
There Are Infinite Ways to Formulate Code: How to Mitigate the Resulting Problems for Better Software Vulnerability Detection †



Abstract
:1. Introduction
2. Related Work
3. Mitigating the Infinity and Randomness
3.1. Feasibility Analysis
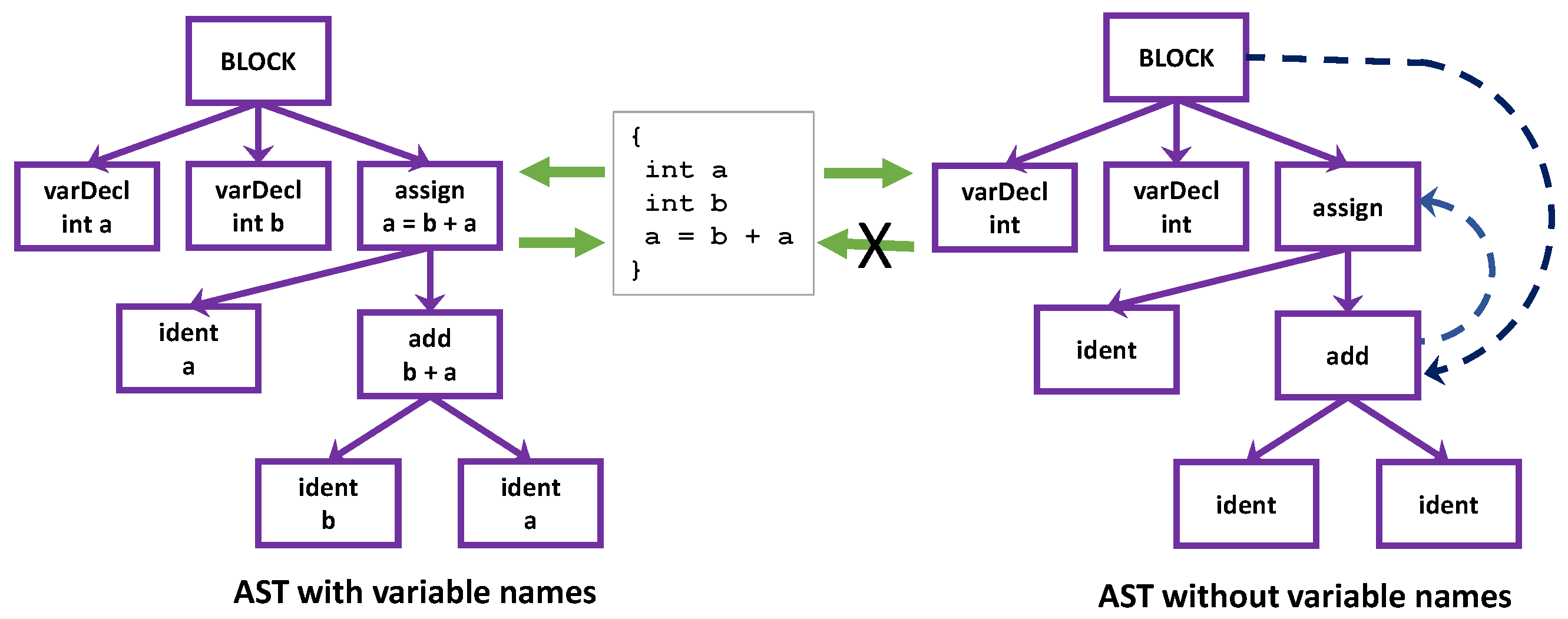
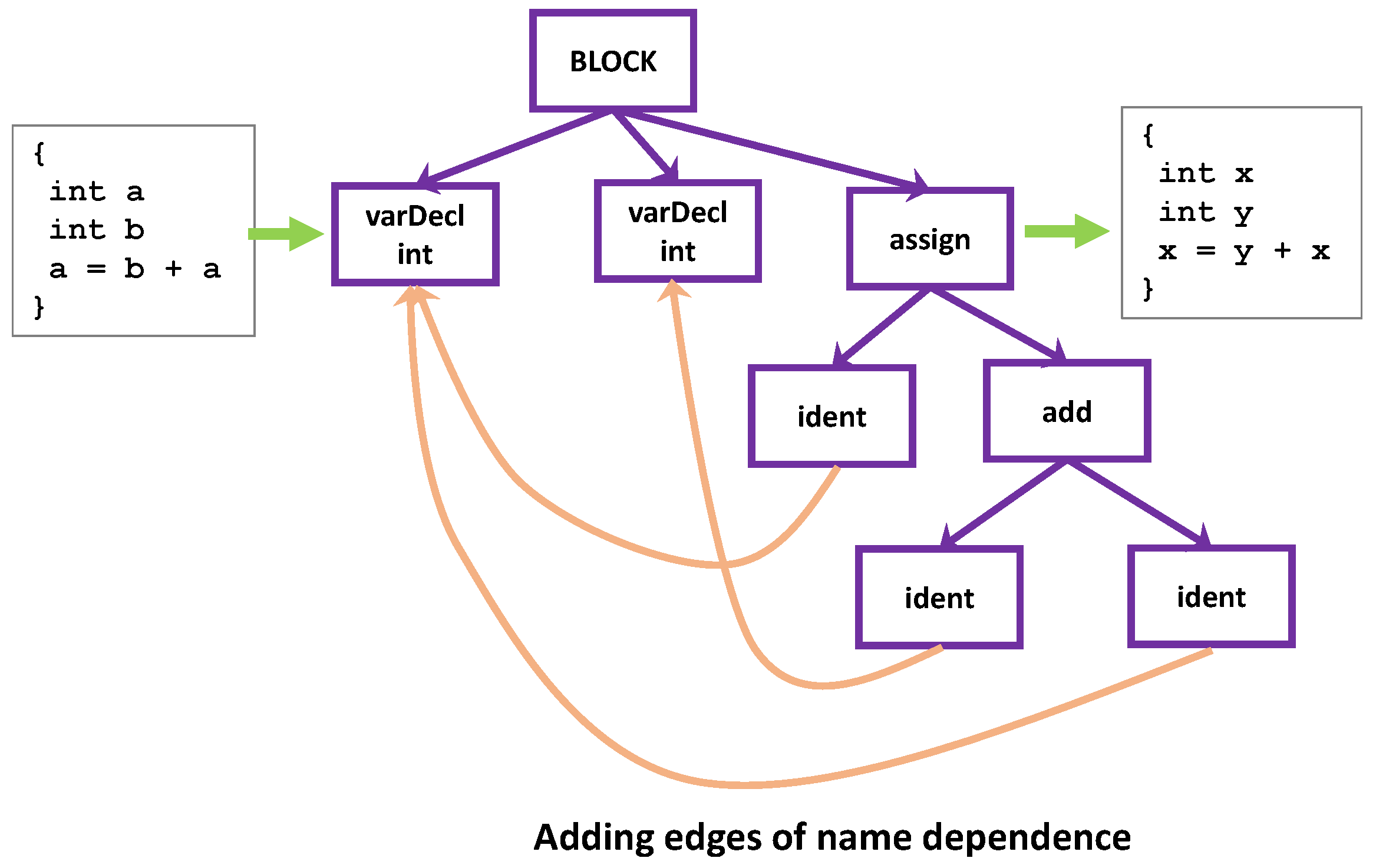
3.2. Name Dependence for Removing Variables
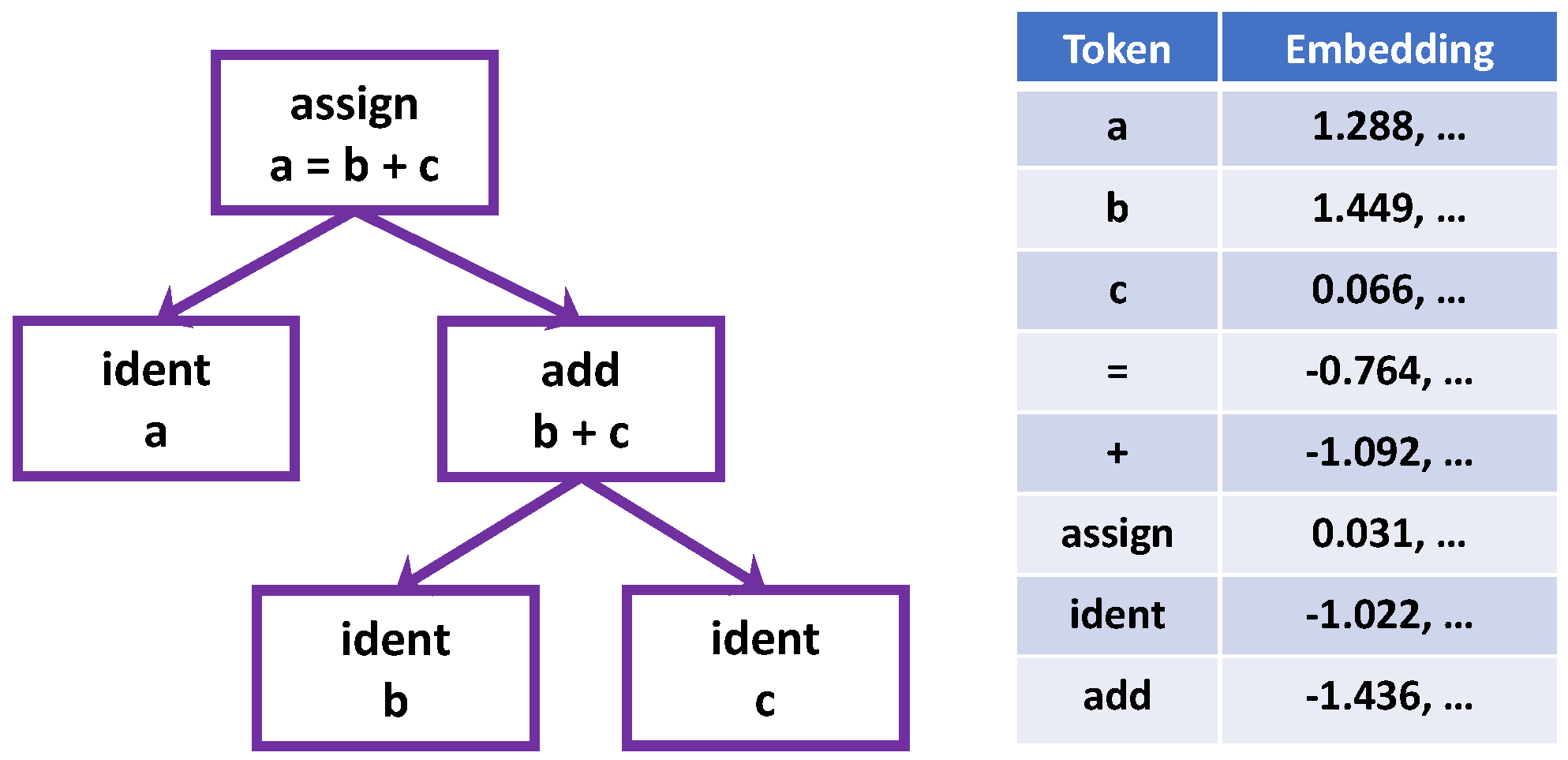
3.3. Property-Based Node Encoding Scheme
4. Evaluation
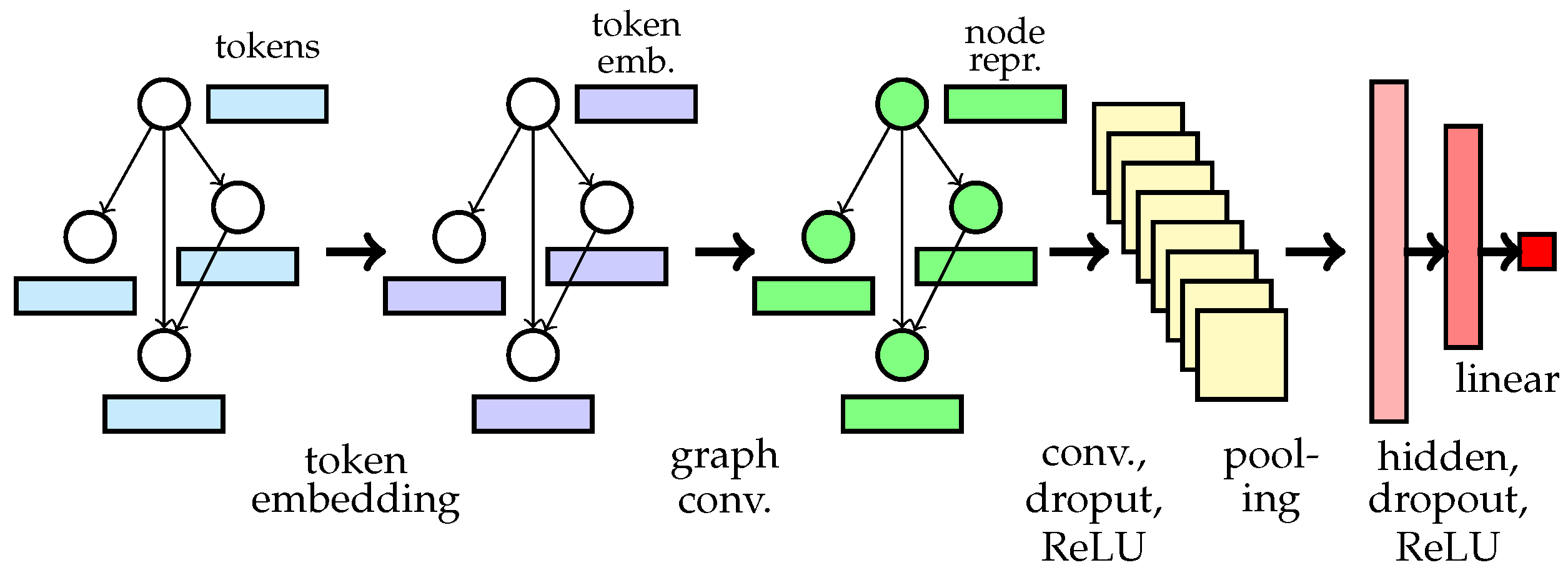
4.1. Models
4.2. Datasets
4.3. Prediction Performance
4.3.1. Best Performances
4.3.2. Average Performances
4.3.3. Basic Graph Structures vs. Extended Ones
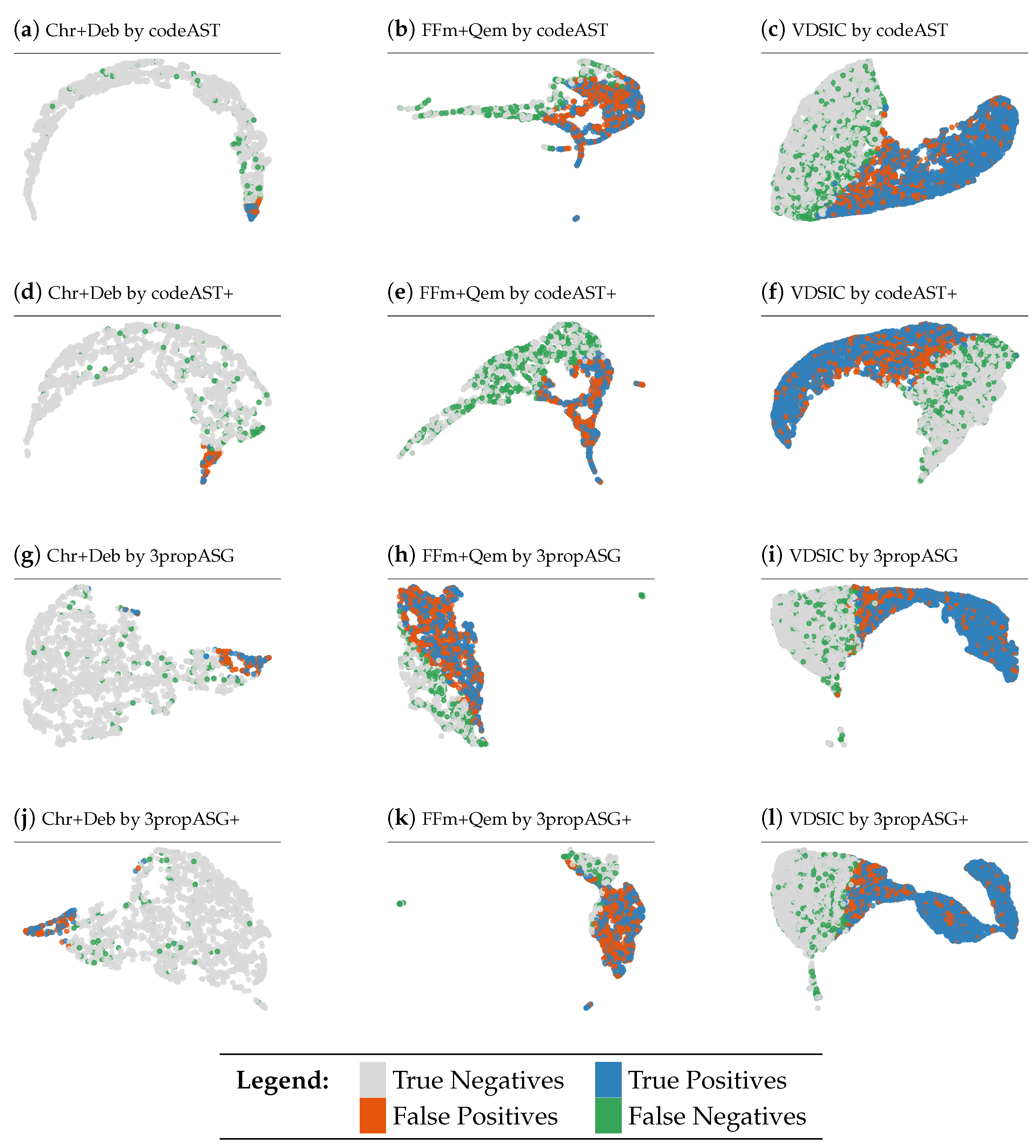
4.4. Quality, Representation and Separability
4.5. Memory Footprint
| 3-property encoding: | |
| code-based encoding: | |
| code-based/3-property: | = |
4.6. Alleviating Vocabulary Explosion
5. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brooks, T.N. Survey of automated vulnerability detection and exploit generation techniques in cyber reasoning systems. In Proceedings of the Science and Information Conference, Semarang, Indonesia, 7–8 August 2018; pp. 1083–1102. [Google Scholar]
- Henzinger, T.A.; Jhala, R.; Majumdar, R.; Sutre, G. Software verification with BLAST. In Proceedings of the Workshop on Model Checking of Software, Portland, OR, USA, 9–10 May 2003; pp. 235–239. [Google Scholar]
- Böhme, M.; Pham, V.T.; Roychoudhury, A. Coverage-based greybox fuzzing as markov chain. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1032–1043. [Google Scholar]
