
GaussianMix: Rethinking Receptive Field for Efficient Data Augmentation


Abstract
1. Introduction
- To the best of our knowledge, this work is the first to leverage CNN receptive field theory for the selection of an appropriate source patch for data augmentation.
- Our method selects the salient source patch without relying on a saliency detection algorithm, resulting in significantly improved augmentation efficiency compared to saliency-based and dual-optimization methods.
- The proposed method outperforms state-of-the-art data augmentation methods on image classification, object detection, and adversarial robustness tasks.
2. Related Work
2.1. Data Augmentation
2.2. Receptive Field
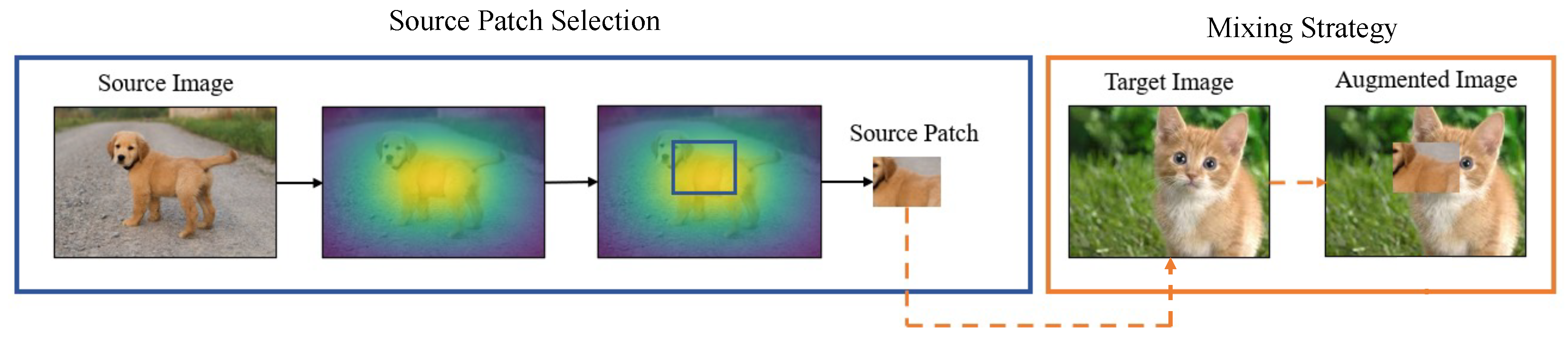
3. Proposed Methods
3.1. Selection of Source Patch
3.2. Mixing the Patches and Labels
| Algorithm 1: Applying GaussianMix to a mini-batch |
 |
4. Experiments and Results
4.1. Classification
4.2. Computational Complexity
4.3. Object Detection
4.4. Adversarial Robustness
5. Ablation Study
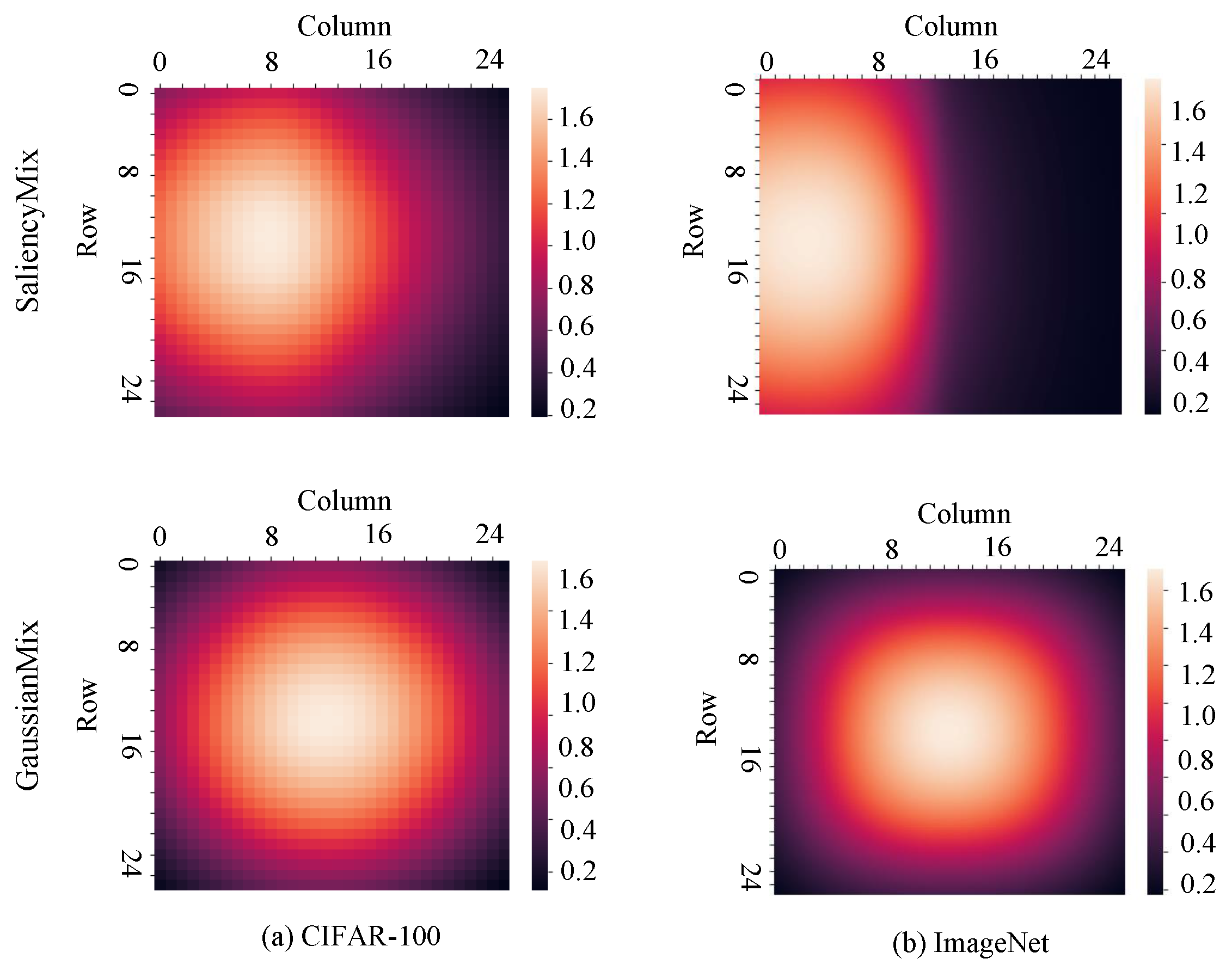
5.1. Mixing Strategies
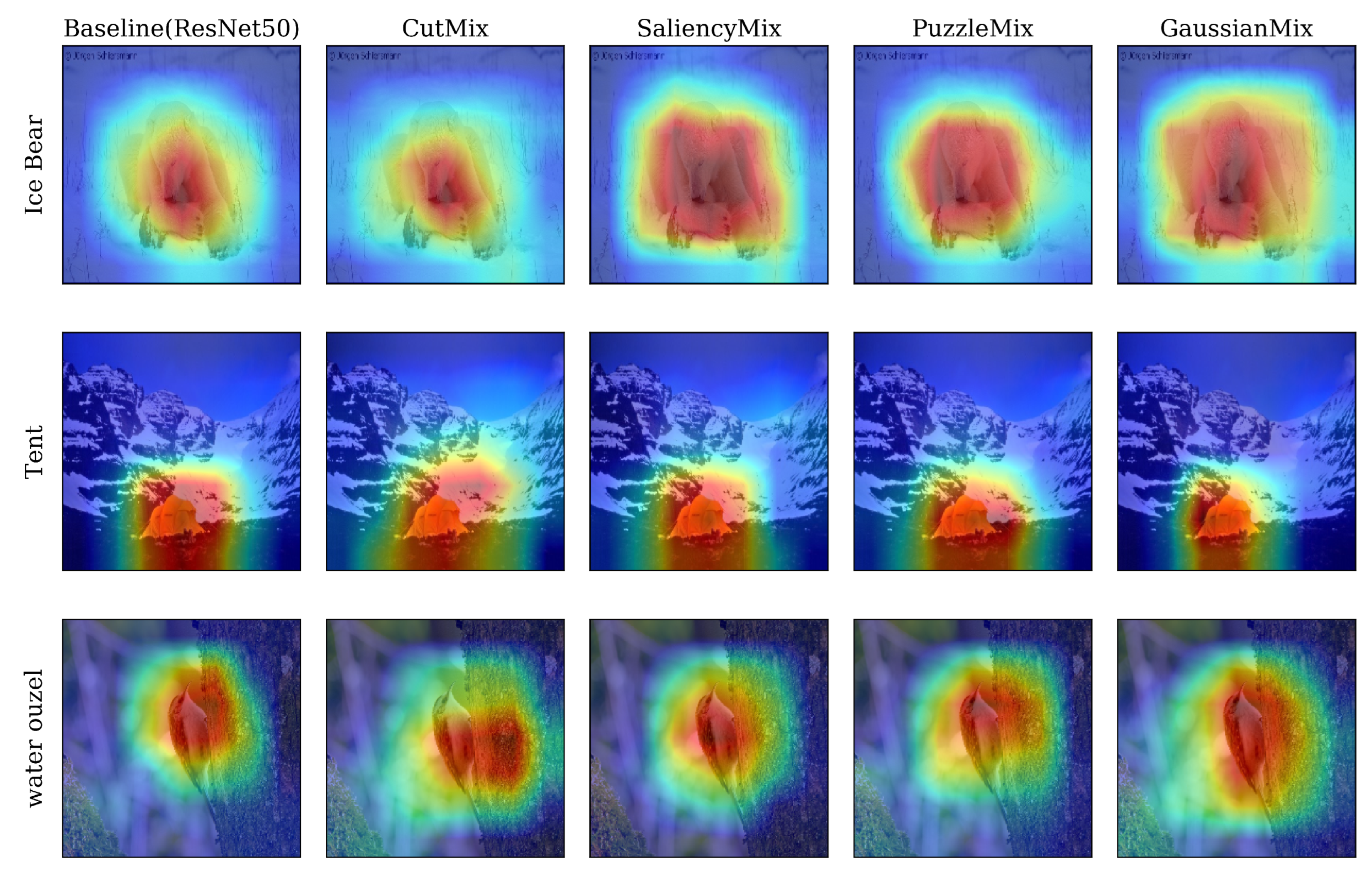
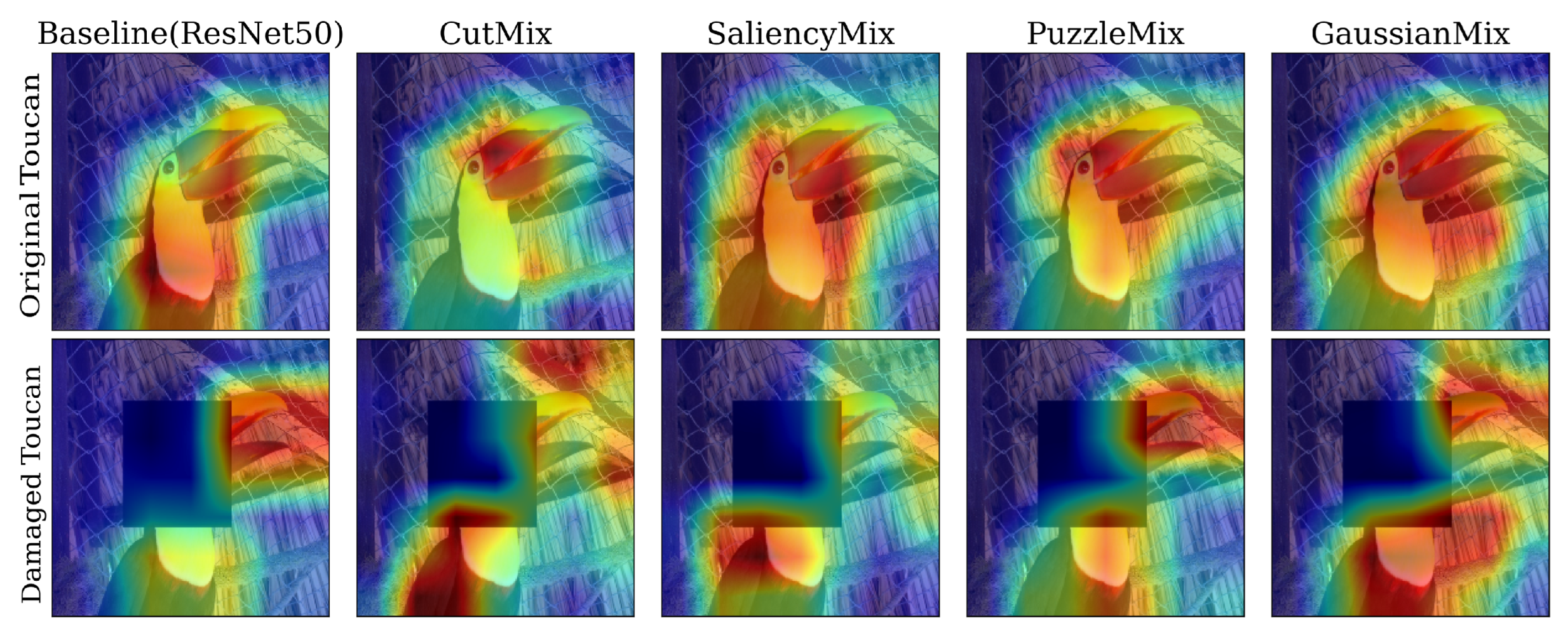
5.2. Class Activation Map (CAM)
