Autocorrelation Modulation-Based Audio Blind Watermarking Robust Against High Efficiency Advanced Audio Coding


Abstract
:1. Introduction
2. Related Works
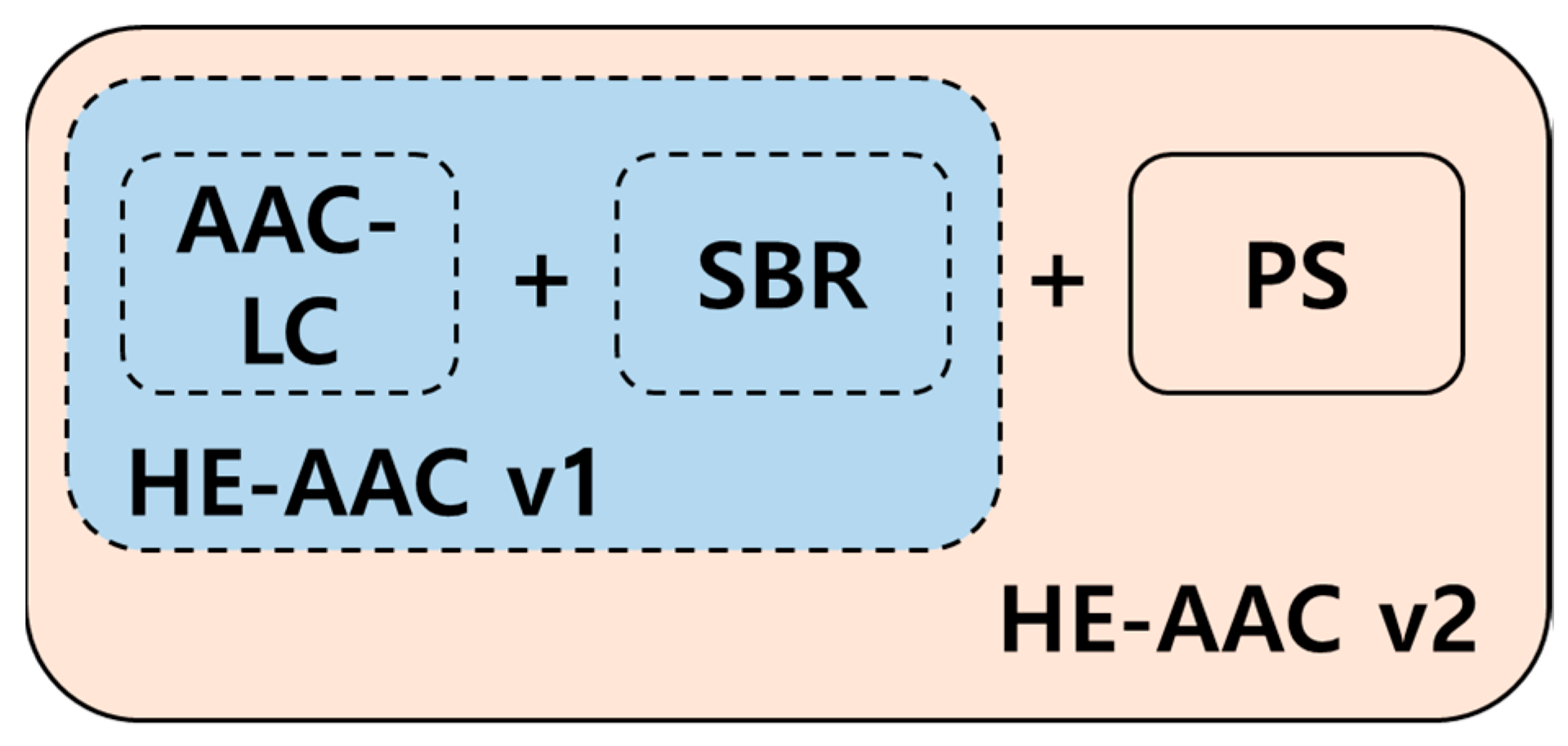
2.1. HE-AAC
2.2. Audio Watermarking Algorithms
3. Proposed Audio Watermarking Method
- The host audio signal is frequency bandpass filtered to outputs the filtered audio signal which is further modulated to be a watermark signal. There are two purposes for the frequency bandpass filtering process. One is to acquire an amount of the host signal, which will reduce disturbance to the audio signal. The other is to avoid embedding watermarks around a high frequency, as the HE-AAC will entirely remove the signals at the range of high frequency on encoding process. The lower and upper cutoff frequencies are denoted as and respectively.
