Abstract
Knowledge graph (KG) reasoning aims to obtain new knowledge based on existing data. Utilizing large language models (LLMs) through in-context learning for KG reasoning has become a significant direction. However, existing methods mainly extract in-context triples by manually defined standards (such as the neighbors that are directly linked with the query triple), without considering whether they are useful for LLM reasoning. Furthermore, the triples beyond the neighbors can also provide important clues for reasoning. Therefore, it is necessary to extract more useful in-context triples of LLMs for KG reasoning. This paper proposes a rule-and-reinforce in-context triple extraction method to enhance the in-context learning of LLMs for KG reasoning. First, we collect the in-context triples specific to each query triple with the guidance of logical rules, and a neural extractor is pre-trained by the collected triples. Subsequently, the feedback of LLMs is collected as rewards to further optimize the extractor, where the policy gradient is utilized to encourage the extractor to explore more useful triples that yield higher rewards. The experimental results on five different knowledge graphs demonstrate that the proposed method can effectively improve the reasoning performance of LLMs. Compared to the traditional reasoning method AnyBURL, the greatest improvement is 0.147 on Hits@10, FB15k-237.
1. Introduction
A knowledge graph is a type of data that represents real-world knowledge in the form of triples , where h and t denote the head entity and tail entity, respectively, and r represents the relation between the two entities [1]. Knowledge graphs contain large-scale structured factual knowledge, which can effectively improve the effectiveness of various tasks [2,3,4,5]. Knowledge graph reasoning is the process of analyzing existing triples of knowledge graphs to infer new knowledge [6].
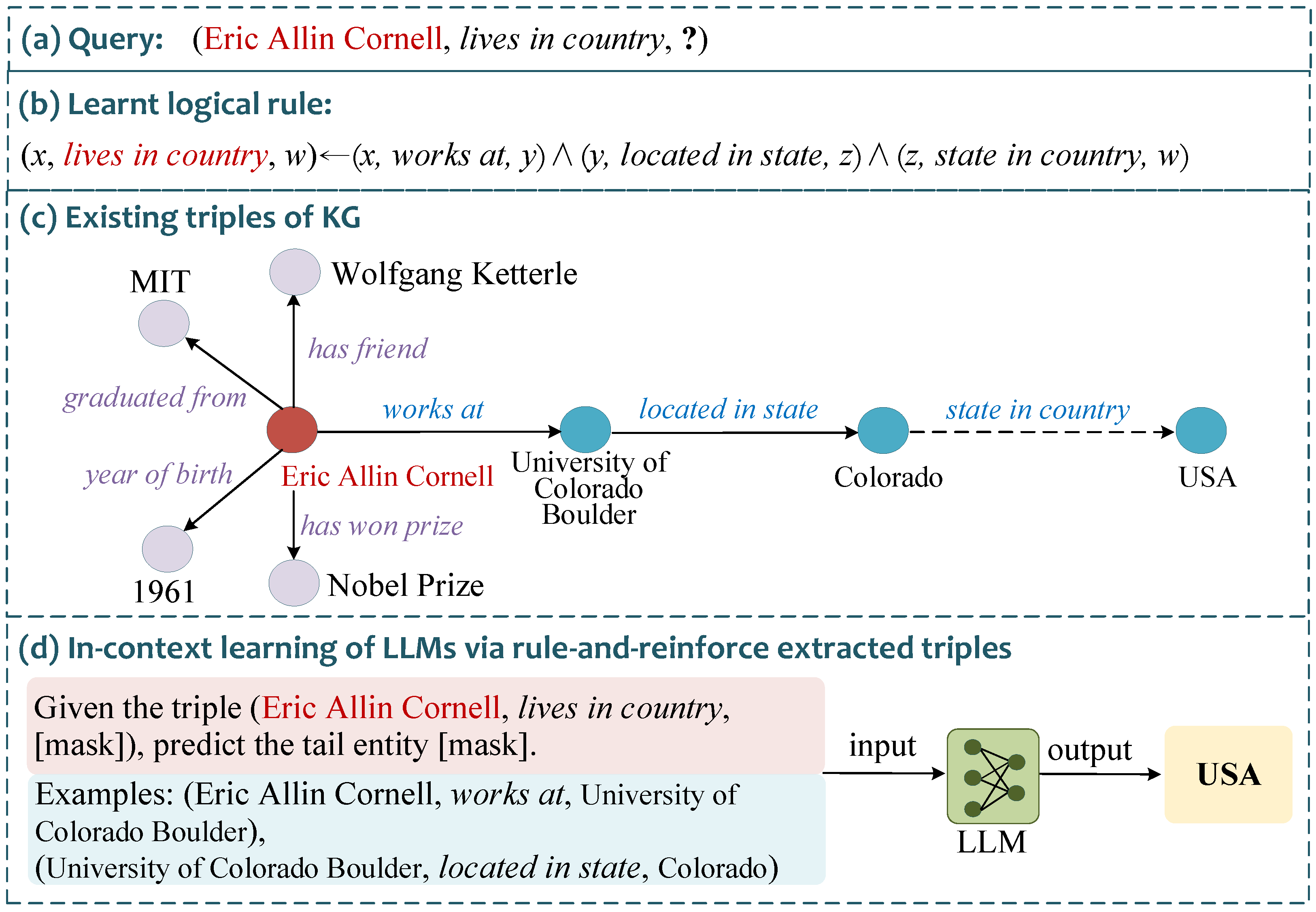
Knowledge graph reasoning has been extensively studied, and existing methods are mainly categorized into two groups: (1) distributed representation-based methods, which project entities and relations into low-dimensional dense vector space and perform reasoning by measuring the distances between vectors; (2) logical rule-based methods, which mine logical rules from knowledge graphs and apply them to existing data to find new triples. However, in practical applications, knowledge graphs are generally constructed by information extraction methods automatically, leading to the incompleteness problem [7]. Since the aforementioned traditional methods are mainly data-driven methods, the incompleteness problem of knowledge graphs limits the knowledge that can be provided by existing data, thereby constraining the reasoning effectiveness of these methods [8,9]. As illustrated in the example shown in Figure 1, given the query triple “(Eric Allin Cornell, lives in country, ?)”, a logical rule can be mined from the knowledge graph through logical rule learning: “(x, lives in country, w)←(x, works at, y)∧(y, located in state, z)∧(z, state in country, w)”. This logical rule indicates that if there exists a path consisting “works at, located in state, state in country” between entities x and w, then we can infer that the relation “lives in country” exists between x and w. However, as shown in Figure 1c, by analyzing the existing triples in the knowledge graph, it can be found that due to the incompleteness problem, the relation “state in country” (depicted with the dashed line) between the entities “Colorado” and “USA” does not exist. Therefore, the path represented by the aforementioned logical rule is not valid in the existing data, ultimately leading to an incomplete reasoning process.
