Abstract
The expressions on human faces reveal the emotions we are experiencing internally. Emotion recognition based on facial expression is one of the subfields of social signal processing. It has several applications in different areas, specifically in the interaction between humans and computers. This study presents a simple CCNN-SVM automated model as a viable approach for FER. The model combines a Convolutional Neural Network for feature extraction, certain image preprocessing techniques, and Support Vector Machine (SVM) for classification. Firstly, the input image is preprocessed using face detection, histogram equalization, gamma correction, and resizing techniques. Secondly, the images go through custom single Deep Convolutional Neural Networks (CCNN) to extract deep features. Finally, SVM uses the generated features to perform the classification. The suggested model was trained and tested on four datasets, CK+, JAFFE, KDEF, and FER. These datasets consist of seven primary emotional categories, which encompass anger, disgust, fear, happiness, sadness, surprise, and neutrality for CK+, and include contempt for JAFFE. The model put forward demonstrates commendable performance in comparison to existing facial expression recognition techniques. It achieves an impressive accuracy of on the CK+ dataset, on the JAFFE dataset, on the KDEF dataset, and on the FER.
1. Introduction
Facial expression is one of the most crucial aspects of human emotion recognition. People can give us a sense of their feelings just by looking at their faces, it can be characterized as changes in facial appearance influenced by an individual’s internal emotional state, objectives, or social interactions []. Applications for facial expression recognition in human–computer interaction include social robots, medical treatments, and monitoring driver weariness.
The facial expression recognition systems are separated into two basic categories. The first category is based on the static images [,] and the second category deals with dynamic image sequences [,]. The feature vector in static-based algorithms only contains data related to the current input image, as they do not employ temporal information. However, sequence-based approaches make use of the temporal information contained in images to identify the expressions gathered. The automated facial expression recognition systems typically process either a single static image or an image sequence as input. Their output usually corresponds to one of the six primary expressions (e.g., anger, sadness, surprise, happiness, disgust, and fear), with some systems also capable of detecting neutral expressions. In this study, the focus will be on static image-based methods, addressing both the six fundamental expressions and the seven-expression sets, which include the six primary emotions plus a neutral expression.
Automatic facial expression analysis, as defined by [], includes four stages: capturing the face, extracting facial data, representation, and recognizing facial emotions. Capturing the face can be broken down into two main stages: head posture estimation [] and face detection []. After capturing the face, it is essential to extract the facial changes induced by different facial expressions.
In the past, researchers have utilized various methods, such as the Naive Bayes Classifier, Ensemble Learning, and Support Vector Machines, to address FER. These techniques relied on extracting information from images using Local binary patterns, Face-landmark features, Harris Corner Detection, and Scale-Invariant Feature Transform (SIFT). Within these methods, neural networks have acquired the most popularity and are widely used for FER. Previous FER approaches typically employed CNNs with only a few layers, despite evidence suggesting that deeper models perform better in other image-processing domains []. This phenomenon may be attributed to the specific challenges posed by FER. Firstly, recognizing emotions necessitates moderately high-resolution images, which translates to handling high-dimensional data. Secondly, the subtle variations in facial expressions across different emotional states pose difficulties for classification tasks. Conversely, very deep CNNs entail a substantial number of hidden convolutional layers. Training such a large number of layers in a CNN proves to be cumbersome and often fails to generalize effectively. Moreover, merely increasing the number of layers does not necessarily lead to improved accuracy beyond a certain threshold, owing to issues such as the vanishing gradient problem [].
Deep learning reduces the burden of discovering new features for every task and has a significant advantage over conventional machine learning in terms of performance as the amount of data increases. The main contributions of this work are:
- Propose CCNN-SVM as an automated model for emotion recognition. A fusion of a deep neural network that include many convolution layers and an SVM classifier to improve the efficiency of facial emotion recognition.
- Investigate the impact of image preprocessing operations on facial recognition tasks.
