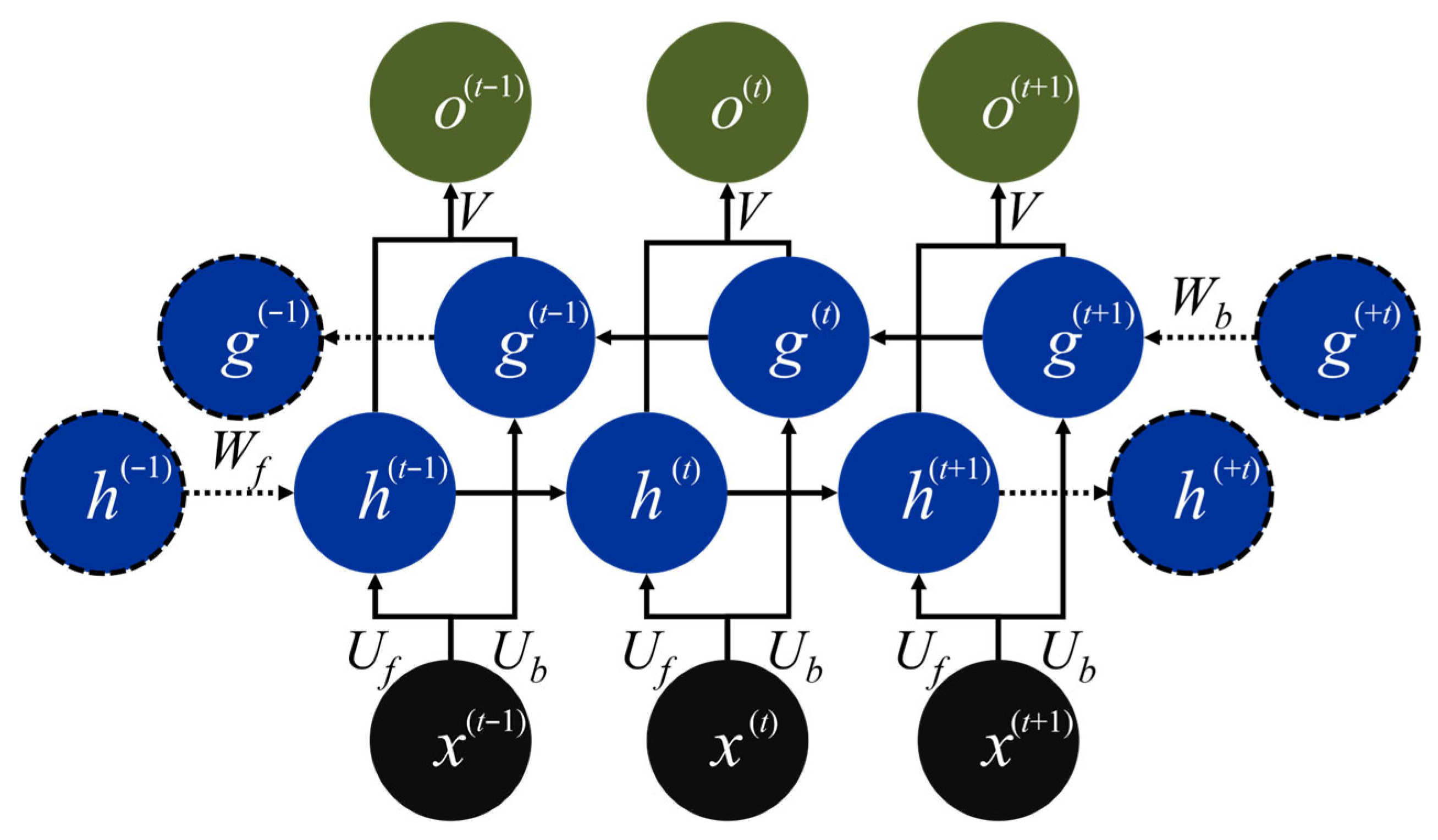
The Bi-RNN architecture processes sequences in both forward and backward directions, leveraging contextual information from both past and future inputs. Figure 4 illustrates the Bi-RNN cell, which introduces a time-reversed hidden stream such that each input x(t) is processed bidirectionally. The conventional forward hidden state is denoted as h(t) and updated using the recurrent weight matrix Wf, while the backward hidden state g(t) propagates from future to past through its own matrix Wb. Each direction uses its own set of input-to-hidden and recurrent weights. Specifically, the parameters for the forward hidden state h(t) are {Uf, Wf}, while those for the backward hidden state g(t) are {Ub, Wb}. At each step, the paired hidden states [h(t), g(t)] are concatenated and projected via a shared output weight matrix V to produce the output o(t). Since Wf and Wb are reused across all time steps, the Bi-RNN achieves bidirectional context modeling with only a modest increase in parameter count compared to the unidirectional RNN. For clarity, only the first instance of each weight is labeled in the figure.
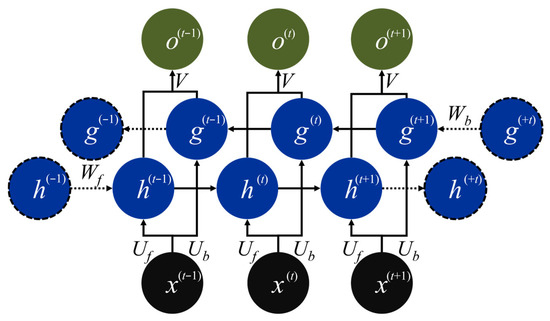
Figure 4.
Architecture of the unfolded Bi-RNN cell.
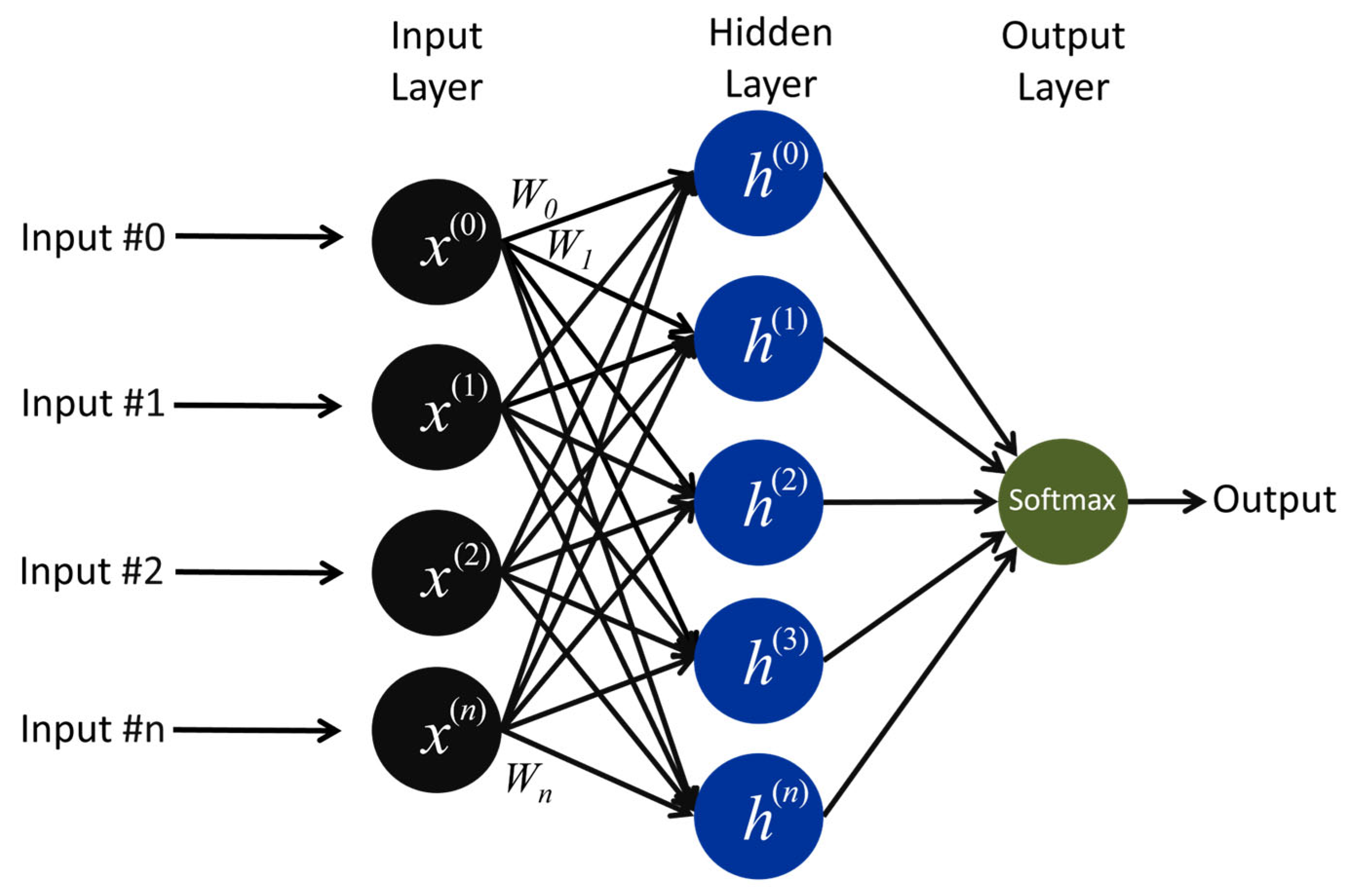
The MLP is the canonical feedforward network, widely popularized through the backpropagation algorithm. Although it lacks explicit temporal recurrency, the MLP remains a strong baseline for various classification tasks due to its universal approximation capability. Figure 5 illustrates the single-hidden-layer MLP architecture used in this study. The input features (x(0), …, x(n)) are fully connected to a hidden layer via a weight matrix W and a bias vector. A Rectified Linear Unit (ReLU) activation function is then applied to produce the hidden representations {h}. These activations are passed to the output layer, where another set of parameters maps them to Softmax neurons, yielding class-posterior probabilities. Since the MLP lacks recurrent connections, it cannot capture temporal dependencies.
