


Discrete Event Systems Theory for Fast Stochastic Simulation via Tree Expansion

Abstract
:1. Introduction
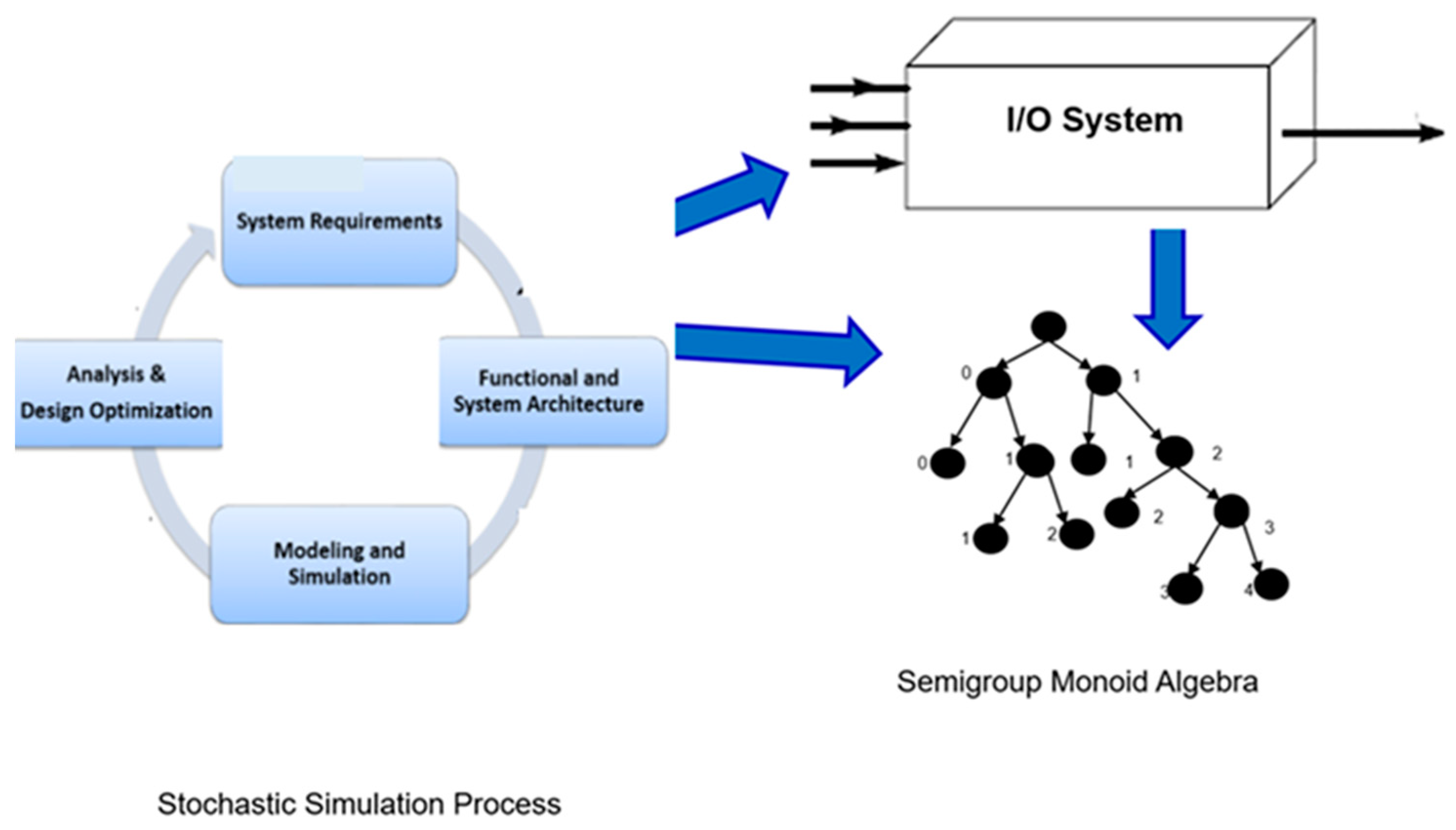
2. Formal Framework for Tree Expansion for Stochastic Simulation
2.1. Definitions
- Not defined at a state, if there is no transition pair with the state as its left member;
- Non-deterministic at a state, if the state is a left member of two transition pairs;
- Deterministic at a state when there is exactly one outbound transition (a left member of exactly one transition pair).

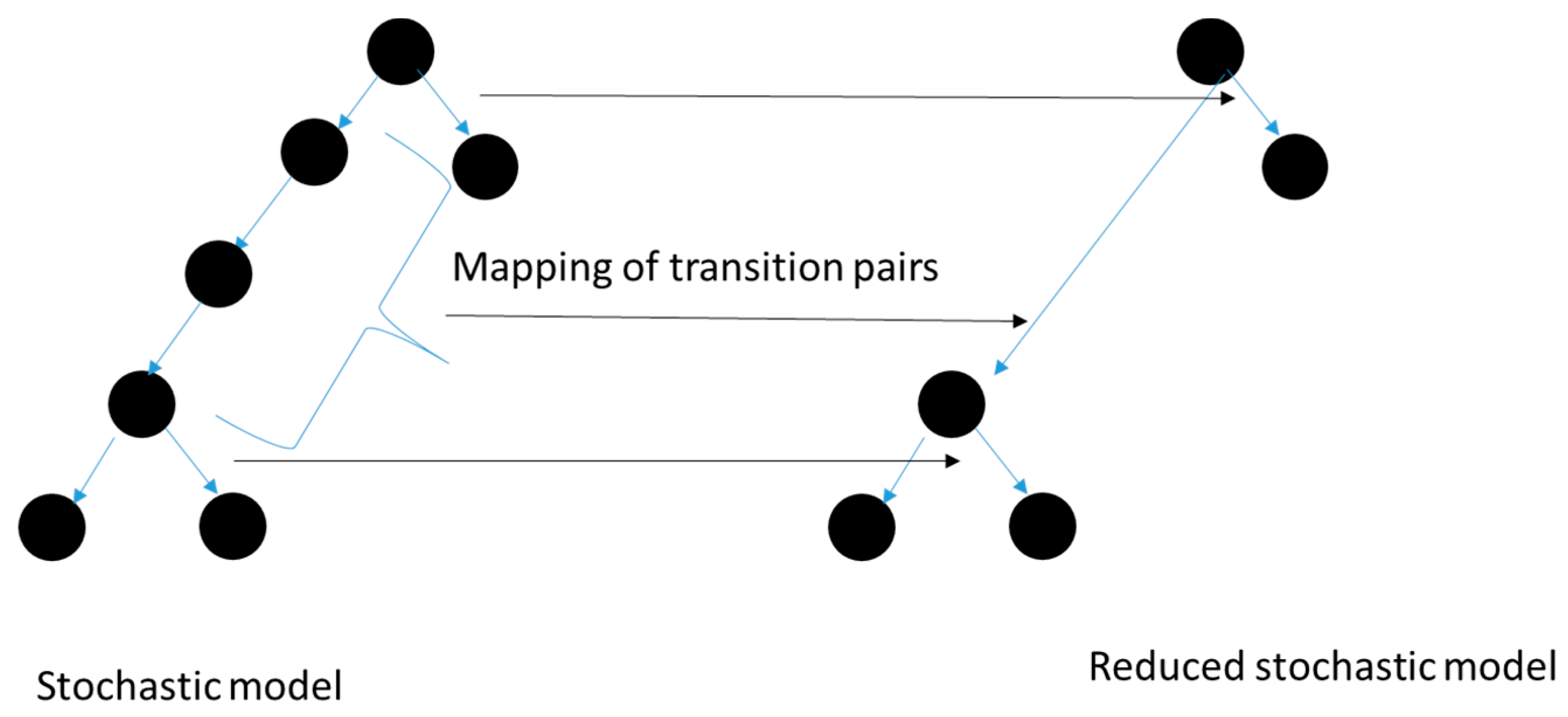
- S’⊆ S is the subset of non-deterministic states of M
- δ’⊆ S’ × S’ = {(s,s’)| if there is a deterministic state trajectory connecting s and s’}
- and ta’: δ’→R0∞
2.2. Assertion 1
- δint: SDEV S→SDEV S is given by
- δint (s, γ1,γ2) = s’ = (SelectPhase Gint (s, γ1), γ1′, γ2′)
- and ta: SDEV S→R+0,∞ is given by
- ta(s,γ1,γ2) = SelectSigma TT S (s, s’,γ2)
- and γi’ = Γ(γi), i = 1, 2.
