

Efficient and Expressive Search Scheme over Encrypted Electronic Medical Records
Abstract
:1. Introduction
- (1)
- We propose a keyword conversion method that can transform a collection of keywords into a vector. Furthermore, based on the characteristics of the range query, we give two ways through which to convert a range query into a vector. These vectors can be utilized to perform both range and keyword searches efficiently.
- (2)
- We design an index tree construction algorithm to speed up the query process. The internal node of the index tree contains only one range vector, and the leaf node contains a small number of vectors for both points and keywords. Based on the index tree, through an efficient prune algorithm, the query time of the proposed scheme is sublinear to the number of documents.
- (3)
- Through using the secure KNN scheme [11] to encrypt the index tree and query, we propose an SSE scheme that can support both range and keyword queries (SSE-RK), which can be applied in searching electronic medical records efficiently.
2. Problem Formulation
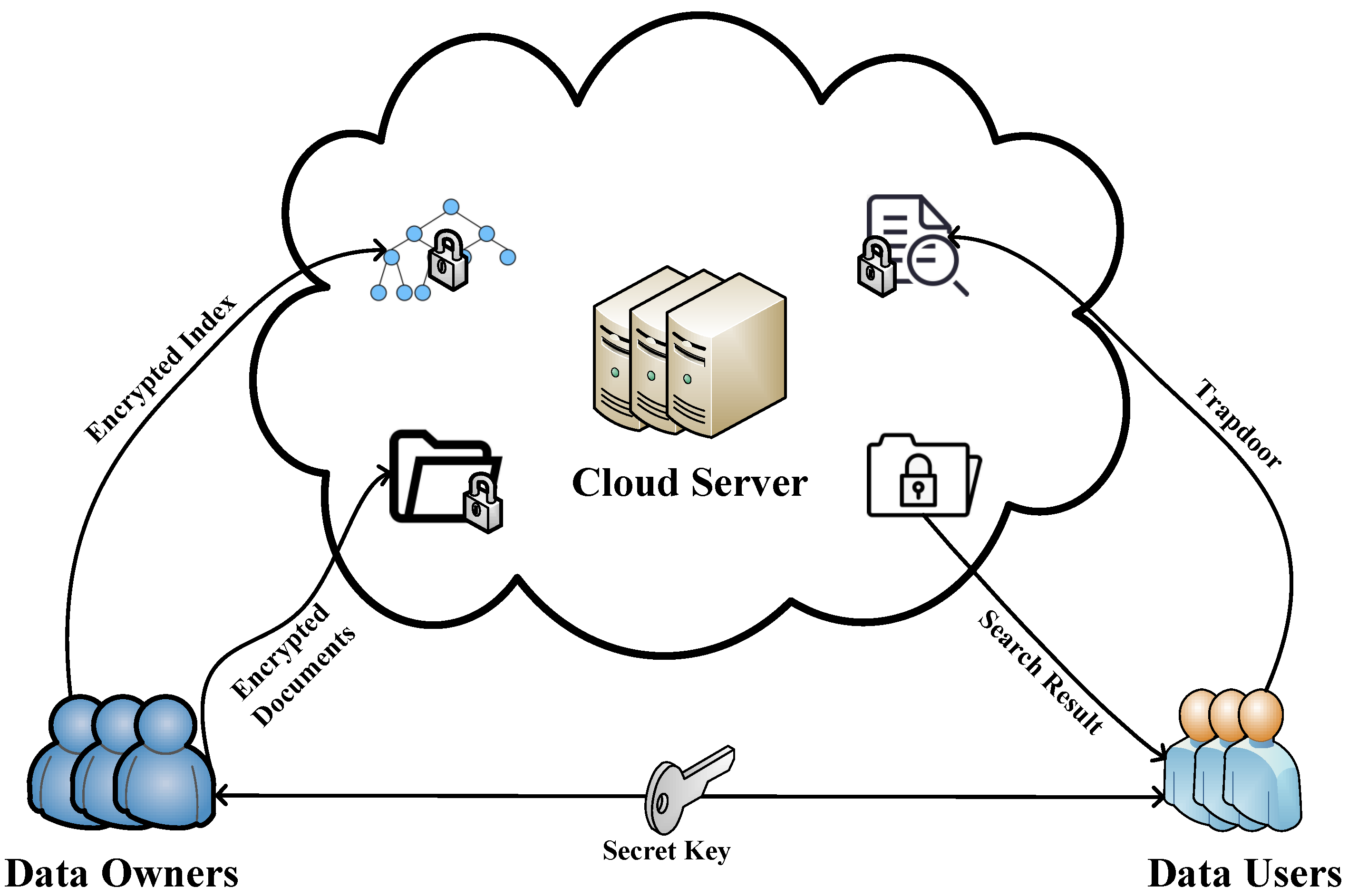
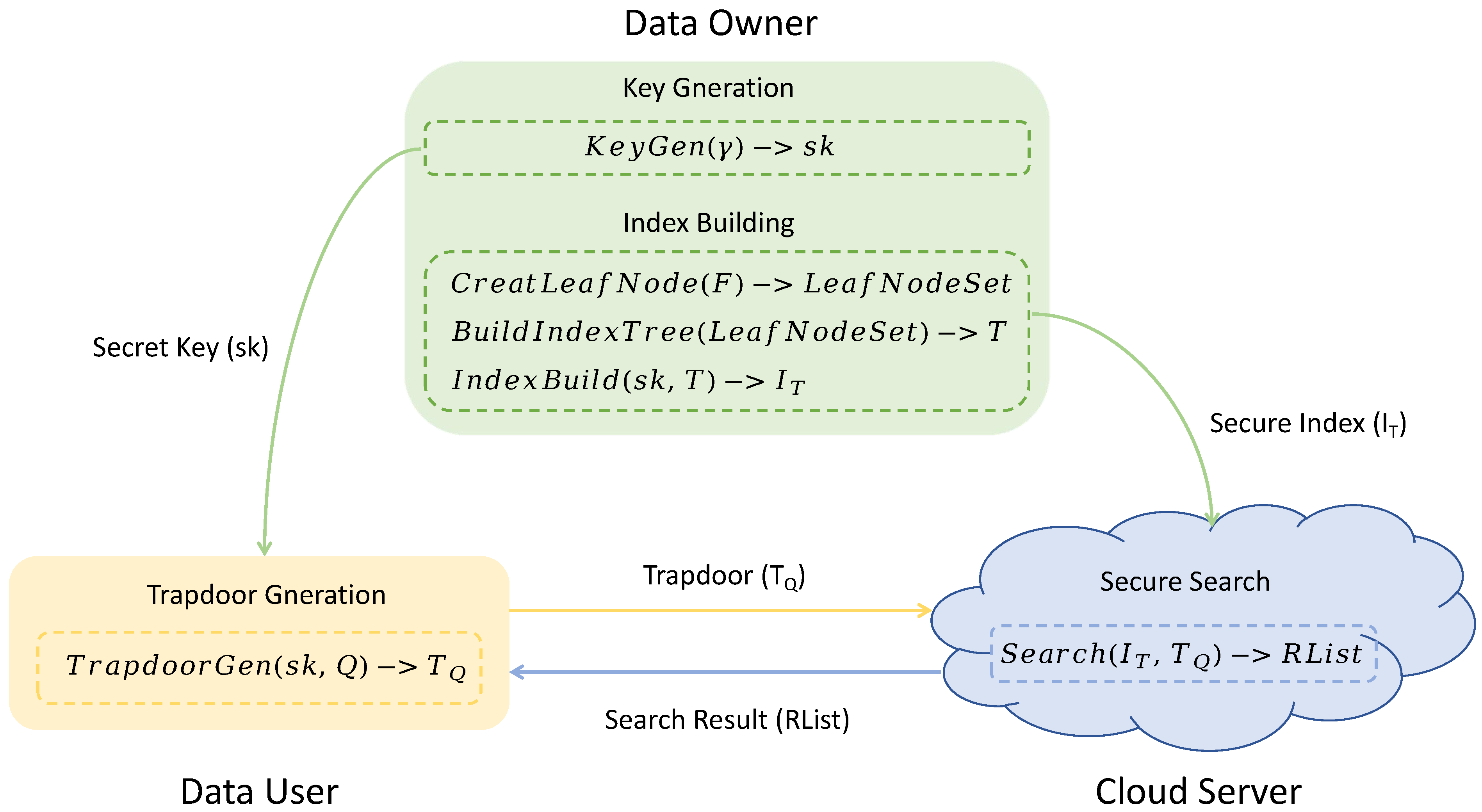
2.1. System Model
- (1)
- Data owner (DO). Before outsourcing a document set to a CS, the DO first generates the secret key, then encrypts F using traditional symmetric encryption algorithms (e.g., AES, etc.), and then constructs a secure index using the generated key. Finally, they upload the encrypted data and the secure index to a CS for storage. When a legitimate DU requests a query, the DO shares the secret key with the legitimate DU through authorization.
- (2)
- Data user (DU). When an authorized DU wants to launch a query Q, DU generates a trapdoor using the secret key shared by DO. After this, the DU sends the trapdoor to a CS. Once the DU receives the encrypted documents back from a CS, they decrypt these documents using the secret key to recover the original plaintext.
- (3)