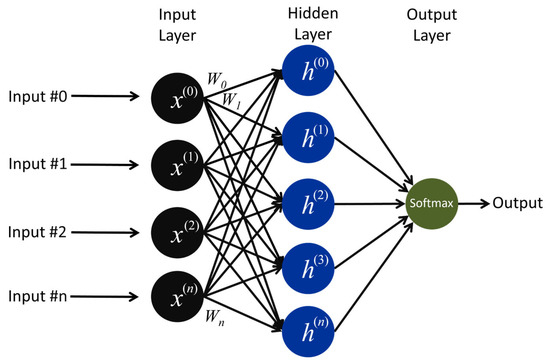
Figure 5.
Architecture of the MLP model.
In addition to the models discussed above, a wide range of architectures has been employed in DL-SCA and DL-based cybersecurity research. A common requirement across such studies is the availability of suitable training data. However, in many domains, publicly available datasets remain insufficient to meet the needs of researchers. Consequently, researchers often develop and utilize their datasets [3,35,36]. In this study, a dataset was constructed and utilized using an automated power trace generation tool. The resulting dataset has been made publicly available [37].
3. Method of Generating Dummy Power Trace Data
This study proposes a systematic approach to generating dummy power trace data that closely resembles actual cryptographic power consumption patterns. By leveraging a controlled simulation environment, the effectiveness of dummy power traces in mitigating SCAs is analyzed and evaluated. The process involves simulating cryptographic algorithm execution, extracting assembly-level instructions, and converting them into power trace data. The actual versions of the tools used are listed in Table 4.
Table 4.
The versions of the tools used.
3.1. Simulation Environment Setup
To generate realistic dummy power traces, a simulation environment is constructed based on the Quick Emulator (QEMU) and the GNU Debugger (GDB), enabling the precise extraction of execution-level data from cryptographic implementations [14]. QEMU is an open-source virtualization tool that emulates various hardware architectures, enabling embedded system code to be executed in a controlled environment without requiring physical hardware. GDB is a widely used tool for debugging programs, enabling step-by-step execution analysis and real-time extraction of assembly instructions.
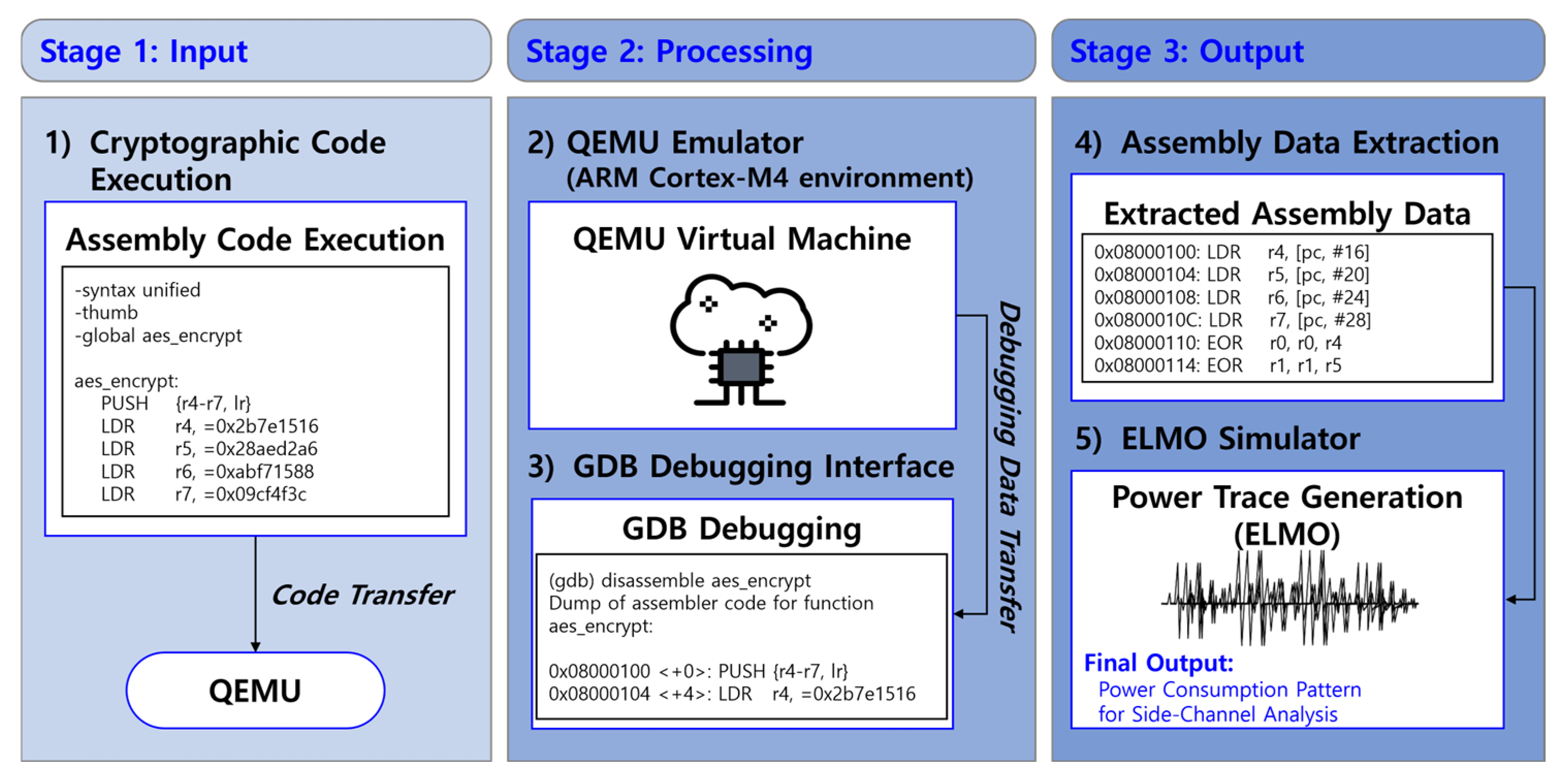
The process of dummy power trace generation consists of three main stages: cryptographic code execution (Stage 1), processing via emulation and debugging (Stage 2), and extraction of assembly data followed by power trace conversion (Stage 3), as illustrated in Figure 6. In Stage 1 (Input), cryptographic code written in assembly is executed within a simulated environment. The code is transferred to QEMU, a virtualized execution platform, where it undergoes controlled execution. In Stage 2 (Processing), QEMU functions as an ARM Cortex-M4 virtual machine, executing cryptographic operations while GDB is utilized for debugging. Through this debugging interface, assembly-level instructions are extracted in real-time, enabling precise tracking of command execution and memory access patterns. Finally, in Stage 3 (Output), the extracted assembly data—comprising memory addresses, instruction sequences, and operand values—is processed using the ELMO simulator. This conversion generates power consumption patterns, which are then analyzed for potential vulnerabilities to SCAs [30].
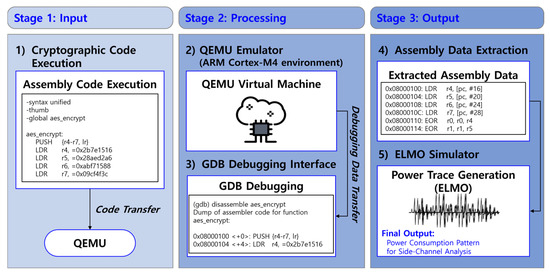
Figure 6.
Simulation environment for generating dummy power trace data.
This structured approach ensures a reproducible and controlled method for assessing cryptographic security against DL-SCAs.
Figure 7 presents the QEMU configuration and simulated execution output for the STM32F4-Discovery board. Before the emulation, each algorithm was compiled using arm-none-eabi-gcc and executed on QEMU with four types of inputs: plaintext, password, plaintext with dummy, and password with dummy.

Figure 7.
QEMU-based simulation of the STM32F4-Discovery board execution.
The QEMU targeted the STM32F4-Discovery board and the STM32F407VG microcontroller (STMicroelectronics, Plan-les-Ouates, Switzerland). The semihosting option was enabled to support debugging. Additionally, the -s option opened a debugging port, and the -S option halted execution until GDB was connected. Once connected, GDB communicated with the running QEMU process via the opened port to execute the compiled binary and generate a detailed execution log.
This log captured low-level execution information, including memory addresses, executed instructions, operand values, and other data generated during the execution of cryptographic operations. The raw log was subsequently preprocessed into a structured CSV file containing memory addresses, operand values, instruction types, opcodes, dummy labels, and execution contexts corresponding to each input algorithm.
3.2. Assembly Instruction Extraction
After executing cryptographic operations within the QEMU-based simulation environment, the next step involves extracting assembly-level instructions for each execution cycle. These instructions contain key details regarding the computational sequences being performed [39]. The extracted data includes memory addresses where instructions are stored, the types of instructions being executed, and the corresponding operand values manipulated during execution. Extracting this information is critical because each instruction contributes differently to power consumption, which is later analyzed in SCAs [30].
