Assessing the Accuracy of ChatGPT in Answering Questions About Prolonged Disorders of Consciousness


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection and Evaluation
- Incorrect and potentially misleading information: the information provided is not consistent with the most recent scientific evidence or best clinical practice and could lead to conclusions unsupported by the data.
- Partially correct information, with significant errors: the information provided contains both correct elements and elements that are not in line with the most recent scientific evidence or best clinical practice.
- Correct but incomplete information: the information provided is consistent with the most recent scientific evidence and best clinical practice, but lacks some necessary elements to fully answer the question.
- Correct and complete information: The information provided is fully consistent with the most recent scientific evidence and best clinical practice.
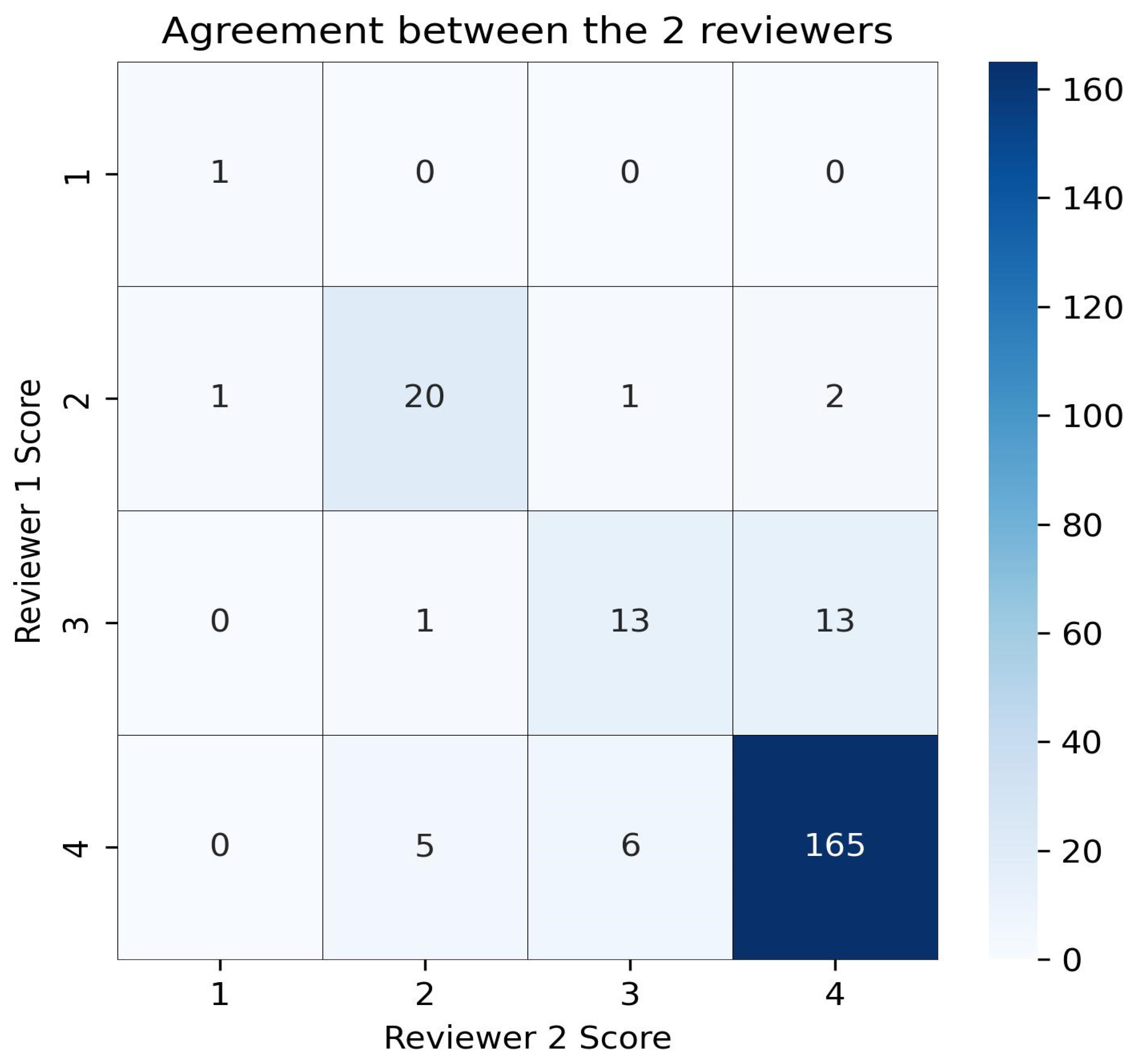
2.2. Data Analysis
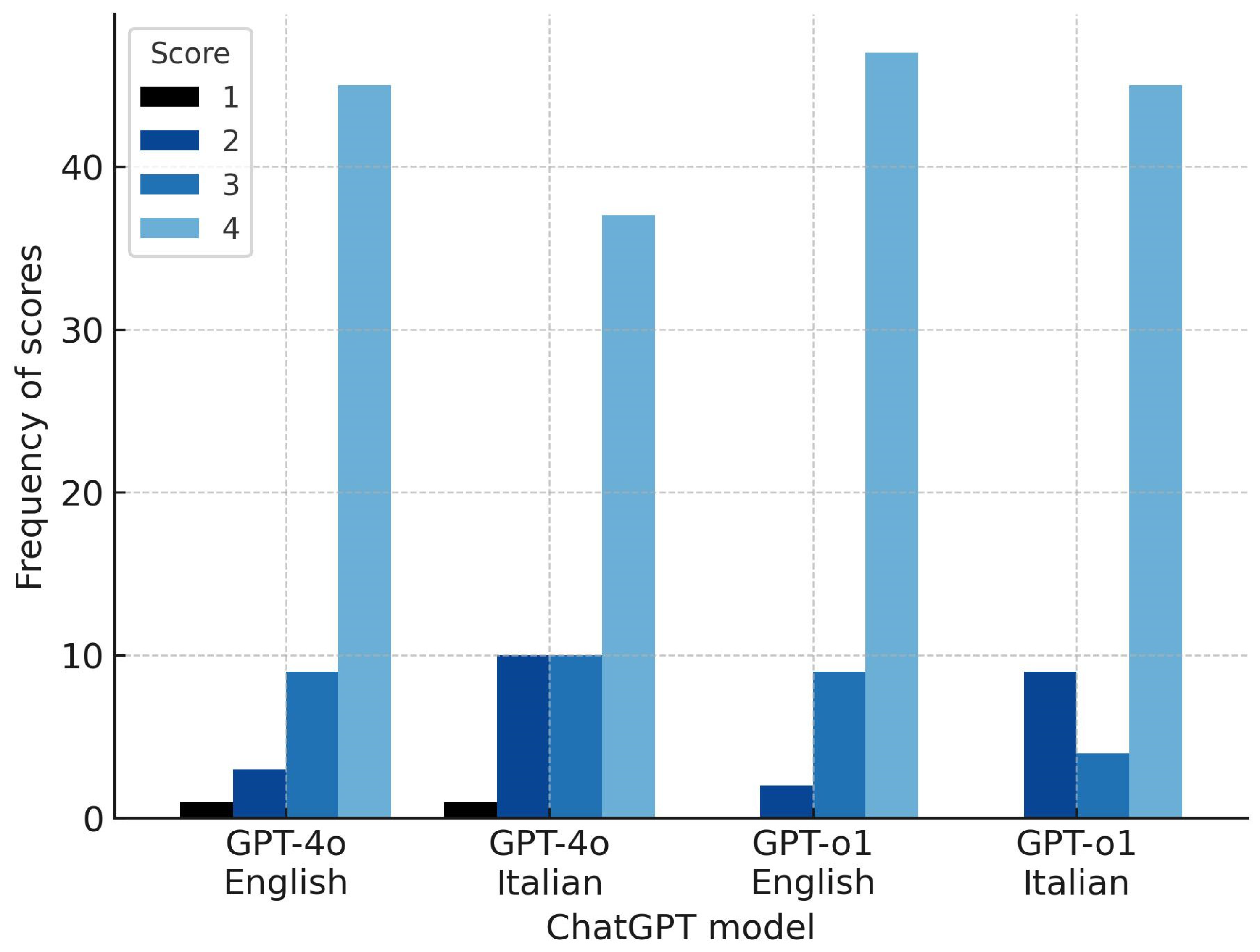
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DoC | Disorders of consciousness |
| UWS | Unresponsive wakefulness syndrome |
| MCS | Minimally conscious state |
| SSEPs | Somatosensory evoked potentials |
| EEG | Electroencephalogram |
References
- Giacino, J.T.; Katz, D.I.; Schiff, N.D.; Whyte, J.; Ashman, E.J.; Ashwal, S.; Barbano, R.; Hammond, F.M.; Laureys, S.; Ling, G.S.F.; et al. Comprehensive systematic review update summary: Disorders of consciousness: Report of the Guideline