- Cloud server (CS). The main function of a CS is to store files and perform retrieval. A CS stores the encrypted data and secure index uploaded by the DO. When an authorized DU uploads a trapdoor without any decryption, a CS performs a matching query on the secure index and the trapdoor, as well as returns the encrypted result of the query to the DU.
2.2. Threat Model
- -
- Known ciphertext model. Only contains information of ciphertexts, secure indexes, and trapdoors that can be obtained by a CS, which means that only ciphertext-only attacks can be performed in this model.
- -
- Known background model. A CS can obtain more background knowledge, e.g., term frequency (TF)-inverse document frequency (IDF), than the aforementioned model. This information is commonly acquired from documents by statistical means. The CS can conduct the statistical attack by utilizing such information.
2.3. Design Goals
- (1)
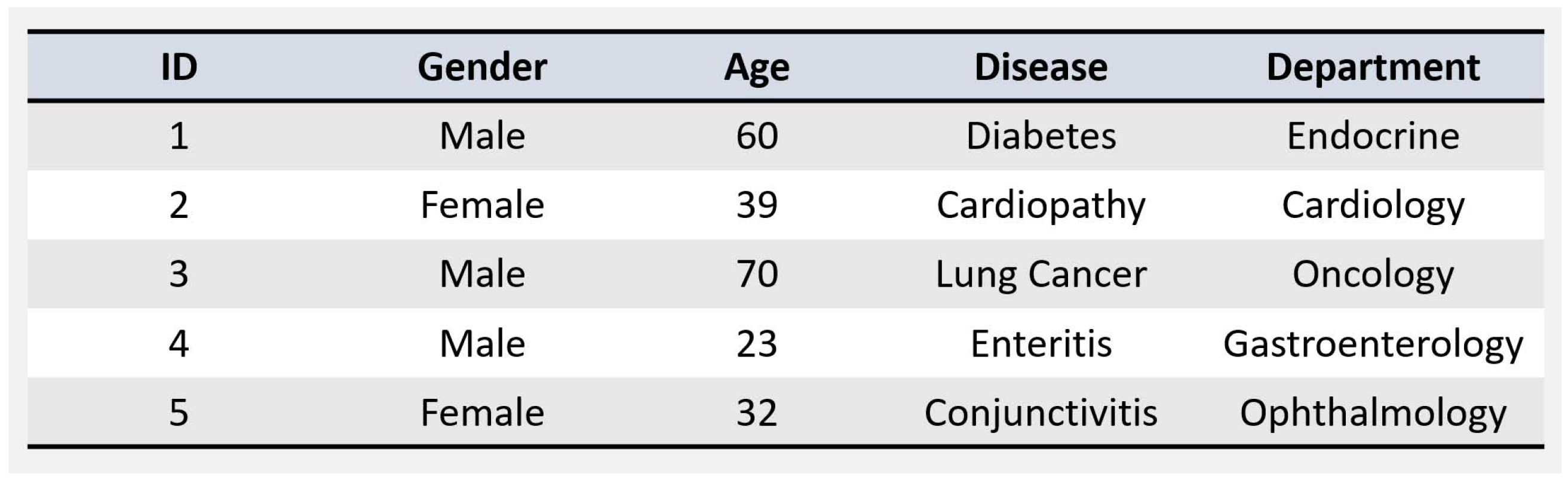
- Functionality. The document of SSE-RK contains a point set and a keyword set . The query Q of SSE-RK can be a hybrid of a range set and a keyword query . The search result of the SSE-RK scheme can be ranked, thus meaning that SSE-RK only returns documents whose point is in the query range and whose keyword set is strongly correlated with the query keywords as the search result, where and .
- (2)
- Efficiency. The query time of the SSE-RK is sublinear to the number of documents. Specifically, the proposed scheme has better search efficiency than other similar schemes without sacrificing much index building efficiency.
- (3)
- Privacy preserving. Similar to previous schemes [19,20,21], the SSE-RK scheme disallows CSs to obtain extra private information. This information can be inferred from ciphertexts, secure indexes, and trapdoors. More explicitly, we list the privacy requirement of SSE-RK as follows.
- -
- Index and trapdoor privacy. SSE-RK prevents CSs from inferring plaintext information that is hidden in indexes and trapdoors. That is to say, information including points, keywords, and their corresponding vectors cannot be disclosed to CSs.
