Abstract
Effective assessment development requires collaboration between multidisciplinary team members, and the process is often time-intensive. This study illustrates a framework for integrating generative artificial intelligence (GenAI) as a collaborator in assessment design, rather than a fully automated tool. The context was the development of a 12-item multiple-choice test for social work interns in a school-based training program, guided by design-based research (DBR) principles. Using ChatGPT to generate draft items, psychometricians refined outputs through structured prompts and then convened a panel of five subject matter experts to evaluate content validity. Results showed that while most AI-assisted items were relevant, 75% required modification, with revisions focused on response option clarity, alignment with learning objectives, and item stems. These findings provide initial evidence that GenAI can serve as a productive collaborator in assessment development when embedded in a human-in-the-loop process, while underscoring the need for continued expert oversight and further validation research.
1. Introduction
Development of high-quality assessments, whether cognitive (e.g., tests, exams) or affective (e.g., surveys), is a science that has traditionally required multidisciplinary team collaboration between subject matter experts (SMEs) and psychometricians to produce effective products [1,2,3]. Numerous educational studies have demonstrated the success of such teams implementing robust, mixed methods design-based research (DBR) processes to gather validity evidence aligned with the Standards for Educational and Psychological Assessment (Standards; [1]) for the purpose of generating high-quality assessment outcomes, e.g., [4,5,6]. Although important, application of rigorous and iterative methodologies in instrument development and validation has been consistently documented as highly time-intensive, e.g., [7,8,9], with item generation being particularly demanding in terms of time and resources [10]. Technology-assisted item creation has been promoted as a means of reducing time burden associated with item development [10,11,12]. For several decades, automatic item generation (AIG) procedures have been explored and refined as a strategy to support large-scale item creation [10]. Traditional AIG methods, however, typically require software engineering expertise and technological infrastructure [10,11] that are not commonly accessible to the broader population of assessment developers such as K–12 and higher education educators or professionals in workforce development and training industries. Recent advancements in generative artificial intelligence (GenAI), particularly in model sophistication and accessibility of item generation platforms [13,14,15], have enabled assessment developers without programming expertise to expeditiously produce a wider variety of items with more diverse language and scenarios [14]. Such progress in GenAI can also facilitate reduced efforts in smaller-scale assessment development and validation processes used in classrooms or training modules for educational purposes [16,17]. Nonetheless, the importance of maintaining human oversight in AI-supported processes has been increasingly emphasized to ensure ethical standards and validation integrity, e.g., [13,17,18,19].
Considering the aforementioned points, the primary purpose of this paper is to illustrate a strategy for integrating GenAI into an assessment development team as a collaborator (AI-assisted item creation) because “there is a need for simple AI use guides that are accessible to non-technical users” [20] (p. 6). Recent calls have been made for AI-produced assessments to be held to the same standards as those created exclusively by humans [13,18,21]. However, methods for evaluating items created through technology-assisted procedures are inconsistent and often considered ill-defined [11,12]. Accordingly, a secondary aim of this manuscript is to describe a process for gathering content validity evidence, demonstrated through an example using multiple-choice items produced by our AI-assisted assessment development team. Although examining multiple sources of validity evidence is essential [1,10,12], content validity evidence serves as the foundational step in assessment validation, providing the basis for subsequent studies [1]. Further, examination of item quality through expert review has yet to be detailed sufficiently in prior technology-assisted item development research [11,12].
1.1. Technology-Assisted Item Development
Research focused on technology-assisted item development dates back to the early 1970s [12]. In a traditional sense, automatic item generation (AIG) involves using computer algorithms to create assessment questions based on multiple inputs such as cognitive models, templates, and rule sets [11,22]. After initial human-informed inputs are specified, AIG can independently generate large numbers of items based on the predefined parameters [12,23]. For example, a simple AIG framework applied to fraction comparison might use a template tied to a fixed real-world context, such as baking. The template could read: “In a baking recipe, [Name 1] used [Fraction 1] cup of flour while [Name 2] used [Fraction 2] cup. Who used more flour?” This template can then be populated with different names and fraction values to generate numerous items automatically. More complex templates make it possible to adjust several elements in a multiple-choice item simultaneously, producing items that tend to look substantially different due to the broader range of content being varied within the model [23].
Traditional rule-based AIG addressed the need for large item banks in high-stakes testing contexts such as certification exams and national assessments, where minimizing item exposure is essential [10,23]. By automating item creation at scale, AIG significantly reduces the time and cost of manual item writing [10,22,24]. While this approach has offered clear benefits, it also has limitations. One such limitation is its reliance on templates, which can constrain contextual and format diversity if sophisticated models are not created and employed [23]. In the absence of software engineering experts and proprietary programs, implementation of traditional AIG has not been feasible for the larger population of educational assessment developers [25].
Advances in GenAI and large language models (LLMs), combined with the emergence of open-access assessment development platforms, have made it possible for non-technical users (e.g., K-12 and higher education educators or workforce development trainers) to efficiently leverage AI as a supportive tool in creating novel items [13,18]. While traditional template-based AIG structures can be approximated within open-access GenAI platforms like ChatGPT, the flexibility of LLMs allows users to generate varied items without relying on rigid, rule-based templates. Instead, they respond to structured prompts, which function as adaptable semantic guides rather than fixed templates, producing probabilistic outputs. Because LLMs generate text by predicting the next word based on patterns in prior input, their outputs are more natural and variable than those produced by traditional AIG [16]. As a result, current research is increasingly focused on developing and refining prompt engineering strategies—methods for crafting inputs that effectively guide GenAI models to produce assessment items [16]. However, prompt engineering is not always required at the user level. Many emerging multiple-choice item generators are built specifically for ease of use and integrate pre-defined prompts behind the scenes, enabling users to generate items directly from uploaded content or structured inputs [13].
