
Identification of Fish Hunger Degree with Deformable Attention Transformer


Abstract
1. Introduction
- We constructed a dataset of fish hunger degrees. Three degrees, including weakly, moderately, and strongly hungry, were defined based on the aggregation levels of fish. The established dataset was then used to train and validate the proposed detection model;
- We proposed the DeformAtt-ViT model by integrating the transformer architecture and the deformable attention mechanism to classify the fish hunger degree. The use of the deformable attention mechanism enabled DeformAtt-ViT to adaptively concentrate on the spatial features that were important to generate the final predictions. The comparative experiment verified the effectiveness of DeformAtt-Vit through the evaluation criteria, including accuracy, precision, F1-score, etc. By accurately classifying the hunger level, we can provide guidance on the appropriate time and bait amount to feed the fish;
- We utilized the Grad-CAM method to provide insights into the decision-making process for both CNNs and ViTs. This approach allowed us to visualize the pixels that contributed the most to the model’s predictions in a given image.
2. Materials and Methods
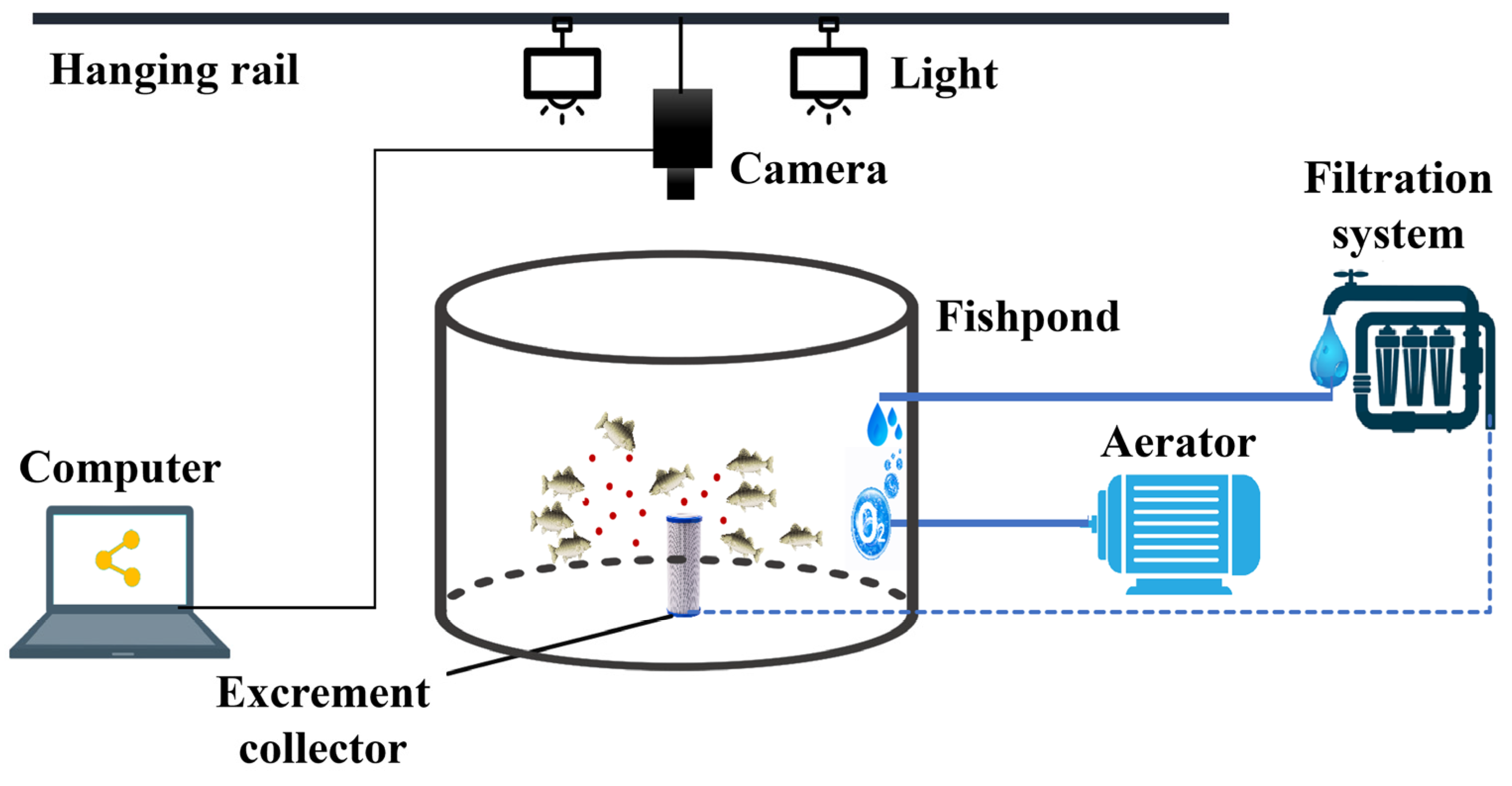
2.1. Fish Samples and Dataset Creation
2.2. Network Architecture of DeformAtt-ViT
2.3. Deformable Attention Module
2.4. Successive Local Attention
2.5. Shift-Window Attention
2.6. Performance Evaluation Metrics
3. Results
3.1. Experiment Setting
3.2. Ablation Study on Deformable Attention
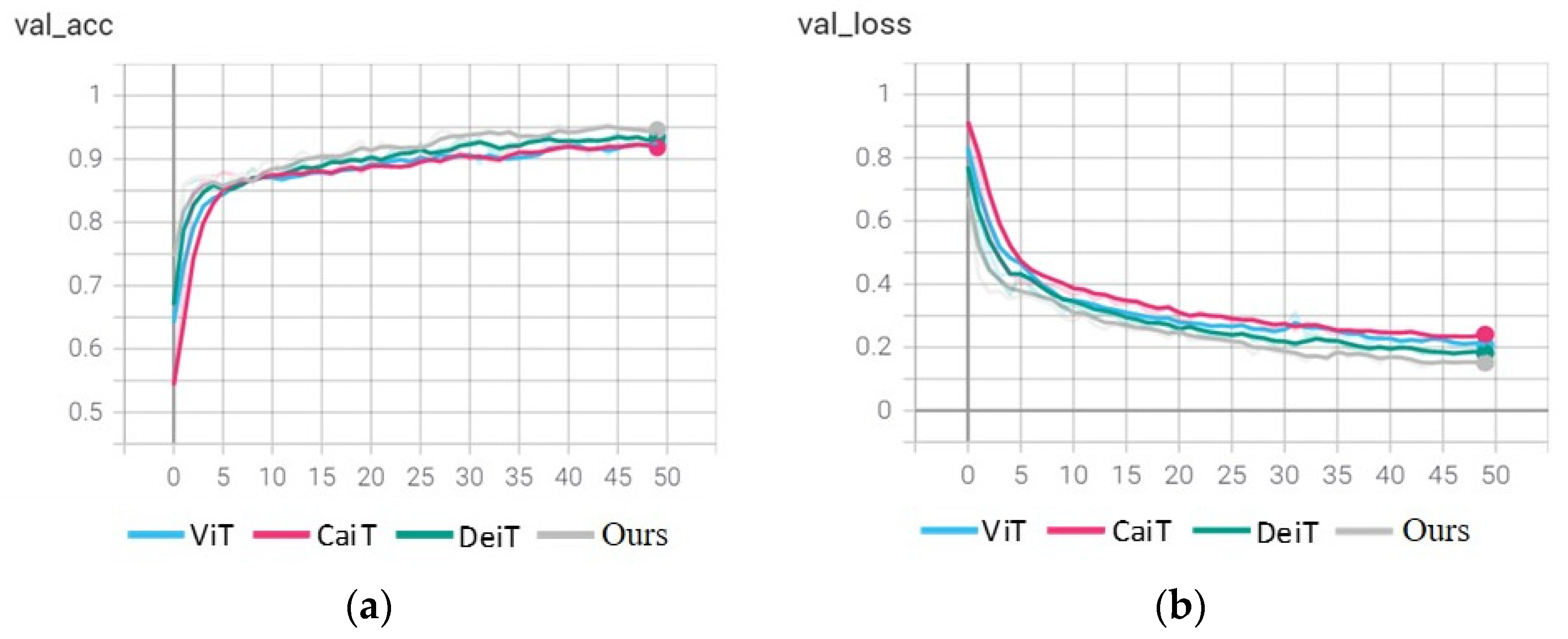
3.3. Comparative Experiments between DeformAtt-ViT and other ViTs
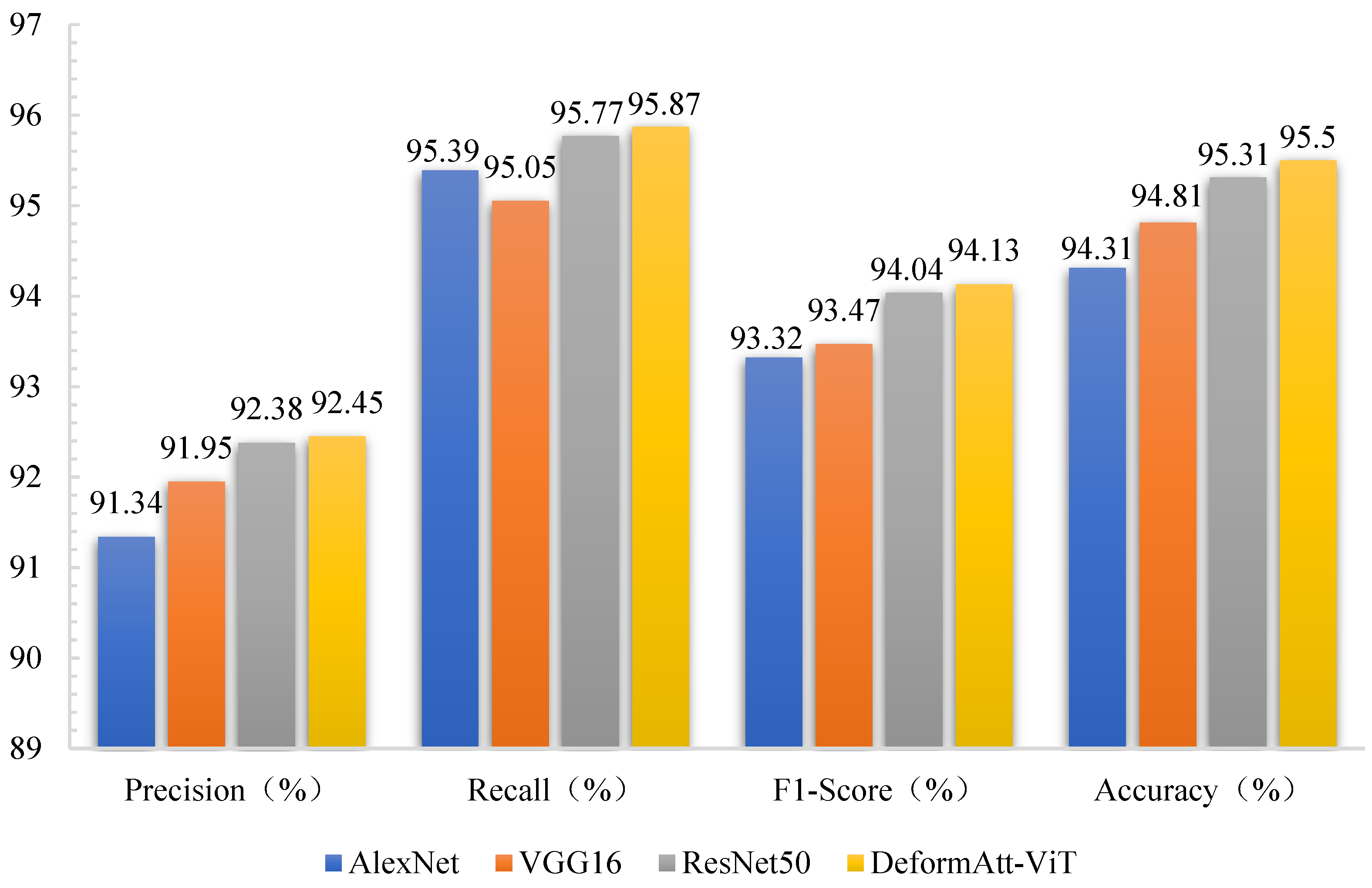
3.4. Comparative Experiments between DeformAtt-ViT and other CNNs
3.5. Model Visualization
4. Discussion
4.1. Comparison Analysis between CNNs and Transformers
