Based on the classification mechanism, the rough sets theory’s research object is the information system [
18]. By introducing an indiscernibility relation as the theoretical basis, and defining the concepts of upper and lower approximations, the rough sets theory focuses on knowledge reduction and determining attribute importance. Through attribute reduction, the fuzziness and uncertainty knowledge can be described by the knowledge in the existing knowledge base.
2.1.1. Indiscernibility Relation
We defined the domain as a non-empty finite set of the samples we are interested in, and any subset which satisfies the condition can be called a concept or a category in . Furthermore, any concept set of can be called basic knowledge of , which represents the individual classification in the domain , referred to as ’s knowledge. Let be an equivalence relation on , denotes all equivalence classes, and represents equivalent classes of that contain element , which satisfies the condition . If and , the intersection of all equivalence relations in is also an equivalence relation, and this equivalence relation is called -indiscernibility relation, denoted as . In the process of classification, the individuals with little difference are classified into the same classification, and their relationship is an indiscernibility relation, which is equivalent to an equivalence relation on .
The concept of indiscernibility relation is the cornerstone of the rough sets theory, which reveals the granular structure of domain knowledge. The concept assumes that some knowledge is in the domain, and uses attributes and attributes’ values to describe the objects. If two objects have the same attributes and attributes’ values, they have an indiscernibility relation. Mathematically, the indiscernibility relation of a set and the division of a set are equivalent concepts, one-to-one, and unique to each other. This concept means that objects in the domain can be described with different attributes’ sets to express exactly the same facts.
2.1.2. Lower and Upper Approximations
Let
denote the subset of elements of the domain
(
and
), and
denote an equivalence relation on
. The lower approximation of
in
, denoted as
, is defined as the union of all these elementary sets contained in
. More formally,
The upper approximation of set
, denoted as
, is the union of these elementary sets, which have a non-empty intersection with
:
In general,
Figure 1 represents the upper approximation and lower approximation. The area in the black box is the domain
, the area in the green curve denotes
, the inner red curve denotes the upper approximation set
, and the blue curve denotes the lower approximation set
.
2.1.3. Core and Attribute Reduction
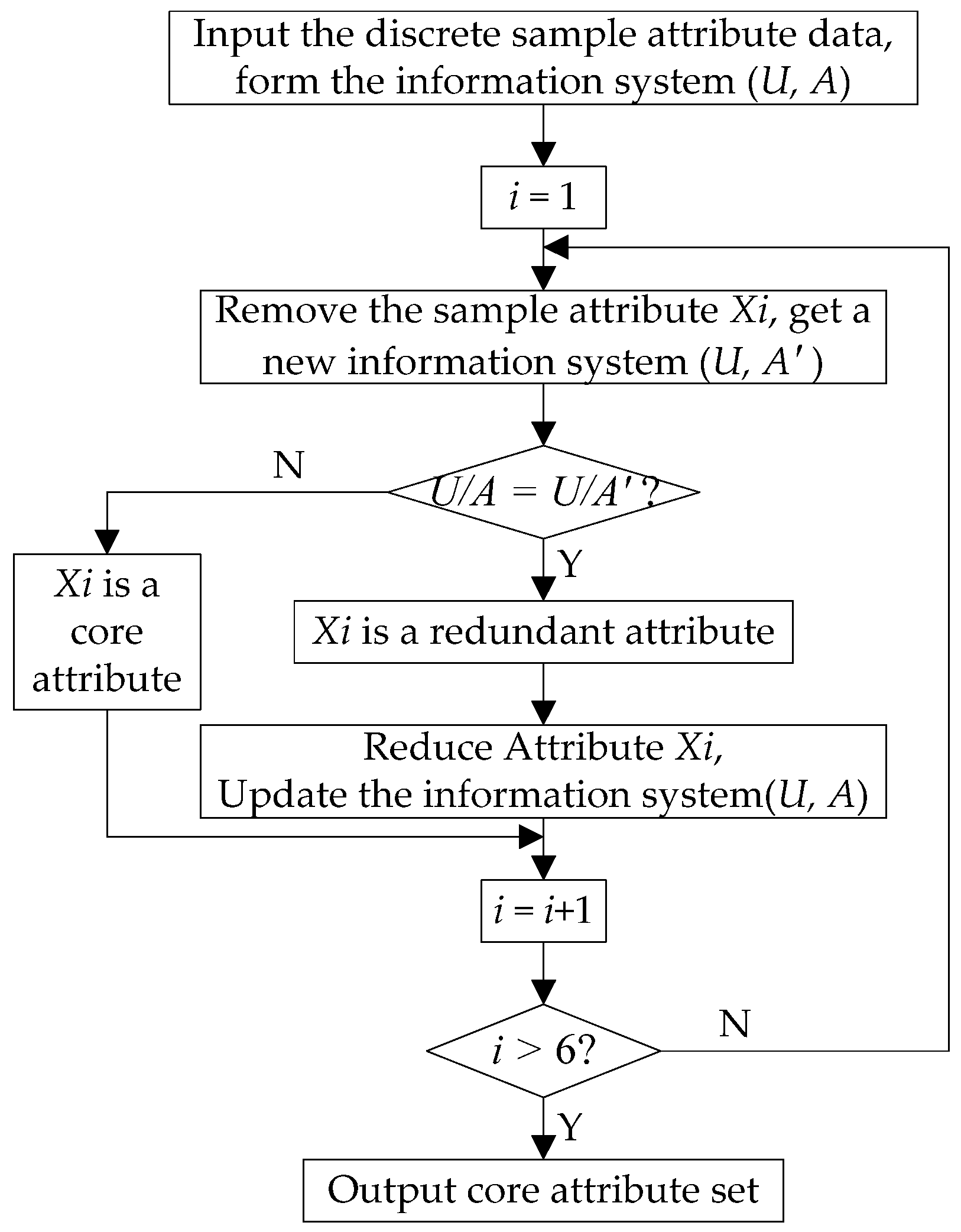
