

A Comparative Study of Privacy-Preserving Techniques in Federated Learning: A Performance and Security Analysis


Abstract
1. Introduction
- To overcome the challenges of traditional ML, we developed an FL model using an artificial neural network (ANN) based on a Malware Dataset for the detection of malware.
- To enhance the privacy of FL, we integrated various privacy-preserving techniques with FL. We developed multiple models for the combination of FL with privacy-preserving techniques. The PATE, SMPC, and HE were used for preserving the privacy of the FL model. The main focus of this work was to analyze how different privacy-preserving techniques interact when combined in federated settings, their collective impact on the model performance, and the resulting security guarantees.
- We evaluated the generated models against various attacks, including poisoning attacks, a model inversion attack, a backdoor attack, and a man in the middle attack.
- To the best of the authors’ knowledge, this is the first work to analyze the performance and security of different possible combinations of privacy-preserving techniques in FL. The generated models did not reduce the performance by a large percentage, but they improved the models’ robustness against various attacks. All combinations performed better than the base FL model for all evaluated attacks.
2. Background and Related Work
2.1. Federated Learning
2.2. Security in Federated Learning
2.3. Privacy-Preserving Techniques
2.3.1. Private Aggregation of Teacher Ensembles
2.3.2. Secure Multi-Party Computation
2.3.3. Homomorphic Encryption
2.4. Related Work
3. Methodology
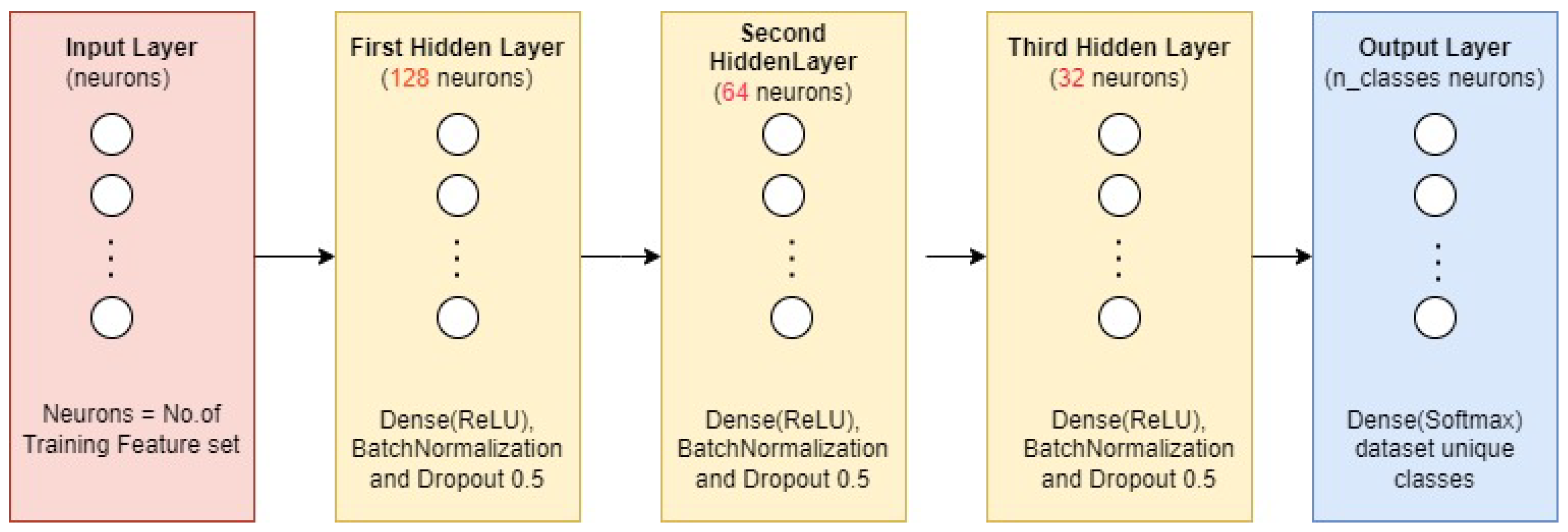
3.1. Federated Learning Model
3.2. Implementation of Privacy-Preserving Techniques
3.2.1. Private Aggregation of Teacher Ensembles
3.2.2. Secure Multi-Party Computation
3.2.3. Homomorphic Encryption
3.3. Configuration Combinations
3.4. Evaluation Metrics
4. Experimental Setup
4.1. Dataset
4.2. Hardware and Software Environment
4.3. Attack Simulation
4.3.1. Poisoning Attack
4.3.2. Backdoor Attack
4.3.3. Model Inversion Attack
4.3.4. The Man in the Middle Attack
5. Results and Analysis
5.1. Performance Analysis
5.2. Security Evaluation
5.3. Trade-Off Analysis
6. Discussion
6.1. Insights on Model Execution Time and Privacy Trade-Offs
6.2. Effect of Privacy-Preserving Techniques on Model Accuracy
6.3. Privacy and Security Effectiveness Against Attacks
6.4. Impact of Privacy Techniques on Poisoning Attacks
6.5. The Impact of Privacy Techniques on the Man in the Middle Attack
6.6. Overall Evaluation and Performance Comparison
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bian, J.; Shen, C.; Xu, J. Federated learning via indirect server-client communications. In Proceedings of the 2023 57th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Zhang, Y.; Zeng, D.; Luo, J.; Fu, X.; Chen, G.; Xu, Z.; King, I. A Survey of Trustworthy Federated Learning: Issues, Solutions, and Challenges. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–47. [Google Scholar] [CrossRef]
- Chang, Y.; Zhang, K.; Gong, J.; Qian, H. Privacy-preserving federated learning via functional encryption, revisited. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1855–1869. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Z.; Huang, Y.; Xu, P. FedOES: An efficient federated learning approach. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 24–26 February 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 135–139. [Google Scholar]
- Ciceri, O.J.; Astudillo, C.A.; Zhu, Z.; da Fonseca, N.L. Federated learning over next-generation ethernet passive optical networks. IEEE Netw. 2022, 37, 70–76. [Google Scholar] [CrossRef]
- Hussain, G.J.; Manoj, G. Federated learning: A survey of a new approach to machine learning. In Proceedings of the 2022 First International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichy, India, 16–18 February 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Li, Y.; Xu, G.; Meng, X.; Du, W.; Ren, X. LF3PFL: A Practical Privacy-Preserving Federated Learning Algorithm Based on Local Federalization Scheme. Entropy 2024, 26, 353. [Google Scholar] [CrossRef]
- Sen, J.; Waghela, H.; Rakshit, S. Privacy in Federated Learning. arXiv 2024, arXiv:2408.08904. [Google Scholar]
- Li, Y.; Hu, J.; Guo, Z.; Yang, N.; Chen, H.; Yuan, D.; Ding, W. Threats and Defenses in Federated Learning Life Cycle: A Comprehensive Survey and Challenges. arXiv 2024, arXiv:2407.06754. [Google Scholar]
- Batool, H.; Anjum, A.; Khan, A.; Izzo, S.; Mazzocca, C.; Jeon, G. A secure and privacy preserved infrastructure for VANETs based on federated learning with local differential privacy. Inf. Sci. 2024, 652, 119717. [Google Scholar] [CrossRef]
