Abstract
Conventional visual SLAM systems often struggle with degraded pose estimation accuracy in dynamic environments due to the interference of moving objects and unstable feature tracking. To address this critical challenge, we present a groundbreaking enhancement to visual SLAM by introducing an innovative architecture that integrates advanced feature extraction and dynamic object filtering mechanisms. At the core of our approach lies a novel Multi-Scale Feature Consolidation (MSFConv) module, which we have developed to significantly boost the feature extraction capabilities of the YOLOv8 network. This module enables superior multi-scale feature representation, leading to significant improvements in object detection accuracy and robustness. Furthermore, we have developed a Dynamic Object Filtering Framework (DOFF) that seamlessly integrates with the ORB-SLAM3 architecture. By leveraging the Lucas-Kanade (LK) optical flow method, DOFF effectively distinguishes and removes dynamic feature points while preserving the integrity of static features. This ensures high-precision pose estimation in highly dynamic environments. Comprehensive experiments on the TUM RGB-D dataset validate the exceptional performance of our proposed method, demonstrating 93.34% and 94.43% improvements in pose estimation accuracy over the baseline ORB-SLAM3 in challenging dynamic sequences. These substantial improvements are achieved through the synergistic combination of enhanced feature extraction and precise dynamic object filtering. Our work represents a significant leap forward in visual SLAM technology, offering a robust solution to the long-standing problem of dynamic environment handling. The proposed innovations not only advance the state-of-the-art in SLAM research but also pave the way for more reliable real-world applications in robotics and autonomous systems.
1. Introduction
Simultaneous Localization and Mapping (SLAM) is a foundational technology for autonomous robotic systems, enabling precise navigation and mapping in unknown environments [1]. Visual SLAM, leveraging affordable and information-rich camera sensors, has emerged as a critical approach due to its ability to provide detailed spatial understanding, supporting applications such as robotic exploration, augmented reality, and autonomous navigation [2]. With advancements in computational power and sensor technology, systems like ORB-SLAM3 have achieved remarkable performance in static environments by relying on robust feature extraction and graph-based optimization [3]. However, these conventional visual SLAM frameworks encounter significant challenges in dynamic indoor settings, where moving objects—such as people or shifting furniture—introduce noise that disrupts feature tracking and degrades pose estimation accuracy [4].
The limitations of traditional visual SLAM in dynamic environments arise from several factors, including the assumption of scene rigidity, the unpredictability of object motion, and the difficulty in distinguishing static from dynamic features [5]. These issues lead to increased trajectory errors and reduced mapping reliability, hindering the deployment of SLAM systems in real-world scenarios where dynamic elements are prevalent. Over the years, researchers have proposed various strategies to address these challenges, ranging from geometric modeling and semantic understanding to the integration of deep learning techniques [6,7]. Despite these efforts, achieving robust and accurate localization in highly dynamic scenes remains an open problem, necessitating innovative solutions that balance performance, efficiency, and adaptability.
In this paper, we introduce Multi-Scale Feature SLAM (MSF-SLAM), a novel framework designed to enhance visual SLAM performance in dynamic environments. MSF-SLAM integrates a Multi-Scale Feature Consolidation (MSFConv) module into the YOLOv8 object detection network to improve feature extraction across multiple scales, coupled with a Dynamic Object Filtering Framework (DOFF) within ORB-SLAM3 that employs the Lucas-Kanade (LK) optical flow method to eliminate dynamic feature points. This dual approach ensures robust detection of moving objects and precise retention of static features critical for pose estimation. The key contributions of this work include:
- i.
- Enhanced Feature Extraction: The MSFConv module augments YOLOv8, enabling superior detection of dynamic objects with minimal computational overhead.
- ii.
- Dynamic Feature Management: The DOFF leverages LK optical flow to filter out dynamic features, enhancing ORB-SLAM3’s robustness in real-time dynamic scenes.
- iii.
- Extensive Validation: Comprehensive experiments on the TUM RGB-D [link] dataset demonstrate significant improvements, with pose estimation accuracy increasing by up to 94.43% over ORB-SLAM3 in dynamic sequences.
The remainder of this paper is organized as follows: Section 2 reviews related work on visual SLAM and dynamic environment handling. Section 3 describes the MSF-SLAM framework, including the MSFConv and DOFF components. Section 4 presents experimental results and analysis. Finally, Section 5 concludes with key findings and future directions.
2. Related Work
The evolution of filter-based SLAM techniques has steadily advanced, driven by the pursuit of greater localization and mapping accuracy. Early approaches, such as EKF-SLAM, established a foundational framework but struggled with scalability due to their high computational complexity. More recent innovations have built upon this groundwork, enhancing robustness in challenging settings. For instance, Yang et al.’s multi-sensor fusion particle filtering [8] and Li et al.’s anti-degeneracy scheme for LiDAR SLAM [9] have improved performance in indoor and feature-scarce essnvironments. Despite these strides, challenges like computational intensity remain, particularly in dynamic contexts, as highlighted by Dhaigude and Kulkarni [10]. Hybrid methods, such as Zhao et al.’s integration of EKF with visual data [11], offer incremental gains but still fall short in highly dynamic scenarios, where adaptability remains a limiting factor.
In parallel, graph optimization has emerged as a powerful tool, significantly boosting SLAM precision and scalability. Pioneering techniques like Sparse Bundle Adjustment and ORB-SLAM introduced 7-DoF pose graph optimization and loop closure, effectively reducing drift in static scenes. Building on these ideas, recent developments have pushed the boundaries further. He et al.’s GNSS graph optimization for LiDAR SLAM [12] and Bavle et al.’s S-Graphs 2.0 with hierarchical-semantic optimization [13] deliver improved accuracy and computational efficiency. Meanwhile, Wu et al.’s DALI-SLAM employs multi-constraint graph optimization to tackle degeneracy in LiDAR-inertial SLAM [14], and He et al.’s LDG-CSLAM leverages factor graphs to enable multi-robot collaboration [15]. Yet, these methods often rely on static scene assumptions, which can undermine their effectiveness in dynamic real-world environments.
The advent of deep learning has brought transformative potential to visual SLAM, particularly in handling dynamic settings. For example, Islam et al. integrate YOLOv8-based segmentation with sparse optical flow to enhance environmental perception, though this comes at the cost of increased computational demands [16]. Similarly, Wu’s approach uses multi-scale prediction and optical flow to track object motion in drone-based SLAM, but its complexity limits real-time applicability [17]. Object detection strategies have also advanced, with Chu et al.’s YOLOv8 paired with geometric constraints [18] and Cai et al.’s DFT-VSLAM using dynamic optical flow tracking [19] improving dynamic object detection—though multi-object scenarios remain a challenge. Cutting-edge innovations like Wang et al.’s [2] Dyna-OpenVINS with multi-scale semantic segmentation and Qian et al.’s LTD-SLAM employing multi-scale YOLOv8 [20] further refine feature extraction and localization accuracy, often sacrificing real-time performance in the process.
Drawing inspiration from these advancements, our work bridges SLAM-specific techniques with broader progress in computer vision. The challenge of managing dynamic features in SLAM echoes the multi-scale feature extraction tasks in object detection, as seen in Feature Pyramid Networks (FPNs) [21] and HRNet [22], which excel at detecting objects across diverse scales. Likewise, motion tracking methods, such as the Lucas-Kanade (LK) optical flow approach, have proven adept at analyzing dynamic scenes. Our proposed MSF-SLAM adapts these concepts, incorporating multi-scale feature extraction through the MSFConv module and dynamic feature filtering via the DOFF framework. This tailored solution strikes a balance between accuracy and efficiency, meeting the real-time demands of visual SLAM in dynamic environments with a practical and effective approach.
