
Sorting of Mountage Cocoons Based on MobileSAM and Target Detection

 , ,
, ,
Abstract
1. Introduction
- (1)
- To address the issue of inaccurate detection of double cocoons and waste cocoons with minor defects, a cooperation detection approach is employed, integrating image segmentation and target detection methodologies. By extracting the cocoon image from the entire image of the mountage, the complexity of the image is reduced, and the target feature difference is maximized.
- (2)
- MobileSAM (Mobile segment anything model) [13] is used for the semantic segmentation of mountage cocoons. Based on the characteristics of the segmented images, we design an area threshold algorithm at the output end of SAM, which achieves the unsupervised learning of cocoon image extraction. This approach significantly reduces the workload associated with pixel-level labeling and training, which is essential for the segmentation network.
- (3)
- In order to detect fine-grained features of cocoons, the BiFPN (Bi-directional Feature Pyramid Network) [14] is utilized for multi-scale feature fusion. Similarly, the Global Attention Module (GAM) [15] is introduced to enhance network performance by reducing information diffusion and amplifying global interactions. In addition, the CIoU [16] loss function is replaced with the WIoU (Wise-IoU) [17], which alleviates the impact of low-quality images on model detection and improves detection speed.
2. Materials and Methods
2.1. Materials
2.1.1. Dataset
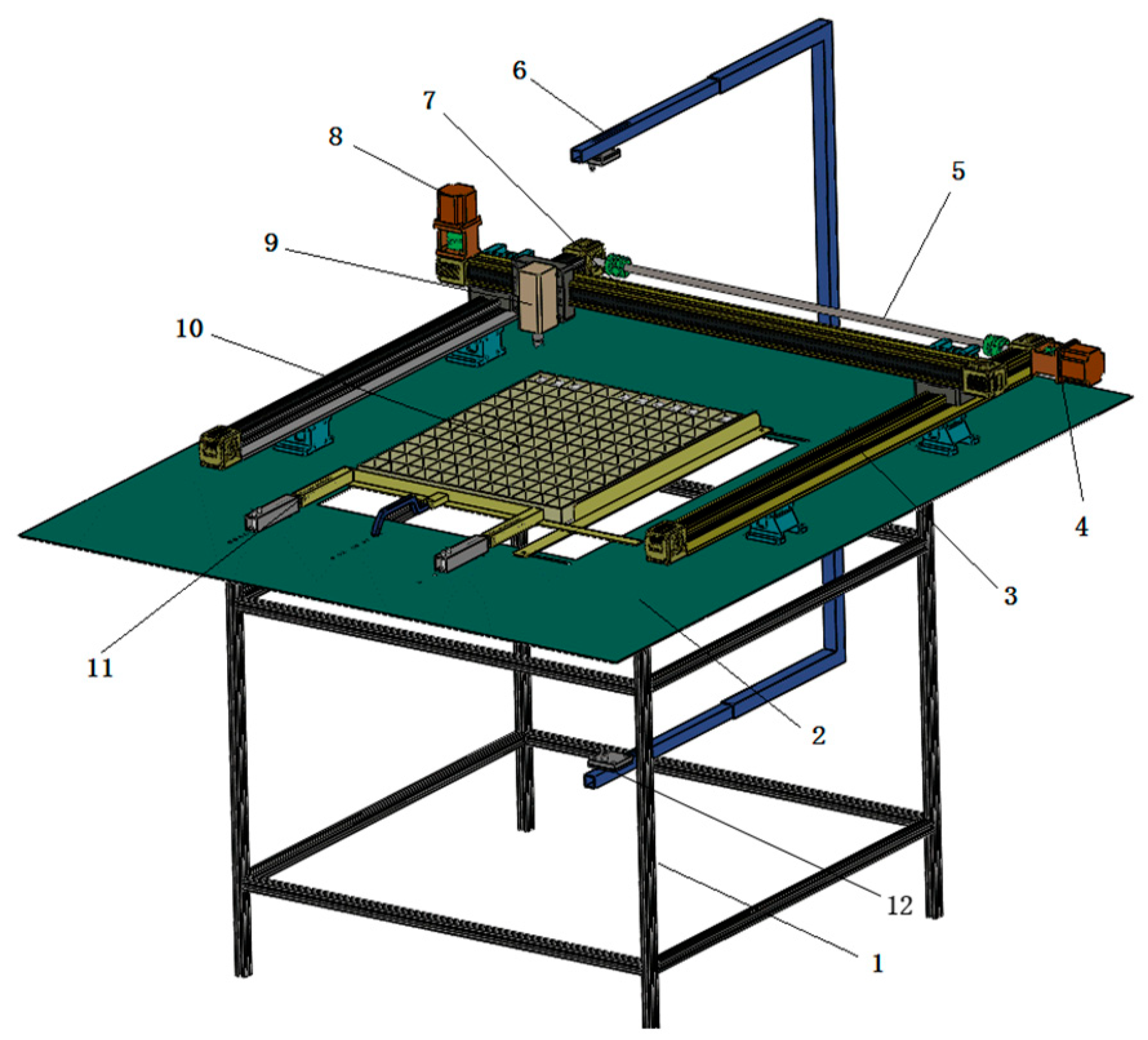
2.1.2. Cartesian Coordinate Automatic Cocoon Harvestor Setup
2.1.3. Experimental Platform
2.1.4. Evaluation Indicators
2.2. Methods
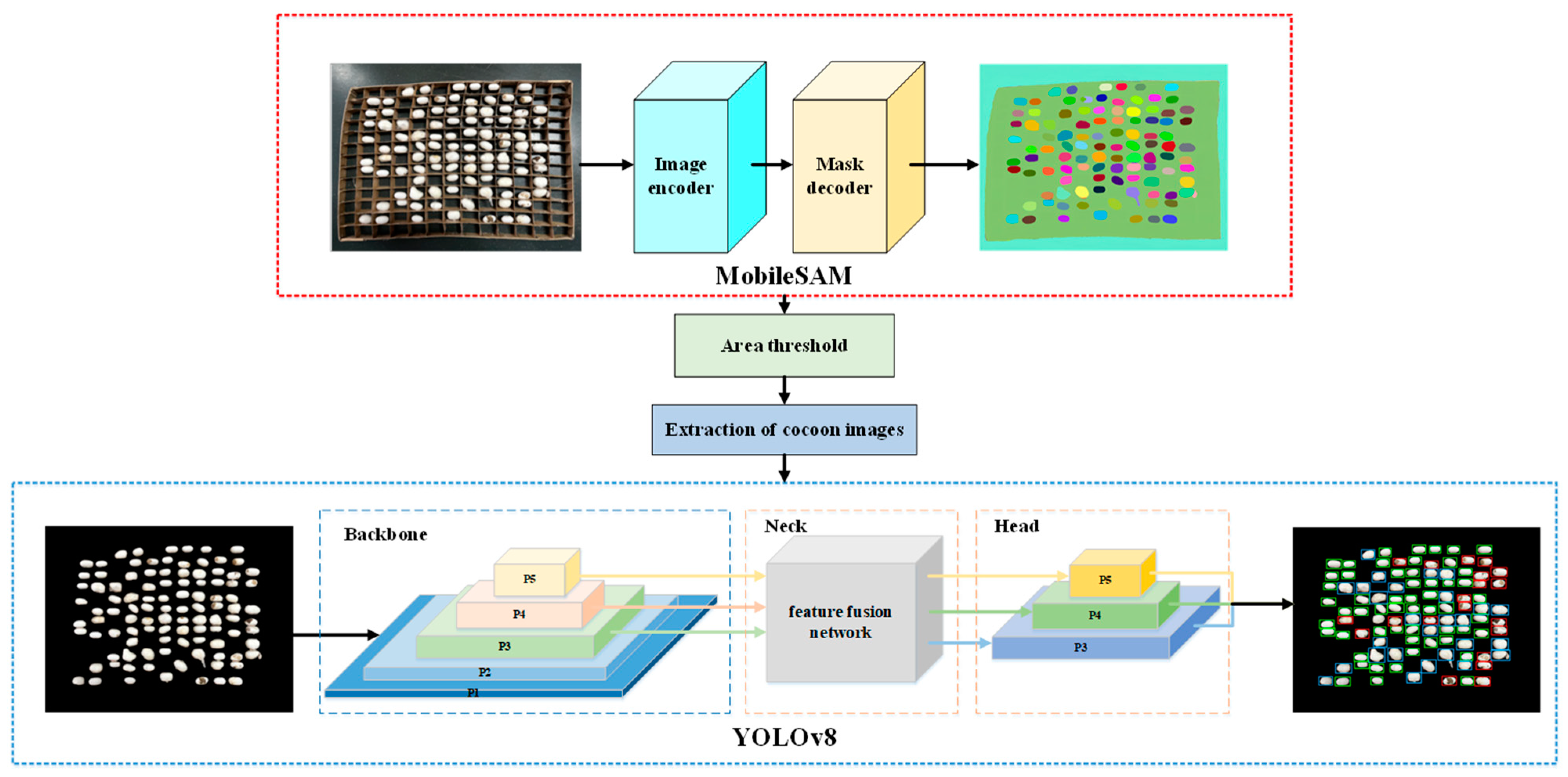
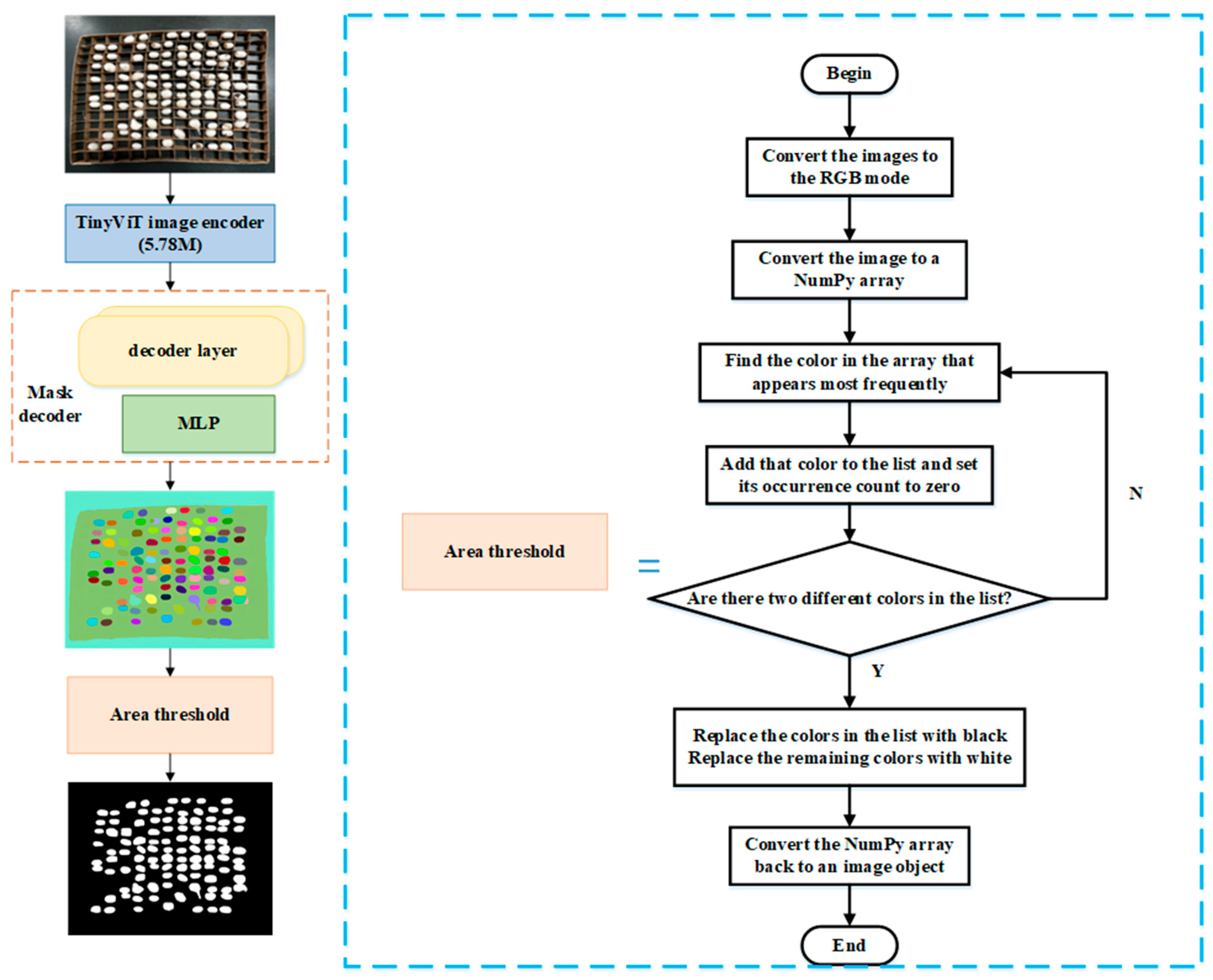
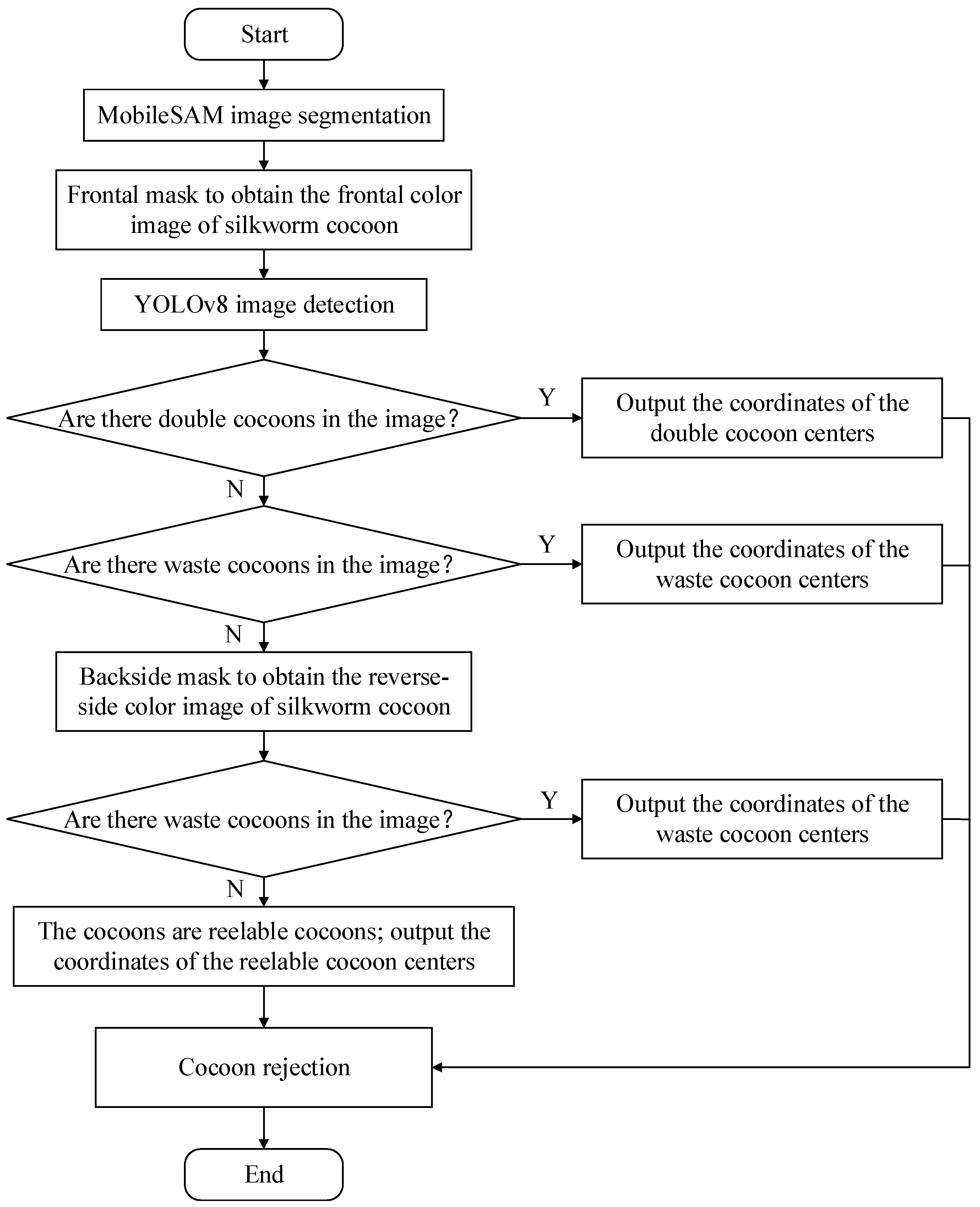
2.2.1. Segmentation Model Based on MobileSAM and Area Threshold
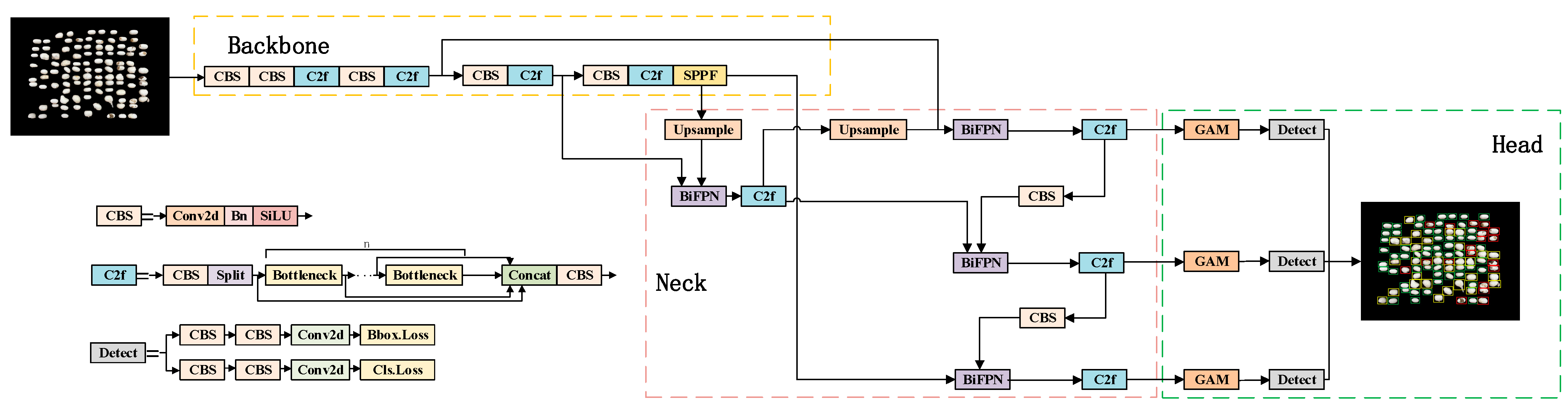
2.2.2. Establishment and Improvement in YOLOv8 Model
- (1)
- YOLOv8 model structure.
