How to Extract Meaningful Insights from UGC: A Knowledge-Based Method Applied to Education




Abstract
1. Introduction
2. Methodology and Research Questions
2.1. Research Questions
2.2. Data Sampling Extraction and Collection
2.3. Knowledge-Based Method to Extract Insights from UGC
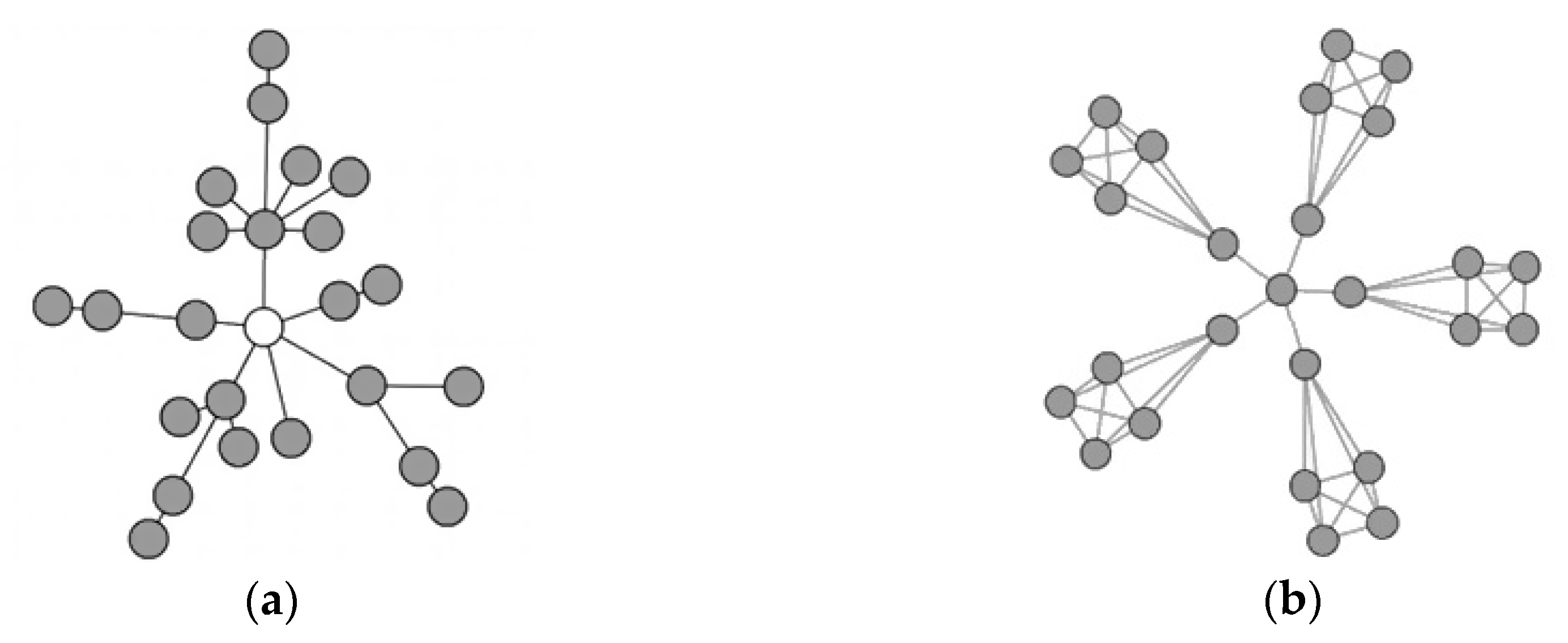
2.4. Data Visualization Algorithms
3. Results
3.1. Knowledge-Based Method Results
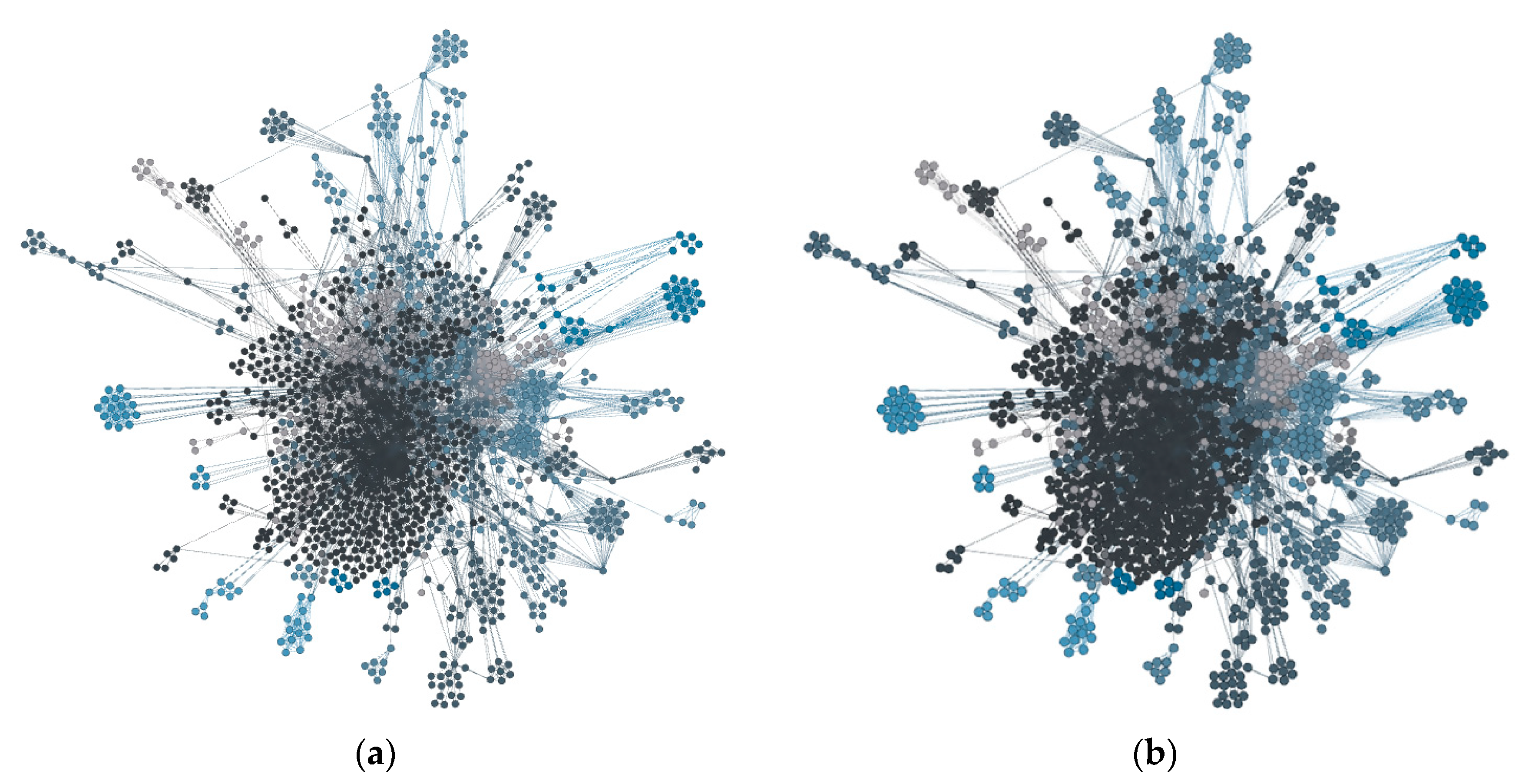
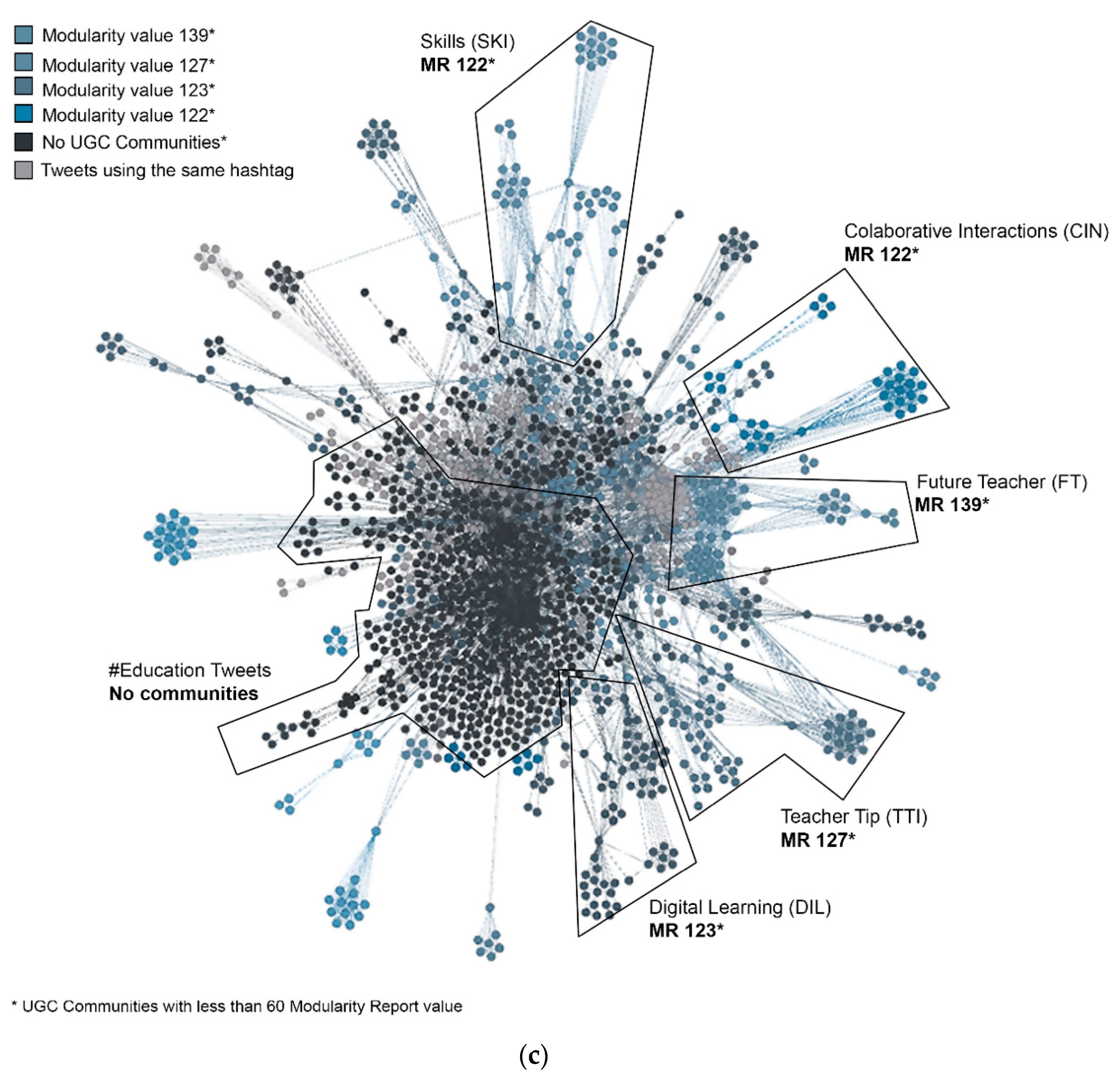
3.2. Data Visualization MR
4. Discussion
5. Conclusions
5.1. Theoretical Implications
5.2. Practical Implications
5.3. Limitations and Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Reyes-Menendez, A.; Saura, J.R.; Martinez-Navalon, J.G. The impact of e-WOM on Hotels Management Reputation: Exploring TripAdvisor Review Credibility with the ELM model. IEEE Access 2019, 8. [Google Scholar] [CrossRef]
- Saura, J.R.; Bennett, D.R. A Three-Stage method for Data Text Mining: Using UGC in Business Intelligence Analysis. Symmetry 2019, 11, 519. [Google Scholar] [CrossRef]
- Matta, J.; Obafemi-Ajayi, T.; Borwey, J.; Sinha, K.; Wunsch, D.; Ercal, G. Node-Based Resilience Measure Clustering with Applications to Noisy and Overlapping Communities in Complex Networks. Appl. Sci. 2018, 8, 1307. [Google Scholar] [CrossRef]
- Wiemer, H.; Drowatzky, L.; Ihlenfeldt, S. Data Mining Methodology for Engineering Applications (DMME)—A Holistic Extension to the CRISP-DM Model. Appl. Sci. 2019, 9, 2407. [Google Scholar] [CrossRef]
- Van den Broek-Altenburg, E.M.; Atherly, A.J. Using Social Media to Identify Consumers’ Sentiments towards Attributes of Health Insurance during Enrollment Season. Appl. Sci. 2019, 9, 2035. [Google Scholar] [CrossRef]
- Herráez, B.; Bustamante, D.; Saura, J.R. Information classification on social networks. Content analysis of e-commerce companies on Twitter. Rev. Espac. 2017, 38, 16. [Google Scholar]
- Saura, J.R.; Rodriguez Herráez, B.; Reyes-Menendez, A. Comparing a traditional approach for financial Brand Communication Analysis with a Big Data Analytics technique. IEEE Access 2019, 7. [Google Scholar] [CrossRef]
