Abstract
Optical flow is defined as the motion field of pixels between two consecutive images. Traditionally, in order to estimate pixel motion field (or optical flow), an energy model is proposed. This energy model is composed of (i) a data term and (ii) a regularization term. The data term is an optical flow error estimation and the regularization term imposes spatial smoothness. Traditional variational models use a linearization in the data term. This linearized version of data term fails when the displacement of the object is larger than its own size. Recently, the precision of the optical flow method has been increased due to the use of additional information, obtained from correspondences computed between two images obtained by different methods such as SIFT, deep-matching, and exhaustive search. This work presents an empirical study in order to evaluate different strategies for locating exhaustive correspondences improving flow estimation. We considered a different location for matching random locations, uniform locations, and locations on maximum gradient magnitude. Additionally, we tested the combination of large and medium gradients with uniform locations. We evaluated our methodology in the MPI-Sintel database, which represents the state-of-the-art evaluation databases. Our results in MPI-Sintel show that our proposal outperforms classical methods such as Horn-Schunk, TV-L1, and LDOF, and our method performs similar to MDP-Flow.
1. Introduction
The apparent movement of pixels in a sequence of images is called the optical flow. Optical flow estimation is one of the most challenging problems in computer vision, especially in real scenarios where large displacements and illumination changes occur. Optical flow has many applications, including autonomous flight of vehicles, insertion of objects on video, slow camera motion generation, and video compression.
In particular, in video compression, the optical flow helps to remove temporal data redundancy and therefore to attain high compression ratios. In video processing, optical flow estimation is used, e.g., for deblurring and noise suppression.
In order to estimate the flow field that represents the motion of pixels in two consecutive frames of a video sequence, most of the optical flow methods are grounded in the optical flow constraint. This constraint is based on the brightness constancy assumption, which states that the brightness or intensity of objects remains constant from frame to frame along the movement of objects.
Let us consider two consecutive image frames, (reference) and (target), of a video sequence, where where is the image domain (which is assumed to be a rectangle in ) and , and i.e., . The aim is to estimate a 2D motion field the optical flow, such that the image points and are observations of the same physical scene point. In other words, the brightness constancy assumption writes
for x ∈ . Let us assume that the displacement is small enough to be valid the following linearized version of the brightness constancy assumption:
where denotes scalar product, and denotes the gradient of with respect to the space coordinates x and y, respectively. This equation can be rewritten as
where denotes . Equation (3) is usually called the optical flow equation or optical flow constraint.
The optical flow constraint expressed by Equation (3) is only suitable when the partial derivatives can be correctly approximated. This is the case when the motion field is small enough or images are very smooth. However, in the presence of large displacements, these conditions are not typically preserved, and it is common to replace it with a nonlinear formulation [1].
for .
Neither Equation (3) nor Equation (4) can be solved pointwise since the number of parameters (the two components of ) to be estimated is larger than the number of equations.
To challenge these problems, a variational approach could be used and compute the optical flow by minimizing the following energy or error measure,
However, Equation (5) is an ill-posed problem, which is usually challenged by adding a regularity prior. Then, the regularization term added to the energy model allows for a definition of the structure of the motion field and ensures that the optical flow computation is well posed. Ref. [2] proposed adding a quadratic regularization term. This work was the first that introduced variational methods to compute dense optical flow. An optical flow is estimated as the minimizer of the following energy functional
where denotes the gradient of the optical flow. This regularity prior does not cope well with motion discontinuities and other regularization terms have been proposed [3,4,5]. Although the original work of Horn and Schunk reveals many limitations (e.g., the computed optical flow is very smooth and sensitive to the presence of noise), it has inspired many proposals. In order to cope with large displacements, optimization typically proceeds in a coarse-to-fine manner (also called a multi-scale strategy).
Let us now focus on the data term in (6), . The brightness constancy constraint assumes that the illumination of the scene is constant over time and that the image brightness of a point remains constant along its motion trajectory. Therefore, changes in brightness are only due to different objects and different movements.
Let us briefly remark that a problem is called ill-posed if its solution either does not exist or it is not unique. We have observed that the optical flow Equation (3) (or (4)) is an ill-posed problem: it cannot be solved pointwise as there is a unique equation as well as two unknowns and . The optical flow expressed by Equation (3) can be rewritten as
where is the temporal derivative of I, by considering a local orthonormal basis of on directions of and . The optical flow can be expressed in this basis, , where is the projection of in the gradient direction and is the projection of the optical flow in the direction perpendicular to the gradient. Thus, Equation (7) can be formally written as
This equation can be solved for , , if . In other words, the only component of the optical flow that can be determined from Equation (3) is the component parallel to the gradient direction. This indeterminacy is called the aperture problem.
1.1. Optical Flow Estimation
The most accurate techniques that address the motion estimation problem are based on the formulation of the optical flow estimation in a variational setting. Energy-based methods are called global methods since they find correspondences by minimizing an energy defined on the whole image (such as inthe minimizing problem of Equation (6)). They provide a dense solution with subpixel accuracy and are usually called dense optical flow methods.
The authors in [2] estimate a dense optical flow field based on two assumptions: the brightness constancy assumption and a smooth spatial variation of the optical flow. They proposed the following functional:
where is a real parameter that controls the influence of the smooth term. This functional is convex and has a unique minimizer. However, the computed optical flow is very smooth and does not preserve discontinuities of the optical flow. This is also the case for Equation (6), which can be considered a variant of Equation (9).
After the initial work in [2], many approaches that focus on accuracy have been developed. These works focus on the use of robust estimators, either in the data or smoothness terms, to be able to deal with motion discontinuities generated by the movement of different objects or by occlusions (e.g., [5,6]). For the data term, or dissimilarity measures have been used as well as more advanced data terms [6]. For the smoothness term, isotropic diffusion, image-adaptive, isotropic diffusion with non-quadratic regularizers, anisotropic diffusion (image or flow-adaptive), and the recent non-local regularizers have been proposed [3,4,5,6].
However, these methods may fail in occlusion areas due to forced, but unreliable, intensity matching. The problem can be further accentuated if the optical flow is smoothed across an object boundaries adjacent to occlusion areas.
1.2. Robust Motion Estimation
Normally, assumptions as brightness constancy and smooth space variation of optical flow are violated in real images. Advanced robust optical flow methods are developed with the goal to perform well even when violations of the optical flow assumptions are present.
The model expressed by Equation (9) to estimate the optical flow penalizes high gradients of and therefore does not allow discontinuities of . This model is highly sensitive to noise in the images and to outliers. The functional can be modified in order to allow discontinuities of the flow field by changing the quadratic data term to an term and by changing the regularization term. In [5], the authors present a novel approach to estimate the optical flow that preserves discontinuities, and it is robust to noise. In order to compute the optical flow between and , the authors propose minimizing the energy:
including robust data attachment and regularization terms (namely, the total variation of ) with a relative weight given by the parameter . This variational model is usually called the TV-L1 formulation. The use of type-norm measures has shown a good performance in front of norms to preserve discontinuities in the flow field and offers increased robustness against noise and illumination changes.
