Coal Seam Thickness Prediction Based on Transition Probability of Structural Elements


Abstract
:1. Introduction
2. RBF-Kriging for Borehole Data Interpolation
2.1. Ordinary Kriging
2.2. Efficient Samples
2.3. Variation Function Determination Using RBF
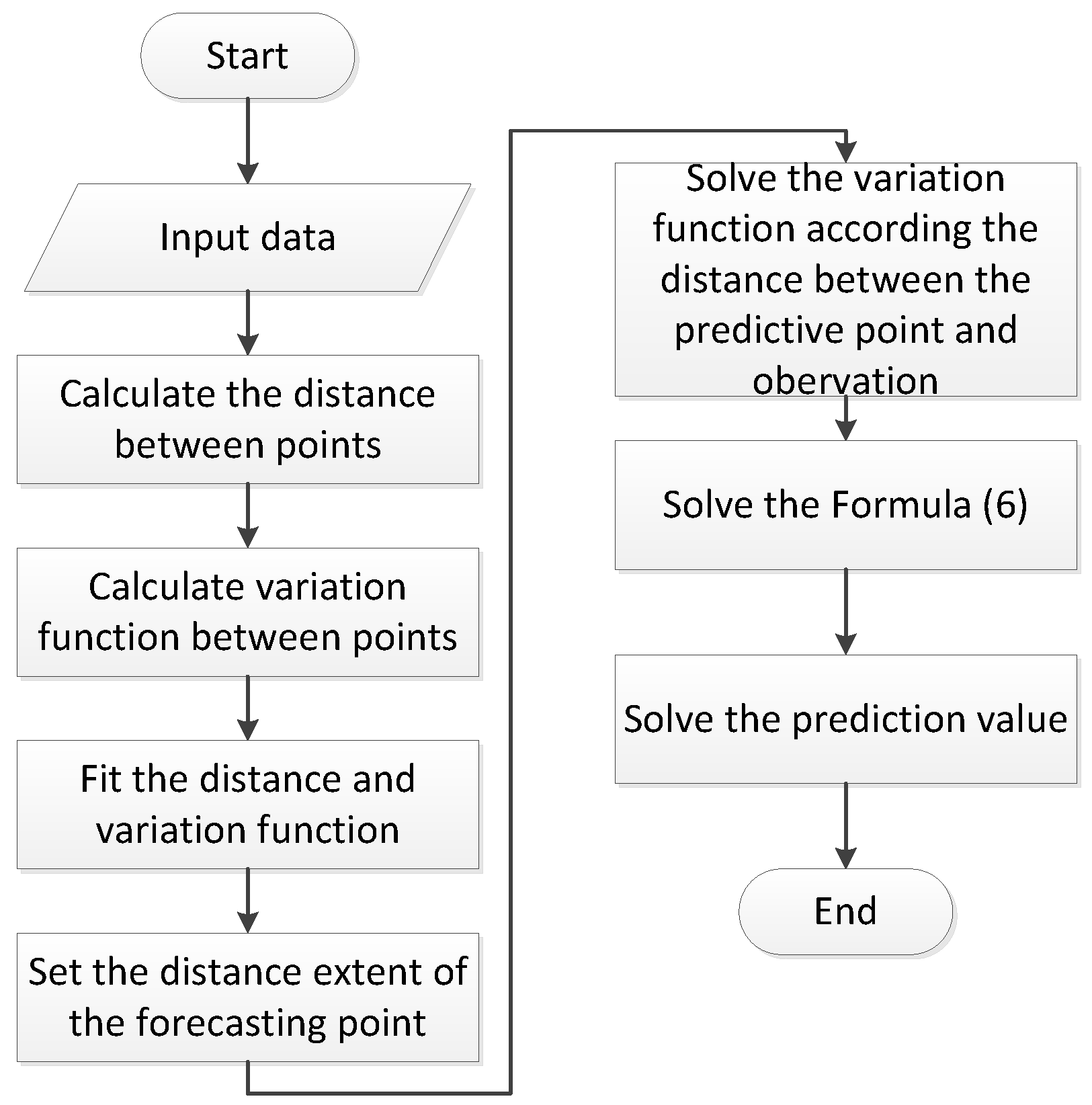
2.4. Implementation of RBF-Kriging
- Step 1: For coal seam data , calculate the distance of from point and point ,where l and w is plane coordinates of the location x
- Step 2: Calculate the variation function values between point pairs as,and one-to-one correspondence with distance, where, and is the number of experimental variation function corresponding to the lag distance d, is the coal seam thickness at the point that its plane coordinates is ;
- Step 3: Using RBF function to fit distance and variation function values and using the following functionwhere is the weight coefficient, is basis function and p is the number of basis function;
- Step 4: Calculate the variance σ of the distance between points and select the efficient data points with around the interpolation point .
- Step 5: According to the distance between the selected data point and the interpolation point, calculate the variation function values through ;
- Step 6: Calculate the interpolation weight vector λ using Equation (6); and,
- Step 7: Calculate interpolation values aswhere indicates the coal seam thickness at the interpolation point.
