
Interpretable Machine Learning for Population Spatialization and Optimal Grid Scale Selection in Shanghai


Abstract
1. Introduction
2. Materials and Methods
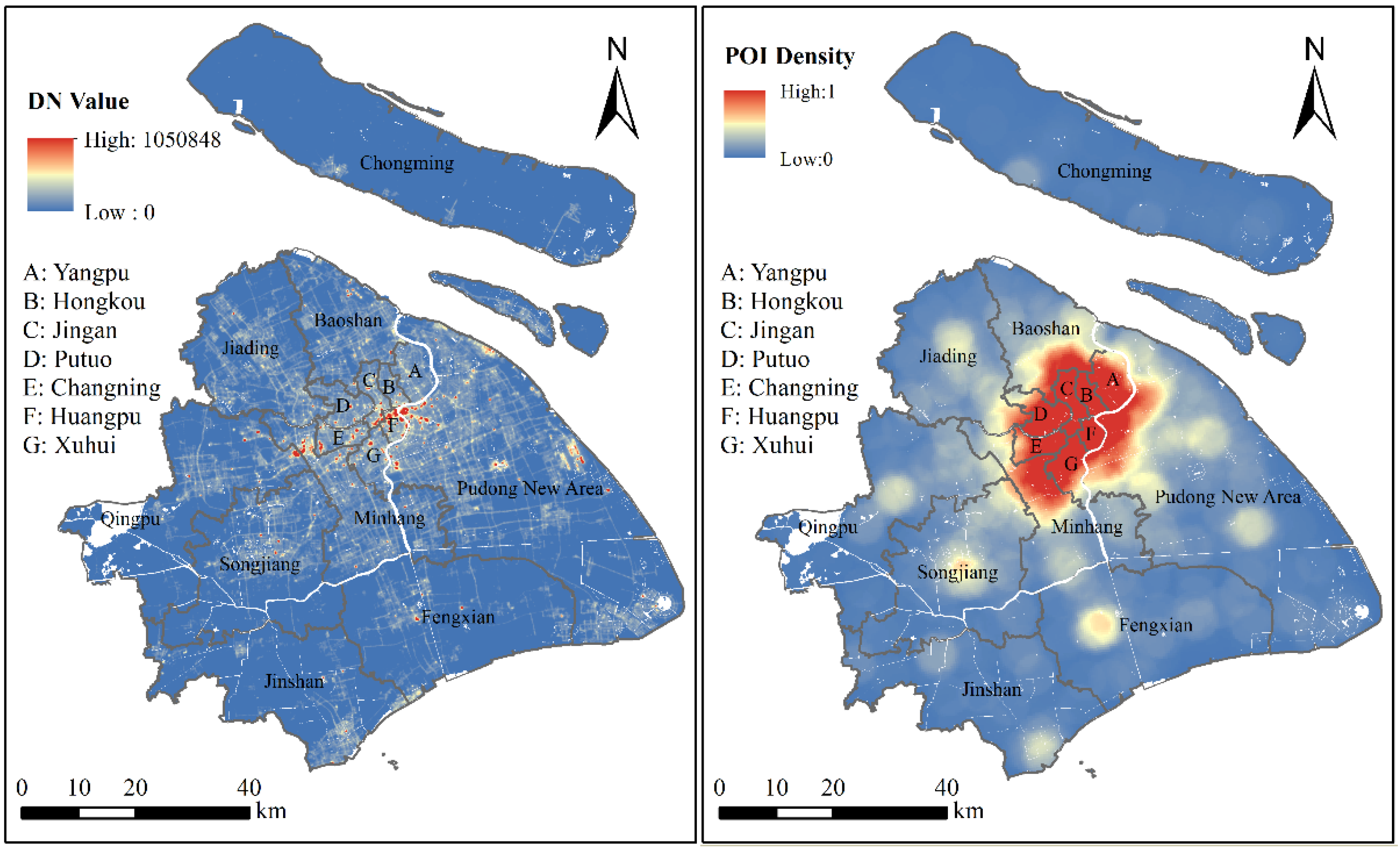
2.1. Data Sources and Preparation
2.2. Methods
2.2.1. XGBoost Model
2.2.2. SHAP Interpretable Method
2.2.3. Model Evaluation Indicators
2.2.4. Suitable Grid Scale Evaluation Method
- (1)
- Standard deviation of population density (SDPD)
- (2)
- Shannon–Wiener Diversity Index (SWDI)
- (3)
- Simpson Diversity Index (SIDI)
3. Results
3.1. Model Parameter Optimization
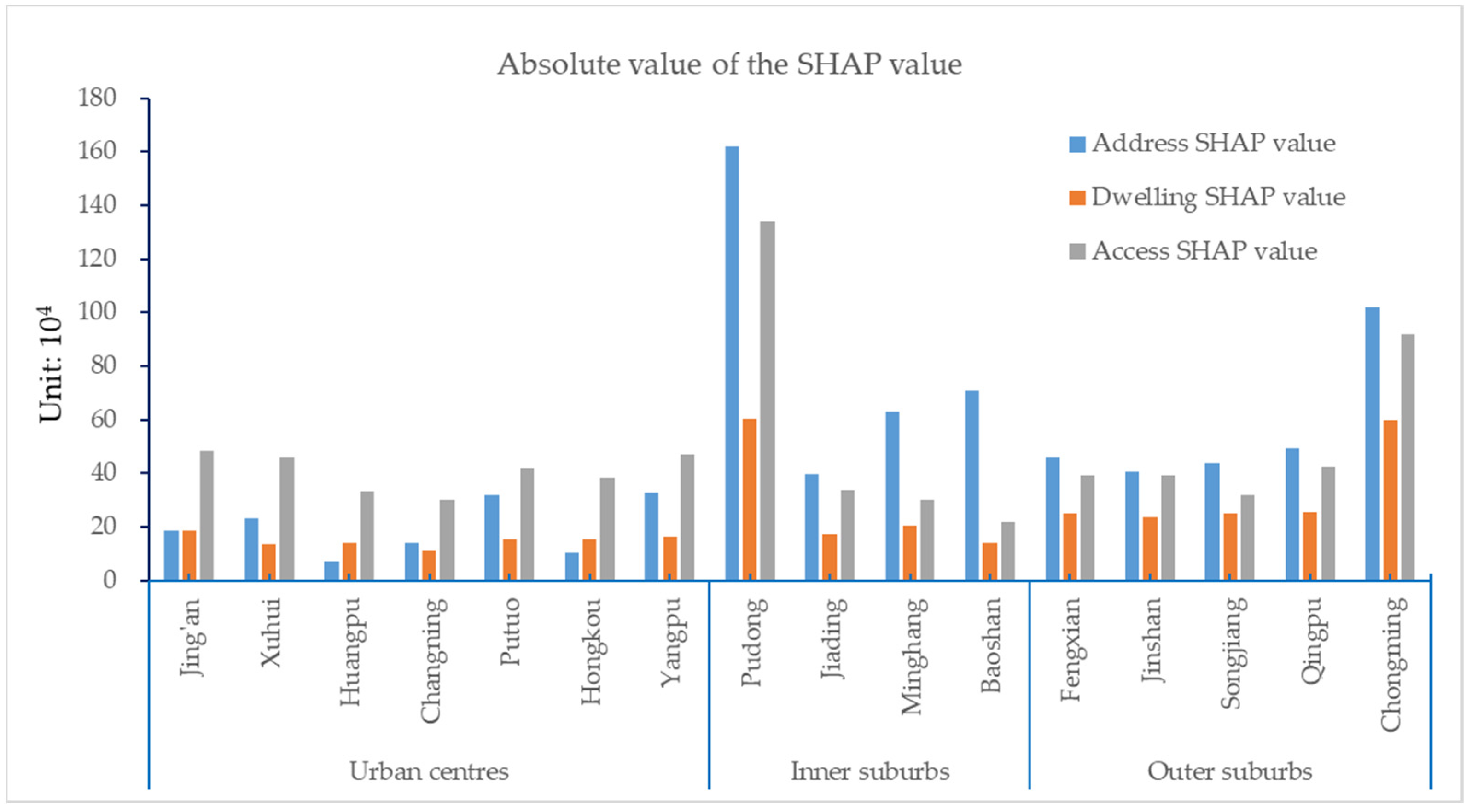
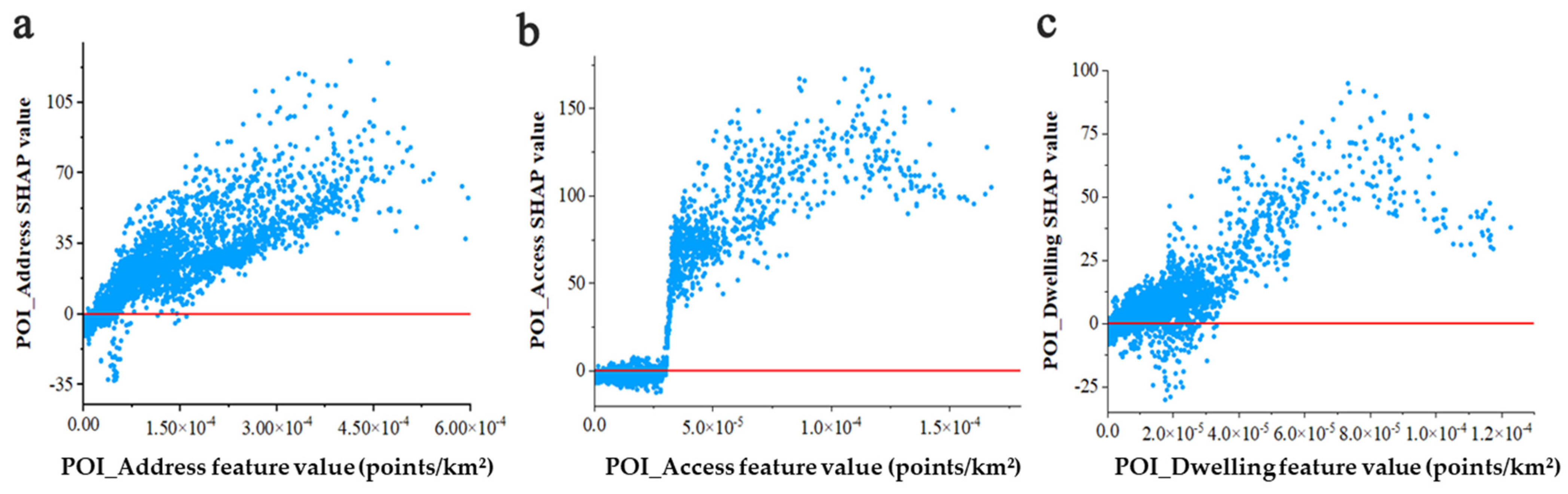
3.2. Feature Variable Selection and Influencing Factor Analysis
3.3. Verification of Population Estimation Results
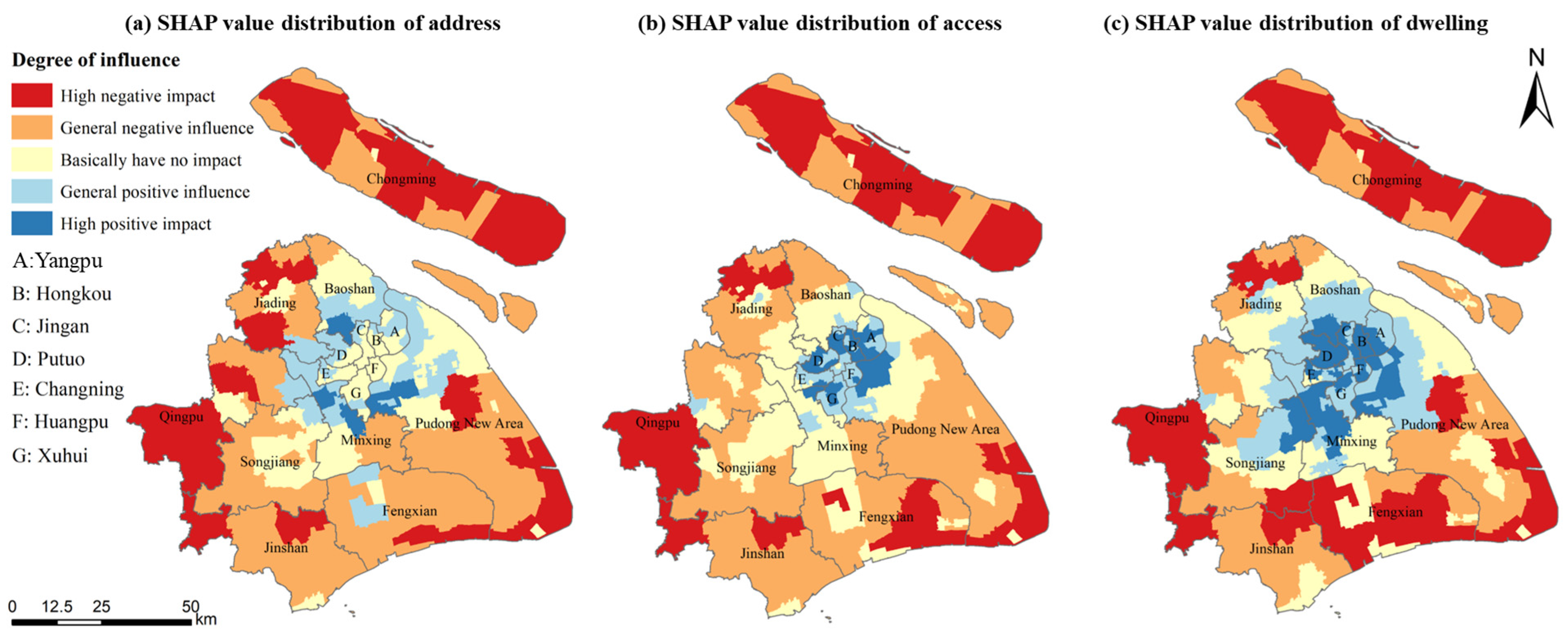
3.4. Distribution Characteristics of Main Influencing Factors
3.5. Analysis of Suitable Grid Scale for Population Spatialization
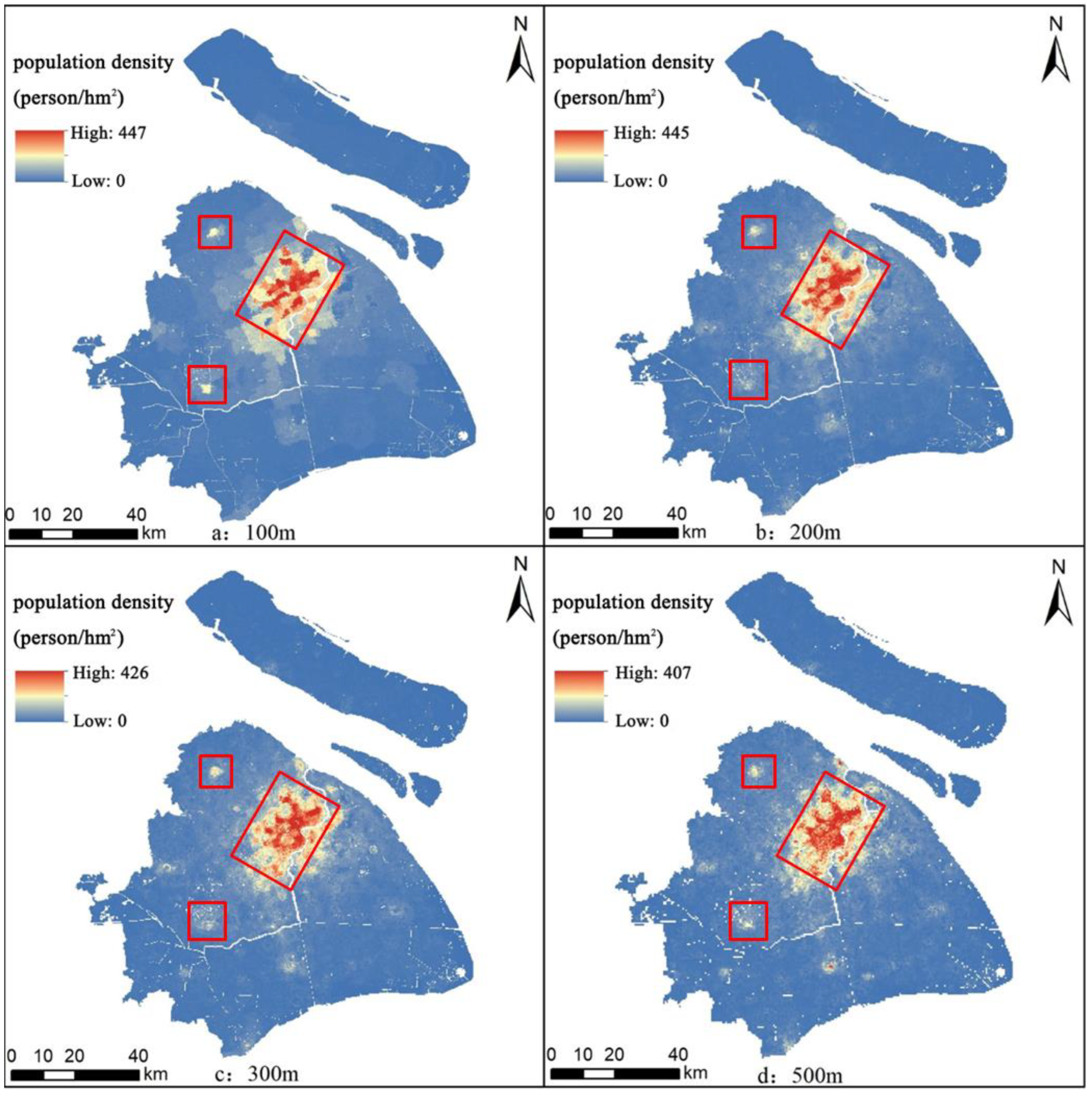
3.5.1. Grid Scale Population Spatialization Estimation Results
3.5.2. Evaluation of Grid Scale Suitability
4. Discussion
5. Conclusions
- (1)
- Through five-fold cross-validation, we identified optimal parameters to construct an XGBoost model for population spatialization, which estimated the population density distribution at 100 m, 200 m, 300 m, and 500 m grid scales. The population spatialization models achieved a determination coefficient (R2) exceeding 0.83 across all scales. The accuracy validation demonstrated that the XGBoost-based population spatialization results outperformed the WorldPop dataset, which may be attributed to the integration of finer-grained data features such as Shanghai’s POI data. These results demonstrate strong correlation between the model’s estimates and official statistics, indicating that the model constructed for Shanghai’s population spatialization based on multi-dimensional datasets is highly reliable;
- (2)
