Abstract
Semantic segmentation is an important component in understanding the 3D point cloud scene. Whether we can effectively obtain local and global contextual information from points is of great significance in improving the performance of 3D point cloud semantic segmentation. In this paper, we propose a self-attention feature extraction module: the local transformer structure. By stacking the encoder layer composed of this structure, we can extract local features while preserving global connectivity. The structure can automatically learn each point feature from its neighborhoods and is invariant to different point orders. We designed two unique key matrices, each of which focuses on the feature similarities and geometric structure relationships between the points to generate attention weight matrices. Additionally, the cross-skip selection of neighbors is used to obtain larger receptive fields for each point without increasing the number of calculations required, and can therefore better deal with the junction between multiple objects. When the new network was verified on the S3DIS, the mean intersection over union was 69.1%, and the segmentation accuracies on the complex outdoor scene datasets Semantic3D and SemanticKITTI were 94.3% and 87.8%, respectively, which demonstrate the effectiveness of the proposed methods.
1. Introduction
The semantic segmentation of 3D point clouds is one of the key problems in the perception of environments in the research on robotics [1] and automatic driving [2]. The use of local and global geometric attributes of a point to generate an effective feature description of the point, thereby improving the accuracy of semantic segmentation, has always been the focus and challenge in this field.
Convolutional neural networks (CNNs) have achieved great success in 2D imaging, with researchers considering how to use a mature CNN network to analyze 3D point clouds. However, unlike 2D images, point clouds are unordered and irregular, which make handling 3D point clouds using a convolutional neural network directly impossible. Some methods [3,4,5,6,7] project the 3D point clouds onto the 2D plane, generating a bird’s eye view (BEV) image, a range view (RV) image, and other intermediate regular representations, and then use them in a convolutional neural network. This kind of method depends on the choice of projection angle, which cannot make full use of accurate spatial and structural information and causes a loss of geometric information in the projection process. The method based on discretization converts the point clouds into a discretized representation, such as a voxel or lattice, and then processes it using a three-dimensional convolution network. However, it is sensitive to voxel size. When the voxel is large, it causes information loss and affects the segmentation accuracy. When the voxel is small, it leads to a sharp increase in the number of calculations required and affects the real-time performance. The point-based method extracts features directly from irregular point clouds without any preprocessing. It has gradually become the mainstream method used in point cloud semantic segmentation. However, the point-based method also has some problems, such as the poor scalability of the point sampling method to the scale of the point cloud, and the inability to effectively learn local features.
With the successful application of a self-attention mechanism in the field of natural language processing (NLP), some studies have considered the applications of the transformer structure to the fields of image and point cloud processing, etc. The input of a transformer is usually a sequence, and position embedding information needs to be added. For point cloud data, each point has a unique coordinate value, which can be directly used as the position embedding information. Zhao et al. [8] proposed the point transformer and proved that a network structure based entirely on self-attention can effectively solve a point cloud task.
The transformer method has been broadly used for object-wise tasks, such as classification and partial segmentation. Inspired by these works, in this study, we use a transformer network for point-wise large-scale point cloud segmentation. We propose a novel multi-scale transformer network for both local and global feature extraction.
The network is based on an encoder–decoder structure. Each encoder layer consists of two parallel local transformers. In the front of the encoder layers, local features can be obtained because of the locality of the local transformer. After random down-sampling of the points, the receptive field of each point becomes larger and every point contains high-level features. Therefore, at the later encoder layers of the encoder, the global features can be easily obtained by the local transformer structure, making full use of the transformer having no inductive bias property.
In contrast to a previous transformer structure with one attention weight matrix, which can find the similarities between point features, we propose two different key matrices to obtain two attention weight matrices in the local transformer structure, which can not only focus on the feature similarity between points but also focus on the local geometric structure relationship. The results of the visualization show that better segmentation results can be obtained between objects with very similar geometries. We also propose two fusion strategies to make full use of the distribution diversity of these two attention weight matrices.
In order to improve the segmentation performance at the semantic edges of multiple objects, we propose a novel neighbor selection method called cross-skip selection, which is very suitable for the parallel encoder layer, and can expand the receptive field of each point without increasing the number of calculations required, and capture more abundant geometric and semantic information.
We then verified our method on open datasets S3DIS and Semantics3D. The best mean class-wise intersection over union (mIoU) on the S3DIS dataset was 69.1% and on the Semantic3D dataset was 75.7%, which are better than those of most benchmark methods.
Our contributions can be summarized as follows:
- We propose a novel multi-scale transformer network to learn local context information and global features, which makes applying the transformer on more sophisticated tasks from the large-scale point cloud datasets possible.
- In order to obtain the feature similarity and local geometry relationship between points, we propose two different key matrices to obtain two attention weight matrices in the local transformer structure, and propose two different fusion strategies to fuse them.
- We also propose a novel neighbor selection method called cross-skip selection to obtain more accurate results on the junction of multiple objects.
The rest of the paper is organized as follows. Section 2 presents related work on 3D point cloud semantic segmentation. Section 3 presents our proposed approach, including the network architecture (Section 3.1), neighbor embedding module (Section 3.2), feature extraction module based on a transformer (Section 3.3), local transformer structure (Section 3.4), parallel encoder layer with cross-skip selection (Section 3.5), and decoder layer (Section 3.6). Section 4 presents our experiments and analysis. Section 5 concludes our work and presents some future work.
2. Related Work
According to the different forms of input point clouds, the semantic segmentation methods of a point cloud can be divided into the projection-based method, the discretization-based method, the point-based method, etc.
The projection-based method is used to project the 3D point cloud onto the 2D plane. Rangenet + + [9] first converted the point cloud into a range image, then used the full convolution network to deal with that, and then mapped the result of the semantic segmentation to the original point cloud. Squeezeseg [10] converted the point cloud to the front view through spherical projection, using the SqueezeNet network for semantic segmentation, and then used a conditional random field (CRF) to refine the results. Liong et al. [11] proposed a multi-view fusion network (AMVNet), which projected the point cloud onto the range view (RV) image and bird’s eye view (BEV) image, and combined the advantages of using two different views of RV and BEV.
VoxNet [12] is a typical discretization-based method. The network divided the point cloud into regular voxels and then extracted the features of these voxels through a 3D convolution operation. However, the point cloud is sparse, and the proportion of non-empty voxels is very small. It is very inefficient to use a dense convolution neural network on spatial sparse data. Graham et al. [13] improved this by proposing a new sparse convolution operation that can process spatial sparse data more effectively.
PointNet [14] was the pioneer work that directly consumed point clouds, and could obtain per-point features by concatenating features learned by the shared multilayer perceptron (MLP) and global features learned by max pooling function. However, PointNet cannot effectively obtain local features and ignores the local context information. The PointNet + + [15] network made some improvements. It paid attention to the relationship between the central point and its neighbors but ignored the relationship between each neighbor pair. Wu et al. [16] proposed a new convolution operation, which defined the convolution kernel as a nonlinear function composed of a weight function and a density function. Zhao et al. [17] proposed a network called PointWeb, which can specify the feature of each point based on the local region characteristics for better representing the region. KPConv [18] defined an explicit convolution kernel, which is composed of fixed or flexible core points. The different weights of influence for each neighbor point on the core point adaptively depends on the distance between them. Hu et al. [19] used MLP to learn the attention weight score of each point and then obtained the weighted local feature map. Finally, the maximum pooling function was used to calculate the central point feature on the weighted local feature map.
In addition, there are some other methods. For example, the dynamic graph convolutional neural network (DGCNN) [20] uses graph networks to capture the local geometric features of a point cloud and dynamically updates a graph to learn the different scale features. Wang et al. [21] proposed a graph attention convolution (GAC), in which the kernels can be dynamically carved into specific shapes to adapt to the structure of an object and generate more accurate representations of local features of points.
Recently, the transformer network has already achieved tremendous success in the language domain; thus, most researchers want to investigate whether it can be applied to computer vision tasks. It is very encouraging that some methods [22] showed that a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. After that work was conducted, research on transformers in computer vision became popular. The operator of the transformer network is invariant to permutation, making it particularly appropriate for point clouds, since a point cloud is permutation-invariant.
Some recent work considered how to effectively extract local and global features at the same time. LocalViT [23] aimed to combine the local performance of a convolutional neural network and the global connectivity of a transformer structure. However, using a transformer structure to learn the long-distance dependence between points requires very high memory and expensive computing costs, which make it difficult to deal with large-scale 3D point cloud data. In this paper, we propose a local transformer structure and a novel neighborhood sampling method for local feature extraction; it can not only effectively focus on local features, but also reduce the computational costs to adapt to the semantic segmentation tasks of large-scale outdoor datasets.
3. Proposed Approach
3.1. Network Architecture
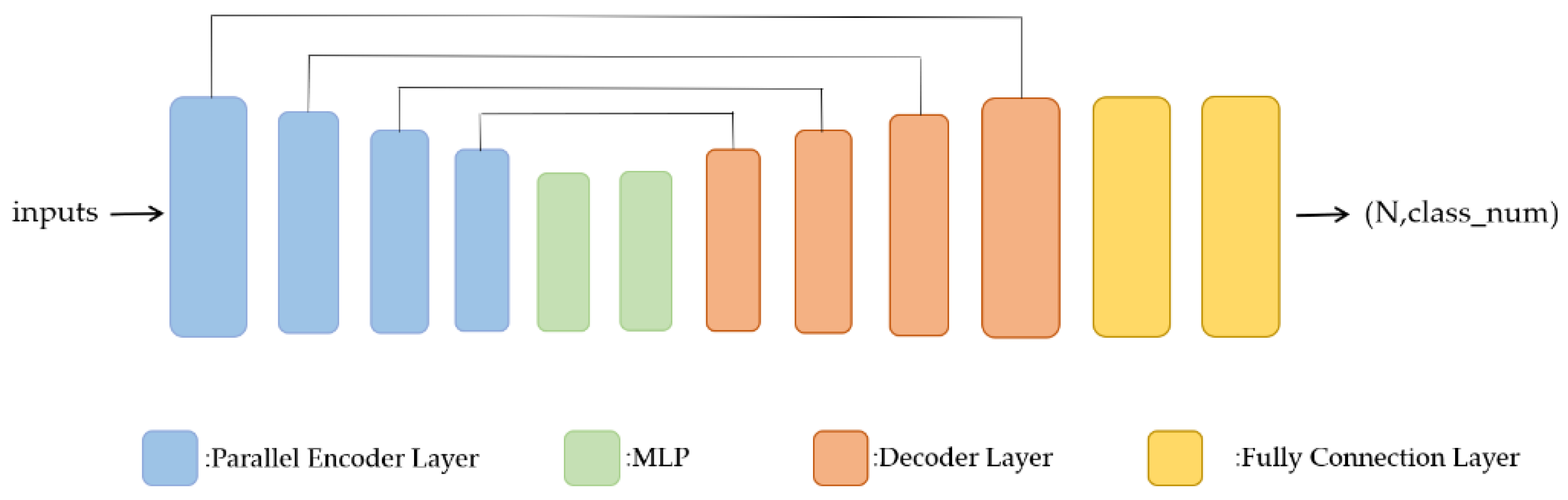
The overall network structure adopts the typical encoder–decoder structure [24]. The encoder is composed of parallel encoder layers (Section 3.5), which consist of two local transformer structures (Section 3.4). The local transformer structure is composed of a neighbor embedding module (Section 3.2) and a feature extraction module based on a transformer (Section 3.3). As shown in Figure 1, after each parallel encoder layer, random down-sampling is used to reduce the number of points and then to stack parallel encoder layers. As the encoder layers are stacked, the semantic features of each point become more and more abstract and contain more contextual information. We set up a different number of encoder layers for different datasets. Then, the number of points is recovered through the decoder layers. In this paper, we use a distance-based weighted linear interpolation up-sampling operation (Section 3.5) to propagate the features from a sparse point cloud to a dense point cloud to predict point-wise labels. The whole network structure adopts a residual connection.