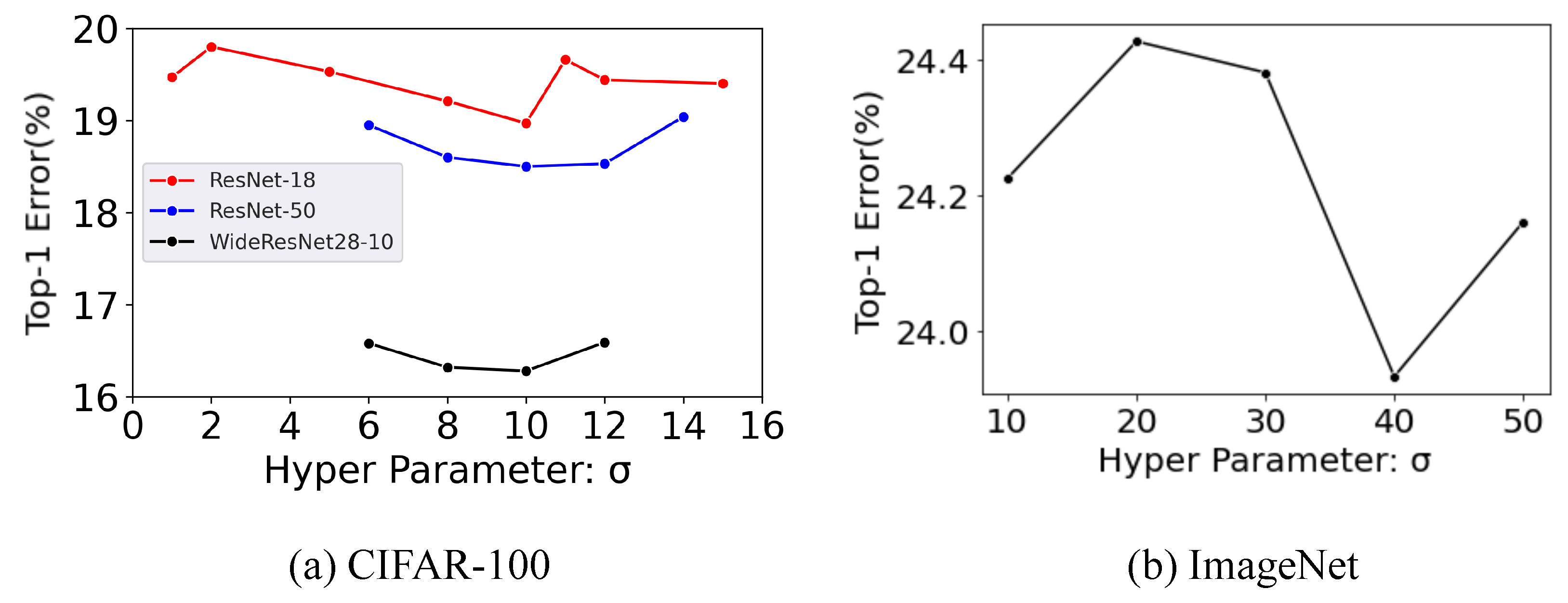
5.3. Exploring Optimal Sigma
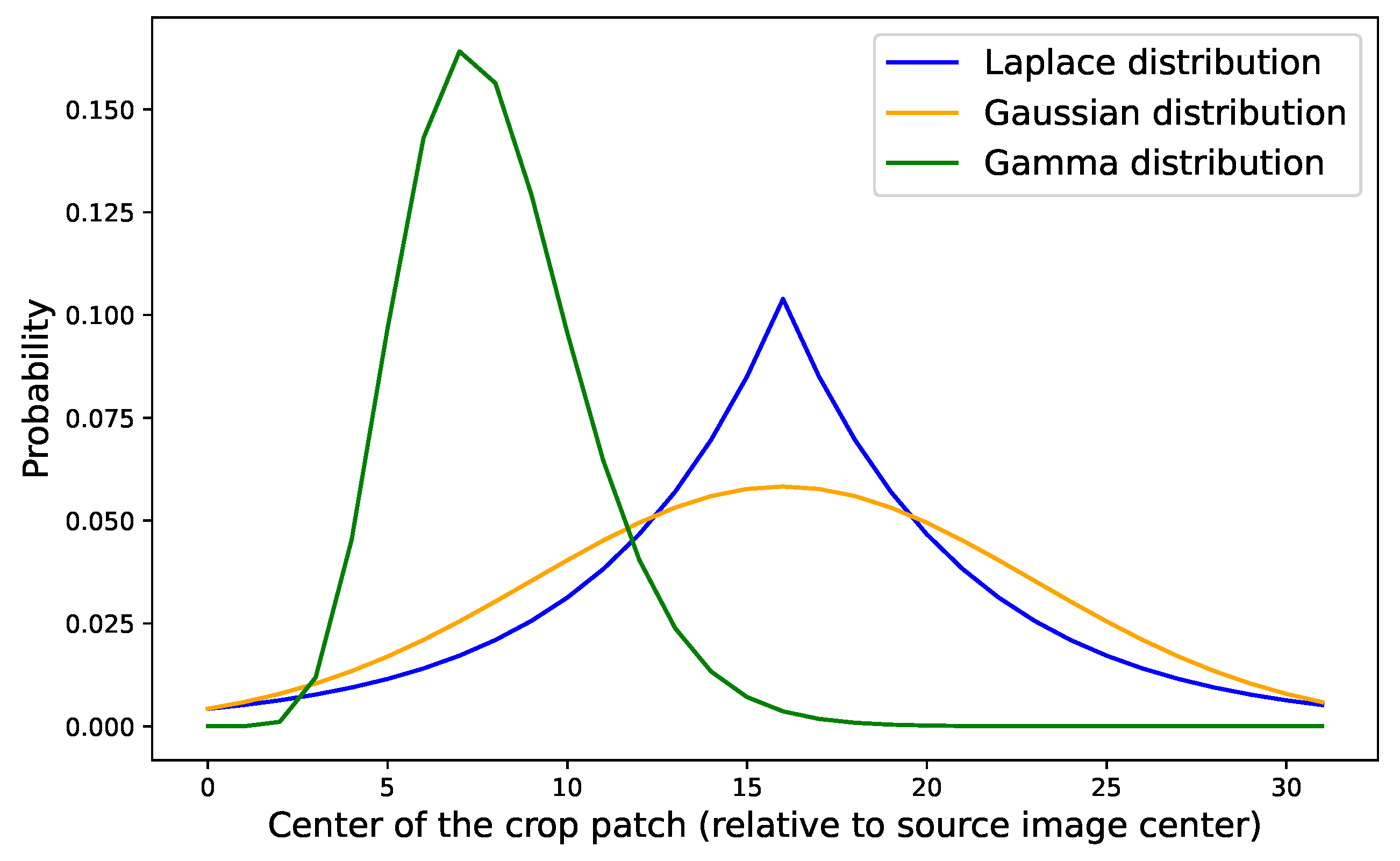
5.4. Different Distributions
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/hash/14bfa6bb14875e45bba028a21ed38046-Abstract.html (accessed on 13 April 2025). [CrossRef] [PubMed]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3d object proposals for accurate object class detection. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper_files/paper/2015/file/6da37dd3139aa4d9aa55b8d237ec5d4a-Paper.pdf (accessed on 13 April 2025).
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef]
- Steinke, D.; Ratnasingham, S.; Agda, J.; Ait Boutou, H.; Box, I.C.; Boyle, M.; Chan, D.; Feng, C.; Lowe, S.C.; McKeown, J.T.; et al. Towards a Taxonomy Machine: A Training Set of 5.6 Million Arthropod Images. Data 2024, 9, 122. [Google Scholar] [CrossRef]
- Kebaili, A.; Lapuyade-Lahorgue, J.; Ruan, S. Deep learning approaches for data augmentation in medical imaging: A review. J. Imaging 2023, 9, 81. [Google Scholar] [CrossRef]
- Alomar, K.; Aysel, H.I.; Cai, X. Data augmentation in classification and segmentation: A survey and new strategies. J. Imaging 2023, 9, 46. [Google Scholar] [CrossRef]