To retrieve these instructions, GDB is utilized to monitor and capture executed commands in real-time. This enables precise tracking of how cryptographic algorithms operate at the machine level, helping to identify which instructions might be susceptible to power analysis. The debugging interface of GDB provides a structured format where assembly instructions, memory access patterns, and register manipulations are recorded.
Table 5 presents an example of extracted assembly data obtained through GDB debugging. The extracted instructions include memory addresses, executed instruction types, and operand values stored in registers. This dataset serves as a representative example of how cryptographic operations are executed at the machine level and is crucial for power trace generation.
Table 5.
Information on extracted assembly data.
The extracted assembly data is then used to generate power traces through the ELMO simulator. Each instruction contributes to a unique power consumption pattern based on factors such as the number of bits changed in a register or memory operation complexity. By mapping these execution patterns to power traces, it becomes possible to assess how DL models identify cryptographic operations and evaluate the vulnerability of existing countermeasures.
3.3. Converting Assembly Instructions to Power Trace Data
After extracting the assembly-level execution data from the QEMU-based simulation environment, the next step involves converting this data into power trace data using the ELMO simulator [28]. ELMO is a widely used tool for modeling power consumption in cryptographic implementations. It estimates power consumption based on instruction-level characteristics and register interactions, providing a realistic power trace that represents the execution of cryptographic algorithms.
The power trace conversion follows a mathematical model, where the power consumption y is expressed as Formula (1).
In this formula, represents the scalar intercept, which serves as the baseline power consumption level. The coefficients and capture the influence of the previous and next instructions, respectively, on power consumption. These coefficients are determined based on predefined instruction categories such as ALU operations, load/store, and shift operations. The operand-related values, represented by , consist of the set [|||], which encodes 128-bit operands and their interactions during execution. A crucial component in this model is , which is assigned a binary matrix value corresponding to the operand of the -th instruction in the execution sequence. The value of is calculated using an XOR operation between the current operand bit matrix and the previously assigned operand matrix. For instance, if the current operand matrix is ‘0101’ and the previous operand matrix is ‘1100’, the XOR operation results in ‘1001’ as the assigned value. Another key factor, , represents the Hamming weight of the previous 32-bit operation and the Hamming distance between the last two operation values. These parameters significantly influence power consumption as they dictate the number of bit transitions occurring within registers. Finally, ϵ denotes an error vector that accounts for noise in power consumption measurements, while β is a coefficient vector determined based on ELMO’s calibrated power model parameters.
In the actual implementation, the ELMO engine received as input the instruction types of the previous, current, and next instructions, along with the operand addresses and values for the previous and current instructions. Based on these inputs, ELMO computed instruction-level power consumption traces for each execution instance.
By applying this model, the extracted assembly data is systematically converted into power traces that replicate real-world power consumption characteristics. These traces provide valuable insight into how cryptographic operations impact power consumption, allowing for an in-depth evaluation of their susceptibility to DL-based classification attacks.
4. Experimental Results
4.1. Data Generation and Preprocessing
To effectively analyze SCAs on embedded systems, a dataset was generated using cryptographic algorithms, including RSA, DES, and Hash functions [40]. The reason for selecting these algorithms in this study is that these algorithms are widely used in embedded systems and IoT environments and have been frequently targeted by recent SCAs. In particular, RSA and DES are suitable examples, given their cryptographic stability and widespread use in various industries [14,40]. The data collection was performed using a controlled simulation environment based on QEMU and GDB, allowing for the extraction of detailed assembly-level execution data.
The generated dataset underwent multiple stages of preprocessing to enhance its usability for DL models. Initially, the extracted instruction data was normalized to ensure consistency across different algorithm implementations. The dataset was then augmented by incorporating variations in memory access patterns and execution timing data, thereby capturing a more comprehensive representation of cryptographic behavior. This preprocessing step was crucial in facilitating robust model training and improving classification accuracy [39].
The dataset was structured to maintain an equal distribution of original and dummy instructions, ensuring a balanced training set. This was essential for assessing the resilience of DL-based classifiers against SCAs and validating the effectiveness of dummy power traces. Table 6 presents the dataset distribution, highlighting the number of original and dummy instructions per cryptographic algorithm.
Table 6.
Dataset distribution.
Although each cryptographic algorithm was executed the same number of times during data generation, the total number of instructions collected per algorithm varied. This variation in instruction count primarily arises from the intrinsic structural differences among the algorithms. DES performs a large number of repetitive operations within each encryption cycle, resulting in a higher instruction count per execution compared to RSA and hash functions. In contrast, RSA involves modular exponentiation and hash functions operate on fixed-length data blocks, both of which result in fewer instruction traces per execution.
Since the primary objective is to classify dummy versus original instructions rather than to compare different algorithms, this difference in instruction count does not compromise the validity of the dataset. Instead, a balanced distribution of original and dummy instructions was maintained to ensure consistency with the experimental objective.
Maintaining such a balanced dataset was crucial for simulating realistic attack scenarios and assessing the effectiveness of countermeasures. Additionally, a thorough evaluation of instruction dependencies and opcode frequency distributions was performed to identify potential biases in data generation, thereby ensuring the robustness of the dataset used for classification tasks.
4.2. Model Training and Experimental Setup
To evaluate the effectiveness of dummy power traces against SCAs, DL models were trained and tested using the generated dataset. Three primary architectures were considered: RNN, Bi-RNN, and MLP [31]. These models were selected due to their ability to capture sequential dependencies in power consumption patterns, making them particularly suitable for time-series classification tasks.
The dataset underwent preprocessing, including data normalization and augmentation, to enhance model generalization. Controlled noise injection and jitter effects were applied to simulate real-world measurement variations. Training was conducted using a high-performance GPU to ensure efficient computation.
Each model was optimized using the Adam optimizer and trained using the cross-entropy loss function. To prevent overfitting, regularization techniques such as dropout and L2 regularization were applied. Specifically, the architecture of each model is as follows:
- RNN. The unidirectional model begins with a simple RNN layer containing 50 hidden units and configured to return the full output sequence. Its output is flattened, followed by a dropout layer with a rate of 30%, a fully connected layer of 10 neurons that use ReLU activation, and a two-unit Softmax output layer.
- Bi-RNN. This architecture mirrors the unidirectional RNN but processes each sequence in both forward and backward directions through 50 units in each direction. The subsequent flattening, dropout, dense, and Softmax layers are identical to those of the RNN.
- MLP. The feed-forward network consists of a single hidden layer with one hundred ReLU-activated neurons and a two-unit Softmax output layer. During training, L2 regularization is used to promote generalization.
Performance evaluation was based on accuracy, precision, recall, F1-score, and the area under the curve (AUC), recorded after each epoch to track model improvement. Specifically, accuracy represents the proportion of all correct predictions; precision quantifies the fraction of instances labeled as positive that are truly positive; recall captures the fraction of actual positives correctly identified; F1-score is the harmonic mean of precision and recall, balancing their trade-off; and AUC summarizes the classifier’s overall discriminative capability across all decision thresholds.
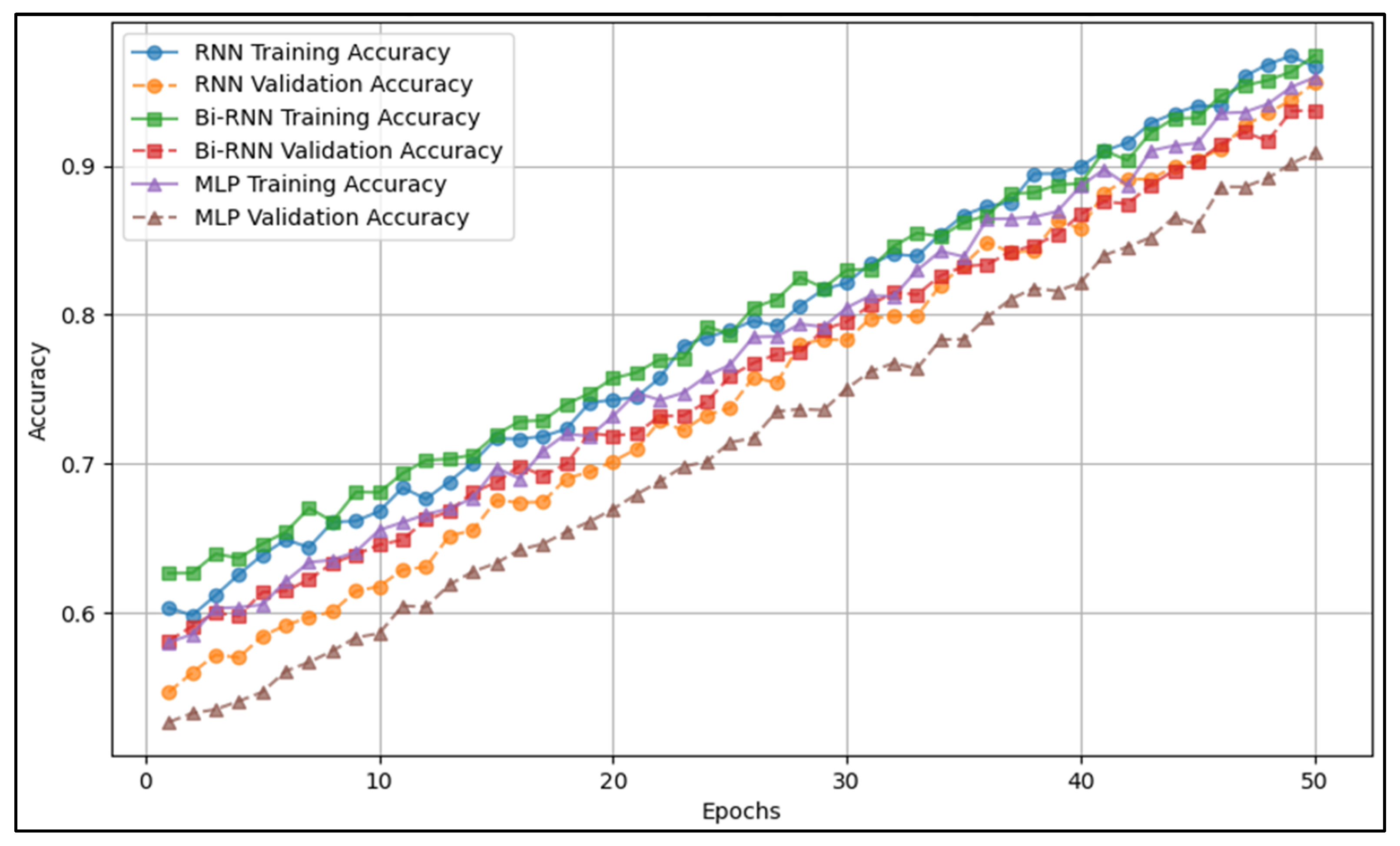
Figure 8 illustrates the accuracy progression during training, showing how each model converges over epochs. This figure provides insights into the training stability and comparative learning efficiency of different models. The results from Figure 8 complement Table 7, which presents final model performance metrics, by demonstrating how training progresses before achieving those final results.
