Review Rating Prediction Based on User Context and Product Context

Abstract
:1. Introduction
- (1)
- We propose a review rating prediction method based on user context and product context.
- (2)
- Aiming at the problem of user context dependency of sentiment words, a review rating the prediction method based on review content and user context is proposed. Aiming at the problem of product context dependency of sentiment words, we proposed a review rating prediction method based on review content and product context.
- (3)
- We conduct comprehensive experiments on four large-scale datasets for RRP. We find that our methods significantly outperform the state-of-the-art baselines.
2. Related Work
2.1. RRP Based on Review Content
2.2. Missing Rating Prediction in User-Item Rating Matrix
2.3. Review-Based Recommendation
3. RRP Based on User Context and Product Context
3.1. Problem Description
3.2. RRP Method Based on Review Content and User Context
3.3. RRP Based on Review Content and Product Context
3.4. RRP Based on User Context and Product Context
4. Experiments and Evaluations
4.1. Datasets and Evaluation Metric
4.2. Experimental Settings and Research Questions
- LR + global: RRP method based on linear regression trained and tested on all users and products.
- LR + global + UPF: We extract user features [36] and corresponding product features (denoted as UPF) from training data, and concatenate them with the features in baseline LR + global.
- LR + individual + product: RRP method based on linear regression trained and tested on individual product.
- LR + individual + user: RRP method based on linear regression trained and tested on individual user.
- KNN: RRP method based on k-nearest neighbor.
- MF: RRP method based on matrix factorization.
