
The Impact of a Skill-Driven Model on Scrum Teams in Software Projects: A Catalyst for Digital Transformation




Abstract
1. Introduction
1.1. Trends in Scrum Teams
1.2. Interest in LinkedIn Data
1.3. Aim of the Study
1.4. Research Question (RQ) and Objectives
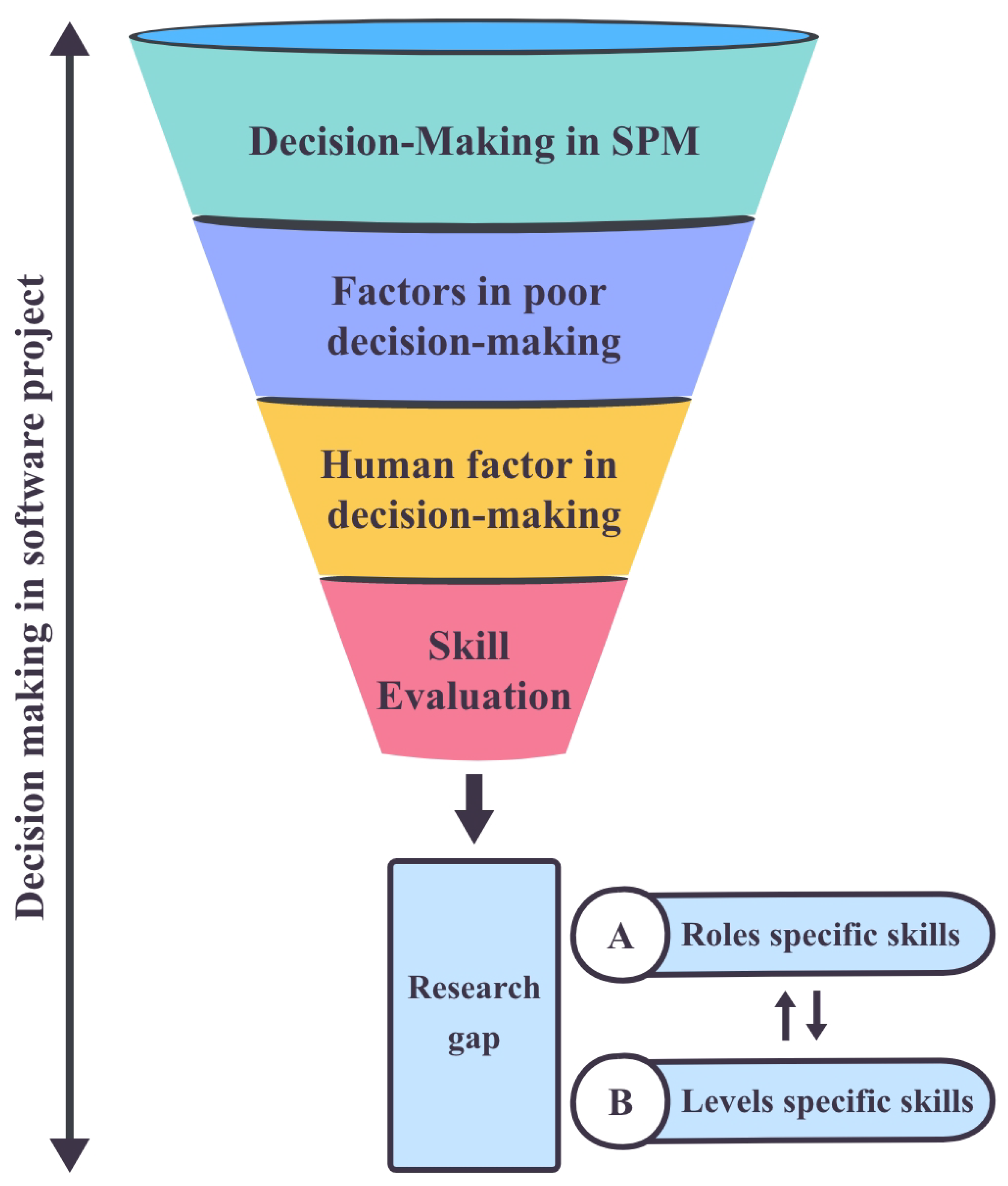
2. Related Work
2.1. Decision Making in SPM
2.2. Factors in Poor Decision Making
2.3. The Human Factor in Decision Making
2.4. Skill Evaluation
2.5. Areas to Research
3. Materials and Methods
3.1. Literature Search Process
- Define the search keywords using the research topic;
- Select databases/search engines and create search expressions;
- Define inclusion and exclusion criteria;
- Select the most related research papers.
3.2. Research Methods
3.3. Data Collection
3.3.1. Dataset
3.3.2. Data Extraction
3.4. Data Analysis
3.4.1. Data Cleansing
- Ignored posts that contained too specific subjects/backgrounds, which can occur due to a special requirement, or with unclear subjects. As an example, mining industry-related tools and technical skills;
- Ignored noisy text formats which contained special characters, HTML tags, and distracting icons;
- Excluded posts older than 60 days;
- Ignored posts which did not offer actual jobs and repeated the same content with slight changes;
- Filtered out only full-time jobs due to consideration of salary and work experience.