- Kumar, T.; Mileo, A.; Brennan, R.; Bendechache, M. Rsmda: Random slices mixing data augmentation. Appl. Sci. 2023, 13, 1711. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Kim, J.H.; Choo, W.; Song, H.O. Puzzle mix: Exploiting saliency and local statistics for optimal mixup. In Proceedings of the International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 5275–5285. [Google Scholar]
- Uddin, A.S.; Monira, M.S.; Shin, W.; Chung, T.; Bae, S.H. SaliencyMix: A Saliency Guided Data Augmentation Strategy for Better Regularization. In Proceedings of the International Conference on Learning Representations, Virtually, 3–7 May 2021. [Google Scholar]
- Kim, J.H.; Choo, W.; Jeong, H.; Song, H.O. Co-mixup: Saliency guided joint mixup with supermodular diversity. arXiv 2021, arXiv:2102.03065. [Google Scholar]
- Montabone, S.; Soto, A. Human detection using a mobile platform and novel features derived from a visual saliency mechanism. Image Vis. Comput. 2010, 28, 391–402. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4905–4913. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 13 April 2025). [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Tagaris, T.; Sdraka, M.; Stafylopatis, A. High-resolution class activation mapping. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4514–4518. [Google Scholar]
- Bengio, Y.; Bastien, F.; Bergeron, A.; Boulanger-Lewandowski, N.; Breuel, T.; Chherawala, Y.; Cisse, M.; Côté, M.; Erhan, D.; Eustache, J.; et al. Deep learners benefit more from out-of-distribution examples. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 164–172. [Google Scholar]
- Bishop, C.M. Training with noise is equivalent to Tikhonov regularization. Neural Comput. 1995, 7, 108–116. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Harris, E.; Marcu, A.; Painter, M.; Niranjan, M.; Prügel-Bennett, A.; Hare, J. Fmix: Enhancing mixed sample data augmentation. arXiv 2020, arXiv:2002.12047. [Google Scholar]
- Takahashi, R.; Matsubara, T.; Uehara, K. Ricap: Random image cropping and patching data augmentation for deep cnns. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 786–798. [Google Scholar]
- Cong, R.; Lei, J.; Fu, H.; Cheng, M.M.; Lin, W.; Huang, Q. Review of visual saliency detection with comprehensive information. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2941–2959. [Google Scholar] [CrossRef]