2.3. Assertion 2
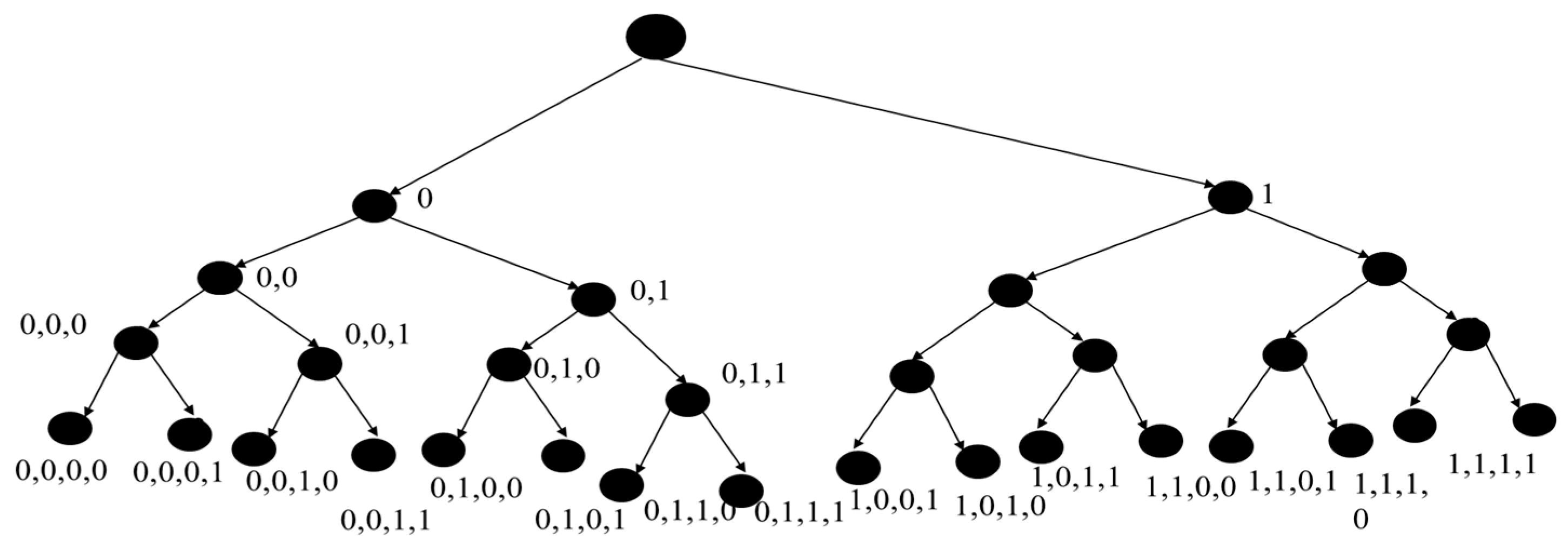
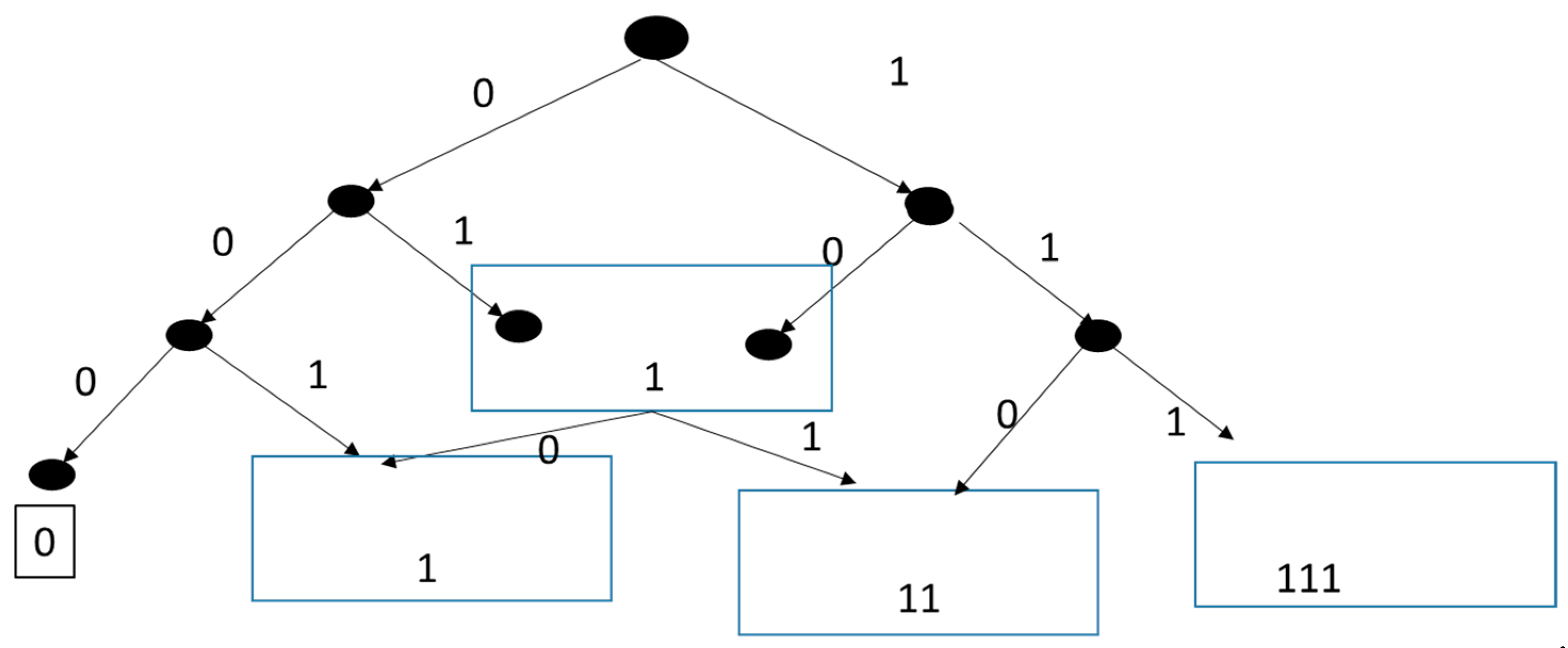
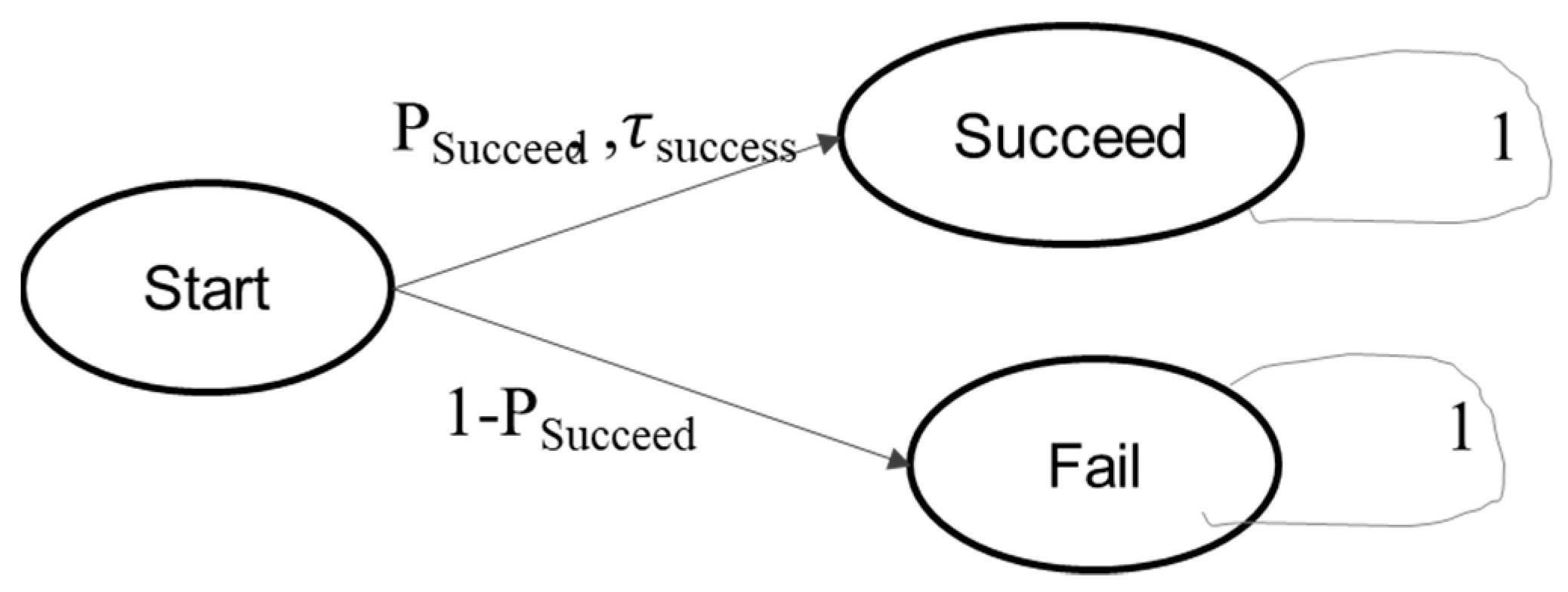
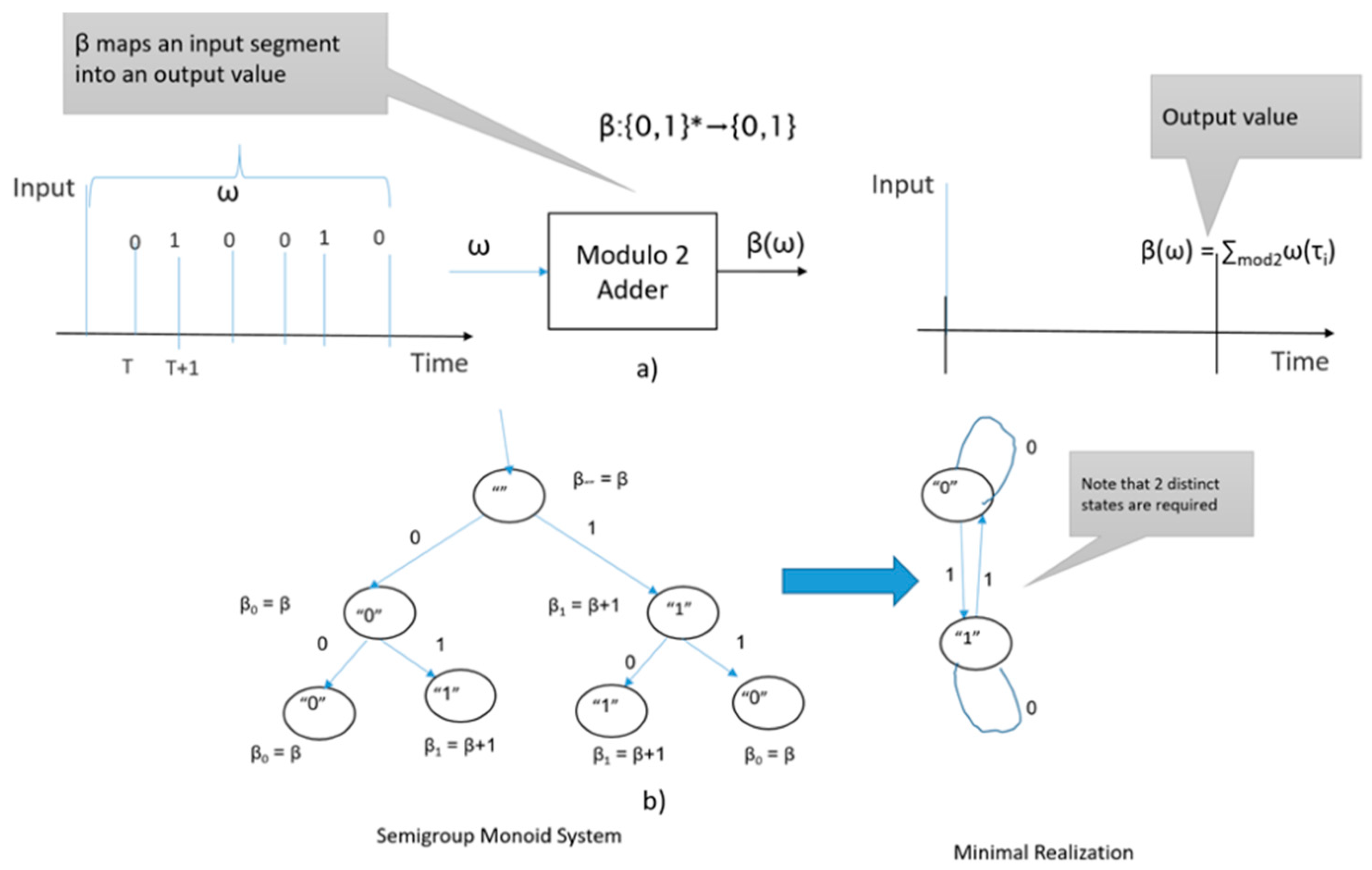
3. Illustrative Example
- The baseline algorithm generates all trajectories one at a time, accumulates the number of 1’s for each, and averages the results.