- -
- Trapdoor unlinkability. In real-world scenarios, CSs sometimes receive the same query request. If a CS can easily capture two trapdoors that are generated from a single query request, an adversary can launch statistical attacks, e.g., an increase in the frequency of a certain query may indicate that the user tends to retrieve popular content, thus compromising the privacy of the query request.
- -
- Keyword privacy. CSs cannot utilize background knowledge and statistics to infer whether a trapdoor contains a particular keyword. When CSd can infer the frequency of keyword occurrences from the trapdoor, it can infer the main content of the ciphertext data.
3. Algorithms for Index Building and Searching
3.1. Keyword Conversion Method
- (1)
- Creating a dictionary by extracting keywords in the corpus, where is a keyword and .
- (2)
- Given a keyword set , this approach first creates a zero vector . Then, it sets according to the Equation (1) if , where , and .In Equation (1), is the number of times appears in the document .
- (3)
- Given a keyword set , this approach first initializes a zero vector . Then, it sets according to the Equation (2) if , where and .The variable in Equation (2) represents the number of documents that contains the keyword .
3.2. Range Conversion Methods
3.3. Algorithm for Creating the Leaf Node
| Algorithm 1 Creating leaf nodes. |
Input: A set of tuples , where and are the keyword set and multi-dimensional point for , respectively, and . Output: A that contains all leaf nodes.
|
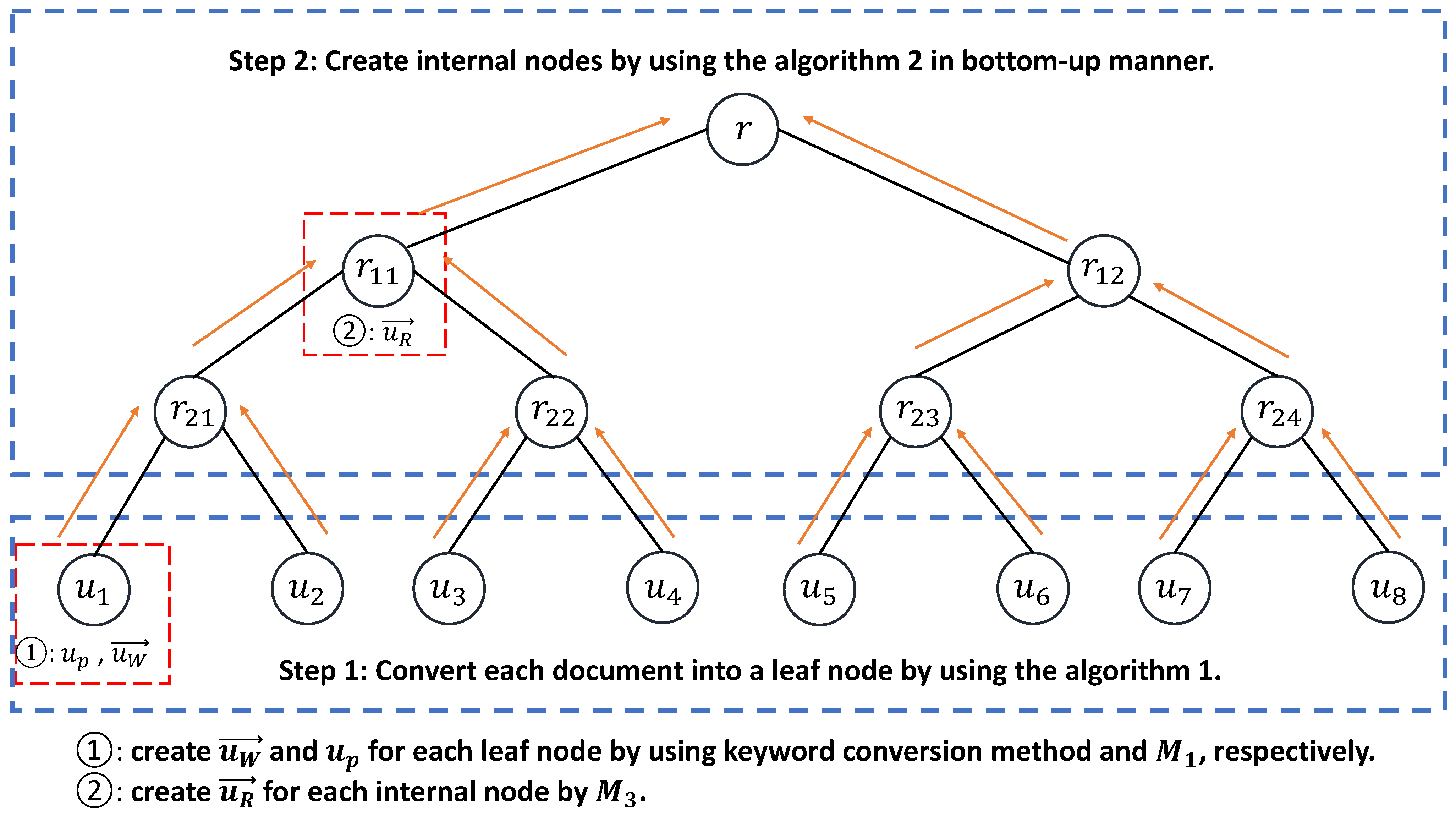
3.4. Algorithm for Building the Index Tree
- (1)
- Let and be two leaf nodes, where the points in and are , , …, and , , …, , respectively. For each sub-range in u, and are set to be and , respectively, where .
- (2)
- Let and be two internal nodes, where the ranges in and are , ,…, and , , …, , respectively. For each sub-range in u, this method sets and , where .
| Algorithm 2 The index tree building algorithm, declared by BuildIndexTree(LeafNodeSet) |
Input: including all the leaf nodes. Output: An index tree T.