Development, Dissemination, and Implementation Subcommittee of the American Academy of Neurology; the American Congress of Rehabilitation Medicine; and the National Institute on Disability, Independent Living, and Rehabilitation Research. Neurology 2018, 91, 461–470. [Google Scholar] [CrossRef] [PubMed]
- Laureys, S.; Celesia, G.G.; Cohadon, F.; Lavrijsen, J.; León-Carrión, J.; Sannita, W.G.; Sazbon, L.; Schmutzhard, E.; von Wild, K.R.; Zeman, A.; et al. Unresponsive wakefulness syndrome: A new name for the vegetative state or apallic syndrome. BMC Med. 2010, 8, 68. [Google Scholar] [CrossRef] [PubMed]
- Giacino, J.T.; Ashwal, S.; Childs, N.; Cranford, R.; Jennett, B.; Katz, D.I.; Kelly, J.P.; Rosenberg, J.H.; Whyte, J.; Zafonte, R.D.; et al. The minimally conscious state: Definition and diagnostic criteria. Neurology 2002, 58, 349–353. [Google Scholar] [CrossRef]
- Giovannetti, A.M.; Leonardi, M.; Pagani, M.; Sattin, D.; Raggi, A. Burden of caregivers of patients in vegetative state and minimally conscious state. Acta Neurol. Scand. 2013, 127, 10–18. [Google Scholar] [CrossRef]
- Gonzalez-Lara, L.E.; Munce, S.; Christian, J.; Owen, A.M.; Weijer, C.; Webster, F. The multiplicity of caregiving burden: A qualitative analysis of families with prolonged disorders of consciousness. Brain Inj. 2021, 35, 200–208. [Google Scholar] [CrossRef] [PubMed]
- Schnakers, C.; Vanhaudenhuyse, A.; Giacino, J.; Ventura, M.; Boly, M.; Majerus, S.; Moonen, G.; Laureys, S. Diagnostic accuracy of the vegetative and minimally conscious state: Clinical consensus versus standardized neurobehavioral assessment. BMC Neurol. 2009, 9, 35. [Google Scholar] [CrossRef]
