
A Solution for Predicting the Timespan Needed for Grinding Roller Bearing Rings



Abstract
1. Introduction
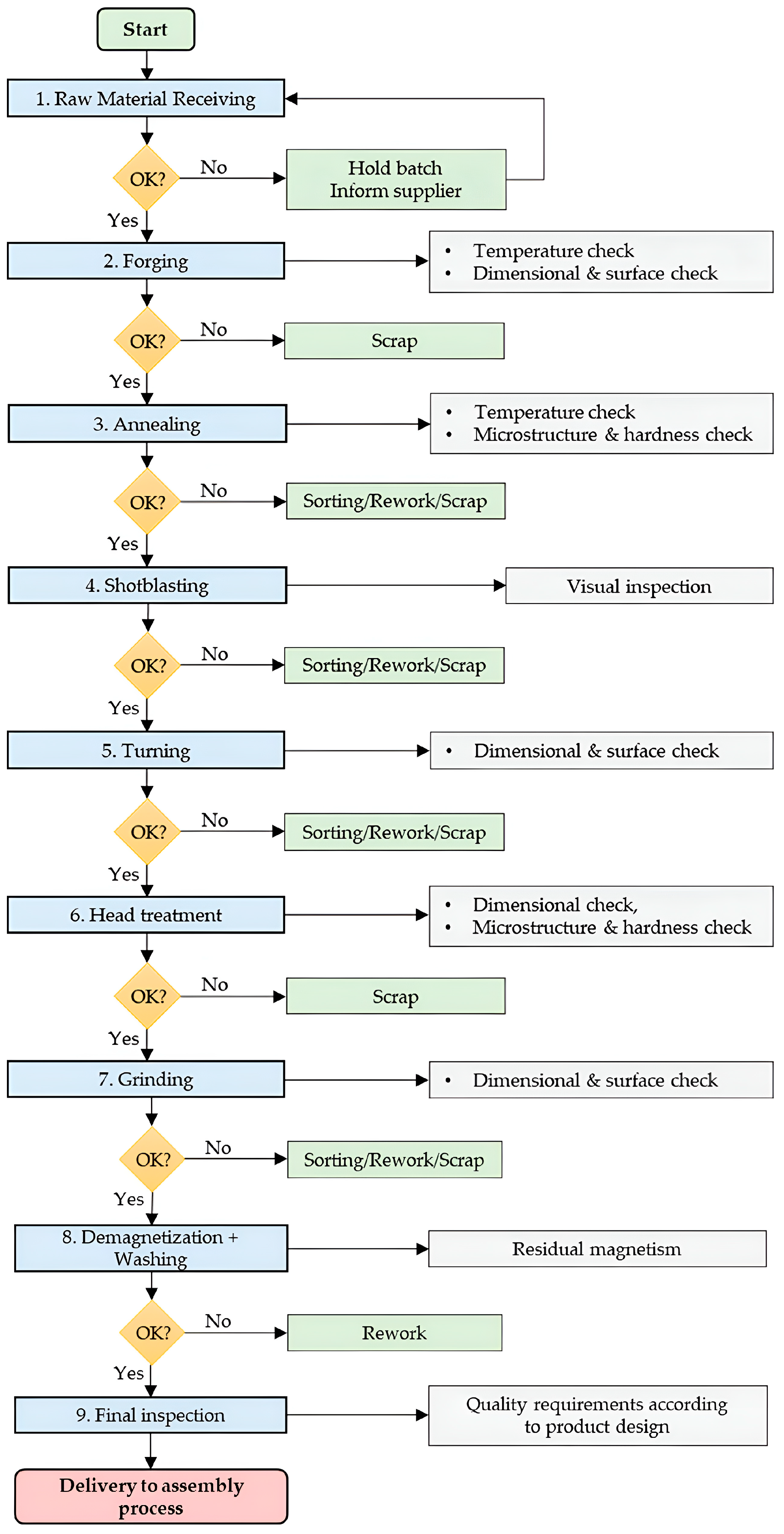
2. Manufacturing Process for Bearing Rings
2.1. The Identification of the Flow Diagram for the Manufacturing of an Inner and Outer Bearing Ring
2.2. Grinding Operations
3. Method for Timespan Prediction
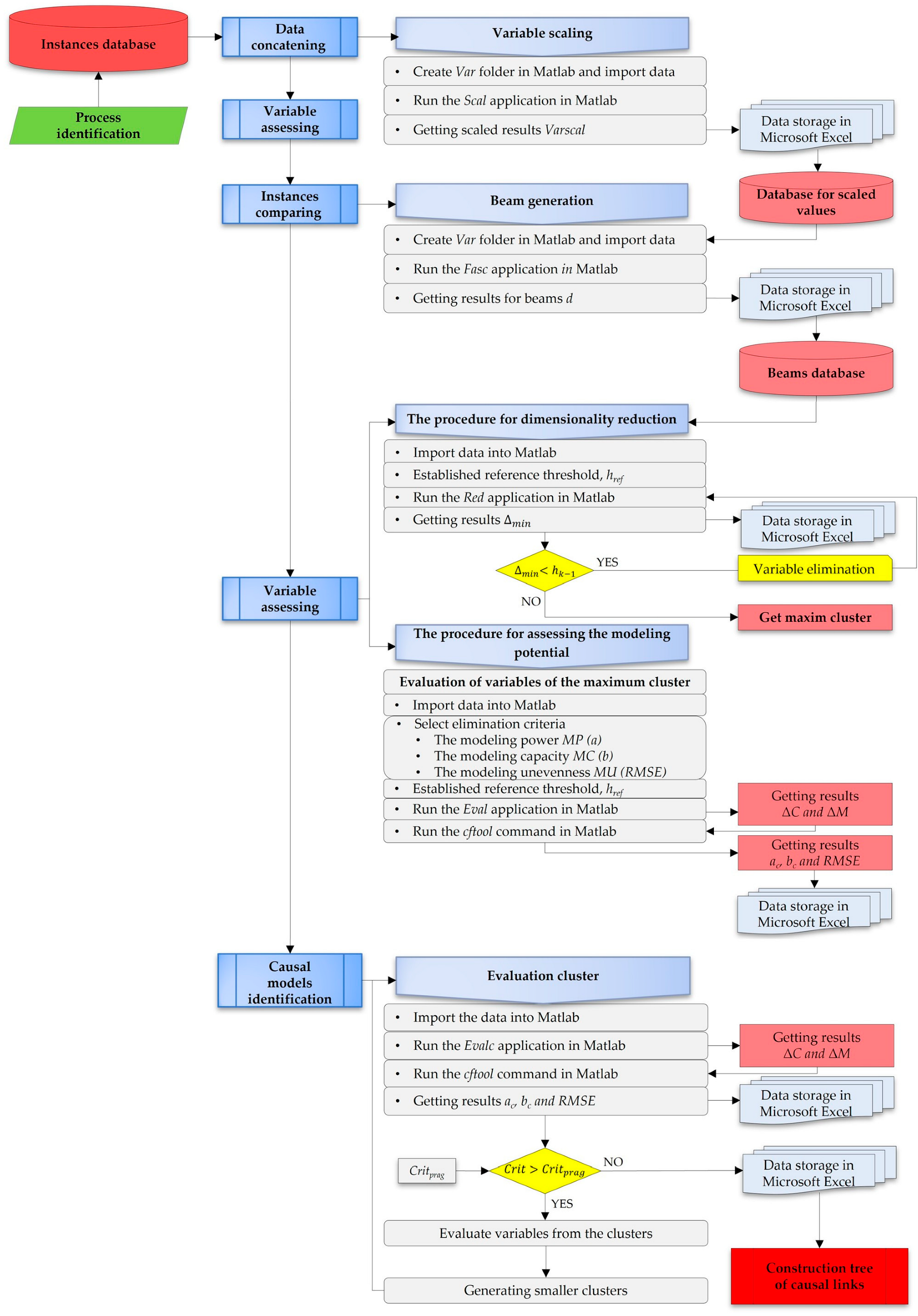
3.1. The Causal Identification Algorithm
- A.
- The first step involves data concatenation—for this purpose, data stored in a database are selected. In addition to selecting the data related to the manufacturing activity which is being analyzed, it is necessary to scale the variables to values between 1 and 0. To achieve this variable scaling, a MATLAB R2018a application (Scal) was developed. After running the scaling algorithm, the scaled values (Varscal) of the variables must be stored; for example, in a new file in Microsoft Excel.
- B.