|
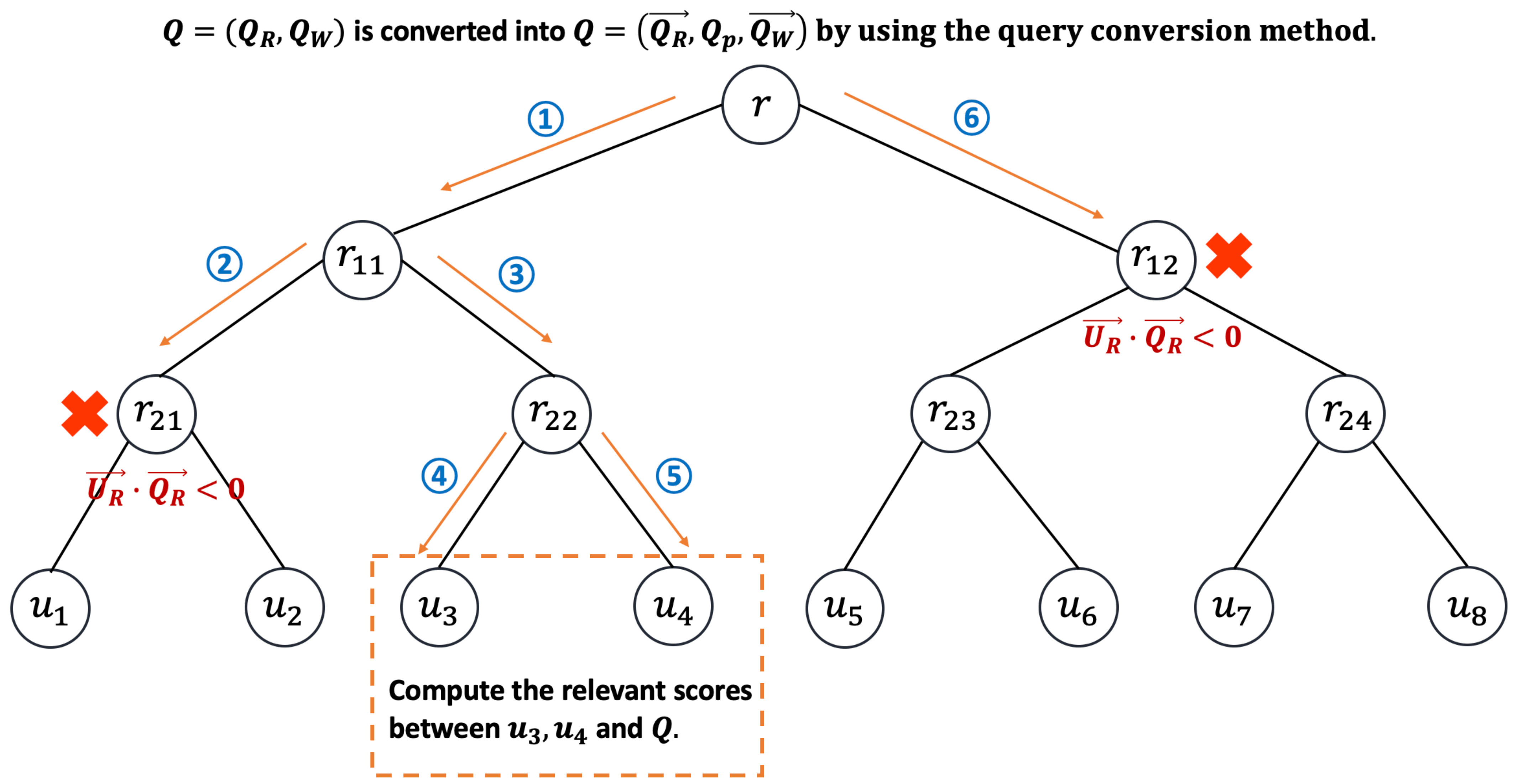
3.5. Algorithm for Searching the Index Tree
- (1)
- Given the query range , based on , each sub-range is converted into , , , , where . According to this conversion, a vector , , , , , , , , …, , , , can be created.
- (2)
- Based on , each sub-range of is converted into , and is set to be , , …, .
- (3)
- Apply the keyword conversion method to transform into , and set .
| Algorithm 3 The index tree search algorithm, declared by SearchIndexTree(, , , u, ) |
Input: A query tuple of query Q, the index tree’s root node u, and an empty result list . Output: .
|
4. Proposed Scheme
4.1. Construction of SSE-RK
- KeyGen(): Given a security parameter as input, it first randomly generates two invertible matrices and ; two invertible matrices and ; and two invertible matrices and . Then, it randomly generates three vectors and , where the dimensions of and are 3, , and , respectively. Finally, it outputs the secret key .
- IndexBuild(, F): Given the document set F, it applies Algorithm 2 to build a plaintext index tree T, and it then encrypts T. The encryption process can be classified into two situations.
- (1)
- For each internal node , the algorithm generates two random vectors of . More precisely, if , it sets ; if , then are set to two random numbers that satisfy condition , where . This procedure can be represented by the following equation.Then, it generates the encrypted internal node , , , , , .
- (2)
- For each leaf node , the encryption process contains two steps.
- -
- The algorithm initializes an empty set . For each vector in , the algorithm generates two random vectors of , where . Similarly, this procedure can be represented by the following equation.After this, it adds into the .
- -
- For the keyword vector in the leaf node, the N-dimension vector is stretched to a -dimension vector . For , the value of is set to be when , and the value of is set as a random number when . Then, the algorithm generates two random vectors of according to the following equations.
After these two steps, it generates the encrypted leaf node , , , , , .
Finally, when the encryption operation is completed for each node, the algorithm outputs the encrypted index tree . - TrapdoorGen(,Q): For a query , this algorithm applies the query conversion method introduced in Section 3.5 to generates a query tuple . After this, it will encrypt the query tuple. The encryption process can be classified into three situations.
- (1)
- For , it generates two random vectors . This division process is similar to the index building algorithm and can still be represented by the following equation.After this, it replaces with .
- (2)
- The algorithm initializes an empty set . For each vector in , the algorithm generates two random vectors of according to the following equations, where .After this, it adds each into .
- (3)
- The N-dimension vector is expanded to a -dimension vector . For each , it sets . For each , it chooses a random number 0 or 1, and it sets to be equal to 0 or 1. Then, it adopts the following equations to create two random vectors .After this, it replaces with .
Finally, this algorithm outputs the trapdoor , , , , for Q. - Search(, ): Given an encrypted index tree and a trapdoor , this algorithm executes the search operation in a pre-order traversal manner. When an internal node , , is accessed, it computes the following:When reaching a leaf node , , , , the computation process has two steps.
- (1)
- For each in and each in , where , it computes the following:
- (2)
- To evaluate the relevance score, it computes the following:
According to the above Equations (6)–(8), the computation result between the encrypted node and the trapdoor is identical to that between the plaintext u and the query Q. Thus, this algorithm can take advantage of Algorithm 3 to execute a ranked search.
4.2. Security Analysis
- -
- S generates a simulated encrypted document set . Firstly, S generates , where and are represented as a binary string of length . Then, S encrypts to create such that , where and are the ciphertexts of and , respectively. Finally, S outputs . Since the AES scheme is secure, it is guaranteed that and cannot be distinguished by an adversary.
- -
- S generates the simulated trapdoor set . S generates t query conditions, i.e., . For each , the algorithm can be utilized to produce it as a trapdoor, where . Since the essence of the algorithm is to encrypt using the secure KNN scheme, it ensures that and cannot be distinguished by an adversary.
- -
- S generates the simulated index tree . For each simulated document , S generates the simulated multi-dimensional point and the keyword set based on the query set . For each query in which , the generated by S needs to satisfy and and . Here, and are the multi-dimensional point and keyword set of the real document , respectively, where . S will generate a simulated index tree for all the the simulated points and keyword sets using the index tree building algorithm, and it will encrypt the using the algorithm to create an encrypted index tree . Since the secure KNN scheme we use is secure under a known ciphertext model, the SSE-RK scheme can guarantee the indistinguishability of from .
