An Improved Ciphertext-Policy Attribute-Based Encryption Scheme in Power Cloud Access Control


Abstract
:1. Introduction
- (1)
- A power cloud access control scheme based on a CP-ABE has been proposed. Considering the generation of the access structure and the heavy computation required for an access tree, PCAC achieves the automatic generation of access structures and effective sharing of the secret key.
- (2)
- In order to resist possible attacks that could come from the data source side and the user side, an action audit phase has been designed, in which the user’s identity is verified without obtaining the user’s private key.
- (3)
- The data confidentiality and the operation efficiency of our PCAC scheme have been analyzed with theory and experiments. The experiments show that our scheme satisfies the requirement of fine-grained access control.
2. Preliminaries and Definitions
2.1. Ciphertext-Policy Attribute-Based Encryption (CP-ABE)
2.2. Attributes and Access Structures
2.3. Bilinear Pairing
- Bilinearity: for all and , we have .
- Non-degeneracy: .
- Computability: to compute the pairing e is efficient.
2.4. Linear Secret-Sharing Schemes
- (1)
- The shares for each party form a vector over.
- (2)
- There exists a matrix M with l rows and n columns called the sharing-generating matrix for II. For all , the i’th row of M, we let the function define the party labeling row i as . When we consider the column vector , where is the secret to be shared, and are randomly chosen, then is the vector of l shares of the secret s according to II. The share belongs to party .
2.5. Access Tree Structure
3. Our Proposed Scheme Model
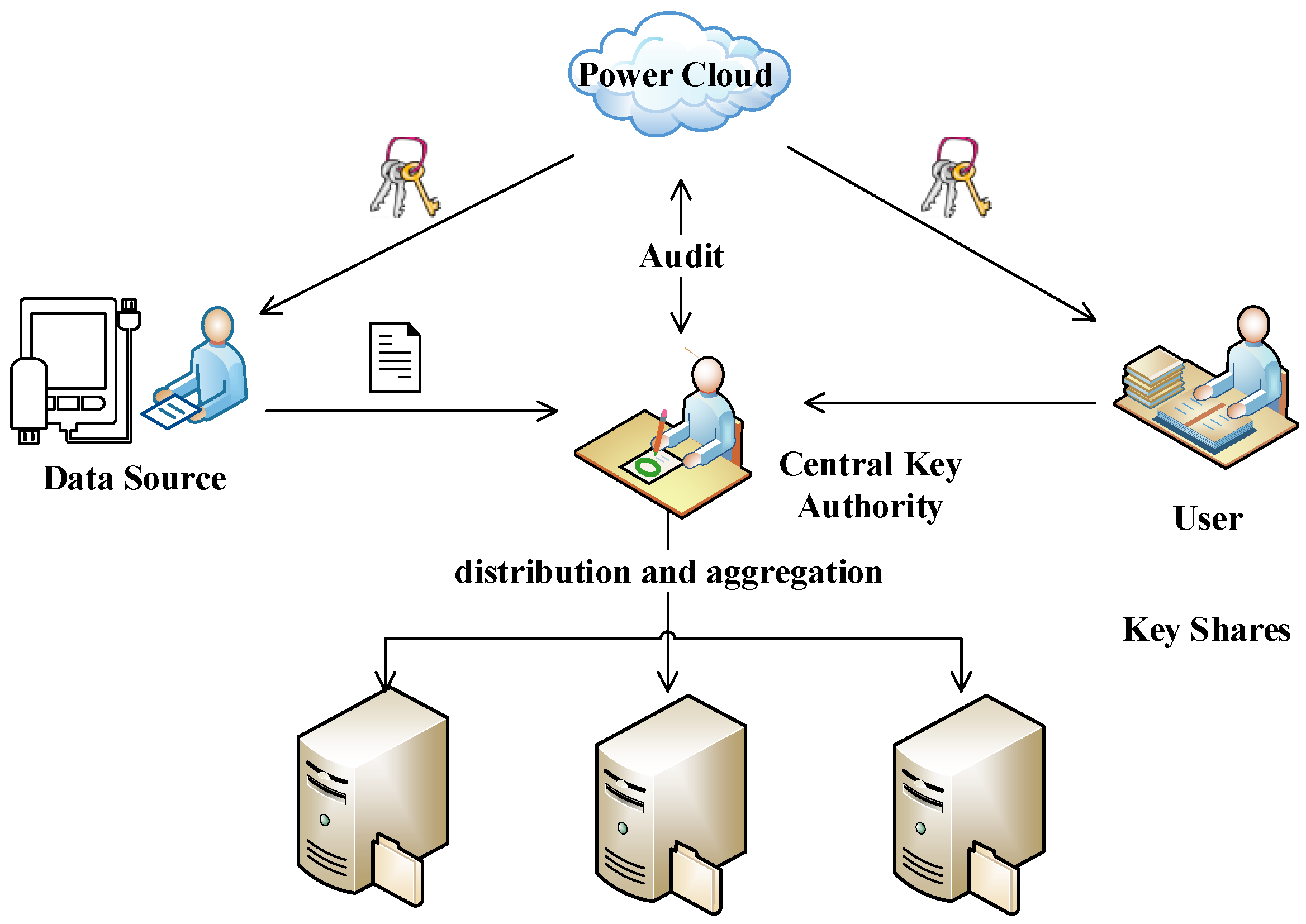
3.1. System Model
3.2. Security Assumption
4. Our Proposed PCAC Scheme
4.1. Overview
4.2. Detail Procedures in PCAC
4.2.1. Init Phase
4.2.2. Data Collection Stage
4.2.3. Data Obtainment Stage
5. Security Analysis and Performance Analysis
5.1. Data Confidentiality and Resist Collusion Attack
5.2. Storage Overhead
5.3. Computation Overhead
6. Experiment Analysis
6.1. Time Consumption in the Data Collection Stage and the Data Obtainment Stage
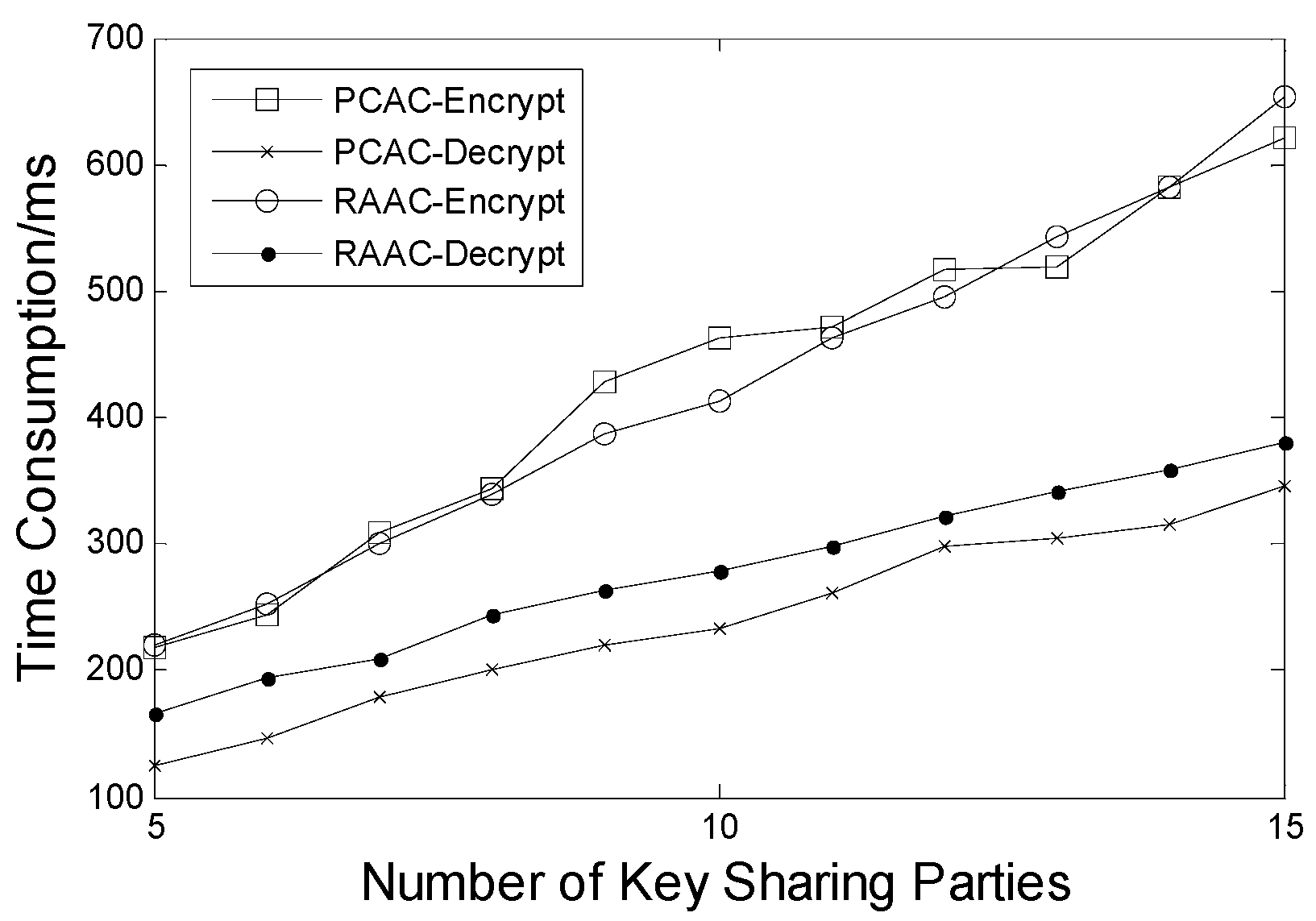
6.2. Time Consumption of the Encrypt and the Decrypt Phase
6.3. Time Consumption of the Act_Audit Phase
6.4. Storage Consumption of CKA
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- US Department of Commerce, NIST. NIST Framework and Roadmap for Smart Grid Interoperability Standards, Release 3.0; US Department of Commerce: Washington, DC, USA, 2014.