- Then, the filtered audio signal is divided into successive frames, each of which has length and contains two non-overlapping sections of samples. These two sections have equal length, and we call them as the front subframe and the back subframe in this paper.
- One piece of watermark information is represented as one binary bit of value ‘0’ or ‘1,’ which is embedded in one frame.
- The normalized correlation of the original signal and its delayed version (NCOD) was selected as the characteristic of each subframe. The embedding and extracting of watermark bits are decided by the difference of NCOD relations between the front subframe and back subframe. The NCOD item is calculated as follows:where represents the frame index. The integration time (in samples) should be to avoid intersymbol interference. For a frame, the and are the NCOD values of the front subframe and back subframe, respectively. Since the correlation value is normalized,.
- The difference between andis computed to obtain:
3.1. Watermark Embedding Scheme
| Algorithm1. Watermark embedding process |
| 1: 2: 3: 4: if ( and ) or ( and ) 5: return // return without performing any action 6: else 7: 8: end 9: front subframe = front subframe 10: back subframe = back subframe |
3.2. Watermark Extraction Scheme
3.3. Feedback Process
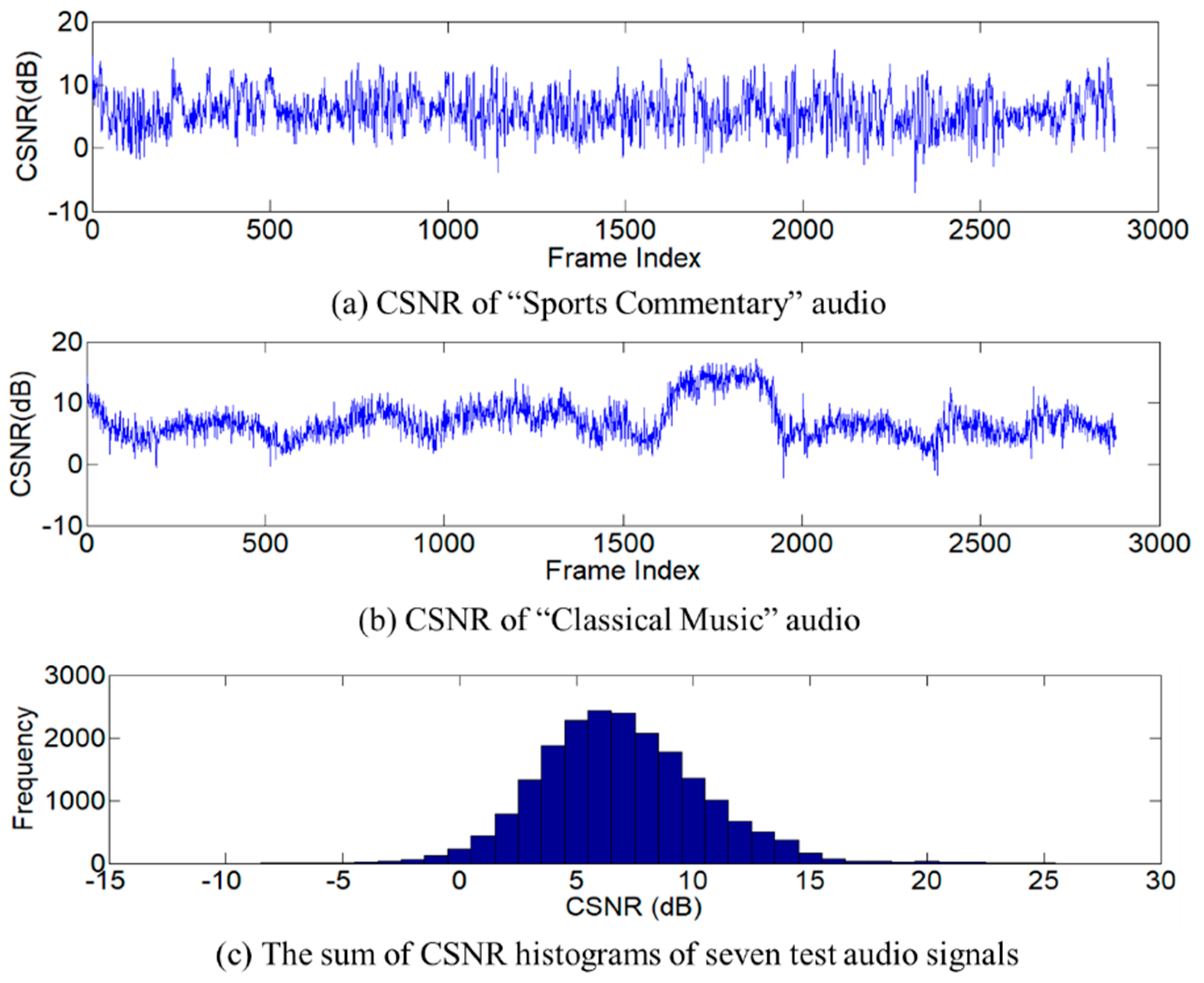
4. Experimental Results
4.1. Experiments on Mono Audio
4.2. Experiments on 5.1 Channel and Stereo Audio
4.3. Synchronization Design
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Herre, J.; Dietz, M. MPEG-4 high-efficiency AAC coding [Standards in a Nutshell]. IEEE Signal. Process. Mag. 2008, 25, 137–142. [Google Scholar] [CrossRef]
- Wolters, M.; Kjorling, K.; Homm, D.; Purnhagen, H. A Closer Look into MPEG-4 High Efficiency AAC; Audio Engineering Society: New York, NY, USA, 2003. [Google Scholar]
- Meltzer, S.; Moser, G. MPEG-4 HE-AAC v2–Audio Coding for Today’s Digital Media World; EBU Technical Review; EBU: Geneva, Switzerland, 2006; pp. 37–48. [Google Scholar]
- Shin, D.; Hong, Y.; Kim, J.; Choi, J. Audio Blind Watermarking Robust Against HE-AAC. In Proceedings of the 8th International Conference on Signal Processing Systems, Auckland, New Zealand, 21–24 November 2016; ACM: New York, NY, USA, 2016; pp. 114–118. [Google Scholar]