1.3. Related Works
As we mentioned above, motion estimation methods use an approximation of the data term. Energies that consider this approximation fail to estimate the optical flow when the displacements are very fast or larger than the size of the objects in the scene. Recently, a new term that considers correspondences between two images have been added to these kinds of models [3,6,7,8]. The inclusion of this additional information (as a prior) has improved the performance of the optical flow estimation, giving the model the capability of handle large displacements. The inclusion of this new term allows the methodology to be systematic and not depending on heuristic and complex rules that depend on the designer of the model.
In [3], the authors propose a model to handle large displacement. This model stated an energy model that considers (i) a data term, (ii) a regularization term, and (iii) a term for additional information. The additional information term proposed in this energy model comes from correspondences obtained either by SIFT or by patch match. Considering these computed correspondences, a constant candidate flow is proposed as a possible motion present in the image. Authors select the optimal flow among the constant candidates for each pixel in the image sequence as a labeling problem. The authors solve this problem using discrete optimization QPBO (quadratic pseudo-Boolean optimization).
In [9], a model is presented for estimating the optical flow that utilizes a robust data term, a regularization term, and a term that considers additional matching. Additional matching is obtained using HoGs (Histograms of Gradients). The incorporation of additional matching is weighted by a confidence value that is not simple to compute. This weight depends on the distance to the second best candidate of the matching and on the ratio between the error of current optical flow estimation and the error of the new correspondence. The location of the matching depends on the minimum eigenvalue of the structure tensor of the image and on the error of the optical flow estimation.
Deep-flow presented in [10] is a motion field estimation method inspired by (i) deep convolution neural networks and (ii) the work of [6]. Deep flow is an optical flow estimation method to handle large displacements, which obtains dense correspondences between two consecutive images. These correspondences are obtained using small patches (of pixels). A patch of is interpreted as composed by 4 patches of pixels, each small patch is called a quadrant. The matching score of an patch is formed by averaging the max-pooled scores of the quadrants [10]. This process is repeated recursively for , , and pixels becoming a more discriminant virtual patch. Computed matching is considered a prior term in an energy model. Deep flow uses a uniform grid to locate the correspondences. A study in depth is necessary for this proposed method. Which patch size is necessary to improve the results and which locations are the best to improve optical flow estimation are questions that must be answered.
Recently, new models have been proposed in order to tackle the problem of large displacements in [4,11,12,13]. These models consider sparse or dense matching using a deep matching algorithm [10], motion candidates [13], or SIFT. The principle idea is to give some “hint” to the variational optical flow approach by using such sparse matching [10]. In [12,13], an occlusion layer is also estimated.
In [11], the authors propose a method called SparseFlow that finds sparse pixel correspondences by mean of a matching algorithm, and these correspondences are used to guide a variational approach to obtain a refined optical flow. The SparseFlow matching algorithm uses an efficient sparse decomposition of pixels surrounding a patch as a linear sum of those found around candidate corresponding pixels [11]. The matching pixel dominating the decomposition is chosen. The pixel pair matching in both directions (forward–backward) are used to refine the optical flow estimation.
In [12], a successful method to compute optical flow is proposed which includes occlusion handling and additional temporal information. Images are divided into discrete triangles, and this allowed the authors to naturally estimate the occlusions that are then incorporated into the optimization algorithm to estimate an optical flow. Combining the “Inertial Estimate” of the flow and classifiers to fusion optical flow, they made some improvements in the final results.
The authors in [13] propose a method to compute motion field, and this method aims to tackle large displacements, motion detail, and occlusion estimation. The method consists of two stages: (i) They supply dense local motion candidates. (ii) They estimate affine motion models over a set of size-varying patches combined with a patch-based pairing.
In [14], an optical flow method that includes this new term for additional information coming from exhaustive matching is proposed. This model also considers an occlusion layer simultaneously estimated with optical flow. The estimation of the occlusion layer helps to improve the motion estimation of regions that are visible in the current frame but not visible in the next frame.
In this work, we present an empirical study to evaluate different strategies to locate additional exhaustive matching (correspondences coming from exhaustive search) in order to improve the precision of the motion field or optical flow estimation. We think that none of the above-revised works has answered precisely the question “What is the best location for additional correspondences in order to improve the precision of a motion estimation method?” We considered three possible locations of matching: (i) uniform locations, (ii) random locations, and (iii) locations in the maximum gradient of the reference frame. We also evaluated combined strategies: uniform locations in large gradients magnitude and uniform locations located in medium gradients magnitude. We performed two evaluations using different features. In the first one we used intensities, and in the second, we used gradients.
We present our complete evaluation strategy in Section 5.
1.4. Contribution of This Version
In this new version of the paper presented in [15], we have implemented the following modifications:
- (a)
- We determine the parameters of the optical flow estimation model using particle swarm optimization (PSO).
- (b)
- Our proposal was evaluated in the large database MIP-Sintel in both of its sets: training and test.
- (c)
- We estimated the occluded pixels in two consecutive images based on the largest values of the optical flow error. We avoided computing exhaustive matching in these occluded pixels because the matching will be unreliable.
- (d)
- We divided the gradient of the image into three sets: (i) small gradients, (ii) medium gradients, and (iii) large gradients. In sets (ii) and (iii), we have located additional matching in uniform locations and we have evaluated the performance in MPI-Sintel.
- (e)
- We extended the Horn-Schunck optical flow to handle additional information coming from exhaustive search. This extended method was evaluated in the MPI-Sintel Database, and the obtained results were compared with the results obtained by our proposal.
- (f)
- We performed exhaustive matching using colors and using gradients in order to make this experimental study more complete.
In Section 2, we present our proposal to estimate the motion field. In Section 3, the implementation of the methods is presented and we present the pseudo-code of the algorithm. In Section 4.3, we present the experiments and the database used, and in Section 5 the obtained results are presented. We present comments and discussions about the obtained results in Section 6.
2. Materials and Methods
We present in Section 2.1 our proposed model to handle large displacements and be robust to illumination changes. In Section 2.3 we extended the classical Horn-Shunck method to handle large displacement. Our aim is to compare the effect of using additional term in our proposed model and in the Horn-Shunck model.
2.1. Proposed Model
Models presented in [3,5,7,16] propose a variational model to estimate the motion field. Those cited models use the norm (a data term which is robust to illumination changes and tolerate discontinuities) and an additional term that incorporates information coming from a correspondences estimation method.
Let and be two consecutive images and let be the motion field between images such that
where , and is the data term and is given by
where is a real constant, and the regularization term is given by
2.2. Linearization
The model presented in [5] considers a linearization of the data term in Equation (11). is linearized around a known point as
where is a known optical flow, is the gradient of the warped image , and the notation represents the internal product. Considering this linearization, we obtain a new data term that can be written as
The data term in Equation (12) is based on the brightness constancy assumption, which states that the intensity of the pixels in the image remains constant along the sequence. In most cases, this assumption does not hold due to shadows, reflections, or illumination changes. The presence of shadows and other intensity changes cause the brightness constancy assumption to fail. The gradient constancy assumption appears as an alternative that can handle pixel intensity changes.
We define a weight map to switch between the brightness and gradient constancy assumption as in [3]. We construct a new data term:
where
Equation (14) represents a linearized version of the brightness constancy assumption, and
represents the gradient constancy assumption, where is a positive constant. In Equation (15), the terms , , and , are the partial derivatives w.r.t. x and y of and , respectively.
