
Deep Feature Fusion via Transfer Learning for Multi-Class Network Intrusion Detection

 , and
, and
Abstract
:1. Introduction
2. Related Work
- This study employs the CIC-IDS dataset for attack-type classification in network anomaly detection. To address the persistent class imbalance challenge documented in previous research, the methodology incorporates strategic data preprocessing: rare attack categories were eliminated, while similar attack types were consolidated. Subsequently, random resampling techniques were implemented to equilibrate data distribution, accompanied by standard scaling to normalize all features to a mean of 0 and variance of 1, thereby enhancing the model’s generalization capabilities across diverse network environments.
- By transferring learned feature representations from source domain models to the target domain, the proposed approach achieves superior detection performance despite limited training data availability. Furthermore, the model effectively leverages common feature spaces even when the source and target domains exhibit partial incongruence, significantly reducing computational training requirements while mitigating overfitting phenomena that commonly plague complex network detection systems.
- To maximize detection efficacy, feature fusion techniques are integrated with the transfer learning-based architecture, amalgamating feature representations utilized in both binary classification and multi-class classification processes. This integration enables the model to synthesize diverse feature perspectives and derive more generalized pattern recognition capabilities, substantially enhancing its precision in identifying and categorizing various network attack typologies.
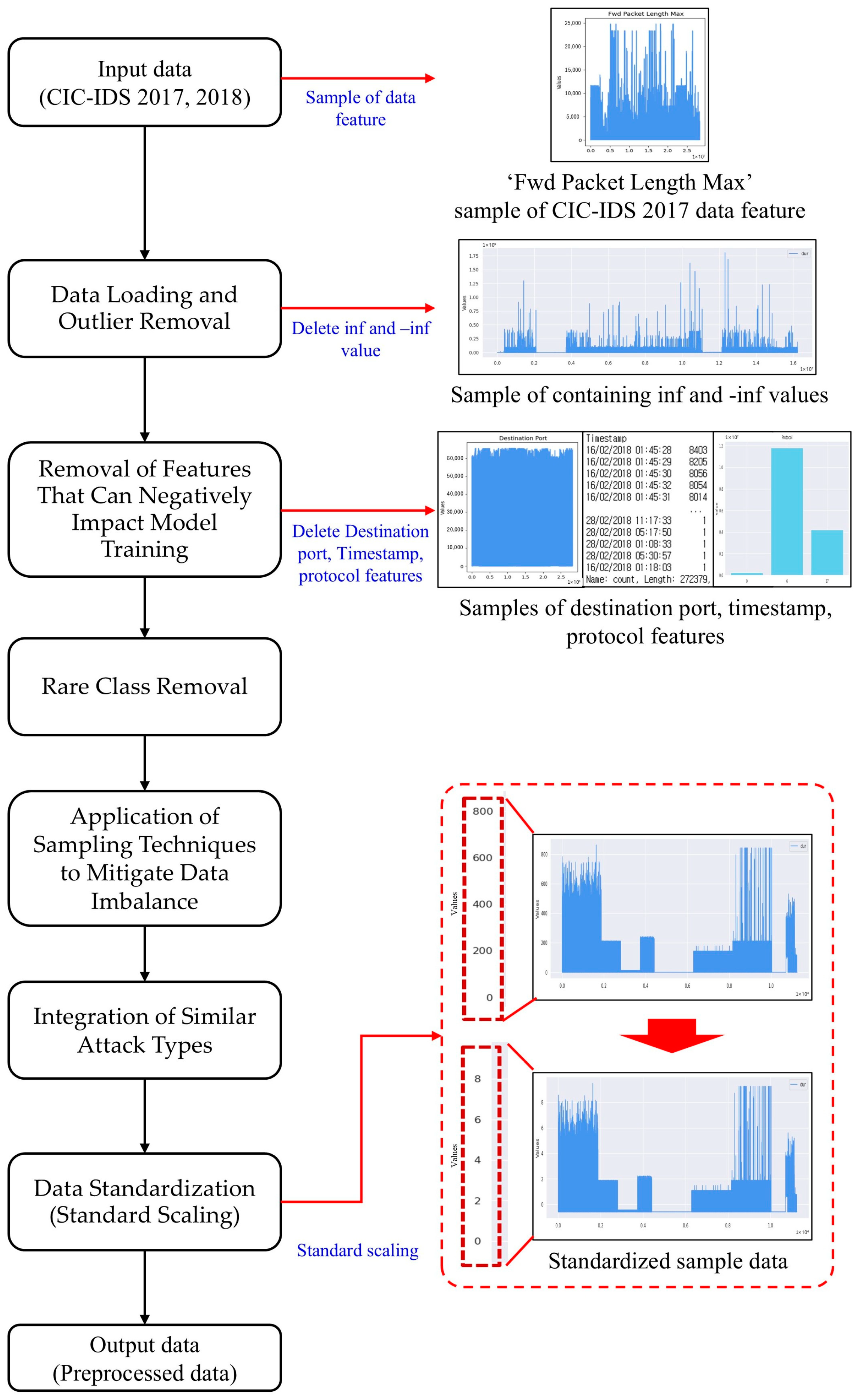
3. Data Processing and Preparation
- Data Loading and Outlier Removal
- 2.
