

A Lightweight Deep Learning Semantic Segmentation Model for Optical-Image-Based Post-Harvest Fruit Ripeness Analysis of Sugar Apples (Annona squamosa)



Abstract
1. Introduction
- This paper explored, for the first time, the feasibility of applying semantic segmentation techniques to the detection of sugar apple (Annona squamosa) ripeness;
- This paper proposed an improved semantic segmentation model (ECD-DeepLabv3+) which, while significantly reducing model complexity (Model Params and Flops), achieves enhancements in performance metrics, such as MIoU, MPA, MF1, and PA;
- This paper created a semantic segmentation dataset for post-harvest sugar apple optical images to evaluate the performance of the ECD-DeepLabv3+.
2. Materials and Methods
2.1. Dataset
2.2. Image Preprocessing
2.3. Data Augmentation
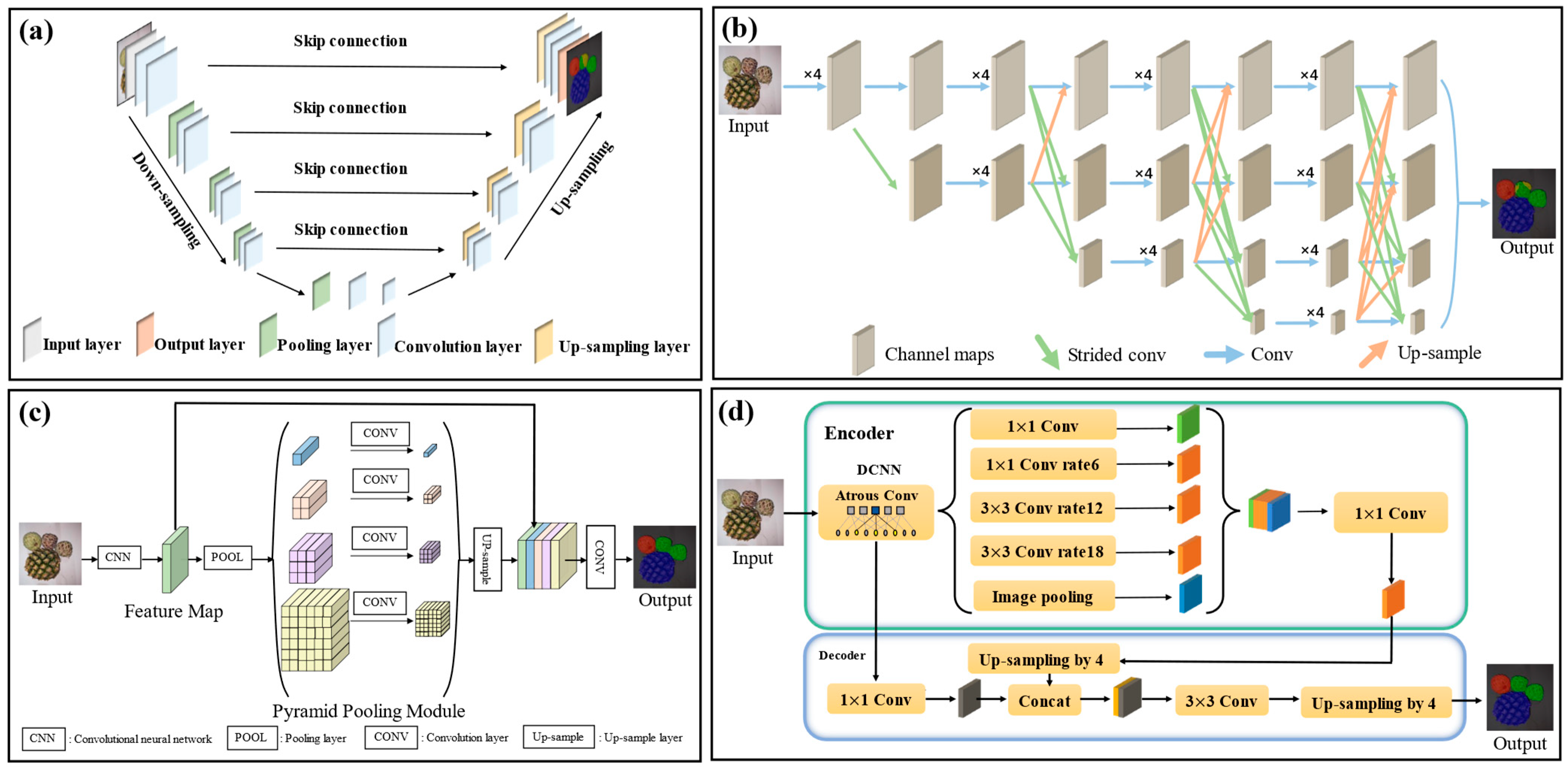
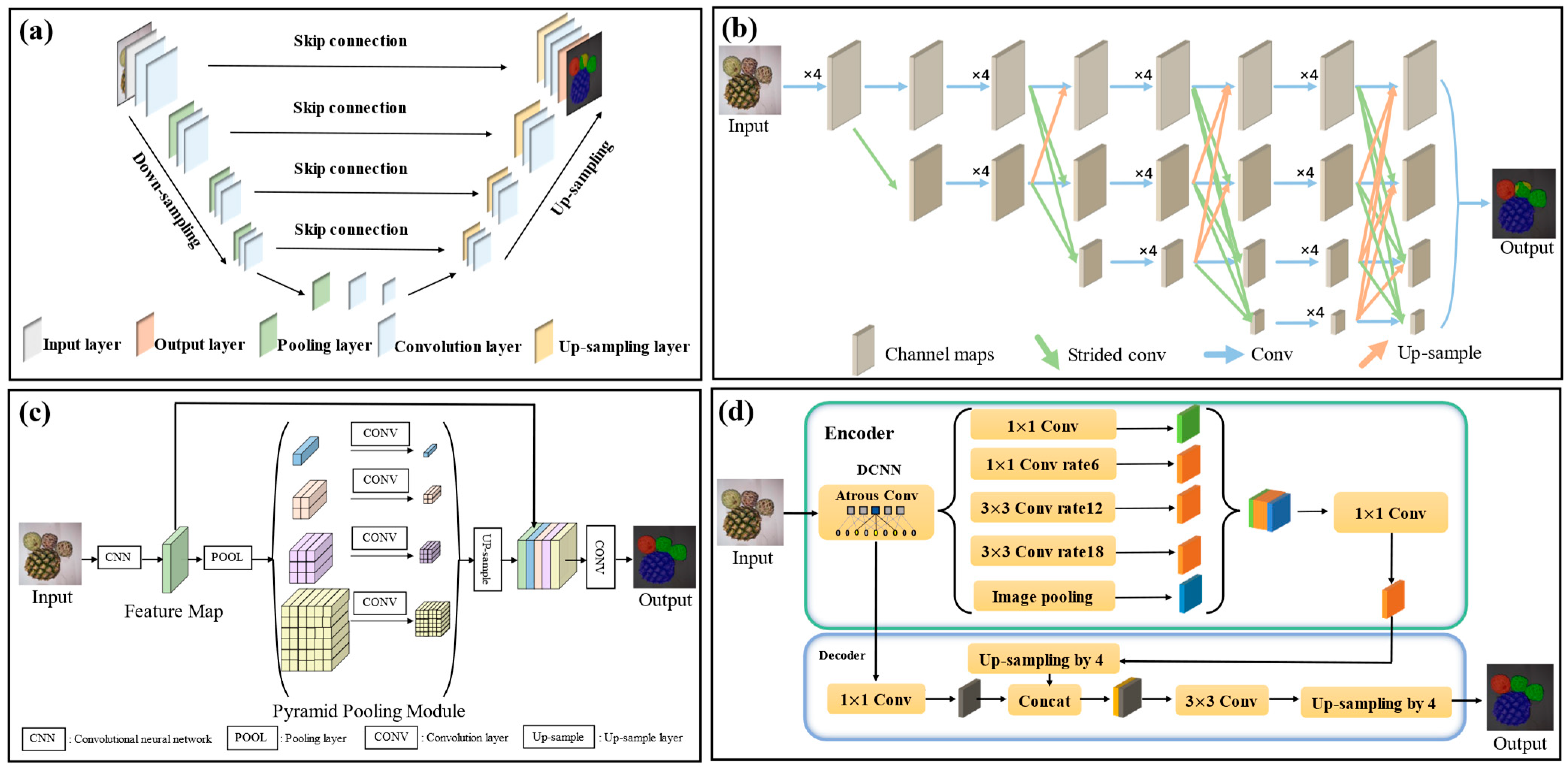
2.4. Four Well-Known Models Being Compared
2.4.1. U-Net
2.4.2. HRNet