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-Policy Attribute-Based Encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Li, L.; Gu, T.; Chang, L.; Xu, Z.; Liu, Y.; Qian, J. A Ciphertext-Policy Attribute-Based Encryption Based on an Ordered Binary Decision Diagram. Proc. IEEE Access 2017, 5, 1137–1145. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, J.; Liu, J.K.; Yu, J.; Chen, J.; Xie, W. An Efficient File Hierarchy Attribute-Based Encryption Scheme in Cloud Computing. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1265–1277. [Google Scholar] [CrossRef]
- Xue, K.; Xue, Y.; Hong, J.; Li, W.; Yue, H.; Wei, D.S.; Hong, P. RAAC: Robust and Auditable Access Control with Multiple Attribute Authorities for Public Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2017, 12, 953–967. [Google Scholar] [CrossRef]
- Wang, S.; Liang, K.; Liu, J.K.; Chen, J.; Yu, J.; Xie, W. Attribute-Based Data Sharing Scheme Revisited in Cloud Computing. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1661–1673. [Google Scholar] [CrossRef]
- Alrawais, A.; Alhothaily, A.; Hu, C.; Xing, X.; Cheng, X. An Attribute-Based Encryption Scheme to Secure Fog Communications. IEEE Access 2017, 5, 9131–9138. [Google Scholar] [CrossRef]
- Xue, K.; Hong, J.; Xue, Y.; Wei, D.S.; Yu, N.; Hong, P. CABE: A New Comparable Attribute-Based Encryption Construction with 0-Encoding and 1-Encoding. IEEE Trans. Comput. 2017, 66, 1491–1503. [Google Scholar] [CrossRef]
- Zhang, R.; Hui, L.; Yiu, S.; Yu, X.; Liu, Z.; Jiang, Z.L. A Traceable Outsourcing CP-ABE Scheme with Attribute Revocation. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, NSW, Australia, 1–4 August 2017; pp. 363–370. [Google Scholar]
- Zhou, Z.; Huang, D.; Wang, Z. Efficient Privacy-Preserving Ciphertext-Policy Attribute Based-Encryption and Broadcast Encryption. IEEE Trans. Comput. 2015, 64, 126–138. [Google Scholar] [CrossRef]
- Yan, Z.; Li, X.; Wang, M.; Vasilakos, A.V. Flexible Data Access Control Based on Trust and Reputation in Cloud Computing. IEEE Trans. Cloud Comput. 2017, 5, 485–498. [Google Scholar] [CrossRef]
- Waters, B. Ciphertext-Policy Attribute-Based Encryption: An Expressive, Efficient, and Provably Secure Realization. Lect. Notes Comput. Sci. 2011, 2008, 321–334. [Google Scholar]
- Han, J.; Susilo, W.; Mu, Y.; Zhou, J.; Au, M.H.A. Improving Privacy and Security in Decentralized Ciphertext-Policy Attribute-Based Encryption. IEEE Trans. Inf. Forensics Secur. 2015, 10, 665–678. [Google Scholar]
- Guo, F.; Mu, Y.; Susilo, W.; Wong, D.S.; Varadharajan, V. CP-ABE with Constant-Size Keys for Lightweight Devices. IEEE Trans. Inf. Forensics Secur. 2014, 9, 763–771. [Google Scholar]
- Lin, G.; Hong, H.; Sun, Z. A Collaborative Key Management Protocol in Ciphertext Policy Attribute-Based Encryption for Cloud Data Sharing. IEEE Access 2017, 5, 9464–9475. [Google Scholar] [CrossRef]