- Stephens, N.; Grosen, J.; Salls, C.; Dutcher, A.; Wang, R.; Corbetta, J.; Shoshitaishvili, Y.; Kruegel, C.; Vigna, G. Driller: Augmenting fuzzing through selective symbolic execution. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016; pp. 1–16. [Google Scholar]
- Johnson, B.; Song, Y.; Murphy-Hill, E.; Bowdidge, R. Why don’t software developers use static analysis tools to find bugs? In Proceedings of the 2013 35th International Conference on Software Engineering (ICSE), San Francisco, CA, USA, 18–26 May 2013; pp. 672–681. [Google Scholar]
- Smith, J.; Johnson, B.; Murphy-Hill, E.; Chu, B.; Lipford, H.R. Questions developers ask while diagnosing potential security vulnerabilities with static analysis. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August–4 September 2015; pp. 248–259. [Google Scholar]
- Ayewah, N.; Pugh, W.; Morgenthaler, J.D.; Penix, J.; Zhou, Y. Evaluating static analysis defect warnings on production software. In Proceedings of the 7th Acm Sigplan-Sigsoft Workshop on Program Analysis for Software Tools and Engineering, San Diego, CA, USA, 13–14 June 2007; pp. 1–8. [Google Scholar]
- Newsome, J.; Song, D.X. Dynamic taint analysis for automatic detection, analysis, and signaturegeneration of exploits on commodity software. Proc. Ndss. Citeseer 2005, 5, 3–4. [Google Scholar]
- Liu, B.; Shi, L.; Cai, Z.; Li, M. Software vulnerability discovery techniques: A survey. In Proceedings of the 2012 Fourth International Conference on Multimedia Information Networking and Security, Nanjing, China, 2–4 November 2012; pp. 152–156. [Google Scholar]
