1. Introduction
Meteorological parameters have reached importance in different fields like energy, tourism, and farming. In terms of energy use today, fossil fuels act as the main energy generation source [
1], generating problems like pollution, greenhouse effects, and increased CO
2 levels. Accordingly, it is necessary to use renewable energy source as wind power, hydro, solar energy, etc. to improve the environment.
Nevertheless, optimization is a weak point in the use of renewable energy. For that reason, to supply clean energy to the population, the combination with fossil fuels is necessary. If efficiency in the generation process increases, the use of nonrenewable sources will be reduced.
One of the projects that pretends to reach self-sufficiency in energetic terms is located on the island of El Hierro (Canary Islands, Spain). It stands out with the capability to supply to the entire island the demand of power through a wind-hydro-pumped station [
2].
Many works have been developed on this field. Then, different works are shown in relation to meteorology.
Meteorological predictions have been object of study for diverse applications like the study of the load in electrical networks, as in [
3,
4,
5], or to help elderly people as in [
6]. The importance of having good weather forecasting will help in various areas. Applications may vary, from the prediction of red tides or rainstorms, like [
7,
8,
9], to comfort applications in buildings or workplaces like [
10,
11,
12,
13].
In relation to temperature prediction, in [
10,
11,
12,
14,
15,
16], they have obtained good results using artificial neural networks (ANN) and support vector machines (SVM). In [
15], the best result reaches a mean square error (MSE) of 0.136 °C.
Concerning solar radiation predictions [
17,
18,
19,
20,
21,
22,
23,
24,
25], classification systems were mainly used, such as ANN and SVM. In particular, in [
25], the best result reached a 99.9% of accuracy.
Respecting to wind speed predictions, works like [
26,
27,
28,
29,
30] makes use of classifications systems like ANN and SVM. Best result was obtained in [
26], where the mean absolute error (MAE) was 0.85 m/s.
As seen on previous works, based on meteorological forecasting, it observes the great importance and application on different fields, as energy generation, or helping elderly people. For this reason, the purpose of this work merges with the motivation to collaborate with these applications. It consists of the design of a prediction system that can be used under different conditions to get a forecasting of different meteorological parameters as wind speed, temperature, solar radiation or precipitation. The innovative point of this work versus previous researches is the adaptability of the method to different meteorological phenomena. The correct meteorological characterization of the study area will allow to determine the moment in which appears a peak of energy demand. The information used in this study comes from the State Meteorological Agency (Agencia Estatal de Meteorología, AEMET, in Spanish) that depends on the Spanish Government. The regression functions used in this study are presented below:
As shown on this section, there are a lot of studies that carries out predictions of meteorological parameters. The statistical used to probe the proposed models varies between MAE and MSE and the classification systems vary between ANN and SVM. Many of them make short time predictions and even long time predictions too. In addition, errors reached in previous researches are higher than those obtained in this research.
But the real proof of the goodness of the proposed model is that, as it is shown on the following sections, we only applied one model to the whole experiment regardless of the meteorological phenomena involved in the prediction. This is a scientific value added into literature.
The novelty of the system consists of the feasibility to use it in different geographical location only using data from meteorological stations. The proposal does not need to introduce data from geopotential highs or sea level pressures (SLP) in order to obtain an accurate prediction in the case of wind and precipitation. Besides, this proposal can be used for different climate parameters. It shows the robustness and any similar works has not been found in the state-of-the-art.
2. Materials and Methods
This study has been made with the database provided by AEMET, an agency that depends on Ministry of Agriculture, Food and Environment of the Spanish government. From all the stations that AEMET has deployed around Spain, this work used two meteorological stations, which are located at Gran Canaria (GC) airport (Gran Canaria, Canary Islands) and South Tenerife (TF) airport (Tenerife, Canary Islands), respectively. This database offers data relative to temperature, humidity, solar radiation, meteors, precipitation, wind speed and clouds. The data from each phenomenon is given in an Excel sheet format (.xls) including the information collected hourly by both stations under study alongside the whole period of study from 2003 to 2007. In the same way a .txt file is given with explanatory information about each .xls sheet as a help to understand data contained on it.
