Abstract
Decentralized partially observable Markov decision processes (Dec-POMDPs) are general multi-agent models for planning under uncertainty, but are intractable to solve. Doubly exponential growth of the search space as the horizon increases makes a brute-force search impossible. Heuristic methods can guide the search towards the right direction quickly and have been successful in different domains. In this paper, we propose a new Q-value function representation—Monte Carlo Q-value function , which is proved to be an upper bound of the optimal Q-value function . We introduce two Monte Carlo tree search enhancements—heavy playout for a simulation policy and adaptive samples—to speed up computation of . Then, we present a clustering and expansion with Monte-Carlo algorithm (CEMC)—an offline planning algorithm using as Q-value function, which is based on the generalized multi-agent A* with incremental clustering and expansion (GMAA*-ICE or ICE). CEMC calculates Q-value functions as required, without computing and storing all Q-value functions. An extended policy pruning strategy is used in CEMC. Finally, we present empirical results demonstrating that CEMC outperforms the best heuristic algorithm with a compact Q-value presentation in term of runtime for the same horizon, and has less memory usage for larger problems.
1. Introduction
Cooperative decision-making under uncertainty is a common problem in many scenarios such as sensor networks and airport service robots. Consider a scenario where a robot soccer team cooperates to beat the opponent. A total of 11 robot players dash in a simulated field, kicking, passing, and shooting a ball to score a goal. Each of them could only acquire his local observation and every action taken is uncertain, which means passing may be unsuccessful or shooting may be biased. Another example is congestion control, which is an important task in the Internet. The router’s buffer accommodates transient packets to guarantee a stable network link. The distributed routers need to come up with a strategy to avoid congestion. These kinds of problems can be modeled as a decentralized partially observable Markov decision process (Dec-POMDP), which provides a general multi-agent model for decision-making under uncertainty. However, Dec-POMDPs are provably intractable (NEXP-Complete, nondeterministic exponential time, it is known that P NP PSPACE EXP NEXP) [1] and difficult to solve with the number of joint policies growing explosively [2]. One of the primary reasons is that the search space of Dec-POMDPs grows exponentially with the number of actions and observations, and doubly exponentially with the horizon of the problem [3]. The optimal policy can be extracted from the optimal Q-value function for Dec-POMDPs, but solving is also proved to be NEXP-Complete [4].
In a previous work [5], Monte Carlo tree search (MCTS) [6] is introduced into the MMDP (Multiagent MDP) model, which is a simplified model for Dec-POMDPs, to solve ad hoc agent teams decision-making. MCTS is a sample-based tree search algorithm using Monte Carlo simulations as state evaluations, which has been successful in Computer Go [7]. MCTS will converge to the optimal value if exploration (find new nodes that are not sampled) and exploitation (find promising nodes that are already sampled) are traded off appropriately when given sufficient time and can be stopped at any time to get an approximate result.
To tackle the doubly exponential problem, we propose an offline algorithm called a clustering and expansion with Monte-Carlo algorithm (CEMC) based on incremental clustering and expansion (ICE), a version of generalized multi-agent A* (GMAA*) with incremental clustering and expansion, which is the best heuristic method in this literature. MCTS is integrated into the CEMC framework to fast obtain the approximate Q-value function. MCTS is an anytime algorithm, and its efficiency is up to sample times and the degree of accuracy of the Q-value function evaluation. Thus, we propose an adaptive sample method according to the horizon and the number of joint actions and observations. The best upper bound found in the MCTS algorithm is used to prune the nodes that will not be the optimal ones in any case. The term MCTS in this paper denotes the specific algorithm that uses UCB1 (a version of upper confidence bound) as the tree selection policy proposed by Kocsis and Szepesvári [6,8].
The key contribution is twofold: We present a new Q-value function representation—Monte Carlo Q-value function and an offline planning algorithm CEMC. Heavy playout for simulation policy and adaptive sample are introduced to speed up the computation of . The algorithm CEMC calculates the Q-value functions as required, without computing and storing all Q-value functions and it uses an extended pruning strategy for the policy pool. We present empirical results demonstrating that CEMC outperforms the best heuristic algorithm with a compact Q-value presentation in term of runtime for the same horizon, and has less memory usage for larger problems.
The remainder of this paper is structured as follows. We first introduce some related work in Section 2. Then, we outline some background knowledge on Dec-POMDPs, ICE algorithm, approximate Q-value functions, MCTS, and collaborative Bayesian Games in Section 3. Section 4 gives the Q-value function representation and proves that is an upper bound of the optimal Q-value function. Then, an adaptive sample and heavy rollout technique are proposed. Section 5 presents the core algorithm CEMC and a pruning strategy. We empirically prove the efficiency and effectiveness of CEMC in Section 6 and discuss the results. We conclude and outline the future research in Section 7.
2. Related Work
The Dec-POMDP is an extension of the POMDP model which has been proved to be doubly exponential [1]. The brute force search becomes intractable when the number of agents or the problem size grows. In recent years, a lot of work has focused on fast computing an optimal policy of larger horizon, such as dynamic programming [9,10,11,12], heuristic search [2,3,4,13,14,15], and mixed integer linear programming [16].
GMAA* framework [4] is one of the state-of-the-art exact algorithms in the heuristic search literature, which is based on multi-agent A* (MAA*) [2] and uses an approximate heuristic function to guide the search in the whole search space. GMAA*-ICE (or ICE) [3] is a heuristically guided algorithm based on a GMAA* framework [4] and has demonstrated impressive performance over GMAA*. Two successful components used in ICE are lossless clustering [13] and incremental expansion [14]. Recently, a Bayesian learning method [17] and approximate inferences and heuristics [18] are proposed for solving Dec-POMDP.
