
An Effective Ensemble Automatic Feature Selection Method for Network Intrusion Detection


Abstract
:1. Introduction
- This paper proposes an automatic feature selection method and designs a hybrid normalized score of mixed (NSOM) for the comprehensive evaluation of a subset performance. This method is able to select feature subsets dynamically and overcome the drawback of fixed thresholds.
- In this paper, an ensemble feature selection method is designed to improve the performance of feature subsets in classification by the intersection and union of different subsets.
- The methodologies designed in this paper are validated on the UNSW-NB15, CIC-IDS2017, and CSE-CIC-IDS2018 datasets and compared with the latest results. The outcomes of the experiments suggest that our framework can produce better results.
2. Related Work
3. Materials and Methods
- Data pre-processing: converting the raw data into the data format required by the classifier, as well as performing a series of operations such as numerical and normalization of the data;
- Feature selection: to remove irrelevant and redundant features and improve model performance, we implement an ensemble automatic feature selection method;
- Classifier training: to test the efficiency of the proposed strategy, RF and DT classifiers are trained using selected subsets;
- Attack identification: to verify the effectiveness and generalization of the method, we test it on multiple intrusion detection public datasets using a 5-fold cross-validation method.
3.1. Benchmark Dataset
3.2. Data Pre-Processing
3.3. Feature Selection
| Algorithm 1 Feature ranking algorithm |
|
| Algorithm 2 Automatic feature selection algorithm |
|
4. Results and Analysis
4.1. Experimental Environment and Setup
4.2. Evaluation Metrics
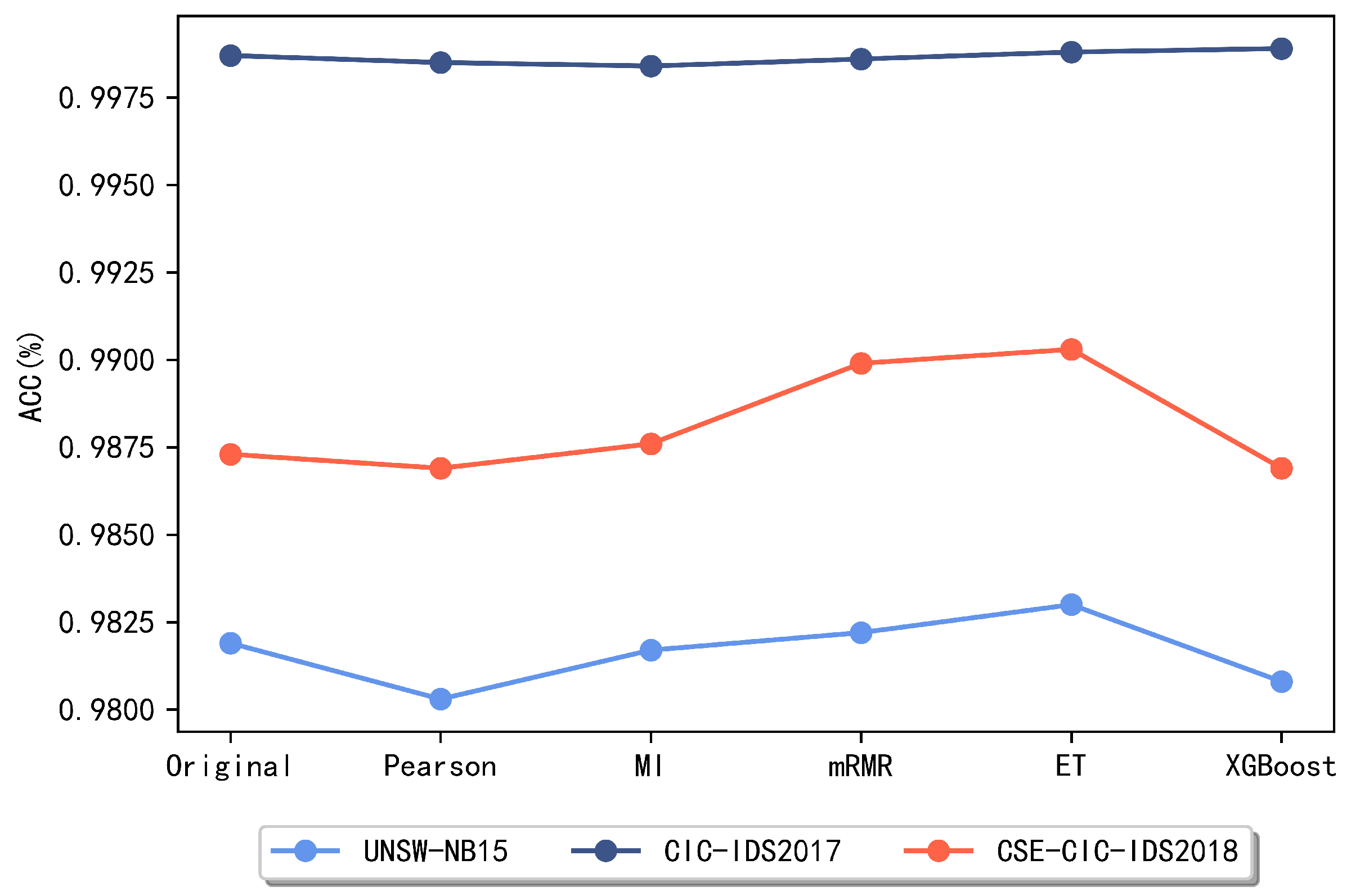
4.3. Automatic Feature Selection Performance Analysis
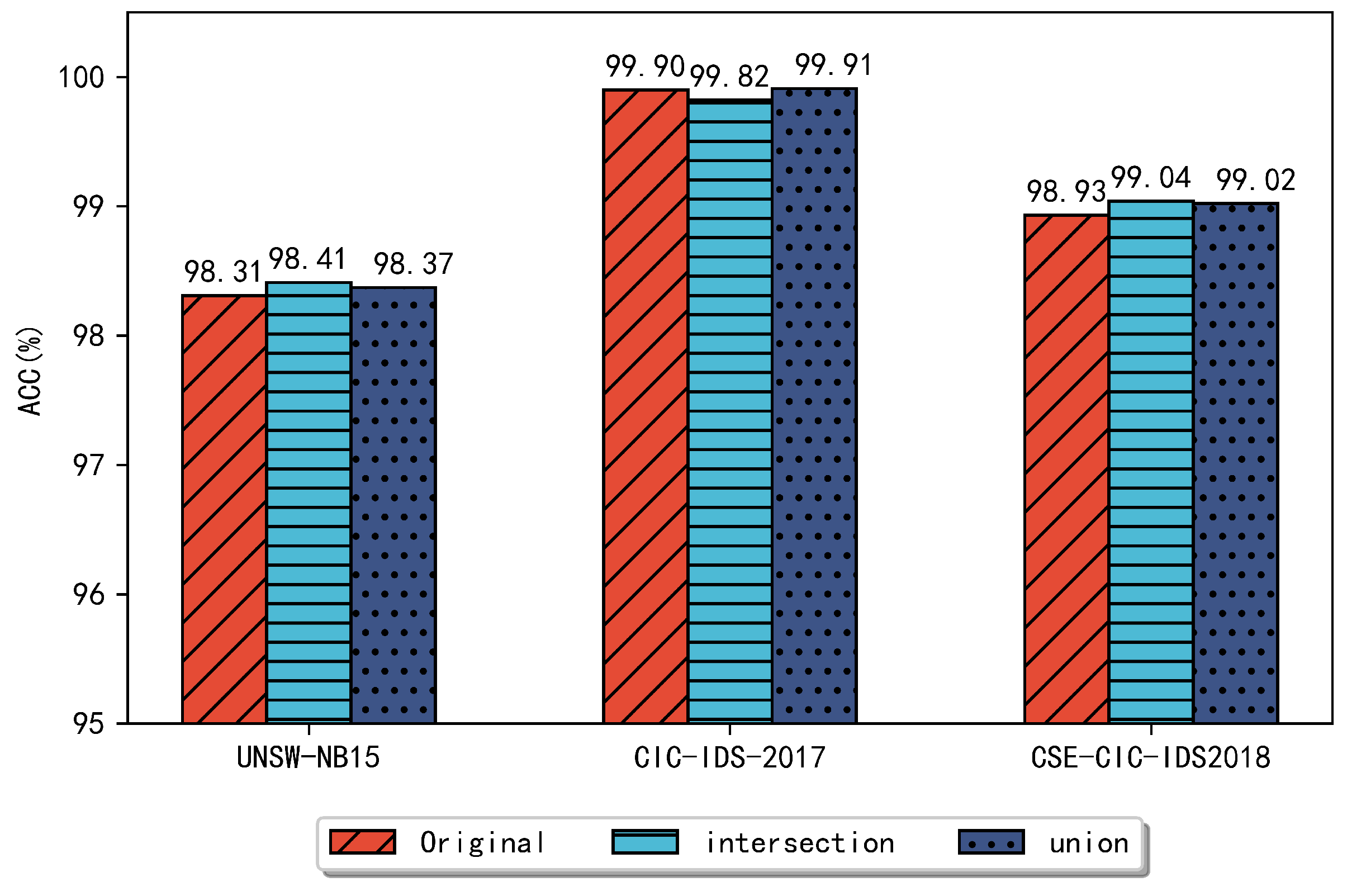
4.4. Ensemble Feature Selection Performance Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Verkerken, M.; D’hooge, L.; Wauters, T.; Volckaert, B.; Turck, D. Towards model generalization for intrusion detection: Unsupervised machine learning techniques. J. Netw. Syst. Manag. 2021, 30, 12. [Google Scholar] [CrossRef]
- Habeeb, R.A.A.; Nasaruddin, F.; Gani, A.; Hashem, I.A.T.; Ahmed, E.; Imran, M. Real-time big data processing for anomaly detection: A Survey. Int. J. Inf. Manag. 2019, 45, 289–307. [Google Scholar] [CrossRef] [Green Version]
