1. Introduction
Cyberattacks have represented a security issue for many years and are continuously becoming more sophisticated, increasing in difficulty for prevention and detection. Companies that rely on Internet-connected IT infrastructures (nowadays, the vast majority, if not all) should have in place counter-measure systems, as those attacks may have devastating consequences in case of a breach (e.g., ex-filtration, tampering, destruction or encryption of data) [
1].
To prevent and detect these incidents, IDSs capable of analyzing network traffic in (near) real-time are needed. As cyberattacks are growing in number and complexity, as well as network links speeds, traditional IDSs may not be effective anymore, requiring more scalable and robust components, as well as the coupling with novel data analysis techniques, namely from the ML domain [
2].
In previous work [
3], an architecture for such a kind of IDS was already introduced. This also included an in-depth statement of the problem under consideration and the selection of the technologies for a reference implementation of the proposed architecture.
This paper goes further, by focusing on the experimental evaluation of an architecture prototype that embodies the reference implementation. The testbed deployed captures raw network data that flows through switching devices on an Ethernet network, at the line rate of 1 Gbps, and sends the data to others modules, which are responsible for data storage and analysis in (near) real-time. Several experiments were conducted, aiming to gain insight on the best values (performance-wise) of critical parameters of the prototype components and assess the capability of performing (near) real-time operation.
Indeed, the design of such a solution requires, right from the start, careful consideration of numerous factors that may affect its performance. Hence, utmost care must be given to the selection of technologies and its precise parameterization. Therefore, this manuscript describes a systematic methodology designed to evaluate a spectrum of parameters with the goal of identifying the most performant configuration for our IDS implementation.
The remainder of this paper is organized as follows:
Section 2 sums up the proposed architecture and the technologies chosen for its prototyping;
Section 3 describes the experimental testbed and the methodology pursued;
Section 4 presents the experimental results and associated discussion; finally,
Section 5 concludes and lays out future work directions.
2. Methods and Materials
As already stated, the architecture and technological choices for the IDS evaluated in this paper were previously defined in [
3]. A summary of its main aspects follows.
2.1. Architecture
The system architecture was designed to be modular and horizontally scalable. This implies the possibility of modifying/replacing a system component with none (or very minor) changes to the other components. It also means that it should be possible to add, in a transparent way, new service units, in order to accommodate extra levels of performance, storage and availability, whenever required.
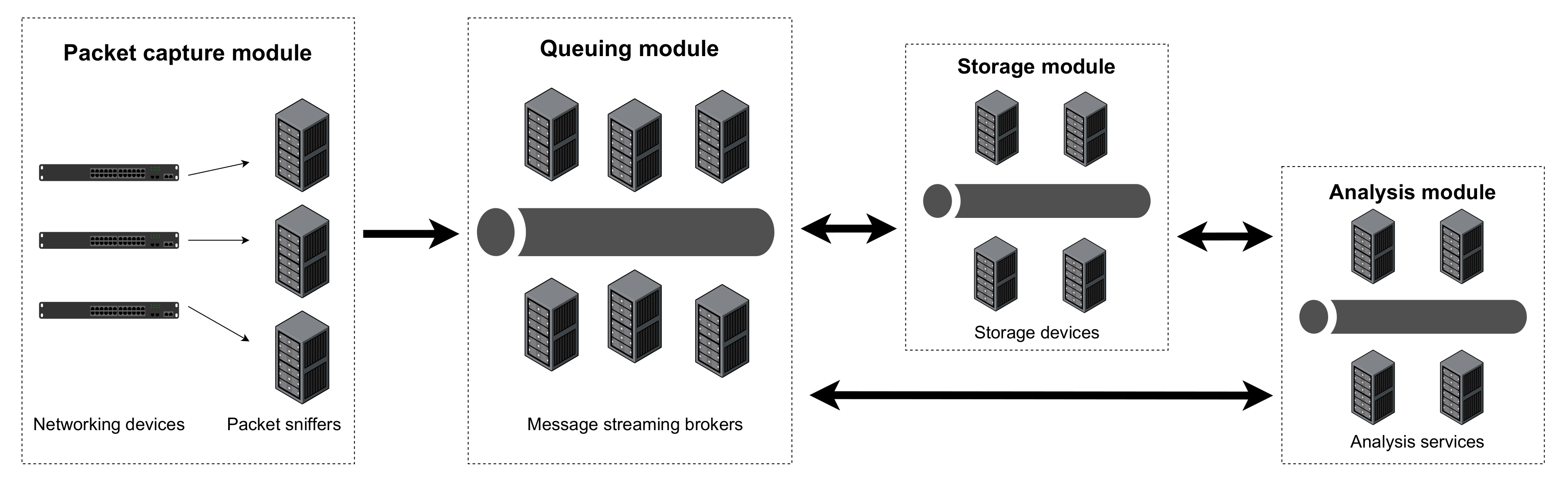
Figure 1 presents an overview of the proposed architecture, which includes four different modules or components. A description of their role and interactions follows.
It all starts at the packet capture module, which is composed of network sniffers, also known as probes. Each probe is connected to a switch with port-mirroring configured, in order to replicate incoming traffic to the port where the probe is attached to. Each probe captures every network packet that reaches its Network Card Interface (NIC). These packets are then published to the messaging system operated by the queuing module.
During a network capture, the data published to the queuing module may be consumed by the storage module and/or by the analysis module. Using a queuing mechanism naturally supports the simultaneous operation of multiple producers (probes) and multiple consumers, increasing the IDS throughput. In particular, more network traffic may be captured, and the acquired data may be split to allow parallel storage and/or processing.
The queuing module can hold data for a limited amount of time, before exhausting its limited internal storage capacity. When local storage runs out, newly arrived messages may be lost, or older messages may be discarded to make room for the new messages, depending on the behavior configured. So that all network data captured is preserved, the storage module consumes all data gathered by the queuing module and saves it in a persistent distributed storage repository. This way, if further analyses are required on specific data segments, the storage module is capable of republishing the required data to the queuing module, so that it may be consumed by the analysis module.
