Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery




Abstract
:1. Introduction
2. Related Work
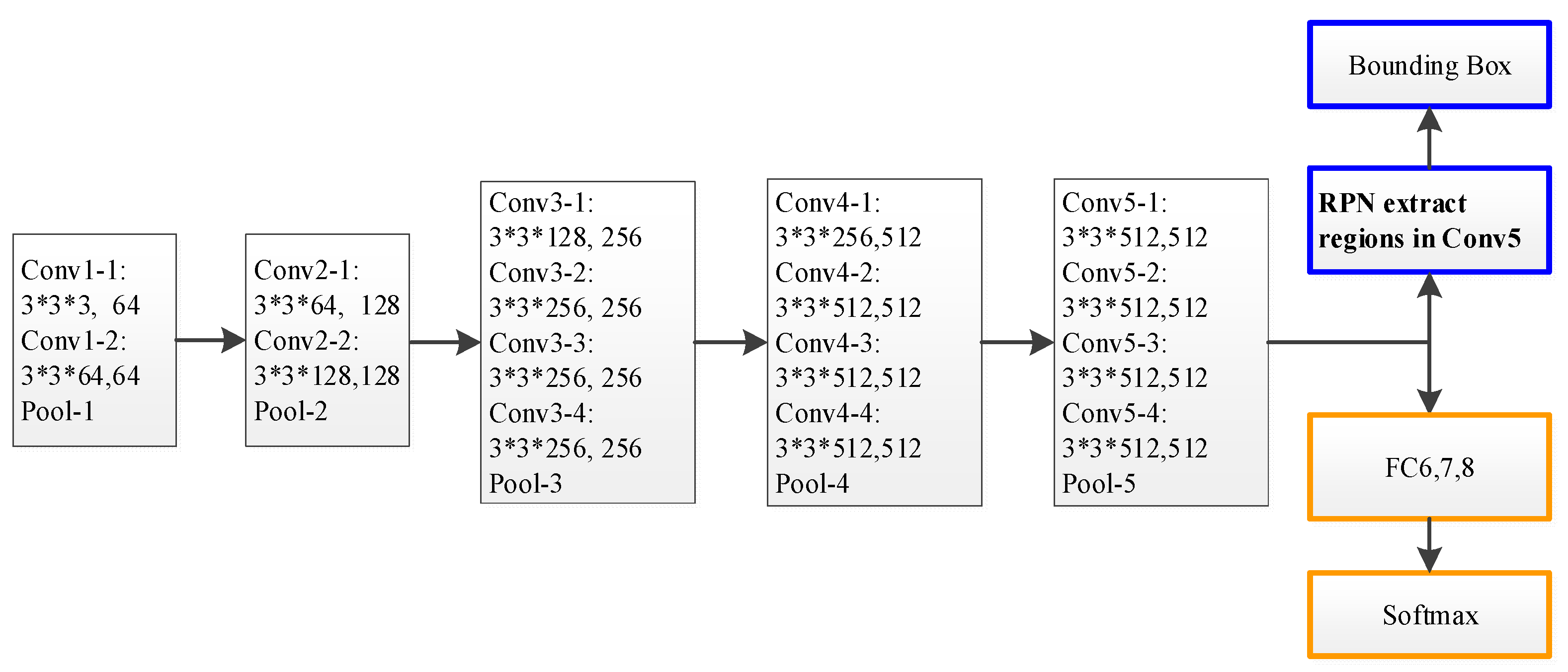
2.1. Region Proposal Network (RPN) on a Backbone Network
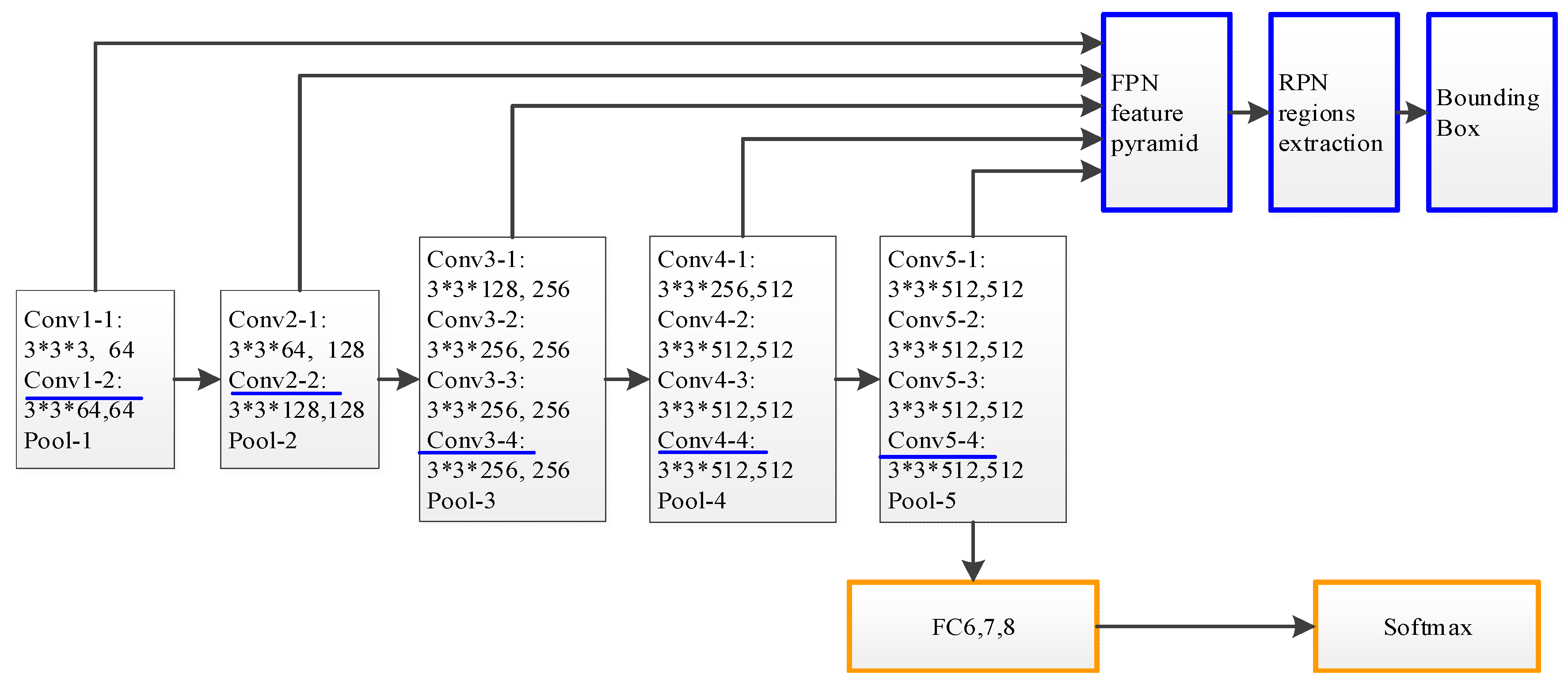
2.2. Feature Pyramid Network (FPN) on Backbone
3. Proposed Method
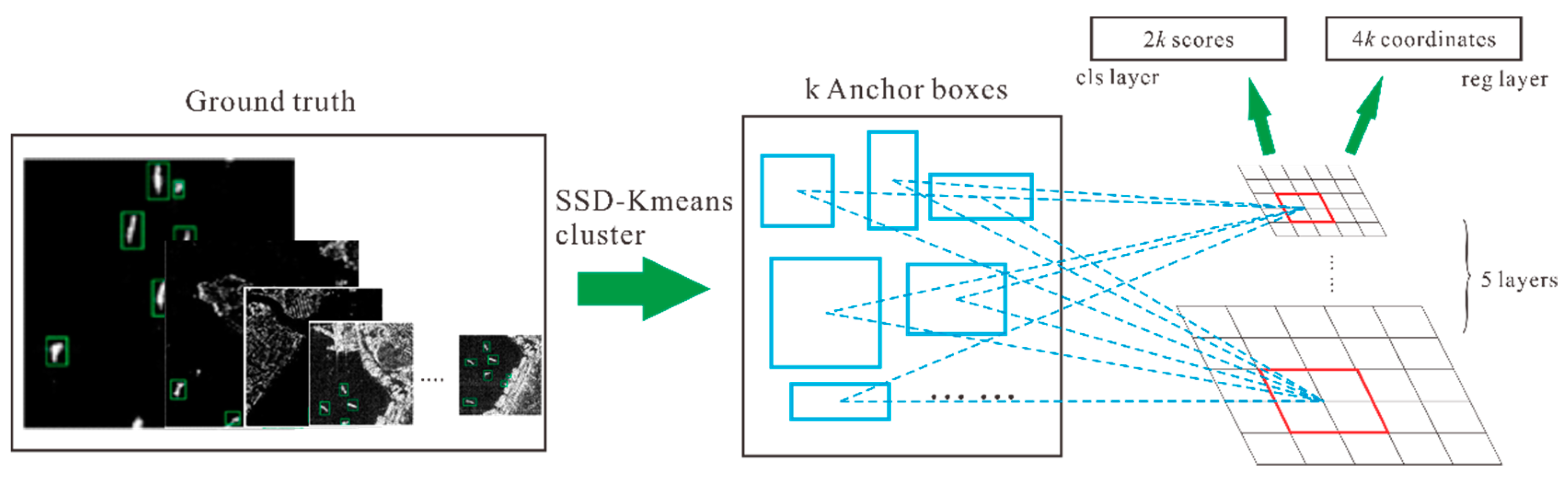
3.1. Anchor Boxes Generation Based on Shape Similar Distance (SSD)-Kmeans
3.2. Anchor Boxes Training
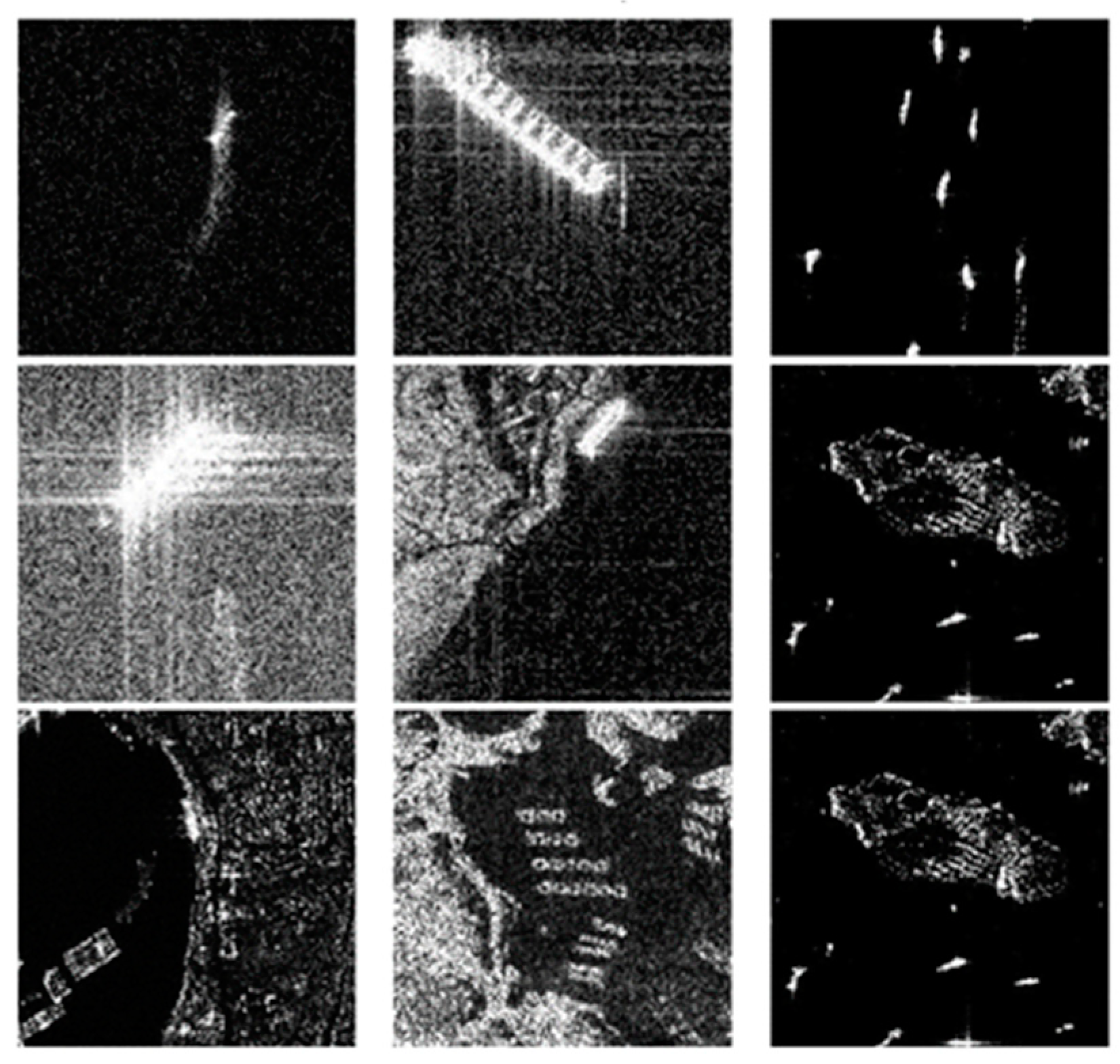
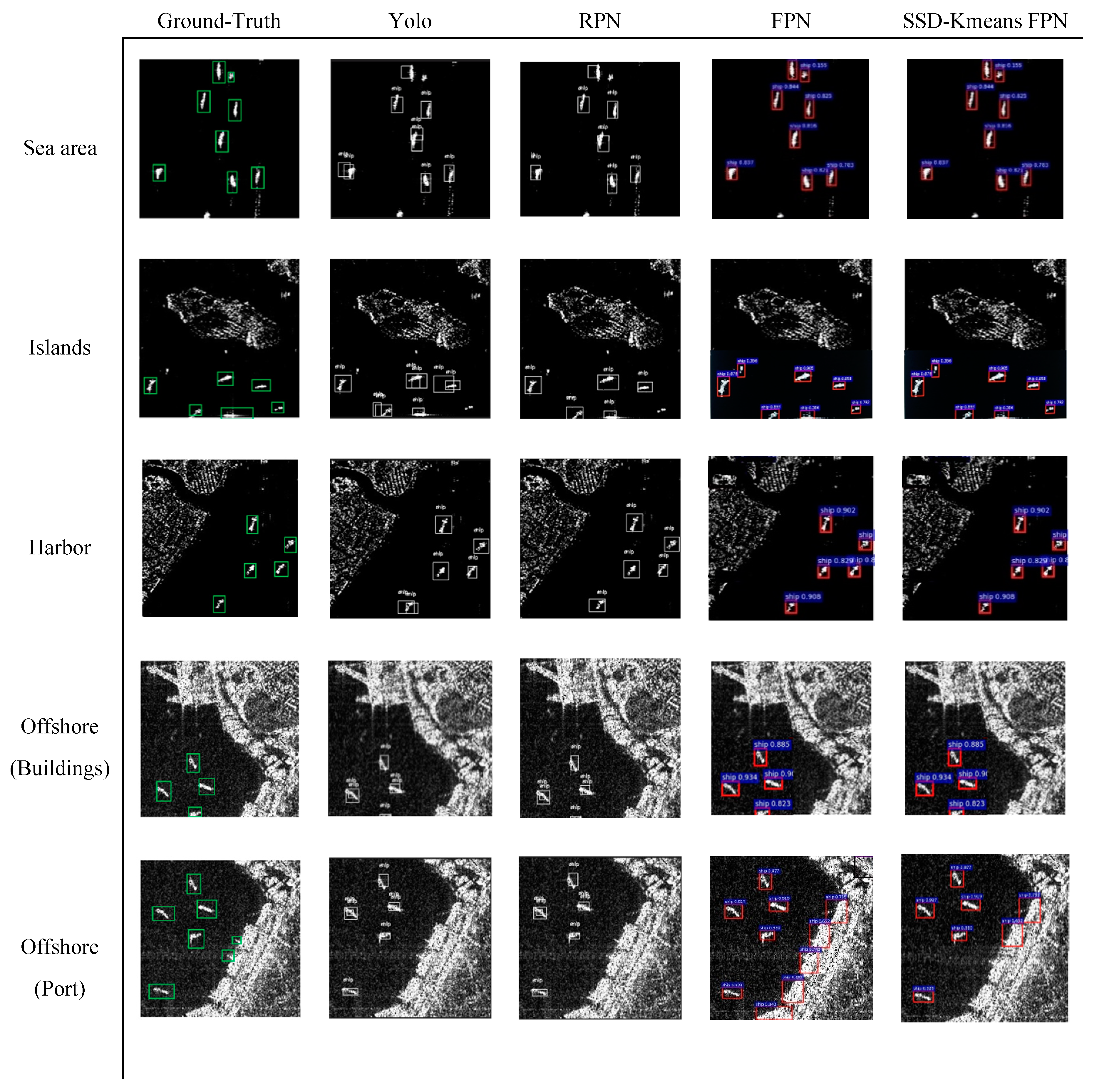
4. Experimental Process and Analysis
4.1. Experiment Preparation
4.1.1. Dataset
4.1.2. Network Training
4.2. Anchor Boxes Generation
4.3. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Eldhuset, K. An automatic ship and ship wake detection system for spaceborne SAR images in coastal regions. IEEE Trans. Geosci. Remote Sens. 1996, 34, 1010–1019. [Google Scholar] [CrossRef]
