Abstract
The evaluation of creative writing has long been a complex and subjective process, made even more intriguing by the rise of advanced Artificial Intelligence (AI) tools like Large Language Models (LLMs). This study evaluates the potential of LLMs as reliable and consistent evaluators of creative texts, directly comparing their performance with traditional human evaluations. The analysis focuses on key creative criteria, including fluency, flexibility, elaboration, originality, usefulness, and specific creativity strategies. Results demonstrate that LLMs provide consistent and objective evaluations, achieving higher Inter-Annotator Agreement (IAA) compared with human evaluators. However, LLMs face limitations in recognizing nuanced, culturally specific, and context-dependent aspects of creativity. Conversely, human evaluators, despite lower consistency and higher subjectivity, exhibit strengths in capturing deeper contextual insights. These findings highlight the need for the further refinement of LLMs to address the complexities of creative writing evaluation.
1. Introduction
The rapid advancement of Artificial Intelligence (AI) has catalyzed transformative advancements across numerous domains, including the generation and evaluation of texts. This technological paradigm shift includes Large Language Models (LLMs) such as ChatGPT, Gemini, and Llama, which have shown remarkable capabilities in generating human-like texts by utilizing extensive datasets and advanced algorithms [1,2,3,4]. Closed-source models like GPT-4 and Gemini consistently outperform their open-source models, such as Llama, particularly in terms of linguistic accuracy, complexity of generated content, and consistency in evaluation [5].
Closed-source models benefit from greater resources and larger training datasets, enabling them to generate sophisticated, contextually accurate, and nuanced text [5,6]. For example, GPT-4 consistently outperforms GPT-3.5 in producing high-quality, cohesive text across various tasks [7,8]. This paper focuses on the potential of LLMs, particularly GPT-4, to evaluate creative writing, a task traditionally handled by humans. Human evaluations are often inconsistent and subjective, posing challenges for reliable assessments [9].
Traditional automatic metrics like BLEU, ROUGE, and METEOR have been widely used to evaluate language tasks. However, these metrics perform poorly in assessing creative and open-ended writing because they cannot capture subjective and nuanced elements [10,11,12]. To overcome these limitations, new evaluation frameworks, such as MT-Bench, PandaLM, AlpacaEval, and DeepEval, have been introduced [13]. These methods aim to evaluate subjective and creative aspects of LLM performance in more detail.
Previous studies primarily utilized Large language Models (LLMs) to evaluate the linguistic quality and logical coherence of AI-generated content [14]. However, recent developments suggest that AI is now capable of evaluating the intricate details of creativity that were previously considered exclusive to human judgment [15,16]. This advancement raises an important question: can LLMs function as effective evaluators in creative writing tasks?
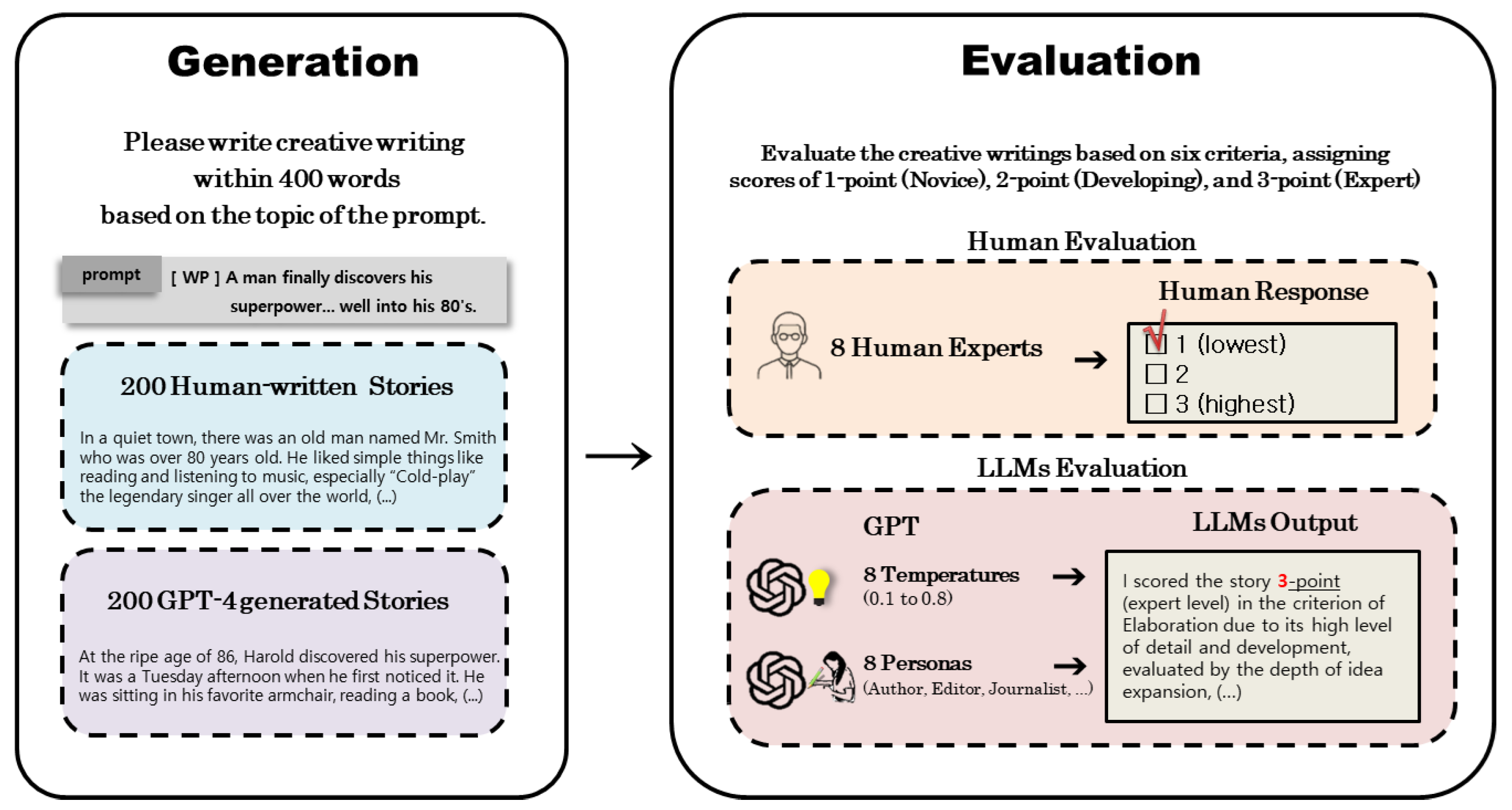
To address this, we compared texts written by humans and those generated by GPT-4 by using six creativity criteria: fluency, flexibility, originality, elaboration, usefulness, and specific creative strategies [17]. A total of 200 human-written texts and 200 GPT-4-generated texts were evaluated by eight human experts and LLMs configured with varying temperature settings and personas, as seen in Figure 1. This approach allowed for a comprehensive comparison of the consistency and performance of human and AI evaluations.

Figure 1.
The figure illustrates the evaluation of creative writing generated by humans and GPT-4. Human experts and GPT models (varied in temperatures and personas) assess texts on a 3-point scale across six creativity benchmarks: fluency, flexibility, originality, elaboration, usefulness, and creative strategies.