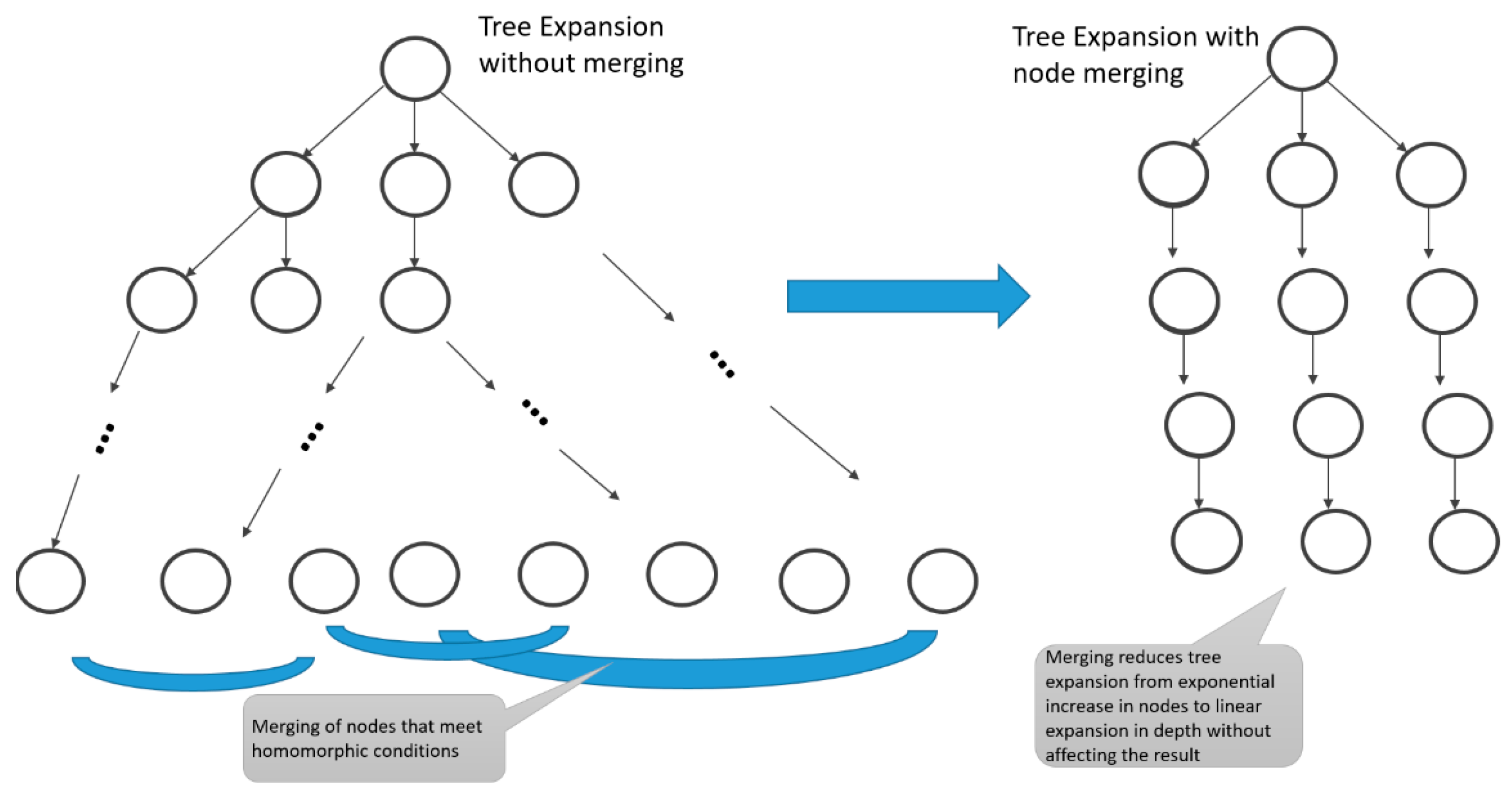
- The tree expansion algorithm generates all nodes in breadth-first traversal without repetition, obtaining the same information and performing the same average.
- The node merging algorithm based on the minimal realization modifies tree expansion by maintaining only the representatives of equivalent classes as successive levels are generated while maintaining the size of the classes as they are developed. The values of the classes are summed weighted by the respective sizes to obtain the desired average.
| Algorithm 1. Node merging tree expansion algorithm. |
| A node n contains data {s, num) where s is a string in {0,1}* and num is the number of nodes equivalentTo n. The root node = (λ,1) //λ is the empty string is the empty string Initiation: Current node = root node; newLeaves = {}, oldLeaves = {(λ,1)} Termination: depth = D Output: For each i = 1,2,…,D the number of strings having number of ones equal to i. Depth = 0 Recursive step: While (depth < D) For each node, n = (s, num) in leaves{ For each branch, b in {0, 1}{ Create child, c = {sb, num) // extend parent’s string and inherit parent’s number of represented equivalents If c is Equivalent To some node, m = {t, num’) in newLeaves, Then set m = {t, num’+num) Else add c to newLeaves. } depth = depth+1 oldLeaves = newLeaves, newLeaves = {} } n = (s, num) isEquivalentTo m = {t, num’) if, and only if, s and t have the same number of ones //Note that only the leaves at each level (including at the final depth) are kept as the expansion advances as required by the required output. |
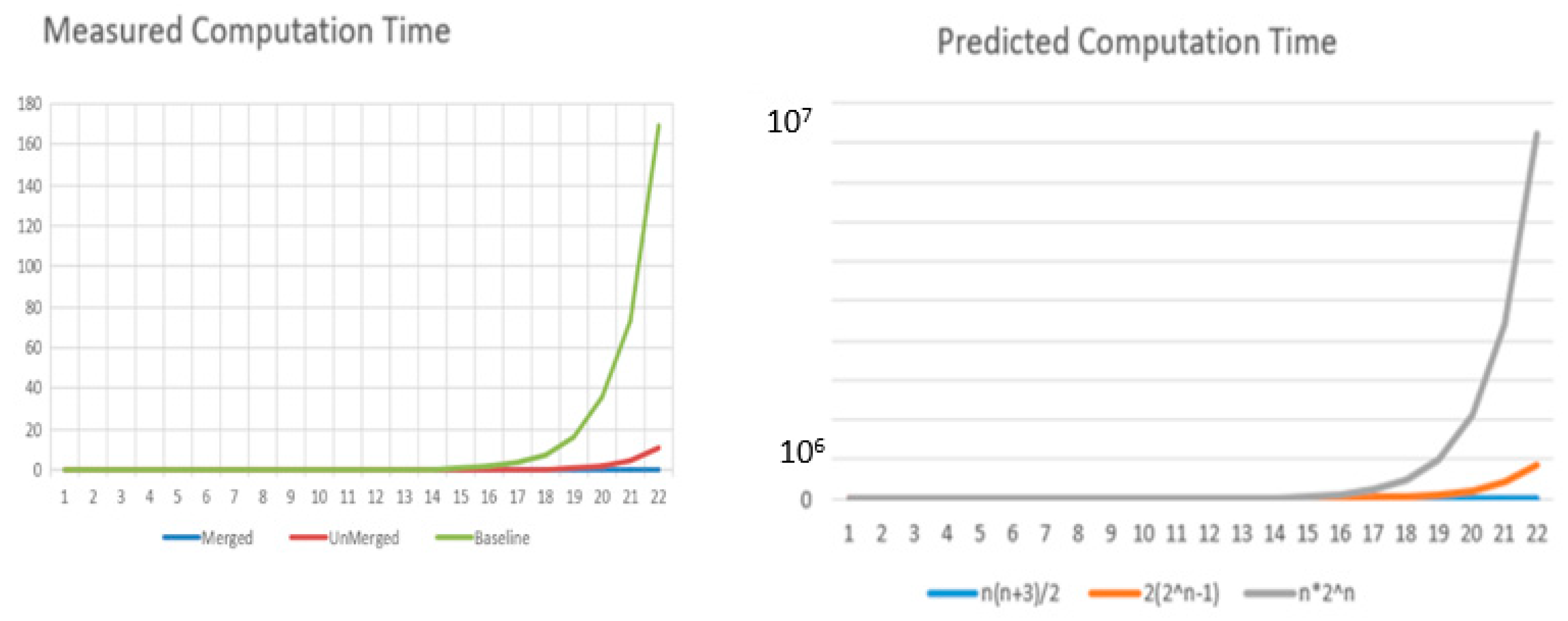
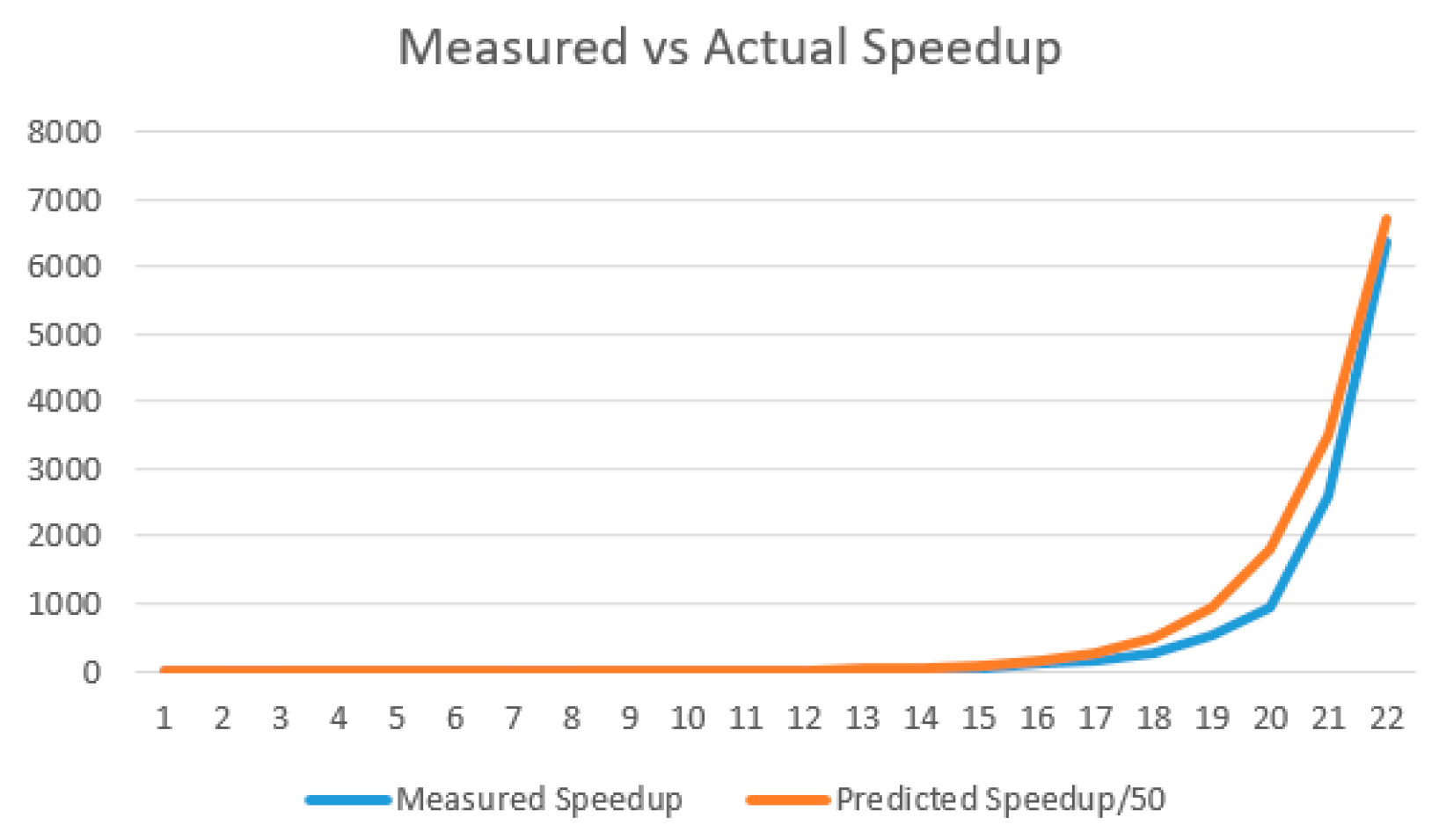
4. Empirical Confirmation of Theory Predictions
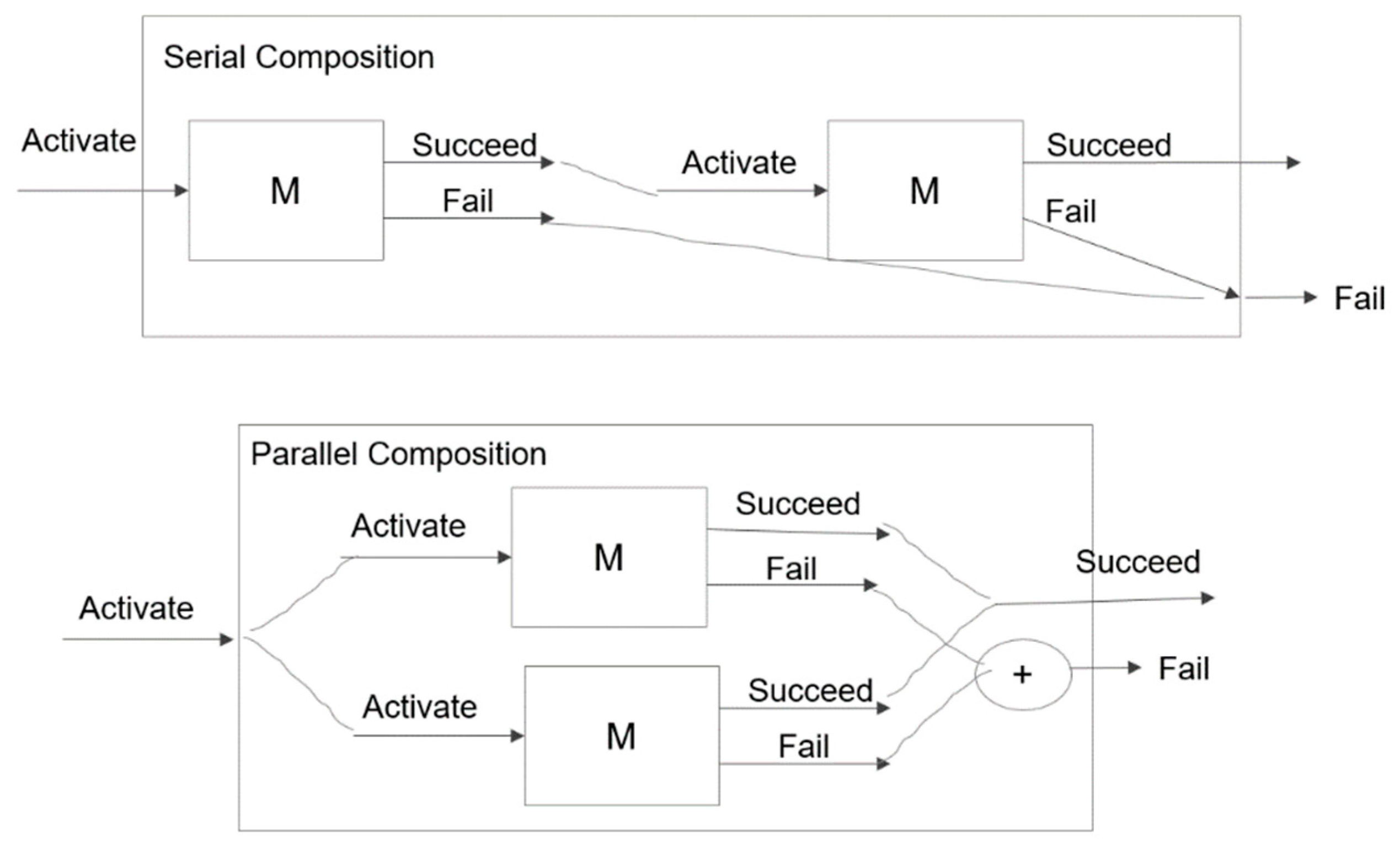
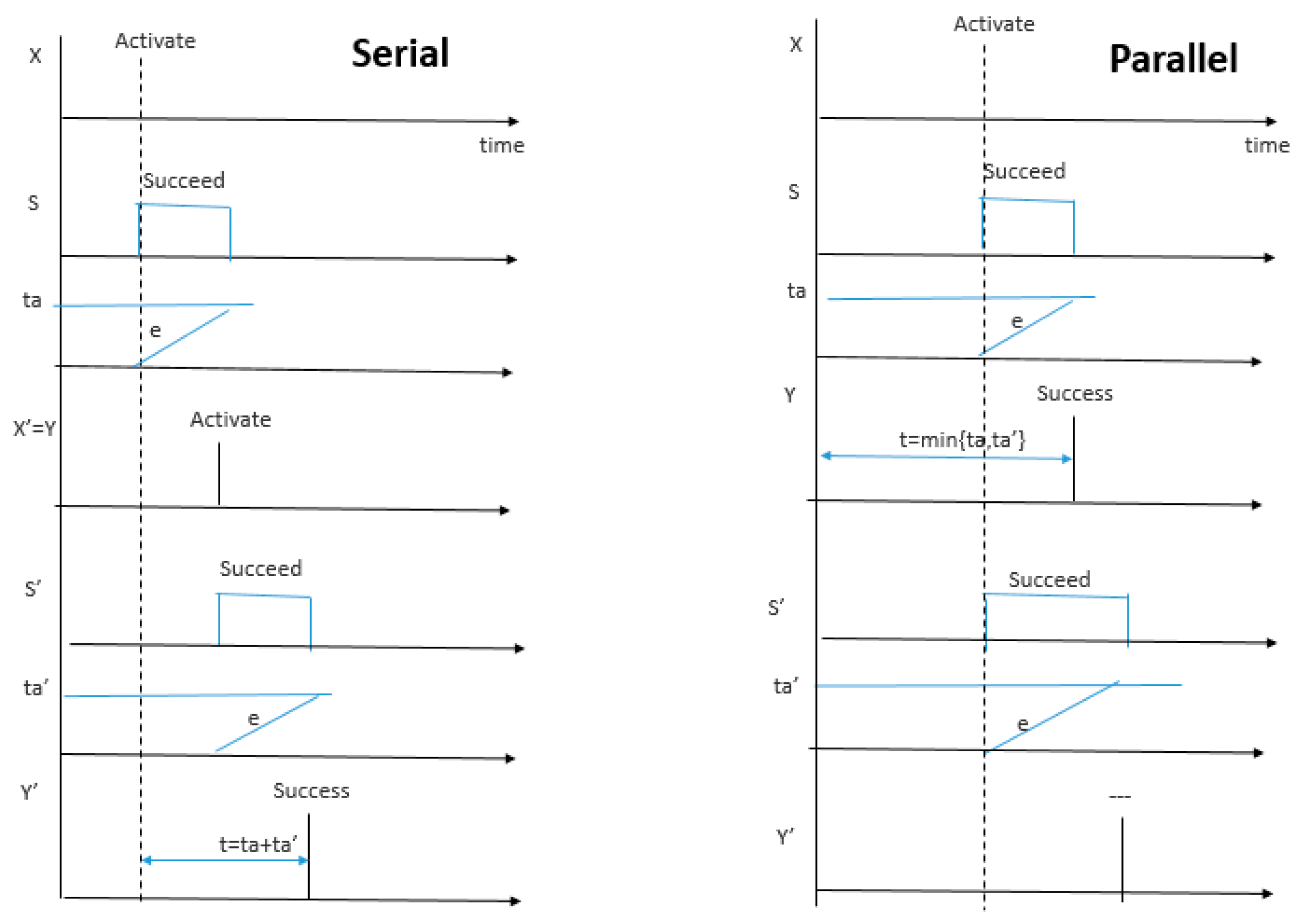
5. Tree Expansion with Merging Applied to Serial and Parallel Compositions
Computation Time Required for Serial and Parallel Compositions
6. Related Work
7. Conclusions and Further Work
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Müller, J.; Shoemaker, C.A.; Piché, R. SO-MI: A surrogate model algorithm for computationally expensive nonlinear mixed-integer black-box global optimization problems. Comput. Oper. Res. 2013, 40, 1383–1400. [Google Scholar] [CrossRef]
- Zabinsiky, Z.B. Stochastic Adaptive Search Methods: Theory and Implementation. In Handbook of Simulation Optimization; Springer: New York, NY, USA, 2015; pp. 293–318. [Google Scholar]
