Abstract
Federated learning (FL) is a distributed machine learning approach that can enable Internet of Things (IoT) edge devices to collaboratively learn a machine learning model without explicitly sharing local data in order to achieve data clustering, prediction, and classification in networks. In previous works, some online multi-armed bandit (MAB)-based FL frameworks were proposed to enable dynamic client scheduling for improving the efficiency of FL in underwater wireless IoT networks. However, the security of online dynamic scheduling, which is especially essential for underwater wireless IoT, is increasingly being questioned. In this work, we study secure dynamic scheduling for FL frameworks that can protect against malicious clients in underwater FL-assisted wireless IoT networks. Specifically, in order to jointly optimize the communication efficiency and security of FL, we employ MAB-based methods and propose upper-confidence-bound-based smart contracts (UCB-SCs) and upper-confidence-bound-based smart contracts with a security prediction model (UCB-SCPs) to address the optimal scheduling scheme over time-varying underwater channels. Then, we give the upper bounds of the expected performance regret of the UCB-SC policy and the UCB-SCP policy; these upper bounds imply that the regret of the two proposed policies grows logarithmically over communication rounds under certain conditions. Our experiment shows that the proposed UCB-SC and UCB-SCP approaches significantly improve the efficiency and security of FL frameworks in underwater wireless IoT networks.
1. Introduction
Various types of marine monitoring IoT [1] networks have been deployed to collect valuable data and perform critical tasks; these networks comprise edge devices performing collaborative sensing, computing, and decision-making for different missions. Edge devices such as autonomous underwater vehicles (AUVs) and remotely operated vehicles (ROV) are expected to provided a huge amount of data to fuel the development of machine learning (ML) [2] for artificial intelligence (AI)-based computing and decision-making in underwater IoT networks, e.g., offshore inspection mission networks [3,4].
Federated learning (FL) [5] is a decentralized machine learning paradigm that enables multiple devices to collaboratively train a shared model without exchanging their local data. In the FL framework, each local client only needs to train a unified model on its own local data and upload the trained model information, such as the parameters and gradients, to the FL center, which aggregates local models into a global model. Meanwhile, no local data are transferred during the FL process, which solves the problem that some clients are unwilling to disclose local data to the central server due to privacy reasons. Therefore, many researchers aim to employ FL frameworks, and they take IoT edge devices as FL clients to achieve flexible AI assistance in practical wireless IoT networks. For underwater IoT networks, how to achieve dynamic scheduling that improves the efficiency of the FL process over usable wireless resources (e.g., bandwidth and power) must be taken into account.
The study focuses on developing a policy to select the best edge devices for participation in each round of FL training, balancing security, efficiency, and resource utilization. We propose novel secure dynamic scheduling for FL in underwater wireless IoT networks without prior information related to channel state information (CSI), available computing power provided by each IoT edge device, etc. In order to guarantee the security of FL in wireless IoT networks, we introduce a voting mechanism that is widely used in decentralized systems and contributes to high performance while guaranteeing security. Multi-armed bandit (MAB) is a framework for sequential decision-making under uncertainty; the goal is to maximize overall winnings by strategically selecting which machines to play. For efficiency, on the one hand, we employ MAB to model the FL process in underwater wireless IoT networks to achieve efficiency in the FL process by reducing the time latency of each communication round; on the other hand, for the loss of efficiency caused by the communication cost of the voting mechanism, a prediction model is proposed to reduce the communication cost and to adapt to rapidly changing underwater wireless IoT networks. Finally, we encode the aforementioned approaches by implementing the FL in underwater wireless IoT networks as a smart contract. The smart contract can encode any set of rules represented in its programming language and has its correct execution enforced by the consensus protocol [6,7]. Overall, an upper confidence bound (UCB)-based smart contract (UCB-SC) policy and a UCB-based smart contract with a prediction model (UCB-SCP) policy are proposed to achieve optimization in terms of both efficiency and security of FL in underwater wireless IoT networks. The secure and efficient scheduling of edge devices in underwater networks enables the capabilities of sensing and computing, contributing to advancements in marine research, environmental monitoring, and maritime safety. Our main contributions in this work are outlined as follows.
- An underwater wireless IoT network that enables FL is designed to empower IoT technology. The network consists of edge devices, an FL server, and controllers, where the controllers can assist FL.
- A MAB-based framework is provided to reformulate the dynamic scheduling problem for FL in underwater wireless IoT networks, and both time efficiency and security are jointly considered in the provided framework.
- We introduce a voting mechanism to enhance the security and propose a prediction model to evaluate the security based on the performance of each edge device in order to reduce the communication costs of the voting mechanism.
- We propose a UCB-SC policy for relatively stable underwater wireless IoT networks and a UCB-SCP policy for rapidly changing networks. They can realize the comprehensive optimization of the security and efficiency of FL in underwater wireless IoT networks. The proposed policies are encoded into the smart contract to ensure their proper execution.
- We give the upper bounds of the expected performance regret of our proposed policies and carry out simulation experiments. Overall, we verify our proposed policies’ feasibility both theoretically and experimentally.
The remainder of the paper is organized as follows. Some background information and related works are introduced in Section 2. Section 3 presents the system architecture and the problem formulation, discussing the specific challenges and methods employed in the FL-enabled underwater wireless IoT network. In Section 4, we introduce the voting mechanism for secure dynamic scheduling and propose the UCB-SC policy, elaborating on the security considerations that are crucial for maintaining secure FL processes. Section 5 details the proposed UCB-SCP policy within the security prediction model, which enhances security assessments through advanced predictive analytics and significantly reduces the operational and communication overheads. Section 6 describes the numerical experiments that are conducted to validate the efficacy of our proposed methods, followed by a discussion of the results. Finally, Section 7 concludes the paper with a summary of our findings and future research directions.
Below Table 1, some common abbreviations used in this paper are listed:

Table 1.
List of Abbreviations.
2. Background and Related Work
2.1. Efficiency of FL
A number of papers focus on how to accelerate the FL process in terrestrial IoT networks and assume the FL framework is secure. Based on some assumptions related to the communication environment and computing power usage, refs. [8,9] accelerate the FL process by reducing the number of communication rounds through client selection. Some works model resource scheduling in the FL as a multi-objective optimization problem and use deep reinforcement learning [10,11], stochastic optimization [12], and other methods to find satisfactory solutions to achieve efficient FL. Further, the authors of [13,14,15] propose to employ a multi-armed bandit (MAB)-based framework to obtain information about the time latency of each training round and realize proper client scheduling to accelerate the FL process in the case of unknown information, and the work in [16] extends this by taking into account both the importance of the training time latency and local updates in order to reduce the time latency per round and the number of training rounds at the same time.
2.2. Security of FL
In addition to the efficiency of FL, it is also essential to consider the security during scheduling for FL in underwater wireless IoT networks, which is ignored by the aforementioned works. Frequent information exchange in the FL process makes FL scheduling vulnerable to malicious attacks. In terms of the security of FL, Xu et al. proposes to use secure protocols to realize the security of FL in [17], but it can only be applied to choose the best arm, leading to restricted usage scenarios. A general approach to enhance the security of FL is the integration of FL with blockchain technology [18]. The authors of [19,20,21] propose different paradigms to apply blockchain technology to FL to realize security. However, the communication cost and time cost of blockchain technology are too high for some actual use conditions in underwater IoT networks, and less consideration is given to the time efficiency of the FL process in these works. If the local data are confidential and sensitive, some works [22,23] introduce differential privacy to make FL have stronger privacy protection against the cloud server or a third party to infer private information from the shared model or intermediate gradients.
To sum up, while numerous works have focused on enhancing the FL process, they often target either the efficiency or the security of the system and predominantly rely on prior information. This reliance limits the applicability of such methods in underwater wireless IoT networks. There is a pressing need for a FL system architecture that is adaptable to unknown underwater environments while simultaneously addressing both efficiency and security. Developing such a system architecture is crucial for the successful deployment of FL in underwater wireless IoT networks.
3. System Architecture and Problem Formulation
3.1. FL-Enabled Underwater Wireless IoT Network
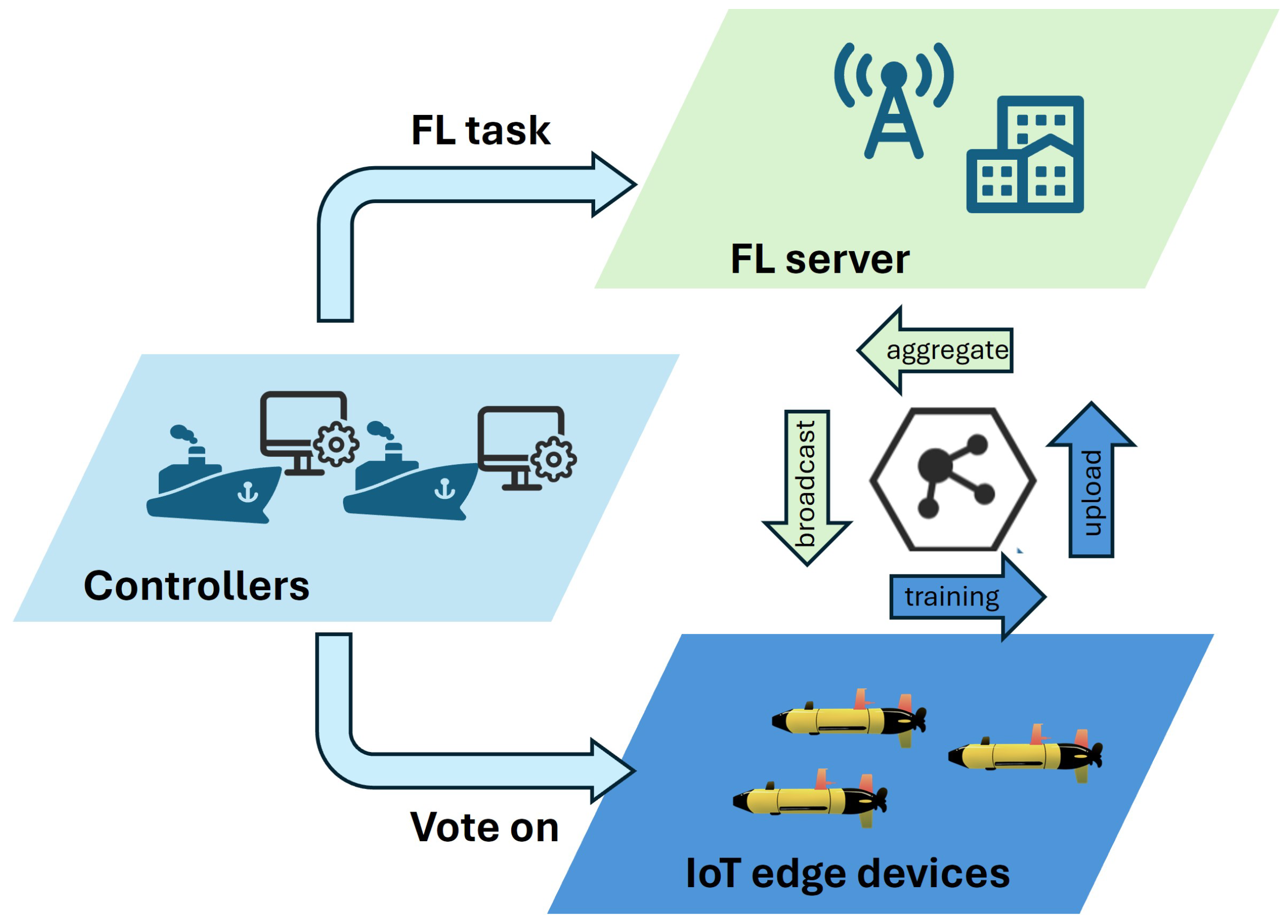
As depicted in Figure 1, we consider an FL-enabled underwater wireless IoT network comprising edge devices, an FL server, and controllers. Similar to the approach in [24], the network consists of various underwater IoT devices:
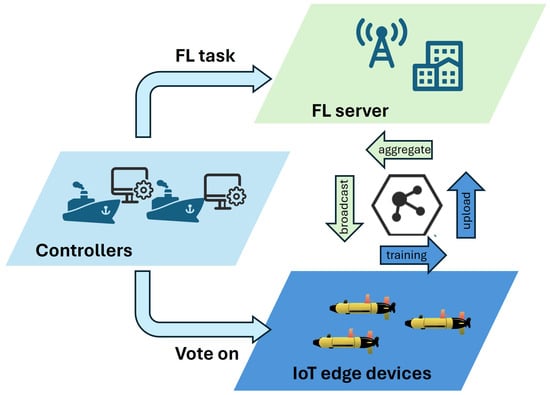
Figure 1.