- Chakraborty, S.; Krishna, R.; Ding, Y.; Ray, B. Deep learning based vulnerability detection: Are we there yet. IEEE Trans. Softw. Eng. 2021, 48, 3280–3296. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Dahl, G.; Ranzato, M.; Mohamed, A.R.; Hinton, G.E. Phone recognition with the mean-covariance restricted Boltzmann machine. Adv. Neural Inf. Process. Syst. 2010, 23, 1–9. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated vulnerability detection in source code using deep representation learning. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 757–762. [Google Scholar]
- Dam, H.K.; Tran, T.; Pham, T.; Ng, S.W.; Grundy, J.; Ghose, A. Automatic feature learning for vulnerability prediction. arXiv 2017, arXiv:1708.02368. [Google Scholar]
- Zou, D.; Wang, S.; Xu, S.; Li, Z.; Jin, H. VulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2224–2236. [Google Scholar]
- Prömel, H.J. Complete disorder is impossible: The mathematical work of Walter Deuber. Comb. Probab. Comput. 2005, 14, 3–16. [Google Scholar] [CrossRef]
- Graham, R.L.; Rothschild, B.L.; Spencer, J.H. Ramsey Theory; John Wiley & Sons: Hoboken, NJ, USA, 1991; Volume 20. [Google Scholar]
- Groppe, J.; Groppe, S.; Möller, R. Variables are a Curse in Software Vulnerability Prediction. In Proceedings of the 34th International Conference on Database and Expert Systems Applications (DEXA 2023), Penang, Malaysia, 28–30 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–6. [Google Scholar]