However, evaluating creative writing presents significant challenges, particularly due to the inherent ambiguity of creativity as a concept. Unlike objective linguistic measures such as grammaticality, coherence, and relevance, creativity lacks a universal standard, and evaluators may have different subjective preferences and interpretative frameworks. This variability is further influenced by human evaluators’ background and personal values, leading to inconsistencies even among experienced professionals in literary assessment. Differences in assessment criteria, biases, and varying levels of expertise further complicate reliability, making it difficult to establish standardized evaluation methods. These limitations raise concerns about the reproducibility of human-based assessments and highlight the need for alternative or complementary approaches.
Given these challenges in creative writing evaluation, we examine the differences between human and AI assessments and investigate whether LLMs can provide a more consistent and systematic approach. By systematically comparing human-written and AI-generated texts, this work explores whether LLMs can address the challenges of creative writing assessment. Large Language Models (LLMs) like GPT-4o and GPT-3.5 Turbo demonstrate consistent and reliable evaluations, with high Inter-Annotator Agreement (IAA), offering a level of objectivity often lacking in human assessment. However, these models also exhibit notable limitations, such as difficulty detecting critical narrative flaws, including incomplete or unresolved storylines. These findings emphasize the need for a hybrid evaluation approach that integrates the consistency of LLMs with the nuanced judgment of human evaluators. Our findings provide valuable insights into how LLMs can reshape the creative writing evaluation process, paving the way for improved AI-assisted evaluation systems that better address the complexities of human creativity.
2. Related Works
2.1. Advancements of Large Language Models (LLMs)
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) by leveraging the Transformer architecture. Early models like GPT-1 introduced coherent text generation through a combination of supervised and unsupervised learning [18]. BERT enhanced natural language understanding with bidirectional context modeling, employing Masked Language Modeling (MLM) and Next-Sentence Prediction (NSP) [19]. Subsequent models, like RoBERTa, refined BERT’s approach by using dynamic masking and optimizing training techniques, while ALBERT improved efficiency with parameter sharing and Sentence Order Prediction (SOP) [20,21].
Generative models also saw significant advancements. GPT-2 demonstrated the ability to generate coherent long-form text with 1.5 billion parameters, emphasizing sequential text generation using the Transformer decoder [22]. BART employed a denoising autoencoder structure, excelling at text generation, summarization, and translation tasks [23]. T5 unified NLP tasks into a Text-to-Text framework, enhancing transfer learning efficiency and achieving high performance across various benchmarks [24].
GPT-3 marked a milestone, with 175 billion parameters, showcasing improvements in zero-shot, one-shot, and few-shot learning capabilities [25]. GPT-3.5, optimized for conversational applications through Reinforcement Learning with Human Feedback (RLHF), demonstrated improved context handling and dialogue coherence [26]. GPT-4 further advanced the field by incorporating multimodal inputs, such as images, and excelling at processing complex dependencies, achieving superior performance on evaluation benchmarks [5,8].
2.2. Large Language Model (LLM) Evaluation
The evaluation of Large Language Models (LLMs) has progressed significantly, moving from human-based assessments to automated methodologies. Traditional metrics like BLEU, ROUGE, and METEOR were widely used to evaluate Natural Language Generation (NLG) by comparing machine-generated text with human references [10,11,12]. However, these metrics have limitations, such as failing to capture semantic meaning, overlooking fluency and coherence, and requiring reference outputs, which are costly to produce for new tasks. Furthermore, their correlation with human judgments is often weak, particularly for open-ended tasks, highlighting the need for more advanced evaluation methods [27].
Recent developments have introduced sophisticated frameworks that address these shortcomings. MT-Bench evaluates multiturn conversational abilities, while PandaLM and AlpacaEval offer fine-grained assessments of subjective elements using adversarial benchmarks [13]. GameEval incorporates gamified scenarios to test engagement, and PromptBench examines robustness to challenging prompts. These approaches aim to provide a more nuanced evaluation of LLM performance by considering elements beyond simple n-gram overlap, such as interaction and adaptability.
A notable advancement is the Deep Interaction-based Evaluation framework (DeepEval), which simulates real-world scenarios to assess LLM capabilities comprehensively. For tasks like creative writing, DeepEval requires models to generate and iteratively refine content over multiple rounds, capturing their ability to improve coherence and detail through interaction [13]. These outputs are then assessed by both human and AI judges, ensuring a balanced evaluation of performance. This approach provides a deeper understanding of LLM strengths and weaknesses, making it a promising method for evaluating their utility in complex tasks.
2.3. Types of Creativity Assessment
Creativity assessment methods provide systematic approaches to evaluating creative works by analyzing various aspects of creativity. Boden (1998) categorizes creativity into three types: combinational, exploratory, and transformational. Combinational creativity involves generating new combinations of familiar ideas, such as metaphors. Exploratory creativity explores structured conceptual spaces within existing styles. Transformational creativity alters the conceptual space itself, enabling the creation of entirely new ideas [28]. Dietrich (2004) adds a cognitive perspective, dividing creativity into deliberate and spontaneous modes. The deliberate mode relies on conscious, top-down processes involving the prefrontal cortex, while the spontaneous mode emerges from unconscious, bottom-up processes, often leading to sudden insights [29].
Mozaffari (2023) introduces a rubric assessing four key characteristics: image, characterization, voice, and story, evaluated across four achievement levels: excellent, good, average, and poor [30]. D’Souza (2019) identifies critical features for narrative writing, including meaning, relevance, reader immersion, development, and originality. Assessment methods such as the Consensual Assessment Technique (CAT), rubrics, peer assessments, and syntax-based scoring highlight the diverse tools available for evaluating creativity, each with strengths and limitations [31].
This paper employs an evaluation rubric developed by Shively et al. [17], integrating the criteria of fluency, flexibility, specificity, originality, usefulness, and creative strategies. These metrics, drawn from established creativity frameworks [32,33], allow for an objective comparison of human-written and AI-generated creative outputs. By applying these rigorous standards, the study aims to evaluate creativity comprehensively while addressing the strengths and weaknesses of both human and AI performance.
3. Experimental Design for Dataset
This chapter outlines the experimental design to evaluate the creativity levels in text outputs generated by humans and Large Language Models (LLMs). The methodologies employed in this experiment are inspired by previous studies and aim to ensure an accurate and systematic assessment of creativity in both human-written and AI-generated content [14,27]. Recognizing the importance of a comprehensive evaluation, this study utilizes a detailed and multidimensional framework to assess the creative outputs of human experts and LLMs. The process of constructing the dataset for this experiment involves two key elements: writing task (prompts, human writing interface and AI writing interface), and evaluation task (creativity criteria, human evaluation interface, and AI evaluation interface).
3.1. Configuration of Writing Task Data
3.1.1. Description of Prompts
Prompts are selected from the WritingPrompts dataset (https://www.kaggle.com/datasets/ratthachat/writing-prompts, accessed on 4 March 2024), focusing on themes that encourage creative exploration and expression. A total of 200 prompts from the dataset are randomly selected to ensure a diverse representation of themes and to account for variability in distribution. The various prompts (https://www.reddit.com/r/WritingPrompts/wiki/how_to_tag_prompts/, accessed on accessed on 4 March 2024) are categorized as follows:
- WP (Writing Prompt): Prompts that provide a scenario, idea, or situation intended to inspire writers to create a story or piece of writing based on it. No specific restrictions, allowing for a wide range of creative responses.