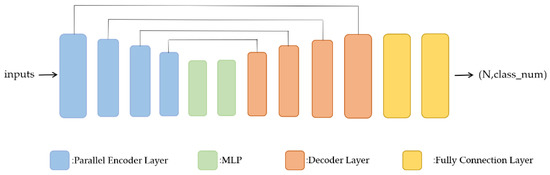
Figure 1.
The proposed network architecture.
3.2. Neighbor Embedding Module
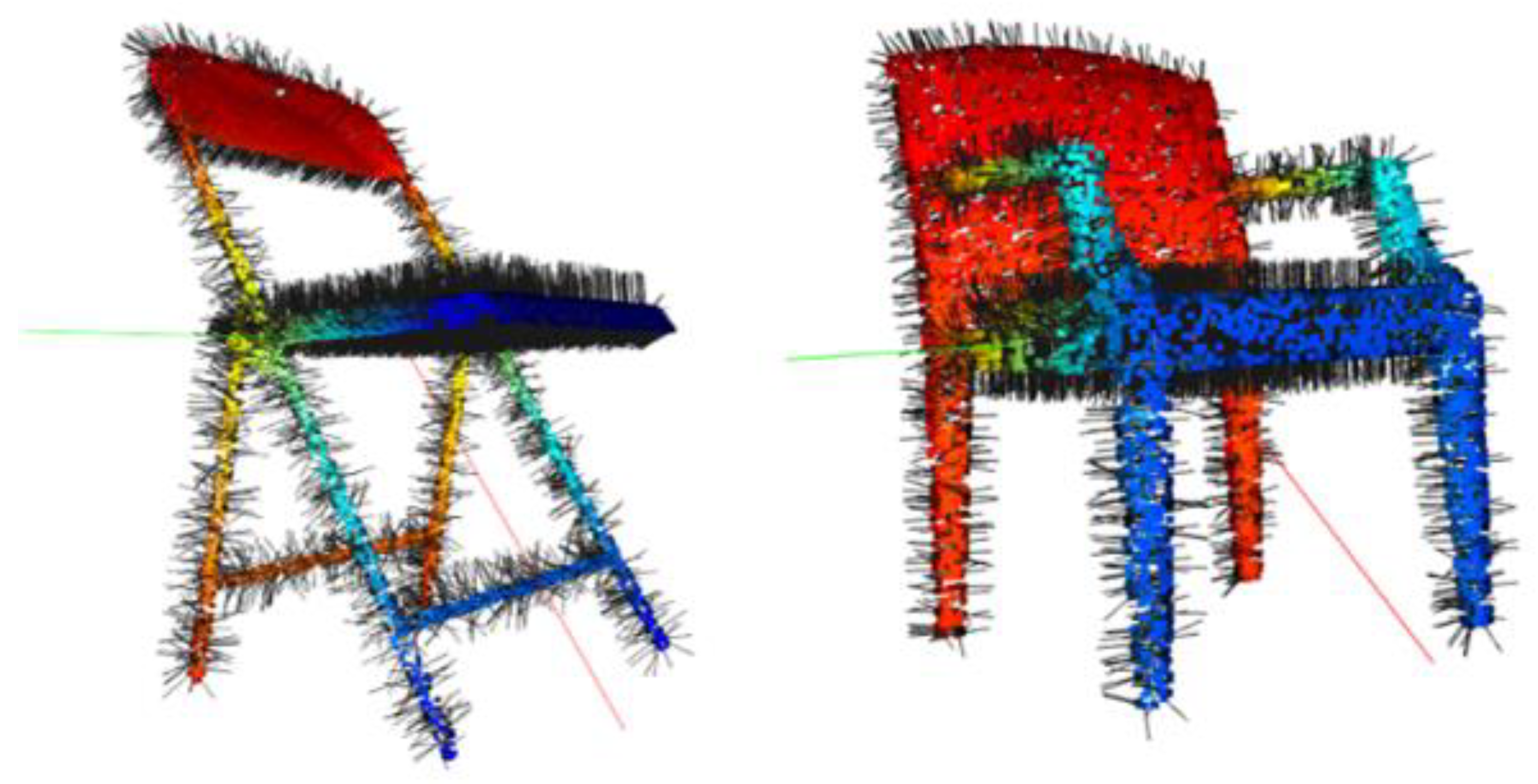
Point-wise local geometric properties, such as the normal vector (the normal vector of each point is the normal direction of the plane fitted by it and its neighbors), are very useful for discovering the similarity between points, since the normal vector of the surface of an object changes continuously. Before the data are input into the network, we compute the normal vector of S3DIS and combine it with their corresponding point coordinates as a rich feature representation. We use principal components analysis (PCA) to compute the normal of every point (as shown in Figure 2). For each point, we choose its neighbors . We want to fit a plane using the neighbors, and then, we can calculate the normal vector of the point. The normal vector is solved by minimizing an objective function as follows:
where is a coordinate of the center of all neighbor points and is the normal vector to be solved.
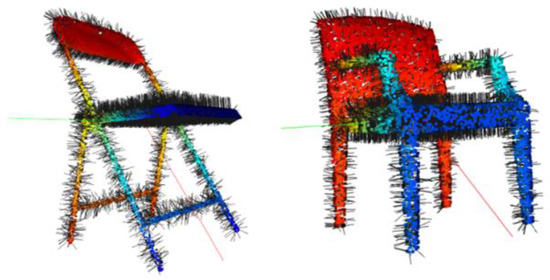
Figure 2.
The normal vector of every point (results of the visualization on two different chairs).
The input point cloud is represented as a coordinate matrix and its feature matrix . and are the number of points and the feature dimensions, respectively. The original input features of the points are concatenated by the normalized x-y-z coordinates, raw RGB, and surface normal information.
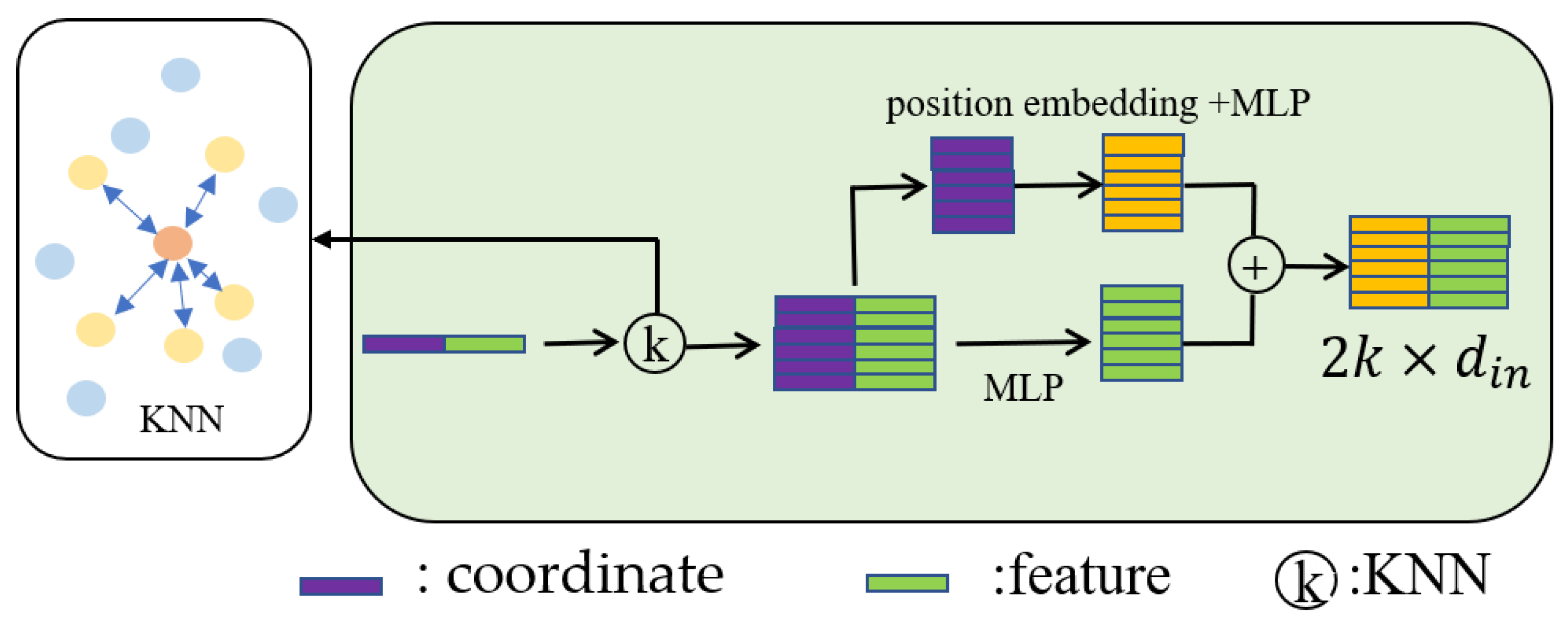
First, we encode the local region in the neighbor embedding module, as shown in Figure 3, similar to a reference point , and find its neighbors, encoding each neighbor point to obtain its position embedding , as shown in Formula (3). is the position embedding of the -th neighbor.
where stands for the concatenation of and on the feature dimension, is the coordinate of the point , is the coordinate of the -th neighbor, and is the norm.
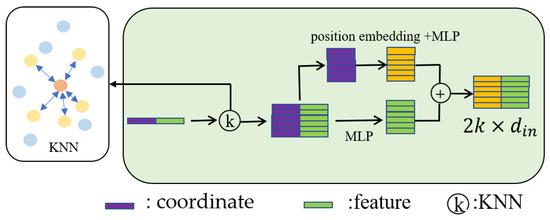
Figure 3.
Neighbor embedding module.
Then, the local region feature matrix can be obtained by concatenating the positional embedding and per-point original features as follows:
where is a multilayer perceptron applied to the positional embedding and features .