- Cox, I.; Miller, M.; Bloom, J.; Fridrich, J.; Kalker, T. Digital Watermarking and Steganography, 2nd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2008; ISBN 978-0-08-055580-5. [Google Scholar]
- Barni, M. What is the future for watermarking? (Part II). IEEE Signal Process. Mag. 2003, 20, 53–59. [Google Scholar] [CrossRef]
- Katzenbeisser, S. Information Hiding Techniques for Steganography and Digital Watermarking, 1st ed.; Katzenbeisser, S., Petitcolas, F.A., Eds.; Artech House, Inc.: Norwood, MA, USA, 2000; ISBN 978-1-58053-035-4. [Google Scholar]
- Cox, I.J.; Kilian, J.; Leighton, F.T.; Shamoon, T. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Xu, S.Z.; Yang, H.Z. Robust audio watermarking based on extended improved spread spectrum with perceptual masking. Int. J. Fuzzy Syst. 2012, 14, 289–295. [Google Scholar]
- Xiang, Y.; Natgunanathan, I.; Rong, Y.; Guo, S. Spread Spectrum-Based High Embedding Capacity Watermarking Method for Audio Signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2228–2237. [Google Scholar] [CrossRef]
- Yang, S.; Tan, W.; Chen, Y.; Ma, W. Quantization—Based Digital Audio Watermarking in Discrete Fourier Transform Domain. J. Multimed. 2010, 5. [Google Scholar] [CrossRef]
- Elshazly, A.R.; Fouad, M.M.; Nasr, M.E. Secure and robust high quality DWT domain audio watermarking algorithm with binary image. In Proceedings of the 2012 Seventh International Conference on Computer Engineering Systems (ICCES), Cairo, Egypt, 27–29 November 2012; pp. 207–212. [Google Scholar]
- Dhar, P.; Shimamura, T. Blind Audio Watermarking in Transform Domain Based on Singular Value Decomposition and Exponential-Log Operations. Radioengineering 2017, 26, 552–561. [Google Scholar] [CrossRef]
- Li, J.; Wang, H.X.; Wu, T.; Sun, X.; Qian, Q. Norm ratio-based audio watermarking scheme in DWT domain. Multimed. Tools Appl. 2018, 77, 14481–14497. [Google Scholar] [CrossRef]
- Bassia, P.; Pitas, I.; Nikolaidis, N. Robust audio watermarking in the time domain. IEEE Trans. Multimed. 2001, 3, 232–241. [Google Scholar] [CrossRef]
- Wen-Nung, L.; Li-Chun, C. Robust and high-quality time-domain audio watermarking based on low-frequency amplitude modification. IEEE Trans. Multimed. 2006, 8, 46–59. [Google Scholar] [CrossRef]