2.4.3. PSPNet
2.4.4. DeepLabv3+
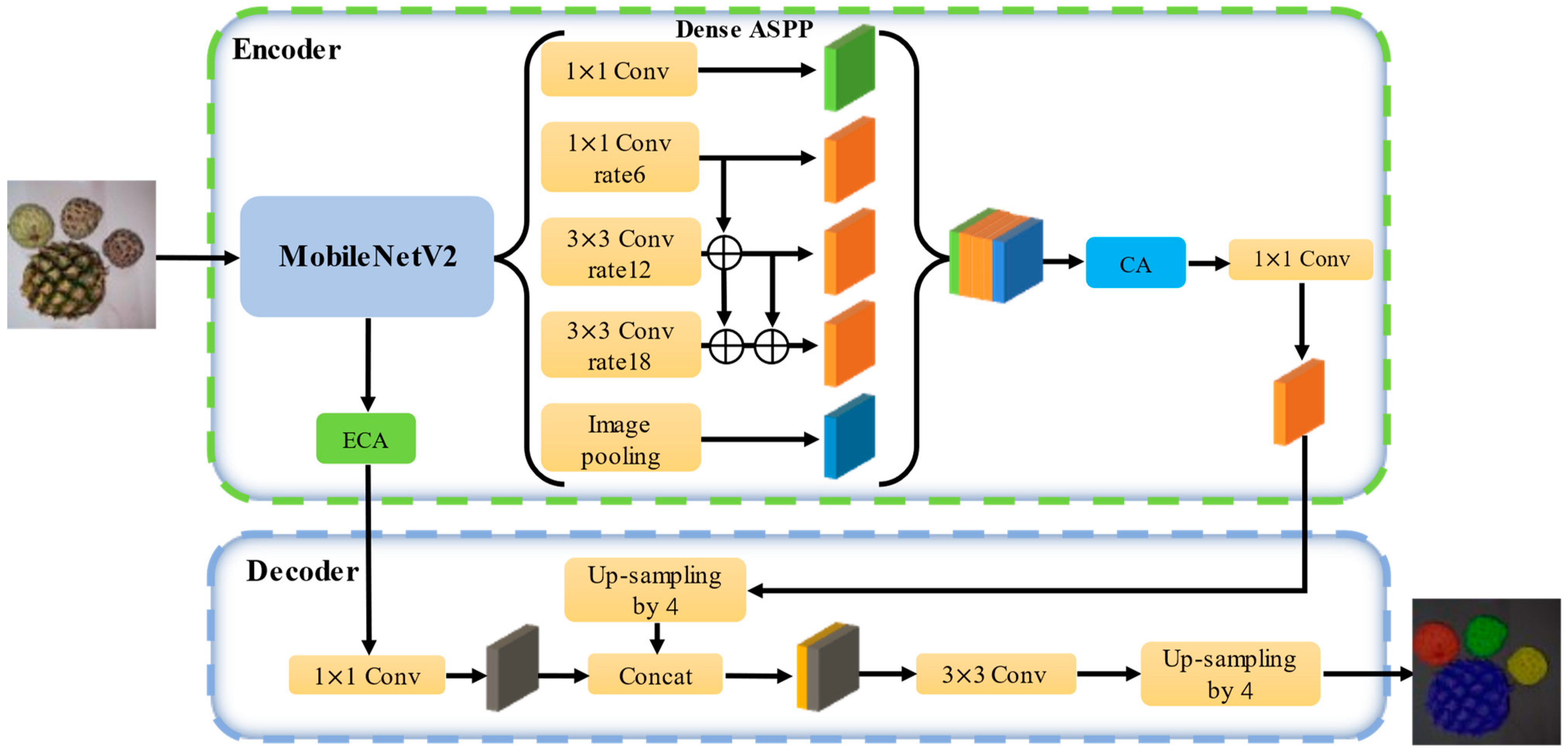
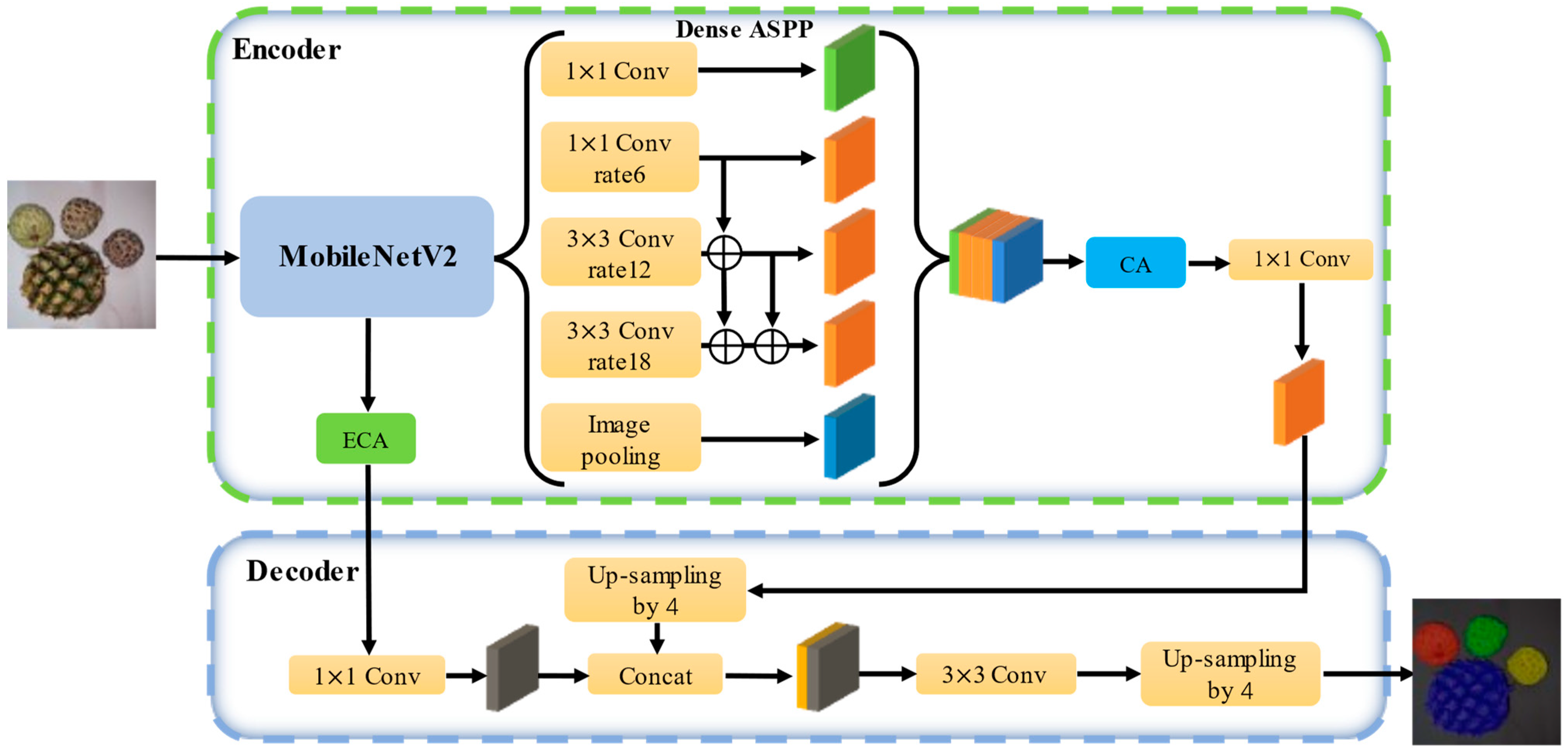
2.5. Architecture of the Proposed ECD-DeepLabv3+
- i.
- Replacing the backbone with MobileNetV2 and introducing an efficient channel attention (ECA) module in the junction between the encoding and decoding regions, which can substantially decrease the complexity of the model, including parameters (Params) and floating-point operations (Flops), while simultaneously boosting its capabilities;
- ii.
- Following the feature maps output by ASPP in DeepLabv3+, adding the coordinate attention (CA) module to improve attention towards the positional and long-range dependency information of post-harvest sugar apple images;
- iii.
- Merging the densely connected atrous spatial pyramid pooling (Dense ASPP), which can minimize overlooked pixel features, preserving the completeness of feature information and achieving an enlarged receptive field.
