The results show the process of removing the outliers with the bootstrap. Then, the confidence intervals are analyzed, and the bootstrap is used to construct these intervals. The type of return to scale of technology (F) was defined to determine which model (CRS or VRS) would be appropriate for analysis, and the eco-efficiencies of the municipalities were computed.
5.1. Removing the Outliers
Because the data can present errors, missing data in the 2017 census (a data protection measure to avoid exposing information certain important properties to third parties) or low homoscedasticity can cause distortions in the results of the DEA analysis or even the heterogeneity of DMUs due to technological differences. Therefore, it is necessary to verify the model’s outliers and remove them so that the result is not biased.
To apply the DEA methodology, the Jackstrap package is used in RStudio to analyze the outliers and apply the bootstrap (available in the R library at:
https://cran.r-project.org/web/packages/jackstrap/index.html (accessed on 1 May 2023)), as proposed by Sousa and Monte (2020). With subsets of 10% of the total DMUs to form a subset, t, and the number of repetitions equal to 1000, the average leverage, overall leverage, and withdrawals of the outliers are calculated, according to the steps described in
Section 3.2.
As there is a large amount of data, a possible solution is partitioning the data analysis by regions (north, northeast, mid-western, southeast, and south). This simplifies the analysis due to the considerable use of computational processing to remove the outliers in a unified way. The Jackstrap function is used for analysis, with Heaviside and Kolmogorov–Smirnov (K–S) criteria for testing which model has a more satisfactory return. In the southeast region, no outliers are identified for