3.4.2. Qualitative Data Analysis
3.4.3. Quantitative Data Analysis
3.5. Ethical Considerations
4. Results and Discussion
4.1. Overview Results in Advertisements
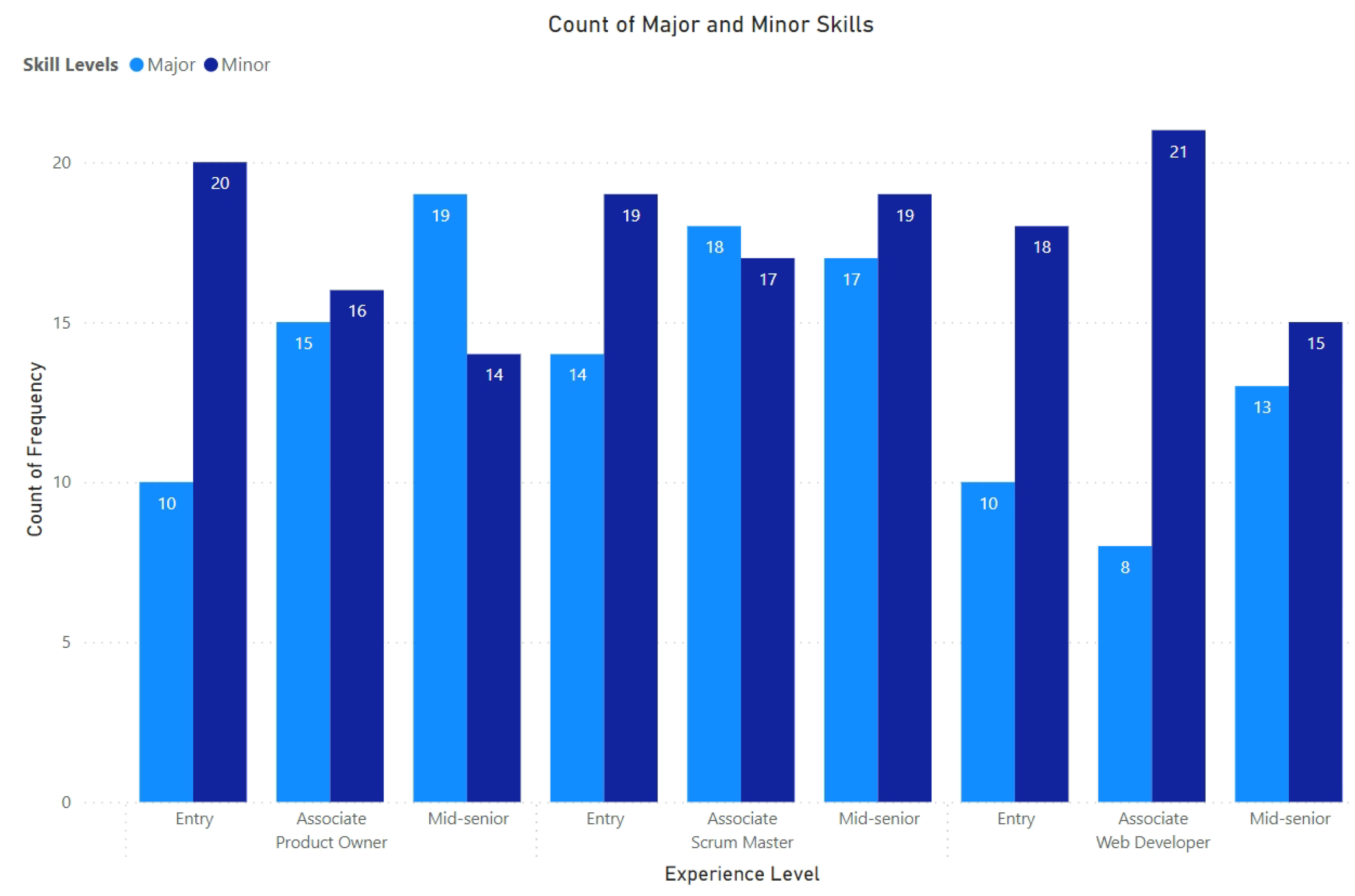
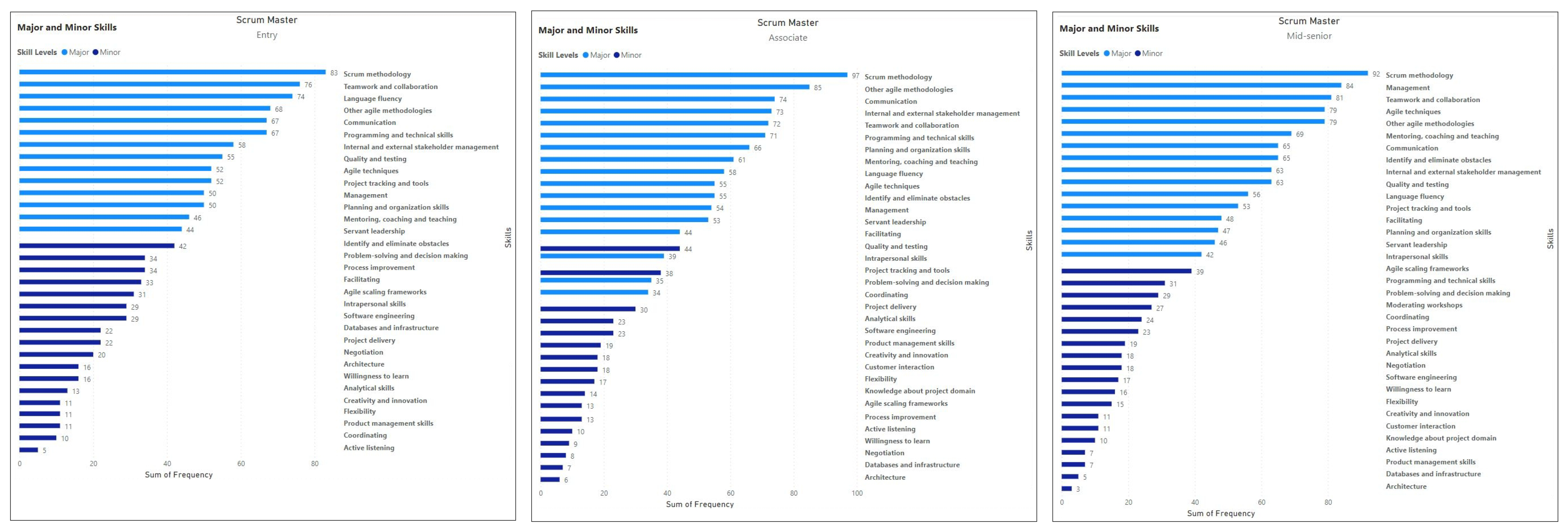
4.2. Objective 1: Major and Minor Skills in Scrum Roles
Skills in Industry Demand
4.3. Objective 2: Patterns and Relationships
4.3.1. Required Major and Minor Skill Patterns
4.3.2. Level-Specific Progression Skill Patterns
4.3.3. Lack of Skill Progression Patterns
4.4. Objective 3: Formulating Mathematical Equations
4.4.1. Initial Relationship and Rating
4.4.2. Individual Skill Time
4.5. Objective 4: Proposed Skill-Based Continuous Evaluation Model
4.5.1. Domain Model
4.5.2. Business Model
4.5.3. User Interfaces
4.6. Objective 5: Model Evaluation with Previous Works
4.6.1. Expertise-Based Skill Management System (EBSMS)
4.6.2. Skill Matrix
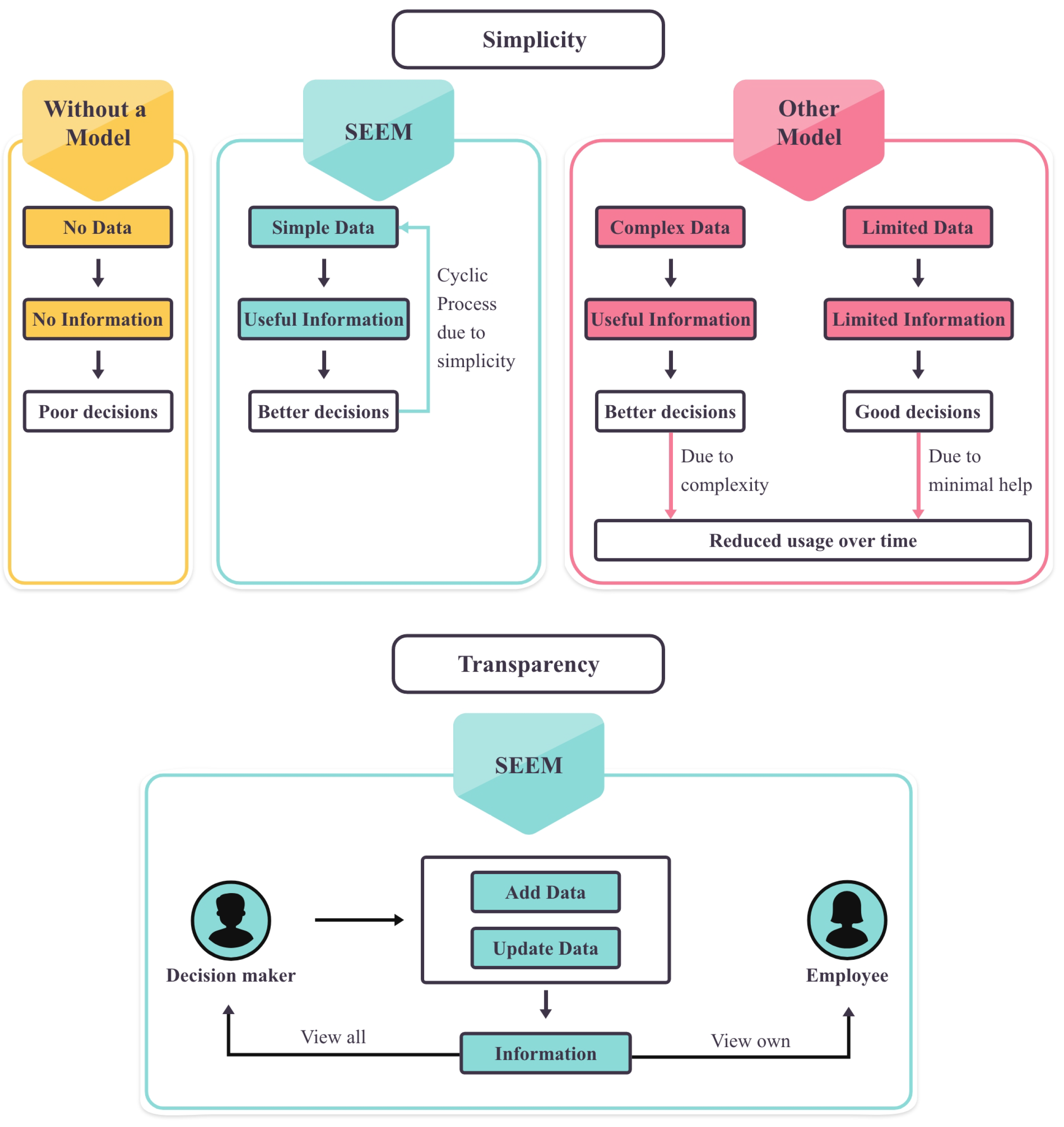
4.6.3. Values of SEEM
- Simplicity:SEEM expects simple inputs (e.g., agreed salary, experience years, updated salary, overall hours, or individual skill hours to be accepted as inputs in different stages) from the decision-maker that encourage continuous engagement. The decision-maker could make better decisions by considering useful information as follows.
- Completed hours to date and the hours needed to be completed to the next level (entry to the associate, associate to mid-senior);
- Initial ratings;
- Overall continuous ratings.
As a cyclic encouragement, the process would continue to have improved results over time. By using SEEM, decision-makers understand better employees’ skills and make better decisions. The decision-makers can input overall project hours into the model and the model distributes those hours to each skill depending on the weights of each skill category (major or minor).As a value addition, SEEM also supports the input of individual skill hours to provide improved results, which would be a