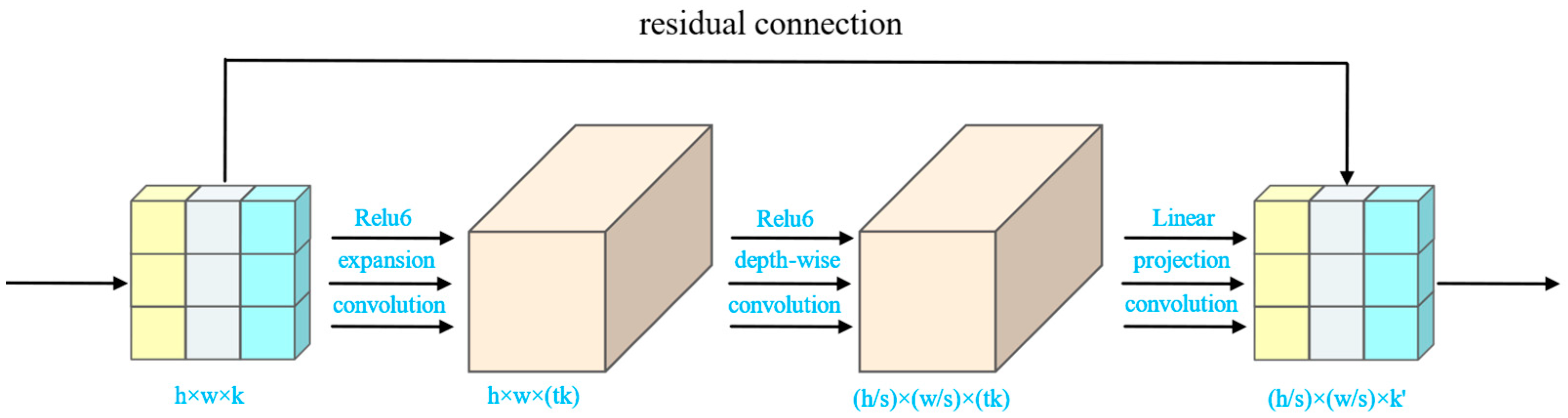
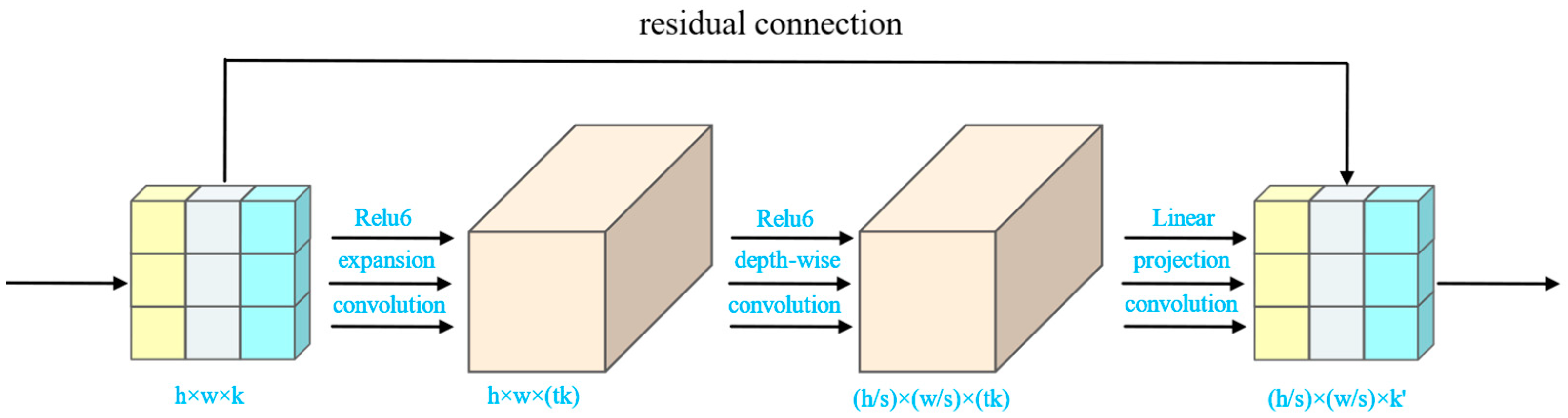
2.5.1. MobileNetv2
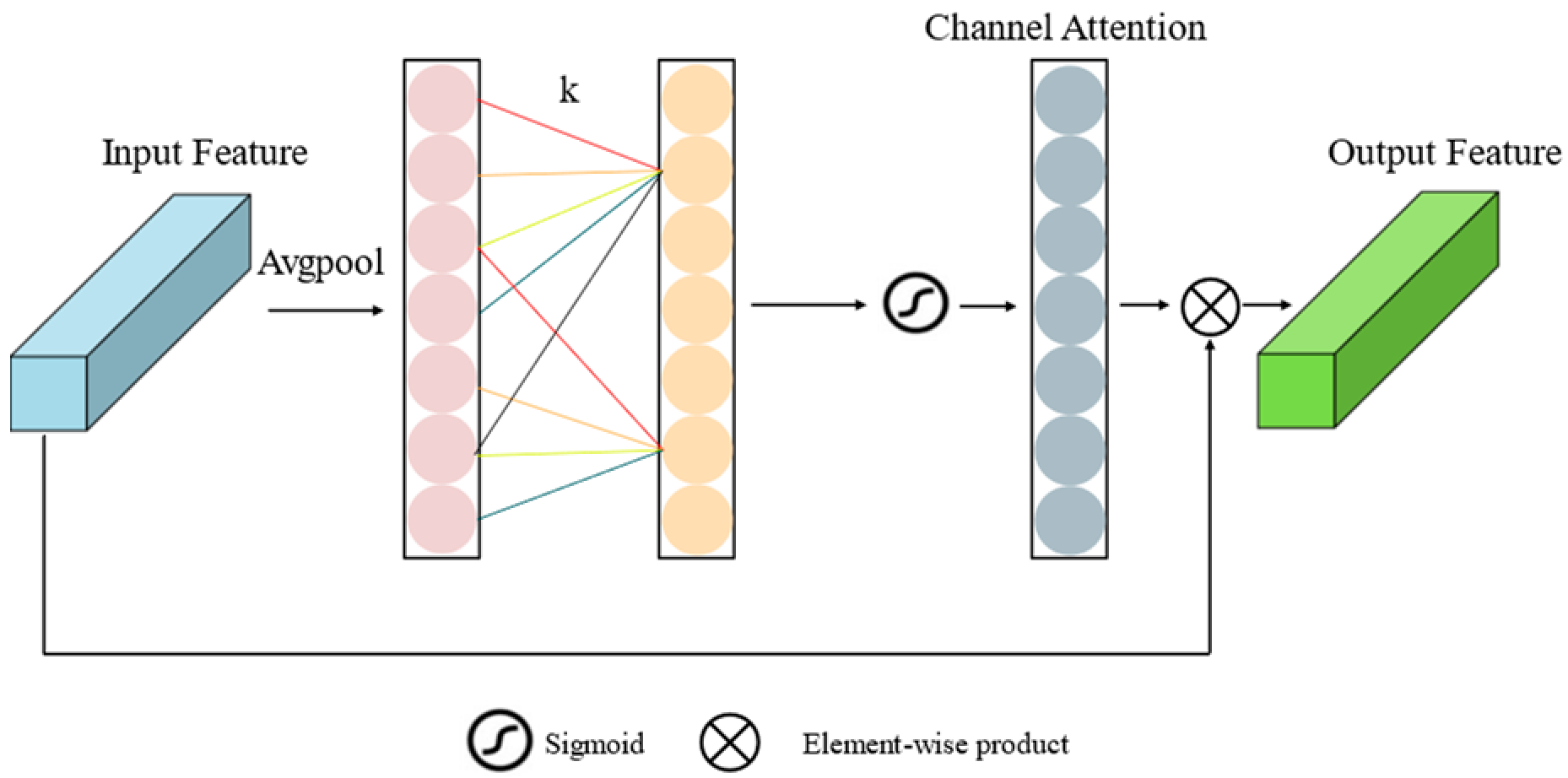
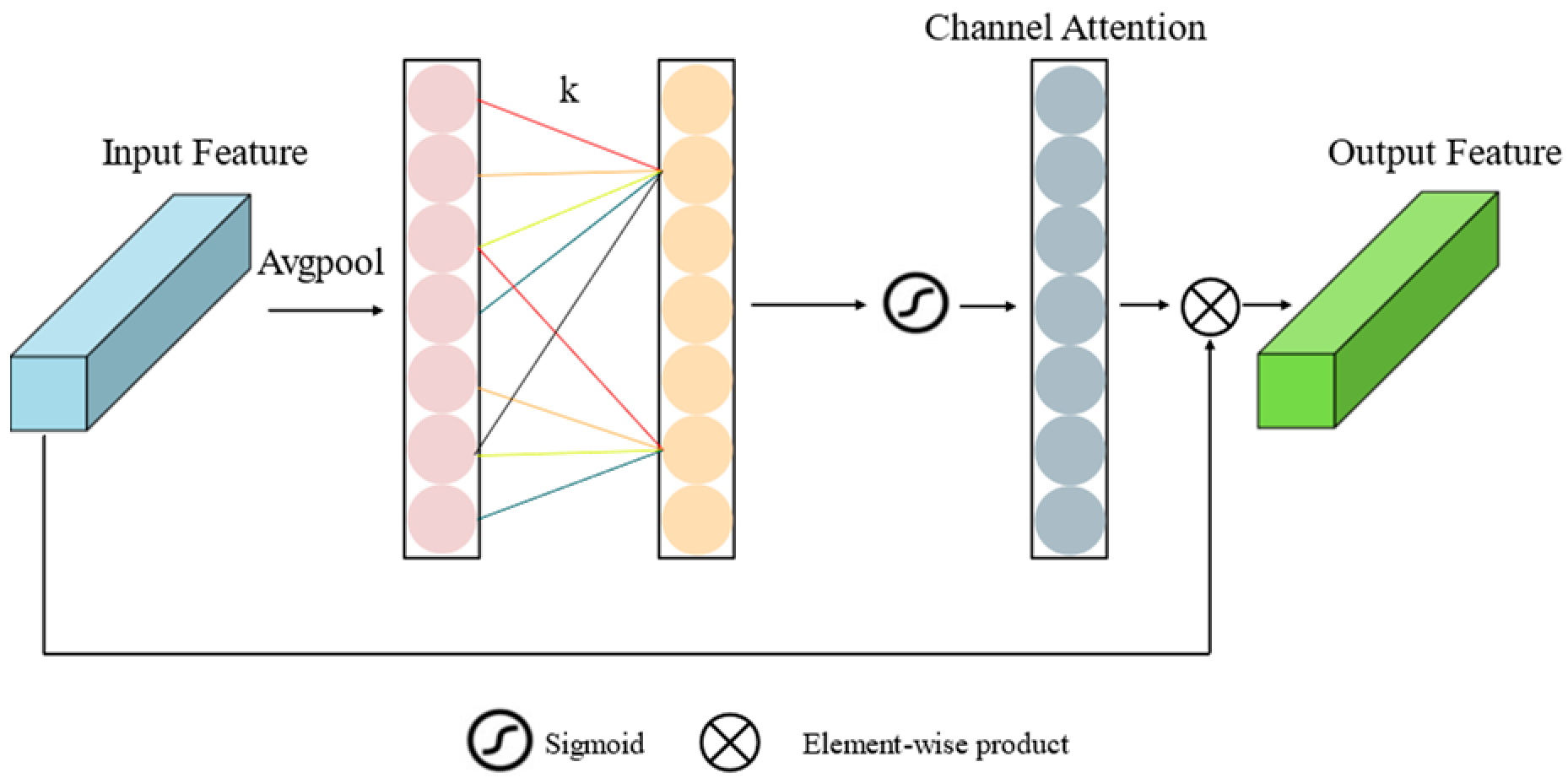
2.5.2. Efficient Channel Attention
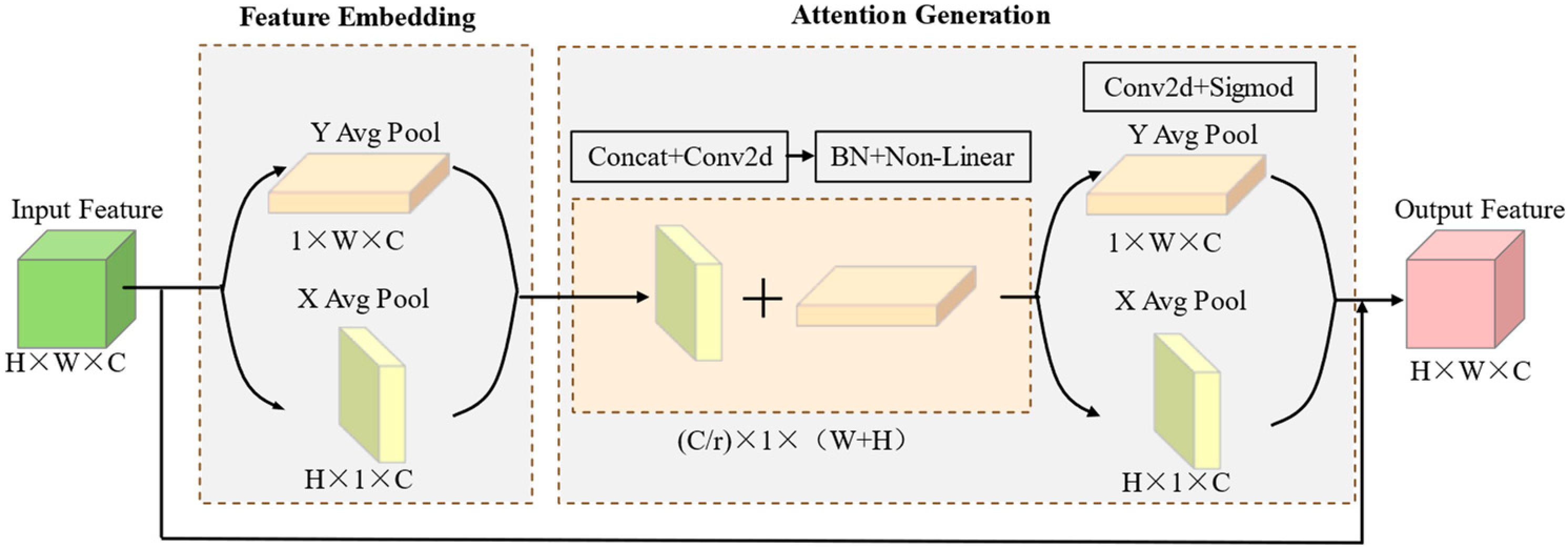
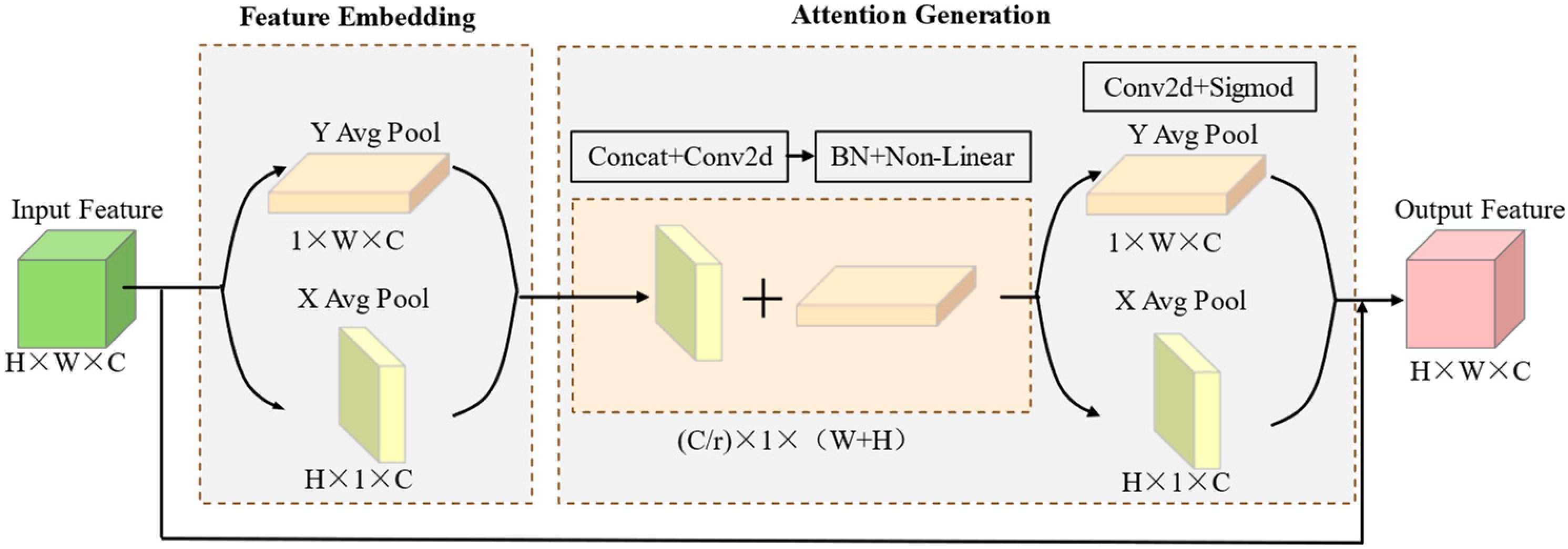
2.5.3. Coordinate Attention
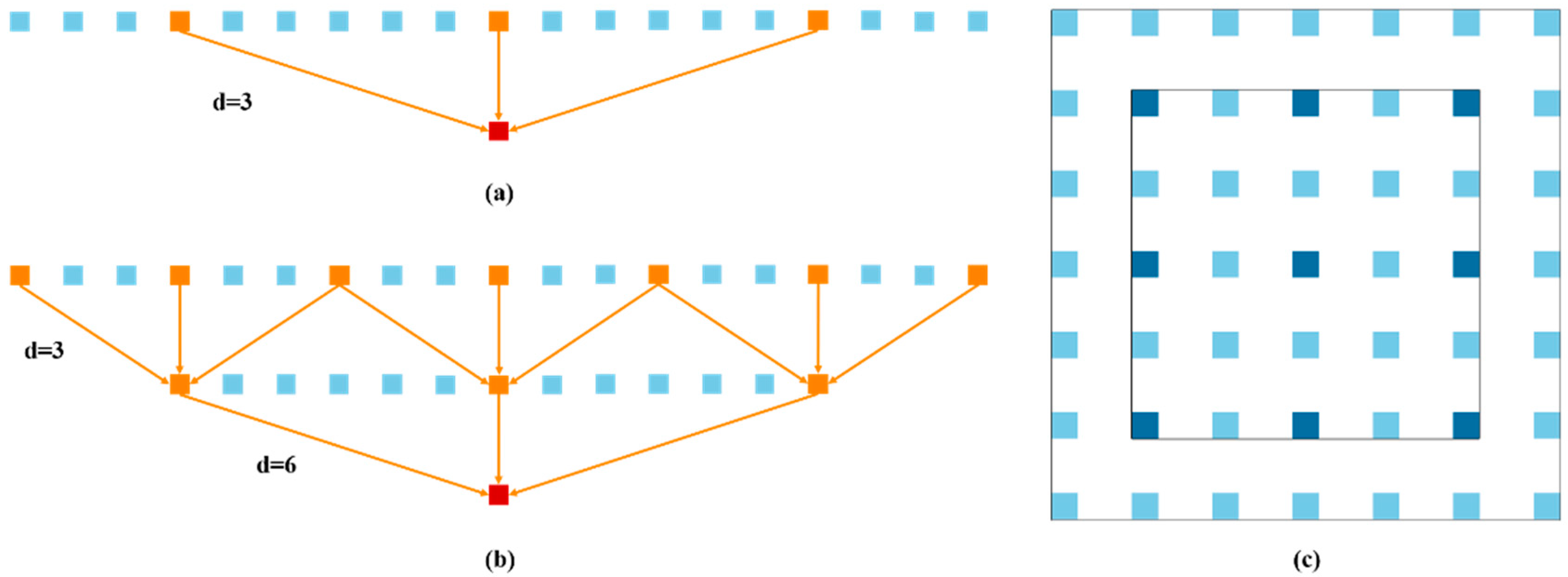
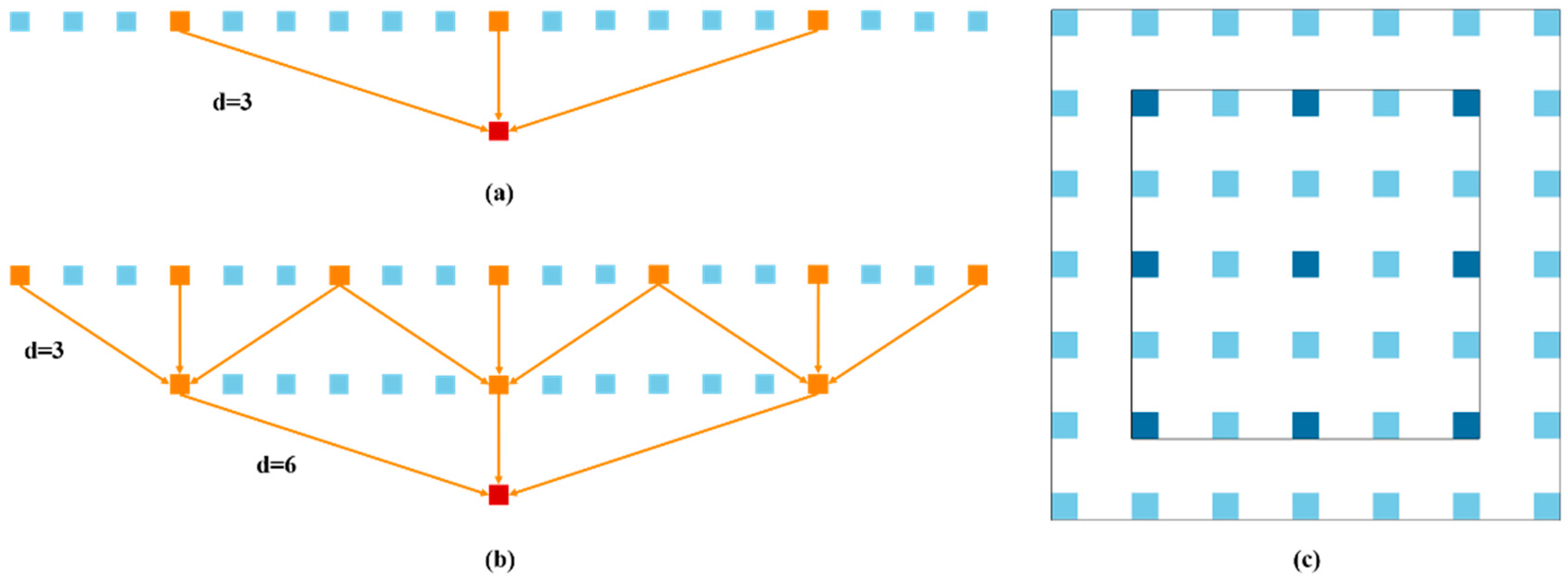
2.5.4. Dense ASPP
2.6. Evaluation Indicators
3. Results
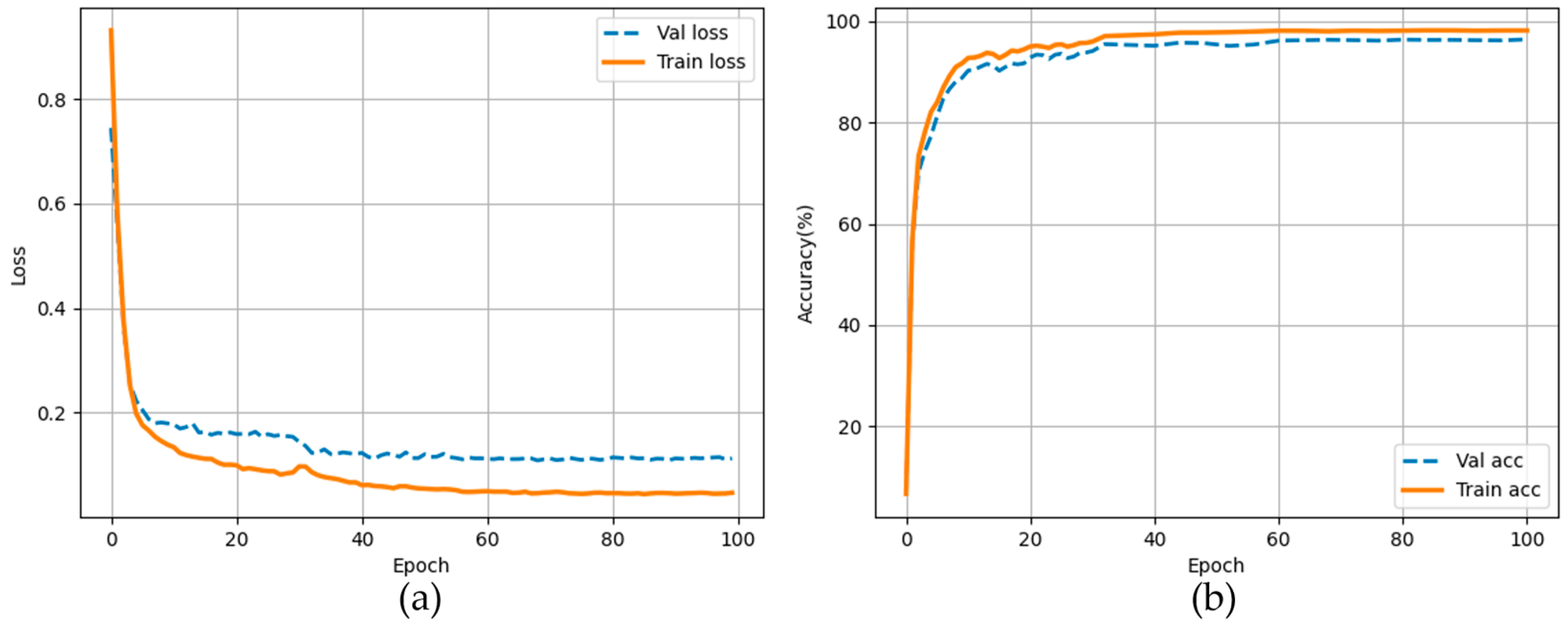
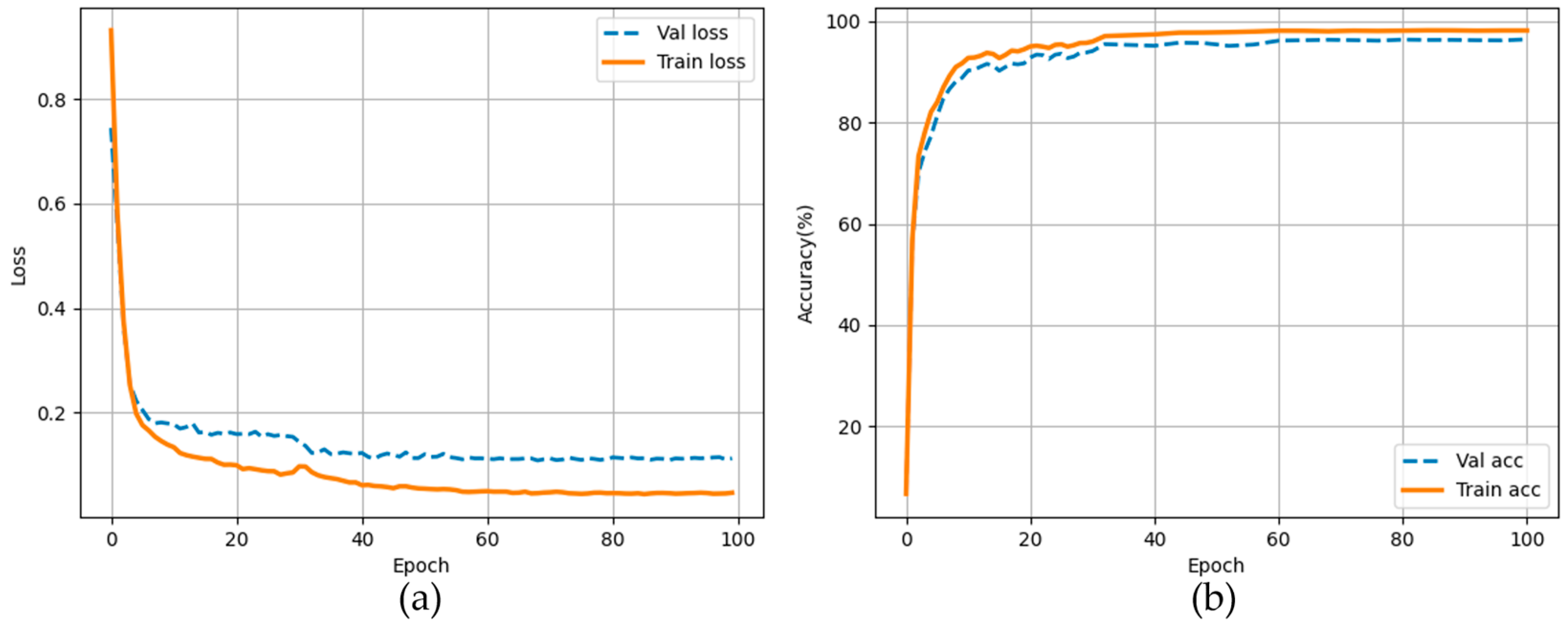
3.1. Experiment Details
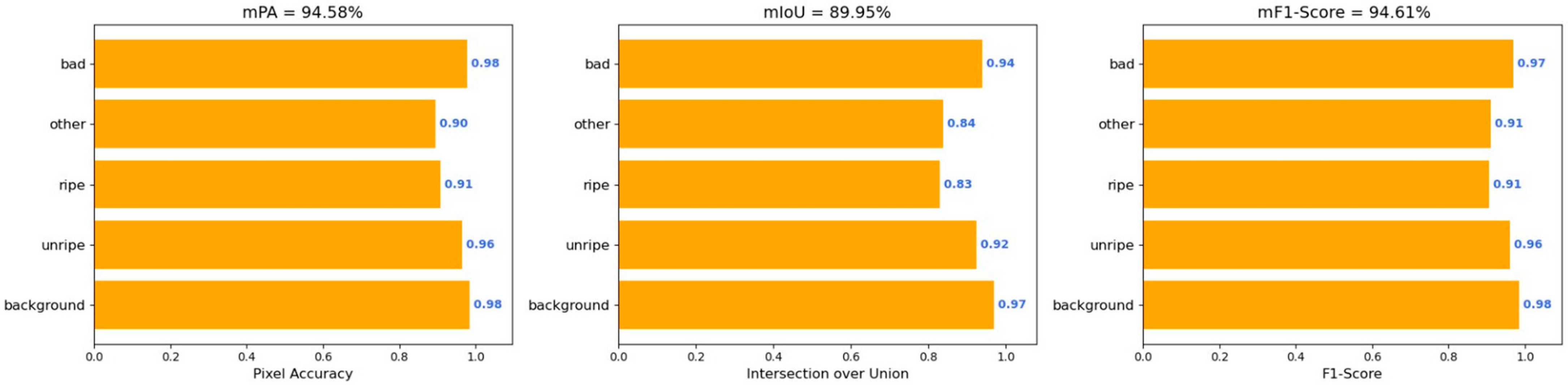
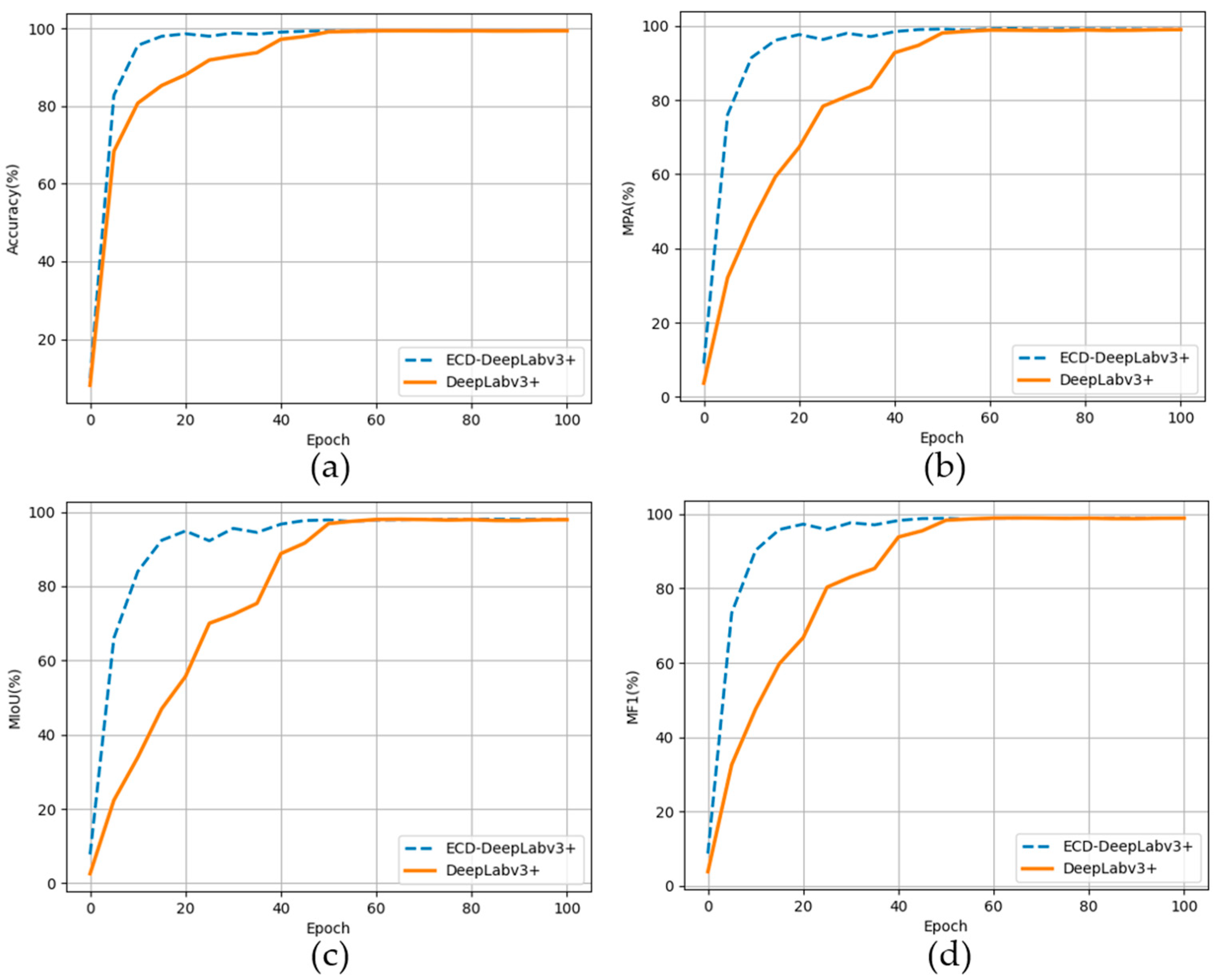
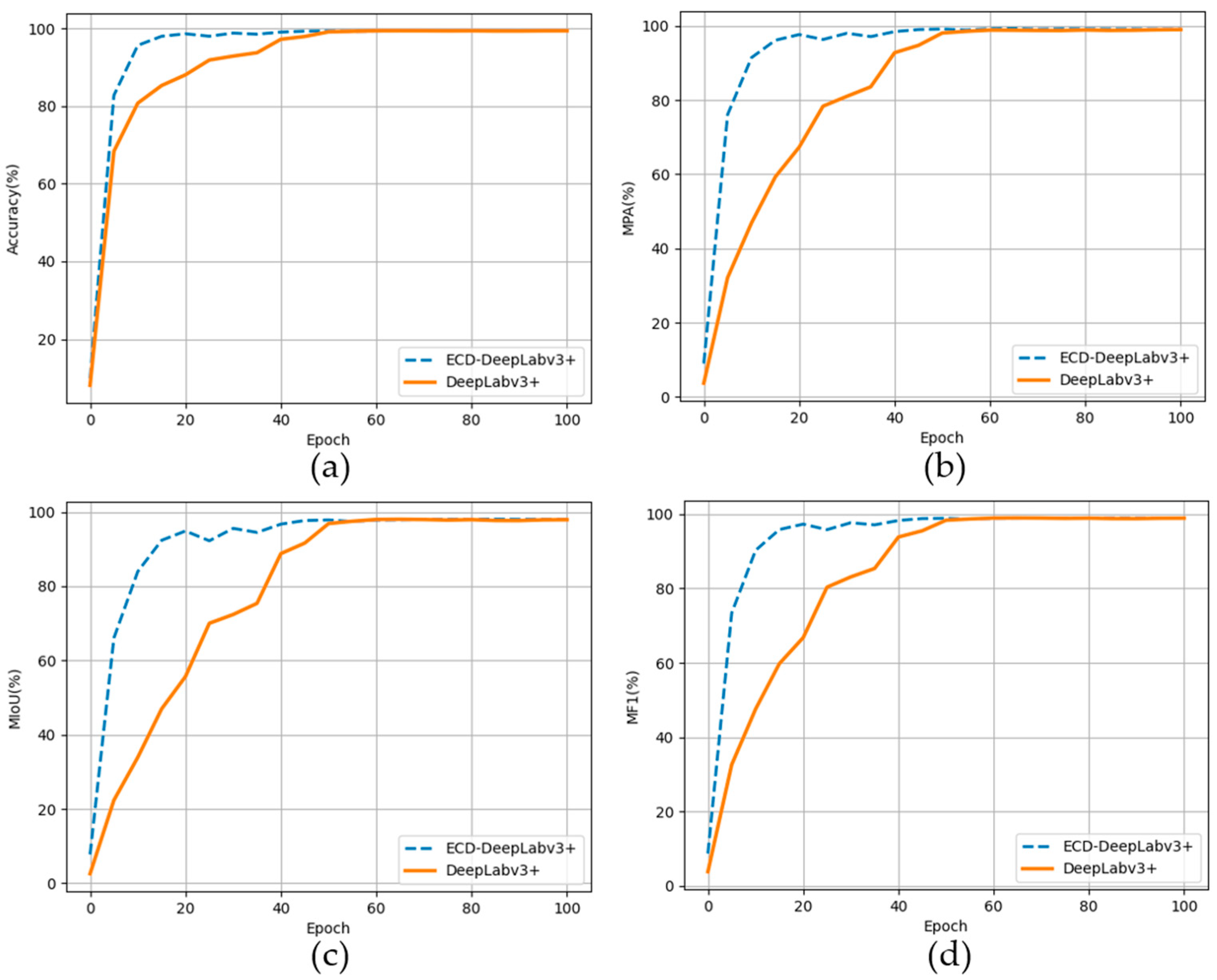
3.2. Quantitative Analysis
3.3. Qualitative Analysis
3.4. Ablaton Analysis
3.5. Generalizability Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yousuf, B.; Qadri, O.S.; Srivastava, A.K. Recent developments in shelf-life extension of fresh-cut fruits and vegetables by application of different edible coatings: A review. LWT-Food Sci. Technol. 2018, 89, 198–209. [Google Scholar] [CrossRef]
- Heasley, C.; Clayton, B.; Muileboom, J.; Schwanke, A.; Rathnayake, S.; Richter, A.; Little, M. “I was eating more fruits and veggies than I have in years”: A mixed methods evaluation of a fresh food prescription intervention. Arch. Public Health 2021, 79, 16. [Google Scholar] [CrossRef] [PubMed]
- Davis, A.-A. Synthesizing Oral and Systemic Health in a Food Desert. J. Healthc. Sci. Humanit. 2019, 9, 51–67. [Google Scholar] [PubMed]
- Ma, L.; Zhang, M.; Bhandari, B.; Gao, Z.X. Recent developments in novel shelf life extension technologies of fresh-cut fruits and vegetables. Trends Food Sci. Technol. 2017, 64, 23–38. [Google Scholar] [CrossRef]
- Gargade, A.; Khandekar, S.A. IEEE: A Review: Custard Apple Leaf Parameter Analysis and Leaf Disease Detection using Digital Image Processing. In Proceedings of the 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 267–271. [Google Scholar]
- Mo, Y.W.; Gong, D.Q.; Liang, G.B.; Han, R.H.; Xie, J.H.; Li, W.C. Enhanced preservation effects of sugar apple fruits by salicylic acid treatment during post-harvest storage. J. Sci. Food Agric. 2008, 88, 2693–2699. [Google Scholar] [CrossRef]
- Kumar, M.; Changan, S.; Tomar, M.; Prajapati, U.; Saurabh, V.; Hasan, M.; Sasi, M.; Maheshwari, C.; Singh, S.; Dhumal, S.; et al. Custard Apple (Annona squamosa L.) Leaves: Nutritional Composition, Phytochemical Profile, and Health-Promoting Biological Activities. Biomolecules 2021, 11, 614. [Google Scholar] [CrossRef] [PubMed]
- Yadav, S. Management of Oral Squamous Papilloma Using Annona squamosa (Custard Apple) Leaves: A Novel Case. Cureus J. Med. Sci. 2023, 15, e34806. [Google Scholar] [CrossRef]
