

Time Series Forecasting with Missing Data Using Generative Adversarial Networks and Bayesian Inference


Abstract
1. Introduction
- Data Quality: High-quality data, free from errors and inconsistencies, is essential for reliable forecasts.
- Method Selection: The choice of an appropriate forecasting method hinges on the characteristics of the time series data. For instance, stationary data are often well-suited for ARIMA (Autoregressive Integrated Moving Average) models. In contrast, non-stationary data may necessitate more advanced techniques. Additionally, nonlinear neural network models can be effective for complex time series.
- Incorporation of External Factors: Often, relevant external factors, like weather patterns or economic trends, can significantly influence future values. Including these factors in the forecasting model can improve its accuracy.
2. Time Series Forecasting with Missing Data Using Neural Networks
2.1. Neural Networks for Time Series Forecasting
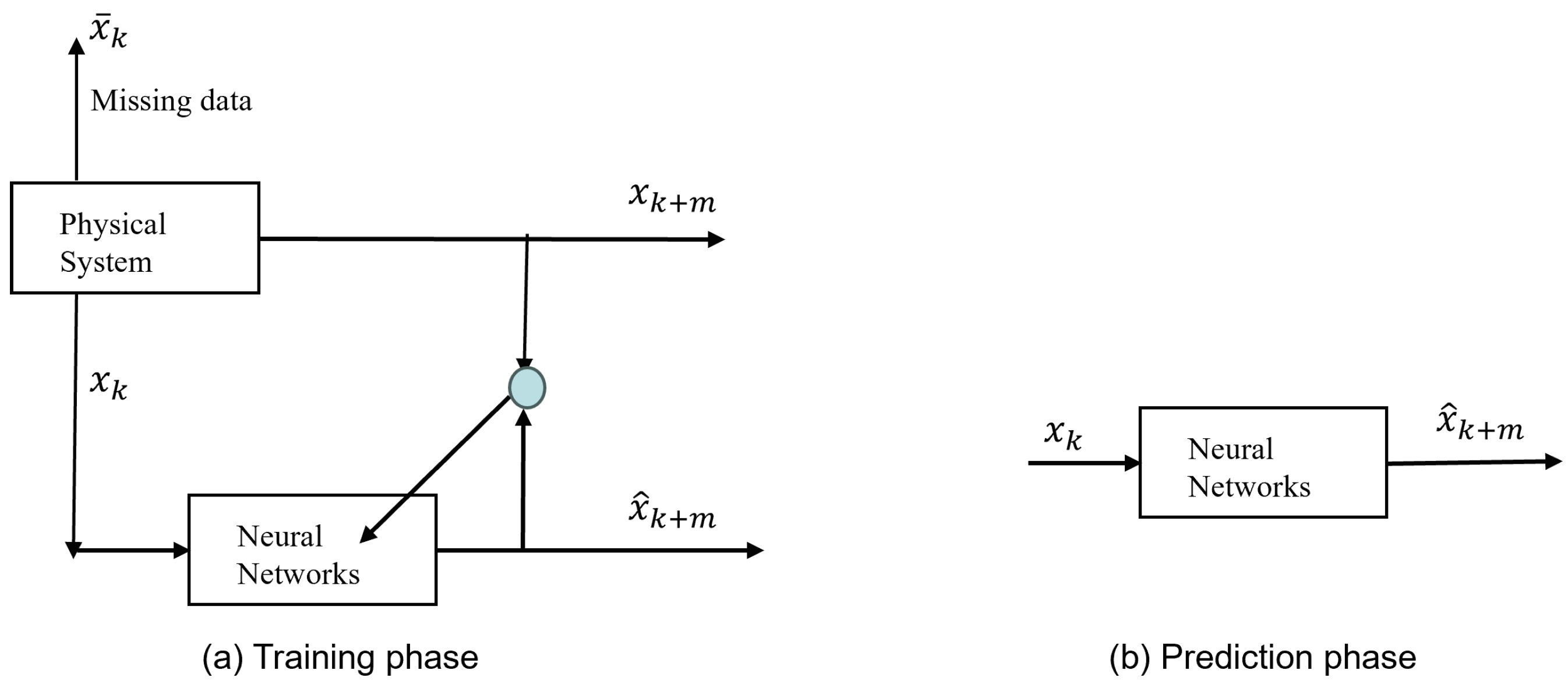
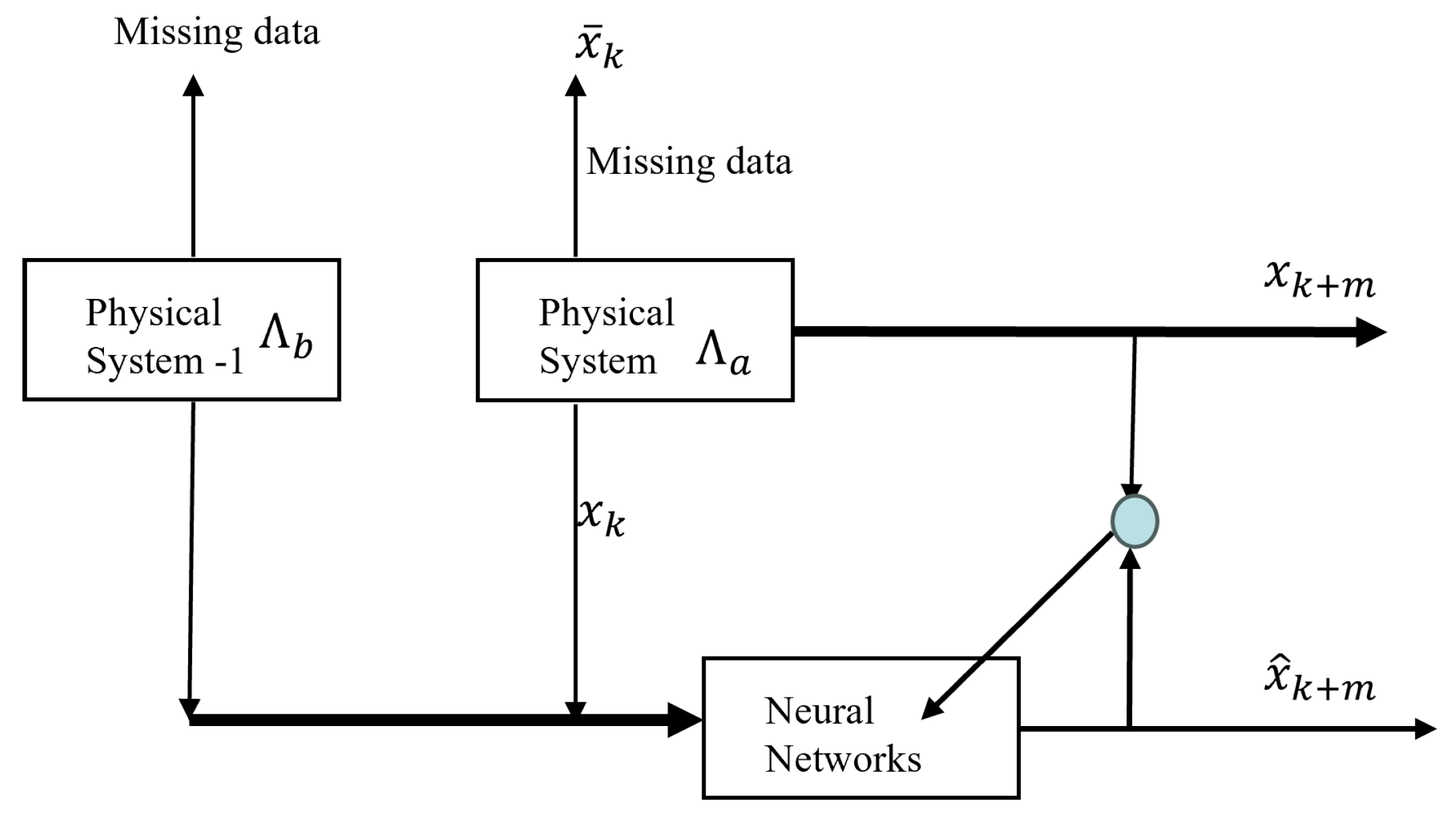
2.2. Neural Networks Training with Missing Data
- Joint Training: Train model directly using both datasets {,}.
- Pre-training and Fine-tuning: Pre-train with the complete data ; then, fine-tune it with the target data .
