



A New Time Series Dataset for Cyber-Threat Correlation, Regression and Neural-Network-Based Forecasting


Abstract
1. Introduction
- Innovative methodology: We developed an automated methodology for the systematic collection of global cyber-attack data, offering a novel and efficient approach to dataset creation.
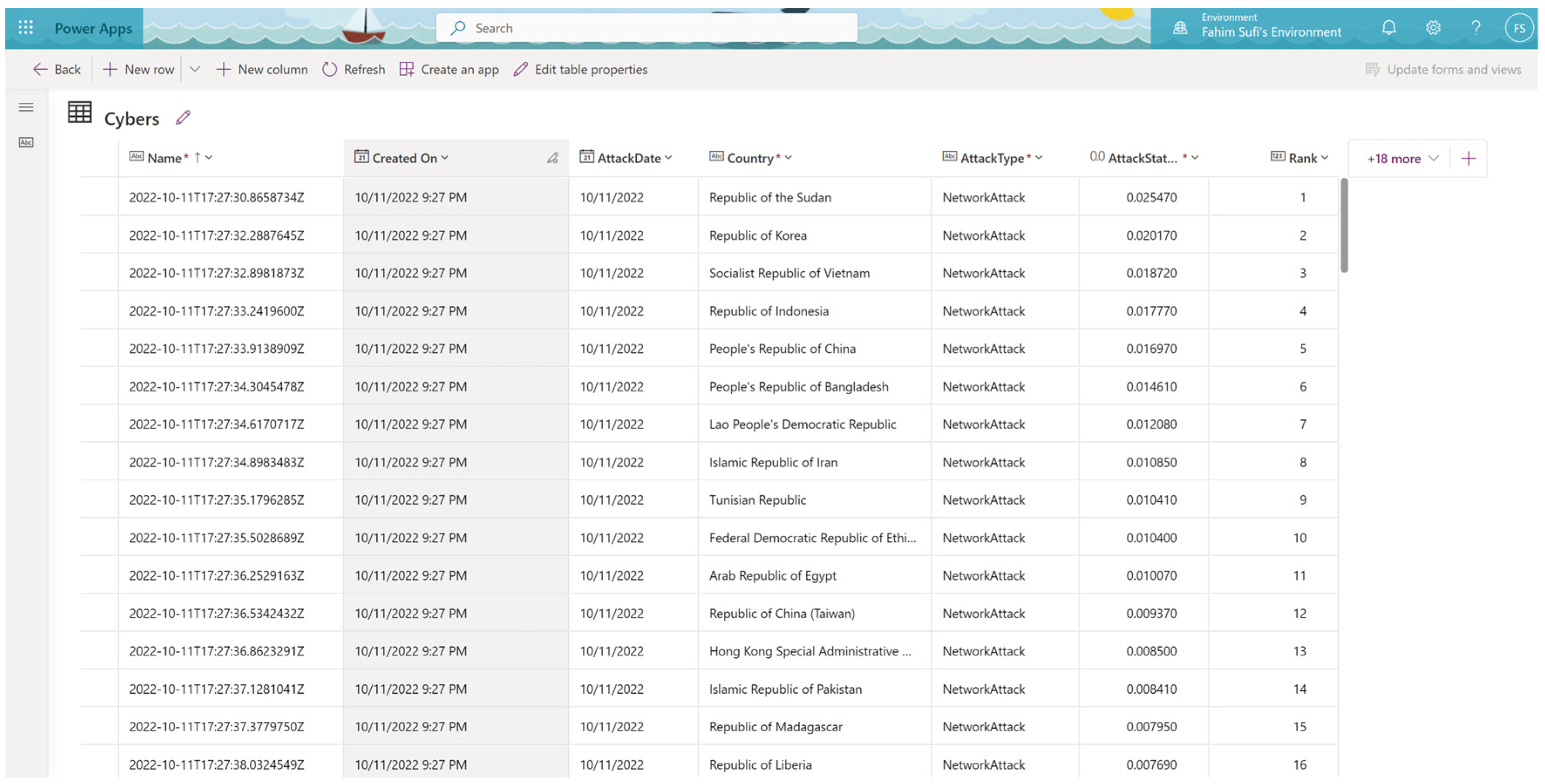
- Comprehensive dataset: We generated a comprehensive dataset spanning 225 countries over a 14-month period, comprising 77,623 rows and 18 fields, capturing the multifaceted nature of cyber-attacks across diverse dimensions (publicly available at https://github.com/DrSufi/CyberData, accessed on 14 February 2024).
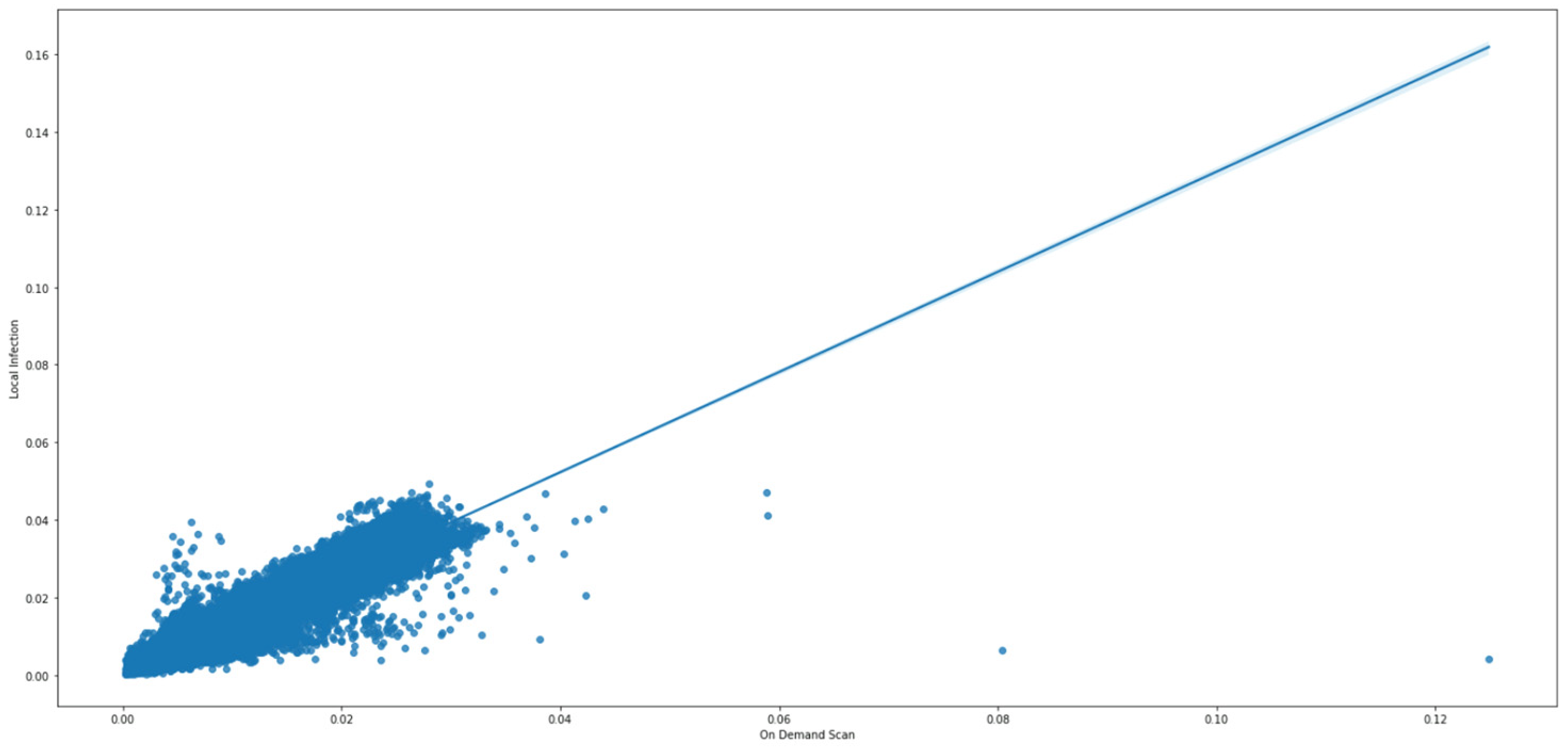
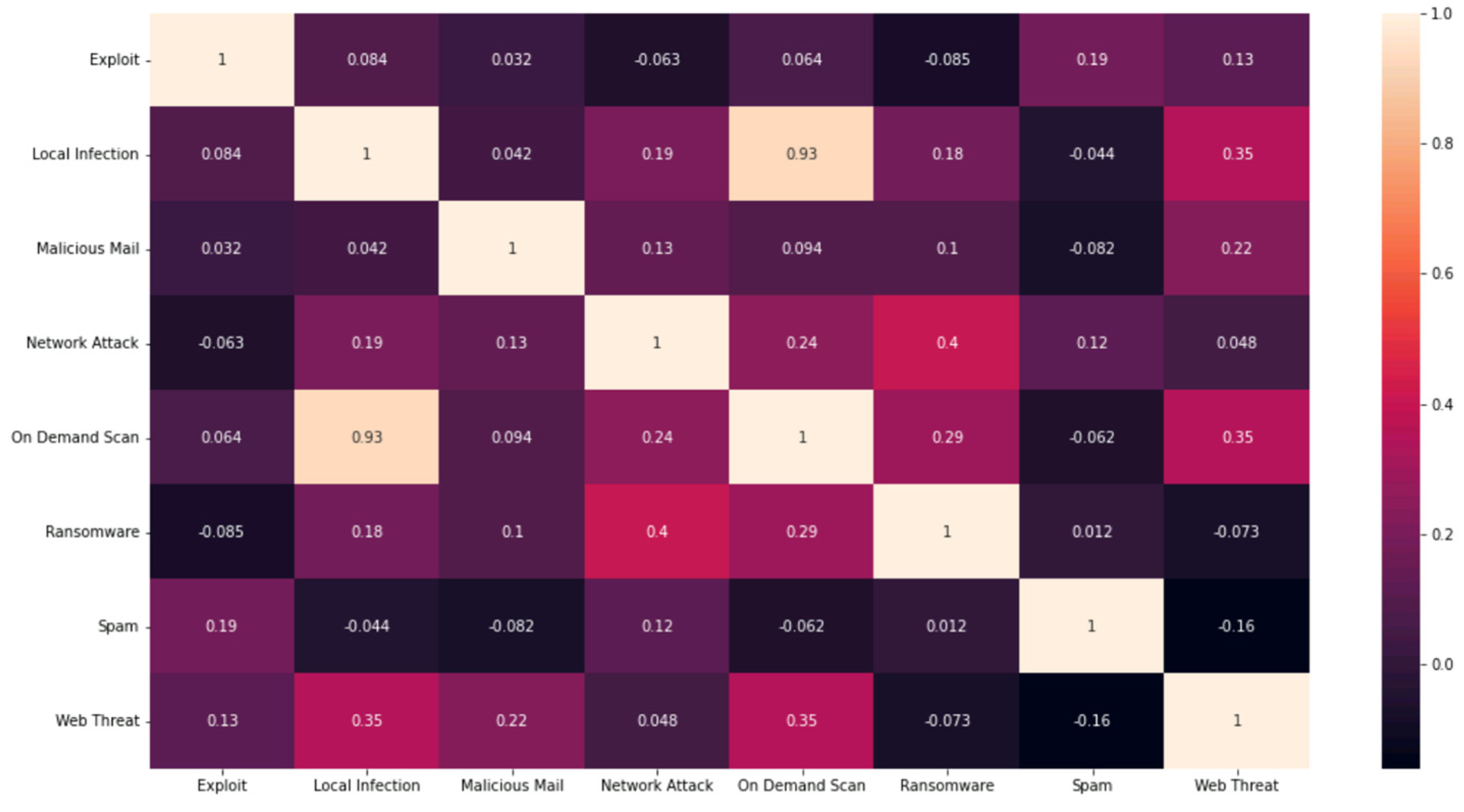
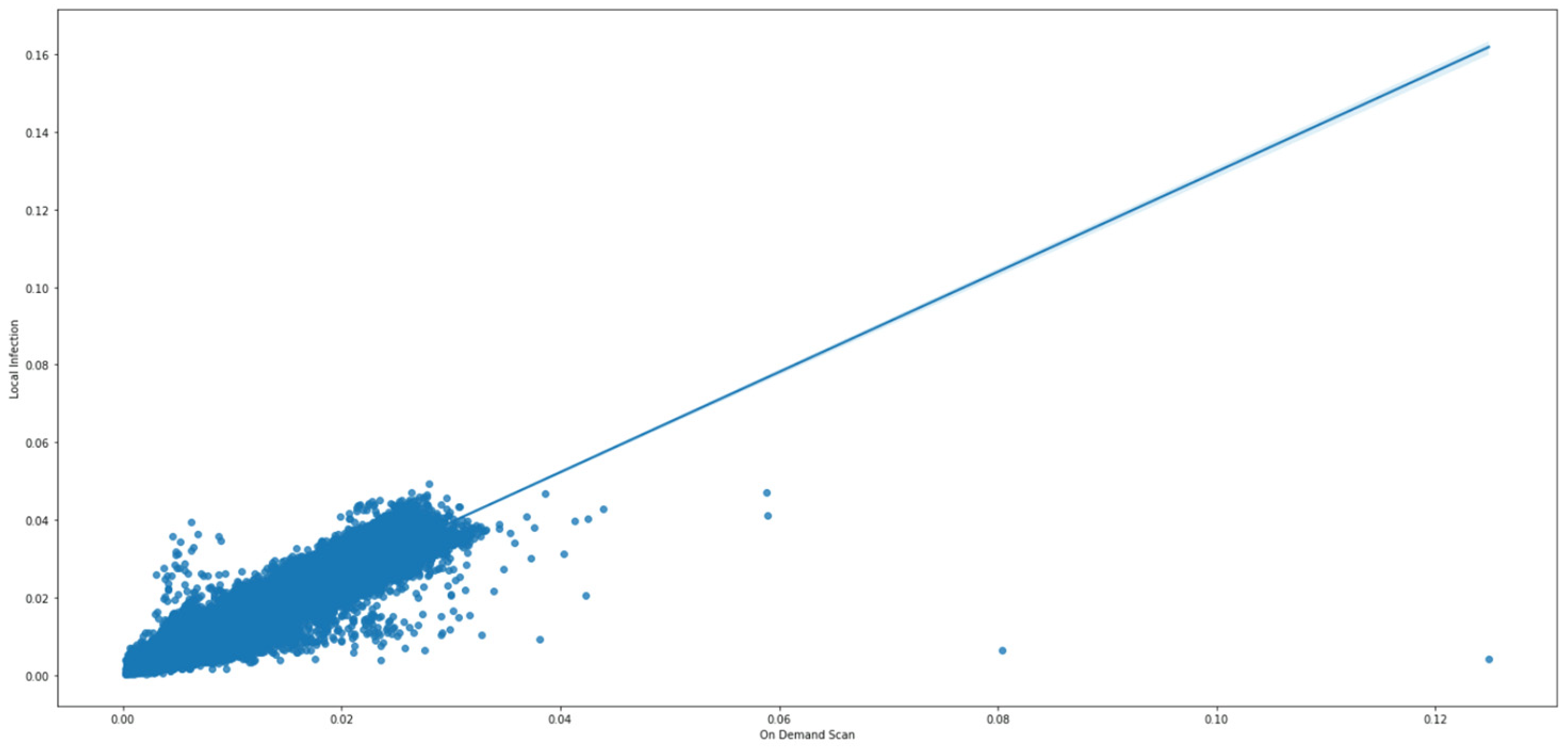
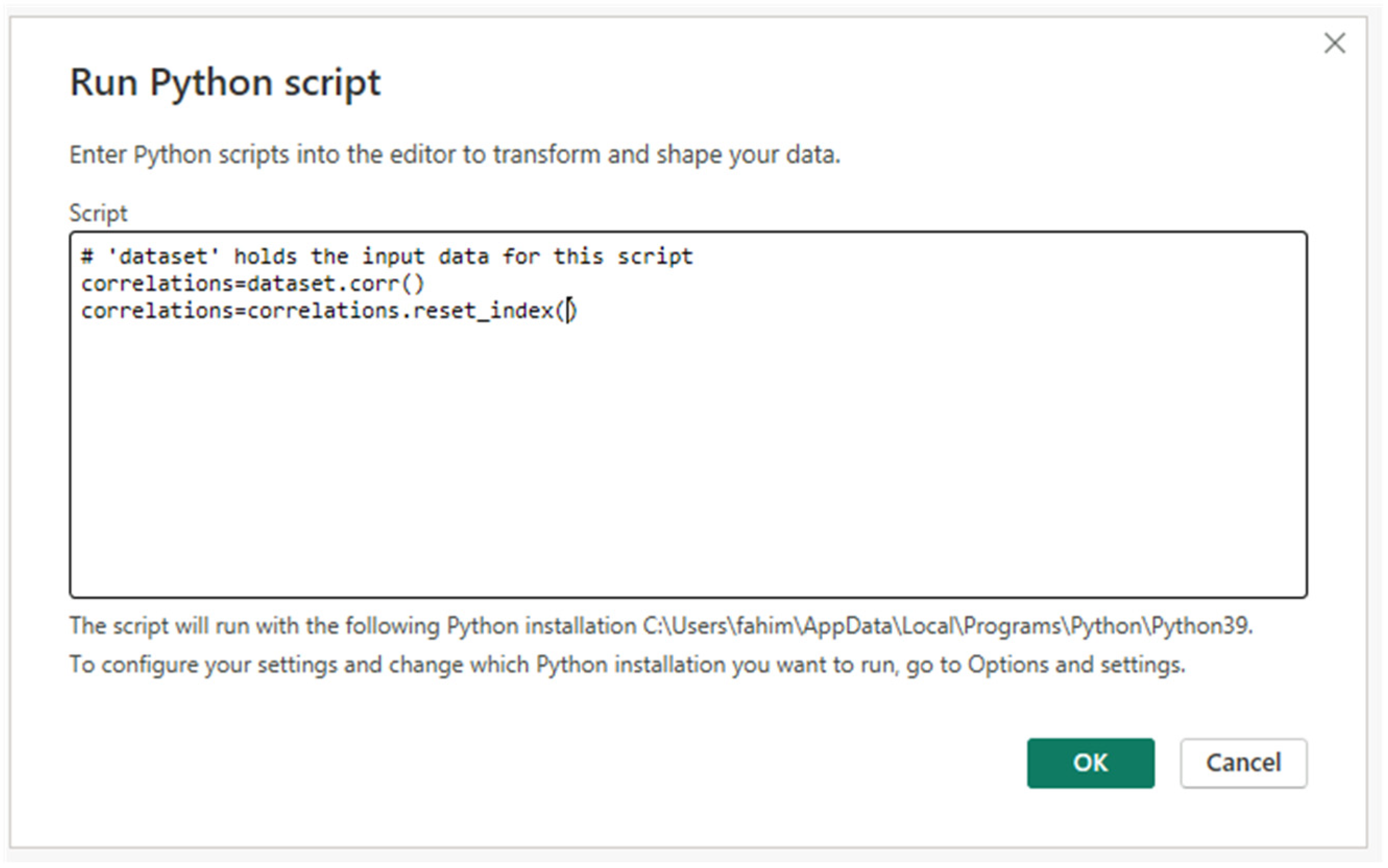
- Correlation and interdependency insights: We unveiled significant correlations between specific cyber-attack dimensions, particularly highlighting a notable correlation (coefficient of 0.93) between on-demand scan and local infection. Subsequent linear regression provided insights into their interdependency.
