Abstract
Potato leaf diseases are recognized as a major threat to agricultural productivity and global food security, emphasizing the need for rapid and accurate detection methods. Conventional manual diagnosis is limited by inefficiency and susceptibility to bias, whereas existing automated approaches are often constrained by insufficient feature extraction, inadequate integration of multiple leaves, and poor generalization under complex field conditions. To overcome these challenges, a ResNet18-SAWF model was developed, integrating a self-attention mechanism with a multi-scale feature-fusion strategy within the ResNet18 framework. The self-attention module was designed to enhance the extraction of key features, including leaf color, texture, and disease spots, while the feature-fusion module was implemented to improve the holistic representation of multi-leaf structures under complex backgrounds. Experimental evaluation was conducted using a comprehensive dataset comprising both simple and complex background conditions. The proposed model was demonstrated to achieve an accuracy of 98.36% on multi-leaf images with complex backgrounds, outperforming baseline ResNet18 (91.80%), EfficientNet-B0 (86.89%), and MobileNet_V2 (88.53%) by 6.56, 11.47, and 9.83 percentage points, respectively. Compared with existing methods, superior performance was observed, with an 11.55 percentage point improvement over the average accuracy of complex background studies (86.81%) and a 0.7 percentage point increase relative to simple background studies (97.66%). These results indicate that the proposed approach provides a robust, accurate, and practical solution for potato leaf disease detection in real field environments, thereby advancing precision agriculture technologies.
1. Introduction
As an important food crop in China [1], potato is recognized for its critical role in agricultural development and the enhancement of farmers’ income [2,3]. However, disease management—particularly for early blight [4] and late blight [5]—remains challenging in traditional cultivation systems [6,7]. Manual detection methods are time-consuming, labor-intensive, and prone to subjective bias. The increasing labor costs and aging workforce render these conventional approaches unsustainable. Consequently, the adoption of automated detection technologies [8,9] has become an inevitable trend, as such technologies not only enhance efficiency and accuracy but also facilitate the sustainable development of the potato industry. With the continuous advancement of artificial intelligence [10,11], deep learning applications in agriculture have expanded substantially [12], providing new research directions for potato disease detection. Intelligent detection based on deep learning enables rapid and accurate disease identification, reduces labor requirements, and markedly improves detection efficiency, thereby contributing to the modernization of the potato industry.
Accurate and timely identification of potato diseases is essential for maintaining agricultural productivity and ensuring food security. In recent years, Convolutional Neural Networks (CNNs) have been widely adopted as effective tools for plant disease detection. Advanced architectures, including GoogLeNet, VGGNet, EfficientNet, AlexNet, and ResNet [13,14,15,16], have been demonstrated to achieve considerable effectiveness in disease classification. Beyond single-model architectures, hybrid approaches—particularly the combination of CNNs with Transformers—have been explored to leverage their complementary strengths. For instance, a CNN–Transformer integration was introduced by Arshad et al. [17], which was shown to enhance prediction performance and improve generalization across multiple crops [18,19,20,21,22].
However, the effectiveness of these models is often constrained by real-world complexities. These challenges are particularly evident in environments with complex backgrounds, including occluded leaves, varying illumination, and visually similar surrounding vegetation. In addition, limited training samples—resulting from the rarity of certain diseases or the difficulty of data acquisition—further hinder model performance. To address these limitations, researchers have increasingly incorporated advanced techniques [23,24,25,26,27] into deep learning frameworks.
Recent advancements in handling complex backgrounds have been achieved through the application of attention mechanisms, which enable models to selectively focus on salient features. For instance, coordinate attention was incorporated into YOLOv5 by Li et al. [28], resulting in a reduction in missed detections for damaged or occluded leaves. Similarly, the CBAM attention mechanism was integrated into an improved VGG16 architecture by Zhang et al. [29], which was demonstrated to enhance CNN performance and achieve higher accuracy in challenging scenarios.
Concurrently, the challenge posed by small sample sizes has necessitated the indispensable use of transfer learning techniques. Effective learning with reduced target sample requirements is facilitated by these methods, which leverage pre-trained models obtained from large-scale datasets [30,31,32,33]. This approach was exemplified by Nazir et al. [34], who employed transfer learning utilizing an EfficientNet-V2 backbone, augmented by a spatial-channel attention mechanism, for the effective classification of various potato leaf diseases, resulting in improved recognition capabilities.
In summary, although the existing research has achieved excellent performance, there are still the following major limitations: ① Most studies are only trained based on public datasets of single background and single leaf, which is difficult to distinguish when dealing with real complex backgrounds. This is because the background is relatively complex in real situations (such as land, potato branches, etc.), and the leaves are mainly multi-leaf, which is difficult to identify, significantly affecting the accuracy and robustness of the disease recognition model; ② Existing studies mostly rely on a large amount of labeled data for training, which not only increases the difficulty of data preparation, but also makes the development of efficient and scalable models more complicated.
To address the above problems, this paper proposes a new method for potato disease leaf recognition based on ResNet18 and combined with self-attention mechanism and feature fusion to meet the challenge of multi-leaf feature extraction in complex backgrounds. The main contributions of this paper are as follows:
- (1)
- Data collection and construction: We collected and photographed single leaves and multiple leaves under real complex backgrounds on site, and classified the collected data according to the real background. In addition to the conventional classification of early blight, late blight, and healthy leaves, we further mixed single leaves and multiple leaves under complex backgrounds to construct a mixed dataset. Through comparative analysis with the basic model, we verified the scientificity and effectiveness of the dataset, laying a solid foundation for subsequent research.
- (2)
- Classification model design and optimization: Under complex backgrounds and multi-leaf conditions, transfer learning was used to load a pre-trained model, and a self-attention mechanism along with a feature-fusion module was introduced into the ResNet18 architecture, resulting in the proposed ResNet18-SAWF model. This model is capable of accurately extracting the color, texture, and specific spot features of the leaves, thereby significantly improving recognition performance. Relative to the ResNet18 baseline, accuracy is elevated. Moreover, substantial accuracy gains are achieved against existing models across both complex and simple background scenarios.
2. Data Sources and Processing
2.1. Sources of Research Data
The dataset originates from both public and private sources. The public component, sourced from Kaggle (Kaggle Potato Disease Dataset, https://www.kaggle.com/datasets/faysalmiah1721758/potato-dataset, accessed on 11 June 2025), comprises 2152 color leaf images. Crucially, each image was captured under controlled conditions. The structure and examples of the public dataset are presented in Figure 1.

Figure 1.