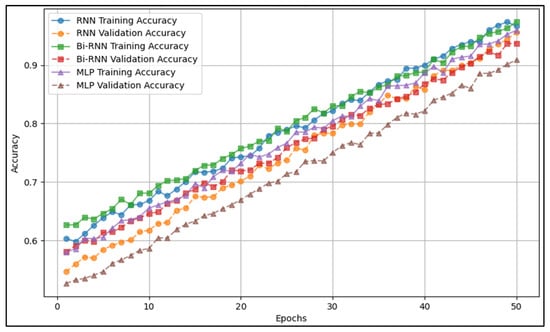
Figure 8.
Model accuracy progression during training.
4.3. Performance Evaluation and Comparison
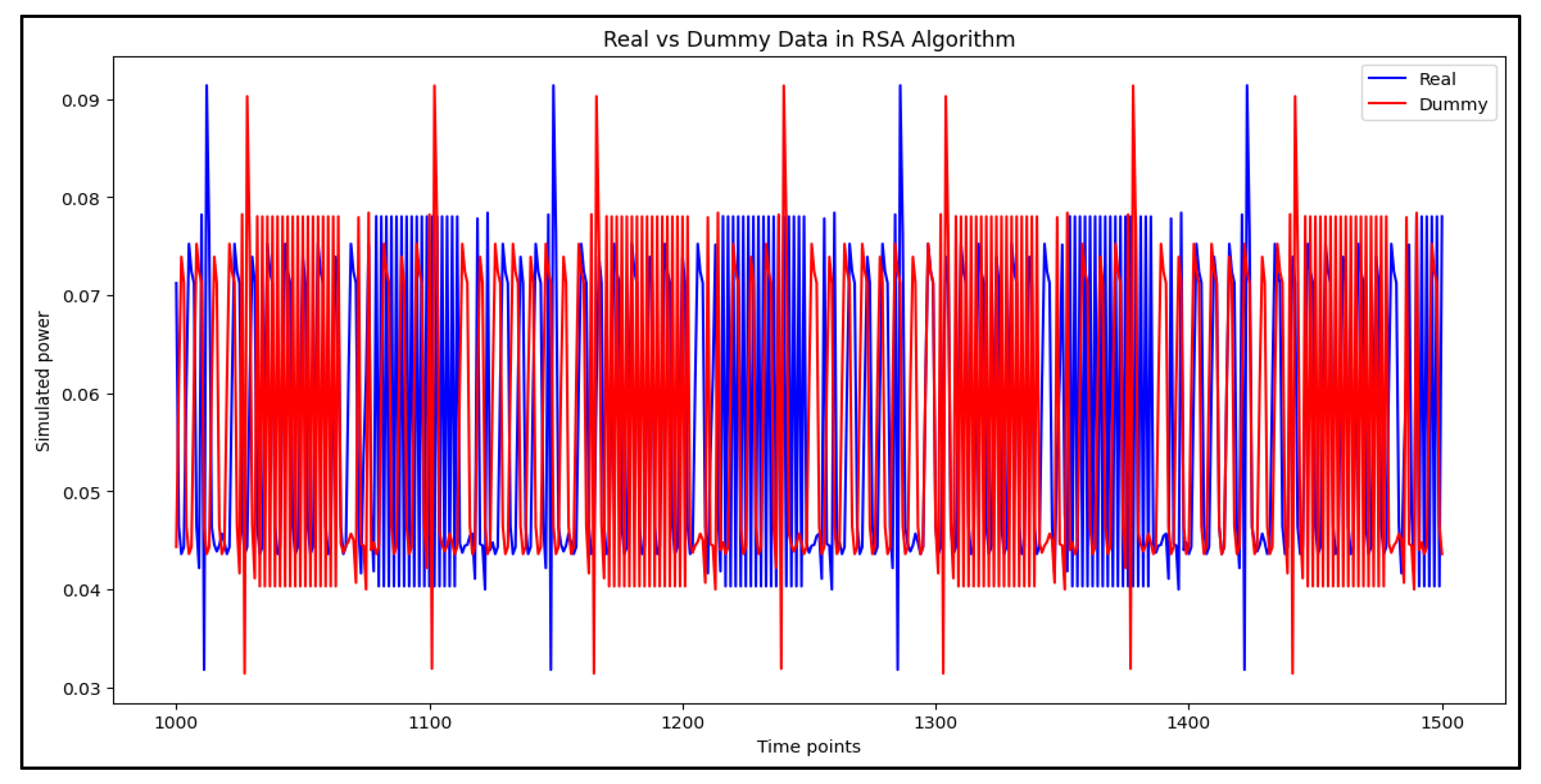
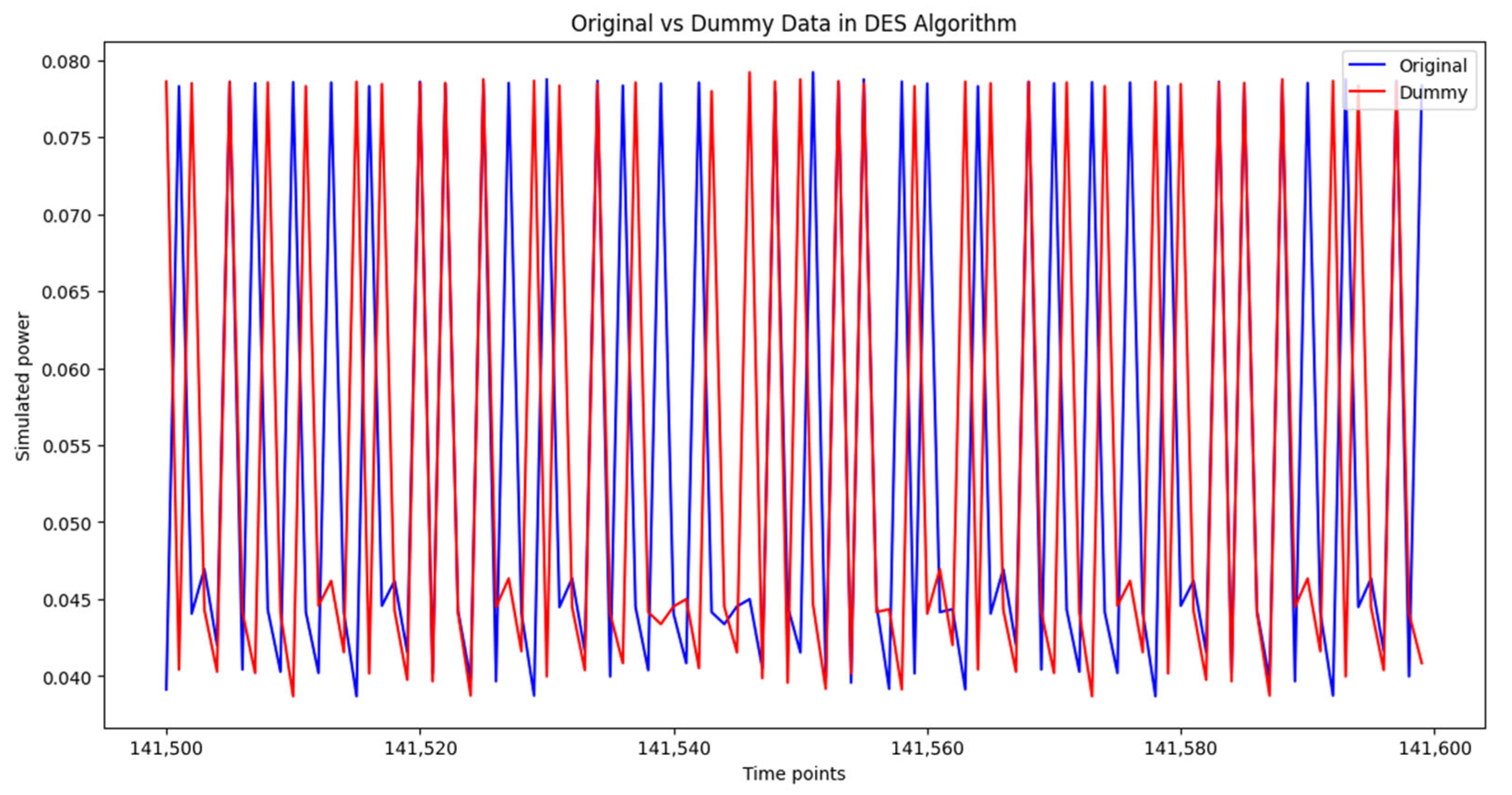
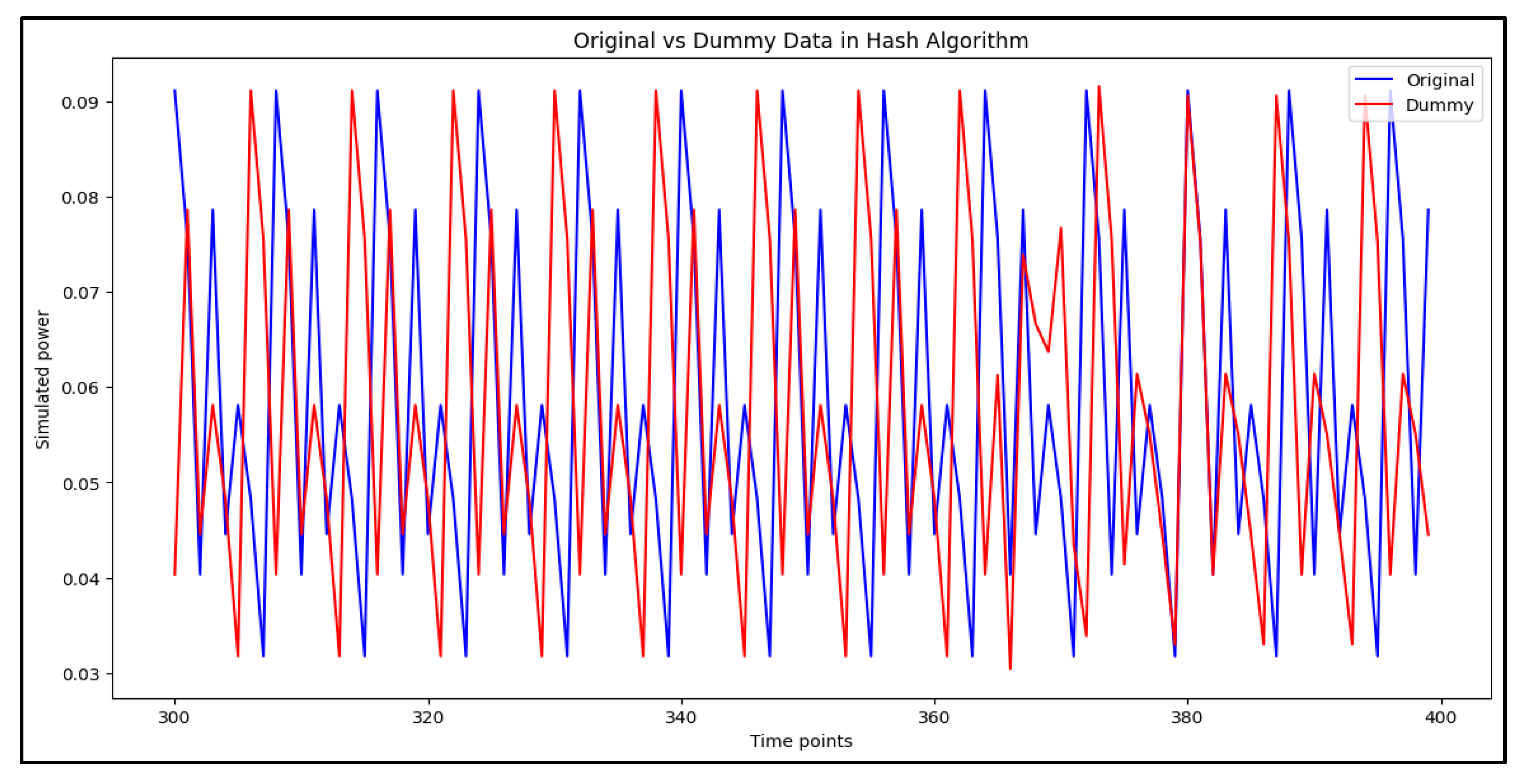
To assess the impact of dummy power traces on classification performance, Figure 9, Figure 10 and Figure 11 provide a comparative visualization of original and dummy power traces for RSA, DES, and Hash algorithms. These figures illustrate how dummy power traces attempt to obscure distinguishable patterns in cryptographic computations.
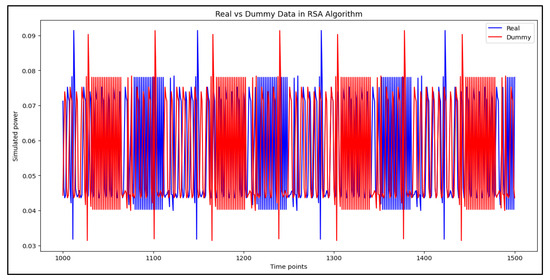
Figure 9.
Comparison of original and dummy power traces for RSA algorithms.
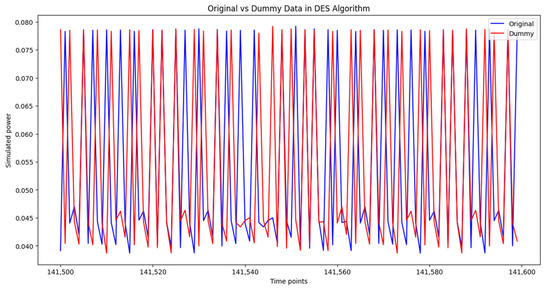
Figure 10.
Comparison of original and dummy power traces for DES algorithms.
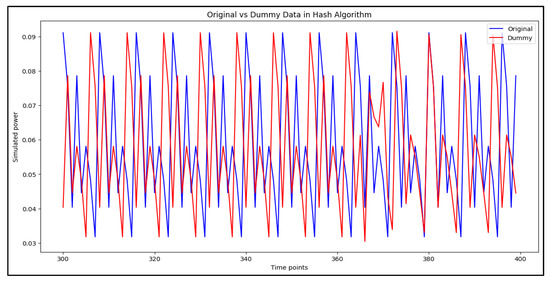
Figure 11.
Comparison of original and dummy power traces for Hash algorithms.
Figure 9 demonstrates the variance between the original and dummy power traces for the RSA algorithm. The dummy traces introduce irregularities in power consumption patterns, making it harder for attackers to extract meaningful information.
