1. Introduction
Along with the rapid growth of the (mobile) Internet, more and more people in China choose to seek medical help by posting questions on some online health and wellness communities, such as DingXiangYuan (
http://dxy.com/) and XunYiWenYao (
http://www.xywy.com/). This provides great convenience for users to get medical advice from qualified doctors, as they need not go to the hospital and are able ask questions anywhere and anytime. However, a large number of users—many of whom often ask similar, if not identical, questions—have placed a tremendous burden on the doctor-side, and cause timely reply to be nearly impossible. Thus, to enhance the user experience, it is essential to develop techniques which can efficiently address the problem of medical question answer matching; namely, selecting automatically from some existing medical answer records (e.g., those posted previously by the registered doctors) the one that best matches a user’s question.
This paper focuses mainly on the problem of
Chinese medical question answer matching, in which the languages of questions and answers under consideration are both limited to be Chinese. Compared with open-domain question answer matching in English studied recently by Feng et al. [
1] and Tan et al. [
2], the problem investigated in this paper is arguably more challenging due to the combination of two main factors: (1) the domain-restricted nature; and (2) some language-specific features of Chinese. The underlying challenges are further discussed as follows.
First of all, due to the lack of delimiters between Chinese words, word segmentation is normally taken as an indispensable preprocessing step for many Chinese natural language processing (NLP) tasks such as part-of-speech (POS) tagging and semantic parsing, and thus considerably impacts the accuracy of those downstream tasks. Though the performance of the off-the-shelf Chinese word segmentation toolkits (e.g., ICTCLAS (
http://ictclas.nlpir.org/), Jieba (
https://github.com/fxsjy/jieba), THULAC (
http://thulac.thunlp.org/), LTP (
https://github.com/HIT-SCIR/ltp)) has reached a level satisfactory to many practical applications, they still yield errors [
3], which would be inevitably propagated through the framework with a pipelined architecture and hence cause overall performance degradation. Moreover, the great variety of proper terms contained would cause further and sometimes very sharp accuracy decline to those general-purpose word segmentation tools when being directly applied to medical texts. For example, the medical terms “盐酸西替利嗪片” (cetirizine hydrochloride tablets) and “葡萄糖酸钙片” (calcium gluconate tablets) in
Table 1 are incorrectly segmented into “盐酸西替利嗪片” and “葡萄糖酸钙片” by the Jieba segmentation toolkit (
https://github.com/fxsjy/jieba). Although the introduction of domain-specific lexicons can mitigate the negative effect of professional terminology on word segmentation, building such lexicons always seems prohibitive, as it involves a large amount of manual labor and requires a great deal of domain-specific knowledge and expertise. Even worse is that pre-defined lexicons tend to be inappropriate when coping with the user-composed and unedited medical questions and answers posted on online communities, as they are written in an informal style and often contain many short-hand notations, non-standard acronyms, and even typos and ungrammatical sentences. For instance, “坐 (sit)” and “不听使唤 (out of control)” are incorrectly typed as “做 (do)” and “不停使唤 (keep calling)” respectively, in the question given in
Table 1.
To address the above issues, we present an end-to-end deep learning framework using character-level multi-scale convolutional neural networks (CNNs). Specifically, the framework adopts a character-level representation, viz. the character embeddings, instead of word embeddings conventionally used, so as to avoid word segmentation during preprocessing as well as its negative impacts on subsequent components. Such representations are pre-trained using the Chinese characters in both questions and answers, and similar to word embeddings, describe each character as a fixed-length vector.
Since characters are less semantically meaningful compared with words in Chinese, the matching task depends more upon the capability of subsequent modules to extract relevant semantic information. This motivates us to introduce CNNs into the proposed framework, which have been proven to be good at capturing the local context of characters and words (i.e., the local interaction and dependency within n-gram). As different Chinese phrases (or words) are often different in length, we employ multi-scale CNNs (multiCNNs) to capture the interaction between them more appropriately, and hence to better encode the semantic association between the questions and answers. The proposed multiCNNs module consists of a stack of feature maps with different scales.
To validate the proposed framework, we develop a dataset by collecting questions and answers from an online Chinese medical questions answering website (
http://www.xywy.com), on which questions posted by users mainly contain the description of symptoms, diagnosis and treatment of diseases, use of drugs, psychological counseling, etc., and only certified doctors are permitted to answer questions. The dataset, named cMedQA, consists of
questions and more than
answers. We made cMedQA publicly available for academic use only (
https://github.com/zhangsheng93/cMedQA).
Table 1 gives an example of our data. More details of cMedQA can be found in
Section 4.1.
In summary, the contribution of this paper is four-fold:
- *
To our best knowledge, we are the first to investigate the challenging problem of medical question answer matching in Chinese.
- *
We propose a character-level multi-scale CNN architecture for representation learning of Chinese medical texts, which employs character embeddings to circumvent the negative influence of Chinese word segmentation, and uses multiple convolutional feature maps to extract semantic information over different scales.
- *
We create and release the cMedQA dataset, which to the best of our knowledge is the first publicly available Chinese medical questions answer matching corpus.
- *
The experimental results on the cMedQA dataset demonstrate that the proposed framework significantly outperforms a variety of strong baselines with an improvement of top-1 accuracy by up to 19%.
The rest of the paper is organized as follows:
Section 2 briefly overviews the related work;
Section 3 presents the end-to-end character-level multi-scale convolutional neural framework; Experimental setting and results are described in
Section 4; Finally, we draw conclusions and discuss future work in
Section 5.
2. Related Work
Two broad classes of related work pertinent to our work are briefly surveyed in this section. First, we review the previous studies on traditional question answering. Next, we overview the recent work on applying deep learning to open-domain question answer matching.
2.1. Traditional Question Answering
Traditional approaches to medical question answering normally involve rule-based algorithms and statistical methods with handcrafted feature sets.
Jain and Dodiya [
4] present rule-based architectures for question-answering systems in the medical domain and also discuss in detail the intricacies of rule-based question processing and answers retrieval. However, as user questions are always presented in a large number of different ways, rule-based methods may not be able to cover all such linguistic variety.
Wang et al. [
5] propose an alternative approach, which first splits sentences into words to train the word vector for each sentence and then evaluates the similarity of each question–answer pair by computing the similarity between individual words. Abacha and Zweigenbaum [
6] translate questions to machine-readable representations. The approach is thus able to convert a wide range of natural language questions into a standard language form. Later, the authors [
7] extend their previous work by applying semantic techniques at both the representation and interrogation levels so as to create a structured query to match the entries in the knowledge base. These methods depend on manually designed patterns and handcrafted features, which often involve tremendous human labor and expertise.
Li [
8] employs a multi-label classification method and the BM25 values [
9] to retrieve from a pre-built corpus multiple questions, together with their answers, that are similar to the input one. The resulting answers are further ranked to form a single passage using the TextRank algorithm proposed by Mihalcea and Tarau [
10]. The proposed approach is essentially an information retrieval (IR)-based one, and the basic ideas are query expansion and retrieval results summarization.
Goodwin and Harabagiu [
11] present a novel framework to select and rank scientific articles containing answers for clinical decision support (CDS) [
12]. However, this method is likely to suffer from the lack of available external resources and the complexity of parsing differently structured texts.