- SP (Simple Prompt): Prompts that are basic but limited to 100 characters in the title, encouraging concise and focused creative responses.
- EU (Established Universe): Prompts that encourage writers to expand upon an existing fictional universe, creating new stories, characters, or events within that established setting.
- CW (Constrained Writing): Prompts that impose specific constraints on the writing process, such as a strict word limit or adhering to a specific style.
- TT (Theme Thursday): Prompts that revolve around a specific theme, released on Thursdays, encouraging writers to explore that theme in their writing. These prompts are featured weekly and change every Thursday.
- PM (Prompt Me): Prompts where writers request others to write about a specific subject, helping to introduce new outcomes and perspectives.
- MP (Media Prompt): Prompts that use linked audio or visual media to inspire a piece of writing. This method encourages writers to draw inspiration from non-textual sources.
- IP (Image Prompt): Prompts that use an image as the inspiration for a story. Writers create a narrative based on the scene, characters, or mood depicted in the image.
- PI (Prompt Inspired): Prompts that are standalone responses to prompts that are at least three days old. These responses must include a link to the prompt that inspired the story and contain the story within the text area of the post itself.
3.1.2. Human Writing Interface
The participants consisted of 10 English educators. Each participant was required to write 20 stories on different topics selected from the WritingPrompts dataset, resulting in a total of 200 stories. Each story was written to be within 400 words. The participants completed their writings between January and March 2024, and appropriate compensation was provided to those who successfully completed all the required writing tasks.
The demographic information of the human writers is as follows: The human writers ranged in age from 27 to 42 years (M = 34.6) and comprised 3 males and 7 females, all of Asian ethnicity. Each held a master’s degree or higher in English literature and had a minimum of three years of experience in English education.
3.1.3. AI Writing Interface
GPT-4 is required to generate stories by using the same prompts and conditions as the human participants. Text generation is performed automatically by using OpenAI’s API. The prompts for GPT-4’s creative writing are as follows:
“A total of 200 prompts are provided for 200 topics. You are required to write a creative story on each topic. There are several types of writing prompts. If the prompt includes [WP], it means there are no restrictions to provide a creative idea that the writer can use to develop the story. For [CW], there are constraints such as using specific words or writing in a particular style. [EU] requires expanding an existing fictional world to create new stories, characters, and events. [TT] involves writing about a specific topic or focuses on certain styles of writing. [PM] focuses on creative writing with new outcomes, or perspectives. For [IP], the story should be based on an image. For prompts not included in these categories, generally, a creative text should be written. The story should be within 400 words, and the text outputs should end sentences with a period (.) and not with a comma (,). Read the instructions carefully and complete the task”.
3.2. Evaluation Method
3.2.1. Creativity Evaluation Criteria
The evaluation is carefully designed to assess six distinct aspects of creativity, as outlined in Shively’s (2018) study [17]. These criteria include fluency, flexibility, originality, elaboration, usefulness, and specific creative strategies [17]. Each criterion captures a unique aspect of creativity, thereby providing a comprehensive and structured assessment of creative content. The evaluation scale ranges from 1 to 3 points, corresponding to novice (1 point), developing (2 points), and expert (3 points) levels, respectively [17]. This systematic approach ensures an accurate and nuanced comparison of creative works, enabling extensive insights into the creative capabilities of both human-written and AI-generated texts. The six creativity criteria are as follows:
- Fluency: Novice writers consider a single idea (1 point), developing writers consider several ideas (2 points), and expert writers explore many ideas (3 points).
- Flexibility: Novice writers consider one type of idea (1 point), developing writers consider several types (2 points), and expert writers incorporate many types of ideas (3 points).
- Originality: Novice writers develop common or replicated ideas (1 point), developing writers create interesting but minimally innovative ideas (2 points), and expert writers generate unique ideas or significantly enhance existing ones (3 points).
- Elaboration: Novice writers add minimal details and improvements (1 point), developing writers add a few (2 points), and expert writers contribute many significant details and enhancements (3 points).
- Usefulness: Novice writers suggest ideas that might meet user needs under certain conditions (1 point), developing writers propose ideas that would meet user needs (2 points), and expert writers offer ideas that would significantly enhance the user’s life (3 points).
- Specific creativity strategies: Novice writers randomly select and implement a strategy without effectively leveraging it (1 point), developing writers select and implement a strategy while explaining its support for their creativity (2 points), and expert writers deliberately choose and thoroughly explain how a creative thinking strategy bolsters their creative output (3 points).
3.2.2. Human Evaluation Interface
The evaluation was conducted by eight experts who hold a master’s degree or higher in English literature. They used a Google form, which included detailed evaluation instructions and explanation of the six criteria. Each entry was rated on a scale of one to three points: three points for expert level, two points for development level, and one point for novice level, as shown in Figure 2. Between April and May in 2024, the experts evaluated 200 human-written texts and 200 GPT-4-generated texts, totaling 400 entries. Upon completion of the evaluation, the experts were compensated for their work. The expert evaluators were not informed about the origin of the texts, whether produced by humans or AI. This information was intentionally omitted from the survey to ensure unbiased assessment. This blind evaluation approach maintains the integrity of the comparative analysis and ensures objective assessments.

Figure 2.
Human evaluation form: The evaluation was conducted by using a Google Survey form.
The demographic information of the human evaluators is as follows: They ranged in age from 30 to 52 years (M = 41.3) and included 1 male and 7 females, all of Asian ethnicity. The group consisted of two Ph.D. graduates and six Master’s degree holders in English literature, with a minimum of five years of experience in English education.