The analysis module may be able to consume data in (near) real-time from the queuing module, as it is published there by the packet capture module. It may also be able to consume data directly from the storage module, if such is found to be more convenient and/or efficient. The analysis at stake may be conducted based on different technologies and approaches, such as machine learning algorithms, clustering techniques, visualization dashboards, etc. Different options may coexist and each option may be supported by several service instances in order to split the load involved and offer increased performance.
2.2. Tools and Technologies
When implementing a system to perform an efficient analysis of possibly huge chunks of data, selecting the appropriate technologies and tools is halfway towards a solid final system [
4].
Based on the architecture presented in
Figure 1, a literature review followed, allowing to choose the best tools and technologies to support each architecture module. As represented in
Figure 2, the choices landed on
tcpdump for the packet capture module,
Apache Kafka for the queuing module,
Apache HDFS for the storage module, and
Apache Spark for the analysis module. The literature review that led to these choices is presented next.
2.2.1. Network Capture
The selection of a network packet capture tool is always a challenging task. A capturing tool should have zero (or very low) packet loss rate while capturing packets in a multi-Gbps rate network. It is also desirable that such tools are open-source and, if possible, free of charge. Several examples, that cope differently with these requisites, are provided next.
Scapy is a Python framework for packet capture [
5]. Although it is very easy to use, Scapy-based applications have limited performance: they cannot reach multi-Gbps capture rates and suffer from very high CPU usage, thus leaving almost no processing resources available to perform other important operations.
nProbe is a capturing tool that applies PF_Ring to reach up to 100 Gbps rates while capturing network packets [
6], but it is not free and thus was not considered for this work.
D. Álvarez et al. [
7] performed a CPU usage comparison between TCPDump [
8], Wireshark [
8] and Tshark [
9] when sniffing the network. While TCPDump kept an average of 1% of CPU usage, Wireshark and Tshark used 100% and 55%, respectively. As such, TCPDump was selected as the network packet capture tool for our IDS. Since TCPDump works on top of the libpcap framework, it utilizes a zero-copy mechanism, reducing the data copies and system calls, and consequently improving the overall performance [
10].
2.2.2. Data Streaming
Event streaming is the practice of capturing data in real-time from one or multiple sources, and storing it for later retrieval. It works based on the publish-subscribe model, where producers publish to a distributed queue and consumers subscribe to obtain the data when available. The data streaming component (queuing module) of our architecture relies on Apache Kafka [
11], a community project maintained by the Apache software foundation.
Kafka runs as a cluster of one or more service instances that can be placed on multiple hosts. Some instances, named
brokers, form the storage layer, while others continuously import and export data as event streams to integrate Kafka with other existing systems. A Kafka cluster offers fault tolerance: if any instance fails, other will take over its work, ensuring continuous operation without data loss [
12]. Other Kafka features include:
Events are organised and stored in topics, and can be consumed as often as needed;
A topic can have zero or multiple producers and consumers;
Topics are partitioned, allowing a topic to be dispersed by several “buckets” located on different (or the same) Kafka brokers;
A topic can be replicated into other brokers; this way, multiple brokers have a copy of the data, allowing the automatic failover to these replicas when an instance fails;
Performance is constant regardless of the data size;
Kakfa uses the pull model, by which consumers request and fetch the data from the queue, instead of the data being pushed to the consumers.
D. Surekha et al. [
13] and S. Mousavi et al. [
6] use Kafka on their systems due to being a scalable and reliable messaging system with excellent throughput and fault tolerance, which are Qualities-of-Service (QoSs) specially relevant in the context of our IDS.
Apache Flume [
14] and Amazon Kinesis [
15] were pondered as possible alternatives to Kafka, but they have some characteristics that make them unsuitable to our IDS. Apache Flume offers features similar to Kafka’s but it uses the push model, whereby instead of being the consumer that fetches the data, it is the service that forwards the data to the consumer; moreover, the push of messages may happen regardless if the consumers are ready or not to receive them. Amazon Kinesis can handle hundreds of terabytes per hour of real-time data flow, but it is a cloud-based solution, thus to be deployed in an environment not currently targeted by our IDS (which focus mainly on private corporate networks).
2.2.3. Persistent Storage
The platform adopted for the storage module was the Hadoop Distributed File System (HDFS) [
16]. This platform is one of the 60 components of the Apache Hadoop ecosystem, having the ability to store large files in a distributed way (split in chunks across multiple nodes), while offering reliability and extreme fault-tolerance. Being based on the Google File System [
17], HDFS is tailored to a write-once-read-many [
18] usage pattern.
HDFS builds on two main entities: (i) one or more NameNodes and (ii) several DataNodes. A NameNode stores the metadata of the files and the location of their chunks. Chunks become replicated across the DataNodes, reducing the risk of losing data. The DataNodes are responsible for the storage and retrieval of data blocks as needed [
19].
There are many HDFS use-cases for real-time scenarios (though none that we could find matching to our specific purpose). K. Madhu et al. [
20], S. Mishra et al. [
21], K. Aziz et al. [
22] and R. Kamal et al. [
23] all perform real-time data analysis on tweets from Twitter that are stored in HDFS. S. Kumar et al. [
14] use HDFS to store real-time massive amounts of data produced by autonomous vehicles sensors. J. Tsai et al. [
24] undertake the analysis of real-time road traffic to estimate future road traffic with the data stored in HDFS.
Several alternatives to HDFS were also considered, including Ceph [
25] and GlusterFS [
26]. Ceph is a reliable, scalable, fault-tolerant and distributed storage system, allowing not only to store files but also objects and blocks. GlusterFS is a scalable file-system capable of storing petabytes of data in a distributed way. C. Yang et al. [
27] compared HDFS, GlusterFS and Ceph performance while writing and reading files. According to their results, the performance of HDFS is superior to the other two platforms.