FL-enabled underwater wireless IoT network.
- Edge devices: These are underwater sensors, robots, or autonomous vehicles equipped with data processing capabilities and local datasets.
- FL server: This is a centralized server responsible for model aggregation, global model broadcasting, and coordinating the federated learning process.
- Controllers: These are trusted entities with the authority to vote on the security of edge devices and generate federated learning tasks based on network needs.
3.2. IoT Edge Device Selection
In the network model, we index all K IoT edge devices by ; the k-th IoT edge device has data samples in its local dataset . Specially, we consider all data samples in as independent and identically distributed (i.i.d.). We take as the parameter of the FL model, as the learned FL model, and as the defined loss function, so our goal is to minimize . We consider each weight of the IoT edge devices to be alike, i.e., , where is the global loss function, and is the loss function of the k-th IoT edge device. The term , where is the global gradient, and is the gradient of the local data of the k-th IoT edge device.
Efficient and secure FL in wireless IoT networks hinges on selecting suitable edge devices for each round’s FL process, given limited resources. We first introduce the general FL process; the steps of the FL process in round t are as follows:
- Step (1)
- The FL server broadcasts the latest version of the global FL model parameter to all IoT edge devices.
- Step (2)
- The FL server selects a subset of IoT edge devices to participate in local updates in round t.
- Step (3)
- The selected IoT edge devices in upload their trained local gradients to the FL server.
- Step (4)
- The FL server updates the global FL model parameters using the local gradients that were successfully uploaded from the IoT edge devices in according towhere is the learning rate for this FL process.
On the basis of the FL process, the appropriate criteria for IoT edge device selection considered in this paper include the following two aspects: time efficiency and security. Therefore, our challenge lies in designing a policy, encoded within a smart contract, to comprehensively optimize both time efficiency and security. First, we introduce time efficiency and security separately as follows.
3.2.1. Time Efficiency
In general scenarios, the number of IoT edge devices we can select every round is limited by the environment and by resources like channels, i.e., , where N is the maximum number of edge devices that can be selected for each round. During the FL process in the underwater wireless IoT network, in order to take full advantage of the considered communication resources, we keep . Given the varying statuses of edge devices in the network (e.g., differences in radio transmission distances or computing power usage), selecting different values will result in varying time efficiencies for each round. The time latency of the selected IoT edge device participating in one round is defined as [13] , where is the time latency for the FL server’s broadcast in round t according to Step (1), is the training time of the k-th edge device that is selected by the FL server in round t, is the time latency for the k-th edge device to upload its updated local gradients to the FL server in round t according to Step (3), and we set as the maximum time interval in order to prevent the FL process in the network from staying too long in a certain round. As for Step (2) and Step (4), which are mainly processed in the FL server, since the calculations involved are not complicated, the FL server can provide sufficient computing power according to the assumption of Section 3.1. Thus, in our designed FL-enabled wireless IoT network, the time latency caused by the FL server in Step (2) and Step (4) can be ignored. In practical applications, we only need to define and observe the total time latency of the k-th edge device in round t instead of disassembling each component of the time latency for theoretical calculations. The end of a round of learning should be bounded by the last edge device, so the time latency of a round is the maximum time latency among the selected edge devices in that round, i.e., , where is the global time latency in round t. At the same time, we define the time efficiency return of the k-th edge device in round t as and the global time efficiency return in round t as . It is easy to infer that minimizing is equivalent to choosing N edge devices with the minimum time latency. In other words, our goal is to select the N IoT edge devices with the largest time efficiency return.
In the FL-enabled underwater wireless IoT network, we discard network-wide channel monitoring to improve the data transmission utilization of the entire network bandwidth, so the FL server cannot know the time efficiency return of each IoT edge device before selecting it. To evaluate the time efficiency return in round t, the FL server calculates the average time efficiency over the previous rounds, denoted as as follows:
where is the number of times the k-th IoT edge device was selected in the past t rounds, i.e.,
According to the above definition, we should select the N edge devices with the maximum to optimize time efficiency.
3.2.2. Security
When the FL server selects edge devices, it should not only consider the time efficiency but also needs to select more secure IoT edge devices for FL. In this paper, we focus on how to defend against attacks from malicious edge nodes, a growing concern in underwater wireless IoT networks [25,26]. Introducing as the security index of the k-th IoT edge device in round t, we can infer that selecting the N edge devices with the highest values equates to selecting the most secure devices for FL participation.
After defining the two aspects, our overall aim becomes to encode an appropriate policy into the smart contract to maximize the combined value of and . We define an evaluation function that is positively correlated with and , i.e., in any round t, the FL server needs to select as follows:
In the following, we handle the problem in (4) using two policies, UCB-SC and UCB-SCP, which are suitable for different conditions.
4. Voting Mechanism for Federated Learning
In Section 3.2, we define a security index for each edge device in round t. In this section, we first address how to obtain the value of , and then we deal with the problem in (4) through the proposed UCB-SC policy.
4.1. Voting Mechanism for Security Index
The voting mechanism is widely used in decentralized autonomous organizations (DAOs), which are typically represented by blockchains. Several platforms facilitating the deployment of DAOs in blockchains are introduced in [27], and they almost always apply voting mechanisms, such as token-based voting in Aragon, holographic consensus in DAOstack, Moloch DAO in DAOhaus, and so on.
The voting mechanism can contribute to high performance while guaranteeing security [28]. In this paper, we employ the voting mechanism for secure dynamic scheduling in our designed FL-enabled wireless IoT network. We follow the voting process for block production from [28]. Specifically, if voting is required, the FL server will query the controllers, and the controllers will judge each IoT edge device. If a controller considers an IoT edge device good, it will return the signature, as shown in Figure 1; otherwise, the edge device remains idle. After the round of the voting process, the FL server calculates the proportion of the received signatures versus the overall number of controllers as the voting rate for each IoT edge device, where it can be inferred that the IoT edge device whose is higher is more secure in round t.
4.2. IoT Edge Device Scheduling
The MAB problem is a common sequential decision problem in which a player is required to decide which arms of the bandit to pull in each time slot [29]. Pulling an arm is seen as an action, and after the action, the player receives a corresponding reward. The traditional MAB [30] requires the decision unit and the rewards of the arms’ update unit to be consistent, i.e., if N IoT edge devices are selected, the overall rewards of the N IoT edge devices are recorded. However, due to the variety of combination methods, a combined optimized MAB will have too high of a complexity. Gai et al. in [31] propose a low-complexity MAB method for combinatorial optimization; we will also use this method for problem reformulation.
The purpose of the MAB problem is to maximize the total reward by making proper sequential decisions. In this paper, we take the time efficiency return as a reward, and our goal is as follows:
which is equivalent to the following equation:
where indicates whether the FL model has converged and is defined as follows:
where q is a constant that evaluates whether the model has converged. If the value of the loss function is less than q, FL stops.
We refer to the UCB algorithm [31,32] to estimate the reward of each IoT edge device k in round t:
where is obtained according to Formula (3).
To deal with the security of each IoT edge device, we introduce the security index through the voting mechanism for secure dynamic IoT edge device scheduling in the FL-enabled wireless IoT network according to Section 4.1. Then, we give the criterion of selecting set of applicable IoT edge devices in each round t in order to maximize the combined value of and , i.e.,
where and can be adjusted according to the wireless IoT network and the preference of the target. For example, for the FL process: if FL in the wireless IoT network is recognized as secure, security can be given less consideration, and a larger value can be taken. If the security of FL in the wireless IoT network cannot be determined, more consideration is required for the security of the IoT edge device, so a smaller value needs to be taken.
4.3. UCB-SC Policy
All of the abovementioned processes are encoded into a smart contract. Thus, secure dynamic scheduling for FL in the wireless IoT network is executed automatically under the smart contract. Once written and approved, the smart contract cannot be modified, and everything will be executed in strict accordance with the smart contract [33,34,35].
We can understand FL in the underwater wireless IoT network guided by the UCB-based smart contract (UCB-SC) in combination with Algorithm 1. Firstly, the controllers generate an FL task to learn or update an FL model and inform the corresponding FL server (Lines 1–2 in Algorithm 1). Secondly, the FL server organizes the IoT edge devices and initializes the FL model (Lines 3–5 in Algorithm 1). Thirdly, the FL server needs to select all IoT edge devices to make a preliminary estimate of the IoT edge devices’ time efficiency return (Lines 6–12 in Algorithm 1). Then, the wireless IoT network enters the main FL process (Lines 13–22 in Algorithm 1). After a preliminary estimate of all IoT edge devices, the controllers vote on IoT edge devices, and the server calculates the voting rate as a security index according to the proposed voting mechanism in Section 4.1, and this voting process executes every I rounds (Lines 15–16 in Algorithm 1). For every learning round, the FL server select IoT edge devices according to the formula in (9) to participate in that round of training for secure dynamic scheduling in the FL-enabled wireless IoT network (Lines 17–21 in Algorithm 1). Finally, a reliable FL model is learned efficiently.
| Algorithm 1 Proposed UCB-SC for FL-enabled underwater wireless IoT networks |
| Input: FL task. Output: learned FL model. 1: The controllers generate an FL task. 2: The controllers send the FL task to the FL server. 3: begin FL in the underwater wireless IoT network: 4: the FL server: 5: Initialize FL model trained by FL. 6: for do 7: Select a set of IoT edge devices consisting of the -th, …, -th IoT edge devices in . 8: Update and according to (2) and (3), respectively. 9: end for 10: . 11: Select a set of IoT edge devices consisting of the -th, …, K-th IoT edge devices in . 12: Update and according to (2) and (3), respectively. 13: main loop: 14: while do 15: Ask for the controllers’ voting on the IoT edge devices according to Section 4.1. 16: Update by the voting result. 17: for do 18: . 19: Select a set of IoT edge devices according to (9). 20: Update and according to (2) and (3), respectively. 21: end for 22: end while |
The UCB-SC policy schedules underwater wireless IoT devices by considering both time efficiency and security based on the devices’ historical data and current behavior, prioritizing devices with short delays and high reliability. Specifically, the policy employs MAB theory to model the delay of IoT devices and uses the UCB algorithm to balance the trade-off between exploration and exploitation. Additionally, the strategy incorporates a voting mechanism from blockchain technology, where the security of IoT devices is dynamically evaluated by authoritative controllers. Ultimately, the strategy effectively schedules devices by comprehensively considering their time efficiency and security, thereby enhancing the time efficiency and security of FL in underwater wireless IoT networks.