result of stimulating decision-makers from previous results with overall hours. Figure 11 indicates the simplicity in the flow of SEEM by comparison with other existing models and without a model. - Transparency:Only a decision-maker adds or updates data, which is also visible to the respective team members. Transparency leads to more accurate, prompt data inputs, as shown in Figure 11.
- Extended values:For SEEM, the skill hours are added sprint-wise or by linking a time-tracker software. This makes the process more efficient, and the decision-maker is free from entering data. This leads to making the model more useful and reduces hesitation. Linking to the payroll with caution could make the process easier to add employees, update salaries, etc. Everyone in the same loop benefits without having to adapt to completely new software or solutions by integrating or linking additional services as described above.The gaps identified in the literature can be solved by using this model as it provides a clear understanding of individual employees’ skill levels. As an example, teamwork, communication skills, and organisational skills ratings should reflect the expected commitment of the employee.The digital transformation in businesses and industries within Industry 4.0 is changing and has significant challenges in the skills market. Skills evaluation and tracking throughout an employment have become a common research area due to the demand [94].
4.6.4. Study Contribution
4.6.5. Limitations
- The use of only one platform (LinkedIn) and a data generation method (document) to extract data could miss out on a different set of recruiters who do not use LinkedIn.
- The data were limited only to European countries for the three specific scrum roles.
- The LinkedIn job adverts expired soon after the recruitment process completed. It was a challenge to extract enough data and review job advertisements after the vacancies were filled on LinkedIn [21].