- Megías, D.; Serra-Ruiz, J.; Fallahpour, M. Efficient Self-synchronised Blind Audio Watermarking System Based on Time Domain and FFT Amplitude Modification. Signal Process. 2010, 90, 3078–3092. [Google Scholar] [CrossRef]
- Zeng, G.R.; Qiu, Z.D. Audio watermarking in DCT: Embedding strategy and algorithm. In Proceedings of the 2008 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; pp. 2193–2196. [Google Scholar]
- Chen, S.T.; Huang, H.N.; Chen, C.J.; Wu, G.D. Energy-proportion based scheme for audio watermarking. IET Signal Process. 2010, 4, 576–587. [Google Scholar] [CrossRef]
- Petrovic, R. Audio signal watermarking based on replica modulation. In Proceedings of the 5th International Conference on Telecommunications in Modern Satellite, Cable and Broadcasting Service, TELSIKS 2001–Proceedings of Papers (Cat. No. 01EX517), Nis, Yugoslavia, 19–21 September 2001; Volume 1, pp. 227–234. [Google Scholar]
- Petrovic, R.; Winograd, J.M.; Jemili, K.; Metois, E. Data hiding within audio signals. In Proceedings of the 4th International Conference on Telecommunications in Modern Satellite, Cable and Broadcasting Services. TELSIKS’99 (Cat. No. 99EX365), Nis, Yugoslavia, 15 October 1999; Volume 1, pp. 88–95. [Google Scholar]
- Muhaimin, H.; Danudirdjo, D.; Suksmono, A.B.; Shin, D. An efficient audio watermark by autocorrelation methods. In Proceedings of the 2015 International Conference on Electrical Engineering and Informatics (ICEEI), Denpasar, Indonesia, 10–11 August 2015; pp. 606–611. [Google Scholar]
- Lei, B.Y.; Soon, I.Y.; Li, Z. Blind and robust audio watermarking scheme based on SVD–DCT. Signal Process. 2011, 91, 1973–1984. [Google Scholar] [CrossRef]
- Khalil, M.; Adib, A. Audio watermarking with high embedding capacity based on multiple access techniques. Digit. Signal Process. 2014, 34, 116–125. [Google Scholar] [CrossRef]
- ITU-R BS.1387-1. Method for Objective Measurements of Perceived Audio Quality; ITU: Geneva, Switzerland, 2001. [Google Scholar]
- Kabal, P. An Examination and Interpretation of ITU-R BS.1387: Perceptual Evaluation of Audio Quality, TSP Lab. Technical Report; Department of Electrical and Computer Engineering, McGill University: Montreal, QC, Canada, 2002. [Google Scholar]
- Fdkaac.exe. Available online: https://www.dbpoweramp.com/codec-central-m4a.htm (accessed on 19 May 2019).