4.4. Upper Bound on Regret
We apply the difference between the expected reward of the optimal actions and the total reward gained by the provided policy to evaluate the policy, which is called regret [29]. We can minimize the regret by maximizing the total reward, which is our given problem (6). We denote by the expected reward of the k-th IoT edge device, and the optimal IoT edge device set in round t is
where includes all good IoT edge devices, which are unknown in actual conditions.
We assume that FL training converges at the end of T, where and . Then, the cumulative regret of a policy is
where is the expected reward of IoT edge device set S.
If we want the proposed policies to achieve good convergence performance, the difference between the upper and lower bounds of the security index of each good IoT edge device in any round t needs to be small. We require that , where , and .
Theorem 1.
The expected regret under the UCB-SC policy is at most
where , and .
Proof.
The proof of Theorem 1 is provided in Appendix A and refers to [31]. □
It is easy to conclude that the regret is affected by multiple factors, including the stability of the security evaluation, i.e., the value of ; the reward of different IoT edge device sets, i.e., and ; the maximum number of IoT edge devices that can be selected for each round, i.e., N; the total number of IoT edge devices, i.e., K; and the selection weight of the time efficiency, i.e., . Given that the abovementioned factors are fixed, the regret grows logarithmically with the number of communication rounds, meaning that the performance gap between the proposed UCB-SC policy and the optimal actions decreases in a logarithmic way with respect to T.
5. Security Prediction for Federated Learning
In Section 4, we introduced the voting mechanism for FL in wireless IoT networks to obtain the security index and further achieved joint optimization of the time efficiency and security. However, there is still a problem in that for a rapidly changing wireless IoT network, if voting is carried out over a large time interval, the security index does not have adequate flexibility; this leads to some security problems due to some insecure factors suddenly appearing in the FL framework. Thus, voting over a large time interval cannot solve the sudden security problem during the FL process. If each round consists of real-time voting, although the real-time security of the IoT edge devices can be guaranteed, this will generate huge communication costs in the FL process, leading to high resource consumption and low time efficiency.
Therefore, in this paper, we further propose a security prediction model whose results are close to those of real-time voting and whose communication costs are consistent with those of interval voting. We divide the implementation of the security prediction model into the following two parts: trust evidence generation and prediction model calculation.
5.1. Trust Evidence Generation
In order to obtain real-time security, it is required to evaluate the security index of each IoT edge device according to the security prediction model every round. Therefore, the trust evidence used to evaluate security is required to be easily available in each round and to reflect the security information of the IoT devices as fully as possible. Based on these requirements, we introduce pieces of trust evidence from four aspects to evaluate the security of IoT edge devices as follows.
5.1.1. Relative Accuracy
After the selected IoT edge devices successfully upload the local model in each round, the FL server updates their relative accuracies, which are calculated as follows. The FL server aggregates the global model according to Formula (1) and obtains the new model parameter and the learned model . The FL server calculates the accuracy rate of the global model with a small random validation dataset. The FL server also calculates the local model of each successfully uploaded IoT edge device according to as well as the corresponding local model . For each successfully uploaded IoT edge device model, the FL server selects a small validation dataset randomly and calculates the accuracy rate according to its model . Finally, the relative accuracy rate of each IoT edge device is updated as follows:
Note that the relative accuracy update process requires the FL server to participate only after the selected IoT edge devices’ uploading. Thus, the FL server can update the relative accuracy when it broadcasts the model, the IoT edge devices update the model, and the IoT edge devices upload the model. In addition, the computing power of the FL server is large enough according to Section 3.1 and the validation dataset is small, so the time for calculating the relative accuracy is sufficient and the relative accuracy update process will not affect the time efficiency of the FL process in the wireless IoT network.
5.1.2. Cosine Similarity Score
Malicious IoT edge devices can manipulate the direction of local model updates to drive global model updates in any direction they want [36]. In the FL training stage, we consider the direction of the global model update to be a trusted direction because (1) the local model parameters participating in model aggregation have been evaluated for security, (2) as long as the good IoT edge devices are in the majority, the update direction of the global model is credible, and (3) the update direction of the global model aggregates multiple local models, so it is more stable and less prone to errors. Therefore, the IoT edge device whose updated direction is more similar to the update direction of the global model is considered more secure. We use the cosine function to express the similarity. Considering that some good IoT edge devices have some opposite similarity due to chance, we further use the ReLU function to make such IoT edge devices suffer less from negative influence. Therefore, the final update formula of the cosine similarity score of the k-th IoT edge device in round t is as follows:
Consistent with the relative accuracy, the update of the cosine similarity score does not affect time efficiency.
5.1.3. Upload Success Rate
After malicious IoT edge devices are selected, they may not train or may execute invalid training to negatively effect the performance of FL, as in an unavailability attack [37,38]. Therefore, security is also related to the upload success rate. In line with common sense, the upload success rate of the k-th IoT edge device is defined as follows:
where is the number of times that the k-th IoT edge device has been selected in the past t rounds, which is obtained from Formula (3), and is the number of times that the k-th IoT edge device has failed to upload the local gradient at the end of round t, as defined by the following formula:
Consistent with the trust evidence above all, updating the upload success rate does not affect the time efficiency.
5.1.4. Training Efficiency
The training efficiency of an edge device is also related to the security of FL. The high training efficiency of an IoT edge device can indicate that the edge device actively participates in FL, which is generally recognized as a positive behavior. However, if the training efficiency exceeds a certain threshold, it may be that: (1) A single IoT edge device with excessive training efficiency cannot improve the overall performance of FL directly but wastes its resources. (2) High training efficiency requires sufficient energy support. If energy support cannot be realized, the IoT edge device falls into an overloaded state and faces a security risk. (3) Consuming too many resources in FL training may affect other functions of an IoT edge device. The training efficiency is inversely proportional to the time latency and is further proportional to the time efficiency return. Thus, we can directly use the time efficiency return to represent the training efficiency according to formula (2).
5.2. Prediction Model Calculation
In order to obtain a real-time security evaluation that does not require voting every round, we need to obtain a security prediction model that takes the abovementioned trust evidence as input and outputs the security evaluation value. In this paper, we introduce a feedforward neural network (FNN) algorithm [39] to train the security prediction model by utilizing the trust evidence. Deep learning algorithms that include a FNN can easily find rules from historical data and can further predict the behavior of IoT edge devices [40].
The process of calculation for the security prediction model is as follows. After the m-th round of voting, the voting rate of each IoT edge device is taken as a label, and the trust evidence of the corresponding round t is taken as a feature for learning, i.e., it becomes a labeled dataset:
In the setting of the FNN model, the quadratic loss function is used as the loss function, and the dataset is trained on the basis of the existing security prediction model ; then, a new security prediction model is obtained. In a non-voting round t, the FL server evaluates the security of the k-th IoT device by leveraging collected trust evidence and the previously trained prediction model. The security assessment is quantified by the function:
These inputs are processed by the prediction model to determine the security level of the device, which, in turn, informs the FL server’s scheduling decisions.
In addition, the advantages of learning on the basis of the existing security prediction model , rather than only learning from the m-th voting results, are as follows: (1) it is equivalent to ensemble learning, with the advantage of lower expected errors and (2) it conducts data enhancement by using more data information.
5.3. IoT Edge Device Scheduling
We also employ the MAB-based framework to reformulate IoT edge device scheduling, which is consistent with Section 4.2. We still define the time efficiency return as a reward, and our aim is Formula (6) as well. We calculate the reward of each IoT edge device in round t according to formula (8).
Different from Section 4.2, to handle the security of each IoT edge device, we evaluate the security index with the proposed security prediction model, i.e.,
where the m-th round of voting is closest to round t.
Thus, after introducing the security prediction model, the IoT edge devices are selected according to
where is in accordance with Section 4.2.
It is important to note that focuses on the overall latency of each round and includes both the computational and communication delays introduced by the proposed security prediction model. These delays are also considered within the scheduling decisions to ensure that the system optimally balances between security enhancements and operational efficiency.
5.4. UCB-SCP Policy
As shown in Algorithm 2, the proposed policy for efficiency and secure FL is a UCB-based smart contract with a security prediction model: namely, UCB-SCP. The key idea behind this policy is to introduce a voting mechanism and security prediction model simultaneously and to use a modified UCB algorithm to deal with the IoT edge device scheduling problem under the MAB-based framework in the FL-enabled wireless IoT network. Then, we write the policy into the smart contract to ensure its correct execution.
Compared to the UCB-SC policy in Algorithm 1, the UCB-SCP policy executes the security prediction model instead of directly using the voting rate to obtain the security index (Line 16 in Algorithm 2). On account of the security prediction model existing, the policy selects the IoT edge device set according to Formula (18) instead of Formula (9) (Line 19 in Algorithm 2) and needs to update the trust evidence every round (Lines 8, 12, and 20 in Algorithm 2).
The UCB-SCP policy enhances FL by integrating a security prediction model, which dynamically assesses the threat level of each participating device, into the scheduling process. This proactive approach allows the system to adjust its scheduling decisions based on real-time security data, reducing the likelihood of including potentially malicious devices and therefore mitigating security risks more effectively. Moreover, the UCB-SCP policy employs a smart contract that encodes the decision-making rules, ensuring that all actions are automatically executed according to predefined criteria and without manual intervention. This not only reduces the time needed for decision-making but also minimizes human errors and biases in the process. The use of MAB-based methods helps to optimize the selection process of participating devices by learning from past interactions to improve both the security and efficiency of the model updates. This is crucial in underwater environments, where communication resources are limited and reliability is paramount. Compared to traditional methods that might not dynamically adapt to changing security conditions or might not optimally allocate resources, the UCB-SCP policy offers a more robust and efficient framework for FL in challenging underwater wireless IoT networks.
| Algorithm 2 Proposed UCB-SCP for FL-enabled underwater wireless IoT networks |
| Input: FL task. Output: learned FL model. 1: The controllers generate an FL task. 2: The controllers send the FL task to the FL server. 3: begin FL in the underwater wireless IoT network: 4: the FL server: 5: Initialize FL model trained by FL. 6: for do 7: Select a set of IoT edge devices consisting of the -th, …, -th IoT edge devices in . 8: Update according to (2), (3), (13), (14), (15) and (16), respectively. 9: end for 10: . 11: Select a set of IoT edge devices consisting of the -th, …, K-th IoT edge devices in . 12: Update according to (2), (3), (13), (14), (15) and (16), respectively. 13: main loop: 14: while do 15: Ask for the controllers’ voting on the IoT edge devices according to Section 4.1. 16: Update security prediction model according to last and new labeled dataset according to Section 5.2. 17: for do 18: 19: Select a set of IoT edge devices according to (18). 20: Update according to (2), (3), (13), (14), (15) and (16), respectively. 21: end for 22: end while |
5.5. Upper Bound on Regret
The main difference between the UCB-SCP policy and the UCB-SC policy lies in the evaluation approach for security, i.e., the value of is different, so the upper bound on regret remains consistent with Formula (12).
Then, for the UCB-SCP policy, we employ an FNN model to calculate the security prediction model; an FNN has strong fitting ability that conforms to the Universal Approximation Theorem from [41,42,43] as follows:
Lemma 1.
(Universal Approximation Theorem) Let be a non-constant, bounded, monotonically increasing function, is a D-dimensional unit hypercube , and is the continuous function set in . For any function , there is an integer M, a group of real numbers , and a real vector , so that we can define a function
as an approximation of function f, i.e.,
where and is a very small positive number.