Some models about Chinese question answering have been proposed recently. Li and Croft [
13] constructed a Chinese question answering system named Marsha. The system recognizes known question types and formulates queries, then searches and extracts answers. Li et al. [
14] proposed a method to calculate the similarity of two sentences by computing the similarity between words. Li et al. [
15] constructed a semantic pattern matching model for musical domain to automatically translate questions to SPARQL queries for building the final answers. However, these methods take word segmentation as an essential step of Chinese text processing, and they do not take the inaccuracy of word segmentation toolkits into consideration, although the accuracy of word segmentation toolkit in general domain is satisfactory. Wang et al. [
16] proposed an approach integrating count-based and embedding-based features. They also point out in their work that character-based models outperform word-based models, which gives us a hint that dealing with Chinese characters may avoid the inaccuracy brought by word segmentation.
To summarize, some traditional question answering methods often rely too much on manually developed rules, well-designed patterns, matching of pre-defined labels, and various external resources, which lead them to be human-labor intensive and vulnerable to concept drift frequently occurring when being applied to new datasets. In addition, some previous studies in Chinese question answering do not consider the adverse effect of word segmentation, and the adverse effect may become particularly prominent when we process domain-specific texts. As far as we know, few works have been dedicated to the key task of Chinese medical question answer matching, which is the focus of this paper.
2.2. Deep Learning in Open-Domain Question Answer Matching
As deep learning techniques have the advantage of capturing both low- and high-level semantics, they begin to be applied to open-domain question answer matching in recent years.
Hu et al. [
17] proposed two different convolutional models to learn representations of sentences, which is the pioneer work for solving general sentence matching problems using neural networks. Following that, Feng et al. [
1] and Zhou et al. [
18] employed CNNs to learn the representations of questions and answers, which are further used to compute the similarity between different questions and their candidate answers. Later, in order to extract sequence information from a sentence, Tan et al. [
2,
19] utilized recurrent neural networks (RNNs) and their variant, long short-term memory networks (LSTMs), to learn the sentence-level representations. It is noteworthy that the authors also exploit attention mechanisms to augment the semantic association between questions and answers.
However, all studies mentioned above are pertinent to English texts. The approaches proposed in them are likely to suffer considerable performance degradation when being applied directly to process Chinese documents, as the latter language differs greatly from English.
3. Methodology