2. Related Works
Facial expressions are very important in conveying emotional information between individuals, often more effectively than direct speech. They can also serve as evidence to determine whether someone is being truthful or not. The use of facial recognition technology has been on the rise [], as evidenced by its application in detecting fake faces in images and distinguishing real faces through the eyes. As technology continues to advance, various methods have emerged for detecting human facial expressions. The following subsections contain a brief description of the methodologies used in the well-known FER methods.
2.1. Facial Expression Recognition Methodologies Based on Machine Learning
This section displays some methods of FER which depend on machine learning. The Gabor filter is a popular and widely utilized technique for recognizing facial expressions. In [], a method for extracting image texture descriptors is Local Binary Patterns (LBP), which has various adaptations for extracting facial feature appearances. Along with LBP, Local Phase Quantization (LPQ) has also been used as an image texture descriptor. In [], they performed feature extraction from facial images by creating specialized features. Subsequently, they introduced innovative classification methods employing SVM classifiers for facial expression recognition, leveraging these extracted features. In [], an innovative method for detecting facial expressions inspired by human vision has been introduced. In another study by [], they utilized an edge-based descriptor for feature extraction in facial expression recognition (FER). LPDP efficiently utilized information from pixels to construct descriptive features in the FER process.
In [], expressions are characterized as a synthesis of various action units that are taken from RGB video sequences and categorized using an SVM for deception detection. However, aspects that depend on appearance are delicate to lighting conditions. First, facial regions are used to identify landmark points in geometric features. Then, the geometric connection between landmark points is used to describe the expression.
2.2. Facial Expression Recognition Methodologies Based on Deep Learning
In this section, we explain some methods of FER which depend on deep learning. Convolutional neural networks (CNNs) have had considerable success lately in a variety of computer vision applications, such as recognizing facial expressions. Using convolutional and subsampling layers as well as training, the networks differ between CNN architectures. The quantity of generated maps and the size of the kernels serve as the primary parameters for convolutional layers. The two primary subsampling layer types are average pooling and maximum pooling. Average pooling calculates the new value of a pixel by taking the average of its neighboring pixels, whereas maximum pooling selects the highest pixel value within the neighborhood region and assigns it as the new value for that region. Obtaining the best weights related to the kernel is the first step in the learning process for CNNs.
In [], the authors incorporated advanced computer vision and machine learning techniques into a framework designed to computationally analyze the facial expression production of both children with Autism Spectrum Disorder (ASD) and typically developing children. The framework utilizes techniques to detect and track a set of landmarks, akin to virtual electromyography sensors, to observe and monitor the movements of facial muscles involved in producing facial expressions. In [], incorporated dense connections across pooling layers to promote feature sharing in a relatively shallow CNN architecture. The authors in [] introduced an innovative approach to facial expression recognition (FER) utilizing support vector machine (SVM) technology. Initially, the FER technique incorporates a face detection algorithm that merges the Haar-like features method with the self-quotient image (SQI) filter. Following this, three methodologies, namely the angular radial transform (ART), the discrete cosine transform (DCT), and the Gabor filter (GF), are simultaneously utilized to extract features for facial expression within the FER technique. The authors created and built a multi-block deep convolutional neural networks (DCNN) model aimed at detecting facial emotions across virtual, stylized, and human characters. Ref. [] introduced an adaptively weighted sharing network capable of conducting action unit identification and emotion recognition concurrently.