- Removal of Features That Can Negatively Impact Model Training
- 3.
- Rare Class Removal
- 4.
- Application of Sampling Techniques to Mitigate Data Imbalance
- 5.
- Integration of Similar Attack Types
- 6.
- Data Standardization (Standard Scaling)
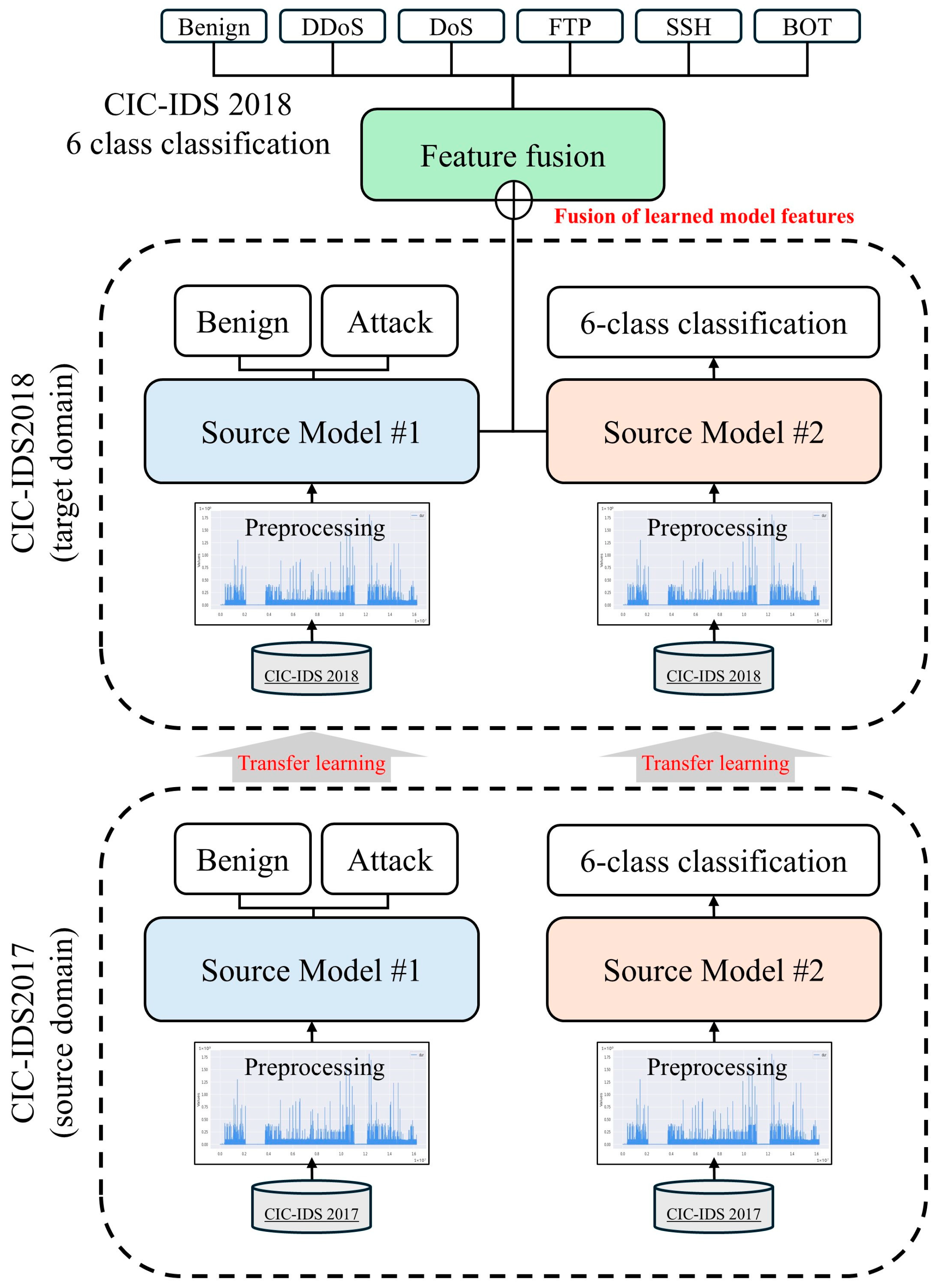
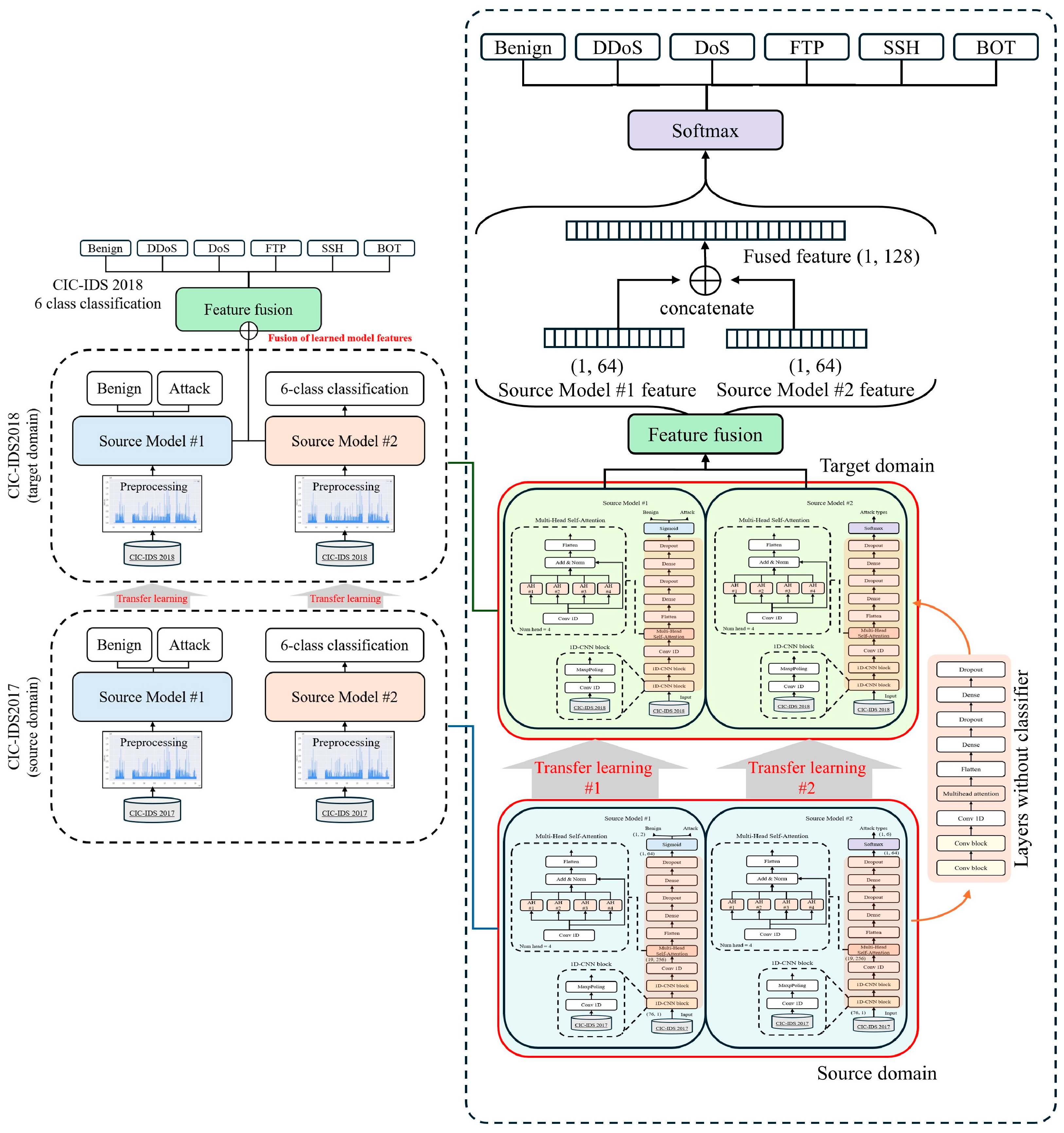
4. Proposed Method
4.1. Overview of the Proposed Model
- (1)
- First, binary and multi-class classification models are constructed by training on the CIC-IDS2017 dataset in the source domain.
