
Using Natural Language Processing and Machine Learning to Detect Online Radicalisation in the Maldivian Language, Dhivehi


Abstract
1. Introduction
- The creation of a dataset of radical/non-radical texts in Dhivehi, the Maldivian native language, through independent validation by Subject Matter Experts. Even though this dataset is relatively small, consisting of 162 radical and 162 non-radical texts, this is the first and the only independently verified radical dataset produced in Dhivehi.
- The creation of a corpus of radicalisation words in Dhivehi for use in Machine Learning to detect radical sentiments. The corpus can be used by other researchers in the domain of radicalisation for Machine Learning and sentiment analysis.
- A primary dataset in the form of transcripts and translations of real-life experiences of self-deradicalised individuals to identify the pathways of self-radicalisation and deradicalisation as well as their beliefs on controversial ideological issues. These kinds of primary data have heretofore only been collected inside prisons. This is the first dataset that is collected from individuals who are self-deradicalised.
- This is the first time Machine Learning and Natural Language Processing (NLP) have been utilised for the detection of radicalisation in Dhivehi. The incorporation of Machine Learning and NLP tools specifically in the domain of radicalisation detection in Dhivehi has not been researched before.
2. Related Works
2.1. The Use of the Internet in Radicalisation
2.2. The Maldivian Context
2.3. Use of the Internet and the Spread of Radicalisation in the Maldives
2.4. Approaches to Processing Large Volumes of Text
2.5. Similarities Between Arabic and Dhivehi
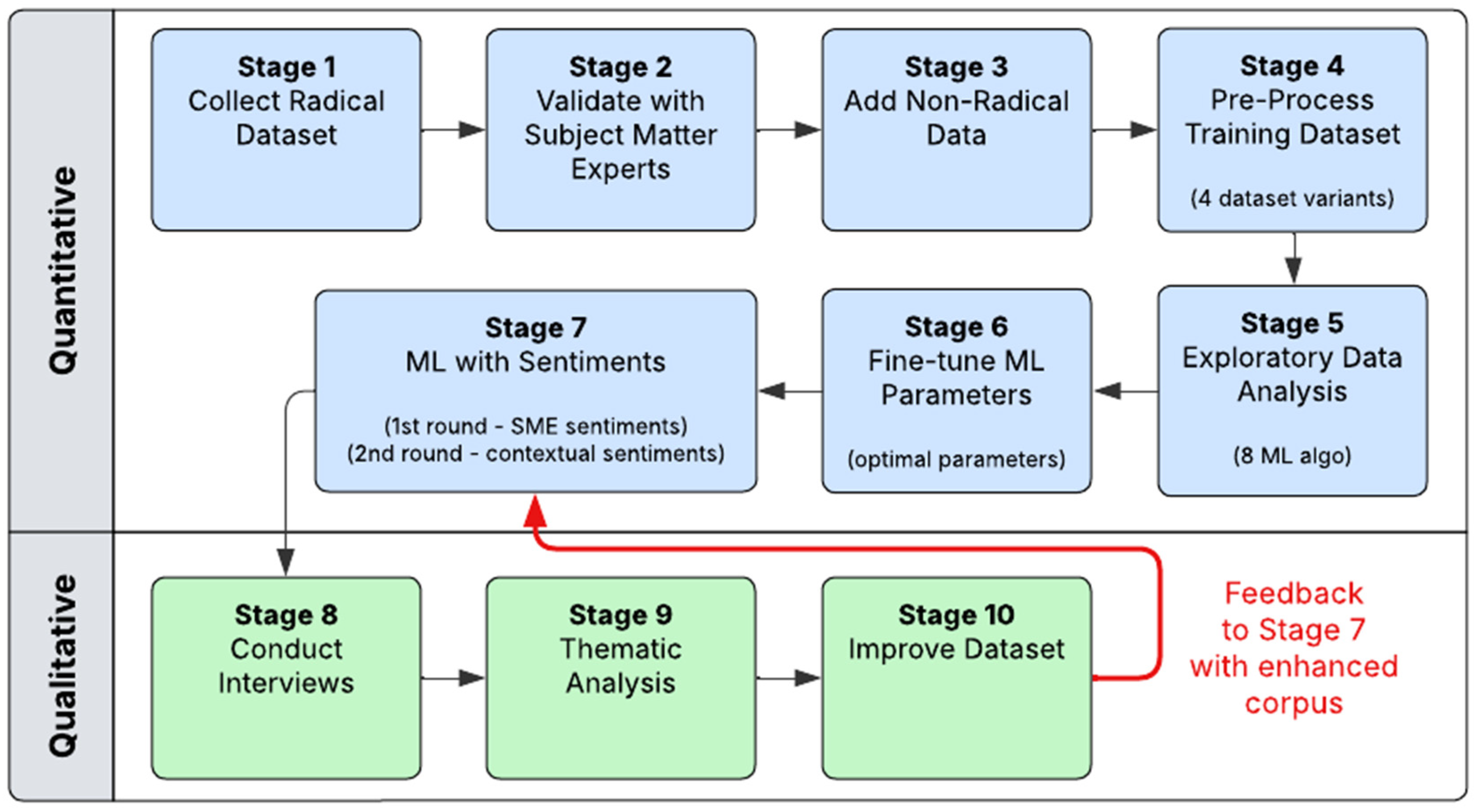
3. Materials and Methods
- The qualitative data were evaluated to identify radicalisation pathways and validate the assumptions made with regard to the role of the Internet in an individual’s radicalisation journey.