3. Methodology
3.1. Improved YOLOv8 Object Detection Algorithm
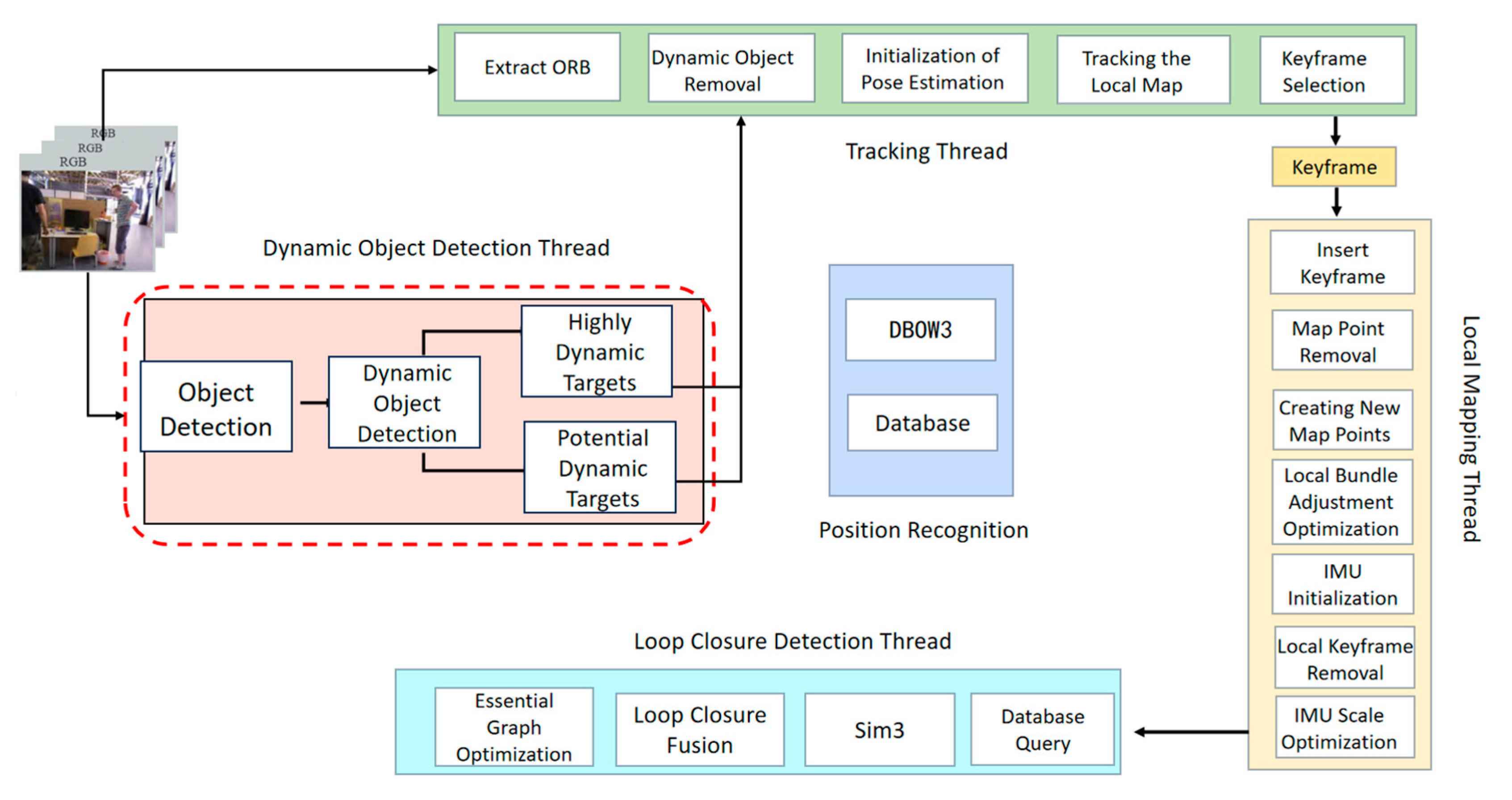
ORB-SLAM3 is composed of three main threads: the front-end tracking thread, the back-end local mapping thread, and the loop closure detection thread. The front-end tracking thread is responsible for extracting and matching features from image frames to estimate the camera pose, and it optimizes the pose by matching the current frame against keyframes in the map. After processing the current frame, the system evaluates whether it should be added as a new keyframe. The back-end local mapping thread employs graph optimization techniques to improve map accuracy by optimizing the spatial relationships between the current frame and associated keyframes. Simultaneously, the loop closure detection thread detects overlaps between the current scene and previously visited areas by matching the current frame with historical keyframes, thereby performing loop closure optimization. This process reduces cumulative errors and enhances the global map’s accuracy and consistency. Collectively, these threads enhance the long-term stability, robustness, and precision of the SLAM system.
In this study, the proposed algorithm extends the ORB-SLAM3 framework by incorporating a dynamic object detection thread based on YOLOv8 and integrating a dynamic feature point removal module into the front-end tracking thread. The architecture of the enhanced ORB-SLAM3 framework is illustrated in Figure 1.
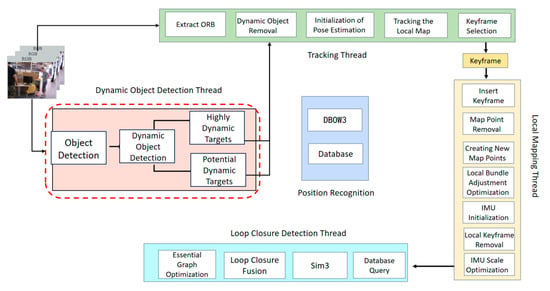
Figure 1.
Improved ORB-SLAM3 Thread Structure.
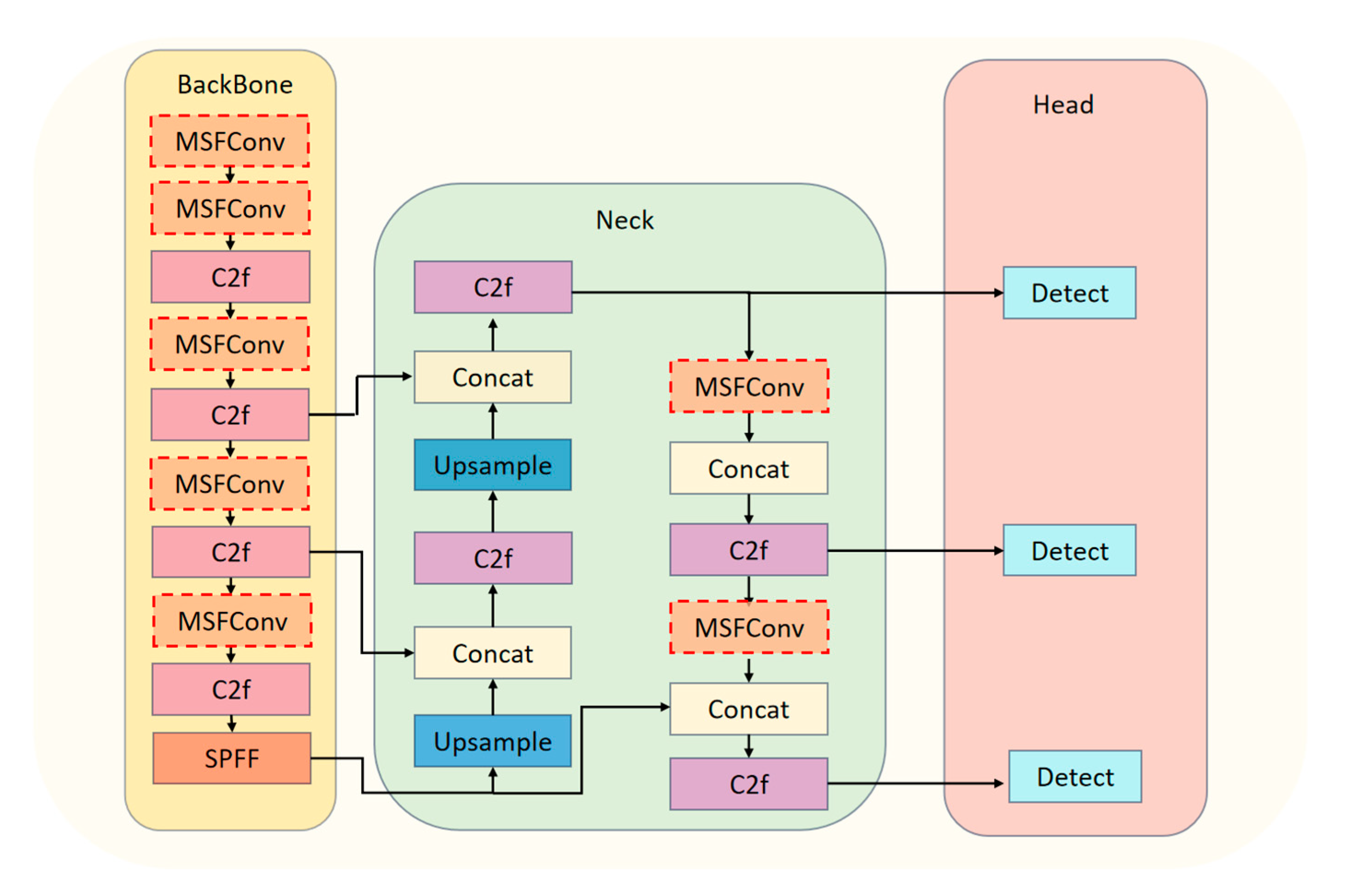
This study employs the YOLOv8 model, recognized for its high accuracy and stability, as the core network for dynamic object detection. The architecture of YOLOv8 comprises three main components: the Backbone, the Neck, and the Head.