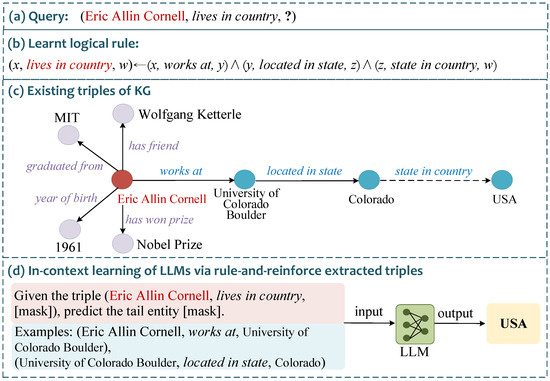
Figure 1.
An example of reasoning on incomplete knowledge graphs.
In recent years, the emergence of large language models (LLMs) has sparked a new wave in the field of artificial intelligence. LLMs, equipped with millions of parameters and trained on large-scale corpora, have acquired immense knowledge and demonstrated superior performance across various natural language tasks, such as machine translation [10], text analysis [11], and intelligent question answering [12]. Consequently, the knowledge implied in LLMs may alleviate the limitations imposed by the incompleteness of knowledge graphs. As a result, leveraging LLMs for knowledge graph reasoning has emerged as a novel direction.
To better adapt the LLMs to reasoning tasks, in-context learning is utilized in the process of reasoning, the main idea is to retrieve relevant triples from existing knowledge graphs based on the given query triple, incorporating them into the prompt [13,14,15]. However, existing methods mainly extract in-context triples from KGs by manually defined standards (such as the neighbors that are directly linked with the given query triple), without considering whether these triples are truly useful for the reasoning of LLMs. In fact, triples directly linked to the query entity may not necessarily be effective for the reasoning of the given query, while triples not directly connected to the query entity may potentially provide crucial reasoning clues. As depicted in Figure 1, for the given query “(Eric Allin Cornell, lives in country, ?)”, existing methods may retrieve triples directly connected to the query entity “Eric Allin Cornell” as in-context triples. Upon analysis, it becomes evident that most of these retrieved triples are irrelevant to the reasoning. Unselectively incorporating them into the context may instead introduce noise, thereby diminishing the reasoning effectiveness. In contrast, it can be determined that introducing triples such as “(Eric Allin Cornell, works at, University of Colorado Boulder), (University of Colorado Boulder, located in state, Colorado)” as in-context triples can provide valuable contextual knowledge, thereby enhancing the performance of LLMs on knowledge graph reasoning.
Therefore, in this paper, we propose the rule-and-reinforce triple extraction method; the method can enhance the in-context learning of LLMs for knowledge graph reasoning. The proposed method contains two parts: (1) logical rules guiding in-context triples retrieval and extractor pre-training. We retrieve the in-context triples involved in the logical rules for each query triple as supervised training data, and train an extractor to generate in-context triples for specific query triples; (2) reinforcement learning with LLMs’ feedback as rewards. The feedback of LLMs is collected as rewards to further optimize the extractor through reinforcement learning, in which the policy gradient is utilized to encourage the extractor to explore more useful triples that yield higher rewards. Through experiments and comparisons conducted on five different knowledge graphs, the results demonstrate that the in-context triples extracted by the proposed method can effectively enhance the performance of large language models in knowledge graph reasoning.
The contributions of this paper are summarized as follows:
- To alleviate the problem that traditional LLM-based reasoning methods fail to fully utilize the existing data of knowledge graphs, we propose the rule-and-reinforce triple extraction method; the method can enhance the in-context learning of LLMs for knowledge graph reasoning;
- In order to obtain more effective in-context triples, we construct an in-context triple extractor, which is designed based on the encoder-decoder architecture. The triples involved in the logical rules of the knowledge graph are utilized as supervised data for pre-training. Then, the extractor is further trained through reinforcement learning methods with the feedback from LLMs;
- The experimental results on five different knowledge graphs indicate that the in-context triples extracted by the proposed method can effectively enhance the capabilities of LLMs in knowledge graph reasoning.
2. Related Work
Knowledge graph reasoning is one of the crucial research directions in the field of artificial intelligence. In this section, the methods of knowledge graph reasoning are introduced from two aspects: traditional knowledge graph reasoning methods, and pre-trained language model and large language model-based reasoning models.
2.1. Traditional Knowledge Graph Reasoning Methods
Traditional knowledge graph reasoning methods mainly contain two streams: (1) distributed representation-based methods. These methods embed entities and relations into low-dimensional continuous vector space, and the plausibility of triples can be formulated as vector computation. TransE [16] is a representative distributed representation learning model; the relation of a triple is modeled as the translation process from the head entity to tail entity. Then, TransH [17], TransR [18], and TransD [19] further extend the method to interpret 1-N, N-1, and N-N relations. In order to model more complex relation patterns of knowledge graphs, some studies project the entities and relations into complex vector space. ComplEx [20] introduces the complex vector to model the symmetric and antisymmetric relations. RotatE [21] transforms the relations as rotational operations from head entities to tail entities.
(2) Logical rule-based methods. The main idea of logical rule-based methods is to learn the frequency patterns of knowledge graphs and represent the patterns by logical rules. Then, the rules are applied to existing triples and the new triples can be obtained through reasoning by logical rules. Amie [22], Amie+ [23], and Amie3 [24] utilize a machine learning method to mine logical rules for specific relations, and prune the rules with low confidence and coverage. RLvLR [25] defines new criteria for the logical rules and enables the method to extend to large-scale knowledge graphs. NeuralLP [26] transforms the logical rule learning to a differentiable process and the process of rule mining can be conducted by the gradient-based optimization. AnyBURL [27] proposes a bottom-up rule mining method; it can learn fuzzy and uncertain rules and can extend to large-scale knowledge graphs with relatively low resource consumption.
However, these methods are mainly data-driven methods, and highly rely on the existing triples in the knowledge graph. The incompleteness problem of knowledge graphs may impair the performance of reasoning [16,22,23].