Research on GenAI in education has accelerated due to its flexibility and ability to generate diverse items across languages and content areas [26]. Yet concerns remain related to hallucinations, limited practitioner expertise in prompt engineering, and ethical considerations [18,19]. To address these issues, assessment developers would benefit from clear integration strategies that position GenAI as a collaborative assistant within development teams, supported by a framework for reviewing and validating the items it generates [13,18,27]. This need is evident in professional training programs such as school social work, where educators often lack the resources or technical expertise to create formal assessments but still require valid tools to evaluate student learning and clinical readiness.
1.2. Evaluating Items Developed Through Technology-Assistance
A recent study by Kurdi et al. [12] found that the most common approach to evaluating machine-generated assessment items is expert review, in which subject matter experts (SMEs) assess a sample of generated items. However, procedures for conducting such reviews are limited, with reported issues including ambiguous instructions and inconsistent interpretations of rating criteria among experts [12]. Another frequently used method involves comparing machine-generated items to those written by humans, typically through blind SME panel reviews [11,12,28,29]. Findings from these comparisons generally indicate that machine-authored items are of comparable quality to human-written ones [10,11]. Despite this, researchers have called for more rigorous validation using quantitative and psychometric methods, which remain underutilized in the evaluation of technology-assisted item development [11,12,18]. While many studies claim that machine-generated items possess educational value, such claims are often assumed rather than empirically verified and warrant further investigation [12].
With the increasing availability of online GenAI item-writing tools, attention has turned toward evaluating the educational value of the items they generate, e.g., [13,16]. Findings to date have been mixed. For example, Elkins et al. [16] conducted an experiment to determine whether LLMs could generate questions that educators consider appropriate for classroom use. They found that both high school and college-level educators overwhelmingly perceived the GenAI-created questions as relevant and useful. Although the LLMs had more difficulty producing questions aligned with higher-order cognitive skills (e.g., “creating” in Bloom’s taxonomy), educators rated the majority as usable with only minor or no revision necessary. In contrast, Authors [13] evaluated the quality of multiple-choice questions generated by nine different online GenAI item-writing tools. In this effectiveness study, psychometricians judged 80% of the items as prone to produce high levels of measurement error, indicating these items should not be used without revision. While these studies significantly differ in terms of their design and scope, a key factor contributing to the contrasting results appears to be background of the item evaluators: educators (content experts) versus psychometricians (assessment experts). Existing literature suggests that although educators are experts in their subject areas, they often lack the training necessary to evaluate the psychometric soundness of assessment items [9,30,31]. To ensure that machine-generated items lead to valid and reliable assessments, forming collaborative teams that bring together both content experts and assessment specialists is essential [13,18]. As such, this manuscript presents a strategy for integrating GenAI into an assessment development and validation team as a collaborative assistant alongside SMEs, psychometricians, and qualitative researchers, while also addressing a critical gap by detailing a robust expert review method for evaluating item quality. In our case, this challenge emerged in the context of preparing school-based social work interns (SWIs), where assessment of their learning directly supports their ability to work effectively with students, families, and educators in school settings.
1.3. Study Context and Research Question
To address the growing mental health needs of students in high-need, rural communities, two grant initiatives were funded through the United States (U.S.) Department of Education’s Mental Health Service Professional (MHSP) Demonstration Grant Program. These five-year grants supported efforts to expand school-based mental health services across six school districts in a rural region of the northeastern United States. Both grants are jointly implemented as one initiative, which provides the context for our assessment development and validation study. The grants aim to build a diverse and well-trained mental health workforce by funding innovative university–school partnerships that train SWIs to deliver inclusive, accessible mental health care. MHSP focused on enhancing mental health service delivery by embedding full-time social work site supervisors into each of the six sites. These individuals supervised graduate-level SWIs, who each provided direct services (e.g., individual and group counseling) to a dedicated caseload of students. The initiative combined intensive professional development (PD) with field-based learning experiences designed to strengthen the clinical competencies of SWIs. Through this initiative, parents/caregivers worked alongside school staff, site supervisors, and SWIs to support families, reduce stigma, and connect students and caregivers to mental health resources.
During the development of the external evaluation, the MHSP leadership team and evaluation team recognized that despite having an evaluation goal seeking to measure SWI knowledge growth resulting from the PD and clinical work with site supervisors, an aligned test did not exist. SMEs leading programming did not have the time nor appropriate training to develop a test on their own. Further, the research team leading external evaluation, comprising psychometricians, qualitative, and quantitative experts, did not have the content knowledge necessary to produce test items. As a result, using an AI-assisted approach seemed reasonable to try. One research question, aligned with the second purpose of this study, guided our work: To what extent do AI-Assisted multiple-choice items developed for college-level social work interns in a school-based setting align with content they are learning in their program?
2. Materials and Methods
2.1. Assessment Development and Validation Frameworks
As described above, research on machine-assisted question development, whether through AI-generated (AIG) or generative AI (GenAI) methods, typically emphasizes the quality of individual items. While item-level quality is essential, it is equally important to consider how these items are combined to create a cohesive assessment that effectively measures learner knowledge in alignment with learning goals. Over the past decade, our research team has refined a process for developing and validating both cognitive and affective assessments created by humans. Our process integrates two well-established frameworks: Standards for Educational and Psychological Testing [1] and design-based research (DBR; [32]). In this section, we outline the key components of each framework and explain how we integrate them in our approach. The following section then describes how we have extended our process use by incorporating GenAI (specifically ChatGPT) as a collaborative partner in assessment development and validation.
Leading U.S. social science organizations (American Educational Research Association [AERA], American Psychological Association [APA], and National Council on Measurement in Education [NCME]) co-created the Standards [1] to underscore the importance of quantitative instrument development and validation in the social sciences. Although numerous forms of validity evidence exist, the Standards encourage evaluation of five key types: content (alignment of items to construct), response processes (participant interpretation of items as developers intended), consequences of testing (potential adverse impacts of instrument use, including bias), internal structure (dimensionality of measure and consistency of results), and relationship to other variables (associations between measure outcomes and theoretically related constructs). While stronger claims about an instrument’s validity can be made when multiple types of evidence are evaluated [1,24], it is common practice to begin with content validity and progressively build a more comprehensive validity argument from this foundational evidence.