- Jin, W.; Yao, Y.; Han, S.; Joe-Wong, C.; Ravi, S.; Avestimehr, S.; He, C. FedML-HE: An efficient homomorphic-encryption-based privacy-preserving federated learning system. arXiv 2023, arXiv:2303.10837. [Google Scholar]
- Geng, T.; Liu, J.; Huang, C.T. A Privacy-Preserving Federated Learning Framework for IoT Environment Based on Secure Multi-party Computation. In Proceedings of the 2024 IEEE Annual Congress on Artificial Intelligence of Things (AIoT), Melbourne, Australia, 24–26 July 2024; pp. 117–122. [Google Scholar] [CrossRef]
- Watkins, W.; Wang, H.; Bae, S.; Tseng, H.H.; Cha, J.; Chen, S.Y.C.; Yoo, S. Quantum Privacy Aggregation of Teacher Ensembles (QPATE) for Privacy Preserving Quantum Machine Learning. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 6875–6879. [Google Scholar]
- Jiang, Z.; Ni, W.; Zhang, Y. PATE-TripleGAN: Privacy-Preserving Image Synthesis with Gaussian Differential Privacy. arXiv 2024, arXiv:2404.12730. [Google Scholar]
- Zhang, Q.; Ma, J.; Lou, J.; Xiong, L.; Jiang, X. Private Semi-supervised Knowledge Transfer for Deep Learning from Noisy Labels. arXiv 2022, arXiv:2211.01628. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, Q.; Zhao, C.; Jiang, H.; Xu, Q. Privacy-enhancing machine learning framework with private aggregation of teacher ensembles. Int. J. Intell. Syst. 2022, 37, 9904–9920. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, Y.; Zhang, J.; Mu, X.; Wang, H.; Yu, Y.; Xu, Z. Secformer: Towards fast and accurate privacy-preserving inference for large language models. arXiv 2024, arXiv:2401.00793. [Google Scholar]
- Song, C.; Huang, R.; Hu, S. Private-preserving language model inference based on secure multi-party computation. Neurocomputing 2024, 592, 127794. [Google Scholar] [CrossRef]
- Hosain, M.T.; Abir, M.R.; Rahat, M.Y.; Mridha, M.; Mukta, S.H. Privacy Preserving Machine Learning with Federated Personalized Learning in Artificially Generated Environment. IEEE Open J. Comput. Soc. 2024, 5, 694–704. [Google Scholar] [CrossRef]
- Shen, C.; Zhang, W.; Zhou, T.; Zhang, L. A security-enhanced federated learning scheme based on homomorphic encryption and secret sharing. Mathematics 2024, 12, 1993. [Google Scholar] [CrossRef]
- Liu, X.; Li, H.; Xu, G.; Chen, Z.; Huang, X.; Lu, R. Privacy-enhanced federated learning against poisoning adversaries. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4574–4588. [Google Scholar] [CrossRef]
- Xu, G.; Li, H.; Zhang, Y.; Xu, S.; Ning, J.; Deng, R.H. Privacy-Preserving Federated Deep Learning With Irregular Users. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1364–1381. [Google Scholar] [CrossRef]
- Pan, Y.; Ni, J.; Su, Z. FL-PATE: Differentially Private Federated Learning with Knowledge Transfer. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Kuala Lumpur, Malaysia, 8–12 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Anastasakis, Z.; Velivassaki, T.H.; Voulkidis, A.; Bourou, S.; Psychogyios, K.; Skias, D.; Zahariadis, T. FREDY: Federated Resilience Enhanced with Differential Privacy. Future Internet 2023, 15, 296. [Google Scholar] [CrossRef]
- Elfares, M.; Reisert, P.; Hu, Z.; Tang, W.; Küsters, R.; Bulling, A. PrivatEyes: Appearance-based Gaze Estimation Using Federated Secure Multi-Party Computation. Proc. ACM Hum.-Comput. Interact. 2024, 8, 1–23. [Google Scholar] [CrossRef]
- Muazu, T.; Mao, Y.; Muhammad, A.U.; Ibrahim, M.; Kumshe, U.M.M.; Samuel, O. A federated learning system with data fusion for healthcare using multi-party computation and additive secret sharing. Comput. Commun. 2024, 216, 168–182. [Google Scholar] [CrossRef]
- Chen, L.; Xiao, D.; Yu, Z.; Zhang, M. Secure and efficient federated learning via novel multi-party computation and compressed sensing. Inf. Sci. 2024, 667, 120481. [Google Scholar] [CrossRef]
- Manh, B.D.; Nguyen, C.H.; Hoang, D.T.; Nguyen, D.N. Homomorphic Encryption-Enabled Federated Learning for Privacy-Preserving Intrusion Detection in Resource-Constrained IoV Networks. arXiv 2024, arXiv:2407.18503. [Google Scholar]
- Guo, Y.; Li, L.; Zheng, Z.; Yun, H.; Zhang, R.; Chang, X.; Gao, Z. Efficient and Privacy-Preserving Federated Learning based on Full Homomorphic Encryption. arXiv 2024, arXiv:2403.11519. [Google Scholar]
- Gao, Q.; Sun, Y.; Chen, X.; Yang, F.; Wang, Y. An Efficient Multi-Party Secure Aggregation Method Based on Multi-Homomorphic Attributes. Electronics 2024, 13, 671. [Google Scholar] [CrossRef]
- Li, X.; Zhao, H.; Chen, X.; Deng, W. Homomorphic Encryption and Secure Aggregation Based Vertical-Horizontal Federated Learning for Flight Operation Data Sharing. In Proceedings of the 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), Nanjing, China, 29–31 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 844–848. [Google Scholar]
- Yang, W.; Yang, Y.; Xi, Y.; Zhang, H.; Xiang, W. FLCP: Federated learning framework with communication-efficient and privacy-preserving. Appl. Intell. 2024, 54, 6816–6835. [Google Scholar] [CrossRef]