According to Lemma 1, we can assume in Formula (12) as the number of communication rounds increases under the UCB-SCP policy.
Theorem 2.
Under Theorem 1 and Lemma 1, with a large number of communication rounds, the expected regret under the UCB-SCP policy is at most
According to Theorem 2, we note that when the evaluation of the security index is stable and accurate, the regret upper bound is consistent with that of the CS-UCB proposed in [13], which is without the consideration of security. The regret grows as , which is strictly logarithmic and is based on the number of communication rounds.
6. Numerical Experiments
In this section, we design experiments to evaluate the performance of the proposed policies to schedule IoT edge devices for FL in underwater wireless IoT networks. In Section 3, we define . Although the value of can be observed directly in practice, we need to analyze , , and individually to obtain the value of for our simulations. We follow the FL process in [13].
The expected broadcast time latency of the k-th IoT edge device in round t is calculated as
where B (in Hz) is the available bandwidth for each channel, (in bits) is the size of the encoded global model parameters for broadcast, and (in bits/s/Hz) is the expected rate for broadcasting the encoded global model parameters to the k-th IoT edge device in round t. The term is expressed as
where is the variance of the additive white Gaussian noise, is the transmit power of the systematizer for broadcasting to the k-th IoT edge device, and is the expected downlink channel gain of the k-th IoT edge device in round t.
In the same way, the expected upload time of the k-th IoT edge device in round t is
where is the size of the encoded local gradients for upload, and is the expected upload rate of the k-th IoT edge device in round t; is expressed as
where is the upload transmit power of the k-th IoT edge device, and is the expected uplink channel gain of the k-th IoT edge device in round t.
The local training time of the k-th IoT edge device in round t is computed as
where is the computing capability of the k-th IoT edge device in round t, and is the size of the data batch for local training of the k-th IoT edge device in each round.
6.1. Methodology for Data Analysis
To evaluate the effectiveness of our proposed secure dynamic scheduling policies, we conducted a series of simulations comparing the performance of different scheduling strategies. Table 2 following summarizes the key characteristics and parameters of each policy.
Table 2.
Comparison of scheduling policies.
We compared the performance of these policies based on the following metrics:
- Cumulative Selected Malicious Edge Devices Rate: The proportion of malicious devices selected for FL training over time.
- Cumulative Selected Failed Edge Devices Rate: The proportion of devices that failed to complete a training round (due to timeouts or malicious behavior) over time.
- Performance Gap (): The difference between the expected reward of the optimal scheduling policy and the actual reward achieved by the proposed policies.
- Test Accuracy: The accuracy of the trained FL model on a separate test dataset.
By comparing the performance of these policies across these metrics, we were able to evaluate the effectiveness of our proposed UCB-SC and UCB-SCP approaches in improving the security and efficiency of FL in underwater wireless IoT networks.
6.2. Experiment Settings
To evaluate the performance of our proposed scheduling policies, we designed a series of simulation experiments based on a representative underwater wireless IoT network scenario. The experimental setup focuses on a federated learning (FL) task for image classification of handwritten digits (0–9) using the MNIST dataset. Our use case simulates a scenario in which a network of underwater sensors (IoT edge devices) collaboratively trains a machine learning model for real-time image classification. This scenario is relevant for various underwater applications, such as underwater monitoring, navigation, and environmental sensing. The following critical parameters were used in our simulations:
- Number of edge devices (K): 20;
- Maximum number of selected devices per round (N): 4;
- Communication rounds (T): 30,000;
- Voting interval (I): varied among experiments (e.g., 1, 5, or 10 rounds);
- Data batch size (): 6 for all edge devices;
- Learning rate (): 0.005.
We employed a widely used path loss model for underwater acoustic communication [44] to simulate the attenuation experienced in the underwater environment. The path loss was modeled as follows; this formula has been widely used in the underwater IoT and communication area:
where , is the geometric spreading loss and is generally set as 1.5, and f is the signal frequency; according to Thorp’s formula [45], the following can be used as a simplified model for frequencies less than 50 kHz:
In the simulation, the transmit power was set as 180 dB, the signal central frequency was 20 kHz, and the distances between IoT edge devices and the FL server were set as random parameters that are subject to a uniform distribution with a range of [0, 0.5] km.
Meanwhile, we assumed that the computing capability () of each edge device was randomly generated within a specified range to represent differences in device processing power. Malicious edge devices were introduced into the network, with their training accuracy and voting behavior designed to simulate adversarial attacks.
We set the size of the encoded global model parameters and encoded local gradients to bits. According to the settings and (22)–(25), we could obtain the values of and in our experiment. The computing capability of each IoT edge device was uniformly distributed in , where we set and .
We employed FL under different policies to learn a general ML model for image classification of handwritten digits 0–9 in the MNIST dataset using a convolutional neural network (CNN). We adopted mini-batch stochastic gradient descent (SGD) with a mini-batch size of 6 for each IoT edge devices. So we could compute according to (26) and then get the value of after setting .
In each round of model learning, the accuracy of a good IoT edge device was set to , which is relatively accurate and stable, where represents a random number generated by a normal distribution. In contrast, the accuracy of a malicious IoT edge device was , which is relatively low, and the high variance means the values are subject to large changes. The accuracy of the global model was defined as , which is more accurate, but the global model may be occasionally attacked by malicious IoT edge devices, which would slightly increase the variance. We used to generate , and it can be considered that the higher accuracy rate is closer to that of the global model. Therefore, we set the cosine similarity score as in our experiment.
In terms of the security evaluation, the voting rate through the voting mechanism reflects the level of security, and its range is . The higher the voting rate, the higher the degree of security. For a trusted IoT edge device, we set the voting rate as , and the voting rate of a malicious edge device was set to each time. For the security prediction model in the UCB-SCP policy, the prediction model uses an FNN model for which the input dimension is 4, the number of neurons is set to 5, the number of hidden layers is 3, and the final output dimension is 1. The nonlinear function uses the ReLU function, the loss function uses the squared loss function, the optimization algorithm uses the Adam algorithm, and the learning rate is 0.005. In addition, we set as 0.6, which balances the consideration of time efficiency and security.
In the experiment, the voting interval is set to different numbers of rounds: namely, UCB-SC-I, where I is the number of voting interval rounds, and in the ideal case without regard to communication cost. Then, the UCB-SCP policy keeps the same voting interval rounds as UCB-SC, and the security prediction model is updated after each round of voting: namely, UCB-SCP-I. Before displaying the performance of the proposed policies, we introduce the following two baseline policies for comparison [13]. One of them is a random policy whereby N IoT edge devices are selected randomly to participate in the FL process every round. The other one is the CS-UCB policy, in which IoT edge devices are selected only according to their previous performance in terms of time latency. Firstly, we set a condition as follows to observe the performance of different policies for communication rounds in a volatile and insecure wireless IoT network. Thus, the statuses of IoT edge devices change every n rounds, where n is uniformly distributed in . After a change, there are h malicious IoT edge devices, where h is uniformly distributed in and comprise an average of of the IoT edge devices. We assume that malicious IoT edge devices upload unsatisfactory parameters to interfere with the performance of FL. Secondly, we discuss the performance of different policies under different levels of attack. Our experiment trains for 30,000 communication rounds for each policy with different numbers of malicious IoT edge devices. The statuses of IoT edge devices also change every rounds, and the number of malicious IoT edge devices after every change is uniformly distributed in , where b is the average malicious IoT edge device rate.
6.3. Numerical Results
IoT edge devices are identified as failed if they timeout, i.e., , or are malicious; failed devices are counted for each round of data updating, and they accumulate round-by-round. The cumulative selected failed IoT edge device rate and the cumulative selected malicious IoT edge devices rate are, respectively, the number of cumulative selected failed IoT edge devices and the number of cumulative selected malicious IoT edge devices divided by the total number of selected IoT edge devices, i.e., , where t is the current communication round. We define as the performance gap (in s).
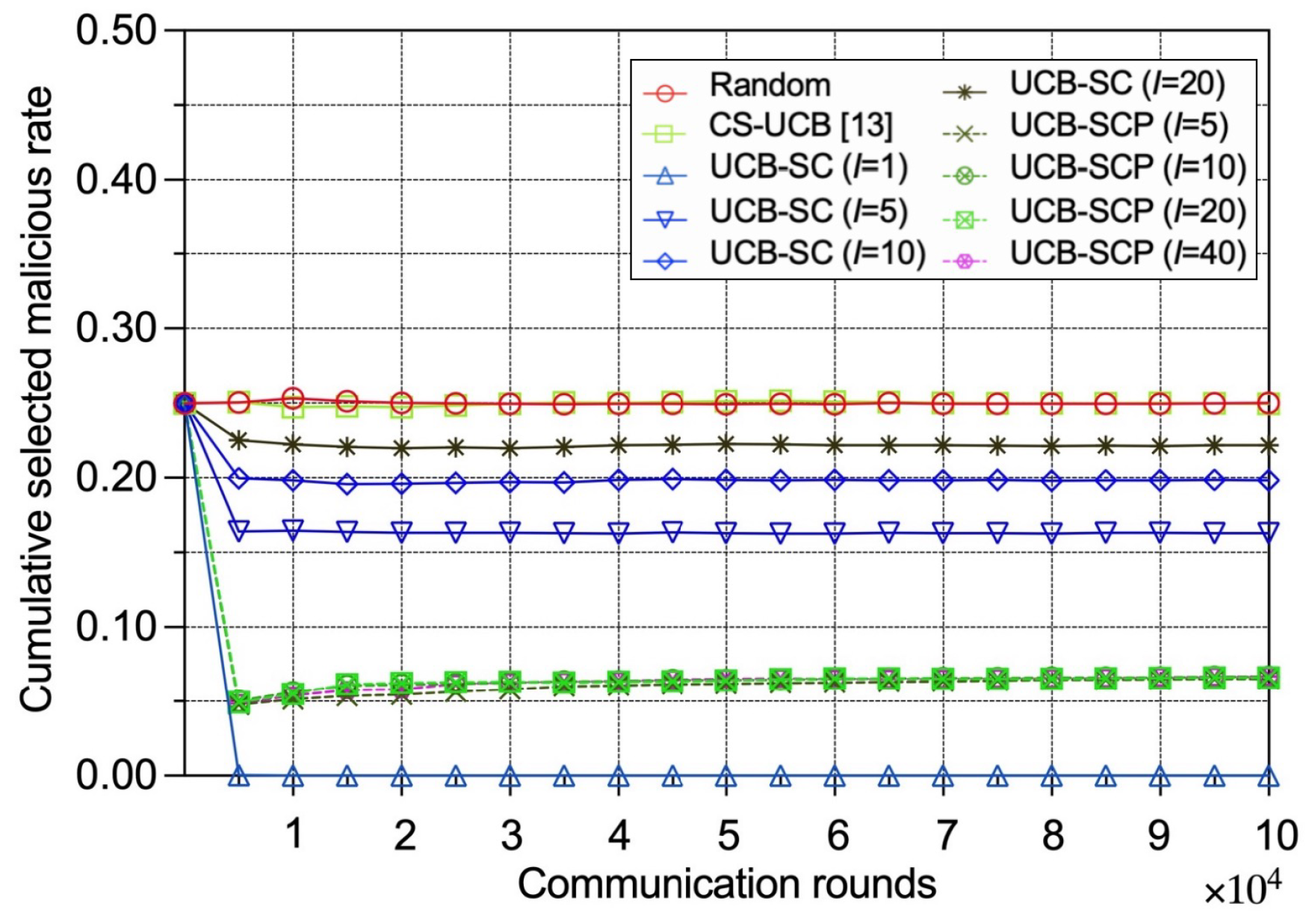
Figure 2 shows the cumulative selected malicious edge device rate for different policies as the number of communication rounds increases. The proposed UCB-SC and UCB-SCP policies are expected to select fewer malicious devices compared to the random and CS-UCB policies. As expected, the rates for the UCB-SC and UCB-SCP policies are significantly lower than those of the random and CS-UCB policies, indicating that our approach successfully mitigates the risk of selecting malicious devices. The random policy and CS-UCB policy do not consider security, so their rates closely reflect the average malicious device rate. UCB-SC-ideal, which votes in every round, almost never selects malicious devices. UCB-SCP demonstrates consistent performance regardless of the voting and prediction model calculation interval due to the model’s convergence.