Considering Equations (14) and (15), we follow [3] and state the adaptive weight map :
where is a positive constant real value.
Computing depends on the difference of two terms: and . On the one hand, if is larger than , the data term will be more confident w.r.t. the gradient constancy constraint. On the other hand, if is less than , the data term will be more confident w.r.t. the color constancy constraint [3,8].
2.2.1. Decoupling Variable
In order to minimize the proposed functional in Equation (11), we propose using three decoupling variables (, , ), and we penalize its deviation from , then the functional becomes
where is a vector in and is defined as .
2.2.2. Color Model
Considering color images in RGB space (, which correspond to red, blue, and green components, respectively), we define five decoupling variables , , and for color components and and for gradients; thus, the functional becomes
where we have defined , and is defined as .
2.2.3. Optical Flow to Handle Large Displacements
In order to cope with large displacements, we use additional information coming from exhaustive matching computed between images of a video sequence used as a precomputed sparse vector field (a priori). The main idea is that this sparse vector field guides the optical flow estimation in regions where the approximated linearized model fails [7] due to fast movements or large displacements.
Let be this sparse vector field. We add to our model a term to enforce the solution to be similar to the sparse flow as in [7], and our model becomes
where is a binary mask indicating where the matching was computed. is a decreasing weight for each scale. Following [7], the is updated for each iteration , where , and n is the iteration number.
We use this binary mask to test different locations of in order to evaluate its influence in the optical flow estimation performance.
2.2.4. Occlusion Estimation
The proposed model cannot handle occluded and dis-occluded pixel. There is no correspondence for pixels that are visible in the current frame and not visible in the target frame. Optical flow computed in those pixels presents a large error due to the forced matching. We used this fact to detect an occlusion and once the occlusion is detected we do not perform exhaustive matching in those points. That is to say, we define regions where the exhaustive matching must not be performed. As a proof of concept, we show in Figure 1 two consecutive frames of the sequence ambush_5 where the girl fights with a man. The sequence presents large regions where pixels are occluded.

Figure 1.
Occlusion estimation comparing optical flow error with a threshold . (a) Frame_0049 of sequence ambush_5; (b) Frame_0050; (c) occlusion estimation.
We present in Figure 1 two consecutive images in (a) and (b), and in (c) we present our occlusion estimation. In the sequence, the hair of the girl moves to the left of the image and the occlusion is correctly estimated. Additionally, dis-occlusion is estimated as we see on the right side of the girl’s head where hair dis-occluded the hand and the lance.
We compare the magnitude of the data term with a threshold () as in [17]. On the one hand, if the magnitude is larger than the threshold, then a binary mask is set to 1. On the other hand, if the magnitude is smaller than the threshold, is set to 0.
2.2.5. Solving the Model
For a fixed and following the notation in [5] we define . Let with . and . If is a small constant, then , , , , and are close to . This convex problem can be minimized by alternating steps as in [5]:
- (1)
- Solve exhaustively
- (2)
- Let us fix , , , , and and then solve for :
- (3)
- Let us fix and solve the problem for , , , , and :
This minimization problem for , , , and can be solved point-wise. Since the propositions in [5] are fundamentals for our work, we adapted them to our model.
Proposition 1.
The solution of Equation (9) is given by
The dual variable is defined as
where .
Proposition 2.
2.3. An Extended Version of Horn-Schunck’s Optical Flow
In [18], the implementation of the classical Horn-Schunk’s optical flow considering a multi-scale pyramid is presented. The model proposed in Equation (9) was extended and solved for the flow with a fixed-point iteration:
and
where w is a constant real value parameter, n is the iteration number, and and are the vertical and horizontal optical flow estimation components, respectively. In the previous scale, , , ∗ is the convolution operator, and G is given by
An Extended Version of the Horn-Schunck’s Optical Flow
We extended the Horn-Schunk’s optical flow to handle large displacements. We modified the solution to the Horn-Schunck scheme by adding terms that consider new information coming from an exhaustive search,
where is given by
and
We minimized the model in Equation (28) for , obtaining
and
where , , and . Let us explain with more detail the term and . These terms consider two binary masks and . The binary mask indicates where the matching should be computed and the binary mask indicates occluded and visible pixels in the target frame. The way mask is constructed is explained in Section 3.3.
3. Implementation and Pseudo-Code
The model was solved by a sequence of optimization steps. First, we performed the exhaustive search in specific locations obtaining flow, and we then fixed to estimate . Finally, we estimated the and the dual variable . These steps were performed iteratively. Our implementation is based on [1], in which a coarse-to-fine multi-scale approach is employed.
3.1. Exhaustive Search
The parameter P defines the size of a neighborhood in the reference image, i.e., a neighborhood of pixels. For each patch in (), we compute
We search for the argument that minimizes this cost value. The functional in Equation (31) always has a solution that depends on , but in many cases there is not only one solution. This issue occurs when the target image contains auto-similarity. In the presence of high auto-similarity, the minimum of the functional presents many local minima. In order to cope with this problem, we use a matching confidence value. This matching confidence value will be zero where high auto-similarity is present, i.e., in cases where there are many solutions where matching is not incorporated in the proposed model.
3.2. Matching Confidence Value
Let be the confidence measure given to each exhaustive matching. The proposed model for is based on the error of the first candidate () and the error of the second candidate (). We have ordered the matching errors of pixels of the target image. We ordered the matching errors from minimum values to maximum values. After that, we computed the confidence value.
3.3. Construction of
Here we explain with more detail the different location strategies or seeding process we performed.
3.3.1. Uniform Location
The uniform location depends on a D parameter. The exhaustive search is performed every D-other pixels with coordinates x and y. Let be this uniform grid where exhaustive matching is performed. In Figure 2, the initial point of the arrow shows the coordinates where a patch is taken in the reference images. The final part of the arrow shows the coordinates where the corresponding patch is located in the target image.
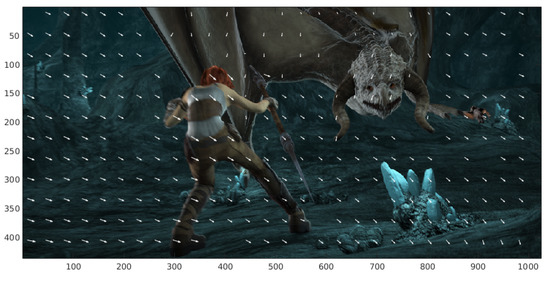
Figure 2.
Correspondences of patches located uniformly in the reference image.
We compute the exhaustive matching in positions given by
where and represent the height and width of the image, respectively, and [ ] represents an integer division.
3.3.2. Random Location
The random location strategy defines a grid where the matching is located. In Figure 3, the matching and its correspondences are represented with white arrows. The initial point of the arrow shows the coordinates where a patch is taken in the reference images. The final part of the arrow shows the coordinates where the corresponding patch is located in the target image. In every realization of the strategy, the grid is changed.
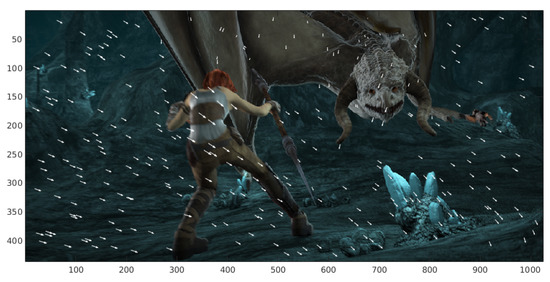
Figure 3.