- Barbu, M.; Vilanova, R.; Vicario, J.; Pereira, M.J.; Alves, P.; Podpora, M.; Fontana, L. Data mining tool for academic data exploitation: Publication report on engineering students profiles. ESTiG-Relatórios Técnicos/Científicos 2019. [Google Scholar]
- Siemens, G.; Baker, R.S.J. DLearning analytics and educational data mining: Towards communication and collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2019; pp. 252–254. [Google Scholar]
- Wang, Y.; Youn, H.Y. Feature Weighting Based on Inter-Category and Intra-Category Strength for Twitter Sentiment Analysis. Appl. Sci. 2019, 9, 92. [Google Scholar] [CrossRef]
- Reyes-Menendez, A.; Saura, J.R.; Alvarez-Alonso, C. Understanding# World Environment Day User Opinions in Twitter: A Topic-Based Sentiment Analysis Approach. Int. J. Environ. Res. Public Health. 2018, 15, 2537. [Google Scholar] [CrossRef]
- Reyes-Menendez, A.; Saura, J.R.; Palos-Sanchez Alvarez, J.M. Understanding User Behavioral Intention to adopt a Search Engine that promotes Sustainable Water Management. Symmetry 2018, 10, 584. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Glaser, R. Education and thinking: The role of knowledge. Am. Psychol. 1984, 39, 93. [Google Scholar] [CrossRef]
- George, E.S. Positioning higher education for the knowledge based economy. High. Educ. 2006, 52, 589–610. [Google Scholar] [CrossRef]
- Bennett, D.; Yábar, D.P.B.; Saura, J.R. University Incubators May Be Socially Valuable, but How Effective Are They? A Case Study on Business Incubators at Universities. In Entrepreneurial Universities. Innovation, Technology, and Knowledge Management; Peris-Ortiz, M., Gómez, J., Merigó-Lindahl, J., Rueda-Armengot, C., Eds.; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Shelton, M.W.; Lane, D.R.; Waldhart, E.S. A review and assessment of national educational trends in communication instruction. Commun. Educ. 1999, 48, 228–237. [Google Scholar] [CrossRef]
- Reyes, J.A. The skinny on big data in education: Learning analytics simplified. TechTrends 2015, 59, 75–80. [Google Scholar] [CrossRef]
- Anshari, M.; Alas, Y.; Sabtu, N.P.H.; Hamid, M.S.A. Online Learning: Trends, issues and challenges in the Big Data Era. J. e-Learn. Knowl. Soc. 2016, 12. [Google Scholar]