- The ranking of feature variables influencing population estimation results was determined based on SHAP values. The SHAP values for address information, access facilities, and dwellings consistently rank among the top three across all districts, demonstrating stronger overall impacts on population spatialization in suburban areas than in urban centers. These features exhibit non-monotonic influences on the population estimation, revealing distinct regional variations in their effects. In urban centers, individual features show significant positive effects on the population spatial distribution. This positive influence progressively diminishes toward the suburbs, where the negative influence becomes more pronounced. The XGBoost-SHAP method effectively explains the key influencing features of population spatialization and their spatial distribution characteristics. Demonstrating strong generalizability, this approach provides a robust methodological framework for population estimation and analysis of distribution heterogeneity across cities with different typologies and varying levels of data availability;
- (3)
- The estimated population density of Shanghai across different grid scales demonstrates consistent spatial characteristics, exhibiting a gradient decrease from the urban centers to the surrounding suburbs. Notably, as the grid scale increases, the distribution of local population density tends to become more dispersed. The comprehensive accuracy evaluation metrics and landscape ecology indices indicate that the population estimation results at the 100 m grid scale have the highest accuracy and effectively reflect the population spatial distribution heterogeneity. These findings strongly support the recommendation of 100 m as the most appropriate grid scale for population spatialization estimation in Shanghai. The high-accuracy population estimation outcomes in Shanghai facilitate the detection of latent urban development imbalances, thereby offering empirical foundations for enhancing functional district planning and the judicious allocation of spatial resources.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, H.; Zhang, H.; Wang, M. A comparative study of population spatialization based on NPP/VIIRS and LJ1-01 night light data: Taking Beijing for an example. Remote Sens. Inf. 2021, 36, 90–97. [Google Scholar] [CrossRef]