- The second step means instance comparison—which proposes the generation of data beams. The causal identification methods start from the premise that the relevance of a cause variable to the effect variable and the modeling of the effect variable is directly related to the degree to which variation in the cause variable is found in the variation in the effect variable. Based on the value lines in the case database, the beams result from the difference between the homologous variables from different lines. To achieve beam generation, a MATLAB application (Fasc) was developed. After running the beam algorithm, the beam values (d) of the variables must be stored; for example, in a new file in Microsoft Excel.
- C.
- The third step is variable assessment—which involves two actions [11]; namely, problem dimensionality reduction and modeling capability assessment. The problem dimensionality reduction aims to eliminate the cause variables that have a redundant effect on the effect variable.
- Modeling power MP, which indicates how much of the variation in the cause variable is reflected in the variation in the effect variable;
- Modeling capacity MC, which measures the extent to which the cause variable is capable to describing the effect variable alone;
- Modeling unevenness MU, which reflects the dispersion of effect variable values when the cause variable exhibits uniform variation.
- D.
- The fourth step is causal model identification, which is used to determine the sets of cause variables that can be effectively used to evaluate the effect variable. This step is conducted by assessing an indicator similar to those evaluated in the individual case. For this purpose, a controlled variation is applied simultaneously to all the variables in the set and the impact on the effect variable is observed.
- E.
- Finally, the causal model tree is elaborated. This is the representation of causal models concerning the same effect variables. The tree results after the identification of the whole set of causal models concerning the addressed effect variable [11].
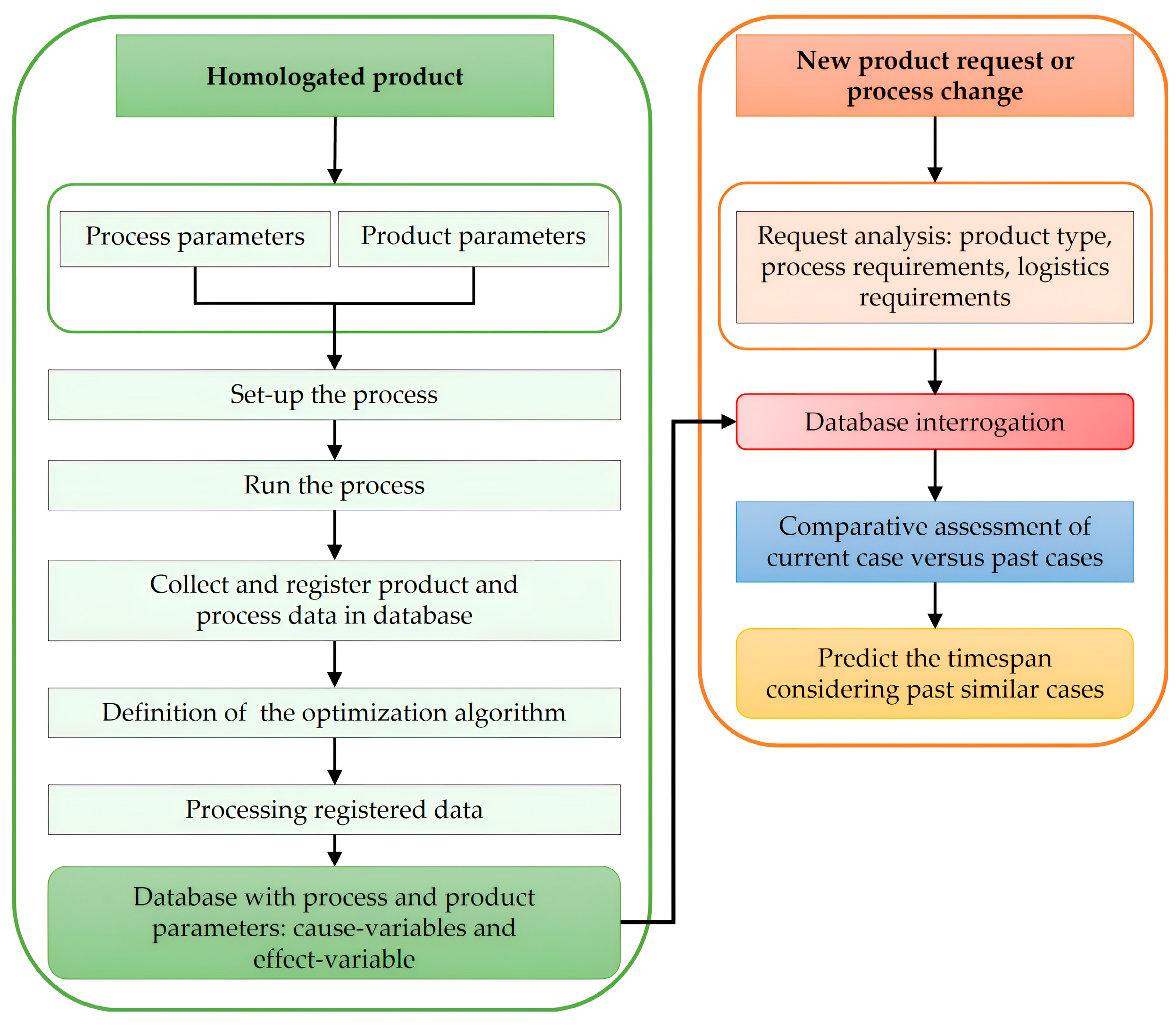
3.2. The Comparative Assessment Algorithm
- The neighborhood delimitation procedure—which aims to find the profile of the neighborhood of a potential case through successive comparisons with cases of processes already performed (with known results).