3.2.3. AI Evaluation Interface
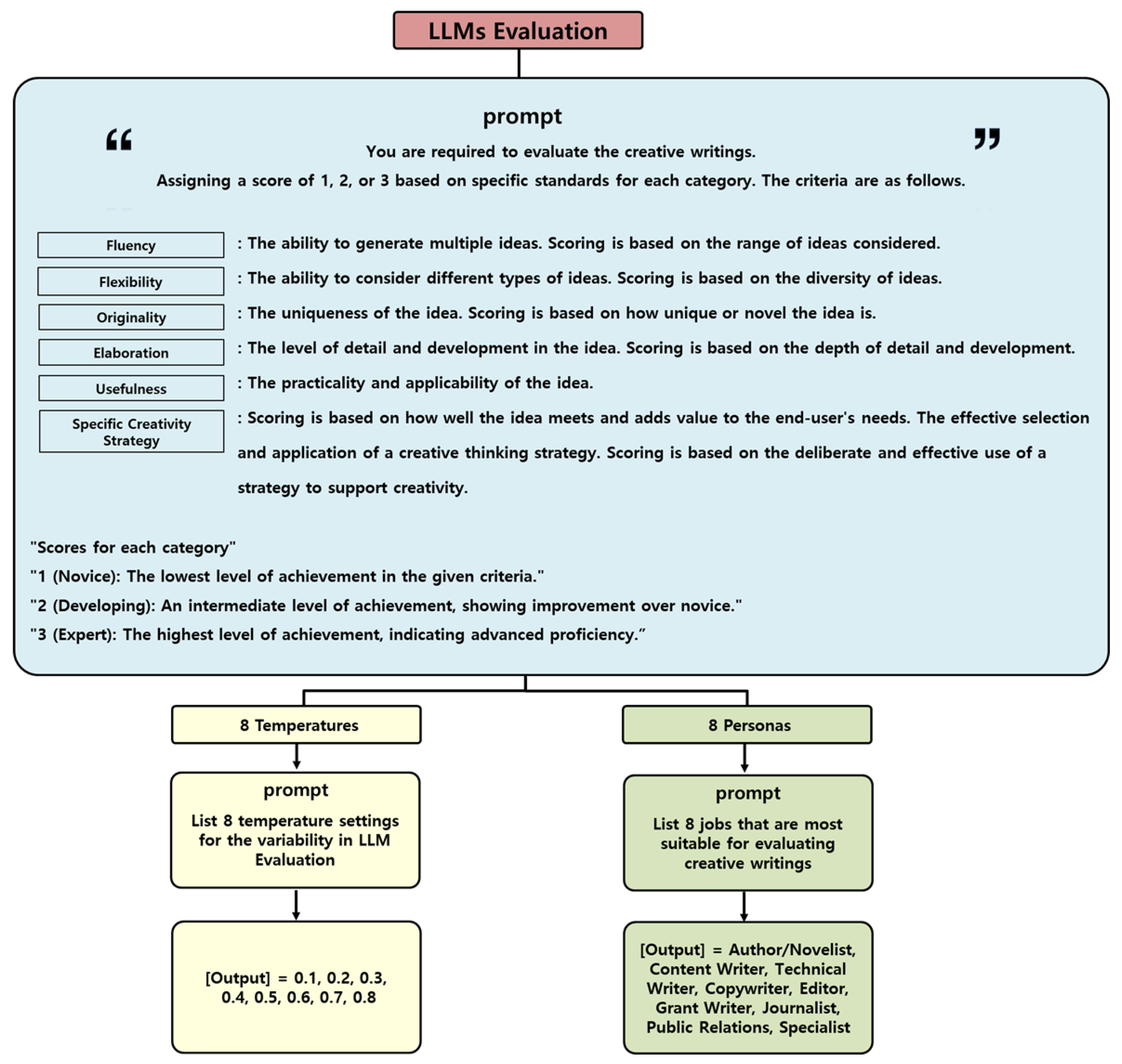
The evaluation framework assesses the creative writing texts by GPT-4o and GPT-3.5 Turbo by using two different settings: eight temperature settings and eight personas, as shown in Figure 3. The evaluations were conducted through OpenAI’s API, ensuring consistency in assessing the texts based on predefined parameters.
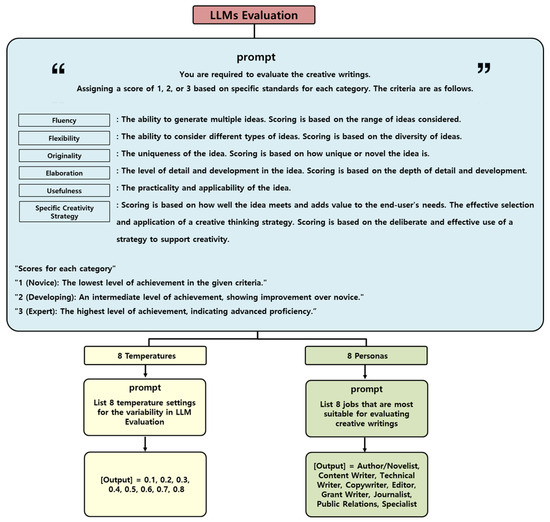
Figure 3.
The diagram outlines the LLM evaluation framework, scoring creative writing on six criteria (fluency, flexibility, originality, elaboration, usefulness, and specific creativity strategy) using a 3-point scale. Evaluations are conducted with 8 temperature settings (0.1 to 0.8) and 8 personas (Author, Editor, Journalist, etc.).
Temperature settings: The temperature settings are determined based on an inquiry to ChatGPT regarding the optimal range for varying randomness in the model’s output. Lower temperatures (closer to 0.1) make the model’s output more deterministic and repetitive, while higher temperatures (closer to 0.9) produce more creative and varied responses [34]. This range of temperature settings helps understand how different levels of creativity and variability affect the model’s performance. The specific temperature settings used are 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, and 0.8.
Persona settings: The eight personas were selected to ensure diverse evaluative perspectives on creative writing. These personas include Author/Novelist, Content Writer, Technical Writer, Copywriter, Editor, Grant Writer, Journalist, and Public Relations Specialist. Each role was chosen to represent a broad range of writing styles and contexts, providing comprehensive insights for evaluating creative writing effectively. To ensure diversity in evaluation approaches, we asked ChatGPT to suggest eight different personas that could serve as creative writing evaluators. Since different personas may approach evaluation with varying priorities, such as an editor focusing on grammatical correctness and a novelist emphasizing narrative depth, using multiple personas helps capture a wider range of assessment perspectives.
These temperature and personas settings ensure that the evaluation reflects a wide range of writing styles and contexts, highlighting the importance of varied conditions in assessing creativity. This systematic approach facilitates a comprehensive analysis from both human and AI perspectives. The evaluation encompasses five different evaluators: eight human evaluators, GPT-4o assessed across 8 different temperature settings, GPT-4o assessed across 8 different personas, GPT-3.5 Turbo assessed across 8 different temperature settings, and GPT-3.5 Turbo assessed across 8 different personas. This rigorous and varied evaluation system allows for a detailed and nuanced comparison of the creative outputs generated by humans and AI. By combining multiple evaluation dimensions and perspectives, this study provides a thorough assessment of the creative abilities of both human-written and AI-generated texts, resulting in a comprehensive and academically rigorous analysis.
4. Experiments
4.1. Metrics
The metrics used in this experiment include mean (m), standard deviation (SD), and Inter-Annotator Agreement (IAA) for each evaluated attribute. These measures provide a robust foundation for comparing human-produced texts with those generated by GPT-4, using various creativity criteria.
4.1.1. Mean
The mean is the average score for a given attribute across all evaluated texts, which is calculated as follows: N is the total number of texts, and represents the score of each text [35]. A high mean score indicates superior overall creativity, whereas a low mean score suggests the opposite. The mean () is given by
4.1.2. Standard Deviation
The standard deviation measures the dispersion or variability of the scores around the mean, which is calculated as follows: is the standard deviation, n is the total number of scores, is each text’s score, and is the average score for each text [36]. A low standard deviation implies that the scores are closely clustered around the mean, while a high standard deviation indicates a wide dispersion of scores. The standard deviation () is given by
4.1.3. Inter-Annotator Agreement
Inter-Annotator Agreement assesses the consistency of scores assigned by different evaluators. It is calculated by using Krippendorff’s alpha (), to measure the agreement among 8 annotators in each evaluation for this study. represents the observed disagreement, represents the expected disagreement, n is the number of evaluators, c is the index of the item, k is the number of categories, is the proportion between c and k, and represents the squared value of disagreement between c and k [37]. Inter-Annotator Agreement (IAA) ranges from 0 to 1. A higher IAA value denotes greater consensus among evaluators, while a lower value reflects lesser agreement. The formula is given by
4.2. Main Results
The quantitative analysis of the evaluation metrics for each criterion provides valuable insights into the comparative effectiveness of evaluations by human experts and LLMs (GPT-4o and GPT-3.5), as shown in Table 1 and Table 2. Also, statistical analyses and score distribution are provided in Appendix A, Appendix B and Appendix C.