The Backbone is responsible for feature extraction, employing a multilayer convolutional network to extract deep features from the input images. The Neck facilitates feature fusion by combining feature maps across multiple scales. Finally, the Head is dedicated to object detection and classification, generating the final recognition outputs.
Despite its strengths, YOLOv8’s existing convolutional structure has a relatively limited capacity for feature extraction when handling dynamic or moving objects. This limitation can lead to reduced detection accuracy for dynamic targets, diminishing the algorithm’s effectiveness in scenarios involving mobile objects. To address this challenge and enhance YOLOv8’s performance in dynamic object detection, this study introduces a Multi-Scale Feature Extraction Convolution module (MSFConv). The MSFConv module replaces the original convolutional structure, improving target detection accuracy without significantly increasing the model’s parameter size. The architecture of the enhanced YOLOv8 network is shown in Figure 2.
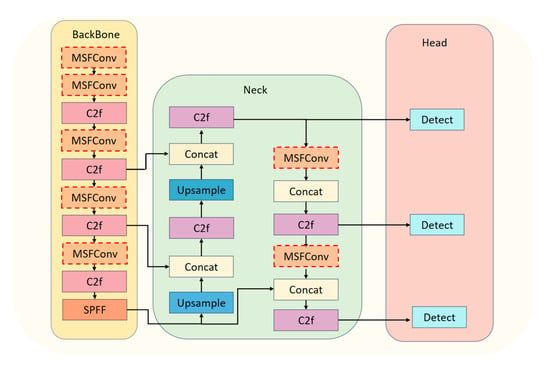
Figure 2.
Improved YOLOv8 Network Architecture.
To improve YOLOv8’s detection accuracy while minimizing the number of parameters, this study replaces the standard convolution in the original network with a custom-designed Multi-Scale Feature Convolution module (MSFConv). Unlike the single-scale convolution used in the original network for feature extraction, the MSFConv module employs a multi-scale design that incorporates convolutional kernels of varying sizes. This design enables the module to effectively capture both fine-grained details and global contextual features, enhancing detection performance across diverse scenarios.
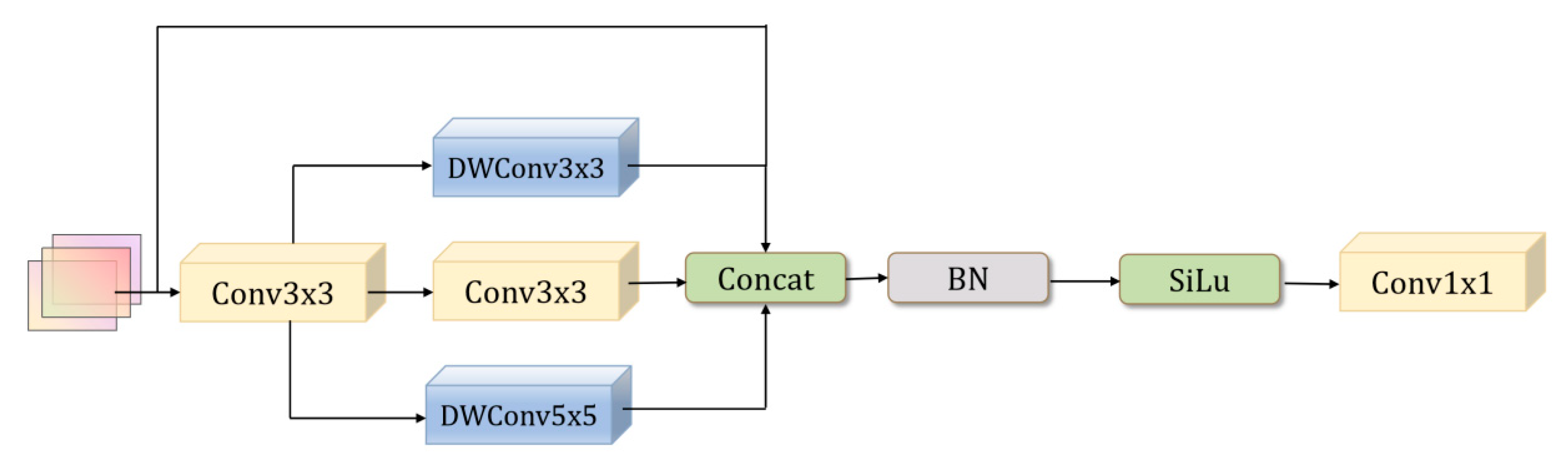
Furthermore, the MSFConv module incorporates depthwise separable convolution (DWConv), which preserves the spatial feature extraction capability while significantly reducing computational complexity and parameter overhead. The inclusion of a residual structure within the module enhances gradient propagation stability and strengthens the network’s representational capacity. Consequently, the model can focus more effectively on critical features, delivering superior detection performance. The detailed architecture of the MSFConv module is presented in Figure 3.
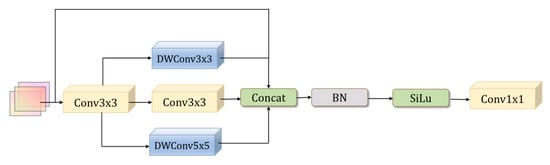
Figure 3.
MSFConv Module.
In the MSFConv module, feature maps are processed through a sequence of transformations and convolutional operations. The overall design can be outlined as follows.
Step 1: Preliminary Feature Extraction
The MSFConv module takes as input the feature maps , where represents the number of channels, H denotes the height, and W denotes the width of the feature maps. It begins by applying a standard convolution operation to extract local spatial information. This operation can be mathematically expressed as follows:
Here, denotes the standard convolution operation, and represents the nonlinear activation function.
Step 2: Multi-Scale Feature Extraction
Subsequently, the feature map is passed through three parallel branches designed to capture contextual information at different scales. These branches utilize a depthwise separable convolution (), a standard convolution (), and a depthwise separable convolution (), respectively.
