Abstract
Table-based question answering (TableQA) has emerged as an important task in natural language processing, yet existing models face challenges in handling complex reasoning and mitigating hallucinations, especially when dealing with diverse table structures. We introduce TQAgent, a framework designed to enhance table-based reasoning by incorporating knowledge graphs and tree-structured reasoning paths. TQAgent reduces hallucinations and improves model reliability by grounding reasoning in external knowledge and dynamically sampling high-confidence paths. Additionally, it employs knowledge distillation techniques for lightweight deployment. Experimental results on the TabFact, WikiTQ, and FeTaQA datasets show significant performance improvements, with accuracy increases of up to 4% over baseline models. TQAgent’s dynamic operation planning and knowledge graph integration enable effective multi-step reasoning and better handling of diverse table data. Furthermore, the framework achieves state-of-the-art results, surpassing traditional large-scale models in both reasoning accuracy and computational efficiency. These findings open new avenues for future research in table-based question answering and model deployment optimization.
1. Introduction
In recent years, table-based question answering has emerged as a significant research direction in the field of Natural Language Processing (NLP), garnering widespread attention. As a common form of data representation, tabular data are extensively utilized in scientific research, business analysis, medical records, and financial reports, among other domains. Extracting knowledge from complex tabular data and enabling effective question-answering is becoming a challenging yet crucial task [1]. With the advancement of research, various table-based tasks and techniques have been progressively proposed, such as entity linking [2], schema enhancement [3], and table-based question answering [4,5], among others.
However, existing table-based question answering methods still face several limitations in practical applications. On the one hand, many methods rely heavily on extensive table pre-training [6,7] and specialized model architectures designed specifically for tables [8]. On the other hand, these methods are often limited to handling specific types of tables and tasks, and they make strong assumptions about the structure of the tables and the types of tasks [7]. Therefore, improving the reasoning capabilities of models and enabling them to adapt to a wider variety of table types and tasks has become an urgent issue to address.
Furthermore, Large Language Models (LLMs) also face the issue of “hallucination” when handling table-based question answering tasks, where the model may generate seemingly plausible but actually inaccurate answers, especially in the face of ambiguous contexts or knowledge gaps [9,10]. This phenomenon not only affects the correctness of reasoning but also undermines the reliability of the models [11]. Although existing research has endeavored to mitigate this issue through knowledge updates and model fine-tuning [12,13], merely adding random information does not effectively enhance the reasoning capabilities of the models. Instead, providing precise and contextually relevant external knowledge, particularly by augmenting the model’s knowledge base through knowledge representation tools such as knowledge graphs, can significantly improve the accuracy of reasoning [14].
This study focuses on utilizing external knowledge to enhance the model’s understanding of tabular data and reduce reasoning hallucinations, developing a structured reasoning approach to handle diverse tabular data and generate high-quality reasoning chains, and applying knowledge distillation for lightweight deployment while preserving reasoning performance in table-based QA tasks.
To address these issues, this article proposes a multi-perspective enhancement method based on knowledge graphs and tree structures, aiming to improve the performance of models in table-based question answering tasks. First, by introducing knowledge graphs, we supplement the world knowledge not contained in the tables or the model, enhancing the model’s understanding of the table content and reducing hallucination phenomena during reasoning. Second, considering the diversity of table data types, this article constructs tree-structured reasoning paths and utilizes confidence scores from each sub-branch for threshold filtering, generating high-quality reasoning chains from different perspectives for the same table data. This not only expands the base data volume but also enhances the model’s multi-dimensional analysis capability for various types of table data. Finally, by combining the reasoning processes generated by the gpt-3.5-turbo model, we fine-tune the 7B model using knowledge distillation, achieving lightweight deployment of a general-purpose model while ensuring reasoning performance and reducing computational costs.
In summary, the main contributions of this article are as follows: (1) We propose a multi-perspective enhancement method based on knowledge graphs and tree structures, which improves the model’s reasoning capabilities and reduces hallucinations by incorporating external knowledge and structured reasoning paths. (2) We employ knowledge distillation to achieve lightweight deployment of a general-purpose model, reducing computational costs while maintaining reasoning performance. (3) Experimental results demonstrate that the proposed method achieves significant improvements in table-based question answering tasks and provides new insights for further research in this area. The fine-tuning data used in this article will be made publicly available.
2. Related Works
TableQA: Recent advancements in TableQA focus on enhancing reasoning accuracy and interpretability through modular frameworks and specialized model tuning. The emergence and development of LLM [15,16] have also spurred a wave of advancements in the TableQA field [17]. TaPERA [18] proposed a three-step pipeline integrating content planning, execution-based reasoning, and answer generation to mitigate hallucination issues in long-form answers; Ye et al. [19] leveraged LLMs as decomposers to break down complex questions and tables into tractable sub-components, achieving human-level performance on TabFact; Zhao et al. [7] introduced OpticalTable-SQA, fine-tuning table-based models for optical-materials data; He et al. [20] developed the Text2Analysis benchmark, extending TableQA to advanced operations like forecasting.