3.3. Feature Extraction Module based on a Transformer
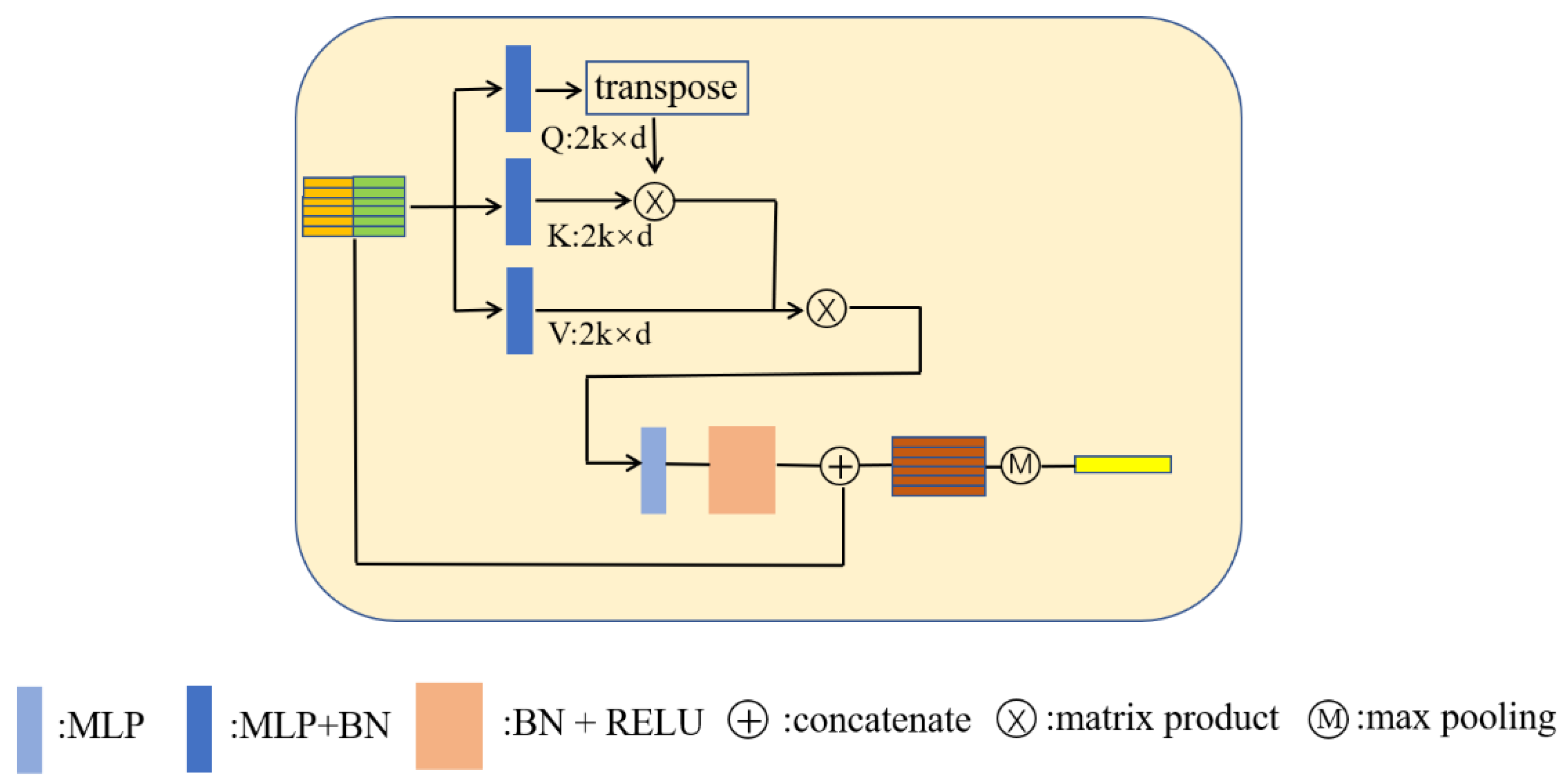
3.3.1. Naïve Transformer Structure
Using the neighbor embedding module, we can obtain the local region feature matrix: ( is the dimension of the features). It is then input into a transformer structure to obtain the weighted features of the reference point. In the naïve transformer structure, are obtained based on , as shown in Formula (5).
where stands for a batch normalization operation after a multilayer perceptron. The batch normalization normalizes the batch input on the feature dimension. It can make the distribution of input data in each layer of the network relatively stable and accelerates the learning speed of the model. is the dimension of . We set the dimensions of to be equal.
The attention score is computed as the inner product between and . The attention weight matrix can be written as follows:
Additionally, a scale and a normalization operation, which is able to obtain measurements of the similarity between any two points in this local region, can be used:
Next, the normalized attention weight matrix is applied on the value matrix to obtain a weighted local feature matrix, which can automatically assign more attention to the useful features. The weighted local feature matrix can be written as follows:
Then, we use batch normalization and non-linear activation on this weighted local feature matrix. After that, we concatenate the activated features matrix and the original input features matrix as follows:
where LBR is the normalization and non-linear activation operation and is the concatenation operation.
We use a symmetric operation such as max pooling to generate the reference point features, which can represent this local region. It is formally defined as follows:
Figure 4 provides an illustration of the naïve transformer structure. Through this transformer, the updated features of each reference point adaptively aggregate the features of its neighbor points.
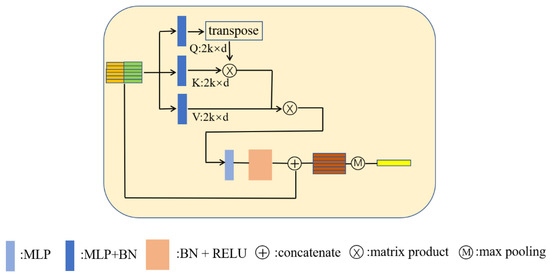
Figure 4.
Naïve transformer structure.
3.3.2. Improve Transformer Structure
We make some improvements to the naïve local transformer structure. Consider that, during the beginning of the network, where each point has not learned enough features yet to obtain the similarity between points, the geometric relationships between points become more significant than the features. Therefore, we propose two different key matrices for obtaining two attention weight matrices. The first key matrix is the same as the naïve local transformer structure, which is obtained by the input feature matrix , as shown in Formula (12):
The attention weight matrix can be written as Formula (13), which can obtain the feature similarity between points:
The query matrix can be obtained by Formula (5).
The second key matrix, which is obtained by the neighbor position embedding matrix , takes the local geometry relationship into account. The second key matrix can be written as follows:
The second attention weight matrix is as follows and can pay more attention to the local geometry relationship between points than :
When the two attention weight matrices are obtained, the most intuitive method for combining them is to add them, which can be shown as follows:
The next operations are the same as the naïve local transformer structure. Finally, we can obtain the weighted local feature matrix.
where is the key matrix, which can be obtained using Formula (5).
However, if we simply add the two attention weight matrices together, we cannot make full use of the distribution diversity of the two attention weight matrices. We propose another fusion method at the feature level. Specifically, we multiply the two scaled and normalized attention weight matrices with the value matrix, as shown in (18) and (19), respectively, and then concatenate the weighted local feature matrices, as shown in (20).
where V is the key matrix, which can be obtained using Formula (5).
By fusing at the feature level, we can obtain weighted feature matrices and with two different distributions, which can inherently capture the features and geometric relationships between points.
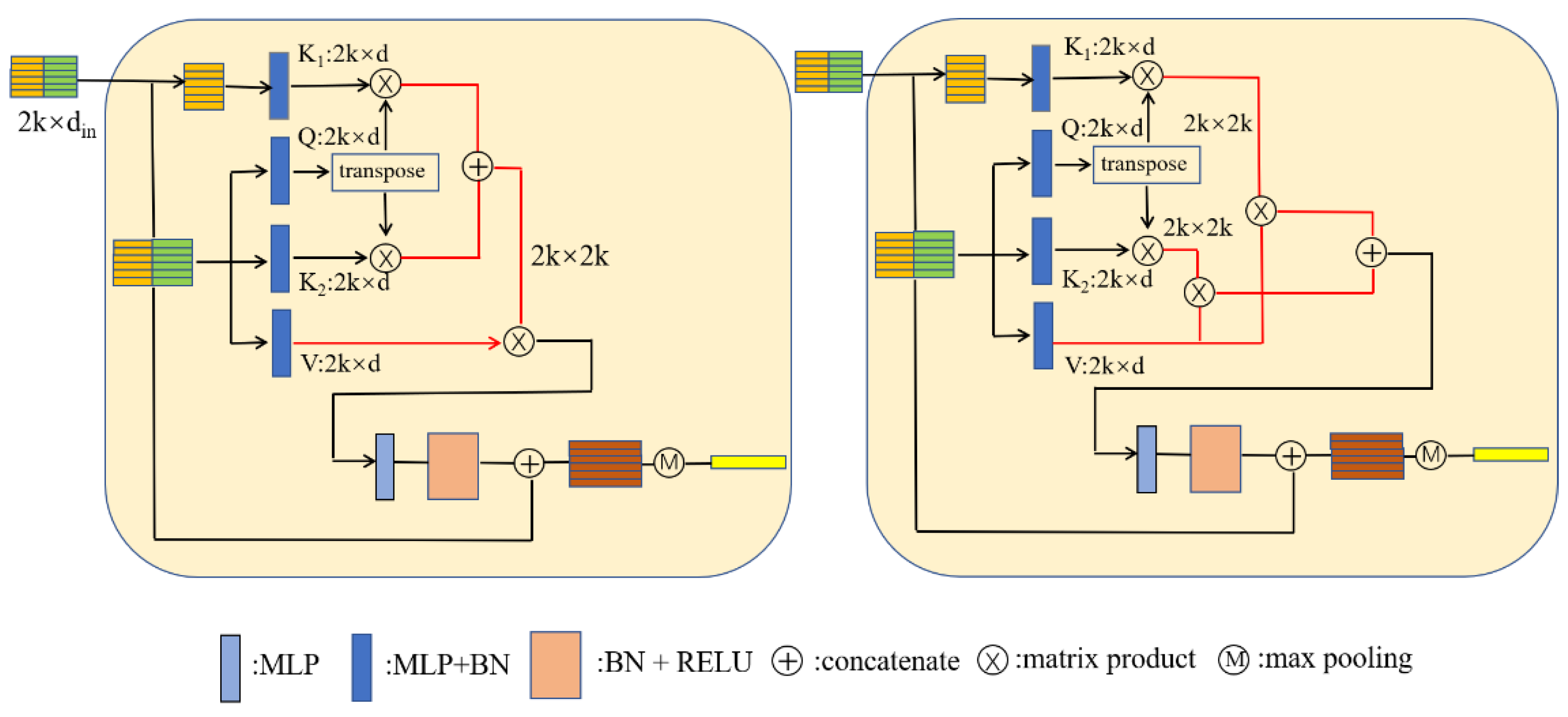
The updated point feature can finally be obtained using the operations in (10) and (11) on . The improved transformer structures are shown in Figure 5:
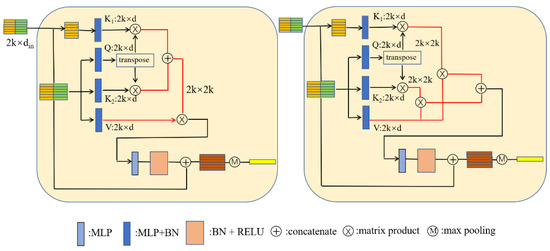
Figure 5.
Improved transformer structure. (Right): the two attention weight matrices added. (Left): the two attention weight matrices fused at the feature level. The red line indicates the difference between them.