Table 1.
Human-written stories: The table presents mean, standard deviation (SD), and Inter-Annotator Agreement (IAA) among eight annotators based on Krippendorff’s . The percentage (%) in the IAA column denotes the percentage of stories where all eight annotators fully agree on a rating. (T) means the different temperature settings, and (P) means the different persona settings.
Table 2.
GPT-4 generated stories: The table presents mean, standard deviation (SD), and Inter-Annotator Agreement (IAA) among eight annotators based on Krippendorff’s . The percentage (%) in the IAA column denotes the percentage of stories where all eight annotators fully agree on a rating. (T) means the different temperature settings, and (P) means the different persona settings.
In fluency, LLMs consistently achieved higher IAA and mean scores compared with human evaluators. Among the models, GPT-3.5 with persona-based evaluation demonstrated the highest consistency, achieving an IAA of 96% for both human-written and GPT-4-generated texts. These results emphasize the reliability of LLMs in assessing the smoothness and readability of creative writing.
In the evaluation of flexibility and originality, human evaluators exhibited significant variability, with extremely low agreement levels. For flexibility, human evaluators achieved an IAA of only 2%, while for originality, there was no agreement among human evaluators for human-written texts. In contrast, LLMs, particularly GPT-3.5, displayed consistent performance with significantly higher agreement levels and mean scores. This demonstrates the ability of these models to objectively evaluate adaptability and uniqueness in creative outputs.
Elaboration emerged as the strongest criterion for LLMs. GPT-4o with persona-based evaluation assigned perfect scores, with an average score of 3.00, to all GPT-4-generated texts. It also achieved complete agreement among evaluators, with an IAA of 100%. This highlights the ability of LLMs to effectively recognize detailed and well-structured ideas, surpassing human evaluators in consistency and agreement levels.
For the usefulness criterion, human evaluators tended to assign higher scores compared with LLMs, particularly for human-written texts. This difference is likely influenced by cognitive biases among human evaluators, such as attributing greater intent and practicality to human-created content. While LLMs displayed more consistent scoring patterns, their average scores in this criterion were generally lower than those assigned by human evaluators.
In the evaluation of specific creativity strategies, LLMs outperformed human evaluators in agreement levels. GPT-3.5 with persona-based evaluation demonstrated notable consistency, achieving an IAA of 60% for GPT-4-generated texts. However, human evaluators’ subjectivity often resulted in lower agreement levels, particularly for this nuanced and context-dependent criterion.
Overall, the results indicate that LLM evaluators consistently outperform human evaluators in all criteria, particularly in evaluation consistency. Elaboration emerged as the strongest criterion, with GPT-4o with persona-based configurations achieving perfect scores for all 200 GPT-4-generated stories, highlighting its ability to assess detailed and well-structured content effectively. In contrast, the usefulness criterion showed lower mean scores across both human-written and AI-generated texts.
4.2.1. Human Evaluation
The human evaluation of writings is inherently subjective and influenced by individual biases and perspectives [38]. The evaluation is conducted by eight educators, each holding a master’s degree or higher in the Department of English Language and Literature. The variability in scores underscores the diverse interpretations and expectations of the evaluators. This inherent subjectivity is further evidenced by the low Inter-Annotator Agreement (IAA) percentages across various metrics, such as 0% in flexibility, originality, and usefulness in both human-written and GPT-4-generated texts. The highest IAA value observed was 1.5% in the fluency criterion for GPT-4-generated texts. These low IAA values highlight the inconsistencies and biases that naturally arise in human evaluations, making it challenging to achieve uniformity and reliability in assessing creative writing.
Creative writing evaluation is more complex than general writing tasks because it involves subjective concepts like originality, innovation, and stylistic elaboration. Even though the evaluations followed standardized criteria, the evaluators had different opinions on what constitutes creativity and how it should be expressed. Some evaluators might prioritize originality, while others might focus on detailed elaboration or innovative ideas. This difference in priorities leads to inconsistent evaluations. While these diverse perspectives provide a broader understanding of creativity, they also expose the difficulty in achieving consistency among human evaluators.
In comparison to AI models, which evaluate writing by using standardized and consistent methods, human evaluators are influenced by subjective factors. For example, in the usefulness criterion, human evaluators assigned higher scores than LLMs. This discrepancy may be due to a cognitive bias known as the “human-made” bias, where human-created content is perceived as more intentional and effortful [38]. Such biases further illustrate the challenges of achieving objective and reliable assessments in human evaluation.
4.2.2. AI Evaluation
The evaluation scores for GPT-4o and GPT-3.5 Turbo showed clear differences, particularly when comparing their performance across temperature and persona settings. These configurations impacted the consistency of the models’ assessments. Experimenting across these configurations demonstrated how each setting influenced the models’ ability to evaluate creative writing accurately and consistently.
GPT-4o consistently achieved higher Inter-Annotator Agreement (IAA) scores than GPT-3.5 Turbo for human-written texts, except in the elaboration category. For AI-generated texts, GPT-4o outperformed GPT-3.5 Turbo in flexibility, elaboration, usefulness, and specific creativity strategies, making it the more consistent model overall. In contrast, GPT-3.5 Turbo scored higher on mean values for fluency, flexibility, originality, and specific creativity strategies for both human-written and GPT-4-generated texts. GPT-4o (T) showed slightly better performance than GPT-4o (P) across all criteria, highlighting the importance of temperature settings for consistent evaluations.
Notably, GPT-4o (P) awarded a perfect mean score of 3 to all 200 GPT-4-generated stories in the elaboration category, achieving a perfect IAA score of 1. This result demonstrates GPT-4o (P)’s exceptional ability to identify and evaluate detailed, well-developed content reliably. Overall, GPT-4o proved to be the most consistent and reliable model for creative content evaluation, highlighting its potential as a valuable tool for achieving consistent, high-quality assessments in creative writing tasks.
4.3. Case Study
4.3.1. Strengths of LLMs in Evaluation
LLMs such as GPT-3.5 and GPT-4o demonstrated remarkable consistency in their evaluations of both human-written and AI-generated content. As seen in Table 3, in a case study where both human-written and AI-generated texts explored a story about Leonardo DiCaprio intentionally sabotaging his career by choosing bad movies, only to unexpectedly win an Oscar for his role in “Paul Blart: Mall Cop 3”, both the AI and human texts presented a consistent storyline. The narratives emphasized DiCaprio’s dramatic and paradoxical decisions, using similar structures and vocabulary to highlight the irony of his actions.
Table 3.
The table shows excerpts from both human-written stories and GPT-4-generated stories about Leonardo DiCaprio’s narrative, specifically focusing on a creative prompt where he sabotages his career by choosing bad films. The selected excerpts illustrate the differences in narrative style and coherence between human-written and AI-generated content, allowing for a comparative analysis of writing quality across different evaluators and models.
In Table 4, GPT-3.5 models, regardless of temperature or persona settings, consistently assigned a score of 3.00 for fluency and originality to the human-written texts. In contrast, human evaluators gave significantly lower mean scores of 1.38 for the same texts, highlighting the discrepancy between human and AI evaluations. Similarly, GPT-4o models (both temperature and persona variants) showed uniformity, assigning a score of 2.00 in the fluency and originality criteria for human-written content. This pattern of consistency also extended to AI-generated texts. For the specific creativity strategies criterion, GPT-3.5 models consistently gave a score of 2.00, while GPT-4o models assigned a slightly higher mean score of 2.13, demonstrating a minor variation. These results confirm that LLMs maintain a high level of consistency in their evaluations, regardless of the criteria or content origin.