- (2)
- Subsequently, these models are transferred to the target domain using the CIC-IDS2018 dataset and retrained to adapt to updated traffic patterns and newly emerging attack types.
- (3)
- Finally, the feature representations extracted from these retrained models are systematically fused, and final fine-tuning [34] is performed utilizing the CIC-IDS2018 dataset to execute a multi-class classification of network attack types.
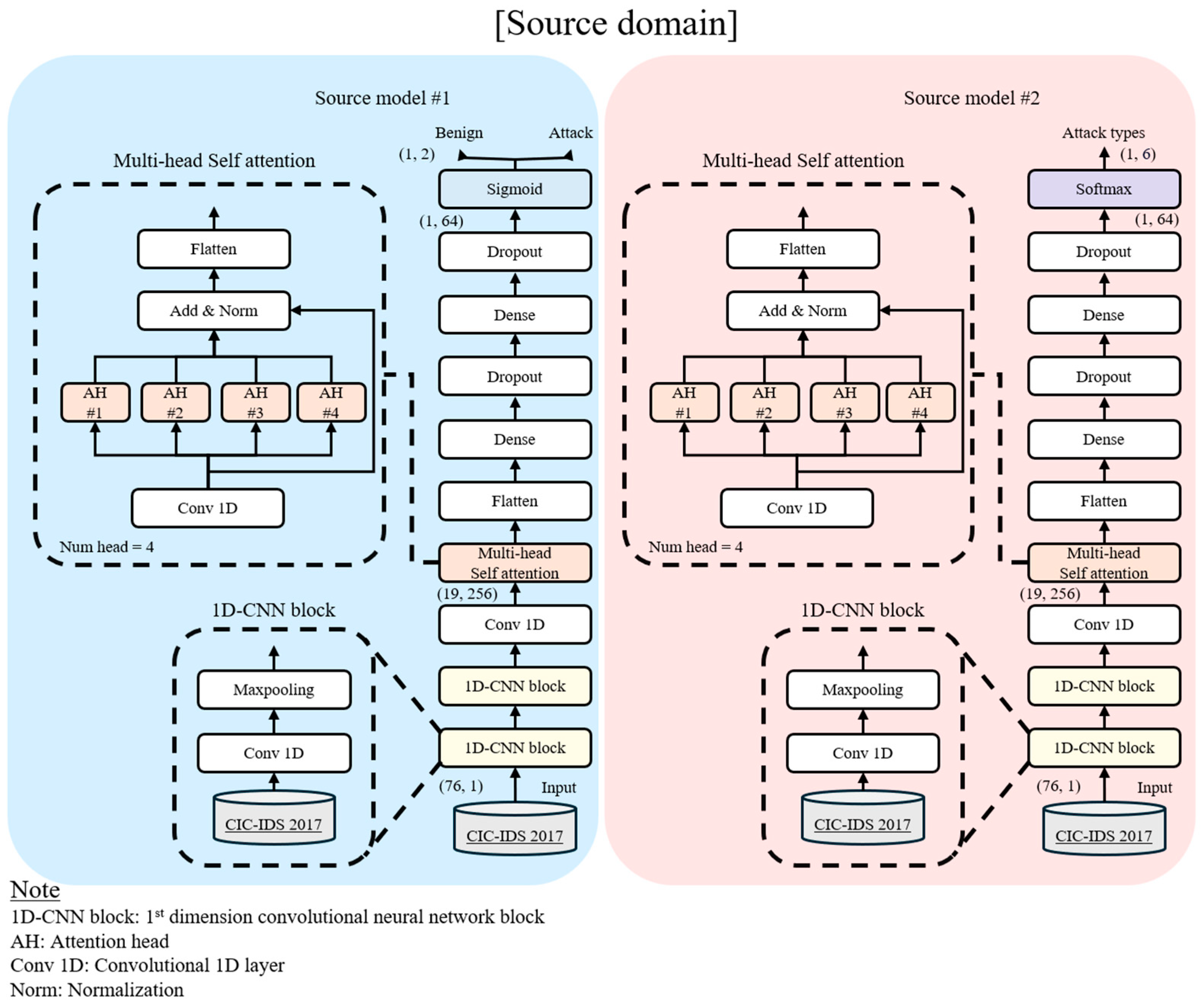
- (1)
- Source Model #1 performs binary classification (normal network traffic and attack traffic) to detect the presence of malicious traffic.