5. Performance Evaluation
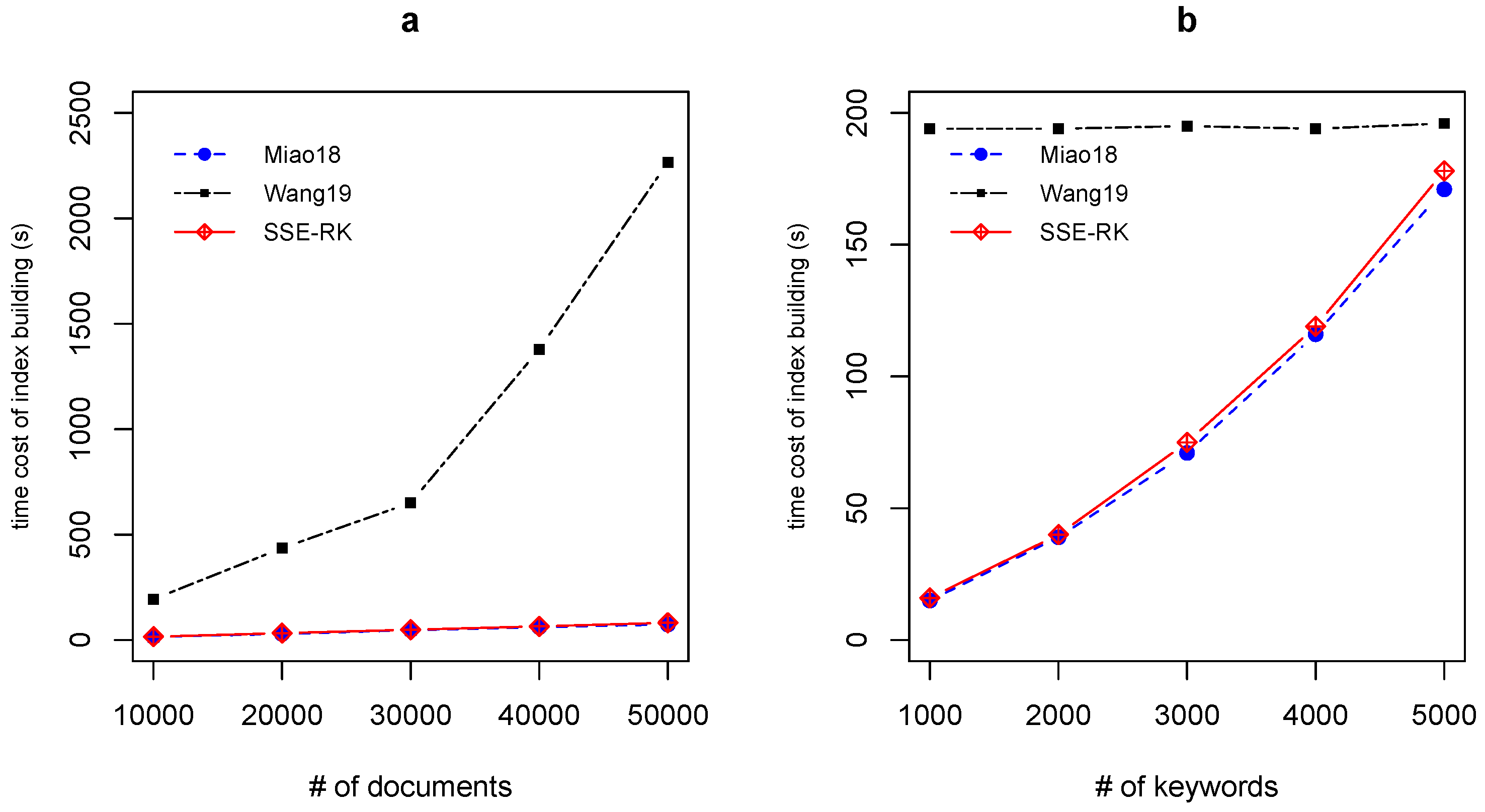
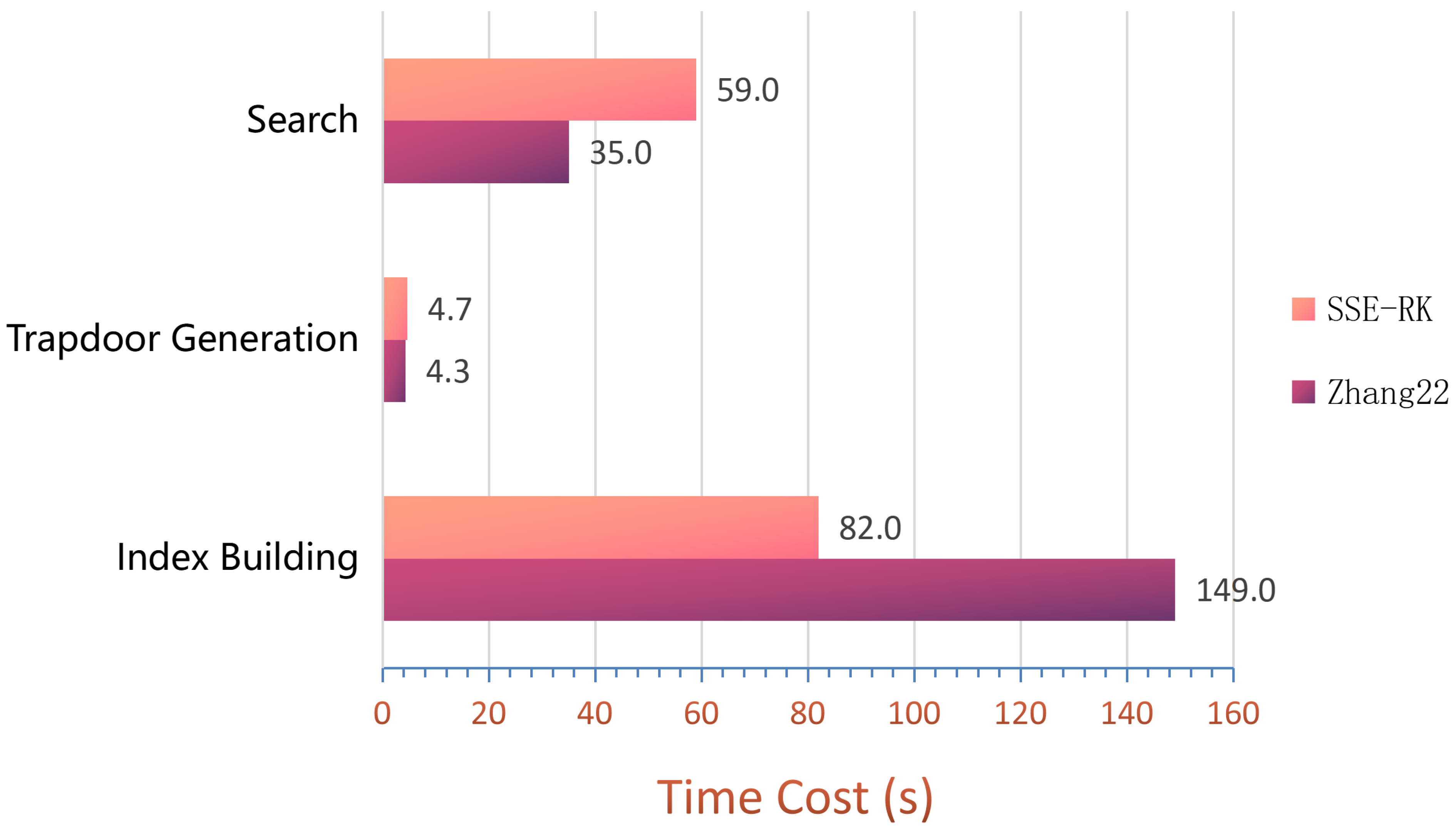
5.1. Efficiency of Index Building
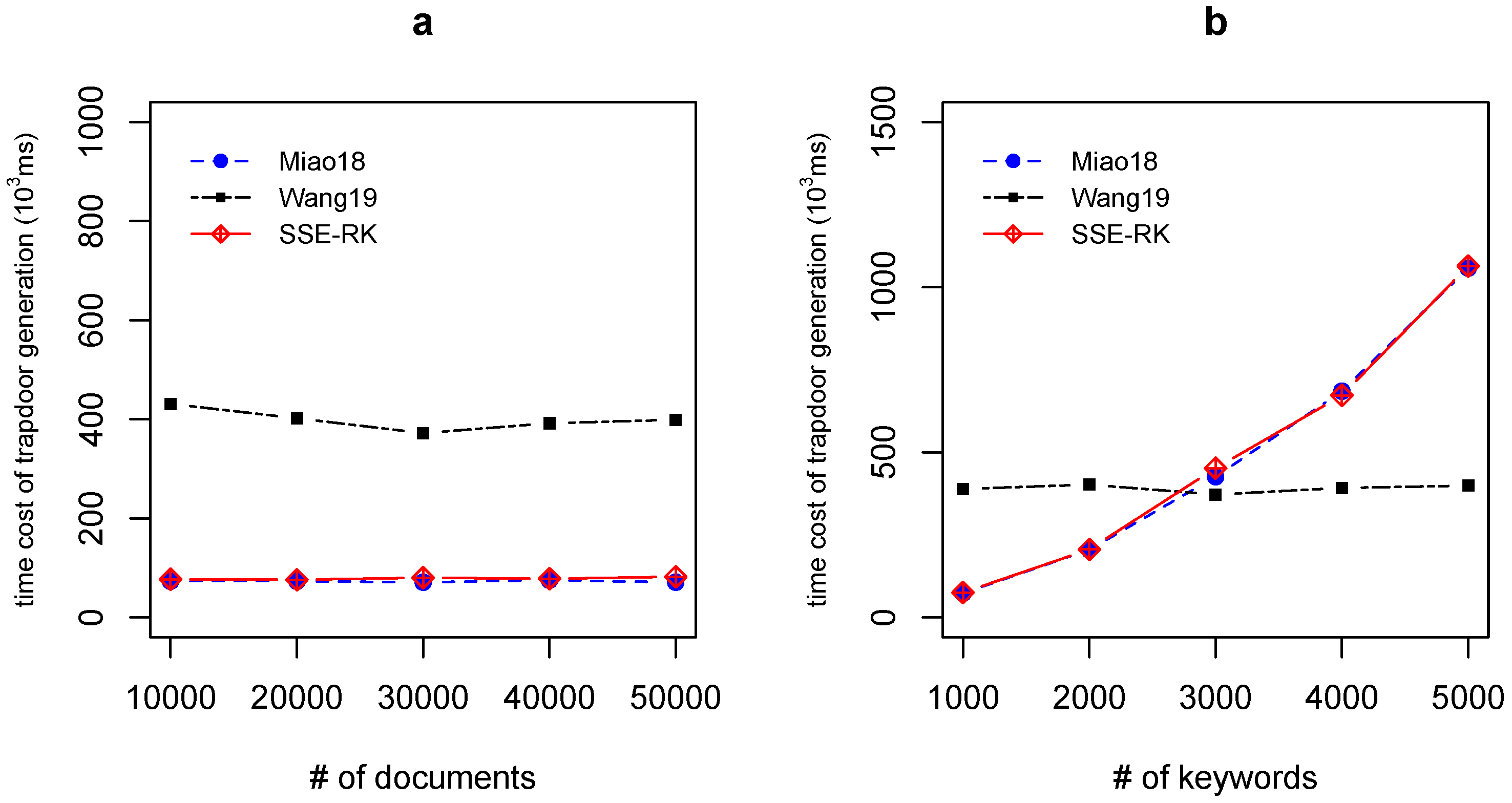
5.2. Efficiency of Trapdoor Generation
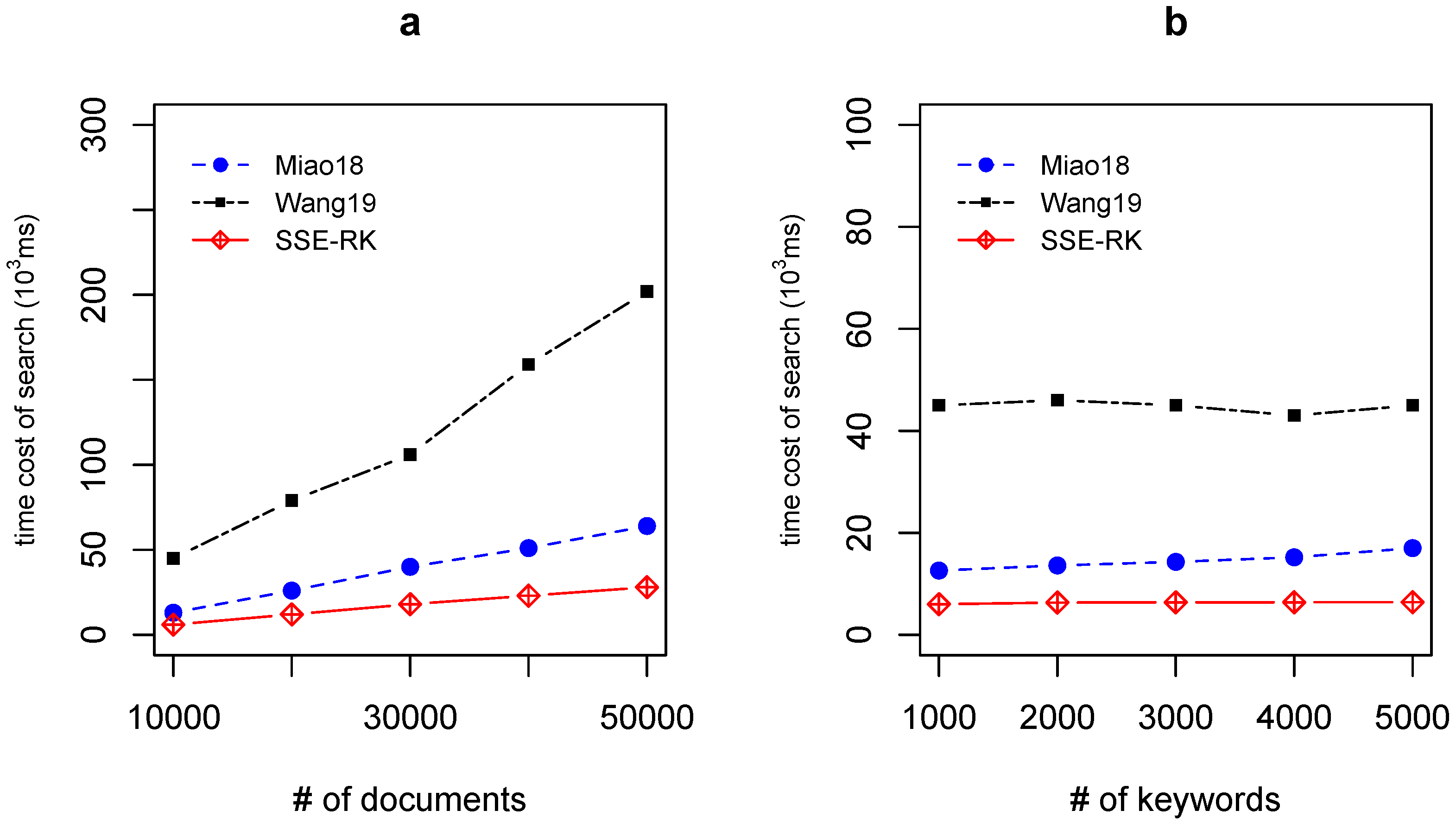
5.3. Efficiency of Search
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, H.; Yang, Y.; Luan, T.H.; Liang, X.; Zhou, L.; Shen, X.S. Enabling fine-grained multi-keyword search supporting classified sub-dictionaries over encrypted cloud data. IEEE Trans. Dependable Secur. Comput. 2015, 13, 312–325. [Google Scholar] [CrossRef]
- Sun, W.; Liu, X.; Lou, W.; Hou, Y.T.; Li, H. Catch you if you lie to me: Efficient verifiable conjunctive keyword search over large dynamic encrypted cloud data. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; pp. 2110–2118. [Google Scholar]
- Miao, Y.; Weng, J.; Liu, X.; Choo, K.R.; Liu, Z.; Li, H. Enabling verifiable multiple keywords search over encrypted cloud data. Inf. Sci. 2018, 465, 21–37. [Google Scholar] [CrossRef]
- Zhu, H.; Lu, R.; Huang, C.; Chen, L.; Li, H. An efficient privacy-preserving location-based services query scheme in outsourced cloud. IEEE Trans. Veh. Technol. 2015, 65, 7729–7739. [Google Scholar] [CrossRef]
- Wang, B.; Li, M.; Wang, H. Geometric range search on encrypted spatial data. IEEE Trans. Inf. Forensics Secur. 2015, 11, 704–719. [Google Scholar] [CrossRef]
- Xu, G.; Li, H.; Dai, Y.; Yang, K.; Lin, X. Enabling efficient and geometric range query with access control over encrypted spatial data. IEEE Trans. Inf. Forensics Secur. 2018, 14, 870–885. [Google Scholar] [CrossRef]
- Tang, Q. Public key encryption schemes supporting equality test with authorisation of different granularity. Int. J. Appl. Cryptogr. 2012, 2, 304–321. [Google Scholar] [CrossRef]
- Miao, Y.; Liu, X.; Deng, R.H.; Wu, H.; Li, H.; Li, J.; Wu, D. Hybrid keyword-field search with efficient key management for industrial internet of things. IEEE Trans. Ind. Inform. 2018, 15, 3206–3217. [Google Scholar] [CrossRef]
- Wang, X.; Ma, J.; Liu, X.; Deng, R.H.; Miao, Y.; Zhu, D.; Ma, Z. Search me in the dark: Privacy-preserving boolean range query over encrypted spatial data. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 2253–2262. [Google Scholar]
- Lai, S.; Patranabis, S.; Sakzad, A.; Liu, J.K.; Mukhopadhyay, D.; Steinfeld, R.; Sun, S.; Liu, D.; Zuo, C. Result pattern hiding searchable encryption for conjunctive queries. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 745–762. [Google Scholar]
- Wong, W.K.; Cheung, D.W.; Kao, B.; Mamoulis, N. Secure kNN computation on encrypted databases. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; pp. 139–152. [Google Scholar]