- The nearness modeling procedure—which aims to ensure that, after delimiting a neighborhood, the nearness between its instances is modeled to find an improved form of the proximity function. For modeling, nonlinear multiple regression has been adopted as the general typology of the nearness function. The algorithm (Comp) of the method was implemented with the help of MATLAB software.
- Building the database;
- Performing the causal identification;
- Selecting a case to model for the comparative assessment;
- Selecting a pivot from the database to use in the case for which we want to make the estimation;
- The two procedures of the comparative assessment algorithm are applied until the shape of the nearness modeling functions stabilizes. Based on the final form of this function, the distance between the values of the effect variable in the pivot case and in the analyzed case is calculated. This results in the value of the effect variable in the analyzed case.
4. Results and Discussion
4.1. Database Building
- -
- In the case of homologated products, both process and set-up parameters are known, and each run of the process will result in a new line in the database. Based on the registered data, an optimization algorithm can be defined, and cause and effect variables can be identified. A key result from the sequences of the flow diagram is the updated database.
- -
- In the case of a new product or a process change (process changes may occur due to an accidental defect or a lack of competencies to run the process under normal conditions), the optimization objectives could include the response time to customer requests during the quotation phase and the lead time in case of process changes according to the above details. By interrogating the database and applying the HOM, a prediction of the timespan can be obtained. In this manner, the obtained solution will help process engineers to minimize the analysis time and the lead time is therefore optimized.
4.2. Example of Timespan Prediction
4.2.1. The Application of the Algorithm for Causal Identification
- A.
- Data concatenation
- B.
- Comparison of instances
- C.
- Variables assessing
- C.1.
- Dimensionality reduction
- C.2.
- Assessing the modeling potential of variables
- D.
- Causal model identification
- D.1.
- Generating smaller clusters
- D.2.
- Assessing the modeling potential of a cluster
- E.
- Causal model tree
4.2.2. The Application of the Algorithm for Comparative Assessment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Yu, Z.; Guo, L. Real-time Online Prediction of Data Driven Bearing Residual Life. J. Phys. Conf. Ser. 2020, 1437, 012025. [Google Scholar] [CrossRef]
- Gao, J.; Bernard, A. An overview of knowledge sharing in new product development. Int. J. Adv. Manuf. Technol. 2018, 94, 1545–1550. [Google Scholar] [CrossRef]
- Mourtzis, D.; Doukas, M.; Fragou, K.; Efthymiou, K.; Matzorou, V. Knowledge-based estimation of manufacturing lead time for complex engineered-to-order products. Procedia CIRP 2014, 17, 499–504. [Google Scholar] [CrossRef]
- Antani, K.R. A Study of the Effects of Manufacturing Complexity on Product Quality in Mixed-Model Automotive Assembly. Master’s Thesis, The Graduate School of Clemson University, Clemson, SC, USA, May 2014. [Google Scholar]