2.2.4. Data Process
Among other alternatives, Apache Spark [
28] was the one selected for the data processing/analysis component. Apache Spark provides a high-level abstraction representing a continuous flow of data [
29]. It receives the data from diverse sources, such as Apache Kafka and Amazon Kinesis, and then processes it as micro-batches [
4]. Apache Spark is implemented in Scala and runs on the Java Virtual Machine (JVM). It provides two options to run algorithms: (i) as an interpreter of Scala, Python or R code, that allows users to run queries on large databases; (ii) to write applications on Scala and upload them to the master node for execution [
30]. Some usage scenarios of Apache Spark are provided next.
S. Mishra et al. [
31] proposed a framework to predict congestion on multivariate IoT data streams in a smart city scenario, using Apache Spark to receive and process data from Apache Kafka. A. Saraswathi et al. [
32] also used Kafka and Spark to predict road traffic in real-time. Y. Drohobytskiy et al. [
33] developed a real-time multi-party data exchange using Apache Spark to obtain data from Apache Kafka, process it and store it in HDFS.
Apache Storm is a free, open-source real-time computation system capable of real-time data processing [
34], just like Apache Spark streaming. J. Karimov et al. [
35] and Z. Karakaya et al. [
36] both performed an experiment comparing Apache Storm, Apache Flink and Apache Spark. Based on the results, they concluded that Apache Spark outperforms Apache Storm, being better at processing incoming streaming data in real-time. Between Apache Spark Streaming and Apache Flink, the choice is more difficult: they exhibit similar results in benchmarks, but they both have their own pros and cons.
According to the experiments of M. Tun et al. [
37], the integration of Apache Kafka and Apache Spark streaming can improve the processing time and the fault-tolerance when dealing with huge amounts of data. Thus, Apache Spark streaming was selected for this work, once it integrates well with Apache Kafka, supporting real-time operations.
Also, Apache Spark uses in-memory operations to perform stream processing, and it recovers from node failure without any loss—something that Apache Flink and Apache Storm are not able to offer [
37]. Moreover, data can be acquired from multiple different sources, like Apache Kafka, Apache Flume, Amazon Kinesis, etc.
Another alternative considered was Apache Hadoop MapReduce, based on Googles’ MapReduce [
38]. This is a framework for writing programs that process multi-terabyte datasets in parallel on multi nodes, offering reliability and fault-tolerance [
39]. However, Apache Spark is up to 100 times faster than MapReduce since it uses in-memory processing for large parallel processing [
37] while MapReduce performs disk-based operations. MapReduce’s approach to tracking tasks is based on heartbeats causing an unnecessary delay while Apache Spark is event-driven [
40].
Hence, compared with MapReduce, Apache Spark suits better our scenario, as it focuses on the processing speed, while MapReduce focuses on dealing with massive amounts of data [
29]. Moreover, Apache Spark contains a vast amount of libraries to support data analysis. Also, other applications in addition to Spark jobs (Python scripts) may be deployed and implemented in the analysis workflow.
3. Experimental Testbed and Methodology
This section describes the experimental testbed assembled, and the evaluation methodology followed, to assess a prototype of the proposed IDS architecture.
3.1. Testbed
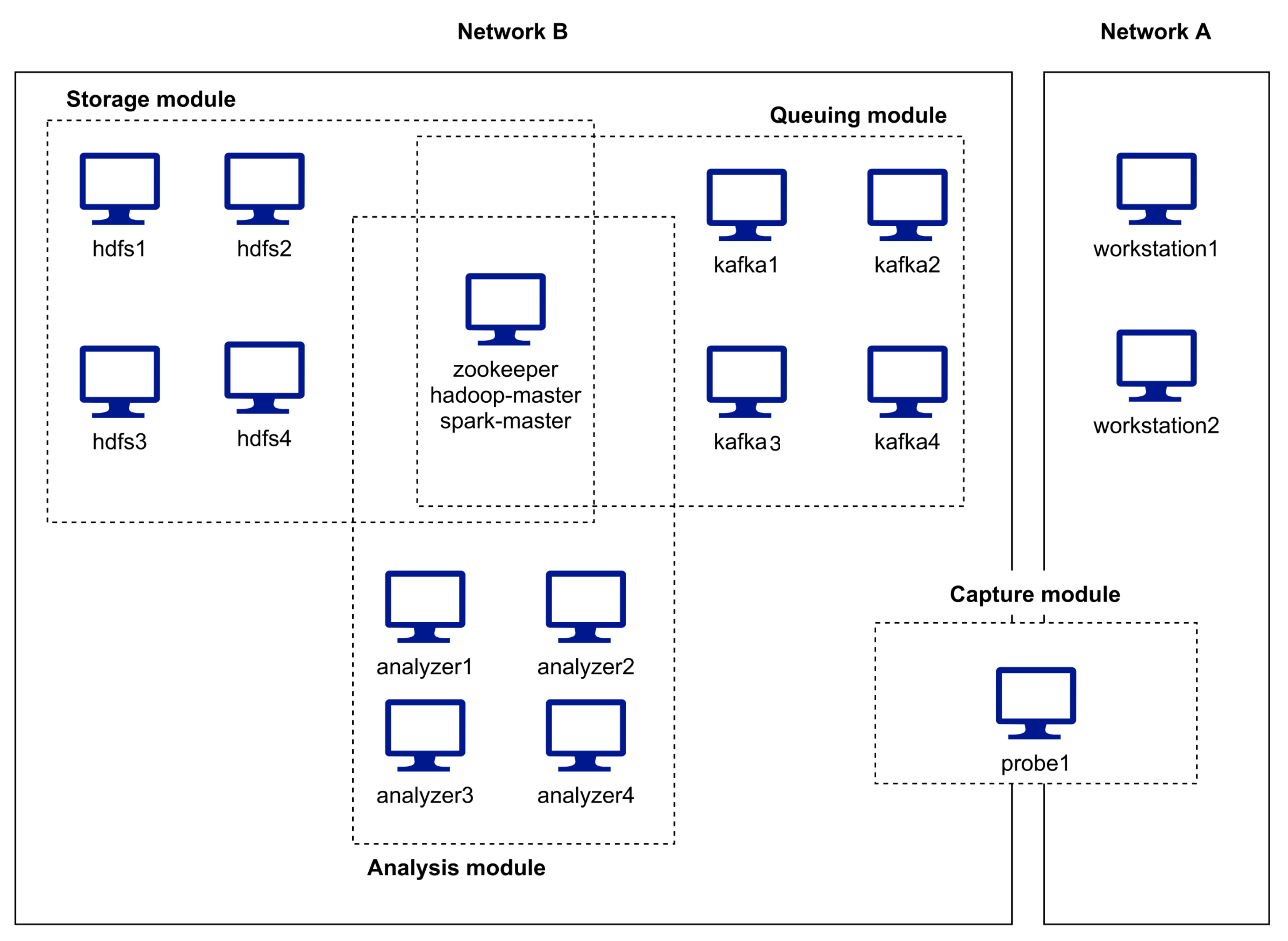
The testbed used for the evaluation is represented in
Figure 3. It includes 16 hosts and involves two different networks (A and B). The hosts that support the IDS modules operate on network B. Two systems, whose traffic exchanged is meant to be captured by a probe, operate on network A. The probe is thus a multi-homed host, once it captures traffic passing by in network A, which it then forwards to the queuing nodes in network B.