Correspondences of patches located randomly in the reference image.
3.3.3. Location in Maximum Values of the Gradient Magnitude
We computed the gradient magnitude of the reference image. We ordered that gradient from the smallest magnitude to the maximum magnitude. We considered the as the largest magnitude of the gradient. The grid is defined by the maximum magnitude positions of the gradient in the reference image. In Figure 4, we show the correspondences given the location in the maximum magnitude of the gradient.
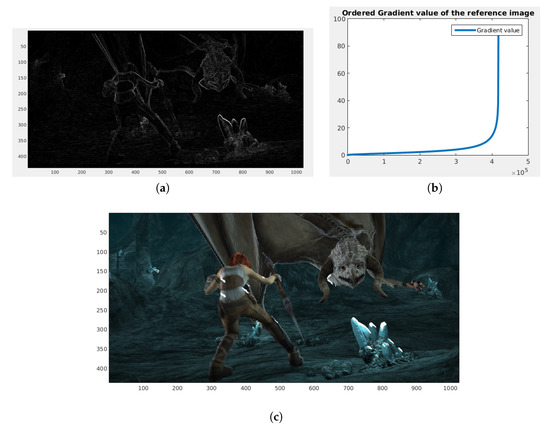
Figure 4.
Correspondence of patches located in the largest magnitude of the gradient. (a) Gradient magnitude of the reference image. (b) Ordered gradient from the minimum magnitude to the maximum magnitude. (c) Correspondences of the patches located in the maximum gradient magnitudes (white arrows).
In Figure 4a, we show the computed magnitude of the gradient. We represent the magnitude of the gradient using intensities: white means the maximum magnitude of the gradient, and black means the minimum magnitude. We ordered the gradient magnitude and plotted it. We took the last magnitude of the gradient. These gradients correspond to locations in the image. In those locations, we performed exhaustive matching. We observe in Figure 4c that the matching is located on the edges of the girl’s cloth, on the dragon face, and on rock edges.
3.3.4. Location in the Large Magnitudes of the Gradient in a Uniform Location
The main idea is to compute matching in a location, where large gradients are present using a uniform grid (a large gradient uniform grid). We divided the gradient of the image into three subsets: a large gradient set, a medium gradient set, and a small gradient sets. In Figure 5c, we show the position of matching in the large gradient uniform grid. We show in (a) the magnitude of the gradient of the image. In (b), we show a binary image where 1 indicates the location of large gradients that coincides with regions that present edges and highly textured surfaces.

Figure 5.
(a) Gradient of the reference image. (b) Large gradient set. (c) Matching result of patches located in the large gradient uniform grid.
In (c), we observe that the matching is located in a uniform location but only in places where the high gradient is present.
3.3.5. Location in the Medium Magnitudes of the Gradient in a Uniform Location
We show in Figure 6a the magnitude of the gradient of the image and the located matching In (b), we show a binary image where 1 indicates the location of medium gradients.

Figure 6.
(a) Gradient of the reference image. (b) Medium gradient set. (c) Matching result of the patches located in the medium gradient uniform grid.
3.3.6. Value
The value of the is given by the confidence value , i.e.,
The is the weight of matching. In the presence of auto-similarity of the target image, will be zero.
3.4. Pseudo Code
The model was implemented based on the available code in IPOL [1] for the TV-L1 model. The model was programmed in C in a laptop with i7 processor and 16 GB RAM. The pseudo code is presented in Algorithm 1.
The algorithm to compute the optical flow using additional information:
| Algorithm 1: Integration of additional information coming from exhaustive matching |
| : Two consecutive color images , . |
| α, λ, P, , , β, , β, κ, , , . |
| : optical flow |
| Initialization |
| to 1 |
| Construct ψ |
| In specific locations defined by the strategy compute using Equation (31) |
| Using compute and update . |
| to |
| Compute and occlusion . |
| Compute , Equations (24) and (25). |
| Compute , Equation (21). |
| Compute ξ Equations (22) and (23). |
| update |
| up-sample |
| Out . |
4. Experiments and Database
4.1. Middlebury Database
The proposed model has been tested in the available Middlebury database training set [19]. This database contains eight image sequences, and its ground truth is also available. We divided the Middlebury sequences into two groups: (i) a training set (two sequences) and (ii) an evaluation set containing the rest of the sequences. These images present illumination changes and shadows (Figure 7e–h).

Figure 7.
Images of the Middlebury database containing small displacements. (a) and (b) frame10 and frame11 of sequence Grove2, respectively. (c) and (d) frame10 and frame11 of sequence Grove3, respectively. (e) and (f) frame10 and frame11 of sequence RubberWhale, respectively. (g) and (h) frame10 and frame11 of sequence Hydrangea, respectively. (i) and (j) frame10 and frame11 of sequence Urban2, respectively and finally (k) and (l) of sequence Urban2, respectively.
Figure 7 shows two consecutive frames, namely, Frame 10 and Frame 11. In our model, corresponds to Frame 10, to Frame 11. Figure 7a,b correspond to the Grove2 sequence, (c) and (d) to he Grove3 sequence, (e) and (f) to RubberWhale, (g) and (h) to the Hydra sequence, (i) and (j) to the Urban2 sequence, and (k) and (l) to the Urban3 sequence.
4.2. The MPI-Sintel Database
The MPI-Sintel database [20] presents long synthetic video sequences containing large displacements and several image degradations as blur or reflections as well as different effects such as fog, shadows, reflections, and blur.
Moreover, there are two versions of the MPI-Sintel database: clean and final. The final version is claimed to be more challenging and includes all effects previously mentioned. For our evaluation, we take the final version of MPI-Sintel. In Figure 8 we compare the same frame extracted from clean version and final version.

Figure 8.
Image extracted from MPI-Sintel clean version and MPI-Sintel final version. We extracted frame_0014 from sequence ambush_2. (a) frame_0014 clean version. (b) frame_0014 final version.
In Figure 8a we show the clean version of frame_0014 of sequence ambush_2. The Figure 8b includes fog and blur effects making this MPI-Stintel version more challenging.
The optical flow (ground truth) of this database is publicly available in order to compare different algorithms. The optical flow was color-coded using the color code presented in Figure 9.
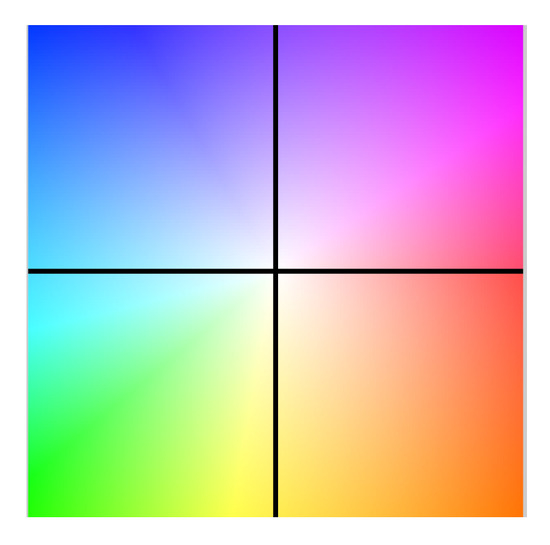
Figure 9.