- Öztürk, A.; Kayaligil, S.; Özdemirel, N.E. Manufacturing lead time estimation using data mining. Eur. J. Oper. Res. 2006, 173, 683–700. [Google Scholar] [CrossRef]
- López-Nicolás, C.; Merono-Cerdán, Á. Strategic knowledge management, innovation and performance. Int. J. Inf. Manag. 2011, 31, 502–509. [Google Scholar] [CrossRef]
- Ganesan, H.; Mohankumar, G.; Ganesan, K.; Kumar, K.R. Optimization of Machining Parameters in Turning Process Using Genetic Algorithm and Particle Swarm Optimization with Experimental Verification. Int. J. Eng. Sci. Technol. 2011, 3, 1091–1102. [Google Scholar]
- Sievers, S.; Seifert, T.; Franzen, M.; Schembecker, G.; Bramsiepe, C. Lead time estimation for modular production plants. Chem. Eng. Res. Des. 2017, 128, 96–106. [Google Scholar] [CrossRef]
- Frumuşanu, G.; Afteni, C.; Păunoiu, V. Estimation of Roller Bearings Manufacturing Cost by Causal Identification and Comparative Assessment—Case Study Performed on Industrial Data. Int. J. Model. Optim. 2020, 10, 114–120. [Google Scholar] [CrossRef]
- Kundakcı, N.; Kulak, O. Hybrid genetic algorithms for minimizing makespan in dynamic job shop scheduling problem. Comput. Ind. Eng. 2016, 96, 31–51. [Google Scholar] [CrossRef]
- Frumusanu, G.R.; Afteni, C.; Epureanu, A. Data-driven causal modelling of the manufacturing system. Trans. Famena 2021, 45, 43–62. [Google Scholar] [CrossRef]
- Afteni, C. Holistic Optimization of Manufacturing Process. Ph.D. Thesis, “Dunarea de Jos” University of Galati, Galati, Romania, May 2020. [Google Scholar]
- Choudhary, A.K.; Harding, J.A.; Tiwari, M.K. Data Mining in manufacturing: A review based on the kind of knowledge. J. Intell. Manuf. 2009, 20, 501–521. [Google Scholar] [CrossRef]
- Afteni, M.; Afteni, C.; Frumusanu, G.-R.; Susac, F. Estimation of components cost by comparative assessment method in the case of bearings with interchangeable construction. Acta Tech. Napocensi 2022, 65, 979–986. [Google Scholar]
- Ji, Z.; Chen, H.; Qiang, Y. Formability analysis of bearing ring produced by short-flow warm extrusion processing. Procedia Manuf. 2019, 37, 111–118. [Google Scholar] [CrossRef]
- Tran, T.-H.; Le, X.-H.; Nguyen, Q.-T.; Le, H.-K.; Hoang, T.-D.; Luu, A.-T.; Banh, T.-L.; Vu, N.-P. Optimization of Replaced Grinding Wheel Diameter for Minimum Grinding Cost in Internal Grinding. Appl. Sci. 2019, 9, 1363. [Google Scholar] [CrossRef]
- Cuong, V.N.; Hong, T.T.; Linh, N.H.; Giang, T.N.; Tu, N.T.; Pi, V.N. Time Optimization Study for External Cylindrical Grinding. Technol. Rep. Kansai Univ. 2020, 62, 315–320. [Google Scholar]
- Zhi, H.; Jie, Z. Condition Monitoring Technology for Bearing Ring Groove Grinding. J. Phys. Conf. Ser. 2019, 1213, 052036. [Google Scholar] [CrossRef]
- Brosed, F.J.; Zaera, A.V.; Padilla, E.; Cebrián, F.; Aguilar, J.J. In-Process Measurement for the Process Control of the Real-Time Manufacturing of Tapered Roller Bearings. Materials 2018, 11, 1371. [Google Scholar] [CrossRef]
- Tuan, N.A. Multi-Objective Optimization of Process Parameters to Enhance Efficiency in the Shoe-Type Centerless Grinding Operation for Internal Raceway of Ball Bearings. Metals 2021, 11, 893. [Google Scholar] [CrossRef]