Step 3: Feature Fusion
The three feature maps are concatenated along the channel dimension and then fused with the input feature map to create a residual structure.
Step 4: Normalization and Activation
The fused feature map is then passed through a Batch Normalization (BN) layer followed by a SiLU activation function to enhance its nonlinear representation capability.
Step 5: Output Adjustment
Finally, a convolution is applied to adjust the number of channels, resulting in the final output feature map.
3.2. Dynamic Feature Point Removal Method
- (1)
- LK Optical Flow Method
In this algorithm, the LK optical flow method is employed to compute the optical flow displacement of feature points. The LK optical flow algorithm is founded on the brightness constancy assumption, and it estimates pixel motion by analyzing brightness variations within a local neighborhood. The method is based on three fundamental assumptions: ① the brightness constancy assumption, ② the small displacement assumption, and ③ the local smoothness assumption.
Let represent the brightness of the pixel at position at time t. According to the brightness constancy assumption, the following relationship holds:
where and represent the motion displacements in the x and y directions, respectively.
By performing a Taylor expansion and neglecting higher-order terms, we obtain the following approximation:
After simplification, the following expression is obtained:
Based on the optical flow equation, we can derive the following matrix form:
To compute the optical flow vector for the feature point , a 5 × 5 pixel window is selected, centered around the feature point. An overdetermined system of equations is then formulated based on the window’s pixel values.
The motion vector is then solved using the least squares method, expressed as follows:
It can be simplified as:
When the coefficient matrix A is overdetermined, the components of the motion vector, u and v, can be computed using the least squares method as follows:
- (2)
- Dynamic Feature Point Removal Algorithm
The LK optical flow algorithm is employed to filter and remove dynamic feature points. Feature points in the current frame are categorized into two groups: those within known and potential dynamic target anchor boxes, classified as dynamic feature points and added to set D, and those outside the anchor boxes, classified as static feature points and placed in set S.
For each feature point in set S, the optical flow displacement (u, v) between the current and subsequent frames is calculated. If the magnitude of this displacement exceeds a predefined threshold L, the feature point is deemed dynamic, removed from set S, and added to set D. The final static feature points set S, with dynamic points removed, is then returned.
Building on the LK optical flow method’s role in distinguishing dynamic feature points, the selection of the threshold L plays a pivotal role in the algorithm’s effectiveness, as it governs the sensitivity of dynamic feature classification. A low L risks misclassifying static points as dynamic (false positives), thereby reducing the pool of usable features for pose estimation. Conversely, a high L may overlook subtle dynamic motions, permitting dynamic points to disrupt tracking accuracy. To identify an optimal L, we conducted a sensitivity analysis using the TUM RGB-D dataset’s “walking_xyz” sequence, which exhibits significant dynamic motion. We evaluated a range of L values (0.5, 1.0, 1.5, 2.0, and 2.5 pixels) based on their impact on pose estimation accuracy (measured by Absolute Trajectory Error, ATE RMSE) and the percentage of feature points retained as static.
The results of this analysis are presented in Table 1. At L = 0.5, the ATE RMSE is 0.0187 m, with only 62.3% of feature points retained, indicating excessive removal of static points. As L increases to 1.5, the ATE RMSE decreases to 0.0134 m, with 87.6% of points retained, striking a balance between dynamic point removal and static point preservation. Beyond L = 1.5, the ATE RMSE increases, as more dynamic points are retained, degrading accuracy. Based on this analysis, we selected L = 1.5 pixels as the default threshold, as it minimizes pose estimation error while maintaining a sufficient number of static features for robust tracking. This value aligns with typical motion characteristics in indoor dynamic scenes, where small displacements often correspond to noise or minor camera motion, while larger displacements indicate object motion.

Table 1.
Sensitivity Analysis of Threshold L on Walking_xyz Sequence.
The proposed algorithm effectively leverages both spatial information from dynamic and potential dynamic objects and the LK optical flow method to analyze feature point motion. Compared to more complex dynamic feature detection methods, it offers lower computational costs, making it suitable for real-time SLAM systems in dynamic environments. The algorithm’s workflow is summarized in Table 1.
The proposed algorithm effectively leverages both spatial information from dynamic and potential dynamic objects and the LK optical flow method to analyze feature point motion. This approach enables efficient estimation of motion changes between frames. Compared to more complex dynamic feature point detection methods, the proposed algorithm offers a lower computational cost, making it suitable for real-time SLAM systems in dynamic environments. The algorithm’s workflow using LK optical flow is summarized in Table 2.
Table 2.
Dynamic Feature Point Removal Algorithm.
4. Experiment and Results Analysis
To evaluate the performance of the improved ORB-SLAM3 algorithm, experiments were conducted on a high-performance system equipped with an Intel Core i9-14900HX CPU (Lenovo, Beijing, China) (24 cores, 32 threads, with a maximum turbo frequency of 5.8 GHz), 32 GB of DDR5-5600 MHz RAM (dual-channel, 2 × 16 GB), and an NVIDIA GeForce RTX 4060 Laptop GPU (Santa Clara, CA, USA). The system ran on Ubuntu 18.04, and the SLAM program was developed using C++ (https://visualstudio.microsoft.com (accessed on 21 June 2024)). To ensure fairness and reproducibility, all experiments were performed under consistent conditions, maintaining the same hardware platform, software environment, and parameter configurations across both the proposed algorithm and the comparison methods.
4.1. Experiment on the Improved YOLOv8 Object Detection Algorithm
To evaluate the effectiveness of the YOLOv8 algorithm enhanced by the MSF convolution module, this experiment utilizes the VOC2007 dataset [23], a standard benchmark for object detection, accessible at http://host.robots.ox.ac.uk/pascal/VOC/voc2007/ (accessed on 21 June 2024). The dataset contains 20 categories, including person, car, sheep, and others. It is split into training, validation, and test sets in a 6:2:2 ratio. The training set consists of 5977 images, the validation set includes 1993 images, and the test set also comprises 1993 images.
Object detection algorithms are commonly evaluated using the mean Average Precision (mAP) metric. A higher mAP value indicates better model performance. The mAP is calculated as follows:
In Equation (16), represents the average precision for a specific class, where c denotes the total number of sample categories, and j refers to the current class sample.
The detection results obtained using the improved YOLOv8 are presented in Figure 4. As shown in Figure 4a,b, even small and distant objects, which are barely visible, are accurately recognized.

Figure 4.
Detection Results. (a) Only a small portion of the features are visible. (b) Small targets at a long distance.
Building on the preliminary results presented in Table 3, this section provides a detailed analysis of the performance of the proposed YOLOv8n+MSFConv model. The evaluation focuses on standard metrics, including precision (P), recall (R), mean Average Precision at IoU = 0.5 (mAP@50), and mAP across IoU thresholds from 0.5 to 0.95 (mAP@50:95), to quantify detection accuracy. Additionally, we examine the computational complexity through parameters (Params), GFLOPs, and inference speed (Frames Per Second, FPS) to assess the trade-offs associated with the improved detection performance. All experiments were conducted on an NVIDIA GeForce RTX 4060 Laptop GPU, ensuring a consistent hardware environment for fair comparison.
Table 3.
Results of Ablation Study.
Table 3 highlights that YOLOv8n+MSFConv achieves a precision of 74.2%, marking a 6.31% improvement over the baseline YOLOv8n’s 69.8%. The mAP@50 increases from 64.0% to 65.1% (a 1.72% improvement), and the mAP@50:95 rises from 42.9% to 43.5% (a 1.40% improvement). These gains indicate that the multi-scale feature extraction capability of MSFConv effectively captures diverse object features, leading to more accurate detection in dynamic environments. However, this enhanced performance comes with a modest increase in computational complexity. The parameter count of YOLOv8n+MSFConv is 3.19 million, a 6.0% increase compared to YOLOv8n’s 3.01 million, and the GFLOPs rise from 8.1 to 8.9, reflecting a 9.9% increase in computational demand. Consequently, the inference speed decreases, with the FPS dropping from 275.1 for YOLOv8n to 233.1 for YOLOv8n+MSFConv, a 15.3% reduction. Despite this trade-off, the FPS of 233.1 remains well above the threshold of 30 FPS typically required for real-time SLAM applications, ensuring practical applicability in dynamic scenarios.