- Job roles changed slightly with the job advertisement titles in the data collection process.
- There were difficulties in finding data for specific roles from October to November because the second largest peak recruitment period is September to October and the quietest hiring months are November to December in the UK due to the influence of seasonal trends [48]. Data were collected during the intermediate time between the hiring trends.
- Some adverts were published as non-English and used Chrome Translate to translate the description [95]. This impacted the process of data collection and additional time was invested to expand the dataset.
- The salaries were not mentioned and left blank in some job adverts. Salary information was not mentioned in 50% of job postings, as also found in another study [48]. Also, experience was not mentioned in several job adverts, but this was not as frequent as salaries not being mentioned.
- The approach did not follow an automated process for data extraction and analysis. Therefore, it was time consuming.
4.6.6. Future Research Directions
- An evaluation of SEEM and its effectiveness could be performed as a future study by using a control group.
- There were specific job titles which related to the scrum roles in job advertisements. This is an opportunity to analyse more specialised roles to detect emerging job roles and career paths in the IT industry.
- More job portals could be used to improve the accuracy of industry standards of the proposed model and eliminate platform bias (LinkedIn).
- Future research could focus on different approaches to improve the efficiency of the process by following an automated process in data extraction.
- Data could be expanded for any IT professionals and levels by following the same approach worldwide.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A



Appendix B

Appendix C

Appendix D

Appendix E

Appendix F

References
- Rodriguez-Repiso, L.; Setchi, R.; Salmeron, J.L. Modelling IT projects success: Emerging methodologies reviewed. Technovation 2007, 27, 582–594. [Google Scholar] [CrossRef]
- Pollack, J.; Helm, J.; Adler, D. What is the Iron Triangle, and how has it changed? Int. J. Manag. Proj. Bus. 2018, 11, 527–547. [Google Scholar] [CrossRef]
- Iriarte, C.; Bayona, S. IT projects success factors: A literature review. Int. J. Inf. Syst. Proj. Manag. 2020, 8, 49–78. [Google Scholar] [CrossRef]
- Yel, İ.; Baysal, M.E.; Sarucan, A. A new approach to developing software projects by assigning teams to projects with interval-valued neutrosophic Z numbers. Eng. Appl. Artif. Intell. 2023, 126, 106984. [Google Scholar] [CrossRef]
- Patil, M.; Suresh, M. Modelling the enablers of workforce agility in IoT projects: A TISM approach. Glob. J. Flex. Syst. Manag. 2019, 20, 157–175. [Google Scholar] [CrossRef]
- Jassawalla, A.R.; Sashittal, H.C. Building collaborative cross-functional new product teams. Acad. Manag. Perspect. 1999, 13, 50–63. [Google Scholar] [CrossRef]
- Lohman, M.C. Cultivating problem-solving skills through problem-based approaches to professional development. Hum. Resour. Dev. Q. 2002, 13, 243–261. [Google Scholar] [CrossRef]
- Maurer, T.J.; Weiss, E.M. Continuous learning skill demands: Associations with managerial job content, age, and experience. J. Bus. Psychol. 2010, 25, 1–13. [Google Scholar] [CrossRef]
- da Cunha, J.A.O.; da Silva, F.Q.; de Moura, H.P.; Vasconcellos, F.J. Towards a substantive theory of decision-making in software project management: Preliminary findings from a qualitative study. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016; pp. 1–10. [Google Scholar]
- Heinsman, H. The Competency Concept Revealed: Its Nature, Relevance, and Practice. Ph.D. Thesis, Research and Graduation Internal, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands, 2008. [Google Scholar]
- Gingnell, L.; Franke, U.; Lagerström, R.; Ericsson, E.; Lilliesköld, J. Quantifying success factors for IT projects—An expert-based Bayesian model. Inf. Syst. Manag. 2014, 31, 21–36. [Google Scholar] [CrossRef]
- Soja, P. Success factors in ERP systems implementations: Lessons from practice. J. Enterp. Inf. Manag. 2006, 19, 418–433. [Google Scholar] [CrossRef]
- Pecherskaya, E.; Kamaletdinov, Y.; Zhabin, A.; Grishina, P. Key success factors analysis in the context of enterprise resourcesplanning systems projects implementation. Int. J. Proj. Organ. Manag. 2015, 9, 199–226. [Google Scholar] [CrossRef][Green Version]
- Pecherskaya, E.P.; Averina, L.V.; Kamaletdinov, Y.A.; Tretyakova, N.V.; Magomadova, T.L. Assessment of critical success factors transformation in ERP projects. Int. Electron. J. Math. Educ. 2016, 11, 2608–2625. [Google Scholar]
- Aranyossy, M.; Blaskovics, B.; Horváth, Á.A. How universal are IT project success and failure factors? Evidence from Hungary. Inf. Syst. Manag. 2018, 35, 15–28. [Google Scholar] [CrossRef]
- Conboy, K.; Fitzgerald, B. Toward a conceptual framework of agile methods: A study of agility in different disciplines. In Proceedings of the 2004 ACM Workshop on Interdisciplinary Software Engineering Research, Newport Beach, CA, USA, 5 November 2004; pp. 37–44. [Google Scholar]
- State of Agile Report. Available online: https://stateofagile.com/ (accessed on 4 October 2023).
- Ciancarini, P.; Giancarlo, R.; Grimaudo, G. Scrum@PA: Tailoring an Agile Methodology to the Digital Transformation in the Public Sector. Information 2024, 15, 110. [Google Scholar] [CrossRef]
- Kadenic, M.D.; Koumaditis, K.; Junker-Jensen, L. Mastering scrum with a focus on team maturity and key components of scrum. Inf. Softw. Technol. 2023, 153, 107079. [Google Scholar] [CrossRef]
- Chow, T.; Cao, D. A survey study of critical success factors in agile software projects. J. Syst. Softw. 2008, 81, 961–971. [Google Scholar] [CrossRef]
- Papoutsoglou, M.; Ampatzoglou, A.; Mittas, N.; Angelis, L. Extracting knowledge from on-line sources for software engineering labor market: A mapping study. IEEE Access 2019, 7, 157595–157613. [Google Scholar] [CrossRef]
- Li, S.; Shi, B.; Yang, J.; Yan, J.; Wang, S.; Chen, F.; He, Q. Deep job understanding at linkedin. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 2145–2148. [Google Scholar]
- Lappas, T. Mining career paths from large resume databases: Evidence from IT professionals. ACM Trans. Knowl. Discov. Data (TKDD) 2020, 14, 1–38. [Google Scholar] [CrossRef]
- 2023–24 Global Recruiting Site Trends Survey. Available online: https://www.jobboarddoctor.com/survey-results/ (accessed on 17 November 2023).