As shown in [], LBP features and the network of attention mechanisms can be combined to improve the attention model and produce better outcomes for facial expression recognition. In order to resolve the conflict between the FER challenge and current deep learning trends, Ref. [] investigated the correlation between the magnitude of input semantic disturbance and the fluctuation in output probabilities. In [], using a multi-block DCNN setup, we introduced two models utilizing ensemble learning methods. The first model combines bagging ensemble with SVM (DCNN-SVM), while the second model utilizes an ensemble of three distinct classifiers with a voting technique (DCNN-VC). The architecture presented by [] employs a novel spatial-channel attention net (SCAN) to obtain local and global attention for each channel at every spatial location. By converting the input data into RGB and depth map images, and subsequently utilizing a recursive procedure with randomized channel concatenation, Ref. [] demonstrated a sparsity-aware deep network capable of automatic recognition of 3D/4D facial expressions. Ref. [] introduced an improved CNN-based structure that integrates multiple branches consisting of radial basis function (RBF) units. In [], the authors introduced a novel method for accurately recognizing facial expressions using a combination of a hybrid feature descriptor and an enhanced classifier. Drawing inspiration from the effectiveness of the stationary wavelet transform in various computer vision applications, the technique initially applies the stationary wavelet transform to preprocess the facial image. Subsequently, the pyramid of histograms of orientation gradient features is computed from the low-frequency stationary wavelet transform coefficients. This step aims to extract more prominent details from facial images, thereby enhancing the recognition process. In [], the authors proposed a novel approach to facial expression recognition, employing a hybrid model that merges convolutional neural networks (CNNs) with a support vector machine (SVM) classifier, utilizing dynamic facial expression data. The method involves utilizing dense facial motion flows and geometry landmark flows extracted from facial expression sequences as inputs for the CNN and SVM classifier, respectively. Additionally, CNN architectures tailored for facial expression recognition based on dense facial motion flows are proposed. Ref. [] delved into the topic of recognizing facial expressions using a deep learning technique known as the Visual-Attention-based Composite Dense Neural Network (VA-CDNN). In this study, the model focuses on extracting specific areas of interest such as the mouth, eyes, and face regions from facial images. These regions are then individually processed through a pretrained Xception deep Convolutional Neural Network (ConvNet) to obtain spatial representations. In [], the authors used the Boosted Histogram of Oriented Gradient descriptor to offer an effective method for FER in static images. Through the extraction of hybrid features from an ellipse and an undirected graph with a -skeleton, the authors in [] enhanced Fusion-CNN for face emotion identification. The outputs are fused and combined to form a feature vector for classification within a deep neural network. Table 1 summarizes the related of work.

Table 1.
Summary of related works.
3. The Proposed Model
Convolutional Neural Networks (CNNs) are effective in learning image characteristics; however, they do not always produce the best results for classification. In contrast, SVMs generate effective decision interfaces by utilizing soft-margin techniques to maximize margins rather than learning complex invariances through their fixed activation functions.
In this section, the proposed model aims to explore an automated framework, where the Custom Convolutional Neural Network (CCNN) is prepared to pick up on subjective characteristics. SVM offers the best options for class labels in the learned feature space, and exchanges the CNN’s output layer (i.e., the CCNN’s fully connected layer acts as an input to the SVM).
Figure 1 shows the general framework of the suggested model that includes three steps. The first step is preprocessing, including image cropping, image equalization, gamma correction, and downsampling. In the second step, the CCNN model extracts the features. Finally, the classification step is based on the SVM classifier. The proposed model is fully explained in the next subsections.
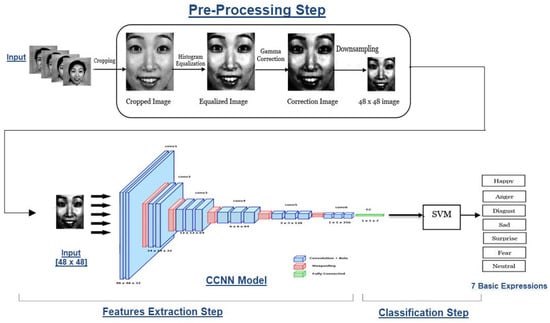
Figure 1.
The framework for the proposed model of facial expression recognition.
3.1. The Preprocessing Step
The proposed model includes a preprocessing step, which is designed to eliminate non-expression specific features from a facial image. There are four stages in the preprocessing step: face detection and cropping, histogram equalization, gamma correction, and downsampling. The preprocessing step is fully explained in the next subsections.
3.1.1. Image Cropping Stage
Many background details in the original image are unimportant to the emotion classification process. These details might make categorization less accurate because the classifier now has to distinguish between background and foreground, which is a new challenge. After cropping, any parts of the image that do not contain expression-related information are eliminated. Moreover, the cropping region is designed to exclude facial features that do not contribute to the expression, such as ears, portions of the forehead, and so on. Therefore, The distance ratio between the eyes is used to define the region of interest. As a result, this technique can manage various people and image sizes without human involvement.