3. TTP-GPR for Coal Seam Thickness Prediction
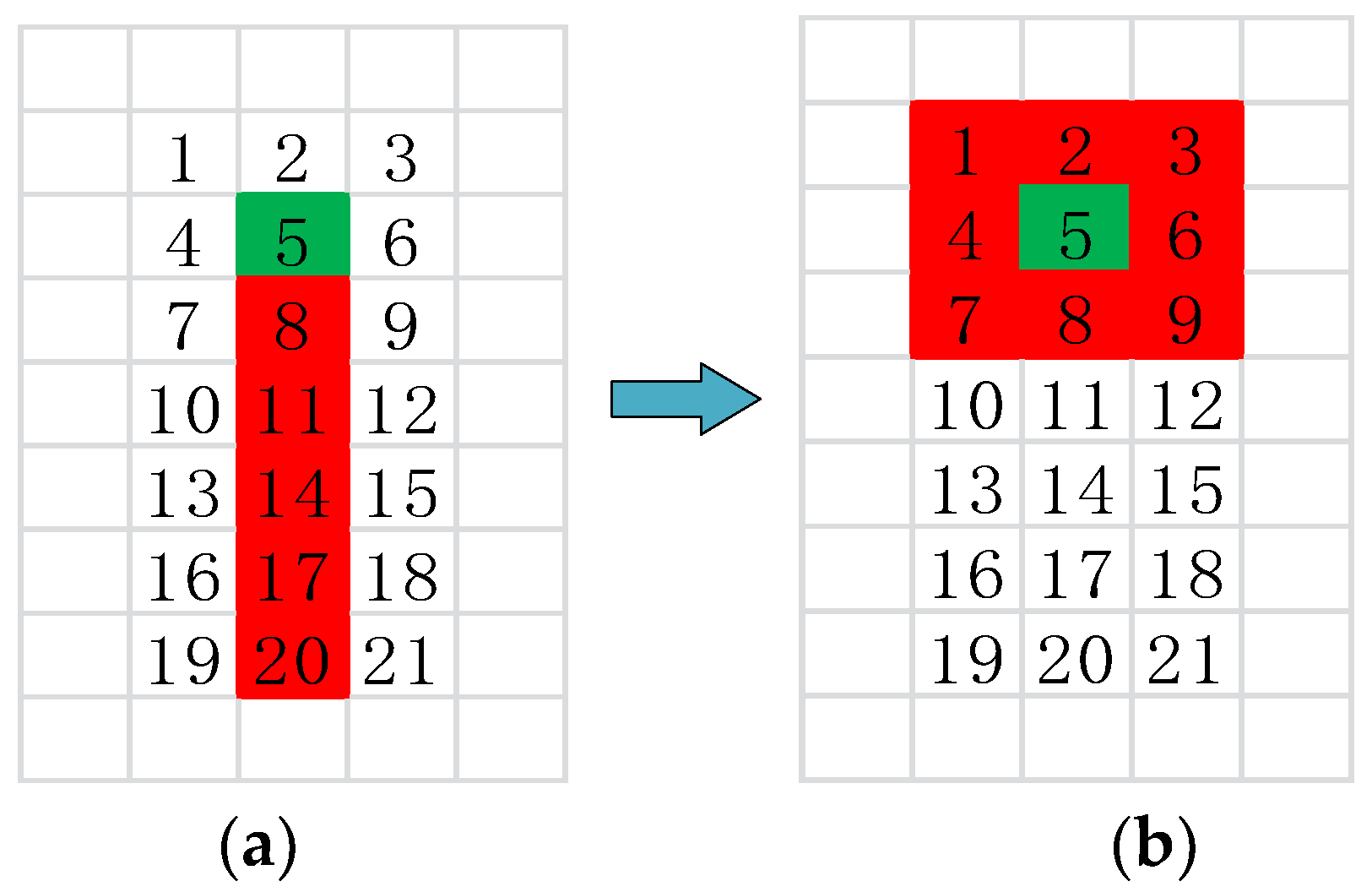
3.1. Data Preprocessing
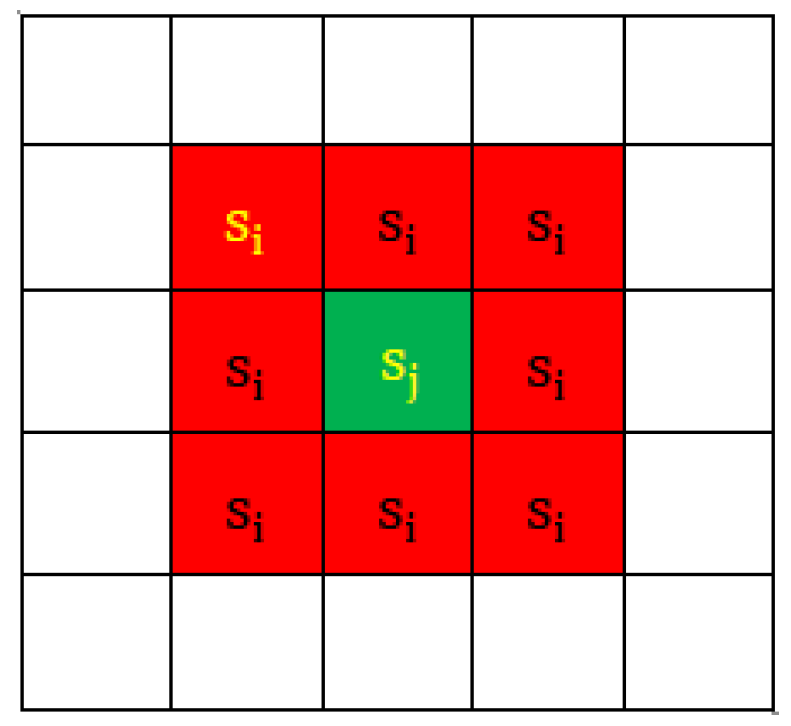
3.2. Structural Element Transition Probability
3.3. The GP Algorithm
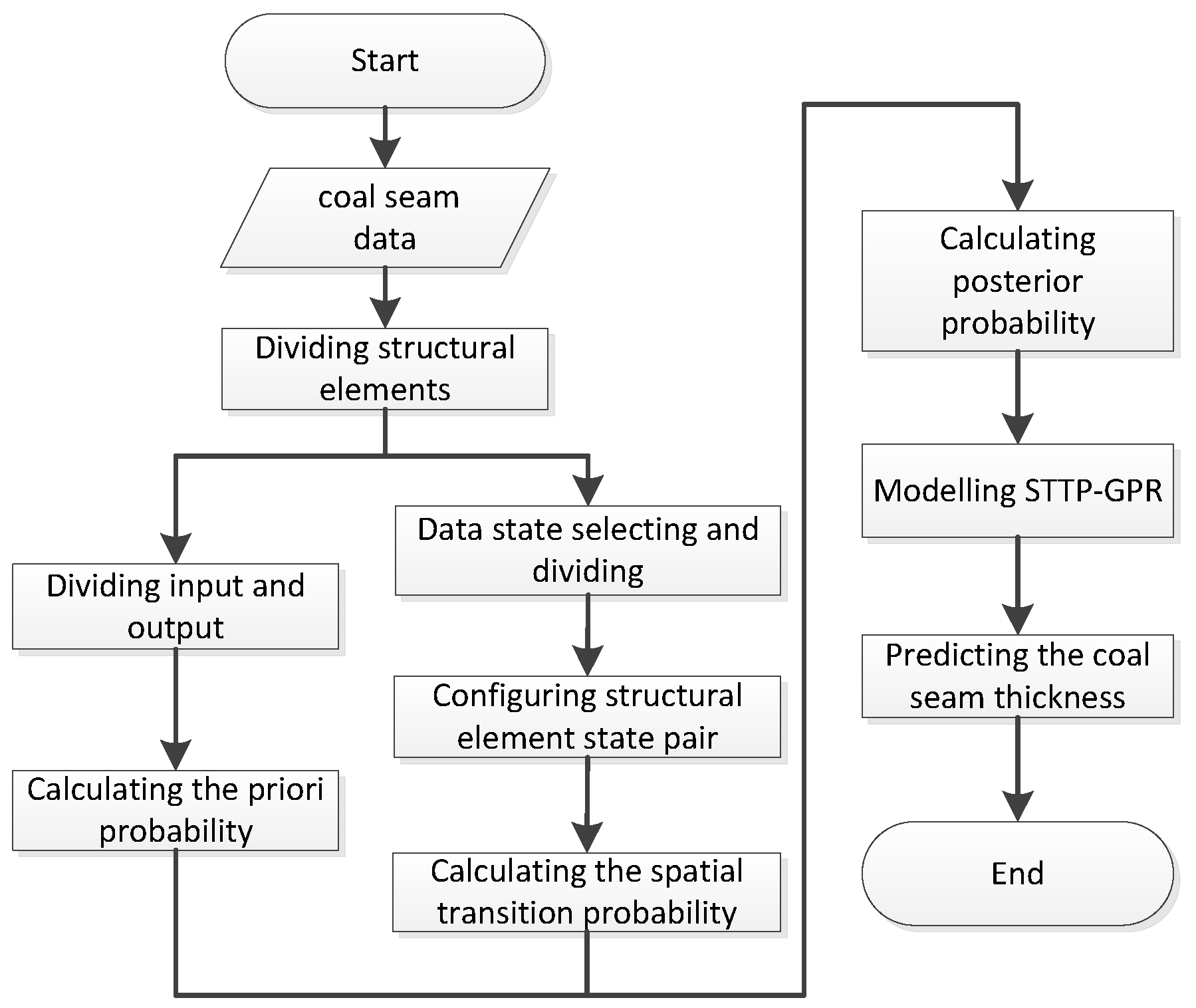
3.4. Implementation of STTP-GPR
- Step 1: acquire the coal seam thickness data, as ;
- Step 2: divide the acquired data into structural elements and the center of each structural element is the prediction point using the method described in Section 3.1;
- Step 3: the structural elements are divided into training sets and test sets according to the data ratio of 8:2, and attains the distribution of known coal seam thickness;
- Step 4: divide the state of each point in the structure element according the Formula (12);
- Step 5: calculate the state transition probability within structural element through the formula is ;
- Step 6: calculate the transition probability between structural elements, and the transition probability is ;
- Step 7: calculate the conditional probability between structural elements, where the conditional probability is ;
- Step 8: combine the structural element transition probabilities and joint distribution of known coal seam thickness to derive a posterior probability distribution of prediction model , that uses the structural element transition probabilities to replace the covariance function in GP algorithm. where represents predicted coal seam thickness value, and represents the mean value of structural elements; and,
- Step 9: predict the coal seam thickness at different positions.