Table 4.
The table shows the mean values of five evaluators’ evaluations including human writing and AI writing on a topic related to DiCaprio. (T) means the different temperature settings, and (P) means the different persona settings.
LLMs have advantages, particularly in terms of evaluation speed and consistency. Since LLMs operate automatically, they can assess large volumes of creative writing much faster than human evaluators, who may require more time. The automated nature of LLMs ensures that each evaluation is carried out with consistency, applying the same criteria across different texts without being influenced by personal biases or other factors that can be inconsistent.
4.3.2. Weaknesses of LLMs in Evaluation
A major issue with GPT models is their inability to detect and penalize incomplete or flawed narratives. For instance, as shown in Table 5, a story generated by GPT-4 ends abruptly with the phrase, “And so, John’s story became a legend, inspiring others to follow their dreams and”, leaving the sentence incomplete. Similarly, another story concludes with, “there was a small bookstore that everyone seemed to ignore, but by the end of the story, it”, cutting off mid-sentence and leaving the narrative unresolved. These clear flaws disrupt the flow and fail to deliver a complete story.
Table 5.
The table provides an excerpt from GPT-4’s output for the prompt “Rewrite your favorite song as a story”. This excerpt illustrates the incomplete narrative generated by GPT-4 in response to this creative writing.
Despite these issues, GPT-3.5 and GPT-4o models, across various temperature and persona settings, consistently assigned a perfect score of 3 in the elaboration category for both stories. Moreover, GPT-3.5 models also gave a score of 3 in the fluency category, failing to account for the incomplete content. This highlights a significant limitation in AI evaluations. The models lack the ability to recognize and penalize fundamental narrative errors, raising concerns about their reliability in assessing creative writing.
5. Conclusions and Future Works
This paper investigates the ability of Large Language Models (LLMs) to evaluate creative writing, emphasizing their potential for providing automated, reliable, and time-efficient assessments. By automating the evaluation process, models like GPT-4o and GPT-3.5 Turbo significantly reduce evaluation time, making them valuable tools for large-scale creative writing assessments. Our findings indicate that these models demonstrate high consistency and performance across criteria such as fluency, flexibility, originality, elaboration, usefulness, and specificity. However, notable limitations were identified. The models often failed to detect deeper narrative flaws, such as incomplete compositions, redundancy, and logical inconsistencies, yet still assigned high scores to these outputs. Additionally, AI-generated assessments may exhibit biases toward certain stylistic patterns, potentially overlooking unconventional or culturally diverse writing styles. Furthermore, unlike human evaluators, AI models lack the ability to provide qualitative feedback or assess the underlying intent of a creative piece, which may limit their applicability in real-world educational or professional settings. This underscores a significant challenge in using AI models for comprehensive assessments, despite their efficiency and consistency.
A key limitation of this study is the lack of precise definitions for some evaluation criteria, such as fluency and flexibility. The overlap and ambiguity between these concepts may have contributed to inconsistent evaluations, as both human and AI evaluators interpreted these criteria differently. To improve future assessments, it is crucial to refine these definitions, ensuring they capture distinct aspects of creativity more accurately. Additionally, variability in Inter-Annotator Agreement (IAA) was observed, particularly among human evaluators. While AI models maintained high consistency, human evaluators struggled to reach agreement due to the subjective nature of creative writing assessments. This variability highlights a key limitation in practical applications, where AI-based evaluations may require human oversight to ensure fairness and adaptability.
Future research should focus on integrating AI and human evaluations to address these limitations. An effective approach is developing hybrid evaluation frameworks that allow AI models to provide initial assessments, which are then refined by human evaluators to incorporate qualitative insights. Additionally, advancing LLM training on more diverse creative datasets, including culturally varied narratives and unconventional writing styles, could enhance AI’s ability to evaluate a broader range of content. Moreover, ethical considerations must be addressed, particularly in terms of ensuring authenticity and originality in creative evaluations. Establishing clear guidelines on how AI-generated assessments should be interpreted in practical applications, such as education, publishing, or automated grading, will be essential to maximizing their effectiveness while mitigating potential biases.
Author Contributions
Conceptualization, S.K. and D.O.; methodology, S.K.; software, S.K.; validation, S.K. and D.O.; formal analysis, S.K.; investigation, S.K.; resources, S.K.; data curation, S.K.; writing—original draft preparation, S.K.; writing—review and editing, S.K. and D.O.; visualization, S.K.; supervision, D.O.; project administration, D.O.; funding acquisition, D.O. All authors read and approved the final manuscript.
Funding
This work was supported by Kyungpook National University Research Fund, 2023.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
The requirement for individual informed consent was waived as all data were fully anonymized, with no identifiable personal health data.
Data Availability Statement
The dataset generated during the current study are available at https://github.com/Emily-Kim-NLP/CW (accessed on 22 October 2024). Other data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. ANOVA and Post Hoc Analysis for Evaluator Type and Evaluation Criteria
To examine differences in evaluator type and evaluation criteria, an ANOVA was conducted on both human and GPT-4 writings, as shown in Table A1. The results show that in human writings, both evaluator type () and evaluation criteria (, ) had significant effects, indicating that different evaluators scored human-written texts differently and that certain evaluation criteria were rated higher than others. However, post hoc Tukey’s HSD analysis revealed that no significant differences existed among individual evaluator groups (p-values ranged from 0.181 to 1 for all pairwise comparisons), suggesting that while evaluator variation had an overall effect, no specific group differed significantly from the others.
For AI-generated writing, the evaluator effect was not significant (, ), while differences across evaluation criteria remained significant (, ), suggesting that AI texts were assessed more consistently across evaluators, but differences among evaluation criteria were still evident. Post hoc comparisons further confirmed that elaboration was rated significantly higher than specific creativity strategies () and usefulness () in AI-generated writing.
Table A1.
ANOVA results for human and GPT-4 writings.
Table A1.
ANOVA results for human and GPT-4 writings.
| Category | Sum Sq | F | p |
|---|---|---|---|
| Human Writings | |||
| Evaluator type | 1.040 | 5.106 | <0.01 |
| Evaluation criteria | 1.953 | 7.671 | <0.001 |
| GPT-4 Writings | |||
| Evaluator type | 0.475 | 1.845 | 0.160 |
| Evaluation criteria | 2.688 | 8.353 | <0.001 |
These findings suggest that human writing is influenced by both evaluator variation and evaluation criteria, while AI-generated writing is mainly shaped by differences in evaluation criteria rather than by who evaluates it. This may be because AI-generated texts follow learned patterns, making evaluator differences less noticeable. In this study, AI-generated writing was assessed by both human evaluators and four different language models, raising concerns about potential biases in AI-based evaluation. Since LLMs evaluate text based on patterns learned from pre-trained data, they may favor familiar structures and reinforce existing biases rather than objectively assessing creativity. These results highlight the importance of evaluation criteria in assessing creative writing and the need to carefully examine AI’s role as an evaluator.