Recently, some studies have shifted attention toward table-tuning and systematic evaluation. Table-GPT [21] enhances generalizability through table-tuning of LLMs; Sui et al. [22] systematically evaluated LLMs’ structural understanding and proposed prompting strategies for improved table reasoning. These works collectively advance TableQA through decomposition strategies, domain specialization, and systematic evaluation frameworks. Rajkumar et al. [23] and Fan et al. [24] aimed to utilize NL2SQL techniques to convert tableQA tasks into SQL queries. TableLlama [25] and SheetAgent [26] leveraged fine-tuning datasets to unlock the potential of small-parameter large language models in the field of table reasoning.
LLM Hallucination Large language model hallucinations refer to instances where models generate plausible but factually incorrect or nonsensical information. The phenomenon of hallucinations in LLMs has garnered significant attention due to its implications for reliability and trustworthiness. Prior studies have explored diverse methodologies to detect, mitigate, and understand this issue. Lavrinovics et al. [27] highlighted the integration of Knowledge Graphs (KGs) to ground LLM outputs in structured factual data, a strategy further advanced by Guan et al. [28], who proposed autonomous KG-based retrofitting to refine LLM responses during reasoning. For hallucination detection, Ledger [29] introduced Monte Carlo simulations on token probabilities to identify low-confidence outputs, while Du et al. [30] leveraged unlabeled LLM generations through the HaloScope framework to train robust classifiers. Architectural innovations, such as combining Graph Neural Networks (GNNs) with LLMs [31], demonstrate enhanced factual consistency by processing relational and textual data jointly. Paradoxically, Taveekitworachai et al. [32] revealed that controlled hallucination via null-shot prompting can improve performance in reasoning tasks, challenging conventional mitigation paradigms. Empirical investigations by Qiu [33] further uncover domain-specific impacts of hallucinations, such as degraded motor skill learning in physical education. Underlying these challenges, Waldo [34] attribute hallucinations to training data limitations, particularly on controversial or niche topics. Collectively, the issue of hallucinations remains a critical challenge in the field of LLM. This paper addresses the problem by introducing Knowledge Graphs as external world knowledge to mitigate hallucinations in large models.
3. Materials and Methods
We introduce TQAgent, as illustrated in Figure 1. The first stage involves Knowledge-Augmented Fine-Tuning, where the model is fine-tuned with multi-step reasoning chains generated by OpenAI’s gpt-3.5-turbo. This enhances the model’s ability to generate and execute complex table operations by incorporating external knowledge. In the second stage, the fine-tuned model performs Question Answering (QA) by dynamically generating and executing action chains based on the table data and the given query.
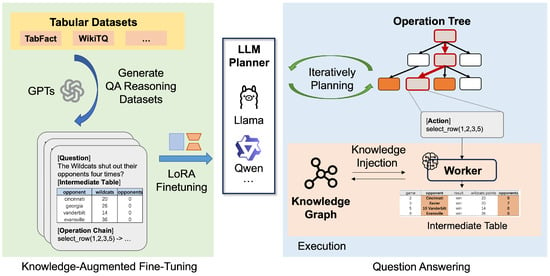
Figure 1.
Pipeline of TQAgent.
3.1. Question Answering Method
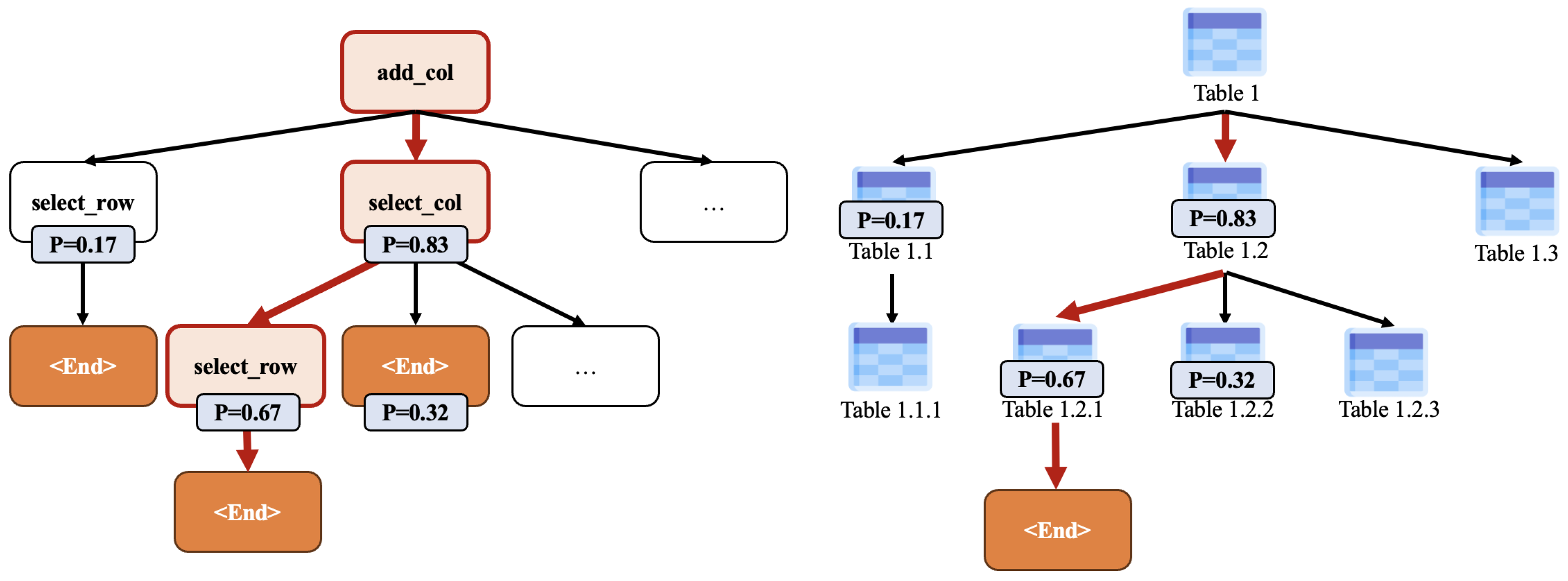
Dynamic Operation Tree Generation. The Planner is responsible for generating the operation tree at each step. As shown in Figure 2, when the number of samples is 1, the operation tree degrades into an operation chain. During each planning process, the Planner combines the current state of the table and the task goal to infer the optimal possible operation for the next step and assigns a confidence level to each operation. The Planner also takes into account the success rate and accuracy of the operation, dynamically adjusting the operation tree to improve the accuracy of the final table generation and the quality of corpus supplementation. The algorithm is presented in Algorithm 1.