- Brekke, C.; Solberg, A. Oil spill detection by satellite remote sensing. Remote Sens. Environ. 2005, 95, 1–13. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Zhang, H.; Wu, F.; Jiang, S.; Zhang, B.; Tang, Y. A Novel Hierarchical Ship Classifier for COSMO-SkyMed SAR Data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 484–488. [Google Scholar] [CrossRef]
- Knapskog, A.O.; Brovoll, S.; Torvik, B. Characteristics of ships in harbour investigated in simultaneous images from TerraSAR-X and PicoSAR. IEEE 2010, 422–427. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Zhou, S.; Xing, X.; Zou, H. 2D comb feature for analysis of ship classification in high-resolution SAR imagery. Electron. Lett. 2017, 53, 500–502. [Google Scholar] [CrossRef]
- Xing, X.; Ji, K.; Zou, H.; Chen, W.; Sun, J. Ship Classification in TerraSAR-X Images With Feature Space Based Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2013, 10, 1562–1566. [Google Scholar] [CrossRef]
- Touzi, R.; Raney, R.K.; Charbonneau, F. On the use of permanent symmetric scatterers for ship characterization. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2039–2045. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–9 December 2015; pp. 91–99. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January –1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7036–7045. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June –1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, Y.; Zhang, M.; Xu, P.; Guo, Z. SAR ship detection using sea-land segmentation-based convolutional neural network. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H. Combining a single shot multibox detector with transfer learning for ship detection using sentinel-1 SAR images. Remote Sens. Lett. 2018, 9, 780–788. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSD-Kmeans | Backbone | Accuracy (%) |
|---|---|---|
| K = 6 | FPN + VGG | 95.6 |
| K = 9 | FPN + VGG | 96.675 |
| K = 12 | FPN + VGG | 96.3 |
| K = 6 | FPN + Resnet101 | 96 |
| K = 9 | FPN + Resnet101 | 97.3 |
| K = 12 | FPN + Resnet101 | 96.8 |
| Scenarios | SSD-Kmeans FPN + VGG | SSD-Kmeans FPN + ResNet101 | ||
|---|---|---|---|---|