- RRP + UC: RRP method based on review content and user context.
- RRP + PC: RRP method based on review content and product context.
- RRP + UC + PC: RRP method based on user context and product context.
- (1)
- Whether our method performance is better than the benchmark method.
- (2)
- The impact of the number of reviews per user and reviews for each product on our methods
- (3)
- The impact of user context and product context on our methods.
4.3. Performance Comparison of Different Methods
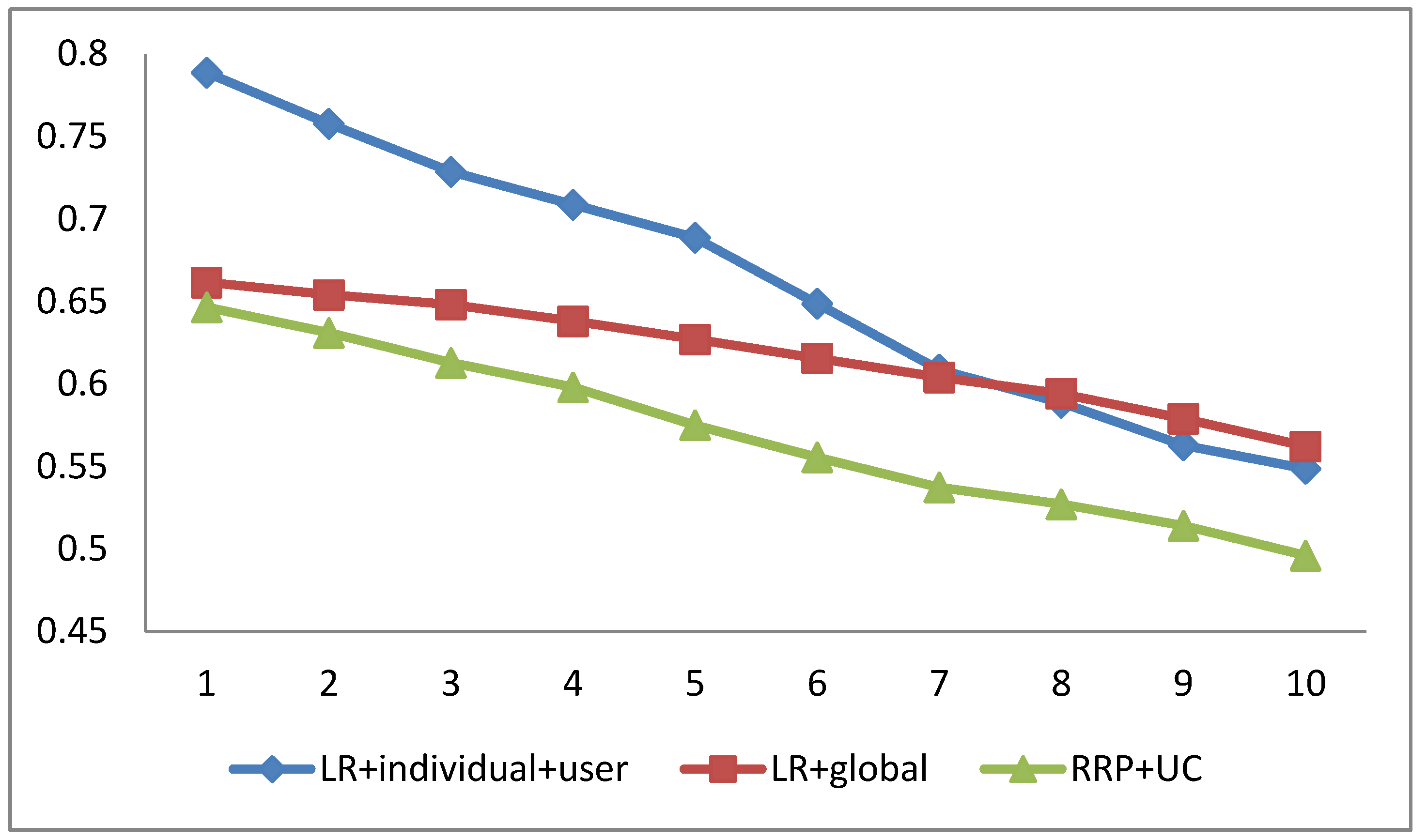
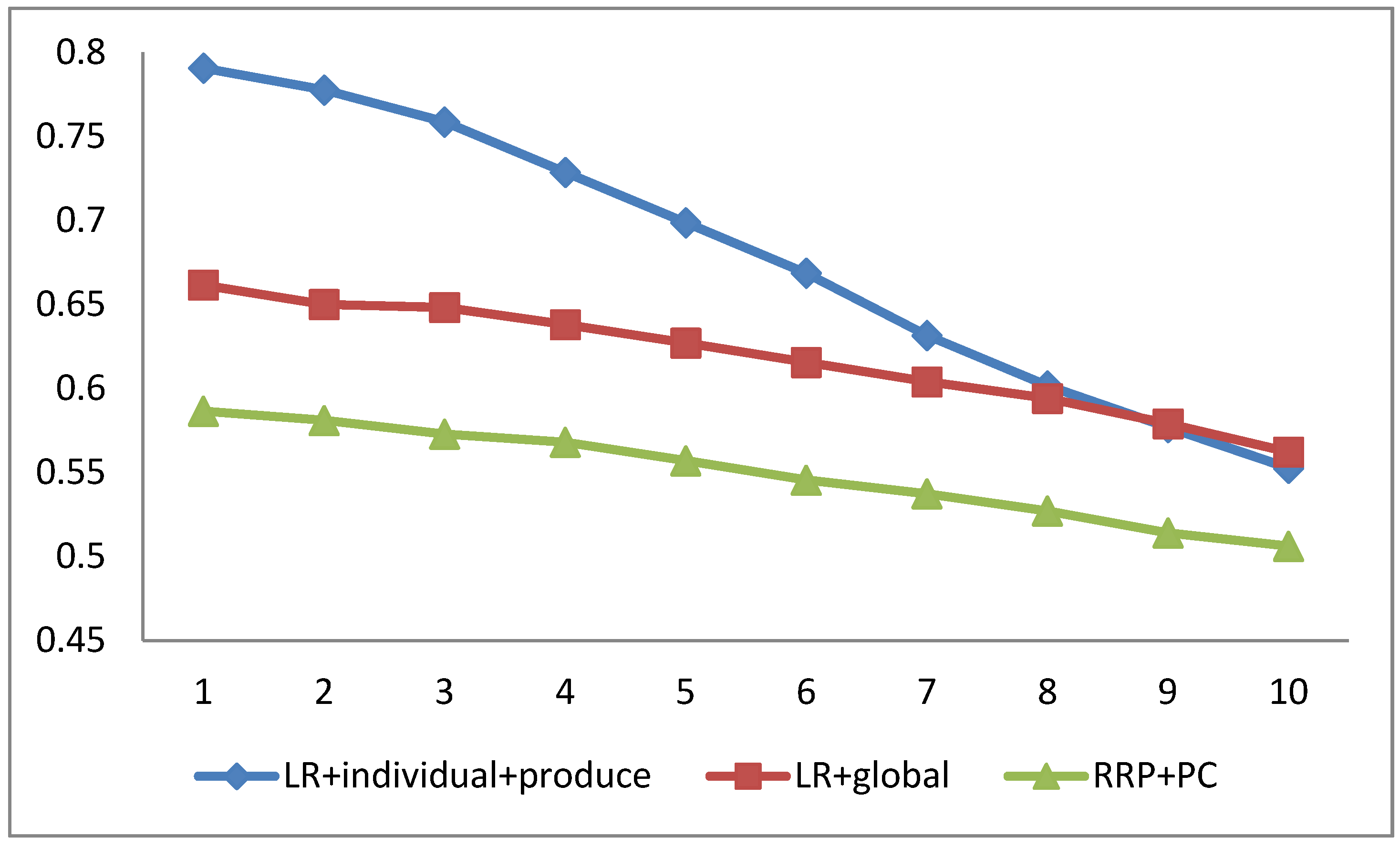
4.4. The Impact of the Number of Reviews Per User and Reviews for Each Product on Our Methods
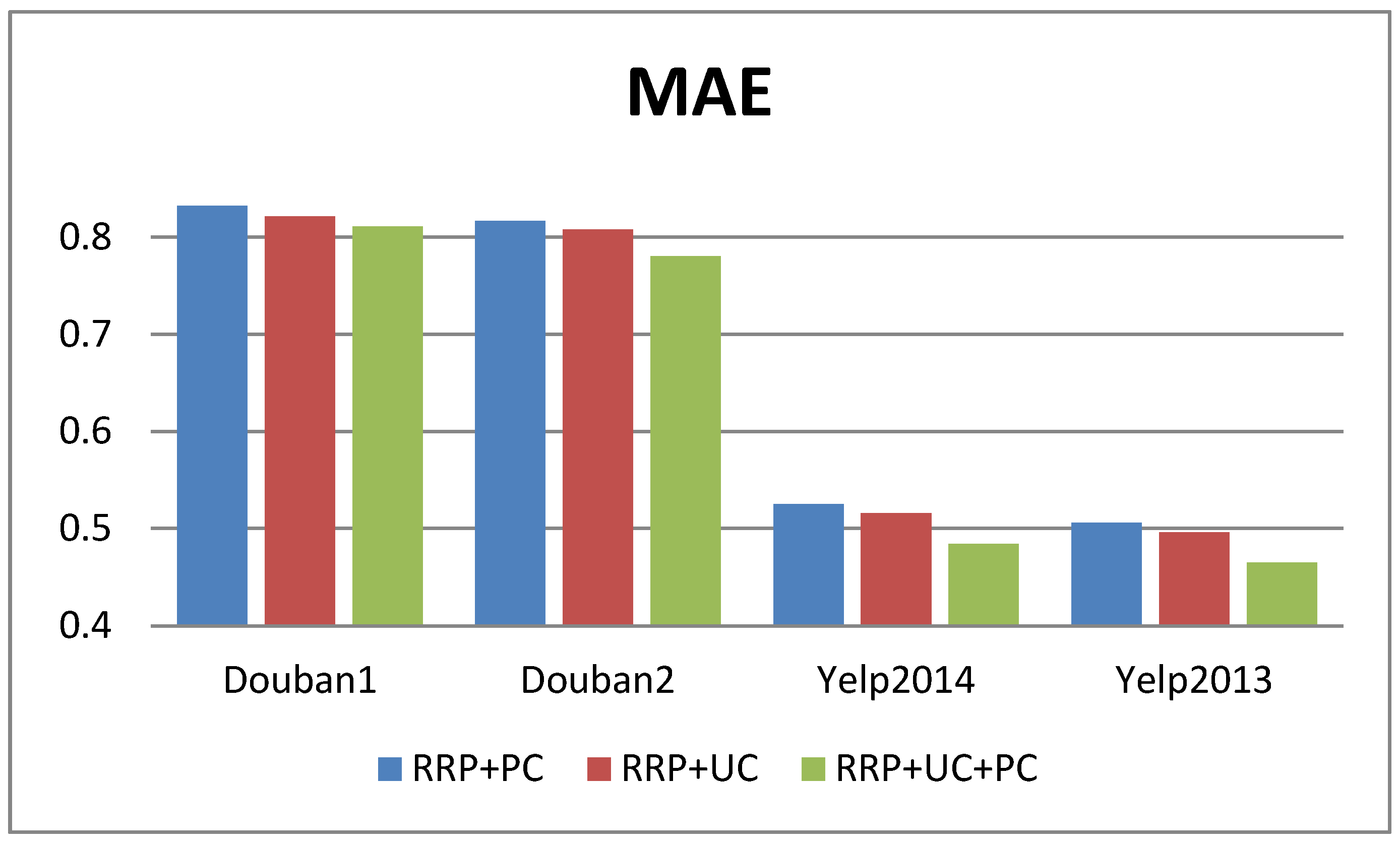
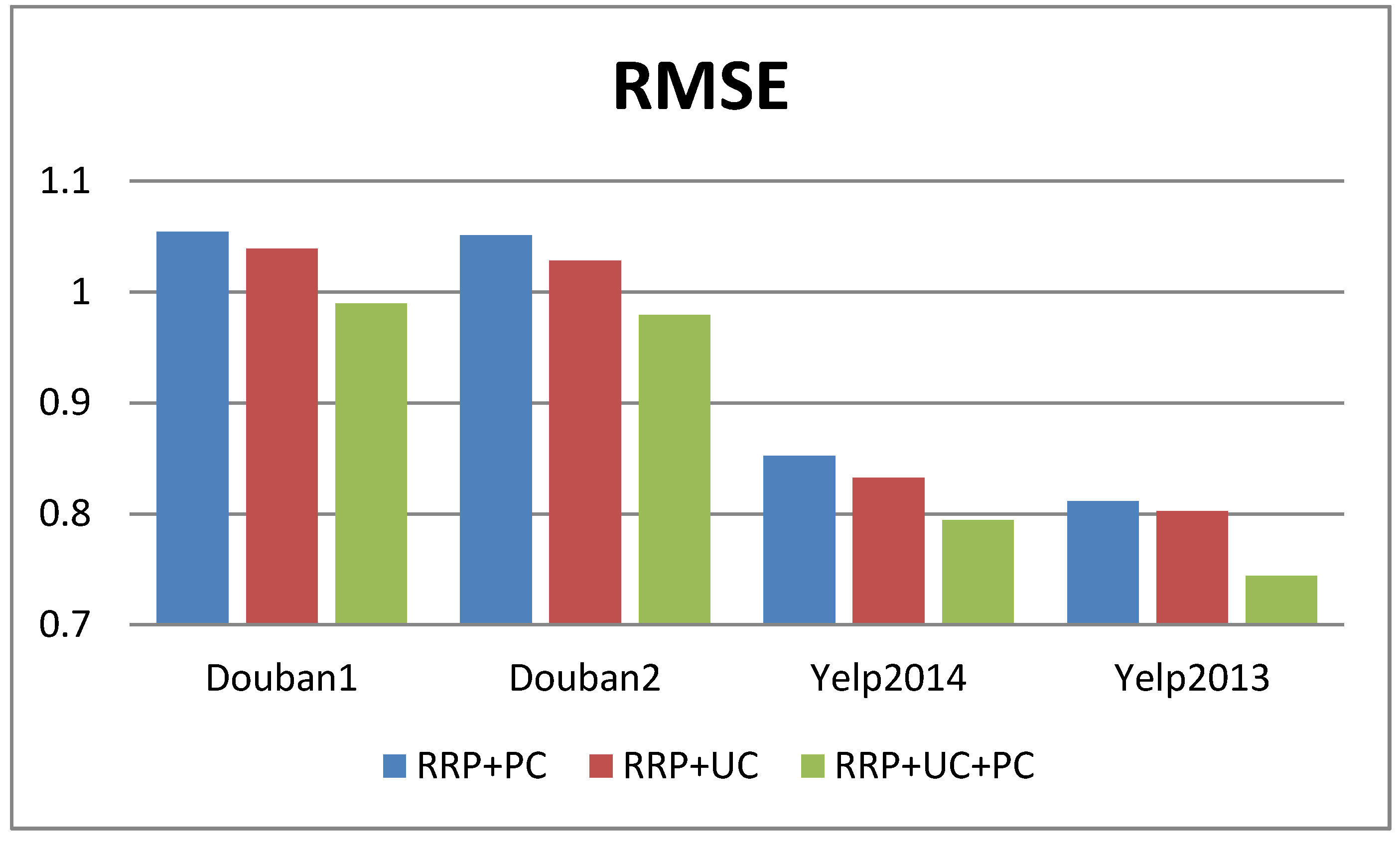
4.5. The Impact of User Context and Product Context on Our Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. A semi-supervised approach to sentiment analysis using revised sentiment strength based on Senti Word Net. Knowl. Inf. Syst. 2017, 51, 851–872. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. e SAP: A decision support framework for enhanced sentiment analysis and polarity classification. Inf. Sci. 2016, 367, 862–873. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. Multi-objective model selection (MOMS)-based semi-supervised framework for sentiment analysis. Cogn. Comput. 2016, 8, 614–628. [Google Scholar] [CrossRef]
- Khan, F.H.; Qamar, U.; Bashir, S. SWIMS: Semi-supervised subjective feature weighting and intelligent model selection for sentiment analysis. Knowl. Based Syst. 2016, 100, 97–111. [Google Scholar] [CrossRef]
- Mishra, S.; Diesner, J.; Byrne, J.; Surbeck, E. Sentiment analysis with incremental human-in-the-loop learning and lexical resource customization. In Proceedings of the 26th ACM Conference on Hypertext & Social Media, Guzelyurt, Cyprus, 1–4 September 2015; pp. 323–325. [Google Scholar]