4. Experimental Results and Analysis
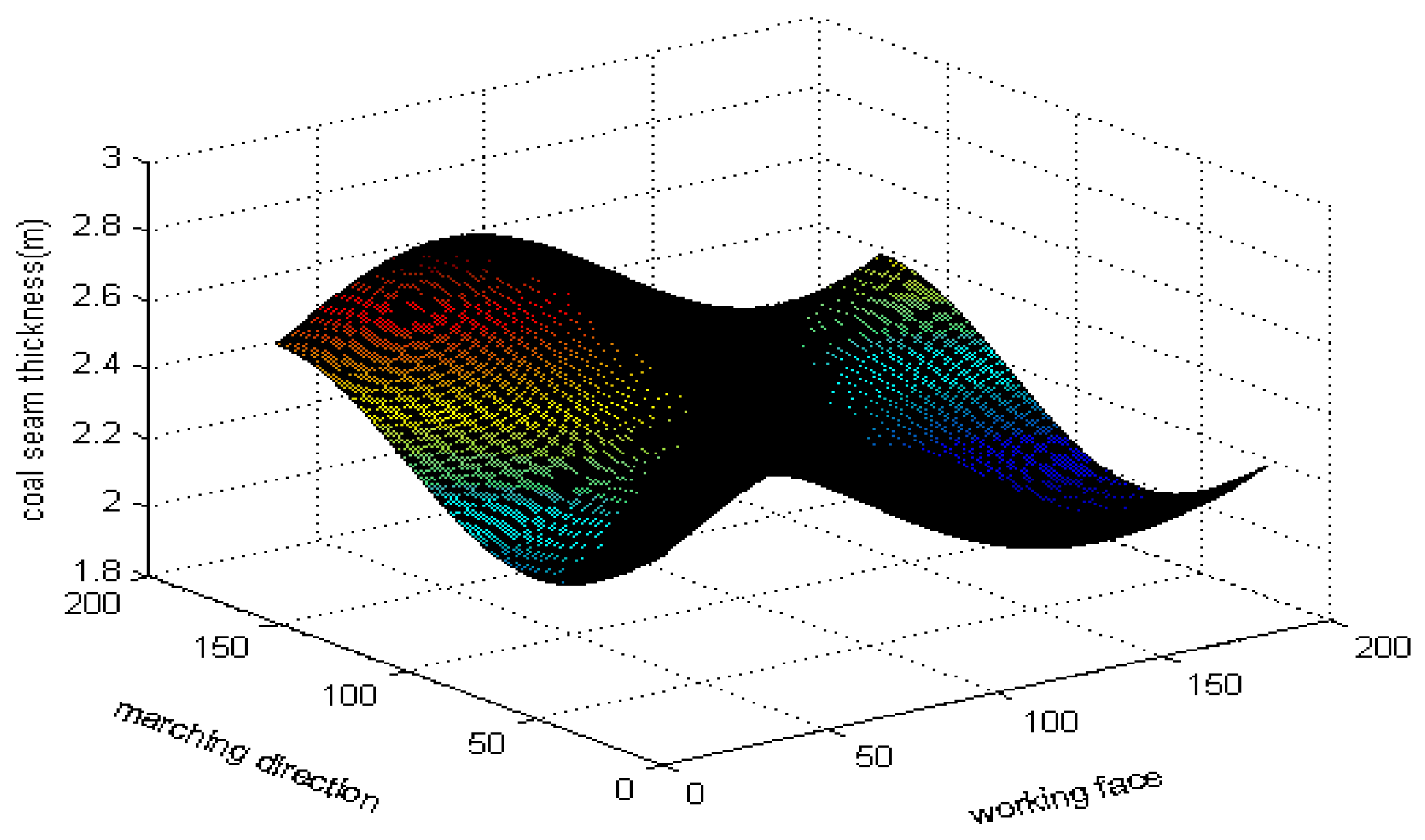
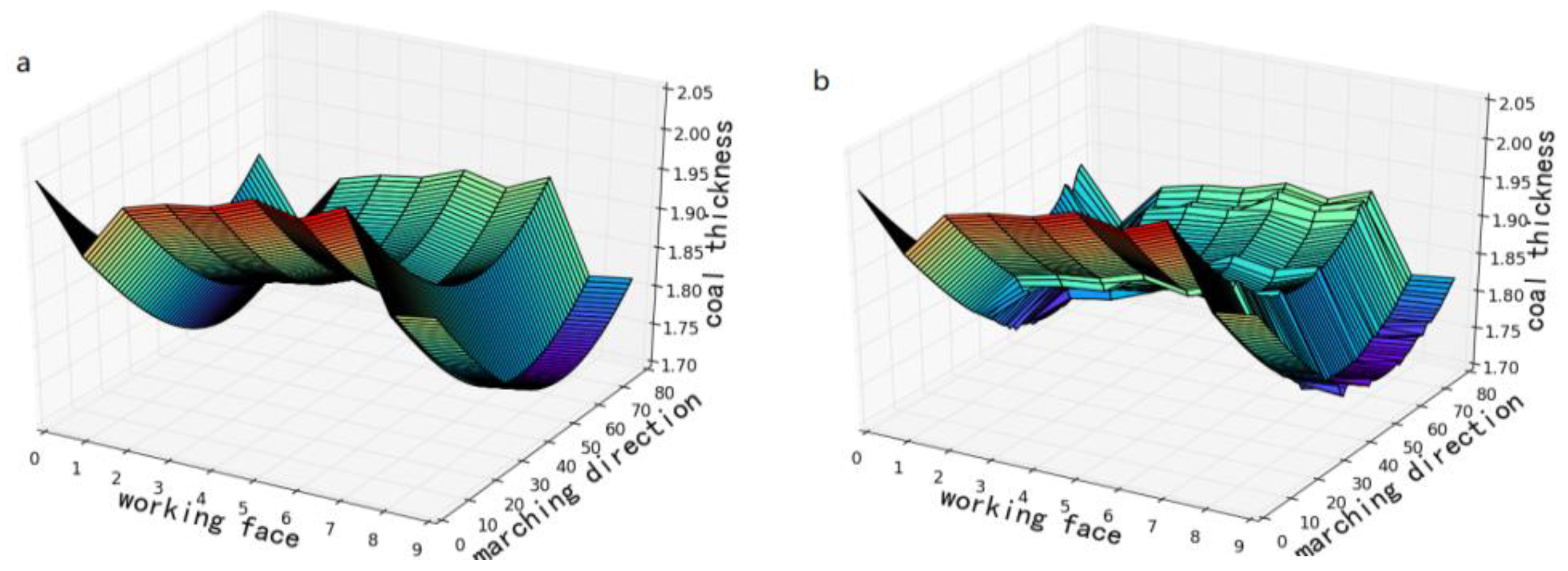
4.1. Coal Seam Forecasting Based on Simulated Data
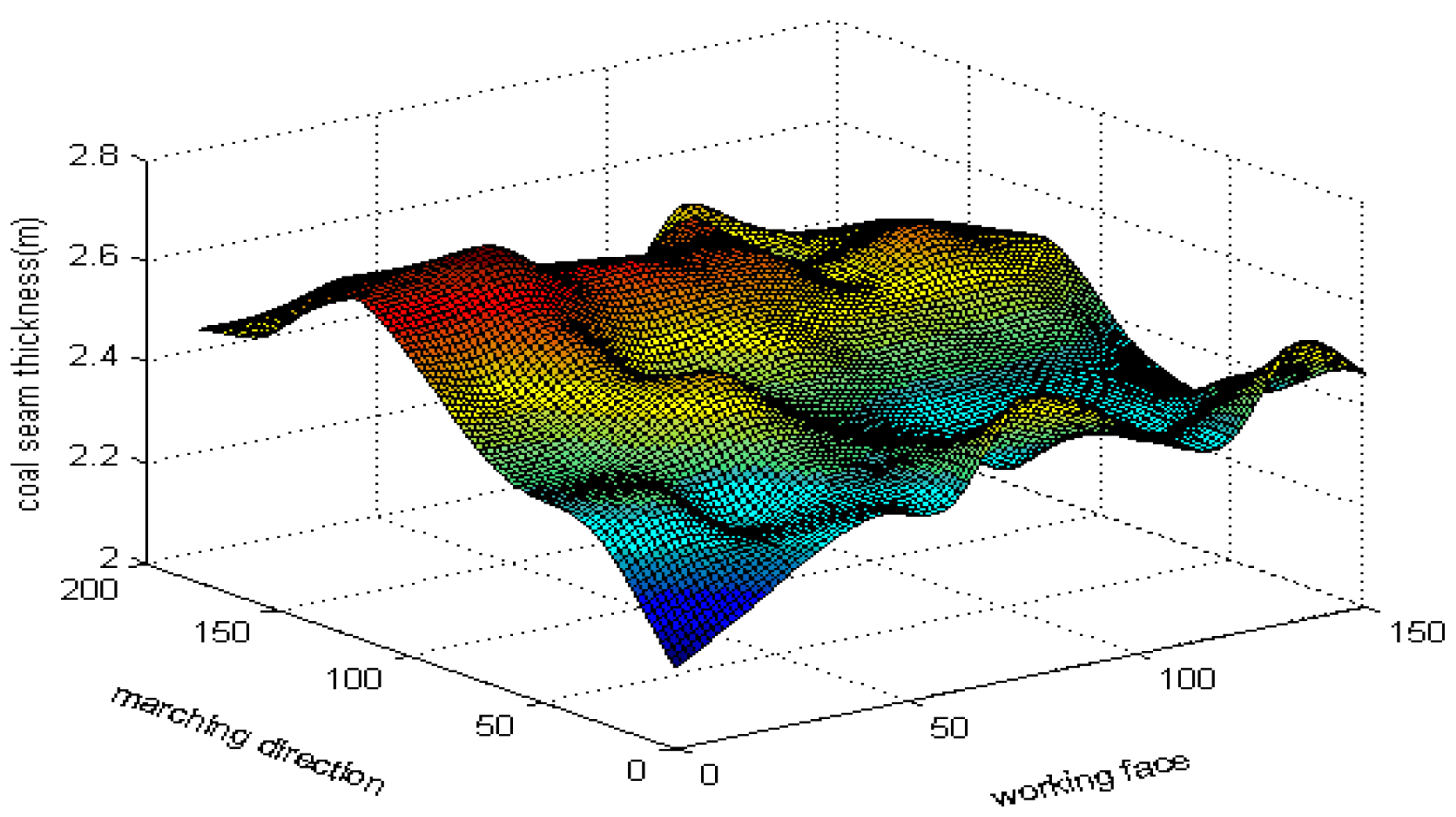
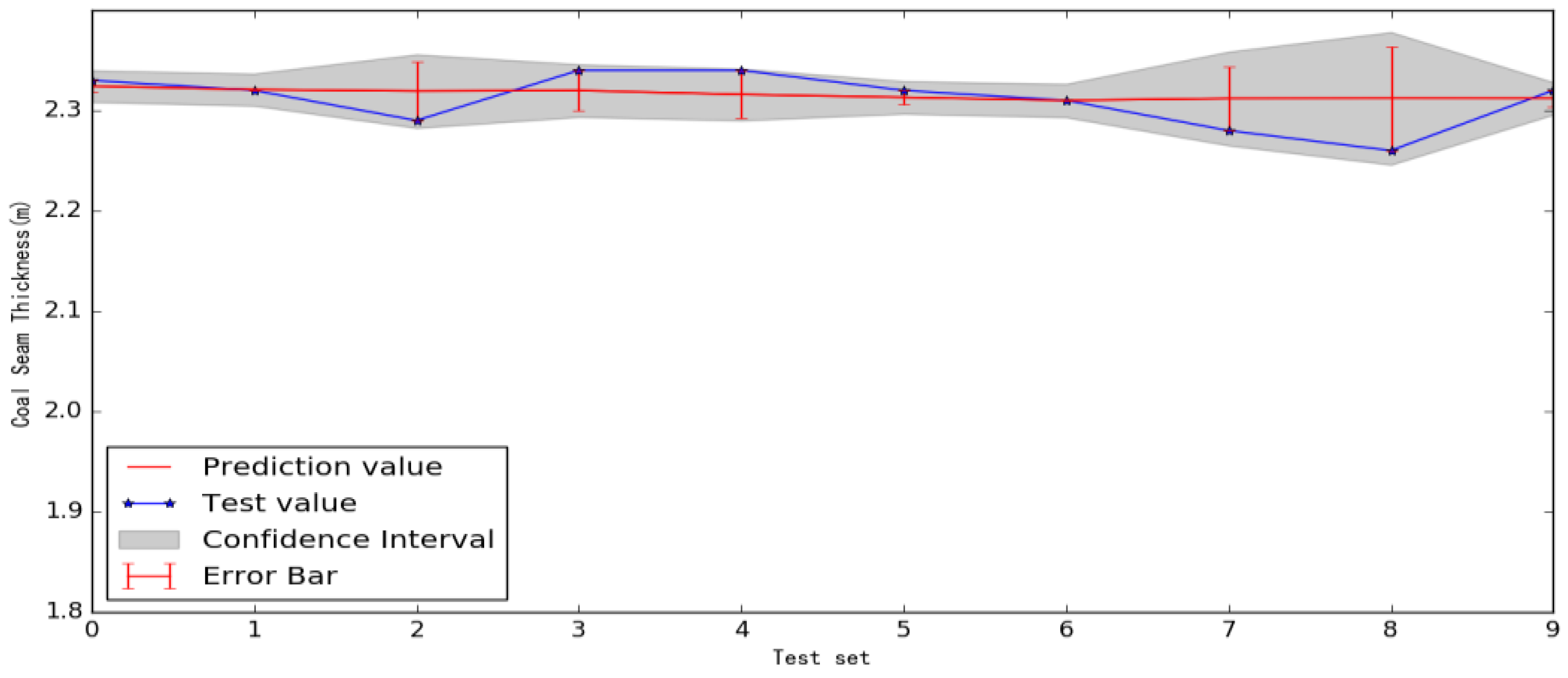
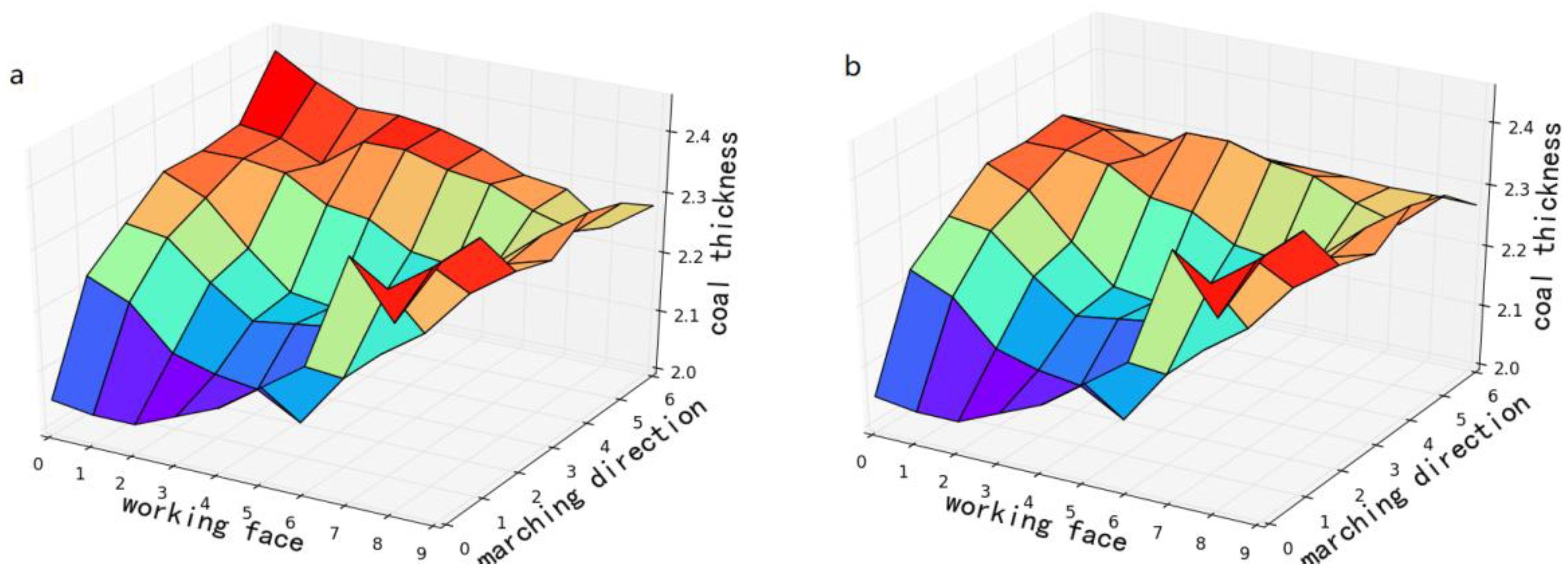
4.2. Coal Seam Forecasting Based on Real Data
4.3. Performance Comparison with the Existing Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yuan, L.; Zhang, N.; Kan, J.G.; Wang, Y. The concept, model and reserve forecast of green coal resources in China. J. China Univ. Min. Technol. 2018, 47, 1–8. [Google Scholar]
- Chen, D. Discussion on the technology and development direction of coal mine safety in China. Sci. Technol. Inf. 2013, 9, 150. [Google Scholar]
- Zhao, T.; Liu, C. Roof instability characteristics and pre-grouting of the roof caving zone in residual coal mining. J. Geophys. Eng. 2017, 14, 1463–1474. [Google Scholar] [CrossRef] [Green Version]
- Xiao, M.; Zhang, G.; Breitkopf, P.; Villon, P.; Zhang, W. Extended Co-Kriging interpolation method based on multi-fidelity data. Appl. Math. Comput. 2018, 323, 120–131. [Google Scholar] [CrossRef]
