Abstract
Semantic ontologies have been widely utilized as crucial tools within natural language processing, underpinning applications such as knowledge extraction, question answering, machine translation, text comprehension, information retrieval, and text summarization. While the Kurdish language, a low-resource language, has been the subject of some ontological research in other dialects, a semantic web ontology for the Badini dialect remains conspicuously absent. This paper addresses this gap by presenting a methodology for constructing and utilizing a semantic web ontology for the Badini dialect of the Kurdish language. A Badini annotated corpus (UOZBDN) was created and manually annotated with part-of-speech (POS) tags. Subsequently, an HMM-based POS tagger model was developed using the UOZBDN corpus and applied to annotate additional text for ontology extraction. Ontology extraction was performed by employing predefined rules to identify nouns and verbs from the model-annotated corpus and subsequently forming semantic predicates. Robust methodologies were adopted for ontology development, resulting in a high degree of precision. The POS tagging model attained an accuracy of 95.04% when applied to the UOZBDN corpus. Furthermore, a manual evaluation conducted by Badini Kurdish language experts yielded a 97.42% accuracy rate for the extracted ontology.
1. Introduction
The Kurdish language, characterized by its diverse scripts, extensive lexicon, and unique grammatical structure, is spoken by over 40 million people across multiple countries [1,2]. Among its dialects, Badini, predominantly used in the Duhok province of Iraqi Kurdistan and the Hakkari region of southeastern Turkey, holds significant importance [3]. Employing an Arabic-based script, Badini is classified as a low-resource dialect with complex morphological features, including the extensive use of prefixes, suffixes, and vocabulary separation [4]. Linguistic resources, essential for language technology and natural language processing (NLP), represent the culture and civilization of a language’s speakers, providing lexical and semantic definitions [5]. While the Kurdish language is composed of multiple dialects, the development of resources for one dialect can contribute to the enrichment of resources for others. However, the computational analysis of such languages requires substantial time and attention [6].
Part-of-speech (POS) tagging, a fundamental task in NLP, involves assigning syntactic categories to words within a sentence. Its applications span question-answering systems, information extraction, information retrieval, machine translation, text-to-speech, and preprocessing for parsers [7]. POS tagging techniques have evolved from rule-based to machine learning and deep learning models, remaining a focal point of NLP research [8,9]. The Kurdish Badini dialect presents specific challenges for POS tagging, including lexical ambiguity and the presence of unknown words. These challenges are exacerbated by the dialect’s limited available resources and complex morphological structure [10]. To address these challenges, three primary approaches have been employed: rule-based, statistical, and hybrid methods. Rule-based systems rely on linguistically defined rules, while statistical approaches utilize machine learning models trained on tagged corpora. Hybrid methods combine elements of both approaches [11].
This study adopted a hybrid approach used in Maulud’s method [12], which integrated a bi-gram Hidden Markov Model (HMM), with a modified rule-based system tailored for Badini. Maximum likelihood estimation was used for parameter estimation, and the Viterbi algorithm was employed for HMM implementation. A module has been developed to refine tag assignments. In addition, the UOZBDN annotated corpus was created, comprising five categories, 51,761 manually annotated words, and 230 articles. The Kurdish Badini tagset, derived from the Stanford POS tagset, consists of 38 tags and was constructed here. Ontologies, abstract models representing concepts and their relationships, provide a structured approach to information retrieval [13]. This paper presents a methodology for developing a Badini-dialect ontology using the UOZBDN annotated corpus. Due to the scarcity of Kurdish language resources, particularly ontologies, this work contributes to the field of Kurdish content annotation. The proposed ontology automatically extracts relationships between words and phrases, providing insights into their semantic connections. A significant advancement in natural language processing for low-resource languages is presented through the development of the first semantic web ontology for the Badini dialect of Kurdish. A notable gap in linguistic research has been addressed by creating a Badini annotated corpus (UOZBDN), which was used to develop a bi-gram Hidden Markov Model (HMM)-based POS tagger. This tagger, combined with a modified rule-based system, enabled the automatic extraction of semantic relationships, achieving an accuracy rate of 97%, as validated by Badini language experts. The field of semantic web technologies is enriched by this work, which also lays the groundwork for further research into other underrepresented dialects.
The paper is structured as follows: Section 2 provides a comprehensive literature review on Kurdish language processing, encompassing POS tagging, corpus development, and ontology extraction. This section also includes a detailed analysis of the existing literature. Section 3 outlines the methodology employed for this research, including the creation of the UOZBDN corpus, preprocessing, tokenization, sentence splitting, POS tagging, and ontology extraction. Section 4 presents the evaluation of the extracted ontology. Section 5 offers a discussion of the results, highlighting key findings and their implications. Finally, Section 6 concludes the paper by summarizing the research contributions, addressing limitations, and outlining potential avenues for future work.
2. Literature Review
The development of natural language processing applications for the Kurdish language is hindered by a paucity of lexical resources and corpora. Existing Kurdish dictionaries often lack lexicographical rigor, with inconsistent part-of-speech tagging and the inclusion of terms from various dialects. Moreover, the prevalence of physical formats limits digital accessibility, impeding the efficient creation of ontological term lists [2]. Research efforts have focused on addressing the challenges posed by the Kurdish language’s complex morphology, low-resource nature, and multi-dialectal characteristics [14]. Preprocessing, tokenization, POS tagging, and ontology extraction have been investigated as potential solutions.
Effective textual analysis requires robust preprocessing techniques. Although data annotation is labor-intensive, it remains essential for model development. In 2021, Amini introduced Awta, the first comprehensive parallel corpus consisting of Central Kurdish and English translations. This corpus, comprising 229,222 meticulously aligned sentence pairs from various text genres and domains, was designed to facilitate the development of robust and practical machine translation systems. However, a comprehensive examination of error types encountered by the machine translation system and their treatment was not included, which could assist in identifying areas where the system faces challenges [15].
Badawi et al. (2023) noted that a significant challenge with existing datasets is the prevalence of grammatical and dictation errors. They emphasized the necessity of having a sufficient dataset to better understand the syntactic and semantic characteristics of the Kurdish language. In their study, headlines from the Kurdish News Dataset (KNDH) were collected for text categorization. The dataset consists of 50,000 news headlines evenly distributed across five categories: social, sport, health, economics, and technology. The Kurdish Language Processing Toolkit (KLPT) was employed for tokenization, spell-checking, stemming, and general preprocessing [15].