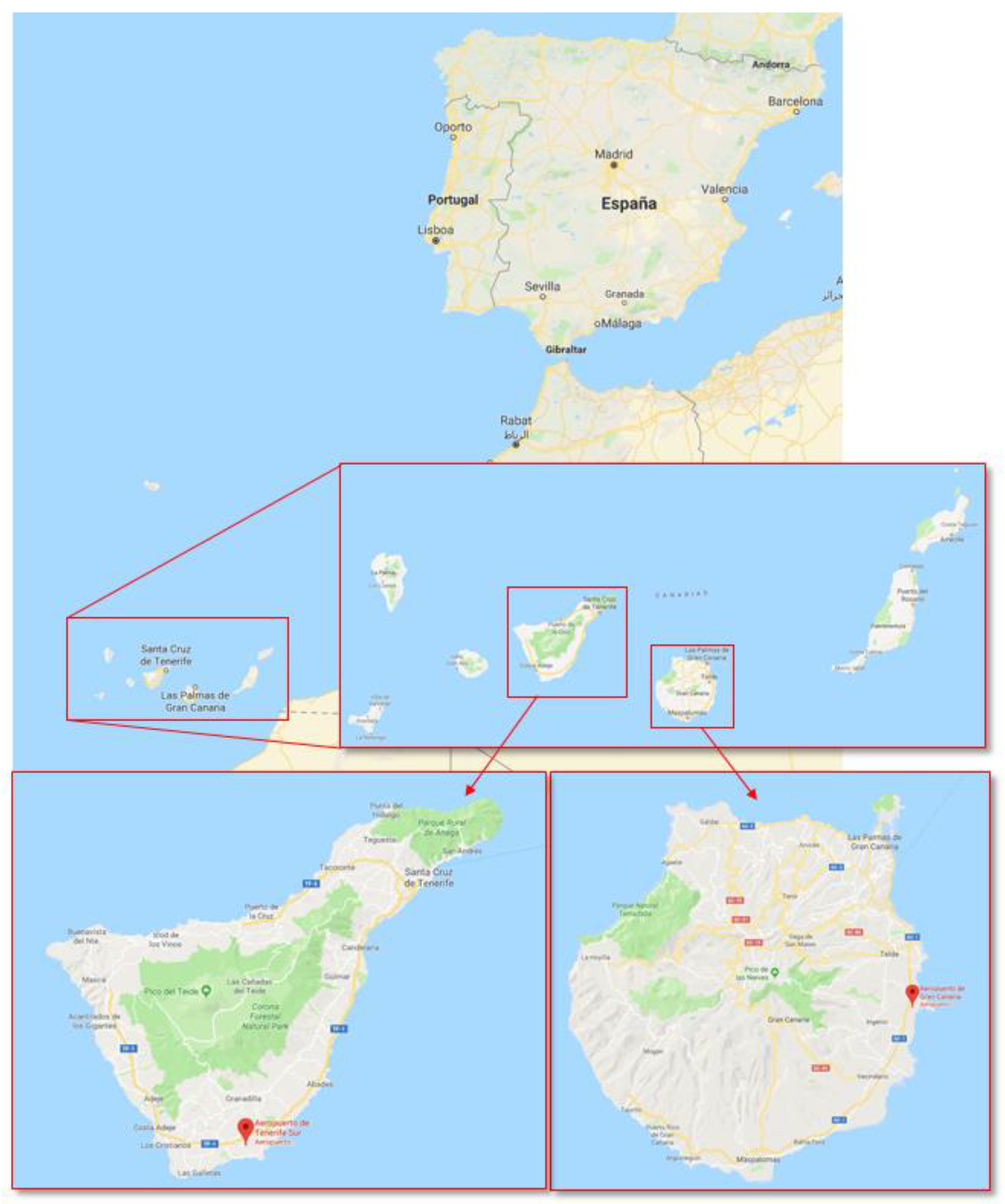
Figure 1 shows the map of the Canary Islands (Spain) and the details of Gran Canaria and Tenerife; the airports’ locations are marked with red dots.