- Patel, D.K.; Goyal, D.; Pabla, B.S. Optimization of parameters in cylindrical and surface grinding for improved surface finish. R. Soc. Open Sci. 2018, 5, 171906. [Google Scholar] [CrossRef]
- Chang, Z.; Jia, Q. Optimization of grinding efficiency considering surface integrity of bearing raceway. SN Appl. Sci. 2019, 1, 679. [Google Scholar] [CrossRef]
- Asokar, P.; Baskar, N.; Babu, K.; Prabhaharan, G.; Saravanan, R. Optimization of Surface Grinding Operations Using Particle Swarm Optimization Technique. J. Manuf. Sci. Eng. 2005, 127, 885–892. [Google Scholar] [CrossRef]
- Al Hazza, M.H.; Adesta, E.Y.T.; Riza, M.; Suprianto, M. Power Consumption Optimization in CNC Turning Process Using Multi Objective Genetic Algorithm. Adv. Mater. Res. 2012, 576, 95–98. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance Crt. no. | De [mm] | Di [mm] | L [mm] | g [kg] | Ra [μm] | va [m/min] | f [mm/rot] | vr [m/min] | t [mm] | Ts [min] |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 215.5 | 204.5 | 22 | 0.6265 | 0.55 | 28.01 | 0.151 | 79.1 | 0.13 | 0.65 |
| 2 | 381.3 | 360.05 | 38.15 | 4.264 | 1.61 | 25.06 | 0.91 | 70.02 | 0.6 | 4.765 |
| 3 | 250.8 | 237 | 24.7 | 0.9452 | 0.58 | 28.2 | 0.152 | 79.4 | 0.151 | 0.75 |
| 4 | 126.1 | 85.75 | 24.9 | 0.88 | 0.59 | 24.2 | 0.08 | 20.05 | 0.1501 | 0.29 |
| 5 | 240.6 | 220.05 | 38.16 | 2.5935 | 0.611 | 60.01 | 0.04 | 32.01 | 0.02 | 0.425 |
| . . . | . . . . . . . . . . . . . . . | |||||||||
| Instance Crt. No. | De [mm] | Di [mm] | l [mm] | g [kg] | Ra [μm] | va [m/min] | f [mm/rot] | vr [m/min] | t [mm] | Ts [min] |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.293063 | 0.312575 | 0.130277 | 0.032378 | 0.290541 | 0.2722739 | 0.1315217 | 0.4923346 | 0.1582915 | 0.025251 |
| 2 | 0.590249 | 0.60881 | 0.27659 | 0.279543 | 1 | 0.2053956 | 0.9565217 | 0.4166806 | 0.748744 | 0.198143 |
| 3 | 0.356336 | 0.374469 | 0.154738 | 0.054033 | 0.310811 | 0.2765813 | 0.1326087 | 0.4948342 | 0.184673 | 0.029453 |
| 4 | 0.13282 | 0.086423 | 0.15655 | 0.049603 | 0.317568 | 0.1858989 | 0.0543478 | 0.0003333 | 0.183543 | 0.010126 |
| 5 | 0.338053 | 0.342189 | 0.276681 | 0.166034 | 0.331757 | 0.9977329 | 0.0108696 | 0.0999833 | 0.020101 | 0.015798 |
| . . . | . . . . . . . . . . . . . . . | |||||||||
| Instance Crt. No. | δDe [mm] | δDi [mm] | δl [mm] | δg [kg] | δRa [μm] | va [m/min] | δf [mm/rot] | δvr [m/min] | δt [mm] | δTs [min] |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.297186 | 0.296235 | 0.146313 | 0.247165 | 0.709459 | 0.066878 | 0.825 | 0.075654 | 0.590452 | 0.172892 |
| 2 | 0.063273 | 0.061894 | 0.024461 | 0.021655 | 0.02027 | 0.004307 | 0.001087 | 0.0025 | 0.026382 | 0.004202 |
| 3 | 0.160244 | 0.226152 | 0.026273 | 0.017225 | 0.027027 | 0.086375 | 0.077174 | 0.492001 | 0.025251 | 0.015125 |
| 4 | 0.04499 | 0.029614 | 0.146403 | 0.133656 | 0.041216 | 0.725459 | 0.120652 | 0.392351 | 0.138191 | 0.009453 |
| 5 | 0.117315 | 0.179207 | 0.362384 | 0.042624 | 0.236486 | 0.432782 | 0.055435 | 0.507499 | 0.037688 | 0.063023 |
| . . . | . . . . . . . . . . . . . . . | |||||||||
| Cause Variables | Successive Steps for Dimensionality Reduction | |||
|---|---|---|---|---|