- Effat, H.A.; Ramadan, M.S. Geospatial modeling for a sustainable urban development zoning map using AHP in Ismailia Governorate, Egypt. Egypt. J. Remote Sens. Space Sci. 2021, 24, 191–202. [Google Scholar] [CrossRef]
- Xiao, D.; Yang, S. A review of population spatial distribution based on nighttime light data. Remote Sens. Land Resour. 2019, 31, 10–19. [Google Scholar] [CrossRef]
- Wu, H.; Hu, Q.; Li, R.; Liu, C. Research progress on spatio-temporal distribution estimation of urban population. Acta Geod. Cartogr. Sin. 2022, 51, 1827–1847. [Google Scholar] [CrossRef]
- Tatem, A.J. WorldPop, open data for spatial demography. Sci. Data 2017, 4, 170004. [Google Scholar] [CrossRef]
- Bai, Z.; Wang, J.; Yang, F. Research progress in spatialization for population data. Prog. Geogr. 2013, 32, 1692–1702. [Google Scholar] [CrossRef]
- Liu, A.; Zou, Z.; Liu, M. On Evolution of Metropolitan Spatial Structure Based on Population Density Models: A Case Study of Tianjin. Urban Dev. Stud. 2015, 22, 141–144. [Google Scholar]
- Newling, B.E. The spatial variation of urban population densities. Geogr. Rev. 1969, 59, 242–252. [Google Scholar] [CrossRef]
- Chen, H.; Quan, D.; Zhao, X.; He, J. Evolutional trends of population spatial distribution in western under-developed city—A case study of Lanzhou. World Reg. Stud. 2019, 28, 105–114. [Google Scholar] [CrossRef]
- Langford, M. An evaluation of small area population estimation techniques using open access ancillary data. Geogr. Anal. 2013, 45, 324–344. [Google Scholar] [CrossRef]
- Schroeder, J.P. Hybrid areal interpolation of census counts from 2000 blocks to 2010 geographies. Comput. Environ. Urban Syst. 2017, 62, 53–63. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Liu, R.; Fan, H.; Li, P.; Liu, Y.; Jia, Y. Multi-Resolution Population Mapping Based on a Stepwise Downscaling Approach Using Multisource Data. Remote Sens 2023, 15, 1947. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, C.; Song, X.; Chen, J.; Li, Z. A semi-parametric geographically weighted (S-GWR) approach for modeling spatial distribution of population. Ecol. Indic. 2018, 85, 1022–1029. [Google Scholar] [CrossRef]