- Smuts, S.; Smuts, H. Society 5.0 and the Future of Work Skills for Software Engineers and Developers. 2022. Available online: http://hdl.handle.net/2263/91094 (accessed on 5 September 2023).
- The Scrum Guide. Available online: https://scrumguides.org/docs/scrumguide/v2020/2020-Scrum-Guide-US.pdf (accessed on 30 October 2023).
- Project Management Institute. Agile Practice Guide; Project Management Institute: Newtown Square, PA, USA, 2017; p. 182. [Google Scholar]
- Maier, P.; Ma, Z.; Bloem, R. Towards a secure scrum process for agile web application development. In Proceedings of the 12th International Conference on Availability, Reliability and Security, Calabria, Italy, 29 August–1 September 2017; pp. 1–8. [Google Scholar]
- Kashive, N.; Khanna, V.T. Emerging HR analytics role in a crisis: An analysis of LinkedIn data. Compet. Rev. Int. Bus. J. 2023, 33, 1179–1204. [Google Scholar] [CrossRef]
- Hsia-Ching, C.; Chen-Ya, W.; Hawamdeh, S. Emerging trends in data analytics and knowledge management job market: Extending KSA framework. J. Knowl. Manag. 2019, 23, 664–686. [Google Scholar] [CrossRef]
- Garg, R.; Kumar, R.; Garg, S. MADM-based parametric selection and ranking of E-learning websites using fuzzy COPRAS. IEEE Trans. Educ. 2018, 62, 11–18. [Google Scholar] [CrossRef]
- Farshidi, S.; Jansen, S.; Deldar, M. A decision model for programming language ecosystem selection: Seven industry case studies. Inf. Softw. Technol. 2021, 139, 106640. [Google Scholar] [CrossRef]
- Shvetsova, O.; Feroz, M.; Salkutsan, S.; Efimov, A. Artificial Intelligence Application for Healthcare Industry: Cases of Developed and Emerging Markets; Lecture Notes in Networks and Systems, 673 LNNS; Springer Nature: Singapore, 2023; pp. 419–432. [Google Scholar]
- Mendes, F.F.; Mendes, E.; Salleh, N. The relationship between personality and decision-making: A Systematic literature review. Inf. Softw. Technol. 2019, 111, 50–71. [Google Scholar] [CrossRef]
- Sadabadi, A.T.; Kama, N. Generating policy for software project management decision support paradigm. In Proceedings of the 2014 IEEE 5th International Conference on Software Engineering and Service Science, Beijing, China, 27–29 June 2014; IEEE: New York, NY, USA, 2014; pp. 58–63. [Google Scholar]
- İmamoğlu, M.Y.; Çetinkaya, D. A rule based decision support system for programming language selection. In Proceedings of the 2017 2nd International Conference on Knowledge Engineering and Applications (ICKEA), London, UK, 21–23 October 2017; pp. 71–75. [Google Scholar]
- Eastham, J.; Tucker, D.J.; Varma, S.; Sutton, S.M. PLM software selection model for project management using hierarchical decision modeling with criteria from PMBOK® knowledge areas. Eng. Manag. J. 2014, 26, 13–24. [Google Scholar] [CrossRef]
- Akbar, S.; Ullah, R.; Khan, R.; Asghar, I.; Zubair, M.; Zheng, Z. A Multi-Criteria Decision-Making Framework for Software Project Management Tool Selection. In Proceedings of the 2023 9th International Conference on Computer Technology Applications, Vienna, Austria, 10–12 May 2023; pp. 184–191. [Google Scholar]
- Capturing the Value of Project Management through Decision Making. Available online: https://www.pmi.org/learning/thought-leadership/pulse/capture-value-decision-making (accessed on 15 October 2023).
- Standish Group 2015 Chaos Report—Q&A with Jennifer Lynch. Available online: https://www.infoq.com/articles/standish-chaos-2015/ (accessed on 2 September 2023).
- BMG Research Factors in Project Success; The Association for Project Management (APM): Birmingham, UK, 2014.