- Huda, M.; Maseleno, A.; Atmotiyoso, P.; Siregar, M.; Ahmad, R.; Jasmi, K.; Muhamad, N. Big data emerging technology: Insights into innovative environment for online learning resources. Int. J. Emerg. Technol. Learn. 2018, 13, 23–36. [Google Scholar] [CrossRef]
- Sin, K.; Muthu, L. Application of Big Data in Education Data Mining and Learning Analytics—A Literature Review. ICTACT J. Soft Comput. 2015, 5. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd annual meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Kogan, M. Higher education communities and academic identity. High. Educ. Q. 2000, 54, 207–216. [Google Scholar] [CrossRef]
- Jongbloed, B.; Enders, J.; Salerno, C. Higher education and its communities: Interconnections, interdependencies and a research agenda. High. Educ. 2008, 56, 303–324. [Google Scholar] [CrossRef]
- La Velle, L.; Kendall, A. Building Research-Informed Teacher Education Communities: A UCET Framework. Profession 2019, 18, 19. [Google Scholar]
- Reyes-Menendez, A.; Saura, J.R.; Filipe, F. The importance of behavioral data to identify online fake reviews for tourism businesses: A systematic review. PeerJ Comput. Sci. 2019, 5, e219. [Google Scholar] [CrossRef]
- Baker, R.S.J.D. Data mining for education. Int. Encycl. Educ. 2010, 7, 112–118. [Google Scholar]
- Alban, M.; Mauricio, D. Predicting University Dropout through Data Mining: A Systematic Literature. Indian J. Sci. Technol. 2019, 12, 4. [Google Scholar] [CrossRef]
- Williamson, B.; Piattoeva, N. Objectivity as standardization in data-scientific education policy, technology and governance. Learn. Media Technol. 2019, 44, 64–76. [Google Scholar] [CrossRef]
- Zou, X.; Zou, S.; Wang, X. New Approach of Big Data and Education: Any Term Must Be in the Characters Chessboard as a Super Matrix. In Proceedings of the 2019 International Conference on Big Data and Education, Bangkok, Thailand, 14–16 September 2019; pp. 129–134. [Google Scholar]
- Daniel, B.K. Big Data and data science: A critical review of issues for educational research. Br. J. Educ. Technol. 2019, 50, 101–113. [Google Scholar] [CrossRef]
- Krippendorff, K. Bivariate Agreement Coefficients for Reliability Data. Sociol. Methodol. 1970, 2, 139–150. [Google Scholar] [CrossRef]
- Krippendorff, K. Measuring the reliability of qualitative text analysis data. Qual. Quant. 2004, 38, 787–800. [Google Scholar] [CrossRef]