Figure 10 illustrates how dummy traces affect DES power consumption patterns. The dummy traces introduce additional fluctuations that obscure identifiable cryptographic signatures.
Figure 11 presents a comparison between original and dummy traces for hash algorithms, highlighting the extent to which dummy traces alter the power profile and reduce trace predictability.
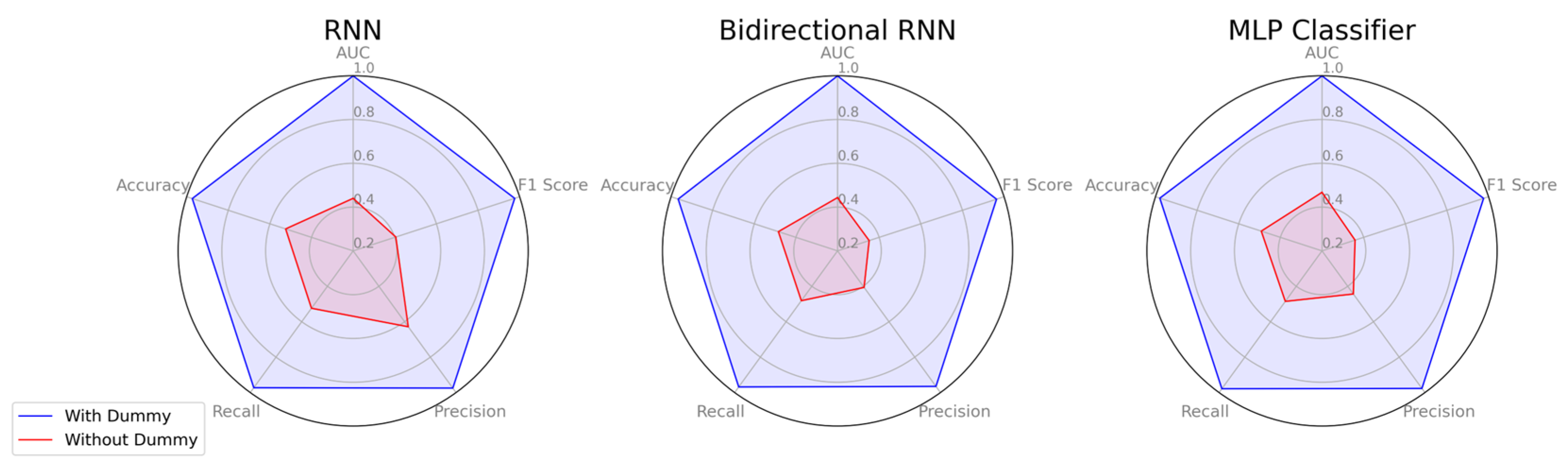
Figure 12 compares the prediction results of models trained exclusively on original power traces and those of models trained on power traces augmented with dummy traces. The model trained only on original traces exhibits low classification performance, indicating the effectiveness of hiding techniques as a countermeasure against conventional DL-SCA. However, when the DL model is trained on power traces augmented with dummy traces, classification performance improves significantly. This suggests that, although hiding operations may initially serve as an effective hiding strategy, they can be vulnerable to advanced SCA models trained to identify and exploit such patterns.