| Algorithm 1 Planner Algorithm | ||
| Require: T is the current state of the table, Q is the task goal, n is the number of samples, k is the number of operations to consider in each iteration, and is the probability threshold. | ||
| Ensure: is the final sequence of candidate actions. | ||
| 1: | Initialize an empty list for the final sequence of actions. | |
| 2: | ||
| 3: | repeat | |
| 4: | Initialize an empty list A for all candidate actions. | |
| 5: | for to n do | ▹ Sample n times |
| 6: | ▹ Generate | |
| 7: | ||
| 8: | ||
| 9: | ||
| 10: | end for | |
| 11: | Sort A by in descending order. | |
| 12: | ▹ Select the top k highest probability actions. | |
| 13: | ▹ Filter actions based on the threshold. | |
| 14: | ▹ Select the next action. | |
| 15: | if then | |
| 16: | ||
| 17: | ▹ Update the table state. | |
| 18: | end if | |
| 19: | until | |
| 20: | return | |
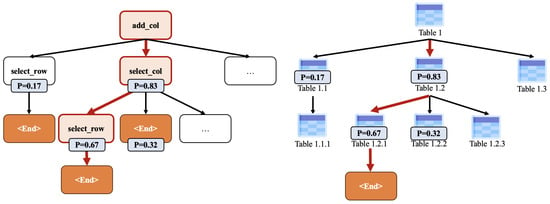
Figure 2.
Example of the operation tree.
- Planner Reads the Initial Table and the Question and Plans: As a dynamic planner, the Planner generates and manages a series of action chains. Based on the current state of the table and the task goal, the Planner performs n samplings, selects the value of as the confidence level, and infers the operation tree. By continuously optimizing the action chain, the Planner improves the decision-making efficiency and accuracy of the system.
- Worker Executes Specific Operations: As the execution component, the Worker executes each operation formulated by the Planner step by step. According to the Planner’s instructions, the Worker makes dynamic adjustments to the table data (such as adding a column with add_col, performing conditional selection with select_where_row, etc.), and retrieves information from the external knowledge base or the knowledge embedded in the model when necessary through operations like retrieve_from_repo or query. The Worker feeds back the result of each step of execution to the Planner for further adjustment and optimization of the action chain. All table operations are managed based on Python’s pandas’ dataframe (https://pandas.pydata.org, accessed on 7 March 2025) to ensure the efficiency and consistency of data processing.
When the number of samples is n, for each sample, the corresponding operation and its are obtained. The term refers to the logarithm of the probability of the first token of the next action generated by the LLM (https://platform.openai.com/docs/api-reference/chat/create#chat-create-logprobs, accessed on 7 March 2025). This log-probability serves as a measure of the model’s confidence in its predicted action, where a more negative log-probability indicates a lower likelihood of the in the given context.
Where , given hyper-parameters k (the maximum number of retained candidates) and (the minimum probability threshold), the formulas are as follows:
For all candidate operations, they are sorted according to the probability size, and the top k operations are selected as the candidate operation set . Operations with probabilities lower than the threshold, , are filtered out. The final retained candidate operation set can be expressed as follows:
Algorithm Complexity Analysis: The time complexity of the algorithm is , where m is the number of iterations, n is the number of candidate actions sampled per iteration, and k is the number of top k actions selected. The space complexity of the algorithm is , accounting for storing candidate actions, Top−k actions, and the final action sequence.
Data Retrieval and Selection: The Retriever, a dynamic example retriever, is used to find appropriate few-shot examples from historical plans, which helps to reduce the probability of operation errors in the current task. The Retriever retrieves the required examples from the vector database based on the embedding of the prompt composed of the sub-table generated after the current operation, the dynamic operation chain, and the task instruction, and provides them to the Worker for execution. This method can significantly reduce errors, especially in complex table operations or scenarios that require dynamic corpus expansion.
Task Execution and Result Generation: The Worker, an executor, specifically executes each action formulated by the Planner, where each action is a pure function. The Worker performs corresponding operations on the table according to the instructions of each step of the action, such as column addition (add_col), conditional selection (select_where_row), etc., and also supports operations like retrieve_from_repo and query to retrieve the required information from the external real-time knowledge base or the knowledge embedded in the model. During the execution process, the Worker reports the operational results to the Planner for subsequent planning adjustments. Table operations rely on the Python pandas dataframe for operation.