- Hu, K.; Gong, S.; Zhang, Q.; Seng, C.; Xia, M.; Jiang, S. An overview of implementing security and privacy in federated learning. Artif. Intell. Rev. 2024, 57, 204. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar] [CrossRef]
- Chai, D.; Wang, L.; Yang, L.; Zhang, J.; Chen, K.; Yang, Q. A Survey for Federated Learning Evaluations: Goals and Measures. IEEE Trans. Knowl. Data Eng. 2024, 36, 5007–5024. [Google Scholar] [CrossRef]
- Karras, A.; Karras, C.; Giotopoulos, K.C.; Tsolis, D.; Oikonomou, K.; Sioutas, S. Peer to peer federated learning: Towards decentralized machine learning on edge devices. In Proceedings of the 2022 7th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Ioannina, Greece, 23–25 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–9. [Google Scholar]
- Rachakonda, S.; Moorthy, S.; Jain, A.; Bukharev, A.; Bucur, A.; Manni, F.; Quiterio, T.M.; Joosten, L.; Mendez, N.I. Privacy enhancing and scalable federated learning to accelerate ai implementation in cross-silo and iomt environments. IEEE J. Biomed. Health Inform. 2022, 27, 744–755. [Google Scholar] [CrossRef]
- Qi, P.; Chiaro, D.; Guzzo, A.; Ianni, M.; Fortino, G.; Piccialli, F. Model aggregation techniques in federated learning: A comprehensive survey. Future Gener. Comput. Syst. 2024, 150, 272–293. [Google Scholar] [CrossRef]
- Ryu, M.; Kim, Y.; Kim, K.; Madduri, R.K. APPFL: Open-source software framework for privacy-preserving federated learning. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lyon, France, 30 May–3 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1074–1083. [Google Scholar]
- Pulido-Gaytan, B.; Tchernykh, A.; Tchernykh, A.; Cortés-Mendoza, J.M.; Babenko, M.; Radchenko, G.; Avetisyan, A.; Drozdov, A.Y. Privacy-preserving neural networks with Homomorphic encryption: Challenges and opportunities. Peer- Netw. Appl. 2021, 14, 1666–1691. [Google Scholar] [CrossRef]
- Liu, G.; Furth, N.; Shi, H.; Khreishah, A.; Lee, J.Y.; Ansari, N.; Liu, C.; Jararweh, Y. Federated Learning Aided Deep Convolutional Neural Network Solution for Smart Traffic Management. In Proceedings of the NOMS 2023-2023 IEEE/IFIP Network Operations and Management Symposium, Miami, FL, USA, 8–12 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar]
- Nazir, S.; Kaleem, M. Federated Learning for Medical Image Analysis with Deep Neural Networks. Diagnostics 2023, 13, 1532. [Google Scholar] [CrossRef]
- Gutiérrez, D.; Hassan, H.M.; Landi, L.; Vitaletti, A.; Chatzigiannakis, I. Application of federated learning techniques for arrhythmia classification using 12-lead ECG signals. arXiv 2022, arXiv:2208.10993. [Google Scholar] [CrossRef]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated-learning-based anomaly detection for IoT security attacks. IEEE Internet Things J. 2021, 9, 2545–2554. [Google Scholar] [CrossRef]
- Subramanian, N.; Ravi, L.; Shaan, M.J.; Devarajan, M.; Choudhury, T.; Kotecha, K.; Vairavasundaram, S. Securing Mobile Devices from Malware: A Faceoff Between Federated Learning and Deep Learning Models for Android Malware Classification. J. Comput. Sci. 2024, 20, 254–264. [Google Scholar] [CrossRef]
- Panagoda, D.; Malinda, C.; Wijetunga, C.; Rupasinghe, L.; Bandara, B.; Liyanapathirana, C. Application of federated learning in health care sector for malware detection and mitigation using software defined networking approach. In Proceedings of the 2022 2nd Asian Conference on Innovation in Technology (ASIANCON), Ravet, India, 26–28 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Sikandar, H.S.; Waheed, H.; Tahir, S.; Malik, S.U.; Rafique, W. A detailed survey on federated learning attacks and defenses. Electronics 2023, 12, 260. [Google Scholar] [CrossRef]
- Xia, G.; Chen, J.; Yu, C.; Ma, J. Poisoning attacks in federated learning: A survey. IEEE Access 2023, 11, 10708–10722. [Google Scholar] [CrossRef]
- Liu, P.; Xu, X.; Wang, W. Threats, attacks and defenses to federated learning: Issues, taxonomy and perspectives. Cybersecurity 2022, 5, 4. [Google Scholar] [CrossRef]
- Xu, H.; Shu, T. Defending against model poisoning attack in federated learning: A variance-minimization approach. J. Inf. Secur. Appl. 2024, 82, 103744. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Nguyen, T.; Le Nguyen, P.; Pham, H.H.; Doan, K.D.; Wong, K.S. Backdoor attacks and defenses in federated learning: Survey, challenges and future research directions. Eng. Appl. Artif. Intell. 2024, 127, 107166. [Google Scholar] [CrossRef]
- Chen, Y.; Gui, Y.; Lin, H.; Gan, W.; Wu, Y. Federated learning attacks and defenses: A survey. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4256–4265. [Google Scholar]
- Zhao, J.C.; Bagchi, S.; Avestimehr, S.; Chan, K.S.; Chaterji, S.; Dimitriadis, D.; Li, J.; Li, N.; Nourian, A.; Roth, H.R. Federated Learning Privacy: Attacks, Defenses, Applications, and Policy Landscape-A Survey. arXiv 2024, arXiv:2405.03636. [Google Scholar]