- Ffmpeg.exe. Available online: https://ffmpeg.zeranoe.com/builds (accessed on 19 May 2019).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Impairment Description | ODG | Quality |
|---|---|---|
| Imperceptible | 0.0 | Excellent |
| Perceptible, but not annoying | −1.0 | Good |
| Slightly annoying | −2.0 | Fair |
| Annoying | −3.0 | Poor |
| Very annoying | −4.0 | Bad |
| Data Payload (bps) | ODG | BER (%) |
|---|---|---|
| 24 | −0.82 | 0.47 |
| 48 | −0.66 | 0.61 |
| 72 | −0.66 | 0.83 |
| 96 | −0.66 | 1.77 |
| 144 | −0.62 | 4.55 |
| 192 | −0.57 | 8.77 |
| Passband Frequency (kHz) | ODG | BER (%) |
|---|---|---|
| 0.5~3.5 | −1.17 | 2.96 |
| 1.5~4.5 | −0.86 | 1.22 |
| 2.5~5.5 | −0.65 | 1.77 |
| 3.5~6.5 | −0.77 | 5.34 |
| 4.5~7.5 | −0.76 | 15.06 |
| 5.5~8.5 | −0.68 | 45.76 |
| Delay | ODG | BER (%) |
|---|---|---|
| 15 | −0.77 | 2.65 |
| 45 | −0.66 | 1.77 |
| 75 | −0.56 | 2.1 |
| 100 | −0.44 | 3.29 |
| 150 | −0.23 | 7.23 |
| 200 | −0.03 | 21.12 |
| Attenuation Length of the Window | ODG | BER (%) |
|---|---|---|
| 5 | −0.75 | 1.69 |
| 15 | −0.61 | 1.83 |
| 25 | −0.54 | 2.26 |
| 35 | −0.48 | 2.89 |
| Reference | Data Payload (bps) | ODG | MP3 Compression BER (%) | HE-AAC v1 Compression BER (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 32 kbps | 64 kbps | 96 kbps | 128 kbps | 16 kbps | 24 kbps | 32 kbps | 64 kbps | |||
| [23] | 43 | −0.57 | 3.00 | 0.00 | 0.00 | 0.00 | --- | --- | --- | --- |
| [8] | 43 | −0.55 | --- | 0.22 | 0.02 | --- | --- | --- | --- | --- |
| [9] | 84 | −0.70 | --- | --- | 0.33 | 0.00 | --- | --- | --- | --- |
| [12] | 172 | −1.05 | 6.13 | --- | --- | --- | --- | --- | --- | --- |
| [13] | 172 | −0.51 | --- | 2.86 | --- | 0.02 | --- | --- | --- | --- |
| [24] | 4000 | −0.91 | --- | 19 | 15 | --- | --- | --- | --- | --- |
| Ours | 48 | −0.66 | 0.46 | 0.21 | 0.21 | 0.17 | 9.15 | 0.61 | 0.24 | 0.20 |
| 96 | −0.65 | 1.29 | 0.31 | 0.15 | 0.18 | 18.02 | 1.77 | 0.50 | 0.16 | |
| 192 | −0.58 | 6.50 | 2.60 | 1.43 | 1.23 | 30 | 8.77 | 3.56 | 1.50 | |
| No. | Audio Name | Description |
|---|---|---|
| 1 | Bach organ | Church organ; lots of stops out |
| 2 | Brass | Orchestral; lots of brass instruments |
| 3 | Harpsichord | Solo harpsichord; isolated notes |
| 4 | Mouth harp | Mouth organ, bass guitar, percussion |
| 5 | Sax Piano | Saxophone and piano |
| 6 | Trumpet | Orchestral piece |
| 7 | Applause | Applause with distinct clapping sounds |
| 8 | Chants | Small choir; large church; Gregorian chant |
| 9 | Classical | Orchestral piece; open sound |