- They were used to improve the dataset of radical text and to improve the corpus of radical words.
- They were used to identify the effect of Thaana text on social media in an individual’s radicalisation journey and to evaluate what worked in their deradicalisation process.
3.1. Quantitative Phase
3.2. Qualitative Phase
3.3. Validity and Reliability
- Bias in labelling the dataset: Efforts have been made to reduce bias in labelling the dataset by independently labelling the dataset by three SMEs. The bias that could arise from gender, cultural background as well as age of the SMEs has been reduced as much as possible through selection of SMEs from different educational and cultural backgrounds and with the use of both female and male SMEs.
- Unbalanced training dataset: The dataset initially shared by DIS produced 162 radical text data and 38 non-radical data items. The dataset was balanced with further scraping of Twitter (X) to produce an equal amount of non-radical data.
- Using a small dataset in a supervised Machine Learning approach: The small dataset of 162 radical and 162 non-radical data items may cause overfitting. However, incorporating the strengths of lexicon-based approaches into the Machine Learning algorithms with lexicon-based features through a semi-supervised approach is expected to mitigate this potential problem. Additional words in the radical corpus incorporated changes that were happening in real time, mitigating the threat to external validity.
3.4. Research Participants and Ethics
- Group 1: Three Subject Matter Experts (SMEs) with experience and knowledge related to terrorism and radicalisation in the Maldives.
- Group 2: Five volunteers of self-deradicalised individuals from the Maldives. They were recruited with the assistance of the NCTC.
3.5. Research Metrics
4. Results
- Radical dataset in PDF form from the DIS, later converted to CSV format for further processing.
- Validation data from SMEs to validate radical dataset from DIS.
- Non-radical data scraped from Twitter based on random everyday topics in the Dhivehi language.
- Interview data from self-deradicalised individuals in the Maldives.
4.1. Description of Datasets
4.2. Fine-Tuning of Parameters of Machine Learning Algoritums
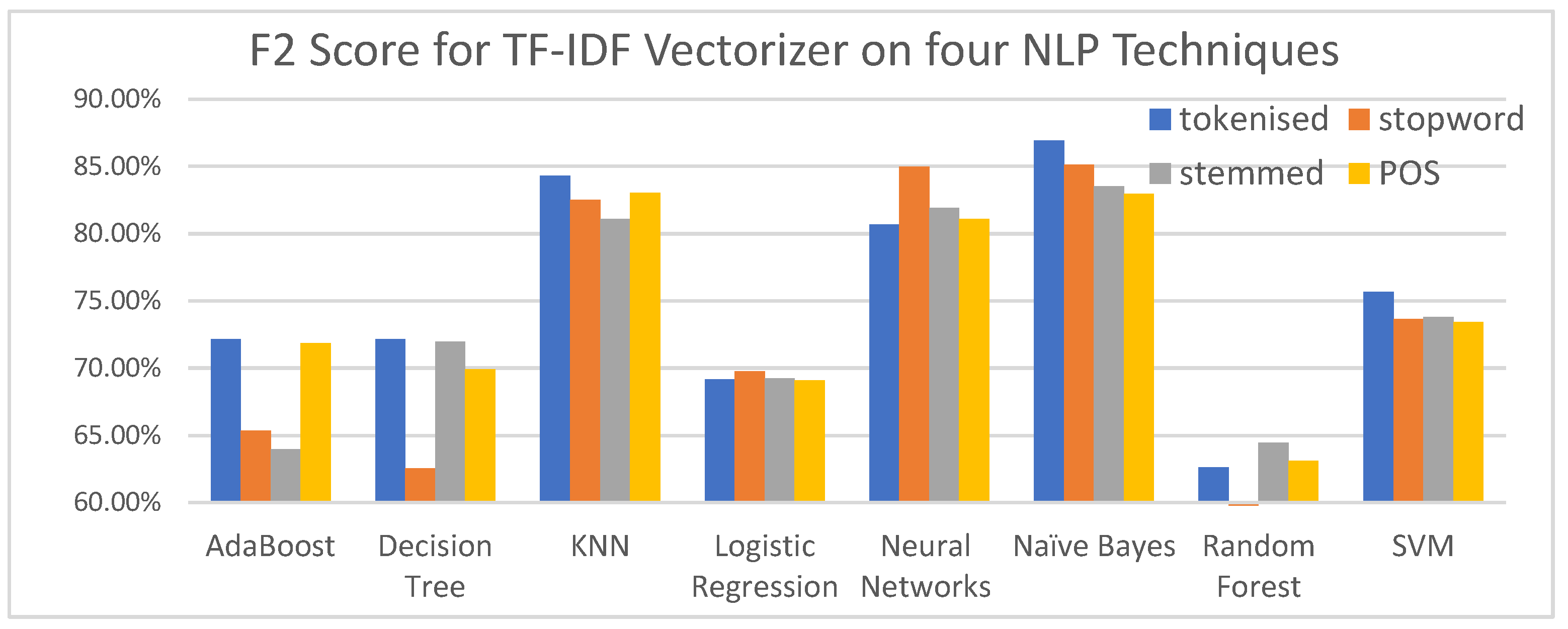
4.3. Performance of Machine Learning Algorithims
5. Discussion
- The Internet plays a major role in the radicalisation of Maldivians.
- The peer network plays an important role in the radicalisation of individuals.
- It is not just uneducated individuals who are radicalised as all the self-deradicalised interview participants had a secondary education or higher.
- Bring about ideological change towards a more radical version of Islam;
- Propagate hatred in society;
- Incite violence.