Color code used for the optical flow.
Figure 10 displays some examples of the MPI-Sintel database. There are images with large displacements: around 170 pixels for the cave_4 sequence and around 300 pixels for temple_3. In the cave_4 sequence, a girl fights with a dragon inside a cave, shown in Figure 10a,b,d,e. In (a) and (b), the girl moves her lance to attack the dragon. In (d) and (e), the dragon moves its jaws very fast. In (g) and (h), we show the girl trying to catch the small dragon, but a claw appears and takes the small dragon away. In (j) and (k), the girl falls in the snow. We observe large displacement and deformation with respect to her hands. We also display the optical flow of the video sequence.

Figure 10.
Examples of images of the MPI-Sintel database video sequence. (a,b) frame_0010 and frame_0011, (c) color-coded ground truth optical flow of the cave_4 sequence, (d) ground truth represented with arrows. (e,f) frame_0045 and frame_0046, (g) color-coded ground truth, and (h) arrow representation of optical flow of the cave_4 sequence, (i,j) frame_0030 and frame_0031, (k) color-coded ground truth optical flow, (l) arrow representation (in blue) of the temple3 sequence. (m,n) frame_0006 and frame_0007, (o) color-coded ground truth and (p) arrow representation (in green) ground truth optical flow of the ambush_4 sequence.
We present in Table 1 the number of images and the names of each sequence of the final MPI-Sintel.

Table 1.
Number of images in each image sequence.
4.3. Experiments with the Middlebury Database
In this section, we present quantitative results obtained by the optical flow estimation model presented above. We have divided the database in the training set and the evaluation set. We used the sequences Grove3 and RubberWhale as the training set (TRAINING_SET). The other sequences are used to validate the method.
4.4. Parameter Estimation
Initially, we estimated the best parameters in our training set considering , i.e., the model cannot handle large displacements. We scan the parameter θ and λ, setting and and estimating the (End Point Error) and (Average Angular Error) error.
We obtained the minimum value for both and error in and . We selected these parameter values. In Figure 11, we show the obtained optical flow, setting θ and λ parameters.
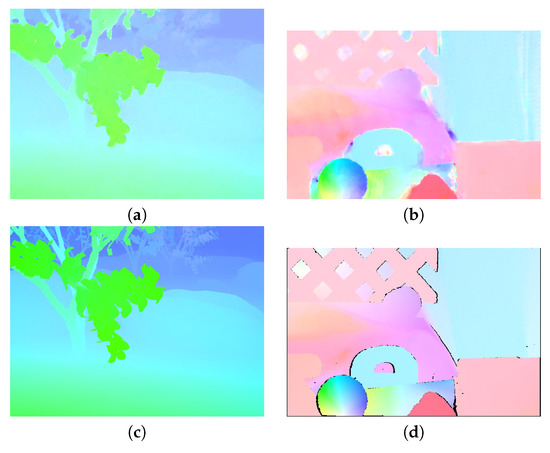
Figure 11.
Color-coded optical flow. (a) Color-coded optical flow for Grove2. (b) Color-coded optical flow for RubberWhale. (c) Ground truth for the Grove2 sequence. (d) Ground truth for the RubberWhale sequence.
With these parameters we obtained an average and .
We fixed the value of θ and λ and then varied from to and β from 1 to 8. We obtained a minimum in and . With these parameters we obtained and average and . In Figure 11c,d, we present the ground truth for the Grove2 sequence and the RubberWhale sequence, respectively, in order to facilitate the visual evaluation of our results.
In Figure 12, we show the optical flow and the weight map .

Figure 12.
Color-coded optical flow. (a) Color-coded coded optical flow for Grove2. (b) Color-coded optical flow for RubberWhale. (c) Ground truth for the Grove2 sequence. (d) Ground truth for the RubberWhale sequence. (e) Weight map for Grove2. (f) Weight map for RubberWhale.
We can observe in Figure 12a,b the obtained optical flow using weight map . There is an improvement in both estimated optical flows. In (c) and (d), we present the function for both sequences. Low gray levels represent low values of ; i.e., the model uses the gradient constancy assumption. Higher gray level means that the model uses the brightness constancy assumption. As we can see in (d), the model uses gradients on shadows in the right side of the whale and the left side of the wheel. In (c), in most locations, .
4.5. Experiments with MPI-Sintel
We performed two evaluations: and . Evaluation considers the proposed model, evaluating different strategies to locate matching. These strategies are (i) uniform locations, (ii) random locations, (iii) locations in maximum gradients of the reference image, (iv) uniform locations in the largest gradients of the image, and (v) uniform locations in the medium gradients of the reference image. In these five evaluations, the matching was computed comparing colors between pixels. Additionally, we performed the previous five evaluations using gradient patches instead of color patches.
In Evaluation , considering the extended Horn-Schunck model, we evaluated its performance in different location strategies. These strategies are the same in Evaluation , i.e., (i) uniform, (ii) random, (iii) maximum gradients, (iv) uniform locations in maximum gradients, and (v) uniform locations in medium gradients.
4.6. Parameter Estimation of the Proposed Model with MPI-Sintel
4.6.1. Parameter Model Estimation
Parameters λ, θ, and β y were estimated by the PSO algorithm [21]. The PSO algorithm is an optimization method that does not compute derivatives of the functional to minimize. It minimizes a functional by iteratively trying to improve many candidate solutions. Each iteration is performed taking into account the functional, and it is minimized considering these candidate solutions and updating them in the space-domain according to dynamics behavior for the position and velocity of solution candidates. Let be a functional to optimize (in this case, we considered the total as the functional to minimize), where n is the number of parameters to estimate. Let be a candidate solution that minimizes the optical flow estimation error. In each iteration, a global best candidate parameter is stored () and jointly is stored the parameter candidate that presents the best performance in the iteration (). Each parameter vector is updated by
where ω is the evolution parameter for each solution , and and are positive weight parameters. A saturation for is usually considered. In our case, we used and . In Table 2, we show the parameters of our PSO algorithm.
Table 2.
PSO parameters.
In each estimated optical flow of the sequence, we computed the and for each sequence, and each PSO iteration we minimized the following functional:
where and is the end point error and the average angular error of each considered sequence, respectively, defined as
where is the ground truth optical flow, and is the estimated optical flow.
In order to estimate the parameters of the model, we selected eight pairs of consecutive images video sequences of the MPI-Sintel database. We selected the first two images from sequences: alley_1, ambush_2, bamboo_2, cave_4, market_5, bandage_1, mountain_1, and temple_3.
In Figure 13, we show image sequences used to estimate the parameter, the ground truth optical flow, and our results.

Figure 13.
Image sequences used to estimate model parameters. In the parameter estimation, we used the first two frames of each considered sequence: (a–d) the frames of the alley_1 sequence, the ground truth, and our results, respectively. (e,f) the ambush_2 sequence, (g) the ground truth, and (h) our result. (i,j) frames of the bamboo_2 sequence, (k) the ground truth, and (l) our result. (m,n) the frame of bandage_1 sequence (o) the ground truth, and (p) our results.