Network A runs at 1 Gbps and is built on a Cisco Catalyst 2960-S switch, while Network B is built on a 10 Gbps Cisco Nexus 93108TC-EX switch. A 1 Gbps link connects both switches. The probe connects only to the Network A switch, using two different ports: one is used as a destination, via port mirroring, of all traffic exchanged by the workstations; the other is used for the traffic outgoing to network B, which will still need to pass through the link between the two switches. Network A and Network B both operate with the same default MTU (1500 bytes). However, in each network, hosts operate in different Virtual LANs.
The hosts in network A are physical hosts, all running Linux (Ubuntu Server 20.04.3 LTS). The traffic generators (workstations) are off-the-shelf PCs (with an Intel 6-core i7-8700 CPU operating at 3.2/4.6Ghz, 16 GB of RAM, 460 GB SATA III SSD, on-board Intel I219-V 1 Gbps Ethernet NIC). The probe host is a system of the same class, although with slightly different hardware characteristics (Intel 4-core i7-920 CPU operating at 2.67/2.93 Ghz, 24 GB of RAM, 240 GB SATA III SSD, two on-board Realtelk 8111C 1 Gbps Ethernet NICs).
The hosts that support the queuing, storage, analysis and coordination functions are all Linux (Debian 11) Virtual Machines (VMs), running in a Proxmox VE 7 virtualization cluster. Each cluster node has 2 AMD EPYC 7351 16-core CPUs, 256 GB of RAM and NVMe (PCIe 3) SSD storage. The characteristics of the virtual machines used are shown in
Table 1:
To reach the dimensions laid out in
Table 1, some calculations were performed considering the following requirements:
) to be able to capture full packets at 1 Gbps line rate, for 10 min;
) to be able to perform two captures simultaneously (
= 2) while keeping one replica for each capture (
= 1) in the Kafka nodes;
) to be able to keep three different captures stored (
= 3), with one replica each (
= 1), in the HDFS nodes.
To begin with, requirement
generates a file per capture with an overall size
= 75 GB. This, together with requirement
implies that the amount of secondary storage needed per Kafka node (VM) is given by
where
is the number of Kafka nodes and
is the amount of storage reserved, in all nodes, for the Operating System (OS). As in this testbed
= 4 and
= 15 GB, then each Kafka node will need at least 90 GB of secondary storage; this was further rounded up to the nearest multiple of 16 GB (96 GB in this case), thus providing some extra storage space to avoid operating with too tight constraints (the same rationale was applied to the virtual disks of the other testbed VMs).
By requirement
, the secondary storage needed by each HDFS node is given by
where
is the number of HDFS nodes, which is 4 in the testbed. Thus, each HDFS node needs 112.5 GB of disk space, further rounded up to 128 GB.
With regard to the Spark nodes, the testbed uses four VMs of three different types: two VMs are of the type Spark1, one is of the type Spark2 and another is of the type Spark3. Each type requires a different amount of storage: Spark1 VMs only perform operations in memory and so, in addition to the disk space needed for the OS (15 GB), a similar extra amount was assigned to ensure a comfortable operation, totaling 32 GB of virtual disk; in addition to the OS, the Spark2 VM also holds a full capture (75 GB), thus requiring 96 GB of storage; finally, besides the OS, the Spark3 VM only holds half a capture (37.5 GB), and so it ends up needing only 64 GB of virtual disk.
The Apache Zookeeper service, the Apache Hadoop NameNode and the Apache Spark master service, are all running on the same virtual machine, since their coordination roles do not require much computational resources. In a real scenario, these services should operate on separate hosts and with more than one instance for fault-tolerance reasons.