- Hong, J.H.; Seo, K.-M.; Kim, T.G. Simulation-based optimization for design parameter exploration in hybrid system: A defense system example. SIMULATION 2013, 89, 362–380. [Google Scholar] [CrossRef]
- Tolk, A. Simulation-Based Optimization: Implications of Complex Adaptive Systems and Deep Uncertainty. Information 2022, 13, 469. [Google Scholar] [CrossRef]
- Davis, P.K. Broad and Selectively Deep: An MRMPM Paradigm for Supporting Analysis. Information 2023, 14, 134. [Google Scholar] [CrossRef]
- Davis, P.K.; Popper, S.W. Confronting Model Uncertainty in Policy Analysis for Complex Systems: What Policymakers Should Demand. J. Policy Complex Syst. 2019, 5, 181–201. [Google Scholar] [CrossRef]
- Hüllermeier, E.; Waegeman, W. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Mach. Learn. 2021, 110, 457–506. [Google Scholar] [CrossRef]
- Kruse, R.; Schwecke, E.; Heinsohn, J. Uncertainty and Vagueness in Knowledge Based Systems: Numerical Methods; Springer: Berlin/Heidelberg, Germany, 1991. [Google Scholar]
- Kwakkel, J.H.; Haasnoot, M. Supporting DMDU: A Taxonomy of Approaches and Tools. In Decision Making under Deep Uncertainty: Rom Theory to Practice; Marchau, V.A., Warren, E.W., Bloemen, P.J., Popper, S.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 355–374. [Google Scholar]
- Marchau, V.A.W.J.; Walker, W.E.; Bloemen, P.J.T.M.; Popper, S.W. Decision Making under Deep Uncertainty: From Theory to Practice; Springer Nature: Cham, Switzerland, 2019. [Google Scholar]
- Amaran, S.; Sahinidis, N.V.; Sharda, B.; Bury, S.J. Simulation optimization: A review of algorithms and applications. Ann. Oper. Res. 2016, 240, 351–380. [Google Scholar] [CrossRef]
- Tsattalios, S.; Tsoukalas, I.; Dimas, P.; Kossieris, P.; Efstratiadis, A.; Makropoulos, C. Advancing surrogate-based optimization of time-expensive environmental problems through adaptive multi-model search. Environ. Model. Softw. 2023, 162, 105639. [Google Scholar] [CrossRef]
- Xu, J.; Huang, E.; Chen, C.-H.; Lee, L.H. Simulation Optimization: A Review and Exploration in the New Era of Cloud Computing and Big Data. Asia-Pac. J. Oper. Res. 2015, 32, 1550019. [Google Scholar] [CrossRef]
- Suman, B.; Kumar, P. A survey of simulated annealing as a tool for single and multiobjective optimization. J. Oper. Res. Soc. 2006, 57, 1143–1160. [Google Scholar] [CrossRef]
- Zhou, Z.; Ong, Y.S.; Nair, P.B.; Keane, A.J.; Lum, K.Y. Combining Global and Local Surrogate Models to Accelerate Evolutionary Optimization. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 66–76. [Google Scholar] [CrossRef]