Public dataset potato leaves ((a) is early blight leaves; (b) is healthy leaves; (c) is late blight leaves).
In addition to the publicly available dataset obtained from Kaggle, a ground dataset was constructed to ensure comprehensive coverage of potato leaf disease scenarios. The ground dataset was collected between 2011 and 2021 across major potato-producing regions in northern China, primarily in Hebei Province (Baoding, Zhangjiakou) and Shandong Province (Weifang, Yantai). Image acquisition took place during the potato growing season, typically from June to September, when disease incidence was most prevalent. Diseased leaves were identified by experienced field technicians under natural conditions, without the use of artificial inoculation. The ground dataset is shown in Figure 2.

Figure 2.
Potato leaves in a Ground dataset ((a) is an early blight leaf; (b) is a healthy leaf; (c) is a late blight leaf).
Approximately 90% of the images were captured directly in the field, encompassing diverse environmental conditions such as variable soil types, natural weed interference, and fluctuating illumination. The remaining ~10% were collected by transporting infected leaves from the field to indoor settings, where they were photographed under natural light to enable more controlled imaging. Data collection was carried out by research assistants and field technicians using mid-range smartphones (8–12 megapixels), thereby ensuring portability and scalability. These procedures ensured that the ground dataset authentically represents real-world agricultural conditions and complements the Kaggle dataset in terms of diversity and field realism. The dataset is shown in Table 1.

Table 1.
Potato data from different datasets (Unit: images (count)).
2.2. Data Preprocessing
A data curation process was conducted on the combined dataset, involving the screening of available samples and the reclassification of potato early blight and late blight categories to generate a refined dataset. Potato leaf images were subsequently organized into two primary groups: (1) single leaves displaying distinct features, and (2) multiple leaves within complex, real-world backgrounds. Subsequent studies predominantly focused on the classification of multiple leaves in real-scene images, as these better represent natural conditions. This categorization is illustrated in Figure 3. Through comprehensive data augmentation and normalization, the dataset was meticulously prepared to facilitate effective model training and to provide a foundation for meaningful exploratory analysis of the learned feature space. Simultaneously, this process effectively mitigated dataset bias arising from class imbalance [35].

Figure 3.
Single- and multi-leaf examples ((a) is single-leaf early blight; (b) is single-leaf late blight; (c) is multi-leaf early blight; (d) is multi-leaf late blight).
To prepare the dataset—which contains images of potato leaves captured under various real-world conditions—for efficient model training and evaluation, we implemented a meticulous preprocessing pipeline. First, we collated and organized the image data into a directory structure, with each subfolder representing a specific potato leaf condition category. In this study, these categories included healthy, early blight, and late blight. This hierarchical structure facilitated automatic image loading and labeling using PyTorch’s ImageFolder dataset class. The dataset used in this study comprised potato leaf images categorized into three classes: early blight, late blight, and healthy. To ensure balanced evaluation, the dataset was partitioned into training and testing subsets at an 80:20 ratio for each class. Specifically, for scenarios involving complex backgrounds with multiple leaves, 80% of the images from each class (a total of 241 images) were allocated to the training set, while the remaining 20% (61 images) were reserved for the testing set. This stratified partitioning strategy ensured that each class was proportionally represented across both subsets, thereby minimizing sampling bias and improving the reliability of model evaluation. This random split was performed to maintain representativeness of both datasets relative to the overall data distribution, and a fixed random seed (seed = 42) was used to ensure reproducibility. To standardize the neural network input and enhance the model’s generalization and resistance to overfitting, separate transformation pipelines were defined for the training and test sets.
For the training set, a comprehensive set of data augmentation techniques was applied. All images were resized to a uniform dimension of 224 × 224 pixels. To enhance orientation invariance, random horizontal and vertical flips were applied with a probability of 0.5. Rotational invariance was achieved via random rotations within the range of [−30°, +30°]. In addition, color jittering simulated variations in lighting and camera capture, adjusting brightness, contrast, and saturation within [0.8, 1.2], and hue within [−0.1, 0.1]. After these geometric and color transformations, images were converted from PIL format to PyTorch tensors and normalized using the ImageNet mean ([0.485, 0.456, 0.406]) and standard deviation ([0.229, 0.224, 0.225]) to stabilize training.
All augmentation operations were applied dynamically within each training batch, thereby eliminating the need for pre-generated augmented images, conserving storage, and improving training efficiency. To quantify the extent of augmentation, an augmentation rate was defined as the proportion of each image subjected to transformation. Higher rates indicated a larger fraction of images undergoing operations such as flips, rotations, or color perturbations, whereas lower rates reflected minimal alterations. The rate was calculated as the ratio of executed operations to total attempts; for example, a 50% probability of horizontal flipping that resulted in 48% of images being flipped corresponded to an augmentation rate of 48%.
The effectiveness of augmentation was monitored using AugmentTracker, which recorded the frequency of each operation and computed the actual augmentation rate. This metric reflected the coverage of training samples and facilitated robust feature learning under variations in leaf orientation, illumination, and background conditions. All augmentation procedures were embedded into the data loading pipeline and executed synchronously with training, thereby introducing batch-wise randomness, mitigating overfitting, and enhancing both accuracy and generalization. Over 50 training epochs, the average augmentation rate was 50.19% (SD 1.66%) (Figure 4). This “on-the-fly augmentation” strategy ensured sufficient randomness and diversity in each training cycle, effectively alleviating overfitting and improving classification performance.
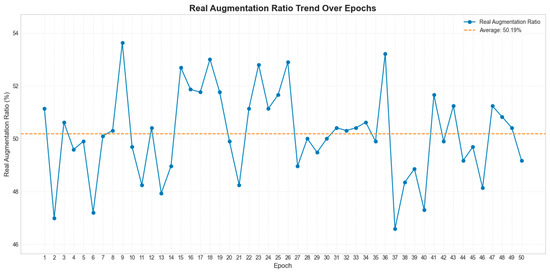
Figure 4.
Augmentation rate results after 50 training epochs.
In contrast, the testing set underwent only deterministic transformations: resizing to 224 × 224 pixels, conversion to PyTorch tensors, and normalization using the aforementioned ImageNet mean and standard deviation values. Finally, the transformed training and testing datasets were loaded using ‘torch.utils.data. DataLoader’ with a batch size of 32. The training data loader was configured with ‘shuffle = True’ to enhance exploration of the training space, while the testing data loader used ‘shuffle = False’ to ensure consistent batch ordering for evaluation.