Design-based research (DBR) methods in education closely parallel those in engineering, as both emphasize the creation of tools for specific purposes and follow a cyclical process of design, testing, and evaluation [33,34]. Although DBR does not prescribe specific research methods [32], it has proven particularly effective for quantitative instrument development and validation in the social sciences when iteratively applying both qualitative and quantitative approaches, e.g., [4,5]. Our team has refined a four-phase process—originally introduced in medical education for questionnaire validation [35]—and adapted it for developing and validating surveys, e.g., [5,6,36], observation tools [4], and assessments [8,37,38]. The four phases include: (1) Planning, (2) Developing, (3) Qualitative Field Testing, and (4) Quantitative Field Testing. Core principles of DBR are embedded throughout these phases, with validity evidence collected and evaluated in accordance with the Standards [1]. Figure 1 illustrates the iterative DBR process as applied to cognitive test development, highlighting typical sources of validity evidence aligned with the Standards. The DBR process is considered complete once the tool (in this case, a multiple-choice question test) requires no further modification and demonstrates sufficient validity evidence for its intended use.
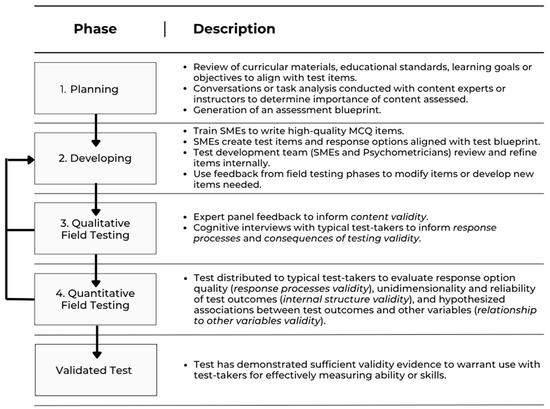
Figure 1.
Four Phase Multiple-Choice Question (MCQ) Test Development Model Integrating DBR and Standards Principles.
2.2. Assessment Development and Validation Process for This Study
To detail our process for integrating GenAI into our traditional test development and validation process, we are only sharing components from Phases 1–3 and results related to content validity evidence from expert panel review. Future studies will provide additional forms of validity evidence for the SWI Test.
2.2.1. Phase 1—Planning
Most well-developed educational activities (e.g., classroom instruction, test development) begin with a clearly defined set of learning objectives [39], as outlined in Phase 1 of Figure 1. Planning for development of the SWI Test similarly began with a comprehensive review of the program’s learning objectives and associated instructional materials. For an assessment to be meaningful and representative of the intended content, these learning objectives must be translated into a structured framework that guides the development and selection of test items, called an assessment blueprint [27,40]. Such a blueprint is essential because learning objectives, while useful in delineating broad content areas, often lack the specificity required to generate items that accurately measure the targeted constructs. To support effective item creation, general content must be supplemented with two important components: (1) expected level of cognitive demand or skill—typically categorized using a taxonomy; and (2) relative emphasis—importance of each objective in relation to others and within the overall construct being assessed.
The assessment blueprint for the SWI Test was established through an iterative collaboration between psychometricians and content experts. GenAI was not utilized during Phase 1, as LLMs currently lack the contextual sensitivity and domain understanding required to interpret learning objectives and organize them into a construct-representative blueprint. Our process began with content experts submitting the program’s learning objectives. Psychometricians then analyzed these objectives and assigned corresponding cognitive skill levels based on Bloom’s Taxonomy of Educational Objectives [41]. In the second step, content experts reviewed the assigned skill levels for accuracy and provided ratings of each objective’s relevance to the construct being measured. Relevance, or emphasis, was classified using a four-level scale represented in Table 1 by dots: 1 dot = not much emphasis, 2 dots = some emphasis, 3 dots = more emphasis, and 4 dots = most significant emphasis.

Table 1.
SWI Test Blueprint.
For the third step, practical considerations related to the SWI Test administration were discussed. While assessments must yield reliable outcomes, characterized by low standard error, they must also be feasible within time constraints. For the SWI Test, a 20-min administration window was deemed feasible, leading to the determination that a maximum of 12 multiple-choice items would provide a suitable balance between construct coverage and measurement precision. Finally, in the fourth step, the joint panel of psychometricians and content experts used both content relevance and emphasis ratings to select 12 learning objectives deemed most central and representative of the construct. One multiple-choice item was then developed for each objective, ensuring full alignment between the blueprint and item distribution. The finalized assessment blueprint, which guided item development in Phase 2, is presented in Table 1.
2.2.2. Phase 2—Developing
As illustrated in Figure 1, the assessment development phase typically includes SME training on high-quality item writing practices, followed by the item-writing process and internal team item review. This phase is both time-consuming and resource-intensive. For example, creating a single well-constructed, human-generated multiple-choice item takes an average of 31.5 min after training [11] and is estimated to cost between $1500 and $2500 (USD) to operationalize [42]. To mitigate these resource demands, our team incorporated GenAI into the item development process to improve efficiency. In reviewing existing GenAI-based multiple-choice item platforms, we found that most produced low-quality items, with poor content alignment and limited adherence to item-writing best practices [13]. Nearly all of these platforms lacked the flexibility to specify learning objectives or target particular content areas. Based on these limitations, and in line with emerging practices among social science researchers, we selected ChatGPT-4 (OpenAI, released March 2023) as an item-writing assistant because of its accessibility, ease of use, relatively low cost [20], and educator rated effectiveness in developing MCQs over other LLMs [43]. All items were generated using default parameters. Although ChatGPT-4 was used in this study, the framework we applied—blueprint-driven prompting combined with structured expert review—is transferable to other GenAI models. While results may vary depending on model sophistication, the process itself is not platform-dependent. Rather than using it as an independent item generator (as with many other platforms) we integrated ChatGPT into our team’s workflow as a collaborative partner, guiding its output through structured prompts aligned with our instructional goals. Two psychometricians divided the assessment blueprint learning targets in half (6 each) and worked with ChatGPT to expedite the item-writing process. While the psychometricians were not prompt engineering experts, they had used GenAI on numerous occasions to assist with similar tasks and used the initial prompt and follow-ups identified below.