- Saura, J.R.; Reyes-Menendez, A.; Alvarez-Alonso, C. Do online comments affect environmental management? Identifying factors related to environmental management and sustainability of hotels. Sustainability 2018, 10, 3016. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, 2008. [Google Scholar] [CrossRef]
- Lambiotte, R.; Delvenne, J.C.; Barahona, M. Random walks, Markov processes and the multiscale modular organization of complex networks. IEEE Trans. Netw. Sci. Eng. 2014, 1, 76–90. [Google Scholar] [CrossRef]
- Saura, J.R.; Reyes-Menendez, A.; Palos-Sanchez, P. Are Black Friday Deals Worth It? Mining Twitter Users’ Sentiment and Behavior Response. J. Open Innov. 2019, 5, 58. [Google Scholar]
- Sherman, K.J.; Cherkin, D.C.; Erro, J.; Miglioretti, D.L.; Deyo, R.A. Comparing yoga, exercise, and a self-care book for chronic low back pain: A randomized, controlled trial. Ann. Intern. Med. 2005, 143, 849–856. [Google Scholar] [CrossRef] [PubMed]
- Banerjee, S.; Chua, A.Y.; Kim, J. Using supervised learning to classify authentic and fake online reviews. In Proceedings of the 9th International Conference on Ubiquitous Information Management and Communication—IMCOM, Bali, Indonesia, 8–10 January 2015. [Google Scholar]
- Saura, J.R.; Palos-Sanchez, P.R.; Grilo, A. Detecting Indicators for Startup Business Success: Sentiment Analysis using Text Data Mining. Sustainability 2019, 15, 553. [Google Scholar] [CrossRef]
- Bifet, A.; Frank, E. Sentiment knowledge discovery in twitter streaming data. In Proceedings of the International Conference on Discovery Science, Canberra, Australia, 6–8 October 2010. [Google Scholar]
- Lai, L.S.; To, W.M. Content analysis of social media: A grounded theory approach. J. Electron. Commer. Res. 2015, 16, 138. [Google Scholar]
- Pritchard, J.K.; Stephens, M.; Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 2000, 155, 945–959. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I.; Lafferty, J. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Jia, S. Leisure Motivation and Satisfaction: A Text Mining of Yoga Centres, Yoga Consumers, and Their Interactions. Sustainability 2018, 10, 4458. [Google Scholar] [CrossRef]
