Channel-Quality Aware RFID Tag Identification Algorithm to Accommodate the Varying Channel Quality of IoT Environment

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- it estimates the channel quality continuously and statistically in the rapidly changing channel quality environment to improve the tag estimation;
- (2)
- it asks the tag for retransmission or to split the collide tags based on the channel quality in order to reduce the number of idle slots;
- (3)
- the number of the groups which it splits tags is based on the estimated number of tags collide in current slot in order to accelerate the tag identification process.
2. Background
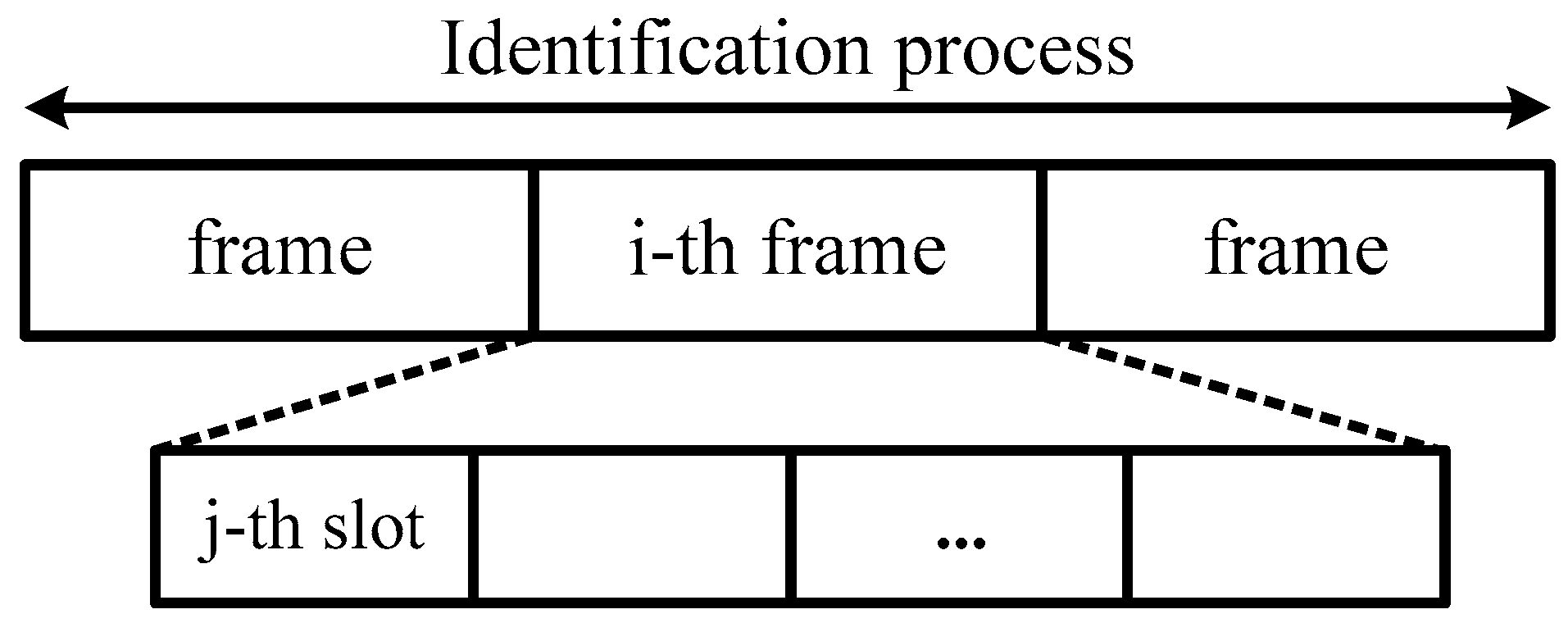
2.1. RFID System Overview
2.2. Error-Prone Channel
2.3. Previous Studies
3. Proposed Channel-Quality Aware Query Tree Algorithm
- (1)
- it estimates PER in each slot including the collision resolution process in order to improve the accuracy of the tag estimation in the rapidly changing channel quality environment;
- (2)
- when a reader receives an unreadable message from tags, it then adopts the most efficient strategy, which is to ask the tag to retransmit it or to split the collide tags, after evaluating the efficiency of regarding this event caused by channel error and that of treating it as a collision event;
- (3)
- the number of the group which it splits is based on the estimated number of tags collide in current slot in order to accelerate the tag identification process.