Tokenization, a fundamental NLP process, is particularly challenging for languages with complex writing systems and spelling variations. A method for tokenizing the Sorani and Kurmanji dialects of Kurdish was proposed by S. Ahmadi in 2020. This approach, employing a lexicon and a morphological analyzer, demonstrated superior performance compared to unsupervised alternatives [16]. Another study by the same author also contributed to the field by compiling corpora for the Zazaki and Gorani dialects of Kurdish. These corpora, comprising over 1.6 million and 194,000 word tokens, respectively, were constructed from news website content to establish foundational resources for these languages [17].
POS tagging is essential for enhancing the utility of Kurdish corpora. Research has explored various methodologies, including rule-based and statistical approaches. In 2023, Maulud et al. introduced a Sorani Kurdish corpus annotated with POS tags. This corpus, comprising 74,258 words and 38 tags, was created using a hybrid approach combining a bigram HMM with a Kurdish rule-based system. Despite the corpus’s limited size, an accuracy rate of approximately 96% was achieved [12]. A study by Morad et al. (2024) focused on addressing the challenges of part-of-speech (POS) tagging and tokenization for Northern Kurdish. They evaluated various statistical, neural, and fine-tuned transformer-based models specifically tailored for Northern Kurdish, utilizing both the Universal Dependency Kurmanji treebank, contributed by Memduh Gökırmak and Francis M. Tyers in 2017 [18], and a newly developed, manually annotated, gold-standard dataset comprising 136 sentences with 2937 tokens. The findings demonstrated that the fine-tuned transformer-based model significantly outperformed the other models, achieving an accuracy of 0.87 and a macro-averaged F1 score of 0.77 [19].
Ontology extraction aims to create structured knowledge representations from textual data. In 2017, H. Hassan presented a technique for accurately extracting proper nouns from Kurdish literature. An application was developed utilizing various name lists, rules, and procedures to identify Kurdish person names [20]. This research contributed to advancing Kurdish information retrieval and simplifying machine translation processes. The proposed method demonstrated accuracy exceeding 95%, with recall ranging from 40% to 80% and an F-measure between 60% and 80%.
The existing works were analyzed by categorizing them into three primary areas: (1) Preprocessing and Tokenization: Preprocessing, tokenization, and POS tagging are emphasized in various Kurdish dialects, particularly Sorani and Kurmanji. These tasks are essential for the development of NLP tools but are not directly linked to ontology extraction. Existing tokenization methods, such as those proposed by Ahmadi, are valuable but fail to address the full complexity of dialectal diversity, especially within the Badini dialect. (2) POS Tagging: Significant advancements in POS tagging have been made through hybrid models and transformer-based approaches, as demonstrated by Maulud et al. and Morad et al. However, the focus remains largely on Kurmanji and Sorani dialects, leaving a gap in tailored solutions for the Badini dialect. Furthermore, these studies concentrate primarily on syntactic classification, rather than addressing the semantic relationships critical to ontology extraction. (3) Ontology Extraction: The primary research in ontology extraction, such as Hassan’s work, has been limited to extracting specific entity types, such as proper nouns. This focus omits more complex tasks, including verb–noun pair identification, which is essential for constructing a more nuanced ontology capable of representing actions, events, and relationships between entities.
The proposed method distinguishes itself from the existing works in several significant ways: (1) Dialectal Focus: While most studies have focused on Sorani and Kurmanji dialects, the proposed method prioritizes the Badini dialect, which uses an Arabic-based script and has not been extensively explored in NLP research. Existing works offer valuable frameworks but lack the specificity required to address the dialectal diversity within Badini. (2) Verb–Noun Pair Extraction: In contrast to the reviewed studies, which primarily focus on proper noun extraction or general POS tagging, the proposed method targets the extraction of verb–noun pairs. This approach provides a more comprehensive ontology that captures actions and relationships within the language, moving beyond the entity-level focus of previous research. (3) Corpus and Dataset Development: The UOZBDN corpus developed in the proposed method addresses the limitations of earlier datasets by focusing specifically on the Badini dialect. Prior corpora, such as Amini’s Awta corpus and Ahmadi’s Sorani and Kurmanji corpora, have not fully captured the linguistic nuances of Badini, particularly concerning its verb and noun structures.
In conclusion, the proposed method significantly differs from previous works through its emphasis on the Badini dialect, its focus on verb–noun pair extraction for ontology development, and the creation of a tailored corpus that directly addresses the challenges specific to this dialect. These contributions fill a critical gap in Kurdish NLP research, expanding the scope of ontology extraction for under-represented dialects.
3. Methodology
The Kurdish language is characterized by a diverse range of dialects, a distinct grammatical structure, and an extensive lexicon. While some linguistic resources for Kurdish exist, a substantial text corpus is required to effectively support practical language processing applications. To date, limited efforts have been undertaken to compile Kurdish linguistic resources, resulting in a scarcity of research on Kurdish language processing. Despite being spoken by a significant population, Kurdish lacks sufficient computational resources. Text corpora, collections of representative texts in a specific language, are indispensable for numerous NLP applications [21].
To address this deficiency, the UOZBDN corpus was created and developed. This corpus was constructed by gathering and processing text data from various domains. Preprocessing techniques were applied, and the KLPT package was employed for tokenization [22]. POS tagging was performed using a Sorani model in [12], with a modified rule-based system tailored for Badini, and Hidden Markov Models with the Viterbi algorithm were utilized for POS tagging and unknown word identification. Moreover, ontology concepts and relationships were extracted from Badini-dialect sentences.