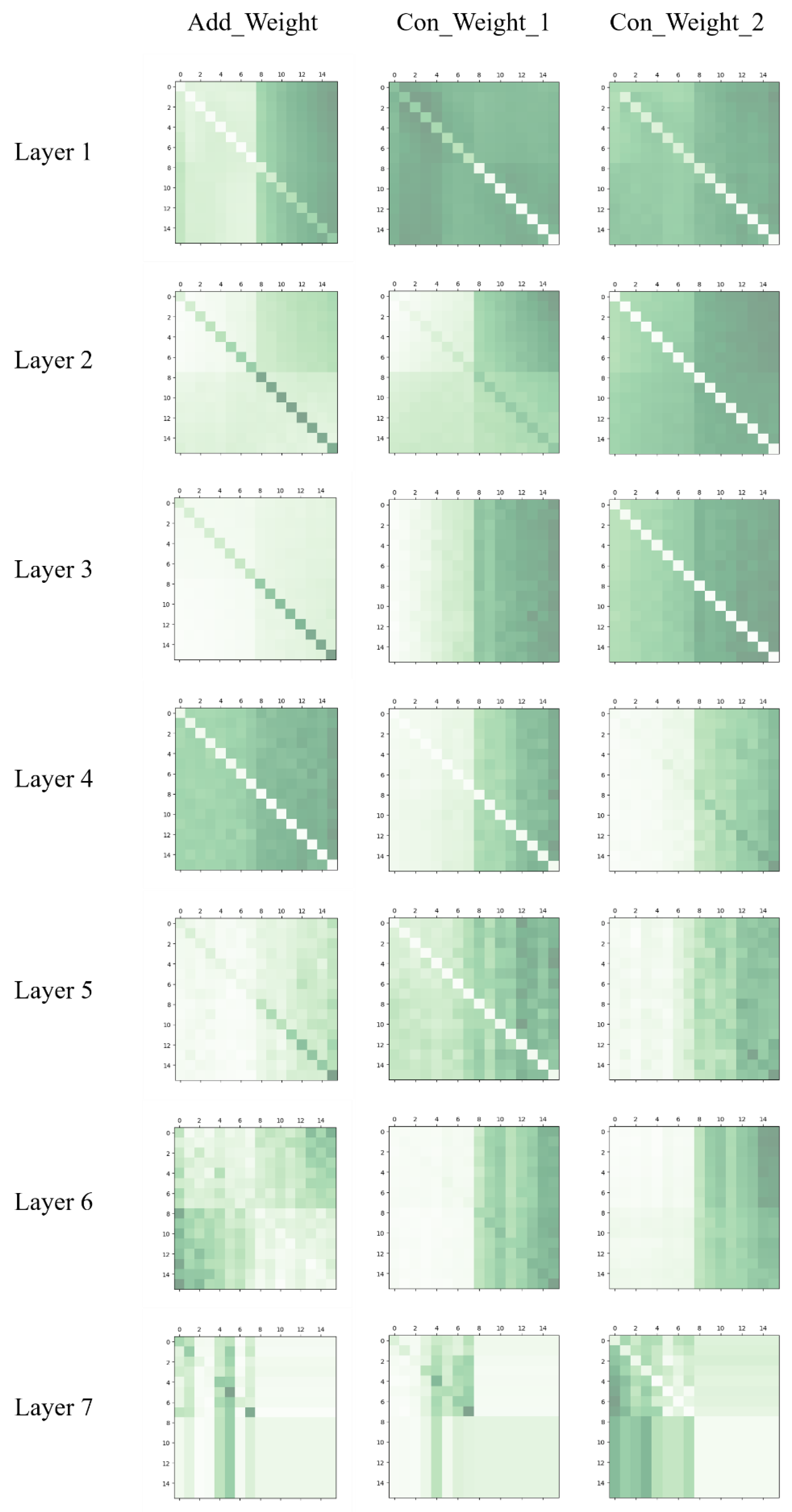
We also visualized the attention weight matrices, presented in Appendix A. From the results of the visualization, we can note that, at the first few layers, shows a locality (the value of the diagonal is significantly different from the others) and, at the last two layers, it shows a discretized distribution, which can be used to find points with key semantic information. When we fuse the attention weight matrices at the feature level, at every layer, and focus on the feature similarities and the geometry relationship between points, respectively. Therefore, they have different distributions.
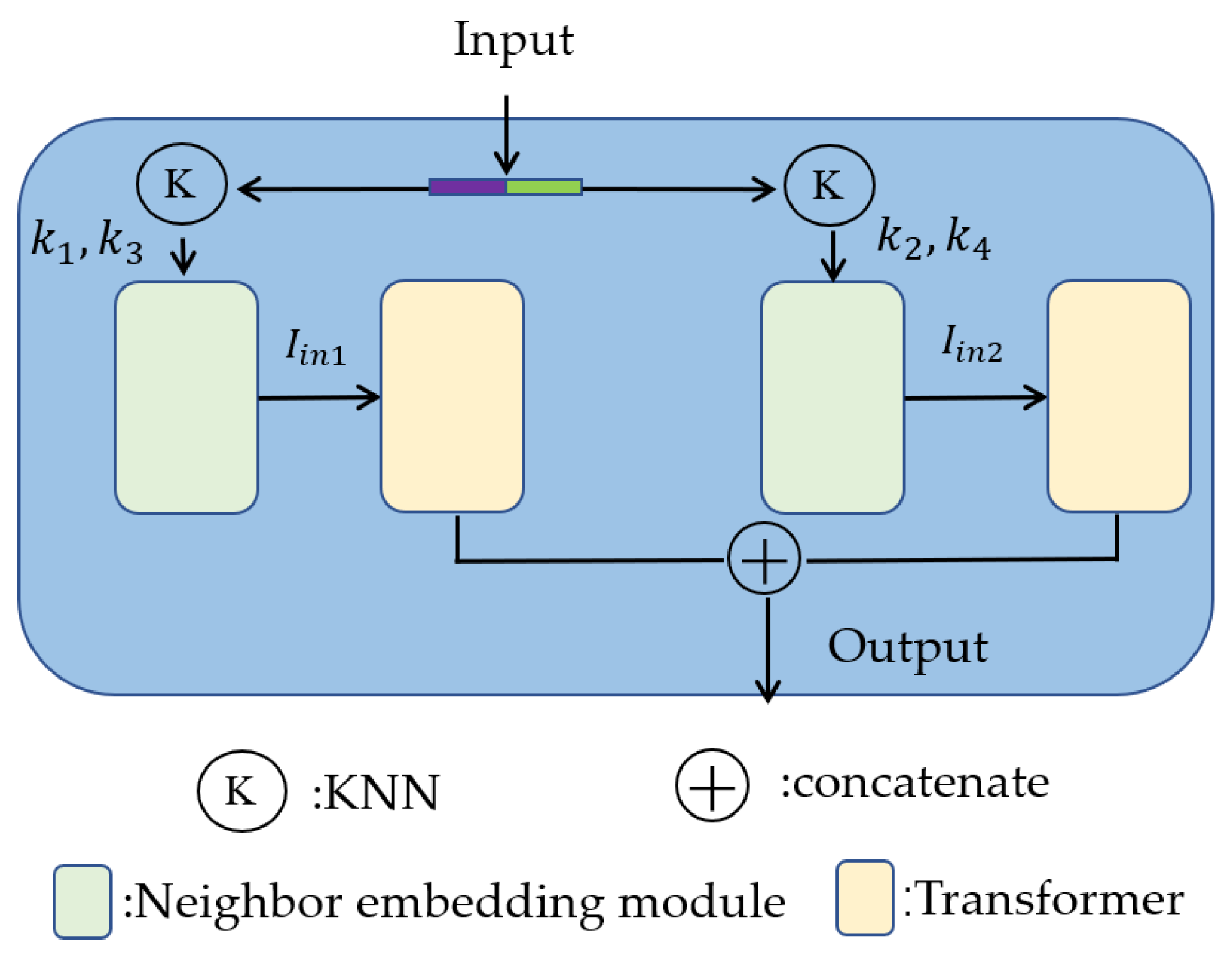
3.4. Local Transformer Structure
The local transformer structure is composed of a neighbor embedding module and a transformer structure, which is shown in Figure 6.

Figure 6.
Local transformer structure.
3.5. Parallel Encoder Layer with Cross-Skip Selection
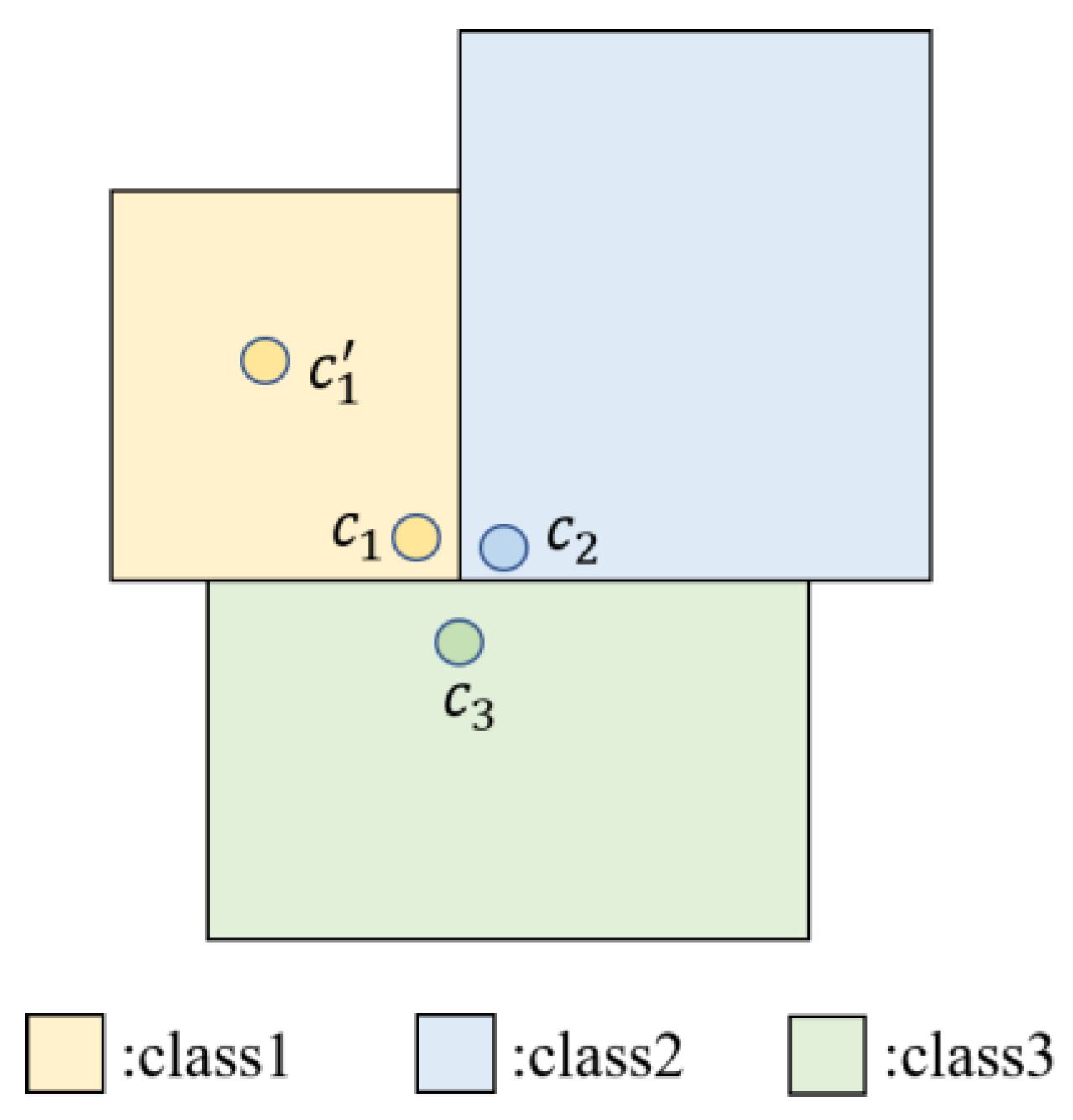
The distance and feature similarities between each point and its neighbors are not necessarily positively correlated, especially at the junction of multiple objects. Therefore, points with similar semantic structures may have greater Euclidean distances and vice versa. As shown in Figure 7, the distance between and is greater than that between and while and belong to class 1 and belongs to class 2.