Initial Prompt: Your task is to help me write multiple-choice items for undergraduates who are in a school-based social work internship. Each item should have a stem (item question) and four options with only one correct answer. Make sure you identify the correct answer. Write a multiple-choice item based on [insert learning objective] that is focused on [insert specific content linked to lesson materials or framework].
To enhance the quality and consistency of item generation, a goal-oriented prompting strategy was employed by explicitly identifying both the target learner population (undergraduates in a school-based social work internship) and the task (generating multiple-choice items). This contextual framing helped constrain the model’s output to the appropriate cognitive and professional level [44]. In addition to this overarching strategy, several prompting techniques, as identified in emerging literature [45], were implemented to improve alignment with the SWI Test assessment blueprint. A structural constraint pattern was embedded in the prompt by requiring a specific item output format: one stem, four options, and a single correct answer explicitly labeled. Additionally, a light persona method was used by framing ChatGPT’s role as an item generator, which helped guide the style and tone of its responses. Further, a loose template was applied by creating a flexible prompt structure with placeholders for learning objectives and content, supporting both standardization and customization. Together, these prompting patterns contributed to greater consistency across runs, although some variation was inherently expected due to the probabilistic nature of LLMs [45].
Once an initial item was created by ChatGPT in mere seconds, psychometricians reviewed each item for alignment with common assessment MCQ item writing guidelines see [46,47,48,49] related to test-taker interpretation to help reduce measurement error. Samples of MCQ item writing guidelines psychometricians were able to evaluate are bulleted below [13].
- Mutually Exclusive Options—answer options do not overlap (e.g., k-type questions)
- Avoid Use of Negatives—stem and options are positively phrased (e.g., do not include not or except)
- Avoid All or Nothing—response options do not include all of the above or none of the above
- Parallel Response Options—content in options is similar (e.g., if correct answer is a potential diagnosis, all options reflect comparable clinical possibilities)
- Similar Option Length—response options are all of similar length literally and conceptually (same number of concepts mentioned)
- Present a Problem in the Stem—a direct question is presented (e.g., avoid items that ask: Which is the following is true?)
- Do Not Clue the Answer—the correct answer should not include language directly associated with the stem as to suggest it is correct simply because of similar wording
- Do Not Teach in the Stem—only information needed for test-takers to answer the question is presented because instruction is done during a lesson, not a test
Follow-up prompts were used to refine stems and options to better align with best practices for MCQ items. These prompts were deliberately concise to reduce miscommunication with the LLM, as shown below.
Follow-Up Prompt Example 1: Make sure the item is positively framed. Do not use negatives in the stem or options.
Follow-Up Prompt Example 2: The correct answer cannot be the longest. Rephrase options so they are all of similar length. Shorter response options are better.
Follow-Up Prompt Example 3: The correct answer has similar language to the stem and others options do not. This clues the correct answer. Adjust language so test-takers cannot correctly guess the answer based on language used.
Follow-Up Prompt Example 4: The stem is too wordy and teaching. Streamline so it is easier to read and does not teach.
This iterative approach enabled greater control over item structure and content, ensuring better alignment with psychometric principles and the SWI Test blueprint. The combination of original and follow-up refinement prompts supported a more purposeful and quality-driven application of ChatGPT in item development.
On average, it took approximately 5 min for each item to be initially created by ChatGPT, refined through follow-up prompting, and deemed acceptable by psychometricians. The full SWI Test of 12 MCQs was then shared with one member of the MHSP Grant leadership team for internal review to ensure academic content of the items were acceptable in terms of the stem presented, distractor plausibility, and the presence of only one correct. Minor modifications were made within 30 min and the SWI Test was considered ready for initial qualitative field-testing.
2.2.3. Phase 3—Initial Qualitative Field-Testing
We used an adapted nominal group technique (NGT) to collect and evaluate expert feedback for content validity evidence of the SWI Test. Recommended practices for gathering such evidence suggest involving a panel of 5–8 subject matter experts [50]. For the SWI Test developed with ChatGPT support, we convened a panel of five social work content experts, each of whom had been directly involved in the development or implementation of the MHSP curricula. The adapted NGT combined two key features: independent judgments and structured group discussion. SMEs first reviewed items individually to ensure equal voice and independent input, and then participated in facilitated consensus sessions where areas of disagreement were discussed until resolution. This approach provided needed structure while reducing bias by balancing individual perspectives with collective consensus. GenAI was not used in this phase, as content validation required expert human judgment to evaluate the disciplinary accuracy, appropriateness, and educational quality of items.
SWI Test Review Questionnaire Procedures
Expert panelists received an email reminding them of the purpose of the SWI Test (previously introduced during an in-person meeting) and outlining their role in reviewing the test items from a SME perspective. The email also described the procedures detailed in Figure 2.

Figure 2.
SME Directions for Providing Feedback on SWI Test Review Questionnaire.
Responses to closed-ended items (Yes/No) were analyzed using descriptive statistics, while responses to open-ended prompts (e.g., explanations or suggested modifications) were pair-coded to enhance credibility [51] using content analysis. Quantitative and qualitative feedback were compiled, and SWI Test items were revised when a majority of experts (three or more) identified the same concern and a clear path to correction was evident. Issues identified by only one or two experts were noted for follow-up during the focused consensus discussion.
Focused Consensus Discussion Procedures
In order to summarize varying SME perspective to the content review process, a document was prepared presenting expert panel feedback for each item, including a side-by-side comparison of the original SWI Test item and suggestions for revisions offered by the test development team, if applicable. The expert panel met virtually on two separate occasions with the test development team. Expert panel members were asked to review the collective feedback, original items, and any proposed modifications on an item-by-item basis. Discussion was guided by prompts designed to facilitate expert consensus on item refinement, drawing on both the individual questionnaire responses and group dialogue. Through this structured exchange of ideas, differing views were explored and together SME and the item development team worked to reconcile any disagreements. Consensus decisions were documented, and a content analysis of the resulting actions using pair-coding was conducted for reporting purposes. Once full agreement on the composition of the SWI Test was reached, the qualitative field-testing process progressed to cognitive interviews with typical participants to evaluate response processes and consequences of testing validity evidence (to be reported in a future study).