- Kumari, N.; Prakash, S.; Kumar, M.; Radha; Zhang, B.H.; Sheri, V.; Rais, N.; Chandran, D.; Dey, A.; Sarkar, T.; et al. Seed Waste from Custard Apple (Annona squamosa L.): A Comprehensive Insight on Bioactive Compounds, Health Promoting Activity and Safety Profile. Processes 2022, 10, 2119. [Google Scholar] [CrossRef]
- Mosca, J.L.; Alves, R.E.; Filgueiras, H.A.C. Harvest and postharvest handling of sugar-apple and soursop: Current research status in Brazil and review of recommended techniques. In Proceedings of the International Symposium on Effect of Preharvest and Postharvest Factors on Storage of Fruit, Warsaw, Poland, 3–7 August 1997; International Society for Horticultural Science: Leuven, Belgium, 1997; pp. 273–280. [Google Scholar]
- Tian, H.-q.; Ying, Y.-b.; Lu, H.-s.; Fu, X.-p.; Yu, H.-y. Measurement of soluble solids content in watermelon by Vis/NIR diffuse transmittance technique. J. Zhejiang Univ. Sci. B 2007, 8, 105–110. [Google Scholar] [CrossRef] [PubMed]
- Abdullah, N.E.; Hashim, H.; Yusof, Y.W.M.; Osman, F.N.; Kusim, A.S.; Adam, M.S. IEEE: A Characterization of Watermelon Leaf Diseases using Fuzzy Logic. In Proceedings of the IEEE Symposium on Business, Engineering and Industrial Applications (ISBEIA), Bandung, Indonesia, 23–26 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–6. [Google Scholar]
- Abdullah, N.E.; Hashim, H.; Sulaiman, M.F.; Madzhi, N.K.; Sampian, A.F.M.; Ismail, F.A. A Rudimentary Optical System in Detecting Ripeness of Red Watermelon. In Proceedings of the 4th International Conference on Electronic Devices, Systems and Applications (ICEDSA), Kuala Lumpur, Malaysia, 14–15 September 2015; Iop Publishing Ltd.: Bristol, UK, 2015. [Google Scholar]
- Hasanuddin, N.H.; Wahid, M.H.A.; Shahimin, M.M.; Hambali, I.; Nazir, N.S.; Khairuddin, N.Z.; Ramli, M.M.; Isa, S.S.M. Design and Development of ZnO Based Gas Sensor for Fruit Ripening Detection. In Proceedings of the 2nd International Conference on Green Design and Manufacture (IConGDM), Phuket, Thailand, 1–2 May 2016; E D P Sciences: Les Ulis, France, 2016. [Google Scholar]
- ArrÁZola, G.; Villadiego, F.; Alvis, A. Mechanical properties and simulation of finite element firmness in Carica papaya L. Tainung F1 cultivated on the high Sinu (Cordoba-Colombia). Rev. Colomb. Cienc. Hortícolas 2021, 15, e10809. [Google Scholar] [CrossRef]
- Phoophuangpairoj, R. Computerized Unripe and Ripe Durian Striking Sound Recognition Using Syllable-based HMMs. In Proceedings of the 2nd International Conference on Mechanics and Control Engineering (ICMCE 2013), Beijing, China, 1–2 September 2013; Trans Tech Publications Ltd.: Wollerau, Switzerland, 2013; pp. 927–935. [Google Scholar]