The diagram in Figure 1 outlines the comprehensive process of ontology extraction for Badini Kurdish text, with each step visually interconnected to form a coherent workflow. The system begins with raw text input, followed by key preprocessing steps: normalization, tokenization, and sentence segmentation. Once preprocessed, manual annotation is performed, which feeds into the tagged corpus. The corpus is then divided into training and test sets. The Hidden Markov Model (HMM) is applied to the training corpus for calculating emission and transition probabilities, enabling tag calculations. These calculated tags are subsequently used to predict parts of speech (POS) for the test corpus via the Viterbi algorithm, especially focusing on unknown words. If unknown words are encountered, the system assigns tags based on regular expression rule-based logic and suffixes. The diagram further indicates the process for ontology extraction through the identification of specific linguistic patterns, including extracted nouns and verbs. The overall architecture clearly emphasizes the integration of rule-based approaches alongside probabilistic modeling (HMM), ensuring robust POS tagging and ontology extraction from the corpus. Each system component, from preprocessing to rule-based tag assignment, plays a crucial role in the ultimate goal of extracting semantic entities like nouns and verbs. In the subsequent sections, each stage of this workflow is explained in greater detail, including the specific methodologies employed for POS tagging and ontology extraction.
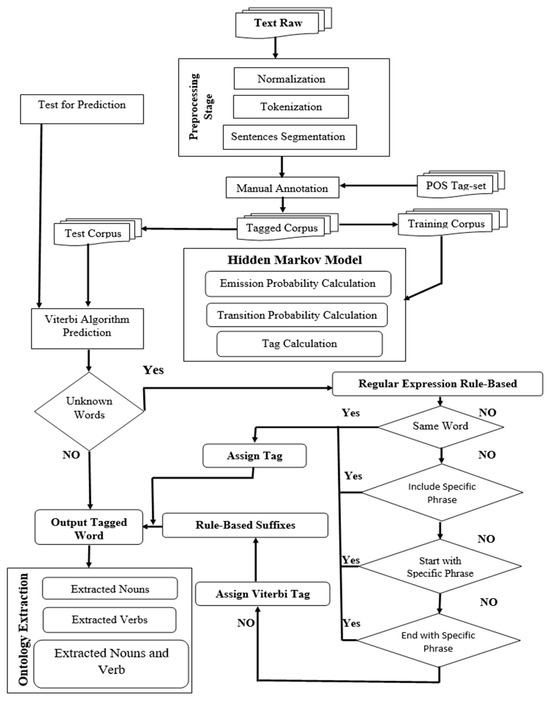
Figure 1.
System architecture for ontology extraction from Badini Kurdish text.
3.1. Corpus Creation
The UOZBDN corpus encompasses five distinct domains: sports, politics, health, society, and economics. It comprises approximately 51,761 words distributed across 230 articles and 896 sentences, as shown in Table 1. Python programming was utilized to implement the necessary software for preprocessing tasks, ensuring compatibility with the diverse dialects and scripts of the Kurdish language, specifically the Badini dialect. The UOZBDN corpus is exclusively composed of Badini-dialect text. Given the challenges associated with collecting extensive data from Kurdish language websites, particularly those featuring the Badini dialect, the EvroNews (https://rojnameyaevro.com), accessed on 8 September 2024 website was selected as the primary data source. Raw data were extracted from this online publication between 31 January 2022 and 22 May 2022.

Table 1.
Details of the unannotated data for UOZBDN.
3.1.1. Preprocessing
The majority of Kurdish textual materials remain undigitized, while those that are accessible often exhibit inconsistencies in format and conversion [23]. The absence of a standardized writing system and limited Unicode keyboard support further compound challenges in Kurdish text processing [24]. Preprocessing, a critical initial step in corpus creation, involves transforming data into a computer-readable format. To establish a foundation for the UOZBDN corpus, character encoding uniformity was achieved through preprocessing. Python modules and the KLPT were employed to standardize character encoding based on the alphabet, with the results stored in a Python-ordered dictionary. A dedicated preprocessing module was developed to normalize Kurdish text, unifying characters and standardizing spelling.
The Badini dialect’s complex word formation, allowing for multiple representations of the same word, presented an additional challenge. This issue was addressed by consolidating word forms into a single standardized representation. For instance, the words “چونا,” “جوونا” and “چوون” were unified as “چوونا” and “ل دووف,” “ل دووڤ” and “لدویڤ” were standardized as “ل دویڤ.” The preprocessing phase encompassed the normalization, standardization, and unification of letters and words based on the specified parameters.
3.1.2. Tokenization and Sentence Splitting
Tokenization, the process of identifying text boundaries at the sentence, phrase, and word levels, presents unique challenges in the Badini dialect compared to Kurmanji and Sorani [25,26]. The complex morphology and affixation within the Badini writing system often hinder accurate word segmentation, despite the use of punctuation and whitespace in the Arabic-based script. To address these complexities, a combination of word-based tokenization and text splitting was employed. The KLPT package was utilized to implement a tokenization strategy that leverages an annotated vocabulary and a morphological analyzer to convert lengthy text sequences into tokens. Sentence segmentation involves identifying sentence boundaries within a text. The KLPT was employed to facilitate tokenization by utilizing punctuation marks. A basic sentence tokenizer relying on punctuation marks and line breaks was applied to determine sentence boundaries in the Badini text.
3.2. The Hybrid Approach to Part-of-Speech Tagging
Part-of-speech tagging, the assignment of grammatical categories to words, is a critical task in natural language processing. Accurate POS tagging is essential for numerous NLP applications. While challenging due to ambiguous and unknown terms, POS tagging involves assigning unique labels to words or tokens, indicating their part of speech and grammatical features [27]. This process encompasses several stages.
3.2.1. Manual Annotation
A tag set is a comprehensive collection of part-of-speech tags within a corpus. Annotated corpora are indispensable for developing NLP tools such as POS taggers, serving as training data to capture the complexities of human language within specific domains or linguistic varieties. In a pioneering effort to apply machine learning to POS tagging for Badini Kurdish using an annotated corpus, significant challenges were encountered. The absence of a pre-existing annotated corpus, undefined textual formats, and language ambiguities posed obstacles. Nevertheless, substantial progress in Badini Kurdish NLP was achieved through addressing these issues.