3.2. Knowledge Injection
A knowledge graph constructed by WikiEvents [35] is incorporated as an external knowledge supplement. During the reasoning process, this knowledge graph assumes a pivotal role. When the model processes table data and questions, it initially parses the questions to extract key entities and relationships. For example, if a question pertains to table data related to a historical event, the model will utilize these key pieces of information to conduct searches and matches within the WikiEvents knowledge graph.
The nodes in the knowledge graph encapsulate rich entity information, while the edges define various relationships between entities. Through interaction with the knowledge graph, the model can access world knowledge that is not explicitly presented in the table. For instance, when handling a table related to a sports event, if the table merely records the game results, yet the question involves the historical head-to-head data of the participating teams or the past honors of a particular athlete, the knowledge graph can furnish this supplementary information to the model. This not only deepens the model’s comprehension of the table content but also effectively mitigates the “hallucination” phenomenon during the reasoning process.
In practical operation, when the Planner generates an operation chain, it determines whether to obtain information from the knowledge graph based on the current task requirements and the state of the table. If necessary, it dispatches instructions to the Retriever. The Retriever screens out the content most relevant to the current task, leveraging the information retrieved from the knowledge graph, and supplies it to the Worker for subsequent operations. For example, in a table QA task involving data analysis, the Worker might need to draw on industry knowledge from the knowledge graph to interpret and process the table data more precisely, thereby generating a more rational answer.
Furthermore, the knowledge graph can assist the model in handling ambiguous or implicit information. When there is ambiguity in the table data, the context information within the knowledge graph can aid the model in resolving the ambiguity and making more accurate judgments. By continuously interacting with the knowledge graph, the model’s reasoning ability in dealing with table QA tasks has been remarkably enhanced. It can better address various complex questions and diverse table data, offering users more dependable answers.
3.3. Knowledge-Augmented Fine-Tuning
First, gpt-3.5-turbo is used to generate dynamic reasoning chains, including table operations in intermediate steps. The multi-step operation chains generated during the QA process are used as the basis for fine-tuning data. These data provide the complete process of the model generating operation chains, covering specific steps such as initial parsing, table operations, and information supplementation. Then, based on 7B models like Llama3 and Qwen2, the LoRA technique is employed. The selected high-quality operation chain dataset is used for fine-tuning, focusing on improving the model’s performance in generating and executing multi-step reasoning chains. Finally, the fine-tuned model replaces the basic large language model used by the Planner in the QA process. The performance of the fine-tuned model is tested on the benchmark dataset to evaluate its multi-step reasoning accuracy and information supplementation ability in the table QA task.
The fine-tuning data are derived from the training datasets of TabFact and WikiTQ, aiming to fine-tune the action planning ability of the large language model. The fine-tuning data consist of 4031 selected action reasoning data instructions. We used Llama-Factory (https://github.com/hiyouga/LLaMA-Factory, accessed on 7 March 2025) to perform supervised fine-tuning (SFT) on the local A40 GPU. The instruction format is shown in Table 1.

Table 1.
Prompt of fine-tuning.
4. Experiments
4.1. Datasets
As shown in Table 2, the TabFact, FeTaQA, and WikiTQ datasets are selected to train and evaluate the method proposed in this paper.
Table 2.
Division of train/test split for TabFact, WikiTQ, and FeTaQA datasets.
TabFact [36] is a dataset for table verification tasks, containing approximately 118,000 statements generated based on Wikipedia tables. These tables cover multiple subject areas, such as sports, people, movies, etc. Each piece of data includes a table, a statement, and a truth-value annotation (True or False) for the statement. The data of TabFact is divided into a training set and a test set. The training set is used to train the model to identify the authenticity of statements, and the test set is used for model verification. During the data processing, the model not only needs to extract table information but also perform complex reasoning, such as comparing data between multiple cells. TabFact is mainly used to verify the authenticity of table-based factual statements and is suitable for research in the fields of information extraction and table QA.
FeTaQA [5] is a table QA dataset for few-shot learning, mainly used to answer complex questions through natural language generation. FeTaQA contains approximately 10,000 question–answer pairs generated based on Wikipedia tables. Each piece of data includes a table, a complex query question, and a detailed answer. The question types cover various complex reasoning scenarios such as statistics, comparison, and induction, requiring the model to extract and integrate multiple pieces of relevant information from the table. The FeTaQA dataset supports few-shot and zero-shot learning and is suitable for evaluating the natural language generation ability of models in QA systems and information generation tasks.
WikiTableQuestions [35] is an open-domain dataset for table QA, containing approximately 22,000 question–answer pairs generated based on Wikipedia tables. The questions in this dataset usually involve operations such as combination, filtering, and sorting of information within the table. The question types are diverse, such as “Find the highest value” and “List the entries that meet specific conditions”. The dataset is divided into a training set and a test set, which are used to train the model to understand and answer data-based questions from tables. The WikiTableQuestions dataset has high requirements for the model’s table understanding ability and is an important evaluation dataset for multi-step reasoning and information integration tasks.
Among them, TabFact and WikiTQ are in-domain datasets, while FeTaQA is an out-of-domain dataset. When fine-tuning the model, the planning data generated from the training sets of TabFact and WikiTQ are used as the dataset for model fine-tuning in this paper.