In this Section, we present our novel end-to-end character-level multi-scale convolutional neural framework for Chinese medical questions answering. First, we discuss the correct embedding methods for encoding Chinese medical texts. Next, we describe in detail the basic convolutional neural network architectures and our improved multi-scale convolutional neural network architectures.
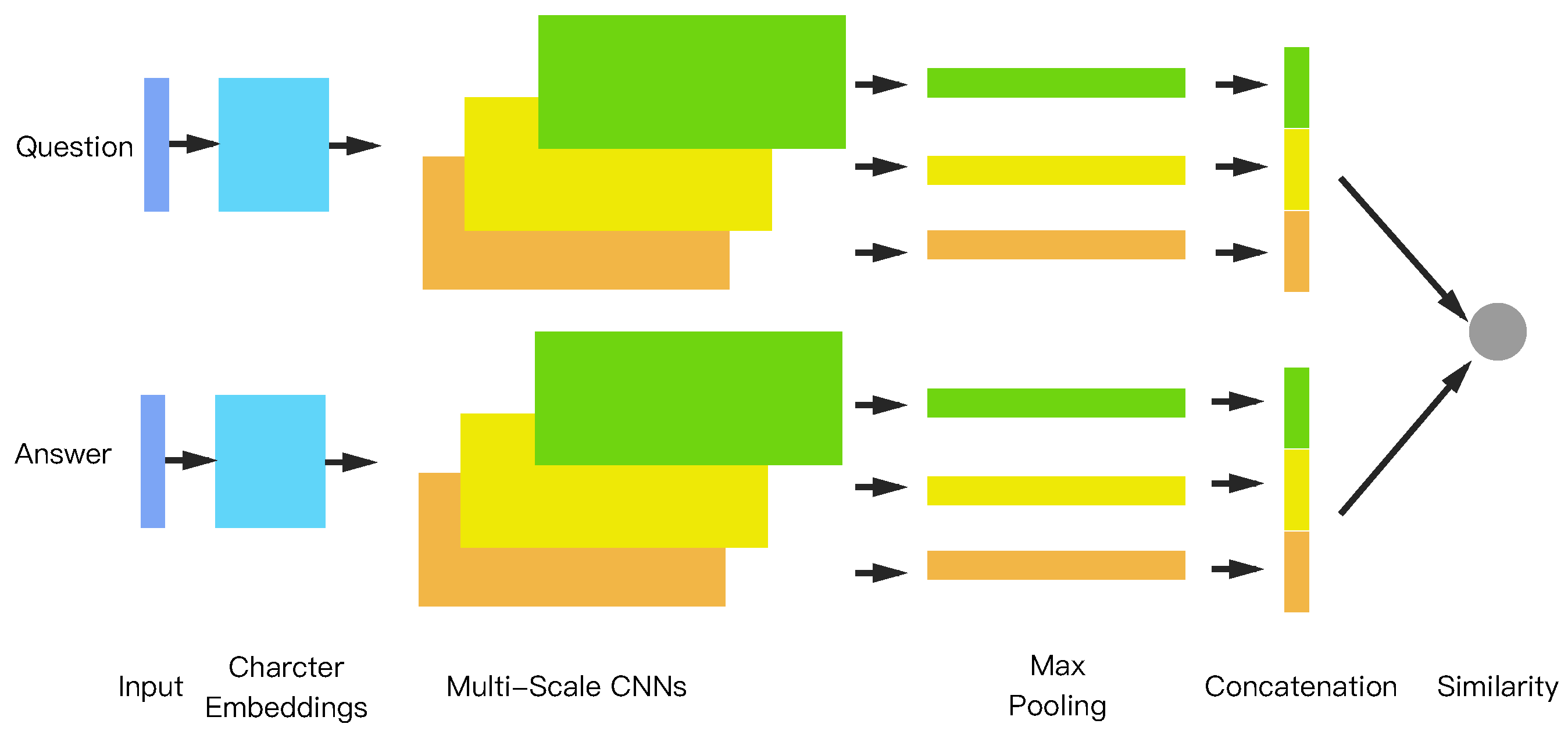
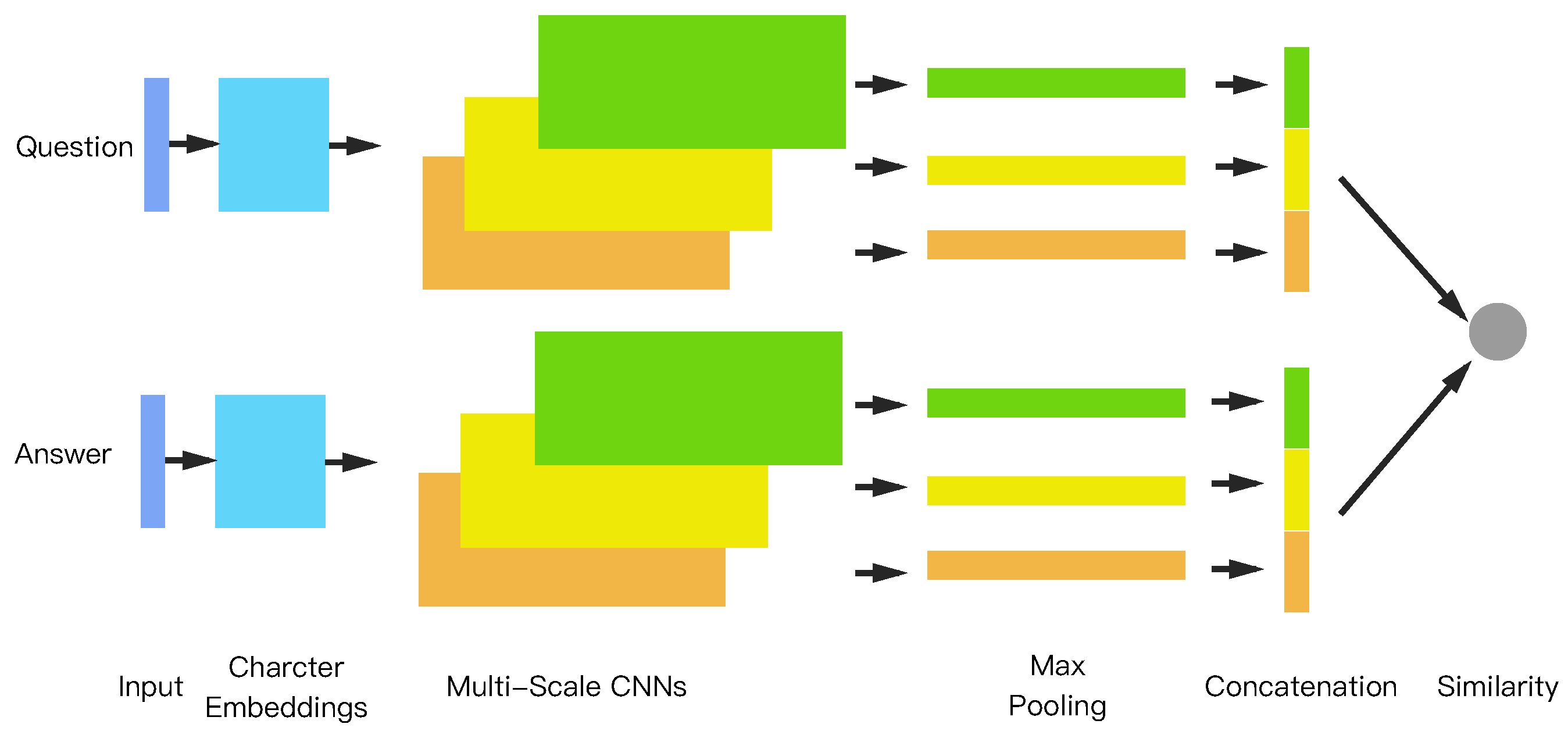
Figure 1 illustrates our framework, given a question and its answer which are represented by character embeddings. The embeddings are used as inputs to our architecture. Next, feature maps of convolutional neural networks at different scales are applied to extract different local n-gram information. Max pooling is then applied to simplify the representation and to generate vectors for the question and the answer. Finally, the cosine value of the two vectors is computed to measure the similarity of the question and the answer. It should be noted that layers with the same color share the same parameters and weights [
1].
3.1. Distributed Representation of Characters
In many natural language processing tasks, one fundamental step is to convert text sequences to machine-readable features, which are always fixed-length vectors. These features determine the upper limit of the effectiveness of the algorithms.
In recent years, embedding-based methods have been used to extract features from text, which shows their utility in semantic representation. A useful and often-mentioned type of embedding method is word embedding, also referred to as the distributed word representation. Bengio et al. [
20] proposed a neural network language model (NNLM) which combined a neural network with natural language processing to train word embeddings. After that, Mikolov et al. [
21] proposed Word2Vec, a very effective language model inspired from NNLM. Word2Vec has received increasing attention in recent years and has been successfully applied to many tasks, such as document classification [
22,
23], knowledge graph extraction [
24,
25], and implicit matrix factorization [
26,
27].
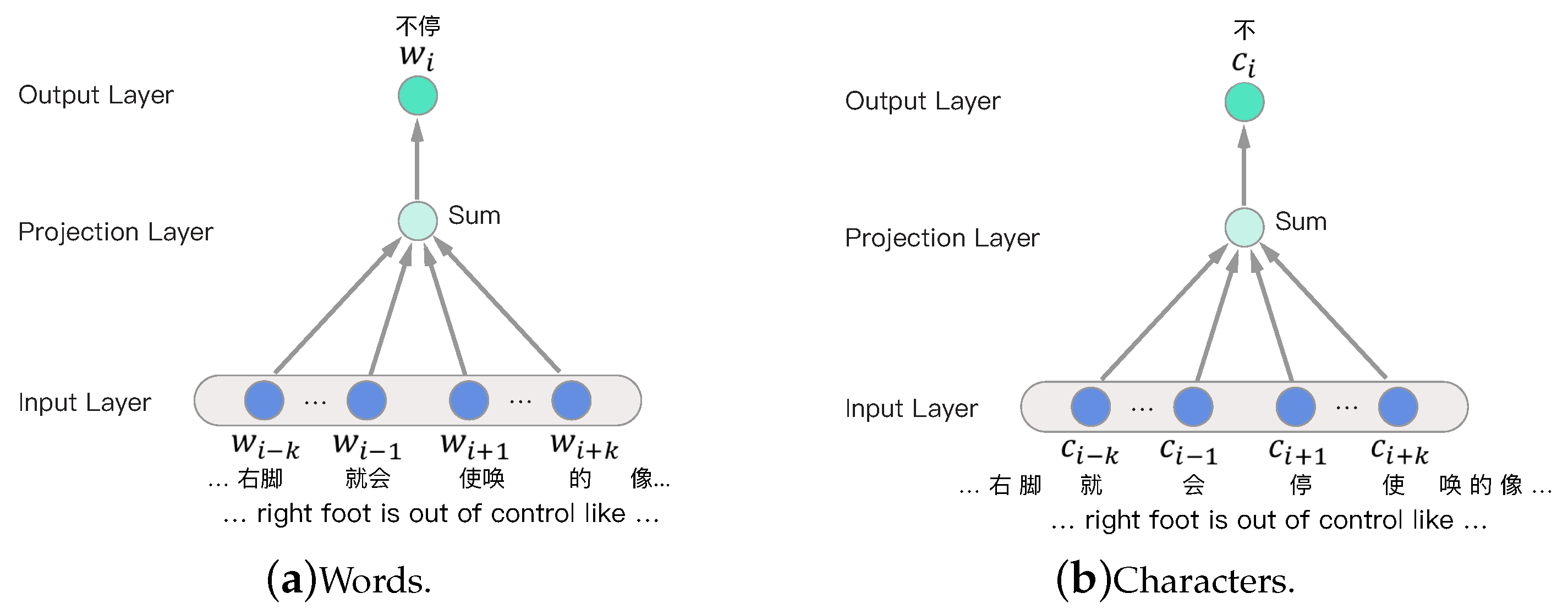
Shown in
Figure 2a is an example of the Word2Vec model. Given a sentence sequence
, where
is the length of the sequence and
indicates the word vector of the
word in the sentence. Let
be the context of
, where
is the size of the contextual window. Let
be the probability of the
word in the sentence being
. The target of the model is to optimize the log maximum likelihood estimation (logMLE):
However, word-level embedding methods may suffer from the following shortcomings:
Word segmentation is an essential preprocessing step for most Chinese NLP tasks. The quality of word segmentation determines the quality of word embeddings, which then influence the accuracy of the down-stream model. Moreover, word segmentation methods suffer a great reduction in accuracy when directly applied to specific domains (e.g., medical domain).
The words that do not or rarely appear in the lexicon or dictionary are called unseen words or rare words. Unseen or rare words may influence the quality of word embeddings.
As the number of words is far greater than that of characters, training word embeddings or adopting word embeddings as features may consume a great deal of computing resources and storage resources.