- Kabir, M.; Hartmann, S. Cyber security challenges: An efficient intrusion detection system design. In Proceedings of the 2018 International Young Engineers Forum (YEF-ECE), Costa da Caparica, Portugal, 4 May 2018. [Google Scholar]
- Buczak, A.; Guven, E. A survey of data mining and machine learning methods for cyber security intrusion detection. IEEE Commun. Surv. Tutor. 2015, 18, 1153–1176. [Google Scholar] [CrossRef]
- Aljawarneh, S.; Aldwairi, M.; Yassein, M.B. Anomaly-based intrusion detection system through feature selection analysis and building hybrid efficient model. J. Comput. Sci. 2018, 25, 152–160. [Google Scholar] [CrossRef]
- Maldonado, J.; Riff, M.C.; Neveu, B. A review of recent approaches on wrapper feature selection for intrusion detection. Expert Syst. Appl. 2022, 198, 116822. [Google Scholar] [CrossRef]
- Fernandes, G.; Rodrigues, J.; Carvalho, L.; Al-Muhtadi, J.; Proença, M. A comprehensive survey on network anomaly detection. Telecommun. Syst. 2019, 70, 447–489. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A survey on intrusion detection system: Feature selection, model, performance measures, application perspective, challenges, and future research directions. Artif. Intell. Rev. 2021, 55, 453–563. [Google Scholar] [CrossRef]
- Wei, G.; Zhao, J.; Feng, Y.; He, A.; Yu, J. A novel hybrid feature selection method based on dynamic feature importance. Appl. Soft. Comput. 2020, 93, 106337. [Google Scholar] [CrossRef]
- Di Mauro, M.; Galatro, G.; Fortino, G.; Liotta, A. Supervised feature selection techniques in network intrusion detection: A critical review. Eng. Appl. Artif. Intell. 2021, 101, 104216. [Google Scholar] [CrossRef]
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A review of unsupervised feature selection methods. Artif. Intell. Rev. 2019, 53, 907–948. [Google Scholar] [CrossRef]
- Kasongo, S.M.; Sun, Y. A deep learning method with wrapper based feature extraction for wireless intrusion detection system. Comput. Secur 2020, 92, 101752. [Google Scholar] [CrossRef]
- Alaiz-Rodriguez, R.; Parnell, A.C. An information theoretic approach to quantify the stability of feature selection and ranking algorithms. Knowl.-Based Syst 2020, 195, 105745. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. Attack classification using feature selection techniques: A comparative study. J. Amb. Intell. Hum. Comp. 2020, 12, 1249–1266. [Google Scholar] [CrossRef]