4.2. Limitation and Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- FAO. The State of World Fisheries and Aquaculture 2022; Food and Agriculture Organization of the United Nations (FAO): Rome, Italy, 2022. [Google Scholar] [CrossRef]
- Yang, L.; Liu, Y.; Yu, H.; Fang, X.; Song, L.; Li, D.; Chen, Y. Computer Vision Models in Intelligent Aquaculture with Emphasis on Fish Detection and Behavior Analysis: A Review. Arch. Comput. Methods Eng. 2021, 28, 2785–2816. [Google Scholar] [CrossRef]
- Zhou, C.; Xu, D.; Lin, K.; Sun, C.; Yang, X. Intelligent feeding control methods in aquaculture with an emphasis on fish: A review. Rev. Aquac. 2018, 10, 975–993. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, S.; Liu, J.; Gao, Q.; Dong, S.; Zhou, C. Deep learning for smart fish farming: Applications, opportunities and challenges. Rev. Aquac. 2021, 13, 66–90. [Google Scholar] [CrossRef]
- Wang, C.; Li, Z.; Wang, T.; Xu, X.; Zhang, X.; Li, D. Intelligent fish farm—The future of aquaculture. Aquac. Int. 2021, 29, 2681–2711. [Google Scholar] [CrossRef]
- Li, D.; Wang, Z.; Wu, S.; Miao, Z.; Du, L.; Duan, Y. Automatic recognition methods of fish feeding behavior in aquaculture: A review. Aquaculture 2020, 528, 735508. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Zhao, S.; Lu, J.; Wang, Y.; Li, D.; Zhao, R. Fast detection of cannibalism behavior of juvenile fish based on deep learning. Comput. Electron. Agric. 2022, 198, 107033. [Google Scholar] [CrossRef]
- Feng, S.; Yang, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yan, Y.; Zhou, C. Fish feeding intensity quantification using machine vision and a lightweight 3D ResNet-GloRe network. Aquac. Eng. 2022, 98, 102244. [Google Scholar] [CrossRef]
- Michael, S.C.J.; Patman, J.; Lutnesky, M.M.F. Water clarity affects collective behavior in two cyprinid fishes. Behav. Ecol. Sociobiol. 2021, 75, 120. [Google Scholar] [CrossRef]