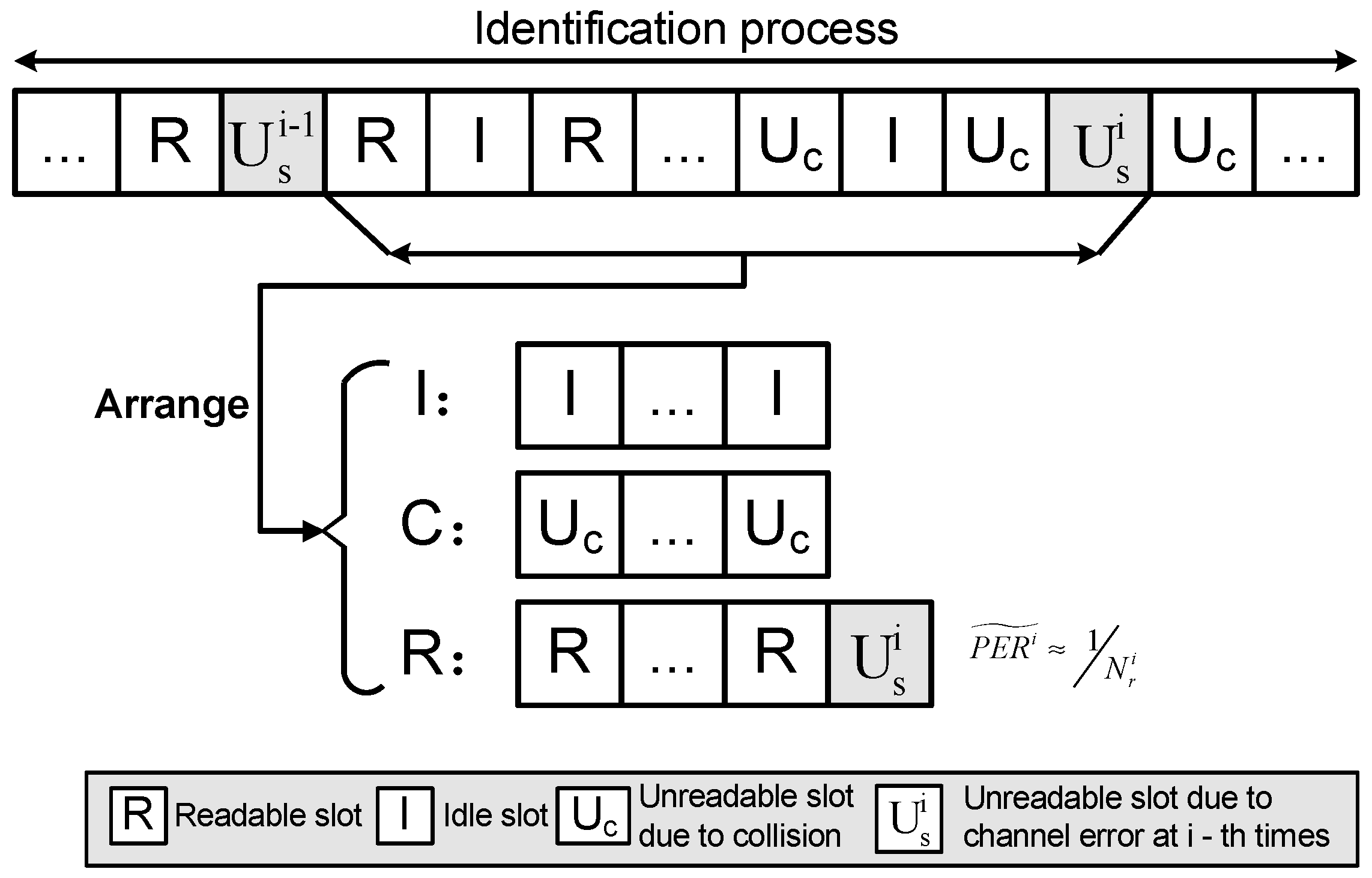
3.1. Channel Error Rate Estimation
3.2. The CAQT Algorithm
4. Simulation Results
- (1)
- it estimated PER in each slot including the collision resolution process in order to improve the accuracy of the tag estimation in the rapidly changing channel quality environment, and
- (2)
- when a reader received an unreadable message from tags, it then statistically determined the most efficient strategy, which was to ask the tag to retransmit it or to split the collide tags.