- Song, D.; Wagner, D.; Perrig, A. Practical techniques for searching on encrypted data. In Proceedings of the IEEE Symposium on Research in Security and Privacy, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Goh, E.J. Secure indexes. IACR Cryptol. Eprint Arch. 2003, 2003, 216. [Google Scholar]
- Byun, J.W.; Lee, D.H.; Lim, J. Efficient conjunctive keyword search on encrypted data storage system. In Proceedings of the European Public Key Infrastructure Workshop, Turin, Italy, 19–20 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 184–196. [Google Scholar]
- Ballard, L.; Kamara, S.; Monrose, F. Achieving efficient conjunctive keyword searches over encrypted data. In Proceedings of the International Conference on Information and Communications Security, Beijing, China, 10–13 December 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 414–426. [Google Scholar]
- Zhu, Y.; Ma, D.; Wang, S. Secure data retrieval of outsourced data with complex query support. In Proceedings of the 2012 32nd International Conference on Distributed Computing Systems Workshops, Macau, China, 18–21 June 2012; pp. 481–490. [Google Scholar]
- Curtmola, R.; Garay, J.; Kamara, S.; Ostrovsky, R. Searchable symmetric encryption: Improved definitions and efficient constructions. J. Comput. Secur. 2011, 19, 895–934. [Google Scholar] [CrossRef]
- Zerr, S.; Olmedilla, D.; Nejdl, W.; Siberski, W. Zerber+R: Top-k retrieval from a confidential index. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology, Saint Petersburg, Russia, 24–26 March 2009; pp. 439–449. [Google Scholar]
- Wang, C.; Cao, N.; Ren, K.; Lou, W. Enabling Secure and Efficient Ranked Keyword Search over Outsourced Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1467–1479. [Google Scholar] [CrossRef]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-preserving multi-keyword ranked search over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 222–233. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Sun, X.; Wang, Q. A Secure and Dynamic Multi-Keyword Ranked Search Scheme over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 340–352. [Google Scholar] [CrossRef]
- Guo, C.; Zhuang, R.; Chang, C.; Yuan, Q. Dynamic multi-keyword ranked search based on bloom filter over encrypted cloud data. IEEE Access 2019, 7, 35826–35837. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, L.; Meng, W.; Wang, H.; Wang, W. Accurate range query with privacy preservation for outsourced location-based service in IOT. IEEE Internet Things J. 2021, 8, 14322–14337. [Google Scholar] [CrossRef]
- Molla, E.; Rizomiliotis, P.; Gritzalis, S. Efficient searchable symmetric encryption supporting range queries. Int. J. Inf. Secur. 2023, 22, 785–798. [Google Scholar] [CrossRef]
- Zheng, Y.; Lu, R.; Guan, Y.; Shao, J.; Zhu, H. Achieving efficient and privacy-preserving exact set similarity search over encrypted data. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1090–1103. [Google Scholar] [CrossRef]