A ratio represents the distance between the midpoint of the eyes and the center of the right eye (in Figure 2 ). A factor of 2.8 applied to the ratio defines the vertical cropping area (considering 0.8 for the area above the eyes and 2.0 for the area below). A factor of 2.5 defines the horizontal cropping area applied to this same distance . The values of these factors were established empirically after trying more values to obtain the optimum, as shown in Figure 2.
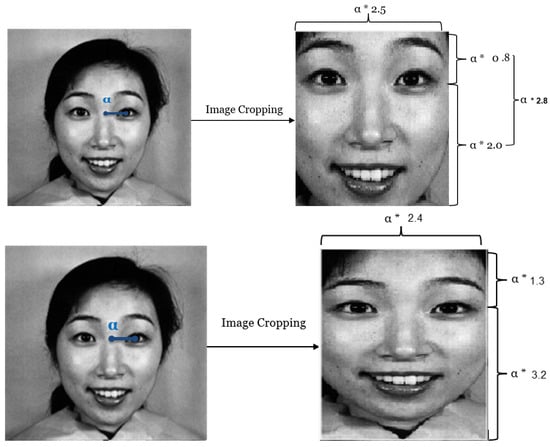
Figure 2.
Two different image cropping examples with
3.1.2. Histogram Equalization Stage
The second stage is normalizing the image’s grey scale value and improving the ability to distinguish between the brightness of the foreground and background in a facial image, which can both be achieved with histogram equalization (Hist-eq). Equation (1) shows the histogram function:
Let represent the histogram function of a set of resized face images consisting of n images. The function represents the cumulative function, while is the minimum non-zero value of the cumulative distribution function. The term indicates the total number of pixels in the image, where M represents the width, N represents the height, and L denotes the number of gray levels. An example of this stage is shown in Figure 3.
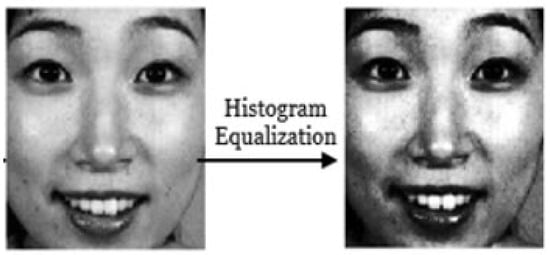
Figure 3.
Image equalization example.
3.1.3. Gamma Correction Stage
The third stage involves Gamma correction, a non-linear operation employed to regulate the overall brightness of an image by manipulating the Gamma parameter. It is defined by Equation (2):
Gamma can take on any value within the range of 0 → ∞. A value of 1 (the default) results in a linear mapping. When gamma is less than 1, the mapping tends to favor higher (brighter) output values. Conversely, for gamma values greater than 1, the mapping is biased toward lower (darker) output values. An example of this operation is shown in Figure 4.

Figure 4.
Gamma correction example.
3.1.4. Downsampling Stage
The final stage is downsampling, which enables CNN to discover which areas are associated with each particular expression. Since most modern graphics cards only have a small amount of memory, the downsampling process also enables convolutions to be executed on the GPU. The final image size of this stage is pixels. Figure 5 shows an example of this stage.

Figure 5.
Downsampling example.
Table 2 presents the test set accuracies for custom CNN on both KDEF and JAFFE datasets for various input sizes, considering different input dimensions. Notably, the highest accuracies were attained with image sizes set at 48 × 48. This preference arises from the model’s compatibility with this specific input size, as larger sizes necessitate more extensive data and a larger model for improved performance. Additionally, we used two datasets, CK+ and Fer, with standard size .
Table 2.
Test set accuracies of a custom CNN on the CK+, JAFFE, and KDEF datasets for various input sizes.