- Horrigan, J. Online Shopping; Pew Internet and American Life Project Report; Pew Research Center: Washington, DC, USA, 2008. [Google Scholar]
- Wu, Y.; Ester, M. FLAME: A probabilistic model combining aspect based opinion mining and collaborative filtering. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 199–208. [Google Scholar]
- Qu, L.; Ifrim, G.; Weikum, G. The bag-of-opinions method for review rating prediction from sparse text patterns. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 913–921. [Google Scholar]
- Zheng, L.; Zhu, F.; Mohammed, A. Attribute and Global Boosting: A Rating Prediction Method in Context-Aware Recommendation. Comput. J. 2018, 60, 957–968. [Google Scholar] [CrossRef]
- Ganu, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions using Review Text Content. In Proceedings of the International Workshop on the Web and Databases, WEBDB 2009, Providence, RI, USA, 28 June 2009. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint Deep Modeling of Users and Items Using Reviews for Recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Wang, H.; Lu, Y.; Zhai, C. Latent aspect rating analysis on review text data: A rating regression approach. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 783–792. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Learning Semantic Representations of Users and Products for Document Level Sentiment Classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1014–1023. [Google Scholar]
- Wu, F.; Huang, Y. Personalized Microblog Sentiment Classification via Multi-Task Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; pp. 3059–3065. [Google Scholar]