- Bradley, M.; Xu, S. A Metric for Machine Learning Vulnerability to Adversarial Examples. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 10–13 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–2. [Google Scholar]
- Yan, H.; Li, X.; Zhang, W.; Wang, R.; Li, H.; Zhao, X.; Li, F.; Lin, X. Automatic evasion of machine learning-based network intrusion detection systems. IEEE Trans. Dependable Secur. Comput. 2023, 21, 153–167. [Google Scholar] [CrossRef]
- Askhatuly, A.; Berdysheva, D.; Yedilkhan, D.; Berdyshev, A. Security Risks of ML Models: Adverserial Machine Learning. In Proceedings of the 2024 IEEE 4th International Conference on Smart Information Systems and Technologies (SIST), Astana, Kazakhstan, 15–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 440–446. [Google Scholar]
- Rashid, A.; Such, J. Effectiveness of moving target defenses for adversarial attacks in ml-based malware detection. arXiv 2023, arXiv:2302.00537. [Google Scholar] [CrossRef]
- Ikenouchi, H.; Hirose, H.; Uto, T. Backdoor Defense with Colored Patches for Machine Learning Models. In Proceedings of the 2024 International Technical Conference on Circuits/Systems, Computers, and Communications (ITC-CSCC), Okinawa, Japan, 2–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Tidjon, L.N.; Khomh, F. Threat assessment in machine learning based systems. arXiv 2022, arXiv:2207.00091. [Google Scholar]
- Surekha, M.; Sagar, A.K.; Khemchandani, V. A Comprehensive Analysis of Poisoning Attack and Defence Strategies in Machine Learning Techniques. In Proceedings of the 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), Greater Noida, India, 9–10 February 2024; IEEE: Piscataway, NJ, USA, 2024; Volume 5, pp. 1662–1668. [Google Scholar]
- Chen, L.; Cheng, M.; Huang, H. Backdoor learning on sequence to sequence models. arXiv 2023, arXiv:2305.02424. [Google Scholar]
- Dibbo, S.V. Sok: Model inversion attack landscape: Taxonomy, challenges, and future roadmap. In Proceedings of the 2023 IEEE 36th Computer Security Foundations Symposium (CSF), Dubrovnik, Croatia, 9–13 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 439–456. [Google Scholar]
- Zhou, S.; Zhu, T.; Ye, D.; Yu, X.; Zhou, W. Boosting model inversion attacks with adversarial examples. IEEE Trans. Dependable Secur. Comput. 2023, 21, 1451–1468. [Google Scholar] [CrossRef]
- Li, H.; Li, Z.; Wu, S.; Hu, C.; Ye, Y.; Zhang, M.; Feng, D.; Zhang, Y. Seqmia: Sequential-metric based membership inference attack. arXiv 2024, arXiv:2407.15098. [Google Scholar]
- Bertran, M.; Tang, S.; Roth, A.; Kearns, M.; Morgenstern, J.H.; Wu, S.Z. Scalable membership inference attacks via quantile regression. Adv. Neural Inf. Process. Syst. 2024, 36, 314–330. [Google Scholar]
- Oliynyk, D.; Mayer, R.; Rauber, A. I know what you trained last summer: A survey on stealing machine learning models and defences. ACM Comput. Surv. 2023, 55, 1–41. [Google Scholar] [CrossRef]
- Rigaki, M.; Garcia, S. Stealing and evading malware classifiers and antivirus at low false positive conditions. Comput. Secur. 2023, 129, 103192. [Google Scholar] [CrossRef]
- Chittibala, D.R.; Jabbireddy, S.R. Security in Machine Learning (ML) Workflows. Int. J. Comput. Eng. 2024, 5, 52–63. [Google Scholar] [CrossRef]
- Papernot, N.; Abadi, M.; Erlingsson, U.; Goodfellow, I.; Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv 2016, arXiv:1610.05755. [Google Scholar]
- Hannemann, A.; Friedl, B.; Buchmann, E. Differentially Private Multi-Label Learning Is Harder Than You’d Think. In Proceedings of the 2024 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Vienna, Austria, 8–12 July 2024; pp. 40–47. [Google Scholar] [CrossRef]
- Tran, C.; Fioretto, F. On the fairness impacts of private ensembles models. arXiv 2023, arXiv:2305.11807. [Google Scholar]
- Malik, J.; Muthalagu, R.; Pawar, P.M. A Systematic Review of Adversarial Machine Learning Attacks, Defensive Controls and Technologies. IEEE Access 2024, 12, 99382–99421. [Google Scholar] [CrossRef]
- Mehta, U.; Vekariya, J.; Mehta, M.; Kaur, H.; Kumar, Y. A review of privacy-preserving machine learning algorithms and systems. In Applied Data Science and Smart Systems; CRC Press: Boca Raton, FL, USA, 2025; pp. 220–225. [Google Scholar]
- Ju, Q.; Xia, R.; Li, S.; Zhang, X. Privacy-preserving classification on deep learning with exponential mechanism. Int. J. Comput. Intell. Syst. 2024, 17, 39. [Google Scholar] [CrossRef]
- Dodwadmath, A.; Stich, S.U. Preserving Privacy with PATE for Heterogeneous Data. In Neural Information Processing Systems Workshop (NeurIPS-W). 2022. Available online: https://publications.cispa.de/articles/conference_contribution/Preserving_privacy_with_PATE_for_heterogeneous_data/24614826?file=43249032 (accessed on 1 February 2025).