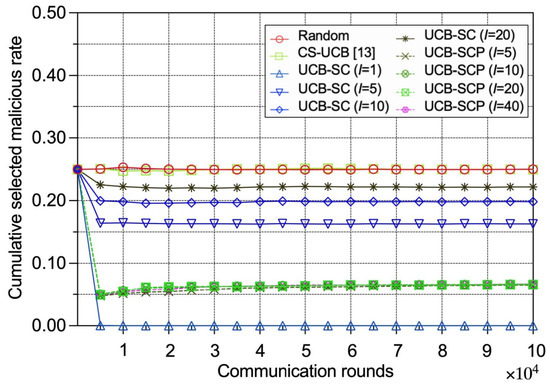
Figure 2.
Performance comparison between different policies in terms of cumulative selected malicious IoT edge device rates.
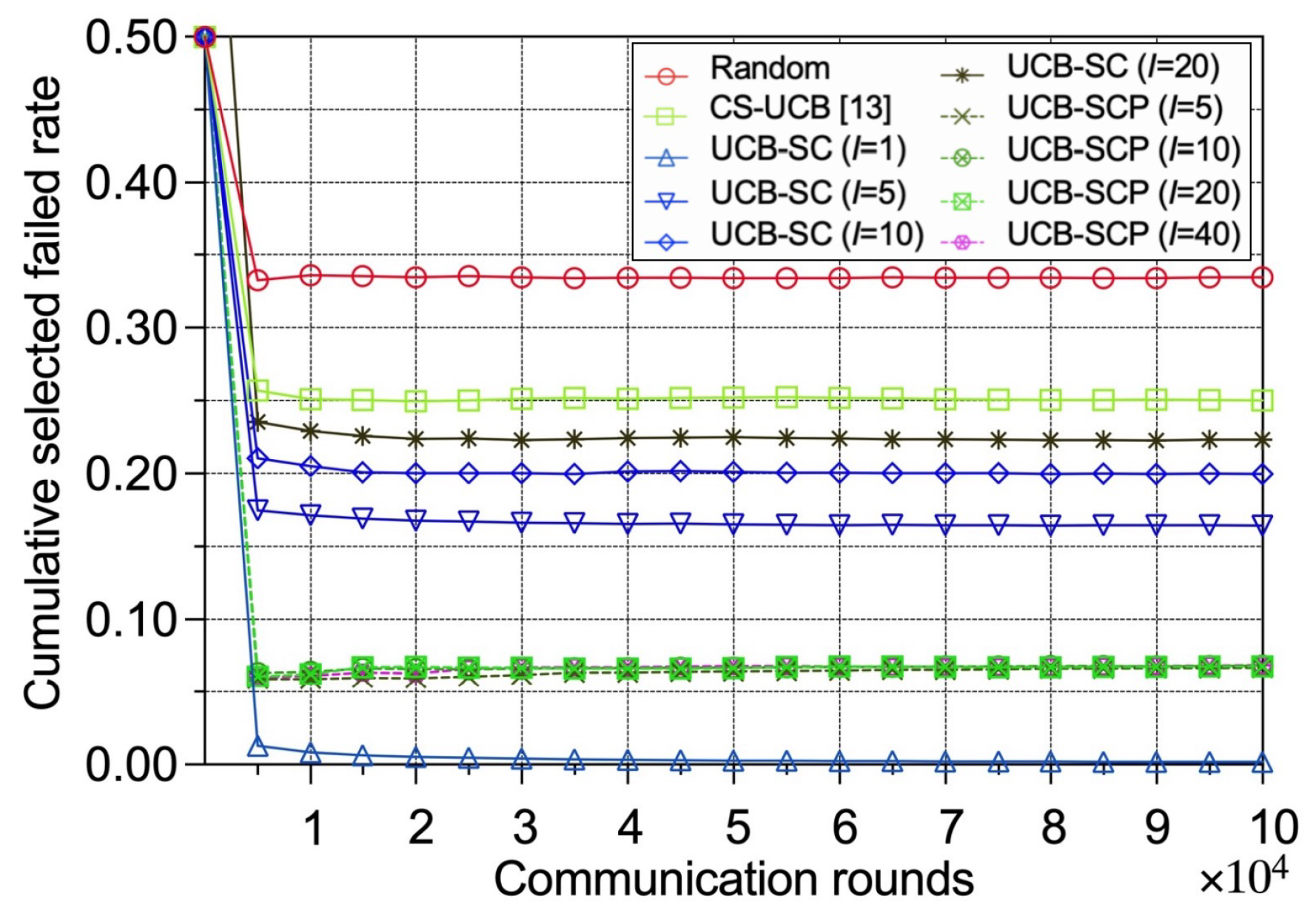
Figure 3 shows the cumulative selected failed edge device rate, which is a comprehensive reflection of time efficiency and security. We anticipated that the proposed policies would select fewer failed devices overall. Figure 3 confirms this expectation. While the random policy shows a significant increase in the failed device rate, UCB-SC and UCB-SCP select fewer failed devices, similar to the CS-UCB policy. This indicates that our policies achieve combined optimization of time efficiency and security.
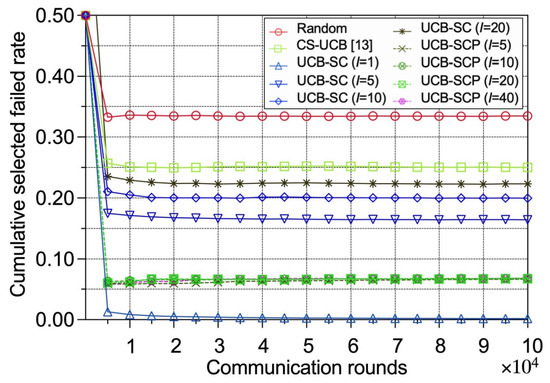
Figure 3.
Performance comparison between different policies in terms of cumulative selected failed IoT edge device rates.
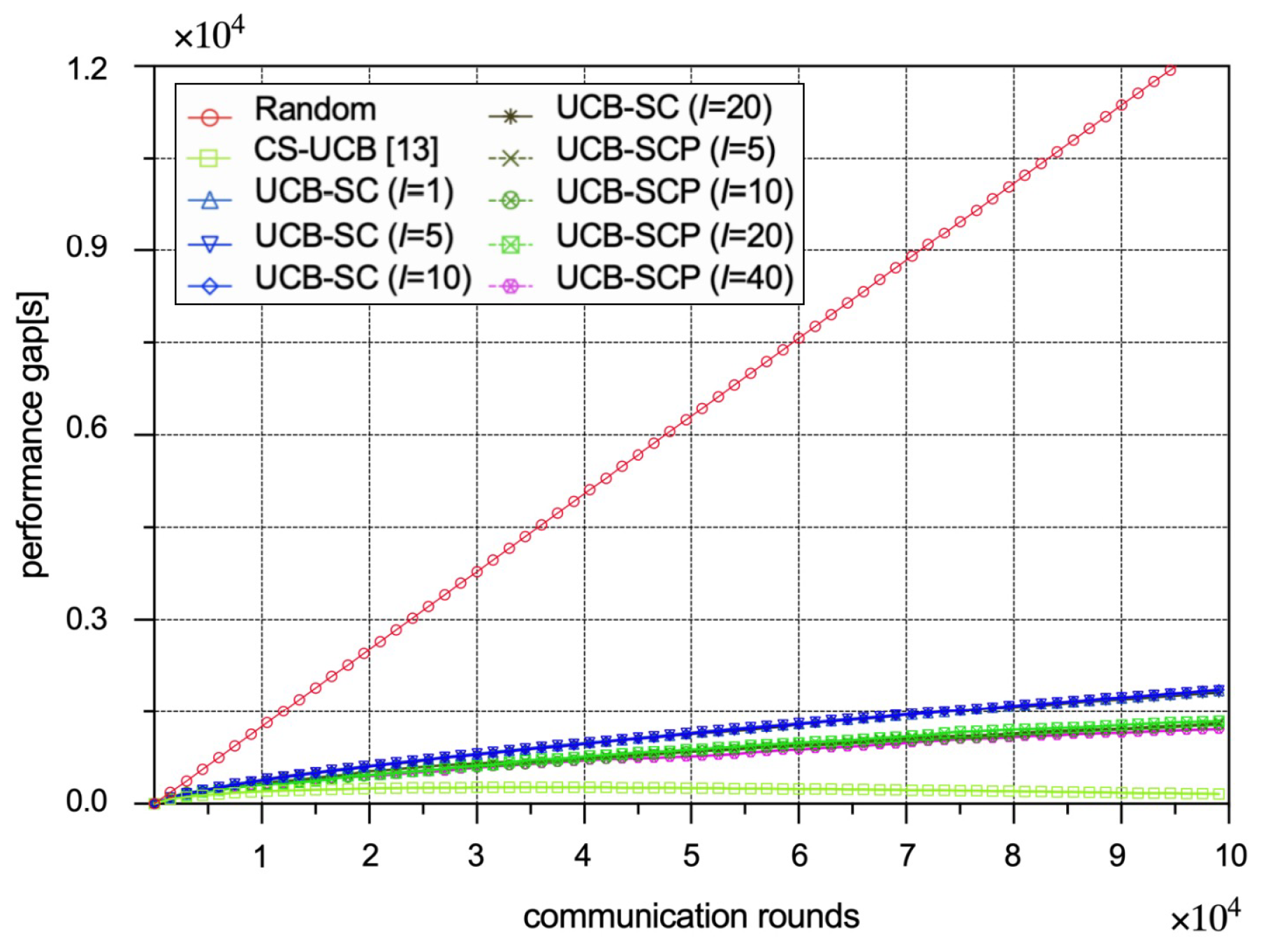
Figure 4 shows the performance gaps for different policies. All other policies end up with a small performance gap: (1) The CS-UCB policy is unaware of the malicious IoT edge devices in the FL process, so its performance gap is lowest and even drops off later in training. (2) Regardless of the number of interval rounds, the performance gaps of all UCB-SC policies are equal, and the performance gaps of all UCB-SCP policies are equal as well, because the regret L only depends on the variables in Formula (7), not on the number of interval rounds. (3) The performance gap of UCB-SCP is lower than that of UCB-SC due to the maximum difference of security index being smaller for the UCB-SCP policy because of its security prediction model.