4.2. Baseline
To comprehensively evaluate model performance, we categorize baseline methods into two classes: Generic Reasoning and Small Language Model (SLM) Reasoning.
- Generic Reasoning
- gpt-3.5 [37,38]: Directly guides GPT-3.5 to generate answers via zero-shot (0-shot) and few-shot (2/4-shot) prompting.
- Text-to-SQL [23]: Converts natural language questions into SQL queries for table-based reasoning.
- Dater [19]: Employs sub-table decomposition strategy with LLaMA2-13b for end-to-end table reasoning.
- Chain-of-Thought [39]: Guides GPT-3.5 through step-by-step reasoning via explicit reasoning chains.
- Small Language Model Reasoning. This category focuses on the reasoning performance of 7B-8B scale models, comparing pre-finetuning and post-finetuning effectiveness:
- Zero-Shot Reasoning [40]: Direct inference using base versions of Qwen2-7b and Llama3-8b.
- Instruction-Finetuned Reasoning: Uses instruction-fine-tuned variants Qwen2-7b-Instruct and Llama3-8b-Instruct.
4.3. Results
In the experiments, the indicators of directly using ChatGPT for QA in zero-shot and few-shot scenarios are compared, as well as the application of the COT method in table QA and the application of the Text-to-SQL method in table QA. The results are shown in Table 3.
Table 3.
Results of table question answering.
It can be seen that after using the method pipeline proposed in this paper, even on a 7B small-scale model, the performance metrics show significant improvements. The fine-tuned model achieves an increase in accuracy of 4% compared to the non-fine-tuned version on the TabFact and WikiTQ datasets. TQAgent, particularly when integrated with instruction-fine-tuned models, demonstrates enhanced performance on these datasets. This improvement stems from TQAgent’s dynamic operation chain planning and multi-step reasoning capabilities, which enable more effective parsing and manipulation of tabular data. Additionally, TQAgentcollaborates with the Retriever to fetch historical examples, thereby minimizing errors and refining reasoning paths.
Experimental results indicate that compared to general large-scale models, small language models (SLM Reasoning) exhibit significant performance gaps without dynamic planning chains. As shown in Table 3, the zero-shot reasoning accuracy of Qwen2-7b and Llama3-8b on TabFact is 60.21% and 61.34%, respectively, nearly 10 percentage points lower than GPT-3.5’s 70.45%, primarily due to parameter size constraints on implicit structured reasoning. Through multi-path sampling of dynamic operation trees and knowledge graph injection, TQAgent empowers the instruction-tuned Llama3-8b-Instruct to reach 73.60% accuracy, exceeding the original GPT-3.5’s 70.45%. This validates that explicit reasoning chain modeling successfully transfers planning capabilities from large to small architectures. Cross-domain analysis further reveals that models without knowledge injection attain a BLEU score of 27.47 on FeTaQA, which rises to 28.62 with knowledge augmentation. The improvement rate (4.2%) substantially surpasses Dater’s cross-domain performance gap on WikiTQ (11.5%), confirming the synergistic effect of dynamic planning and knowledge injection.
This agent framework can be seamlessly adapted to other large models. While it primarily leverages the planning capabilities of large-scale models, its planning logic is implemented locally. When substituting the base model, GPT still outperforms the 8B small-scale variant, yet given the scaling advantages of large models, our method remains effective. Notably, the fine-tuned model exhibits markedly superior performance to its non-fine-tuned counterpart, proving successful migration of Instruct models to dynamic-planning agent capabilities.
- Impact of Sample: This section investigates the impact of varying sample counts (n) on model performance under a fixed probability threshold . As shown in Table 4,
Table 4. Impact of sampling values.
- Low-sample (): Limited sampling efficiently captures critical decision paths, with each new sample providing novel information (e.g., WikiTQ accuracy increases from 46.23% to 50.78% as n grows from 1 to 3).
- High-sample (): Redundant samples emerge due to overlapping information, reducing marginal benefits (e.g., FeTaQA BLEU score plateaus at 28.62 despite n increasing from 4 to 6).
The system achieves 95% of peak performance at n = 4, suggesting practical sampling limits to balance computational cost and model enhancement.
As shown in Table 5, the integration of knowledge graphs significantly enhances model performance across multiple table-based reasoning tasks. On the TabFact dataset, knowledge injection improves accuracy by 3.89%, demonstrating enhanced factual verification capabilities through external knowledge supplementation. For WikiTQ, the 4.13% accuracy gain highlights the effectiveness of Knowledge Graphs in resolving complex entity relationships within heterogeneous tables. In the FeTaQA generation task, the BLEU score increases from 27.47 to 28.62, indicating improved semantic alignment between generated answers and reference texts.
Table 5.
Impact of Knowledge Graph injection on model performance.
Notably, the unchanged ROUGE-1 score suggests that knowledge injection primarily optimizes semantic reasoning rather than lexical overlap. These results validate that knowledge graphs mitigate LLM hallucinations by providing structured world knowledge and constrained reasoning paths, particularly for cross-domain commonsense reasoning and implicit relationship inference in tabular data. The synergy between dynamic operation trees and knowledge retrieval mechanisms enables multi-dimensional table analysis while maintaining lightweight model deployment.