- Wang, S.; Liu, T.; Tan, L. Automatically learning semantic features for defect prediction. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; pp. 297–308. [Google Scholar]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; Xiang, Y.; De Vel, O.; Montague, P. Cross-project transfer representation learning for vulnerable function discovery. IEEE Trans. Ind. Inform. 2018, 14, 3289–3297. [Google Scholar] [CrossRef]
- Pradel, M.; Sen, K. Deepbugs: A learning approach to name-based bug detection. Proc. ACM Program. Lang. 2018, 2, 1–25. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and Evaluating Contextual Embedding of Source Code. arXiv 2020, arXiv:2001.00059. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. Graphcodebert: Pre-training code representations with data flow. arXiv 2020, arXiv:2009.08366. [Google Scholar]
- Wang, X.; Wang, Y.; Mi, F.; Zhou, P.; Wan, Y.; Liu, X.; Li, L.; Wu, H.; Liu, J.; Jiang, X. Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation. arXiv 2021, arXiv:2108.04556. [Google Scholar]
- Du, Q.; Kuang, X.; Zhao, G. Code Vulnerability Detection via Nearest Neighbor Mechanism. In Proceedings of the Findings of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. Sysevr: A framework for using deep learning to detect software vulnerabilities. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2244–2258. [Google Scholar] [CrossRef]
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and Discovering Vulnerabilities with Code Property Graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 590–604. [Google Scholar]
- Yamaguchi, F.; Maier, A.; Gascon, H.; Rieck, K. Automatic inference of search patterns for taint-style vulnerabilities. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 797–812. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast graph representation learning with PyTorch Geometric. arXiv 2019, arXiv:1903.02428. [Google Scholar]