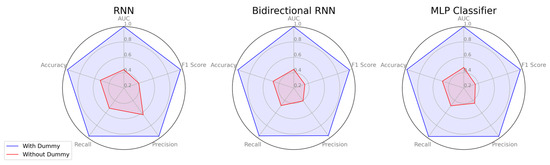
Figure 12.
Comparison of model performance for detecting hiding operations in Hash algorithms.
Table 7.
Deep learning model performance comparison for detecting Hiding operations.
Table 7.
Deep learning model performance comparison for detecting Hiding operations.
| Model Type | Dummy Traces | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC (%) |
|---|---|---|---|---|---|---|
| RNN | With | 97.50 | 99.01 | 95.97 | 97.46 | 99.68 |
| Bi-RNN | With | 97.38 | 98.77 | 95.96 | 97.34 | 99.65 |
| MLP | With | 97.81 | 99.71 | 95.90 | 97.77 | 99.76 |
| RNN | Without | 52.46 | 75.26 | 7.51 | 13.66 | 44.05 |
| Bi-RNN | Without | 48.15 | 32.11 | 3.20 | 5.83 | 44.05 |
| MLP | Without | 48.89 | 39.54 | 3.94 | 7.18 | 46.79 |
Table 7 highlights the impact of dummy traces on classification performance. The models trained with dummy traces achieved significantly higher accuracy, precision, recall, and F1-score, indicating that the presence of dummy traces improves the model’s ability to differentiate between power traces. Conversely, models trained without dummy traces exhibited a drastic drop in performance when evaluated on traces containing dummy traces, indicating poor generalization and highlighting the defensive effectiveness of the hiding technique in obfuscating cryptographic execution patterns. This phenomenon can be viewed as the reverse effect of increasing training data to mitigate overfitting. When dummy traces are introduced only at inference time, the model trained solely on original traces fails to generalize and exhibits behavior similar to overfitting.
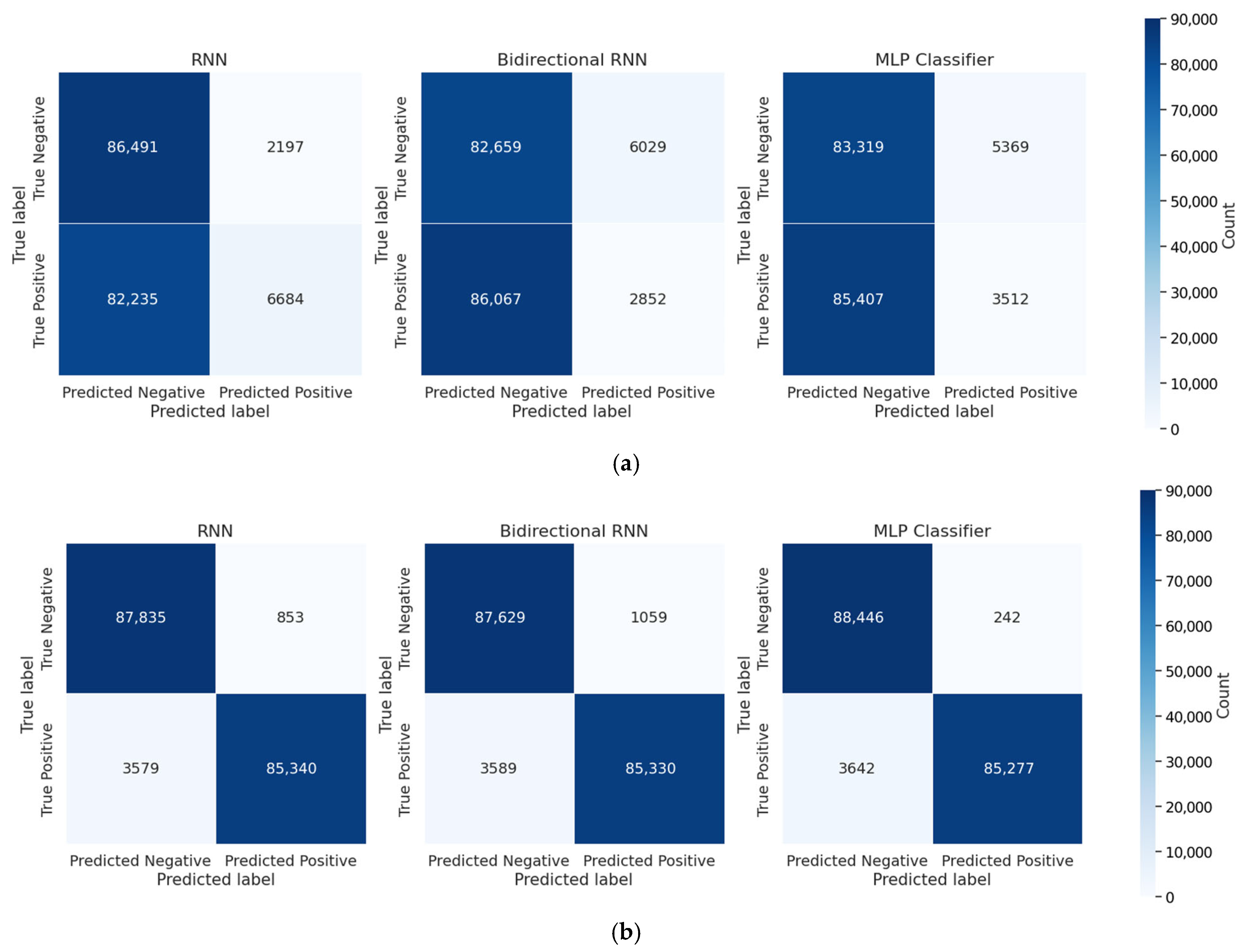
Figure 13 presents confusion matrices that compare the classification performance of models trained with and without dummy traces. Figure 13a shows the results for models trained without dummy traces, where a high misclassification rate indicates limited classification capability. In contrast, Figure 13b shows the results for models trained with dummy traces, highlighting improved accuracy through a more balanced distribution of true positives and true negatives.
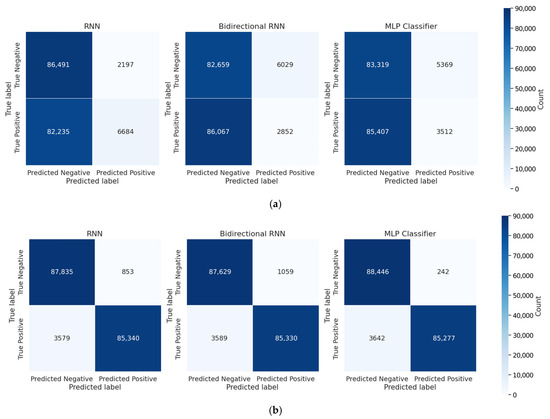
Figure 13.
Confusion matrices of classification results for models trained with and without dummy traces: (a) without dummy traces; (b) with dummy traces.
In the experimental results, the superior performance of MLP over RNN-based models when dummy data were added can be attributed to the fact that dummy power traces could be distinguished based on pattern features that appear at specific time points, rather than relying on temporal dependencies [17,25]. Although RNN-based models are designed to capture long-term dependencies, the data in this study emphasizes pattern changes at individual time points, which is why MLP showed better classification performance.
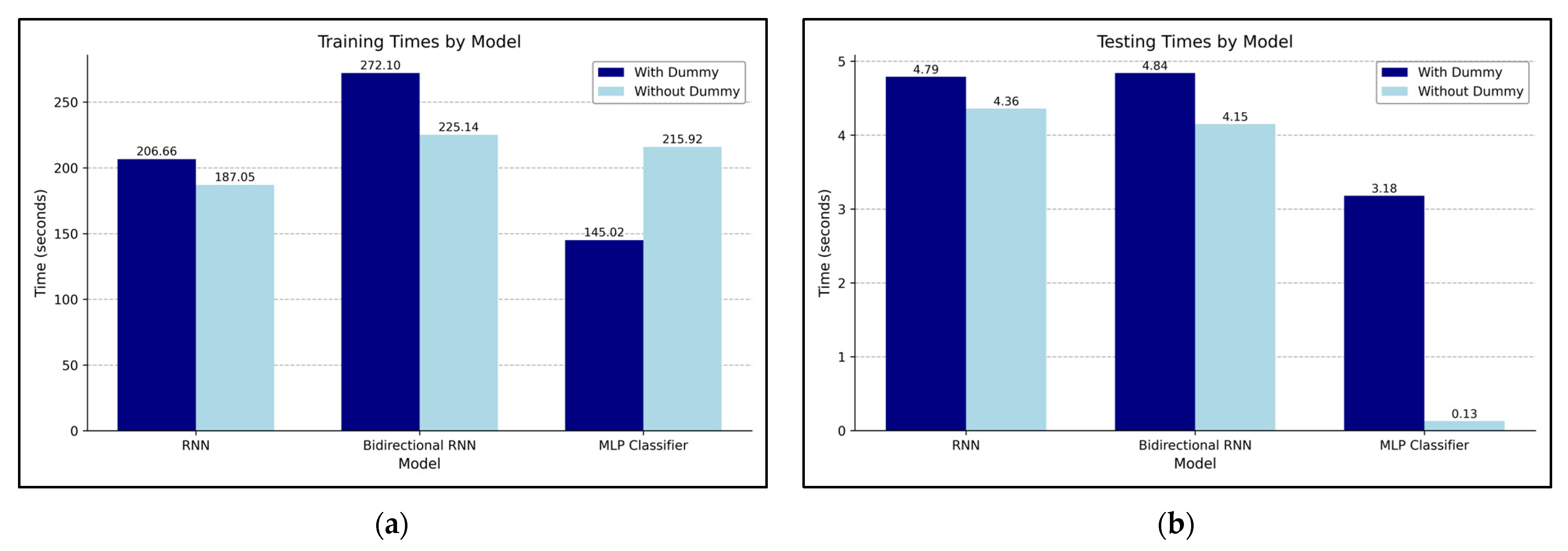
Figure 14 illustrates the training and testing times under both conditions. Figure 14a shows the training times of models trained on either the original power traces or the power traces augmented with dummy traces, and Figure 14b shows the corresponding testing times. The training was conducted using 710,428 data samples, with 10 epochs performed for both the RNN and Bi-RNN models and 50 epochs for the MLP model. Testing was uniformly performed on 177,607 test data samples. In terms of training time, the RNN and MLP models took longer to train when using dummy traces, whereas the Bi-RNN model required more time when trained without dummy traces. For testing time, all three models exhibited faster performance when trained on power traces augmented with dummy traces. Notably, although the MLP model showed an increase in training time of approximately 70 s, its testing time was significantly reduced, decreasing from 3.18 s to 0.13 s.