3. Addressing Missing Data in Time Series Forecasting with Generative Adverserial Networks (GANs) and Bayesian Inference
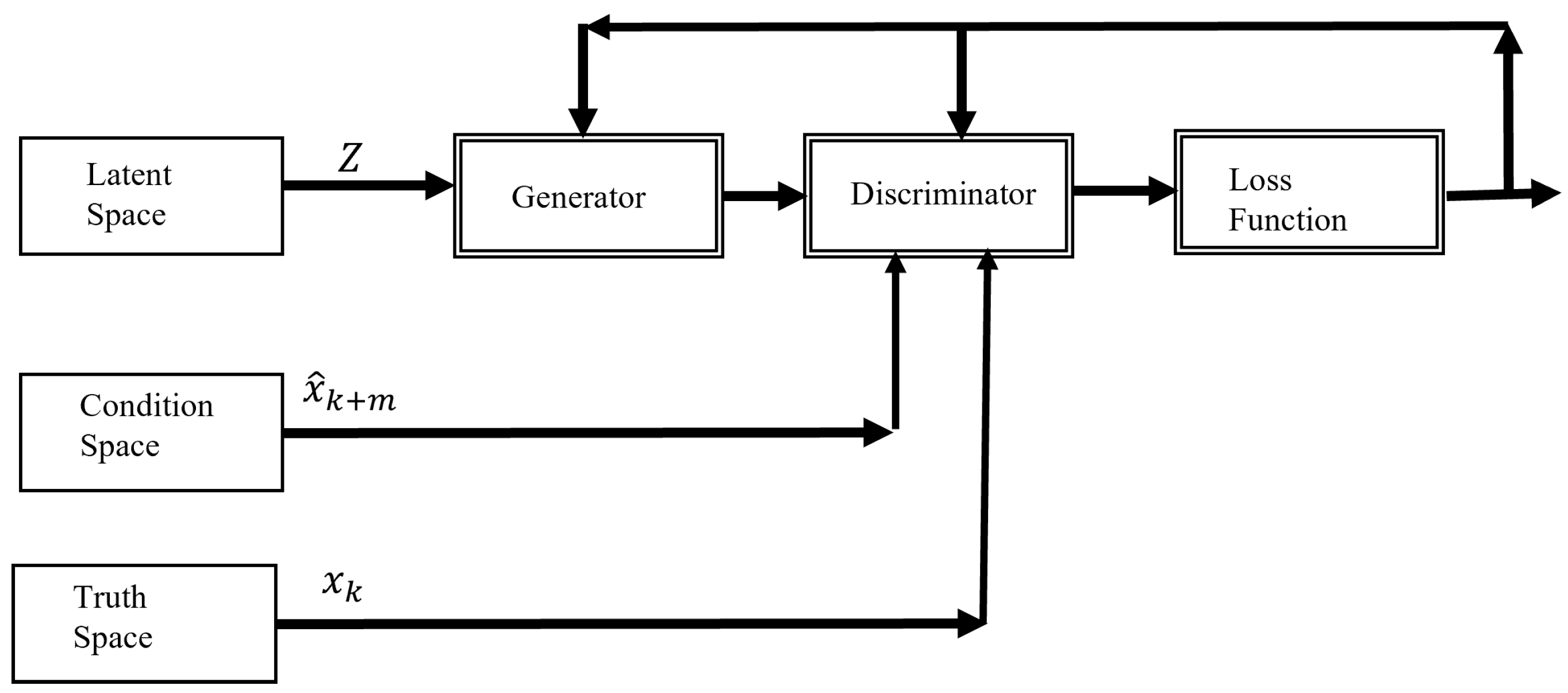
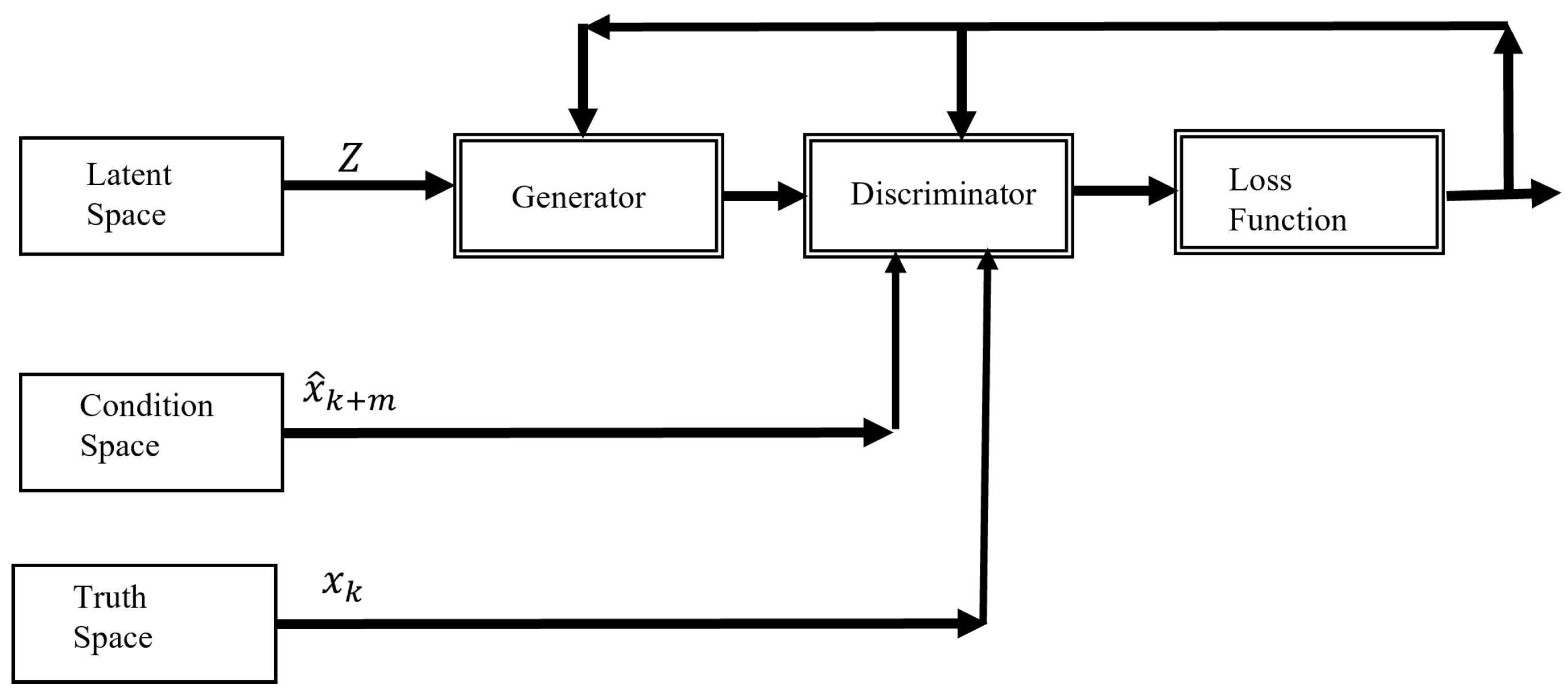
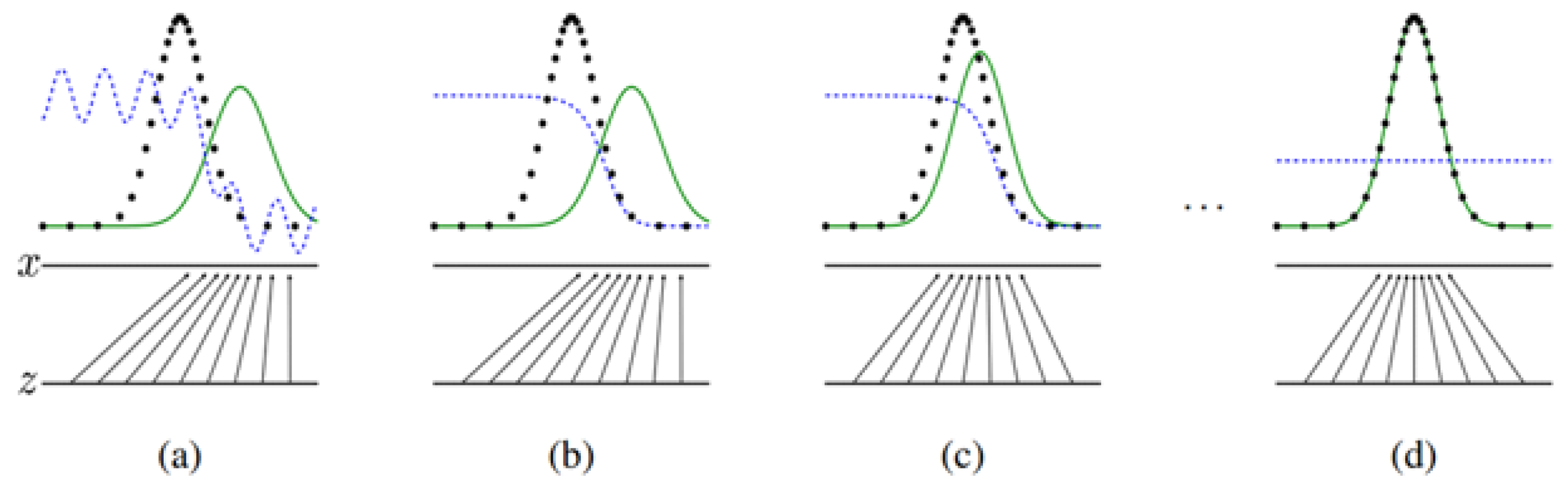
3.1. Learning the Underlying Distribution with Conditional GANs
3.2. Bayesian Inference for Forecasting
4. Air Pollution Forecasting
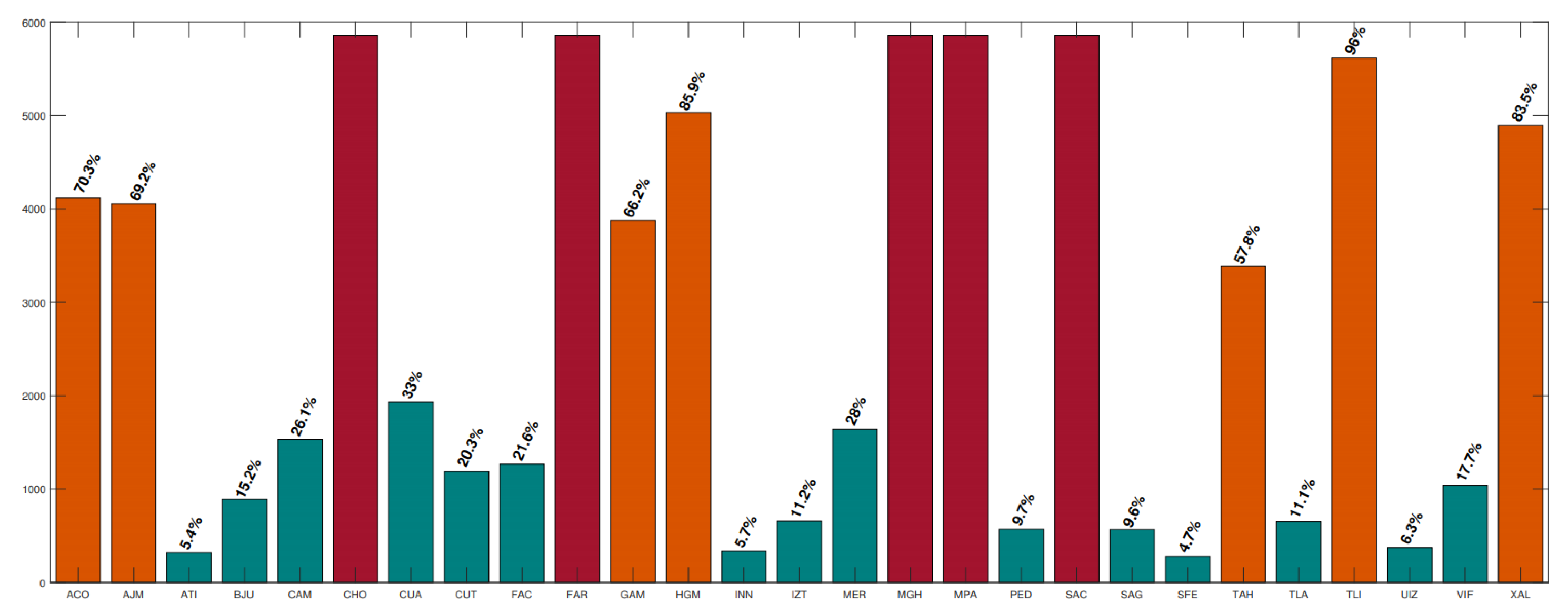
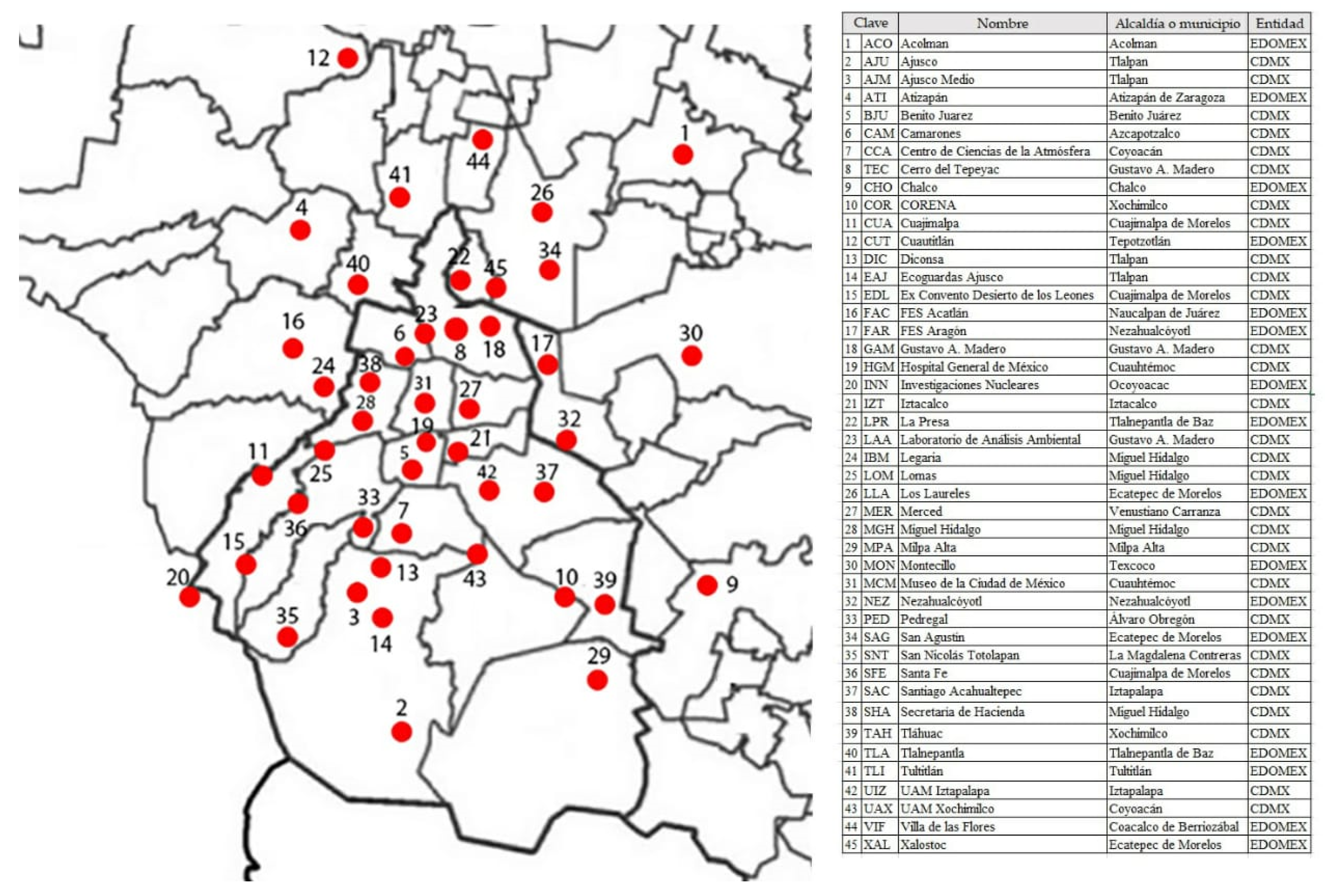
4.1. Air Pollution Data of Mexico City
4.2. Air Pollution Forecasting Using Neural Networks
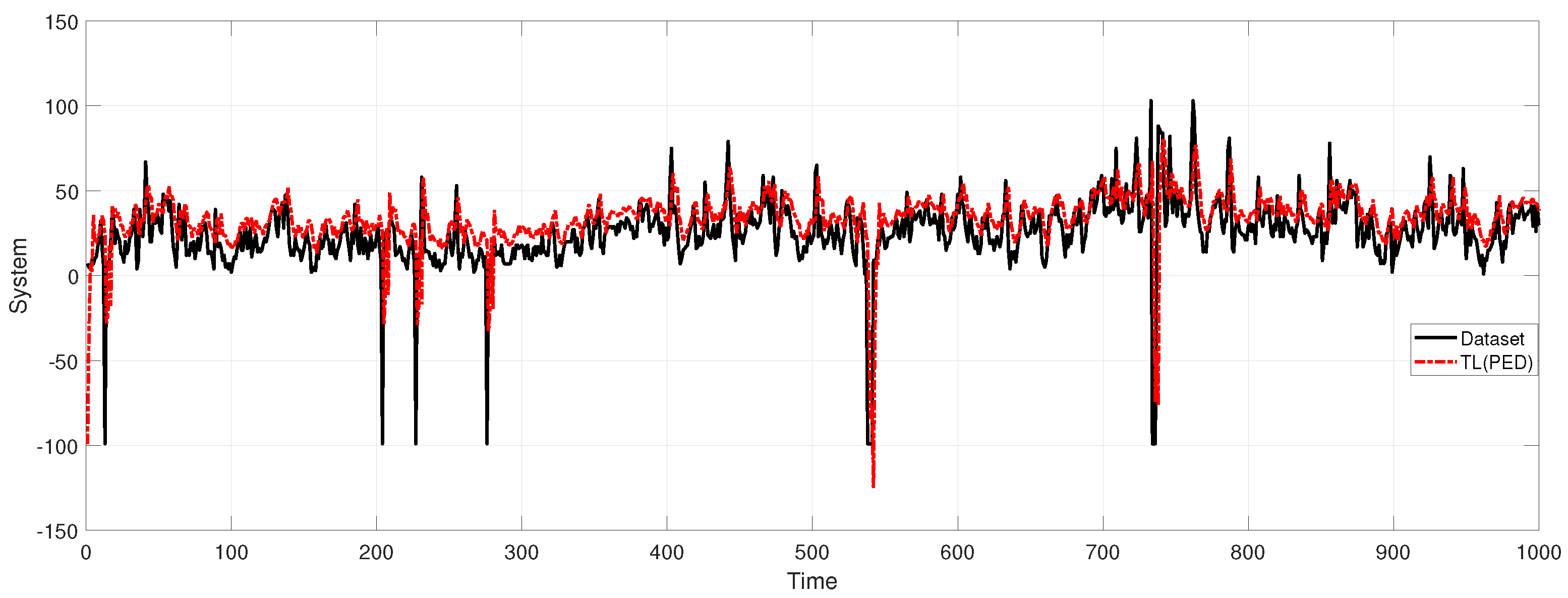
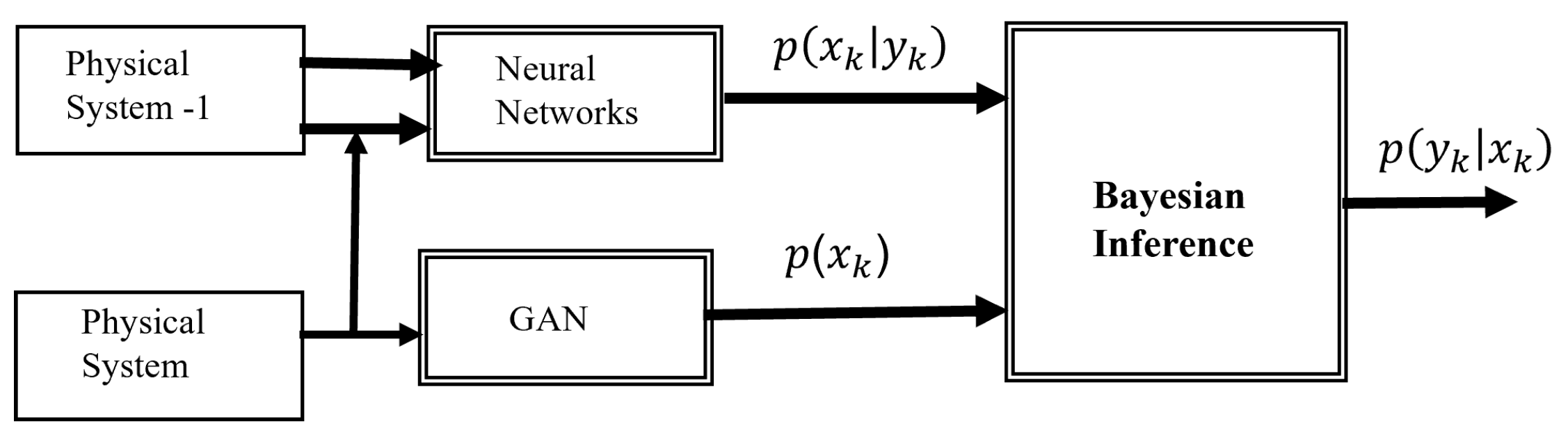
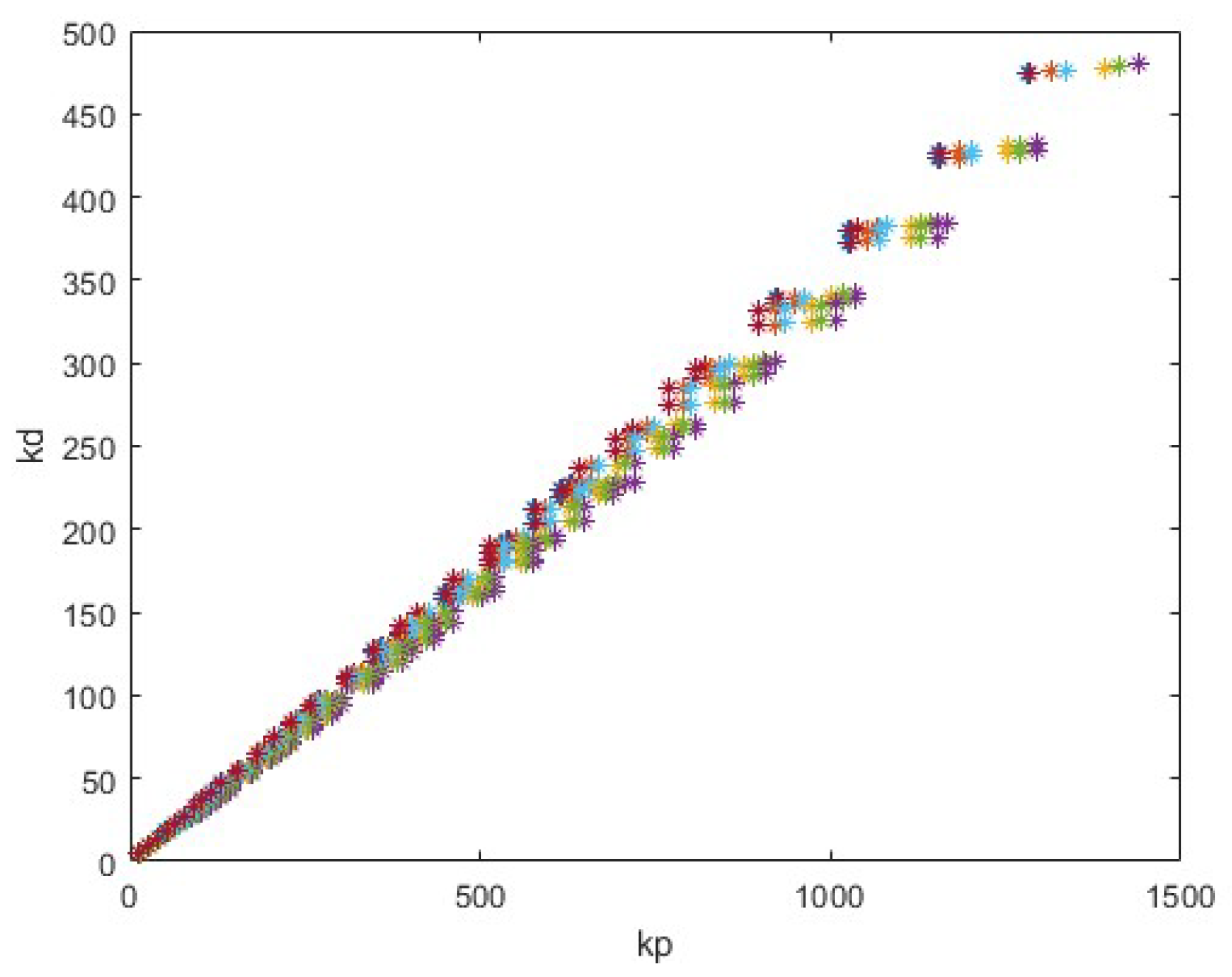
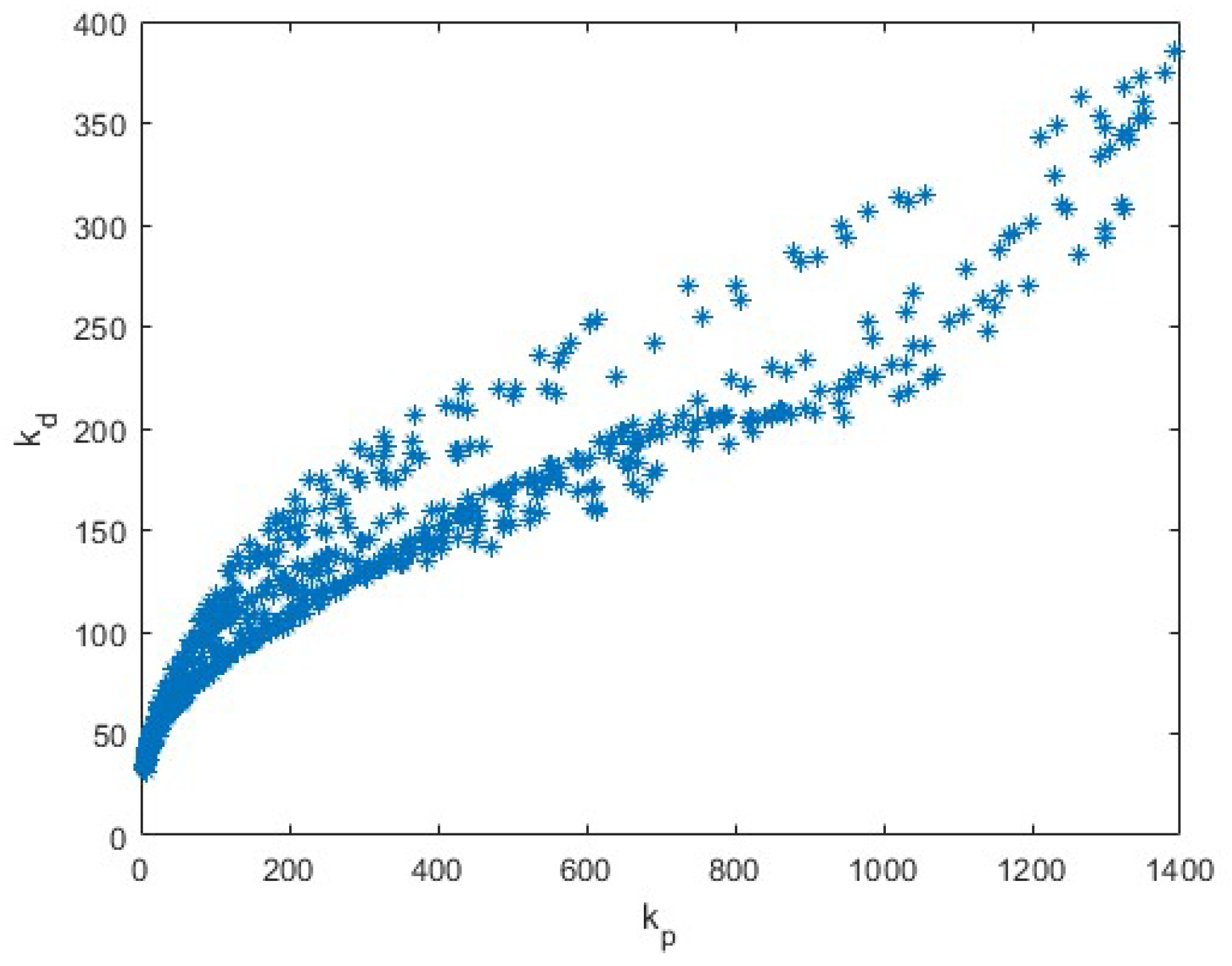
4.3. GAN and Bayesian Inference for Air Pollution Forecasting