3. Results
3.1. SWI Test Review Questionnaire
Figure 3 graphically displays SME affirmative responses by item review criteria across the 12 items. Overall, SMEs reported relatively positive perceptions, and they identified the most accurate item information for learning objective (LO) alignment (93% affirmative) followed by stem appropriateness (85% affirmative) and then option appropriateness and one correct answer (72% affirmative for both).
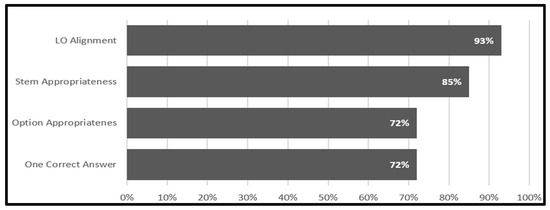
Figure 3.
SME Summarized Percent Affirmative Feedback from SWI Test Review Questionnaire.
Table 2 presents an item-level summary of negative incidents identified by SMEs across each evaluative criterion. On average, 20% (f = 4) of responses indicated a negative incident, with a range from 5% to 55% (f = 1–11). When SMEs provided written feedback about potential problems, their comments addressed how issues could be corrected through revised language. For example, one SME suggested adjusting an item’s stem: “Consider revising ‘student is unable to articulate specific goals’ to ‘unable to articulate specific reasons.’ I think this is less about goals and more about being able to talk about why the student is frustrated with school.” Although some items received only one comment indicating a potential issue, each SME-identified concern was deemed worthy of further consensus discussion by the full SME group. Based on SME individual-level feedback, suggested item modifications fell into three main categories:
- Revise Response Option(s) (n = 8, 67% items)
- Confusing language (n = 3)
- More than one correct answer (n = 5)
- Change stem (n = 2, 17% items)
- LO alignment concern (n = 2)
- No suggestions offered (n = 3, 25% items)
- SME feedback did not warrant changes (n = 1)
- SME conflicting feedback (n = 2)
Table 2.
Item-Level Findings: Incidents of SME Concerns Noted and Research Team Modifications.
Table 2.
Item-Level Findings: Incidents of SME Concerns Noted and Research Team Modifications.
| Test Item | LO Alignment | Appropriate Stem | One Correct Answer | Appropriate Options | Total Concerns | Research Team Suggested Modifications |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 1 | 1 (5%) | Revise response option(s): Confusing language. |
| 2 | 0 | 1 | 1 | 1 | 3 (15%) | Revise response option(s): Confusing language. |
| 3 | 0 | 1 | 1 | 1 | 3 (15%) | Revise response option(s): More than one correct answer. |
| 4 | 3 | 3 | 4 | 1 | 11 (55%) | Change stem: LO alignment concern. |
| 5 | 0 | 1 | 0 | 0 | 1 (5%) | No suggestions offered: SME feedback did not warrant changes. |
| 6 | 0 | 0 | 3 | 3 | 6 (30%) | Revise response option(s): More than one correct answer. |
| 7 | 0 | 1 | 1 | 1 | 3 (15%) | Change stem: LO alignment concern. Revise response option(s): Confusing language. |
| 8 | 1 | 1 | 2 | 3 | 7 (35%) | No suggestions offered: SME conflicting feedback. |
| 9 | 0 | 0 | 2 | 1 | 3 (15%) | Revise response option(s): More than one correct answer. |
| 10 | 0 | 1 | 1 | 4 | 6 (30%) | Revise response option(s): More than one correct answer. |
| 11 | 0 | 1 | 0 | 0 | 1 (5%) | No suggestions offered: SME conflicting feedback. |
| 12 | 0 | 0 | 1 | 2 | 3 (15%) | Revise response option(s): More than one correct answer. |
3.2. Focused Consensus Discussion
During the consensus discussion, SMEs determined three items (25%) required no modification and could remain in original format, regardless of item development team suggested modifications from a synthesis of individual-level feedback. At the same time, SMEs identified nine items (75%) required further revision. Final item modifications were classified by three main types: Response(s) Modification (n = 5, 56%), Stem and Response(s) Modification (n = 3, 33%), and Delete Item (n = 1, 11%). Table 3 presents an annotated example of each final item modification type.
Table 3.
Item Revision Examples Resulting from Consensus Discussion by Modification Type.
4. Discussion
Our study had two objectives: presenting a framework for integrating GenAI as a collaborative team member, and detailing a structured approach for evaluating content validity in an AI-assisted multiple-choice test. Contributions from our work extend a growing body of literature on technology-assisted item development, where prior research has focused mainly on item generation capabilities rather than systematic validation processes [11,12]. Few studies to date have addressed the educational value of technology-assisted items [13,16] or rigorously investigated validity evidence of assessments composed of GenAI-written items. Our approach provides initial evidence that GenAI can serve as a productive collaborator in assessment development when embedded in a clearly specified, supervised role focused on supporting item development within a DBR process, and without requiring technical expertise in software engineering or AI programming. These findings should be interpreted as context-specific and foundational rather than conclusive.
Aligning with prior research, we found that most AI-generated items required modifications before being considered educationally useful, with many containing more than one potential correct answer [13]. However, most items were judged relevant by SMEs and only minor modifications were needed to address the issues, consistent with results reported by Elkins et al. [16]. Our study confirms the value of assembling a multidisciplinary team of experts to systematically review and refine AI-assisted items to ensure both academic content quality and adherence to assessment best practices [2,3,13,18,21,27]. Collectively, these findings emphasize that keeping humans-in-the-loop through review from content and psychometric specialists along with consensus building is essential when the aim is to move beyond evaluating the acceptability of individual AI-generated items to ensuring that a set of such items functions as a sound measure of learning.