- (2)
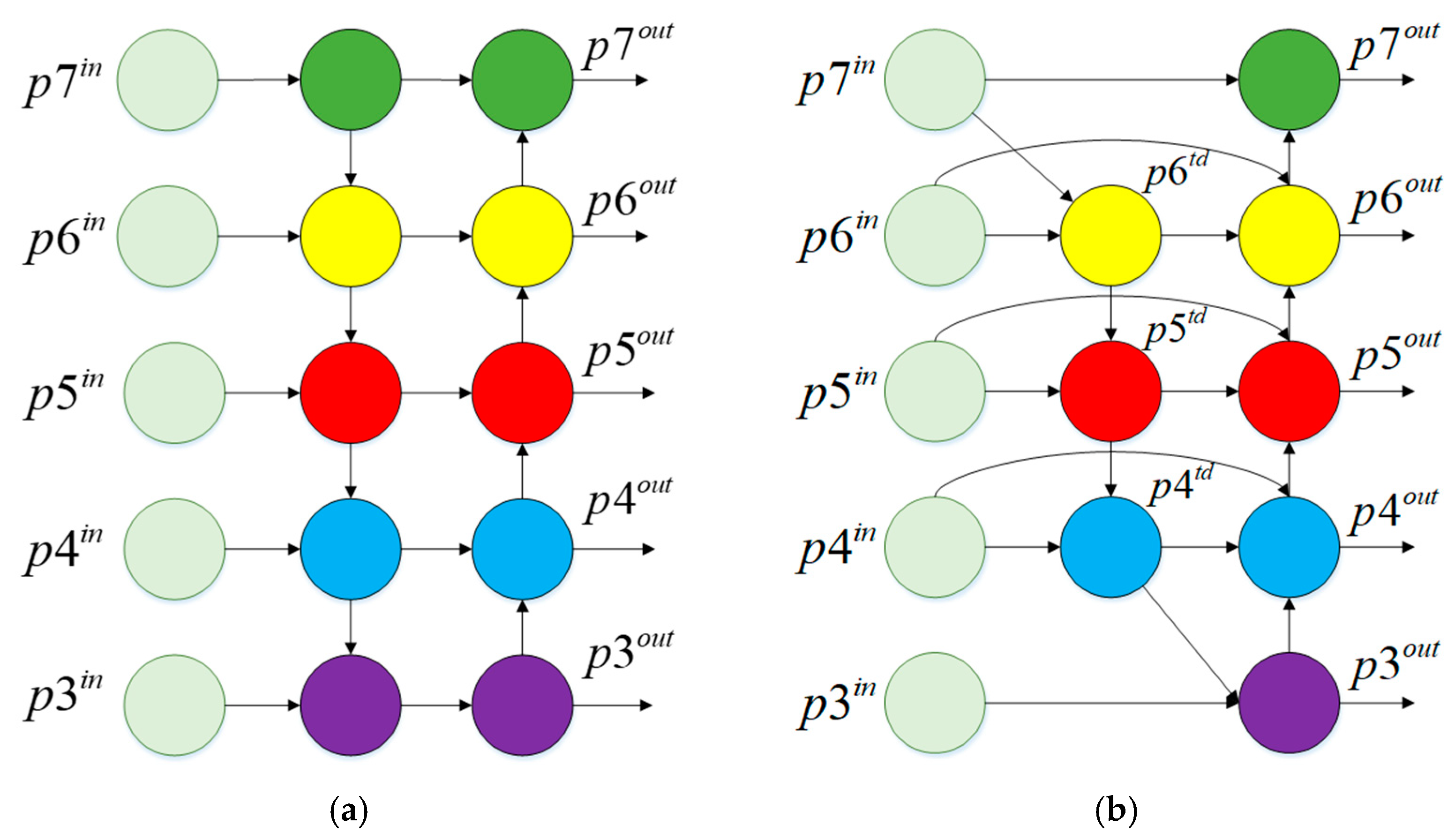
- Multiscale feature fusion.