- Neural-network-based forecasting: We applied neural-network-based forecasting to predict temporal patterns of highly correlated cyber threat dimensions (on-demand scan and local infection), achieving a high level of predictive accuracy with mean squared error (MSE) and mean absolute percentage error (MAPE) values of 1.616 and 80.13, respectively.
- Practical applicability: We positioned the research within the realm of practical cybersecurity applications, offering valuable tools for risk assessment, strategic planning, and informed decision-making in the face of dynamic and evolving cyber threats.
2. Methods
2.1. Data Collection and Treatment
2.1.1. Automated Data Collection
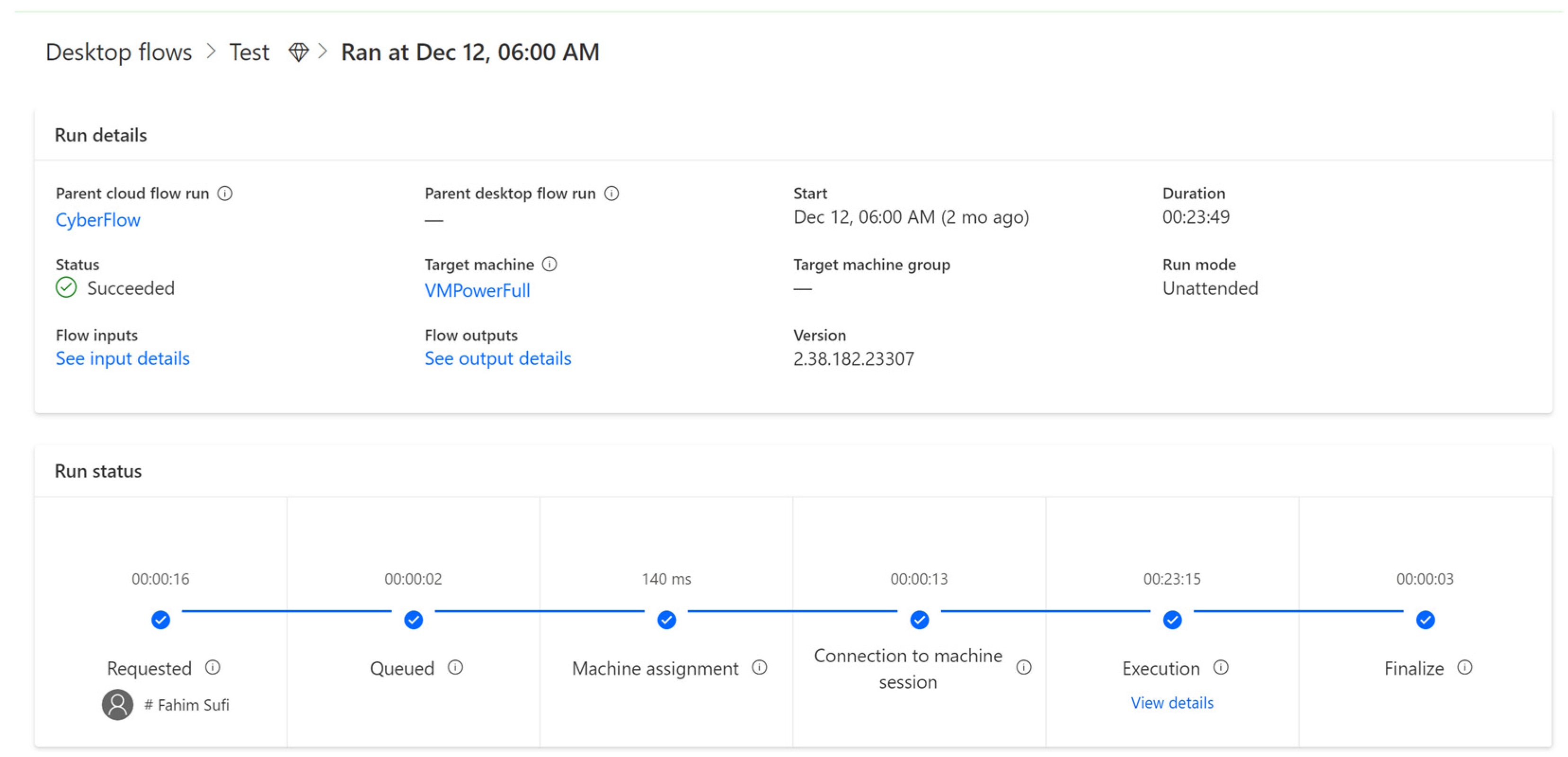
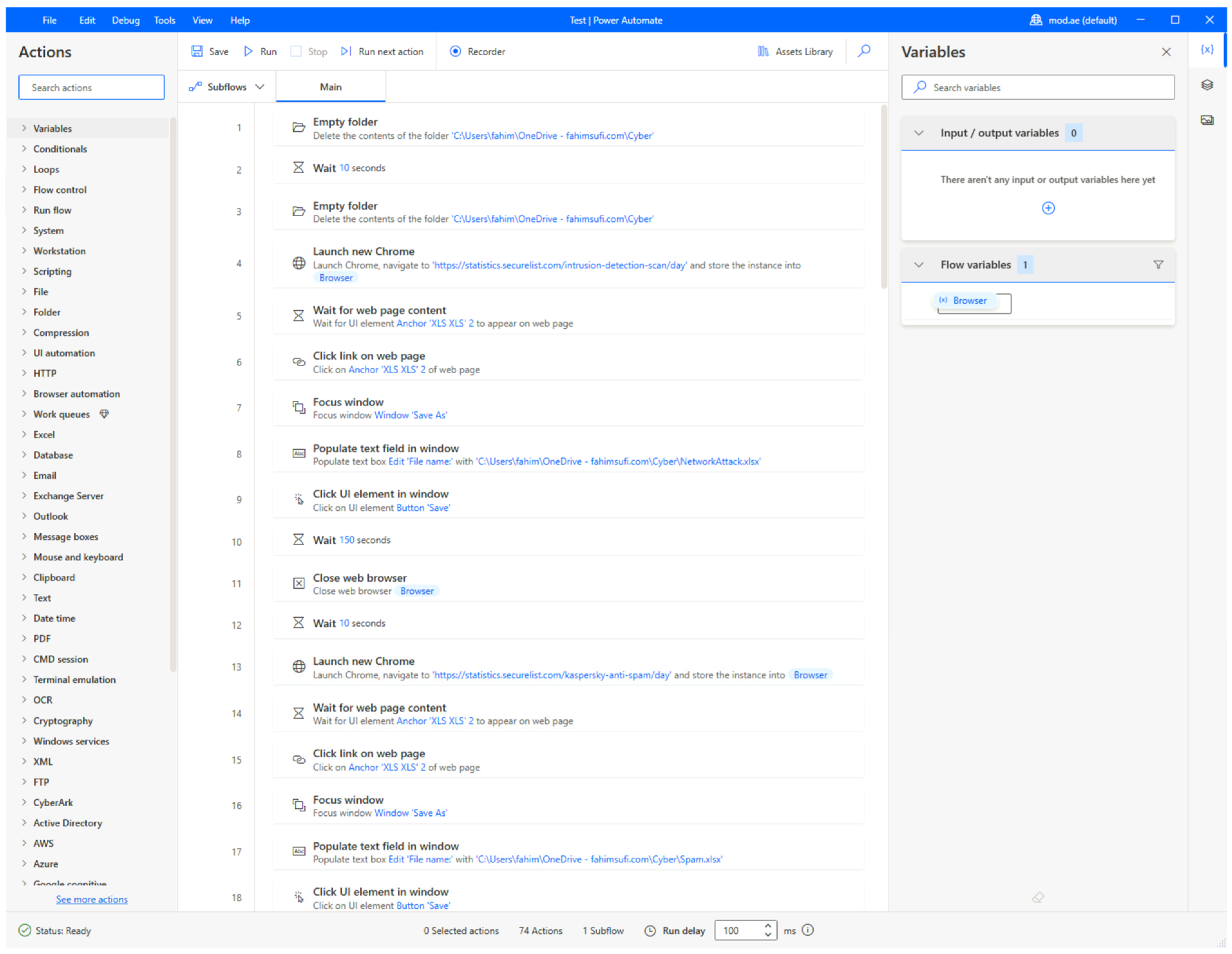
2.1.2. Robotic Process Automation
2.1.3. Data Storage and Integration
2.1.4. Data Manipulation and Analysis
2.2. Validation and Curation
- Automated process monitoring: The automated data collection process was closely monitored. It was noted that, for 17 days of the 14-month period, the process was interrupted due to essential updates required by the Azure Virtual Machine or Power Automate Desktop. These interruptions were promptly addressed to minimize data loss.