- Hu, H.; Han, Q.; Ma, Z.; Yan, Y.; Xiong, Z.; Jiang, L.; Zhang, Y. PV-PATE: An Improved PATE for Deep Learning with Differential Privacy in Trusted Industrial Data Matrix. In Proceedings of the Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, Wuhan, China, 6–8 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 477–491. [Google Scholar]
- Truong, N.; Sun, K.; Wang, S.; Guitton, F.; Guo, Y. Privacy preservation in federated learning: An insightful survey from the GDPR perspective. Comput. Secur. 2021, 110, 102402. [Google Scholar] [CrossRef]
- Zhou, I.; Tofigh, F.; Piccardi, M.; Abolhasan, M.; Franklin, D.; Lipman, J. Secure Multi-Party Computation for Machine Learning: A Survey. IEEE Access 2024, 12, 53881–53899. [Google Scholar] [CrossRef]
- Khan, T.; Budzys, M.; Nguyen, K.; Michalas, A. Wildest Dreams: Reproducible Research in Privacy-preserving Neural Network Training. arXiv 2024, arXiv:2403.03592. [Google Scholar] [CrossRef]
- Parikh, D.; Radadia, S.; Eranna, R.K. Privacy-Preserving Machine Learning Techniques, Challenges And Research Directions. Int. Res. J. Eng. Technol. 2024, 11, 499. [Google Scholar]
- Adelipour, S.; Haeri, M. Private outsourced model predictive control via secure multi-party computation. Comput. Electr. Eng. 2024, 116, 109208. [Google Scholar] [CrossRef]
- Liu, S.; Luo, J.; Zhang, Y.; Wang, H.; Yu, Y.; Xu, Z. Efficient privacy-preserving Gaussian process via secure multi-party computation. J. Syst. Archit. 2024, 151, 103134. [Google Scholar] [CrossRef]
- Tran, A.T.; Luong, T.D.; Pham, X.S. A Novel Privacy-Preserving Federated Learning Model Based on Secure Multi-party Computation. In Proceedings of the International Symposium on Integrated Uncertainty in Knowledge Modelling and Decision Making, Kanazawa, Japan, 2–4 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 321–333. [Google Scholar]
- Krishna, N.; Raju, K.M.; Gowda, V.D.; Arun, G.; Suneetha, S. Homomorphic Encryption and Machine Learning in the Encrypted Domain. In Innovative Machine Learning Applications for Cryptography; IGI Global: Hershey, PA, USA, 2024; pp. 173–190. [Google Scholar]
- Amorim, I.; Costa, I. Homomorphic Encryption: An Analysis of its Applications in Searchable Encryption. arXiv 2023, arXiv:2306.14407. [Google Scholar]
- Gouert, C.; Mouris, D.; Tsoutsos, N. Sok: New insights into fully homomorphic encryption libraries via standardized benchmarks. Proc. Priv. Enhancing Technol. 2023, 2023, 154–172. [Google Scholar] [CrossRef]
- Galymzhankyzy, Z.; Rinatov, I.; Abdiraman, A.; Unaybaev, S. Assessing electoral integrity: Paillier’s partial homomorphic encryption in E-voting system. In Proceedings of the 2024 IEEE 4th International Conference on Smart Information Systems and Technologies (SIST), Astana, Kazakhstan, 15–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 194–201. [Google Scholar]
- Subramaniyaswamy, V.; Jagadeeswari, V.; Indragandhi, V.; Jhaveri, R.H.; Vijayakumar, V.; Kotecha, K.; Ravi, L. Somewhat homomorphic encryption: Ring learning with error algorithm for faster encryption of IoT sensor signal-based edge devices. Secur. Commun. Netw. 2022, 2022, 2793998. [Google Scholar] [CrossRef]
- van de Haterd, R.; El-Hajj, M. Enhancing Privacy and Security in IoT Environments through Secure Multiparty Computation. In Proceedings of the International Conference on Intelligent Systems and New Applications, Hanoi, Vietnam, 24–25 October 2024; Volume 2, pp. 64–69. [Google Scholar]
- Doan, T.V.T.; Messai, M.L.; Gavin, G.; Darmont, J. A survey on implementations of homomorphic encryption schemes. J. Supercomput. 2023, 79, 15098–15139. [Google Scholar] [CrossRef]
- Singh, V.K.; Chauhan, A.S.; Singh, A.; Thakur, R. Homomorphic Encryption: Hands Inside the Gloves. In Proceedings of the 2023 3rd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bengaluru, India, 21–23 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 248–253. [Google Scholar]