- Wang, H.; Song, S.; Huang, G. GridMix: Exploring Spatial Modulation for Neural Fields in PDE Modeling. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025. [Google Scholar]
- Huang, G.B.; Bai, Z.; Kasun, L.L.C.; Vong, C.M. Local receptive fields based extreme learning machine. IEEE Comput. Intell. Mag. 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Vázquez-Hernández, M.; Morales-Rosales, L.A.; Algredo-Badillo, I.; Fernández-Gregorio, S.I.; Rodríguez-Rangel, H.; Córdoba-Tlaxcalteco, M.L. A Survey of Adversarial Attacks: An Open Issue for Deep Learning Sentiment Analysis Models. Appl. Sci. 2024, 14, 4614. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Moore, D.S.; McCabe, G.P.; Craig, B.A. Introduction to the Practice of Statistics; WH Freeman: New York, NY, USA, 2009; Volume 4. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://papers.nips.cc/paper_files/paper/2012/hash/05311655a15b75fab86956663e1819cd-Abstract.html (accessed on 13 April 2025).
- Rong, G.; Li, K.; Su, Y.; Tong, Z.; Liu, X.; Zhang, J.; Zhang, Y.; Li, T. Comparison of tree-structured parzen estimator optimization in three typical neural network models for landslide susceptibility assessment. Remote Sens. 2021, 13, 4694. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Top-1 Error |