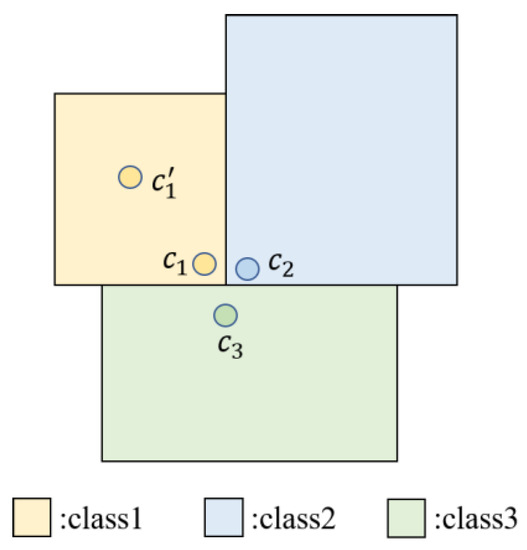
Figure 7.
Junction of multiple objects.
We propose a cross-skip selection method to obtain neighbors in the neighbor embedding module. The method is as follows: find the nearest neighbor points of each point and divide them into four groups with the same number. Each group contains points. Concatenate the point feature in and in , , and , and then encode the two original point feature matrices in the neighbor embedding module to obtain the local region feature matrices and .
In order to adapt to the cross-skip selection method, we propose a parallel encoder layer composed of two parallel local transformer structures, as shown in Figure 8. The two input matrices of the same dimension and are composed of different neighbor points selected based on cross-skip selection. This structure allows each point to obtain a larger receptive field without increasing the dimension of the input matrices and Concatenate the two update feature vectors and to obtain the final output .
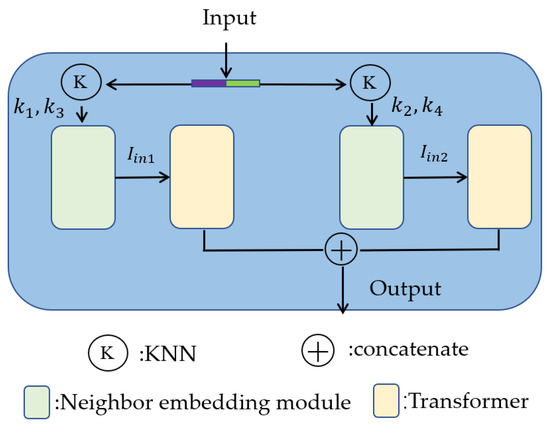
Figure 8.
Parallel encoder layer.
3.6. Decoder Layer
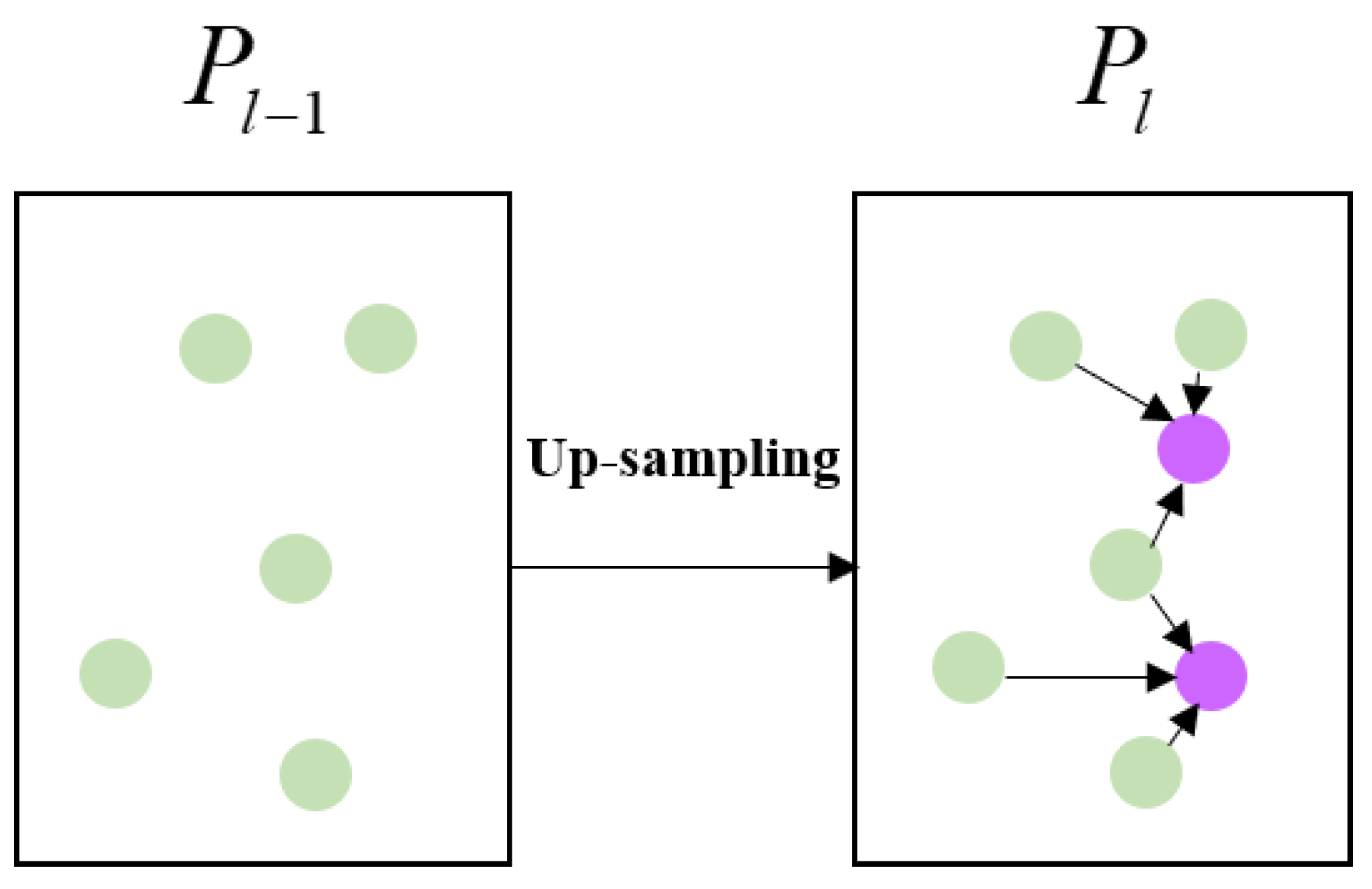
To finally obtain each original point feature, we simply adopt a distance-based weighted linear interpolation up-sampling operation, shown in Figure 9. Let and be the coordinate set of the (-th layer and ()-th layer at the decoder block, respectively. To obtain the feature of point at , we search the nearest three neighbors () of in . The coordinates of neighbors are , and we obtain the influence of each neighbor point on based on the distance between the point and , as follows:
where is the influence weight and is the coordinate of the -th neighbor of the point .
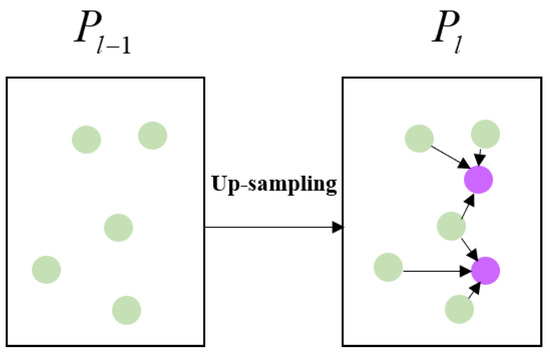
Figure 9.
Decoder layer: distance-based weighted linear interpolation up-sampling.
Finally, the feature of is as follows:
where is the weight of influence for each neighbor point obtained by Formula (22).
4. Experiments and Analysis
4.1. Datasets
S3DIS [25]: the Stanford 3D Large-Scale Indoor Spaces (S3DIS) dataset addresses semantic tasks with pixel-level semantic annotations developed by Stanford University. It consists of six areas, each of which contains 13 categories such as ceiling, floor, and wall. We evaluated our network using two methods: (1) six-fold cross-validation and (2) area 5 testing. Moreover, we used the mean class-wise intersection over union (mIoU), the mean of class-wise accuracy (mAcc), and the overall point-wise accuracy (OA) as evaluation metrics.
Semantic3D [26]: the Semantic3D dataset is composed of 30 non-overlapping outdoor point cloud scenes, of which 15 scenes are used for training and other scenes are used for online testing. The dataset contains eight categories. The scenes cover rural, urban, and suburban areas, and each scene covers sizes of . In addition to 3D coordinates, the dataset provides RGB values and intensity values. We used the mean class-wise intersection over union (mIoU) and the overall point-wise accuracy (OA) as evaluation metrics.
SemanticKITTI [27]: the SemanticKITTI dataset is composed of 21 sequences and 43,552 densely annotated laser scanning frames. Among these, sequences 00–07 and 09–10 are used for training, sequence 08 is used for verification, and sequences 11–21 are used for online testing. The raw data contain the 3D coordinate information of the points. We used the mean class-wise intersection over union (mIoU) as an evaluation metric.
4.2. Implementation Details
When verifying the proposed model based on the S3DIS dataset, we first obtained the normal vector of each point as the original feature. We set the number of encoder layers as 7. After each layer extracts the characteristics of each point through the encoder layer, random down-sampling is used to reduce the number of points. The random down-sampling is more efficient than other down-sampling methods, which have a high calculation cost and high GPU memory requirements. We set the sampling ratio to [2, 2, 4, 4, 4, 4, 4] and the output dimension of each layer to [16, 64, 256, 256, 512, 512]. Through distance-based weighted interpolation linear up-sampling, three nearest neighbors are selected to restore the feature of the input points. Finally, three fully connected layers are stacked to obtain the output with a category number dimension. When verifying the model on the SemanticKITTI and Semantic3D datasets, because the number of points in each frame is very large, calculating the normal vector of each point consumes a very large amount of memory, so we only calculate the normal features in an indoor dataset.
In addition, we used a residual connection to retain more point feature information. In this paper, the Adam optimizer and weighted cross entropy loss based on inverse frequency were used for training. All experiments used Tensorflow as the platform and applied an NVIDIA Corporation gp102 (Titan XP) GPU.