- Frimpong, E.; Nguyen, K.; Budzys, M.; Khan, T.; Michalas, A. GuardML: Efficient Privacy-Preserving Machine Learning Services Through Hybrid Homomorphic Encryption. In Proceedings of the 39th ACM/SIGAPP Symposium on Applied Computing, Ávila, Spain, 8–12 April 2024; pp. 953–962. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast fully homomorphic encryption over the torus. J. Cryptol. 2020, 33, 34–91. [Google Scholar] [CrossRef]
- Fan, J.; Vercauteren, F. Somewhat practical fully homomorphic encryption. Cryptol. Eprint Arch. 2012. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the Advances in Cryptology–ASIACRYPT 2017: 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Proceedings, Part I 23. Springer: Berlin/Heidelberg, Germany, 2017; pp. 409–437. [Google Scholar]
- Kim, A.; Papadimitriou, A.; Polyakov, Y. Approximate homomorphic encryption with reduced approximation error. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 1–2 March 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 120–144. [Google Scholar]
- Wiryen, Y.B.; Vigny, N.W.A.; Joseph, M.N.; Aimé, F.L. A Comparative Study of BFV and CKKs Schemes to Secure IoT Data Using TenSeal and Pyfhel Homomorphic Encryption Libraries. Int. J. Smart Secur. Technol. (IJSST) 2024, 10, 1–17. [Google Scholar] [CrossRef]
- Patterson, V.L. Hitchhiker’s Guide to the TFHE Scheme. J. Cryptogr. Eng. 2023. [Google Scholar] [CrossRef]
- Lee, S.; Lee, G.; Kim, J.W.; Shin, J.; Lee, M.K. HETAL: Efficient privacy-preserving transfer learning with homomorphic encryption. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19010–19035. [Google Scholar]
- Zhang, Q.Y.; Wen, Y.W.; Huang, Y.B.; Li, F.P. Secure speech retrieval method using deep hashing and CKKS fully homomorphic encryption. Multimed. Tools Appl. 2024, 83, 67469–67500. [Google Scholar] [CrossRef]
- Reddi, S.; Rao, P.M.; Saraswathi, P.; Jangirala, S.; Das, A.K.; Jamal, S.S.; Park, Y. Privacy-preserving electronic medical record sharing for IoT-enabled healthcare system using fully homomorphic encryption, IOTA, and masked authenticated messaging. IEEE Trans. Ind. Inform. 2024, 20, 10802–10813. [Google Scholar] [CrossRef]
- Kuo, T.H.; Wu, J.L. A High Throughput BFV-Encryption-Based Secure Comparison Protocol. Mathematics 2023, 11, 1227. [Google Scholar] [CrossRef]
- Shen, S.; Yang, H.; Dai, W.; Zhou, L.; Liu, Z.; Zhao, Y. Leveraging GPU in Homomorphic Encryption: Framework Design and Analysis of BFV Variants. IEEE Trans. Comput. 2024, 73, 2817–2829. [Google Scholar] [CrossRef]
- Klemsa, J.; Önen, M.; Akin, Y. A Practical TFHE-Based Multi-Key Homomorphic Encryption with Linear Complexity and Low Noise Growth. In Proceedings of the 28th European Symposium on Research in Computer Security, The Hague, The Netherlands, 25–29 September 2023. [Google Scholar]
- Wei, B.; Lu, X.; Wang, R.; Liu, K.; Li, Z.; Wang, K. Thunderbird: Efficient Homomorphic Evaluation of Symmetric Ciphers in 3GPP by combining two modes of TFHE. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2024, 2024, 530–573. [Google Scholar] [CrossRef]
- Rey, V.; Sánchez, P.M.S.; Celdrán, A.H.; Bovet, G. Federated learning for malware detection in IoT devices. Comput. Netw. 2022, 204, 108693. [Google Scholar] [CrossRef]
- Fang, W.; He, J.; Li, W.; Lan, X.; Chen, Y.; Li, T.; Huang, J.; Zhang, L. Comprehensive Android Malware Detection Based on Federated Learning Architecture. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3977–3990. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, C.; Liu, R.; Yang, S. Federated Rnn-Based Detection of Ransomware Attacks: A Privacy-Preserving Approach; OSF: Alton, IL, USA, 2024. [Google Scholar]
- Jiang, C.; Yin, K.; Xia, C.; Huang, W. Fedhgcdroid: An adaptive multi-dimensional federated learning for privacy-preserving android malware classification. Entropy 2022, 24, 919. [Google Scholar] [CrossRef]
- Nobakht, M.; Javidan, R.; Pourebrahimi, A. SIM-FED: Secure IoT malware detection model with federated learning. Comput. Electr. Eng. 2024, 116, 109139. [Google Scholar] [CrossRef]