- Wang, M.; Zheng, D.; Ye, Z.; Gan, Q.; Li, M.; Song, X.; Zhou, J.; Ma, C.; Yu, L.; Gai, Y.; et al. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv 2019, arXiv:1909.01315. [Google Scholar]
- Ehrig, H.; Rozenberg, G.; Kreowski, H.J. Handbook of Graph Grammars and Computing by Graph Transformation; World Scientific: London, UK, 1999; Volume 3. [Google Scholar]
- Garner, R. An abstract view on syntax with sharing. J. Log. Comput. 2012, 22, 1427–1452. [Google Scholar] [CrossRef]
- Wang, Y.; Li, H. Code completion by modeling flattened abstract syntax trees as graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 8 February 2021; pp. 14015–14023. [Google Scholar]
- Fowler, M. Refactoring: Improving the Design of Existing Code; Addison-Wesley Professional: Boston, MA, USA, 2018. [Google Scholar]
- Raghavan, S.; Rohana, R.; Leon, D.; Podgurski, A.; Augustine, V. Dex: A semantic-graph differencing tool for studying changes in large code bases. In Proceedings of the 20th IEEE International Conference on Software Maintenance, Chicago, IL, USA, 11–17 September 2004; pp. 188–197. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Fukushima, K. Cognitron: A self-organizing multilayered neural network. Biol. Cybern. 1975, 20, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Groppe, J.; Schlichting, R.; Groppe, S.; Möller, R. Deep Learning-based Classification of Customer Communications of a German Utility Company. In Lecture Notes in Electrical Engineering; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–16. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 3-prop. Encoding With Variable Names | 3-prop. Encoding Without Variable Names | |||||