- Al Neimat, T. Why IT projects fail. Proj. Perfect White Pap. Collect. 2005, 8, 1–8. [Google Scholar]
- Paklina, S.; Shakina, E. Which professional skills value more under digital transformation? J. Econ. Stud. 2022, 49, 1524–1547. [Google Scholar] [CrossRef]
- Deutsch, M.S. An exploratory analysis relating the software project management process to project success. IEEE Trans. Eng. Manag. 1991, 38, 365–375. [Google Scholar] [CrossRef]
- Florea, R.; Stray, V.; Sjøberg, D.I. On the roles of software testers: An exploratory study. J. Syst. Softw. 2023, 111742. [Google Scholar] [CrossRef]
- Potter, L.E. Preparing for projects: It student self-evaluation of technical and professional skills. In Proceedings of the 2020 on Computers and People Research Conference, Nuremberg, Germany, 19–21 June 2020; pp. 63–69. [Google Scholar]
- Hranický, R.; Breitinger, F.; Ryšavý, O.; Sheppard, J.; Schaedler, F.; Morgenstern, H.; Malik, S. What do incident response practitioners need to know? A skillmap for the years ahead. Forensic Sci. Int. Digit. Investig. 2021, 37, 301184. [Google Scholar] [CrossRef]
- Romanko, O.; O’Mahony, M. The use of online job sites for measuring skills and labour market trends: A review. In Economic Statistics Centre of Excellence (ESCoE) Technical Reports; Office for National Statistics: Newport, UK, 2022. [Google Scholar]
- Galster, M.; Mitrovic, A.; Malinen, S.; Holland, J. What soft skills does the software industry* really* want? An exploratory study of software positions in New Zealand. In Proceedings of the 16th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, New Orleans, LA, USA, 26–27 October 2022; pp. 272–282. [Google Scholar]
- Gottipati, S.; Shim, K.J.; Sahoo, S. Glassdoor Job Description Analytics—Analyzing Data Science Professional Roles and Skills. In Proceedings of the 2021 IEEE Global Engineering Education Conference (EDUCON), Vienna, Austria, 20–23 April 2021; pp. 1329–1336. [Google Scholar]
- Smaldone, F.; Ippolito, A.; Lagger, J.; Pellicano, M. Employability skills: Profiling data scientists in the digital labour market. Eur. Manag. J. 2022, 40, 671–684. [Google Scholar] [CrossRef]
- Sun, Y.; Zhuang, F.; Zhu, H.; He, Q.; Xiong, H. Cost-effective and interpretable job skill recommendation with deep reinforcement learning. In Proceedings of the Web Conference, Virtual, Slovenia, 19–23 April 2021; pp. 3827–3838. [Google Scholar]
- Anwar, Z.; Bibi, N.; Ahsan, A. Expertise based skill management model for effective project resource allocation under stress in software industry of Pakistan. In Proceedings of the 2013 6th International Conference on Information Management, Innovation Management and Industrial Engineering, Xi’an, China, 23–24 November 2013; pp. 509–513. [Google Scholar]
- Cui, B.; Hong, W.; Zhu, J.; Wu, X. Digitalization capability evaluation system and practice. In Proceedings of the 2021 16th International Conference on Computer Science & Education (ICCSE), Lancaster, UK, 17–21 August 2021; pp. 164–167. [Google Scholar]
- Ericsson, A.; Towne, T.J. Expertise. Wiley Interdiscip. Rev. Cogn. Sci. 2010, 1, 404–416. [Google Scholar] [CrossRef] [PubMed]
- Stylianou, C.; Andreou, A.S. Investigating the impact of developer productivity, task interdependence type and communication overhead in a multi-objective optimization approach for software project planning. Adv. Eng. Softw. 2016, 98, 79–96. [Google Scholar] [CrossRef]
- Vega-Velázquez, M.Á.; García-Nájera, A.; Cervantes, H. A survey on the Software Project Scheduling Problem. Int. J. Prod. Econ. 2018, 202, 145–161. [Google Scholar] [CrossRef]
- Ramirez, A.; Romero, J.R.; Ventura, S. A survey of many-objective optimisation in search-based software engineering. J. Syst. Softw. 2019, 149, 382–395. [Google Scholar] [CrossRef]
- Ferrucci, F.; Harman, M.; Sarro, F. Search-based software project management. Softw. Proj. Manag. Chang. World 2014, 373–399. [Google Scholar]
- McKim, C.A. The value of mixed methods research: A mixed methods study. J. Mix. Methods Res. 2017, 11, 202–222. [Google Scholar] [CrossRef]
- Oates, B.J.; Griffiths, M.; McLean, R. Researching Information Systems and Computing, 2nd ed.; Sage: London, UK, 2022. [Google Scholar]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic mapping studies in software engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE), Bari, Italy, 26–27 June 2008; pp. 1–10. [Google Scholar]
- Research, Journal Articles & Databases. Available online: https://libguides.tees.ac.uk/computing/research (accessed on 2 September 2023).
- Wang, C.; Cui, P.; Daneva, M.; Kassab, M. Understanding what industry wants from requirements engineers: An exploration of RE jobs in Canada. In Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Oulu, Finland, 11–12 October 2018; pp. 1–10. [Google Scholar]
- Wang, C.; Tang, Y.; Liang, P.; Daneva, M.; van Sinderen, M. What industry wants from requirements engineers in China? An exploratory and comparative study on RE job ads. In Proceedings of the 14th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Bari, Italy, 5–9 October 2020; pp. 1–11. [Google Scholar]
- Pejic-Bach, M.; Bertoncel, T.; Meško, M.; Krstić, Ž. Text mining of industry 4.0 job advertisements. Int. J. Inf. Manag. 2020, 50, 416–431. [Google Scholar] [CrossRef]
- Europe: Human Geography. Available online: https://education.nationalgeographic.org/resource/europe-human-geography/ (accessed on 10 November 2023).
- Microsoft Power BI. Available online: https://powerbi.microsoft.com/en-gb/desktop/ (accessed on 5 September 2023).
- European Centre for the Development of Vocational Training. Online Job Vacancies and Skills Analysis: A Cedefop Pan-European Approach; Cedefop: Luxembourg, 2019.
- Oanda Currency Converter. Available online: https://www.oanda.com/ (accessed on 5 November 2023).
- Hidayati, A.; Budiardjo, E.K.; Purwandari, B. Hard and soft skills for scrum global software development teams. In Proceedings of the 3rd International Conference on Software Engineering and Information Management, Sydney, NSW, Australia, 12–15 January 2020; pp. 110–114. [Google Scholar]
- Vadlamani, S.L.; Baysal, O. Studying software developer expertise and contributions in Stack Overflow and GitHub. In Proceedings of the 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), Adelaide, Australia, 28 September–2 October 2020; pp. 312–323. [Google Scholar]
- Kadenic, M.D.; de Jesus Pacheco, D.A.; Koumaditis, K.; Tjørnehøj, G.; Tambo, T. Investigating the role of Product Owner in Scrum teams: Differentiation between organisational and individual impacts and opportunities. J. Syst. Softw. 2023, 206, 111841. [Google Scholar] [CrossRef]
- Daneva, M.; Wang, C.; Hoener, P. What the job market wants from requirements engineers? An empirical analysis of online job ads from the Netherlands. In Proceedings of the 2017 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Toronto, ON, Canada, 9–10 November 2017; pp. 448–453. [Google Scholar]
- Unger-Windeler, C.; Schneider, K. Expectations on the Product Owner role in systems engineering-A scrum team’s point of view. In Proceedings of the 2019 45th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Kallithea-Chalkidiki, Greece, 28–30 August 2019; 276–283. [Google Scholar]
- Pham, Y.D.; Montgomery, L.; Maalej, W. Renovating requirements engineering: First thoughts to shape requirements engineering as a profession. In Proceedings of the 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW), Jeju, Republic of Korea, 23–27 September 2019; pp. 7–11. [Google Scholar]
- Gupta, R.K.; Reddy, P.M. Adapting agile in a globally distributed software development. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 5360–5367. [Google Scholar]
- Petrescu, M.A.; Motogna, S.; Berciu, L. Women in Scrum Master Role: Challenges and Opportunities. In Proceedings of the 2023 IEEE/ACM 4th Workshop on Gender Equity, Diversity, and Inclusion in Software Engineering (GEICSE), Melbourne, Australia, 20 May 2023; pp. 49–55. [Google Scholar]
- Khurana, M.; Kaur, K. Impact of Agile Scrum Methodology on Team’s Productivity and Client Satisfaction–A Case Study. In Proceedings of the 2021 3rd International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), Greater Noida, India, 17–18 December 2021; pp. 1686–1691. [Google Scholar]
- Portman, H. The Ideal Scrum Master. XI. 1–7. 2022. Available online: https://pmworldlibrary.net/ (accessed on 28 October 2023).