- Schnakers, C.; Hirsch, M.; Noé, E.; Llorens, R.; Lejeune, N.; Veeramuthu, V.; De Marco, S.; Demertzi, A.; Duclos, C.; Morrissey, A.M.; et al. Covert Cognition in Disorders of Consciousness: A Meta-Analysis. Brain Sci. 2020, 10, 930. [Google Scholar] [CrossRef]
- Song, M.; Yang, Y.; Yang, Z.; Cui, Y.; Yu, S.; He, J.; Jiang, T. Prognostic models for prolonged disorders of consciousness: An integrative review. Cell Mol. Life Sci. 2020, 77, 3945–3961. [Google Scholar] [CrossRef]
- Ganesh, S.; Guernon, A.; Chalcraft, L.; Harton, B.; Smith, B.; Louise-Bender Pape, T. Medical comorbidities in disorders of consciousness patients and their association with functional outcomes. Arch. Phys. Med. Rehabil. 2013, 94, 1899–1907. [Google Scholar] [CrossRef]
- Bagnato, S.; Boccagni, C.; Sant’angelo, A.; Prestandrea, C.; Romano, M.C.; Galardi, G. Neuromuscular involvement in vegetative and minimally conscious states following acute brain injury. J. Peripher. Nerv. Syst. 2011, 16, 315–321. [Google Scholar] [CrossRef]
- Bagnato, S.; Boccagni, C.; Galardi, G. Structural epilepsy occurrence in vegetative and minimally conscious states. Epilepsy Res. 2013, 103, 106–109. [Google Scholar] [CrossRef] [PubMed]
- OpenAI. ChatGPT: Optimizing Language Models for Dialogue. Available online: https://openai.com/blog/chatgpt/ (accessed on 27 March 2025).
- Introducing OpenAI o1-Preview. 2024. Available online: https://openai.com/index/introducing-openai-o1-preview/ (accessed on 6 April 2025).