Silver and Veness [19] proposed a Monte-Carlo algorithm—POMCP—for online planning in large POMDPs. Unlike our approach, POMCP combines a Monte-Carlo update of the agent’s belief state with a Monte-Carlo tree search from the current belief state. Importantly, POMCP is suitable for single-agent partially-observable and unfactored Markov decision process (MDP). Amato and Oliehoek [20] proposed a scalable approach based on sample-based planning called factored-value partially observable Monte Carlo planning (FV-POMCP), to combat the intractability of an increasing number of agents. However, FV-POMCP requires a decomposition of the value function into a set of overlapping factors.
3. Background
Consider a scenario where a number of agents inhabit in a particular environment modeled with a Dec-POMDP, where the perception of the agents is uncertain and they must work together to achieve their goal. At each discrete time step every agent takes an action and the combination of these actions influences the world, making it transform to the next state. The goal of the agents is to try to come up with a plan that maximizes their expected long-term rewards. The goal or task need to be completed with cooperation, because no single agent is competent enough. Therefore, the plan computed should be decentralized.
In this section, we briefly review some background of the decentralized POMDPs model, ICE, approximate Q-value functions, MCTS, and collaborative Bayesian games. We refer the readers to the previous work [2,3,4,21,22] about the detailed background.
3.1. Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) Model
Dec-POMDP generalizes POMDP to a multi-agent version where rewards are common and based on joint actions, but observations are individualistic [23,24]. The detail definition is as follows.
Definition 1.
A decentralized partially observable Markov decision process is defined as a 9-tuple <I, S, A, T, , O, R, b0, h>, where
- is the finite set of agents;
- is the finite set of states, where is the initial state;
- is the set of joint actions where , and is the finite set of individual actions of agent . The component in the joint action belongs to ;
- is the transition function where denotes the probability of transiting to the new state when taking the joint action in state ;
- is the set of joint observations where = <o1, ..., on> ∈ , and i is the finite set of individual observations of agent i. The component in the joint observation belongs to i;
- O is the observation function where P() denotes the probability of observing when the system state transfer to taking the joint action ;
- is the reward function, where denotes the immediate reward when taking the joint action in state ;
- is the initial state distribution;
- is the finite horizon.
At every step , the environment is in a particular state , which emits a joint observation according to the observation model. Each agent obtains its individual observation component . Each agent selects its individual action , forming a joint action , which leads to a state according to the transition model. Every agent receives an immediate reward .
The action-observation history for agent is the sequence of actions taken and observations received, which is denoted as a sequence . Thus, the joint action-observation history is . A policy for agent is a mapping from history to actions , and a joint policy is denoted as which specifies a policy for each agent. The goal of solving Dec-POMDPs is to calculate an optimal joint policy to maximize the expected long-term accumulated reward, which is defined as
The value of an optimal joint policy can be defined as follows:
where denotes the joint action that specifies for , and
is the optimal Q-value function.
The policy of agent specifies actions for all steps of Dec-POMDPs, and can be represented as a sequence of decision rules . The decision rule for agent at step is a mapping from the length- history to action . The partial joint policy is defined as a sequence of decision rules specified for steps , which is denoted as .
3.2. Generalized MAA* with Incremental Clustering and Expansion (GMAA*-ICE)
GMAA*-ICE (or ICE) [3] is a heuristically guided algorithm based on GMAA* framework [4], which generalizes the first multi-agent A* search MAA* [2]. It uses to guide A* search over partially specified joint policies to construct a tree from top–down, where is the actual expected reward achieved over the first steps and is a heuristic value for the remaining h-t steps. ICE uses an admissible heuristic to guarantee that it can find an optimal policy.
The key contributions of ICE are lossless clustering and incremental expansion. The authors introduced a probabilistic equivalence criterion that can be used to decide whether two individual action-observation histories, , for agent , can be clustered. Especially in problems that have many histories satisfying probabilistic equivalence, ICE can significantly speed up planning. Incremental expansion defines a method of incrementally constructing a search tree by expanding the most promising child where is the optimal solution of collaborative Bayesian games. The author defined a node priority which helps find the tight lower bound early by first expanding deeper nodes [2].
ICE [3] is our baseline algorithm, but our methods are different from it as we integrate Q-value function computing with policy solving, so CEMC calculates the Q-value functions as required, and does not have to store and maintain a large matrix of the Q-value function.
3.3. Approximate Q-Value Functions
As mentioned above, ICE uses to guide the search and is a heuristically estimated value using approximate Q-value functions. There are three well-known approximate Q-value functions, , and , which are all approximations for the optimal Q-value function . Although the optimal policy can be extracted from , it is costly and impractical to compute.
Szer and Charpillet [25] used to solve Dec-POMDP that is approximated as an underlying MDP. This underlying MDP is defined by a single agent which takes joint actions but has the same state set, transition function, and reward function as original Dec-POMDPs. It assumes that the state can be fully observed and the single agent gains more information than Dec-POMDPs do.
[25] is another approximation for . In this case, Dec-POMDPs are treated as underlying POMDPs defined by a single agent which takes joint actions and receives joint observations but has the same state set, transition function, observation function, and reward function. It assumes that underlying POMDPs are settings of centralized control, which allow for better coordination. This means that the single agent knows the joint action-observation history while the agents in Dec-POMDPs can only gain local information such as individual actions and observations.
is proposed by Oliehoek et al. [4], which assumes that the agents know the joint action-observation history and the joint action for the previous time step . This assumption defines a Bayesian games (BGs) for each (,) pair. The actions taken by agents can be solved by constructing BGs.