- Data integrity checks: Regular integrity checks were performed to ensure the accuracy and completeness of the data collected. This involved verifying the data against secondary sources and conducting random sample checks. It should be mentioned that the same methodology was implemented on another virtual machine for ensuring business continuity. In case of the unavailability of one virtual machine (due to maintenance or any other reasons), the other virtual machine would be automatically utilized.
2.3. Data Quality and Noise
- Noise reduction: Efforts were made to reduce noise and irrelevant information during the data collection phase. This was achieved through the careful configuration of the RPA scripts to selectively download relevant data.
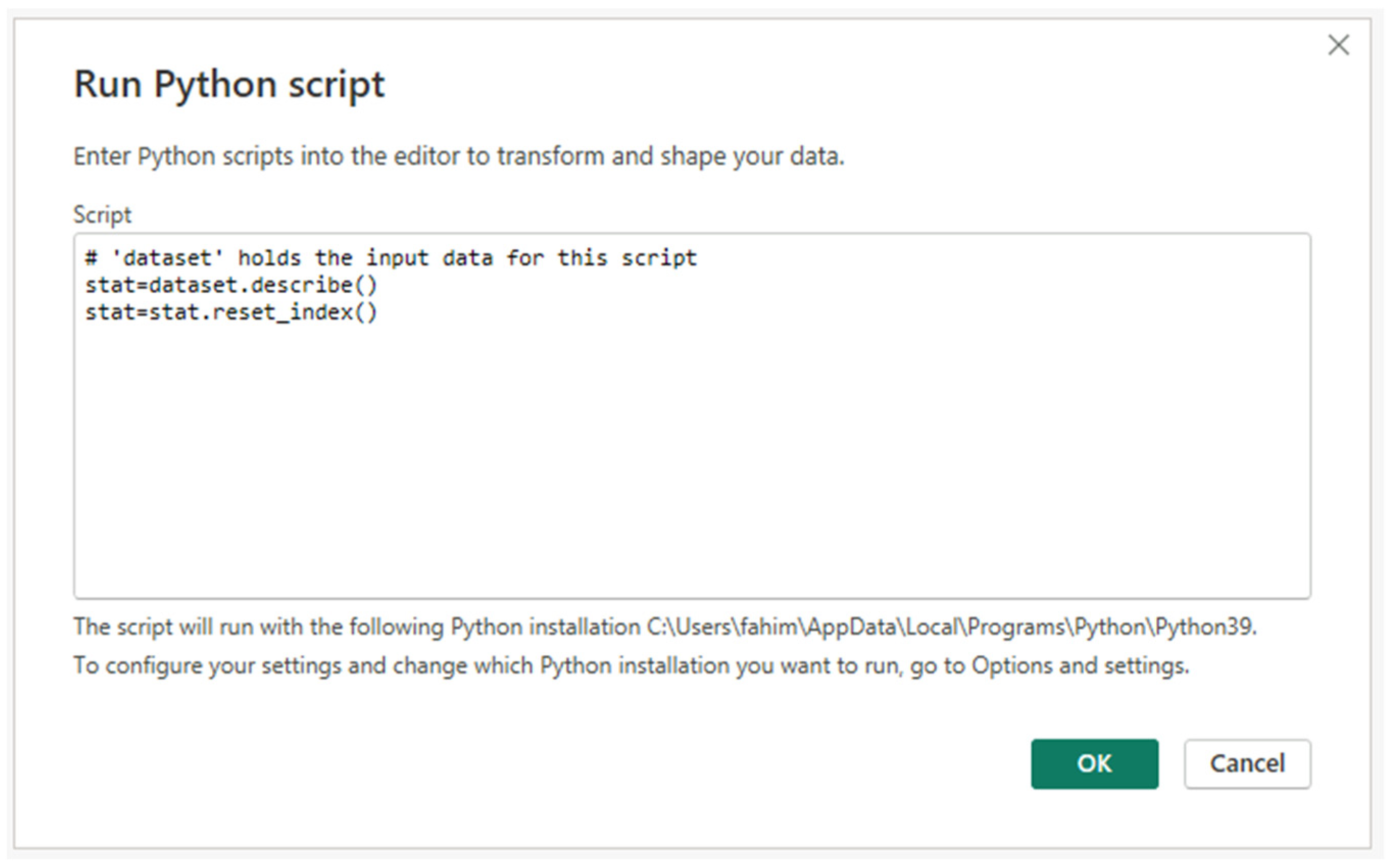
- Quality assurance and data cleaning: The quality of the data was maintained through rigorous validation protocols. In the data manipulation phase, Power BI was used to clean the dataset. This involved removing duplicates, correcting inconsistencies, and handling missing values, thereby enhancing the quality and usability of the dataset. For example, an automated script replaced the null values (as seen in Figure 5) with 0.
2.4. Data Analysis and Forecasting
- 1: A perfect positive correlation, meaning that, as one variable increases, the other variable also increases proportionally.
- 0: No correlation, indicating that there is no linear relationship between the variables.
- −1: A perfect negative correlation, signifying that, as one variable increases, the other variable decreases proportionally.
3. Results
- Attack date (date): Records the date of each cyber-attack. All 77,623 entries are valid, indicating a complete dataset with no missing dates (as shown in Table 3).
- Country (text): Specifies the country of the cyber-attack occurrence. All entries are valid, covering 225 countries, and provide a global perspective on cyber threats (as shown in Table 3).
- Spam (decimal): Records the percentage of spam-related attacks for a specific country on a particular day (percentage value in decimal). The sample data, as shown in Table 3, for spam is 0.01358, meaning that Bangladesh suffered 1.358% of spam attacks on that day. With 62,982 valid entries, the mean is 0.006094, and the standard deviation is 0.024337. The range is from a minimum of 0.000010 to a maximum of 0.302490. The 25th, 50th, and 75th percentiles are 0.000090, 0.000590, and 0.003530, respectively (as shown in Table 3 and Table 4).