- Lwin, K.K.; Sugiura, K.; Zettsu, K. Space–time multiple regression model for grid-based population estimation in urban areas. Int. J. Geogr. Inf. Sci. 2016, 30, 1579–1593. [Google Scholar] [CrossRef]
- Yang, R.; Dong, C.; Zhang, Y. Method of population spatialization under the support of geographic national conditions data. Sci. Surv. Mapp. 2017, 42, 76–81. [Google Scholar] [CrossRef]
- Guo, H.; Zhu, W. A review on the spatial disaggregation of socioeconomic statistical data. Acta Geogr. Sin. 2022, 77, 2650–2667. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, T.; Gu, J.; Liu, J. Fine spatio-temporal scale estimation of urban population’s socio-economic characteristics based on big data: Data, methods and applications. Popul. Econ. 2022, 1, 42–57. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, H.; Luo, K.; Wu, C.; Li, S. Study on Spatialization and Spatial Pattern of Population Based on Multi-Source Data—A Case Study of the Urban Agglomeration on the North Slope of Tianshan Mountain in Xinjiang, China. Sustainability 2024, 16, 4106. [Google Scholar] [CrossRef]
- Batista e Silva, F.; Freire, S.; Schiavina, M.; Rosina, K.; Marín-Herrera, M.A.; Ziemba, L.; Craglia, M.; Koomen, E.; Lavalle, C. Uncovering temporal changes in Europe’s population density patterns using a data fusion approach. Nat. Commun 2020, 11, 4631. [Google Scholar] [CrossRef]
- Tu, W.; Liu, Z.; Du, Y.; Yi, J.; Liang, F.; Wang, N.; Qian, J.; Huang, S.; Wang, H. An ensemble method to generate high-resolution gridded population data for China from digital footprint and ancillary geospatial data. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102709. [Google Scholar] [CrossRef]
- Wang, C.; Kan, A.; Zeng, Y.; Li, G.; Wang, M.; Ci, R. Population distribution pattern and influencing factors in Tibet based on random forest model. Acta Geogr. Sin. 2019, 74, 664–680. [Google Scholar] [CrossRef]