- Tang, D.; Qin, B.; Yang, Y.; Liu, T. User Modeling with Neural Network for Review Rating Prediction. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015; pp. 1340–1346. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar]
- Li, F.; Liu, N.; Jin, H.; Zhao, K.; Yang, Q.; Zhu, X. Incorporating reviewer and product information for review rating prediction. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1820–1825. [Google Scholar]
- Liu, J.; Seneff, S. Review sentiment scoring via a parse-and-paraphrase paradigm. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1, Singapore, 6–7 August 2009; pp. 161–169. [Google Scholar]
- Lee, H.C.; Lee, S.J.; Chung, Y.J. A study on the improved collaborative filtering algorithm for recommender system. In Proceedings of the 5th ACIS International Conference on Software Engineering Research, Management &Applications (SERA 2007), Busan, Korea, 20–22 August 2007; pp. 297–304. [Google Scholar]
- Jeong, B.; Lee, J.; Cho, H. Improving memory-based collaborative filtering via similarity updating and prediction modulation. Inf. Sci. 2010, 180, 602–612. [Google Scholar] [CrossRef]
- Shi, Y.; Larson, M.; Hanjalic, A. Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Comput. Surv. 2014, 47. [Google Scholar] [CrossRef]
- Li, P.; Wang, Z.; Ren, Z.; Bing, L.; Lam, W. Neural rating regression with abstractive tips generation for recommendation. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; pp. 345–354. [Google Scholar]
- Catherine, R.; Cohen, W. TransNets: Learning to Transform for Recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 288–296. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 297–305. [Google Scholar]
- He, X.; Chen, T.; Kan, M.; Chen, X. TriRank: Review-aware explainable recommendation by modeling aspects. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 1661–1670. [Google Scholar]