Canary Islands are located in a subtropical climate area beaten by Trade Winds with warm temperatures. However, they suffer from the remains of tropical storms that hit the Caribbean when they turn around the Atlantic Ocean. The study areas was located on the southeastern of both islands, were winds allows the generation of green energy.
To achieve an accurate prediction, a preprocessing stage is applied to adapt the information given to the input of the prediction system. Consequently, the procedure must be quick, avoiding large delays when the prediction is performed; and thus reaching almost a real-time prediction approach.
Firstly, it is necessary to check each sheet to not introduce false or nonexisting data to the system. The reason is due to the periods of time where there is no data, caused by any damage or inactivity of the station or anyone of its sensors.
Secondly, the concatenation and adaptation (in terms of measurement unit) are done before to insert the parameter information to the system. Temperature and wind speed are two examples of meteorological phenomena that have more information during the study period. For this reason, they are two of the phenomena chosen to obtain the prediction.
Finally, once the preprocessing stage has been done, resulting in the obtaining of the input data, it is possible to apply the classification systems. Our forecasting system is based on the use of the regression functions, which is described below.
The number of samples that will be used in this study are shown in
Table 1.
2.1. Support Vector Machines (SVM)
Given a training set of instance-label pairs
,
where
and
, the SVM require the solution of the following optimization problem:
subject to
Where
w are the weight and the support vector is there are different zero,
C is the cost function,
b is the bias,
is the kernel of the input,
y is the output and
is the value of the plane.
Here training vectors
are mapped into a higher (maybe infinite) dimensional space by the function
. SVM finds a linear separating hyperplane with the maximal margin in this higher dimensional space.
is the penalty parameter of the error term. Furthermore,
is called the kernel function [
31].
To obtain a system able to reach the smallest error, it has been tested using diverse kernel functions with the aim to obtain a better forecasting approach. Year 2006 was used in the training mode, the reason is explained at the end of this section. During training and test modes, the kernel functions used in this supervised classifier were as follows:
Radial basis function (RBF) kernel:
Polynomial kernel:
being
,
and
the parameters of the kernel.
As a result of the training function, MATLAB returns a structure called SVMStruct, which contains information about the trained SVM classifier.
2.2. Regression Tree
The classification and regression trees are methods of machine learning for building predictive models from temporal series. The models are obtained by recursive partitioning of the data space and fitting a simple prediction model within each partition. As a result, the partition can be graphically represented as a decision tree. Classification trees are designed for dependent variables that have a finite number of unordered values with prediction error measured by the squared difference between observed and predicted values [
32,
33]. An alternative approach to nonlinear regression is to subdivide or partition the space into smaller regions, where interactions are more manageable. Then subdivisions are divided again. Finally, more manageable pieces of space are obtained, which can be fitted by simple models. This process is called recursive partitioning. Thus, the global model has two parts: one is the recursive partition, and the other is a simple model for each cell of the partition.
Prediction trees use the tree to represent the recursive partition. Each of the terminal nodes or leaves of the tree represents a cell partition and has attached to it a simple model that is applied only in that cell. A point belongs to a leaf if falls in the corresponding cell in the partition. In order to determine the cell, it begins at the root node of the tree, and a series of questions about the features is made. Interior nodes are labeled with questions, and the edges or branches between them are marked with responses. Depending on the answer to the previous question, the next question is made. In the classic version of a prediction tree, each question refers to a single attribute, and only has an affirmative or negative response (binary).
For classical regression trees, the model in each cell is only an estimate of Y constant. That is, it can be assumed that the points are all the samples belonging to the leaf of the node .
Then, the model for is , the sample mean of the response variable in that cell (Shalizi, 2006). This is a piecewise-constant model.
An example of regression tree is shown on
Figure 2.
2.3. Fit Linear Model (FITLM)
The measured values in the real world never fit perfectly for a model due to measurement errors and to some mathematical models is a simplification of the real world. If it is taken into account all factors influencing a set of variables, it would be unmanageable, committing the model some error.
The chosen model indicates that variable (dependent variable) is a function of the variables (independent variables). That is, all variables corresponding to a subset of all possible cases are measured. By applying the model, the difference between the measured variable and the predicted value minimizes the error values, fitting the model.