Inspired by Zhang et al. [
28], we separate the sentence into individual characters. In order to train distributed representation of characters, we have made minor changes to Word2Vec. As can be seen from
Figure 2b, in the context window, each character is used to predict the middle character. After being trained, each character is mapped into a fixed-length vector
, where
is the dimensionality.
More specifically, given a sentence sequence
, where
is the number of characters in the sequence, the context of
is
. Therefore, Equation (
1) can be modified into:
Character embeddings reduce the chances of errors brought about by word segmentation algorithms [
28]. Furthermore, since the number of characters is much less than the number of words, and the number of unseen or rare characters is also much smaller than that of unseen or rare words, character-level methods reduce the size of the representation of sentences and accelerate the computation. Therefore, character-level embeddings are able to mitigate the adverse effects of word embeddings described above.
Character embeddings have been applied to many tasks, such as neural machine translation [
29,
30,
31,
32], text classification [
33], English factoid question answering [
34], and Chinese dependency parsing [
28].
Though character embeddings are able to tackle the second and third issues listed above both for English and Chinese, it should be noted that there are still differences between Chinese and English with regard to character embeddings. Character-level methods in Chinese are mainly focused on mitigating the negative impact of word segmentation because there is no natural delimiter in Chinese texts to separate the phrases [
28], while various methods in English have been proposed to solve the phenomenon that the words which share the same lexeme have different morphological forms [
29]. Besides, the number of Chinese characters is far greater than English characters (only 26) and the characters in Chinese texts also contain more information than those in English.
3.2. A Single Convolutional Neural Network Architecture
As is already known, the meaning of a word (character) is usually affected by its surroundings, especially the context. Currently, the convolutional neural network (CNN) has been proven to be superior in a wide variety of NLP tasks [
17,
35,
36,
37], since the CNN is capable of explicitly capturing local contextual information. The network does not depend on other external information such as part-of-speech tags or a parse tree.
In general, a convolutional neural network architecture consists of two main steps: convolution and pooling. The convolution step extracts local context features using a fixed-size sliding window, while the pooling step selects the maximum or average value of the features extracted from the former layer to reduce the presentation.
More specifically, the question and answer are represented by character embedding sequences having a fixed length: . We denote the dimensionality of the character vectors by , and each element is a real-valued number, thus . Each sentence is normalized to a fixed length sequence by adding zero paddings if the sentence is short or by truncating the excess otherwise. After embeddings, each question and answer can be presented by matrix and .
Given a sequence
, where the size of feature map is
s, and
is the concatenation of continuous
s character vectors of the sentence, we can define the convolutional operation as follows:
where
is the output of convolutional operation, matrix
and vector
b are the parameters to be trained,
is the activation function, and
indicates the element-wise multiplication of
W with each element in
Z. If the number of filter maps is
, the output of the layer is
. Thus, embedding matrices
and
are converted into
and
through a convolutional neural layer and by sharing the same parameters (
and
b).
A pooling layer is then applied after the convolutional layer. Max pooling and average pooling are commonly used in the pooling layer, which chooses the max or average value of the features extracted from the former layer to reduce the representation. In this paper, we use 1-max pooling as our method to select the max value of each filter, and max value may be relatively more sensitive to the existence of some pattern in pooled region. The max pooling operation is shown as follows:
where
selects the max value in
, and
is the output vector of the pooling layer.
A vector
is acquired after max pooling layer, which can be used as a representation of a question. Similarly, a vector
is also extracted from the answer. The formula that may be used to measure the similarity between the questions and the answers is given as follows:
where
is the length of the vector.
3.3. A Multi-Scale Convolutional Neural Networks Architecture
As we described above, convolutional neural networks are capable of capturing local contextual information. However, the single CNN architecture usually has single-sized feature maps with a fixed sliding convolutional window. Therefore, the scale of information extracted from the model is limited. Considering the expression structure of Chinese phrases and the variety of expressions available in the language, a single CNN architecture may be insufficient to extract character-level information.
The multi-scale convolutional neural networks (multiCNNs) architecture works in a similar way to the singleCNNs described above, except that they employ feature maps at different scales to extract the information. As shown in
Figure 1, the question and the answer are represented using a concatenation of several vectors from the max pooling layer.
More specifically, given a set of filter map sizes
, where the
CNN filter’s map size is denoted with
, similar to Equation (
3), the output of the convolution for the
CNN is given by:
where
.
Therefore, the output of the layer becomes .
Similarly, after the pooling layer, the output vector from the
CNN is:
Unlike singleCNN, we concatenate output vectors from different-scale CNNs as the final representation of the question or the answer:
After that, the similarity measurement is calculated similarly using Equation (
5).
The multiCNNs architecture is fully capable of extracting the relevant language features from Chinese texts.
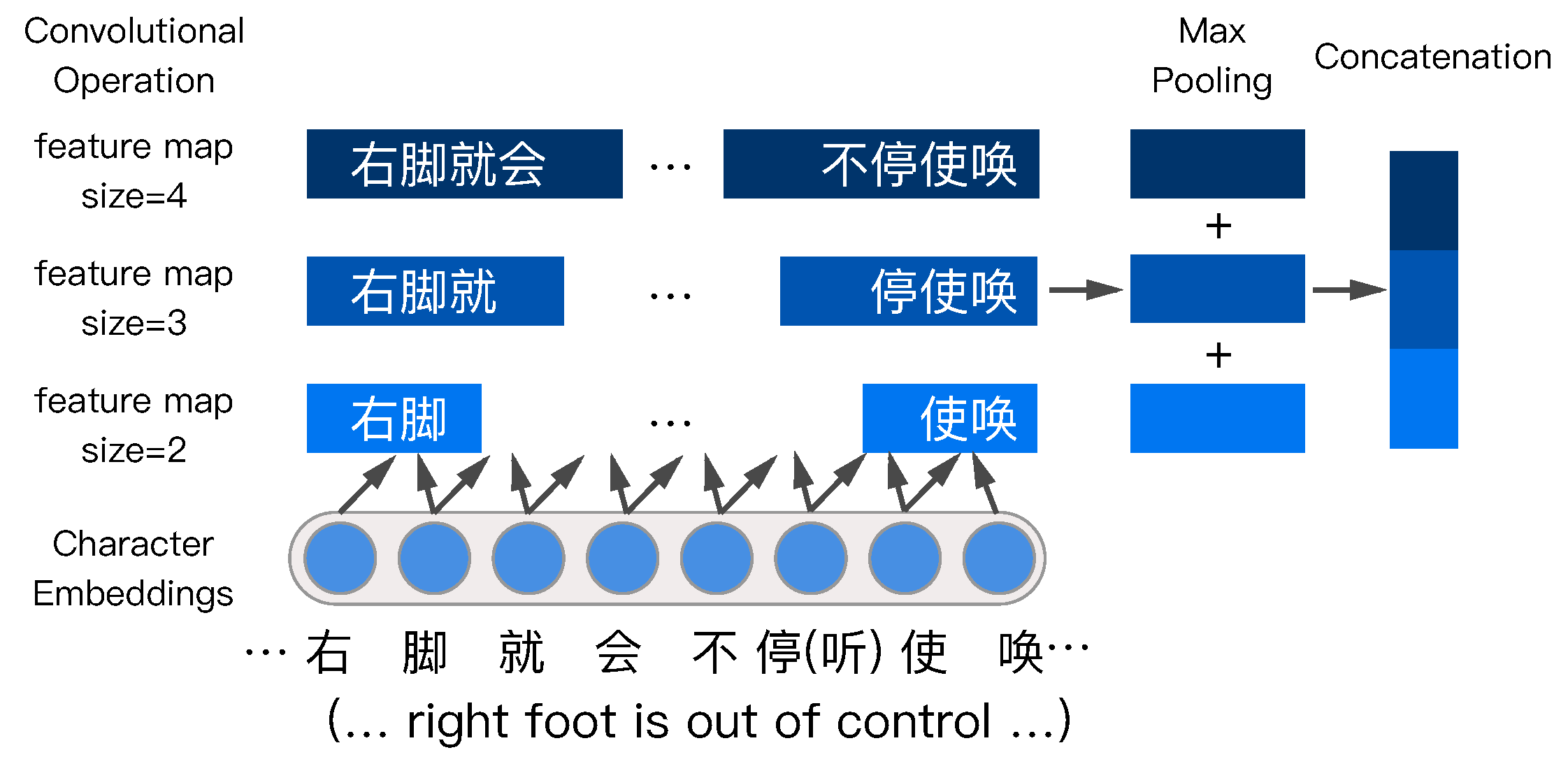
Figure 3 shows an example of the process using which the multiCNNs architecture extracts local information from a region. As we already know, different Chinese phrases usually contain different numbers of characters; therefore, a single convolutional neural network will perform convolutional operation over a fixed-length region, which is similar to combining several adjacent characters into words. Therefore, the multiCNNs architecture performs convolutional operation over different fixed-length regions and extracts a different number of adjacent character embeddings.