, and are all proved to be upper bounds of [4]. These approximate Q-value functions form a hierarchy of upper bounds to :
This means that all these approximate Q-value functions are admissible heuristic for Dec-POMDPs.
Apart from the Q-value functions mentioned above, Oliehoek et al. [18] proposed a factored Q-value function as a heuristic payoff function for factored Dec-POMDP. The precondition of a decomposition is that the Q-value function of every joint policy is factored. Each local component of this kind of Q-value function depends on a subset of state factors and the action-observation histories and actions of a subset of agents.
3.4. Monte Carlo Tree Search (MCTS)
MCTS builds a search tree incrementally and asymmetrically in a given domain by taking a random sample. Each node in the tree denotes a state and links to child nodes which represent actions taken. It works by repeating selection, expansion, simulation, and backpropagation on a loop until some predefined computational budget, usually runtime or memory, is reached [26].
Many extensions have been reviewed in the literature [22]. MCTS is used to find the optimal feature subset through the feature space in [27]. In this paper, we use plain UCT (upper confidence bounds for trees) [6] as the tree policy for computing the Q-value function. Plain UCT is MCTS with UCB1 (a version of upper confidence bound), the tree policy of which is:
where is the mean value; is the number of times that the parent node has been visited; is the number of times child has been visited, and is a constant.
The role of a tree policy is to select and create a node, which is carried out in the selection and expansion phase. A default policy is in the simulation phase. Its function is to play out the domain to estimate a state value. In a previous paper [28], four criteria for selecting actions are listed: (i) max child, (ii) robust child, (iii) max-robust child, and (iv) secure child. If the search terminates, one can choose one of the four selection mechanisms above for selecting an action to take. Our tree policy chooses the highest value node in the selection phase and only one node is expanded in the expansion phase. In the default policy (simulation phase), we replaced a random sample with simulation enhancement best-first policy. The advantage of randomly selecting actions is that it is simple, requires no domain knowledge, and can quickly simulate many times. However, it is not likely to be realistic compared to rational players [22]. The enhancement we proposed can use domain knowledge to simulate realistically. The details will be introduced in Section 3.3.
3.5. Collaborative Bayesian Games
A Bayesian game (BG) [29] is an augmented normal form game in which a number of agents interact in a one-shot manner, and each of them holds some private information. This private information defines the type of the agent. A collaborative Bayesian game (CBG) is a BG in which agents receive identical payoffs. A CBG is defined as follows:
Definition 2.
A collaborative Bayesian game (CBG) [3,4] modeling stage of a Dec-POMDP, given initial state distribution and past joint policy , consists of:
- is the finite set of agents;
- is the set of joint actions;
- is the set of joint types, each of which specifies a type for each agent ;
- is a probability distribution over joint types;
- is a heuristic payoff function mapping joint types and joint actions to a real number: .
That is, given , for each , it is possible to construct a CBG . Therefore, represents a decision-making problem for stage , if was followed for the first stages starting from . We simply write below.
In a CBG, each agent uses a Bayesian game policy that maps individual types to actions . If denotes the joint policy for the CBG, it corresponds to a joint decision rule: . Oliehoek et al. [4] model Dec-POMDP with series of CBGs, or in other words, a stage of a Dec-POMDP can be modeled with a CBG. Therefore, we can solve a Dec-POMDP problem stage by stage, which facilitates A*-like search algorithms.
4. Monte Carlo Q-Value Function
In this section, we propose a new Q-value function representation—Monte Carlo Q-value function —and give proof of an upper bound of the optimal Q-value function . combines the precision of tree search and the anytime character of sample-based Monte Carlo, and has more flexibility than other Q-value functions do. Then, we present two MCTS enhancements—heavy playout for simulation policy and adaptive sample—to speed up the computation of .
4.1.
In reinforcement learning [30], the Q-value function is defined as the expected return starting from state , taking action , and then following policy :
Different from the former, the state in is the joint history at time step . We define as:
where MC is the Monte Carlo method, which returns the optimal action when observing . Because of the partially observability, the probability multiplied by is a conditional probability of all observations at and .
The solution of can be illustrated in Figure 1. The black filled nodes are joint histories, and the solid links and dotted links are respectively joint actions taken and joint observations received by agents. Each joint history node contains two statistical values—, visiting count of node and , number of taking at .
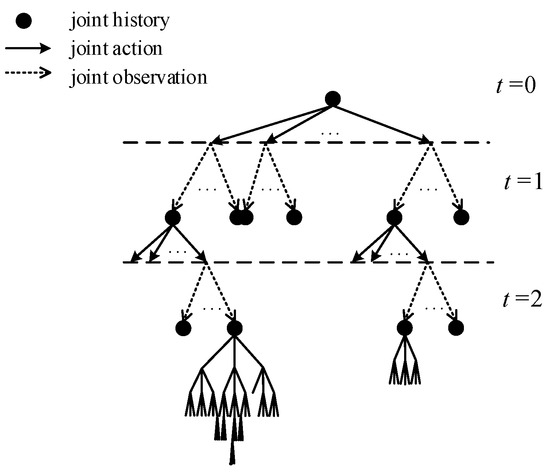
Figure 1.
Tree of Monte Carlo Q-value function.
At the selection phase of , UCB1 is used to choose the best action
where and are respectively the immediate and future reward at .., and the term added to it is called a UCT bonus, which is used to balance exploitation and exploration. is the mean value of reward. The parameter is a constant (), which is used to tune how much influence the bonus has on the action selection. It is set bigger for problems with more branches and smaller for deeper ones. We did not consider adaptive setting of parameter in this paper.