The input to the system are the different preprocessed values of meteorological parameters previous to its target value. After the corresponding prediction process is performed, it will be obtained a single output value, being the value of the weather parameter to predict.
The different operating modes of the prediction systems are:
Training mode, in which the model used later on the test mode is created
Testing mode, in which the desired output is obtained.
Figure 3 shows the concept of the sliding window.
The sliding window is an important parameter that must be considered when the input data is introduced into the forecast system. To it, it is assigned a certain value or size. This window contains past data or attributes (highlighted in orange) of the phenomenon that it is wanted to predict, called target value (highlighted in blue). It moves in order to change its attributes in every iteration to obtain the system outputs or target values. When an iteration happens, the window moves one position forward. The last target value becomes an attribute of the new sliding window to predict the next target value. In this way, a prediction of a specific meteorological parameter is performed. The target value corresponding to each row is set into the target values vector, which is another important parameter for the training mode.
The training matrix is generated with this sliding window principle. Each row of the matrix contains the sliding window corresponding to every iteration. Every row is a vector with the information previous to a specific target value. If the window size is “n”, there will be “n” values of each type of meteorological parameter used to predict in that row of the matrix.
For example, if it is wanted to make a prediction about temperature using temperature and wind as input parameters using a sliding window size of five samples. The first row of the training matrix will consist of the first five temperature values concatenated with the first five values of the wind speed. Thus, it is intended to predict the sixth temperature value, which is in the first position of the target values vector. An example of the training matrix and target values vector, are shown in
Table 2.
Size of the sliding window is a critical part in the prediction system in terms of accuracy in the obtained prediction. For that reason, it is necessary to make several test to obtain the appropriate size of the window.
As a result of the training mode, with all the information obtained on it, the model is created and used in the test mode as input.
The block diagram of the forecasting system is shown on
Figure 4.
A training mode and, subsequently, a testing mode has been realized, forming the supervised classifier, to obtain kernel parameters.
The MSE is the parameter that gives the measure of the goodness of the system, defined by:
where
is a vector of
predictions, and
is the vector observed values of the variable being predicted.
The optimal size of the sliding window is calculated using a loop function where there is a supervised classifier. Errors are obtained comparing the predicted values with the originals. In each iteration of the loop, the size of the sliding window is modified and the error will also be modified. This size depends on the MSE reached once the testing stage have been done. The lower MSE, the better sliding window size.
Data from the year 2006 were used in the training mode, the reason to choose this year is due to the number of samples, different in every year caused by acquisition data problems of the sensors. In 2006, the number of samples were quite similar of the average number of samples of the rest of the years of study, giving us the possibility of modelling an entire year. Once the model has been obtained, it is used to the test stage with the data from years 2003, 2004, 2005, and 2007. The system is trained with the 20% of the samples. With the resulting model, the test mode is performed with the remaining 80% of the samples. This is one of the strengths of the system.
In the specific case of solar radiation parameter, the data for 2005 are used in the training mode because the number of samples in this year is similar to the average of other years. In the case of Gran Canaria station, there is not information about solar radiation in the year 2003.
According to this, the following experiments have been carried out:
Temperature (°C) forecasting using as input data:
- ○
Temperature (°C).
- ○
Temperature (°C) and precipitation (mm).
- ○
Temperature (°C) and wind speed (km/h).
- ○
Temperature (°C) and temperature (tenths of °C).
- ○
Temperature (°C), temperature (tenths of °C) and wind speed (km/h).
Wind speed (km/h) forecasting using wind speed (km/h) as input data.
Solar radiation (tenths of kJ/m2) forecasting using solar radiation (tenths of kJ/m2) as input data.
Precipitation (mm) forecasting using precipitation (mm) as input data.
3. Results and Discussion
In order to analyze results and to observe the system accuracy, they are graphically represented, making a comparison between the predicted values, in red, and the original values (target values), in blue, with labels “predicted value” and “original value”, respectively. The time period represented in these graphs is eight days, the first eight days of the year. Although errors are calculated with the information belonging to all days of the every year. Because of the great number of experiments and cases, it will only be represented graphically the forecasting corresponding to the use of the regression function which gets best results.