We observe in Figure 13a,b a girl that moves a fruit upward. Our method estimates correctly the direction of the motion. . Figure 13e,f show the lance as well as the girl and the man fighting. The method cannot estimate correctly the motion due to large displacements. . Figure 13l shows that the large displacements of the butterfly cannot be correctly estimated. In Figure 13p, we observe that the displacements are correctly estimated. .
In Figure 14b, we show the performance of the PSO algorithm minimizing the functional in Equation (34).
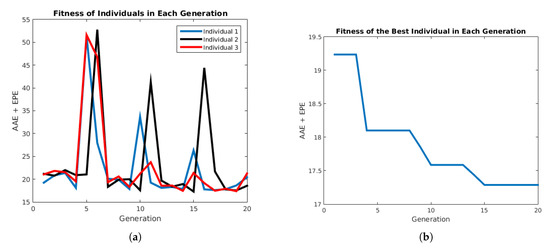
Figure 14.
Performance of the PSO algorithm. (a) Performance of each individual. (b) Performance of the best individual in each generation.
Figure 14a shows the performance of each individual for 20 generations. It is observed that the variation of the performance decreases along the iterations. In Figure 14, the performance of the best individual for each iteration decreases its functional value; the final value is .
We present in Table 3 the final and value for our selected training set.
Table 3.
Results obtained by PSO in the MPI-Sintel selected training set.
As is shown in Table 3, the best performance was for the sequence alley_1 that presents small displacements, and the worst performance was for the sequence market_5, which presents large displacements. Final parameters for the proposed model are , , , and .
4.6.2. Exhaustive Search Parameter Estimation
Parameters P and D are estimated once the model parameter is estimated. Because these parameters are discrete, we estimate them, scanning P and D values in an exhaustive way. We varied P from 2 to 20 pixels with a step of 2 pixels, and D varied from 32 to 64 with a step of 4 pixels. In Figure 15, we show the obtained performance by the functional in Section 4.6.1 for the MPI-Sintel selected video sequences.
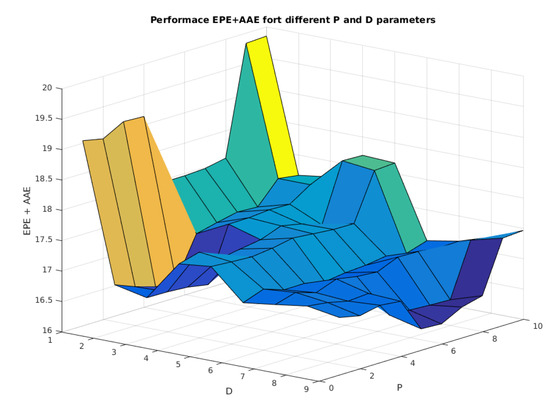
Figure 15.
Performance of the proposed model considering variation in P and D parameters.
We show in Figure 15 the performance for a different grid size D and for a different patch size P. It is observed that the minimum of the surface is located at and , reaching a performance of . We prefer the second minimum located at and , reaching a performance of . This second minimum implies a more dense grid that would perform better in terms of handling small objects. The model using patches outperforms the original model, which does not consider exhaustive search correspondences.
4.7. Parameter Estimation of the Extended Horn-Schunk
4.7.1. Parameter
The multi-scale model has a principal parameter α. This parameter represents the balance between the data term and regularization. We adjusted this parameter using the selected training set which contains eight video sequences. In Figure 16, we show the obtained values for different α values:
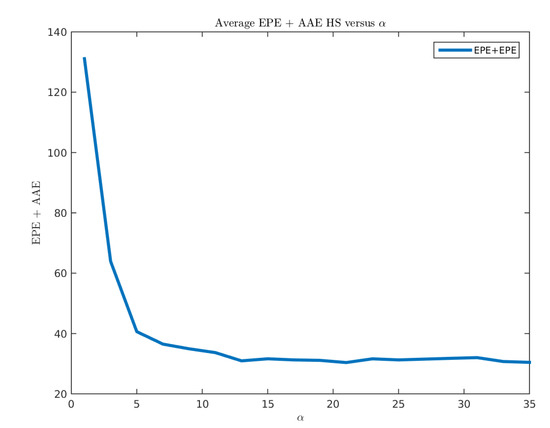
Figure 16.
Performance of the Horn-Schunck method for different values.
Figure 16 shows that the minimum value of the error is reached for . We presented in Table 4 the performance obtained by Horn-Schunck for each sequence.
Table 4.
Results obtained by PSO in the MPI-Sintel selected training set.
Total average and is and , respectively. If we compare this with Table 3, where the results of our proposed model are presented, it is evident that the proposed model outperforms the extended Horn-Schunck model.
4.7.2. Exhaustive Search Parameter Estimation
We varied the P and D with discrete steps in order to find the combination to improve the performance of the optical flow estimation. The parameter P varied from 2 to 20 with a step of 2 pixels, and D varied from 32 to 64 with a step of four pixels. We evaluated the performance of the extended Horn-Schunck method in the selected training set. In Figure 17, we present the obtained results of this experiment.
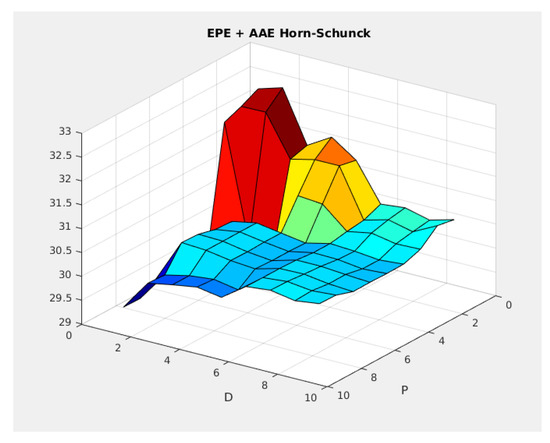
Figure 17.
Performance of the Horn-Schunck model for different P and D parameters.
For these parameters, the obtained and are presented in Table 5.
Table 5.
Results obtained by the PSO in the MPI-Sintel selected training set.
Comparing this table with Table 4, we observe that in sequence alley_1, bandage_1, market_5, and temple_3, there is an improvement in performance. Sequences ambush_2, bamboo_2, and mountain_1 approximately maintain the performance. Sequence cave_4 present an increment in the from to . On average, the total performance is and , which represent an improvement compared with the results obtained in Table 4.
5. Results
5.1. Reported Results in Middlebury
We show in Table 6 the reported values for TV-L1 in [1] using gray level images of the Middlebury database.
Table 6.
The reported performance of TV-L1 in Middlebury [1].
In Table 7, we present our results obtained using the set of parameters determined above.
Table 7.
Obtained results of our model in Middlebury with .
5.2. Specific Location of Matching
Considering the integration of exhaustive matching to our variational model, we perform an empirical evaluation to determine the best location of exhaustive matching in order to improve the optical flow estimation. We compare three strategies to locate exhaustive matching: (i) uniform location in a grid , (ii) random location of matching, and (iii) matching located in the maximum of the magnitude of the gradient.
5.2.1. Uniform Locations
This is the most simple strategy to locate exhaustive matching. Location depends on the size of the grid .
In Figure 18, we present exhaustive correspondences computed in a uniform grid. We present a zoomed area for Grove2 and Rubberwhale sequences.