- (2)
- Source Model #2 handles multi-class classification to categorize attack traffic into specific attack typologies further.
4.2. Detailed Description of the Proposed Model Structure
5. Results
5.1. Experimental Environment and Parameter Settings
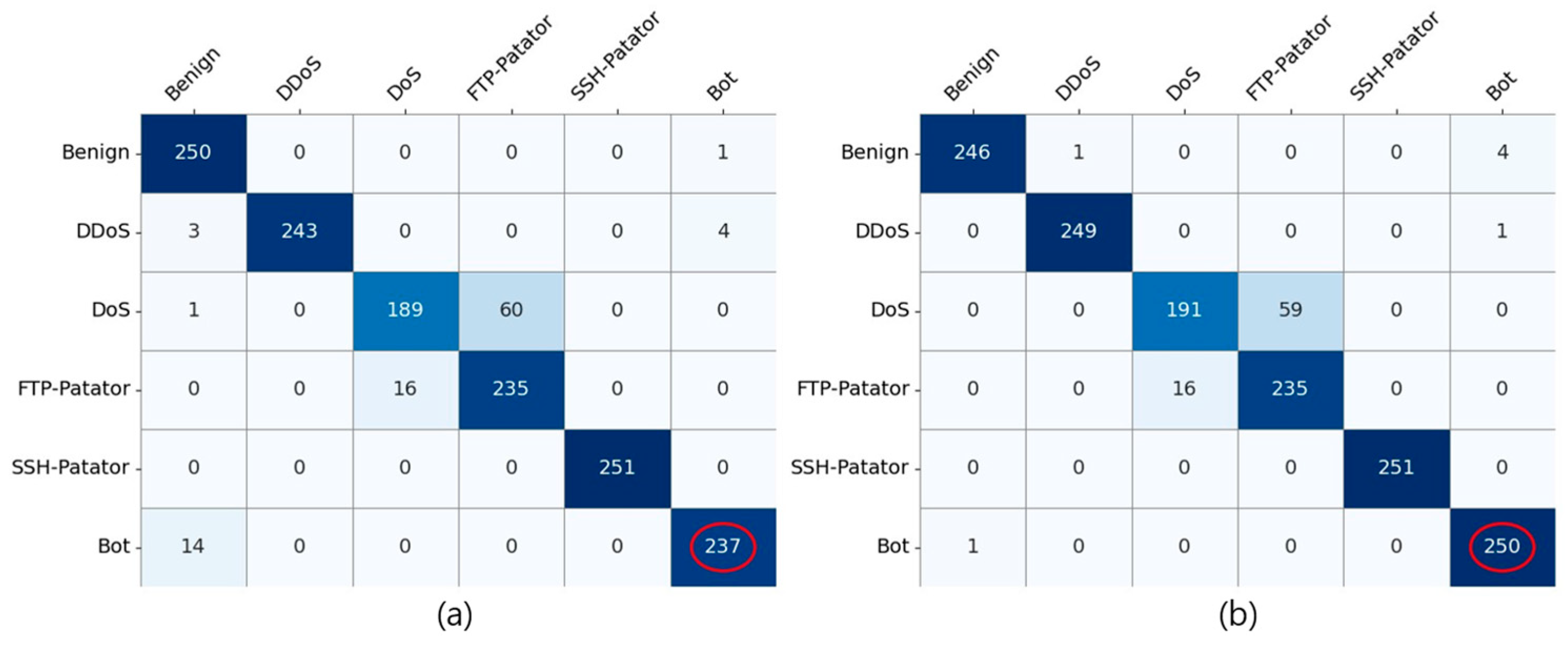
5.2. Analysis of Results for the Proposed Method
5.3. Comprehensive Performance Analysis of the Proposed Method
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dutton, W.H.; Peltu, M. Information and Communication Technologies: Visions and Realities; Oxford University Press: New York, NY, USA, 1996; pp. 113–115. ISBN 0198774966. [Google Scholar]
- Falowo, O.I.; Ozer, M.; Li, C.; Abdo, J.B. Evolving malware and DDoS attacks: Decadal longitudinal study. IEEE Access 2024, 12, 39221–39237. [Google Scholar] [CrossRef]
- Schmitt, M. Securing the digital world: Protecting smart infrastructures and digital industries with artificial intelligence (AI)-enabled malware and intrusion detection. J. Ind. Inf. Integr. 2023, 36, 100520. [Google Scholar] [CrossRef]
- Zhang, C.; Jia, D.; Wang, L.; Wang, W.; Liu, F.; Yang, A. Comparative research on network intrusion detection methods based on machine learning. Comput. Secur. 2022, 121, 102861. [Google Scholar] [CrossRef]
- Zaman, M.; Lung, C.-H. Evaluation of Machine Learning Techniques for Network Intrusion Detection. In Proceedings of the NOMS 2018—2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Li, J.; Qu, Y.; Chao, F.; Shum, H.P.H.; Ho, E.S.L.; Yang, L. Machine learning algorithms for network intrusion detection. In AI in Cybersecurity; Intelligent Systems Reference Library; Sikos, L., Ed.; Springer: Cham, Switzerland, 2018; pp. 151–179. [Google Scholar] [CrossRef]
- Ashiku, L.; Dagli, C. Network intrusion detection system using deep learning. Procedia Comput. Sci. 2021, 185, 239–247. [Google Scholar] [CrossRef]
- Cantone, M.; Marrocco, C.; Bria, A. On the cross-dataset generalization of machine learning for network intrusion detection. arXiv 2024, arXiv:2402.10974. [Google Scholar] [CrossRef]
- Mehedi, S.T.; Anwar, A.; Rahman, Z.; Ahmed, K. Deep transfer learning based intrusion detection system for electric vehicular networks. Sensors 2021, 21, 4736. [Google Scholar] [CrossRef]
- Chen, Z.; Simsek, M.; Kantarci, B.; Bagheri, M.; Djukic, P. Machine learning-enabled hybrid intrusion detection system with host data transformation and an advanced two-stage classifier. Comput. Netw. 2024, 250, 110576. [Google Scholar] [CrossRef]