either criterion. Since the Heaviside criterion presented more restricted data, that method was chosen. At the end of the five regions, 143 DMUs were considered outliers. The results are presented in
Table 2.
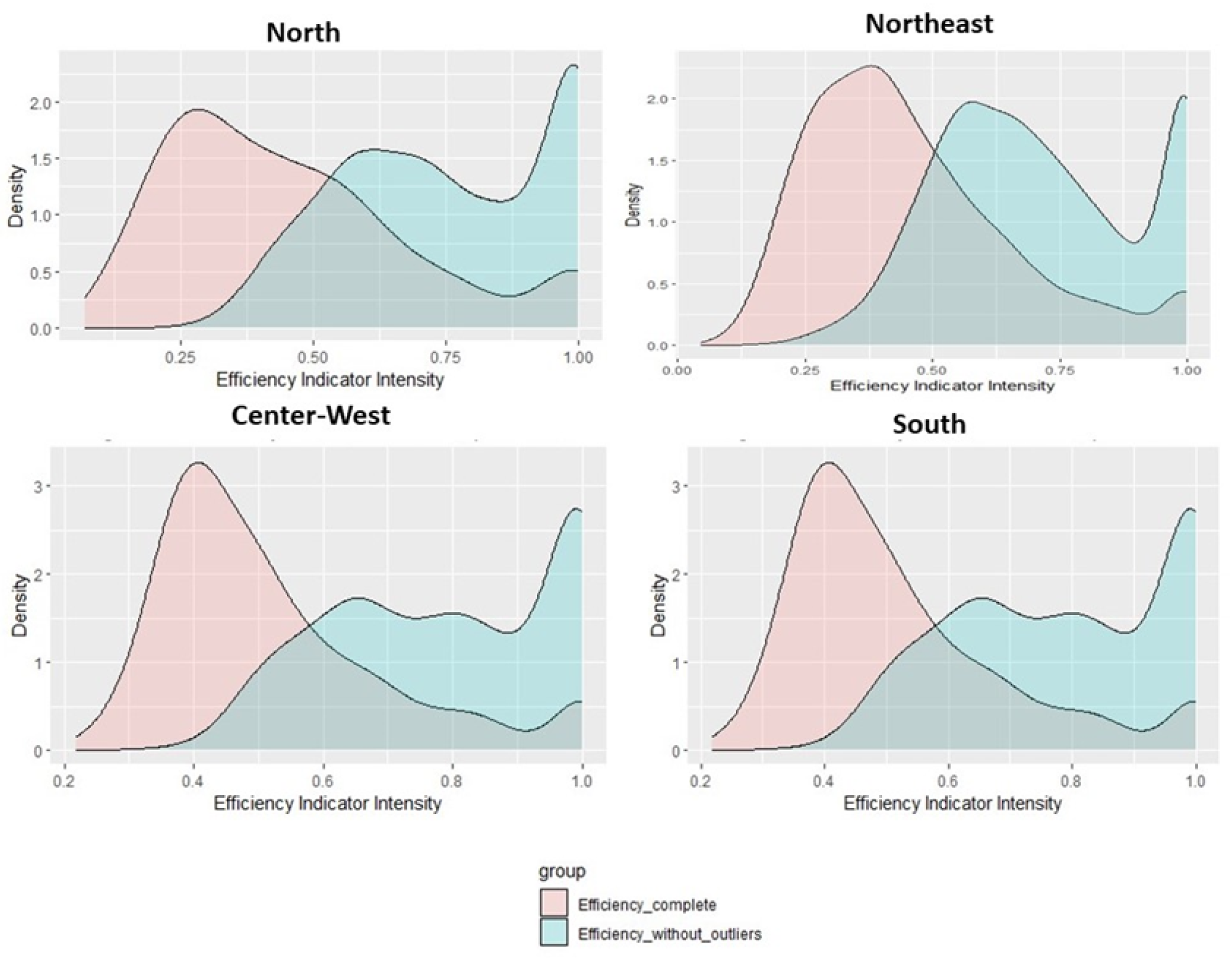
To understand the influence of outliers on the measurements, the density plots present the frequencies of each region where outliers were found (
Figure 1).
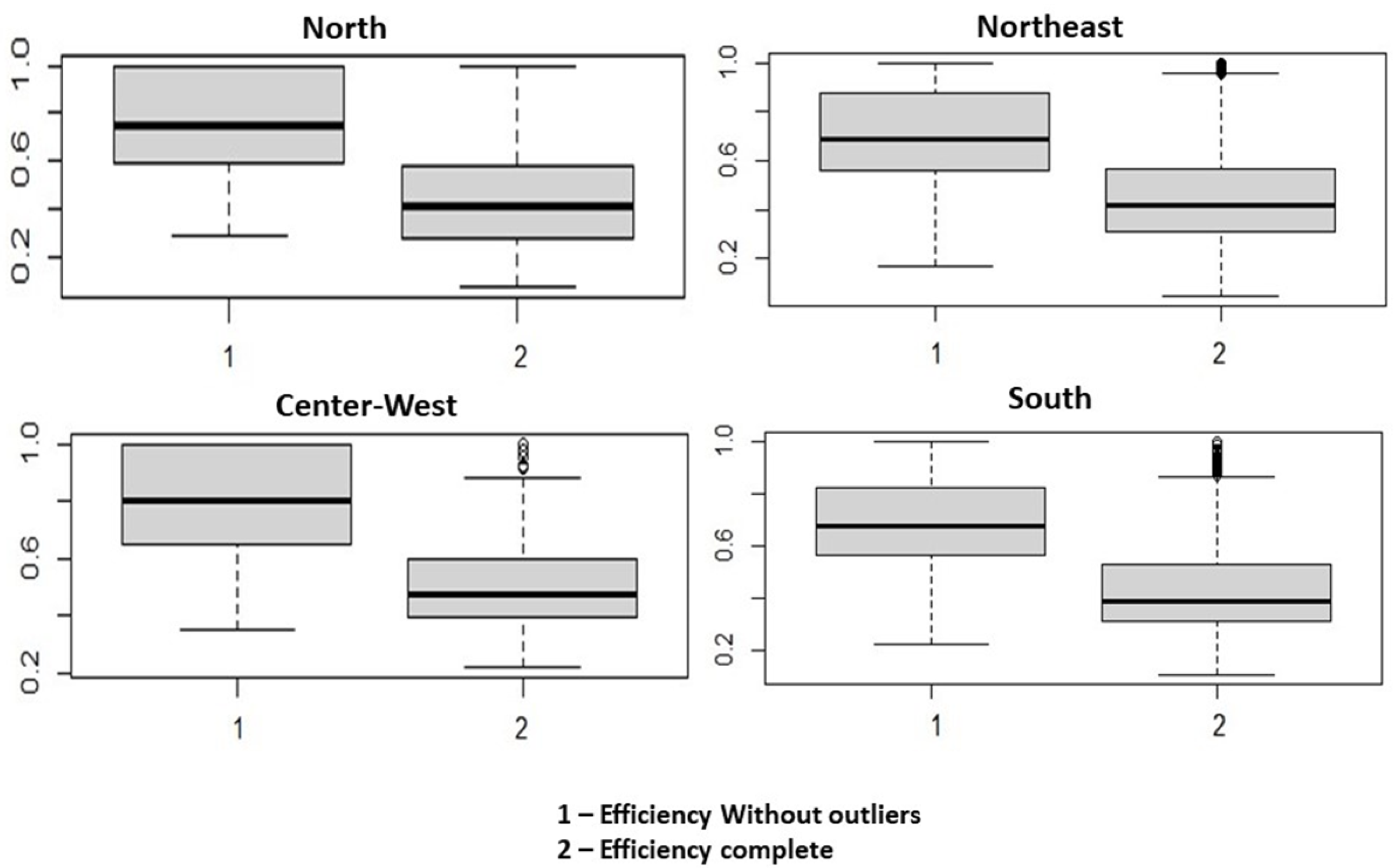
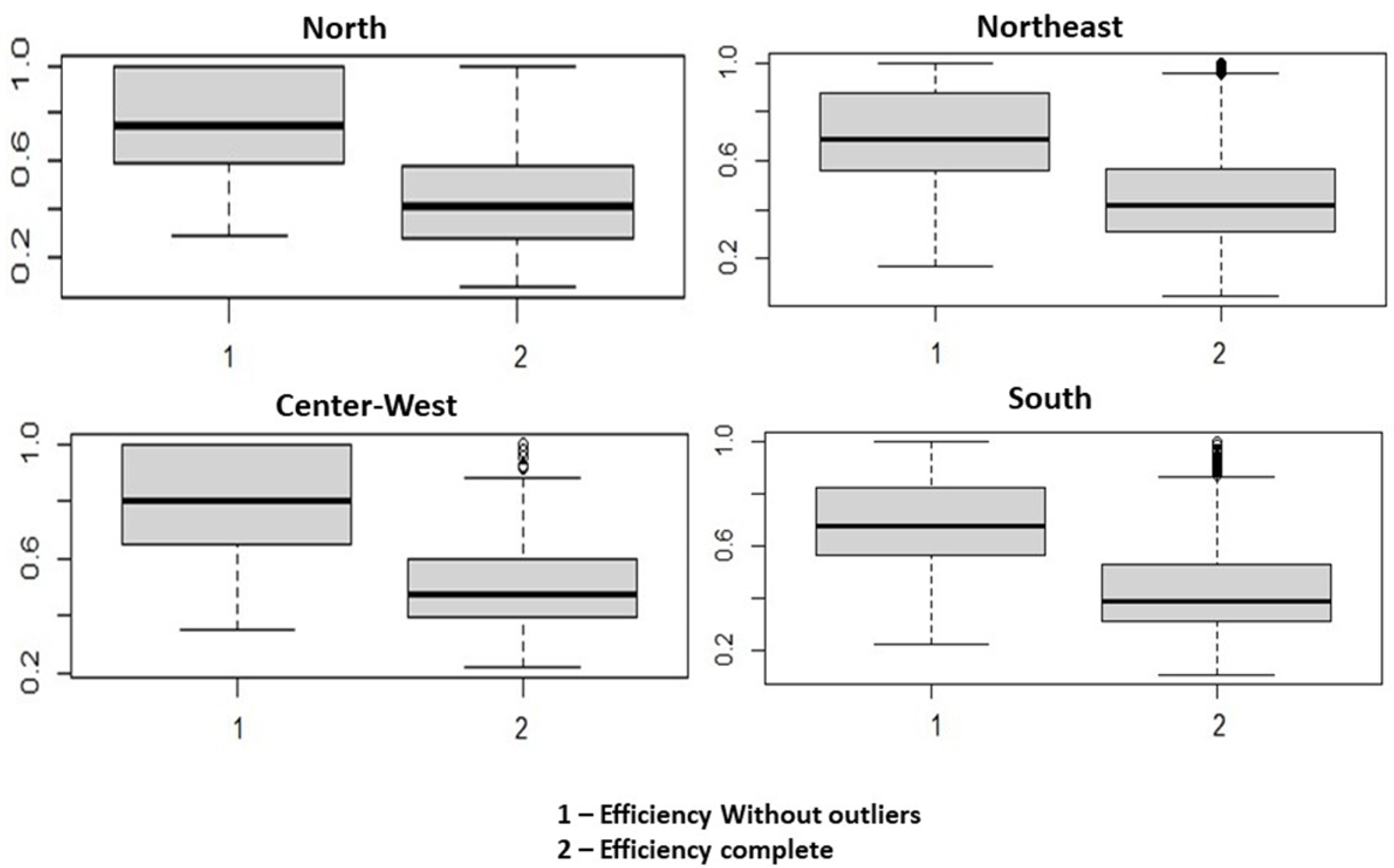
Therefore, it is verified that the outliers cause misrepresentation of the data, all biased towards lower eco-efficiency values. The Wilcoxon test comparing the efficiencies with and without outliers found that the mean and median of the two distributions diverged (
p-value
, in the regions where outliers were identified). These divergences become more explicit in the boxplots of the efficiencies for each region (
Figure 2).