The concepts of core and attribute reduction are two fundamental concepts of the rough sets theory. The attribute reduction is the essential part of an information system, which can discern all dispensable objects from the original information system. The core is the basis of attribute reduction. The information system may not have only one reduction, the intersection of all reductions is called the core of the information system.
Let be a set of equivalence relations, and and . If , then the set can be dispensed in the set , otherwise it cannot be dispensed. If each in the set is not dispensable, is independent, otherwise it is dependent. If the set of condition attributes is independent, one may be interested in finding all possible minimal subset of attributes and the set of all indispensable attributes (core).
Given an information system , in which is a non-empty finite set and and , indicates the set of the condition attributes, and indicates the set of decision attributes. If and , is the relative positive region of the decision attribute with respect to .
Let and be equivalence relationship sets. If , then can be reduced by . The set of all irreducible equivalence relationships of in is called the core of , and is denoted as . Core is the set containing the most important attributes for classification in the condition attributes, and without them, the quality of the classification will drop.
The relation between the reduction of attributes’ set and the core is as follows:
The expression represents all the reductions of . The expression contains all the equivalence relations in the reduction of , which is the important and indispensable attributes’ set in .
The concept of
has two meanings:
- (1)
the is used as the basis for the calculation of attribute reduction.
- (2)
the is a feature set that cannot be eliminated in attribute reduction.
The concept of provides a powerful mathematical tool for extracting important attributes and their values from the condition attributes by attribute reduction. The attributes in the set of condition attributes are not equally important, even some of them are redundant. The processing of attribute reduction aims to reduce the unnecessary condition attributes or remove redundant attributes in the information system, and obtain the smallest set of condition attributes that can ensure correct classification. In other words, the classification quality of the reduced attributes’ set is the same as that of the original attributes’ set. Under the condition of guaranteeing the classification ability of the information system, attribute reduction can get a simpler and more effective decision rule. Lastly, attribute reduction is not only the approach and method of obtaining classified knowledge from an information system, but also the focus and essence of the rough sets theory research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}