- Liu, B.; Koziel, S.; Zhang, Q. A multi-fidelity surrogate-model-assisted evolutionary algorithm for computationally expensive optimization problems. J. Comput. Sci. 2016, 12, 28–37. [Google Scholar] [CrossRef]
- Gallagher, M.A.; Hackman, D.V.; Lad, A.A. Better analysis using the models and simulations hierarchy. J. Def. Model. Simul. 2018, 15, 279–288. [Google Scholar] [CrossRef]
- Moon, I.C.; Hong, J.H. Theoretic interplay between abstraction, resolution, and fidelity in model information. In Proceedings of the 2013 Winter Simulation Conference, Washington, DC, USA, 8–11 December 2013. [Google Scholar]
- Choi, S.H.; Seo, K.-M.; Kim, T.G. Accelerated Simulation of Discrete Event Dynamic Systems via a Multi-Fidelity Modeling Framework. Appl. Sci. 2017, 7, 1056. [Google Scholar] [CrossRef]
- Celik, N.; Lee, S.; Vasudevan, K.; Son, Y.-J. DDDAS-based multi-fidelity simulation framework for supply chain systems. IIE Trans. 2010, 42, 325–341. [Google Scholar] [CrossRef]
- Choi, C.; Seo, K.-M.; Kim, T.G. DEXSim: An experimental environment for distributed execution of replicated simulators using a concept of single simulation multiple scenarios. SIMULATION 2014, 90, 355–376. [Google Scholar] [CrossRef]
- Choi, S.H.; Lee, S.J.; Kim, T.G. Multi-fidelity modeling & simulation methodology for simulation speed up. In Proceedings of the 2nd ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, Denver, CO, USA, 18–21 May 2014. [Google Scholar]
- Keeney, R.; Raiffa, H. Decisions with Multiple Objectives: Preferences and Value Tradeoffs; Cambridge University Press: Cambridge, UK; New York, NY, USA, 1993. [Google Scholar]
- Kim, H.; McGinnis, L.F.; Zhou, C. On fidelity and model selection for discrete event simulation. SIMULATION 2012, 88, 97–109. [Google Scholar] [CrossRef]
- Molina-Cristobal, A.; Palmer, P.R.; Parks, G.T. Multi-fidelity Simulation modeling in optimization of a hybrid submarine propulsion system. In Proceedings of the European Conference on Power Electronics and Applications, Birmingham, UK, 30 August–1 September 2011. [Google Scholar]
- Ören, T.; Zeigler, B.P.; Tolk, A. Body of Knowledge for Modeling and Simulation: A Handbook by the Society for Modeling and Simulation International; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Park, H.; Fishwick, P.A. A GPU-Based Application Framework Supporting Fast Discrete-Event Simulation. SIMULATION 2010, 86, 613–628. [Google Scholar] [CrossRef]
- Lammers, C.; Steinman, J.; Valinski, M.; Roth, K. Five-dimensional simulation for advanced decision making. In Proceedings of the SPIE Defense, Security, and Sensing, Orlando, FL, USA, 13–17 April 2009; p. 73480H. [Google Scholar]