2.2. Pre-Trained Language Model- and Large Language Model-Based Methods
Based on the self-attention mechanism, pre-trained language models are constructed and are pre-trained on a large corpus of text. These models have learnt vast amounts of knowledge and can be well adapted to a variety of downstream tasks through simply fine-tuning, such as machine translation [10], text analysis [11], and intelligent question answering [12]. Some studies also utilize the pre-trained language models to enhance the performance of knowledge graph reasoning. KG-BERT [28] represents the query triple as a textual sequence with the special token [CLS] in front of the sequence. Then, the sequence is encoded by the pre-trained language model BERT [29] and the hidden state of [CLS] is put into a classifier to predict the missing entity. KGT5 [30] further trains T5 small [31] on link prediction and question answering tasks with multiple forms; then, the reasoning can be completed by integrating the query triple and simple instructions. GenKGC [32] is developed based on the model BART [33]. Besides the query triple, the method also incorporates demonstration triples which contain the same query relation to improve the reasoning results.
Subsequently, large language models are proposed and bring new waves in multiple fields. LLMs are trained on a very large corpus and contain hundreds of billions of parameters. Many experiments have proven that LLMs perform well at various natural language processing tasks without further training for the tasks [10,11,12]. In order to make the LLMs comprehend different downstream tasks, in-context learning is widely used [13]. It is a type of few-shot learning method which incorporates a few examples into the prompt [15]. AutoKG [34] utilizes the LLMs GPT4 and chatGPT (https://openai.com/blog/chatgpt (accessed on 15 January 2025)), and adopts in-context learning on knowledge graph reasoning through one-shot learning. A triple is extracted as the in-context example to enhance the reasoning performance. KAPING [35] first links the entities in the query and that of knowledge graphs, and the triples which contain the linked entities are retrieved as in-context triples. KoPA [36] selects the triples which contain the query head entity as in-context learning triples to enhance the performance of triple classification. KICGPT [37] first conducts the knowledge graph reasoning through the distributed representation learning method RotatE, and the results are further refined by the LLMs through multiple interactions.
However, the in-context triples utilized in previous LLM-based reasoning methods are mainly retrieved around the query entities or query relations, which cannot make full use of the existing triples of knowledge graphs. The triples that are not directly connected to the query entities, as well as those that do not contain the query relations, may also potentially provide important knowledge for reasoning. While our proposed method can retrieve these useful in-context triples with the guidance of logical rules and the feedback of LLMs, the experimental results also demonstrate the effectiveness of the model.
3. Formalized Description of the Proposed Solution
Knowledge graph reasoning aims to obtain new knowledge based on the existing knowledge graphs. In this paper, we formulate the knowledge graph reasoning task as link prediction. Formally, a knowledge graph is a collection of triples, i.e., , where and represent the sets of entities and relations, respectively, and N is the number of triples of . For the link prediction task, given a query triple , where h is the query head entity (), and r is the query relation (), the ? denotes the tail entity to be predicted.
More specifically, in the proposed model, besides the query triple , the in-context triples are also retrieved from the knowledge graph . We denote the set of retrieved in-context triples as , where , and . To simplify the process of connecting the predicted results of LLMs with the entities in the knowledge graph, we also extract the potential candidate entities from the knowledge graph and denote the set of candidate entities as .
Based on the given query triple , retrieved in-context triples , and candidate tail entities , the prompt can be constructed and put into the LLMs; finally, the predicted entities can be generated by the LLMs.
4. Methodology
In order to extract the in-context triples which provide useful clues for reasoning, an in-context triple extractor is proposed. The extractor is designed based on the encoder-decoder structure. Figure 2 depicts the overall framework of the proposed rule-and-reinforce triple extracting method. The training procedure of the extractor is composed of two main phases:
(1) Logical rules guide in-context triples retrieval and extractor pre-training (Figure 2a). In this phase, the in-context triples for each query triple are retrieved based on whether they can support the logical rules corresponding to the current reasoning. These in-context triples with corresponding query triples are collected as training data, and the extractor can be trained with the guidance of logical rules;
(2) Reinforcement learning with LLM’s feedback as rewards (Figure 2b). In this phase, the feedback of LLMs when incorporating the in-context triples generated by the pre-trained extractor is collected. The feedback is utilized as the rewards to further train the extractor through reinforcement learning.
4.1. Logical Rules-Guided in-Context Triples Retrieval and Extractor Pre-Training
The in-context triple extractor employs a transformer-inspired encoder-decoder-based architecture. Initially, the supervised data are constructed from the logical rules-guided triples to pre-train the extractor, enabling it to adapt well to the task of generating the in-context triplets for a given query triple.
4.1.1. Logical Rules-Guided in-Context Triples Retrieval
Knowledge graphs contain a vast amount of frequency patterns, which can be expressed in the form of logical rules. These logical rules can serve as explicit reasoning bases for reasoning. Based on this, for a given query triple, the in-context triples can be retrieved from the knowledge graph by searching for those that support the relevant logical rules associated with the query triple.
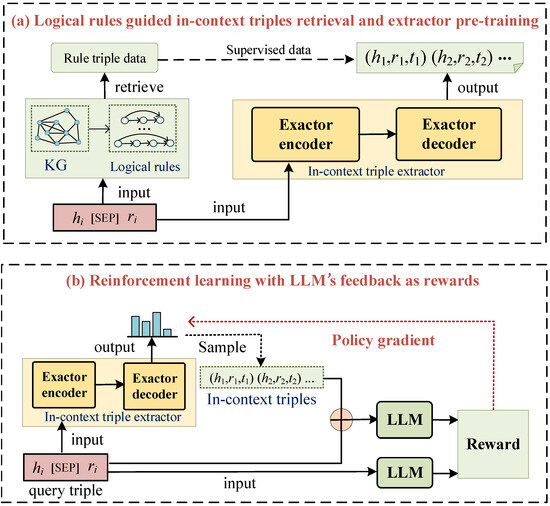
Figure 2.
Framework of the proposed rule-and-reinforce in-context triple extraction method.
Figure 2.
Framework of the proposed rule-and-reinforce in-context triple extraction method.
For example, assuming that a query triple is “(Zuckerberg, nationality, ?)”, then two logical rules about “nationality” can be obtained by the logical rule learning models (logical rule learning models generally take the given knowledge graph as input and mine a series of logical rules through analyzing the frequency patterns. Meanwhile, the confidence can be measured for each logical rule to reflect the degree of support for the corresponding logical rule within the existing knowledge graph data. There are various logical rule learning models, such as AMIE [22], AMIE3 [24], and AnyBURL [27], see Section 2.1 for more details.): “(x, nationality, y)←(x, works in, z)∧(z, located in state, w)∧(w, state in country, y)”, and “(x, nationality, y)←(x, born in, z)∧(z, located in state, w)∧(w, state in country, y)”. Then, the triples which support each logical rule can be extracted from knowledge graph (see more examples of this part in Appendix A). These in-context triples can provide crucial in-context clues for LLMs to reason on this given query triple. Therefore, we can construct the training data by retrieving triples from the given knowledge graph that can support the corresponding logical rules, and further pre-train the in-context triple extractor.