- Kalapaaking, A.P.; Stephanie, V.; Khalil, I.; Atiquzzaman, M.; Yi, X.; Almashor, M. Smpc-based federated learning for 6g-enabled internet of medical things. IEEE Netw. 2022, 36, 182–189. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Included Methods | |||||
|---|---|---|---|---|---|
| Model No. | Model | FL | PATE | SMPC | HE |
| 1 | FL_only | ✓ | x | x | x |
| 2 | FL_SMPC | ✓ | x | ✓ | x |
| 3 | FL_SMPC_DP | ✓ | x | ✓ | x |
| 4 | FL_PATE | ✓ | ✓ | x | x |
| 5 | FL_PATE_SMPC | ✓ | ✓ | ✓ | x |
| 6 | FL_CKKS | ✓ | x | x | ✓ |
| 7 | FL_CKKS_DP | ✓ | x | x | ✓ |
| 8 | FL_CKKS_SMPC | ✓ | x | ✓ | ✓ |
| 9 | FL_PATE_CKKS | ✓ | ✓ | x | ✓ |
| 10 | FL_PATE_CKKS_SMPC | ✓ | ✓ | ✓ | ✓ |
| Privacy Budget () | FL_CKKS_DP Accuracy |
|---|---|
| 0.01 (extremely strong privacy) | 60.10% |
| 0.1 (very strong privacy) | 70.50% |
| 0.5 (strong privacy) | 75.90% |
| 1.0 (strong privacy) | 84.10% |
| 2.0 (moderate privacy) | 85.80% |
| 5.0 (moderate privacy) | 88.40% |
| Feature | Feature Explanation | Feature Type |
|---|---|---|
| hash | Unique identifier for each file | Identification and Classification |
| classification | Indicates whether the entry file is classified as “malware” or “benign” | Identification and Classification |
| millisecond | Time offset within each file’s time series data | Identification and Classification |
| state | Current state of the process | Process State and Priority |
| prio | Priority value | Process State and Priority |
| static_prio | Static priority | Process State and Priority |
| normal_prio | Normal priority | Process State and Priority |
| policy | Scheduling policy | Process State and Priority |
| vm_pgoff | Virtual memory page offset | Memory Usage and Management |
| vm_truncate_count | Virtual memory truncated count | Memory Usage and Management |
| task_size | Size of the task | Memory Usage and Management |
| cached_hole_size | Size of cached memory hole | Memory Usage and Management |
| free_area_cache | Free area cache size | Memory Usage and Management |
| mm_users | Memory management users | Memory Usage and Management |
| map_count | Number of memory mappings | Memory Usage and Management |
| hiwater_rss | High-water mark for resident set size | Memory Usage and Management |
| total_vm | Total virtual memory | Memory Usage and Management |
| shared_vm | Shared virtual memory | Memory Usage and Management |
| exec_vm | Executable virtual memory | Memory Usage and Management |
| reserved_vm | Reserved virtual memory | Memory Usage and Management |
| nr_ptes | Number of page table entries | Memory Usage and Management |
| end_data | End of data segment | Memory Usage and Management |
| last_interval | Last scheduling interval | CPU Usage and Scheduling |
| nvcsw | Number of voluntary context switches | CPU Usage and Scheduling |
| nivcsw | Number of involuntary context switches | CPU Usage and Scheduling |
| utime | User mode time | CPU Usage and Scheduling |
| stime | System time | CPU Usage and Scheduling |
| gtime | Guest time | CPU Usage and Scheduling |
| cgtime | Cumulative guest time | CPU Usage and Scheduling |
| signal_nvcsw | Signal-related voluntary context switches | CPU Usage and Scheduling |
| fs_excl_counter | File system exclusive counter | File System and I/O |
| min_flt | Minor page faults | File System and I/O |
| maj_flt | Major page faults | File System and I/O |
| usage_counter | Usage counter | Miscellaneous |
| lock | Lock value | Miscellaneous |
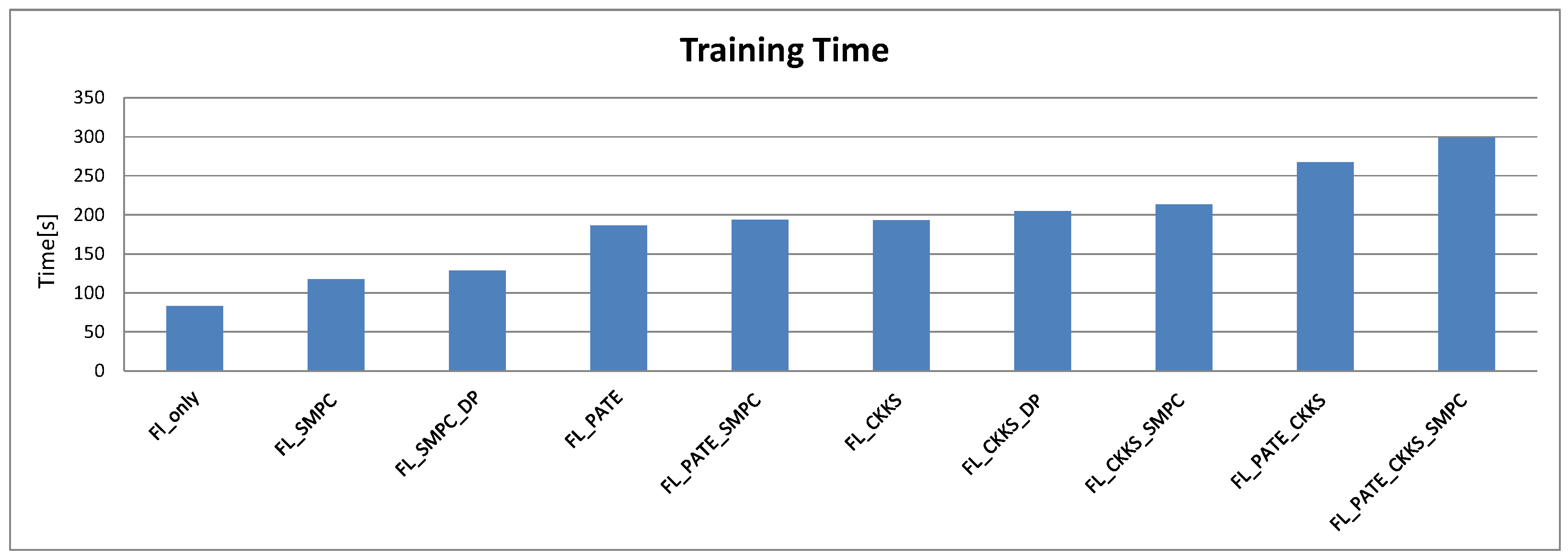
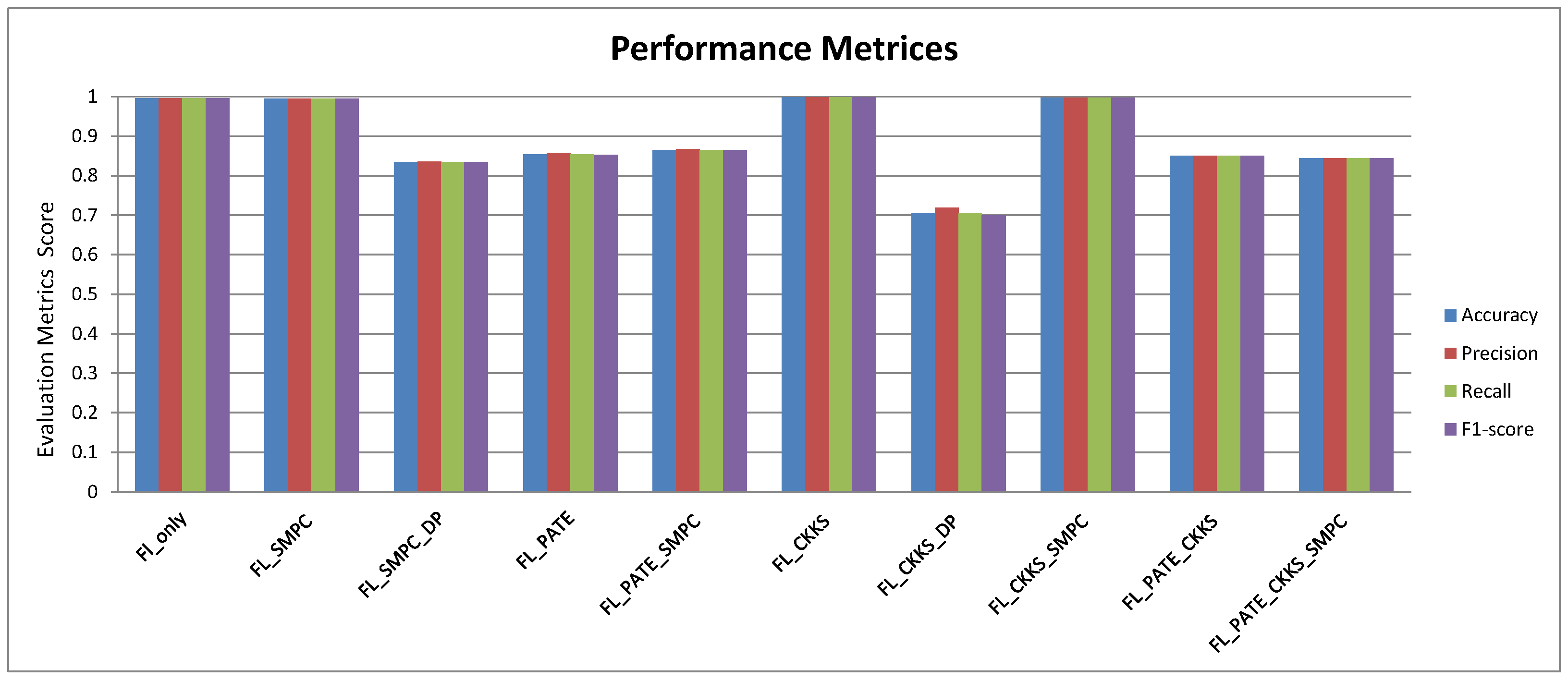
| Reduced Dataset | Time (s) | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Fl_only | 82.85 | 0.9930 | 0.9930 | 0.9930 | 0.9930 |
| FL_SMPC | 117.73 | 0.9950 | 0.9950 | 0.9950 | 0.9950 |
| FL_SMPC_DP | 128.54 | 0.8350 | 0.8356 | 0.8350 | 0.8349 |
| FL_PATE | 186.43 | 0.8530 | 0.8573 | 0.8530 | 0.8526 |
| FL_PATE_SMPC | 193.60 | 0.8650 | 0.8675 | 0.8650 | 0.8648 |
| FL_CKKS | 192.87 | 0.9980 | 0.9980 | 0.9980 | 0.9980 |
| FL_CKKS_DP | 204.76 | 0.7050 | 0.7196 | 0.7050 | 0.7000 |