At the expansion phase of , it expands only one node. At the simulation phase, replaces the default random policy with heavy playout—an enhancement of Monte Carlo, which is presented in Section 3.3. At the backpropagation phase, updates the values or statistics of nodes that are visited in this iteration with the result of the finished play.
Lemma 1.
is an upper bound of the optimal Q-value function Q*.
Proof
See appendix. ☐
From the representation of we can see that it treats Dec-POMDPs as models in which a single agent takes joint actions and receives joint observations, but has the same state set , transition function , observation function and reward function . The assumption makes more information available than the underlying Dec-POMDPs. is an overestimation of the optimal Q-value function and makes A*-like search find the optimal policy. The pseudocode of computing is shown in Algorithms 1 and 2.


4.2. Adaptive Sample
Due to the anytime character of MCTS, sufficient sample times () can make converge to , but it is costly to calculate a converged . However, a small leads to a loose Q-value function or even a wrong policy. Thus, in this article, we present a method for an adaptive sample, which is a function of joint actions and time steps. That is:
where is a constant, determined by the specific problem, is the number of joint actions and is a time step.
is in proportion to joint actions and inverse proportion to the square of time steps. This means that problems with more joint actions need larger to make converge. With the tree of constructed from top–down, shrinks gradually. We use this technique to balance the accuracy of convergence and computing time.
4.3. Best-First Simulation Policy
Simulation policy uses a default policy to play a game quickly. After that, MCTS propagates back the simulation results. The default policy is typically domain dependent. As there is no value like for guiding the action selection, uniformly choosing available actions is a common scheme. However, the heuristic knowledge of the problem can be involved into the default policy to strengthen simulation. Silver [31] discusses some factors that influence simulation performance. In this paper, we extend the rollout phase by incorporating domain knowledge into playouts, which are called heavy playouts [32]. If it is not the last time step, the algorithm recursively calls for the Rollout function. Then it returns the best immediate reward (immR) and backpropagates the value obtained and updates and . This Best-First Simulation Policy (BFSP) returns the promising node first to ensure that the heuristic value is admissible or a guaranteed overestimation. The detail is shown in Algorithm 3.
Especially we would like to note that the selectBestA() function selects the best action combining an idea of reinforcement learning and the history heuristic. Reinforcement learning (RL) reinforces the actions that make success. The history heuristic assumes that an action good in one position may be good in another. Joint actions, which acquire the highest simulating value, will be given more chances in the later simulation. Concretely, we keep an average accumulated value of each joint action in a playout. Apart from , a separate visit of each action and total visits of all actions, in the simulation phase is also stored. An action is selected by a softmax function with inputs . This implies that the larger will correspond to a larger probability. If it is at an initial state or the chance of nodes are equal, a random legal action will be selected. For example, if a problem has nine joint actions, in the start of a simulation phase, an action is selected through this softmax function. After the simulation ends, its accumulated value to the terminal is recorded and the visit number increases by one. In another simulation phase, the statistics are reused, which we call the history heuristic.

5. Multi Agent Planning Using
In this section, we present our offline planning algorithm—CEMC—which is based on an ICE framework. Then, we introduce a new policy pruning strategy to speed up planning. CEMC integrates Q-value function computing and plan solving, and calculates the Q-value functions as required, which avoids the need to compute and store all Q-value functions. Thus, CEMC does not calculate and maintain a large matrix for Q-value, which achieves improvement in runtime and memory.
5.1. Offline Planning Algorithm—CEMC
Offline algorithms generate a complete policy before execution begins. The policy specifies what actions to take in any possible runtime situation. Before presenting CEMC, we first introduce two successful techniques used in ICE, which is also adopted by CEMC.
The first one is lossless clustering. Two individual action-observation histories , for agent can be losslessly clustered when they satisfy probabilistic equivalence criterion:
where is the joint action-observation histories of all agents except agent . This means that the probability distribution over the other agent’s joint action-observation histories are identical for both , .
The second one is incremental expansion which defines a method of incrementally constructing a search tree by expanding the most promising child where is the optimal solution of CBGs. A child is selected by node priority. Node in the search tree is a 3-tuple . Node priority if:
That is, if the heuristic values are equal, the greater depth will be chosen first. This helps find the tight lower bound early by first expanding deeper nodes and converge quickly.
The CEMC algorithm (Algorithm 4) starts planning with an unspecified partial joint policy in an initialized policy pool. It greedily selects the best partial joint policy in the pool according to the node priority(Select(L)). Then, it proceeds by constructing a CBG using lossless clustering (ClusterBG()). After that, the CBG is solved, which returns a 2-tupe where is a Bayesian game policy, and is given by the function Solver():
where is the probability distribution over joint histories and is the Q-value function computed by Algorithm 1.

The set of child nodes is expanded using the incremental expansion technique and only the promising child node will be put into (IncExp()). The heuristic value of the node is given by the function ComputePolicyAndValue():
where is the actual expected reward of and is given by Equation (12).
We use two pruning strategies during planning. If time step , nodes with values less than the best Q-value function will be pruned in advance. If , CEMC computes fully expanded policies. Nodes with values less than the best lower bound can be pruned. CEMC ends when the policy pool becomes empty or the highest value in the policy pool is less than that of the best full policy.
The main idea of CEMC is that it integrates the Q-value function computing with plan solving, which benefits from the anytime character of . The original ICE computes and stores the Q-value functions in a matrix, where is the number of joint action-observation histories and is the number of joint actions. It is costly to calculate complete Q-value functions in advance. For example, for the benchmark problem, Mars Rovers (Appendix Table A1), there are about 2.82 × 1014 joint action-observation histories and 36 joint actions. It needs to compute about 1.02 × 1016 value pairs. The algorithm CEMC calculates the Q-value functions only when required, without computing and storing all Q-value functions.