Despite getting several types of errors, only the values of the MSE are represented in tables for the classification systems explained in
Section 2 (i.e., SVM linear, SVM RBF, SVM polynomial, regression tree and fit linear model). In all cases, results are presented with seven decimal places due to the similarity between the results.
When the SVM predictor is used, the optimal kernel parameters are obtained using a loop that contains the training and testing modes. It modifies the values of the kernel parameters leading to values that achieves smallest error, which are the best. Being , , and the parameters of the kernel.
This section may be divided by subheadings. It should provide a concise and precise description of the experimental results, their interpretation as well as the experimental conclusions that can be drawn.
3.1. Forecast of Temperature
In this case, temperature in °C is the weather information to be predicted.
3.1.1. With Temperature as Input Data
The optimal size of the sliding window is 1. Best results are shown in
Table 3 and
Figure 5.
The support vector machine system with linear kernel reaches greater accuracy in predicting temperature, using as input the temperature information in Gran Canaria.
3.1.2. With Temperature and Precipitation as Input Data
The optimal size of the sliding window is 1.
Table 4 and
Figure 6 shown best results when temperature (°C) and precipitation in mm are involved.
The system gets best results in Gran Canaria using the SVM system with linear kernel, using as input the information of temperature and precipitation.
3.1.3. With Input Data from Temperature and Wind Speed
The optimal size of the sliding window is 1, and best results are shown in
Table 5 and
Figure 7. The data of wind speed in kilometers per hour (km/h) are used in this test.
3.1.4. With Input Data from Temperature in °C and Temperature in Tenths of °C
Table 6 and
Figure 8 shows best results obtained. The optimal size of the sliding window is 1.
3.1.5. With Input Data from Temperature in °C and Temperature in Tenths of °C and Wind Speed
The optimal size of the sliding window is 1, reaching best results showed in
Table 7 and
Figure 9.
3.2. Forecast of Wind Speed
In this case, the weather information to predict is the wind speed in km/h, using as input parameters wind speed (km/h).
Due to the number of samples relating to wind parameter is similar to the number of samples available of temperature, the optimal size of the sliding window is 1. The results are shown in
Table 8 and
Figure 10.
When the prediction of the wind speed is done only using wind speed as input data, the best results are achieved by means of SVM with polynomial kernel. The system reaches good results in both places, getting an average of MSE smaller than 1 km/h.
3.3. Forecast of Solar Radiation
In order to predict solar radiation in tenths of kilojoules per square meter (kJ/m
2), the input data used were solar radiation in tenths of kJ/m
2. The optimal size of the sliding window is 1. The system was trained using data of 2005 and testing with the remaining years. Best results are shown in
Table 9 and
Figure 11.
The best classification system to use to predict solar radiation are those based on SVM with linear or polynomial kernels.
3.4. Forecast of Precipitation
To predict precipitation in mm, solar radiation in tenths of kJ/m2 and precipitation in mm were used as input data. The system, it is trained with the information of 2006 and testing with the remaining years.
The complexity of this parameter is different from the others. As it does not happen too often, the value of precipitation is low and constant for a long period of time. However, when it happens, the value of this parameter increases considerably, whereupon the amount of previously recorded information required to make an accurate forecasting has to be big enough. As an effect, the optimal size of the sliding window is 33. The best results are shown in
Table 10 and
Figure 12.
The best system to predict precipitation varies depending on the location. In South Tenerife best results are achieved using a setting based on fit linear model system, while for Gran Canaria, SVM with polynomial kernel was used.
This is another innovation of the system, allowing to obtain forecasting of precipitation in a specific location despite of the difficulty of the amount of information needed to make it, by adapting the optimal size of the sliding window.
The MSE averages of the best systems (higher accuracy) in all cases are represented in
Table 11, high variability data offers more difficulty to obtain high accuracy forecasting (e.g., wind and solar radiation).
Once the test has been conducted, it proceeds to discuss which system is best for predicting each weather parameter and differences between error rates depending on location. In addition, a comparison is also made with results obtained in other works.