- (3)
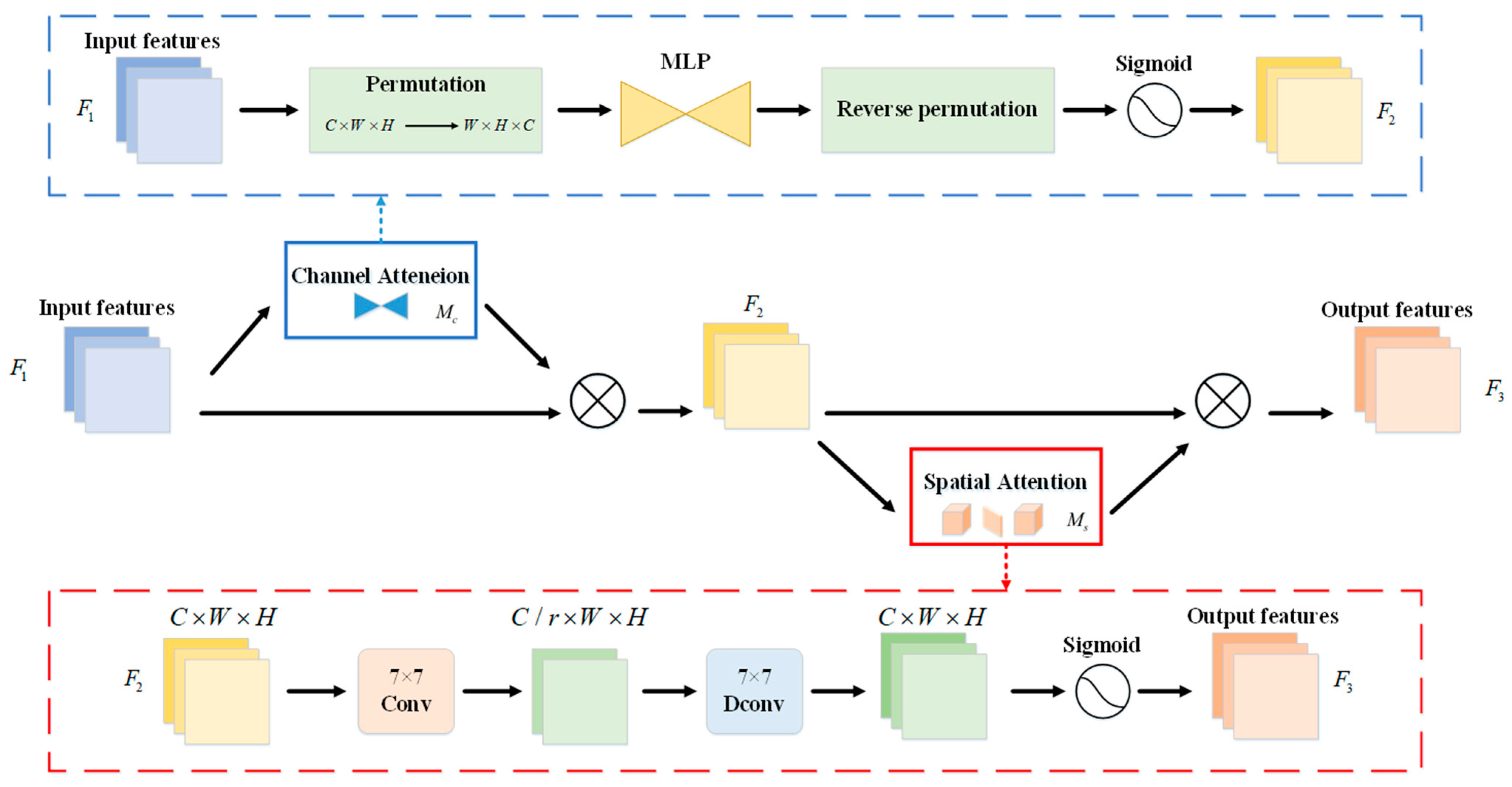
- Add an attention mechanism for double cocoon recognition.
- (4)
- Optimization of the loss function for the waste cocoon recognition.
3. Experimental Results and Discussions
3.1. Silkworm Cocoon Sorting Experiment
3.1.1. Silkworm Cocoon Segmentation Experiment
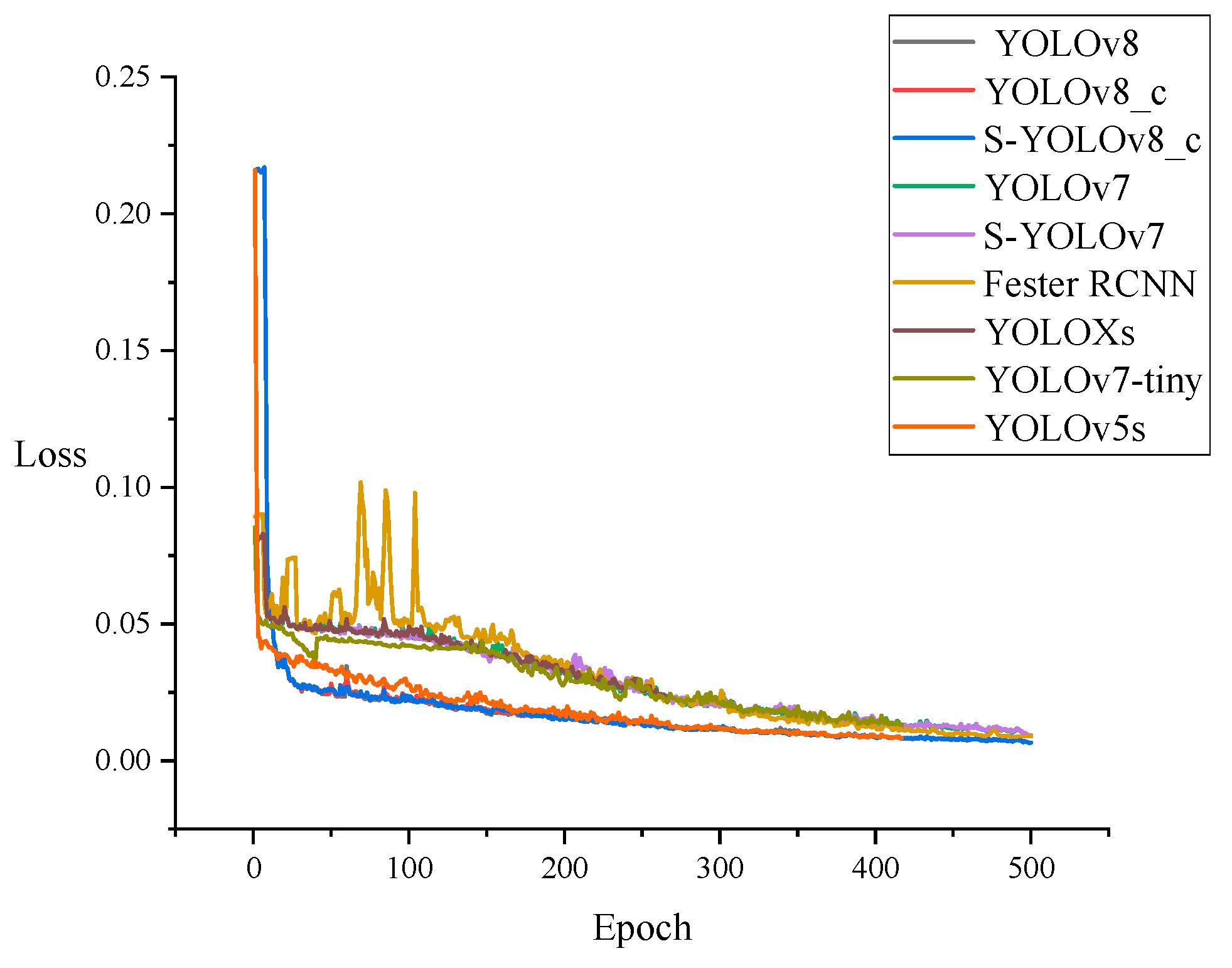
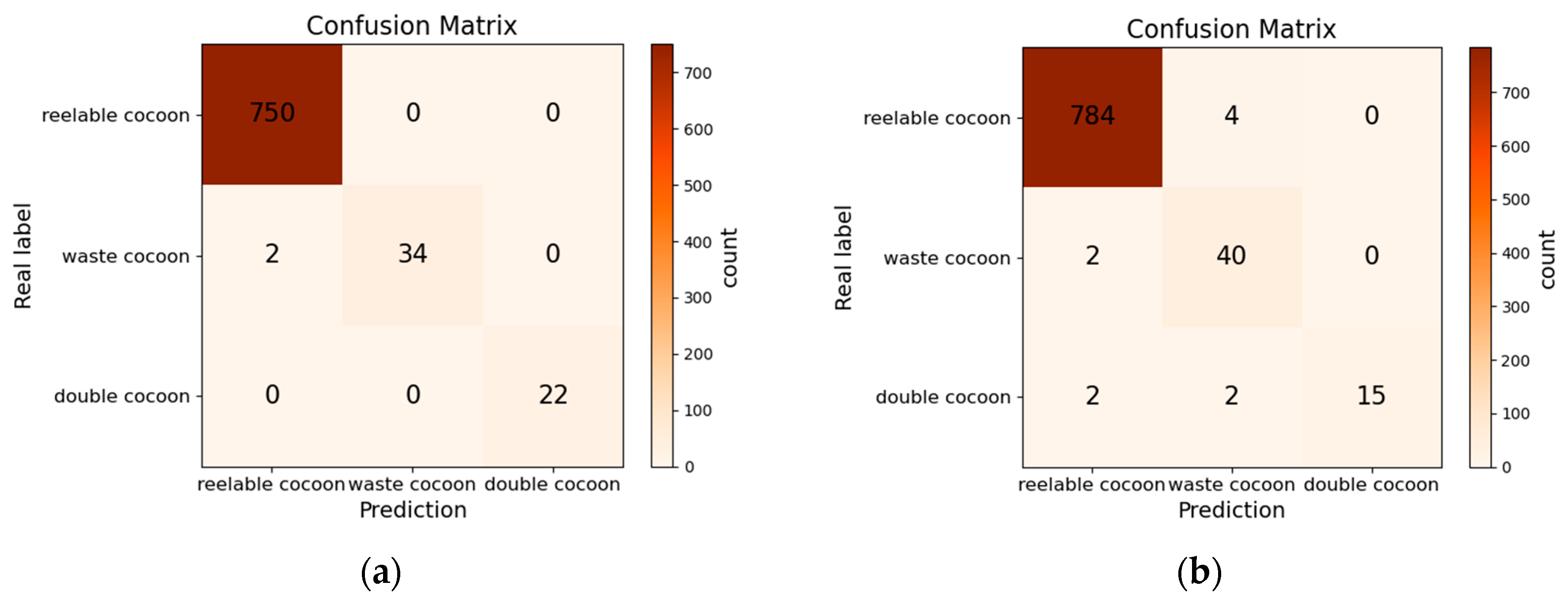
3.1.2. Silkworm Cocoon Detection Experiment
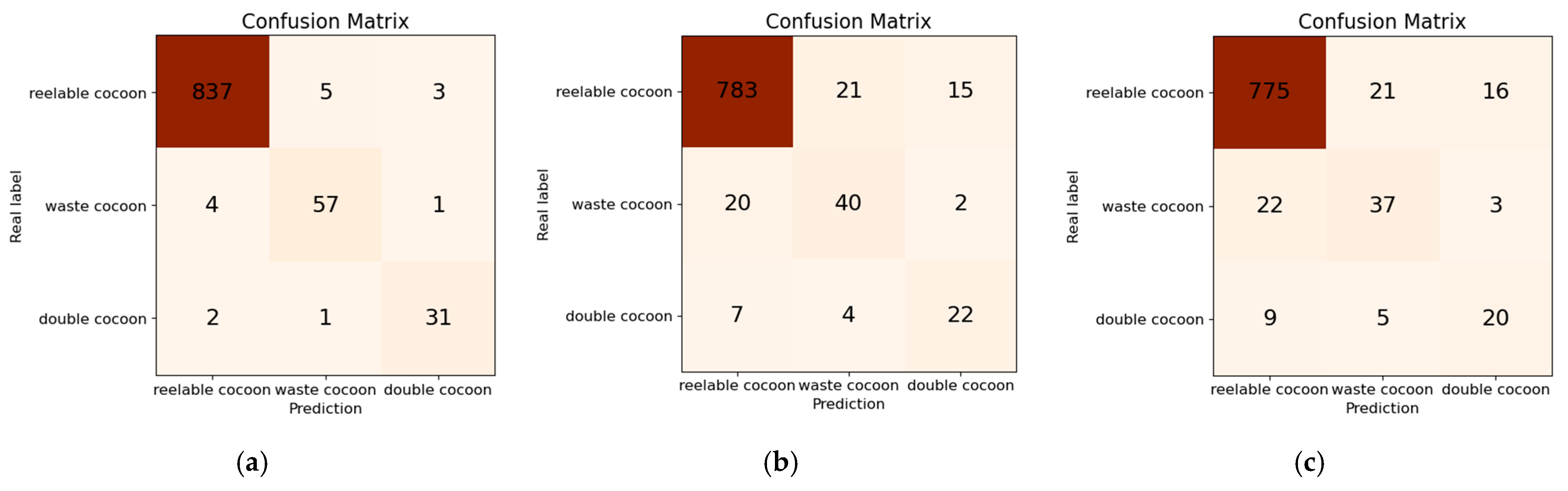
3.2. Ablation Study
3.3. Experiments in Different Brightness
3.4. Algorithm Validation Experiment Based on Cartesian Coordinate Automatic Cocoon Harvestor
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Qian, Y.; Liu, W.; Liu, E. Data report: Analysis on operation of Chinese silk industry in 2022 and prospect in 2023. J. Silk 2023, 60, 59–163. [Google Scholar]
- GB/T 9111-2015; Methods of Mulberry Silkworm Dried Cocoons. China National Standardization Administration, General Administration of Quality Supervision, Inspection and Quarantine of the People's Republic of China: Beijing, China, 2015.