The superior performance of YOLOv8n+MSFConv can be attributed to its multi-scale feature consolidation mechanism, which leverages parallel convolutional branches (3 × 3, 5 × 5, and 7 × 7) to extract features at varying scales. This approach enhances the model’s ability to detect objects of different sizes and shapes, a critical requirement in dynamic indoor scenes where objects like people or furniture may vary significantly in scale. The slight decrease in recall (from 58.9% to 57.8%) suggests that while MSFConv improves precision by reducing false positives, it may occasionally miss some true positives, possibly due to the increased model complexity affecting feature generalization. Future optimizations could focus on balancing precision and recall to further improve overall performance.
To contextualize the proposed Multi-Scale Feature Consolidation (MSFConv) module, we compare it with established multi-scale feature extraction methods—Feature Pyramid Networks (FPNs) [21], HRNet [22], and Wu’s SLAM-specific approach [17]—focusing on detection accuracy, computational efficiency, and real-time suitability for SLAM.
Table 4 summarizes the results. YOLOv8n+MSFConv achieves a precision of 74.2%, mAP@50 of 65.1%, and mAP@50:95 of 43.5%, with 3.19 M parameters, 8.9 GFLOPs, and 233.1 FPS. YOLOv8n+FPN, with hierarchical feature fusion, improves precision to 76.1% and mAP@50 to 66.8%, but increases complexity, reducing FPS to 198.4. YOLOv8n+HRNet, maintaining high-resolution features, excels with 77.3% precision and 67.5% mAP@50, yet its 10.2 M parameters and 12.5 GFLOPs yield a 165.2 FPS. Wu’s method [17], tailored for dynamic SLAM, scores 73.5% precision and 64.8% mAP@50, with 3.45 M parameters and 9.8 GFLOPs, resulting in 210.6 FPS.
Table 4.
Comparison of MSFConv with Existing Feature Extraction Techniques on VOC2007 Dataset.
MSFConv’s parallel multi-scale branches and depthwise separable convolutions balance accuracy and efficiency, outperforming Wu in detection and speed while staying lighter than FPN and HRNet. Its 233.1 FPS ensures real-time SLAM applicability, unlike the heavier alternatives. While FPN and HRNet offer superior accuracy, their computational cost limits practicality in dynamic SLAM. MSFConv thus provides an optimal trade-off, with the potential for future hybrid enhancements.
4.2. Pose Estimation Error Analysis Experiment
- (1)
- TUM Dataset
To evaluate the performance of the proposed algorithm, we utilized the TUM RGB-D dataset [24], a widely recognized benchmark for visual SLAM systems, accessible at https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 21 June 2024). This dataset provides synchronized RGB and depth image pairs captured using a Microsoft Kinect sensor at a resolution of 640 × 480 pixels and a frame rate of 30 Hz, alongside ground truth camera poses for accuracy assessment. The dataset includes a variety of indoor sequences designed to test SLAM algorithms under different conditions, such as static scenes, slow motions, and highly dynamic environments. In our experiments, we selected sequences from the “fr3” category, which are captured in a typical office environment and divided into two primary scene types: “sitting” and “walking”. The “sitting” sequences feature slow actions, such as gesturing and conversing at a desk with minimal object motion, while the “walking” sequences involve significant indoor movements, including people walking, which introduce dynamic elements challenging for SLAM systems.
Each scene type includes three distinct camera motion patterns: “halfsphere”, where the camera moves in a hemispherical trajectory approximately 1 m in diameter; “static”, where the camera remains stationary; and “XYZ”, where the camera translates along the x, y, and z axes while maintaining a consistent orientation. These motion patterns test the algorithm’s robustness across varying degrees of camera dynamics. Specifically, we evaluated the following sequences:
- (a)
- sitting_static: Stationary camera with minor gestures.
- (b)
- sitting_xyz: Translational camera motion in a low-dynamic setting.
- (c)
- walking_half: Hemispherical camera path with multiple moving people.
- (d)
- walking_static: Stationary camera observing walking individuals.
- (e)
- walking_xyz: Translational camera motion with significant dynamic activity.
These frame counts reflect the full sequences as provided in the TUM RGB-D dataset, though our evaluation used all available frames per sequence to ensure comprehensive testing across motion types. The “sitting” sequences (totaling ~1700 frames across static and XYZ) represent low-dynamic conditions, while the “walking” sequences (totaling ~3100 frames across halfsphere, static, and XYZ) provide high-dynamic challenges, allowing us to assess MSF-SLAM’s performance in diverse scenarios.
The ground truth information in the TUM RGB-D dataset was collected using a high-precision motion capture system consisting of eight infrared cameras operating at 100 Hz. This system tracks reflective markers attached to the Kinect sensor, providing accurate 6-DoF (degrees of freedom) pose estimates with sub-millimeter precision. The recorded RGB-D frames were temporally aligned with the motion capture data using timestamps, ensuring that each frame has a corresponding ground truth pose. This setup enables reliable evaluation of SLAM algorithms by comparing estimated trajectories against these externally measured poses, particularly valuable in dynamic scenes where internal sensor drift could otherwise skew results.
To ensure a fair comparison, all algorithms (including ORB-SLAM3 and other baselines) were tested on the same sequences—e.g., “walking_half” and “walking_xyz”—using identical parameter configurations, such as feature extraction thresholds and optimization settings. This consistency allows us to isolate the impact of MSF-SLAM’s enhancements on pose estimation accuracy across the specified camera motion types.
- (2)
- Experimental Results Analysis
To assess the experimental results, we employed two primary metrics: absolute trajectory error (ATE) and relative pose error (RPE), which evaluate the precision of pose estimation relative to the ground truth. Various metrics, including root mean square error (RMSE), standard deviation (STD), mean error, and median error, were utilized to provide a thorough evaluation of the algorithm’s performance. Table 5, Table 6 and Table 7 present the ATE, RPE, and absolute error comparisons between the proposed method and other algorithms.
Table 5.
Comparison of Absolute Trajectory Error (ATE) (Unit: m).
Table 6.
Comparison of Relative Pose Error (RPE) (Unit: m).
Table 7.
Comparison of RMSE Absolute Errors with Other Algorithms (m).
As shown in Table 5 and Table 6, the improved algorithm incorporates dynamic feature point rejection into the traditional ORB-SLAM framework, achieving significant enhancements over ORB-SLAM3 in highly dynamic scenarios (e.g., the walking_half and walking_xyz datasets). Specifically, the ATE RMSE is reduced by 93.34% and 94.43%, while the RPE RMSE is reduced by 45.8% and 68.31%, effectively mitigating the impact of dynamic objects on global trajectory estimation and local pose estimation. These improvements can be attributed to the integration of the multi-scale convolutional module (MSFConv), which enhances the detection of fast-moving objects, and the LK optical flow method, which accurately filters dynamic feature points.
In low-dynamic scenarios, such as sitting_static and sitting_xyz, where dynamic objects are almost stationary, ORB_SLAM3 benefits from retaining all feature points in the scene. In contrast, the proposed algorithm occasionally misclassifies some static feature points as dynamic and removes them, reducing the number of usable feature points for tracking. This leads to varied performance in these environments. For example, in the sitting_xyz dataset, the ATE RMSE increased by 16.92% compared to ORB-SLAM3. However, in the sitting_static dataset, the ATE and RPE RMSEs were reduced by 26.85% and 65.98%, respectively, highlighting the ability of the algorithm to suppress interference from low-quality feature points, even under near-static conditions.