| FL_CKKS_SMPC | 213.08 | 0.9970 | 0.9970 | 0.9970 | 0.9970 |
| FL_PATE_CKKS | 267.34 | 0.8500 | 0.8502 | 0.8500 | 0.8500 |
| FL_PATE_CKKS_SMPC | 298.60 | 0.8440 | 0.8442 | 0.8440 | 0.8440 |
| Model (Accuracy) | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Fl_only (0.99) | malware | 0.99 | 1.00 | 0.99 |
| benign | 1.00 | 0.99 | 0.99 | |
| macro avg | 0.99 | 0.99 | 0.99 | |
| weighted avg | 0.99 | 0.99 | 0.99 | |
| FL_SMPC (0.99) | malware | 0.99 | 1.00 | 1.00 |
| benign | 1.00 | 0.99 | 0.99 | |
| macro avg | 1.00 | 0.99 | 0.99 | |
| weighted avg | 1.00 | 0.99 | 0.99 | |
| FL_SMPC_DP (0.83) | malware | 0.85 | 0.81 | 0.83 |
| benign | 0.82 | 0.86 | 0.84 | |
| macro avg | 0.84 | 0.83 | 0.83 | |
| weighted avg | 0.84 | 0.83 | 0.83 | |
| FL_PATE (0.85) | malware | 0.90 | 0.80 | 0.84 |
| benign | 0.82 | 0.91 | 0.86 | |
| macro avg | 0.86 | 0.85 | 0.85 | |
| weighted avg | 0.86 | 0.85 | 0.85 | |
| FL_PATE_SMPC (0.86) | malware | 0.84 | 0.91 | 0.87 |
| benign | 0.90 | 0.82 | 0.86 | |
| macro avg | 0.87 | 0.86 | 0.86 | |
| weighted avg | 0.87 | 0.86 | 0.86 | |
| FL_CKKS (1.00) | malware | 1.00 | 1.00 | 1.00 |
| benign | 1.00 | 1.00 | 1.00 | |
| macro avg | 1.00 | 1.00 | 1.00 | |
| weighted avg | 1.00 | 1.00 | 1.00 | |
| FL_CKKS_DP (0.70) | malware | 0.66 | 0.83 | 0.74 |
| benign | 0.78 | 0.58 | 0.66 | |
| macro avg | 0.72 | 0.70 | 0.70 | |
| weighted avg | 0.72 | 0.70 | 0.70 | |
| FL_CKKS_SMPC (1.00) | malware | 0.99 | 1.00 | 1.00 |
| benign | 1.00 | 0.99 | 1.00 | |
| macro avg | 1.00 | 1.00 | 1.00 | |
| weighted avg | 1.00 | 1.00 | 1.00 | |
| FL_PATE_CKKS (0.85) | malware | 0.86 | 0.84 | 0.85 |
| benign | 0.84 | 0.86 | 0.85 | |
| macro avg | 0.85 | 0.85 | 0.85 | |
| weighted avg | 0.85 | 0.85 | 0.85 | |
| FL_PATE_CKKS_SMPC (0.84) | malware | 0.84 | 0.86 | 0.85 |
| benign | 0.85 | 0.83 | 0.84 | |
| macro avg | 0.84 | 0.84 | 0.84 | |
| weighted avg | 0.84 | 0.84 | 0.84 |
Model | Accuracy Degradation | Precision Degradation | Recall Degradation | F1-Score Degradation |
|---|---|---|---|---|
| Fl_only | 48.45% | 74.24% | 48.45% | 65.64% |
| FL_SMPC | 48.51% | 74.26% | 48.51% | 65.67% |
| FL_SMPC_DP | 24.92% | 68.52% | 24.92% | 46.68% |
| FL_PATE | 34.73% | 69.01% | 34.73% | 56.02% |
| FL_PATE_SMPC | 36.79% | 68.77% | 36.79% | 57.77% |
| FL_CKKS | 16.95% | 15.80% | 16.95% | 17.10% |
| FL_CKKS_DP | 25.37% | 62.69% | 25.37% | 50.25% |
| FL_CKKS_SMPC | 11.62% | 11.61% | 11.62% | 11.62% |
| FL_CKKS_PATE | 11.31% | 5.24% | 11.31% | 12.70% |
| FL_CKKS _PATE_SMPC | 1.68% | 1.94% | 1.68% | 1.64% |
| Component | Server Side | Client Side |
|---|---|---|
| Model Training/PATE Training | 41.97% ± 6.51% | 13.71% ± 5.14% |
| Encryption Time | N/A | 19.44% ± 8.55% |
| Decryption Time | 3.57% ± 1.22% | N/A |
| Gradient Calculation Time | N/A | 0.25% ± 0.09% |
| Communication Time | 36.48% ± 7.89% | 71.51% ± 27.83% |
| Aggregation Time | 7.19% ± 1.99% | N/A |
| Teacher Model Creation Time | 27.13% ± 4.51% | N/A |
| Model Loading Time | N/A | 0.77% ± 0.29% |
| Average Round Time | 4.21% ± 0.77% | 32.85% ± 3.13% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shalabi, E.; Khedr, W.; Rushdy, E.; Salah, A. A Comparative Study of Privacy-Preserving Techniques in Federated Learning: A Performance and Security Analysis. Information 2025, 16, 244. https://doi.org/10.3390/info16030244
Shalabi E, Khedr W, Rushdy E, Salah A. A Comparative Study of Privacy-Preserving Techniques in Federated Learning: A Performance and Security Analysis. Information. 2025; 16(3):244. https://doi.org/10.3390/info16030244
Chicago/Turabian StyleShalabi, Eman, Walid Khedr, Ehab Rushdy, and Ahmad Salah. 2025. "A Comparative Study of Privacy-Preserving Techniques in Federated Learning: A Performance and Security Analysis" Information 16, no. 3: 244. https://doi.org/10.3390/info16030244
APA StyleShalabi, E., Khedr, W., Rushdy, E., & Salah, A. (2025). A Comparative Study of Privacy-Preserving Techniques in Federated Learning: A Performance and Security Analysis. Information, 16(3), 244. https://doi.org/10.3390/info16030244