- Saif, H.; Fernandez, M.; He, Y.; Alani, H. Evaluation datasets for Twitter sentiment analysis: A survey and a new dataset, the STS-Gold. In Proceedings of the 1st Interantional Workshop on Emotion and Sentiment in Social and Expressive Media: Approaches and Perspectives from AI (ESSEM 2013), Turin, Italy, 3 December 2013. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends® Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Saura, J.R.; Reyes-Menendez, A.; Filipe, F. Comparing Data-Driven Methods for Extracting Knowledge from User Generated Content. J. Open Innov. Technol. Mark. Complex. 2019, 5, 74. [Google Scholar] [CrossRef]
- Krippendorff, K. (Ed.) Reliability Chapter 11. In Content Analysis; An Introduction to its Methodology, 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2004; pp. 211–256. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology, 3rd ed.; Sage: Thousand Oaks, CA, USA, 2013; pp. 221–250. [Google Scholar]
- Gil, M.; El Sherif, R.; Pluye, M.; Fung, B.C.; Grad, R.; Pluye, P. Towards a Knowledge-Based Recommender System for Linking Electronic Patient Records with Continuing Medical Education Information at the Point of Care. IEEE Access 2019, 7, 15955–15966. [Google Scholar] [CrossRef]
- Al-Rahmi, W.M.; Yahaya, N.; Aldraiweesh, A.A.; Alturki, U.; Alamri, M.M.; Saud, M.S.B.; Alhamed, O.A. Big Data Adoption and Knowledge Management Sharing: An Empirical Investigation on Their Adoption and Sustainability as a Purpose of Education. IEEE Access 2019, 7, 47245–47258. [Google Scholar] [CrossRef]
- Fernandes, E.; Holanda, M.; Victorino, M.; Borges, V.; Carvalho, R.; Van Erven, G. Educational data mining: Predictive analysis of academic performance of public school students in the capital of Brazil. J. Bus. Res. 2019, 94, 335–343. [Google Scholar] [CrossRef]
- West, D.M. Big data for education: Data mining, data analytics, and web dashboards. Gov. Stud. Brook. 2012, 4. [Google Scholar]
- Jabreel, M.; Moreno, A. A Deep Learning-Based Approach for Multi-Label Emotion Classification in Tweets. Appl. Sci. 2019, 9, 1123. [Google Scholar] [CrossRef]
- Saura, J.R.; Palos-Sanchez, P.; Blanco-González, A. The importance of information service offerings of collaborative CRMs on decision-making in B2B marketing. J. Bus. Ind. Mark. 2019. ahead-of-print(ahead-of-print). [Google Scholar] [CrossRef]