- He, M.; Xu, Y.; Li, N. Population spatialization in Beijing city based on machine learning and multisource remote sensing data. Remote Sens. 2020, 12, 1910. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, N.; Xu, Y.; Huang, X.; Li, M. Mapping Population Distribution Based on XGBoost Using Multisource Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11567–11580. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y. Xgboost: Extreme Gradient Boosting. R package version 0.4-2. 2015; pp. 1–4. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.; Chen, H.; Degrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, Q.; Li, T.; Zhang, K. Dynamic Vegetation Responses to Climate and Land Use Changes over the Inner Mongolia Reach of the Yellow River Basin, China. Remote Sens. 2023, 15, 3531. [Google Scholar] [CrossRef]
- Li, L.; Zeng, Z.; Zhang, G.; Duan, K.; Liu, B.; Cai, X. Exploring the Individualized Effect of Climatic Drivers on MODIS Net Primary Productivity through an Explainable Machine Learning Framework. Remote Sens. 2022, 14, 4401. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B. Interpretable and explainable AI (XAI) model for spatial drought prediction. Sci. Total Environ. 2021, 801, 149797. [Google Scholar] [CrossRef]
- Li, X.; Wu, C.; Meadows, M.E.; Zhang, Z.; Lin, X.; Zhang, Z.; Chi, Y.; Feng, M.; Li, E.; Hu, Y. Factors Underlying Spatiotemporal Variations in Atmospheric PM2.5 Concentrations in Zhejiang Province, China. Remote Sens. 2021, 13, 3011. [Google Scholar] [CrossRef]
- Luo, Y.; Dong, C.; Zhang, Y. Research on the evaluation method of population spatialization suitable grid. J. Geo-Inf. Sci. 2023, 25, 896–908. [Google Scholar]
- GB/T 35648-2017; General Administration of Quality Supervision, Inspection and Quarantine of the People’s Republic of China, National Standardization Administration. Classification and Coding of Geographic Information Points of Interest. Standardization and Administration of the People’s Republic of China: Beijing, China, 2017.