Case Study
In the case of verifying whether the statement “the wildcats kept the opposing team scoreless in four games” is true, multiple steps are involved. The key information is extracted through the step-by-step processing of the table, and finally, the authenticity of the statement is confirmed. As shown in Figure 3, this case demonstrates how to use basic atomic operations such as row selection, column selection, and group statistics to process complex table data into a form convenient for verifying the statement. The process starts from the original table containing game information. First, specific rows (rows 2, 3, 5, and 9) are selected according to the instruction. Then, the “opponent” and “opponents” columns are selected from the obtained sub-table. Next, grouping statistics are performed according to the “opponents” column. Finally, based on the grouping results, it is determined that the statement “The wildcats kept the opposing team scoreless in 3 games” is true, and the answer “YES” is given.
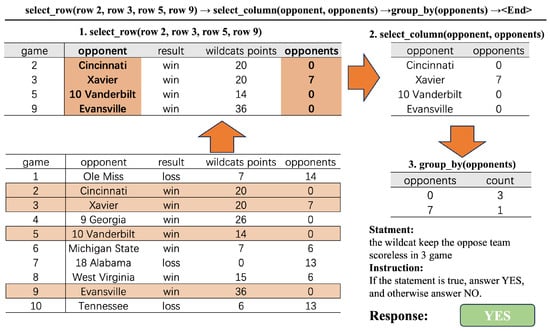
Figure 3.
Examples of table dynamic actions.
In the case shown in Figure 4, the process of KG injection is demonstrated. After the initial table operations are performed, the system identifies the need for additional contextual information—specifically, the country to which each city belongs. To address this, the model executes a action, triggering a self-reflection mechanism powered by the LLM. During this self-reflection, the model identifies that the table lacks the country information necessary for a more comprehensive analysis.
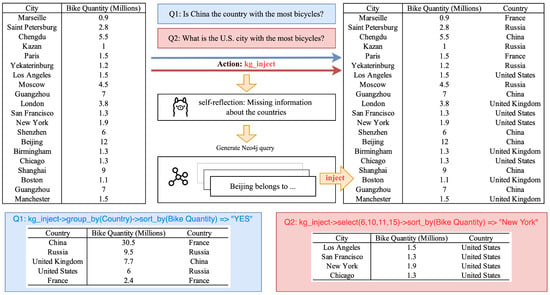
Figure 4.
Example of KG injection.
To retrieve the missing information, the system generates Neo4j query statements that search the Knowledge Graph for the corresponding country of each city. For instance, given a city name such as “Paris”, the query retrieves the associated country, “France”. Once the missing country data are obtained, they are injected back into the table, enriching the information and enabling more accurate reasoning.
This case highlights the effectiveness of KG injection in enhancing table-based reasoning by dynamically expanding the available information. The process combines atomic table operations (e.g., row selection, column selection, and group statistics) with Knowledge Graph augmentation, enabling the system to verify statements more accurately and thoroughly.
5. Conclusions
This paper introduces TQAgent, a framework that combines Knowledge Graphs (KGs) and tree-structured reasoning to address hallucinations and limited reasoning in table-based question answering. TQAgent enhances model reliability by grounding reasoning in external world knowledge, dynamically sampling high-confidence paths, and enabling lightweight deployment through knowledge distillation with GPT-3.5. Experimental results show a 4% accuracy improvement on TabFact and WikiTQ, demonstrating its robustness across datasets and models. Future work will explore real-time KG updates and multimodal extensions, with resources made publicly available for reproducibility.
This paper introduces TQAgent, a novel framework that integrates Knowledge Graphs (KGs) and tree-structured reasoning to address two critical challenges in table-based question answering (TableQA): hallucinations and limited reasoning capabilities. By grounding the reasoning process in external world knowledge, dynamically sampling high-confidence reasoning paths, and employing knowledge distillation techniques for lightweight deployment, TQAgent achieves significant improvements in both accuracy and computational efficiency.
Experimental evaluations on three benchmark datasets—TabFact, WikiTQ, and FeTaQA—demonstrate the robustness of our approach. Specifically, TQAgent achieves up to a 4% accuracy improvement over baseline models on TabFact and WikiTQ, while also enhancing semantic alignment in natural language generation tasks on FeTaQA, as evidenced by a BLEU score increase of 4.2%. These results underscore the effectiveness of combining structured knowledge from KGs with dynamic operation planning and multi-step reasoning. The integration of Knowledge Graphs plays a pivotal role in mitigating hallucinations, particularly in scenarios involving implicit relationships or ambiguous information within tables. Additionally, the tree-structured reasoning mechanism enables the model to adapt to diverse table structures and complex reasoning tasks, offering a versatile solution for real-world applications.
Looking ahead, several promising directions remain to be explored. First, enabling real-time updates of Knowledge Graphs could further enhance the model’s ability to handle dynamic data environments. Second, extending TQAgent to support multimodal inputs (e.g., integrating visual and textual data) would broaden its applicability in domains like scientific research and business analytics. Finally, optimizing the framework for resource-constrained settings through advanced compression techniques will ensure scalability across different deployment scenarios.