- Vassileva, J. Toward social learning environments. IEEE Trans. Learn. Technol. 2008, 1, 199–214. [Google Scholar] [CrossRef]
- Novak, J.; Wurst, M. Collaborative knowledge visualization for cross-community learning. In Knowledge and Information Visualization; Springer: Berlin/Heidelberg, Germany, 2005; pp. 95–116. [Google Scholar]
- Chen, B.J.; Ting, I.H. Applying social networks analysis methods to discover key users in an interest-oriented virtual community. In 7th International Conference on Knowledge Management in Organizations: Service and Cloud Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 333–344. [Google Scholar]
- Tsvetovat, M.; Kouznetsov, A. Social Network Analysis for Startups: Finding Connections on the Social Web; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2011. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Lisboa, Portugal, 17 September 2005. [Google Scholar]
- Mazzoni, E. Social Network Analysis to support interactions in virtual communities for the construction of knowledge. Ital. J. Educ. Technol. 2005, 13, 54. [Google Scholar]
- Liu, B. Sentiment Analysis and Subjectivity. Handb. Nat. Lang. Process. 2010, 2, 627–666. [Google Scholar]
- Liu, B.; Zhang, L. A survey of opinion mining and sentiment analysis. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 415–463. [Google Scholar]
- McLoughlin, C.; Lee, M. Mapping the digital terrain: New media and social software as catalysts for pedagogical change. Ascilite Melb. 2008, 12, 641–652. [Google Scholar]
- Quercia, D.; Ellis, J.; Capra, L.; Crowcroft, J. Tracking gross community happiness from tweets. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work, Washington, DC, USA, 11–15 February 2012. [Google Scholar]
- Sluban, B.; Smailović, J.; Battiston, S.; Mozetič, I. Sentiment leaning of influential communities in social networks. Comput. Soc. Netw. 2015, 2, 9. [Google Scholar] [CrossRef]
- Brush, T.; Glazewski, K.D.; Hew, K.F. Development of an instrument to measure preservice teachers’ technology skills, technology beliefs, and technology barriers. Comput. Sch. 2008, 25, 112–125. [Google Scholar] [CrossRef]