- Selvam, R.; Velliangiri, S. An Improving Intrusion Detection Model Based on Novel CNN Technique Using Recent CIC-IDS Datasets. In Proceedings of the 2024 International Conference on Distributed Computing and Optimization Techniques (ICDCOT), Bengaluru, India, 15–16 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Gayatri, K.; Premamayudu, B.; Yadav, M.S. A Two-Level Hybrid Intrusion Detection Learning Method. In Machine Intelligence and Soft Computing, Proceedings of the ICMISC 2021, Guntur, India, 22–24 September 2021; Bhattacharyya, D., Thirupathi Rao, N., Eds.; Springer: Singapore, 2021; pp. 241–253. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, S.; Ermon, S.; Lobell, D.B. Transfer learning in environmental remote sensing. Remote Sens. Environ. 2024, 301, 113924. [Google Scholar] [CrossRef]
- Lu, H.; Zhao, Y.; Song, Y.; Yang, Y.; He, G.; Yu, H.; Ren, Y. A transfer learning-based intrusion detection system for zero-day attack in communication-based train control system. Clust. Comput. 2024, 27, 8477–8492. [Google Scholar] [CrossRef]
- Li, X.; Hu, Z.; Xu, M.; Wang, Y.; Ma, J. Transfer learning based intrusion detection scheme for Internet of vehicles. Inf. Sci. 2021, 547, 119–135. [Google Scholar] [CrossRef]
- Dai, G.; Tian, Z.; Fan, J.; Sunil, C.K.; Dewi, C. DFN-PSAN: Multi-level deep information feature fusion extraction network for interpretable plant disease classification. Comput. Electron. Agric. 2024, 216, 108481. [Google Scholar] [CrossRef]
- Jabeen, K.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Zhang, Y.-D.; Hamza, A.; Mickus, A.; Damaševičius, R. Breast cancer classification from ultrasound images using probability-based optimal deep learning feature fusion. Sensors 2022, 22, 807. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Wang, Y.; Si, T.; Ullah, K.; Han, W.; Wang, L. MFFSP: Multi-scale feature fusion scene parsing network for landslides detection based on high-resolution satellite images. Eng. Appl. Artif. Intell. 2024, 127, 107337. [Google Scholar] [CrossRef]
- Li, M.; Chen, Y.; Lu, Z.; Ding, F.; Hu, B. ADED: Method and device for automatically detecting early depression using multimodal physiological signals evoked and perceived via various emotional scenes in virtual reality. IEEE Trans. Instrum. Meas. 2025, 74, 1–16. [Google Scholar] [CrossRef]
- Han, Y.; Choi, Y.; Lee, J.; Bae, J.-H. Feature fusion model using transfer learning and bidirectional attention mechanism for plant pipeline leak detection. Appl. Sci. 2025, 15, 490. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Funchal–Madeira, Portugal, 22–24 January 2018; Mori, P., Furnell, S., Camp, O., Eds.; Springer: Cham, Switzerland, 2019; pp. 108–116. [Google Scholar]
- The CIC-IDS2017 Dataset and CIC-IDS2018 Dataset. Available online: https://www.unb.ca/cic/datasets/index.html (accessed on 22 April 2025).