Formally, for a relation , the logical rules learning models can be employed on the knowledge graph , and the set of logical rules specific to the relation can be obtained, where , and is a logical rule about the relation . Based on a logical rule , a set of triplets that support the reasoning of can be retrieved from the knowledge graph, which is denoted by . Subsequently, we merge the sets of triples that support the rules in , denoted as . If the number of in-context triples of is greater than M, then these in-context triples are sorted in descending order according to the confidence and order of the logical rules they support, and select the top M triples. Finally, for each query triple , the logical rules set can be obtained, and then the in-context triples which support the reasoning of are retrieved according to . Together, they constitute the pre-training data for the in-context triple extractor:
4.1.2. Supervised Extractor Pre-Training
The in-context triple extractor is pre-trained based on the former training data . It is an encoder-decoder generation model , and takes a query triple as input, then outputs the set of in-context triples guided by the logical rules. The encoder, decoder, and the process of pre-training are introduced as follows:
Encoder. Given a query triple , it is first converted into a sequence and then encoded to obtain the corresponding hidden states:
where the input is the sequence , and is a separation token between and . are the hidden states of the given sequence . represents the length of sequence , and d is the dimension of the hidden states.
Decoder. The decoder aims to decode the obtained hidden states , and generate the set of the in-context triples for reasoning. The procedure of generating in-context triples at the k-th decoder step can be represented by:
where are the output hidden states of the extractor decoder. represents the probability distribution at the k-th decode step. denotes the decoded sequence in the previous decoding steps. W and b are trainable parameters.
Training. During the training phase, the optimization of parameters is achieved by reducing the negative log-likelihood of the parallel training data to its minimum value:
where is the generated sequence in the previous k-1 decoding steps. is the length of the sequence of the in-context triples , where i denotes the index of the training data.
After pre-training, given a query triple , the in-context triple extractor can output the corresponding in-context triples which can be used for LLM reasoning.
4.2. Reinforcement Learning with LLM’s Feedback as Rewards
In previous phases, the extractor has been trained by the in-context triples which are retrieved by the logical rules. However, triples generated solely by the extractor supervised by the logical rules may not necessarily strengthen the reasoning process of LLMs. To alleviate this, in addition to the aforementioned training, we collect feedback from LLMs and further optimize the extractor through reinforcement learning.
4.2.1. Feedback of LLM Collecting
In this subsection, we collect the feedback of the LLM on knowledge graph reasoning, and the feedback is further utilized to optimize the in-context triple extractor.
First, we sample the in-context learning data based on the current extractor models , where can be calculated by Equation (3). Then, we initially concatenate the query triple and the candidate tail entities (in order to simplify the entity linking of predicted entities by the LLMs and entities in knowledge graphs, for each query triple and corresponding in-context triples , the entities contained in triples of and entities which are connected with in m hops are collected as candidate tail entities. This set of entities is denoted by ) as a prediction prompt (the Top-N prediction prompt is to enable the LLM to predict the N tail entities sorted by the probabilities. The prompt can be formulated as: “Given the query triple , please predict the top n tail entities by probabilities in descending order from the candidates { }. Below are triples that might be helpful for answering this question { }. Then, the is:”.), and the predicted entities can be obtained by the LLM. We denote the probability of the ground truth tail entity by .
After that, we incorporate the in-context triples into the prompt for LLM reasoning, and the probability of generating gold standard tail entities is represented as . If , it is deemed as incorporating the in-context triples which are helpful for the reasoning of LLMs; thus, the are used as rewards:
where denotes the LLM, and represent the probability distributions of the LLM outputting the gold standard answer when the prompt does not contain the in-context triples and when it contains the in-context triples, respectively. As a result, we utilize the difference between these two probabilities, denoted as , as the reward to further optimize the in-context triple extractor.
4.2.2. Reinforcement Learning with LLM’s Feedback
Based on the feedback of LLMs, the expected reward of LLM can be formulated by:
where is the reward for the sampled in-context triples . If the reward is large, it indicates that the sampled in-context triple could enhance the LLM to generate the correct answer, so the sampled in-context triple should be encouraged.
By utilizing the policy gradient, the extractor could be optimized by:
It encourages the extractor to explore more in-context triples that yield higher rewards.
4.3. In-Context Learning and Reasoning
After obtaining the in-context triple extractor, here, we leverage the extractor and LLM to conduct the knowledge graph reasoning. Given a query triple , the necessary in-context triples can be obtained by the extractor, and the candidate tail entities can be retrieved. Then, the contexts above are used to construct the prompt. Finally, the prompt is put into the LLM and the predicted tail entities can be generated by the LLM. This procedure can be formally represented by:
where is the set of predicted tail entities sorted by the probabilities.
5. Experimental Setup
This section mainly introduces the datasets used in the experiments, the compared baseline methods, the evaluation metrics, and the experimental settings.
5.1. Datasets
In the experiments, we utilize five different knowledge graphs to evaluate the proposed reasoning method:
- WN18RR [38], obtained from the knowledge graph WordNet [39], with the reverse relations removed;
- FB15k [16], a subset of the universal knowledge graph Freebase [40];
- FB15k-237 [41], derived from FB15k, and some reverse relations are deleted.
- YAGO3-10-dr [42], derieved from YAGO3-10 [38] with the reciprocal relations removed.
- Wikidata5m [43], derieved from Wikidata [44]. The scale is much larger than for the previous four datasets.
The statistics for the datasets are shown in Table 1, where “#entity” and “#relation” represent the numbers of entities and relations, respectively. “#train”, “#valid”, and “#test” denote the number of triples in the training set, validation set, and test set for each dataset, respectively.

Table 1.
The statistics for the five knowledge graphs.
5.2. Baseline Methods
In the experiments, we employ seven methods for comparison, and these methods can be categorized into the following three types:
- Distributed representation-based methods. TransE [16] is a translation-based distributed representation learning method, and RotatE [21] is a complex vector space-based method which can better model the complex relations;
- Logical rule-based methods. We use two representative models: AMIE [24] is one of the representative logical rule learning methods, and AnyBURL [27] improves the process of logical rule learning by extension to large-scale datasets;
- Pre-trained language model- and large language model-based methods. The models KG-BERT [28] and KGT5 [30] are pre-trained language model-based reasoning methods. is the implementation version of the one-shot in-context learning of the model AutoKG [34] on the large language model GPT3.5.