- Wu, W.; Yang, Y.; Chen, Y. Kriging Interpolation Method Optimized by LSSVM and Its Application in Predicting Coal Thickness. Coal Technol. 2015, 34, 89–91. [Google Scholar]
- Qiao, G.; Cai, H.; Zhou, A.; Yang, F.; Wang, H.; Jing, Y.; Yang, L.; Ma, L. Coal Quality Prediction Model of Drilling Coal Based on Kriging Interpolation Method. Coal Technol. 2016, 35, 151–153. [Google Scholar]
- Li, Y.M.; Liu, E.M.; Xue, G.H.; Miao, W. Coal-Rock Interface Identification Method Based on Dimensionless Parameters and Support Vector Machine. Appl. Mech. Mater. 2015, 716–717, 843–847. [Google Scholar] [CrossRef]
- Wang, B.; Liu, S.; Huang, L. Comprehensive forecast system of the thickness of coal seam and its application. In Proceedings of the International Conference on Mechatronic Science, Jilin, China, 19–22 August 2011. [Google Scholar]
- Mair, S.; Brefeld, U. Distributed robust Gaussian Process regression. Knowl. Inf. Syst. 2017, 55, 415–435. [Google Scholar] [CrossRef]
- Richardson, R.R.; Osborne, M.A.; Howey, D.A. Gaussian process regression for forecasting battery state of health. J. Power Sources 2017, 357, 209–219. [Google Scholar] [CrossRef]
- Marcotte, D.; David, M. Trend surface analysis as a special case of IRF-k, kriging. Math. Geol. 1988, 20, 821–824. [Google Scholar] [CrossRef]
- Ghiasi, Y.; Nafisi, V. Strain estimation using ordinary Kriging interpolation. Surv. Rev. 2016, 48, 361–366. [Google Scholar] [CrossRef]
- Klauberg, C.; Hudak, A.T.; Bright, B.C.; Boschetti, L.; Dickinson, M.B.; Kremens, R.L.; Silva, C.A. Use of ordinary kriging and Gaussian conditional simulation to interpolate airborne fire radiative energy density estimates. Int. J. Wildland Fire 2018, 27, 228–240. [Google Scholar] [CrossRef]
- Mukhtar, A.; Ching, N.K.; Yusoff, M.Z. Optimal Design of Opening Ventilation Shaft by Kriging Metamodel Assisted Multi-objective Genetic Algorithm. Int. J. Model. Optim. 2017, 7, 92–97. [Google Scholar] [CrossRef]
- Li, W.; Luo, C.; Yang, H.; Fan, Q. Memory cutting of adjacent coal seams based on a hidden Markov model. Arab. J. Geosci. 2014, 7, 5051–5060. [Google Scholar] [CrossRef]