- Islamic brotherhood;
- Arabised terms and norms;
- Lack of respect for human rights.
6. Conclusions
- Tokenisation without the additional normalisation of stop word removal, stemming or POS tagging worked best for six out of the eight Machine Learning algorithms tested.
- Interviews assisted in the identification of categories of radicalisation and the themes on which people are radicalised.
- Inclusion of radical sentiment data improved the performance.
- The creation of a dataset of radical/non-radical texts in Dhivehi through independent validation by Subject Matter Experts.
- The creation of a corpus of radicalisation words in Dhivehi for use in Machine Learning algorithms in the detection of radical sentiments. This was carried out through the interviews with the SMEs and self-deradicalised individuals.
- A primary dataset in the form of transcripts and translations of real-life experiences of self-deradicalised individuals to identify the pathways of self-radicalisation and deradicalisation as well as their beliefs on controversial ideological issues.
- A methodology that utilised Machine Learning and NLP for the first time in the detection of radicalisation text in Dhivehi.
- The scope of this research was deliberately restricted to Dhivehi language alone. It is common for Maldivians to communicate by mixing Dhivehi and English. This was also observed in some radical text; however, English was excluded in this study.
- Due to the limited dataset used in the research, Large Language Models could not be used. However, with the identification of additional radical data, this is an approach that could be explored. Furthermore, recent progress [24,25] made in adopting transformer models (e.g., BERT, DistilBERT) shows great potential for adopting to multilingual radicalisation detection in social media.
- The timeline of the radical dataset provided by DIS was since its formation in 2016. Hence, the size of the dataset was limited.
- This research project commenced in 2019; therefore, data collection coincided with the COVID-19 pandemic travel restrictions. This prevented our ability to conduct face-to-face interviews with the self-deradicalised individuals. This limited the ability to recruit more participants as well as establish more trust that could have led to more open conversations.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- von Behr, I.; Reding, A.; Edwards, C.; Gribbon, L. Radicalisation in the Digital Era: The Use of the Internet in 15 Cases of Terrorism and Extremism; Rand: Brussels, Belgium, 2013. [Google Scholar]
- National Counter Terrorism Centre (Ed.) Harukashi Fikuru Maanakurun; National Counter Terrorism Centre: Malé, Maldives, 2019. Available online: https://nctc.gov.mv/announcement/anncmnt4.pdf (accessed on 10 June 2021).