5.2. Policy Pruning Strategy
Pruning is split into hard pruning, which removes branches of the tree permanently, and soft pruning, which temporarily removes branches, but then adds them back into the search at some later point [33]. In this paper, we use hard pruning as our pruning strategy.
The ICE algorithm maintains a policy pool. A node in the pool is denoted as a tuple , where is a partial policy, is its value, and is its depth. We know the value of a node is an actual value plus an estimated value: . The estimated value is an overestimation of the actual value from this node to a terminal. Actually, the value of a node is the value of a path or a policy across this node. Therefore, with the search descending deep down to the terminal or the finite horizon, the value of a node is also descending (note that the actual value becomes larger and larger, and the estimated value becomes close to the actual value). When the search reaches the terminal, the value of the terminal node can be seen as the best lower bound ever found. If the value of a node in the policy pool is smaller than the best lower bound, it would never be the optimal. Therefore, it uses the best lower bound to prune the policy pool. However, for some problems in the literature, the policy pool shrinks slowly, which wastes a lot of time in computing useless nodes.
We use an example to illustrate it. Consider, for example, Figure 2 is a search tree. The policy pool is a priority list, which has several nodes, such as [,,,,…]. The superscript of is its time step or its depth. At each loop the ICE algorithm chooses the first node in the pool and expands it. If the algorithm reaches the last step, it returns the fully expanded node () as the best lower bound to prune the policy pool. However, node > node according to the node priority, and it will not be pruned. Assuming that the child of the node is , this fully expanded policy is obviously not the optimal one and should have been pruned in advance, but node will be still expanded in these iterations. Not pruning in advance makes the search algorithm go the wrong direction and this is to be solved in our policy pruning strategy.
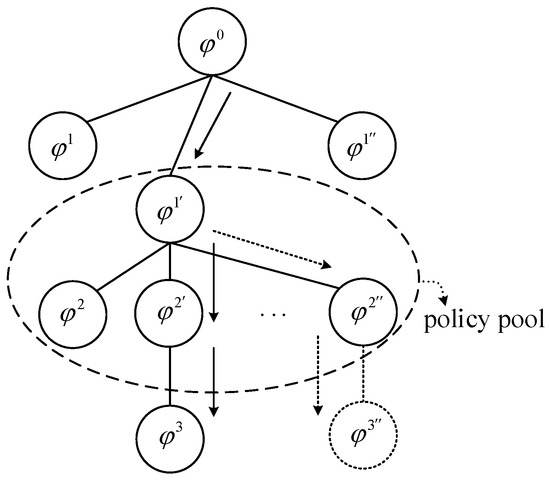
Figure 2.
Incremental clustering and expansion (ICE) search tree. Due to inappropriate policy pruning, some nodes like will be left in the policy pool and they may be still expanded in later iterations. The dashed circle is an unvisited node.
Thus, these useless nodes like should be removed as early as possible. We improve the pruning function using the max Q-value function at time step , combined with the best lower bound , that is:
where is the deepest level in the policy pool, is computed through :
The Equation (14) illustrates that if , all nodes with values less than can be pruned and if CEMC reaches the last step, any node with values less than can be pruned. Note that pruning using is done during the planning, it does not have to wait for full expansion. This technique can reduce the number of nodes in the policy pool and make the algorithm converge quickly, which is tested experimentally in Section 5.
6. Experiments
This section experimentally demonstrates and validates the effectiveness of all techniques proposed: the new Q-value function representation , the adaptive sample, best-first simulation policy (BFSP), policy pruning strategy, and the core algorithm CEMC. We give several benchmark problems in the literature, followed by experimental data. Finally, we analyze and discuss the results.
6.1. Experiments Setup
We give some benchmark problems, including Dec-Tiger, Grid-Small, Recycling Robots, Box Pushing, Mars Rovers, Broadcast Channel. All these problems have two agents, with different numbers of states, actions and observations, as shown in Table A1 (see Appendix A), which lists the number of joint policies for different horizons. These domains can be downloaded at MASPlan (http://masplan.org/).
The problem, Broadcast Channel, has two agents, each of them must choose whether or not to send a message in a Broadcast Channel. If both agents send, a collision occurs. Therefore, they must cooperate to send messages. The problem, Recycling Robots, also has two agents in the environment, in which both of them move around using their motors, pick up cans, and place them in a specified place using their mechanical arms. They must complete the task cooperatively. The benchmark Mars Rovers involve two rovers performing certain scientific experiments by choosing to check, drill, or sample. They can move in four directions. Some locations need only one agent and some locations require their cooperation.
Experiments were run on Ubuntu 16.04 with Intel Core i5 CPU and 6 GB memory. CEMC was implemented in C++ based on the MADP Toolbox [34]. Every average result was run over 100 times. We compared CEMC with the state-of-the-art exact heuristic algorithm ICE with a compact Q-value function implementation . Five statistics are taken into consideration: time of computing Q-value function , time of calculating the optimal joint policy , overall time , value of optimal policy , and value of random policy . We would like to note that ICE may not get the same performance contrasted with the original paper due to the computing resources, but all results including ICE and CEMC were tested in the same environment, so the time and scalability results are directly comparable.