4.3. Evaluation Metrics
For the S3DIS dataset, the mean class-wise intersection over union (mIoU), mean class Accuracy (mAcc), and Overall Accuracy (OA) of the total 13 classes were compared. For Semantic 3D, the mIoU and OA were used as the evaluation metrics. For SemanticKITTI, we used mIoU. The evaluation metrics can be defined as follows:
where is the number of classes, is the ground-truth label, j is the prediction label, is the number of the samples that belong to but are mistakenly predicted as , is the number of the samples that belong to but are mistakenly predicted as , is the number of correctly predicted samples, and is the total number of samples.
4.4. Experimental Results
We used area 5 of S3DIS for testing and the other areas for training. The results are shown in Table 1. Table 2 shows the results with six-fold cross-validation. Table 3 and Table 4 show the results on the Semantic3D and SemanticKITTI datasets, respectively. The results show that the proposed method is better than most benchmark models. The results of the visualization on S3DIS and SemanticKITTI are shown in Figure 10 and Figure 11.

Table 1.
Segmentation results on area 5 of S3DIS (add: the two attention weight matrices added; con: the two attention weight matrices fused at the feature level).
Table 2.
Quantitative results on the S3DIS dataset (six-fold cross validation) (add: the two attention weight matrices added; con: the two attention weight matrices fused at the feature level).
Table 3.
Quantitative results on the Semantic3D dataset (add: the two attention weight matrices added; con: the two attention weight matrices fused at the feature level).
Table 4.
Quantitative results on the SemanticKITTI dataset (add: the two attention weight matrices added; con: the two attention weight matrices fused at the feature level).
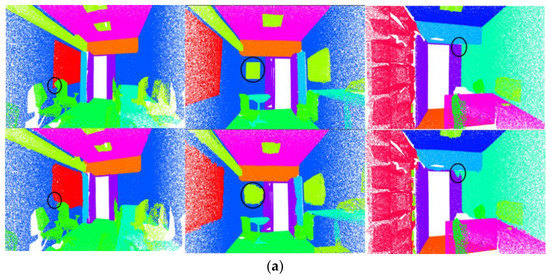
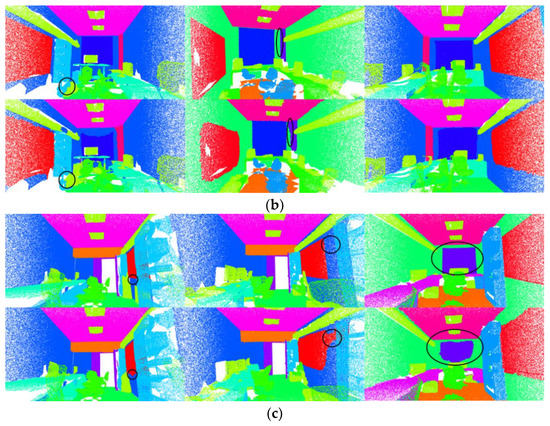
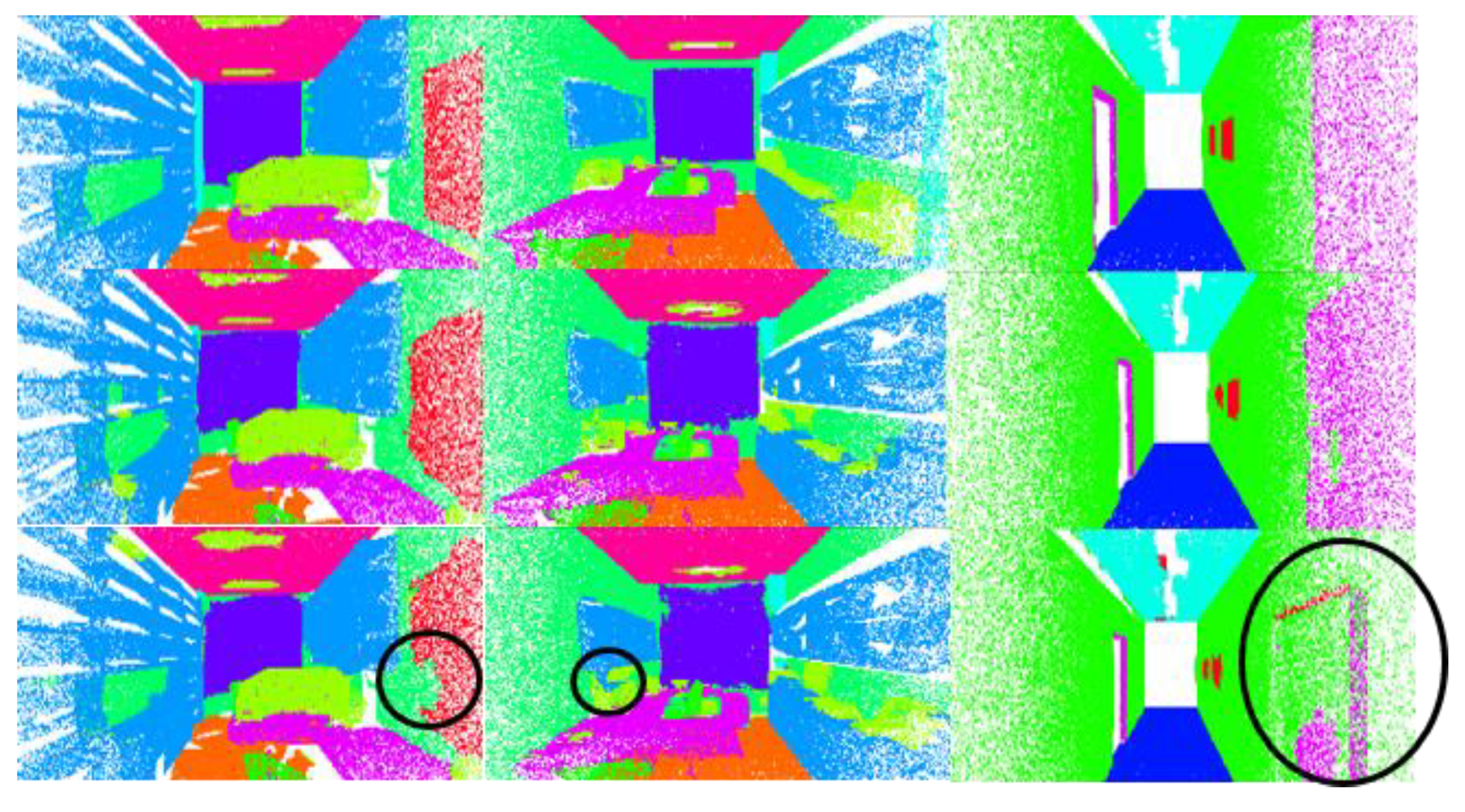
Figure 10.
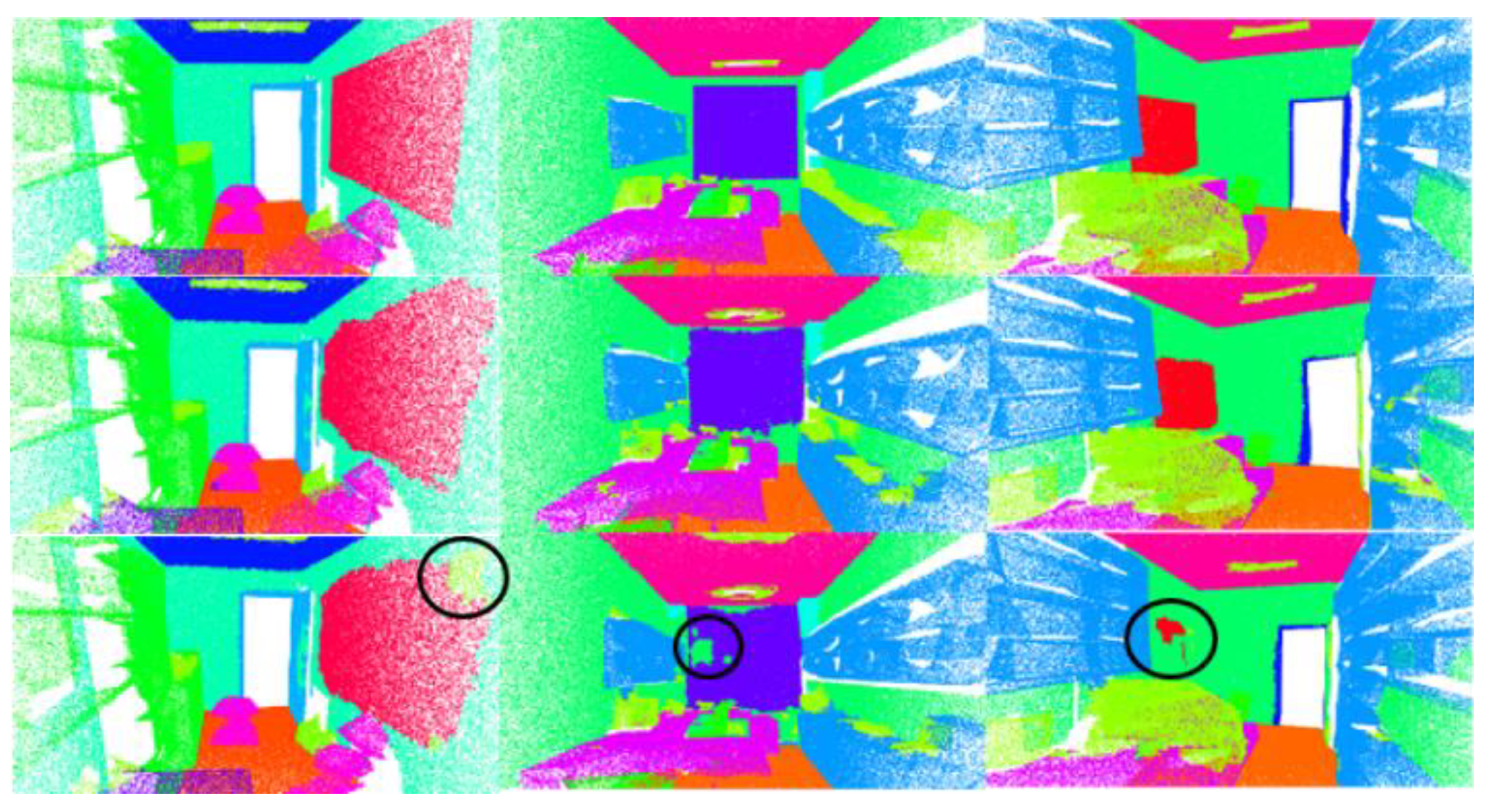
Results of the visualization on S3DIS. First row is the ground truth. Second row shows the prediction results, where an incorrect prediction is circled. (a–c) Three different scenarios in the S3DIS dataset. The figure shows the prediction results of nine different scenarios in total.
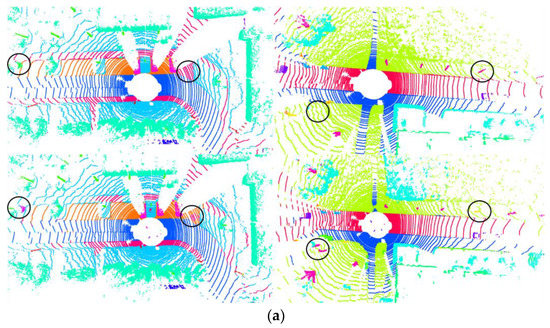

Figure 11.