- Real Time Series (): The actual air pollution data points surrounding the missing value.
- Real Predicted Value (): The predicted value for the next time step based on the available data.
- Gaussian Noise Vector (z): A random noise vector that introduces variability and helps the generator create diverse imputations.
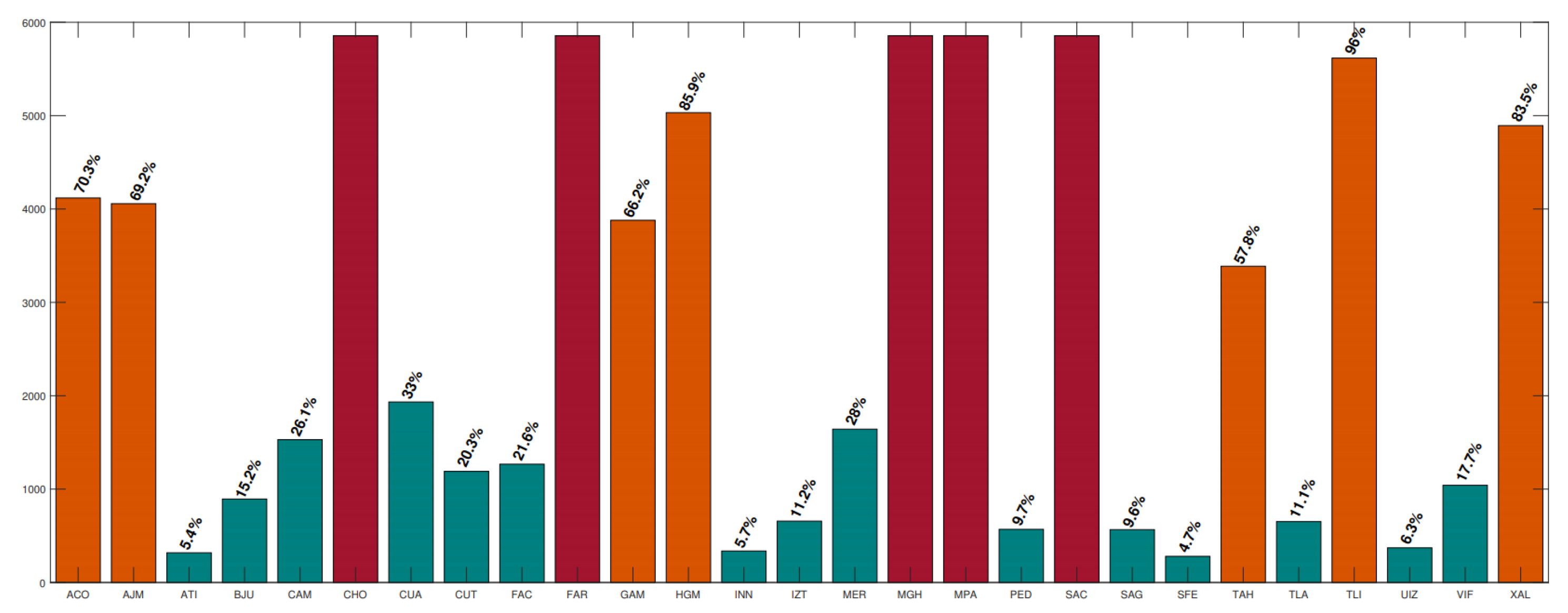
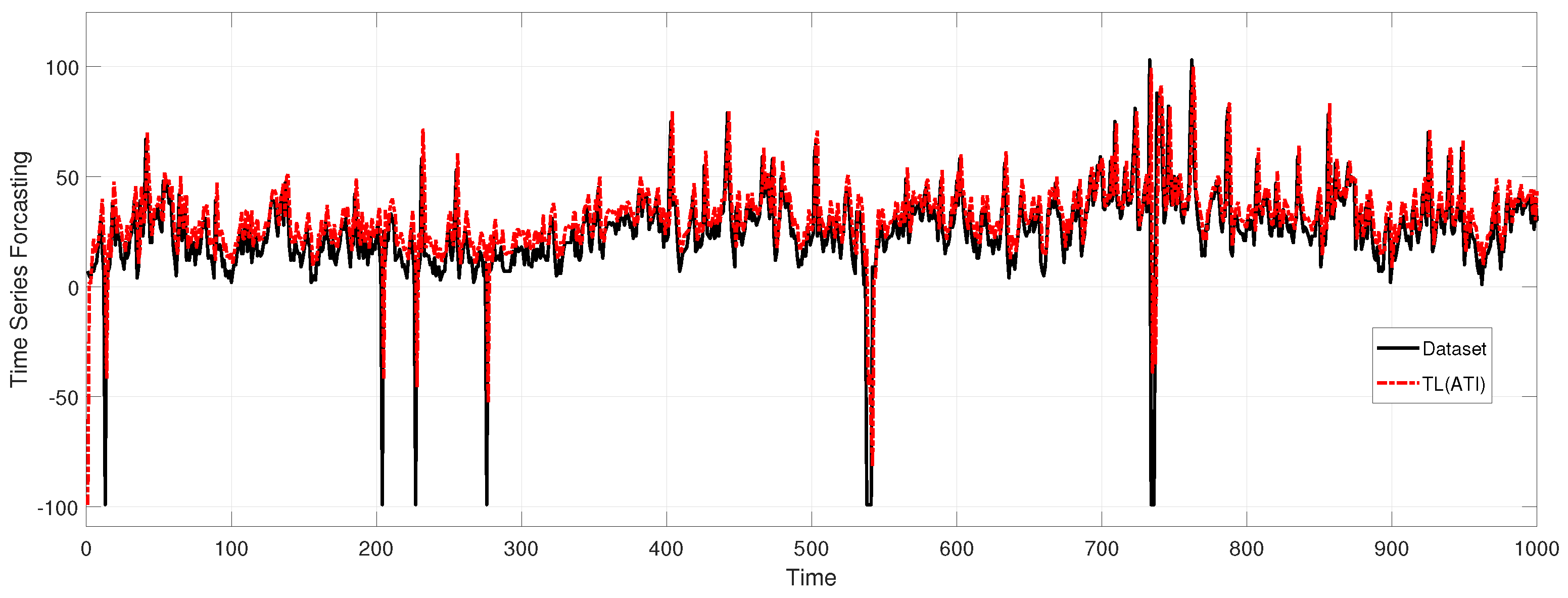
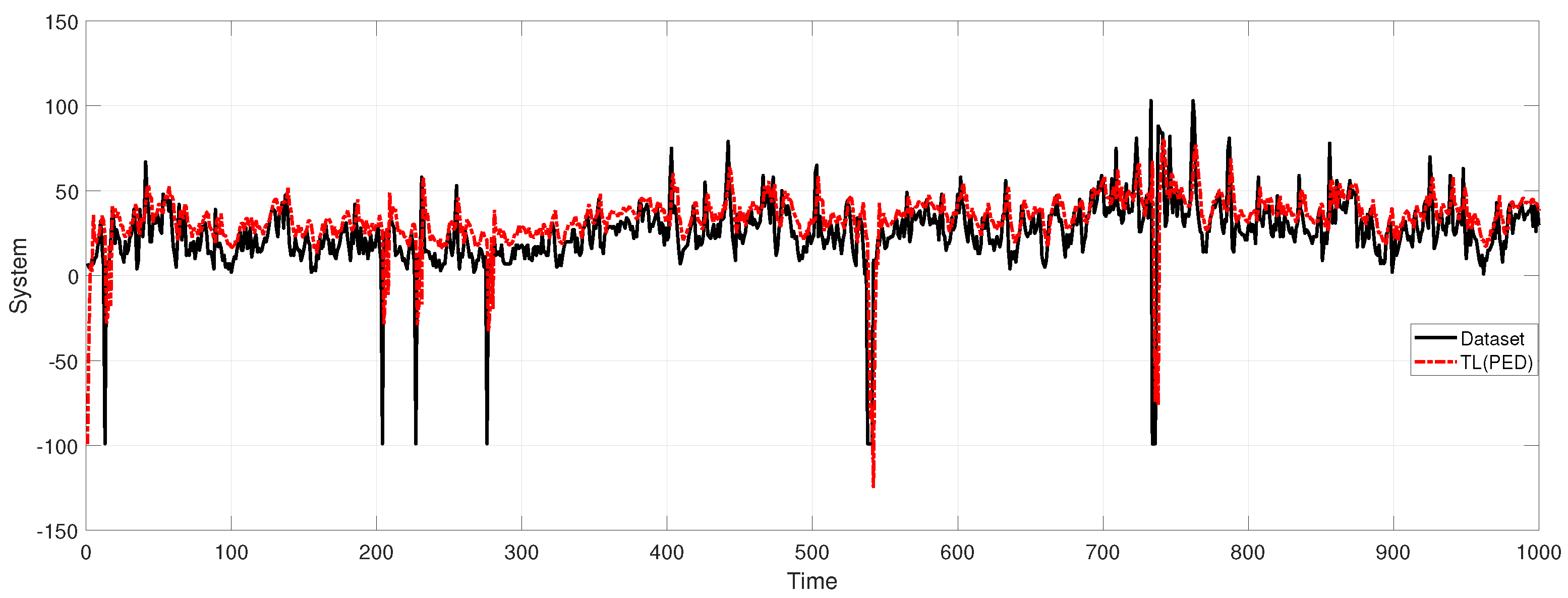
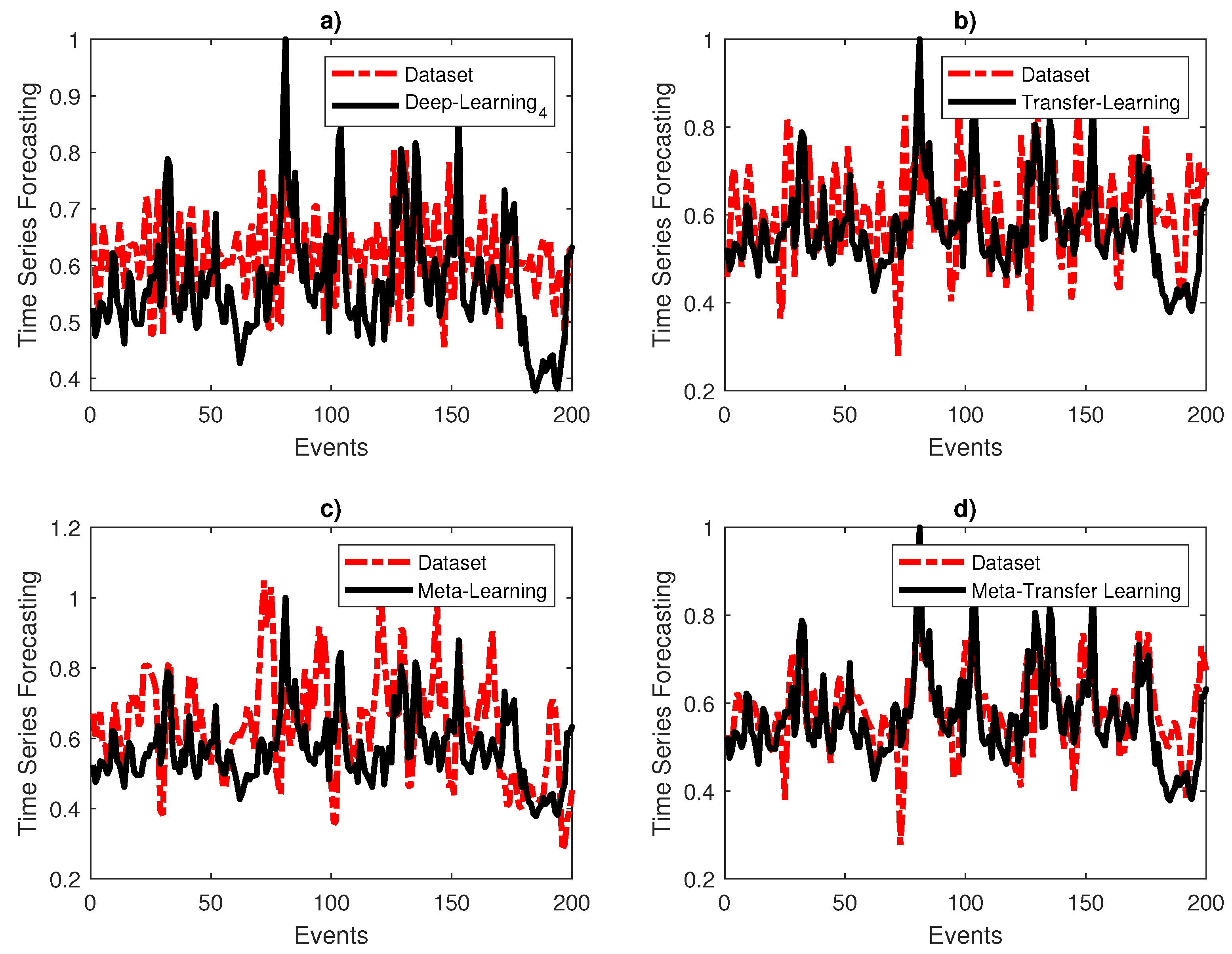
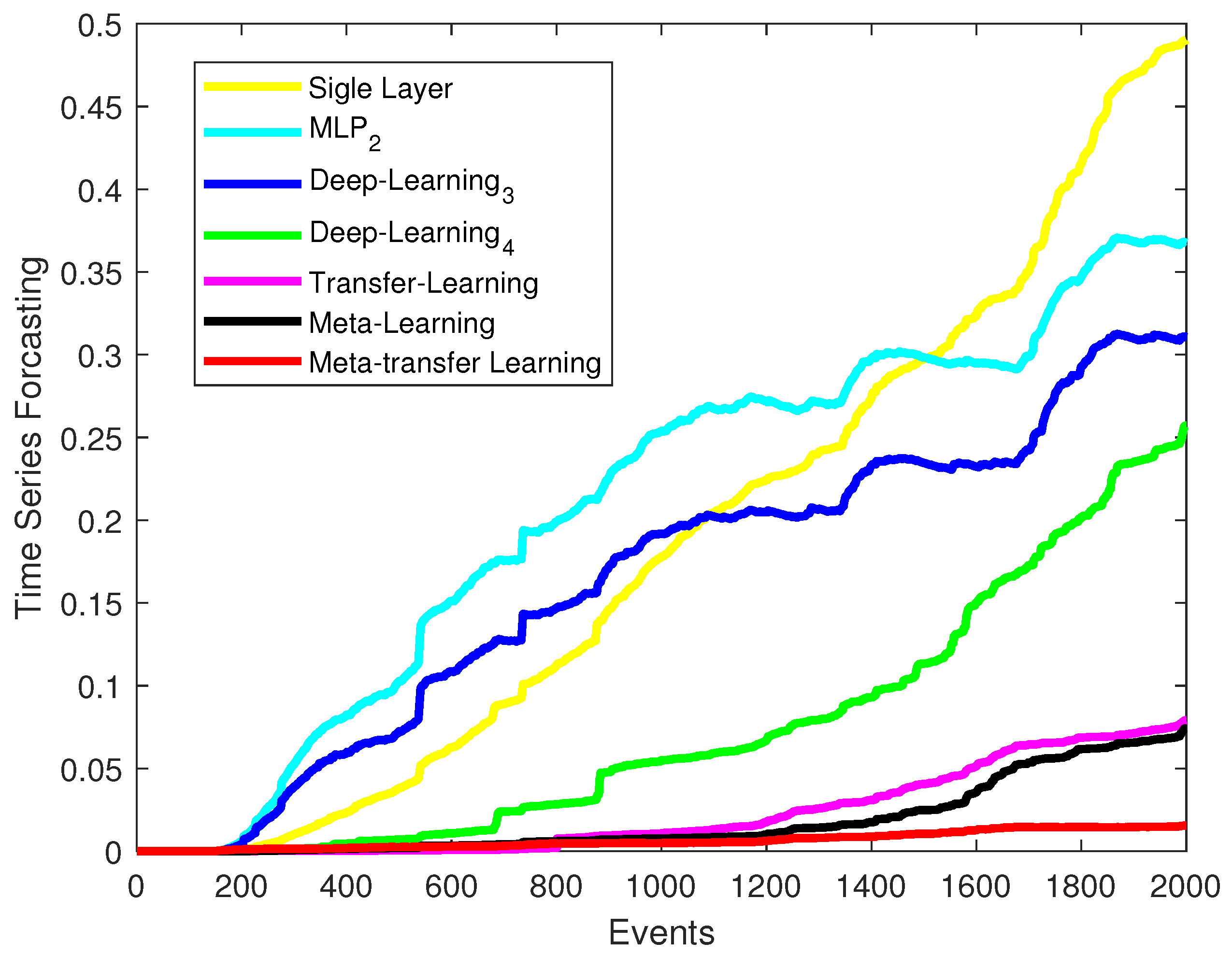
4.4. Comparison with Other Methods
- Single-Layer Neural Network (NN) [3]: This network has one hidden layer with 10 neurons ().
- MutiLayer Perceptron (MLP) [3]: This network has two hidden layers, with 10 and 35 neurons, respectively ().