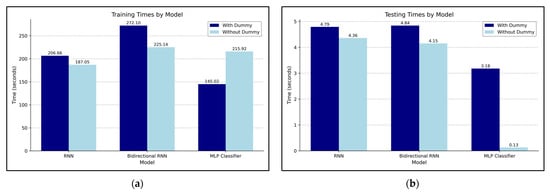
Figure 14.
Training and testing times of models with and without dummy traces: (a) Training times; (b) Testing times.
5. Discussion
This study systematically evaluated the effectiveness of dummy power traces in mitigating SCAs when analyzed using DL models. Using a simulated environment built on QEMU, GDB, and ELMO, a large-scale dataset of power traces was generated, systematically incorporating dummy traces to analyze their impact on cryptographic security. Experiments using RNN, Bi-RNN, and MLP models demonstrated that although dummy insertion increases trace complexity, DL-based classifiers consistently achieved high accuracy in distinguishing real traces from dummy ones. The average F1-score of 97.65% indicates that conventional hiding techniques are insufficient against the inference capabilities of DL-SCAs.
To evaluate the ability of the attack models to bypass dummy-based obfuscation, a balanced dataset was deliberately constructed, consisting of an equal ratio of original and dummy traces. While this design facilitated the evaluation of DL models under controlled conditions, subsequent studies should investigate the effects of varying the proportion of dummy traces, both in the obfuscation scheme and the training dataset. Such an analysis could enable a more rigorous quantification of the relationship between trace complexity and security robustness.
The simulation-based methodology used in this study offers a notable advantage, as it allows for the precise generation of intended data under fully controlled conditions [18]. However, it also introduces several limitations. First, ELMO supports only a limited subset of instructions from the target microcontroller, as detailed in Table 3 (Section 2.3), which necessitated grouping of instruction types and use of representative categories in the experiments. Second, the generated traces, although realistic in terms of leakage patterns, lack the data-independent noise typically observed in real-world environments. As a result, models trained on simulated traces may not fully generalize to physical hardware [29]. Addressing these limitations, such as by incorporating synthetic noise models or adopting hybrid simulation-real data training, could substantially enhance the realism and practical relevance of simulation-based side-channel research.
Building on these experimental insights, the results demonstrated that DL models can distinguish genuine traces from dummy ones with high reliability. This capability reveals a critical vulnerability in hiding-based defenses. While conventional evaluations of DL-SCAs rely on metrics such as classification accuracy, F1-score, or guessing entropy [15,16,17,18,19,20,21], these performance indicators alone are insufficient to determine whether the recovered outputs correspond to meaningful operations or artifacts of obfuscation. Given that DL-SCAs can infer execution semantics and explicitly detect obfuscation patterns, evaluating their threat potential necessitates more nuanced and multi-dimensional assessment criteria. In particular, incorporating physical-layer indicators such as SNR into the evaluation framework can provide a complementary perspective on leakage severity and help quantify the conditions under which obfuscation fails. Future assessments should consider not only prediction performance but also the model’s ability to recover functional behavior and to detect or circumvent obfuscation strategies under varying leakage conditions.
To further enhance the offensive capabilities of DL-SCAs, future research should investigate the application of adversarial ML techniques. Specifically, emphasis should be placed on data filtering and robustness evaluation as essential countermeasures against model degradation caused by data poisoning attacks [24,29]. Additionally, to improve the practical applicability of the research findings, it is necessary to evaluate the effects of measurement errors and environmental noise, factors not typically present in simulation environments, through real hardware implementations [39].
From a defense perspective, this study suggests that static obfuscation, although intuitive and low-cost, is inadequate against adaptive DL adversaries. As SCAs continue to evolve, cryptographic security mechanisms must advance in parallel. Based on the findings of this study, developers of embedded systems and IoT devices should move beyond static obfuscation strategies and consider adopting dynamic obfuscation techniques that modify patterns in real time or at regular intervals [23]. For example, recent research has demonstrated that device-level hardening frameworks can employ Bayesian optimization to dynamically tune DL-based defenses on mobile processors, thereby minimizing side-channel leakage without incurring significant overhead [41]. Moreover, a novel line of research repurposes neural networks as inline circuit abstractions that obfuscate power signatures, effectively transforming ML models from offensive tools into embedded countermeasures [28].
In addition to technical considerations, this study raises important ethical implications, particularly in the context of CPS. These systems, which closely integrate computing components with physical processes, are increasingly deployed in safety-critical domains such as autonomous vehicles, industrial automation, smart grids, and healthcare [2,3,5]. The demonstrated ability of DL models to extract fine-grained operational details from side-channel data, even when obfuscation is applied, raises significant concerns regarding the confidentiality and integrity of CPS operations [6,17]. An attacker equipped with such techniques could infer internal control states or manipulate actuation patterns, potentially leading to physical disruption or safety violations [7].
Given the dual-use nature of the findings, it is essential to adopt a responsible research posture [1]. Future work should be guided by ethical frameworks that consider not only how to maximize technical robustness but also how to prevent misuse in real-world deployments. This includes responsible disclosure of vulnerabilities, the adoption of privacy-preserving architectural designs, and adherence to sector-specific safety standards [2,13,35]. Research into CPS security must, therefore, strike an appropriate balance between scientific advancement and practical safeguards to ensure the trustworthiness of these increasingly ubiquitous systems [5,7].
6. Conclusions
This study proposed a novel framework for generating and evaluating dummy power traces in a fully virtualized and controlled environment, enabling reproducible and cost-effective experimentation in SCA. By systematically training DL models on both original and generated dummy traces, the results demonstrated that executions protected by dummy insertion still exhibit exploitable leakage patterns. Empirical evaluations using RNN, Bi-RNN, and MLP models confirmed their effectiveness in distinguishing dummy traces from genuine ones, thereby enabling the models to circumvent traditional hiding-based countermeasures by selectively identifying residual leakage from actual operations.
These findings reaffirm that static obfuscation techniques, while increasing the complexity of side-channel traces, are insufficient to provide robustness against DL-based attacks. By incorporating complex microarchitectural features and a diverse set of instruction types into the trace generation process, the proposed framework enhances the realism and cross-platform applicability of DL-SCA. This increased generalizability enables DL models to effectively adapt to a wide range of heterogeneous devices. As a result, any CPS device accessible to an adversary may be vulnerable to such attacks. These observations underscore the need for adaptive, dynamic, and learning-driven defense mechanisms that can respond to evolving attack strategies.
An essential next step is to develop integrated evaluation frameworks that not only assess information recovery capabilities but also incorporate mechanisms for distinguishing between genuine and obfuscated operations. Embedding such discriminative capacity into DL-based assessment pipelines would provide a more interpretable and security-relevant characterization of vulnerabilities in embedded systems. Furthermore, to improve its practical applicability, it is essential to evaluate the framework under real-world noise and hardware conditions [38].
In parallel, future research should extend the proposed framework by incorporating adversarial ML techniques to enhance DL-SCA capabilities, particularly in the context of data poisoning and model robustness [24,26]. On the defensive side, static obfuscation techniques should be complemented or replaced by dynamic obfuscation strategies that adapt leakage patterns over time, thereby enabling more resilient protection for IoT and CPS environments [12,22,28].
Overall, this study contributes a reproducible and extensible methodology for DL-SCA, while highlighting the urgent need for countermeasures that are not only technically robust but also adaptable to the rapidly evolving landscape of AI-driven attacks.