Results of the visualization on SemanticKITTI. First row is the ground truth. Second row shows the prediction results, where an incorrect prediction is circled. (a–c) Two different scenarios in the SemanticKITTI dataset. The figure shows the prediction results of six different scenarios in total.
4.5. Ablation Experiment
4.5.1. Naïve Local Transformer Structure and Improved Local Transformer Structure
Table 5 shows a comparison of the performances between the naïve local transformer structure and the improved local transformer structure on the S3DIS dataset. In the ablation experiment, we fused the two attention weight matrices by adding them. The experiment results proved the importance of adding the key matrix obtained by the position embedding matrix. Using the improved local transformer structure, OA improved by 0.8%, mAcc improved by 1.6%, and mIoU improved by 1.5%.
Table 5.
Segmentation results on area 5 of S3DIS. (Naïve: naïve local transformer; Improved: improved local transformer).
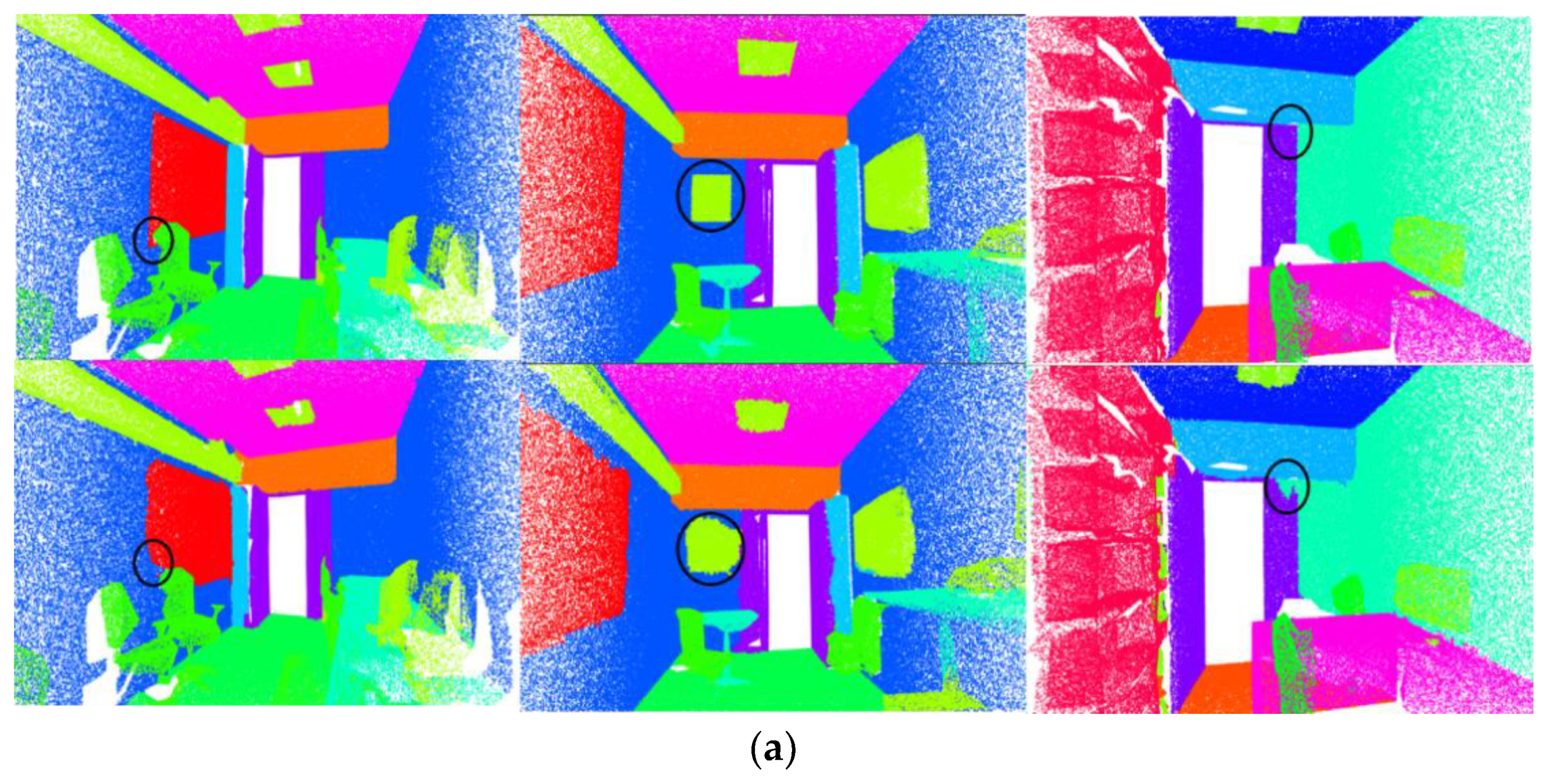
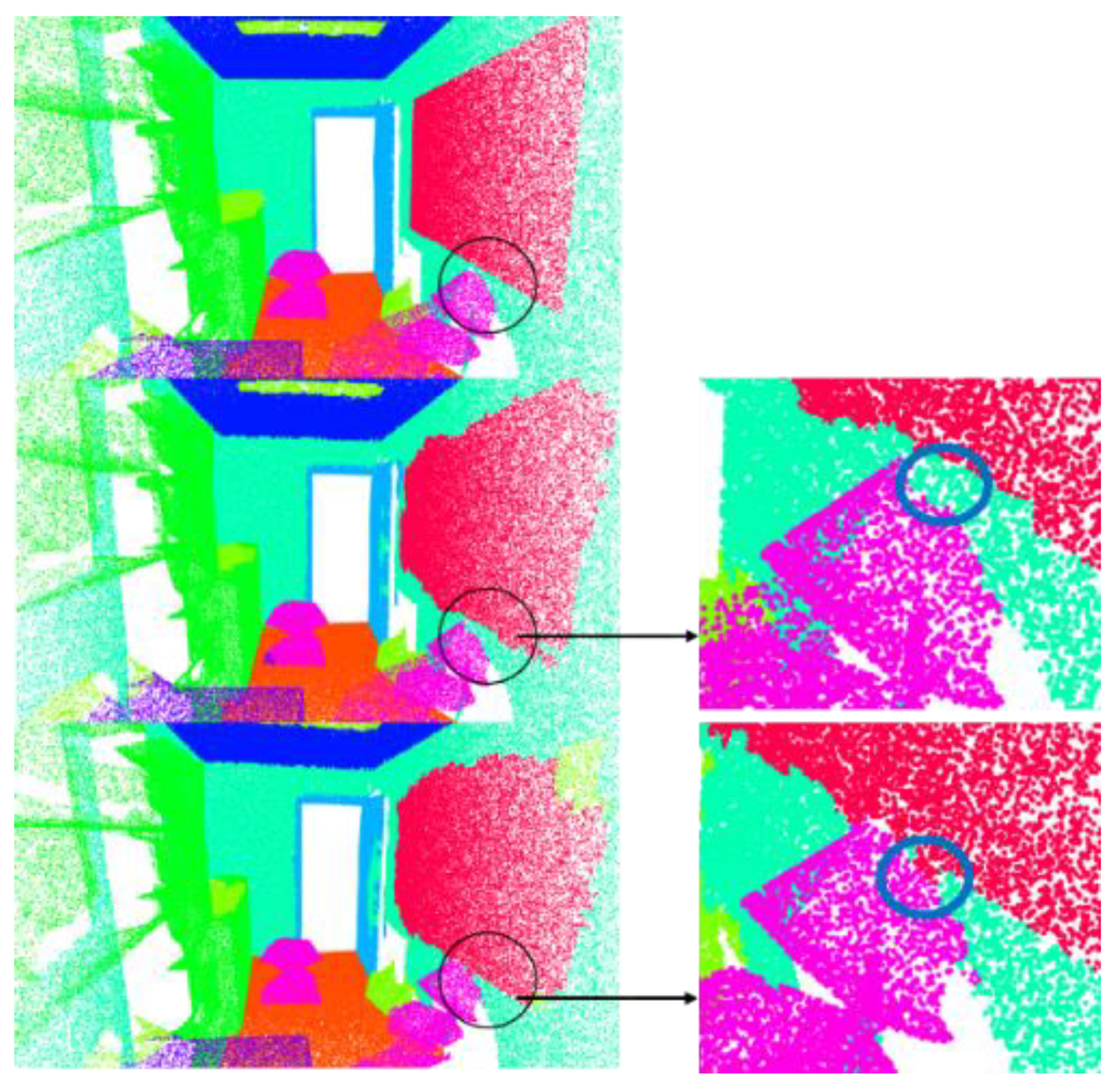
The results of the visualization are shown in Figure 12. According to these results (the part circled in the figure), it can be seen that between some objects in which the geometric structures are too similar and cause confusion (such as walls and windows, and walls and doors), the improved local transformer structure (adding the attention weight matrix to explore the geometric relationship) obtains better segmentation results than the naïve local transformer structure.
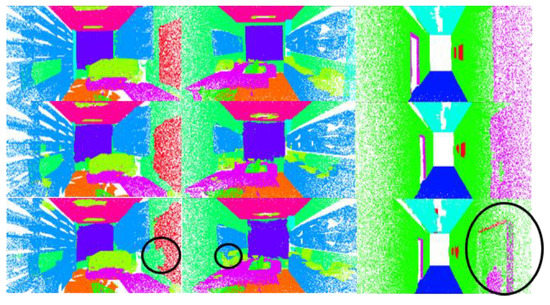
Figure 12.
Visualization results. First row is the ground truth. Second row shows the results when using the improved local transformer block. The third row shows the results when using the original local transformer block.