- Ning, J.; Cao, Z.; Dong, X.; Liang, K.; Ma, H.; Wei, L. Auditable sigma-Time Outsourced Attribute-Based Encryption for Access Control in Cloud Computing. IEEE Trans. Inf. Forensics Secur. 2018, 13, 94–105. [Google Scholar] [CrossRef]
- Liu, J.K.; Au, M.H.; Huang, X.; Lu, R.; Li, J. Fine-Grained Two-Factor Access Control for Web-Based Cloud Computing Services. IEEE Trans. Inf. Forensics Secur. 2016, 11, 484–497. [Google Scholar] [CrossRef]
- Li, J.; Lin, X.; Zhang, Y.; Han, J. KSF-OABE: Outsourced Attribute-Based Encryption with Keyword Search Function for Cloud Storage. IEEE Trans. Serv. Comput. 2017, 10, 715–725. [Google Scholar] [CrossRef]
- Balu, A.; Kuppusamy, K. An expressive and provably secure Ciphertext-Policy Attribute-Based Encryption. Inf. Sci. 2014, 276, 354–362. [Google Scholar] [CrossRef]
- De Caro, A.; Iovino, V. JPBC: Java pairing based cryptography. In Proceedings of the 2011 IEEE Symposium on Computers and Communications (ISCC), Kerkyra, Greece, 28 June–1 July 2011; pp. 850–855. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agencies | PC | CKA | KS | U | DS/Owner |
|---|---|---|---|---|---|
| Waters [12] | N/A | 2Lp | N/A | (|SU| + 3)Lp + LZp | (|S| + 3)Lp + LZp |
| RAAC [5] | (6 + 2|S|)Lp + 4LZp | N/A | N/A | (|SU| + 5)Lp + LZp | (|S| + 5)Lp + LZp |
| PCAC | (3 + |NKS|)Lp + 2LZp | 3Lp + |S|Lp | Lp | 4Lp + LZp | LZp + Lp |
| Phases | Init | Gen Stru | Encrypt | Gen_key | Decrypt | Act_Audit | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| agencies | PC | CKA | CKA | CKA | DS | CKA | KS | PC | U | PC | CKA | U |
| Waters [12] | N/A | O(NU) | N/A | N/A | O(NSK) | N/A | N/A | O(Nas) | O(NSK) | N/A | N/A | N/A |
| RAAC [5] | O(NS + NDS + NU) | N/A | N/A | N/A | O(NSK) | O(Nas) | N/A | O(Nas) | O(NSK) | O(1) | O(1) | O(1) |
| PCAC | O(NS + NDS + NU) | N/A | O(1) | O(NSK) | O(1) | O(Nas) | O(1) | O(1) | O(NSK) | O(1) | O(1) | O(1) |
| Number of Us | 100,000 | 300,000 | 500,000 | 1,000,000 | |
|---|---|---|---|---|---|
| Number of Attributes | |||||
| 10 | 122 MB | 366 MB | 615 MB | 1.18 GB | |
| 15 | 168 MB | 505 MB | 842 MB | 1.65 GB | |
| 20 | 216 MB | 644 MB | 1.04 GB | 2.07 GB | |
| 25 | 260 MB | 789 MB | 1.28 GB | 2.57 GB | |
| 30 | 309 MB | 930 MB | 1.51 GB | 2.99 GB | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, P.; Wang, B. An Improved Ciphertext-Policy Attribute-Based Encryption Scheme in Power Cloud Access Control. Appl. Sci. 2018, 8, 1836. https://doi.org/10.3390/app8101836
Li Y, Zhang P, Wang B. An Improved Ciphertext-Policy Attribute-Based Encryption Scheme in Power Cloud Access Control. Applied Sciences. 2018; 8(10):1836. https://doi.org/10.3390/app8101836
Chicago/Turabian StyleLi, Yuancheng, Pan Zhang, and Boyan Wang. 2018. "An Improved Ciphertext-Policy Attribute-Based Encryption Scheme in Power Cloud Access Control" Applied Sciences 8, no. 10: 1836. https://doi.org/10.3390/app8101836