Author Contributions
Conceptualization, S.P., A.S. and Y.S.; methodology, S.P., A.S., M.C. and Y.S.; software, A.S., M.C. and H.K.; validation, S.P. and A.S.; formal analysis, A.S., M.C., J.K. and Y.S.; investigation, S.P., A.S. and M.C.; resources, S.P. and A.S.; data curation, A.S. and M.C.; writing—original draft preparation, S.P., A.S. and M.C.; writing—review and editing, S.P. and Y.S.; visualization, A.S. and M.C.; supervision, Y.S.; project administration, Y.S.; funding acquisition, Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This study was supported by the commercialization promotion agency for R&D outcomes grant funded by the Korea government (MSIT) (RS-2025-02315174). This work was supported by the Korea Institute of Energy Technology Evaluation and Planning (KETEP) and the Ministry of Trade, Industry & Energy (MOTIE) of the Republic of Korea (No. 20224000000020).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The SCADataset generated in this study can be accessed at https://github.com/PLASS-Lab/SCADataset (accessed on 5 June 2025) [37].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Picek, S.; Perin, G.; Mariot, L.; Wu, L.; Batina, L. SoK: Deep Learning-based Physical Side-channel Analysis. ACM Comput. Surv. 2023, 55, 227. [Google Scholar] [CrossRef]
- El Jaouhari, S.; Bouvet, E. Secure firmware Over-The-Air updates for IoT: Survey, challenges, and discussions. Internet Things 2022, 18, 100508. [Google Scholar] [CrossRef]
- Gaggero, G.B.; Armellin, A.; Portomauro, G.; Marchese, M. Industrial Control System-Anomaly Detection Dataset (ICS-ADD) for Cyber-Physical Security Monitoring in Smart Industry Environments. IEEE Access 2024, 12, 64140–64149. [Google Scholar] [CrossRef]
- Alabdulwahab, S.; Kim, Y.-T.; Seo, A.; Son, Y. Generating Synthetic Dataset for ML-Based IDS Using CTGAN and Feature Selection to Protect Smart IoT Environments. Appl. Sci. 2023, 13, 10951. [Google Scholar] [CrossRef]
- Alsabbagh, W.; Langendörfer, P. Security of Programmable Logic Controllers and Related Systems: Today and Tomorrow. IEEE Open J. Ind. Electron. Soc. 2023, 4, 659–693. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Y.; Chen, Y.; Liu, H.; Wang, B.; Wang, C. A Survey on Programmable Logic Controller Vulnerabilities, Attacks, Detections, and Forensics. Processes 2023, 11, 918. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, J.; Zhu, Q. Adaptive Secure Control for Uncertain Cyber-Physical Systems With Markov Switching Against Both Sensor and Actuator Attacks. IEEE Trans. Syst. Man Cybern. Syst. 2025, 55, 3917–3928. [Google Scholar] [CrossRef]
- Sengupta, A.; Mazumdar, B.; Yasin, M.; Sinanoglu, O. Logic Locking With Provable Security Against Power Analysis Attacks. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 766–778. [Google Scholar] [CrossRef]
- Ghandali, S.; Ghandali, S.; Tehranipoor, S. Profiled Power-Analysis Attacks by an Efficient Architectural Extension of a CNN Implementation. In Proceedings of the 2021 22nd International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 7–9 April 2021; pp. 395–400. [Google Scholar] [CrossRef]
- Hu, F.; Wang, H.; Wang, J. Multi-Leak Deep-Learning Side-Channel Analysis. IEEE Access 2022, 10, 22610–22621. [Google Scholar] [CrossRef]
- Tychalas, D.; Maniatakos, M. Special Session: Potentially Leaky Controller: Examining Cache Side-Channel Attacks in Programmable Logic Controllers. In Proceedings of the 2020 IEEE 38th International Conference on Computer Design (ICCD), Hartford, CT, USA, 18–21 October 2020; pp. 33–36. [Google Scholar] [CrossRef]
- Park, J.; Tyagi, A. Using Power Clues to Hack IoT Devices: The power side channel provides for instruction-level disassembly. IEEE Consum. Electron. Mag. 2017, 6, 92–102. [Google Scholar] [CrossRef]
- Papp, D.; Ma, Z.; Buttyan, L. Embedded systems security: Threats, vulnerabilities, and attack taxonomy. In Proceedings of the 2015 13th Annual Conference on Privacy, Security and Trust (PST), Izmir, Turkey, 21–23 July 2015; pp. 145–152. [Google Scholar] [CrossRef]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDoS in the IoT: Mirai and Other Botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Park, J.; Xu, X.; Jin, Y.; Forte, D.; Tehranipoor, M. Power-based Side-Channel Instruction-level Disassembler. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Kocher, P.; Jaffe, J.; Jun, B. Differential Power Analysis. In Proceedings of the 19th Annual International Cryptology Conference (CRYPTO), Santa Barbara, CA, USA, 15–19 August 1999; pp. 388–397. [Google Scholar] [CrossRef]
- Li, L.; Ou, Y. A deep learning-based side channel attack model for different block ciphers. J. Comput. Sci. 2023, 72, 102078. [Google Scholar] [CrossRef]
- Alabdulwahab, S.; Cheong, M.; Seo, A.; Kim, Y.-T.; Son, Y. Enhancing deep learning-based side-channel analysis using feature engineering in a fully simulated IoT system. Expert Syst. Appl. 2025, 266, 126079. [Google Scholar] [CrossRef]
- Huang, H.; Wu, J.; Tang, X.; Zhao, S.; Liu, Z.; Yu, B. Deep learning-based improved side-channel attacks using data denoising and feature fusion. PLoS ONE 2025, 20, e0315340. [Google Scholar] [CrossRef]
- Robissout, D.; Bossuet, L.; Habrard, A. Scoring the predictions: A way to improve profiling side-channel attacks. J. Cryptogr. Eng. 2024, 14, 513–535. [Google Scholar] [CrossRef]
- Hameed, F.; Alkhzaimi, H. Advanced Side-Channel Profiling Attacks with Deep Neural Networks: A Hill Climbing Approach. Electronics 2024, 13, 3530. [Google Scholar] [CrossRef]
- He, D.; Wang, H.; Deng, T.; Liu, J.; Wang, J. Improving IIoT security: Unveiling threats through advanced side-channel analysis. Comput. Secur. 2025, 148, 104135. [Google Scholar] [CrossRef]
- Shan, W.; Fu, X.; Xu, Z. A Secure Reconfigurable Crypto IC With Countermeasures Against SPA, DPA, and EMA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2015, 34, 1201–1205. [Google Scholar] [CrossRef]
- Weissbart, L.; Picek, S.; Batina, L. One Trace Is All It Takes: Machine Learning-Based Side-Channel Attack on EdDSA. In Proceedings of the 9th International Conference on Security, Privacy, and Applied Cryptography Engineering (SPACE), Gandhinagar, India, 3–7 December 2019; pp. 86–105. [Google Scholar] [CrossRef]
- Mangard, S.; Oswald, E.; Popp, T. Power Analysis Attacks: Revealing the Secrets of Smart Cards; Springer: New York, NY, USA, 2007; ISBN 978-0-387-30857-9. [Google Scholar] [CrossRef]
- Lee, J.; Han, D.-G. DLDDO: Deep Learning to Detect Dummy Operations. In Proceedings of the Information Security Applications: 21st International Conference, WISA 2020, Jeju Island, Republic of Korea, 26–28 August 2020; pp. 73–85. [Google Scholar] [CrossRef]
- Masure, L.; Dumas, C.; Prouff, E. A Comprehensive Study of Deep Learning for Side-Channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2020, 348–375. [Google Scholar] [CrossRef]
- Krautter, J.; Tahoori, M.B. Neural Networks as a Side-Channel Countermeasure: Challenges and Opportunities. In Proceedings of the 2021 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Tampa, FL, USA, 7–9 July 2021; pp. 272–277. [Google Scholar] [CrossRef]
- McCann, D.; Oswald, E.; Whitnall, C. Towards practical tools for side channel aware software engineering: Grey box’ modelling for instruction leakages. In Proceedings of the 26th USENIX Conference on Security Symposium, Vancouver, BC, Canada, 16–18 August 2017; pp. 199–216. [Google Scholar]
- Vaish, N.; Khosla, C. Uniform debugging interface for simulators. In Proceedings of the Third International Conference on Advanced Informatics for Computing Research, Shimla, India, 15–16 June 2019; p. 29. [Google Scholar] [CrossRef]
- Brier, E.; Clavier, C.; Olivier, F. Correlation power analysis with a leakage model. In Proceedings of the 6th International Workshop on Cryptographic Hardware and Embedded Systems (CHES), Cambridge, MA, USA, 11–13 August 2004; pp. 16–29. [Google Scholar] [CrossRef]
- Feng, W.; Guan, N.; Li, Y.; Zhang, X.; Luo, Z. Audio visual speech recognition with multimodal recurrent neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 681–688. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Alabdulwahab, S.; Kim, Y.T.; Son, Y. Privacy-Preserving Synthetic Data Generation Method for IoT-Sensor Network IDS Using CTGAN. Sensors 2024, 24, 7389. [Google Scholar] [CrossRef] [PubMed]
- Alabdulwahab, S.; Kim, J.; Kim, Y.-T.; Son, Y. Advanced Side-Channel Evaluation Using Contextual Deep Learning-Based Leakage Modeling. ACM Trans. Softw. Eng. Methodol. 2025. [Google Scholar] [CrossRef]
- PLASS-Lab. SCADataset. Available online: https://github.com/PLASS-Lab/SCADataset (accessed on 5 June 2025).
- ThFeneuil. Python-elmo. Available online: https://github.com/ThFeneuil/python-elmo (accessed on 5 June 2025).
- Díaz, E.; Mateos, R.; Bueno, E.J.; Nieto, R. Enabling Parallelized-QEMU for Hardware/Software Co-Simulation Virtual Platforms. Electronics 2021, 10, 759. [Google Scholar] [CrossRef]
- Su, N.; Zhang, Y.; Li, M. Research on Data Encryption Standard Based on AES Algorithm in Internet of Things Environment. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 2071–2075. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Hasan, M.K.; Memon, I.; Aman, A.H.M.; Islam, S.; Gadekallu, T.R.; Memon, S.A. Secure AI for 6G Mobile Devices: Deep Learning Optimization Against Side-Channel Attacks. IEEE Trans. Consum. Electron. 2024, 70, 3951–3959. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).