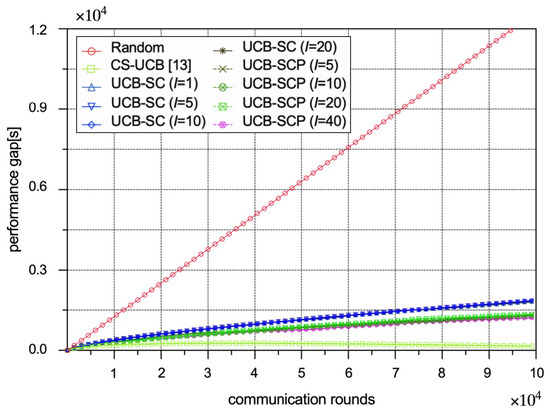
Figure 4.
Performance comparison between different policies in terms of performance gaps.
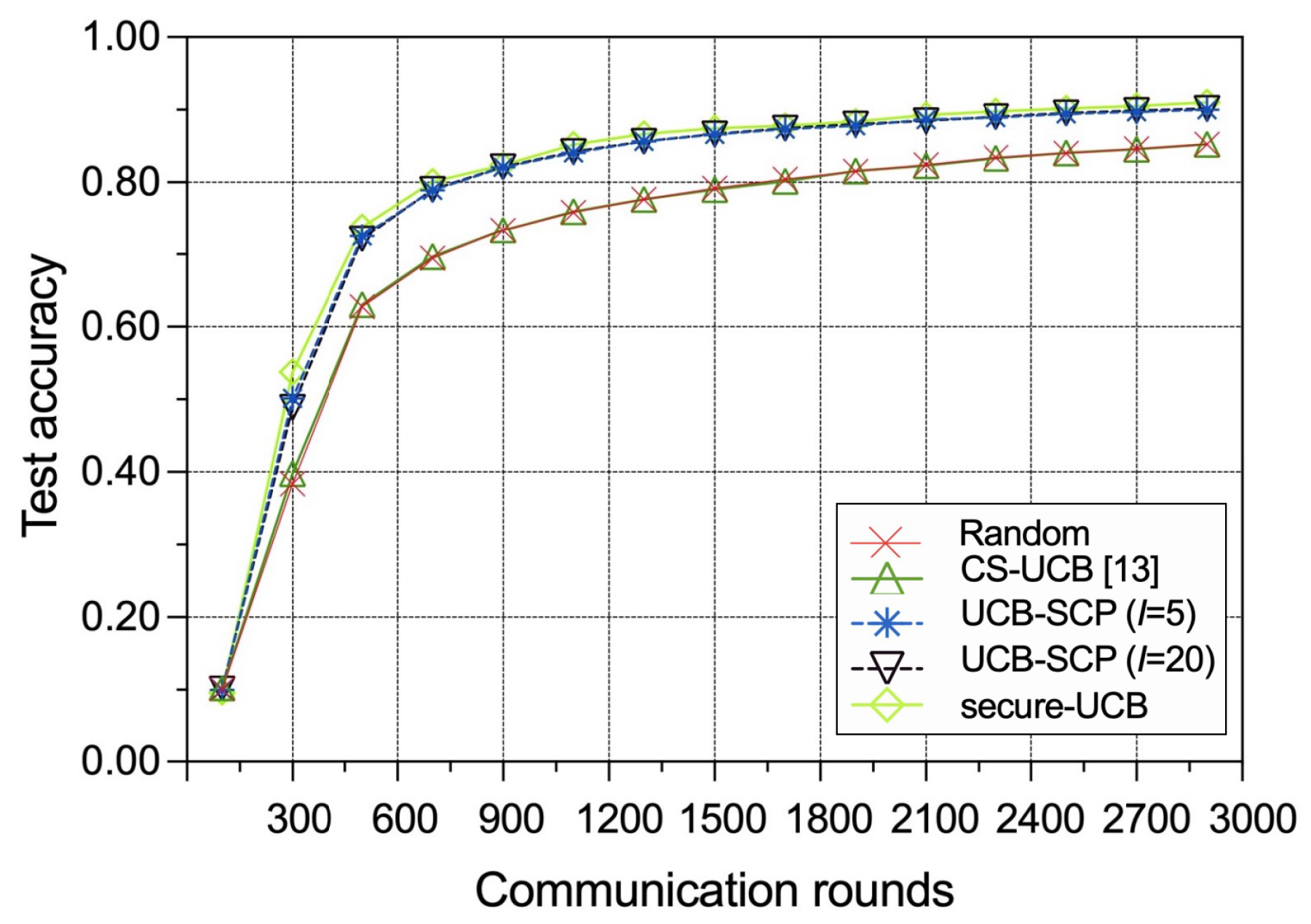
The test accuracies of the ML model trained by FL versus the number of communication rounds for different policies are presented in Figure 5. We introduce a baseline called secure-UCB, wherein CS-UCB is applied in a secure wireless IoT network with no malicious IoT edge device instead of the aforementioned volatile and insecure network; hence, its learning performance can be seen as an ideal standard. We find that our proposed UCB-SCP policy is very close to the ideal secure-UCB in terms of convergence speed and test accuracy, and it has better performance in both aspects compared to the random policy and the CS-UCB policy. The reason is that UCB-SCP can select the good IoT edge devices and eliminate interference from malicious IoT edge devices in the FL-enabled wireless IoT network. Thus, the results also prove that the UCB-SCP policy has good improvement to the security.
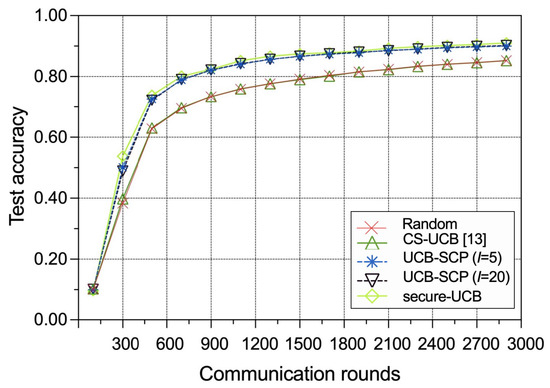
Figure 5.
Performance comparison between different policies in terms of test accuracy.
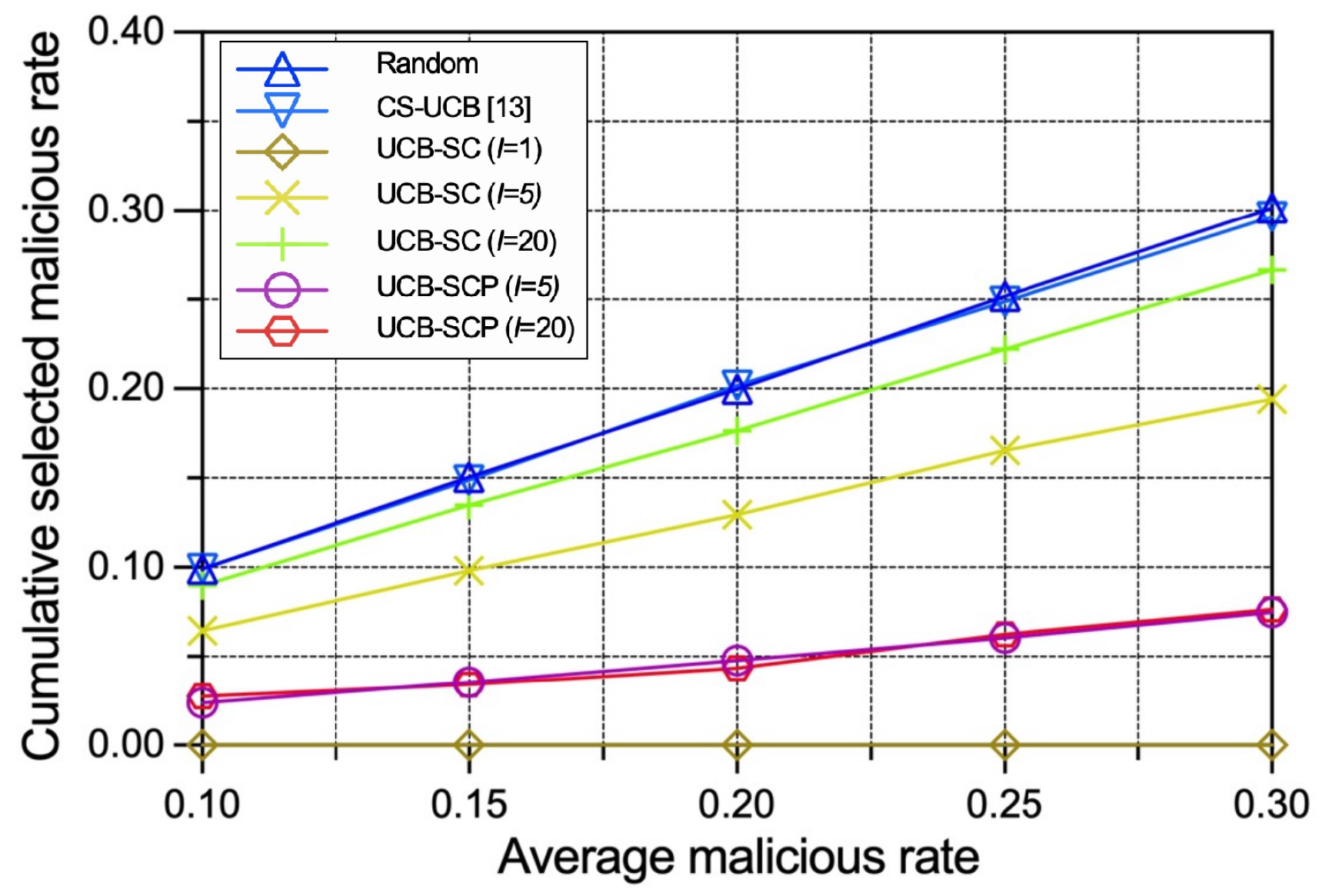
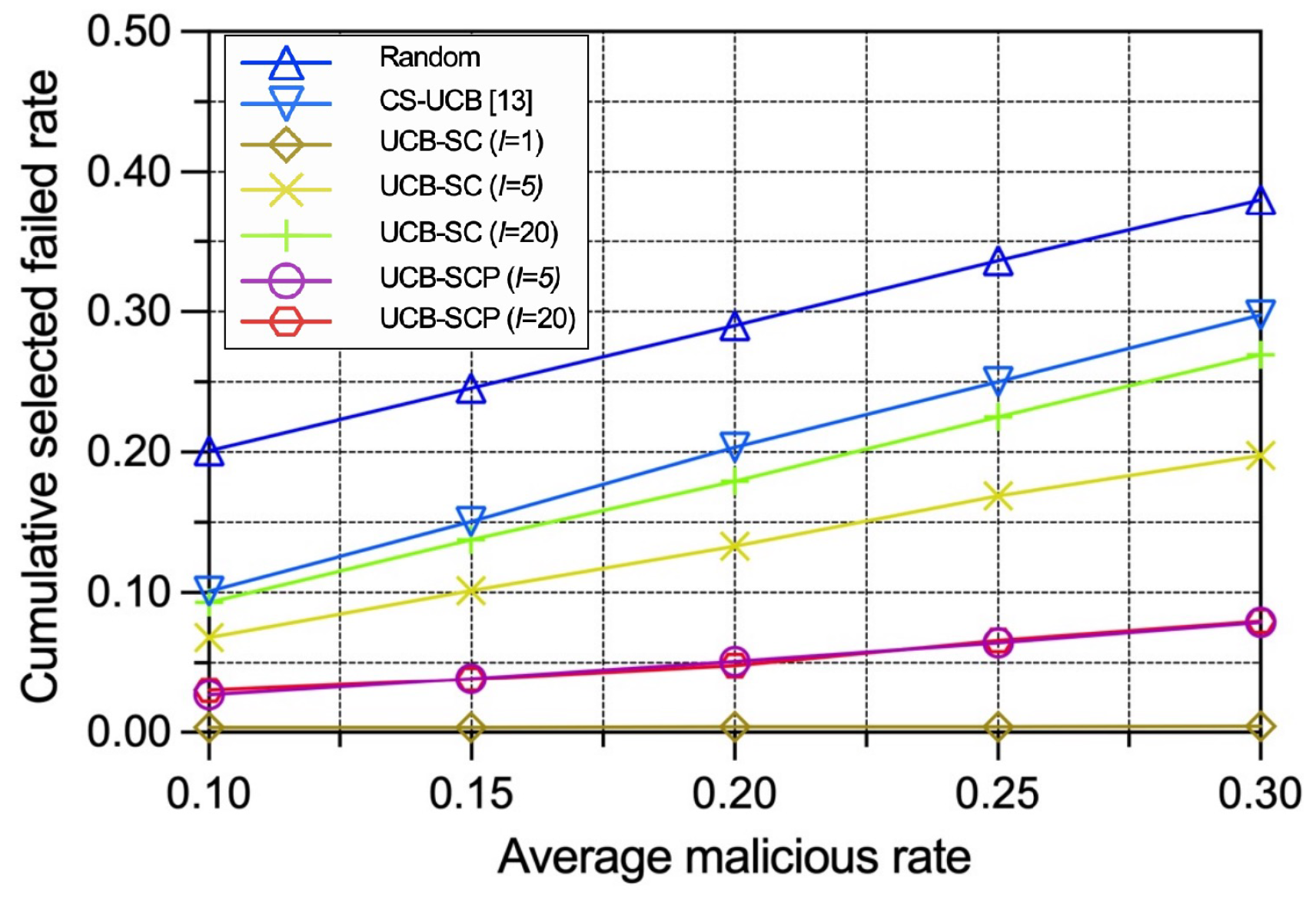
To evaluate the robustness of our policies under different levels of attack, we vary the average malicious device rate while keeping the other settings consistent. Some of the conclusions drawn earlier still hold. In Figure 6, we can see: (1) The cumulative selected malicious IoT edge device rates under the random policy and the CS-UCB policy are directly proportional to the global average malicious IoT edge device rate owing to the policies being unaware of security. (2) The growth rate of the selected malicious IoT edge device rate in relation to the global average malicious IoT edge device rate under the UCB-SC policy is positively correlated with number of voting interval rounds. (3) The selected malicious IoT edge device rate of the UCB-SCP policy grows slowly regardless of the number of voting and prediction model calculation interval rounds. Figure 7 presents that, based on the lower cumulative malicious IoT edge device rates, our proposed UCB-SC and UCB-SCP policies perform better in terms of a comprehensive consideration of the time efficiency and security for any malicious IoT edge device rate.