Limitations, Implications, and Future Research
Several limitations of this study shape important implications for practice and directions for future research. While our process yielded strong content validity evidence, this represents only one type of validity recommended by the Standards [1]. Additional validity evidence (i.e., response processes, internal structure, consequences of testing, relationships to other variables) should be collected to build a robust validity argument for using the SWI Test as a measure of learning growth among college-level social work interns in school-based settings. In addition, the SWI Test consisted of only 12 items and was reviewed by a panel of five SMEs, which represents the lower end of recommended expert review panel sizes. While appropriate for the applied context and aligned with published guidance [49], these design choices limit the breadth of evidence available and should be expanded in future research to strengthen generalizability and reliability. Although our focused context provided a valuable demonstration of feasibility, generalizability to other disciplines, learner populations, and item types continues to be uncertain. This creates an opportunity for future research to examine how AI-assisted item development processes can be adapted and evaluated across diverse educational contexts and assessment formats. Despite these constraints, documenting this early-phase process contributes much-needed detail on how content validity can be established for AI-assisted assessments, thereby laying the groundwork for future validation studies.
In terms of item development efficiency, the comparison between GenAI-assisted and human-authored item development should be interpreted cautiously. Our descriptive findings suggested that AI-assisted items could be generated more quickly than those reported in prior research, but this was not examined under controlled conditions. Future studies should formally investigate efficiency and cost-effectiveness by accounting for task equivalence, reviewer expertise, and revision stages, and by reporting standardized effect sizes. Such analyses would provide a more rigorous understanding of potential time and resource savings associated with GenAI-assisted assessment development.
Another limitation of our research is that our item development team comprised prompt engineering novices, a common characteristic of non-technical researchers employing AI strategies [20]. Our prompting approach was pragmatic and iterative, but not systematically optimized. These limitations inform a range of practical implications. Basic AI literacy is essential for test developers seeking to responsibly use GenAI as a collaborator. While tools like ChatGPT can generate draft items quickly and at scale, quality and appropriateness of outputs depend heavily on how prompts are crafted and the ways in which outputs are interpreted. Accordingly, substantial expert review and refinement will remain necessary for AI-assisted test items to meet psychometric and content standards, just as is required with human-developed assessments [13,21,27].
Future research should explore potential benefits of implementing more advanced prompting methods [43]. Such approaches could improve the relevance and psychometric quality of AI-generated items. Researchers and test developers should also examine how collaborations with AI-technical experts might further enhance item development efficiency and quality control. These collaborations could lead to standardized prompting protocols or integrated item development platforms. Resulting tools could help ensure that AI-generated items follow assessment best practices and self-audit for common pitfalls such as negatively worded stems, clued answers, and inconsistent option structures [13].
5. Conclusions
Grounded in our study of AI-assisted item development for school-based social work training, our final reflections consider the broader ethical and conceptual role of GenAI in educational assessment. Developing valid, high-quality assessments remains a complex and iterative process that demands expert judgment at every stage. Crafting individual test items requires careful attention to content, context, and psychometric principles. Assembling these items into an educationally useful, coherent assessment adds another layer of complexity and expertise. While GenAI offers significant time-saving benefits and creativity support for specific aspects of this work, our study reinforces that it still cannot replace the nuanced skills required to design fair and high-quality assessments. As AI technologies become increasingly embedded in many aspects of our daily lives, it is incumbent upon researchers, test developers, and practitioners to grapple with important decisions about how and when to engage with these tools ethically. We are only beginning to understand AI’s potential contributions. Thus, it is imperative to integrate AI thoughtfully and with critical human oversight, especially when it is being applied to tasks intended to inform educational or employment-related decision-making.
Author Contributions
Conceptualization, T.A.M., K.L.K.K., K.P., and G.E.S.; methodology, T.A.M., K.L.K.K., K.P., G.E.S. and C.J.S.; validation, J.N.A. and N.R.; formal analysis, T.A.M., K.P., K.L.K.K. and C.J.S.; investigation, T.A.M., K.P., K.L.K.K. and G.E.S.; data curation, T.A.M., K.P., K.L.K.K. and C.J.S.; writing—original draft preparation, T.A.M., K.P., G.E.S., C.J.S. and K.L.K.K.; writing—review and editing, J.N.A. and N.R.; visualization, T.A.M. and C.J.S.; project administration, K.P. and T.A.M.; funding acquisition, N.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was produced from funding for two School-Based Mental Health Services Grants funded by The U.S. Department of Education: S184X230137, S184X230139.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and approved by the Institutional Review Board (or Ethics Committee) of State University of New York at Binghamton (protocol code 00004907, date of approval 22 April 2024).
Informed Consent Statement
Informed consent was deemed not necessary as instrument development and validation are not considered research and therefore classified as Exempt.
Data Availability Statement
Samples and summaries of data are provided within text. Full datasets available on request from the lead author.
Acknowledgments
As described in the methods section of this manuscript, GenAI (specifically ChatGPT) supported generation of multiple choice items used in this research. Additionally, ChatGPT was used to assist with formatting references from APA to ACS style and reviewing text for grammatical errors/considerations. The authors have reviewed and edited all output and take full responsibility for the content of this publication.
Conflicts of Interest
Author James N. Archer was employed by the company IBM Corp. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AERA | American Educational Research Association |
| AIG | Automatic Item Generation |
| DBR | Design-Based Research |
| LO | Learning Objectives |
| MHSP | Mental Health Service Professional |
| NCME | National Council on Measurement in Education |
| NGT | Nominal Group Technique |
| NRC | National Research Council |
| OET | Office of Educational Technology |
| PD | Professional Development |
| SME | Subject Matter Expert |
References
- American Educational Research Association; American Psychological Association; National Council on Measurement in Education. Standards for Educational and Psychological Testing; American Educational Research Association: Washington, DC, USA, 2014. [Google Scholar]
- Kisker, E.E.; Boller, K. Forming a Team to Ensure High-Quality Measurement in Education Studies (REL 2014-052); U.S. Department of Education, Institute of Education Sciences, National Center for Education Evaluation and Regional Assistance, Analytic Technical Assistance and Development: Washington, DC, USA, 2014. Available online: http://ies.ed.gov/ncee/edlabs (accessed on 25 April 2025).