|---|---|---|---|---|---|---|
| Construct | Class | Name | Type | Class | Name | Type |
| int x | varDecl | x | int | varDecl | - | int |
| if (x ≥ 0) | control | if | - | control | if | - |
| x·0.05 | mathOp | mul | - | mathOp | mul | - |
| fputs(x, stdout) | call | fputs | - | call | fputs | - |
| x | ident | x | int | ident | var | int |
| stdout | ident | stdout | - | ident | stdout | - |
| {…} | block | - | - | block | - | - |
| 0.05 | literal | 0.05 | float | literal | - | float |
| ‘Hello’ | literal | ‘Hello’ | str | literal | - | str |
| char[6] y | varDecl | y | char[6] | varDecl | - | char[N] |
| Dataset | Total- Bad, Good | 80% for Training- Bad, Good |
|---|---|---|
| Chromium+Debian | 754 (7.05%), 9945 (92.95%) | 592 (6.92%), 7967 (93.08%) |
| FFmpeg+Quemu | 5865 (43.68%), 7563 (56.32%) | 4687 (43.63%), 6055 (56.37%) |
| VDISC | 31,723 (46.38%), 36,675 (53.62%) | 25,304 (46.24%), 29,414 (53.76%) |
| Model | Graph | Encoding | Acc | Prec | Recall | F1 | AUC | |
|---|---|---|---|---|---|---|---|---|
| codeAST | AST | code | with best F1 aver. of 10 trainings | 92.01 | 44.58 | 22.84 | 30.20 | 60.26 |
| 92.4 | 10.34 | 2.9 | 4.14 | 51.32 | ||||
| 3propASG | ASG | 3-prop. | with best F1 aver. of 10 trainings | 92.34 | 49.26 | 41.36 | 44.97 | 68.93 |
| 92.52 | 46.87 | 24.75 | 31.88 | 61.41 | ||||