Generally speaking, best results are obtained using systems based on SVM with a polynomial kernel most of the time. However, with the other systems are also achieved good results, as observed in the figures and tables below.
Only for comparison purposes, using the same database (AEMET), authors have made a test with a system based on ANNs, better results are also achieved with the system used in this research, as shown in
Table 12. The characteristics of the ANN used in the tests are back-propagation algorithm, 24 neurons on the hidden layer and one neuron on the output layer; more details available in [
16,
26].
Table 13 introduces best results obtained. If temperature is the weather parameter to predict (see
Table 13), the best solution is to use temperature in °C and temperature in tenths of °C as input parameters. As regressive function to obtain a predictive model, the best option is to use SVM with a polynomial function kernel. The reason why worst results are obtained in TF is because the variation between consecutive samples is higher in TF than GC. However, good results are achieved in both cases. In case of predicting wind speed (see
Table 13), using as input parameters the previous values of wind speed in km/h, the best system is SVM with polynomial kernel function. The reason for the different results (better in GC than in TF) is the same as before. When predicting solar radiation parameters (see
Table 13) when using registered data about radiation in tenth of kJ/m
2 as input, the best system can vary by location. In both cases, good results are obtained. For the forecasting of precipitation (see
Table 13), and looking to data presented above, the best results are achieved in TF than in GC. The reason is that it occurs more often in TF, which allows for a better forecasting model.
Table 14 shows a comparison between the results obtained in this research versus previous studies, related to temperature, described in the introduction section [
10,
11,
12,
15,
16]. In all cases, our approach presents an important improvement versus all works.
Regarding the sampling period, samples are collected hourly in [
10], there are no data about sampling frequency in [
11], samples are collected every 10 min from October 2012 to February 2013 in [
12], samples are collected every 30 min in [
15] and the same database of this study and under the same conditions has been used in [
16]. It comes from different geographical locations, from Tunisia in [
10], from China in [
11], from Australia in [
12], from Costa Rica in [
15] and from Canary Islands (Spain) in [
16], thus the climate conditions has a great variation from one location to another. Our work and [
19] presents the same result even with different sampling period. Under the same conditions and with the same database our work improves the results of [
16], proving the goodness of the system. If sampling period could be reduced in stations used for testing this system, the approach can be improved in the future.
In addition, this work can compare two geographical locations where meteorological data varies differently. In Tenerife (28°02′40″ N 16°34′21″ O), data from temperature and wind speed have more variability that in Gran Canaria due to the location of the station in the south zone of the island. In Gran Canaria (27°55′55″ N 15°23′12″ O). The location is in the south east of the island in the border line of the zone under influence of the Trade Winds that causes softest conditions, as a result of this less variation in data leads to better results in temperature. Conversely, results of wind speed offer bigger error in Tenerife, although it is still a good result versus the state-of-the-art. Meteorological parameters like solar radiation does not have high variability in both locations, they offer similar results. This capability to validate the system in two different geographical locations is also an innovation versus previous researches.
4. Conclusions
There are different methods to obtain meteorological predictions with different methods to acquire information about weather.
Some actual problems are associated with meteorological parameters. To solve this situation, it is necessary to have an accurate forecasting about those parameters. The innovation of this research is to obtain different forecasting—one per phenomenon—in different geographical locations just applying the same method.
Final results, shown in
Table 13, reveals that it is obtained better forecasting accuracy than other systems based on other type of classifiers [
10,
11,
12,
15,
16]. For example, in temperature prediction, wind speed and solar radiation, best results are 0.136 °C, 0.56 km/h and 7.45 tenths of kJ/m
2 respectively.
In addition, methodology and results show the adding value of this work. The same proposal has been checked for different climate parameters and to show an approach th at can be used for any meteorological parameter. This is an important goal of this work.
Taking into account all the results obtained, the feasibility to execute the system, and the low cost of materials needed to make the system possible, this is an interesting tool to be used in the energy generation processes by means of renewable sources. Future works will include the study of the fusion of classification systems, testing which system offers best result in the fusion.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}