| Training Accuracy (%) | Validation Accuracy (%) | Training Accuracy (%) | Validation Accuracy (%) | |
| Sea area | 100 | 99 | 100 | 99 |
| Islands | 100 | 96.3 | 100 | 97.6 |
| Harbor | 100 | 98.2 | 100 | 98.6 |
| Offshore | 100 | 93.2 | 100 | 94 |
| Model | Backbone | Sea Area | Islands | Harbor | Offshore | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pd (%) | Pf (%) | Pd (%) | Pf (%) | Pd (%) | Pf (%) | Pd (%) | Pf (%) | Pd (%) | Pf (%) | F1 Score | ||
| Yolo | —— | 92.82 | 12.92 | 92.32 | 14.07 | 83.46 | 29.19 | 78.21 | 32.84 | 86.71 | 22.25 | 0.819 |
| RPN | VGG | 95.9 | 6.25 | 93.75 | 10.05 | 89.28 | 23.31 | 79.47 | 28.67 | 89.6 | 17.07 | 0.861 |
| FPN | VGG | 96.53 | 4.03 | 95.56 | 4.42 | 91.07 | 19.93 | 90.04 | 22.58 | 93.3 | 12.74 | 0.901 |
| SSD-kmeans + FPN | VGG | 99.1 | 3.63 | 98.32 | 3.56 | 97.31 | 14.01 | 97.27 | 19.92 | 98.0 | 10.28 | 0.936 |
| RPN | Resnet101 | 96.4 | 6.25 | 94.26 | 6.28 | 92.85 | 22.07 | 85.73 | 29.68 | 92.31 | 16.07 | 0.879 |
| FPN | Resnet101 | 97.82 | 3.47 | 97.61 | 3.7 | 97.72 | 19.32 | 93.65 | 22.31 | 96.7 | 12.2 | 0.92 |
| SSD-Kmeans + FPN | Resnet101 | 99.2 | 3.32 | 98.9 | 3.51 | 98.85 | 13.56 | 97.53 | 19.89 | 98.62 | 10.07 | 0.941 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Li, Y.; Zhou, H.; Liu, B.; Liu, P. Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery. J. Mar. Sci. Eng. 2020, 8, 112. https://doi.org/10.3390/jmse8020112
Chen P, Li Y, Zhou H, Liu B, Liu P. Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery. Journal of Marine Science and Engineering. 2020; 8(2):112. https://doi.org/10.3390/jmse8020112
Chicago/Turabian StyleChen, Peng, Ying Li, Hui Zhou, Bingxin Liu, and Peng Liu. 2020. "Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery" Journal of Marine Science and Engineering 8, no. 2: 112. https://doi.org/10.3390/jmse8020112
APA StyleChen, P., Li, Y., Zhou, H., Liu, B., & Liu, P. (2020). Detection of Small Ship Objects Using Anchor Boxes Cluster and Feature Pyramid Network Model for SAR Imagery. Journal of Marine Science and Engineering, 8(2), 112. https://doi.org/10.3390/jmse8020112