3.4. Objective Function
Given a question , the ground truth answer is , while is the incorrect answer randomly sampled from the complete answer pool. A good network would be capable of maximizing while minimizing .
In order to train the neural networks, we follow an approach to [
1,
17,
19], whereby we define the training max-margin loss function as follows:
where
M is the margin value, which is a constant. If
, the cost is zero and no updates are required.
When training the network, we provide each question separately, the ground truth answer and a randomly-sampled negative answer to the network for up to K times. Then, we compute the loss , and use optimizers such as GradientDescentOptimizer or AdagradOptimizer to update the parameters of networks.
4. Experiments and Results
4.1. Datasets
As there are no public Chinese medical questions and answers datasets available, we have developed and collected a dataset from the Internet. The dataset was acquired from an online Chinese medical question answering forum (
http://www.xywy.com/). Questions are proposed by users and are responded to by qualified medical doctors. Each question is often answered by several doctors, and only certified doctors are eligible to answer questions.
To the best of our knowledge, this is the first publicly available dataset based on Chinese medical questions and answers. The dataset is in version 1.0 and is available for non-commercial research (
https://github.com/zhangsheng93/cMedQA). We will update and expand the database from time to time. In order to protect privacy, the data is anonymized and no personal information is included.
As shown in
Table 2, the data which we refer to as cMedQA is split into three sets—namely, training set, development set, and test set. The second and third columns show the number of questions and answers, respectively. The following two columns illustrate the average number of words per question and answer, while the last two columns indicate the average number of characters.
While training the framework, for each question in training data, there is a ground truth answer (if a question has multiple ground truth answers, we will choose one randomly each time) and a randomly sampled answer from the complete answer pool. Using this mechanism, we generate 30 tuples of for each question. Thus, during the training phase, a total of tuples are fed into the network at each epoch.
To evaluate the framework, for each question in the development set and test set, we randomly sample 100 candidate answers, including ground truth answers. The development set is used for parameter search and optimization, while the test set is used to evaluate the models. It should be noted that the whole answer space can be regarded as the candidate pool, so each question should be computed for similarities with
candidate answers. However, this is impractical because of time-consuming computations [
1]. Therefore, we set the pool size to be 100 in our study, which is practical and still a challenging task.
4.2. Metrics
In this study, the top-1 accuracy is used as a metric to evaluate the accuracy of the technique. Top-k accuracy is a commonly used metric in many different information retrieval tasks. The definition of top-k accuracy (
) is given as follows:
where
is the ground truth answer for question
, and
is the candidate set with top-k highest similar answers.
denotes the indicator function. When the condition in parentheses is true, the function value is 1, otherwise it is 0.
Unlike traditional information retrieval [
38], answering a question requires the provision of the best possible answer rather than a ranked list of answers. Therefore, we have adopted top-1 accuracy (ACC@1) as our metric, which is a highly demanding measurement. Specifically, in terms of a question, if the size of the answers candidate pool is 100, the ACC@1 for random selection methods is only 1%. It should be noted that in our experiment, if a question has multiple ground truth answers, any correctly selected ground truth answer will contribute to the accuracy.
4.3. Baselines
- *
Character Matching: Character matching method counts the number of characters that are the same in the question and the answer.
- *
Word Matching: Similar to the character matching method, the word matching method counts the number of words that are the same. However, this method requires word segmentation; therefore, we use two word segmentation toolkits and present a discussion of the impact of different toolkits.
- *
BM25: BM25 (Best Matching) is a ranking function in Information Retrieval (IR); it has also been used in question answer matching [
8,
16]. The definition of BM25 is given as follows:
where
is the inverse document frequency (IDF) value of word (character)
in question,
is the length of the answer
,
is the average length of answers, and
is the frequency of
in
.
k and
b are free parameters. In our experiment, according to Christopher et al. [
39], we set
and
.
- *
Average of Embeddings: Character (Word) embeddings contain semantic and syntactic information, and an average of these can be used to directly represent features. Thus, we compute the average of each question and answer embeddings, and calculate the cosine similarity between the two average embeddings.
- *
Embedding Matching: Inspired by Li et al. [
14], we compute the similarity of two sentences by calculating the similarity of words (characters). We modified the algorithm by computing the similarity of every two embeddings, and find the best matching score of each word (character) of the question. The answer with the best matching score will be chosen.
- *
biLSTM: Tan et al. [
2] used bi-directional LSTM networks to extract the semantic representations of questions and answers. LSTM networks are a variant of recurrent neural networks (RNN), which are capable of capturing sequence information [
2,
40,
41].
4.4. Experimental Settings
Models presented in our paper were implemented using TensorFlow and TensorLayer from scratch. All questions and answers in the training set are used to train the character embeddings using gensim (
https://radimrehurek.com/gensim/). In order to make a comparison between word embeddings and character embeddings, we use two word segmentation toolkits (Jieba and ICTCLAS) for Chinese words segmentation. ICTCLAS is a popular toolkit and reported good F-scores in many segmentation tasks (
http://thulac.thunlp.org/). Jieba provides an easy-to-use interface, and we use it as a control. The Python package gensim is used to train both word embeddings and character embeddings. After training, we get dictionaries with
(Jieba) words,
(ICTCLAS) words, and 3922 characters, respectively. The max sequence length of the question and answer are fixed at 400 for characters and 200 for words. We add paddings to the beginning if the original sequence is short and truncate the excessive parts.
For the CNN, the filter has a size of 3 with 800 feature maps, while the multiCNN architectures have filters of sizes (3,4), respectively, with 800 feature maps each. In this paper, we also use biLSTM [
2] to make a comparison. The biLSTM has the output length of 200 in each direction and the hidden states are provided directly for pooling.
AdagradOptimizer is used in this paper, the learning rate is initially set to 0.01, and the margin value is set to 0.05.
4.5. Results
In this section, a detailed examination of the experimental results are presented.
Table 3 summarizes the results for different approaches on cMedQA.