- Francazi, E.; Baity-Jesi, M.; Lucchi, A. A theoretical analysis of the learning dynamics under class imbalance. arXiv 2024, arXiv:2207.00391. [Google Scholar]
- Michelucci, U.; Venturini, F. New metric formulas that include measurement errors in machine learning for natural sciences. Expert Syst. Appl. 2023, 224, 120013. [Google Scholar] [CrossRef]
- Ayinde, B.O.; Zurada, J.M. Building efficient ConvNets using redundant feature pruning. arXiv 2018, arXiv:1802.07653. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Mujahid, M.; Kına, E.; Rustam, F.; Villar, M.G.; Alvarado, E.S.; de la Torre Diez, I.; Ashraf, I. Data oversampling and imbalanced datasets: An investigation of performance for machine learning and feature engineering. J. Big Data 2024, 11, 87. [Google Scholar] [CrossRef]
- Abu Elsoud, E.; Hassan, M.; Alidmat, O.; Al Henawi, E.; Alshdaifat, N.; Igtait, M.; Ghaben, A.; Katrawi, A.; Dmour, M. Under sampling techniques for handling unbalanced data with various imbalance rates: A comparative study. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1274–1284. [Google Scholar] [CrossRef]
- Kim, J.-M.; Chung, Y.-J. Clustering based under-sampling for imbalanced data classification. J. Korean Inst. Inf. Technol. 2024, 22, 51–60. [Google Scholar] [CrossRef]
- Ryu, K.J.; Shin, D.-I.; Shin, D.-G.; Park, J.-C.; Kim, J.-G. A pre-processing study to solve the problem of rare class classification of network traffic data. KIPS Trans. Softw. Data Eng. 2020, 9, 411–418. [Google Scholar] [CrossRef]
- De Amorim, L.B.V.; Cavalcanti, G.D.C.; Cruz, R.M.O. The choice of scaling technique matters for classification performance. Appl. Soft Comput. 2023, 133, 109924. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Yao, R.; Zhao, H.; Zhao, Z.; Guo, C.; Deng, W. Parallel convolutional transfer network for bearing fault diagnosis under varying operation states. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Ravikumar, A.; Harini, S. A comprehensive review of transfer learning on deep convolutional neural network models. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 8272–8278. [Google Scholar] [CrossRef]
- Mungoli, N. Adaptive ensemble learning: Boosting model performance through intelligent feature fusion in deep neural networks. arXiv 2023, arXiv:2304.02653. [Google Scholar]
- Al-Deen, H.S.S.; Zeng, Z.; Al-Sabri, R.; Hekmat, A. An improved model for analyzing textual sentiment based on a deep neural network using multi-head attention mechanism. Appl. Syst. Innov. 2021, 4, 85. [Google Scholar] [CrossRef]
- Roy, S.; Mehera, R.; Pal, R.K.; Bandyopadhyay, S.K. Hyperparameter optimization for deep neural network models: A comprehensive study on methods and techniques. Innov. Syst. Softw. Eng. 2023. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties; USAF School of Aviation Medicine: Dayton, OH, USA, 1951. [Google Scholar]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B Stat. Methodol. 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Output Dimension | Layer |