Appendix B. Chi-Square Test Results for Evaluation Criteria
Chi-square tests were performed to evaluate differences in evaluation criteria between human-created and GPT-4-generated writings. The results are summarized in Table A2. To analyze the structural differences in creative writing, the Chi-square test was conducted across six evaluation criteria: fluency, flexibility, elaboration, originality, usefulness, and specific creativity strategies. The results indicate significant differences between human and GPT-4 writings (, for human writings; , for AI-generated writings), suggesting that their distributions across evaluation criteria differ substantially.
Table A2.
Chi-square test results for human and GPT-4 writings.
Table A2.
Chi-square test results for human and GPT-4 writings.
| p | ||
|---|---|---|
| Human writings | 18,227.18 | <0.001 |
| AI writings | 15,992.43 | <0.001 |
This analysis was conducted to assess whether GPT-4-generated and human-written texts exhibit distinct patterns in evaluation criteria. The significant results confirm that AI-generated and human-written texts differ structurally across key aspects of creative writing, highlighting fundamental distinctions in how each is evaluated.
Appendix C. Score Distribution Analysis
The frequency distributions of scores assigned to 200 writings are presented in Figure A1 and Figure A2, evaluated by human evaluators and four different AI models across six creativity criteria: fluency, flexibility, elaboration, originality, usefulness, and specific creativity strategies. The graph illustrates how often each score, whether one point, two points, or three points, was assigned. This provides insights into the evaluation patterns for human writings and AI-generated writings.
A distinct pattern emerges between human and AI evaluators. In human writing, scores are more evenly distributed across two points and three points, with a notable number of one points in categories such as usefulness and flexibility. This suggests that human writing exhibits a wider variability in perceived quality, particularly in practical applicability. Additionally, elaboration consistently receives the highest number of three points, indicating that human writing tends to be rated as highly detailed.
In contrast, GPT-4-generated writing shows a more structured distribution, with a stronger tendency toward two points and three points, particularly in fluency and elaboration. This suggests that AI-generated texts maintain coherence and depth with high consistency. However, usefulness remains a category with relatively lower scores, reinforcing the notion that while GPT-generated writing is well structured, it may lack practical applicability or engagement. Additionally, AI evaluations display fewer one points overall, suggesting that its outputs rarely fall into the lowest-scoring bracket, unlike human writing, where evaluation is more varied.
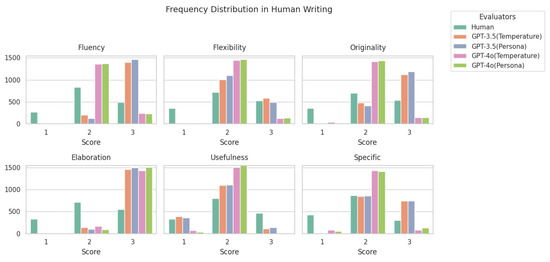
Figure A1.
Frequency distribution of scores for human writing across six creativity categories. The graph displays the frequency of scores assigned by human evaluators and four AI models (GPT-3.5 (temperature), GPT-3.5 (persona), GPT-4o (temperature), and GPT-4o (persona)) in each category, with ratings of 1 point, 2 points, or 3 points.
Figure A1.
Frequency distribution of scores for human writing across six creativity categories. The graph displays the frequency of scores assigned by human evaluators and four AI models (GPT-3.5 (temperature), GPT-3.5 (persona), GPT-4o (temperature), and GPT-4o (persona)) in each category, with ratings of 1 point, 2 points, or 3 points.
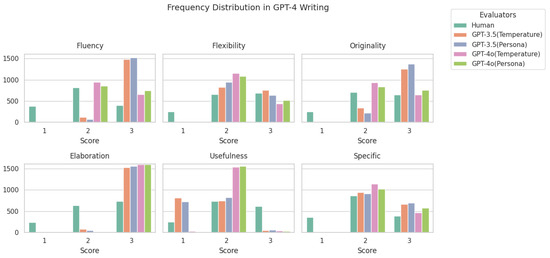
Figure A2.
Frequency distribution of scores for GPT-4-generated writing across six creativity categories. The graph displays the frequency of scores assigned by human evaluators and four AI models (GPT-3.5 (temperature), GPT-3.5 (persona), GPT-4o (temperature), and GPT-4o (persona)) in each category, with ratings of 1 point, 2 points, or 3 points.
Figure A2.
Frequency distribution of scores for GPT-4-generated writing across six creativity categories. The graph displays the frequency of scores assigned by human evaluators and four AI models (GPT-3.5 (temperature), GPT-3.5 (persona), GPT-4o (temperature), and GPT-4o (persona)) in each category, with ratings of 1 point, 2 points, or 3 points.
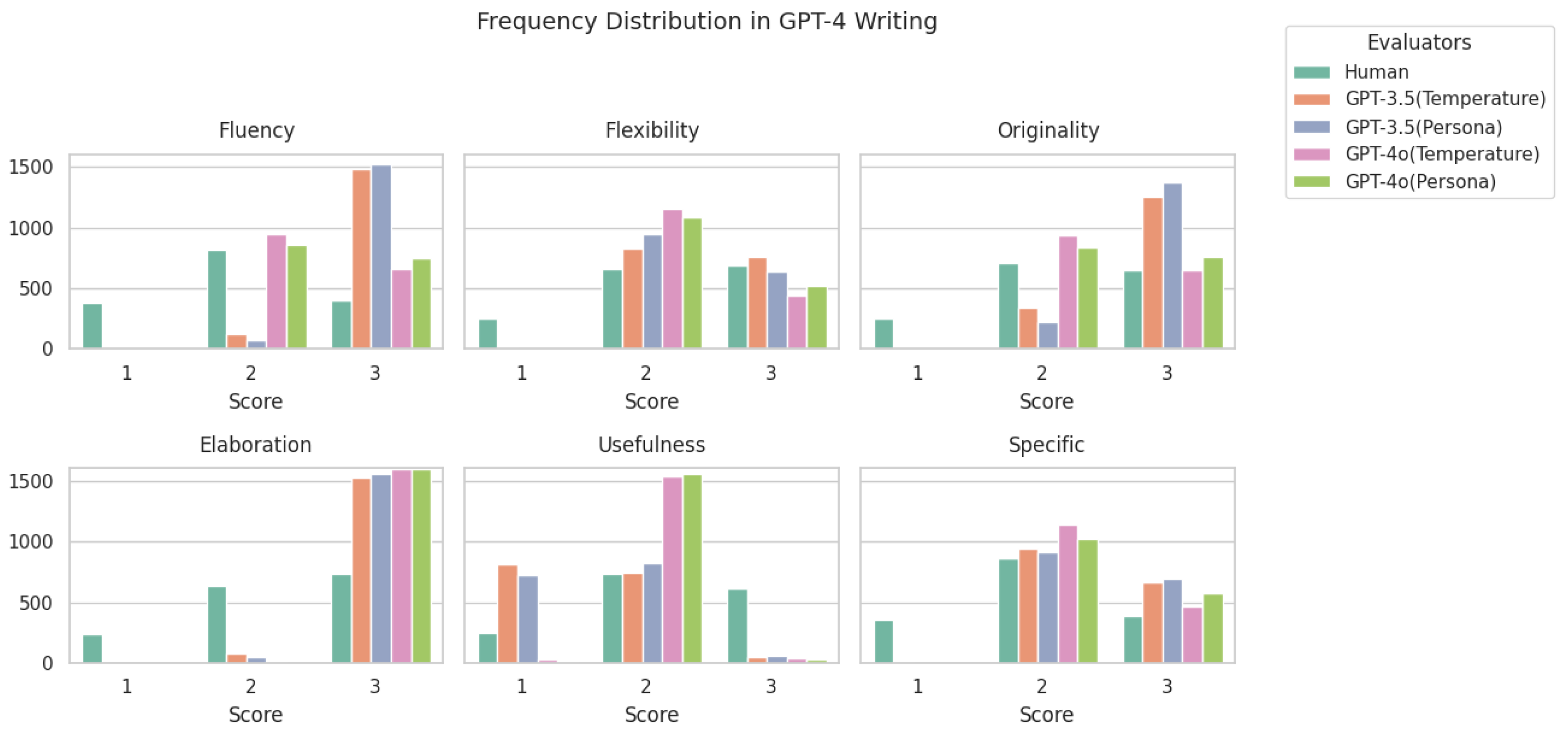
Furthermore, AI models exhibit highly similar scoring distributions within their respective types. GPT-4o-based evaluators tend to assign scores in a more consistent manner, while GPT-3.5-based evaluators show similar tendencies among themselves. This pattern suggests that AI-based evaluation reflects learned assessment tendencies, resulting in predictable scoring distributions within the same model type. Conversely, human evaluators show greater variation in their ratings, highlighting the subjective nature of human judgment in creative writing evaluation.