Rows 1 to 13 provide a survey of the results of the baseline methods without using neural network architectures. More specifically, as can be seen from Rows 2 to 4, which show the results of matching based methods, the results of the two methods differ by less than 1%. Due to the abundant information contained in words, word-based methods (Rows 2 and Row 3) surpass the character-based method (Row 4). In comparison to word (character) matching methods, BM25 methods (Rows 5 to 7) utilize more statistical information and show up to 11% improvement.
Row 8 to Row 13 show the results of embedding-based shallow methods. Character embedding methods (Row 10,13) take the lead, which indicates that the semantic information of embeddings is better extracted from characters. Word embeddings preprocessed by the ICTCLAS toolkit rank second. However, the average of the embeddings methods is inferior to word matching methods, which may be due to their incomplete semantic information extraction capability.
The following three rows (Rows 14 to 16) illustrate the results of three deep neural models when they are fed with word embeddings preprocessed by the Jieba toolkit. It is observed that the biLSTMs architecture stands out amongst these three models. The potential reason may be that recurrent neural networks include the variant LSTM which is capable of extracting sequence information. They are able to extract the semantic information of the whole sentence, which can effectively reduce the semantic gap between the questions and answers. Our results are consistent with experimental results reported by Tan et al. [
19]. Moreover, the multiCNN model shows more than 2 to 3% improvement on the development and test data-sets, respectively.
The next three rows (Rows 17 to 19) show the similarity trends: biLSTM is ranked first, followed by multiCNNs. It is shown that the ICTCLAS method is much more accurate for words segmentation as compared to Jieba in most cases, although it runs slower than Jieba (
http://thulac.thunlp.org/). It is also shown in the table that the word embedding methods based on ICTCLAS (Rows 17 to 19) outperform the methods based on Jieba (Rows 14 to 16).
The following three rows (Rows 20 to 22) summarize the results of these models on character embeddings. The multiCNNs architecture achieves the highest performance due to the benefits of multi-scale local information extraction. The singleCNN model ranks second. The performance indicates the effectiveness of the multi-scale convolution operations. Compared to biLSTM models, CNN-based models are shown to be superior to the LSTM-based model with regard to character embeddings. The reason for this is that the CNN models take advantage of local information, which is similar to combining several adjacent characters into words. The biLSTM architecture draws greater attention to sequence information and less attention to local information, as the effectiveness of character-level information extraction is inferior to CNN models.
To summarize, neural network-based methods are superior to word (character) matching methods, which demonstrates that highly diverse and non-formal expressions may confuse the matching methods. Character embedding methods (Rows 20 to 22) significantly outperform the word-level methods (Rows 14 to 19) by up to 19%. The improvements for both CNN-based models and the RNN-based model from character embeddings are remarkable, which demonstrates the effectiveness of our character-level embeddings model for medical-domain questions answer matching.
4.6. Discussion
4.6.1. Random Embeddings vs. Pre-Trained Embeddings
A character embedding matrix is a concatenation of character vectors. The number of rows in the matrix is the total number of characters appearing in texts, while the number of columns is the dimensionality of the character vector.