To further evaluate the performance of the proposed algorithm, comparative experiments were conducted with several state-of-the-art visual SLAM methods, including RDS-SLAM, DM-SLAM, RDMO-SLAM, Huai et al., and DIO-SLAM, under consistent experimental settings. All algorithms were tested on the same datasets (e.g., walking_half and walking_xyz) with identical parameter configurations to ensure fairness. As shown in Table 7, MSF-SLAM achieves superior results in highly dynamic scenes, with significantly lower RMSE in trajectory estimation compared to all baselines. For instance, in the walking_half sequence, MSF-SLAM records an RMSE of 0.0202 m, outperforming DIO-SLAM (0.0212 m), Huai et al. (0.0303 m), and RDMO-SLAM (0.0304 m), while in walking_xyz, it achieves an RMSE of 0.0134 m against DIO-SLAM’s 0.0141 m and Huai et al.’s 0.0143 m. These improvements are attributed to the integration of the Multi-Scale Feature Consolidation module (MSFConv), which enhances the detection of fast-moving objects, and the Dynamic Object Filtering Framework (DOFF), which leverages LK optical flow to effectively remove dynamic features. Together, these components enable MSF-SLAM to mitigate the impact of dynamic objects more effectively and maintain robustness in challenging environments.
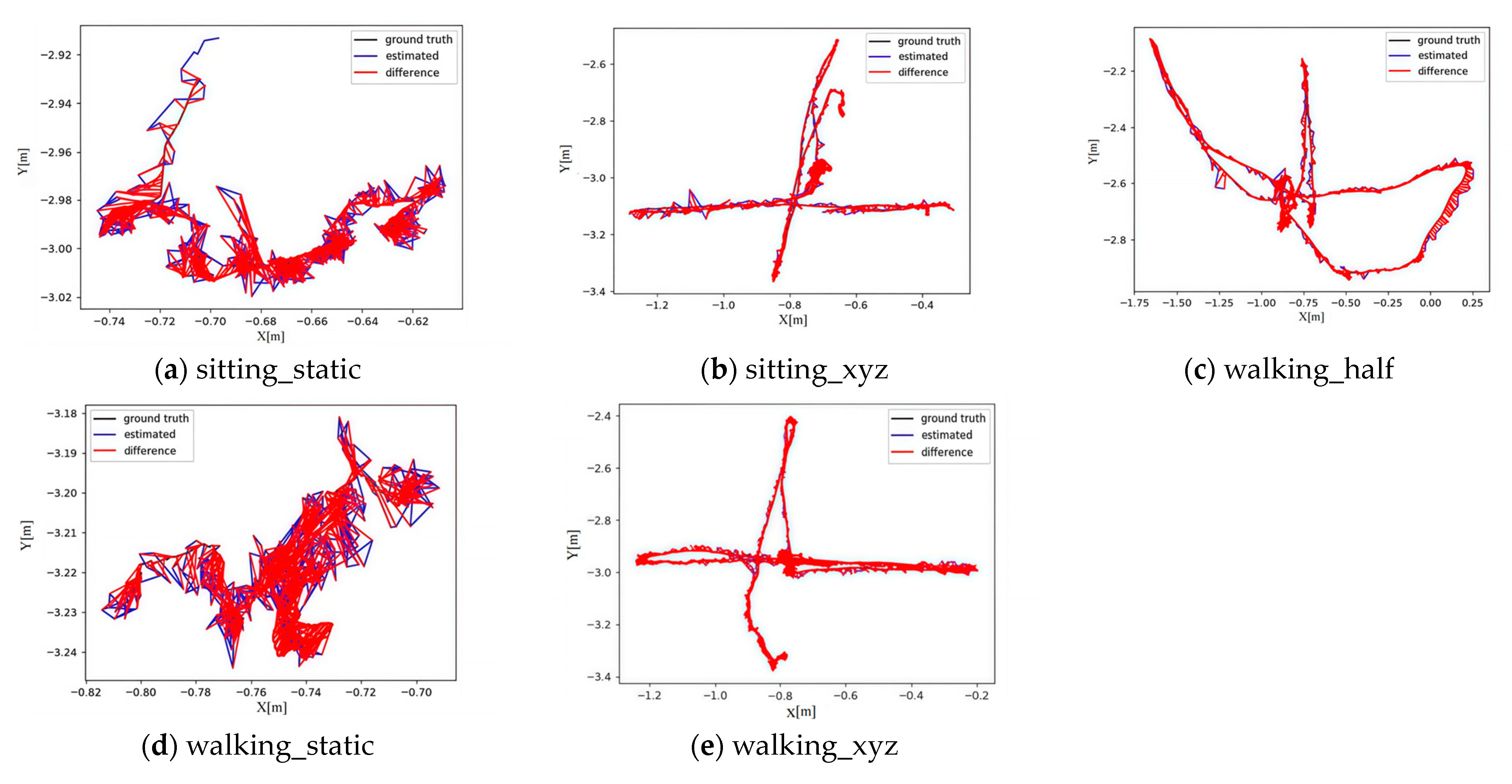
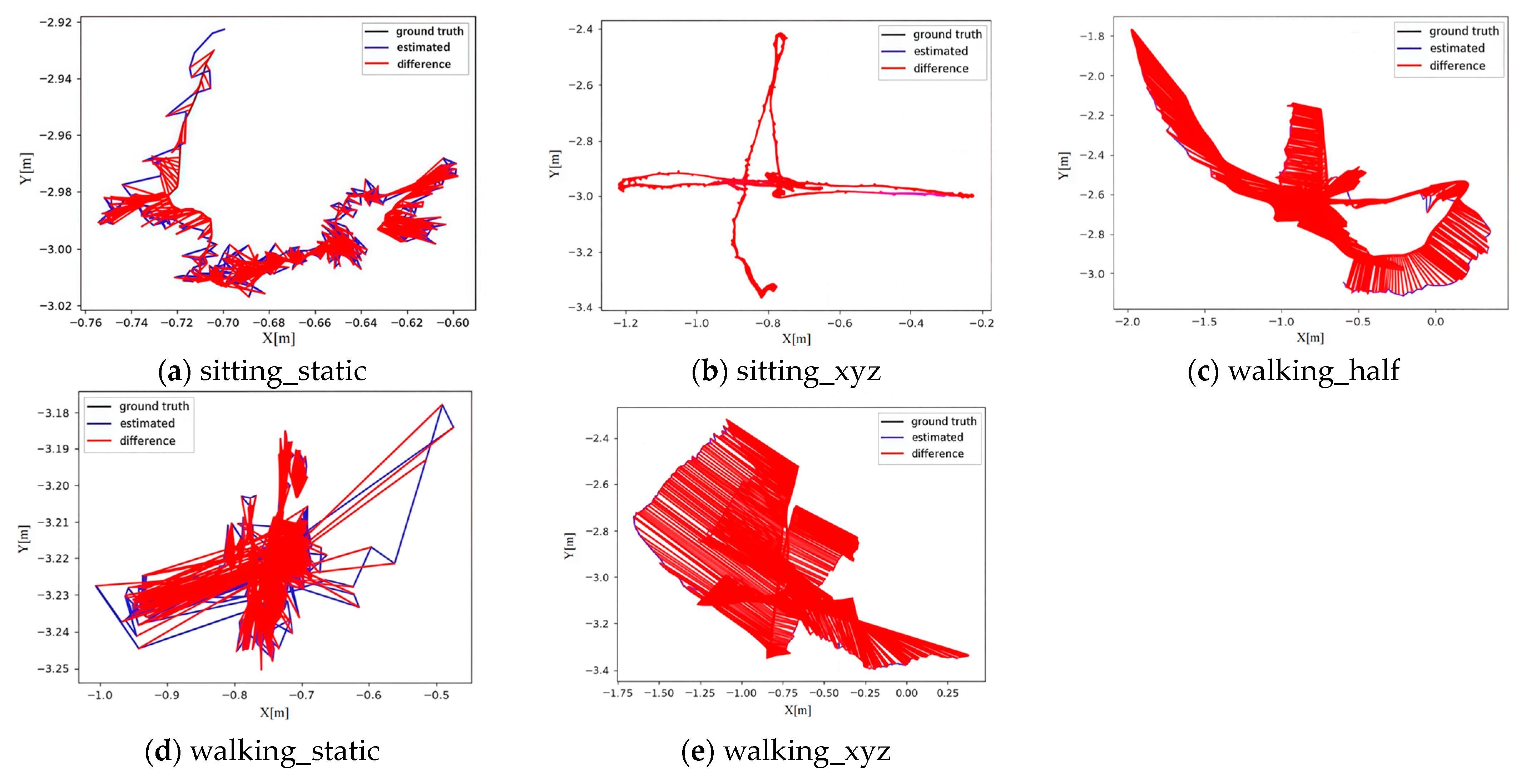
Figure 5 and Figure 6 compare the real and estimated trajectories between the improved algorithm and ORB_SLAM3. The black solid line represents the real trajectory, the blue solid line denotes the estimated trajectory, and the red shaded area highlights the error between the two trajectories. The smaller the shaded area, the higher the system’s walking_static, walking_half, and walking_xyz, the improved algorithm significantly outperforms ORB_SLAM3 with substantially smaller trajectory errors.