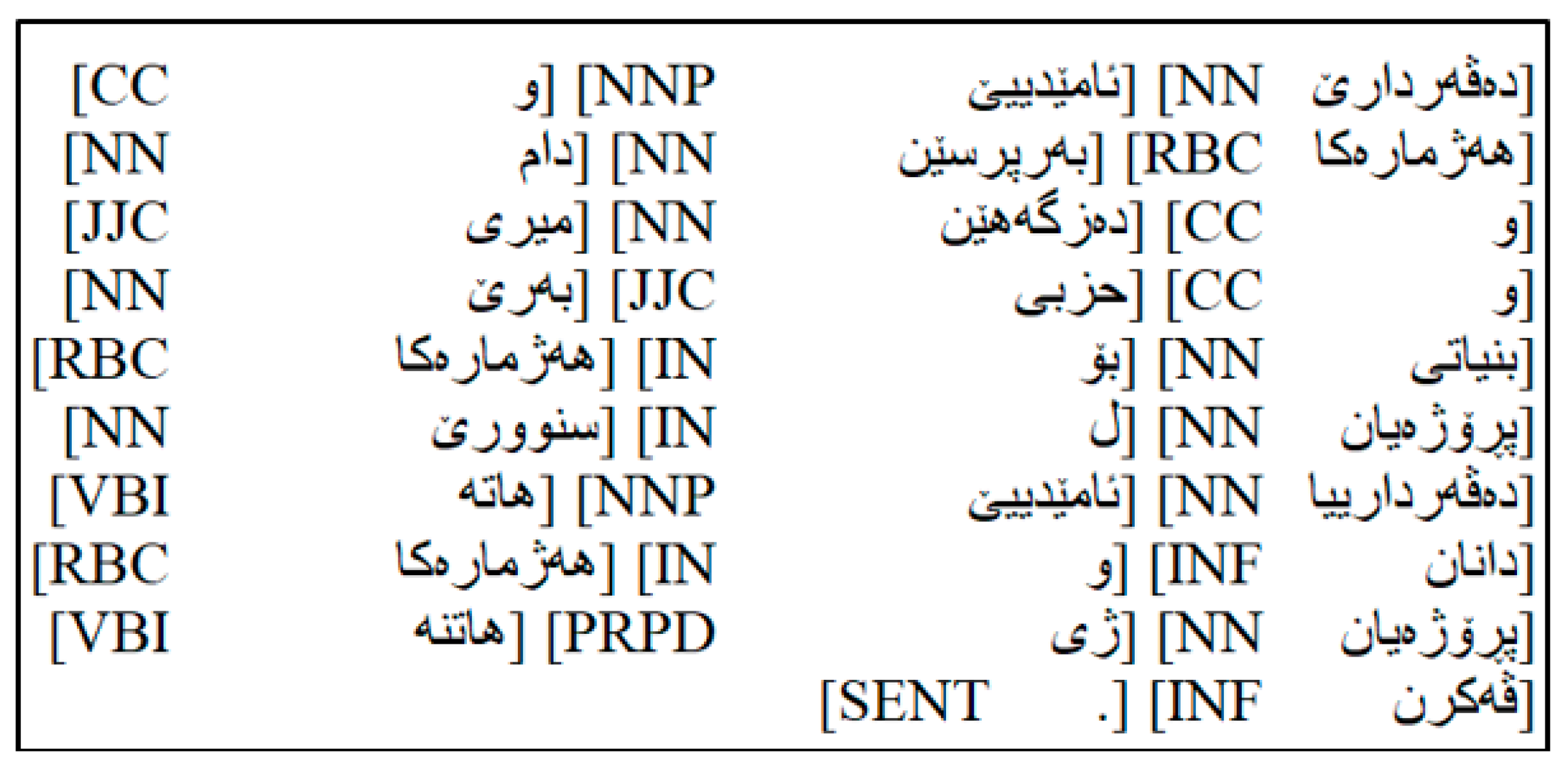
The corpus was manually annotated using a specific tag set under the guidance of the Zakho Center for Kurdish Studies (https://zcks.uoz.edu.krd), accessed on 7 September 2024, at the University of Zakho. This involved assigning POS tags to each word in the unannotated data. Accurate manual annotation is crucial for evaluating POS tagger performance. Figure 2 presents a sample of manually annotated text.
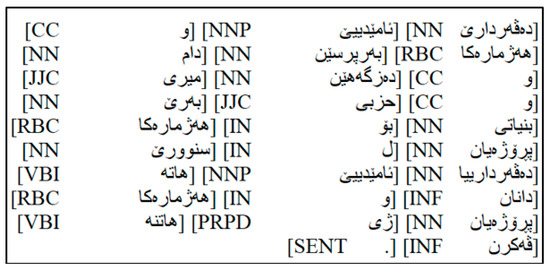
Figure 2.
A sample of manually annotated text.
3.2.2. Part-of-Speech Tagset
Part-of-speech (POS) tagging involves assigning appropriate POS labels to individual words within a text. These labels, also known as word classes, morphological classes, or lexical labels, provide valuable contextual information for language processing [28]. A tagset encompasses the entire set of POS tags utilized within a corpus.
The creation of an annotated Badini Kurdish corpus presented significant challenges due to the absence of existing POS-tagged corpora, inconsistent writing standards, and ambiguous word meanings within phrases. To address these issues, a tailored tagset was developed and applied through manual annotation. The lack of standardized writing, variations across dialects, spelling inconsistencies, and disparities between spoken and written language further complicated the process.
Basic POS tags were assigned to each word through manual annotation. The UOZBDN corpus employs a tagset consisting of 38 tags to categorize different parts of speech, including nouns (NN), proper nouns (NNP), verbs (VBT), adjectives (ADJ), pronouns (PR), adverbs (RB), infinitives (IN), coordinating conjunctions (CC), interjections (UH), abbreviations (ABR), numerals (NUM), foreign words (FW), symbols (SYM), and others. Table 2 provides a detailed description of the tagset, while Table 3 presents tag frequency statistics within the UOZBDN corpus.
Table 2.
Tagset of the Badini dialect.
Table 3.
Statistics on the frequency of tag use in the UOZBDN corpus.
3.2.3. Hidden Markov Model
The UOZBDN annotated corpus comprises multiple sequential processes. Statistical language models are constructed, refined, and applied to automate POS tagging within statistical techniques. Contemporary research predominantly focuses on statistically based or Hidden Markov Model (HMM) approaches for POS tagging [29]. Initially, the corpus was divided into training and testing subsets. Subsequently, transition probabilities, emission probabilities, and tags were determined using the Hidden Markov Model. The Viterbi algorithm was applied to calculate transition and emission probabilities for the HMM bi-gram. The UOZBDN corpus achieved accuracy of 95%, as indicated in Table 4, which presents system accuracy across various scenarios.