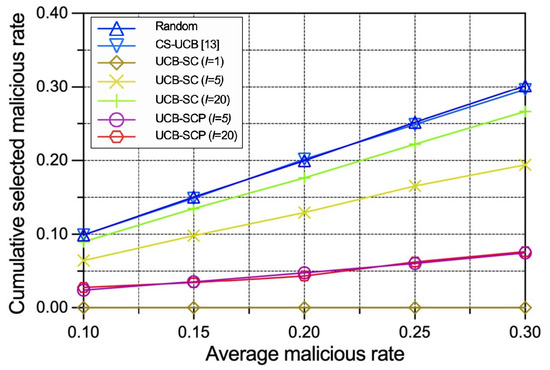
Figure 6.
Performance comparison between different policies with varying average malicious IoT edge device rates in terms of cumulative selected malicious IoT edge device rate.
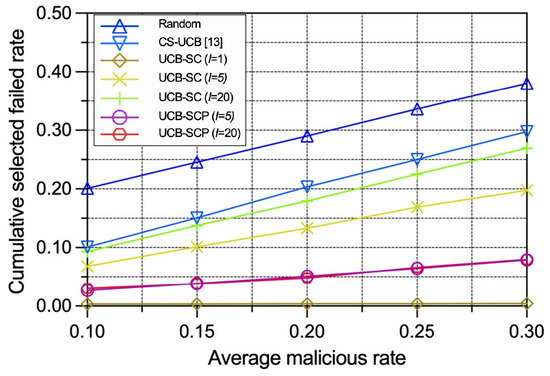
Figure 7.
Performance comparison between different policies with varying average malicious IoT edge device rates in terms of cumulative selected failed IoT edge device rate.
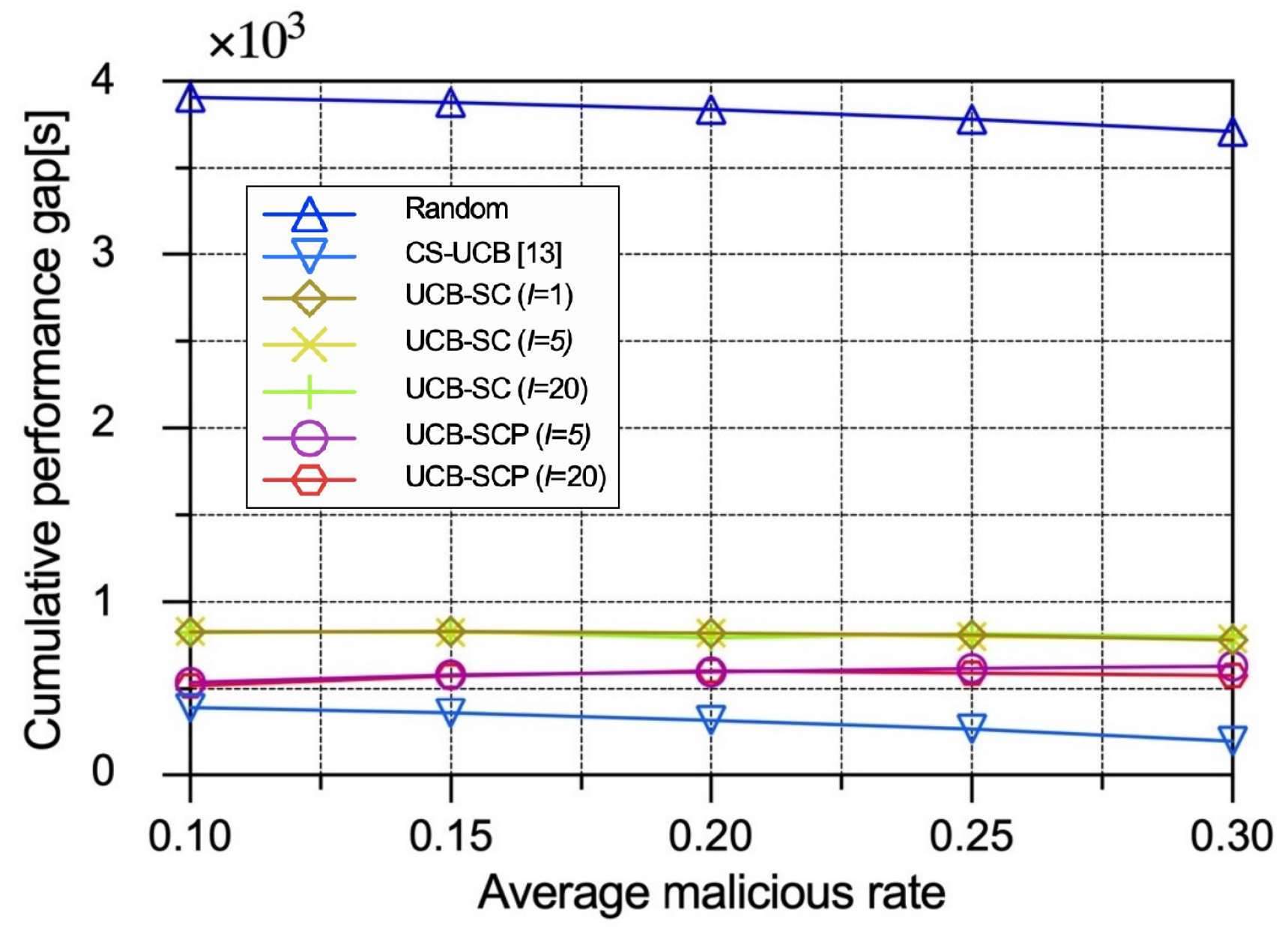
As shown in Figure 8, the performance gaps of the random policy and the CS-UCB policy decrease as the malicious IoT edge device rate increases. The reason is that there are fewer good IoT edge devices in , leading to a more constrained generation of so that in Formula (11) is smaller, but in Formula (11) is not affected under these two policies, which are unaware of the security. By contrast, the performance gaps of the UCB-SC policy and the UCB-SCP policy are stable with different malicious IoT edge device rates because security considerations contribute to similarly to .
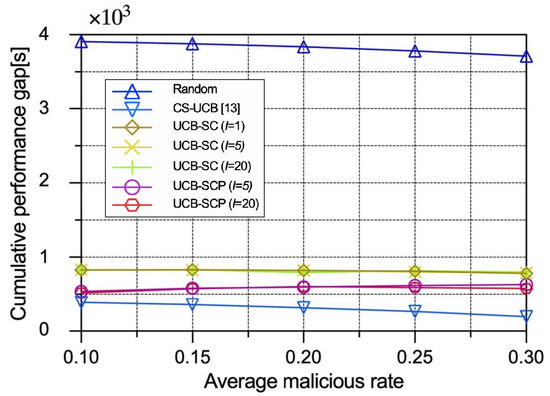
Figure 8.
Performance comparison between different policies with varying average malicious IoT edge device rates in terms of performance gap.
6.4. Discussion
We introduced a novel system architecture to secure dynamic scheduling for FL in underwater wireless IoT networks by utilizing MAB-based methods integrated with smart contracts. The implementation of UCB-SC and its extension, UCB-SCP, which includes a security prediction model, effectively addresses key challenges to optimizing both communication efficiency and security. In the UCB-SC policy, IoT devices are dynamically evaluated by authoritative controllers to identify and mitigate rapidly changing malicious behaviors. In the UCB-SCP policy, machine learning is utilized to predict the trustworthiness of devices in real-time based on a wide range of behaviors and historical data. As new data become available, the model is updated in real-time or near-real-time. If there is a change in device behavior, the model quickly adjusts its predictions to reflect these changes, thereby enhancing its response capability to dynamic threats.
The results demonstrated that the proposed UCB-SC and UCB-SCP policies significantly improve the efficiency and security of FL over traditional methods, which typically overlook dynamic and secure scheduling. Compared to existing approaches that lack security considerations, like those described by Xia et al. [13], our proposed policies demonstrate enhanced robustness by dynamically predicting security threats and adapting the scheduling accordingly, thereby providing an effective defense against malicious actions from underwater wireless IoT edge devices.
7. Conclusions
In this paper, we aim to achieve efficient and secure FL in underwater wireless IoT networks through IoT edge device scheduling. We design an FL-enabled network that consists of controllers, an FL server, and IoT edge devices. Time efficiency and security during scheduling are defined in the network. Then, we employ a voting mechanism to enhance the security of scheduling. Considering the case of a limited communication cost budget and violent instability, we further propose a security prediction model to reduce the communication cost of voting. An FNN model is used to formulate a security prediction model with a labeled dataset that includes the defined trust evidence and the voting rate. The security prediction model makes each round of voting similar in terms of the security evaluation and consistent with interval voting in terms of communication cost. Considering the unknowns of the communication environment, computing power, and malicious attacks, we provide a MAB-based framework to reformulate the problem and to optimize it online using modified UCB algorithms. Finally, a smart contract is introduced to guarantee the correct execution of the above process. Overall, the complete UCB-SC and UCB-SCP policies are formed to secure dynamic scheduling for FL in wireless IoT networks. Experiments show that our proposed UCB-SC and UCB-SCP policies can enhance FL in terms of both efficiency and security in underwater wireless IoT networks.