Author Contributions
Conceptualization, J.Z., P.Z., Y.W., R.X., X.L., R.L. and S.L.; project administration, P.Z., Z.O. and M.S.; validation, X.L. and S.L.; writing—original draft, X.L. and R.L.; writing—review and editing, S.L., Z.O. and M.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the State Grid Hebei Electric Power Company under the project “Research on Energy Internet Knowledge-Guided Answering Technology between Large Models Driven by Data and Knowledge” (Project Number: KJ2023-093).
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
This work was supported by the State Grid Hebei Electric Power Company. I would like to express my sincere gratitude to everyone who contributed to this article. Without everyone’s concerted efforts, this article has could not have been accomplished. Special thanks to Haotong Bao, Yifan Zhu, and Bo Zhang for their invaluable contributions. During the preparation of this study, the authors used ChatGPT for the purposes of generating Fine-Tuning Dataset. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest regarding the present study.
References
- Fang, X.; Xu, W.; Tan, F.A.; Zhang, J.; Hu, Z.; Qi, Y.; Nickleach, S.; Socolinsky, D.; Sengamedu, S.; Faloutsos, C. Large Language Models (LLMs) on Tabular Data: Prediction, Generation, and Understanding—A Survey. arXiv 2024, arXiv:2402.17944. [Google Scholar]
- Ritze, D.; Lehmberg, O.; Bizer, C. Matching html tables to dbpedia. In Proceedings of the 5th International Conference on Web Intelligence, Mining and Semantics, Larnaca, Cyprus, 13–15 July 2015; pp. 1–6. [Google Scholar]
- Zhang, S.; Balog, K. Entitables: Smart assistance for entity-focused tables. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 255–264. [Google Scholar]
- Cheng, Z.; Dong, H.; Wang, Z.; Jia, R.; Guo, J.; Gao, Y.; Han, S.; Lou, J.G.; Zhang, D. Hitab: A hierarchical table dataset for question answering and natural language generation. arXiv 2021, arXiv:2108.06712. [Google Scholar]
- Nan, L.; Hsieh, C.; Mao, Z.; Lin, X.V.; Verma, N.; Zhang, R.; Kryściński, W.; Schoelkopf, H.; Kong, R.; Tang, X.; et al. FeTaQA: Free-form table question answering. Trans. Assoc. Comput. Linguist. 2022, 10, 35–49. [Google Scholar]
- Liu, Q.; Chen, B.; Guo, J.; Ziyadi, M.; Lin, Z.; Chen, W.; Lou, J.G. TAPEX: Table pre-training via learning a neural SQL executor. arXiv 2021, arXiv:2107.07653. [Google Scholar]
- Zhao, J.; Huang, S.; Cole, J.M. OpticalBERT and OpticalTable-SQA: Text-and table-based language models for the optical-materials domain. J. Chem. Inf. Model. 2023, 63, 1961–1981. [Google Scholar]
- Deng, X.; Sun, H.; Lees, A.; Wu, Y.; Yu, C. Turl: Table understanding through representation learning. ACM SIGMOD Rec. 2022, 51, 33–40. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar]
- Lenat, D.; Marcus, G. Getting from generative ai to trustworthy ai: What llms might learn from cyc. arXiv 2023, arXiv:2308.04445. [Google Scholar]
- Mallen, A.; Asai, A.; Zhong, V.; Das, R.; Khashabi, D.; Hajishirzi, H. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. arXiv 2022, arXiv:2212.10511. [Google Scholar]
- Zhang, M.; Press, O.; Merrill, W.; Liu, A.; Smith, N.A. How language model hallucinations can snowball. arXiv 2023, arXiv:2305.13534. [Google Scholar]
- Mialon, G.; Dessì, R.; Lomeli, M.; Nalmpantis, C.; Pasunuru, R.; Raileanu, R.; Rozière, B.; Schick, T.; Dwivedi-Yu, J.; Celikyilmaz, A.; et al. Augmented language models: A survey. arXiv 2023, arXiv:2302.07842. [Google Scholar]
- Mruthyunjaya, V.; Pezeshkpour, P.; Hruschka, E.; Bhutani, N. Rethinking language models as symbolic knowledge graphs. arXiv 2023, arXiv:2308.13676. [Google Scholar]
- Strich, J. Adapt LLM for Multi-turn Reasoning QA using Tidy Data. In Proceedings of the Joint Workshop of the 9th Financial Technology and Natural Language Processing (FinNLP), the 6th Financial Narrative Processing (FNP), and the 1st Workshop on Large Language Models for Finance and Legal (LLMFinLegal), Abu Dhabi, United Arab Emirates, 19–20 January 2025; pp. 392–400. [Google Scholar]
- Martynova, A.; Tishin, V.; Semenova, N. Learn Together: Joint Multitask Finetuning of Pretrained KG-enhanced LLM for Downstream Tasks. In Proceedings of the Workshop on Generative AI and Knowledge Graphs (GenAIK), Abu Dhabi, United Arab Emirates, 19 January 2025; pp. 13–19. [Google Scholar]
- Zhang, W.; Wang, Y.; Song, Y.; Wei, V.J.; Tian, Y.; Qi, Y.; Chan, J.H.; Wong, R.C.W.; Yang, H. Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey. IEEE Trans. Knowl. Data Eng. 2024, 36, 6699–6718. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, L.; Cohan, A.; Zhao, C. TaPERA: Enhancing faithfulness and interpretability in long-form table QA by content planning and execution-based reasoning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; pp. 12824–12840. [Google Scholar]