3.2. The Feature Extraction Step
This section introduces the newly proposed convolutional neural network for feature extraction. The architecture of the Custom Convolutional Neural Network (CCNN) is shown in Figure 6. A grayscale image is provided as input to the network, and the output is the expression. The new CCNN architecture consists of six convolutional layers, each with a ReLU activation function, six batch normalization layers, five max pooling layers, and one fully connected layer. Finally, we used SVM instead of Softmax for the classification. The convolutional neural network parameters are presented in Table 3. The details of the proposed network are shown in Table 4.
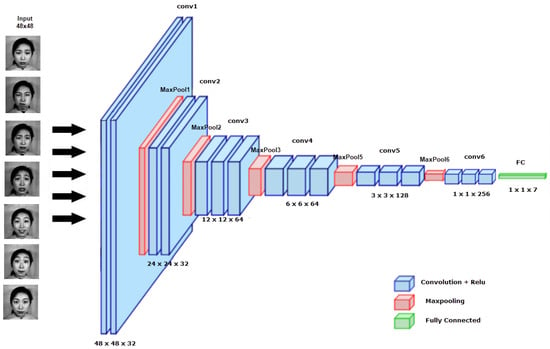
Figure 6.
The proposed custom CNN model (CCNN) architecture.
Table 3.
CNN parameters.
Table 4.
The proposed custom CNN model’s specifics.
3.3. The Classification Step
Support Vector Machine (SVM) is a supervised algorithm utilized for both regression and classification tasks. It operates as a classifier aiming to find optimal hyperplanes for effective separation in accordance with specific generalization criteria. SVM replaces the softmax output layer to determine the classes. Finally, the SVM classifier classifies subjective features.
SVM is constructed based on statistical learning theory and the principle of structural risk minimization [], exhibits strong generalization capabilities, and can effectively tackle small sample problems. By employing the Gaussian kernel function method, SVM maps vectors from low-dimensional space to high-dimensional space to address classification problems, as shown in Figure 7.
Figure 7.
SVM classifier.
4. Experimental Results
The preprocessing and CCNN for the proposed model are implemented in MATLAB R2021b. It is tested on a Dell PC with the following configurations: Intel (R) Core (TM) i7-9750H CPU @ 2.60GHz, 2.59 GHz, 16 GB RAM, and 64-bit, with Windows 11 as the operating system. The performance evaluation of the proposed model is performed using the CK+ and JAFFE datasets, which are discusses in Section 4.1. The experiments were conducted using two distinct approaches to partition the dataset into training and test sets: In the first approach, of the images from dataset were randomly selected for the training set, while the remaining were reserved for the test set. In the second approach, a five-fold cross-validation method was employed. Section 4.2 describe a discussion of the experimental results and a comparison with other most recent models.
4.1. Datasets
The facial expression recognition research made use of four renowned datasets commonly employed in this field: the Extended Cohn-Kanade (CK+) dataset, the Japanese Female Facial Expressions (JAFFE) dataset, KDEF dataset, and FER dataset. Both fundamental emotion datasets comprised seven categories: anger, disgust, fear, happiness, sadness, and surprise, in addition to neutrality for CK+ and contempt for JAFFE. Table 5 summarizes the dataset description, and Figure 8 shows a sample and number of images in each class.
Table 5.
Datasets’ description.

Figure 8.
The seven expressions for the CK+ and JAFFE datasets.
4.2. Experiments
This section demonstrates the impact of each preprocessing step on the model’s accuracy. Each experiment is first shown and thoroughly discussed in Table 6 and Table 7. Second, a comparison with the most advanced techniques available is shown in Table 13.
Table 6.
Measurements of the accuracy of the proposed model using different preprocessing stages on the CK+ dataset.
Table 7.
Measurements of the accuracy of the proposed model using different preprocessing stages on the JAFFE dataset.
4.2.1. Accuracy with Different Preprocessing Stages
There are five preprocessing steps to enhance CNN performances: (a) raw data or without preprocessing, (b) image cropping, (c) image cropping and equalization, (d) image cropping and gamma correction, (e) all the preprocessing steps. Table 6 and Table 7 demonstrate the effect of each preprocessing step on the model’s accuracy.