| 10 | Radio drama | Clarinet, orchestra, male speaker, tenor, ambience |
| 11 | Sedambonjou | Atmospheric performance of Latin-American music |
| 12 | Moonriver | Mouth organ and string orchestra |
| No. | FL | FR | C | LFE | SL | SR | Avg BER | ODG |
|---|---|---|---|---|---|---|---|---|
| 1 | 2.93 | 6.21 | 0.18 | --- | 3.87 | 5.21 | 3.68 | −0.70 |
| 2 | 3.95 | 2.44 | 0.29 | --- | 5.03 | 1.94 | 2.73 | −0.84 |
| 3 | 0.88 | 1.24 | 0.12 | --- | 1.18 | 0.65 | 0.81 | −1.06 |
| 4 | 1.87 | 1.74 | 0.37 | --- | 1.55 | 1.99 | 1.51 | −0.73 |
| 5 | 3.83 | 3.32 | 0.22 | --- | 0.30 | 0.30 | 1.59 | −0.54 |
| 6 | 3.81 | 1.57 | 0.00 | --- | 3.47 | 2.35 | 2.24 | −0.86 |
| 7 | 0.06 | 0.24 | 0.77 | --- | 1.42 | 4.56 | 1.41 | −0.48 |
| 8 | 0.59 | 1.00 | 2.17 | --- | 0.06 | 1.00 | 0.96 | −0.86 |
| 9 | 4.90 | 3.74 | 0.27 | --- | 2.76 | 3.48 | 3.03 | −1.14 |
| 10 | 7.84 | 8.67 | 0.46 | --- | 8.39 | 9.03 | 6.88 | −0.93 |
| 11 | 2.78 | 2.83 | 0.64 | --- | 2.95 | 2.78 | 2.39 | −1.04 |
| 12 | 3.47 | 4.02 | 0.64 | --- | 3.29 | 4.48 | 3.18 | −0.95 |
| Avg | --- | --- | --- | --- | --- | --- | 2.53 | -0.84 |
| No. | Left Channel | Right Channel | Avg BER | ODG |
|---|---|---|---|---|
| 1 | 0.70 | 1.70 | 1.20 | −0.42 |
| 2 | 0.57 | 0.93 | 0.75 | −0.78 |
| 3 | 0.35 | 0.88 | 0.62 | −0.98 |
| 4 | 0.56 | 0.12 | 0.34 | −0.62 |
| 5 | 1.62 | 0.81 | 1.22 | −0.73 |
| 6 | 1.01 | 0.78 | 0.90 | −0.83 |
| 7 | 0.06 | 0.06 | 0.06 | −0.45 |
| 8 | 0.18 | 0.64 | 0.33 | −0.83 |
| 9 | 1.78 | 0.45 | 1.12 | −1.07 |
| 10 | 3.19 | 3.01 | 3.10 | −0.87 |
| 11 | 4.80 | 4.40 | 4.60 | −0.87 |
| 12 | 1.10 | 1.19 | 1.15 | −0.89 |
| Avg | --- | --- | 1.28 | −0.78 |
| 5.1 Channel | Stereo | ||||||
|---|---|---|---|---|---|---|---|
| 64 kbps | 96 kbps | 128 kbps | 160 kbps | 16 kbps | 24 kbps | 32 kbps | 48 kbps |
| 24.04 | 6.67 | 2.53 | 0.54 | 27.9 | 7.87 | 2.30 | 1.29 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, Y.; Kim, J. Autocorrelation Modulation-Based Audio Blind Watermarking Robust Against High Efficiency Advanced Audio Coding. Appl. Sci. 2019, 9, 2780. https://doi.org/10.3390/app9142780
Hong Y, Kim J. Autocorrelation Modulation-Based Audio Blind Watermarking Robust Against High Efficiency Advanced Audio Coding. Applied Sciences. 2019; 9(14):2780. https://doi.org/10.3390/app9142780
Chicago/Turabian StyleHong, Yiyu, and Jongweon Kim. 2019. "Autocorrelation Modulation-Based Audio Blind Watermarking Robust Against High Efficiency Advanced Audio Coding" Applied Sciences 9, no. 14: 2780. https://doi.org/10.3390/app9142780