3.2. Methodology
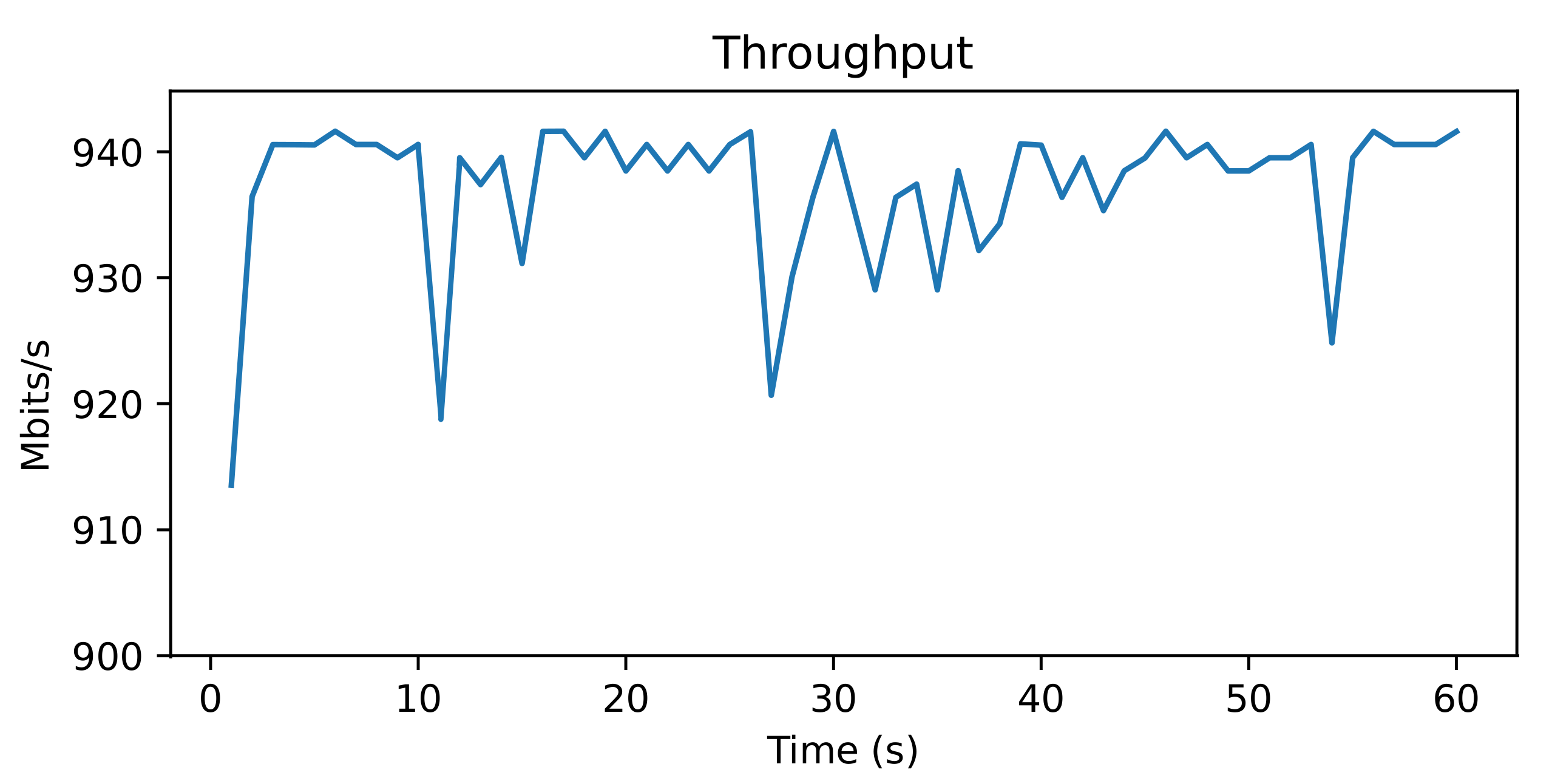
Due to the characteristics of the testbed, the network captures on Network A were limited to a nominal maximum of 1 Gbps. However, before beginning the evaluation of the architecture, a test was made to verify what was the effective maximum bandwidth achievable between the workstations. The test consisted of running the iPerf3 [
41] benchmark for 60 s, to measure the bandwidth of a single TCP connection between the workstations. The actual throughput can be found in
Figure 4, with most values sitting between 930 and 940 Mbps. These values set a ceiling for the expected probe capture rate.
Depending on the specific scenario, two different types of network captures were performed: full-packet captures or headers-only (truncated) captures. In the first type, each network packet is captured as is (minus the layer 1 of the OSI model), whereas in the second type only the headers are captured (and the OSI layer 1 is also not captured).
In the following experiments, the headers-only capture has the packets truncated at 96 bytes, allowing to acquire the data link, network and transport layers, and also some bytes of the payload, which permits to collect some intel regarding the network activity. Also, every network transaction in Network B was secured by SSL, unless stated otherwise.
Each experiment, involving a specific combination of parameters, was repeated five times. The relevant metrics for each of the five runs are shown, as well as their average value and corresponding standard deviation (allowing to assess the stability of the prototype).
There are two base parameters regarding the packet flow on all experiments (except the one from
Section 4.4): one is the duration of the capture (60 or 300 s) and the other is the size of the captured packets (
full-packets or
headers-only packets truncated at 96 bytes).
Several experiments were thus performed, in the following order:
Study the impact of the message size for the messages published on the queuing module (
Section 4.1). A specific size will be selected to be used on the remaining tests.
Assess the effect of a different number of partitions for a topic in the Kafka cluster (
Section 4.2). There are four Kafka nodes, meaning a topic can have up to four partitions (one per node). A specific number of partitions will be selected to be used thereafter.
Investigate the repercussions of using or not encryption (HTTPS vs HTTP) when storing the network captures in the HDFS cluster (
Section 4.3). Depending on the deployment scenario of our IDS, encrypting the Kafka–HDFS channel may or may not be necessary, and so it is important to understand the performance trade-offs involved.
As this IDS also performs packet analysis, it is necessary to find the fastest packet parser, which will be the core of the analysis applications. To this extent, three different parsers are compared (
Section 4.4) and one is selected to be used in the last experiment.
Assess the IDS in the context of a live (online) packet analysis (
Section 4.5).