- GB/T21010-2017; Current Land Use Classification. General Administration of Quality Supervision, Inspection Quarantine of P. R. C. Standardization and Administration of the People’s Republic of China: Beijing, China, 2017.
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Mousa, S.R.; Bakhit, P.R.; Ishak, S. An extreme gradient boosting method for identifying the factors contributing to crash/near-crash events: A naturalistic driving study. Can. J. Civ. Eng. 2019, 46, 712–721. [Google Scholar] [CrossRef]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar] [CrossRef]
- Shapley, L.S. A value for n-person games. Contrib. Theory Game 1953, 2, 307–317. [Google Scholar] [CrossRef]
- Bao, W.; Gong, A.; Zhao, Y.; Chen, S.; Ba, W.; He, Y. High-Precision Population Spatialization in Metropolises Based on Ensemble Learning: A Case Study of Beijing, China. Remote Sens. 2022, 14, 3654. [Google Scholar] [CrossRef]
- Yeh, C.-T.; Huang, S.-L. Investigating spatiotemporal patterns of landscape diversity in response to urbanization. Landsc. Urban Plan. 2009, 93, 151–162. [Google Scholar] [CrossRef]
- Gaughan, A.E.; Stevens, F.R.; Huang, Z.J.; Jeremiah, J.N.; Sorichetta, A.; Lai, S.J.; Ye, X.Y.; Linard, C.; Hornby, G.M.; Hay, S.I.; et al. Spatiotemporal patternsof population in China’s mainland, 1990 to 2010. Sci. Data 2016, 3, 160005. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Liu, Y.; Zhang, R.; Fu, B. China’s population spatialization based on three machine learning models. J. Clean. Prod. 2020, 256, 120644. [Google Scholar] [CrossRef]
- Song, Y.; Wu, S.; Chen, B.; Bell, M.L. Unraveling near real-time spatial dynamics of population using geographical ensemble learning. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103882. [Google Scholar] [CrossRef] [PubMed]
- Guo, W.; Zhang, J.; Zhao, X.; Li, Y.; Liu, J.; Sun, W.; Fan, D. Combining Luojia1-01 nighttime light and points-of-interest data for fine mapping of population spatialization based on the zonal classification method. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1589–1600. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, X. Using POI and multisource satellite datasets for mainland China’s population spatialization and spatiotemporal changes based on regional heterogeneity. Sci. Total Environ. 2024, 912, 169499. [Google Scholar] [CrossRef]