- Kramer, D.L. Dissolved oxygen and fish behavior. Environ. Biol. Fish. 1987, 18, 81–92. [Google Scholar] [CrossRef]
- Volkoff, H.; Rønnestad, I. Effects of temperature on feeding and digestive processes in fish. Temperature 2020, 7, 307–320. [Google Scholar] [CrossRef]
- Assan, D.; Huang, Y.; Mustapha, U.F.; Addah, M.N.; Li, G.; Chen, H. Fish feed intake, feeding behavior, and the physiological response of apelin to fasting and refeeding. Front. Endocrinol. 2021, 12, 798903. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Wang, X.; Zhang, X.; Shi, Y.; Li, W. Locomotor posture and swimming-intensity quantification in starvation-stress behavior detection of individual fish. Comput. Electron. Agric. 2022, 202, 107399. [Google Scholar] [CrossRef]
- Iqbal, U.; Li, D.; Akhter, M. Intelligent Diagnosis of Fish Behavior Using Deep Learning Method. Fishes 2022, 7, 201. [Google Scholar] [CrossRef]
- Zhu, M.; Zhang, Z.; Huang, H.; Chen, Y.; Liu, Y.; Dong, T. Classification of perch ingesting condition using light-weight neural network MobileNetV3-Small. Nongye Gongcheng Xuebao/Trans. Chin. Soc. Agric. Eng. 2021, 37, 165–172. [Google Scholar] [CrossRef]
- Zhou, C.; Xu, D.; Chen, L.; Zhang, S.; Sun, C.; Yang, X.; Wang, Y. Evaluation of fish feeding intensity in aquaculture using a convolutional neural network and machine vision. Aquaculture 2019, 507, 457–465. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Cohn, A.G.; Zhou, M.; Zhang, D.; Man, J. A hierarchical DCNN-based approach for classifying imbalanced water inflow in rock tunnel faces. Tunn. Undergr. Space Technol. 2022, 122, 104399. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Bashmal, L.; Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Al Ajlan, N. UAV Image Multi-Labeling with Data-Efficient Transformers. Appl. Sci. 2021, 11, 3974. [Google Scholar] [CrossRef]