|---|---|
| ResNet-18 (Baseline) | 22.46 ± 0.3 |
| ResNet-18+CutOut | 21.96 ± 0.24 |
| ResNet-18+FMix | 20.15 ± 0.27 |
| ResNet-18+CutMix | 19.42 ± 0.24 |
| ResNet-18+SaliencyMix | 19.29 ± 0.21 |
| ResNet-18+PuzzleMix (200 Epoch) | 31.78 ± 0.20 |
| ResNet-18+PuzzleMix (1200 Epoch) | 19.66 ± 0.18 |
| ResNet-18+GaussianMix | 18.97 ± 0.14 |
| ResNet-50 (BASELINE) | 21.58 ± 0.43 |
| ResNet-50+CutOut | 21.38 ± 0.69 |
| ResNet-50+CutMix | 18.72 ± 0.23 |
| ResNet-50+SaliencyMix | 18.57 ± 0.29 |
| ResNet-50+PuzzleMix (200 Epoch) | 26.61 ± 0.51 |
| ResNet-50+PuzzleMix (1200 Epoch) | 17.17 ± 0.42 |
| ResNet-50+GaussianMix | 18.50 ± 0.37 |
| WideResNet28-10 (BASELINE) | 18.80 ± 0.08 |
| WideResNet28-10+CutOut | 18.41 ± 0.27 |
| WideResNet28-10+FMix | 17.97 ± 0.27 |
| WideResNet28-10+CutMix | 16.66 ± 0.20 |
| WideResNet28-10+SaliencyMix | 16.56 ± 0.17 |
| WideResNet28-10+PuzzleMix | 16.23 ± 0.17 |
| WideResNet28-10+GaussianMix | 16.28 ± 0.26 |
| Method | Top-1 Error |
|---|---|
| ResNet-50 (Baseline) | 23.68 |
| ResNet-50+CutOut | 22.93 |