- Awan, A.N. Radicalization on the Internet? RUSI J. 2007, 152, 76–81. [Google Scholar] [CrossRef]
- Aly, A. The Internet as Ideological Battleground. In Proceedings of the 1st Australian Counter Terrorism Conference, Perth, WA, Australia, 30 November 2010. [Google Scholar]
- Correa, D.; Sureka, A. Solutions to detect and analyze online radicalization: A survey. arXiv 2013, arXiv:1301.4916. [Google Scholar]
- Wadhwa, P.; Bhatia, M.P.S. Tracking on-line radicalization using investigative data mining. In Proceedings of the IEEE International Conference on Communications, New Delhi, India, 15–17 February 2013. [Google Scholar]
- Gunton, K. The Impact of the Internet and Social Media Platforms on Radicalisation to Terrorism and Violent Extremism. In Privacy, Security and Forensics in the Internet of Things (IoT); Springer: Cham, Switzerland, 2022; pp. 167–177. [Google Scholar]
- American Foreign Policy Council. Quick Facts, Maldives. 2013. Available online: https://almanac.afpc.org/uploads/documents/Maldives%202020%20Website.pdf (accessed on 10 June 2021).
- Sharuhan, M. Police: IS Sympathizers Behind Attempt on Ex-Maldives Leader. Associated Press. 2021. Available online: https://apnews.com/article/government-and-politics-religion-islamic-state-group-maldives-0b491f40f6a5a72ad31b82b193af0322 (accessed on 30 July 2021).
- Aiham, A. Murder commission pushes for charges against culprits behind Yameen, Rilwan, Afrasheem’s murders. The Edition, 3 December 2019. [Google Scholar]
- Benmelech, E.; Klor, E. What explains the flow of foreign fighters to ISIS? Terror. Political Violence 2020, 32, 1458–1481. [Google Scholar] [CrossRef]
- ITU. 2019. Available online: https://www.itu.int/en/ITU-D/Statistics/Pages/stat/default.aspx (accessed on 10 June 2021).
- Bitter, C.; Elizondo, D.A.; Yang, Y.J. Natural language processing: A prolog perspective. Artif. Intell. Rev. 2010, 33, 151–173. [Google Scholar] [CrossRef]
- Thompson, R. Radicalization and the Use of Social Media. J. Strateg. Secur. 2011, 4, 167–190. [Google Scholar] [CrossRef]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef] [PubMed]
- Adek, R.; Ula, M. Systematics review on the application of social media analytics for detecting radical and extremist group. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1071, 012029. [Google Scholar] [CrossRef]
- Aldera, S.; Emam, A.; Al-Qurishi, M.; Alrubaian, M.; Alothaim, A. Online extremism detection in textual content: A systematic literature review. IEEE Access 2021, 9, 42384–42396. [Google Scholar] [CrossRef]
- Agarwal, S.; Sureka, A. Applying social media intelligence for predicting and identifying on-line radicalization and civil unrest oriented threats. arXiv 2015, arXiv:1511.06858. [Google Scholar]
- Boudad, N.; Faizi, R.; Thami, R.O.; Chiheb, R. Sentiment analysis in Arabic: A review of the literature. Ain Shams Eng. J. 2018, 9, 2479–2490. [Google Scholar] [CrossRef]
- Naseem, A.; Mushfique, M. Maldives: The Long Road from Islam to Islamism, A Short History. Dhivehi Sitee. Available online: https://www.dhivehisitee.com/religion/islamism-maldives/ (accessed on 10 June 2021).