- Li, W.; Liu, Y.; Wang, W.; Li, Z.; Yue, J. TFMFT: Transformer-based multiple fish tracking. Comput. Electron. Agric. 2024, 217, 108600. [Google Scholar] [CrossRef]
- Zeng, Y.; Yang, X.; Pan, L.; Zhu, W.; Wang, D.; Zhao, Z.; Liu, J.; Sun, C.; Zhou, C. Fish school feeding behavior quantification using acoustic signal and improved Swin Transformer. Comput. Electron. Agric. 2023, 204, 107580. [Google Scholar] [CrossRef]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. arXiv 2022, arXiv:2201.00520. [Google Scholar] [CrossRef]
- Zhou, B.; Yu, X.; Liu, J.; An, D.; Wei, Y. Effective Vision Transformer Training: A Data-Centric Perspective. arXiv 2022, arXiv:2209.15006. [Google Scholar] [CrossRef]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. arXiv 2021, arXiv:2107.00652. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Trans-former using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. arXiv 2017, arXiv:1703.06211. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2016, 128, 336–359. [Google Scholar] [CrossRef]
- Tuli, S.; Dasgupta, I.; Grant, E.; Griffiths, T.L. Are Convolutional Neural Networks or Transformers more like human vision? arXiv 2021, arXiv:2105.07197. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. arXiv 2020, arXiv:2012.12877. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhang, M.; Dong, Q.; Zhang, G.; Wang, Z.; Wei, P. SugarcaneGAN: A novel dataset generating approach for sugarcane leaf diseases based on lightweight hybrid CNN-Transformer network. Comput. Electron. Agric. 2024, 219, 108762. [Google Scholar] [CrossRef]
- Li, X.; Xiang, Y.; Li, S. Combining convolutional and vision transformer structures for sheep face recognition. Comput. Electron. Agric. 2023, 205, 107651. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Y.; He, N.; Ma, K.; Zheng, Y. Improving vision transformer for medical image classification via token-wise perturbation. J. Vis. Commun. Image Represent. 2023, 98, 104022. [Google Scholar] [CrossRef]