- González-Araiza, J.R.; Ortiz-Sánchez, M.C.; Vargas-Luna, F.M.; Cabrera-Sixto, J.M. Application of electrical bio-impedance for the evaluation of strawberry ripeness. Int. J. Food Prop. 2017, 20, 1044–1050. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A real-time apple targets detection method for picking robot based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Ji, W.; Zhang, T.; Xu, B.; He, G. Apple recognition and picking sequence planning for harvesting robot in the complex environment. J. Agric. Eng. 2023, 55, 1549. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Li, K.S.; Wang, J.C.; Jalil, H.; Wang, H. A fast and lightweight detection algorithm for passion fruit pests based on improved YOLOv5. Comput. Electron. Agric. 2023, 204, 107534. [Google Scholar] [CrossRef]
- Xiao, B.J.; Nguyen, M.; Yan, W.Q. Apple ripeness identification from digital images using transformers. Multimed. Tools Appl. 2023, 83, 7811–7825. [Google Scholar] [CrossRef]
- Appe, S.N.; Arulselvi, G.; Balaji, G.N. CAM-YOLO: Tomato detection and classification based on improved YOLOv5 using combining attention mechanism. PeerJ Comput. Sci. 2023, 9, e1463. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.J.; Jeong, S.; Kim, H.; Jeong, S.; Yun, G.Y.; Park, K. IEEE: Detecting Ripeness of Strawberry and Coordinates of Strawberry Stalk using Deep Learning. In Proceedings of the 13th International Conference on Ubiquitous and Future Networks (ICUFN), Electr Network, Barcelona, Spain, 5–8 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 454–458. [Google Scholar]
- Zhao, Z.; Hicks, Y.; Sun, X.F.; Luo, C.X. Peach ripeness classification based on a new one-stage instance segmentation model. Comput. Electron. Agric. 2023, 214, 108369. [Google Scholar] [CrossRef]
- Sanchez, R.B.; Angelo, C.; Esteves, J.; Linsangan, N.B. Determination of Sugar Apple Ripeness via Image Processing Using Convolutional Neural Network. In Proceedings of the 2023 15th International Conference on Computer and Automation Engineering (ICCAE), Sydney, Australia, 3–5 March 2023; pp. 333–337. [Google Scholar]
- Peng, H.X.; Xue, C.; Shao, Y.Y.; Chen, K.Y.; Xiong, J.T.; Xie, Z.H.; Zhang, L.H. Semantic Segmentation of Litchi Branches Using DeepLabV3+ Model. IEEE Access 2020, 8, 164546–164555. [Google Scholar] [CrossRef]
- Al-Abri, A.S.; Mahgoub, O.; Kadim, I.T.; Al-Marzooqi, W.; Goddard, S.R. Effects of feeding fish-wheat bran meal on performance and meat quality of Omani sheep. J. Appl. Anim. Res. 2017, 45, 234–238. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Feng, C.C.; Zhang, H.; Wang, H.R.; Wang, S.; Li, Y.L. Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network. Sensors 2020, 20, 2069. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.Q.; Xu, G.X.; An, Z.L.; Liu, Y.B. EPSTO-ARIMA: Electric Power Stochastic Optimization Predicting Based on ARIMA. In Proceedings of the 2021 IEEE 9th International Conference on Smart City and Informatization (iSCI), Shenyang, China, 18–22 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 70–75. [Google Scholar]