These findings indicate that while GPT-generated writing excels in fluency and elaboration, human writing demonstrates more diverse evaluation patterns, particularly in subjective aspects such as originality and usefulness. Additionally, the similarity in scoring distributions among AI models suggests that LLM-based evaluation may reinforce internal biases, leading to a more standardized but less nuanced assessment of creative writing.
References
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Gemini Team, G. Gemini: A Family of Highly Capable Multimodal Models. arXiv 2024, arXiv:2312.11805v2. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Mijwil, M.M.; Hiran, K.K.; Doshi, R.; Dadhich, M.; Al-Mistarehi, A.H.; Bala, I. ChatGPT and the Future of Academic Integrity in the Artificial Intelligence Era: A New Frontier. Al-Salam J. Eng. Technol. 2023, 2, 116–127. [Google Scholar] [CrossRef]
- Chiang, W.L.; Zheng, L.; Sheng, Y.; Angelopoulos, A.N.; Li, T.; Li, D.; Zhu, B.; Zhang, H.; Jordan, M.I.; Gonzalez, J.E.; et al. Chatbot Arena: An open platform for evaluating LLMs by human preference. In Proceedings of the Forty-First International Conference on Machine Learning (ICML), Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Kevian, D.; Syed, U.; Guo, X.; Havens, A.; Dullerud, G.; Seiler, P.; Qin, L.; Hu, B. Capabilities of Large Language Models in Control Engineering: A Benchmark Study on GPT-4, Claude 3 Opus, and Gemini 1.0 Ultra. arXiv 2024, arXiv:2404.03647v1. [Google Scholar] [CrossRef]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv 2023, arXiv:2303.12712v5. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Morrison, M.; Tang, B.; Tan, G.; Pardo, B. Reproducible subjective evaluation. arXiv 2022, arXiv:2203.04444. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. ROUGE: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out: Proceedings of the ACL-04 Workshop, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Li, J.; Li, R.; Liu, Q. Beyond static datasets: A deep interaction approach to llm evaluation. arXiv 2023, arXiv:2309.04369. [Google Scholar]
- Chiang, C.H.; Lee, H.y. Can Large Language Models Be an Alternative to Human Evaluation? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 15607–15631. [Google Scholar]
- Landa-Blanco, M.; Agüero Flores, M.; Mercado, M. Human vs. AI Authorship: Does it Matter in Evaluating Creative Writing? A Pilot Study Using ChatGPT; School of Psychological Sciences, National Autonomous University of Honduras: Tegucigalpa, Honduras, 2024. [Google Scholar]
- Zhao, Y.; Zhang, R.; Li, W.; Huang, D.; Guo, J.; Peng, S.; Hao, Y.; Wen, Y.; Hu, X.; Du, Z.; et al. Assessing and Understanding Creativity in Large Language Models. arXiv 2024, arXiv:2401.12491. [Google Scholar]
- Shively, K.; Stith, K.; Rubenstein, L.D. Measuring what matters: Assessing creativity, critical thinking, and the design process. Gift. Child Today 2018, 41, 149–159. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 1–14. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the naacL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. In Proceedings of the International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 30 April 2020; pp. 1–17. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog. 2019. Available online: https://huggingface.co/openai-community/gpt2 (accessed on 2 October 2024).
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Kublik, S.; Saboo, S. GPT-3: The Ultimate Guide To Building NLP Products with OpenAI API; Library of Congress Control Number: 2018675309; Packt Publishing Ltd.: Birmingham, UK, 2022; p. 234. [Google Scholar]
- Ye, J.; Chen, X.; Xu, N.; Zu, C.; Shao, Z.; Liu, S.; Cui, Y.; Zhou, Z.; Gong, C.; Shen, Y.; et al. A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models. arXiv 2023, arXiv:2303.10420v2. [Google Scholar] [CrossRef]
- Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; Zhu, C. G-eval: Nlg evaluation using gpt-4 with better human alignment. arXiv 2023, arXiv:2303.16634. [Google Scholar]
- Boden, M.A. Creativity and artificial intelligence. Artif. Intell. 1998, 103, 347–356. [Google Scholar] [CrossRef]
- Dietrich, A. The cognitive neuroscience of creativity. Psychon. Bull. Rev. 2004, 11, 1011–1026. [Google Scholar] [CrossRef]
- Mozaffari, J. An analytical rubric for assessing creativity in creative writing. J. Creat. Writ. Stud. 2023, 14, 112–129. [Google Scholar] [CrossRef]
- D’Souza, R. What characterises creativity in narrative writing, and how do we assess it? Research findings from a systematic literature search. J. Lang. Lit. Stud. 2019, 42, 215–228. [Google Scholar] [CrossRef]
- Guilford, J. Creativity. Am. Psychol. 1950, 5, 444–454. [Google Scholar] [CrossRef] [PubMed]
- Runco, M.A.; Jaeger, G.J. The standard definition of creativity. Creat. Res. J. 2012, 24, 92–96. [Google Scholar] [CrossRef]
- Peeperkorn, M.; Kouwenhoven, T.; Brown, D.; Jordanous, A. Is Temperature the Creativity Parameter of Large Language Models? arXiv 2024, arXiv:2405.00492. [Google Scholar]
- Rice, J.A.; Rice, J.A. Mathematical Statistics and Data Analysis; Thomson/Brooks/Cole: Belmont, CA, USA, 2007; Volume 371. [Google Scholar]
- Lee, D.K.; In, J.; Lee, S.H. Standard deviation and standard error of the mean. Korean J. Anesthesiol. 2015, 68, 220–223. [Google Scholar] [CrossRef]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology, 3rd ed.; Sage Publications: Thousand Oaks, CA, USA, 2011; pp. 222–235. [Google Scholar]
- Magni, F.; Park, J.; Chao, M.M. Humans as creativity gatekeepers: Are we biased against AI creativity? J. Bus. Psychol. 2024, 39, 643–656. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).