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- ISO. Information technology—Radio Frequency Identification for Item Management—Part 6: Parameters for Air Interface Communications at 860 MHz to 960 MHz, Amendment 1: Extension with Type C and Update of Types A and B. ISO/IEC 18000-6:2004/Amd. 1:(E); ISO: Geneva, Swtitzerland, 2006. [Google Scholar]
- EPCglobal IncTM. EPCTM Radio-Frequency Identity Protocols Class 1 Generation-2 UHF RFID Protocol for Communications at 860-960MHz Version 1.2.0; EPCglobal Inc.: Brussles, Belgium, 2008. [Google Scholar]
- Azambuja, M.; Marcon, C.A.M.; Hessel, F.P. Survey of standardized ISO 18000-6 RFID anti-collision protocols. In Proceedings of the Second International Conference on Sensor Technologies and Applications, Cap Esterel, France, 25–31 August 2008; pp. 468–473. [Google Scholar]
- Cha, J.R.; Kim, J.H. Dynamic framed slotted ALOHA algorithms using fast tag estimation method for RFID system. In Proceedings of the IEEE Consumer Communications and Networking Conference, Las Vegas, NV, USA, 8–10 January 2006; pp. 768–772. [Google Scholar]
- Vinod, N.; Lixin, G. Energy-aware tag anti-collision protocols for RFID systems. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications, White Plains, NY, USA, 19–23 March 2007; pp. 33–36. [Google Scholar]
- Park, J.; Lee, T.J. Error resilient estimation and adaptive binary selection for fast and reliable identification of RFID tags in error-prone channel. IEEE Trans. Mob. Comput. 2012, 11, 959–969. [Google Scholar] [CrossRef]
- Shakiba, M.; Singh, M.J.; Islam, M.T.; Sundararajan, E. Applying cubic spline method to estimate the number of RFID tags in error-prone communication channels. Wirel. Pers. Commun. 2015, 83, 361–382. [Google Scholar] [CrossRef]
- Zhang, L.; Gandino, F.; Ferrero, R.; Rebaudengo, M. Evaluation of the additive interference model for RFID reader collision problem. In Proceedings of the 2012 Fourth International EURASIP Workshop on RFID Technology, Torino, Italy, 27–28 September 2012. [Google Scholar]
- Zhang, L.; Ferrero, R.; Gandino, F.; Rebaudengo, M. Evaluation of single and additive interference models for RFID collisions. Math. Comput. Model. 2013, 58, 1236–1248. [Google Scholar] [CrossRef]
- Vogt, H. Efficient object identification with passive RFID tags. In Proceedings of the First International Conference on Pervasive Computing, Zürich, Switzerland, 26–28 August 2002; LNCS 2414. pp. 98–113. [Google Scholar]
- Lei, Z.; Yum, T.S.P. The optimal reading strategy for EPC Gen-2 RFID anti-collision systems. IEEE Trans. Commun. 2010, 58, 2725–2733. [Google Scholar]
- Maguire, Y.; Pappu, R. An optimal Q-Algorithm for the ISO 18000-6C RFID protocol. IEEE Trans. Autom. Sci. Eng. 2009, 6, 16–24. [Google Scholar] [CrossRef]
- Lei, Z.; Yum, T.S.P. Optimal framed aloha based anti-collision algorithms for RFID systems. IEEE Trans. Commun. 2010, 58, 3583–3592. [Google Scholar]