As can be seen in
Figure 1 and
Figure 2, the averages of both graphs are shifted to a lower efficiency score, pulling the eco-efficiencies to a lower performance.
Thus, it is understood that the outliers influence the consistency of the results. Their removal is necessary to analyze the eco-efficiency of the municipalities assertively, resulting in more robust efficiencies. The 143 DMUs removed represent approximately 2.57% of the total, thus consolidating 5420 municipalities for efficiency analysis.
5.2. Scale Return Test
From the new sample resulting from the data without outliers, we can analyze the type of scale return of the data, thus defining which is the best model (CRS or VRS), because the use of any kind of scale return (constant or variable) can generate inadequate results, and it can also cause misrepresentations in the analyses by the evaluation being of a different nature from the real behavior of the sample. As described in
Section 3.3, the first hypothesis,
, is that the technology Frontier (F) has constant returns to scale as long as the scale efficiency,
, is equal to 1 (CRS); the
considers that the technology Frontier (F) has variable returns to scale as long as the scale efficiency,
, is less than 1 (VRS). Given the alternative hypothesis,
, we can accept
if the estimated value is greater than the critical value
.
The output orientation is used because the problem deals with undesirable outputs. It is not attractive to keep the emissions as they are to minimize the resources. Still, it is more appealing to keep the inputs and maximize the outputs, which, in the case of undesirable outputs, will be minimized by the model. The data is not partitioned in this step, so the 5420 municipalities return eco-efficiency scores jointly, with 1000 resamples obtained by bootstrap and .
The estimated value and the critical value is calculated. Thus, is accepted and F is considered with Constant Returns to Scale (CRS). Therefore, it is understood that regardless of the size of the farm, it can be eco-efficient. This is a good indication for agricultural production since approximately 89% of farmers own a farm of less than 100 hectares and are responsible for 80% of the rural income.
At first, this may be somewhat difficult to understand, considering that most of the sets analyzed often have variable scale behavior, especially in the private sector when analyzing industry [
39]. However, from the results, Brazilian agriculture shows different and constant behavior, which confirms an issue related to the fact that inequality in agriculture does not occur by the size of the properties but by the technological availability of them [
40].
5.3. Statistical Inference of DEA Eco-Efficiency of Municipalities
It is accepted that the technology is CRS and that the production-oriented eco-efficiency indices are estimated. Due to the abundance of data, the analysis is divided into two parts.
Table 3 and
Table 4 refer to the results of the application of the DEA methodology with bootstrap and the ranking of the best and worst eco-efficiency indices by region, where through the application of the bootstrap the confidence intervals of
of the eco-efficiency indices of the values (with correction) are structured. Thus, through the methodology adopted, more robust and reliable results were found than the simple application of the classic DEA model (without correction).
The municipalities listed in
Table 3 are the highest ranked, thus providing valuable information on which municipalities should be considered as benchmarks so that other municipalities can improve their practices in terms of economic and environmental outputs.
Table 4 shows which municipalities are in a worrying situation, serving as a reference point for other municipalities to check whether they are close to the least eco-efficient municipalities.