- Li, J.; Feng, H. Review and Prospects of 40 Years of Reform and Development of China’s Sericulture Industry. China Seric. 2019, 40, e0220912. [Google Scholar]
- Fu, S.; Wei, G.; Wang, L. Effects of Mountage on Silkworm Cocoon Yield, Quality and Feeding Efficiency. J. Zhejiang Agric. Sci. 2013, 5, 34–337. [Google Scholar]
- Bian, K.; Yang, H.; Lu, Y. Application Review of Deep Learning in Detection and Identification of Agricultural Pests and Diseases. Softw. Guide 2021, 20, 26–33. [Google Scholar]
- Prasobhkumar, P.P.; Francis, C.R.; Gorthi, S.S. Automated quality assessment of cocoons using a smart camera based system. Eng. Agric. Environ. Food 2018, 11, 202–210. [Google Scholar] [CrossRef]
- Prasobhkumar, P.; Francis, C.; Gorthi, S.S. Cocoon quality assessment system using vibration impact acoustic emission processing. Eng. Agric. Environ. Food 2019, 12, 556–563. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Z.; Gu, T.; Ye, F.; Wang, X. Cocoons counting and classification based on image processing. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 148–152. [Google Scholar]
- Zhou, X.; Han, Z.; Liu, C. Silkworm Cocoon Identification Method Based on Improved Convolution Neural Network and Image Processing. J. Chin. Agric. Mech. 2023, 44, 100. [Google Scholar]
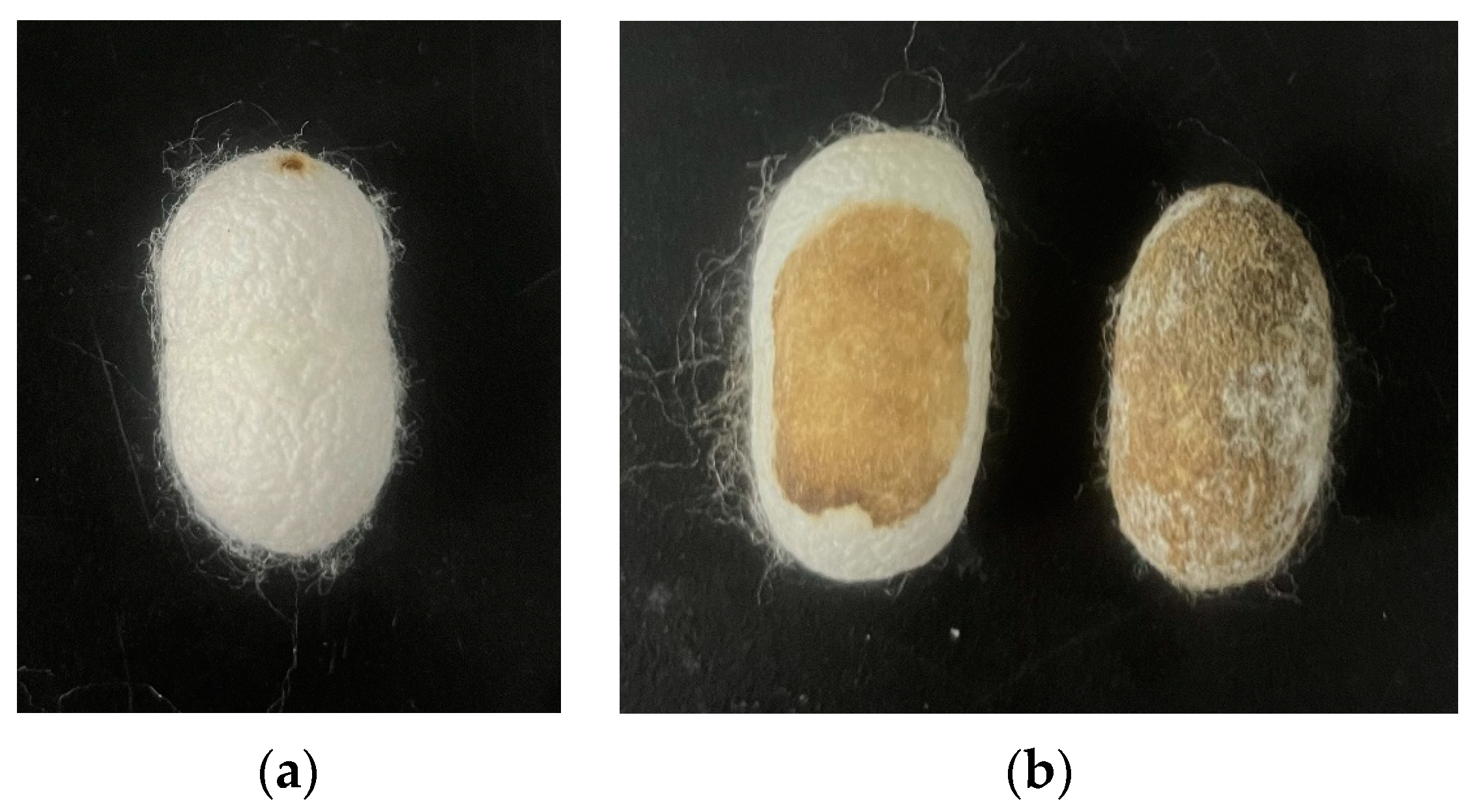
- Sun, W.; Yang, C.; Shao, T.; Liang, M.; Zheng, J. Intelligence Recognition Algorithm of Group Cocoons Based on MSRCR and CBAM. J. Silk 2022, 59, 58–65. [Google Scholar]
- Liu, M.; Xu, R.; Yan, X.; Yan, Y.; Li, F.; Liu, S. Detection and Elimination of Yellow Spotted Cocoon in Mountage Based on FCM Algorithm and HSV Color Model. Trans. Chin. Soc. Agric. Mach. 2018, 49, 31–38. [Google Scholar]
- Liu, M.; Xu, R.; Li, F.; Song, Z.; Yan, Y.; Han, S. Algorithm and Experiment of Cocoon Segmentation and Location Based on Color and Area Feature. Trans. Chin. Soc. Agric. Mach. 2018, 49, 43–50. [Google Scholar]
- Zhang, C.; Han, D.; Qiao, Y.; Kim, J.U.; Bae, S.-H.; Lee, S.; Hong, C.S. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv 2023, arXiv:2306.14289. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In Proceedings of the 17th European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 280–296. [Google Scholar]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Classification | Image Classification | Number of Images |
|---|---|---|
| Training set | reelable cocoon | 70,761 |
| waste cocoon | 6551 | |
| double cocoon | 3246 | |
| Validation set | reelable cocoon | 7510 |
| waste cocoon | 986 | |