- Fianu, S.; Davis, L.B. A Markov Decision Process Model for Equitable Distribution of Supplies under Uncertainty. Eur. J. Oper. Res. 2017, 264, 1101–1115. [Google Scholar] [CrossRef]
- Amsalu, S.B.; Homaifar, A.; Esterline, A. A Simplified Matrix Formulation for Sensitivity Analysis of Hidden Markov Models. Algorithms 2017, 10, 97. [Google Scholar] [CrossRef]
- Eidsvik, J.; Mukerji, T.; Switzer, P. Estimation of Geological Attributes from a Well Log: An Application of Hidden Markov Chains. Math. Geol. 2004, 36, 379–397. [Google Scholar] [CrossRef]
- Larsen, A.L.; Ulvmoen, M.; Omre, H.; Buland, A. Bayesian lithology/fluid prediction and simulation on the basis of a Markov-chain prior model. Geophysics 2006, 71, R69–R78. [Google Scholar] [CrossRef]
- Li, J.; Qu, Y.; Li, C.; Xie, Y.; Wu, Y.; Fan, J. Learning local Gaussian process regression for image super-resolution. Neurocomputing 2015, 154, 284–295. [Google Scholar] [CrossRef]
- Min, Z.; He, Y. Research on Prediction of Coal and Rock Based on Grey Neural Network. Autom. Instrum. 2012, 2, 16–18. [Google Scholar]