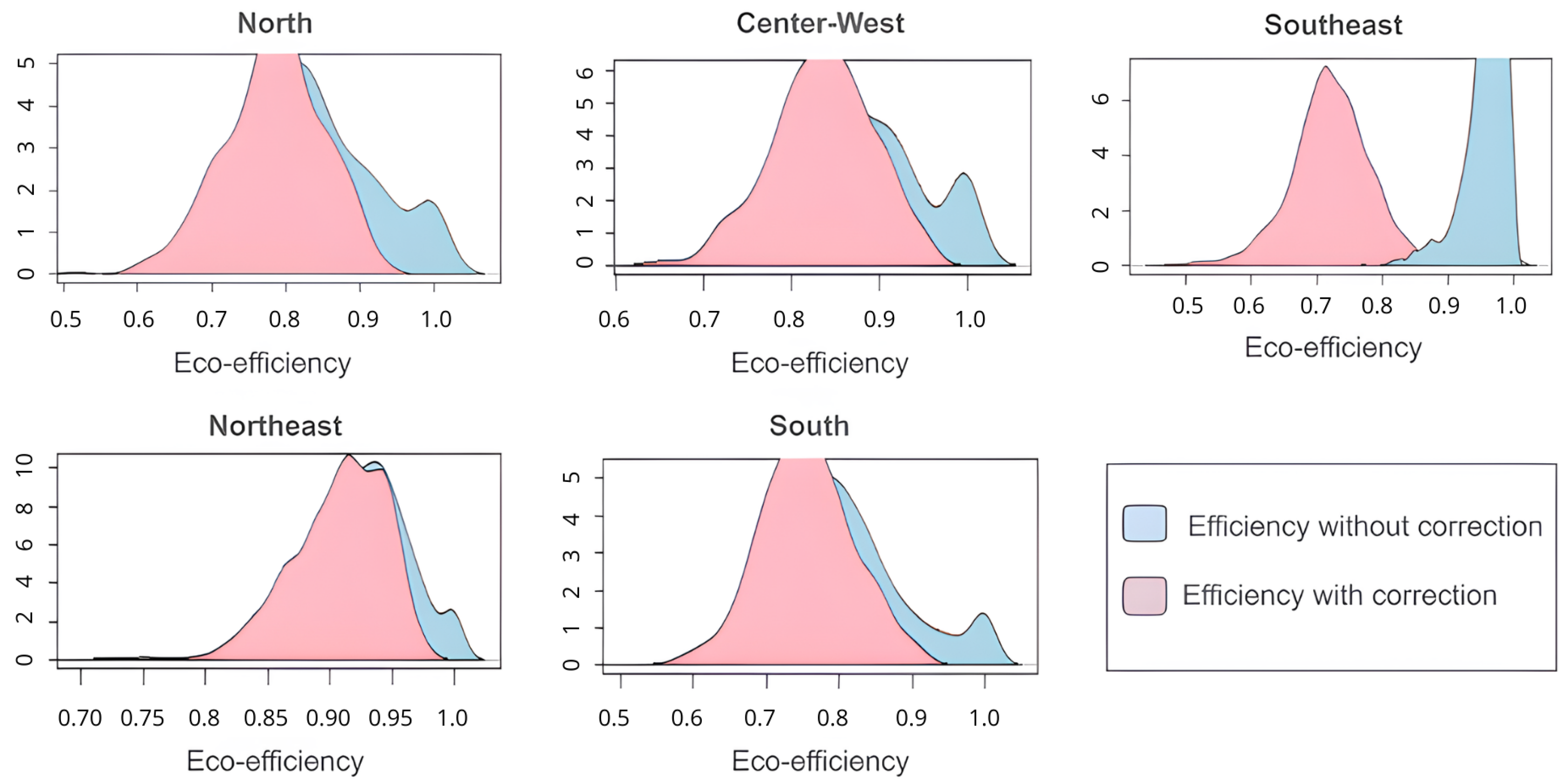
It is verified for the inefficient DMUs that the uncorrected values benefit the eco-efficiency scores, making the inefficient DMUs’ scores higher compared to the corrected scores of the same DMUs. Also, the uncorrected eco-efficiency scores of the efficient DMUs are underestimated; that is, they presented values below the scores with corrected values. One can visualize this difference in the corrected and uncorrected scores in
Figure 3.
The regions had higher means, medians, and interquartile ranges of the uncorrected data than the corrected data. In this way, the most robust data are obtained.
Table 5 contains the descriptive statistics of the efficiencies calculated with outliers, without outliers, and with correction without outliers.