- Gupta, B.B.; Lytras, M.D. Fog-enabled secure and efficient fine-grained searchable data sharing and management scheme for IoT-based healthcare systems. IEEE Trans. Eng. Manag. 2022. [Google Scholar] [CrossRef]
- Fu, Z.; Ren, K.; Shu, J.; Sun, X.; Huang, F. Enabling personalized search over encrypted outsourced data with efficiency improvement. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 2546–2559. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Wang, Y. Efficient Searchable Symmetric Encryption Supporting Dynamic Multikeyword Ranked Search. Secur. Commun. Netw. 2020, 2020, 7298518. [Google Scholar] [CrossRef]
- Fu, Z.; Wu, X.; Guan, C.; Sun, X.; Ren, K. Toward Efficient Multi-Keyword Fuzzy Search over Encrypted Outsourced Data with Accuracy Improvement. IEEE Trans. Inf. Forensics Secur. 2017, 11, 2706–2716. [Google Scholar] [CrossRef]
- Kuzu, M.; Islam, M.S.; Kantarcioglu, M. Efficient similarity search over encrypted data. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1156–1167. [Google Scholar]
- Boneh, D.; Crescenzo, G.D.; Ostrovsky, R.; Persiano, G. Public key encryption with keyword search. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 506–522. [Google Scholar]
- Park, D.J.; Kim, K.; Lee, P.J. Public key encryption with conjunctive field keyword search. In Proceedings of the International Workshop on Information Security Applications, Jeju, Republic of Korea, 23–25 August 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 73–86. [Google Scholar]
- Katz, J.; Sahai, A.; Waters, B. Predicate encryption supporting disjunctions, polynomial equations, and inner products. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Istanbul, Turkey, 13–17 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 146–162. [Google Scholar]
- Zhang, Y.; Li, Y.; Wang, Y. Secure and Efficient Searchable Public Key Encryption for Resource Constrained Environment Based on Pairings under Prime Order Group. Secur. Commun. Netw. 2019, 2019, 5280806. [Google Scholar] [CrossRef]
- Kim, I.; Hwang, S.O.; Park, J.H.; Park, C. An Efficient Predicate Encryption with Constant Pairing Computations and Minimum Costs. IEEE Trans. Comput. 2016, 65, 2947–2958. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, J.; Song, Z.; Wang, X. An enhanced searchable encryption scheme for secure data outsourcing. Sci. China Inf. Sci. 2020, 63, 132102. [Google Scholar] [CrossRef]
- Miao, Y.; Liu, X.; Choo, K.K.R.; Deng, R.H.; Li, J.; Li, H.; Ma, J. Privacy-preserving attribute-based keyword search in shared multi-owner setting. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1080–1094. [Google Scholar] [CrossRef]
- He, W.; Zhang, Y.; Li, Y. Fast, Searchable, Symmetric Encryption Scheme Supporting Ranked Search. Symmetry 2022, 14, 1029. [Google Scholar] [CrossRef]