- Mumuni, A.; Mumuni, F. Data augmentation: A comprehensive survey of modern approaches. Array 2022, 16, 100258. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Springer International Publishing Ag: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Wang, J.D.; Sun, K.; Cheng, T.H.; Jiang, B.R.; Deng, C.R.; Zhao, Y.; Liu, D.; Mu, Y.D.; Tan, M.K.; Wang, X.G.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. IEEE: Pyramid Scene Parsing Network. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.C.E.; Zhu, Y.K.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer International Publishing Ag: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. IEEE: MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Wang, Q.; Aramoon, O.; Qiu, P.F.; Qu, G. IEEE: Efficient Transfer Learning on Modeling Physical Unclonable Functions. In Proceedings of the 21st International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 25–26 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S.; Ieee Comp, S.O.C. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Virtual, 19–25 June 2021; IEEE Computer Soc: Piscataway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar]
- Fu, H.X.; Meng, D.; Li, W.H.; Wang, Y.C. Bridge Crack Semantic Segmentation Based on Improved Deeplabv3+. J. Mar. Sci. Eng. 2021, 9, 671. [Google Scholar] [CrossRef]
- Mainasara, M.M.; Abu Bakar, M.F.; Mohamed, M.; Linatoc, A.C.; Sabran, F. Sugar Apple—Annona squamosa Linn. In Exotic Fruits; Rodrigues, S., de Oliveira Silva, E., de Brito, E.S., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 397–402. [Google Scholar] [CrossRef]
- Roy, K.; Chaudhuri, S.S.; Pramanik, S. Deep learning based real-time Industrial framework for rotten and fresh fruit detection using semantic segmentation. Microsyst. Technol. 2021, 27, 3365–3375. [Google Scholar] [CrossRef]
- Fang, H.R.; Deng, J.; Bai, Y.X.; Feng, B.; Li, S.; Shao, S.Y.; Chen, D.S. CLFormer: A Lightweight Transformer Based on Convolutional Embedding and Linear Self-Attention with Strong Robustness for Bearing Fault Diagnosis Under Limited Sample Conditions. IEEE Trans. Instrum. Meas. 2022, 71, 8. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.F.; He, L.L.; Pan, G.Y.; Ma, H. IEEE: ART: An Efficient Transformer with Atrous Residual Learning for Medical Images. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1907–1912. [Google Scholar]