Given the average eco-efficiency of the results from the corrected data for the north, northeast, center-west, southeast, and south regions of 0.7839, 0.9067, 0.8348, 0.6802, and 0.7526, respectively, it indicates a possibility for the municipalities of improvements of 21.62%, 9.33%, 16.52%, 31.98%, and 24.74% from each region, which results in an average increase of 20.84% of gross revenue and natural area on farms. There is a decrease in greenhouse gas emissions from the agricultural sector and Shannon–Weaver diversity index, with an average value of 20.84%.
Thus, it is verified that the removal of the outliers, the parameterization of the data, and the correction of the data generate more robust efficiency scores, thus bringing the results closer to the reality of each municipality and Brazilian region.
There is an analysis to define which region has the most eco-efficient municipalities; however, it would be unfair to compare the region that has the most eco-efficient municipalities, given that some regions have more than twice as many municipalities as other regions. One way is to compare eco-efficiency oriented to output and the selection of the five best DMUs in each Region.
In the comparison of the ten best municipalities, it is verified that the southeast, south, and north regions were the ones that came out best, respectively. The northeast and mid-western regions (which did not appear among the ten best municipalities in
Table 6) had the worst performance.
Regarding the best-placed municipalities, the values with corrections presented values above the uncorrected scores, and some DMUs presented values above the corrected score. By the confidence interval, we can differentiate the eco-efficiency among these units. Thus, a confidence interval for the scores is defined.
The overall average of the municipalities is 0.7891 (value without outliers and with confidence bias), which is different from the regional averages of the eco-efficiency index of the north (0.7839), northeast (0.9067), center-west (0.8348), southeast (0.6802), and south (0.7526) regions. An interesting point of the regional averages is that the northeast region presents, on average, higher score values than all regions, which shows that the region, despite having few eco-efficient municipalities, is closer to the productive frontier compared to other regions; this shows a greater homogeneity between the areas of agricultural activity in the region.
The southeast and the south have the lowest averages per region of 0.6802 and 0.7526, respectively, below the general average, which shows that the municipalities that are not part of the productive frontier of these regions are more distant from the eco-efficient frontier, pointing to a greater heterogeneity between the areas of agricultural activity in the region.
This is the case of the Ataléia (MG) municipality, with an eco-efficiency score of 0.3782. Therefore, the southeast and south regions present good performances for some DMUs but also represent the lowest municipal performances.
5.4. Geocoding of Eco-Efficiency Score Data in Brazilian Municipalities
Geocoding was used to describe different production and sustainability patterns in municipalities and regions. In this way, the greater the homogeneity between the municipalities of a region, the better distributed the resources and sustainable measures are because the municipalities are equally efficient, as well as pointing to a lesser influence of location on eco-efficiency; thus, in this region, improvements in policies and incentives could occur at the state or regional level, different from the heterogeneous areas, which demonstrate that some municipalities are not very eco-efficient in comparison with neighboring municipalities that have similar resources and conditions in terms of location, climate, and precipitation, among other external factors that can influence production, so policies and tax incentives must be evaluated on a more individual basis for each municipality as they address a local problem.