Table 4.
Accuracy of the system in different cases for POS tagging.
Standard practice in POS tagging involves partitioning the dataset into training and testing subsets for parameter learning and evaluation, respectively. Five iterations were conducted, with each iteration randomly selecting 15% of UOZBDN corpus sentences for the test set and utilizing the remaining data for training. System performance was assessed using accuracy, recall, precision, and F-score metrics. Table 5 presents the system’s precision, recall, and F1 score across different scenarios.
Table 5.
The results of the system in different cases for POS tagging.
3.2.4. Application of the Viterbi Algorithm for POS Tagging
The Viterbi algorithm was employed in conjunction with the HMM algorithm to determine the most probable tag sequence through a decoding process. This phase involved applying the Viterbi algorithm to explore potential tag sequences, select the most likely sequence, and generate predictions for both known and unknown terms. Text prediction was conducted on the training corpus and evaluated on the test corpus to assess model performance. The UOZBDN corpus includes word labels representing grammatical roles such as nouns, verbs, adjectives, adverbs, pronouns, prepositions, conjunctions, and interjections. When testing words within the tagger, they are categorized as either known or unknown, with the latter labeled as “--unk--.” The following example demonstrates how the Viterbi algorithm is employed to address the challenges of POS tagging in low-resource languages like Badini Kurdish. Table 6 presents POS tagging examples for sentences containing grammatical elements.
Table 6.
POS tagging for sentences in the UOZBDN corpus.
Example: Sentence
“ حکومەتا هەرێما کوردستانێ ڕازیبوون ل سەر دامەزراندنا ١٠٠ کارمەندێن ساخلەمیێ د بیاڤێن جوداجودا دا کرییە و ناڤ ژی بۆ جهێن بلند هاتینە هنارتن و د دەمەکێ نێزیک دا ناڤ دێ هێنە ڕاگەهاندن. # ”
“The government of the Kurdistan Region has approved the employment of 100 healthcare workers across various fields. The names have been submitted to the relevant authorities, and they will be announced soon.”
The algorithm accurately assigns POS tags to words like “حكومەتا” (government) and “ڕازیبوون” (agreement), demonstrating its effectiveness in handling complex grammatical structures.
3.2.5. Rule-Based Suffixes Approach
Rule-based approaches are widely adopted due to their accuracy and practicality, particularly when addressing languages with complex morphology, such as Kurdish [30]. To enhance accuracy and reduce the number of unknown words, a rule-based technique was integrated into the Sorani model for POS tagging. Additionally, a rule-based suffixes approach was implemented to optimize outcomes and facilitate the annotation of findings through the application of appropriate rules. A rule-based POS tagger was developed using Python, incorporating a set of organized rules. These rules were applied to assign POS tags, with a particular focus on reducing the number of unknown words. The combination of rule-based procedures and the rule-based suffixes approach proved effective in mitigating unknown phrase occurrences.
To further improve accuracy and address unknown terminology, supplementary criteria for identifying words with suffixes were established. A collaborative effort involving Badini Kurdish experts, reference grammarians, academics, and translators resulted in the creation of a comprehensive set of suffix rules. These rules were designed to assign appropriate tags based on word attributes.
Noun Suffixes
Certain suffixes differentiate between common and proper nouns in both singular and plural forms, as illustrated in Figure 3 and Figure 4.

Figure 3.
Noun suffixes.

Figure 4.
Suffixes for proper nouns.
Verb Suffixes
Suffixes explicitly distinguish between transitive and intransitive verbs, as demonstrated in Figure 5.

Figure 5.
Suffixes used for transitive and intransitive verbs.
Adverb Suffixes
Suffixes clearly denote time adverbs, place adverbs, description adverbs, and degree adverbs, as shown in Figure 6.

Figure 6.
Suffixes used for time adverbs, location adverbs, description adverbs, and degree adverbs.
Adjective Suffixes
Suffixes differentiate between descriptive and indefinite adjectives, as presented in Figure 7.

Figure 7.
Suffixes for descriptive adjectives and indefinite adjectives.
A comparison between the Badini model and the Sorani model for POS tagging revealed overall accuracy of 96% for the Sorani model, proposed in [12], and approximately 95% for the current proposed Badini model. The UOZBDN corpus comprises 896 phrases, 38 tags, and a vocabulary of approximately 51,761 words across 230 articles, while DASTAN’s corpus, which is used by the Sorani model, includes 74,259 words, 218 articles, 3163 phrases, and 38 tags. Although the Badini model exhibited 1% lower accuracy compared to the Sorani model, this is most likely due to corpus size differences; the results demonstrate the effectiveness of the proposed approach.
3.3. Comparison of Badini and Sorani Models for POS Tagging
In this section, a comparison is made between the performance of the proposed Badini model and the Sorani model for part-of-speech (POS) tagging. This comparison is particularly insightful given that both models utilize corpora written in the Arabic script, although they address different Kurdish dialects—Badini and Sorani, respectively. The Badini annotated corpus (UOZBDN) was developed as part of this work, marking a significant contribution to the field as the first corpus specifically created for the Badini dialect. The UOZBDN corpus comprises 896 phrases, 38 tags, and a vocabulary of approximately 51,761 words across 230 articles. In contrast, DASTAN’s corpus, used by the Sorani model, includes 3163 phrases, 38 tags, and 74,259 words across 218 articles. Despite these differences in corpus size, comparable performance was demonstrated by the model on both datasets. Overall accuracy of approximately 95% was achieved by the Badini model on the UOZBDN corpus, while slightly higher accuracy of 96% was achieved by our model on DASTAN’s corpus. This slight discrepancy is likely due to the larger size and broader coverage of the Sorani corpus, which may have provided more robust training data for the model. Additionally, an innovative feature for the automatic extraction of semantic relationships has been included in the method, with the results validated by experts in the Badini language. This capability further distinguishes this work, offering a structured approach to understanding and processing the semantic connections within the Badini dialect. In summary, the results demonstrate the efficacy and adaptability of the method across different Kurdish dialects, while also highlighting the unique contributions of this research, particularly the creation of the first-ever Badini corpus and the development of a POS tagging model specifically tailored for this dialect.