- Ransomware (decimal): Records the percentage of ransomware related attacks for a specific country on a particular day. This consists of 52,144 valid entries (Table 3). As per Table 4, the average value is 0.000130, with a standard deviation of 0.000186. The range spans from 0.000010 to 0.009180. The percentiles are 0.000040 (25th), 0.000070 (50th), and 0.000140 (75th).
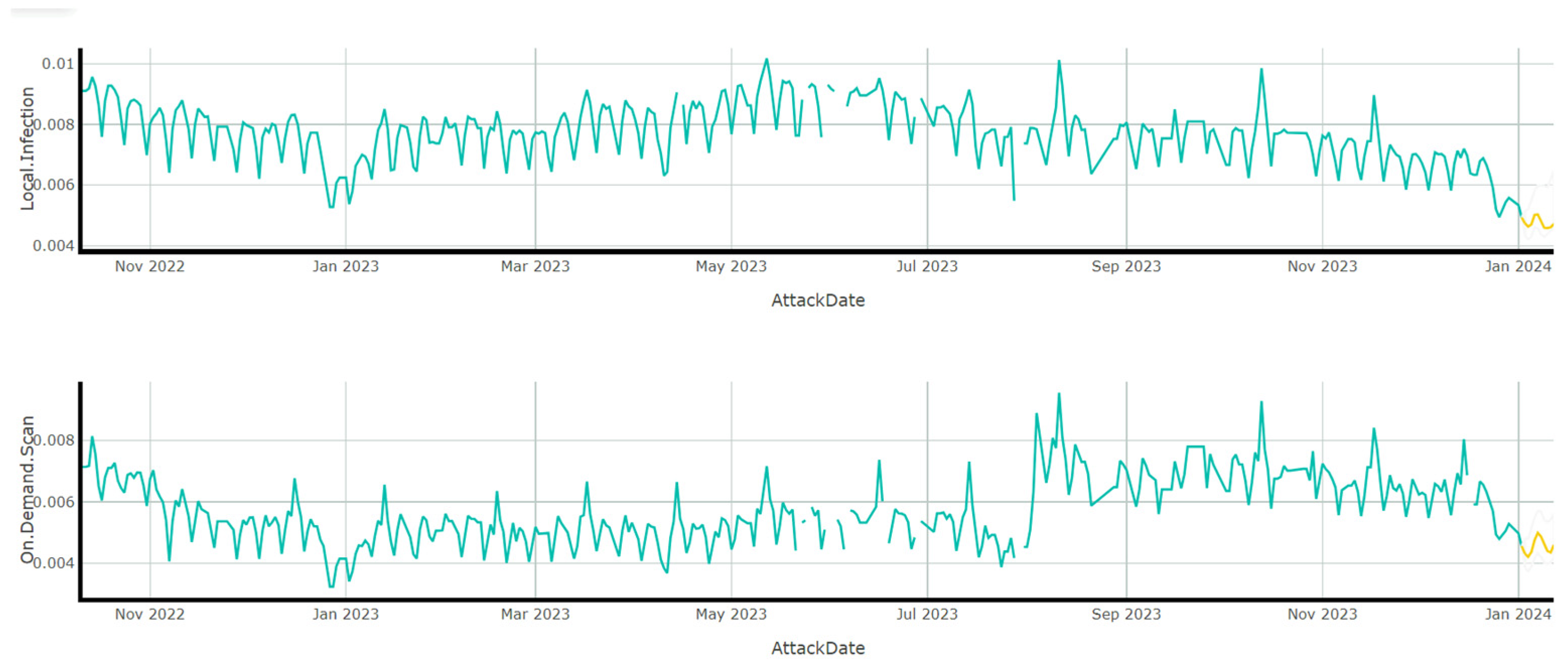
- Local infection (decimal): Records the percentage of local infections for a specific country on a particular day. With 74,469 entries, the mean is 0.013350, and the standard deviation is 0.008415. The values range from 0.000240 to 0.049370. The percentiles are 0.007150 (25th), 0.010790 (50th), and 0.017660 (75th) (detailed in Table 3 and Table 4).
- Exploit (decimal): Records the percentage of exploit-related attacks for a specific country on a particular day. Contains 64,264 valid entries. The mean is 0.000469, with a standard deviation of 0.000368. The range is from 0.000010 to 0.004660. The 25th, 50th, and 75th percentiles are 0.000210, 0.000390, and 0.000620, respectively (shown in Table 3 and Table 4).
- Malicious mail (decimal): Records the percentage of malicious-mail-related attacks for a specific country on a particular day. Comprises 69,184 entries. The mean is 0.001292, with a standard deviation of 0.001606. The range spans from 0.000010 to 0.043220. The percentiles are 0.000300 (25th), 0.000730 (50th), and 0.001690 (75th) (Table 3 and Table 4).
- Network attack (decimal): Records the percentage of network-attack-related incidents for a specific country on a particular day. With 71,532 entries, the average value is 0.002222, and the standard deviation is 0.003034. The range is from 0.000020 to 0.058260. The 25th, 50th, and 75th percentiles are 0.000700, 0.001290, and 0.002350, respectively (shown in Table 3 and Table 4).
- On-demand scan (decimal): Records the percentage of on-demand scans (by the anti-virus program) for a specific country on a particular day. This contains 74,231 valid entries. The mean is 0.009756, with a standard deviation of 0.006080. The minimum and maximum values are 0.000240 and 0.124880, respectively. The percentiles are 0.005210 (25th), 0.008140 (50th), and 0.012870 (75th) (detailed in Table 3 and Table 4).
- Web threat (decimal): Records the percentage of web-threat-related attacks for a specific country on a particular day. This comprises 73,892 entries. The mean value is 0.013006, with a standard deviation of 0.004943. The range spans from 0.000240 to 0.048630. The 25th, 50th, and 75th percentiles are 0.009700, 0.012570, and 0.015973, respectively (shown in Table 3 and Table 4).
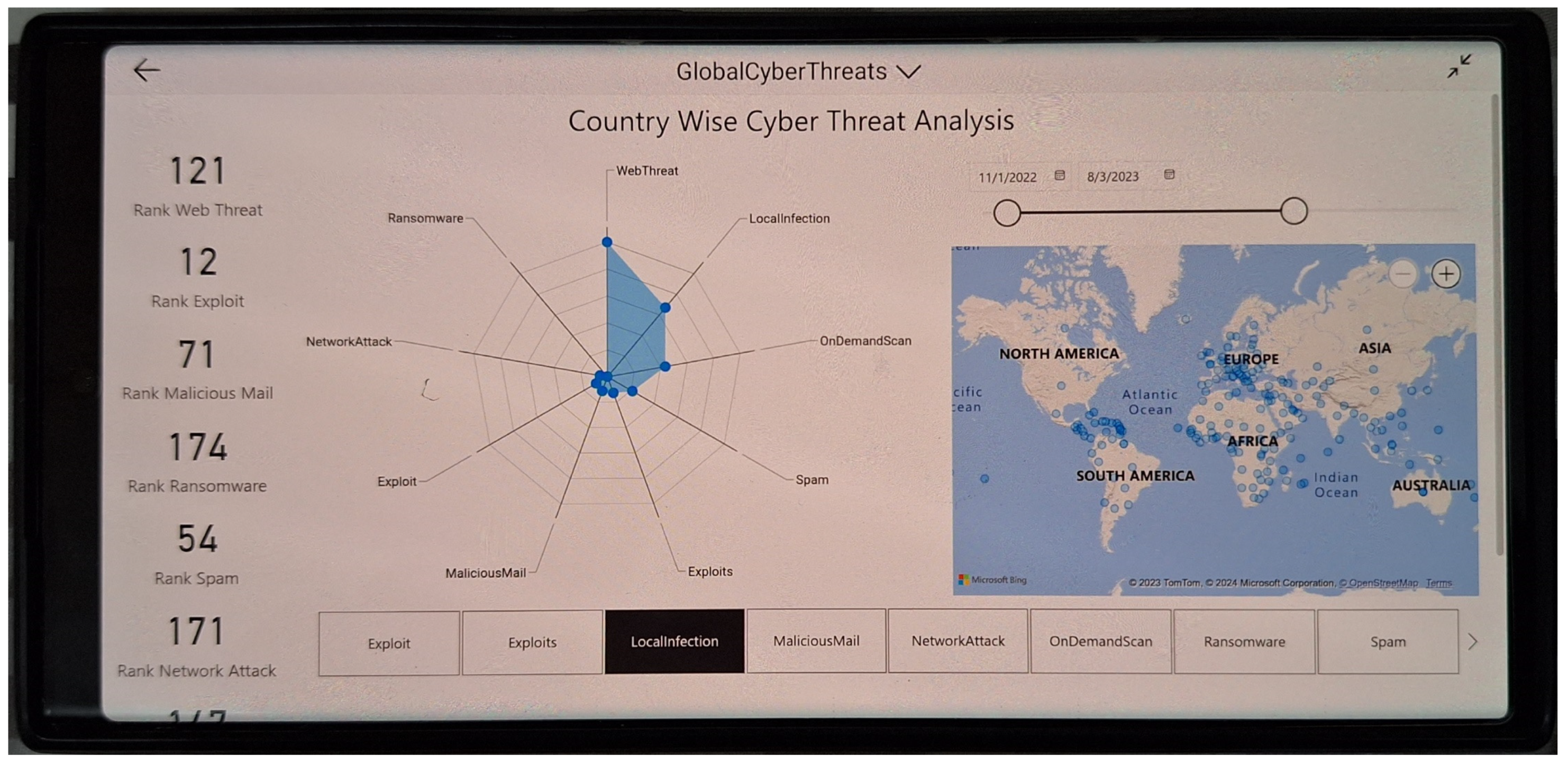
- 11–18. Rank fields (text): These fields (rank spam, rank ransomware, rank local infection, rank exploit, rank malicious mail, rank network attack, rank on-demand scan, and rank web threat) provide the world ranking of each country in the respective cyber-attack dimension. The rankings range from 1 to a maximum of 196, with the mean rankings varying slightly across different attack types. The standard deviation in these rankings indicates a moderate spread, reflecting the varying impact of cyber threats across different countries (as detailed in Table 3 and Table 4).