- Li, X.; Cai, W.; Turner, S.J. Cloning Agent-Based Simulation. ACM Trans. Model. Comput. Simul. 2017, 27, 15. [Google Scholar] [CrossRef]
- Yoginath, S.B.; Alam, M.; Perumalla, K.S. Energy Conservation Through Cloned Execution of Simulations. In Proceedings of the 2019 Winter Simulation Conference (WSC), National Harbor, MD, USA, 8–11 December 2019; pp. 2572–2582. [Google Scholar]
- Nutaro, J.; Zeigler, B.P.; Yoginath, S.; Zanni, C.; Seal, S.; Shukla, P.; Koertje, C. Using Simulation Cloning to Sample without Duplication; Working Paper; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2024. [Google Scholar]
- Zeigler, B.P.; Muzy, A.; Kofman, E. Theory of Modeling and Simulation: Discrete Event Iterative System Computational Foundations; Academic Press: New York, NY, USA, 2018. [Google Scholar]
- Wymore, W.A. A Mathematical Theory of Systems Engineering—The Elements; Wiley: Hoboken, NJ, USA, 1967. [Google Scholar]
- Alshareef, A.; Seo, C.; Kim, A.; Zeigler, B.P. DEVS Markov Modeling and Simulation of Activity-Based Models for MBSE Application. In Proceedings of the 2021 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 12–15 December 2021; pp. 1–12. [Google Scholar]
- Zeigler, B.P.; Seo, C.; Kim, D. DEVS Modeling and Simulation Methodology with MS4 Me Software. In Proceedings of the DEVS 13: Proceedings of the Symposium on Theory of Modeling & Simulation—DEVS Integrative M&S Symposium, San Diego, CA, USA, 7–10 April 2013. [Google Scholar]
- Wikipedia. 2023. Available online: https://en.wikipedia.org/wiki/Pascal%27s_triangle (accessed on 15 June 2023).
- Rice, R.E. Calculating the Probability of Successfully Executing the Kill Chain to Analyze Hypersonics. Phalanx 2022, 55, 22–27. [Google Scholar]
- Baohong, L. A Formal Description Specification for Multi-resolution Modeling (MRM) Based on DEVS Formalism and Its Applications. J. Def. Model. Simul. Appl. Methodol. Technol. 2004, 4, 229–251. [Google Scholar]
- Yilmaz, L.; Lim, A.; Bowen, S.; Ören, T. Requirements and Design Principles for Multisimulation itwh Multiresolution Multistage Models. In Proceedings of the 2007 Winter Simulation Conference, Washington, DC, USA, 9–12 December 2007. [Google Scholar]
- Davis, P.K.; Bigelow, J.H. Experiments in Multiresolution Modeling (MRM); RAND Corporation: Santa Monica, CA, USA, 1998; Available online: https://www.rand.org/pubs/monograph_reports/MR1004.html (accessed on 15 February 2023).