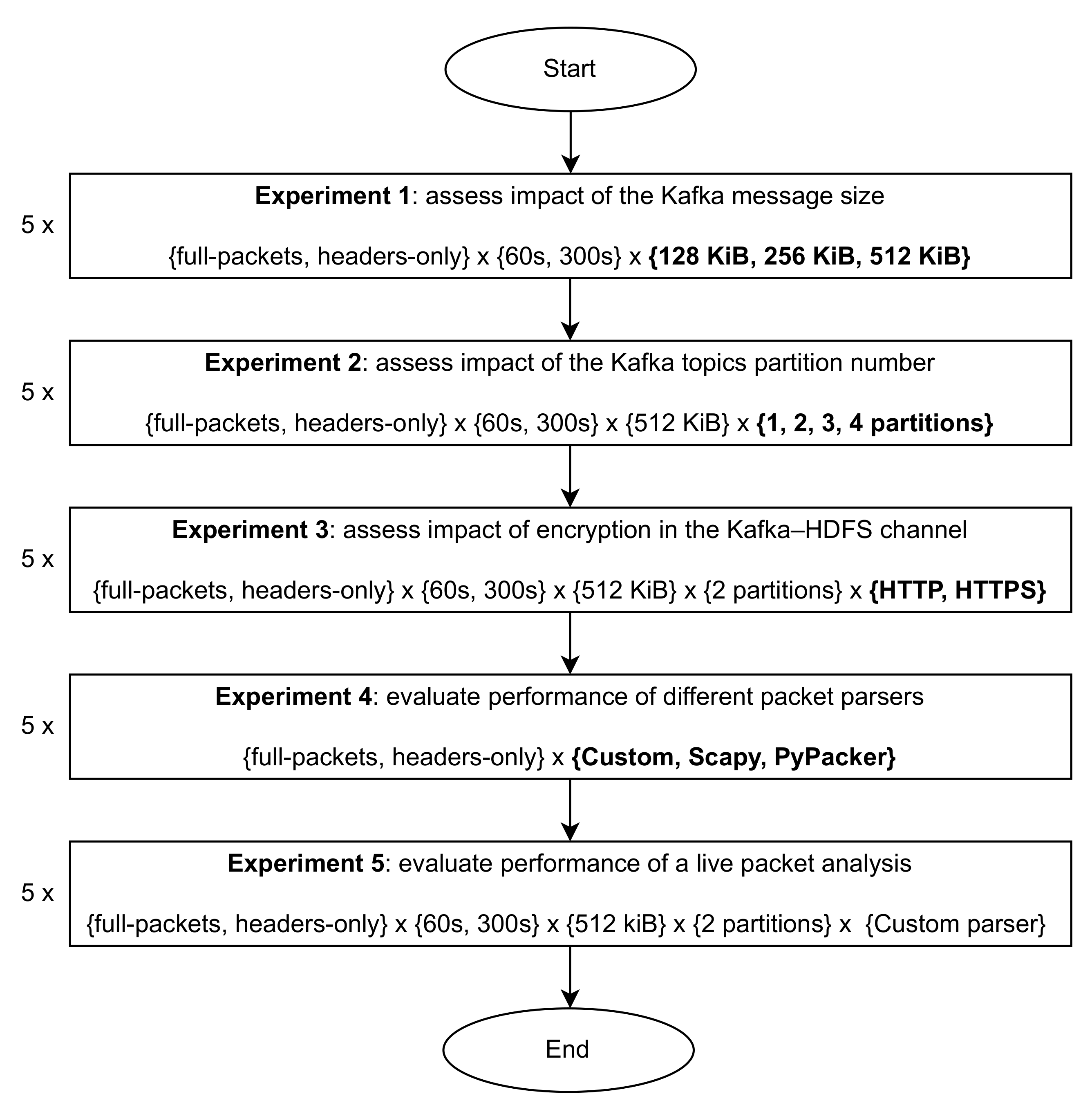
The experimental methodology followed to evaluate our IDS protytpe is summarized in
Figure 5. In each experiment, different parameter combinations are tested (each combination is tested five times). Also, some experiments adopt specific values for certain parameters, depending on the conclusions drawn in the previous experiments; this is the case for the adoption of a message size of 512 KB after Experiment 1, two topic partitions after Experiment 2, and the use of our custom parser after Experiment 4—see
Section 4 for details.
4. Experimental Results and Discussion
This section presents the detailed results of the experiments in the stipulated order.
4.1. Impact of the Kafka Message Size
(Near) Real-time network captures are very time-sensitive and so they must be as optimized as possible. In this experiment the goal is to find the Apache Kafka message size that minimizes the data streaming time, that is, the time spent in publishing and consuming the network captures. Apache Kafka was not designed to handle large-size messages, not being recommended to produce messages above 1 Megabyte (MB). Therefore, only the following messages sizes were tested (all bellow the 1 MB limit and up to half of that value):
128 KB ( or 131,072 bytes) ;
256 KB ( or 262,144 bytes);
512 KB ( or 524,288 bytes).
The outputs (metrics collected) of the experiment are an upload delay, a download delay and a total delay (sum of the upload and download delays), all measured in seconds. The upload delay is the time elapsed between the capture of the last network packet and its publication on Kafka. The download delay is the time elapsed between the moment in which the last message was uploaded on Kafka and its consumption by a Spark consumer.
This experiment was executed on a Kafka topic with two partitions and one replica, thus using two of the Kafka VMs (one per partition) available in the testbed. Also, only one Spark VM (Spark 4 configuration) was used, and none HDFS VMs were involved.
Table 2 and
Table 3 show the results of the
full-packet and
headers-only captures during 60 s, and
Table 4 and
Table 5 show the same type of results for a 300 s capture.
Looking at the results, the message size that minimizes the total delay for
full-packet captures is consistently 512 KB (see (*) on
Table 2 and
Table 4). For truncated captures, the best message size under the same criteria is 128 KB, but closely followed by 512 KB which, in turn, exhibits a smaller standard deviation, thus having a more predictable behavior. Moreover, once all the delays for truncated captures are very small (in comparison to full captures), making their differences also very small (even if the relative standard deviations tend to be higher), then a best message size of 512 KB can be generalized both for full and truncated captures, and this is the message size assumed henceforth in the next experiments.