- Xiong, B.; Chen, W.; Niu, Y.; Gan, Z.; Mao, G.; Xu, Y. A Global and Local Feature fused CNN architecture for the sEMG-based hand gesture recognition. Comput. Biol. Med. 2023, 166, 107497. [Google Scholar] [CrossRef]
- Zhou, D.; Kang, B.; Jin, X.; Yang, L.; Lian, X.; Jiang, Z.; Hou, Q.; Feng, J. DeepViT: Towards Deeper Vision Trans-former. arXiv 2021, arXiv:2103.11886. [Google Scholar] [CrossRef]
- Asswin, C.R.; KS, D.K.; Dora, A.; Ravi, V.; Sowmya, V.; Gopalakrishnan, E.A.; Soman, K.P. Transfer learning approach for pediatric pneumonia diagnosis using channel attention deep CNN architectures. Eng. Appl. Artif. Intell. 2023, 123, 106416. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar] [CrossRef]
- Jiang, X.; Li, Y.; Jiang, T.; Xie, J.; Wu, Y.; Cai, Q.; Jiang, J.; Xu, J.; Zhang, H. RoadFormer: Pyramidal deformable vision transformers for road network extraction with remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102987. [Google Scholar] [CrossRef]
- Gong, B.; Dai, K.; Shao, J.; Jing, L.; Chen, Y. Fish-TViT: A novel fish species classification method in multi water areas based on transfer learning and vision transformer. Heliyon 2023, 9, e16761. [Google Scholar] [CrossRef]
- Yang, W.; Wu, J.; Zhang, J.; Gao, K.; Du, R.; Wu, Z.; Firkat, E.; Li, D. Deformable convolution and coordinate attention for fast cattle detection. Comput. Electron. Agric. 2023, 211, 108006. [Google Scholar] [CrossRef]
- Beyan, C.; Fisher, R.B.; Katsageorgiou, V.-M. Extracting statistically significant behaviour from fish tracking data with and without large dataset cleaning. IET Comput. Vis. 2018, 12, 162–170. [Google Scholar] [CrossRef]