- Davis, P.; Hillestad, R. Families of Models that Cross Levels of Resolution: Issues for Design, Calibration and Management. In Proceedings of the 1993 Winter Simulation Conference—(WSC ’93), Los Angeles, CA, USA, 12–15 December 1993; pp. 1003–1012. [Google Scholar]
- Davis, P.K.; Hillestad, R. Proceedings of Conference on Variable Resolution Modeling, Washington, DC, 5–6 May 1992; RAND Corp.: Santa Monica, CA, USA, 1992. [Google Scholar]
- Davis, P.K.; Reiner, H. Variable Resolution Modeling: Issues, Principles and Challenges; N-3400; RAND Corporation: Santa Monica, CA, USA, 1992. [Google Scholar]
- Hadi, M.; Zhou, X.; Hale, D. Multiresolution Modeling for Traffic Analysis: Case Studies Report; U.S. Federal Highway Administration: Washington, DC, USA, 2022. [Google Scholar]
- Rabelo, L.; Park, T.W.; Kim, K.; Pastrana, J.; Marin, M.; Lee, G.; Nagadi, K.; Ibrahim, B.; Gutierrez, E. Multi Resolution Modeling. In Proceedings of the 2015 Winter Simulation Conference, Huntington Beach, CA, USA, 6–9 December 2015; Yilmaz, L., Chan, V., Mood, I., Roemer, T., Macal, C., Rossetti, M., Eds.; IEEE: Piscataway, NJ, USA, 2015; pp. 2523–2534. [Google Scholar]
- Emanuele, B. Discrete Event Modeling and Simulation of Large Markov Decision Process, Application to the Leverage Effects in Financial Asset Optimization Processes. Ph.D. Thesis, Université Pascal Paoli, Corte, France, 2023. [Google Scholar]
- Folkerts, H.; Pawletta, T.; Deatcu, C.; Santucci, J.; Capocchi, L. An Integrated Modeling, Simulation and Experimentation Environment in Python Based on SES/MB and DEVS. In Proceedings of the SummerSim-SCSC, Berlin, Germany, 22–24 July 2019. [Google Scholar]
- Wilsdorf, P.; Heller, J.; Budde, K.; Zimmermann, J.; Warnke, T.; Haubelt, C.; Timmermann, D.; van Rienen, U.; Uhrmacher, A.M. A Model-Driven Approach for Conducting Simulation Experiments. Appl. Sci. 2022, 12, 7977. [Google Scholar] [CrossRef]
- Bordón-Ruiz, J.; Besada-Portas, E.; López-Orozco, J.A. Cloud DEVS-based computation of UAVs trajectories for search and rescue missions. J. Simul. 2022, 16, 572–588. [Google Scholar] [CrossRef]
- Neto, V.V.G.; Kassab, M. Modeling and Simulation for Smart City Development. In What Every Engineer Should Know about Smart Cities; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Gourlis, G.; Kovacic, I. Energy efficient operation of industrial facilities: The role of the building in simulation-based optimization. IOP Conf. Ser. Earth Environ. Sci. 2020, 410, 012019. [Google Scholar] [CrossRef]
- Xie, K.; Li, X.; Zhang, L.; Gu, P.; Chen, Z. SES-X: A MBSE methodology based on SES/MB and X Language. Inf. J. 2023, 14, 23. [Google Scholar] [CrossRef]
- Laurent, C.; Santucci, J.-F.; Zeigler, B.P. Markov chains aggregation using discrete event optimization via simulation. In Proceedings of the SummerSim ’19: Proceedings of the 2019 Summer Simulation Conference, Article No. 7. Berlin, Germany, 22–24 July 2019; pp. 1–12. [Google Scholar]
- Zeigler, B.P.; Woon, S.W.; Koertje, C.; Zanni, C. The Utility of Homomorphism Concepts in Simulation: Building Families of Models from Base-Lumped Model Pairs. Simulation J. 2024. in process. [Google Scholar]
- Zeigler, B.P. Constructing and evaluating multi-resolution model pairs: An attrition modeling example. J. Def. Model. Simul. Appl. Methodol. Technol. 2017, 14, 427–437. [Google Scholar] [CrossRef]
- Kim, T.G.; Sung, C.H.; Hong, S.-Y.; Hong, J.H.; Choi, C.B.; Kim, J.H.; Seo, K.M.; Bae, J.W. DEVSim++ Toolset for Defense Modeling and Simulation and Interoperation. J. Def. Model. Simul. Appl. Methodol. Technol. 2011, 8, 129–142. [Google Scholar] [CrossRef]
- Davis, P.K. Exploratory Analysis and Implications for Modeling. In New Challenges, New Tools for Defense Decisionmaking; Johnson, S., Libicki, M., Treverton, G., Eds.; RAND Corporation: Santa Monica, CA, USA, 2003; pp. 255–283. [Google Scholar]
- Seo, K.-M.; Choi, C.; Kim, T.G.; Kim, J.H. DEVS-based combat modeling for engagement-level simulation. SIMULATION 2014, 90, 759–781. [Google Scholar] [CrossRef]
- Seo, K.-M.; Hong, W.; Kim, T.G. Enhancing model composability and reusability for entity-level combat simulation: A conceptual modeling approach. SIMULATION 2017, 93, 825–840. [Google Scholar] [CrossRef]
- Tolk, A. Engineering Principles of Combat Modeling and Distributed Simulation; John Wiley & Sons: Hoboken, NJ, USA, 2012; pp. 79–95. ISBN 978-0-470-87429-5. [Google Scholar]
- McNaughton, R.; Yamada, H. Regular Expressions and State Graphs for Automata. IRE Trans. Electron. Comput. 1960, EC-9, 39–47. [Google Scholar] [CrossRef]
- Zeigler, B. DEVS-Based Building Blocks and Architectural Patterns for Intelligent Hybrid Cyberphysical System Design. Information 2021, 12, 531. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computation Time for | General Case | Illustrative Example n = 4 | Reduction Ratio |
|---|---|---|---|
| Baseline algorithm | n2n | 4×16 = 64 | |
| Reuse earlier nodes | 2(2n − 1) | 2× (24 − 1) = 30 | O(n) |
| Minimal realization | n(n + 3)/2 | 2 + 3 + 4 = 9 | O(2n/n2) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeigler, B.P. Discrete Event Systems Theory for Fast Stochastic Simulation via Tree Expansion. Systems 2024, 12, 80. https://doi.org/10.3390/systems12030080
Zeigler BP. Discrete Event Systems Theory for Fast Stochastic Simulation via Tree Expansion. Systems. 2024; 12(3):80. https://doi.org/10.3390/systems12030080
Chicago/Turabian StyleZeigler, Bernard P. 2024. "Discrete Event Systems Theory for Fast Stochastic Simulation via Tree Expansion" Systems 12, no. 3: 80. https://doi.org/10.3390/systems12030080
APA StyleZeigler, B. P. (2024). Discrete Event Systems Theory for Fast Stochastic Simulation via Tree Expansion. Systems, 12(3), 80. https://doi.org/10.3390/systems12030080