| codeAST+ | AST+ | code | with best F1 aver. of 10 trainings | 90.89 | 33.66 | 20.99 | 25.86 | 58.80 |
| 92.28 | 15.14 | 3.83 | 5.36 | 51.68 | ||||
| 3propASG+ | ASG+ | 3-prop. | with best F1 aver. of 10 trainings | 92.34 | 49.25 | 40.74 | 44.59 | 68.65 |
| 92.41 | 34.93 | 18.09 | 23.35 | 58.29 |
| Model | Graph | Encoding | Acc | Prec | Recall | F1 | AUC | |
|---|---|---|---|---|---|---|---|---|
| codeAST | AST | code | with best F1 aver. of 10 trainings | 55.36 | 49.35 | 67.49 | 57.01 | 56.69 |
| 58.14 | 51.32 | 35.07 | 37.61 | 55.61 | ||||
| 3propASG | ASG | 3-prop | with best F1 aver. of 10 trainings | 60.35 | 53.43 | 74.70 | 62.30 | 61.92 |
| 59.71 | 53.64 | 64.91 | 57.67 | 60.28 | ||||
| codeAST+ | AST+ | code | with best F1 aver. of 10 trainings | 58.38 | 53.27 | 41.51 | 46.66 | 56.53 |
| 58.03 | 52.94 | 18.37 | 25.04 | 53.7 | ||||
| 3propASG+ | ASG+ | 3-prop | with best F1 aver. of 10 trainings | 57.04 | 50.62 | 83.36 | 62.99 | 59.92 |
| 58.9 | 52.76 | 65.49 | 56.85 | 59.62 |
| Model | Graph | Encoding | Acc | Prec | Recall | F1 | AUC | |
|---|---|---|---|---|---|---|---|---|
| codeAST | AST | code | with best F1 aver. of 10 trainings | 77.82 | 78.2 | 73.11 | 75.57 | 77.55 |
| 77.0 | 78.3 | 70.63 | 74.22 | 76.63 | ||||
| 3prorASG | ASG | 3-prop | with best F1 aver. of 10 trainings | 81.27 | 80.62 | 79.11 | 79.86 | 81.15 |
| 80.81 | 79.68 | 79.36 | 79.51 | 80.73 | ||||
| codeAST+ | AST+ | code | with best F1 aver. of 10 trainings | 75.67 | 73.32 | 75.7 | 74.49 | 75.67 |
| 74.88 | 74.36 | 71.1 | 72.61 | 74.66 | ||||
| 3propASG+ | ASG+ | 3-prop | with best F1 aver. of 10 trainings | 80.94 | 79.85 | 79.4 | 79.63 | 80.85 |