- Ling, G.; Lyu, M.R.; King, I. Ratings meet reviews, a combined approach to recommend. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, CA, USA, 6–10 October 2014; pp. 105–112. [Google Scholar]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 165–172. [Google Scholar]
- Ren, Z.; Liang, S.; Li, P.; Wang, S.; de Rijke, M. Social Collaborative Viewpoint Regression with Explainable Recommendations. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 485–494. [Google Scholar]
- Bao, Y.; Fang, H.; Zhang, J. Topicmf: Simultaneously exploiting ratings and reviews for recommendation. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 2–8. [Google Scholar]
- Diao, Q.; Qiu, M.; Wu, C.; Smola, A.J.; Jiang, J.; Wang, C. Jointly modeling aspects, ratings and sentiments for movie recommendation (JMARS). In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 193–202. [Google Scholar]
- Jakob, N.; Weber, S.H.; Müller, M.C.; Gurevych, I. Beyond the stars: Exploiting free-text user reviews to improve the accuracy of movie recommendations. In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion, Hong Kong, China, 2–6 November 2009; pp. 57–64. [Google Scholar]
- Gong, L.; Al Boni, M.; Wang, H. Modeling social norms evolution for personalized sentiment classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 855–865. [Google Scholar]
- Gao, W.; Yoshinaga, N.; Kaji, N.; Kitsuregawa, M. Modeling user leniency and product popularity for sentiment classification. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 1107–1111. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | #Users | #Reviews | #Items | #Reviews/User | #Reviews/Product |
|---|---|---|---|---|---|