5.3. Evaluation Metrics
In the experiments, we utilize the mean reciprocal rank (MRR) and Hits@n [16] as metrics to evaluate the results. Specifically, the reasoning results of the proposed method are multiple entities sorted in descending order of probabilities, so the metric Hits@n means the proportion of gold standard entities in the top n of the predicted results. MRR measures the average of the reciprocal ranks of all the testing data. These methods are widely used in various knowledge graph reasoning studies [42,45].
5.4. Experimental Settings
In the procedure of logical rule mining, we utilize the model AnyBURL [27] to mine the logical rules on the given knowledge graph . The maximum number of in-context triples M is set to 5. During the process of logical rule learning, the parameters of AnyBURL are configured to be identical to the paper [27]. The in-context triple extractor adopts the generative model Transformer [46,47], the dimension d is set to 512, and the batch size is 4096. The iterations of the layers in the encoder and decoder are set to 6. The other parameters of are the same as in [48]. When collecting the candidate tail entities , the number of hops m is set to 4. In the in-context learning and reasoning procedure, we utilize the large language model gpt-3.5-turbo. The temperature is set to 0.8, and the maximum number of tokens is 1024. The experiments are conducted with Nvidia P100 GPUs.
6. Experimental Results and Discussion
In this section, the performance of the proposed method and the baselines are evaluated on five datasets. The results are compared and analyzed in detail.
6.1. Comparison with Baselines
In this section, the reasoning results of the baselines and the proposed method on five datasets are compared and analyzed. The main results are shown in Table 2 and Table 3 (in Table 2 and Table 3, the results of rows 1 to 3 are quoted from [42]. The results of rows 4 to 6 are obtained from the original papers [27,28,30]. The results of rows 7 and 8 are obtained by our implementation) and the best results are marked in bold.
Table 2.
Performance of baselines and proposed model on WN18RR, FB15k, and FB15k-237.
Table 3.
Performance of baselines and proposed model on YAGO3-10-dr and Wikidata5m.
In Table 2 and Table 3, the results in rows 1–2 are obtained by distributed representation learning models, and the rows 3–4 are the performance of the logical rules learning methods. Rows 5–7 display the performance of the pre-trained language models and the large language models. The results in row 8 are obtained by our proposed method.
- Comparing the results in rows 1–4 (traditional methods) and rows 5–8 (pre-trained language model- and large language model-based methods) in two tables, among 15 metrics, the 10 best results are obtained by the language model-based methods. These results demonstrate that employing a large language model can enhance the performance of knowledge graph reasoning. One reason could be that compared to reasoning based on limited knowledge graph triples, pre-trained language models contain more extensive knowledge, which is more conducive to completing the reasoning process.
- Considering the results in rows 5–6 and rows 7–8 of the two tables, most of the performances in rows 7–8 are better than rows 5–6. The reason may be that the methods and RuleLLM employ in-context learning in reasoning, which can help LLMs to comprehend the given reasoning task and further improve the reasoning performance. These results validate the importance and effectiveness of in-context learning for LLMs on reasoning.
- Our proposed method performs the best on three datasets (WN18RR, FB15k-237, and Wikidata5m). Compared with traditional reasoning methods, the greatest improvement is 0.147 on Hits@10 for FB15k-237 (compared with the model AnyBURL). These results demonstrate the effectiveness of our proposed method. One reason may be that the proposed rule-and-reinforce in-context triple selection method is able to extract better in-context examples with respect to the specific reasoning task, providing more helpful factual evidence for reasoning.
Although the experimental results show that the proposed method can achieve certain improvements, there are still several limitations: (1) First, the reasoning results entirely depend on the output of LLMs, which suffer from hallucination issues. Therefore, even if the in-context triples are correct, the reasoning results may still be wrong. This is one of the limitations of the proposed method. In the future, we should focus on retrieving more accurate in-context triples on the one hand, and processing the outputs of the LLMs on the other hand, to further improve the quality of the reasoning results. (2) In addition, in this method, one of the important bases for exploring the in-context triples are the logical rules, which are mainly obtained through probabilistic methods by analyzing the frequent patterns. In practical applications, the logical rules used are not always appropriate for the given reasoning task. This is another limitation of the proposed method. Therefore, considering more reasoning factors to improve the accuracy of extracting in-context triples is also one of the directions that is worth further investigation.
6.2. Ablation Study
In the proposed model, we utilize in-context learning on LLMs for knowledge graph reasoning. The in-context triples are extracted by the extractor, which is trained by the logical rule-guided supervisory data as well as the reasoning feedback of LLMs. So, in this section, we study the performance when different in-context triples are incorporated on the validation sets of WN18RR and FB15k-237. The results are displayed in Table 4.
Table 4.
Ablation study of proposed method.
In Table 4, row 1 displays the results when only the query triple is fed into the LLMs for reasoning. The method of row 2 incorporates the triples which are directly connected to the query entity, but the in-context query may not necessarily be effective for the reasoning of a given query task. In row 3, the in-context triples are obtained by the extractor, which is trained by the logical rule-guided supervision data. Row 4 shows the performance when both the logical rule-guided triples and the LLM’s feedback are all used to train the extractor.
Comparing the results of rows 1 and 2, all the results of rows 3 and 4 are better than those of rows 1 and 2. These results confirm that refining in-context triples into the prompt can enhance the performance of knowledge graph reasoning. When the in-context triples are obtained by the extractor which is trained by both the logical rules-guided triples and the LLM’s feedback (row 4), we can obtain the best performance. This performance indicates that the in-context triples obtained based only on the logical rules may not always be useful for LLM reasoning. Therefore, it is necessary to further optimize the extractor using feedback from the LLMs on top of the logical rules, so that it can extract triples that are more suitable for LLM reasoning. Comparing the results in row 4 and row 1, the greatest improvement is 0.317 on Hits@1 for WN18RR. These results demonstrate the effectiveness of our proposed method.