- (a)
- Without preprocessingThe initial experiment was conducted using the dataset without any modifications or image preprocessing. The suggested CNN is trained using a gradient descendant method. The order of the provided samples is used by gradient descendant methods to find the local minimum.Every experimental setup is repeated ten times, both during training and testing, with diverse image presentations to avoid fluctuations. This adjustment enables the descending gradient algorithm to explore more pathways and adjust the recognition rate by either decreasing or increasing it. The accuracy is presented as the highest value achieved among all ten runs, along with the average performance. We demonstrate that the approach still produces good accuracy rates even when the presentation order is not optimal by using the accuracy as an average.In this experiment, the highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was . When compared to most recent models, the recognition rate achieved using only CNN without any image preprocessing is significantly lower.
- (b)
- Image CroppingTo enhance the accuracy of the suggested model, the image is automatically cropped to eliminate areas that are not related to a facial regions as shown in Section 3. In this experiment, the highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was . Because the input of the suggested network is a fixed pixels image, downsampling is also performed here.By merely adding the cropping procedure, we can observe a considerable improvement in the recognition rate when compared to the results previously displayed. The primary factor contributing to the improvement in accuracy is the removal of a significant amount of irrelevant data that the classifier would otherwise have to process to find out the subject expression and make better use of the image space present in the network input.
- (c)
- Image Cropping and EqualizationThe cropping and equalization results provide the erroneous impression that the model’s accuracy might be reduced. The highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was .
- (d)
- Image Cropping and Gamma CorrectionThe result of the cropping and gamma correction also gives a false impression that the gamma correction might make the technique less accurate. The highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was .
- (e)
- Image Cropping, Equalization and Gamma CorrectionThe best results achieved in the proposed model apply the three image preprocessing steps: image cropping, equalization, and gamma correction. The highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was .
4.2.2. Accuracy with a Five-Fold Cross-Validation Method
This method divided the available images into five approximately equal sets. During each iteration of the cross-validation process, one set was designated as the test set, while the remaining four sets were used for training. This process was repeated five times, with each set being used as the test set once. The final outcome was obtained by averaging the results from these five individual runs, as shown in Table 8.
Table 8.
The evaluation performance of the proposed model for each fold on the CK+, JAFFE, KDEF, and FER datasets.
4.2.3. Comparisons with the State of the Art
The proposed CCNN model’s confusion matrix for the CK+ dataset is presented in Table 9, the confusion matrix for the JAFFE dataset is presented in Table 10, the confusion matrix for the KDEF dataset is presented in Table 11 and the confusion matrix for the FER dataset is presented in Table 12. The proposed model’s facial expression recognition can reach 99.3%, 98.4%, 90.5%, and 69.6% for CK+, JAFFE, KDEF, and FER datasets, respectively.
Table 9.
The classification’s confusion matrix for the CK+ dataset.
Table 10.
The classification’s confusion matrix for the JAFFE dataset.
Table 11.
The classification’s confusion matrix for the KDEF dataset.
Table 12.
The classification’s confusion matrix for the FER dataset.
The performance of the suggested CCNN-SVM model on the CK+ and JAFFE datasets is compared to other recent deep learning models in Table 13.
Table 13.
Comparison of the recognition performance of the proposed model with the state of the art on the JAFFE and CK+ datasets.
5. Conclusions
This paper proposed the CCNN-SVM combined model for facial expression recognition. The model proposes a custom single Deep Convolutional Neural Network (CCNN) to extract features and an SVM classifier for classification. The proposed model was evaluated under different circumstances and hyperparameters to properly tune the proposed model. Based on the outcomes of the experiment, it is clear that preprocessing step achieved the best improvement for CCNN performance. To assess the effectiveness of the suggested model, four publicly available datasets were used, i.e., CK+, JAFFE, KDEF, and FER. Studies have shown that the accuracy of the proposed model is considerably increased when all preprocessing methods are combined. Based on the outcomes, the proposed model obtains higher accuracy and offers a more straightforward solution when compared to the most recent models that employ the same facial expression datasets.