- Deep Neural Network (DNN1) [24], : DNN1 has four hidden layers
- Deep Neural Network (DNN2) [24], : DNN2 has three hidden layers
- Bayesian Inference with neural networks (Bayesian) [34]: This network uses the same deep neural network architecture as DNN1.
- Meta-transfer learning (MTL) [4]: This network uses the same deep neural network architecture as DNN1.
- Proposed mothed in this paper (BayesianGAN): GAN with Bayesian inference.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, P.; Ye, L.; Tang, Y.; Zhao, Y.; Zhong, W.; Qu, Y.; Zhai, B. Ultra-short-term combined prediction approach based on kernel function switch mechanism. Renew. Energy 2021, 164, 842–866. [Google Scholar] [CrossRef]
- Mushtaq, M.; Akram, U.; Aamir, M.; Ali, H.; Zulqarnain, M. Neural Network Techniques for Time Series Prediction: A Review. Int. J. Inform. Vis. 2019, 3, 314–320. [Google Scholar] [CrossRef]
- Hooyberghs, J.; Mensink, C.; Dumont, G.; Fierens, F.; Brasseur, O. A neural network forecast for daily average PM10 concentrations in Belgium. Atmos. Environ. 2005, 39, 3279–3289. [Google Scholar] [CrossRef]
- Maya, M.; Yu, W.; Li, X. Time series forecasting with missing data using neural network and meta-transfer learning. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI 2021), Orlando, FL, USA, 5–7 December 2021; pp. 1–6. [Google Scholar]
- Zhang, L.; Zhang, D. Domain Adaptation Extreme Learning Machines for Drift Compensation in E-Nose Systems. IEEE Trans. Instrum. Meas. 2015, 64, 1790–1801. [Google Scholar] [CrossRef]