6.2. Experiment Results
6.2.1. Comparing CEMC and ICE
Table 1 shows performance results for ICE and CEMC. “-” indicates unknown values, caused by getting the wrong results or a time limit violation (less than 3600 s is valid). “*” indicates out of memory. Table 1 clearly shows that CEMC outperforms the state-of-the-art heuristic algorithm with . Especially in solving scalable problems such as Grid-Small, Box Pushing, and Mars Rovers, CEMC shows significant improvement without computing and storing all Q-values. CEMC allows for getting the needed Q-value to guide A* search without pre-computation of all Q-value function.
From Table 1 we can see that in some problems like Grid-Small, Box Pushing, and Mars Rovers, CEMC is significantly better than ICE, while in some problems like Dec-Tiger, Recycling Robots, and Broadcast Channel the difference between both may not be as obvious as the three previous ones. Actually, the number of joint decision rules for time step in the search tree is
which means the complexity is exponential with the number of actions and observations, and doubly exponential with the time step. The search tree contains the action-observation histories, the actions taken, and the observations received. Therefore, the number of branches is related to the action and observation space. Although the domain Mars Rovers has a larger state space, it has little influence on the scale of the search tree. What it influences is the efficiency of state transition and the computing time of the probability like .
6.2.2. Analysis of Policy Pruning Strategy
To illustrate the effectiveness of the extended policy pruning strategy, we list the max number of policies in the policy pool for different horizons. Figure 3 shows a comparison of the original ICE and CEMC. Note that the original ICE maintains a larger policy pool than CEMC. For problems with approximatively , ICE expands nodes back and forth to construct a tree carefully. This will significantly increase the search time. We use Equation (14) to prune the policy pool, and the promising nodes are left.
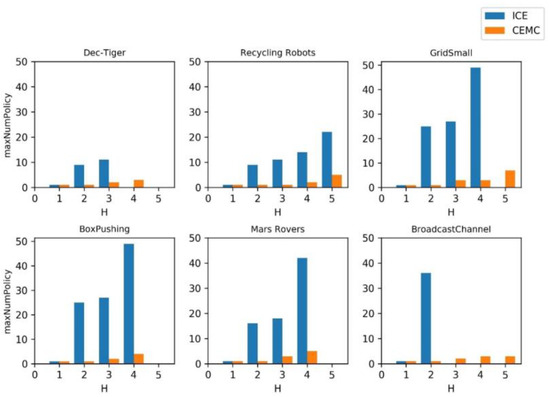
Figure 3.
Max number of policies in the policy pool for different horizons. This indicator illustrates that ICE maintains a larger policy pool than CEMC, which may make the former expand useless nodes.
6.2.3. Convergence of
More sample times can make the approximate Q-value function converge and be close to , but it needs more runtime. To illustrate the convergence of , we gathered the statistics of the max of Dec-Tiger with the sample time increasing, as shown in Figure 4. The max values of , and for Dec-Tiger with horizon = 3 and = 4 are also listed. We can see from the figure that the max declines and converges as increases. Note that is as compact as with horizon = 3. In horizon = 4, is more compact than but looser than . The goal of Figure 4 is to show that is an upper bound of and we can use a less compact Q-value function to reduce time of computing, but it still can guide A* to search the optimal policy.
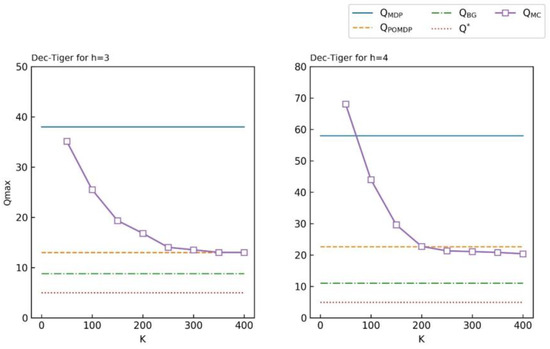
Figure 4.
Convergence of . as the sample time increases. converges to , which means is an upper bound for , but is less compact than .
6.3. Analysis and Discussion
CEMC outperforms the state-of-the-art exact heuristic algorithm ICE with compact Q-value function in terms of runtime and memory. There are three reasons for CEMC’s performance.
Firstly, we propose a new Q-value function representation , which is an upper bound for the optimal Q-value function . QMC is an anytime Q-value function, which makes it possible to compute as required. Adaptive sample and heavy rollout speed up the computation of .
Secondly, CEMC calculates the Q-value function as required and does not maintain a large matrix to store all . For problems with a large joint action-observation space and horizon, maintaining the matrix will run out of memory. In addition, it can be seen from problems, Box Pushing and Mars Rovers, in Table 1 that it is costly to calculate the Q-value function (time of computing Q-value for ICE is more than 1100 s). If not every pair is computed, it will save much time. A tighter upper bound can speed up planning, as it allows the algorithm to prune the policy pool more [4], but a tighter value function increases time of computing Q-value function, which accordingly increases the overall time (total time for computing Q-value and planning).
Thirdly, an extended policy pruning strategy is used in CEMC. The pruning strategy uses the best lower bound ever found and the best accumulated Q-value function at time step to prune the policy pool. This technique avoids expanding those nodes that will not be the optimal ones in any case.
7. Conclusions
In this paper, we combine the advantages of the heuristic algorithm and MCTS, and propose a new Q-value function representation and a novel offline algorithm CEMC, generalizing the prior method. In particular, we demonstrate two important results: (i) Computation of the Q-value function as required is an important reason for the CEMC’s performance. This permits us no longer to maintain a large matrix to store all Q-value function pairs, which saves much memory; (ii) There is no need to compute Q-value functions as compact as possible. Experimental results demonstrate that it is costly to compute compact Q-value functions. Other techniques such as an adaptive sample, heavy rollout, and policy pruning strategy are introduced to speed up the algorithm. In the future work, we plan to analyze the relationship between the loose extent and sample times in order to find the smallest to optimally solving Dec-POMDPs.