6.3. Performance on Entities with Different Frequencies
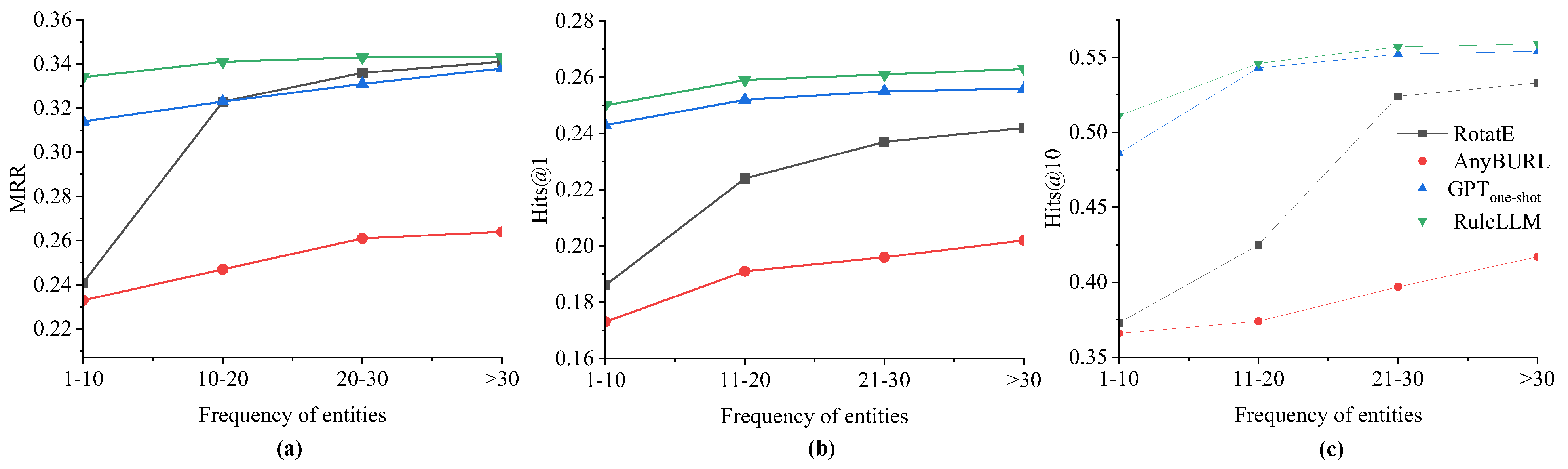
Considering the long tail distribution of entities in the knowledge graphs [7], in this experiment, we divide the data based on the frequency of entities and observe the performance of the proposed method in reasoning. Specifically, the validation set of FB15k-237 is separated into four subsets according to the frequencies of the entities: 1–10, 10–20, 20–30, and >30. As the quantities of the four subsets are different, we randomly sample 500 query triples from each subset. The reasoning results are depicted in Figure 3.
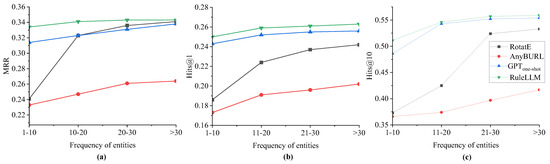
Figure 3.
Performance on entities with different frequencies, including (a) MRR, (b) Hits@1, and (c) Hits@10.
Figure 3 depicts the reasoning results on query triples with different entity frequencies. The x-axis of each sub-figure represents different frequencies of entity, and the y-axes denote the MRR (Figure 3a), Hits@1 (Figure 3b), and Hits@10 (Figure 3c), respectively. We can conclude that the performance of the traditional reasoning methods (RotatE and AnyBURL) is greatly affected by the frequency of entities. Only when the frequency of entities is high can better results be achieved (only when the frequency of entities is larger than 20 are the results of RotatE slightly better than those of on MRR in Figure 3a). One reason could be that the traditional data-driven models perform better on entities with higher frequencies. In contrast, our model performs well across varying frequencies with the best performance occurring at the lowest ones.
6.4. Performance of Methods with Different Number of in-Context Triples
Previous experiments have demonstrated that in-context triples retrieved by the proposed method can enhance the reasoning of LLMs. In this experiment, we discuss the performance when introducing different numbers of in-context triples. The experiments are conducted on the validation set of FB15k-237. The numbers of in-context triples are set to 1, 3, 5, 7, and 9, respectively. The results are depicted in Figure 4.
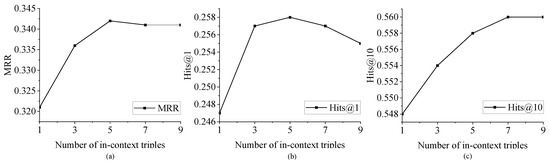
Figure 4.
Performance of methods with different number of in-context triples, including (a) MRR, (b) Hits@1, and (c) Hits@10.
Figure 4 demonstrates the MRR (Figure 4a), Hits@1 (Figure 4b), and Hits@10 (Figure 4c) of the reasoning results when varying the number of in-context triples. It can be observed that as the number of in-context triples increases from 1 to 5, the reasoning performance gradually improves. However, as the number continues to grow beyond 5, there is a slight decline in the reasoning results. This phenomenon may be attributed to the fact that when the number of in-context triples becomes larger, more noise may be introduced into the reasoning and consequently deteriorate the results. Taking the query triple in Figure 1 as an example, when the number of in-context triples are set to 5, the extracted in-context triples are (Eric Allin Cornell, works at, University of Colorado Boulder), (University of Colorado Boulder, is located in, Colorado), (Eric Allin Cornell, was born in, Palo Alto), (Palo Alto, is located in, California), (Eric Allin Cornell, graduated from, Massachusetts Institute of Technology), these triples are enough to provide necessary clues for reasoning. If the number is set to 9, four more triples (Eric Allin Cornell, has won prize, King Faisal International Prize), (Eric Allin Cornell, has friend, Wolfgang Ketterle), (Wolfgang Ketterle, nationality, Germany), (Wolfgang Ketterle, graduated from, Heidelberg University) are extracted, and it is obvious that they are not helpful for reasoning. In summary, the optimal performance is achieved when the number of in-context triples is set to 5.
6.5. Manual Evaluation of in-Context Triples by Different Methods
In order to further evaluate whether the in-context triples retrieved by the proposed method are more effective for reasoning, in this experiment, we randomly select 200 query triples from the test set of FB15k-237, and invite experts to evaluate the effectiveness of the extracted triples for reasoning. Specifically, five experts in the field of natural language processing are invited and are required to score the effectiveness of the extracted in-context triples for reasoning based on the corresponding query triple, with a scoring range of 0–10, where a higher score represents higher effectiveness. Furthermore, for the convenience of comparison, we also utilize the triples connected to the query entities and ask the experts to score them as well. Table 5 shows an example. It displays the scores given by five experts on the in-context triples extracted by three different methods.
Table 5.
An example of manual scoring. The query triple is (Eric Allin Cornell, lives in country, ? ), then the in-context triples extracted by three different methods are displayed and scored by five experts manually.
In Table 5, the query triple is (Eric Allin Cornell, lives in country, ?), and the in-context triples extracted by the different methods are scored manually. Considering the in-context triples in row 1, we can see that all the five triples cannot help for the reasoning of the given query. Then, considering the in-context triples in row 3, the triples about the work place can provide useful clues for the reasoning. As a consequence, the scores in row 1 are quite low, and the scores in the last row are the highest.