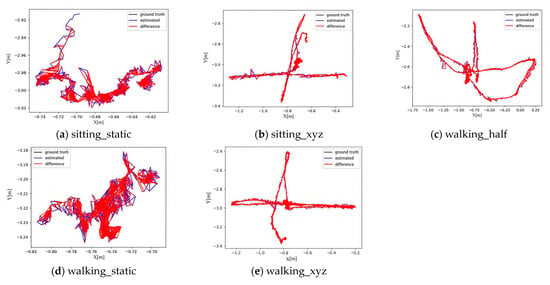
Figure 5.
Trajectory of the Algorithm in this Paper.
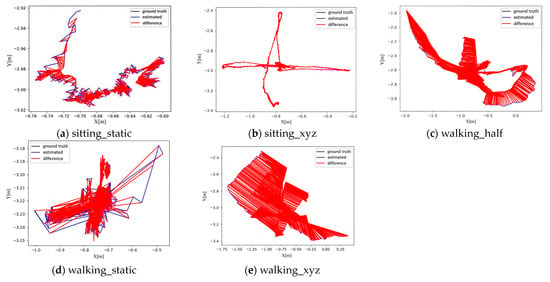
Figure 6.
ORB_SLAM3 Operation Trajectory.
4.3. Computational Performance Analysis
To evaluate the computational efficiency of MSF-SLAM, we benchmarked resource usage against ORB-SLAM3 on two platforms: a high-performance laptop (Intel i9-14900HX, NVIDIA RTX 4060, 32 GB RAM) and an edge device (NVIDIA Jetson Xavier NX, 8 GB RAM). Table 8 summarizes the results for the “walking_xyz” sequence (1000 frames).
Table 8.
Computational Performance Comparison.
On the laptop, MSF-SLAM achieves 233.1 FPS with 65% GPU utilization, 8.2 GB VRAM, and 12.5 GB RAM, compared to ORB-SLAM3’s 275.1 FPS, 20% GPU utilization, 1.5 GB VRAM, and 6.8 GB RAM. The increased resource demand reflects the integration of YOLOv8+MSFConv, which adds ~9.9% computational overhead (8.9 vs. 8.1 GFLOPs). On the Jetson Xavier NX, MSF-SLAM runs at 45.2 FPS with 5.8 GB VRAM, suitable for real-time robotics applications (>30 FPS), while ORB-SLAM3 achieves 78.4 FPS with 1.2 GB VRAM. Per-frame latency for MSF-SLAM is 4.3 ms (laptop) and 22.1 ms (Jetson), compared to ORB-SLAM3’s 3.6 ms and 12.8 ms, respectively.
These results indicate that MSF-SLAM’s enhanced accuracy (94.43% ATE reduction) comes with a manageable resource trade-off, enabling deployment on mid-range edge devices for dynamic SLAM tasks, such as autonomous navigation in indoor environments.
5. Conclusions
This paper presents an enhanced visual dynamic object elimination SLAM algorithm, based on an improved YOLOv8, designed to reduce the impact of dynamic objects on localization and mapping accuracy in complex environments. The algorithm builds upon the ORB_SLAM3 framework by integrating a modified YOLOv8 with the LK optical flow method and introducing a dynamic feature point elimination algorithm. This approach efficiently detects and removes dynamic object feature points, minimizing their interference and thereby improving the SLAM system’s accuracy. Key enhancements include replacing the YOLOv8 convolution module with the MSFConv module, which enhances both object detection precision and speed; utilizing the LK optical flow method to compute feature point optical flow vectors; and designing a dynamic feature point elimination strategy that combines optical flow vectors with object detection results. These modifications collectively enhance trajectory estimation accuracy in dynamic scenes.
Experimental results demonstrate that the proposed method significantly outperforms ORB_SLAM3 and other state-of-the-art methods in high-dynamic scenarios, such as walking_half and walking_xyz sequences. Specifically, it achieves a reduction of 93.34% and 94.43% in the root mean square error (RMSE) of the absolute trajectory error (ATE), respectively. In low-dynamic scenes, such as sitting_static, the algorithm not only improves global accuracy but also achieves some local optimizations. MSF-SLAM’s computational requirements (233.1 FPS on high-end hardware, 45.2 FPS on Jetson Xavier NX) make it viable for real-time robotics applications, including edge devices commonly used in autonomous systems. While ORB-SLAM3 is lighter, MSF-SLAM’s superior accuracy in dynamic scenes justifies its resource demands for applications prioritizing robustness over minimal hardware constraints. This research has significant implications for robot localization and map construction in complex dynamic environments. Future work may focus on further optimizing feature extraction mechanisms to enhance performance in static scenes.
The method excels in dynamic environments but faces challenges in near-static scenes (e.g., “sitting_xyz”, ATE up 16.92%) due to over-removal of static features, struggles with poor lighting or occlusion due to YOLOv8 reliance, and incurs a computational cost (FPS drops from 275.1 to 233.1) that may limit use on low-power systems. In handling partially dynamic objects—such as a person sitting then standing—DOFF uses YOLOv8 anchor boxes and a 1.5-pixel optical flow threshold to distinguish static and moving features; however, subtle or intermittent motion can delay detection, potentially introducing errors in scenes like “sitting_static”. Building on these findings, future work should enhance SLAM performance by tackling feature extraction and dynamic feature handling challenges, with directions including:
- i.
- Exploring more advanced feature extraction modules that can further improve detection accuracy while reducing computational overhead.
- ii.
- Investigating adaptive dynamic point removal strategies to improve performance in low-dynamic or near-static environments.
- iii.
- Extending the framework to multi-sensor fusion scenarios to enhance SLAM robustness in real-world applications.