- Wang, C.S.; Du, P.F.; Wu, H.R.; Li, J.X.; Zhao, C.J.; Zhu, H.J. A cucumber leaf disease severity classification method based on the fusion of DeepLabV3+and U-Net. Comput. Electron. Agric. 2021, 189, 106373. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple flower detection using deep convolutional networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef]
- Kolhar, S.; Jagtap, J. Convolutional neural network based encoder-decoder architectures for semantic segmentation of plants. Ecol. Inform. 2021, 64, 101373. [Google Scholar] [CrossRef]
- Hussein, B.R.; Malik, O.A.; Ong, W.H.; Slik, J.W.F. Automated Extraction of Phenotypic Leaf Traits of Individual Intact Herbarium Leaves from Herbarium Specimen Images Using Deep Learning Based Semantic Segmentation. Sensors 2021, 21, 4549. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.W.; Jia, W.K.; Sun, M.L.; Hou, S.J.; Zheng, Y.J. A novel green apple segmentation algorithm based on ensemble U-Net under complex orchard environment. Comput. Electron. Agric. 2021, 180, 105900. [Google Scholar] [CrossRef]
- Xu, Y.L.; Zhao, B.; Zhai, Y.T.; Chen, Q.Y.; Zhou, Y. Maize Diseases Identification Method Based on Multi-Scale Convolutional Global Pooling Neural Network. IEEE Access 2021, 9, 27959–27970. [Google Scholar] [CrossRef]
- Emami, S.; Martínez-Muñoz, G. A Gradient Boosting Approach for Training Convolutional and Deep Neural Networks. IEEE Open J. Signal Process. 2023, 4, 313–321. [Google Scholar] [CrossRef]
- Yang, H.; Weng, F.Z.; Anderson, K. Estimation of ATMS Antenna Emission From Cold Space Observations. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4479–4487. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Train (Original) | Train (Augmented) | Val | Test | Total (Original) | Total (Augmented) |
|---|---|---|---|---|---|---|
| Unripe | 449 | 898 | 162 | 157 | 768 | 1217 |
| Ripe | 595 | 1190 | 196 | 195 | 986 | 1581 |
| Bad | 502 | 1004 | 187 | 181 | 870 | 1372 |
| Other (Kiwifruit) | 503 | 1006 | 146 | 145 | 794 | 1297 |
| Other (Pineapple) | 231 | 462 | 77 | 88 | 396 | 627 |
| Other (Total) | 581 | 1162 | 156 | 198 | 935 | 1516 |
| Background | 600 | 1200 | 200 | 200 | 1000 | 1600 |
| ASPP | Dense ASPP | ||
|---|---|---|---|
| Atrous Rate | Receptive Field | Atrous Rate | Receptive Field |
| 6 | 13 | 6, 12 | 37 |
| 12 | 25 | 12, 18 | 61 |
| 18 | 37 | 6, 12, 18 | 73 |
| Parameter | Configuration |
|---|---|
| CPU | Intel Xeon E5-2678 V3 processor |
| GPU | NVIDIA GeForce RTX 3090 |
| CUDA version | CUDA 12.2 |
| Operating system | Windows 10 |
| Programming language | Python 3.9 |
| Deep learning framework | Pytorch 2.0.0 |