3. Methods
3.1. ResNet18 Network
In this study, the baseline model employed is ResNet-18, a deep residual network architecture extensively used for image recognition and classification tasks. ResNet-18 effectively mitigates the vanishing and exploding gradient problems commonly encountered in deep networks through its residual learning framework. The network consists of 18 layers, including five residual blocks. Each residual block comprises multiple basic blocks, each containing two convolutional layers and incorporating skip connections that allow signals to bypass intermediate layers, thereby facilitating gradient flow and improving training stability. ResNet-18 is typically initialized with weights pre-trained on large-scale image datasets, such as ImageNet. This initialization strategy enables the model to exploit features learned from extensive datasets, accelerating convergence and improving overall performance. In this work, a pre-trained ResNet-18 was employed due to its robust feature extraction capabilities, which facilitate rapid convergence and improved performance on small-scale datasets. To extract comprehensive features from a limited dataset while maintaining training accuracy, the ResNet-18 architecture was combined with transfer learning. Transfer learning is a widely adopted technique in deep learning, particularly effective in addressing the challenges posed by insufficient data. Here, this approach was applied to potato disease classification: a deep neural network pre-trained on a large-scale dataset was fine-tuned on a smaller, domain-specific dataset to enhance model performance.
3.2. The Overall Architecture of the ResNet18-SAWF Model
Traditional Convolutional Neural Networks (CNNs) perform effectively in various visual tasks; however, their inherent local receptive fields and perception mechanisms constrain their ability to capture global information. This often leads to limited feature expressiveness, particularly when confronted with highly complex, multi-scale, and fine-grained scenes. Furthermore, general CNN architectures struggle to dynamically adjust the importance of different spatial regions and are susceptible to interference from background noise, which can consequently impair the model’s discriminative capabilities. Consequently, attention mechanisms and multi-scale feature-fusion techniques are introduced to enhance the model’s overall efficiency and robustness. The proposed model is built upon the ResNet-18 architecture, a deep residual network widely recognized in computer vision for its strong performance and relatively efficient parameter count. Named ResNet18-SAWF (as depicted in Figure 5), this module integrates self-attention mechanisms and multi-scale feature fusion, specifically designed to enhance performance in image classification tasks.
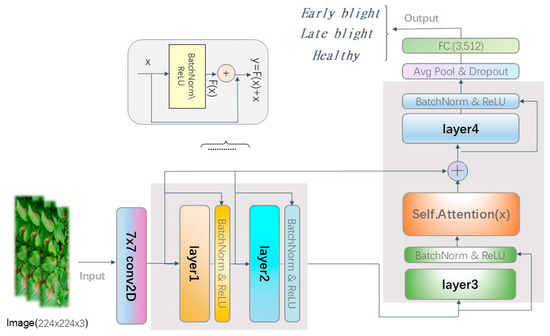
Figure 5.
ResNet18-SAWF model.
This paper introduces an improved network architecture that integrates a self-attention mechanism with Multi-scale Feature Fusion. The self-attention module generates an attention map by computing Query, Key, and Value representations, then performs a weighted summation on the input feature map to emphasize salient regions. This attention map is subsequently normalized using the Softmax function, ensuring that the accumulated weights sum to unity. Concurrently, the multi-scale feature-fusion module ingests feature maps from various ResNet layers (e.g., ResNet’s layer1, layer2, and layer3). It then aligns their channel dimensions using 1 × 1 convolutions and subsequently upsamples them to a consistent spatial resolution (e.g., 14 × 14) via bilinear interpolation. Finally, these processed feature maps are concatenated and subsequently fused through a 3 × 3 convolution. This fusion approach effectively integrates feature information across diverse scales, thereby significantly enhancing the model’s perception of multi-scale characteristics.
The model was trained using the Adam optimizer with an initial learning rate of 1 × 10−4. A ‘torch.optim.lr_scheduler.StepLR’ decayed the learning rate by a factor of 0.5 every five epochs, facilitating rapid exploration during early training and fine-tuning in later stages. L2 regularization with a weight decay of 1 × 10−5 was applied to mitigate overfitting. Training was conducted with a batch size of 32 for 30–50 epochs. To address class imbalance, a weighted random sampling strategy based on inverse class frequencies was employed, ensuring higher sampling probability for rare classes. Rather than using a fixed early stopping mechanism, model performance was continuously monitored, and the best-performing weights were saved; after each epoch, if the test set accuracy reached a new peak, the weights were updated and saved. At the start of training, all model parameters—including the backbone and newly added modules—were fully unfrozen to enable end-to-end learning and optimization.
The incorporation of Self-Attention mechanisms and Multi-scale Feature Fusion into the ResNet18 model markedly improves its ability to prioritize crucial feature regions and process multi-scale information, consequently boosting performance in image classification tasks. Details of blocks and layers used in the proposed model are shown in Table 2.
Table 2.
Details of blocks and layers used in the proposed model.
3.3. Self-Attention Mechanism Module
In the context of image target classification, the attention mechanism is employed to direct focus towards the target area and suppress the interference of non-target areas, such as the background. The Self-attention (SA) mechanism enables the model to discern relationships between different parts when processing sequences, e.g., images or text. This mechanism facilitates the dynamic assignment of varied attention weights among different positions within the sequence, thereby capturing global dependencies. The core premise of the Self-attention mechanism is to compute the influence of each element within the input sequence on other elements, specifically, the attention weight. These weights quantitatively represent the relationships among distinct elements, enabling the model to prioritize information critical to the current task. In image processing, Self-attention can be conceptualized as a feature recalibration process, where the importance of each pixel or feature point is adjusted based on its relationship with other pixels or feature points.
The Self-attention (SA) mechanism learns the correlations between elements in an input sequence X by mapping it into three representations: query (Q), key (K), and value (V). Specifically, the input sequence X undergoes a learnable linear transformation to generate Q, K, and V. An attention score matrix is then calculated by taking the dot product of the transpose of Q and K, which is then scaled to stabilize training. The scaled scores are subsequently converted into attention weights using a softmax function, quantifying the strength of the correlations between elements in the sequence. Finally, these attention weights are used to perform a weighted sum over V to produce the output sequence Y, which encapsulates contextual information. The overall structure of the Self-attention mechanism module is illustrated in Figure 6.
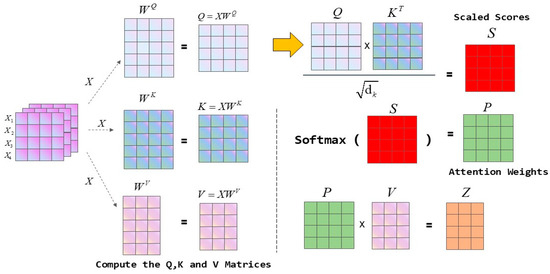
Figure 6.