- Lu, M. Embedded feature selection accounting for unknown data heterogeneity. Expert Syst. Appl. 2019, 119, 350–361. [Google Scholar] [CrossRef]
- Tsai, C.F.; Sung, Y.T. Ensemble feature selection in high dimension, low sample size datasets: Parallel and serial combination approaches. Knowl.-Based Syst. 2020, 203, 106097. [Google Scholar] [CrossRef]
- Shukla, A.K.; Singh, P. Building an effective approach toward intrusion detection using ensemble feature selection. Int. Inf. Secur. Priv. 2019, 13, 31–47. [Google Scholar] [CrossRef]
- Krishnaveni, S.; Sivamohan, S.; Sridhar, S.S.; Prabakaran, S. Efficient feature selection and classification through ensemble method for network intrusion detection on cloud computing. Clust. Comput. 2021, 24, 1761–1779. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.R.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 130. [Google Scholar] [CrossRef] [Green Version]
- Binbusayyis, A.; Vaiyapuri, T. Identifying and benchmarking key features for cyber intrusion detection: An ensemble approach. IEEE Access 2019, 7, 106495–106513. [Google Scholar] [CrossRef]
- Odhiambo Omuya, E.; Onyango Okeyo, G.; Waema Kimwele, M. Feature selection for classification using principal component analysis and information gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Bansal, A.; Kaur, S. Extreme gradient boosting based tuning for classification in intrusion detection systems. In Advances in Computing and Data Sciences; Singh, M., Gupta, P., Tyagi, V., Flusser, J., Ören, T., Eds.; Springer: Singapore, 2018; pp. 372–380. [Google Scholar]
- Fitni, Q.R.S.; Ramli, K. Implementation of ensemble learning and feature selection for performance improvements in anomaly-based intrusion detection systems. In Proceedings of the 2020 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bali, Indonesia, 7–8 July 2020. [Google Scholar]
- Bansal, A.; Kaur, S. Dynamic betwork anomaly detection system by using deep learning techniques. In Advances in Computing and Data Sciences; Da Silva, D., Wang, Q., Zhang, L.J., Eds.; Springer: Cham, Switzerland, 2019; pp. 161–176. [Google Scholar]