- Huang, D.; Yang, X.; Dong, N.; Cai, H. Evaluating grid size suitability of population distribution data via improved ALV method: A case study in Anhui Province, China. Sustainability 2017, 10, 41. [Google Scholar] [CrossRef]
- Ge, M.; Feng, Z. Study on the distribution pattern of China’s population in 2000 based on GIS: Comparison with Hu Huanyong’s research in 1935. Popul. Res. 2008, 32, 51–57. [Google Scholar]
- Balk, D.L.; Deichmann, U.; Yetman, G.; Pozzi, F.; Hay, S.I.; Nelson, A. Determining Global Population Distribution: Methods, Applications and Data. Adv. Parasitol. 2006, 62, 119–156. [Google Scholar] [CrossRef] [PubMed]
- Tobler, W.; Deichmann, U.; Gottsegen, J.; Maloy, K. World population in a grid of spherical quadrilaterals. Int. J. Popul. Geogr 1997, 3, 203–225. [Google Scholar] [CrossRef]
- Dobson, J.E.; Bright, E.A.; Coleman, P.R.; Durfee, R.C.; Worley, B.A. LandScan: A global population database for estimating populations at risk. Photogramm. Eng. Remote Sens. 2000, 66, 849–857. [Google Scholar]
- Dong, N.; Yang, X.; Cai, H.; Xu, F. Research on grid size suitability of gridded population distribution in urban area: A case study in urban area of Xuanzhou district, China. PLoS ONE 2017, 12, e0170830. [Google Scholar] [CrossRef]
- Ye, J.; Yang, X.; Jiang, D. The grid scale effect analysis on town leveled population statistical data spatialization. J. Geo-Inf. Sci. 2010, 12, 40–47. [Google Scholar] [CrossRef]
- Wu, J.; Gui, Z.; Shen, L.; Wu, H.; Liu, H.; Li, R.; Mei, Y.; Peng, D. Population spatialization by considering pixel-Level attribute grading and spatial association. Geomat. Inf. Sci. Wuhan Univ. 2022, 47, 1364–1375. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Data Sources |
|---|---|
| POI | AutoNavi Map Open Platform (https://lbs.amap.com/) |
| Luojia-1 Remote Sensing Image | High Resolution Earth Observation System Hubei Data and Application Center (http://59.175.109.173:8888/) |