While our proposed UCB-SC and UCB-SCP policies significantly enhance the security and efficiency of FL in underwater wireless IoT networks, they are not without limitations. The effectiveness of these policies is contingent on several assumptions that may not hold in all operational scenarios. For instance, the accuracy of the security prediction model relies heavily on the quality and quantity of data available for training. Inadequate or biased data can lead to less effective security assessments. Moreover, the proposed models assume stable communication conditions and overlook the potential disruptions typical in underwater environments, such as signal attenuation and noise interference. These factors can affect the real-time performance and reliability of the policies.
Our future research will focus on expanding the scalability of our proposed system architecture to accommodate multi-user network scenarios This expansion is crucial as it addresses the increasing need for federated learning systems that can operate efficiently in environments with multiple users and devices. Additionally, a promising direction involves the development of federated learning models that support collaborative tasks among multiple robots. Such models could significantly enhance the coordination and efficiency of robotic systems in complex underwater missions. This approach will not only refine the robustness of our system for diverse network configurations but will also broaden the applicability of our methods to more dynamic and challenging environments.
Author Contributions
Methodology, L.Y.; software, L.W. and J.S.; funding acquisition, L.Y.; system design and analysis, G.L.; project implementation and testing, Z.X.; algorithm analysis, L.Y. and L.W.; All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under grant 62301136.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
Authors Guanjun Li, Jingwei Shao, Zhixin Xia were employed by the company Shulian Technology Co., Ltd., Hebei Port Group. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Appendix A. Proof of Theorem 1
To prove Theorem 1, we use the following inequalities.
Lemma A1
(Chernoff–Hoeffding Bound [46]). are random variables, and , . Let . Then for all ,
We denote the upper bound of security evaluation of good IoT edge devices as u and the lower bound of security evaluation of good IoT edge devices as d, and are any good IoT edge devices in any rounds.
We introduce as follows.
where , which makes a preliminary estimate of all K IoT edge devices, and there is exactly one among that is incremented by 1 when after completing the preliminary estimate. We also note that
where T is the total number of communication rounds.
We further define to indicate whether is incremented as follows.
Then, we can obtain the following equation:
where is the indicator function, the result of which is 1 when · is true, and , which makes a preliminary estimate of all K IoT edge devices.
As defined above, means that and . Then,
Note that , and . Hence, we have (A7).
where denotes the j-th IoT edge device in and denotes the j-th IoT edge device in .
implies that at least one of the following must hold:
We bound the probabilities of Formulas (A8) and (A9).
Then, we can apply the Chernoff–Hoeffding bound stated in Lemma 2 to obtain the following:
Hence,
Similarly, we can obtain the following:
For ,
which implies that
So we have
Finally, we can obtain the upper bound of regret as follows:
References
- Xu, G.; Shi, Y.; Sun, X.; Shen, W. Internet of things in marine environment monitoring: A review. Sensors 2019, 19, 1711. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- Zhao, C.; Thies, P.R.; Johanning, L. Offshore inspection mission modelling for an ASV/ROV system. Ocean. Eng. 2022, 259, 111899. [Google Scholar] [CrossRef]
- Fun Sang Cepeda, M.; Freitas Machado, M.d.S.; Sousa Barbosa, F.H.; Santana Souza Moreira, D.; Legaz Almansa, M.J.; Lourenço de Souza, M.I.; Caprace, J.D. Exploring Autonomous and Remotely Operated Vehicles in Offshore Structure Inspections. J. Mar. Sci. Eng. 2023, 11, 2172. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Szabo, N. The idea of smart contracts. Nick Szabo’S Pap. Concise Tutor. 1997, 6, 199. [Google Scholar]
- Luu, L.; Chu, D.H.; Olickel, H.; Saxena, P.; Hobor, A. Making smart contracts smarter. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 254–269. [Google Scholar]
- Luping, W.; Wei, W.; Bo, L. CMFL: Mitigating communication overhead for federated learning. In Proceedings of the IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–9 July 2019; pp. 954–964. [Google Scholar]
- Cho, Y.J.; Wang, J.; Joshi, G. Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Zhang, T.; Lam, K.Y.; Zhao, J.; Feng, J. Joint Device Scheduling and Bandwidth Allocation for Federated Learning over Wireless Networks. IEEE Trans. Wirel. Commun. 2023. early access. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, W.; Ye, Q.; Zhang, C.; Zhang, N.; Huang, C.; Zhang, H.; Shen, X. DetFed: Dynamic Resource Scheduling for Deterministic Federated Learning Over Time-Sensitive Networks. IEEE Trans. Mob. Comput. 2024, 23, 5162–5178. [Google Scholar] [CrossRef]
- Perazzone, J.; Wang, S.; Ji, M.; Chan, K.S. Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, Virtual, 2–5 May 2022; pp. 1449–1458. [Google Scholar] [CrossRef]
- Xia, W.; Quek, T.Q.S.; Guo, K.; Wen, W.; Yang, H.H.; Zhu, H. Multi-Armed Bandit Based Client Scheduling for Federated Learning. IEEE Trans. Wireless Commun. 2020, 19, 7108–7123. [Google Scholar]
- Yoshida, N.; Nishio, T.; Morikura, M.; Yamamoto, K. MAB-based client selection for federated learning with uncertain resources in mobile networks. In Proceedings of the IEEE Global Communications Conference Workshops, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Huang, T.; Lin, W.; Wu, W.; He, L.; Li, K.; Zomaya, A.Y. An efficiency-boosting client selection scheme for federated learning with fairness guarantee. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1552–1564. [Google Scholar] [CrossRef]
- Xu, B.; Xia, W.; Zhang, J.; Quek, T.Q.; Zhu, H. Online client scheduling for fast federated learning. IEEE Wireless Commun. Lett. 2021, 10, 1434–1438. [Google Scholar] [CrossRef]
- Ciucanu, R.; Delabrouille, A.; Lafourcade, P.; Soare, M. Secure Protocols for Best Arm Identification in Federated Stochastic Multi-Armed Bandits. IEEE Trans. Depend. Sec. Comput. 2022, 20, 1378–1389. [Google Scholar] [CrossRef]
- Taylor, P.J.; Dargahi, T.; Dehghantanha, A.; Parizi, R.M.; Choo, K.K.R. A systematic literature review of blockchain cyber security. Digit. Commun. Netw. 2020, 6, 147–156. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT. IEEE Trans. Ind. Informat. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Xu, Y.; Lu, Z.; Gai, K.; Duan, Q.; Lin, J.; Wu, J.; Choo, K.K.R. BESIFL: Blockchain Empowered Secure and Incentive Federated Learning Paradigm in IoT. IEEE Internet Things J. 2021, 10, 6561–6573. [Google Scholar] [CrossRef]
- Deng, R.; Du, X.; Lu, Z.; Duan, Q.; Huang, S.C.; Wu, J. HSFL: Efficient and Privacy-Preserving Offloading for Split and Federated Learning in IoT Services. In Proceedings of the 2023 IEEE International Conference on Web Services (ICWS), Chicago, IL, USA, 2–8 July 2023; pp. 658–668. [Google Scholar] [CrossRef]
- Chen, L.; Ding, X.; Bao, Z.; Zhou, P.; Jin, H. Differentially Private Federated Learning on Non-iid Data: Convergence Analysis and Adaptive Optimization. IEEE Trans. Knowl. Data Eng. 2024, 36, 4567–4581. [Google Scholar] [CrossRef]
- Jiang, L.; Zheng, H.; Tian, H.; Xie, S.; Zhang, Y. Cooperative federated learning and model update verification in blockchain empowered digital twin edge networks. IEEE Internet Things J. 2021, 9, 11154–11167. [Google Scholar] [CrossRef]
- Zhu, R.; Boukerche, A.; Feng, L.; Yang, Q. A trust management-based secure routing protocol with AUV-aided path repairing for Underwater Acoustic Sensor Networks. Ad Hoc Netw. 2023, 149, 103212. [Google Scholar] [CrossRef]
- Han, G.; He, Y.; Jiang, J.; Wang, H.; Peng, Y.; Fan, K. Fault-tolerant trust model for hybrid attack mode in underwater acoustic sensor networks. IEEE Netw. 2020, 34, 330–336. [Google Scholar] [CrossRef]
- El Faqir, Y.; Arroyo, J.; Hassan, S. An overview of decentralized autonomous organizations on the blockchain. In Proceedings of the 16th International Symposium on Open Collaboration, Virtual, 26–27 August 2020; pp. 1–8. [Google Scholar]
- Li, K.; Li, H.; Hou, H.; Li, K.; Chen, Y. Proof of vote: A high-performance consensus protocol based on vote mechanism & consortium blockchain. In Proceedings of the IEEE 19th International Conference on High Performance Computing and Communications; IEEE 15th International Conference on Smart City; IEEE 3rd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Bangkok, Thailand, 18–20 December 2017; pp. 466–473. [Google Scholar]
- Lai, T.L.; Robbins, H. Asymptotically efficient adaptive allocation rules. Adv. Appl. Math. 1985, 6, 4–22. [Google Scholar] [CrossRef]
- Bubeck, S.; Cesa-Bianchi, N. Regret analysis of stochastic and nonstochastic multi-armed bandit problems. Found. Trends Mach. Learn. 2012, 5, 1–122. [Google Scholar] [CrossRef]
- Gai, Y.; Krishnamachari, B.; Jain, R. Combinatorial network optimization with unknown variables: Multi-armed bandits with linear rewards and individual observations. IEEE/ACM Trans. Netw. 2012, 20, 1466–1478. [Google Scholar] [CrossRef]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Mohanta, B.K.; Panda, S.S.; Jena, D. An overview of smart contract and use cases in blockchain technology. In Proceedings of the IEEE 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–4. [Google Scholar]
- Zhu, L.; Wu, Y.; Gai, K.; Choo, K.K.R. Controllable and trustworthy blockchain-based cloud data management. Future Gener. Comput. Syst. 2018, 91, 527–535. [Google Scholar] [CrossRef]
- Huang, X.; Ye, D.; Yu, R.; Shu, L. Securing parked vehicle assisted fog computing with blockchain and optimal smart contract design. IEEE/CAA J. Autom. Sin. 2020, 7, 426–441. [Google Scholar] [CrossRef]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. Fltrust: Byzantine-robust federated learning via trust bootstrapping. arXiv 2020, arXiv:2012.13995. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern recognition and machine learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 2, pp. 1122–1128. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Leshno, M.; Lin, V.Y.; Pinkus, A.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 2005, 6, 861–867. [Google Scholar] [CrossRef]
- Xu, J.; Kishk, M.A.; Zhang, Q.; Alouini, M.S. Three-Hop Underwater Wireless Communications: A Novel Relay Deployment Technique. IEEE Internet Things J. 2023, 10, 13354–13369. [Google Scholar] [CrossRef]
- Saeed, N.; Celik, A.; Al-Naffouri, T.Y.; Alouini, M.S. Energy Harvesting Hybrid Acoustic-Optical Underwater Wireless Sensor Networks Localization. Sensors 2018, 18, 51. [Google Scholar] [CrossRef] [PubMed]
- Pollard, D. Convergence of Stochastic Processes; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).