Author Contributions
J.Z. proposed the method and wrote the main part of this paper; Y.P. designed the experiment of this paper; R.W. and Y.F. checked the grammar; H.Y. supported this work financially and checked the paper.
Funding
This research was funded by the research foundation of Space Engineering University, grant number: zx10356.
Acknowledgments
The authors acknowledge the financial support received from the research foundation of Space Engineering University, grant number: zx10356, for their support and encouragement in carrying out this research.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A

Table A1.
Domain parameters and number of for different .
Table A1.
Domain parameters and number of for different .
| Problem | Domain Parameters | ||||||
|---|---|---|---|---|---|---|---|
| n | |S| | |A| | |O| | h = 2 | h = 5 | h = 10 | |
| Dec-Tiger | 2 | 2 | 3 | 2 | 6561 | 3.43 × 1030 | 1.39 × 10977 |
| Recycling Robots | 2 | 4 | 3 | 2 | 6561 | 3.43 × 1030 | 1.39 × 10977 |
| Grid-Small | 2 | 16 | 5 | 2 | 390625 | 5.42 × 1044 | 3.09 × 101431 |
| Box Pushing | 2 | 100 | 4 | 5 | 3.34 × 107 | 5.23 × 10940 | 1.25 × 102,939,746 |
| Mars Rovers | 2 | 256 | 6 | 8 | 1.69 × 1014 | 1.88 × 107285 | 2.57 × 10238,723,869 |
| Broadcast Channel | 2 | 4 | 2 | 2 | 256 | 1.84 × 1019 | 3.23 × 10616 |
Lemma 1. Proofs
We use a Dec-POMDP with k steps delayed communication model to prove Lemma 1. This model can be denoted as an augmented MDP, which is a reformulation of the prior work [35,36] and extended to the Dec-POMDP setting [4].
The augmented MDP is defined as , where an augmented state is composed of a joint action-observation history and a joint policy tree :
The contained is a joint depth-k policy tree starting from stage and is a -steps-to-go sub-tree policy. For example, if k = 2, represents a joint depth-2 policy tree for . For , state contains and .
An augmented action is a joint policy mapping length-k observation histories to joint actions at stage t + k. The transition model is a probability with an empty observation at stage t, where , is an initial joint action at stage and meaning appending a policy to . The reward model is defined as .
Therefore, the optimal Q-value function for a k-steps delayed communication model for is as follows.
For , there are stages to go and the Q-value function is the same as the original one.
If = 0, is a depth-0 policy and reduces to or , reduces to . Equation (18) reduces to . Contrasting with Equation (7), we can get that corresponds to the Q-value function of a 0-delayed communication system. According to the theory of [4], a Dec-POMDP is identical to an h-steps delayed communication system. The optimal Q-value function of a Dec-POMDP with k-steps delayed communication is an upper bound to , that of a k + 1-steps delayed communication system. This means that , the Q-value function of a 0-delayed communication system, is an upper bound of the optimal Q-value function of a Dec-POMDP (h-steps delayed communication system), that is:
References
- Bernstein, D.S.; Givan, R.; Immerman, N.; Zilberstein, S. The complexity of decentralized control of Markov decision processes. Math. Oper. Res. 2002, 27, 819–840. [Google Scholar] [CrossRef]
- Szer, D.; Charpillet, F.; Zilberstein, S. MAA*: A heuristic search algorithm for solving decentralized POMDPs. In Proceedings of the 21st Conference on Uncertainty in Artificial Intelligence, Edinburgh, UK, 4 June 2005; pp. 576–583. [Google Scholar]
- Oliehoek, F.A.; Spaan, M.T.; Amato, C.; Whiteson, S. Incremental clustering and expansion for faster optimal planning in Dec-POMDPs. J. Artif. Intell. Res. 2013, 46, 449–509. [Google Scholar] [CrossRef][Green Version]
- Oliehoek, F.A.; Spaan, M.T.; Vlassis, N. Optimal and approximate Q-value functions for decentralized POMDPs. J. Artif. Intell. Res. 2008, 32, 289–353. [Google Scholar] [CrossRef]
- Wu, F.; Zilberstein, S.; Chen, X. Online planning for ad hoc autonomous agent teams. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, 28 June 2011; pp. 439–445. [Google Scholar]
- Kocsis, L.; Szepesvári, C. Bandit based Monte-Carlo planning. In Proceedings of the 17th European Conference on Machine Learning, Berlin, Germany, 18 September 2006; pp. 282–293. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Kocsis, L.; Szepesvári, C.; Willemson, J. Improved Monte-Carlo Search; University of Tartu: Tartu, Estonia, 2006. [Google Scholar]
- Amato, C.; Dibangoye, J.S.; Zilberstein, S. Incremental policy generation for finite-horizon DEC-POMDPs. In Proceedings of the Proceedings of the Nineteenth International Conference on Automated Planning and Scheduling, Thessaloniki, Greece, 16 October 2009; pp. 569–576. [Google Scholar]
- Lam, R.; Willcox, K.; Wolpert, D.H. Bayesian Optimization with a Finite Budget: An Approximate Dynamic Programming Approach. In Advances in Neural Information Processing Systems; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Barcelona, Spain, 2016; pp. 883–891. [Google Scholar]
- Rahmanian, H.; Warmuth, M.K. Online Dynamic Programming. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Bench/Los Angeles, CA, USA, 2017; pp. 2827–2837. [Google Scholar]