Normally, there are three approaches to initializing a character (word) embeddings matrix. First, an embedding matrix is randomly initialized with uniformly distributed random real values when constructing a deep neural network. The embeddings matrix is regarded as a parameter and will be updated while training the neural network. This method is used by [
35,
37,
42]. Another initialization method is to use publicly available pre-trained embeddings. These embeddings are pre-trained with some large corpora, such as Wikipedia and Google News. Because of the large number of texts in the corpus, the trained vectors are rich in semantic information and are suitable to be directly used to other models, especially when the dataset is small. This strategy is widely used in general-domain tasks [
2,
3,
43]. Finally, we can also train the embedding matrix with texts according to the specific task. Vectors trained in this way correspond to the dataset. Fundamentally, our proposed architectures belong to the last category.
Since we are focusing on medical care, no pre-trained embedding matrix from a large corpus existed for this application. Hence, we decide to make a comparison between randomly initialized embeddings and pre-trained embeddings from the cMedQA dataset. We also changed the embedding initialization method for the multiCNNs architecture and fixed other parameters.
The multiCNNs architecture with randomly initialized embeddings acquired 62.25% and 63.45% accuracy on development set and test set, respectively. Compared to the results in
Table 3, it shows an over 3% decrease on development sets and 1% on test sets, which illustrates that pre-training embeddings from the task-related corpus contributes to the accuracies.
4.6.2. Relationship between SingleCNN and MultiCNNs
From the description in
Section 3.3, the multi-scale CNNs architectures can be regarded as an ensemble of different types of CNNs. Therefore, we discuss the relationship between singleCNN and MultiCNNs.
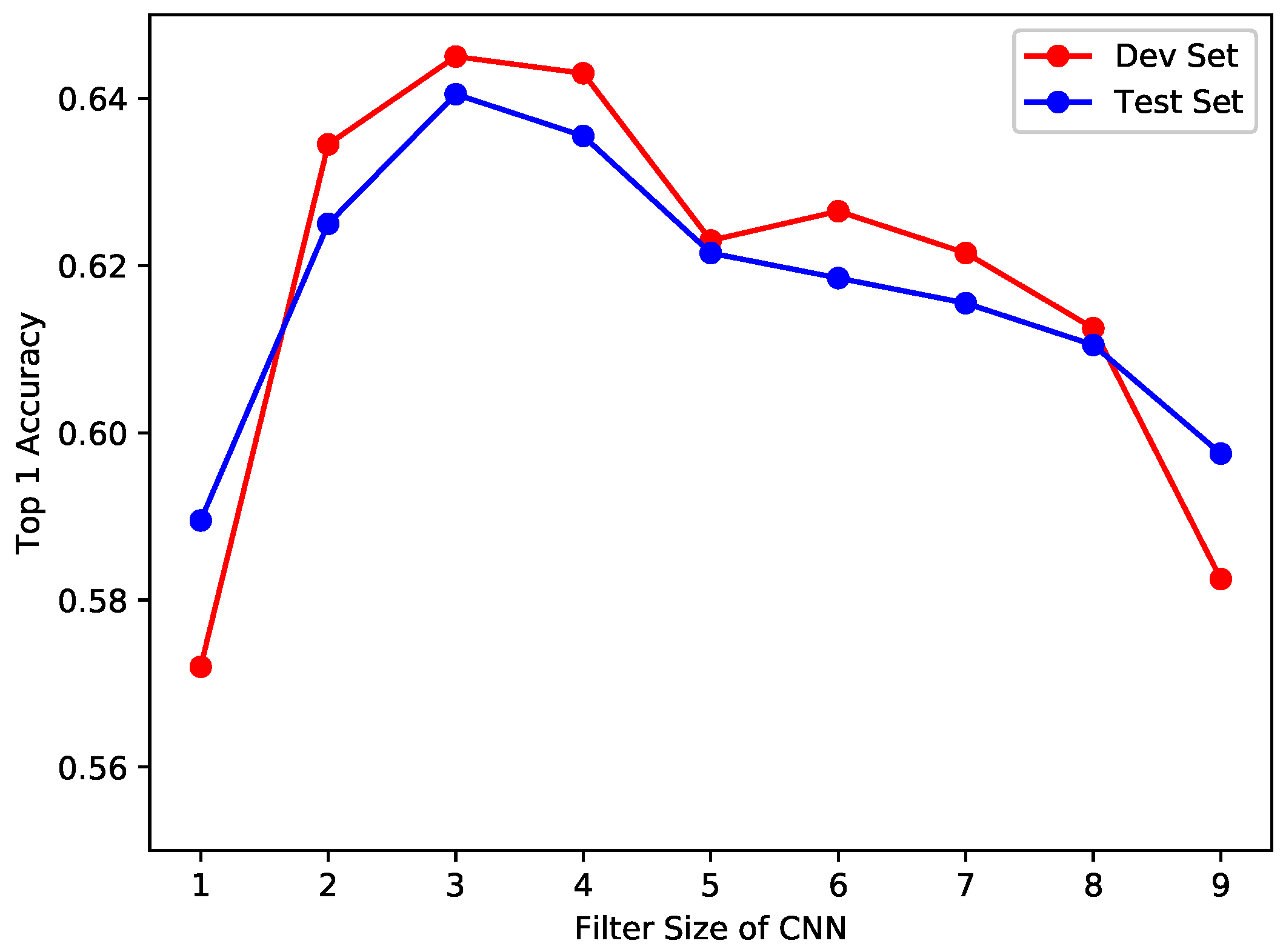
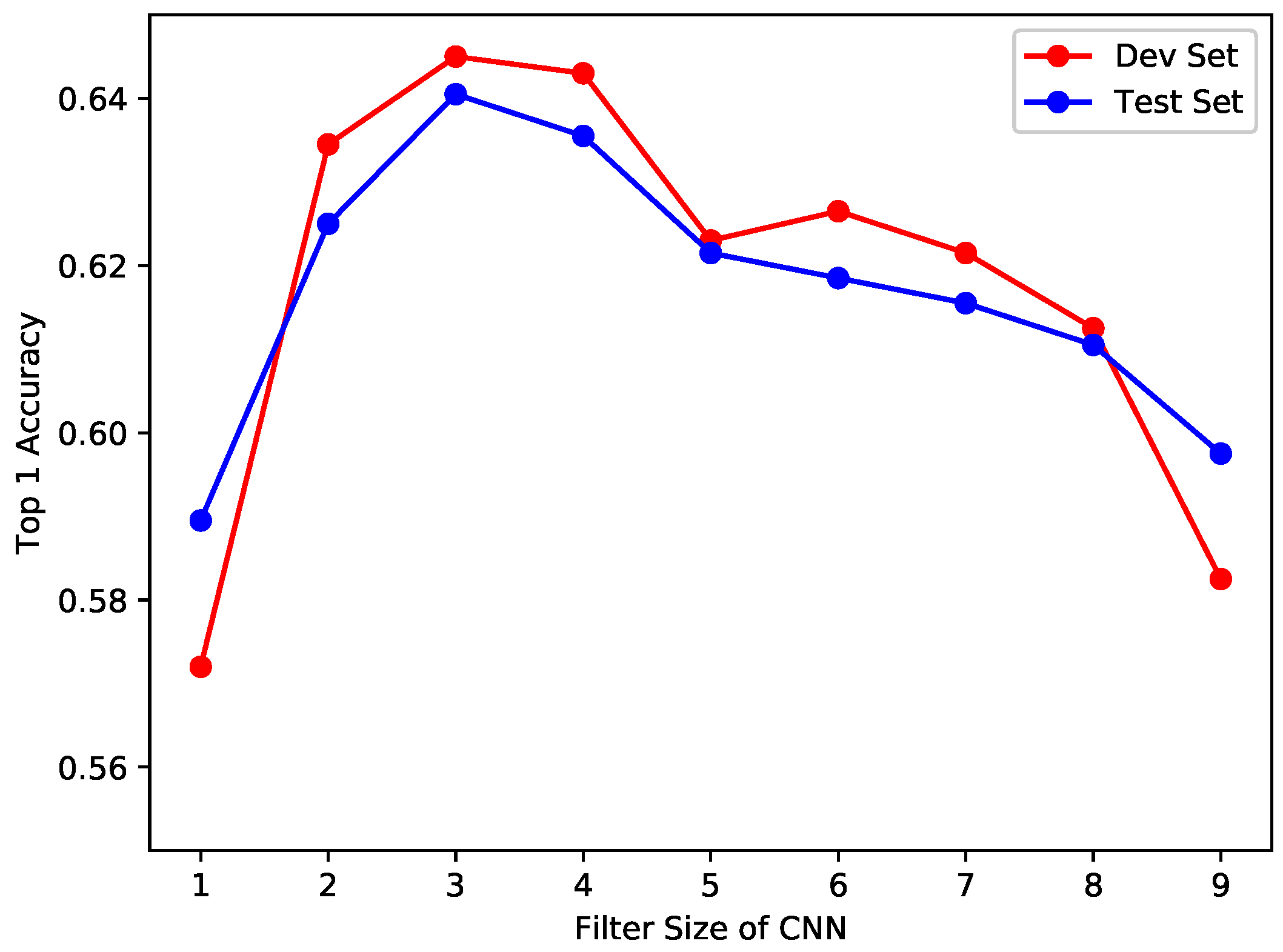
Figure 4 illustrates the top-1 accuracy results for different CNNs with different feature map sizes. As can be seen from the figure, the optimal size of a single feature map is three for both the development set and test set, followed by four and two. It also shows a sharp decrease when the filter size goes up. It is easily understood that words are made up of characters, and two, three, or four are the common number of characters that compose a word.
Table 4 provides a survey of the effect of combining different filter sizes. As can be seen from the table, when we set the filter sizes of multiCNNs to (3,4), it achieves the highest performance, which is in accordance with the results in
Table 4. Similarly, when we combine different top sizes (Rows 1 to 4), the performance surpasses that of singleCNN.
4.6.3. Accuracy of Multiple Selection
Traditional information retrieval methods provide several candidates for users to use to select relevant information, while the question answer matching requires the most credible answer rather than a ranked list of answers. However, the lexical gap between questions and answers usually confuses the matching-based methods. Therefore, selecting the correct answer is a crucial step in question answering and requires non-trivial techniques to fully capture the complex and diverse semantic relationship between the questions and answers.
We have proved the effectiveness of our framework in mitigating the lexical gap problem. However, in order to demonstrate that our approaches are superior to existing methods (even when it is allowed to acquire multiple candidate answers for users), we expand top-1 accuracy to top-k accuracy and examine scores for different k values.