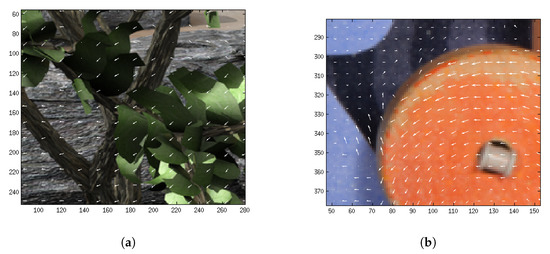
Figure 18.
Exhaustive matching represented with white arrows. (a) Exhaustive matching using and for Grove2. (b) Exhaustive matching using and for Rubberwhale.
We vary these parameters P and D from 2 to 10 and from 2 to 18, respectively. The minimum of the error is obtained for large values of D since the exhaustive search frequently yields some false matching, as can be seen in Figure 18b. Increasing the D parameter produces more confident matching. Thus, we select and . With these parameters, we include in the model around 900 matches. Considering these selected parameters, we obtained an average of and in TRAINING_SET. In VALIDATION_SET, we obtained the results showed in Table 8.
Table 8.
Results obtained by the uniform matching location strategy in VALIDATION_SET.
For the Urban3 sequence, we used and . This image is produce by CGI and presents auto-similarities.
5.2.2. Random Locations
We performed experiments locating the matching and using a grid created randomly. We computed around 900 matches in each experiment. We performed each experiment three times, obtaining results shown in Table 9.
Table 9.
Average and obtained by Random Location Strategy in VALIDATION_SET set.
5.2.3. Locations for Maximum Magnitudes of the Gradient
We present in Table 10 our results using the maximum gradient.
Table 10.
Average and obtained by the maximum gradient location strategy in VALIDATION_SET.
Comparing the average and obtained for each strategy, we observe that the best performance was obtained by the uniform location strategy, the second best performance by the random location strategy, the third best by the maximum gradient strategy.
5.3. Evaluation in MPI-Sintel
5.3.1. Uniform Location
As a first experiment, we computed the optical flow for the whole MPI-Sintel training database. We did not compute the optical flow in the images used to estimate the parameters of the algorithm. We computed 1033 optical flow and evaluated its and for each sequence. In Table 11, we present our results for MPI-Sintel:
Table 11.
Summary of results. The end point error and average angular error obtained by uniform locations in the MPI-Sintel training set.
In Table 11, we show our obtained results by our proposed model using uniform location. We obtained as the error. We observe that the best performance was obtained for the sleeping sequence. This sequence presents the dragon and the sleeping girl and contains small displacements. The worst performance was obtained for the Ambush sequence, where the girl fights with a man in the snow. This sequence presents extremely large displacements that are very hard to handle.
5.3.2. Random Location
In the second experiment, we computed the optical flow for the MPI-Sintel training set. We performed two realizations of the optical flow estimation and computed the and average value on these realizations. In Table 12, we present our results:
Table 12.
Summary of results. The end point error and average angular error obtained by random locations in the MPI-Sintel training set.
5.3.3. Location on Maximum Gradients
In the third experiment, we computed the optical flow for the MPI-Sintel training set. We performed matching with patches located in the maximum gradient magnitude of the current frame. Our obtained results are presented in Table 13.
Table 13.
Summary of results. The end point error and average angular error obtained by locations on maximum gradients in the MPI-Sintel training set.
5.4. Summary
We summarize our results of these three sections in Table 14.
Table 14.
Summary of the obtained results for different strategies.
The best performance of these three strategies was obtained by uniform locations. We processed the MIP-Sintel test database and uploaded our results to the website http://www.sintel.is.tue.mpg.de/results. The test database consists of eight sequences of 500 images in two versions: clean and final. The final MPI-Sintel version considers effects such as blur, shadows, illumination changes, and large displacements. This database is very challenging and represents the state-of-the-art evaluation dataset.
In Figure 19, we show the position reached by our method:
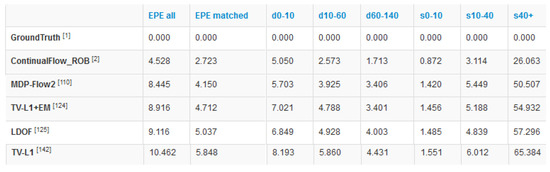
Figure 19.
Obtained results by our method in the MPI-Sintel test database (at 18 October 2018).
In Figure 19, we can observe that our method (TV-L1+EM) obtained and is located in Position 124 of the 155 methods. Our proposal outperforms TV-L1 and LDOF. Our performance is similar to that obtained by MDP-Flow2 [3].
5.4.1. Combined Uniform–Large Gradient Locations
We obtained the best performance using uniform locations, so we decided to mix two strategies: uniform locations with large gradient locations. In order to implement this new strategy, we took the magnitude of the gradient of the reference frame and ordered them from large to small values. We then considered the first third of this ordered data as a large gradient and the second third of the data as the medium gradient. Pixels in the reference frame can belong to a large gradient set, a medium gradient set, or a small gradient set. In uniform locations where the gradient of pixels belongs to the large gradient, we set ; else, we set .
In Table 15, we show our results obtained by this strategy using the MPI-Sintel database.
Table 15.
Summary of results. The end point error and average angular error obtained by the combination of uniform and large gradients in the MPI-Sintel training set.
We observe in Table 15 that the performance of the strategy is outperformed by the uniform locations strategy. It seems that those two conditions, uniform location and large gradients, eliminate good correspondences located in medium or small gradients magnitude.
5.4.2. Combined Uniform–Medium Gradient Locations
We combined the location between uniform and medium gradient locations.
In Table 16, we show our results obtained by this combined strategy in the MPI-Sintel database.
Table 16.
Summary of results. The end point error and average angular error obtained by the combination of uniform and medium gradients in the MPI-Sintel training set.
We observe in Table 16 that the performance of the strategy is outperformed by the uniform locations strategy. It seems that those two conditions, uniform location, and medium gradients, eliminate good correspondences located in large or small gradients magnitude.
5.4.3. Results Obtained by Horn-Schunck
As a starting point, we evaluated the implementation of Horn-Schunck in [18] in MPI-Sintel. The obtained results are shown in Table 17.
Table 17.
Summary of results. The end point error and average angular error obtained by Horn-Schunck in the MPI-Sintel training set.
In Table 17, we show the performance obtained by the Horn-Schunck method using . The performance is almost double the performance of our proposed model.
5.4.4. Results Obtained by Horn-Schunck Using Uniform Locations
We performed the evaluation of MPI-Sintel using the extended version of Horn-Schunck to handle large displacements. In Table 18, we show the obtained results:
Table 18.
Summary of results. The end point error and average angular error obtained by Horn-Schunck using uniform locations in the MPI-Sintel training set.
In Table 18, we show that the performance obtained by the Horn-Schunck using patches in uniform locations is outperformed by the results in Table 17. This extended version of Horn-Schunck presents . We explain this fact considering correct and false correspondences (outliers) given by the exhaustive search. The Horn-Schunck model is not robust to outliers because the method considers in its formulation an data term and an regularization term. On the other hand, is robust to outliers and performs better using additional information.