4. Discussion
4.1. Use of This Dataset
- Date format and chronological analysis: The ‘Attack-Date’ field is crucial for any time-series analysis. Users should ensure that their analytical tools correctly interpret the date format for accurate temporal analysis.
- Handling missing values: Fields such as spam, ransomware, and others contain empty entries, representing days with no recorded activities. Users should decide on their approach to handling these missing values based on their research objectives, i.e., whether to treat them as zeros, ignore them, or use imputation techniques.
- Statistical analysis: The dataset provides rich ground for statistical analysis, with fields showing varying degrees of standard deviation and range. Users should consider appropriate statistical methods to analyze these fields, keeping in mind the distribution characteristics like mean, median, percentiles, and range.
- Comparative and ranking analysis: The rank fields offer a unique opportunity for comparative analysis across countries and cyber-attack dimensions. Researchers interested in global or regional comparisons will find these fields particularly useful.
- Data visualization: Given the dataset’s complexity and breadth, effective visualization tools (like Microsoft Power BI used in its creation) are recommended for a more intuitive understanding of trends and patterns.
- Cross-referencing with external data: Users are encouraged to augment this dataset with external data sources for more comprehensive analysis (e.g., [15]). This could include socio-economic data, digital infrastructure metrics, or other relevant datasets.
- Ethical considerations: While the dataset does not contain personal data, users should still adhere to ethical guidelines in their analysis, particularly when publishing results or drawing conclusions that might influence public policy or perception.
- Updates and version control: Users should note that the dataset covers up to December 2023. Any developments in the cyber threat landscape post this period will not be reflected. Keeping track of dataset versions and updates is crucial for longitudinal studies.
- Collaboration and sharing findings: Users are encouraged to share their findings with the broader research community. Collaboration can lead to more robust insights and a deeper understanding of the global cyber threat landscape.
4.2. Performance Evaluation
4.3. Limitations of This Study
5. Conclusions
Supplementary Materials
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


| Algorithm A1 DAX Code for transposing the AttackType Column in Power BI |
| TransposedTable = ADDCOLUMNS ( SUMMARIZE ( DataverseCyberTable, DataverseCyberTable[Country], DataverseCyberTable[AttackDate] ), “Spam Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Spam” ), “Ransomware Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Ransomware” ), “Local Infection Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Local Infection” ), “Exploit Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Exploit” ), “Malicious Mail Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Malicious Mail” ), “Network Attack Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Network Attack” ), “On Demand Scan Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “On Demand Scan” ), “Web Threat Percentage”, CALCULATE ( MAX ( DataverseCyberTable[AttackPercentage] ), DataverseCyberTable[AttackType] = “Web Threat” ), “Rank Spam”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Spam” ), “Rank Ransomware”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Ransomware” ), “Rank Local Infection”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Local Infection” ), “Rank Exploit”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Exploit” ), “Rank Malicious Mail”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Malicious Mail” ), “Rank Network Attack”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Network Attack” ), “Rank On Demand Scan”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “On Demand Scan” ), “Rank Web Threat”, CALCULATE ( MAX ( DataverseCyberTable[Rank] ), DataverseCyberTable[AttackType] = “Web Threat” ) ) |
| Algorithm A2 Python code for linear regression |
| import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error # Assuming your dataset is stored in a variable named ‘data’ # Extracting relevant features for linear regression features = data[[‘local_infection_percentage’, ‘on_demand_scan_percentage’]] # Assuming ‘target_variable’ is the dependent variable you want to predict target_variable = data[‘target_variable’] # Splitting the dataset into training and testing sets X_train, X_test, y_train, y_test = train_test_split(features, target_variable, test_size = 0.2, random_state = 42) # Initializing the Linear Regression model linear_reg_model = LinearRegression() # Training the model linear_reg_model.fit(X_train, y_train) # Making predictions on the test set predictions = linear_reg_model.predict(X_test) # Calculating Mean Squared Error (MSE) for evaluation mse = mean_squared_error(y_test, predictions) print(f’Mean Squared Error (MSE): {mse}’) # Displaying the coefficients of the linear regression model coefficients = linear_reg_model.coef_ intercept = linear_reg_model.intercept_ print(f’Coefficients: {coefficients}’) print(f’Intercept: {intercept}’) |
| Algorithm A3 Python Code for forecasting using a neural network (predicting cyber-attacks for 10 days with a 0.8 confidence level) |
| # Importing the requisite libraries import pandas as pd from sklearn.neural_network import MLPRegressor from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # Reading the dataset into a Pandas DataFrame data = pd.read_csv(“your_dataset.csv”) # Replace “your_dataset.csv” with the actual file path # Filtering data for the illustrious country of Australia australia_data = data[data[‘country’] == ‘Australia’] # Extracting relevant features for forecasting features = australia_data[[‘local_infection_percentage’, ‘on_demand_scan_percentage’]] # Extracting the target variable target = australia_data[‘date’] # Assuming ‘date’ is the target variable, please replace it accordingly # Splitting the dataset into training and testing sets X_train, X_test, y_train, y_test = train_test_split(features, target, test_size = 0.2, random_state = 42) # Standardizing the features for optimal neural network performance scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Initializing the Neural Network model model = MLPRegressor(hidden_layer_sizes = (100, 50), max_iter = 1000, random_state = 42) # Training the model model.fit(X_train_scaled, y_train) # Forecasting for the next 10 days with a confidence level of 0.8 forecasted_dates = pd.date_range(start = data[‘date’].max(), periods = 10, freq = ‘D’) forecasted_features = scaler.transform(your_forecasting_data) # Replace with your own forecasting data forecasted_results = model.predict(forecasted_features) # Displaying the comprehensive results forecasted_data = pd.DataFrame({‘date’: forecasted_dates, ‘forecasted_result’: forecasted_results}) print(forecasted_data) |
| Algorithm A4 Python code for the evaluation of performance with MSE and MAPE |
| from sklearn.metrics import mean_squared_error import numpy as np # Assuming you have the actual values for the next 10 days in a variable named ‘actual_values’ actual_values = np.array([your_actual_values]) # Replace with your actual values # Predicting the values for the next 10 days using the trained model predicted_values = model.predict(forecasted_features) # Calculating Mean Squared Error (MSE) mse = mean_squared_error(actual_values, predicted_values) print(f’Mean Squared Error (MSE): {mse}’) # Calculating Mean Absolute Percentage Error (MAPE) mape = np.mean(np.abs((actual_values—predicted_values)/actual_values)) * 100 print(f’Mean Absolute Percentage Error (MAPE): {mape}%’) |
References
- Cremer, F.; Sheehan, B.; Fortmann, M.; Kia, A.N.; Mullins, M.; Murphy, F.; Materne, S. Cyber risk and cybersecurity: A systematic review of data availability. Geneva Pap. Risk Insur.-Issues Pract. 2022, 47, 698–736. [Google Scholar] [CrossRef] [PubMed]
- Cybercrime Magazine. Cybercrime to Cost the World $10.5 Trillion Annually by 2025. 2020. Available online: https://cybersecurityventures.com/hackerpocalypse-cybercrime-report-2016/ (accessed on 15 October 2022).