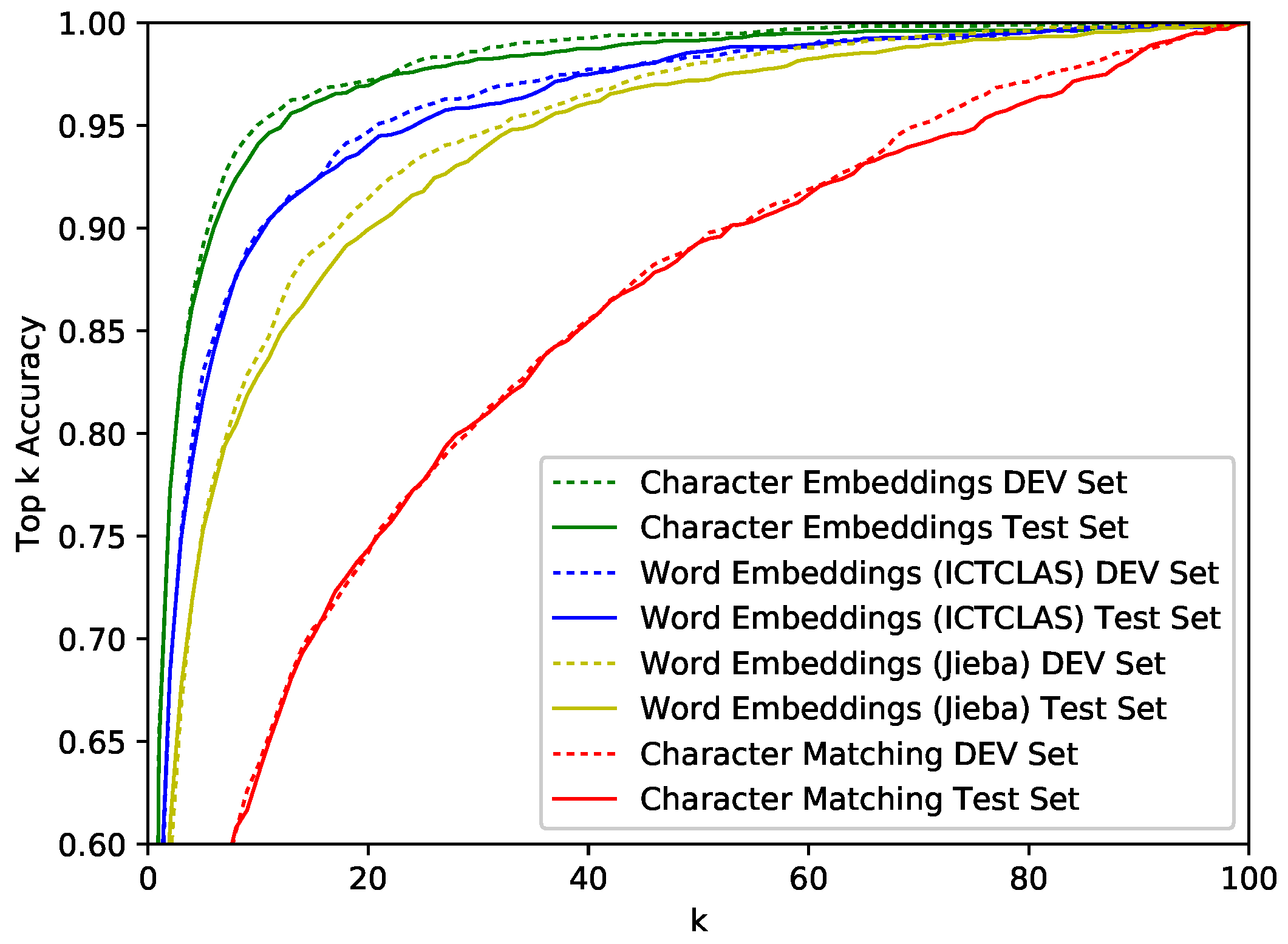
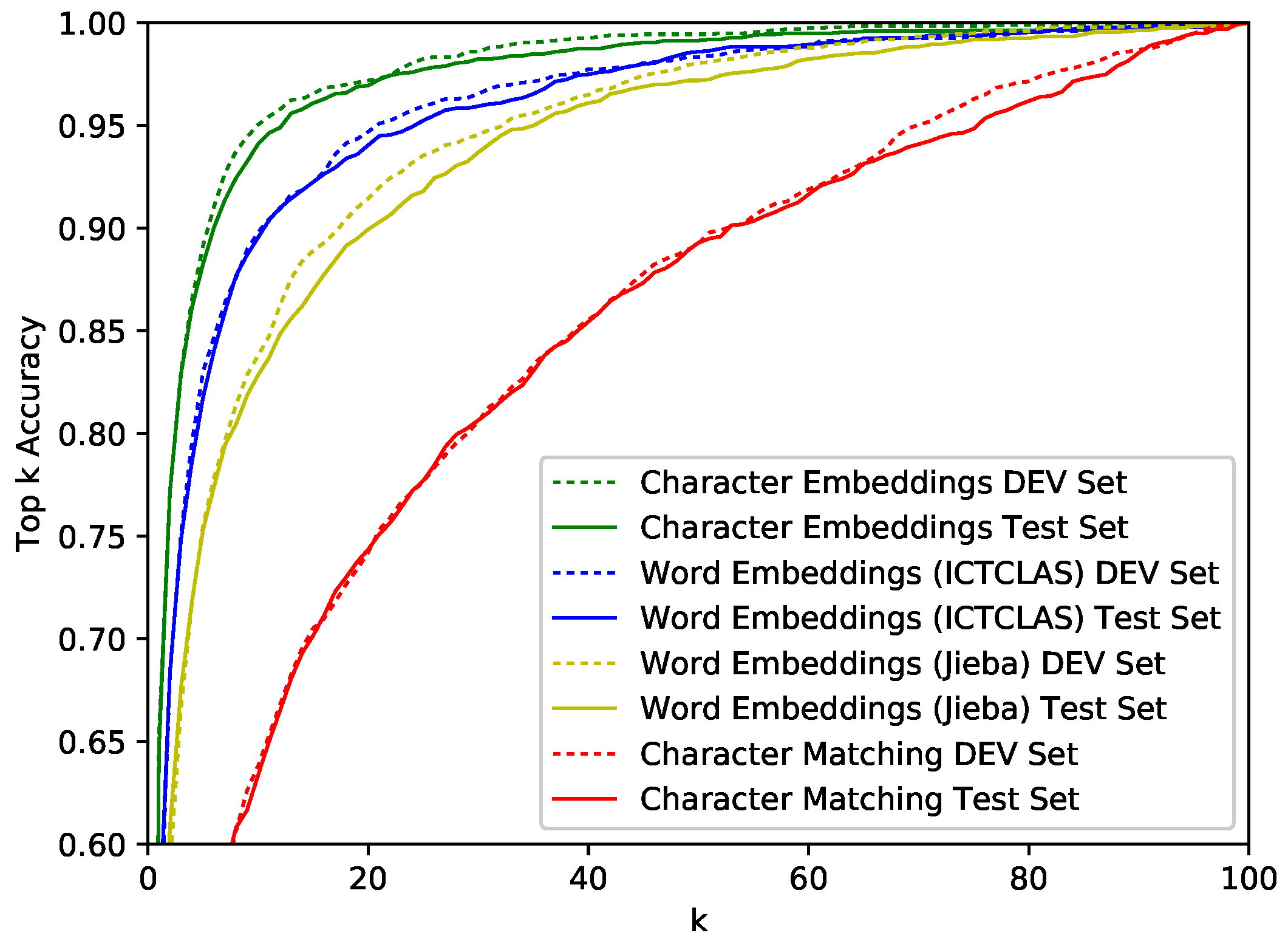
Figure 5 shows top-k accuracy results for different k values. Embedding-based methods are applied to multiCNNs architecture. As is shown in the figure, embedding-based multiCNNs architectures outperform matching-based models, regardless of the k value. In addition, these embedding-based methods show rapid growth to
when k is small. When the accuracy is fixed to
, the k values of green lines are about twice as low as blue lines and four times lower than yellow lines. The same phenomenon occurs when the accuracy is fixed at
, which demonstrates that our character-level embedding-based multiCNNs architecture retrieves relevant information effectively.
5. Conclusions
In this paper, we presented an approach to address the Chinese medical question answer matching task using an end-to-end character-level multi-scale convolutional neural network framework. The framework does not require any extra rule-based patterns, syntactic information, or any other external resources. According to the experimental results, our framework outperforms word-embedding methods, and our multi-scale strategy is capable of capturing character-level information well.
In the future, we would extend our model for disease diagnosis and treatment recommendations according to the description of the symptoms given by users. We aim to construct a hybrid framework that integrates medical domain knowledge into our medical question answering technique. In addition, Chung et al. [
41] propose a recurrent neural network model to infer the scale of data by themselves. If the network can discover the latent structure of the sequence, then it can efficiently adjust multi-scale representation of the network to achieve better performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}