- Bonk, C.J. The World is Open: How Web Technology is Revolutionizing Education; Association for the Advancement of Computing in Education (AACE): Morgantown, WV, USA, 2009; pp. 3371–3380. [Google Scholar]
- Goh, K.Y.; Heng, C.S.; Lin, Z. Social media brand community and consumer behavior: Quantifying the relative impact of user-and marketer-generated content. Inf. Syst. Res. 2013, 24, 88–107. [Google Scholar] [CrossRef]
- Yannopoulou, N.; Moufahim, M.; Bian, X. User-generated brands and social media: Couchsurfing and AirBnb. Contemp. Manag. Res. 2013, 9. [Google Scholar] [CrossRef]
- Christensen, C.M.; Eyring, H.J. The Innovative University: Changing the DNA of Higher Education from the Inside Out; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Pereira, E.T.; Villas-Boas, M.; Rebelo, C.C. Does Entrepreneurship and Innovative Education Matter to Increase Employability Skills?: A Framework Based on the Evidence From Five European Countries. In Global Considerations in Entrepreneurship Education and Training; IGI Global: Hershey, PA, USA, 2019; pp. 218–231. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Nº | Name | Description | Sentiment |
|---|---|---|---|
| 1 | Innovative teaching (IT) | Learning models based on new teaching innovation processes. | Positive |
| 2 | Tutorials and tips for teaching (TTE) | Tutorials and tips for new tools for teaching. | Neutral |
| 3 | Digital teaching and learning (DLE) | New platforms related to education in digital environments. | Positive |
| 4 | Innovative teaching skills (ITS) | Skills related to new information technologies for teaching and tutoring. | Negative |
| 5 | Digital interaction and engagement (DIE) | Thematic linked to engagement and the reciprocal connection of communication through digital environments in the field of education. | Positive |
| Conclusion Reliability | Krippendorff’s Alpha Value | This Research Study | Average KAV |
|---|---|---|---|
| High | α ≥ 0.800 | Positive Sentiment | 0.876 |
| Tentative | α ≥ 0.667 | Negative Sentiment | 0.882 |
| Low | α < 0.667 | Neutral Sentiment | 0.641 |
| Nº | Topic | Insight | Count | WP |
|---|---|---|---|---|
| 1 | IT | Innovative learning processes increase positive results in teaching. | 273 | 0.302 |
| 2 | TTE | Tutorials and tips on new teaching tools are a useful internet resource for teachers | 213 | 0.291 |