- Ye, R.; Dai, Q. A novel transfer learning framework for time series forecasting. Knowl.-Based Syst. 2018, 156, 74–99. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Yu, Y.; Srivastava, A.; Canales, S. Conditional lstm-gan for melody generation from lyrics. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–20. [Google Scholar] [CrossRef]
- Fan, B.; Lu, X.; Li, H.X. Probabilistic inference-based least squares support vector machine for modeling under noisy environment. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 1703–1710. [Google Scholar] [CrossRef]
- Gernoth, K.A.; Clark, J.W. Neural networks that learn to predict probabilities: Global models of nuclear stability and decay. Neural Netw. 1995, 8, 291–311. [Google Scholar] [CrossRef]
- Horger, F.; Würfl, T.; Christlein, V.; Maier, A. Deep learning for sampling from arbitrary probability distributions. arXiv 2018, arXiv:1801.04211. [Google Scholar]
- Billings, S.A. Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Ratliff, L.J.; Burden, S.A.; Sastry, S.S. Characterization and computation of local Nash equilibria in continuous games. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; pp. 917–924. [Google Scholar] [CrossRef]
- Goodfellow, I. Nips 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Dirección de Monitoreo Atmosférico, S.d.M.A. Technical Report, Secretaría del Medio Ambiente de la Ciudad de México. 2020. Available online: http://www.aire.cdmx.gob.mx/default.php (accessed on 20 March 2024).