- Boularias, A.; Chaib-Draa, B. Exact dynamic programming for decentralized POMDPs with lossless policy compression. In Proceedings of the Eighteenth International Conference on Automated Planning and Scheduling, Sydney, Australia, 14 September 2008; pp. 20–27. [Google Scholar]
- Oliehoek, F.A.; Whiteson, S.; Spaan, M.T.J. Lossless clustering of histories in decentralized POMDPs. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, Budapest, Hungary, 10 May 2009; pp. 577–584. [Google Scholar]
- Spaan, M.T.J.; Oliehoek, F.A.; Amato, C. Scaling up optimal heuristic search in Dec-POMDPs via incremental expansion. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 28 June 2011; pp. 2027–2032. [Google Scholar]
- Lanctot, M.; Winands, M.H.M.; Pepels, T.; Sturtevant, N.R. Monte Carlo Tree Search with heuristic evaluations using implicit minimax backups. In Proceedings of the 2014 IEEE Conference on Computational Intelligence and Games, Dortmund, Germany, 26 August 2014; pp. 1–8. [Google Scholar]
- Aras, R.; Dutech, A. An investigation into mathematical programming for finite horizon decentralized POMDPs. J. Artif. Intell. Res. 2010, 37, 329–396. [Google Scholar] [CrossRef]
- Liu, M.; Amato, C.; Liao, X.; Carin, L.; How, J.P. Stick-Breaking Policy Learning in Dec-POMDPs. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2011–2017. [Google Scholar]
- Oliehoek, F.; Whiteson, S.; Spaan, M.T.J. Approximate Solutions for Factored Dec-POMDPs with Many Agents. In Proceedings of the 12th International Conference on Autonomous Agents and Multiagent Systems (AAMAS), St. Paul, MN, USA, 6–10 May 2013; Volume 1, pp. 563–570. [Google Scholar]
- Silver, D.; Veness, J. Monte-Carlo Planning in Large POMDPs. In Advances in Neural Information Processing Systems 23; Lafferty, J.D., Williams, C.K.I., Shawe-Taylor, J., Zemel, R.S., Culotta, A., Eds.; Curran Associates, Inc.: Barcelona, Spain, 2010; pp. 2164–2172. [Google Scholar]
- Amato, C.; Oliehoek, F.A. Scalable Planning and Learning for Multiagent POMDPs. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Oliehoek, F.A.; Amato, C. A Concise Introduction to Decentralized POMDPs; Springer: Berlin, Germany, 2016. [Google Scholar]
- Browne, C.B.; Powley, E.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; Colton, S. A Survey of Monte Carlo Tree Search Methods. IEEE Trans. Comput. Intell. Ai Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Amato, C.; Chowdhary, G.; Geramifard, A.; Üre, N.K. Decentralized control of partially observable Markov decision processes. In Proceedings of the IEEE Conference on Decision and Control, Florence, Italy, 10–13 December 2013; pp. 2398–2405. [Google Scholar]
- Omidshafiei, S.; Aghamohammadi, A.; Amato, C.; How, J.P. Decentralized Control of Partially Observable Markov Decision Processes using Belief Space Macro-actions. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 5962–5969. [Google Scholar]
- Szer, D.; Charpillet, F. An Optimal Best-First Search Algorithm for Solving Infinite Horizon Dec-POMDPs. In Machine Learning: ECML 2005; Springer: Berlin/Heidelberg, Germany; Porto, Portugal, 2005; Volume 3720, pp. 389–399. [Google Scholar]
- Chaslot, G.; Bakkes, S.; Szita, I.; Spronck, P. Monte-Carlo Tree Search: A New Framework for Game AI. In Proceedings of the Fourth Artificial Intelligence and Interactive Digital Entertainment Conference, Stanford, CA, USA, 22 October 2008; pp. 216–217. [Google Scholar]
- Chaudhry, M.U.; Lee, J.-H. MOTiFS: Monte Carlo Tree Search Based Feature Selection. Entropy 2018, 20, 385. [Google Scholar] [CrossRef]
- Schadd, F. Monte-Carlo Search Techniques in the Modern Board Game Thurn and Taxis; Maastricht University: Maastricht, The Netherlands, 2009. [Google Scholar]
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Silver, D.; Tesauro, G. Monte-Carlo simulation balancing. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 14 June 2009; pp. 945–952. [Google Scholar]
- Drake, P.; Uurtamo, S. Move Ordering vs Heavy Playouts: Where Should Heuristics Be Applied in Monte Carlo Go. In Proceedings of the 3rd North American Game-On Conference, Shiga, Japan, 15 September 2007; pp. 171–175. [Google Scholar]
- Sephton, N.; Cowling, P.I.; Powley, E.; Slaven, N.H. Heuristic move pruning in Monte Carlo Tree Search for the strategic card game Lords of War. In Proceedings of the 2014 IEEE Conference on Computational Intelligence and Games, Dortmund, Germany, 26–29 August 2014; pp. 1–7. [Google Scholar]
- Oliehoek, F.A.; Spaan, M.T.J.; Terwijn, B.; Robbel, P.; Messias, J.V. The MADP toolbox: An open source library for planning and learning in (multi-)agent systems. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Aicardi, M.; Davoli, F.; Minciardi, R. Decentralized optimal control of Markov chains with a common past information set. IEEE Trans. Autom. Control 1987, 32, 1028–1031. [Google Scholar] [CrossRef]
- Ooi, J.M.; Wornell, G.W. Decentralized control of a multiple access broadcast channel: Performance bounds. In Proceedings of the 35th IEEE Conference on Decision and Control, Kobe, Japan, 11 December 1996; Volume 1, pp. 293–298. [Google Scholar]




© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).