- Khammassi, C.; Krichen, S. A GA-LR wrapper approach for feature selection in network intrusion detection. Comput. Secur. 2017, 70, 255–277. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. Building an efficient intrusion detection system based on feature selection and ensemble classifier. Comput. Netw. 2020, 174, 107247. [Google Scholar] [CrossRef] [Green Version]
- Nazir, A.; Khan, R.A. A novel combinatorial optimization based feature selection method for network intrusion detection. Comput. Secur. 2021, 102, 102164. [Google Scholar] [CrossRef]
- Farahani, G. Feature selection based on cross-correlation for the intrusion detection system. Secur. Commun. Netw. 2020, 2020, 8875404. [Google Scholar] [CrossRef]
- Benmessahel, I.; Xie, K.; Chellal, M.; Semong, T. A new evolutionary neural networks based on intrusion detection systems using locust swarm optimization. Evol. Intell. 2019, 12, 131–146. [Google Scholar] [CrossRef]
- Vijayanand, R.; Devaraj, D.; Kannapiran, B. Intrusion detection system for wireless mesh network using multiple support vector machine classifiers with genetic-algorithm-based feature selection. Comput. Secur. 2018, 77, 304–314. [Google Scholar] [CrossRef]
- Akashdeep; Manzoor, I.; Kumar, N. A feature reduced intrusion detection system using ANN classifier. Expert Syst. Appl. 2017, 88, 249–257. [Google Scholar] [CrossRef]
- Selvakumar, B.; Muneeswaran, K. Firefly algorithm based feature selection for network intrusion detection. Comput. Secur. 2019, 81, 148–155. [Google Scholar]
- Kshirsagar, D.; Kumar, S. A feature reduction based reflected and exploited DDoS attacks detection system. J. Ambient Intell. Hum. Comput. 2022, 13, 393–405. [Google Scholar] [CrossRef]
- Muthamil Sudar, K.; Deepalakshmi, P. An intelligent flow-based and signature-based IDS for SDNs using ensemble feature selection and a multi-layer machine learning-based classifier. J. Intell. Fuzzy Syst. 2021, 40, 4237–4256. [Google Scholar] [CrossRef]
- Bhatia, M.P.S.; Sangwan, S.R. Soft computing for anomaly detection and prediction to mitigate IoT-based real-time abuse. Pers. Ubiquit. Comput. 2021, 1–11. [Google Scholar] [CrossRef]
- Ayo, F.; Folorunso, S.; Adebayo, A.-A.; Adekunle, A.; Bamidele, A. Network intrusion detection based on deep learning model optimized with rule-based hybrid feature selection. Inf. Secur. J. Glob. Perspect. 2021, 29, 267–283. [Google Scholar] [CrossRef]