- National Research Council. Knowing What Students Know: The Science and Design of Educational Assessment; The National Academies Press: Washington, DC, USA, 2001. [Google Scholar] [CrossRef]
- Sondergeld, T.A. Shifting sights on STEM education instrumentation development: The importance of moving validity evidence to the forefront rather than a footnote. Sch. Sci. Math. 2020, 120, 259–261. [Google Scholar] [CrossRef]
- May, T.A.; Bright, D.; Fan, Y.; Fornaro, C.; Koskey, K.L.; Heverin, T. Development of a college student validation survey: A design-based research approach. J. Coll. Stud. Dev. 2023, 64, 370–377. [Google Scholar] [CrossRef]
- May, T.A.; Koskey, K.L.K.; Provinzano, K.P. Developing and Validating the Preschool Nutrition Education Practices Survey. J. Nutr. Educ. Behav. 2024, 56, 545–555. [Google Scholar] [CrossRef]
- Severino, L.; DeCarlo, M.J.; Sondergeld, T.A.; Ammar, A.; Izzetoglu, M. A validation study of an eighth grade reading comprehension assessment. Res. Middle Level Educ. 2018, 41, 1–16. [Google Scholar]
- Bostic, J.D.; Matney, G.T.; Sondergeld, T.A. A validation process for observation protocols: Using the Revised SMPs Look-for Protocol as a lens on teachers’ promotion of the standards. Investig. Math. Learn. 2019, 11, 69–82. [Google Scholar] [CrossRef]
- Sondergeld, T.A.; Johnson, C.C. Development and validation of a 21st Century Skills assessment: Using an iterative multi-method approach. Sch. Sci. Math. 2019, 119, 312–326. [Google Scholar] [CrossRef]
- Falcão, F.; Costa, P.; Pêgo, J.M. Feasibility assurance: A review of automatic item generation in medical assessment. Adv. Health Sci. Educ. 2022, 27, 405–425. Available online: https://link.springer.com/article/10.1007/s10459-022-10092-z (accessed on 4 March 2025). [CrossRef]
- Falcão, F.; Marques Pereira, D.; Gonçalves, N.; De Champlain, A.; Costa, P.; Pêgo, J.M. A suggestive approach for assessing item quality, usability and validity of automated item generation. Adv. Health Sci. Educ. 2023, 28, 1441–1465. [Google Scholar] [CrossRef] [PubMed]
- Kurdi, G.; Leo, J.; Parsia, B.; Sattler, U.; Al-Emari, S. A systematic review of automatic question generation for education purposes. Int. J. Artif. Intell. Educ. 2020, 30, 121–204. [Google Scholar] [CrossRef]
- May, T.A.; Fan, Y.K.; Stone, G.E.; Koskey, K.L.K.; Sondergeld, C.J.; Folger, T.D.; Archer, J.N.; Provinzano, K.; Johnson, C.C. An effectiveness study of generative artificial intelligence tools used to develop multiple-choice test items. Educ. Sci. 2025, 15, 144. [Google Scholar] [CrossRef]
- Maity, S.; Deroy, A. The future of learning in the age of generative AI: Automated question generation and assessment with large language models. arXiv 2024, arXiv:2410.09576. [Google Scholar] [CrossRef]
- Scaria, N.; Dharani Chenna, S.; Subramani, D. Automated educational question generation at different Bloom’s skill levels using large language models: Strategies and evaluation. arXiv 2024, arXiv:2408.04394. [Google Scholar] [CrossRef]
- Elkins, S.; Kochmar, E.; Serban, I.; Cheung, J.C.K. How useful are educational questions generated by large language models? In Communications in Computer and Information Science; Wang, N., Rebolledo-Mendez, G., Dimitrova, V., Matsuda, N., Santos, O.C., Eds.; Springer: Cham, Switzerland, 2023; Volume 1831, pp. 536–542. [Google Scholar] [CrossRef]
- Mollick, E.; Mollick, L. Using AI to Implement Effective Teaching Strategies in Classrooms: Five Strategies, Including Prompts; Wharton School of the University of Pennsylvania & Wharton Interactive: Philadelphia, PA, USA, 2023. [Google Scholar] [CrossRef]
- Bulut, O.; Beiting-Parrish, M.; Casabianca, J.M.; Slater, S.C.; Jiao, H.; Song, D.; Ormerod, C.; Fabiyi, D.G.; Ivan, R.; Walsh, C.; et al. The rise of artificial intelligence in educational measurement: Opportunities and ethical challenges. Chin.-Engl. J. Educ. Meas. Eval. 2024, 5, 3. [Google Scholar] [CrossRef]
- Office of Educational Technology. Artificial Intelligence and the Future of Teaching and Learning: Insights and Recommendations; U.S. Department of Education: Washington, DC, USA, 2023. Available online: https://www.ce-jeme.org/cgi/viewcontent.cgi?article=1090&context=journal (accessed on 4 March 2025).