| Step 1 | Step 2 | Step 3 | Step 4 | |
| De | 0.1433 | 0.1433 | - | - |
| Di | 0.1705 | 0.1705 | 0.6869 | 0.6869 |
| l | 0.1753 | 0.3352 | 0.3352 | 0.6940 |
| g | 0.1736 | 0.1736 | 0.1736 | - |
| Ra | 0.9122 | 0.9122 | 0.9122 | 0.9122 |
| va | 0.1179 | - | - | - |
| f | 0.7609 | 0.8043 | 0.8043 | 0.8043 |
| vr | 0.4155 | 0.9251 | 0.9251 | 0.9251 |
| t | 0.2927 | 0.2927 | 0.2927 | 0.2927 |
| Di | l | Ra | f | vr | t | |
|---|---|---|---|---|---|---|
| a | 0.1883 | 0.2208 | 0.0714 | 0.0077 | 0.00085 | 0.1726 |
| b | 0.0254 | 0.0261 | 0.0407 | 0.1308 | 0.0399 | 0.0326 |
| RMSE | 0.0072 | 0.0024 | 0.0037 | 0.00068 | 0.00068 | 0.00027 |
| (a) | ||||||
| Variables | Di | l | Ra | f | vr | t |
| b | 0.0254 | 0.0261 | 0.0407 | 0.1308 | 0.0399 | 0.0326 |
| Resulted clusters | [Di, l, Ra, vr, t] [Di, l, f, vr, t] | |||||
| (b) | ||||||
| Variables | Di | l | Ra | vr | t | |
| b | 0.0424 | 0.0306 | 0.0384 | 0.0428 | 0.0319 | |
| Resulting clusters | [Di, l, Ra, t] [l, Ra, vr, t] | |||||
| Variables | Di | l | f | vr | t | |
| b | 0.0507 | 0.0443 | 0.057 | 0.0569 | 0.0535 | |
| Resulting clusters | [Di, l, f, t] [Di, l, vr, t] | |||||
| (c) | ||||||
| Variables | Di | l | Ra | t | ||
| b | 0.0322 | 0.0349 | 0.0461 | 0.0445 | ||
| Resulting clusters | [Di, l, Ra] [Di, l, t] | |||||
| Variables | l | Ra | vr | t | ||
| b | 0.0307 | 0.0315 | 0.0475 | 0.0115 | ||
| Resulting clusters | [l, Ra, t] [l, vr, t] | |||||
| Variables | Di | l | f | t | ||
| b | 0.036 | 0.0319 | 0.0494 | 0.0377 | ||
| Resulting clusters | [Di, l, f] [Di, l, t] | |||||
| Variables | Di | l | vr | t | ||
| b | 0.0471 | 0.0391 | 0.0489 | 0.0469 | ||
| Resulting clusters | [Di, l, t] [l, vr, t] | |||||
| Set of Cause Variables | ac | bc | RMSE |
|---|---|---|---|
| [Di, l, Ra, f, vr, t] | 0.0611 | 0.08703 | 0.0796 |
| [Di, l, Ra, vr, t] | 0.0793 | 0.0837 | 0.0806 |
| [Di, l, f, vr, t] | 0.3205 | 0.0481 | 0.0268 |
| [Di, l, Ra, t] | 0.0705 | 0.0821 | 0.0816 |
| [l, Ra, vr, t] | 0.3684 | 0.0806 | 0.0789 |
| [Di, l, f, t] | 0.3535 | 0.0424 | 0.0266 |
| [Di, l, vr, t] | 0.3047 | 0.0466 | 0.0271 |
| [Di, l, Ra] | 0.3752 | 0.03901 | 0.0204 |
| [Di, l, t] | 0.3891 | 0.0326 | 0.0219 |
| [l, Ra, t] | 0.651 | 0.0386 | 0.0292 |
| [l, vr, t] | 0.5902 | 0.0459 | 0.0159 |
| [Di, l, f] | 0.393 | 0.0359 | 0.018 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chivu, C.; Afteni, M.; Frumusanu, G.R.; Susac, F. A Solution for Predicting the Timespan Needed for Grinding Roller Bearing Rings. Appl. Sci. 2025, 15, 4846. https://doi.org/10.3390/app15094846
Chivu C, Afteni M, Frumusanu GR, Susac F. A Solution for Predicting the Timespan Needed for Grinding Roller Bearing Rings. Applied Sciences. 2025; 15(9):4846. https://doi.org/10.3390/app15094846
Chicago/Turabian StyleChivu, Cezarina, Mitica Afteni, Gabriel Radu Frumusanu, and Florin Susac. 2025. "A Solution for Predicting the Timespan Needed for Grinding Roller Bearing Rings" Applied Sciences 15, no. 9: 4846. https://doi.org/10.3390/app15094846
APA StyleChivu, C., Afteni, M., Frumusanu, G. R., & Susac, F. (2025). A Solution for Predicting the Timespan Needed for Grinding Roller Bearing Rings. Applied Sciences, 15(9), 4846. https://doi.org/10.3390/app15094846