Self-attention mechanism module.
The SA module is integrated strategically after the output of Layer 3 and before the input of Layer 4 of the ResNet18 backbone. It processes the high-level features generated by Layer 3, thereby enhancing the representation that serves as input for Layer 4. Within the SA module, the dimensions of the Q and K matrices are projected to one-eighth of the input channels using a ‘nn.Conv2d (in_channels, in_channels // 8, kernel_size = 1)’ operation. In contrast, the dimension of the V remains unchanged, matching the number of input channels. To maintain model simplicity, single-head self-attention is employed.
These attention weights are then used to compute a weighted sum of the value vectors, producing a new context-aware representation for each element. This representation effectively fuses the information of the element itself with a weighted aggregation of information from its contextual elements. This mechanism allows the model to capture intricate relationships and dependencies across the sequence, thereby enhancing its ability to understand the meaning of each element within its specific context.
3.4. Multi-Scale Feature-Fusion Module
The Multi-scale feature-fusion module represents a specialized implementation designed to integrate features extracted from various layers of a neural network, leveraging the self-attention mechanism. This fusion approach aims to integrate multi-level feature information, thereby enhancing the model’s robustness and capability in recognizing objects across diverse scales within an image. At its core, this involves combining feature maps generated at various depths of the network to effectively leverage their complementary information. In deep convolutional neural networks (CNNs), lower-level feature maps typically preserve fine-grained spatial details, whereas higher-level feature maps encapsulate richer semantic context. By strategically fusing these disparate feature representations, the model simultaneously acquires the capacity to discern both localized details and broader global context. The architectural details of this module are depicted in Figure 7.
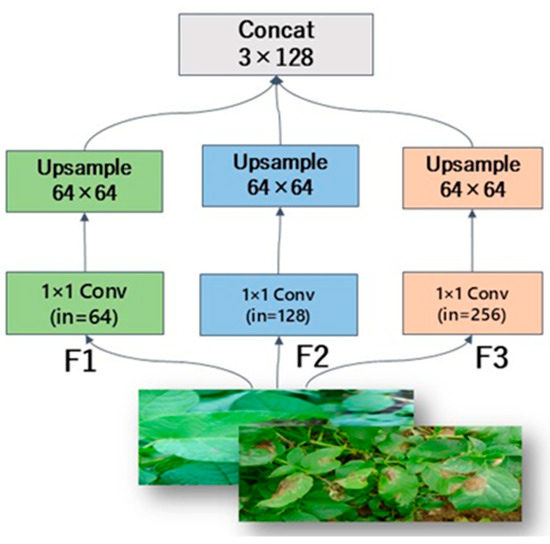
Figure 7.
Multi-scale feature-fusion module.
First, the feature map channel conversion, for each input feature map Fi (where i represents the level), use 1 × 1 convolution to convert the number of channels of the feature map for subsequent processing. This can be expressed by the following formula:
Among them: C (Fi) is the converted feature map, Wi is the weight matrix of the 1 × 1 convolution kernel, and Fi is the original feature map.
Subsequently, feature alignment is performed, primarily through an upsampling process. Given that feature maps derived from distinct levels of the network often possess varying spatial resolutions, it becomes imperative to standardize their dimensions. This standardization is achieved by upsampling lower-resolution maps to match a target spatial size, typically employing interpolation techniques such as bilinear interpolation. The general formulation for this upsampling operation is presented as follows:
where u (Fi) is the upsampled feature map, Upsample is the upsampling operation, H and W are the target space sizes.
After alignment, the features are fused and all Upsampled feature maps are concatenated in the channel dimension. This can be expressed by the following formula:
Among them: Ffused is the fused feature map, Concat represents the concatenation in the channel dimension, and Fi is the upsampled feature map.
Finally, feature integration uses a 3 × 3 convolutional layer to integrate the fused feature maps and output the final fused feature map. This can be expressed by the following formula:
where Ffinal is the final fused feature map, Conv represents the 3 × 3 convolution operation, and K is the weight matrix of the 3 × 3 convolution kernel.
The Multi-scale feature-fusion module (as illustrated in Figure 6) effectively integrates features extracted from diverse network layers. This integration profoundly enhances the model’s capability to recognize objects across a wide range of scales within an image. This fusion strategy capitalizes on the complementary information inherent in feature maps from varying levels, enabling the model to simultaneously capture fine-grained local details and broader global context.
3.5. Evaluation Metrics
To comprehensively evaluate the performance of the proposed model, standard quality metrics were employed, including Accuracy (A), Precision (P), Recall (R), and F1-score (F). Accuracy was defined as the proportion of correctly predicted instances among all samples. Precision was calculated as the proportion of true positive predictions among all positive predictions made by the model. Recall, also referred to as sensitivity, was measured as the proportion of actual positive samples correctly identified by the model. The F1-score, representing the harmonic mean of Precision and Recall, was used to provide a balanced assessment of the model’s performance. Each metric captures distinct aspects of the classification capability, and through appropriate weighting, a comprehensive evaluation of the overall effectiveness was achieved.
Among them, TP is true positive, TN is true negative, FP is false positive, and FN is false negative.
4. Results and Discussion
4.1. Experimental SETUP
Model training was conducted on a server at the Beijing Super Cloud Computing Center. The server ran Windows 10 and was equipped with a 12th-generation Intel® Core™ i7-12700 CPU, 16 GB RAM, and an NVIDIA RTX 4090 GPU. Experiments were implemented using CUDA 11.6, Python 3.9, and PyTorch 1.12.0.
4.2. Base Models Comparison Experiment
The original dataset, comprising single-leaf and multi-leaf images, was used to train various network models, with 50 independent training runs conducted for each model to evaluate their feasibility. It was observed that the ResNet18 model outperformed EfficientNet-B0, MobileNet_V2, ResNet50, and VGG16 across multiple key performance indicators. Accuracy and mean accuracy were compared for each model, and the corresponding standard deviations were calculated. Precision (P), Recall (R), and F1-score (F) were reported as macro-averaged values. The results are summarized in Table 3 and illustrated in Figure 8.
Table 3.
Comparison of different model indicators and their standard deviations.