- Al-Rubaiee, H.; Qiu, R.; Li, D. Identifying Mubasher software products through sentiment analysis of Arabic tweets. In Proceedings of the 2016 International Conference on Industrial Informatics and Computer Systems (CIICS), Sharjah, United Arab Emirates, 13–15 March 2016. [Google Scholar]
- Albadi, N.; Kurdi, M.; Mishra, S. Are they Our Brothers? Analysis and Detection of Religious Hate Speech in the Arabic Twittersphere. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 69–76. [Google Scholar] [CrossRef]
- Hung, B.W.K.; Muramudalige, S.R.; Jayasumana, A.P.; Klausen, J.; Moloney, E. Recognizing Radicalization Indicators in Text Documents Using Human-in-the-Loop Information Extraction and NLP Techniques. In Proceedings of the 2019 IEEE International Symposium on Technologies for Homeland Security (HST), Woburn, MA, USA, 5–6 November 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Zerrouki, K.; Benblidia, N. Multilingual Text Preprocessing and Classification for the Detection of Extremism and Radicalization in Social Networks. Res. Sq. 2024. [Google Scholar] [CrossRef]
- Shah, M.S.S.; Abuaieta, A.M.; Almazrouei, S.S. Safeguarding Online Communications using DistilRoBERTa for Detection of Terrorism and Offensive Chats. JISCR 2024, 7, 93–107. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | [16] | [17] | [18] | Total |
|---|---|---|---|---|
| SVM | 13 | 10 | 13 | 36 |
| Naïve Bayes | 9 | 1 | 9 | 19 |
| KNN | 6 | 6 | ||
| Rule-based Classifier | 4 | 1 | 5 | |
| Clustering | 4 | 4 | ||
| Exploratory Data Analysis | 4 | 4 | ||
| Decision Tree | 3 | 3 | ||
| Random Forest | 4 | 8 | 12 | |
| AdaBoost | 2 | 2 | ||
| Neural Networks | 2 | 2 | ||
| Best First Search | 1 | 1 | ||
| Logistic Regression | 6 | 6 | ||
| Boosting | 5 | 5 | ||
| Other | 3 | 3 |
| Metric | [16] | [17] | [18] | Total |
|---|---|---|---|---|
| Precision | 12 | 17 | 29 | |
| Recall | 9 | 6 | 16 | 31 |
| F1 Score | 8 | 8 | 12 | 28 |
| K-fold validation | 1 | 1 | ||
| Accuracy | 11 | 11 | 22 | |
| Precision | 6 | 6 | ||
| ROC | 1 | 7 | 8 | |
| Confusion Matrix | 3 | 3 |
| Algorithm | Count Vectoriser | Hashing Vectoriser | TF-IDF Vectoriser |
|---|---|---|---|
| AdaBoost | learning_rate = 0.1 n_estimators = 1000 | learning_rate = 0.1 n_estimators = 1000 | learning_rate = 0.1 n_estimators = 500 |
| Decision Tree | Criterion = ‘entropy’ min_samples_leaf = 4 min_samples_split = 25 | criterion = ‘entropy’ min_samples_leaf = 4 min_samples_split = 25 | criterion = ‘entropy’ min_samples_leaf = 2 min_samples_split = 15 |
| K Nearest Neighbours | leaf_size = 30 n_neighbours = 5 | leaf_size = 10 n_neighbours = 9 | leaf_size = 30 n_neighbours = 5 |
| Logistic Regression | C = 0.5 max_iter = 30 solver = ‘liblinear’ | C = 0.7 max_iter = 30 solver = ‘liblinear’ | C = 0.7 max_iter = 30 solver = ‘liblinear’ |
| Naïve Bayes (Multinomial) | alpha = 0.9 | alpha = 0.8 | alpha = 0.4 |
| Neural Network (MLP) | alpha = 0.0001 hidden_layer_sizes = 100 max_iter = 200 | alpha = 0.0001 hidden_layer_sizes = 150 max_iter = 300 | alpha = 0.001 hidden_layer_sizes = 150 max_iter = 300 |
| Random Forest | max_depth = 35 max_leaf_nodes = 35 min_samples_leaf = 0.005 n_estimators = 110 | max_depth = 50 max_leaf_nodes = 35 min_samples_leaf = 0.005 n_estimators = 110 | max_depth = 35 max_leaf_nodes = 50 min_samples_leaf = 0.006 n_estimators = 50 |
| Support Vector Machine (SVM) | C = 0.3 kernel = ‘linear’ | C = 2.1 kernel = ‘linear’ | C = 1.3 kernel = ‘linear’ |
| Machine Learning Algorithm | Vectoriser | Accuracy | Precision | Recall | F2 Score |
|---|---|---|---|---|---|
| AdaBoost | Count | 81.43% | 78.59% | 88.14% | 86.05% |