| double cocoon | 632 | |
| Test set | reelable cocoon | 7327 |
| waste cocoon | 1067 | |
| double cocoon | 681 |
| Configuration | Parameter |
|---|---|
| CPU | Intel Xeon Gold 5218R |
| Memory | 128G |
| GPU | GeForce RTX 3090 |
| Accelerated environment | CUDA 11.1 cuDNN 8.0.5 |
| Operating system | Windows 10.0 |
| Development environment | Python 3.9 Pytorch 1.9.1 |
| Model | mAP/% | F1/% Reelable cocoon | F1/% Waste cocoon | F1/% Double cocoon | Avg (FTime)/ms |
|---|---|---|---|---|---|
| YOLOv8 | 85.4 | 89.8 | 63.0 | 60.4 | 22.1 |
| YOLOv8_c | 90.8 | 93.7 | 86.3 | 82.3 | 17.5 |
| S-YOLOv8_c | 95.8 | 98.6 | 93.9 | 91.9 | 35.1 |
| YOLOv7 | 83.1 | 90.3 | 61.4 | 56.5 | 25.5 |
| S-YOLOv7 | 88.5 | 91.2 | 86.9 | 75.1 | 47.1 |
| Fester RCNN | 82.1 | 85.0 | 75.6 | 71.2 | 65.7 |
| YOLOXs | 68.3 | 74.1 | 41.7 | 40.4 | 15.4 |
| YOLOv7-tiny | 70.2 | 76.6 | 46.1 | 52.6 | 14.9 |
| YOLOv5s | 65.7 | 71.5 | 57.2 | 45.8 | 16.3 |
| Measure | BiFPN | WIoU | GAM | mAP/% | F1/% Reelable cocoon | F1/% Waste cocoon | F1/% Double cocoon | Avg (FTime)/ms |
|---|---|---|---|---|---|---|---|---|
| S-YOLOv8 | 90.2 | 92.7 | 85.1 | 83.2 | 43.2 | |||
| A | √ | × | × | 93.5 | 95.1 | 88.7 | 83.4 | 45.6 |
| B | × | √ | × | 92.7 | 94.3 | 91.6 | 83.7 | 31.5 |
| C | × | × | √ | 92.3 | 93.6 | 86.9 | 89.6 | 44.1 |
| D | √ | √ | × | 95.4 | 97.7 | 92.6 | 91.1 | 33.6 |
| E | √ | × | √ | 94.7 | 96.4 | 90.1 | 89.9 | 47.1 |
| F | × | √ | √ | 93.9 | 95.4 | 89.5 | 88.2 | 33.1 |
| Ours | √ | √ | √ | 95.8 | 98.6 | 93.9 | 91.9 | 35.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Cui, M.; Wei, W.; Xu, X.; Sun, C.; Li, F.; Song, Z.; Lu, Y.; Zhang, J.; Tian, F.; et al. Sorting of Mountage Cocoons Based on MobileSAM and Target Detection. Agriculture 2024, 14, 599. https://doi.org/10.3390/agriculture14040599
Liu M, Cui M, Wei W, Xu X, Sun C, Li F, Song Z, Lu Y, Zhang J, Tian F, et al. Sorting of Mountage Cocoons Based on MobileSAM and Target Detection. Agriculture. 2024; 14(4):599. https://doi.org/10.3390/agriculture14040599
Chicago/Turabian StyleLiu, Mochen, Mingshi Cui, Wei Wei, Xiaoli Xu, Chongkai Sun, Fade Li, Zhanhua Song, Yao Lu, Ji Zhang, Fuyang Tian, and et al. 2024. "Sorting of Mountage Cocoons Based on MobileSAM and Target Detection" Agriculture 14, no. 4: 599. https://doi.org/10.3390/agriculture14040599
APA StyleLiu, M., Cui, M., Wei, W., Xu, X., Sun, C., Li, F., Song, Z., Lu, Y., Zhang, J., Tian, F., Zhang, G., & Yan, Y. (2024). Sorting of Mountage Cocoons Based on MobileSAM and Target Detection. Agriculture, 14(4), 599. https://doi.org/10.3390/agriculture14040599