4.5.2. Cross-Skip Selection Method
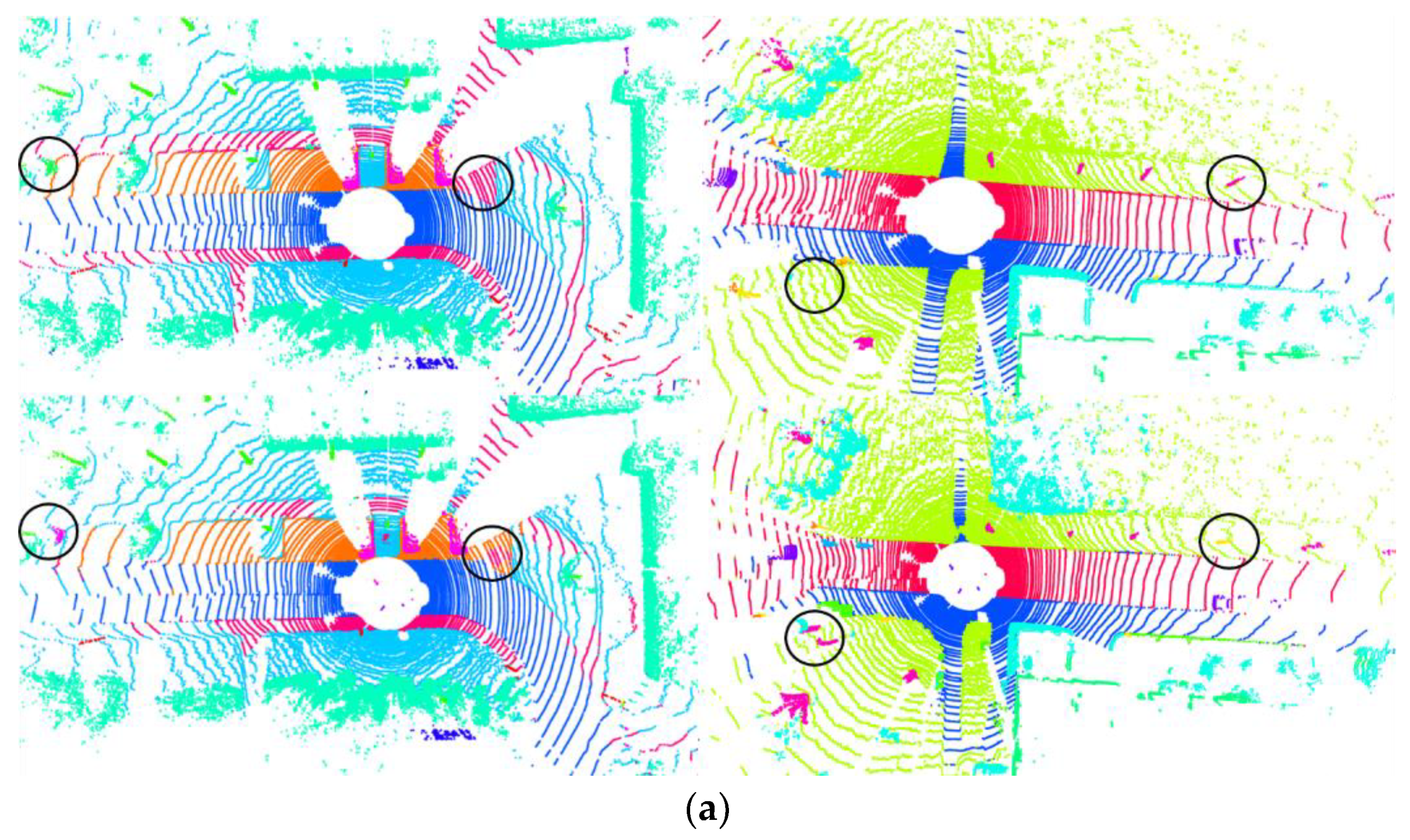
Our experiments verified the effectiveness of the cross-skip selection of neighbors. The results are shown in Table 5. The OA will increase by 0.6%, mAcc will increase by 1.8%, and mIoU will increase by 1.6%. The results of the visualization are shown in Figure 13. At the junction between objects, the similarity between points is not necessarily positively correlated with the distance between them. Points belonging to different objects may interfere with each other and affect the segmentation performance. Using cross-skip selection of the neighbors can expand the receptive field of each point. The results of the visualization are shown in Figure 14. In the places marked in blue circles, using this method will obtain better segmentation results.
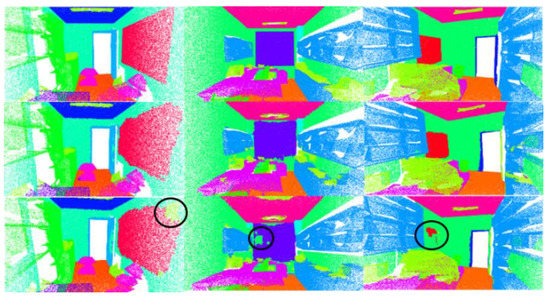
Figure 13.
Visualization results. First row is the ground truth. Second row shows the results when using cross-skip selection. The third row shows the results when not using cross-skip selection.
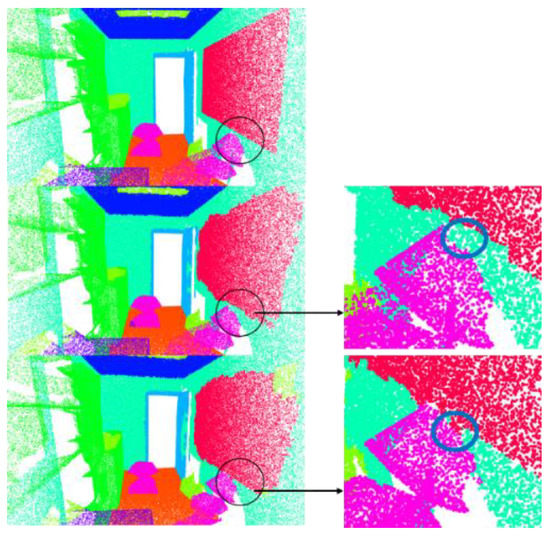
Figure 14.
Visualization results. First row is the ground truth. Second row shows the results when using cross-skip selection. The third row shows the results when not using cross-skip selection.
4.5.3. Normal Feature
Table 5 shows a comparison between the results when using and not using normal vector features on the S3DIS dataset. It can be found that, after using normal vector features, OA will be improved by 0.5%, mAcc will be improved by 3%, and mIoU will be improved by 2.5%. This is mainly due to the fact that the normal vectors of most points belonging to the same object are similar or continuously changing.
5. Conclusions
In this paper, we first proposed a muti-scale transformer network for semantic segmentation of a 3D point cloud. This network structure can effectively extract the local and global features of a 3D point cloud. Second, in the local transformer structure, two different attention weight matrices are obtained, with the aim of obtaining the feature similarities and local geometric structure relationships between points. Moreover, we proposed two strategies for fusing the two attention weight matrices. Through ablation experiments, it was proven that the structure can extract the nearest neighbor feature and obtain better segmentation performances between objects with similar geometric structures. Third, we proposed a parallel encoder layer with the cross-skip neighbor selection method, which obtains a larger receptive field for each point without increasing the dimensions of the neighbor feature matrix. From the results of the visualization, it can be seen that this method obtains better results at the junction of multiple objects.
In future work, the following two aspects will be explored. First, this paper proposed two methods for fusing two different attention weight matrices in the local transformer. Whether there is a more effective and efficient fusion method is worthy of further exploration and research. Second, the transformer itself has the disadvantages of requiring a large number of calculations and having low efficiency. The work conducted in this paper was an attempt at applying it to large-scale datasets. However, improving the efficiency and real-time performance without losing accuracy needs further research.
Author Contributions
Conceptualization, Z.W. and Y.W.; methodology, Z.W. and L.A.; software, Z.W. and L.A.; validation, Z.W.; formal analysis, Z.W.; investigation, Z.W.; resources, Z.W., Y.W. and H.L.; data curation, Z.W.; writing—original draft preparation, Z.W.; writing—review and editing, Z.W., Y.W., L.A., H.L. and J.L.; visualization, Z.W.; supervision, H.L. and J.L.; project administration, Y.W. and J.L.; funding acquisition, H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by National Natural Science Foundation of China (Grant Nos. 61871376).
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
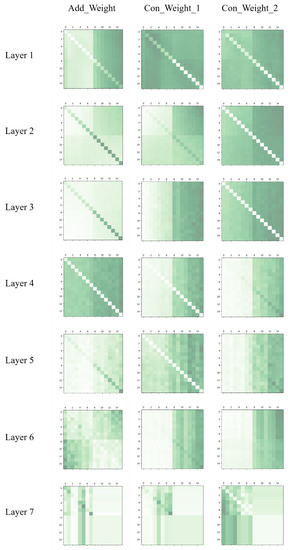
Figure A1.
Visualization of the attention weight matrices. The first column is obtained using Formula (16). The second and the third columns are and when using the second fusion method, which can be obtained using Formulas (13) and (15).
Figure A1.
Visualization of the attention weight matrices. The first column is obtained using Formula (16). The second and the third columns are and when using the second fusion method, which can be obtained using Formulas (13) and (15).
References
- Tran, L.V.; Lin, H.Y. BiLuNetICP: A Deep Neural Network for Object Semantic Segmentation and 6D Pose Recognition. IEEE Sens. J. 2021, 21, 11748–11757. [Google Scholar] [CrossRef]
- Claudine, B.; Rânik, G.; Raphael, V.C.; Pedro, A.; Vinicius, B.C.; Avelino, F.; Luan, J.; Rodrigo, B.; Thiago, M.P.; Filipe, M.; et al. Self-Driving Cars: A Survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. arXiv 2020, arXiv:2003.03653. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9598–9607. [Google Scholar]
- Rao, Y.; Lu, J.; Zhou, J. Spherical Fractal Convolutional Neural Networks for Point Cloud Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27–28 October 2019; pp. 452–460. [Google Scholar]
- Gerdzhev, M.; Razani, R.; Taghavi, E.; Liu, B. TORNADO-Net: MulTiview tOtal vaRiatioN semAntic segmentation with Diamond inception module. In Proceedings of the IEEE international Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 9543–9549. [Google Scholar]
- Zhou, Z.; Zhang, Y.; Foroosh, H. Panoptic-PolarNet: Proposal-Free LIDAR Point Cloud Panoptic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13194–13203. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.; Koltun, V. Point Transformer. arXiv 2020, arXiv:2012.09164. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 4–8 November 2019; pp. 4213–4220. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the International Conference on Robotics and Automation, Orlando, FL, USA, 21–26 May 2018; pp. 1887–1893. [Google Scholar]
- Liong, V.E.; Nguyen, T.N.T.; Widjaja, S.; Sharma, D.; Chong, Z.J. AMVNet: Assertion-based Multi-View Fusion Network for LiDAR Semantic Segmentation. arXiv 2020, arXiv:2012.04934. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Graham, B.; Engelcke, M.; Maaten, L.V.D. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9224–9232. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–7 December 2017; pp. 5105–5114. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9613–9622. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C. PointWeb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5560–5568. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6410–6419. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, A.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11105–11114. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Transact. Graph. 2019, 149, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10288–10297. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Li, Y.; Zhang, K.; Gao, J. LocalViT: Bringing Locality to Vision Transformers. arXiv 2021, arXiv:2104.05707. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Armeni, I.; Sax, S.; Zamir, A.R.; Savarese, S. Joint 2D-3D-semantic data for indoor scene understanding. arXiv 2017, arXiv:1702.01105. [Google Scholar]
- Hackel, T.; Savimov, N.; LADICKY, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar] [CrossRef] [Green Version]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9297–9307. [Google Scholar]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q. Tangent Convolutions for Dense Prediction in 3D. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3887–3896. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. arXiv 2018, arXiv:1801.07791. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar]
- Qiu, S.; Anwar, S.; Barnes, N. Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1757–1767. [Google Scholar]
- Boulch, A.; Puy, G.; Marlet, R. FKAConv: Feature-Kernel Alignment for Point Cloud Convolution. In Proceedings of the Asian Conference on Computer Vision, Cham, Switzerland, 30 November–4 December 2020. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14499–14508. [Google Scholar]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 1607–1616. [Google Scholar]
- Truong, G.; Gilani, S.Z.; Islam, S.M.S.; Suter, D. Fast Point Cloud Registration using Semantic Segmentation. In Proceedings of the Digital Image Computing: Techniques and Applications, Perth, Australia, 2–4 December 2019; pp. 1–8. [Google Scholar]
- Gong, J.; Xu, J.; Tan, X.; Song, H.; Qu, Y.; Xie, Y.; Ma, L. Omni-supervised Point Cloud Segmentation via Gradual Receptive Field Component Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11668–11677. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the International Conference on Robotics and Automation, Montreal, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).