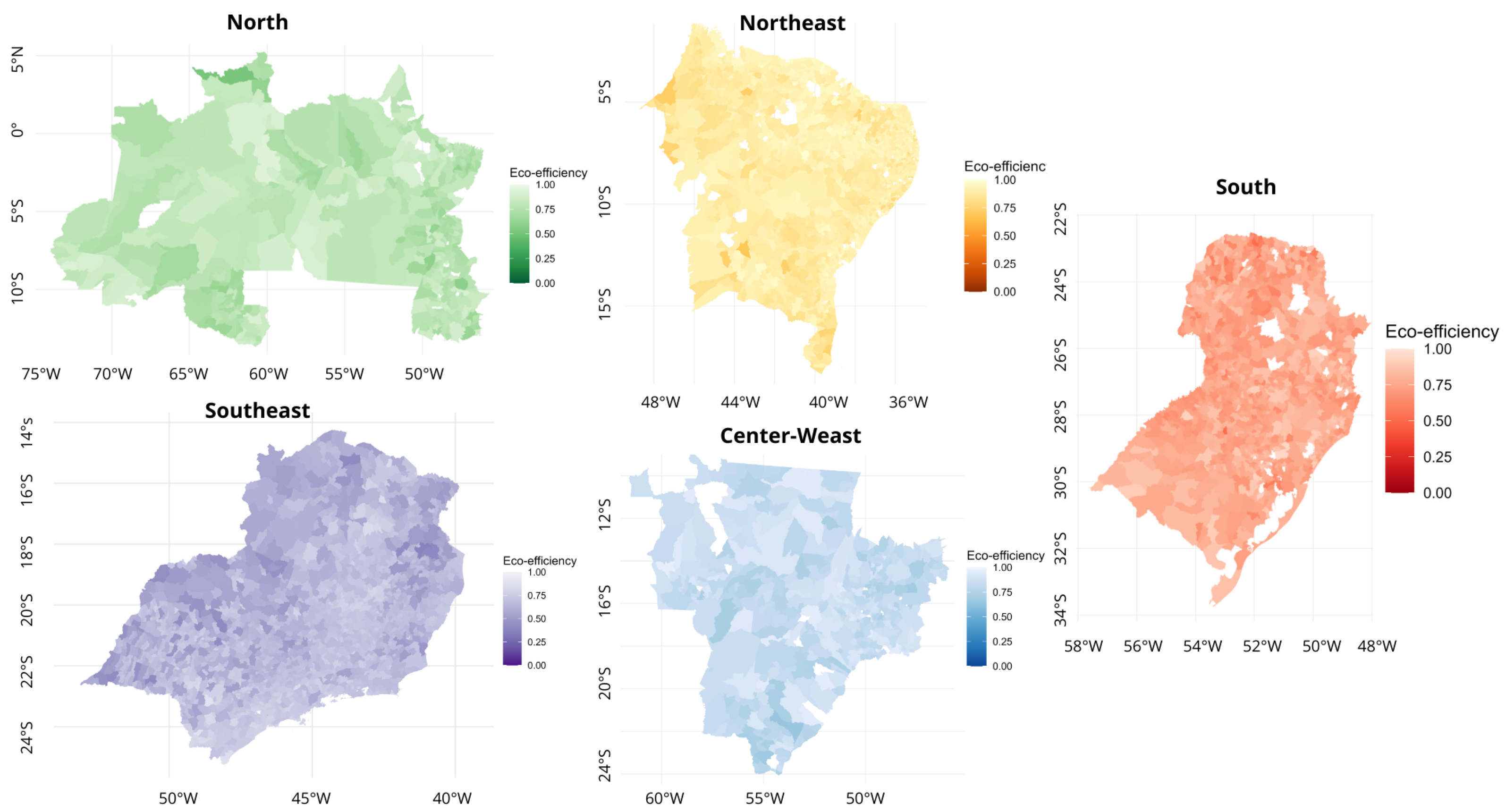
This can be visualized in the geocoding of eco-efficiency score data in municipalities, generated using the geobr package from RStudio (Available in the R library at
https://cran.r-project.org/package=geobr (accessed on 5 March 2024) by Pereira et al. (2022)). It pulls data from IBGE to carry out the geocoding; this way, the scores calculated for eco-efficiency and the geocoding information available from IBGE from 2017 are combined, and the available scale graphs are plotted in
Figure 4. The blank sites are the missing municipalities that do not present eco-efficiency scores because they are considered outliers.
In the north region, the most inefficient DMUs are located in the coastal part and close to the northeast region; as the location moves towards the inner part of the region under analysis, the eco-efficiency scores tend to increase. However, the scale of the map as a whole also shows homogeneity.
In the northeast region, as in the north region, the scores of the most inefficient DMUs are closer to the coast or close to the borders of other states; however, this does not present a significant scale contrast, presenting more homogeneous scores.
In the center-west region, we notice a greater heterogeneity among the scores compared to the north and northeast regions, with a greater contrast among the scales of each municipality. That is, both the efficient and the less efficient DMUs are randomly distributed by the geographic spacing. However, the scale of the municipalities in this region mainly presents scores closer to 1.
In the southeast region, a more excellent contrast is visualized, which points to high heterogeneity in the data between the eco-efficiency score scales and a tendency for the most inefficient DMUs to be located in the border areas of the mid-western and northeast regions. In contrast, efficient DMUs tend to be located in the inner part of the region.
In the south, as in the southeast, the eco-efficiency scores show greater heterogeneity among the municipalities, and the scores tend to be higher in the southern part of the graph.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}