- Xu, W.; Liu, C.; Wang, G.; Zhao, Y.; Yu, J.; Muhammad, A.; Li, D. Behavioral response of fish under ammonia nitrogen stress based on machine vision. Eng. Appl. Artif. Intell. 2024, 128, 107442. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, X.; Liu, J.; Zhao, R.; Zhang, L.; An, D.; Wei, Y. Research on quantitative method of fish feeding activity with semi-supervised based on appearance-motion representation. Biosyst. Eng. 2023, 230, 409–423. [Google Scholar] [CrossRef]
- Kim, W.; Jung, W.-S.; Choi, H.K. Lightweight Driver Monitoring System Based on Multi-Task Mobilenets. Sensors 2019, 19, 3200. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment Name | Stages w/Deformable Attention | Accuracy (%) | |||
|---|---|---|---|---|---|
| Stage 1 | Stage 2 | Stage 3 | Stage 4 | ||
| Model-A | ○ | ○ | ○ | ○ | 95.2 |
| Model-B | ○ | ○ | ○ | 95.4 | |
| Model-C | ○ | ○ | 95.5 | ||
| Model-D | ○ | 94.8 | |||
| Model-E | Swin transformer | 94.6 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Xu, H.; Wu, X.; Wang, H.; Zhai, Z. Identification of Fish Hunger Degree with Deformable Attention Transformer. J. Mar. Sci. Eng. 2024, 12, 726. https://doi.org/10.3390/jmse12050726
Wu Y, Xu H, Wu X, Wang H, Zhai Z. Identification of Fish Hunger Degree with Deformable Attention Transformer. Journal of Marine Science and Engineering. 2024; 12(5):726. https://doi.org/10.3390/jmse12050726
Chicago/Turabian StyleWu, Yuqiang, Huanliang Xu, Xuehui Wu, Haiqing Wang, and Zhaoyu Zhai. 2024. "Identification of Fish Hunger Degree with Deformable Attention Transformer" Journal of Marine Science and Engineering 12, no. 5: 726. https://doi.org/10.3390/jmse12050726
APA StyleWu, Y., Xu, H., Wu, X., Wang, H., & Zhai, Z. (2024). Identification of Fish Hunger Degree with Deformable Attention Transformer. Journal of Marine Science and Engineering, 12(5), 726. https://doi.org/10.3390/jmse12050726