| Douban 1 | 1476 | 22,593 | 3041 | 15.31 | 7.43 |
| Douban 2 | 1079 | 13,858 | 2087 | 12.84 | 6.64 |
| Yelp 2014 | 4818 | 231,163 | 4194 | 47.97 | 55.12 |
| Yelp 2013 | 1631 | 78,966 | 1633 | 48.42 | 48.36 |
| Datasets | Douban1 | Douban1 | Douban2 | Douban2 | Yelp2014 | Yelp2014 | Yelp2013 | Yelp2013 |
|---|---|---|---|---|---|---|---|---|
| Metric | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| KNN | 1.0659 | 1.4547 | 1.0626 | 1.4271 | 0.7112 | 0.9993 | 0.6987 | 0.9856 |
| MF | 0.8341 | 1.0653 | 0.8056 | 1.0387 | 0.5132 | 0.8146 | 0.4871 | 0.8042 |
| LR + global | 0.8477 | 1.1008 | 0.8277 | 1.0741 | 0.5686 | 0.8985 | 0.5623 | 0.8931 |
| LR + global + UPF | 0.8365 | 1.0681 | 0.8154 | 1.0684 | 0.5305 | 0.8606 | 0.5225 | 0.8334 |
| LR + individual+product | 0.8431 | 1.0909 | 0.8231 | 1.0702 | 0.5589 | 0.8884 | 0.5526 | 0.8736 |
| LR + individual + use | 0.8370 | 1.0703 | 0.8124 | 1.0645 | 0.5383 | 0.8682 | 0.5324 | 0.8533 |
| RRP + PC | 0.8325 | 1.0542 | 0.8170 | 1.0513 | 0.5252 | 0.8523 | 0.5062 | 0.8114 |
| RRP + UC | 0.8216 | 1.0391 | 0.8081 | 1.0282 | 0.5158 | 0.8326 | 0.4961 | 0.8024 |
| RRP + RC + PC | 0.8111 | 0.9899 | 0.7803 | 0.9794 | 0.4841 | 0.7946 | 0.4652 | 0.7441 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Xiong, S.; Huang, Y.; Li, X. Review Rating Prediction Based on User Context and Product Context. Appl. Sci. 2018, 8, 1849. https://doi.org/10.3390/app8101849
Wang B, Xiong S, Huang Y, Li X. Review Rating Prediction Based on User Context and Product Context. Applied Sciences. 2018; 8(10):1849. https://doi.org/10.3390/app8101849
Chicago/Turabian StyleWang, Bingkun, Shufeng Xiong, Yongfeng Huang, and Xing Li. 2018. "Review Rating Prediction Based on User Context and Product Context" Applied Sciences 8, no. 10: 1849. https://doi.org/10.3390/app8101849