- Shastri, Y.; Hoda, R.; Amor, R. The role of the project manager in agile software development projects. J. Syst. Softw. 2021, 173, 110871. [Google Scholar] [CrossRef]
- Groeneveld, W.; Becker, B.A.; Vennekens, J. Soft skills: What do computing program syllabi reveal about non-technical expectations of undergraduate students? In Proceedings of the 2020 ACM Conference on Innovation and Technology in Computer Science Education, Trondheim, Norway, 15–19 June 2020; pp. 287–293. [Google Scholar]
- Stamm, S. Desired Qualifications Sought in Entry Level Software Engineers. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education, Toronto, ON, Canada, 15–18 March 2023; pp. 854–860. [Google Scholar]
- Galster, M.; Mitrovic, A.; Malinen, S.; Holland, J.; Peiris, P. Soft skills required from software professionals in New Zealand. Inf. Softw. Technol. 2023, 160, 107232. [Google Scholar] [CrossRef]
- Christensen, E.L.; Paasivaara, M. Learning soft skills through distributed software development. In Proceedings of the International Conference on Software and System Processes and International Conference on Global Software Engineering, Pittsburgh, PA, USA, 19–20 May 2022; pp. 93–103. [Google Scholar]
- Data Analysis Expressions (DAX) Reference. Available online: https://learn.microsoft.com/en-us/dax/ (accessed on 7 November 2023).
- Research Ethics. Available online: https://www.tees.ac.uk/sections/research/ethics.cfm (accessed on 12 November 2023).
- The GDPR. Available online: https://www.legislation.gov.uk/ukpga/2018/12/part/2/chapter/2/enacted (accessed on 24 November 2023).
- Rêgo, B.S.; Lourenço, D.; Moreira, F.; Pereira, C.S. Digital transformation, skills and education: A systematic literature review. Ind. High. Educ. 2023, 09504222231208969. [Google Scholar] [CrossRef]
- Luo, Y.; Liang, P.; Wang, C.; Shahin, M.; Zhan, J. Characteristics and challenges of low-code development: The practitioners’ perspective. In Proceedings of the 15th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Bari, Italy, 11–15 October 2021; pp. 1–11. [Google Scholar]
- Richardson, C.; Rymer, J.R. Vendor Landscape: The Fractured, Fertile Terrain of Low-Code Application Platforms; Forrester: Cambridge, MA, USA, 2016; Volume 12. [Google Scholar]
- Poe, L.; Mew, L. The effects of using the agile methodology as an instructional format for software development courses. Ind. High. Educ. 2022, 36, 638–646. [Google Scholar] [CrossRef]
- Gürcan, F.; Taentzer, G. Using Microsoft PowerApps, Mendix and OutSystems in two development scenarios: An experience report. In Proceedings of the 2021 ACM/IEEE International Conference on Model Driven Engineering Languages and Systems Companion (MODELS-C), Fukuoka, Japan, 10–15 October 2021; pp. 67–72. [Google Scholar]
- Goulart, V.G.; Liboni, L.B.; Cezarino, L.O. Balancing skills in the digital transformation era: The future of jobs and the role of higher education. Ind. High. Educ. 2022, 36, 118–127. [Google Scholar] [CrossRef]
- Change Chrome Languages and Translate Web Pages. Available online: https://support.google.com/chrome/answer/173424 (accessed on 28 October 2023).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Job Advertisements (e.g., Job Boards/ Professional Social Networks | Skill Categorisation (e.g., Soft, Hard, Technical) | Role-Specific Skills | Experience-Level Specific Skills | Salary | Skill Evaluation |
|---|---|---|---|---|---|---|
| [21] | Yes | Yes | No | No | No | No |
| [23] | Yes | No | No | No | No | No |
| [25] | No | No | Yes | No | No | Yes |
| [36] | Yes | No | No | No | No | No |
| [46] | No | Yes | No | No | No | Yes |
| [47] | Yes | Yes | Yes | No | No | Yes |
| [48] | Yes | Yes | Yes | No | Yes | No |
| [49] | Yes | Yes | Yes | No | No | No |
| [50] | Yes | Yes | Yes | No | No | No |
| [51] | Yes | Yes | Yes | No | No | No |
| [52] | Yes | No | No | No | Yes | No |
| [53] | No | Yes | No | Yes | No | Yes |
| Current study | Yes | Yes | Yes | Yes | Yes | Yes |
| Keywords | Synonyms/Other Names |
|---|---|
| Skill | Expertise, competence |
| Scrum | Scrum roles, scrum teams |
| Software projects | IT projects |
| Model | Application, systems, frameworks |
| Digital transformation | - |
| Job advertisements | Job adverts, job posts, vacancies |
| Job boards | Job portals |
| Job Role | Experience Level | Code | Total Entries | Selected Entries |
|---|---|---|---|---|
| Product Owner (PO) | Entry | POE | 140 | 100 |
| Associate | POA | 402 | 100 | |
| Mid-senior | POM | 811 | 100 | |
| Scrum Master (SM) | Entry | SME | 112 | 100 |
| Associate | SMA | 192 | 100 | |
| Mid-senior | SMM | 1229 | 100 | |
| Web Developer (WD) | Entry | WDE | 425 | 100 |
| Associate | WDA | 115 | 100 | |
| Mid-senior | WDM | 263 | 100 | |
| Total | 3689 | 900 | ||
| Extracted Data | Type of Data | Located in the Advert | Research Objective |
|---|---|---|---|
| Skills | Unstructured | Job description | 1, 2 |
| Salary | Unstructured | ||
| Experience years | Unstructured | Job description or header section | 2–4 |
| Experience level | Structured | Header section as predefined value | 1–4 |
| Job Posts | Experience Level | Experience Years (ExYrs) | Minimum Salary (MinSal) | Maximum Salary (MaxSal) | S1 | S2 | S3 | … |
|---|---|---|---|---|---|---|---|---|
| P1 | Entry | ExYrs 1 | MinSal 1 | MaxSal 1 | 1 | 0 | 1 | … |
| P2 | Entry | ExYrs 2 | MinSal 2 | MaxSal 2 | 0 | 1 | 1 | … |
| P3 | Entry | ExYrs 3 | MinSal 3 | MaxSal 3 | 1 | 1 | 1 | … |
| P4 | Entry | ExYrs 4 | MinSal 4 | MaxSal 4 | 1 | 1 | 0 | … |