The statistics for the overall scores are shown in Table 6.
Table 6.
Scores of manual evaluations for in-context triples by different methods.
Table 6 shows the average score of each expert for the effectiveness of the in-context triples extracted by different methods. “Ex. 1” is an abbreviation of “Expert 1”, and the “average” in the last column is the average score of the former five columns. In the first row, the triples which are directly connected by the query entities are retrieved as in-context triples. In the second row, the in-context triples are obtained by the extractor, which is trained only by logical rules-guided triples. In the last row, the in-context triples are retrieved by our proposed method. We can see that the average scores of rows 2 and 3 are higher than those of row 1; these results demonstrate the effectiveness of refining the in-context triples. Finally, the scores of row 3 are the best. The results demonstrate that our proposed extractor, which is trained by both logical rules and feedback of LLMs, can extract more useful in-context triples for each specific reasoning task.
7. Conclusions and Future Work
We consider the problem that existing LLM-based knowledge graph reasoning methods extract the in-context triples only through fixable metrics, such as triples surrounding the query entities, or triples contain the query relations. These methods cannot make full use of the triples of knowledge graphs, resulting in difficulties in ensuring the effectiveness of knowledge graph reasoning. To alleviate this problem, in this paper, a rule-and-reinforce in-context triple extraction method is proposed to enhance the in-context learning of LLMs for KG reasoning. Specifically, the encoder-decoder structure-based extractor is trained by the triples which support the reasoning of the logical rules. Furthermore, the LLM’s feedback is also collected and is formulated as rewards to optimize the in-context triple extractor. Finally, given a query triple, the extractor can generate the necessary in-context triples to enhance the reasoning of the LLMs. The proposed method and its experimental results demonstrate that both logical rules and the feedback of LLMs are effective for in-context triples extraction. Furthermore, the extracted in-context triples obtained by the proposed method can improve the effectiveness of knowledge graph reasoning.
In this study, we mainly consider the logical rules which can be represented by multiple hops on KGs. However, in practical applications, there exist many more complex types of KG reasoning. For example, the reasoning query “who is the person who has both starred in the movie ‘New Police Story’ and directed the movie ‘On the Run’?” introduces a logical conjunction while reasoning. So in the future, we will expand the proposed method to cover more types of complex reasoning.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in [16,38,41,42,43].
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Examples of the Logical Rules-Guided in-Context Triples Retrieval
In this appendix, some examples are given to explain the details of the parts: logical rules-guided in-context triples retrieval.
The aim of this part is to construct training data to pre-train the in-context triple extractor. Assuming that a triple is sampled from the knowledge graph :
(Zuckerberg, nationality, USA)
The logical rules about the relation “nationality” can be learnt from the knowledge graph by existing logical rule learning models:
- (x, nationality, y)←(x, works in, z)∧(z, located in state, w)∧(w, state in country, y)
- (x, nationality, y)←(x, born in, z)∧(z, located in state, w)∧(w, state in country, y)
Then, we can extract triples which support each rule from the knowledge graph :
- {(Zuckerberg, works in, Facebook), (Facebook, located in state, California), (California, state in country, USA)}
- {(Zuckerberg, born in, New York City), (New York City, located in state, New York State), (New York State, state in country, USA)}
Thus, we can obtain the set of in-context triples through combining the extracted triples above:
{(Zuckerberg, born in, New York City),
(New York City, located in state, New York State),
(New York State, state in country, USA)
(Zuckerberg, works in, Facebook),
(Facebook, located in state, California) }
Finally, training data can be constructed which mainly contain the in-context triples with the corresponding query triple.
Appendix B. Top-N Prediction Prompt
As mentioned in Section 4.2, the top-N prediction prompt is constructed to make the LLM predict N tail entities sorted by the probabilities. The process is formally represented by:
Here, we use an example to explain this process. Assuming the given query triple is is:
(Eric Allin Cornell, lives in country, ?)
Then, the corresponding in-context triples extracted by the proposed method are as follows:
(Eric Allin Cornell, works at, University of Colorado Boulder),
(University of Colorado Boulder, is located in, Colorado),
(Eric Allin Cornell, was born in, Palo Alto)
(Palo Alto, is located in, California)
(Eric Allin Cornell, graduated from, Massachusetts Institute of Technology)
Besides that, the retrieved set of candidate tail entities is:
{Germany, Stanford University, Denton, Colorado,
Sweden, California, USA, University of California, physics,
scientist, New York City, Benjamin Franklin Medal}.
Based on the query triple, in-context triples, and the set of candidate tail entities, we can construct the prompt as:
“Given the triple (Eric Allin Cornell, lives in country, [mask]), please predict the top 10 tail entities [mask] by probabilities in descending order from the candidates {Germany, Stanford University, Denton, Colorado, Sweden, California, USA, University of California, physics, scientist, New York City, Benjamin Franklin Medal}. Below are triples that might be helpful for answer this question {(Eric Allin Cornell, works at, University of Colorado Boulder), (University of Colorado Boulder, is located in, Colorado), (Eric Allin Cornell, was born in, Palo Alto), (Palo Alto, is located in, California), (Eric Allin Cornell, graduated from, Massachusetts Institute of Technology)}. Then, the [mask] is:”
The LLM takes the prompt above as input, and conducts the reasoning through in-context learning. Finally, the output of the LLM are the predicted tail entities in the candidate tail entity set which are sorted by the probabilities in descending order. For example:
“USA, Colorado, California, Germany, Denton, Sweden, New York City, Stanford University, University of California, physics, scientist, Benjamin Franklin Medal.”
Among a series of entities output by LLM, the entity USA ranks the first, indicating that the LLM considers USA as the most likely tail entity for this query.