Author Contributions
Methodology, Y.D.; Validation, J.L.; Writing—original draft, Y.D. and J.L.; Writing—review, and editing, Y.D.; resources, X.Z.; Supersion, X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study utilizes two publicly available datasets: the TUM RGB-D dataset (https://vision.in.tum.de/data/datasets/rgbd-dataset (accessed on 21 June 2024)) and the VOC2007 dataset (http://host.robots.ox.ac.uk/pascal/VOC/voc2007/ (accessed on 21 June 2024)). The TUM RGB-D dataset is used for evaluating the proposed MSF-SLAM algorithm, while the VOC2007 dataset is used for training and testing the improved YOLOv8 object detection algorithm. All experimental results, including performance metrics and trajectory comparisons, are presented in the manuscript in the form of tables (Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8) and figures (Figure 4, Figure 5 and Figure 6). The source code, trained network models, and replication scripts are publicly available in the master branch of the following repository: https://github.com/duan12345-cmk/slam.git (accessed on 21 June 2024). A detailed description of the methodology is provided in Section 3 of the manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Smith, R.; Self, M.; Cheeseman, P.C. Estimating uncertain spatial relationships in robotics. In Proceedings of the 1987 IEEE International Conference on Robotics and Automation, Raleigh, NC, USA, 31 March–3 April 1987; Volume 4, p. 850. [Google Scholar]
- Wang, T.; Zhao, P. Research on Visual SLAM Navigation Techniques for Dynamic Environments. Int. J. Distrib. Sens. Netw. 2023, 2023, 2025844. [Google Scholar] [CrossRef]
- Duan, R.; Feng, Y.; Wen, C.-Y. Deep Pose Graph-Matching-Based Loop Closure Detection for Semantic Visual SLAM. Sustainability 2022, 14, 11864. [Google Scholar] [CrossRef]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. VDO-SLAM: A Visual Dynamic Object-aware SLAM System. arXiv 2020, arXiv:2005.11052. [Google Scholar]
- Shu, F.; Xie, Y.; Rambach, J.R.; Pagani, A.; Stricker, D. Visual SLAM with Graph-Cut Optimized Multi-Plane Reconstruction. In Proceedings of the 2021 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Bari, Italy, 4–8 October 2021; pp. 165–170. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.; Xie, F.; Yang, Y.; Wei, Q.; Qiao, F. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2018, Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Zhang, R.; Zhang, X. Geometric Constraint-Based and Improved YOLOv5 Semantic SLAM for Dynamic Scenes. ISPRS Int. J. Geo-Inf. 2023, 12, 211. [Google Scholar] [CrossRef]
- Yang, X.; Huang, X.; Zhang, Y.; Liu, Z.; Pang, Y. Multi-Sensor fusion and semantic map-based particle filtering for robust indoor localization. Measurement 2025, 242, 115874. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, W.; Zhang, Z.; Shi, X.; Li, Z.; Zhang, M.; Xie, H.; Chi, W. Anti-Degeneracy Scheme for Lidar SLAM based on Particle Filter in Geometry Feature-Less Environments. arXiv 2025, arXiv:2502.11486. [Google Scholar]
- Dhaigude, V.; Kulkarni, A. A Comprehensive Review of Sensor Fusion Techniques in SLAM: Trends, Challenges and Future Directions. In Proceedings of the 2025 1st International Conference on AIML-Applications for Engineering & Technology (ICAET), Pune, India, 17 January 2025; pp. 1–8. [Google Scholar]
- Zhao, J.; Wu, Y.; Bao, W.; Shi, J.; Liu, X. Indoor Robot Mapping and Navigation System Based on Cyber-Physical Systems: Integration of SLAM Algorithm and Visual Information. IEEE Trans. Intell. Transp. Syst. 2025. early access. [Google Scholar] [CrossRef]
- He, W.; Li, R.; Liu, T.; Yu, Y. LiDAR-based SLAM pose estimation via GNSS graph optimization algorithm. Meas. Sci. Technol. 2024, 35, 096304. [Google Scholar] [CrossRef]
- Bavle, H.; Sanchez-Lopez, J.L.; Shaheer, M.; Civera, J.; Voos, H. S-Graphs 2.0—A Hierarchical-Semantic Optimization and Loop Closure for SLAM. arXiv 2025, arXiv:2502.18044. [Google Scholar]
- Wu, W.; Chen, C.; Yang, B.; Zou, X.; Liang, F.; Xu, Y.; He, X. DALI-SLAM: Degeneracy-aware LiDAR-inertial SLAM with novel distortion correction and accurate multi-constraint pose graph optimization. ISPRS J. Photogramm. Remote Sens. 2025, 221, 92–108. [Google Scholar] [CrossRef]
- He, K.; Jia, R.; Hong, H.; Wang, N.; Hu, Y. LDG-CSLAM: Multi-Robot Collaborative SLAM Based on Curve Analysis, Normal Distribution, and Factor Graph Optimization. J. Field Robot. 2025. early view. [Google Scholar] [CrossRef]
- Islam, Q.U.; Ibrahim, H.; Chin, P.K.; Lim, K.; Abdullah, M.Z.; Khozaei, F. Advancing real-world visual SLAM: Integrating adaptive segmentation with dynamic object detection for enhanced environmental perception. Expert Syst. Appl. 2024, 255, 124474. [Google Scholar] [CrossRef]
- Wu, D. Object detection and tracking for drones: A system design using dynamic visual SLAM. Appl. Comput. Eng. 2024, 81, 71–82. [Google Scholar] [CrossRef]
- Chu, G.; Peng, Y.; Luo, X.; Gong, J. YG-SLAM: Enhancing Visual SLAM in Dynamic Environments with YOLOv8 and Geometric Constraints. IEEE Access 2023, 11, 141421–141434. [Google Scholar] [CrossRef]
- Cai, D.; Li, S.; Qi, W.; Ding, K.; Lu, J.; Liu, G.; Hu, Z. DFT-VSLAM: A Dynamic Optical Flow Tracking VSLAM Method. J. Intell. Robot. Syst. 2024, 110, 135. [Google Scholar] [CrossRef]
- Qian, L.; Su, J.; Wu, L. LTD-SLAM: Multi-Scale Ligh-Weight Model and Adaptive Thresholds Based Dynamic Object Detection for Semantic Visual SLAM. In Proceedings of the 2024 17th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 26–28 October 2024; pp. 1–7. [Google Scholar]
- Chen, K.; Cao, Y.; Loy, C.C.; Lin, D.; Feichtenhofer, C. Feature pyramid grids. arXiv 2020, arXiv:2004.03580. [Google Scholar]
- Chen, P.; Liu, Y.; Liu, Y.; Ren, Y.; Zhang, B.; Gao, X. High-resolution feature pyramid attention network for high spatial resolution images land-cover classification in arid oasis zones. Int. J. Remote Sens. 2024, 45, 3664–3688. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007). Available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/ (accessed on 21 June 2024).
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A Benchmark for the Evaluation of RGB-D SLAM Systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Liu, Y.; Miura, J. RDS-SLAM: Real-time dynamic SLAM using semantic segmentation methods. IEEE Access 2021, 9, 23772–23785. [Google Scholar] [CrossRef]
- Cheng, J.; Wang, Z.; Zhou, H.; Li, L.; Yao, J. DM-SLAM: A feature-based SLAM system for rigid dynamic scenes. ISPRS Int. J. Geo-Inf. 2020, 9, 202. [Google Scholar] [CrossRef]
- Liu, Y.; Miura, J. RDMO-SLAM: Real-time visual SLAM for dynamic environments using semantic label prediction with optical flow. IEEE Access 2021, 9, 106981–106997. [Google Scholar] [CrossRef]
- Huai, S.; Cao, L.; Zhou, Y.; Guo, Z.; Gai, J. A Multi-Strategy Visual SLAM System for Motion Blur Handling in Indoor Dynamic Environments. Sensors 2025, 25, 1696. [Google Scholar] [CrossRef]
- He, L.; Li, S.; Qiu, J.; Zhang, C. DIO-SLAM: A Dynamic RGB-D SLAM Method Combining Instance Segmentation and Optical Flow. Sensors 2024, 24, 5929. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).