- Wu, W.; Zhang, N.; Li, Z.; Li, L.; Liu, Y. Convergence of the gradient method with momentum for back-propagation neural networks. J. Comput. Math. 2008, 26, 613–623. [Google Scholar]
- Cortina-Januchs, M.G.; Quintanilla-Dominguez, J.; Vega-Corona, A.; Andina, D. Development of a model for forecasting of PM10 concentrations in Salamanca, Mexico. Atmos. Pollut. Res. 2015, 6, 626–634. [Google Scholar] [CrossRef]
- Cabaneros, S.M.; Calautit, J.K.; Hughes, B.R. A review of artificial neural network models for ambient air pollution prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Chaloulakou, A.; Grivas, G.; Spyrellis, N. Neural network and multiple regression models for PM10 prediction in Athens: A comparative assessment. J. Air Waste Manag. Assoc. 2003, 53, 1183–1190. [Google Scholar] [CrossRef]
- Corani, G. Air quality prediction in Milan: Feed-forward neural networks, pruned neural networks and lazy learning. Ecol. Model. 2005, 185, 513–529. [Google Scholar] [CrossRef]
- Grivas, G.; Chaloulakou, A. Artificial neural network models for prediction of PM10 hourly concentrations, in the Greater Area of Athens, Greece. Atmos. Environ. 2006, 40, 1216–1229. [Google Scholar] [CrossRef]
- Chelani, A.B.; Gajghate, D.; Hasan, M. Prediction of ambient PM10 and toxic metals using artificial neural networks. J. Air Waste Manag. Assoc. 2002, 52, 805–810. [Google Scholar] [CrossRef]
- Perez, P.; Reyes, J. An integrated neural network model for PM10 forecasting. Atmos. Environ. 2006, 40, 2845–2851. [Google Scholar] [CrossRef]
- Papanastasiou, D.K.; Melas, D.; Kioutsioukis, I. Development and assessment of neural network and multiple regression models in order to predict PM10 levels in a medium-sized Mediterranean city. Water Air Soil Pollut. 2007, 182, 325–334. [Google Scholar] [CrossRef]
- Cai, M.; Yin, Y.; Xie, M. Prediction of hourly air pollutant concentrations near urban arterials using artificial neural network approach. Transp. Res. Part D Transp. Environ. 2009, 14, 32–41. [Google Scholar] [CrossRef]
- McKendry, I.G. Evaluation of Artificial Neural Networks for Fine Particulate Pollution (PM10 and PM2.5) Forecasting. J. Air Waste Manag. Assoc. 2002, 52, 1096–1101. [Google Scholar] [CrossRef] [PubMed]
- Hrust, L.; Klaić, Z.B.; Križan, J.; Antonić, O.; Hercog, P. Neural network forecasting of air pollutants hourly concentrations using optimised temporal averages of meteorological variables and pollutant concentrations. Atmos. Environ. 2009, 43, 5588–5596. [Google Scholar] [CrossRef]
- Paschalidou, A.K.; Karakitsios, S.; Kleanthous, S.; Kassomenos, P.A. Forecasting hourly PM10 concentration in Cyprus through artificial neural networks and multiple regression models: Implications to local environmental management. Environ. Sci. Pollut. Res. 2011, 18, 316–327. [Google Scholar] [CrossRef] [PubMed]
- Fernando, H.J.S.; Mammarella, M.C.; Grandoni, G.; Fedele, P.; Marco, R.D.; Dimitrova, R.; Hyde, P. Forecasting PM10 in metropolitan areas: Efficacy of neural networks. Environ. Pollut. 2012, 163, 62–67. [Google Scholar] [CrossRef] [PubMed]
- Perez, P. Combined model for PM10 forecasting in a large city. Atmos. Environ. 2012, 60, 271–276. [Google Scholar] [CrossRef]
- Nejadkoorki, F.; Baroutian, S. Forecasting PM10 in metropolitan areas: Efficacy of neural networks. Int. J. Environ. Res. 2012, 6, 277–284. [Google Scholar]
- Liu, W.; Li, X.; Chen, Z.; Zeng, G.; León, T.; Liang, J.; Huang, G.; Gao, Z.; Jiao, S.; He, X.; et al. Land use regression models coupled with meteorology to model spatial and temporal variability of NO2 and PM10 in Changsha, China. Atmos. Environ. 2015, 116, 272–280. [Google Scholar] [CrossRef]
- Jorge Morales, W.Y. Improving Neural Network’s Performance Using Bayesian Inference. Neurocomputing 2015, 461, 319–326. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | PM10 | Time-Scale | Input | Training | Testing | Hidden Layer | Hidden Node | Active Function | Epochs | Missing Data | R | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [20] | Monthly | - | 5 | 72 | 12 | 1 | 20 | Tansigmoidal | 0.01–1 | 0.5 | 5000 | - | 0.7 |
| [21] | Daily | Mean and maximum one day ahead | 25 | 1460 | 365 | - | - | - | - | - | - | - | 0.65 |
| [3] | Daily | One-day | 5 | 488 | 244 | 2 | 5 | Tanh | - | - | - | 15 | 0.8 |
| [22] | Daily | One-day | 4 | Cross validation shuffle | Cross validation shuffle | 1 | - | Tanh | 0.0001–1 | - | - | - | 0.88 |
| [23] | Daily | One-day ahead | 6 | 1460 | 365 | 1 | 4 | - | - | - | - | Averaged | 0.67–0.81 |
| [24] | Hourly | 24 h ahead | 8 | 13,140 | 4380 | 1 | 7 | Logistic | - | - | - | - | 0.7–0.82 |
| [24] | Hourly | 24 h ahead | 8 | 13,140 | 4380 | 1 | 6 | Logistic | - | - | - | - | 0.65–0.83 |
| [25] | Daily | Maximum one-day ahead | 18 | 150 | 90 | 1 | 7 | - | - | - | - | - | - |
| [26] | Daily | One day ahead | 5 | 722 | 372 | 1 | 3 | - | - | - | - | 25 | 0.78 |
| [27] | Hourly | Hourly | 16 | 495 | 42 | 1 | 8 | Sigmoid | 0.3 | 0.3 | - | 2 | 0.912 |
| [28] | Hourly | One hour ahead | 7 | - | Random | 1 | 9–36 | Logistic | 0.1 | 0.3 | 5000 | 2–11 | 0.72 |
| [29] | Hourly | One hour ahead | 15 | 12,800 | 2240 | 1 | 26 | - | - | - | - | 7 | 0.8–0.87 |
| [30] | Hourly | 24 h ahead | 5 | - | - | 1 | 3 | Tanh | - | - | - | - | 0.61 |
| [31] | Daily Maximum | One day ahead | 27 | 500 | 150 | 1 | 8 | Sigmoid | - | - | - | - | - |
| [32] | Daily | Maximum one day ahead | 5 | 2000 | 650 | 1 | 10 | Tanh Sigmoid | - | - | 1000 | 35 | 0.05–0.72 |
| [33] | Daily | - | 9 | 240 | 125 | 1 | - | - | - | - | - | Averaged | 0.68 |
| Neural Model | MSE | MAPE |
|---|---|---|
| NN | ||
| MLP | ||
| DNN1 | ||
| DNN2 | ||
| Bayesian | ||
| MTL | ||
| BayesianGAN |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X. Time Series Forecasting with Missing Data Using Generative Adversarial Networks and Bayesian Inference. Information 2024, 15, 222. https://doi.org/10.3390/info15040222
Li X. Time Series Forecasting with Missing Data Using Generative Adversarial Networks and Bayesian Inference. Information. 2024; 15(4):222. https://doi.org/10.3390/info15040222
Chicago/Turabian StyleLi, Xiaoou. 2024. "Time Series Forecasting with Missing Data Using Generative Adversarial Networks and Bayesian Inference" Information 15, no. 4: 222. https://doi.org/10.3390/info15040222
APA StyleLi, X. (2024). Time Series Forecasting with Missing Data Using Generative Adversarial Networks and Bayesian Inference. Information, 15(4), 222. https://doi.org/10.3390/info15040222