- Bada, J.R.N.M. Chapter 4—The social and psychological impact of cyberattacks. In Emerging Cyber Threats and Cognitive Vulnerabilities; Academic Press: Cambridge, MA, USA, 2020; pp. 73–92. [Google Scholar]
- Kaspersky. Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/ (accessed on 3 August 2023).
- Kaspersky. Daily Spam Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/kaspersky-anti-spam/day (accessed on 11 November 2023).
- Kaspersky. Daily Ransomware Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/ransomware/day (accessed on 11 November 2023).
- Kaspersky. Daily Local Infections Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/on-access-scan/day (accessed on 3 August 2023).
- Kaspersky. Daily Exploit Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/vulnerability-scan/day (accessed on 11 November 2023).
- Kaspersky. Daily Mailicious Mail Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/mail-anti-virus/day (accessed on 3 August 2023).
- Kaspersky. Daily Network Attack Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/intrusion-detection-scan/day (accessed on 3 August 2023).
- Kaspersky. Daily On-Demand Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/on-demand-scan/day (accessed on 3 August 2023).
- Kaspersky. Day Web Threat Cyber Threat Statistics. 2023. Available online: https://statistics.securelist.com/web-anti-virus/day (accessed on 11 November 2023).
- Sufi, F. A global cyber-threat intelligence system with artificial intelligence and convolutional neural network. Decis. Anal. J. 2023, 9, 100364. [Google Scholar] [CrossRef]
- Sufi, F. Novel Application of Open-Source Cyber Intelligence. Electronics 2023, 12, 3610. [Google Scholar] [CrossRef]
- Sufi, F. A New AI-Based Semantic Cyber Intelligence Agent. Future Internet 2023, 15, 231. [Google Scholar] [CrossRef]
- Sufi, F. Algorithms in Low-Code-No-Code for Research Applications: A Practical Review. Algorithms 2023, 16, 108. [Google Scholar] [CrossRef]
- Lalou, M.; Kheddouci, H.; Hariri, S. Identifying the Cyber Attack Origin with Partial Observation: A Linear Regression Based Approach. In Proceedings of the IEEE 2nd International Workshops on Foundations and Applications of Self* Systems (FAS*W), Tucson, AZ, USA, 18–22 September 2017. [Google Scholar]
- Cai, F.; Ozdagli, A.; Koutsoukos, X. Variational Autoencoder for Classification and Regression for Out-of-Distribution Detection in Learning-Enabled Cyber-Physical Systems. Appl. Artif. Intell. 2022, 36, 2131056. [Google Scholar] [CrossRef]
- Ghafouri, A.; Vorobeychik, Y.; Koutsoukos, X. Adversarial Regression for Detecting Attacks in Cyber-Physical Systems. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Albasheer, H.; Siraj, M.M.; Mubarakali, A. Cyber-Attack Prediction Based on Network Intrusion Detection Systems for Alert Correlation Techniques: A Survey. Sensors 2022, 22, 1494. [Google Scholar] [CrossRef]
- Pires, S.; Mascarenhas, C. Cyber Threat Analysis Using Pearson and Spearman Correlation via Exploratory Data Analysis. In Proceedings of the Third International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 5 May 2023. [Google Scholar]
- Werner, G.; Yang, S.; McConky, K. Time Series Forecasting of Cyber A‚ack Intensity. In Proceedings of the Cyber and Information Security Research (CISR) Conference, Oak Ridge, TN, USA, 4–6 April 2017. [Google Scholar]
- Bakdash, J.Z.; Hutchinson, S.; Zaroukian, E.G.; Marusich, L.R.; Thirumuruganathan, S.; Sample, C.; Hoffman, B.; Das, G. Malware in the future? Forecasting of analyst detection of cyber events. J. Cybersecur. 2018, 4, tyy007. [Google Scholar] [CrossRef]
- Husák, M.; Komárková, J.; Bou-Harb, E.; Celeda, P. Survey of Attack Projection, Prediction, and Forecasting in Cyber Security. IEEE Commun. Surv. Tutor. 2018, 21, 640–660. [Google Scholar] [CrossRef]
- Aflaki, A.; Gitizadeh, M.; Kantarci, B. Accuracy improvement of electrical load forecasting against new cyber-attack architectures. Sustain. Cities Soc. 2022, 77, 103523. [Google Scholar] [CrossRef]
- Alrahmani, Z.A.; Elleithy, K. DDoS Attack Forecasting Using Transformers. In Proceedings of the IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Abu Dhabi, United Arab Emirates, 14 November 2023. [Google Scholar]
- Choi, C.; Shin, S.; Shin, C. Performance evaluation method of cyber attack behaviour forecasting based on mitigation. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20 October 2021. [Google Scholar]
- Alrawi, O.; Ike, M.; Pruett, M.; Kasturi, R.P.; Barua, S.; Hirani, T.; Hill, B.; Saltaformaggio, B. Forecasting Malware Capabilities From Cyber Attack Memory Images. In Proceedings of the 30th Usenix Security Symposium, Vancouver, BC, Canada, 11–13 August 2021. [Google Scholar]
- Qasaimeh, M.; Hammour, R.A.; Yassein, M.B.; Al-Qassas, R.S.; Torralbo, J.A.L.; Lizcano, D. Advanced security testing using a cyber-attack forecastingmodel: A case study of financial institutions. J. Softw. Evol. Process 2022, 34, e2489. [Google Scholar] [CrossRef]
- Microsoft Power Automate Documentation. 2021. Available online: https://docs.microsoft.com/en-us/power-automate/ (accessed on 29 August 2021).
- Serverless Notes. Use Wait for Image Action When Trying to Locate Objects. Available online: https://www.serverlessnotes.com/docs/wait-for-image-action-power-automate-desktop (accessed on 12 February 2024).
- Microsoft Learn. Use AI Builder in Power Automate. 2023. Available online: https://learn.microsoft.com/en-us/power-automate/use-ai-builder (accessed on 12 February 2024).
- Microsoft Learn. OCR Actions. 2022. Available online: https://learn.microsoft.com/en-us/power-automate/desktop-flows/actions-reference/ocr (accessed on 12 February 2024).
- Microsoft Dataverse. 2022. Available online: https://powerplatform.microsoft.com/en-us/dataverse/ (accessed on 25 October 2022).
- Microsoft. Microsoft Power BI Documentation. 2022. Available online: https://docs.microsoft.com/en-us/power-bi/ (accessed on 21 March 2022).
- Xu, S.; Qian, Y.; Hu, R.Q. Data-Driven Network Intelligence for Anomaly Detection. IEEE Netw. 2019, 33, 88–95. [Google Scholar] [CrossRef]
- Keshk, M.; Sitnikova, E.; Moustafa, N.; Hu, J.; Khalil, I. An Integrated Framework for Privacy-Preserving Based Anomaly Detection for Cyber-Physical Systems. IEEE Trans. Sustain. Comput. 2021, 6, 66–79. [Google Scholar] [CrossRef]
- Shi, D.; Guo, Z.; Johansson, K.H.; Shi, L. Causality Countermeasures for Anomaly Detection in Cyber-Physical Systems. IEEE Trans. Autom. Control 2018, 63, 386–401. [Google Scholar] [CrossRef]
- Bartolomei, S.M.; Sweet, A.L. A note on a comparison of exponential smoothing methods for forecasting seasonal series. Int. J. Forecast. 1989, 5, 111–116. [Google Scholar] [CrossRef]
- Zhang, G. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, R.; Li, Z.; Li, J.; Ge, Y.; Wa, S.; Huang, S.; Lv, C. Time-Series Neural Network: A High-Accuracy Time-Series Forecasting Method Based on Kernel Filter and Time Attention. Information 2023, 14, 500. [Google Scholar] [CrossRef]
- Interactive Chaos. Forecast Using Neural Network by MAQ Software. Available online: https://interactivechaos.com/es/powerbi/visual/forecast-using-neural-network-maq-software (accessed on 11 November 2023).
- Bitdefender. Bitdefencer Cyberthreat Real-Time Map. Available online: https://threatmap.bitdefender.com/ (accessed on 12 February 2024).
- Fortinet. Fortinet Live Threatmap. Available online: https://threatmap.fortiguard.com/ (accessed on 12 February 2024).
- Kaspersky. Cyber Threat Real-Time Map. Available online: https://cybermap.kaspersky.com/ (accessed on 12 February 2024).
- Radware. Radware Live Threat Map. Available online: https://livethreatmap.radware.com/ (accessed on 12 February 2024).