- Eom, J.B.; Lee, T.J.; Rietman, R.; Yener, A. An efficient framed-slotted aloha algorithm with pilot frame and binary selection for anti-collision of RFID tags. IEEE Commun. Lett. 2008, 12, 861–863. [Google Scholar] [CrossRef]
- Chen, W.T. An accurate tag estimate method for improving the performance of an RFID anti-collision algorithm based on dynamic frame length ALOHA. IEEE Trans. Autom. Sci. Eng. 2009, 6, 9–15. [Google Scholar] [CrossRef]
- Li, B.; Wang, J. Efficient anti-collision algorithm utilizing the capture effect for ISO 18000-6C RFID protocol. IEEE Commun. Lett. 2011, 15, 352–354. [Google Scholar] [CrossRef]
- Park, J.; Chung, M.Y.; Lee, T.J. Identification of RFID tags in Framed-Slotted Aloha with robust estimation and binary selection. IEEE Commun. Lett. 2007, 11, 452–454. [Google Scholar] [CrossRef]
- Lin, C.F.; Lin, F.Y.S. Efficient estimation and collision-group-based anti-collision algorithms for dynamic frame-slotted aloha in RFID networks. IEEE Trans. Autom. Sci. Eng. 2010, 7, 840–848. [Google Scholar] [CrossRef]
- Yeh, M.K.; Jiang, J.R.; Huang, S.T. Parallel response query tree splitting for RFID tag anti-collision. In Proceedings of the 40th International Conference on Parallel Processing Workshops, Taipei City, Taiwan, 13–16 September 2011; pp. 6–15. [Google Scholar]
- Myung, J.; Lee, W.; Shih, T.K. An adaptive memoryless protocol for RFID tag collision arbitration. IEEE Trans. Multimed. 2006, 8, 1096–1101. [Google Scholar] [CrossRef]
- Choi, J.H.; Lee, D.; Lee, H. Query tree-based reservation for efficient RFID tag anti-collision. IEEE Commun. Lett. 2007, 11, 85–87. [Google Scholar] [CrossRef]
- Gou, H.; Jeong, H.C.; Yoo, Y. A bit collision detection based query tree protocol for anti-collision in RFID system. In Proceedings of the 6th IEEE International Conference on Wireless and Mobile Computing, Networking and Communications, Niagara Falls, ON, Canada, 11–12 October 2010; pp. 421–428. [Google Scholar]
- Zein-Elabdeen, W.; Shaaban, E. An enhanced binary tree anti-collision technique for dynamically added tags in RFID systems. In Proceedings of the 2nd International Conference on Computer Engineering and Technology, Chengdu, China, 16–18 April 2010; pp. 349–353. [Google Scholar]
- Lai, Y.C.; Lin, C.C. Two blocking algorithms on adaptive binary splitting: Single and pair resolutions for RFID tag identification. IEEE/ACM Trans. Netw. 2009, 17, 962–975. [Google Scholar]
- Lai, Y.C.; Lin, C.C. Two couple-resolution blocking protocols on adaptive query splitting for RFID tag identification. IEEE Trans. Mob. Comp. 2011, 11, 1450–1463. [Google Scholar] [CrossRef]
- Namboodiri, V.; Gao, L. Energy-aware tag anticollision protocols for RFID systems. IEEE Trans. Mob. Comput. 2010, 9, 44–59. [Google Scholar] [CrossRef]
- Lai, Y.C.; Hsiao, L.Y. General binary tree protocol for coping with the capture effect in RFID tag identification. IEEE Commun. Lett. 2010, 14, 208–210. [Google Scholar] [CrossRef]