The fact that the delays for
headers-only captures are very small means that the system does not throttle while capturing truncated network packets, allowing its operation for an unlimited time in such regime, as long it has enough disk space to store the captured data. Or, if the system performs only the analysis of the data (without storing it), it may operate forever (depending on the core parser performance—see
Section 4.5).
On the other hand, for full-packet captures, the delays are much higher (up to two orders of magnitude) and seem to increase in direct proportion of the capture duration (e.g., going from a 1 min to a 5 min capture increases the delay roughly five times, for any message size). Therefore, having the publishing delay increasing along the time of operation makes it impossible to perform a real-time network traffic capture and analysis, even if such data is not stored in persistent storage (which would add a further delay).
It should also be noticed that the packet loss for full captures is very low, and totally absent for truncated captures, regardless of the capture duration.
4.2. Impact of the Kafka Topics Partition Number
When creating a Kafka topic it is necessary to define the number of partitions for that topic (in the previous experiment, that number was two). The partitions may be distributed across Kafka nodes or placed on the same host. It is up to Kafka to decide which host will be responsible for which partitions, though prioritizing the ones holding fewer partitions, but how many partitions should a topic have to ensure the best performance?
In principle, more partitions should benefit performance (for load balance reasons), but the extra effort involved (communication and coordination) may not pay off. In order to answer such a question conclusively for our testbed, further experiments were conducted, whereby the number of partitions varied from one to four, with each partition assigned to a separate Kafka node (and so the number of Kafka nodes used varied accordingly). As before, only the Spark 4 VM was used, and no HDFS VMs were involved in the experiment.
Table 6 and
Table 7 show the results of the
full-packet and
headers-only captures during 60 s, and
Table 8 and
Table 9 show the same results for a 300 s capture. The metrics collected (upload delay, download delay, total delay, and packet loss) are the same, and have the same meaning, as those collected in the experiment of the previous section.
For full captures the results leave no doubt: it is surely better, performance-wise, to use more topic partitions; in fact, increasing the number of partitions by one unit makes the total delay to be roughly halved. However, for truncated captures, the results are somewhat inconclusive, once there are no significant differences in the overall Kafka delay (it is true that three partitions ensure the absolute lowest delays, but by a small margin). Again, there is no packet loss for the truncated captures, and the loss is negligible for full captures.
All things considered, this seems to point to the general conclusion that more partitions ensures better performance (or, at least, do not impair it), and having a single partition per Kafka node should yield a good load balance. However, more partitions may not be feasible, or even justifiable, in a real scenario. For instance, the possible number of Kafka nodes may be too small, thus limiting Kafka’s scalability. Or, as it happens in our IDS prototype, real-time (or even near real-time) assessment of full-packet captures is currently not possible, even with four partitions, and so there is no need to fully use them in a single capture, as they may be used on other captures that are being performed at the same time. For this reason, the number of partitions will be kept at two for the remaining experiments.
Also note that the partition configuration depends on the specific target scenario. Our IDS is flexible enough to accommodate multiple Kafka topics with different numbers of partitions and such is completely transparent to the consumers and producers (they will always work with all the partitions that are assigned to a specific topic).
4.3. Impact of Encryption in the Kafka–HDFS Channel
The goal of this experiment is to assess the IDS performance when capturing and storing data persistently into the HDFS cluster, using either clear-text or TLS encryption for the communication between the Kafka and the HDFS components. By default, communications between all testbed components are TLS-encrypted. However, depending on the IDS deployment scenario (e.g., private/public/cloud-based network), the privacy requirements may vary. For instance, it is expected that the communication channel between Kafka and HDFS sits on a private network, whereas Kafka may be exposed in a public network in order to be feed with public captures. Therefore, it is important to gain insight on the possible performance gains of removing encryption wherever such is deemed as safe.
The experiment was executed with a Kafka topic with two partitions and, as in the previous tests, the messages were published to Kafka in chunks of 512 KB. For this specific experiment, two HDFS nodes were made available and the replication level was set to two, meaning any file placed in HDFS is replicated in the two nodes.
The metrics collected are similar to the ones collected in the experiments of the previous two sections, but with the download delay now representing the time elapsed between the publication of the last message on Kafka and its storage on the HDFS cluster.
The results of the experiment may be seen in
Table 10 and
Table 11 (60 s capture), and
Table 12 and
Table 13 (300 s capture), for both full-packet and truncated captures.
The conclusion is somehow expected. For truncated captures (with very small amounts of network data involved) it makes little or no difference to use HTTPS (the fact that, during the 300 s capture, using HTTPS ended up being faster than using HTTP, should not be prone to any generalization, once the delays at stake are very small and thus very susceptible to even small fluctuations, as hinted by the higher relative standard deviations).
However, for full captures, using HTTPS makes the total delay become more than twice (roughly 2.5 times) of that delay when using HTTP, regardless of the capture duration. The specific reason for this increase lies in the download delay (HDFS insertion), which increases approximately 100 times for the 60 s capture, and near 700 times for the 300 s capture, while the upload delay remains essentially the same whether HTTPS or HTTP is used. Therefore, it is very advantageous, performance-wise, to have an IDS deployment that dispense with communications encryption. This, of course, requires an isolated environment for the IDS services and some degree of administrative access to the underlying platforms (network and compute), in order to ensure a secure execution.
Still concerning full captures, another observation that deserves to be highlighted is that, as already verified in the experiment of
Section 4.1, the total delays increase in direct proportion of the duration of the captures, that is, during a 300 s capture, the delays are roughly five times higher than those observed during a 60 s capture, whether HTTP or HTTPS is used. This reinforces the statement already made in
Section 4.1, whereby it was assumed that, currently, our IDS cannot sustain continuous (or even medium duration) captures.
For the packet loss, the same scenario of the previous experiments was again observed (no packet loss for truncated captures, and negligible for full-captures).
4.4. Performance of Different Core Parsers
In our IDS, every analysis application includes a core parser. Its function is to obtain the raw data from a Kafka topic and extract the relevant information for the analysis.