Author Contributions
Conceptualization, D.M.A., M.A. and A.H.A.-A.; Formal analysis, M.A. and A.A.E.-S.; Investigation, M.R. and M.A.; Methodology, D.M.A., A.A.E.-S. and A.H.A.-A.; Software, D.M.A.; Supervision, M.R., A.A.E.-S. and A.H.A.-A.; Validation, M.R.; Writing—original draft, D.M.A.; Writing—review and editing, M.R. and A.H.A.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deanship of Scientific Research, Prince Sattam bin Abdulaziz University, Al-Kharj, Saudi Arabia, supporting this research via funding from Prince sattam bin Abdulaziz University project number (PSAU/2024/R/1445).
Institutional Review Board Statement
Not applicable. No humans or animals were studied, and thus, the university Ethics Committee did not need to be consulted.
Informed Consent Statement
All interviewees agreed to the use of their anonymized responses and feedback for research purposes.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
Acknowledgments
The authors would like to thank the Deanship of Scientific Research, Prince Sattam bin Abdulaziz University, Al-Kharj, Saudi Arabia, for supporting this research via funding from Prince sattam bin Abdulaziz University project number (PSAU/2024/R/1445).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jain, A.K.; Li, S.Z. Handbook of Face Recognition; Springer: New York, NY, USA, 2011; Volume 1. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- Ali, G.; Iqbal, M.A.; Choi, T.S. Boosted NNE collections for multicultural facial expression recognition. Pattern Recognit. 2016, 55, 14–27. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y.; Ma, L.; Guan, J.; Gong, S. Multimodal learning for facial expression recognition. Pattern Recognit. 2015, 48, 3191–3202. [Google Scholar] [CrossRef]
- Fan, X.; Tjahjadi, T. A spatial-temporal framework based on histogram of gradients and optical flow for facial expression recognition in video sequences. Pattern Recognit. 2015, 48, 3407–3416. [Google Scholar] [CrossRef]
- Demirkus, M.; Precup, D.; Clark, J.J.; Arbel, T. Multi-layer temporal graphical model for head pose estimation in real-world videos. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 3392–3396. [Google Scholar]
- Liu, P.; Reale, M.; Yin, L. 3d head pose estimation based on scene flow and generic head model. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 794–799. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Bynagari, N.B. The difficulty of learning long-term dependencies with gradient flow in recurrent nets. Eng. Int. 2020, 8, 127–138. [Google Scholar] [CrossRef]
- Jain, D.K.; Shamsolmoali, P.; Sehdev, P. Extended deep neural network for facial emotion recognition. Pattern Recognit. Lett. 2019, 120, 69–74. [Google Scholar] [CrossRef]
- Sadeghi, H.; Raie, A.A. Suitable models for face geometry normalization in facial expression recognition. J. Electron. Imaging 2015, 24, 013005. [Google Scholar] [CrossRef]
- Farajzadeh, N.; Hashemzadeh, M. Exemplar-based facial expression recognition. Inf. Sci. 2018, 460, 318–330. [Google Scholar] [CrossRef]
- Sadeghi, H.; Raie, A.A. Human vision inspired feature extraction for facial expression recognition. Multimed. Tools Appl. 2019, 78, 30335–30353. [Google Scholar] [CrossRef]
- Makhmudkhujaev, F.; Abdullah-Al-Wadud, M.; Iqbal, M.T.B.; Ryu, B.; Chae, O. Facial expression recognition with local prominent directional pattern. Signal Process. Image Commun. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Automatic deception detection in rgb videos using facial action units. In Proceedings of the 13th International Conference on Distributed Smart Cameras, Trento, Italy, 9–11 September 2019; pp. 1–6. [Google Scholar]
- Leo, M.; Carcagnì, P.; Distante, C.; Mazzeo, P.L.; Spagnolo, P.; Levante, A.; Petrocchi, S.; Lecciso, F. Computational analysis of deep visual data for quantifying facial expression production. Appl. Sci. 2019, 9, 4542. [Google Scholar] [CrossRef]