- Yang, C.N.; He, J.Y. An effective 16-bit random number aided query tree algorithm for RFID tag anti-collision. IEEE Commun. Lett. 2011, 15, 539–541. [Google Scholar] [CrossRef]
- Annur, R.; Jig, T.L.; Nakpeerayuth, S.; Wuttitsittikulkij, L. Tree-based anti-collision algorithm with single error bit tracking for RFID systems. In Proceedings of the 2017 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2017; pp. 25–28. [Google Scholar]
- Hou, Y.; Zheng, Y. PHY-tree: Physical layer tree-based RFID identification. IEEE/ACM Trans. Netw. 2018, 26, 711–723. [Google Scholar] [CrossRef]
- Sasiwat, Y. Bi-slotted fast query tree-based anti-collision algorithm for large scale of RFID systems. In Proceedings of the 10th International Conference on Knowledge and Smart Technology (KST), Chiang Mai, Thailand, 31 January–3 February 2018; pp. 221–224. [Google Scholar]
- Shiha, D.H.; Suna, P.L.; Yenb, D.C.; Huangc, S.M. Taxonomy and survey of RFID anti-collision protocols. Comput. Commun. 2006, 29, 2150–2166. [Google Scholar] [CrossRef]
- Yeh, M.K.; Jiang, J.R. Adaptive k-way splitting and pre-signaling for RFID tag anti-collision. In Proceedings of the 33rd Annual Conference of the IEEE Industrial Electronics Society, Taipei, Taiwan, 5–8 November 2007; pp. 40–45. [Google Scholar]
- Yeh, M.K.; Jiang, J.R.; Huang, S.T. Adaptive splitting and pre-signaling for RFID tag anti-collision. Comput. Commun. 2009, 32, 862–1870. [Google Scholar] [CrossRef]
- Su, X.H.; Liu, B.L. An investigation on tree-based tags anti-collision algorithms in RFID. In Proceedings of the International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–25 September 2017; pp. 5–11. [Google Scholar]
- Chen, W.-T. A Fast Anticollision algorithm with early adjustment of frame length for the EPCglobal UHF Class-1 Generation-2 RFID Standard. Proc. Eng. Technol. Innov. 2016, 3, 16–18. Available online: http://ojs.imeti.org/index.php/PETI/article/view/234 (accessed on 18 December 2018).










© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-H.; Hung, R.-Z.; Chen, L.-K.; Jan, P.-T.; Su, Y.-R. Channel-Quality Aware RFID Tag Identification Algorithm to Accommodate the Varying Channel Quality of IoT Environment. Appl. Sci. 2019, 9, 321. https://doi.org/10.3390/app9020321
Chen Y-H, Hung R-Z, Chen L-K, Jan P-T, Su Y-R. Channel-Quality Aware RFID Tag Identification Algorithm to Accommodate the Varying Channel Quality of IoT Environment. Applied Sciences. 2019; 9(2):321. https://doi.org/10.3390/app9020321
Chicago/Turabian StyleChen, Yen-Hung, Rui-Ze Hung, Lin-Kung Chen, Pi-Tzong Jan, and Yin-Rung Su. 2019. "Channel-Quality Aware RFID Tag Identification Algorithm to Accommodate the Varying Channel Quality of IoT Environment" Applied Sciences 9, no. 2: 321. https://doi.org/10.3390/app9020321
APA StyleChen, Y. -H., Hung, R. -Z., Chen, L. -K., Jan, P. -T., & Su, Y. -R. (2019). Channel-Quality Aware RFID Tag Identification Algorithm to Accommodate the Varying Channel Quality of IoT Environment. Applied Sciences, 9(2), 321. https://doi.org/10.3390/app9020321