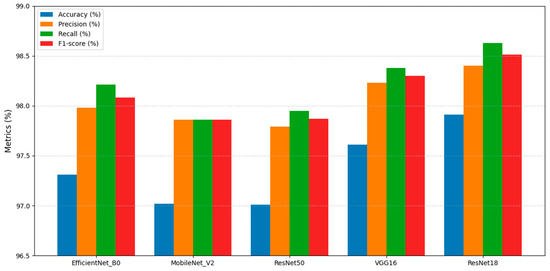
Figure 8.
Comparison of different models.
In the experimental results, A (%) denotes the accuracy of a single test, whereas A.avg (%) represents the mean accuracy and stability across multiple experiments. For single-shot accuracy, ResNet18 was observed to outperform the other models, achieving a maximum accuracy of 97.91%, corresponding to improvements of 0.6%, 0.89%, 0.9%, and 0.3% over the four aforementioned models, respectively. These results indicate its superior discriminative capability in single-shot prediction tasks. Moreover, ResNet18 attained an average accuracy of 96.51% ± 1.84%, maintaining high accuracy while exhibiting low variance and strong stability. By contrast, although ResNet50 achieved a higher average accuracy, its single-shot performance was slightly inferior to that of ResNet18, whereas EfficientNet-B0 demonstrated poor stability. Overall, ResNet18 achieved a favorable balance between accuracy and stability, underscoring its effectiveness and applicability for this task. Precision and Recall were recorded at 98.40% and 98.63%, respectively, with an F1-score (macro average) of 98.51%, representing the highest performance among all evaluated models. The superior performance of ResNet18 in Recall and F1-score indicates its capability not only to accurately classify the majority of samples, but also to effectively identify difficult-to-classify cases, thereby reducing missed detections. In comparison, models such as VGG16 and EfficientNet-B0 also exhibited strong performance, with F1-scores of 98.30% and 98.08%, respectively; however, slightly lower Recall and F1-scores were observed, suggesting that ResNet18 provides superior robustness and generalization while maintaining high accuracy.
The superior performance of ResNet18 over other models can be attributed to the rationality and efficiency of its network architecture. ResNet18 belongs to the residual network architecture family, in which the introduction of skip connections effectively alleviates the gradient vanishing problem encountered during deep network training. Although ResNet18 is shallower and contains fewer parameters than ResNet50, it is sufficient to capture the essential image semantics and boundary features required for the complexity of this task, while avoiding overfitting issues associated with excessive depth.
In comparison with VGG16, the residual structure of ResNet18 enables more stable information transmission during forward and backward propagation, resulting in a training process that converges more readily and exhibits greater robustness. When compared with lightweight models such as MobileNet_V2 and EfficientNet-B0, ResNet18, despite possessing slightly more parameters, demonstrates more pronounced improvements in accuracy. These observations suggest that, for the present task, an optimal balance between feature extraction capability and model capacity has been achieved. ResNet18 is therefore neither excessively complex, as in ResNet50, nor overly lightweight, as with MobileNet_V2, making it a moderate and balanced choice for this application.
4.3. Ablation Comparison Test Under Complex Background
In this experimental group, images containing multiple leaves within complex backgrounds were selected for training, and various models were compared with and without different attention mechanisms for ablation analysis. The baseline ResNet18 model demonstrated superior performance compared to MobileNet_V2 and EfficientNet-B0 across several key evaluation metrics.
Specifically, an accuracy of 91.80% was achieved by ResNet18, significantly exceeding the scores of EfficientNet-B0 (86.89%) and MobileNet_V2 (88.53%), with respective margins of 4.91% and 3.27%. These results suggest that ResNet18 exhibits stronger generalization capability in overall classification performance. In terms of Precision (93.26%) and Recall (91.88%), ResNet18 also outperformed EfficientNet-B0 (Precision: 88.89%) and MobileNet_V2 (Precision: 90.80%, Recall: 89.10%), indicating superior identification of positive samples and a reduced missed detection rate. Furthermore, the F1-score of ResNet18 reached 92.45%, surpassing that of EfficientNet-B0 (88.89%) and MobileNet_V2 (89.75%), indicating a more effective balance between precision and recall, as presented in Table 4.
Table 4.
Ablation comparison results.
Following the incorporation of various modules into the original ResNet18, significant differences in model performance were observed. Firstly, with the addition of the SA module, a slight decrease in model performance was observed: accuracy declined from 91.80% to 90.16%, while Precision and Recall decreased to 91.83% and 90.49%, respectively. Although the decrease in performance was modest, this suggests that the SA module may increase the model’s complexity or the risk of overfitting, while still maintaining a strong recognition capability.
When Dynamic Convolution (DC) was subsequently incorporated into ResNet18 + SA, a sharp decline in model performance was observed, with accuracy dropping to 42.62% and the F1-score reaching only 30.94%. These results indicate that, in this experimental scenario, the instability introduced by dynamic convolution substantially compromised the discriminative capability of the original model. Possible explanations include the difficulty in achieving convergence of dynamic parameters or the insufficiency of the sample size to support the learning of dynamic weights, which may impede the model’s ability to align semantic features during training or inference.
In contrast, the addition of the feature-fusion module to ResNet18 + SA significantly improved model performance, achieving an accuracy of 98.36% and an F1-score of 98.61%. This represents an improvement of more than 6 percentage points over the original ResNet18’s F1-score (92.45%) and surpasses the performance of the strongest mainstream lightweight model, MobileNet_V2. These results suggest that the SAWF module effectively enhances multi-scale semantic fusion, strengthens inter-channel information interaction, and significantly improves the model’s ability to interpret image features. Although enhancements such as dynamic convolution may lead to performance degradation, the integration of feature fusion considerably enhances the classification capability of ResNet18, rendering it markedly superior to other architectural models.
In our previous study, a ResNet18-GABM model was developed using the same dataset employed in the present work. The model was constructed on the ResNet18 architecture, into which a Global Grouped Coordinate Attention (GGCA) module and a Bitemporal Fusion Module (BFM) were integrated to enhance image classification accuracy. Specifically, height- and width-dependent attention maps were generated by the GGCA module, while multi-scale feature extraction was combined with channel- and spatial-attention mechanisms by the BFM, thereby improving the robustness and reliability of feature fusion. Experimental results demonstrated that an accuracy of 95.08% was achieved by the ResNet18-GABM model. By comparison, the ResNet18-SAWF model achieved an accuracy of 98.36%, corresponding to an improvement of 3.28 percentage points. This performance gap was partly attributed to the additional computational complexity and parameter overhead introduced by the GABM module, which increased the risk of overfitting and dependence on specific datasets.