|---|---|---|
| Input | Input Layer | |
| 1D CNN | ||
| MaxPooling1D | Pool size = 2 | |
| 1D CNN | ||
| MaxPooling1D | Pool size = 2 | |
| 1D CNN | ||
| MultiHeadAttention | Head = 4 | |
| Flatten | 4864 | - |
| Dense Layer 1 | 256 | ] |
| Dense Layer 2 | 64 | ] |
| Concatenate | 128 | - |
| Classifier | 6 | ] Softmax |
| # params | 2,598,790 | |
| Parameter | CIC-IDS 2017 (Source Domain) | CIC-IDS 2018 (Target Domain) |
|---|---|---|
| Train data | 74,236 | 4510 |
| Test data | 24,746 | 1503 |
| Optimizer | Adam | Adam |
| Loss function | Binary, categorical | Binary, categorical |
| Learning rate | ||
| Epoch | 25 | 25 |
| Batch size | 16 | 64 |
| Class | CIC-IDS 2017 (Source Domain) | CIC-IDS 2018 (Target Domain) |
|---|---|---|
| Benign | 21,996 | 1003 |
| PortScan | 21,996 | - |
| DoS | 21,996 | 1001 |
| DDoS | 21,996 | 1001 |
| FTP-Patator | 5499 | 1003 |
| SSH-Patator | 5499 | 1003 |
| Bot | - | 1003 |
| Total | 98,982 | 6014 |
| Model | Accuracy (%) | F1-Score (%) |
|---|---|---|
| KNN | 94.12 | 94.05 |
| LR | 90.86 | 90.77 |
| SVM | 92.06 | 91.84 |
| CNN (NoTL) | 92.70 | 92.63 |
| CNN + Attention (NoTL) | 93.71 | 93.64 |
| CNN + Attention (TL) | 93.96 | 93.90 |
| Proposed model | 94.21 | 94.16 |
| Model | Train 100% | Train 66% | Train 33% |
|---|---|---|---|
| KNN | 94.12 | 93.67 | 93.02 |
| LR | 90.86 | 90.74 | 90.41 |
| SVM | 92.06 | 91.82 | 91.38 |
| CNN (NoTL) | 92.70 | 92.40 | 91.38 |
| CNN + Attention (NoTL) | 93.71 | 93.32 | 92.43 |
| CNN + Attention (TL) | 93.96 | 93.77 | 93.08 |
| Proposed model | 94.21 | 94.10 | 93.66 |
| Model | Train 100% | Train 66% | Train 33% |
|---|---|---|---|
| KNN | 94.05 | 93.58 | 92.92 |
| LR | 90.77 | 90.64 | 90.29 |
| SVM | 91.84 | 91.59 | 91.14 |
| CNN(NoTL) | 92.63 | 92.33 | 91.25 |
| CNN + Attention (NoTL) | 93.64 | 93.27 | 92.33 |
| CNN + Attention (TL) | 93.90 | 93.70 | 92.99 |
| Proposed model | 94.16 | 94.05 | 93.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Roh, D.; Yu, J.; Moon, D.; Lee, J.; Bae, J.-H. Deep Feature Fusion via Transfer Learning for Multi-Class Network Intrusion Detection. Appl. Sci. 2025, 15, 4851. https://doi.org/10.3390/app15094851
Lee S, Roh D, Yu J, Moon D, Lee J, Bae J-H. Deep Feature Fusion via Transfer Learning for Multi-Class Network Intrusion Detection. Applied Sciences. 2025; 15(9):4851. https://doi.org/10.3390/app15094851
Chicago/Turabian StyleLee, Sunghyuk, Donghwan Roh, Jaehak Yu, Daesung Moon, Jonghyuk Lee, and Ji-Hoon Bae. 2025. "Deep Feature Fusion via Transfer Learning for Multi-Class Network Intrusion Detection" Applied Sciences 15, no. 9: 4851. https://doi.org/10.3390/app15094851
APA StyleLee, S., Roh, D., Yu, J., Moon, D., Lee, J., & Bae, J.-H. (2025). Deep Feature Fusion via Transfer Learning for Multi-Class Network Intrusion Detection. Applied Sciences, 15(9), 4851. https://doi.org/10.3390/app15094851