3.4. Ontology Extraction for the Badini Dialect
Due to the paucity of substantial linguistic resources and literature, this ontology extraction initiative represents a pioneering effort for the Badini dialect. Ontology, a critical component of the Semantic Web, enhances information extraction efficiency [31]. Ontology extraction, drawing upon natural language processing and knowledge representation techniques, finds applications in information retrieval, data integration, semantic web development, and knowledge management [32]. The primary objective of this ontology is to streamline the semantic tagging of Badini-dialect text. The UOZBDN corpus data are organized into an ontology, serving as a formal knowledge representation.
Extraction of Noun–Verb Pairs
Given the frequent use of lengthy sentences with commas in Badini Kurdish writing, points and commas were employed to divide sentences for enhanced ontology extraction precision. The extracted ontology encompasses concepts, definitions, properties, and relationships identified within the text. A focus on noun–verb pairs and accompanying phrases facilitated the analysis of the grammatical structure of Badini text. The extraction process commenced with verb identification within Badini sentences. Subsequent POS tagging categorized words into nouns, verbs, adjectives, adverbs, and other parts of speech. Generated lists containing words and corresponding POS tags were then examined to identify noun–verb pairs or sequences, such as [VBT (NN1, NN2, …, NNn)] or [VBT (NN1, NNP2, …, NNn)]. Given the diverse grammatical forms in Badini sentences, including adjectives, pronouns, adverbs, and others, these elements were represented symbolically in the results. Ultimately, noun–verb pairs were extracted from the Badini text, as shown in the following example. Table 7 presents POS tagging results, while Table 8 illustrates the ontology extraction process for nouns and verbs within a given sentence in the following example.
Table 7.
POS tagging for the given example.
Table 8.
Ontology extraction and relationships for each word.
Example, in the input sentence:
“پشتی عەمرێ 6 سالیێ پێدڤیە زارۆکێ خۆ فێربکەی ڕێزێ ل کەسێن مەزنتر بگریت و ب جوانی ڕەفتارێ لگەل بكەت.”
“After the age of 6, a child needs to be taught to respect elders and to interact with them politely.”
The extraction process yielded sequences such as the following:
- ○
- (عەمرێ, زارۆکێ) فێربکەی)) → VBT (NN, NN).
- ○
- (ڕێزێ,کەسێن) بگریت)) → VBT (NN, NN).
- ○
- (ڕەفتارێ) بكەت)) → VBT (NN).
4. Evaluation
Corpus-based techniques, also known as data-driven approaches, are employed to assess the topical coverage of an ontology. This methodology involves comparing the extracted ontology with a comprehensive corpus representing a specific domain. Unlike traditional ontology comparison methods that rely on pre-existing ontologies, this approach enables the comparison of multiple ontologies with a corpus [33]. A data-driven approach was utilized to evaluate the developed system. The corpus, encompassing five previously unexplored domains (economics, health, politics, social, and sports), served as the evaluation basis. By analyzing the Badini-dialect corpus, a robust ontology was constructed. Nouns and verbs were identified and extracted from the text, and their correctness was calculated using data-driven methodologies. The resulting ontology contained 2249 ontological sentences and 1320 normal phrases.
The evaluation approach relied on precision, recall, and F1-measure metrics. Recall was calculated as the ratio of accurately identified ontology sentences to the total number of phrases in the sample. Precision was determined by dividing the number of accurately identified ontologies by the total number of identified ontologies. A data-driven evaluation yielded precision of 97.06%, recall of 97.78%, and F-measure of approximately 97.42%. These results represent a significant achievement in the field of Kurdish language processing, particularly for the Badini dialect, as this level of accuracy has not been previously reported. Table 9 presents the detailed results of the evaluated ontology. The values for true positive (TP), false positive (FP), false negative (FN), and true negative (TN) were obtained by comparing the findings to the original text.
Table 9.
Results of the evaluated ontology sentences.
Given the importance of both precision and recall in ontology extraction, the G-measure, a metric that combines these two measures, was deemed appropriate for evaluating our system. The G-measure’s impartiality towards accuracy and recall makes it suitable for tasks where both aspects are equally critical. By considering both the proportion of correctly extracted entities (precision) and the proportion of relevant entities successfully extracted (recall), the G-measure provides a balanced assessment of the ontology extraction system’s performance.
In the evaluation of ontology extraction from textual data, confidence intervals were calculated to assess the reliability of the system’s performance in extracting ontological predicates. A 95% confidence interval was selected, corresponding to a Z-value of 1.96, as 95% of data fall within ±1.96 standard deviations of the mean in a normal distribution. With a sample size of 2249 extracted predicates, the system’s performance metrics were as follows: precision (0.9706), recall (0.9778), F1 score (0.9742), and G-measure (0.9742). The 95% confidence intervals for these metrics were calculated as precision [0.9636, 0.9776], recall [0.9717, 0.9839], F1 score [0.9677, 0.9807], and G-measure [0.9677, 0.9807]. The confidence interval for precision indicates that the true precision of the system, representing the proportion of correctly extracted predicates, lies between 96.36% and 97.76%, reflecting high reliability. The recall interval suggests that the system accurately captures between 97.17% and 98.39% of relevant predicates, demonstrating minimal omission of actual predicates. The F1 score, a harmonic mean of precision and recall, indicates a balanced performance with a likely value between 96.77% and 98.07%, further supported by the identical confidence interval for the G-measure. These consistently narrow intervals indicate a highly reliable and effective ontology extraction system, with performance metrics consistently above 96%, underscoring the system’s robustness in extracting both correct and relevant predicates from textual data.
5. Discussion
The Badini dialect presents several challenges, particularly due to the absence of a fully standardized writing system, complicating the development of comprehensive linguistic resources. While semi-standardized writing methods for Badini exist, they remain inadequately established, and no uniform system has been universally adopted. During the creation of the UOZBDN corpus, these challenges were encountered and addressed with the assistance of language experts at the Zakho Center for Kurdish Studies, who are actively working towards the standardization of the Badini dialect. Despite their critical input in managing linguistic diversity, the lack of a finalized standard remains a limitation of the current study.
To address variation within the dialect, text from official publications such as newspapers, which adhere to semi-standardized writing conventions, was used. These sources reflect recent efforts towards a more consistent form of Badini, mitigating some of the challenges posed by its variability. However, it is acknowledged that dialectal diversity, particularly in spoken forms, may continue to impact the system’s performance in extracting semantic ontologies and classifying linguistic features.