The ResNet18-SAWF model, proposed in this study, exhibits significant improvements in robustness and accuracy when confronted with complex backgrounds, occlusions, and variations in lesion scale—challenges frequently encountered in potato leaf disease detection. In contrast to conventional CNN baseline models that rely exclusively on transfer learning and networks employing only local enhanced attention, the fundamental innovation of SAWF is its deeply integrated self-attention mechanism and its novel multi-scale feature-fusion module. The training results (accuracy and loss curve) are shown in Figure 9. The self-attention mechanism dynamically computes dependencies across the entire image, thereby transcending the limitations imposed by the local receptive fields characteristic of traditional CNNs. This mechanism explicitly captures global contextual information and effectively mitigates the partial loss of lesion features that can occur due to leaf occlusion. The confusion matrix, PR and ROC curves of the training are shown in Figure 10 and Figure 11, respectively.
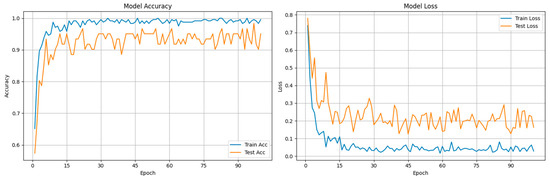
Figure 9.
Training results (Accuracy and Loss curve).
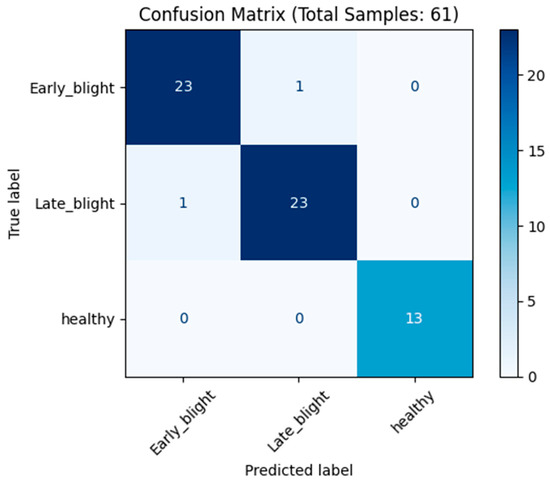
Figure 10.
Confusion Matrix.
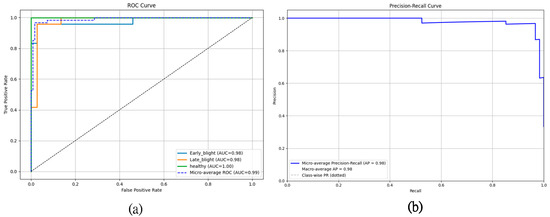
Figure 11.
ROC and PR Curve ((a) is the ROC curve, (b) is the PR curve).
In addition, the multi-scale feature-fusion module of SAWF differs from conventional approaches in that it does not merely stack features from different layers but instead emphasizes lesion localization while suppressing background information. The visualization of the Grad-CAM gradients is presented in Figure 12. Instead, it employs an adaptive strategy to effectively integrate the rich, fine-grained details from earlier layers—encompassing the microscopic morphology of nascent lesions—with the macroscopic contextual information from deeper layers, such as the overall distribution of lesions. This cross-scale information integration is instrumental in discerning lesions across various developmental stages, from initial small manifestations to extensive formations. The synergistic interplay between self-attention and multi-scale fusion forms the cornerstone of the SAWF approach. Specifically, self-attention dynamically guides the fusion process, directing its focus towards the most discriminative feature scales that effectively bridge information gaps. Conversely, the multi-scale fusion mechanism furnishes a richer feature representation, thereby augmenting the global modeling capabilities inherent to self-attention.
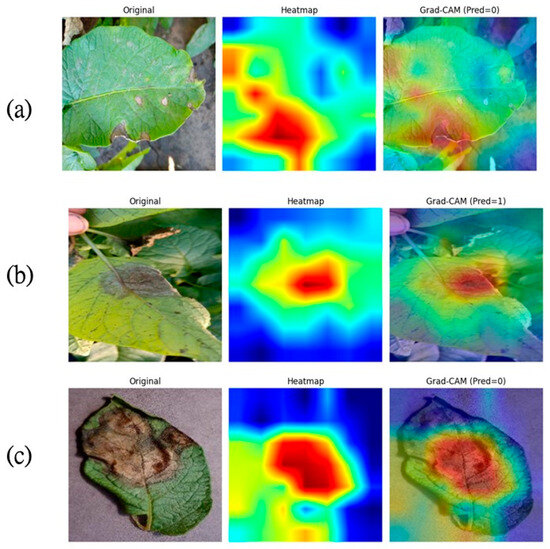
Figure 12.
Grad-CAM visualization ((a) is early blight, (b) is late blight, and (c) is late blight from the public dataset).
4.4. Compared with Existing Studies
Given that most existing research has concentrated on single-context scenarios, with relatively few studies addressing complex contexts, a comparative analysis was conducted. Specifically, the proposed model was compared with prior studies in both simple and complex contexts, as well as with other potato disease classification methods reported in the literature. Several state-of-the-art approaches [28,29,34,36,37,38] were selected for comparison. However, due to limited access to private datasets, the performance of these methods is reported based on the original datasets used in their respective studies. Consequently, only horizontal comparisons based on model accuracy could be performed. The results are summarized in Table 5.
Table 5.
Comparison of the proposed method with existing methods (Sr. No 1–3 are simple backgrounds; Sr. No 4–6 are complex backgrounds).
Barman et al. [36] developed a custom CNN model for classifying potato leaf infections, achieving an accuracy of 96.98%. Similarly, Zhang et al. [29] and Nazir et al. [34] introduced enhancement algorithms that achieved accuracies of 97.87% and 98.12%, respectively, for potato leaf disease classification. However, these studies predominantly utilized datasets with simple backgrounds. While some research has addressed complex background conditions [28], Sinamenye et al. [37] proposed a hybrid deep learning model (EfficientNetV2B3 + ViT) for detecting and identifying potato plant diseases, achieving an accuracy of 85.06%. Chen et al. [38] proposed MobOca_Net, a deep learning model integrating pixel-level and channel-level attention mechanisms into its base network to identify different potato leaf types, reaching an accuracy of 97.73%. Given the prevalence of simple backgrounds in available datasets and limitations in accessing private ones, the following comparison relies on reported performance metrics of existing technologies. In comparison, the proposed method achieves a maximum accuracy of 98.36%. This represents an improvement of 0.7 percentage points over the average accuracy for simple backgrounds (97.66%) and 11.55 percentage points over the average accuracy for complex backgrounds (86.81%). These results underscore the superior generalization capabilities of the proposed method when contrasted with existing approaches.