| … | … | … | … | … | … | … | … | … |
| Scrum Roles | Technical Skills | Soft Skills | ||
|---|---|---|---|---|
| Product owner [19,73,74,75,76,77] | Overall strategic and vision | Improve team productivity | Language fluency | Conceptual skills |
| Return on investment (ROI) responsibility | Product delivery and release management | Teamwork and collaboration | Problem solving and decision making | |
| Customer satisfaction | Risk assessment | Communication skills | Self-organisation | |
| Business savvy | Analytical skills | Innovation and creativity | ||
| Overall domain knowledge | Responsibility and accountability | Intrapersonal skills | ||
| Lead product lifecycle | Flexibility | Leadership | ||
| Product backlog management | Customer and stakeholder orientation | Validation and negotiation | ||
| Scrum master [19,78,79,80,81] | Databases and Infrastructure | Scrum methodology | Teamwork and collaboration | Servant leadership |
| Programming and technical skills | Agile techniques | Management | Planning and organisation skills | |
| Software engineering | Knowledge about the project domain | Negotiation | Creativity and innovation | |
| Architecture | Communication | Problem solving and decision making | Active listening | |
| Quality and testing | Flexibility | Facilitating | ||
| Improve team productivity | Mentoring, coaching, and teaching | |||
| Process improvement | Coordinating | |||
| Software development team [71,72,82,83,84,85] | Programming and technical | Software engineering best practices | Communication | Intrapersonal skills |
| Agile and scrum expertise | Software integration and cloud development techniques | Analytical thinking | Organisational and planning | |
| Database | Teamwork and collaborative | Willingness to learn | ||
| Vision and requirements | Leadership | Creativity and innovation | ||
| Self-tracking and time-tracking tools | Problem solving and decision making | Internal/external stakeholder management | ||
| Debugging skills and testing tools | Language fluency | Mentoring | ||
| Scrum Roles | Technical Skills | Soft Skills | |
|---|---|---|---|
| Product owner | Scrum methodology | Designing knowledge | Coordinating skill |
| Software quality management | Project management tools | ||
| Other agile methodologies | Microsoft and other tools | ||
| IT and software knowledge | Product road mapping | ||
| Scrum master | Identify and eliminate obstacles | Project delivery | Willingness to learn |
| Other agile methodologies | Product management skills | Analytical skills | |
| Internal and external stakeholder management | Customer interaction | Language fluency | |
| Project tracking and tools | Moderating workshops | Intrapersonal skills | |
| Agile scaling frameworks | |||
| Web developer | Frontend web technologies and frameworks | CMS | Flexible and adaptability |
| Backend web technologies and frameworks | Web performance and optimisation | Accessibility and usability | |
| Web design and tools | Microsoft and other tools | Committed and responsible | |
| Entry | Associate | Mid-Senior |
|---|---|---|
| Minor | Major | Minor |
| Major | Minor | Major |
| Major | Major | Minor |
| Major | Minor | Minor |
| Variable/Notation | Interpretation |
|---|---|
| Maximum salary in a dataset | |
| Minimum salary in a dataset | |
| Salary difference between actual and expected | |
| Maximum experience in a dataset | |
| Minimum experience in a dataset | |
| Expected salary for a given experience in industry | |
| Actual salary from the recruited company in GBP | |
| Actual previous work experience in years |
| Variable/Notation | Interpretation |
|---|---|
| Role-specific average experience difference between two sequence levels | |
| Working days per year | |
| Working hours per day | |
| Total hours to work until next level | |
| Role-specific frequency count for majors | |
| Role-specific frequency count for minors | |
| Role-specific major skills count | |
| Role-specific minor skills count | |
| Hours per major skill | |
| Hours per minor skill |
| Skills | … | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| DFIR (L1) | X | X | X | X | X | X | X | X | … |
| L2 skill | X | X | X | X | X | X | … | ||
| L3 skill | X | X | X | … | |||||
| L3 skill | X | X | X | X | X | … | |||
| L4 skill | X | X | … | ||||||
| L4 skill | X | X | X | … | |||||
| L2 skill | X | X | X | X | X | X | … | ||
| L3 skill | X | X | … | ||||||
| L3 skill | X | X | … | ||||||
| … | … | … | … | … | … | … | … | … | … |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haputhanthrige, V.; Asghar, I.; Saleem, S.; Shamim, S. The Impact of a Skill-Driven Model on Scrum Teams in Software Projects: A Catalyst for Digital Transformation. Systems 2024, 12, 149. https://doi.org/10.3390/systems12050149
Haputhanthrige V, Asghar I, Saleem S, Shamim S. The Impact of a Skill-Driven Model on Scrum Teams in Software Projects: A Catalyst for Digital Transformation. Systems. 2024; 12(5):149. https://doi.org/10.3390/systems12050149
Chicago/Turabian StyleHaputhanthrige, Vayodya, Ikram Asghar, Sidra Saleem, and Saqib Shamim. 2024. "The Impact of a Skill-Driven Model on Scrum Teams in Software Projects: A Catalyst for Digital Transformation" Systems 12, no. 5: 149. https://doi.org/10.3390/systems12050149
APA StyleHaputhanthrige, V., Asghar, I., Saleem, S., & Shamim, S. (2024). The Impact of a Skill-Driven Model on Scrum Teams in Software Projects: A Catalyst for Digital Transformation. Systems, 12(5), 149. https://doi.org/10.3390/systems12050149