- Karna, I.; Madam, A.; Deokule, C.; Adhao, R.; Pachghare, V. Ensemble-based filter feature selection technique for building flow-based IDS. In Proceedings of the 2021 2nd International Conference on Advances in Computing, Communication, Embedded and Secure Systems (ACCESS), Ernakulam, India, 2–4 September 2021. [Google Scholar]
- Dwivedi, S.; Vardhan, M.; Tripathi, S. An effect of chaos grasshopper optimization algorithm for protection of network infrastructure. Comput. Netw. 2020, 176, 107251. [Google Scholar] [CrossRef]
- Leevy, J.L.; Hancock, J.; Zuech, R.; Khoshgoftaar, T.M. Detecting cybersecurity attacks across different network features and learners. J. Big Data 2021, 8, 38. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems. In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015. [Google Scholar]
- Ghorbani, A.A.; Habibi Lashkari, A.; Sharafaldin, I. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Madeira, Portugal, 22–24 January 2018. [Google Scholar]
- Salo, F.; Nassif, A.B.; Essex, A. Dimensionality reduction with IG-PCA and ensemble classifier for network intrusion detection. Comput. Netw. 2019, 148, 164–175. [Google Scholar] [CrossRef]
- Çavuşoğlu, Ü. A new hybrid approach for intrusion detection using machine learning methods. Appl. Intell. 2019, 49, 2735–2761. [Google Scholar] [CrossRef]
- Vaca, F.D.; Niyaz, Q. An Ensemble Learning Based Wi-Fi Network Intrusion Detection System (WNIDS). In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UNSW-NB15 | CIC-IDS2017 | CSE-CIC-IDS-2018 | |||
|---|---|---|---|---|---|
| Class | Numbers | Class | Numbers | Class | Numbers |
| Benign | 2,218,764 | Benign | 2,273,097 | Benign | 13,484,708 |
| Exploits | 44,525 | DDOS | 128,027 | DDOS | 1,263,933 |
| Reconnaissance | 13,987 | DOS | 252,661 | DOS | 654,300 |
| DoS | 16,353 | Bot | 1966 | Bot | 286,191 |
| Generic | 215,481 | Patator | 13,835 | Brute Force | 380,949 |
| Shellcode | 1511 | Heartbleed | 11 | Infiltration | 161,934 |
| Fuzzers | 24,246 | Infiltration | 36 | Web Attack | 928 |
| Worms | 174 | PortScan | 158,930 | ||
| Backdoors | 2329 | Web Attack | 2180 | ||
| Analysis | 2677 | ||||
| Total | 2,540,047 | Total | 2,830,743 | Total | 16,232,943 |
| Classifier | Acc(%) | DR(%) | F1(%) | FAR(%) | Training Time(s) | Predicted Time(s) |
|---|---|---|---|---|---|---|
| Comparison of classification performance on the UNSW-NB15 dataset | ||||||
| RF | 98.31 | 98.31 | 98.24 | 1.70 | 42 | 1.78 |
| DT | 98.19 | 98.19 | 98.14 | 1.83 | 14 | 0.09 |