- Ye, Y.; Hui, B.; Yang, M.; Li, B.; Huang, F.; Li, Y. Large language models are versatile decomposers: Decomposing evidence and questions for table-based reasoning. In Proceedings of the 46th International ACM SIGIR Conference on Research and development In Information Retrieval, Taipei, China, 23–27 July 2023; pp. 174–184. [Google Scholar]
- He, X.; Zhou, M.; Xu, X.; Ma, X.; Ding, R.; Du, L.; Gao, Y.; Jia, R.; Chen, X.; Han, S.; et al. Text2analysis: A benchmark of table question answering with advanced data analysis and unclear queries. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 18206–18215. [Google Scholar]
- Li, P.; He, Y.; Yashar, D.; Cui, W.; Ge, S.; Zhang, H.; Rifinski Fainman, D.; Zhang, D.; Chaudhuri, S. Table-gpt: Table fine-tuned gpt for diverse table tasks. Proc. Acm Manag. Data 2024, 2, 1–28. [Google Scholar]
- Sui, Y.; Zhou, M.; Zhou, M.; Han, S.; Zhang, D. Table meets llm: Can large language models understand structured table data? A benchmark and empirical study. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Virtual, 4–8 March 2024; pp. 645–654. [Google Scholar]
- Rajkumar, N.; Li, R.; Bahdanau, D. Evaluating the Text-to-SQL Capabilities of Large Language Models. arXiv 2022, arXiv:2204.00498. [Google Scholar]
- Fan, J.; Gu, Z.; Zhang, S.; Zhang, Y.; Chen, Z.; Cao, L.; Li, G.; Madden, S.; Du, X.; Tang, N. Combining Small Language Models and Large Language Models for Zero-Shot NL2SQL. Proc. VLDB Endow. 2024, 17, 2750–2763. [Google Scholar] [CrossRef]
- Zhang, T.; Yue, X.; Li, Y.; Sun, H. TableLlama: Towards Open Large Generalist Models for Tables. arXiv 2024, arXiv:2403.03636. [Google Scholar]
- Chen, Y.; Yuan, Y.; Zhang, Z.; Zheng, Y.; Liu, J.; Ni, F.; Hao, J.; Mao, H.; Zhang, F. SheetAgent: Towards A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models. arXiv 2025, arXiv:2403.03636. [Google Scholar]
- Lavrinovics, E.; Biswas, R.; Bjerva, J.; Hose, K. Knowledge Graphs, Large Language Models, and Hallucinations: An NLP Perspective. J. Web Semant. 2025, 85, 100844. [Google Scholar]
- Guan, X.; Liu, Y.; Lin, H.; Lu, Y.; He, B.; Han, X.; Sun, L. Mitigating large language model hallucinations via autonomous knowledge graph-based retrofitting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 18126–18134. [Google Scholar]
- Ledger, G.; Mancinni, R. Detecting llm hallucinations using monte carlo simulations on token probabilities. Authorea Prepr. 2024; preprint. [Google Scholar]
- Du, X.; Xiao, C.; Li, S. Haloscope: Harnessing unlabeled llm generations for hallucination detection. Adv. Neural Inf. Process. Syst. 2025, 37, 102948–102972. [Google Scholar]
- Fairburn, S.; Ainsworth, J. Mitigate large language model hallucinations with probabilistic inference in graph neural networks. Authorea Prepr. 2024; preprint. [Google Scholar]
- Taveekitworachai, P.; Abdullah, F.; Thawonmas, R. Null-shot prompting: Rethinking prompting large language models with hallucination. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 13321–13361. [Google Scholar]
- Qiu, Y. The Impact of LLM Hallucinations on Motor Skill Learning: A Case Study in Badminton. IEEE Access 2024, 12, 139669–139682. [Google Scholar] [CrossRef]
- Waldo, J.; Boussard, S. GPTs and Hallucination: Why do large language models hallucinate? Queue 2024, 22, 19–33. [Google Scholar]
- Li, S.; Ji, H.; Han, J. Document-Level Event Argument Extraction by Conditional Generation. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Online, 6–11 June 2021. [Google Scholar]
- Chen, W.; Wang, H.; Chen, J.; Zhang, Y.; Wang, H.; Li, S.; Zhou, X.; Wang, W.Y. Tabfact: A large-scale dataset for table-based fact verification. arXiv 2019, arXiv:1909.02164. [Google Scholar]
- Srivastava, P.; Ganu, T.; Guha, S. Towards Zero-Shot and Few-Shot Table Question Answering using GPT-3. arXiv 2022, arXiv:2210.17284. [Google Scholar]
- Ren, Y.; Yu, C.; Li, W.; Li, W.; Zhu, Z.; Zhang, T.; Qin, C.; Ji, W.; Zhang, J. TableGPT: A novel table understanding method based on table recognition and large language model collaborative enhancement. Appl. Intell. 2025, 55, 311. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2023, arXiv:2201.11903. [Google Scholar]
- Zhang, H.; Si, S.; Zhao, Y.; Xie, L.; Xu, Z.; Chen, L.; Nan, L.; Wang, P.; Tang, X.; Cohan, A. OpenT2T: An Open-Source Toolkit for Table-to-Text Generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Miami, FL, USA, 12–16 November 2024; Hernandez Farias, D.I., Hope, T., Li, M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 259–269. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).