- Check Point. Check Point Live Cyber Threat Map. Available online: https://threatmap.checkpoint.com/ (accessed on 12 February 2024).
- Kim, N.; Lee, S.; Cho, H.; Kim, B.-I.; Jun, M. Design of a Cyber Threat Information Collection System for Cyber Attack Correlation. In Proceedings of the International Conference on Platform Technology and Service (PlatCon), Jeju, Republic of Korea, 29–31 January 2018. [Google Scholar]
- Maosa, H.; Ouazzane, K.; Sowinski-Mydlarz, V. Real-Time Cyber Analytics Data Collection Framework. Int. J. Inf. Secur. Priv. (IJISP) 2022, 16, 1–10. [Google Scholar] [CrossRef]
- Milenkovic, D.Z. Cyber Security and Data Collection. Secur. Sci. J. 2023, 4, 102–118. [Google Scholar] [CrossRef]
- Doenhoff, J.; Tamura, Y.; Tsuji, D.; Shigemoto, T. Data collection method for security digital twin on cyber physical systems. IEICE Commun. Express 2022, 11, 829–834. [Google Scholar] [CrossRef]
- Koloveas, P.; Chantzios, T.; Alevizopoulou, S.; Skiadopoulos, S.; Tryfonopoulos, C. INTIME: A Machine Learning-Based Framework for Gathering and Leveraging Web Data to Cyber-Threat Intelligence. Electronics 2021, 10, 818. [Google Scholar] [CrossRef]
- Simmons, C.; Ellis, C.; Shiva, S.; Dasgupta, D.; Wu, Q. AVOIDIT: A Cyber Attack Taxonomy; CTIT Technical Reports Series; University of Twente: Enschede, The Netherlands, 2009. [Google Scholar]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Start Date | End Date | Day | Public Release with Data Descriptors | Correlation Analysis | Regression Analysis | Neural-Network-Based Forecasting |
|---|---|---|---|---|---|---|---|
| [13] | 11 October 2022 | 31 October 2022 | 21 | No | No | No | No |
| [16] | 11 October 2022 | 25 December 2022 | 76 | No | No | No | No |
| [15] | 11 October 2022 | 6 April 2023 | 178 | No | No | No | No |
| [14] | 11 October 2022 | 12 July 2023 | 275 | No | No | No | No |
| This | 11 October 2022 | 11 December 2023 | 427 | Yes | Yes | Yes | Yes |
| Technology Component | Automate Data Acquisition | Correlation | Regression | Neural-Network-Based Forecasting | Deployment in iOS, Android, and Windows Devices |
|---|---|---|---|---|---|
| Microsoft Power Automate Desktop | ⚫ | ||||
| Microsoft Power Automate Cloud Flow | ⚫ | ||||
| Microsoft One Drive | ⚫ | ||||
| Microsoft Dataverse | ⚫ | ||||
| Microsoft Power BI Desktop | ⚫ | ⚫ | ⚫ | ⚫ | |
| Python on Power BI | ⚫ | ⚫ | ⚫ | ⚫ | |
| Microsoft Power BI Service | ⚫ |
| Field Name | Data Type | Valid # | Valid % | Error # | Error % | Empty # | Empty % | Sample Data |
|---|---|---|---|---|---|---|---|---|
| Attack date | Date | 77,623 | 100% | 0 | 0% | 0 | 0% | 25 April 2023 |
| Country | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | Bangladesh |
| Spam | Decimal | 62,982 | 81% | 0 | 0% | 14,641 | 19% | 0.01358 |
| ransomware | Decimal | 52,144 | 67% | 0 | 0% | 25,479 | 33% | 0.00025 |
| Local infection | Decimal | 74,469 | 96% | 0 | 0% | 3154 | 4% | 0.00726 |
| Exploit | Decimal | 64,264 | 83% | 0 | 0% | 13,359 | 17% | 0.00021 |
| Malicious mail | Decimal | 69,184 | 89% | 0 | 0% | 8439 | 11% | 0.00019 |
| Network attack | Decimal | 71,532 | 92% | 0 | 0% | 6091 | 8% | 0.00076 |
| On-demand scan | Decimal | 74,231 | 96% | 0 | 0% | 3392 | 4% | 0.00445 |
| Web threat | Decimal | 73,892 | 95% | 0 | 0% | 3731 | 5% | 0.01116 |
| Rank spam | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 34 |
| Rank ransomware | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 6 |
| Rank local infection | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 100 |
| Rank exploit | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 108 |
| Rank malicious mail | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 56 |
| Rank network attack | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 94 |
| Rank on-demand scan | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 109 |
| Rank web threat | Text | 77,623 | 100% | 0 | 0% | 0 | 0% | 109 |
| Index | Spam | Ransomware | Local Infection | Exploit | Malicious Mail | Network Attack | On-Demand Scan | Web Threat |
|---|---|---|---|---|---|---|---|---|
| min | 0.00001 | 0.00001 | 0.00024 | 0.00001 | 0.00001 | 0.00002 | 0.00024 | 0.00024 |
| 25% | 0.00009 | 0.00004 | 0.00715 | 0.00021 | 0.0003 | 0.0007 | 0.00521 | 0.0097 |
| 50% | 0.00059 | 0.00007 | 0.01079 | 0.00039 | 0.00073 | 0.00129 | 0.00814 | 0.01257 |
| 75% | 0.00353 | 0.00014 | 0.01766 | 0.00062 | 0.00169 | 0.00235 | 0.01287 | 0.015973 |
| max | 0.30249 | 0.00918 | 0.04937 | 0.00466 | 0.04322 | 0.05826 | 0.12488 | 0.04863 |
| mean | 0.006094 | 0.00013 | 0.01335 | 0.000469 | 0.001292 | 0.002222 | 0.009756 | 0.013006 |
| std | 0.024337 | 0.000186 | 0.008415 | 0.000368 | 0.001606 | 0.003034 | 0.00608 | 0.004943 |
| count | 62,982 | 52,144 | 74,469 | 64,264 | 69,184 | 71,532 | 74,231 | 73,892 |
| Index | Rank Spam | Rank Ransomware | Rank Local Infection | Rank Exploit | Rank Malicious Mail | Rank Network Attack | Rank On-Demand Scan | Rank Web Threat |
|---|---|---|---|---|---|---|---|---|
| min | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 25% | 48 | 41 | 47 | 38 | 48 | 48 | 47 | 46 |
| 50% | 98 | 88 | 98 | 90 | 98 | 98 | 97 | 97 |
| 75% | 144 | 131 | 148 | 144 | 147 | 148 | 148 | 148 |
| max | 186 | 158 | 196 | 188 | 194 | 192 | 196 | 196 |
| mean | 94.53299 | 84.00165 | 97.73 | 90.46 | 96.80494 | 97.76224 | 97.42858 | 96.97435 |
| std | 52.67272 | 48.97654 | 58.05 | 58.98 | 55.90629 | 56.90058 | 58.17745 | 58.45481 |
| count | 77,623 | 77,623 | 77,623 | 77,623 | 77,623 | 77,623 | 77,623 | 77,623 |
| Country | Attack Type | MSE | MAPE (%) |
|---|---|---|---|
| Australia | Local infection | 1.45 | 79.2% |
| Australia | On-demand scan | 1.85 | 88.4% |
| New Zealand | Local infection | 1.72 | 83.1% |
| New Zealand | On-demand scan | 1.55 | 81.3% |
| Saudi Arabia | Local infection | 1.32 | 71.7% |
| Saudi Arabia | On-demand scan | 1.39 | 72% |
| UAE | Local infection | 1.68 | 80.3% |
| UAE | On-demand scan | 1.71 | 82.9% |
| Qatar | Local infection | 1.66 | 78.5% |
| Qatar | On-demand scan | 1.73 | 83.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sufi, F. A New Time Series Dataset for Cyber-Threat Correlation, Regression and Neural-Network-Based Forecasting. Information 2024, 15, 199. https://doi.org/10.3390/info15040199
Sufi F. A New Time Series Dataset for Cyber-Threat Correlation, Regression and Neural-Network-Based Forecasting. Information. 2024; 15(4):199. https://doi.org/10.3390/info15040199
Chicago/Turabian StyleSufi, Fahim. 2024. "A New Time Series Dataset for Cyber-Threat Correlation, Regression and Neural-Network-Based Forecasting" Information 15, no. 4: 199. https://doi.org/10.3390/info15040199
APA StyleSufi, F. (2024). A New Time Series Dataset for Cyber-Threat Correlation, Regression and Neural-Network-Based Forecasting. Information, 15(4), 199. https://doi.org/10.3390/info15040199