- Youkuo, C.; Yongguo, Y.; Wangwen, W. Coal seam thickness prediction based on least squares support vector machines and kriging method. Electron. J. Geotech. Eng. 2015, 20, 167–176. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | MAE(m) |
|---|---|
| SVR | 0.061 |
| BPNNs | 0.043 |
| GPR | 0.036 |
| STTP-GPR | 0.025 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, A.; Kang, W.; Zhang, G.; Lei, H. Coal Seam Thickness Prediction Based on Transition Probability of Structural Elements. Appl. Sci. 2019, 9, 1144. https://doi.org/10.3390/app9061144
Qi A, Kang W, Zhang G, Lei H. Coal Seam Thickness Prediction Based on Transition Probability of Structural Elements. Applied Sciences. 2019; 9(6):1144. https://doi.org/10.3390/app9061144
Chicago/Turabian StyleQi, Ailing, Wenhui Kang, Guangming Zhang, and Haijun Lei. 2019. "Coal Seam Thickness Prediction Based on Transition Probability of Structural Elements" Applied Sciences 9, no. 6: 1144. https://doi.org/10.3390/app9061144
APA StyleQi, A., Kang, W., Zhang, G., & Lei, H. (2019). Coal Seam Thickness Prediction Based on Transition Probability of Structural Elements. Applied Sciences, 9(6), 1144. https://doi.org/10.3390/app9061144