| ResNet-50+Mixup | 22.58 |
| ResNet-50+CutMix | 21.40 |
| ResNet-50+SaliencyMix | 21.26 |
| ResNet-50+PuzzleMix | 21.24 |
| ResNet-50+GaussianMix | 21.24 |
| ResNet-101 (BASELINE) | 21.87 |
| ResNet-101+Cutout | 22.30 |
| ResNet-101+Cutout | 20.72 |
| ResNet-101+Mixup | 20.57 |
| ResNet-101+CutMix | 20.17 |
| ResNet-101+SaliencyMix | 20.09 |
| ResNet-101+PuzzleMix | 19.71 |
| ResNet-101+GaussianMix | 19.80 |
| Backbone Network | ImageNet Classification Error | Object Detection Performance |
|---|---|---|
| Top-1 (%) | Faster-RCNN (mAP) | |
| ResNet-101 (Baseline) | 21.87 | 77.53 (+0.00) |
| CutMix-Trained | 20.17 | 80.04 (+2.51) |
| SaliencyMix-Trained | 20.09 | 79.91 (+2.38) |
| GaussianMix-Trained | 19.80 | 80.00 (+2.47) |
| Baseline | CutMix | SaliencyMix | GaussianMix |
|---|---|---|---|
| 23.71 | 41.83 | 40.49 | 41.85 |
| Method | Top-1 Error |
|---|---|
| ResNet-18 | |
| + Corresponding position | 18.97 ± 0.14 |
| + Center position | 19.87 ± 0.13 |
| + Random position (Uniform) | 19.22 ± 0.18 |
| + Random position (Gaussian) | 19.62 ± 0.32 |
| Method | Top-1 Error |
|---|---|
| ResNet-50 | |
| + Corresponding position | 33.47 ± 1.04 |
| + Center position | 34.55 ± 0.46 |