5. Conclusions
To address the challenges of complex background feature extraction, inadequate multi-leaf feature fusion, and limited model generalization in potato leaf disease recognition, a classification method combining ResNet18 with a Self-Attention mechanism and Feature Fusion (ResNet18-SAWF) is presented in this study.
A mixed dataset comprising single-leaf and multi-leaf samples was used to train and evaluate five mainstream convolutional neural networks: ResNet18, EfficientNet-B0, MobileNetV2, ResNet50, and VGG16. The evaluation results indicate that ResNet18 outperformed the other models across all performance metrics. Specifically, ResNet18 achieved a maximum accuracy of 97.91%, corresponding to improvements of 0.6%, 0.89%, 0.9%, and 0.3% over EfficientNet-B0, MobileNetV2, ResNet50, and VGG16, respectively. Overall, ResNet18 demonstrated superior classification capabilities. Although VGG16 and EfficientNet-B0 exhibited strong performance, their overall metrics were slightly lower than those of ResNet18.
In the multi-leaf classification task under complex backgrounds, the incorporation of the Self-Attention mechanism and Feature-Fusion module (SAWF) increased the accuracy to 98.36%, significantly enhancing performance relative to the baseline ResNet18 model (91.80%) and outperforming EfficientNet-B0 (86.89%) and MobileNetV2 (88.53%). Compared with dynamic convolution, which exhibited a sharp decline in accuracy to 42.62%, the SAWF module proved more effective in enhancing semantic information fusion and channel-level interaction. The enhanced model exhibited strong performance in terms of accuracy, Recall, and robustness. Therefore, the ResNet18-SAWF model achieved the best performance in this task and demonstrates broad application potential.
Future research may focus on further optimization of the model architecture to improve real-time performance and reduce computational resource requirements, while maintaining accuracy, in order to better meet the application demands encountered in practical agricultural settings.
Author Contributions
Conceptualization, K.X. and S.C.; Data curation, K.X. and S.C.; Formal analysis, K.X. and D.X.; Funding acquisition, D.X. and S.C.; Investigation, K.X.; Methodology, K.X. and S.C.; Project administration, K.X.; Resources, K.X. and S.C.; Software, K.X.; Supervision, K.X.; Validation, K.X. and S.C.; Visualization, K.X.; Writing—original draft, K.X.; Writing—review and editing, K.X., D.X. and S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Jilin Province Natural Science Foundation Free Exploration Project (YDZJ202501ZYTS597), the National Key R&D Program of China (2017YFE0122700), the Jilin Province Department of Education Industrialization Cultivation Project (JJKH20230514CY), and the National Natural Science Foundation of China (62401004, 61901005).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding authors upon reasonable request.
Acknowledgments
The authors would like to express their sincere gratitude to the laboratory staff and technical assistants for their valuable support in data collection and equipment maintenance. Special thanks are also extended to the colleagues who provided constructive suggestions during discussions, as well as to the institutions that facilitated access to research facilities. The authors also appreciate the administrative support received throughout the course of this study.
Conflicts of Interest
The authors declare no conflicts of interest. All authors have no financial or personal relationships with other people or organizations that could inappropriately influence (or be perceived to influence) their work. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Su, W.; Wang, J. Potato and food security in China. Am. J. Potato Res. 2019, 96, 100–101. [Google Scholar] [CrossRef]
- Devaux, A.; Goffart, J.P.; Kromann, P.; Andrade-Piedra, J.; Polar, V.; Hareau, G. The potato of the future: Opportunities and challenges in sustainable agri-food systems. Potato Res. 2021, 64, 681–720. [Google Scholar] [CrossRef] [PubMed]
- Zeng, S.Q. The Ministry of Agriculture held an international seminar on potato staple food products and industrial development. Agric. Prod. Mark. Wkly. 2015, 31, 19. [Google Scholar]
- Gold, K.M.; Townsend, P.A.; Chlus, A.; Herrmann, I.; Couture, J.J.; Larson, E.R.; Gevens, A.J. Hyperspectral measurements enable pre-symptomatic detection and differentiation of contrasting physiological effects of late blight and early blight in potato. Remote Sens. 2020, 12, 286. [Google Scholar] [CrossRef]
- Majeed, A.; Muhammad, Z.; Ullah, Z.; Ullah, R.; Ahmad, H. Late blight of potato (Phytophthora infestans) I: Fungicides application and associated challenges. Turk. J. Agric.-Food Sci. Technol. 2017, 5, 261–266. [Google Scholar] [CrossRef]
- Wang, S.; Xu, D.; Liang, H.; Bai, Y.; Li, X.; Zhou, J.; Su, C.; Wei, W. Advances in deep learning applications for plant disease and pest detection: A review. Remote Sens. 2025, 17, 698. [Google Scholar] [CrossRef]
- Franceschini, M.H.D.; Bartholomeus, H.; Van Apeldoorn, D.F.; Suomalainen, J.; Kooistra, L. Feasibility of unmanned aerial vehicle optical imagery for early detection and severity assessment of late blight in potato. Remote Sens. 2019, 11, 224. [Google Scholar] [CrossRef]
- Shin, J.; Mahmud, M.S.; Rehman, T.U.; Ravichandran, P.; Heung, B.; Chang, Y.K. Trends and prospect of machine vision technology for stresses and diseases detection in precision agriculture. AgriEngineering 2022, 5, 20–39. [Google Scholar] [CrossRef]
- Edan, Y.; Adamides, G.; Oberti, R. Agriculture automation. In Springer Handbook of Automation; Springer: Cham, Switzerland, 2023; pp. 1055–1078. [Google Scholar]
- Nath, P.C.; Mishra, A.K.; Sharma, R.; Bhunia, B.; Mishra, B.; Tiwari, A.; Nayak, P.K.; Sharma, M.; Bhuyan, T.; Kaushal, S. Recent advances in artificial intelligence towards the sustainable future of agri-food industry. Food Chem. 2024, 447, 138945. [Google Scholar] [CrossRef]