| RF | 98.37 | 98.37 | 98.31 | 1.65 | 19 | 1.55 |
| DT | 98.30 | 98.30 | 98.25 | 1.72 | 6 | 0.09 |
| Comparison of classification performance on the CIC-IDS2017 dataset | ||||||
| RF | 99.90 | 99.90 | 99.90 | 0.10 | 139 | 2.21 |
| DT | 99.87 | 99.87 | 99.87 | 0.13 | 107 | 0.13 |
| RF | 99.92 | 99.92 | 99.91 | 0.09 | 79 | 1.80 |
| DT | 99.88 | 99.88 | 99.88 | 0.12 | 24 | 0.07 |
| Comparison of classification performance on the CSE-CIC-IDS2018 dataset | ||||||
| RF | 98.93 | 98.93 | 98.77 | 1.07 | 1596 | 21 |
| DT | 98.73 | 98.73 | 98.69 | 1.27 | 1127 | 0.83 |
| RF | 99.04 | 99.04 | 98.83 | 0.96 | 243 | 12 |
| DT | 99.03 | 99.03 | 98.83 | 0.97 | 40 | 0.30 |
| Dataset | Reference | Technology | Acc | DR | F1 | FAR |
|---|---|---|---|---|---|---|
| UNSW-NB15 | Khammassi [27] | GA-LR | 81.42 | - | - | 6.39 |
| Nazir [29] | TS-RF | 83.12 | - | - | 3.70 | |
| Benmessahel [31] | LSO-FNN | 95.42 | 99.33 | 95.98 | 9.40 | |
| Binbusayyis [21] | SCM3-RF | 95.87 | 97.40 | - | 7.40 | |
| Femi [38] | RHF-ANN | 97.60 | - | 97.70 | 1.30 | |
| This work | EAFS-RF | 98.36 | 98.36 | 98.31 | 1.65 | |
| CIC-IDS2017 | Bansal [24] | XGBoost | 99.54 | - | - | 0.237 |
| Vijayanand [32] | GA-SVM | 99.85 | - | - | 0.09 | |
| Zhou [28] | CFS-BA | 99.89 | 99.90 | - | 0.12 | |
| Binbusayyis [21] | SCM3-RF | 99.88 | 99.90 | - | 0.20 | |
| Karna [39] | CPM-voting | 99.16 | - | 99.17 | - | |
| Shubhra [40] | EFW-SVM | 99.25 | 99.52 | - | 0.007 | |
| This work | EAFS- RF | 99.92 | 99.92 | 99.92 | 0.08 | |
| CSE-CIC-IDS2018 | Fitni [25] | spearman | 98.80 | 97.10 | 97.90 | - |
| Lin [26] | LSTM-Attention | 96.20 | 96.00 | 93.00 | - | |
| Leevy [41] | vote-LightGBM | - | - | 95.88 | - | |
| This work | EAFS- RF | 99.04 | 99.04 | 98.83 | 0.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, H.; Zhang, B. An Effective Ensemble Automatic Feature Selection Method for Network Intrusion Detection. Information 2022, 13, 314. https://doi.org/10.3390/info13070314
Zhang Y, Zhang H, Zhang B. An Effective Ensemble Automatic Feature Selection Method for Network Intrusion Detection. Information. 2022; 13(7):314. https://doi.org/10.3390/info13070314
Chicago/Turabian StyleZhang, Yang, Hongpo Zhang, and Bo Zhang. 2022. "An Effective Ensemble Automatic Feature Selection Method for Network Intrusion Detection" Information 13, no. 7: 314. https://doi.org/10.3390/info13070314