| 3 | DLE | The platforms for online education are an efficient resource for teachers. | 209 | 0.283 |
| 4 | ITS | There is a gap in the digital skills of teachers regarding the use of digital tools for teaching. | 179 | 0.209 |
| 5 | DIE | The communication between teachers on social networks is enriching and attracts new ideas and teaching tools. | 141 | 0.199 |
| Test | Communities | Modularity | MR * | Resolution | MMC * | MiMC * |
|---|---|---|---|---|---|---|
| 1 | 42 | 0.213 | 0.175 | 1.0 | 140 | 0 |
| 3 | 153 | 0.098 | −0.012 | 0.1 | 136 | 0 |
| 3 | 978 | 0.007 | −0.011 | 0.001 | 124 | 0 |
| Data Visualization Filters | Value |
|---|---|
| Threads number | 1 |
| Tolerance | 1.0 |
| Approximation | 0.1 |
| Scaling | 0.2 |
| Gravity | 1.0 |
| Prevent Overlap | True |
| Edge Weight Influence | 4.0 |
| Nº | Community | Modularity |
|---|---|---|
| 1 | GradStudent | 140 |
| 2 | Future Teacher (FT) | 139 * |
| 3 | School Reform | 139 |
| 4 | Wanna Be Teacher | 139 |
| 5 | Scholarships | 135 |
| 6 | Special Education | 131 |
| 7 | Teacher Tip (TTI) | 127 * |
| 8 | Teacher Hack | 125 |
| 9 | Education Spaces | 125 |
| 10 | Collaborative Interactions (CIN) | 122 * |
| 11 | Digital Learning (DIL) | 123 * |
| 12 | Education Reform | 123 |
| 13 | Skills (SKI) | 122 * |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saura, J.R.; Reyes-Menendez, A.; Bennett, D.R. How to Extract Meaningful Insights from UGC: A Knowledge-Based Method Applied to Education. Appl. Sci. 2019, 9, 4603. https://doi.org/10.3390/app9214603
Saura JR, Reyes-Menendez A, Bennett DR. How to Extract Meaningful Insights from UGC: A Knowledge-Based Method Applied to Education. Applied Sciences. 2019; 9(21):4603. https://doi.org/10.3390/app9214603
Chicago/Turabian StyleSaura, Jose Ramon, Ana Reyes-Menendez, and Dag R. Bennett. 2019. "How to Extract Meaningful Insights from UGC: A Knowledge-Based Method Applied to Education" Applied Sciences 9, no. 21: 4603. https://doi.org/10.3390/app9214603
APA StyleSaura, J. R., Reyes-Menendez, A., & Bennett, D. R. (2019). How to Extract Meaningful Insights from UGC: A Knowledge-Based Method Applied to Education. Applied Sciences, 9(21), 4603. https://doi.org/10.3390/app9214603