- Tyagi, A.K.; Tiwari, S. The future of artificial intelligence in blockchain applications. In Machine Learning Algorithms Using Scikit and Tensorflow Environments; IGI Global Scientific Publishing: Hershey, PA, USA, 2024; pp. 346–373. [Google Scholar]
- Hernandez, D.; Pasha, L.; Yusuf, D.A.; Nurfaizi, R.; Julianingsih, D. The role of artificial intelligence in sustainable agriculture and waste management: Towards a green future. Int. Trans. Artif. Intell. 2024, 2, 150–157. [Google Scholar] [CrossRef]
- Afzaal, H.; Farooque, A.A.; Schumann, A.W.; Hussain, N.; McKenzie-Gopsill, A.; Esau, T.; Abbas, F.; Acharya, B. Detection of a potato disease (early blight) using artificial intelligence. Remote Sens. 2021, 13, 411. [Google Scholar] [CrossRef]
- Dai, G.; Hu, L.; Fan, J.; Yan, S.; Wang, X.; Man, R.; Liu, T. Based on GLCM feature extraction and voting classification model Potato Early and Late Disease Detection of Type. Jiangsu Agric. Sci. 2023, 51, 185–192. [Google Scholar]
- Sangar, G.; Rajasekar, V. Potato Leaf Disease Classification using Pre Trained Deep Learning Techniques-A Comparative Analysis. In Proceedings of the 2024 5th International Conference for Emerging Technology (INCET), Belgaum, India, 24–26 May 2024; pp. 1–6. [Google Scholar]
- Mahmood ur Rehman, M.; Liu, J.; Nijabat, A.; Faheem, M.; Wang, W.; Zhao, S. Leveraging convolutional neural networks for disease detection in vegetables: A comprehensive review. Agronomy 2024, 14, 2231. [Google Scholar] [CrossRef]
- Arshad, F.; Mateen, M.; Hayat, S.; Wardah, M.; Al-Huda, Z.; Gu, Y.H.; Al-antari, M.A. PLDPNet: End-to-end hybrid deep learning framework for potato leaf disease prediction. Alex. Eng. J. 2023, 78, 406–418. [Google Scholar] [CrossRef]
- Munir, G.; Ansari, M.A.; Zai, S.; Bhacho, I. Deep Learning Based Multi Crop Disease Detection System. Int. J. Innov. Sci. Technol. 2024, 6, 1009–1020. [Google Scholar]
- Panchal, A.V.; Patel, S.C.; Bagyalakshmi, K.; Kumar, P.; Khan, I.R.; Soni, M. Image-based plant diseases detection using deep learning. Mater. Today Proc. 2023, 80, 3500–3506. [Google Scholar] [CrossRef]
- Negi, A.S.; Rawat, A.; Mehra, P. Precision Agriculture: Enhancing Potato Disease Classification using Deep Learning. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–6. [Google Scholar]
- Sarfarazi, S.; Zefrehi, H.G.; Toygar, Ö. Potato leaf disease classification using fusion of multiple color spaces with weighted majority voting on deep learning architectures. Multimed. Tools Appl. 2024, 84, 27281–27310. [Google Scholar] [CrossRef]
- Upadhyay, S.; Jain, J.; Prasad, R. Early blight and late blight disease detection in potato using Efficientnetb0. Int. J. Exp. Res. Rev. 2024, 38, 15–25. [Google Scholar] [CrossRef]
- Liu, J.W.; Liu, J.W.; Luo, X.L. Research progress in attention mechanism in deep learning. Chin. J. Eng. 2021, 43, 1499–1511. [Google Scholar]
- Yang, X. An overview of the attention mechanisms in computer vision. J. Phys. Conf. Ser. 2020, 1693, 012173. [Google Scholar] [CrossRef]
- Gupta, J.; Pathak, S.; Kumar, G. Deep learning (CNN) and transfer learning: A review. J. Phys. Conf. Ser. 2022, 2273, 012029. [Google Scholar] [CrossRef]
- Feng, J.; Hou, B.; Yu, C.; Yang, H.; Wang, C.; Shi, X.; Hu, Y. Research and validation of potato late blight detection method based on deep learning. Agronomy 2023, 13, 1659. [Google Scholar] [CrossRef]
- Natesan, B.; Singaravelan, A.; Hsu, J.-L.; Lin, Y.-H.; Lei, B.; Liu, C.-M. Channel–Spatial segmentation network for classifying leaf diseases. Agriculture 2022, 12, 1886. [Google Scholar] [CrossRef]
- Li, J.; Wu, J.; Liu, R.; Shu, G.; Liu, X.; Zhu, K.; Wang, C.; Zhu, T. Potato late blight leaf detection in complex environments. Sci. Rep. 2024, 14, 31046. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Wang, S.; Wang, C.; Wang, H.; Du, Y.; Zong, Z. Research on a Potato Leaf Disease Diagnosis System Based on Deep Learning. Agriculture 2025, 15, 424. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Zhang, D.; Sun, Y.; Nanehkaran, Y.A. Using deep transfer learning for image-based plant disease identification. Comput. Electron. Agric. 2020, 173, 105393. [Google Scholar] [CrossRef]
- Shafik, W.; Tufail, A.; De Silva Liyanage, C.; Apong, R.A.A.H.M. Using transfer learning-based plant disease classification and detection for sustainable agriculture. BMC Plant Biol. 2024, 24, 136. [Google Scholar] [CrossRef]
- Zhao, X.; Li, K.; Li, Y.; Ma, J.; Zhang, L. Identification method of vegetable diseases based on transfer learning and attention mechanism. Comput. Electron. Agric. 2022, 193, 106703. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, Q.; Chen, J.; Zhou, H. Deep learning-based classification and application test of multiple crop leaf diseases using transfer learning and the attention mechanism. Computing 2024, 106, 3063–3084. [Google Scholar] [CrossRef]
- Nazir, T.; Iqbal, M.M.; Jabbar, S.; Hussain, A.; Albathan, M. EfficientPNet—An optimized and efficient deep learning approach for classifying disease of potato plant leaves. Agriculture 2023, 13, 841. [Google Scholar] [CrossRef]
- Lespinats, S.; Colange, B.; Dutykh, D. Nonlinear Dimensionality Reduction Techniques; Springer International Publishing: Berlin, Germany, 2022. [Google Scholar]
- Barman, U.; Sahu, D.; Barman, G.G.; Das, J. Comparative assessment of deep learning to detect the leaf diseases of potato based on data augmentation. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 682–687. [Google Scholar]
- Sinamenye, J.H.; Chatterjee, A.; Shrestha, R. Potato plant disease detection: Leveraging hybrid deep learning models. BMC Plant Biol. 2025, 25, 647. [Google Scholar] [CrossRef]
- Chen, W.; Chen, J.; Zeb, A.; Yang, S.; Zhang, D. Mobile convolution neural network for the recognition of potato leaf disease images. Multimed. Tools Appl. 2022, 81, 20797–20816. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).