| Administrative Division Data | Resource and Environmental Science Data Center (http://www.resdc.cn/) |
| Street (Town) Population Data | 2019 Statistical Yearbook of Shanghai Districts |
| WorldPop Dataset | Institute for Geographic Data, University of Southampton, UK (http://www.worldpop.org/) |
| DEM | Geospatial Data Cloud (http://www.gscloud.cn/) |
| Land Use Data | Shanghai Land Use Status Database in 2017 |
| OSM Water Area Data | OpenStreetMap (https://www.openstreetmap.org/) |
| RE Range (%) | WorldPop Estimation Results | XGBoost Model Estimation Results | ||
|---|---|---|---|---|
| Town (Unit) | Proportion (%) | Town (Unit) | Proportion (%) | |
| [0, 10] | 33 | 15.4 | 194 | 90.9 |
| (10, 20] | 36 | 16.8 | 7 | 3.0 |
| (20, 50] | 89 | 41.6 | 5 | 2.2 |
| (50, 100] | 40 | 18.7 | 3 | 1.3 |
| >100 | 16 | 7.5 | 5 | 2.6 |
| Total | 214 | 100 | 214 | 100.0 |
| Grid Scale | R2 | MRE | RMSE |
|---|---|---|---|
| 100 m | 0.98 | 0.09 | 10,375.9 |
| 200 m | 0.91 | 0.2 | 22,037.7 |
| 300 m | 0.88 | 0.22 | 24,544.6 |
| 500 m | 0.83 | 0.28 | 28,929.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Wang, H.; Guo, L.; Zhang, A.; Wu, X. Interpretable Machine Learning for Population Spatialization and Optimal Grid Scale Selection in Shanghai. Appl. Sci. 2025, 15, 4755. https://doi.org/10.3390/app15094755
Cao Y, Wang H, Guo L, Zhang A, Wu X. Interpretable Machine Learning for Population Spatialization and Optimal Grid Scale Selection in Shanghai. Applied Sciences. 2025; 15(9):4755. https://doi.org/10.3390/app15094755
Chicago/Turabian StyleCao, Yuan, Hefeng Wang, Lanxuan Guo, Anbing Zhang, and Xiaohu Wu. 2025. "Interpretable Machine Learning for Population Spatialization and Optimal Grid Scale Selection in Shanghai" Applied Sciences 15, no. 9: 4755. https://doi.org/10.3390/app15094755
APA StyleCao, Y., Wang, H., Guo, L., Zhang, A., & Wu, X. (2025). Interpretable Machine Learning for Population Spatialization and Optimal Grid Scale Selection in Shanghai. Applied Sciences, 15(9), 4755. https://doi.org/10.3390/app15094755