| Parameter | Freeze Train | Unfreeze Train |
|---|---|---|
| Epoch | 30 | 70 |
| Batch size | 8 | 4 |
| Optimizer | SGD | SGD |
| Min learning rate | 7 × 10−5 | 7 × 10−5 |
| Model | MIoU (%) | MPA (%) | PA (%) | MF1 (%) | Params (M) | Flops (G) |
|---|---|---|---|---|---|---|
| U-Net | 87.03 | 93.22 | 95.77 | 92.86 | 24.89 | 451.77 |
| HRNet | 86.55 | 93.01 | 95.3 | 92.57 | 29.54 | 90.97 |
| PSPNet | 87.55 | 92.41 | 95.56 | 93.25 | 46.71 | 118.43 |
| DeepLabv3+ (Xception) | 87.82 | 92.81 | 95.98 | 93.34 | 54.71 | 166.86 |
| DeepLabv3+ (MobileNetv2) | 88.26 | 93.46 | 96.05 | 93.62 | 5.81 | 52.89 |
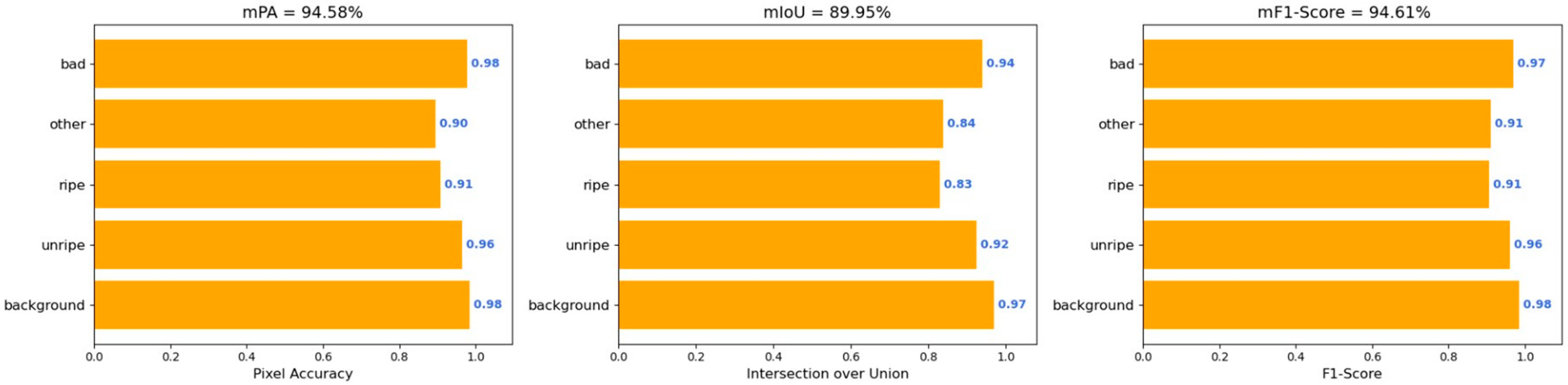
| ECD-DeepLabv3+ (Ours) | 89.95 | 94.58 | 96.6 | 94.61 | 5.91 | 53.24 |
| Method | MobileNetv2 | ECA | CA | Dense | MIoU (%) | MPA (%) | PA (%) | MF1 (%) | Params (M) | Flops (G) |
|---|---|---|---|---|---|---|---|---|---|---|
| (1) | 87.82 | 92.81 | 95.98 | 93.34 | 54.71 | 166.86 | ||||
| (2) | √ | 88.26 | 93.46 | 96.05 | 93.62 | 5.81 | 52.89 | |||
| (3) | √ | √ | 88.69 | 93.72 | 96.20 | 93.88 | 5.81 | 52.89 | ||
| (4) | √ | √ | 88.98 | 93.79 | 96.25 | 94.04 | 5.83 | 52.89 | ||
| (5) | √ | √ | 89.05 | 93.84 | 96.27 | 94.10 | 5.90 | 53.23 | ||
| (6) | √ | √ | √ | √ | 89.95 | 94.58 | 96.60 | 94.61 | 5.91 | 53.24 |
| Model | MIoU (%) | MPA (%) | PA (%) | MF1 (%) | Params (M) | Flops (G) |
|---|---|---|---|---|---|---|
| DeepLabv3+ | 98.03 | 99.06 | 99.35 | 99.00 | 54.71 | 166.86 |
| ECD-DeepLabv3+ | 98.08 | 99.08 | 99.35 | 99.03 | 5.91 | 53.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Z.; Ke, Z.; Chen, K.; Wang, Y.; Tang, Y.; Wang, W. A Lightweight Deep Learning Semantic Segmentation Model for Optical-Image-Based Post-Harvest Fruit Ripeness Analysis of Sugar Apples (Annona squamosa). Agriculture 2024, 14, 591. https://doi.org/10.3390/agriculture14040591
Xie Z, Ke Z, Chen K, Wang Y, Tang Y, Wang W. A Lightweight Deep Learning Semantic Segmentation Model for Optical-Image-Based Post-Harvest Fruit Ripeness Analysis of Sugar Apples (Annona squamosa). Agriculture. 2024; 14(4):591. https://doi.org/10.3390/agriculture14040591
Chicago/Turabian StyleXie, Zewen, Zhenyu Ke, Kuigeng Chen, Yinglin Wang, Yadong Tang, and Wenlong Wang. 2024. "A Lightweight Deep Learning Semantic Segmentation Model for Optical-Image-Based Post-Harvest Fruit Ripeness Analysis of Sugar Apples (Annona squamosa)" Agriculture 14, no. 4: 591. https://doi.org/10.3390/agriculture14040591
APA StyleXie, Z., Ke, Z., Chen, K., Wang, Y., Tang, Y., & Wang, W. (2024). A Lightweight Deep Learning Semantic Segmentation Model for Optical-Image-Based Post-Harvest Fruit Ripeness Analysis of Sugar Apples (Annona squamosa). Agriculture, 14(4), 591. https://doi.org/10.3390/agriculture14040591