| Hashing | 70.79% | 67.08% | 81.81% | 78.37% | |
| TF-IDF | 73.23% | 74.65% | 71.57% | 72.17% | |
| Decision Tree | Count | 74.61% | 75.73% | 70.14% | 71.19% |
| Hashing | 72.54% | 75.07% | 67.43% | 68.83% | |
| TF-IDF | 68.76% | 69.00% | 73.00% | 72.16% | |
| KNN | Count | 51.86% | 53.74% | 89.24% | 78.82% |
| Hashing | 69.07% | 64.24% | 86.05% | 80.58% | |
| TF-IDF | 77.70% | 73.74% | 87.43% | 84.30% | |
| Logistic Regression | Count | 75.97% | 80.16% | 69.33% | 71.26% |
| Hashing | 75.32% | 80.56% | 65.38% | 67.94% | |
| TF-IDF | 77.34% | 85.88% | 65.95% | 69.16% | |
| Neural Network (MLP) | Count | 77.70% | 74.27% | 84.86% | 82.50% |
| Hashing | 78.36% | 75.66% | 84.76% | 82.77% | |
| TF-IDF | 77.70% | 75.85% | 82.00% | 80.69% | |
| Naïve Bayes | Count | 82.52% | 84.19% | 80.76% | 81.42% |
| Hashing | 79.39% | 75.37% | 87.52% | 84.79% | |
| TF-IDF | 82.85% | 79.48% | 89.00% | 86.92% | |
| Random Forest | Count | 72.56% | 82.40% | 56.90% | 60.66% |
| Hashing | 74.95% | 82.84% | 63.86% | 66.92% | |
| TF-IDF | 73.94% | 83.82% | 58.90% | 62.63% | |
| SVM | Count | 78.71% | 81.52% | 74.24% | 75.59% |
| Hashing | 79.09% | 82.38% | 74.38% | 75.85% | |
| TF-IDF | 78.72% | 81.91% | 74.29% | 75.70% |
| Machine Learning Algorithm | Vectoriser | Accuracy | Precision | Recall | F2 Score |
|---|---|---|---|---|---|
| AdaBoost | Count | 81.82% | 81.50% | 84.14% | 83.60% |
| Hashing | 84.92% | 82.81% | 88.90% | 87.62% | |
| TF-IDF | 84.25% | 82.90% | 87.57% | 86.59% | |
| Decision Tree | Count | 78.71% | 80.70% | 77.19% | 77.87% |
| Hashing | 80.78% | 83.60% | 77.95% | 79.02% | |
| TF-IDF | 81.53% | 84.57% | 78.05% | 79.27% | |
| KNN | Count | 54.60% | 54.83% | 95.29% | 83.03% |
| Hashing | 82.51% | 81.90% | 84.71% | 84.14% | |
| TF-IDF | 83.54% | 83.78% | 84.14% | 84.07% | |
| Logistic Regression | Count | 84.91% | 85.65% | 84.00% | 84.32% |
| Hashing | 83.53% | 88.80% | 77.14% | 79.22% | |
| TF-IDF | 83.20% | 88.63% | 76.48% | 78.63% | |
| Neural Network | Count | 83.53% | 78.33% | 93.14% | 89.75% |
| Hashing | 86.60% | 84.23% | 91.00% | 89.56% | |
| TF-IDF | 85.26% | 81.63% | 91.71% | 89.50% | |
| Naïve Bayes | Count | 87.67% | 85.35% | 92.52% | 90.99% |
| Hashing | 80.10% | 72.48% | 97.95% | 91.52% | |
| TF-IDF | 80.46% | 73.33% | 96.57% | 90.81% | |
| Random Forest | Count | 82.86% | 85.94% | 79.24% | 80.49% |
| Hashing | 84.25% | 87.77% | 80.62% | 81.95% | |
| TF-IDF | 80.46% | 82.72% | 77.90% | 78.82% | |
| SVM | Count | 84.23% | 83.49% | 85.43% | 85.03% |
| Hashing | 84.23% | 87.26% | 79.86% | 81.24% | |
| TF-IDF | 84.92% | 88.18% | 81.33% | 82.62% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahim, H.; Ibrahim, A.; Johnstone, M.N. Using Natural Language Processing and Machine Learning to Detect Online Radicalisation in the Maldivian Language, Dhivehi. Information 2025, 16, 342. https://doi.org/10.3390/info16050342
Ibrahim H, Ibrahim A, Johnstone MN. Using Natural Language Processing and Machine Learning to Detect Online Radicalisation in the Maldivian Language, Dhivehi. Information. 2025; 16(5):342. https://doi.org/10.3390/info16050342
Chicago/Turabian StyleIbrahim, Hussain, Ahmed Ibrahim, and Michael N. Johnstone. 2025. "Using Natural Language Processing and Machine Learning to Detect Online Radicalisation in the Maldivian Language, Dhivehi" Information 16, no. 5: 342. https://doi.org/10.3390/info16050342
APA StyleIbrahim, H., Ibrahim, A., & Johnstone, M. N. (2025). Using Natural Language Processing and Machine Learning to Detect Online Radicalisation in the Maldivian Language, Dhivehi. Information, 16(5), 342. https://doi.org/10.3390/info16050342