- Dong, J.; Zheng, H.; Lian, L. Dynamic facial expression recognition based on convolutional neural networks with dense connections. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3433–3438. [Google Scholar]
- Tsai, H.H.; Chang, Y.C. Facial expression recognition using a combination of multiple facial features and support vector machine. Soft Comput. 2018, 22, 4389–4405. [Google Scholar] [CrossRef]
- Wang, C.; Zeng, J.; Shan, S.; Chen, X. Multi-task learning of emotion recognition and facial action unit detection with adaptively weights sharing network. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 56–60. [Google Scholar]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.; Li, X.; Pan, Z.; Luo, D. Semantic neighborhood-aware deep facial expression recognition. IEEE Trans. Image Process. 2020, 29, 6535–6548. [Google Scholar] [CrossRef] [PubMed]
- Chirra, V.R.R.; Uyyala, S.R.; Kolli, V.K.K. Virtual facial expression recognition using deep CNN with ensemble learning. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 10581–10599. [Google Scholar] [CrossRef]
- Gera, D.; Balasubramanian, S. Landmark guidance independent spatio-channel attention and complementary context information based facial expression recognition. Pattern Recognit. Lett. 2021, 145, 58–66. [Google Scholar] [CrossRef]
- Behzad, M.; Vo, N.; Li, X.; Zhao, G. Towards reading beyond faces for sparsity-aware 3d/4d affect recognition. Neurocomputing 2021, 458, 297–307. [Google Scholar] [CrossRef]
- Hernández-Luquin, F.; Escalante, H.J. Multi-branch deep radial basis function networks for facial emotion recognition. Neural Comput. Appl. 2023, 35, 18131–18145. [Google Scholar] [CrossRef]
- Kar, N.B.; Nayak, D.R.; Babu, K.S.; Zhang, Y.D. A hybrid feature descriptor with Jaya optimised least squares SVM for facial expression recognition. IET Image Process. 2021, 15, 1471–1483. [Google Scholar] [CrossRef]
- Kim, J.C.; Kim, M.H.; Suh, H.E.; Naseem, M.T.; Lee, C.S. Hybrid approach for facial expression recognition using convolutional neural networks and SVM. Appl. Sci. 2022, 12, 5493. [Google Scholar] [CrossRef]
- Shaik, N.S.; Cherukuri, T.K. Visual attention based composite dense neural network for facial expression recognition. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 16229–16242. [Google Scholar] [CrossRef]
- Saurav, S.; Saini, R.; Singh, S. Fast facial expression recognition using Boosted Histogram of Oriented Gradient (BHOG) features. Pattern Anal. Appl. 2022, 26, 381–402. [Google Scholar] [CrossRef]
- Jabbooree, A.I.; Khanli, L.M.; Salehpour, P.; Pourbahrami, S. A novel facial expression recognition algorithm using geometry β–skeleton in fusion based on deep CNN. Image Vis. Comput. 2023, 134, 104677. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Liew, C.F.; Yairi, T. Facial expression recognition and analysis: A comparison study of feature descriptors. IPSJ Trans. Comput. Vis. Appl. 2015, 7, 104–120. [Google Scholar] [CrossRef]
- Shima, Y.; Omori, Y. Image augmentation for classifying facial expression images by using deep neural network pre-trained with object image database. In Proceedings of the 3rd International Conference on Robotics, Control and Automation, Chengdu, China, 11–13 August 2018; pp. 140–146. [Google Scholar]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Niu, B.; Gao, Z.; Guo, B. Facial expression recognition with LBP and ORB features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef] [PubMed]
- Gowda, S.M.; Suresh, H. Facial Expression Analysis and Estimation Based on Facial Salient Points and Action Unit (AUs). IJEER 2022, 10, 7–17. [Google Scholar] [CrossRef]
- Borgalli, M.R.A.; Surve, S. Deep learning for facial emotion recognition using custom CNN architecture. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2236, p. 012004. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).