- Nguyen-Trung, K. ChatGPT in thematic analysis: Can AI become a research assistant in qualitative research? Qual. Quant. 2025, 1–34. [Google Scholar] [CrossRef]
- Kaldaras, L.; Akaeze, H.O.; Reckase, M.D. Developing valid assessments in the era of generative artificial intelligence. Front. Educ. 2024, 9, 1399377. [Google Scholar] [CrossRef]
- Circi, R.; Hicks, J.; Sikali, E. Automatic item generation: Foundations and machine learning-based approaches for assessments. Front. Educ. 2023, 8, 858273. [Google Scholar] [CrossRef]
- Gierl, M.J.; Lai, H. Instructional topics in educational measurement (ITEMS) module: Using automated processes to generate test items. Educ. Meas. Issues Pract. 2013, 32, 36–50. [Google Scholar] [CrossRef]
- Kane, M. Validating the interpretations and uses of test scores. J. Educ. Meas. 2013, 50, 1–73. [Google Scholar] [CrossRef]
- Kosh, A.E.; Simpson, M.A.; Bickel, L.; Kellogg, M.; Sanford-Moore, E. A cost–benefit analysis of automatic item generation. Educ. Meas. Issues Pract. 2019, 38, 48–53. [Google Scholar] [CrossRef]
- Tan, B.; Armoush, N.; Mazzullo, E.; Bulut, O.; Gierl, M. A review of automatic item generation techniques leveraging large language models. Int. J. Assess. Tools Educ. 2025, 12, 317–340. [Google Scholar] [CrossRef]
- Magzoub, M.E.; Zafar, I.; Munshi, F.; Shersad, F. Ten tips to harnessing generative AI for high-quality MCQs in medical education assessment. Med. Educ. Online 2025, 30, 2532682. [Google Scholar] [CrossRef] [PubMed]
- Gierl, M.J.; Lai, H. Evaluating the quality of medical multiple-choice items created with automated processes. Med. Educ. 2013, 47, 726–733. [Google Scholar] [CrossRef] [PubMed]
- Pugh, D.; De Champlain, A.; Gierl, M.; Lai, H.; Touchie, C. Can automated item generation be used to develop high-quality MCQs that assess applications of knowledge? Res. Pract. Technol. Enhanc. Learn. 2020, 15, 12. [Google Scholar] [CrossRef]
- Caldwell, D.J.; Pate, A.N. Effects of question formats on student and item performance. Am. J. Pharm. Educ. 2013, 77, 71. [Google Scholar] [CrossRef]
- Coombs, A.; DeLuca, C.; LaPointe-McEwan, D.; Chalas, A. Changing approaches to classroom assessment: An empirical study across teacher career stages. Teach. Teach. Educ. 2018, 71, 134–144. [Google Scholar] [CrossRef]
- Scott, E.E.; Wenderoth, M.P.; Doherty, J.H. Design based research: A methodology to extend and enrich biology education research. CBE—Life Sci. Educ. 2020, 19, es11. [Google Scholar] [CrossRef]
- Cobb, P.; Confrey, J.; diSessa, A.; Lehrer, R.; Schauble, L. Design experiments in educational research. Educ. Res. 2003, 32, 9–13. [Google Scholar] [CrossRef]
- Middleton, J.A.; Gorard, S.; Taylor, C.; Bannon-Ritland, B. The compleat design experiment: From soup to nuts. In Design Research: Investigating and Assessing Complex Systems in Mathematics, Science and Technology Education; Kelly, E., Lesh, R., Baek, J., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2008. [Google Scholar]
- Artino, A.R., Jr.; La Rochelle, J.; Dezee, K.; Gehlbach, H. Developing questionnaires for educational research: AMEE guide no. 87. Med. Teach. 2014, 36, 463–474. [Google Scholar] [CrossRef]
- May, T.A.; Johnson, C.C.; Walton, J.B.; Harold, S. The development and validation of a K-12 STEM engagement participant outcome instrument. Educ. Sci. 2025, 15, 377. [Google Scholar] [CrossRef]
- Bostic, J.D.; Sondergeld, T.A. Measuring sixth-grade students’ problem-solving: Validating an instrument addressing the mathematics common core. Sch. Sci. Math. 2015, 115, 281–291. [Google Scholar] [CrossRef]
- Bostic, J.D.; Sondergeld, T.A.; Folger, T.; Kruse, L. PSM7 and PSM8: Validating two problem-solving measures. J. Appl. Meas. 2017, 18, 151–162. [Google Scholar] [PubMed]
- Orr, R.B.; Csikari, M.M.; Freeman, S.; Rodriguez, M.C. Writing and using learning objectives. CBE—Life Sci. Educ. 2022, 21, fe3. [Google Scholar] [CrossRef]
- Eweda, G.; Bukhary, Z.A.; Hamed, O. Quality assurance of test blueprinting. J. Prof. Nurs. 2020, 36, 166–170. [Google Scholar] [CrossRef]
- Bloom, B.S.; Engelhart, M.D.; Furst, E.J.; Hill, W.H.; Krathwohl, D.R. Taxonomy of Educational Objectives: The Classification of Educational Goals. Handbook I: Cognitive Domain; David McKay Co.: New York, NY, USA, 1956. [Google Scholar]
- Rudner, L. Implementing the Graduate Management Admission Test computerized adaptive test. In Elements of Adaptive Testing; van der Linden, W., Glas, C., Eds.; Springer: New York, NY, USA, 2010; pp. 151–165. [Google Scholar]
- Bianchini, G.; Ferrato, A.; Limongelli, C. Multiple choice question generation using large language models: Methodology and educator insights. arXiv 2025, arXiv:2506.04851. [Google Scholar] [CrossRef]
- Ramlochan, S. Goal-Oriented vs Process-Oriented Prompting in Large Language Models; Prompt Engineering & AI Institute: 2024. Available online: https://promptengineering.org/unlocking-the-power-of-goal-oriented-prompting-for-ai-assistants/ (accessed on 20 April 2025).
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D.C. A prompt pattern catalog to enhance prompt engineering with ChatGPT. arXiv 2023, arXiv:2302.11382. [Google Scholar] [CrossRef]
- Brookhart, S.M.; Nitko, A.J. Assessment and Grading in Classrooms, 5th ed.; Pearson: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- McMillan, J.H. Classroom Assessment: Principles and Practices for Effective Standards-Based Instruction, 5th ed.; Pearson: Upper Saddle River, NJ, USA, 2011. [Google Scholar]
- Miller, D.M.; Linn, R.L.; Gronlund, N.E. Measurement and Assessment in Teaching, 11th ed.; Pearson: Boston, MA, USA, 2021. [Google Scholar]
- Popham, W.J. Classroom Assessment: What Teachers Need to Know, 7th ed.; Pearson: Boston, MA, USA, 2014. [Google Scholar]
- Yusoff, M.S.B. ABC of content validation and content validity index calculation. Educ. Med. J. 2019, 11, 49–54. [Google Scholar] [CrossRef]
- Lincoln, Y.S.; Guba, E.G. Naturalistic Inquiry; Sage: Beverly Hills, CA, USA, 1985. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).