6. Discussion
We present here a method to estimate optical flow for realistic scenarios using two consecutive color images. In realistic scenarios, occlusions, illumination changes, and large displacements occur. Classical optical flow models may fail in realistic scenarios. The presented model incorporates the occlusion information on its energy based on the maximum error of the optical flow estimation.
This model handles illumination changes using a balance-term between gradients and intensities. The inclusion of this balance term allows the model to improve the performance of the optical flow estimation in scenarios with illumination changes, reflections, and shadows.
Thanks to the use of supplementary matching (given by exhaustive searches in specific locations), this model is able to handle large displacements.
We tested five strategies of specific matching locations: uniform locations, random locations, maximum gradient locations, uniform-maximum gradient locations, and uniform-medium gradient locations. The obtained results show that the best performance was obtained by the uniform location strategy and the second best performance was achieved by the random location strategy. Empirically, we demonstrated that the best criteria to localize exhaustive matching does not depend on image gradients but on a uniform spatial location. Additionally, we have used gradient patches instead of color patches to compute correspondences and have used this information in order to estimate optical flow. The obtained results show that the use of gradient patches outperform the model based on color.
We also tested the classical Horn-Schunk model and extended it to handle additional information coming from an exhaustive search. The obtained results show that this extended Horn-Schunck model cannot handle large displacements in this way due to the presence of many outliers given by the exhaustive search. The Horn-Schunck model uses an norm in its formulation, which is not robust to outliers. On the other hand, the proposed model that uses the norm is robust to outliers and performs better using additional information. The use of an occlusion estimation that depends on optical flow error lets us eliminate simultaneously false exhaustive correspondences and good correspondences. Some correspondences (i.e., good correspondences) present large errors due to illumination changes, blur, reflections, shadows, or fog that may be present in the MPI-Sintel sequence. These correspondences are eliminated because they present large optical flow errors.
We estimated parameters of the model using the PSO algorithm, which helped us to improve the global performance based on the and error computed in a training subset of MPI-Sintel. The final result obtained in the whole database was similar to the one obtained in this small dataset. That means that the small dataset was representative of the database.
The proposed model needs a methodology to validate matching processes. This new methodology should assign to each match a reliable value in order to eliminate false matching.
The number of good matching is necessary to be increased in order to improve optical flow estimations. One way to do that is by the use of deformable patches. Performing an exhaustive search using deformable patches is necessary to have a good correspondence between two patches of the reference frame and the target frame. Once a good correspondence in the target frame is found, a patch in the reference frame can be divided into smaller patches. For each smaller patch, a local search on the target image can be performed in order to increase the number of matching.
Funding
This research received no external funding.
Acknowledgments
We thank Francisco Rivera for correcting grammatical and spelling of this manuscript.
Conflicts of Interest
The author declare no conflict of interest.
References
- Sánchez, J.; Meinhardt-Llopis, E.; Facciolo, G. TV-L1 Optical Flow Estimation. Image Process. Line 2013, 2013, 137–150. [Google Scholar] [CrossRef]
- Horn, B.K.P.; Schunck, B.G. Determining Optical Flow. Artif. Intell. 1981, 17, 185–204. [Google Scholar] [CrossRef]
- Xu, L.; Jia, J.; Matsushita, Y. Motion Detail Preserving Optical Flow. In Proceedings of the IEEE CVPR, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Palomares, R.P.; Haro, G.; Ballester, C. A Rotation-Invariant Regularization Term for Optical Flow Related Problems. In Lectures Notes in Computer Science, Proceedings of the ACCV’14, Singapore, 1–5 November 2014; Springer: Cham, Switzerland, 2014; Volume 9007, pp. 304–319. [Google Scholar]
- Wedel, A.; Pock, T.; Zach, C.; Bischof, H.; Cremers, D. An Improved Algorithm for TV-L1 Optical Flow, Statistical and Geometrical Approaches to Visual Motion Analysis. In Proceedings of the International Dagstuhl Seminar, Dagstuhl Castle, Germany, 13–18 July 2008; Volume 5604. [Google Scholar]
- Brox, T.; Bregler, C.; Malik, J. Large Displacemnet Optical Flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar]
- Stoll, M.; Volz, S.; Bruhn, A. Adaptive Integration of Features Matches into Variational Optical Flow Methods. In Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012. [Google Scholar]
- Lazcano, V. Some Problems in Depth Enhanced Video Processing. Ph.D. Thesis, Universitat Pompeu Fabra, Barcelona, Spain, 2016. Available online: http://www.tdx.cat/handle/10803/373917 (accessed on 17 October 2018).
- Bruhn, A.; Weickert, J.; Feddern, C.; Kohlberger, T.; Schnoerr, C. Real-time Optical Flow Computation with Variational Methods. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Groningen, The Netherlands, 25–27 August 2003; pp. 222–229. [Google Scholar]
- Weinzaepfel, P.; Revaud, J.; Harchaoui, Z.; Schmid, C. DeepFlow: Large displacement optical flow with deep matching. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Timofte, R.; van Gool, L. Sparseflow: Sparse matching for small to large displacement optical flow. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015. [Google Scholar]
- Kennedy, R.; Taylor, C.J. Optical flow with geometric occlusion estimation and fusion of multiple frames. In Energy Minimization Methods in Computer Vision and Pattern Recognition, Proceedings of the International Workshop on Energy Minimization Methods in Computer Vision and Pattern Recognition, Hong Kong, China, 13–16 January 2015; Springer: Cham, Switzerland, 2015; Volume 8932, pp. 364–377. [Google Scholar]
- Fortun, D.; Bouthemy, P.; Kervrann, C. Aggregation of local parametric candidates with exemplar-based occlusion handling for optical flow. Comput. Vis. Image Underst. 2016, 145, 81–94. [Google Scholar] [CrossRef]
- Lazcano, V.; Garrido, L.; Ballester, C. Jointly Optical Flow and Occlusion Estimation for Images with Large Displacements. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Madeira, Portugal, 27–29 January 2018; Volume 5, pp. 588–595. [Google Scholar] [CrossRef]
- Lazcano, V. Study of Specific Location of Exhaustive Matching in Order to Improve the Optical Flow Estimation. Information Technology—New Generations. In Proceedings of the 15th International Conference on Information Technology, Las Vegas, NV, USA, 16–18 April 2018; pp. 603–661. [Google Scholar]
- Steinbruecker, F.; Pock, T.; Cremers, D. Large Displacement Optical Flow Computation without Warping. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 185–203. [Google Scholar]
- Xiao, J.; Cheng, H.; Sawhney, H.; Rao, C.; Isnardi, M. Bilateral Filetring-based Flow Estimation with Occlusion Detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 221–224. [Google Scholar]
- Meinhardt-Llopis, E.; Sanchez, J.; Kondermann, D. Horn-Schunck Optical Flow with a Multi-Scale Strategy. Image Processing Line 2013, 2013, 151–172. [Google Scholar] [CrossRef]
- Baker, S.; Scharstein, D.; Lewis, J.; Roth, S.; Black, M.; Szelinsky, R. A Database and Evaluation Methodology for Optical Flow. Int. J. Comput. Vis. 2011, 92, 1–31. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; Part IV, LNCS 7577. Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 611–625. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks. IV, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]



















© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).