The system’s performance was evaluated against large language models (LLMs), including ChatGPT, which exhibit strong capabilities in general natural language understanding. It was observed, however, that the proposed model outperformed these LLMs in the context of Badini, particularly in handling the dialect’s specific linguistic nuances. This suggests that specialized models may offer superior performance for low-resource languages, as discussed in Section 3.3.
Significant modifications were necessary when adapting the Sorani model to the Badini dialect, particularly in the rule-based components of the system. The unique linguistic features of Badini required substantial adjustments, emphasizing the need for NLP tools to be tailored to the specific characteristics of each dialect, rather than relying on generalized models designed for related languages.
The size of the UOZBDN corpus also poses a limitation in capturing the full range of linguistic nuances in Badini. Although the corpus was completed in 2024 as part of an ongoing research project at the Semantic Web Lab at the University of Zakho, further expansion is necessary to enhance the system’s performance and better reflect the dialect’s complexity. Steps have already been taken to expand the corpus, which is expected to improve the system’s ability to manage the diversity of Badini and enhance overall model performance.
6. Conclusions
Extracting ontology from the Kurdish Badini dialect presents significant challenges due to dialectal diversity and limited available resources. Nonetheless, it offers substantial benefits in supporting and preserving the Kurdish community through the development of machine-readable Kurdish semantic web content. This study introduces a novel methodology for Badini-dialect ontology extraction. The UOZBDN corpus, comprising 51,761 words, was created to support this research.
The integration of the Sorani model with the HMM and rule-based methodologies, tailored for the Badini dialect, significantly improved POS tagging accuracy. A customized ontology was designed to annotate lexical semantic relations within Badini text. The resulting ontology effectively enabled the extraction of concepts and relationships between nouns and verbs within sentences. This research offers a novel perspective on Badini-dialect ontology and contributes to the field by introducing the UOZBDN corpus, thereby advancing the technological development of the Badini Kurdish language. An accuracy rate of 95.04% was achieved for POS tagging using the UOZBDN corpus, while the ontology extraction evaluation yielded accuracy of 97.42%.
The limitations of the proposed method have been identified and should be considered in future research. Although the UOZBDN corpus was specifically designed for the Badini dialect, its limited size and domain coverage restrict the generalizability of the ontology extraction process to other dialects and broader linguistic contexts. Additionally, the focus on the Badini dialect introduces challenges in handling the linguistic diversity of Kurdish dialects, which may reduce the system’s effectiveness when applied to other dialects such as Sorani without significant adaptation. Furthermore, the reliance on manual annotation for ontology extraction remains labor-intensive and susceptible to human error, underscoring the need for more automated approaches to improve scalability and accuracy. Finally, the absence of publicly available, large-scale Kurdish corpora limits the ability to benchmark and compare the proposed system with other methodologies, constraining comprehensive evaluation efforts.
Future research will focus on expanding the UOZBDN corpus and incorporating more diverse data sources to enhance the system’s accuracy and adaptability. This expansion will further address the linguistic diversity of Badini, with ongoing efforts aimed at standardizing the dialect. Overall, this work offers substantial contributions to Kurdish language processing, advancing the understanding and technology available for low-resource languages.
Author Contributions
Conceptualization, M.A. and K.J.; methodology, M.A.; software, M.A.; validation, M.A., I.A. and K.J.; formal analysis, M.A.; investigation, M.A.; resources, M.A.; data curation, M.A.; writing—original draft preparation, M.A.; writing—review and editing, I.A.; visualization, M.A.; supervision, K.J.; project administration, M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This project received no external funding and was supported by internal resources from the Semantic Web Lab at the University of Zakho.
Data Availability Statement
Data can be made available upon reasonable request.
Acknowledgments
The authors express sincere gratitude to the language experts at the Zakho Center for Kurdish Studies, led by Abdulsalam Najimaldeen Abdullah, for their invaluable contributions to this research. Their expertise in the Badini dialect was instrumental in the creation and refinement of the UOZBDN annotated corpus.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Saeed, A.M.; Ismael, A.N.; Rasul, D.L.; Majeed, R.S.; Rashid, T.A. Hate Speech Detection in Social Media for the Kurdish Language. In Proceedings of the ICR’22 International Conference on Innovations in Computing Research, Athens, Greece, 29–31 August 2022; Daimi, K., Al Sadoon, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 253–260. [Google Scholar]
- Naserzade, M.; Mahmudi, A.; Veisi, H.; Hosseini, H.; MohammadAmini, M. CKMorph: A comprehensive morphological analyzer for Central Kurdish. Int. J. Digit. Humanit. 2023, 5, 187–232. [Google Scholar] [CrossRef]
- Weeden, M.J.N. Postgate (ed.): Languages of Iraq, Ancient and Modern. ix, 187 pp. London: British School of Archaeology in Iraq, 2007. ISBN 978 0 903472 21 0. Bull. Sch. Orient. Afr. Stud. 2008, 71, 397–399. [Google Scholar] [CrossRef]
- Syan, K.A.Q. Media in an Emergent Democracy: The Development of Online Journalism in the Kurdistan Region of Iraq. Ph.D. Thesis, University of Bradford, Bradford, UK, 2017. [Google Scholar]