The raw data is processed message by message. When the analyzer receives a message (chunk) from Kafka, it extracts the packet header to know the exact length of the network packet, and then retrieves the full packet. Right after, the core parser analyses the packet, layer by layer. Since the network packets are captured from the Ethernet layer (OSI Layer 2), the parser knows how to start the extraction process. It reads which protocol is in the next layer; this way, it can extract the information accordingly to the protocol specification (available on RFC documents). After it finishes extracting the information of the packet, the parser will advance to the next packet, until it reaches the end of the chunk; when that happens, it will fetch another chunk (if available); otherwise, it will wait for new data.
In this work, three options for the core parser were considered: two community tools (Scapy [
42] and PyPacker [
43]), and a custom parser specifically crafted for our IDS. The later was developed as a simple alternative, meant to be faster, once it only parses the necessary data for a specific analysis, while Scapy and PyPacker perform a full parsing.
In order to highlight the performance of the custom parser, an experiment was conducted with the three parsers to evaluate their peak performance. Thus, the experiment was performed in offline mode, parsing data from PCAP files instead of a live Kafka stream. Two PCAP files were parsed, both with a total size of 10 GB. One of the files—file A—contains a full-packet capture carrying 5,708,800 packets. The other file—file B—contains a headers-only (packets truncated at 96 bytes) packet capture carrying 102,152,015 packets.
For each run of the experiment, the total execution time (parsing time) was registered and the number of packets processed per second (parsing rate) was calculated.
Table 14 and
Table 15 show the results of the experiments obtained with file A and file B, respectively.
The results show that the custom parser is much faster than Scapy and considerably faster than PyPacker: when parsing full captures (file A), our custom parser is 27 times faster than Scapy and ≈ 4.5 faster than PyPacker; and when parsing truncated captures (file B), the custom parser is 32 times faster than Scapy and ≈ 5.2 faster than PyPacker.
It may also be observed that Scapy and PyPacker keep a similar Parsing Rate for full-packets and truncated packets, meaning that, in opposition to our custom parser, they do not receive any performance benefit when dealing with truncated (thus, smaller) packets.
Despite its performance advantage, it should be stressed that the custom parser brings with it an added cost: the developer needs to know where the necessary specific raw data is located in order to parse it faster. Also, being a niche tool, it does not benefit from the contributions of the community involved in the development of more generic parsers.
4.5. Performance of a Live Packet Analysis
Having selected our custom parser as the analysis core parser, it is time to find out how it behaves in a live traffic capture. It should be clarified, though, that this experiment was not carried out through the Spark pipeline. Instead, and once the architecture is sufficiently generic to accommodate different analysis tools, we opted to run our custom parser as an isolated client in one of the VMs of the Spark cluster. Again, the idea is to measure the peak-performance attainable for a live analysis and verify if a (near) real-time is achievable.
As before, the experiment was executed with a Kafka topic containing two partitions, and the messages were published in chunks of 512 KB. Also, no HDFS nodes were used. The custom core parser was executed in the VM that hosts the Spark 4 cluster instance.
The metrics collected were an upload delay (the time elapsed between the capture of the last network packet and its publication on Kafka), an analysis delay (time elapsed between the retrieval of the last message and the conclusion of its analysis), the total delay, and the analysis rate (average number of packets analysed per second). The experiment results are shown in
Table 16 and
Table 17 (60 s capture), and
Table 18 and
Table 19 (300 s capture).
Accordingly with the results, our custom analyzer is clearly capable of a (near) real-time analysis: for any capture size, the analyzer shows no signs of slowing down when expanding the capture duration from 60 s to 300 s; also, the analysis delay is very small and similar in all scenarios (≈1 s), with the upload delay being even smaller for the headers-only captures while becoming much larger (up to two orders of magnitude) for full-packet captures.
Moreover, the custom analyzer could take much more load, once the maximum rates achieved for the live analysis (≈28,000 packets/s for full packets, and ≈80,000 packets/s for truncated packets) are far from those measured in the offline stress test of the previous experiment (≈103,000 packets/s for full packets and ≈125,000 packets for truncated packets). A common observation, though, is that truncated packets are analysed (much) faster than full packets in all scenarios, with the speedup in the analysis rate being noticeably higher in a live analyses (≈2.85) compared to an offline analysis (≈1.21).
5. Conclusions and Future Work
This study has provided valuable insight through the experimental evaluation of a prototype-level implementation designed for near-real-time network packet capture and analysis. Our initial efforts were directed towards enhancing various parameters that are crucial for the performance of the Kafka-based queuing module. Furthermore, we examined the impact of encryption on the communication channel between the queuing module and the HDFS-based storage module. Finally, we evaluated the performance of a streamlined custom parser, which is a precursor to its future integration within the analysis module. These investigations collectively contribute to a more thorough understanding of the system’s capabilities and lay a foundation for further enhancements and refinements in real-time network monitoring and analysis.
With the support of the experiments results, it is safe to say that the current deployment of the architecture is able to capture and parse network data in near real-time when performing a headers-only packet capture in 1 Gbps Ethernet links. However, regarding full-packet capture, when the maximum network capacity is being used, the platform assembled introduces some delays that may prevent it to achieve near real-time operation. Nevertheless, all the experiments were performed in the worst-case (and unrealistic) scenario of a permanently saturated network, in order to stress the system to the fullest. In a real-world operation, such saturation, although possible, is not expected to be continuous, and so the platform should behave closest to the intended goal of near real-time operation.
The system developed will enable the creation of datasets and the research and deployment of novel IDS algorithms, to be deployed in the Spark-based analysis module. Tests will also be made in other network environments, including local wireless networks, faster local cabled networks (e.g., 10 Gbps) and WAN links, in order to assess the readiness of the solution for those scenarios. Software Defined Network (SDN) sniffers probes will also be added to the system, enabling it to be used on any network, physical or virtual.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}