| + Random position (Uniform) | 34.28 ± 0.38 |
| + Random position (Gaussian) | 34.66 ± 0.36 |
| Distribution | Top-1 Error |
|---|---|
| ResNEt-18 (BASELINE) | 22.46 |
| ResNet-18+Laplace distribution | 20.15 |
| ResNEt-18+Gamma distribution | 19.24 |
| ResNEt-18+Gaussian distribution | 18.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, A.F.M.S.; Qamar, M.; Mun, J.; Lee, Y.; Bae, S.-H. GaussianMix: Rethinking Receptive Field for Efficient Data Augmentation. Appl. Sci. 2025, 15, 4704. https://doi.org/10.3390/app15094704
Uddin AFMS, Qamar M, Mun J, Lee Y, Bae S-H. GaussianMix: Rethinking Receptive Field for Efficient Data Augmentation. Applied Sciences. 2025; 15(9):4704. https://doi.org/10.3390/app15094704
Chicago/Turabian StyleUddin, A. F. M. Shahab, Maryam Qamar, Jueun Mun, Yuje Lee, and Sung-Ho Bae. 2025. "GaussianMix: Rethinking Receptive Field for Efficient Data Augmentation" Applied Sciences 15, no. 9: 4704. https://doi.org/10.3390/app15094704
APA StyleUddin, A. F. M. S., Qamar, M., Mun, J., Lee, Y., & Bae, S.-H. (2025). GaussianMix: Rethinking Receptive Field for Efficient Data Augmentation. Applied Sciences, 15(9), 4704. https://doi.org/10.3390/app15094704