References
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Ren, Z.; Zhao, Y.; Zong, C. Towards Informative Open-ended Text Generation with Dynamic Knowledge Triples. In Proceedings of the Empirical Methods in Natural Language Processing 2023, Singapore, 6–10 December 2023; pp. 3189–3203. [Google Scholar]
- Wang, S.; Dang, D. Robust cross-lingual knowledge base question answering via knowledge distillation. Data Technol. Appl. 2021, 55, 661–681. [Google Scholar] [CrossRef]
- Zhao, Y.; Xiang, L.; Zhu, J.; Zhang, J.; Zhou, Y.; Zong, C. Knowledge graph enhanced neural machine translation via multi-task learning on sub-entity granularity. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 4495–4505. [Google Scholar]
- Zhao, Y.; Zhang, J.; Zhou, Y.; Zong, C. Knowledge graphs enhanced neural machine translation. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4039–4045. [Google Scholar]
- Zhang, W.; Chen, J.; Li, J.; Xu, Z.; Pan, J.Z.; Chen, H. Knowledge graph reasoning with logics and embeddings: Survey and perspective. arXiv 2022, arXiv:2202.07412. [Google Scholar]
- Xue, B.; Zou, L. Knowledge graph quality management: A comprehensive survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 4969–4988. [Google Scholar] [CrossRef]
- Shen, T.; Zhang, F.; Cheng, J. A comprehensive overview of knowledge graph completion. Knowl. Based Syst. 2022, 255, 109597–109661. [Google Scholar] [CrossRef]
- Jia, N.; Yao, C. A Brief Survey on Deep Learning-Based Temporal Knowledge Graph Completion. Appl. Sci. 2024, 14, 8871. [Google Scholar] [CrossRef]
- Liang, Y.; Zhang, Y.; Ma, C.; Zhang, Z.; Zhao, Y.; Xiang, L.; Zong, C.; Zhou, Y. Document Image Machine Translation with Dynamic Multi-pre-trained Models Assembling. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Mexico City, Mexico, 16–21 June 2024; pp. 7077–7088. [Google Scholar]
- Krawczyk, N.; Probierz, B.; Kozak, J. Towards AI-Generated Essay Classification Using Numerical Text Representation. Appl. Sci. 2024, 14, 9795. [Google Scholar] [CrossRef]
- Iaroshev, I.; Pillai, R.; Vaglietti, L.; Hanne, T. Evaluating Retrieval-Augmented Generation Models for Financial Report Question and Answering. Appl. Sci. 2024, 14, 9318. [Google Scholar] [CrossRef]
- Hu, L.; Liu, Z.; Zhao, Z.; Hou, L.; Nie, L.; Li, J. A survey of knowledge enhanced pre-trained language models. IEEE Trans. Knowl. Data Eng. 2023, 36, 1413–1430. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, W.; Saxon, M.; Steyvers, M.; Wang, W.Y. Large language models are latent variable models: Explaining and finding good demonstrations for in-context learning. In Advances in Neural Information Processing Systems, Proceedings of the Thirty-seventh Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Curran Associates, Inc.: Red Hook, New York, USA, 2024; Volume 36. [Google Scholar]
- Zhou, D.; Schärli, N.; Hou, L.; Wei, J.; Scales, N.; Wang, X.; Schuurmans, D.; Cui, C.; Bousquet, O.; Le, Q.V.; et al. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems, Proceedings of the 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, Nevada, 5–8 December 2013; Curran Associates, Inc.: Red Hook, New York, USA, 2013; Volume 26, p. 26. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Galárraga, L.A.; Teflioudi, C.; Hose, K.; Suchanek, F. AMIE: Association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 413–422. [Google Scholar]
- Galárraga, L.; Teflioudi, C.; Hose, K.; Suchanek, F.M. Fast rule mining in ontological knowledge bases with AMIE+. VLDB J. 2015, 24, 707–730. [Google Scholar] [CrossRef]
- Lajus, J.; Galárraga, L.; Suchanek, F. Fast and exact rule mining with AMIE 3. In The Semantic Web: 17th International Conference, ESWC 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 36–52. [Google Scholar]
- Omran, P.G.; Wang, K.; Wang, Z. An embedding-based approach to rule learning in knowledge graphs. IEEE Trans. Knowl. Data Eng. 2019, 33, 1348–1359. [Google Scholar] [CrossRef]
- Yang, F.; Yang, Z.; Cohen, W.W. Differentiable learning of logical rules for knowledge base reasoning. In Advances in Neural Information Processing Systems, Proceedings of the Thirty-First Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, New York, USA, 2017; Volume 30. [Google Scholar]
- Meilicke, C.; Chekol, M.W.; Ruffinelli, D.; Stuckenschmidt, H. Anytime bottom-up rule learning for knowledge graph completion. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3137–3143. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Saxena, A.; Kochsiek, A.; Gemulla, R. Sequence-to-Sequence Knowledge Graph Completion and Question Answering. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 2814–2828. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Xie, X.; Zhang, N.; Li, Z.; Deng, S.; Chen, H.; Xiong, F.; Chen, M.; Chen, H. From discrimination to generation: Knowledge graph completion with generative transformer. In Proceedings of the Companion Proceedings of the Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 162–165. [Google Scholar]
- Lewis, M. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Zhu, Y.; Wang, X.; Chen, J.; Qiao, S.; Ou, Y.; Yao, Y.; Deng, S.; Chen, H.; Zhang, N. Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities. World Wide Web 2024, 27, 58. [Google Scholar] [CrossRef]
- Baek, J.; Aji, A.F.; Saffari, A. Knowledge-augmented language model prompting for zero-shot knowledge graph question answering. arXiv 2023, arXiv:2306.04136. [Google Scholar]
- Zhang, Y.; Chen, Z.; Zhang, W.; Chen, H. Making Large Language Models Perform Better in Knowledge Graph Completion. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024. [Google Scholar]
- Wei, Y.; Huang, Q.; Zhang, Y.; Kwok, J. KICGPT: Large Language Model with Knowledge in Context for Knowledge Graph Completion. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, Beijing, China, 26–31 July 2015; pp. 57–66. [Google Scholar]
- Akrami, F.; Saeef, M.S.; Zhang, Q.; Hu, W.; Li, C. Realistic re-evaluation of knowledge graph completion methods: An experimental study. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1995–2010. [Google Scholar]
- Wang, X.; Gao, T.; Zhu, Z.; Zhang, Z.; Liu, Z.; Li, J.; Tang, J. KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. Trans. Assoc. Comput. Linguist. 2021, 9, 176–194. [Google Scholar] [CrossRef]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Wang, S.; Li, S.; Zou, L. Analogy-Triple Enhanced Fine-Grained Transformer for Sparse Knowledge Graph Completion. In Proceedings of the International Conference on Database Systems for Advanced Applications, Tianjin, China, 17–20 April 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 742–757. [Google Scholar]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhao, Y.; Zhang, J.; Zong, C. Transformer: A general framework from machine translation to others. Mach. Intell. Res. 2023, 20, 514–538. [Google Scholar] [CrossRef]
- Tan, Z.; Zhang, J.; Huang, X.; Chen, G.; Wang, S.; Sun, M.; Luan, H.; Liu, Y. THUMT: An open-source toolkit for neural machine translation. In Proceedings of the 14th Conference of the Association for Machine Translation in the Americas (Volume 1: Research Track), Online, 6–9 October 2020; pp. 116–122. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).