- Temsah, M.H.; Jamal, A.; Alhasan, K.; Temsah, A.A.; Malki, K.H. OpenAI o1-preview vs. ChatGPT in healthcare: A new frontier in medical AI reasoning. Cureus 2024, 16, e70640. [Google Scholar] [CrossRef] [PubMed]
- Volkmer, S.; Meyer-Lindenberg, A.; Schwarz, E. Large language models in psychiatry: Opportunities and challenges. Psychiatry Res. 2024, 339, 116026. [Google Scholar] [CrossRef] [PubMed]
- Sridi, C.; Brigui, S. The use of ChatGPT in occupational medicine: Opportunities and threats. Ann. Occup. Environ. Med. 2023, 35, e42. [Google Scholar] [CrossRef]
- Cohen, I.G. What Should ChatGPT Mean for Bioethics? Am. J. Bioeth. 2023, 23, 8–16. [Google Scholar] [CrossRef]
- Pan, A.; Musheyev, D.; Bockelman, D.; Loeb, S.; Kabarriti, A.E. Assessment of Artificial Intelligence Chatbot Responses to Top Searched Queries About Cancer. JAMA Oncol. 2023, 9, 1437–1440. [Google Scholar] [CrossRef]
- Yeo, Y.H.; Samaan, J.S.; Ng, W.H.; Ting, P.S.; Trivedi, H.; Vipani, A.; Ayoub, W.; Yang, J.D.; Liran, O.; Spiegel, B.; et al. Assessing the performance of ChatGPT in answering questions regarding cirrhosis and hepatocellular carcinoma. Clin. Mol. Hepatol. 2023, 29, 721–732. [Google Scholar] [CrossRef]
- Samaan, J.S.; Yeo, Y.H.; Rajeev, N.; Hawley, L.; Abel, S.; Ng, W.H.; Srinivasan, N.; Park, J.; Burch, M.; Watson, R.; et al. Assessing the Accuracy of Responses by the Language Model ChatGPT to Questions Regarding Bariatric Surgery. Obes. Surg. 2023, 33, 1790–1796. [Google Scholar] [CrossRef]
- Oliveira, A.L.; Coelho, M.; Guedes, L.C.; Cattoni, M.B.; Carvalho, H.; Duarte-Batista, P. Performance of ChatGPT 3.5 and 4 as a tool for patient support before and after DBS surgery for Parkinson’s disease. Neurol. Sci. 2024, 45, 5757–5764. [Google Scholar] [CrossRef]
- Horiuchi, D.; Tatekawa, H.; Shimono, T.; Walston, S.L.; Takita, H.; Matsushita, S.; Oura, T.; Mitsuyama, Y.; Miki, Y.; Ueda, D. Accuracy of ChatGPT generated diagnosis from patient’s medical history and imaging findings in neuroradiology cases. Neuroradiology 2024, 66, 73–79. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef] [PubMed]
- Giacino, J.T.; Katz, D.I.; Schiff, N.D.; Whyte, J.; Ashman, E.J.; Ashwal, S.; Barbano, R.; Hammond, F.M.; Laureys, S.; Ling, G.S.F.; et al. Practice guideline update recommendations summary: Disorders of consciousness: Report of the Guideline Development, Dissemination, and Implementation Subcommittee of the American Academy of Neurology; the American Congress of Rehabilitation Medicine; and the National Institute on Disability, Independent Living, and Rehabilitation Research. Neurology 2018, 91, 450–460. [Google Scholar] [CrossRef] [PubMed]
- Kondziella, D.; Bender, A.; Diserens, K.; van Erp, W.; Estraneo, A.; Formisano, R.; Laureys, S.; Naccache, L.; Ozturk, S.; Rohaut, B.; et al. European Academy of Neurology guideline on the diagnosis of coma and other disorders of consciousness. Eur. J. Neurol. 2020, 27, 741–756. [Google Scholar] [CrossRef] [PubMed]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589–596. [Google Scholar] [CrossRef]
- Goodman, R.S.; Patrinely, J.R.; Stone, C.A., Jr.; Zimmerman, E.; Donald, R.R.; Chang, S.S.; Berkowitz, S.T.; Finn, A.P.; Jahangir, E.; Scoville, E.A.; et al. Accuracy and Reliability of Chatbot Responses to Physician Questions. JAMA Netw. Open 2023, 6, e2336483. [Google Scholar] [CrossRef]
- Zhou, S.; Luo, X.; Chen, C.; Jiang, H.; Yang, C.; Ran, G.; Yu, J.; Yin, C. The performance of large language model-powered chatbots compared to oncology physicians on colorectal cancer queries. Int. J. Surg. 2024, 110, 6509–6517. [Google Scholar] [CrossRef]
- Huang, A.S.; Hirabayashi, K.; Barna, L.; Parikh, D.; Pasquale, L.R. Assessment of a Large Language Model’s Responses to Questions and Cases About Glaucoma and Retina Management. JAMA Ophthalmol. 2024, 142, 371–375, Erratum in JAMA Ophthalmol. 2024, 142, 393. [Google Scholar] [CrossRef]