| 80.25 | 78.24 | 80.39 | 79.26 | 80.26 |
| Code ID | #Nodes | #Tokens | Code-Based | 3-prop. | Code-Based /3-prop. |
|---|---|---|---|---|---|
| -6552851419396579257 | 4409 | 33,659 | 59 G | 5.3 M | 11,220 |
| 2388171415474875762 | 7012 | 54,157 | 152 G | 8.4 M | 18,052 |
| 5045872831385413038 | 12,077 | 96,805 | 468 G | 14.5 M | 32,268 |
| Dataset | Code-Based | 3-prop. | 3-prop./Code-Based |
|---|---|---|---|
| Chromium+Debian | 57,027 | 35,416 | 62.10% |
| FFmpeg+Qume | 66,791 | 45,795 | 68.56% |
| VDSIC | 449,148 | 312,948 | 69.68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Groppe, J.; Groppe, S.; Senf, D.; Möller, R. There Are Infinite Ways to Formulate Code: How to Mitigate the Resulting Problems for Better Software Vulnerability Detection. Information 2024, 15, 216. https://doi.org/10.3390/info15040216
Groppe J, Groppe S, Senf D, Möller R. There Are Infinite Ways to Formulate Code: How to Mitigate the Resulting Problems for Better Software Vulnerability Detection. Information. 2024; 15(4):216. https://doi.org/10.3390/info15040216
Chicago/Turabian StyleGroppe, Jinghua, Sven Groppe, Daniel Senf, and Ralf Möller. 2024. "There Are Infinite Ways to Formulate Code: How to Mitigate the Resulting Problems for Better Software Vulnerability Detection" Information 15, no. 4: 216. https://doi.org/10.3390/info15040216
APA StyleGroppe, J., Groppe, S., Senf, D., & Möller, R. (2024). There Are Infinite Ways to Formulate Code: How to Mitigate the Resulting Problems for Better Software Vulnerability Detection. Information, 15(4), 216. https://doi.org/10.3390/info15040216