- Hersh, W.; Buckley, C.; Leone, T.J.; Hickam, D. OHSUMED:An interactive retrieval evaluation and new large test collection for research. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 3–6 July 1994; pp. 192–201. [Google Scholar]
- Shin, K.G.; Ju, X.; Chen, Z.; Hu, X. Privacy protection for users of location-based services. IEEE Wirel. Commun. 2012, 19, 30–39. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, X.; Zhou, F.; Li, B.; Li, Y. TYLER, a fast method that accurately predicts cyclin-dependent proteins by using computation-based motifs and sequence-derived features. Math. Biosci. Eng. 2021, 18, 6410–6429. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F | A set of documents . |
| d | The number of documents in F |
| The dictionary of a corpus. | |
| The keyword set for the document , where . | |
| The number of keywords in , and . | |
| The j-th keywords in , and , . | |
| The vector representation for . | |
| The multi-dimension point for a document , where . | |
| m | The dimension of a multi-dimension point. |
| u | A node in the index tree. |
| The encrypted node u in the index. | |
| The encrypted index tree of F. | |
| The vector set for a multi-dimension point in a leaf node u. | |
| The vector representation for a keyword set in a leaf node u. | |
| The vector representation for a range in an internal node u. | |
| A query tuple. | |
| A query range. | |
| A query keyword set. | |
| The vector representation used to search internal nodes. | |
| The vector set for search leaf nodes. | |
| The vector representation for making keyword search. | |
| The trapdoor of the query Q. |
| N | The number of keywords in the dictionary. |
| d | The number of documents in the corpus. |
| m | The dimension of the point in the document. |
| L | The average length of a query range. |
| M | The dimension of bloom filter used in Wang19. |
| The average number of documents that match the query. |
| Schemes | Index Building | Trapdoor Generation | Search |
|---|---|---|---|
| Miao18 | |||
| Wang19 | |||
| SSE-RK |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Zhang, Y.; Wang, Y.; Li, Y. Efficient and Expressive Search Scheme over Encrypted Electronic Medical Records. Information 2023, 14, 643. https://doi.org/10.3390/info14120643
Yang X, Zhang Y, Wang Y, Li Y. Efficient and Expressive Search Scheme over Encrypted Electronic Medical Records. Information. 2023; 14(12):643. https://doi.org/10.3390/info14120643
Chicago/Turabian StyleYang, Xiaopei, Yu Zhang, Yifan Wang, and Yin Li. 2023. "Efficient and Expressive Search Scheme over Encrypted Electronic Medical Records" Information 14, no. 12: 643. https://doi.org/10.3390/info14120643
APA StyleYang, X., Zhang, Y., Wang, Y., & Li, Y. (2023). Efficient and Expressive Search Scheme over Encrypted Electronic Medical Records. Information, 14(12), 643. https://doi.org/10.3390/info14120643