- Haver, H.L.; Lin, C.T.; Sirajuddin, A.; Yi, P.H.; Jeudy, J. Use of ChatGPT, GPT-4, and Bard to Improve Readability of ChatGPT’s Answers to Common Questions About Lung Cancer and Lung Cancer Screening. AJR Am. J. Roentgenol. 2023, 221, 701–704. [Google Scholar] [CrossRef]
- Kaiser, K.N.; Hughes, A.J.; Yang, A.D.; Mohanty, S.; Maatman, T.K.; Gonzalez, A.A.; Patzer, R.E.; Bilimoria, K.Y.; Ellis, R.J. Use of large language models as clinical decision support tools for management pancreatic adenocarcinoma using National Comprehensive Cancer Network guidelines. Surgery 2025, 109267. [Google Scholar] [CrossRef]
- Taniguchi, M.; Lindsey, J.S. Performance of chatbots in queries concerning fundamental concepts in photochemistry. Photochem. Photobiol. 2024; online ahead of print. [Google Scholar] [CrossRef]
- Estraneo, A.; Moretta, P.; Loreto, V.; Lanzillo, B.; Cozzolino, A.; Saltalamacchia, A.; Lullo, F.; Santoro, L.; Trojano, L. Predictors of recovery of responsiveness in prolonged anoxic vegetative state. Neurology 2013, 80, 464–470. [Google Scholar] [CrossRef] [PubMed]
- Bagnato, S.; Prestandrea, C.; D’Agostino, T.; Boccagni, C.; Rubino, F. Somatosensory evoked potential amplitudes correlate with long-term consciousness recovery in patients with unresponsive wakefulness syndrome. Clin. Neurophysiol. 2021, 132, 793–799. [Google Scholar] [CrossRef] [PubMed]
- Covelli, V.; Sattin, D.; Giovannetti, A.M.; Scaratti, C.; Willems, M.; Leonardi, M. Caregiver’s burden in disorders of consciousness: A longitudinal study. Acta Neurol. Scand. 2016, 134, 352–359. [Google Scholar] [CrossRef]
- Pagani, M.; Giovannetti, A.M.; Covelli, V.; Sattin, D.; Raggi, A.; Leonardi, M. Physical and mental health, anxiety and depressive symptoms in caregivers of patients in vegetative state and minimally conscious state. Clin. Psychol. Psychother. 2014, 21, 420–426. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Category | Questions in English | Questions in Italian | ||
|---|---|---|---|---|
| ChatGPT 4o | ChatGPT o1 | ChatGPT 4o | ChatGPT o1 | |
| Clinical data (n = 29) | ||||
| 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| 1 (3.4%) | 2 (6.9%) | 5 (17.2%) | 6 (20.7%) |
| 2 (6.9%) | 5 (17.2%) | 6 (20.7%) | 2 (6.9%) |
| 26 (89.7) | 22 (75.9%) | 18 (62.1%) | 21 (72.4%) |
| Instrumental diagnostics (n = 14) | ||||
| 1 (7.1%) | 0 (0%) | 1 (7.1%) | 0 (0%) |
| 0 (0%) | 0 (0%) | 3 (21.4%) | 3 (21.4%) |
| 2 (14.3%) | 2 (14.3%) | 1 (7.1%) | 0 (0%) |
| 11 (78.6%) | 12 (85.7%) | 9 (64.3%) | 11 (78.6%) |
| Therapy (n = 14) | ||||
| 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| 2 (14.3%) | 0 (0%) | 2 (14.3%) | 0 (0%) |
| 4 (28.6) | 1 (7.1%) | 2 (14.3%) | 1 (7.1%) |
| 8 (57.1) | 13 (92.9%) | 10 (71.4%) | 13 (92.9%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bagnato, S.; Boccagni, C.; Bonavita, J. Assessing the Accuracy of ChatGPT in Answering Questions About Prolonged Disorders of Consciousness. Brain Sci. 2025, 15, 392. https://doi.org/10.3390/brainsci15040392
Bagnato S, Boccagni C, Bonavita J. Assessing the Accuracy of ChatGPT in Answering Questions About Prolonged Disorders of Consciousness. Brain Sciences. 2025; 15(4):392. https://doi.org/10.3390/brainsci15040392
Chicago/Turabian StyleBagnato, Sergio, Cristina Boccagni, and Jacopo Bonavita. 2025. "Assessing the Accuracy of ChatGPT in Answering Questions About Prolonged Disorders of Consciousness" Brain Sciences 15, no. 4: 392. https://doi.org/10.3390/brainsci15040392
APA StyleBagnato, S., Boccagni, C., & Bonavita, J. (2025). Assessing the Accuracy of ChatGPT in Answering Questions About Prolonged Disorders of Consciousness. Brain Sciences, 15(4), 392. https://doi.org/10.3390/brainsci15040392