- Azin, Z.; Ahmadi, S. Creating an Electronic Lexicon for the Under-resourced Southern Varieties of Kurdish Language. In Proceedings of the Electronic Lexicography in the 21st Century Conference, Brno, Czech Republic, 5–7 July 2021; pp. 479–488. [Google Scholar]
- Tavadze, G. Spreading of the Kurdish Language Dialects and Writing Systems Used in the Middle East. Bull. Georg. Natl. Acad. Sci. 2019, 13, 170–174. [Google Scholar]
- Hassani, H. Part of Speech Tagging (POST) of a Low-Resource Language Using Another Language (Developing a POS-Tagged Lexicon for Kurdish (Sorani) using a Tagged Persian (Farsi) Corpus). arXiv 2022, arXiv:2201.12793. [Google Scholar]
- Amri, S.; Zenkouar, L. Amazigh POS Tagging using TreeTagger: A Language Independant Model; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2019; Volume 915, ISBN 978-3-030-11927-0. [Google Scholar] [CrossRef]
- Maulud, D.H.; Ameen, S.Y.; Omar, N.; Kak, S.F.; Rashid, Z.N.; Yasin, H.M.; Ibrahim, I.M.; Salih, A.A.; Salim, N.O.; Ahmed, D.M. Review on Natural Language Processing Based on Different Techniques. Asian J. Res. Comput. Sci. 2021, 10, 1–17. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. CSUR 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Ahmadi, S.; Hassani, H.; McCrae, J.P. Towards electronic lexicography for the Kurdish language. In Proceedings of the Sixth Biennial Conference on Electronic Lexicography (eLex), Sintra, Portugal, 1–3 October 2019. [Google Scholar]
- Maulud, D.; Jacksi, K.; Ali, I. A hybrid part-of-speech tagger with annotated Kurdish corpus: Advancements in POS tagging. Digit. Scholarsh. Humanit. 2023, 38, 1604–1612. [Google Scholar] [CrossRef]
- Sharipov, M.; Kuriyozov, E.; Yuldashev, O.; Sobirov, O. UzbekTagger: The Rule-Based POS Tagger for Uzbek Language. arXiv 2023, arXiv:2301.12711. [Google Scholar]
- Azzat, M.; Jacksi, K.; Ali, I. The Kurdish Language Corpus: State of the Art. Sci. J. Univ. Zakho 2023, 11, 125–131. [Google Scholar] [CrossRef]
- Badawi, S.; Saeed, A.M.; Ahmed, S.A.; Abdalla, P.A.; Hassan, D.A. Kurdish News Dataset Headlines (KNDH) through multiclass classification. Data Brief 2023, 48, 109120. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, S. A Tokenization System for the Kurdish Language. In Proceedings of the 7th VarDial Workshop on NLP for Similar Languages, Varieties and Dialects, Barcelona, Spain, 13 December 2020; pp. 114–127. [Google Scholar]
- Ahmadi, S. Building a Corpus for the Zaza–Gorani Language Family. In Proceedings of the 7th VarDial Workshop on NLP for Similar Languages, Barcelona, Spain, 13 December 2020; pp. 70–78. [Google Scholar]
- Gökırmak, M.; Tyers, F.M. A Dependency Treebank for Kurmanji Kurdish. In Proceedings of the Fourth International Conference on Dependency Linguistics (Depling 2017), Pisa, Italy, 18–20 September 2017; Montemagni, S., Nivre, J., Eds.; Linköping University Electronic Press: Pisa, Italy, 2017; pp. 64–72. Available online: https://aclanthology.org/W17-6509 (accessed on 15 April 2024).
- Morad, P.; Ahmadi, S.; Gatti, L. Part-of-Speech Tagging for Northern Kurdish. In Proceedings of the Joint Workshop on Multiword Expressions and Universal Dependencies (MWE-UD) @ LREC-COLING 2024, Torino, Italy, 25 May 2024; pp. 70–80. [Google Scholar]
- Hassani, H. A method for proper noun extraction in Kurdish. In Proceedings of the 6th Symposium on Languages, Applications and Technologies (SLATE 2017), Vila do Conde, Portugal, 26–27 June 2017. [Google Scholar] [CrossRef]
- Veisi, H.; MohammadAmini, M.; Hosseini, H. Toward Kurdish language processing: Experiments in collecting and processing the AsoSoft text corpus. Digit. Scholarsh. Humanit. 2019, 35, 176–193. [Google Scholar] [CrossRef]
- Ahmadi, S. KLPT—Kurdish Language Processing Toolkit. In Proceedings of the Second Workshop for NLP Open Source Software (NLP-OSS), Online, 19 November 2020; pp. 72–84. [Google Scholar] [CrossRef]
- Ahmad, H.A.; Rashid, T.A. Gigant-KTTS dataset: Towards building an extensive gigant dataset for Kurdish text-to-speech systems. Data Brief 2024, 55, 110753. [Google Scholar] [CrossRef]
- Maulud, D.; Jacksi, K.; Ali, I. Towards a Complete Kurdish NLP Pipeline: Challenges and Opportunities. J. Inform. 2023, 17, 1–17. [Google Scholar]
- Ahmadi, S.; Hassani, H. Towards Finite-State Morphology of Kurdish. arXiv 2020, arXiv:2005.10652. [Google Scholar]
- Salehi, A.; Jacobs, C.L. The effect of model capacity and script diversity on subword tokenization for Soranî Kurdish. In Proceedings of the 21st SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morpholog, Mexico City, Mexico, 20 June 2024; pp. 51–56. [Google Scholar]
- Cing, D.L.; Soe, K.M. Improving accuracy of part-of-speech (POS) tagging using hidden markov model and morphological analysis for Myanmar Language. Int. J. Electr. Comput. Eng. 2020, 10, 2023–2030. [Google Scholar] [CrossRef]
- Lam Cing, D.; Mar Soe, K. Joint Word Segmentation and Part-of-Speech (POS) Tagging for Myanmar Language. In Proceedings of the 17th International Conference on Computer Application, Yangon, Myanmar, 27–28 February 2019; pp. 141–146. [Google Scholar]
- Tukur, A.; Umar, K.; Sa, A. Parts-of-Speech Tagging of Hausa-Based Texts Using Hidden Markov Model. Dutse J. Pure Appl. Sci. 2020, 6, 303–313. [Google Scholar]
- Ahmadi, S. Hunspell for Sorani Kurdish Spell Checking and Morphological Analysis. arXiv 2021, arXiv:2021.06374. [Google Scholar]
- Jain, V.; Singh, M. Ontology Based Information Retrieval in Semantic Web: A Survey. Int. J. Inf. Technol. Comput. Sci. 2013, 5, 62–69. [Google Scholar] [CrossRef]
- Al-Yahya, M.; Al-Shaman, M.; Al-Otaiby, N.; Al-Sultan, W.; Al-Zahrani, A.; Al-Dalbahie, M. Ontology-Based Semantic Annotation of Arabic Language Text. Int. J. Mod. Educ. Comput. Sci. 2015, 7, 53–59. [Google Scholar] [CrossRef]
- Raad, J.; Cruz, C. A survey on ontology evaluation methods. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; Volume 2, pp. 179–186. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).