
Data Integrity Preservation Schemes in Smart Healthcare Systems That Use Fog Computing Distribution


Abstract
:1. Introduction
2. Literature Review
2.1. Security and Privacy Issues in Fog Computing
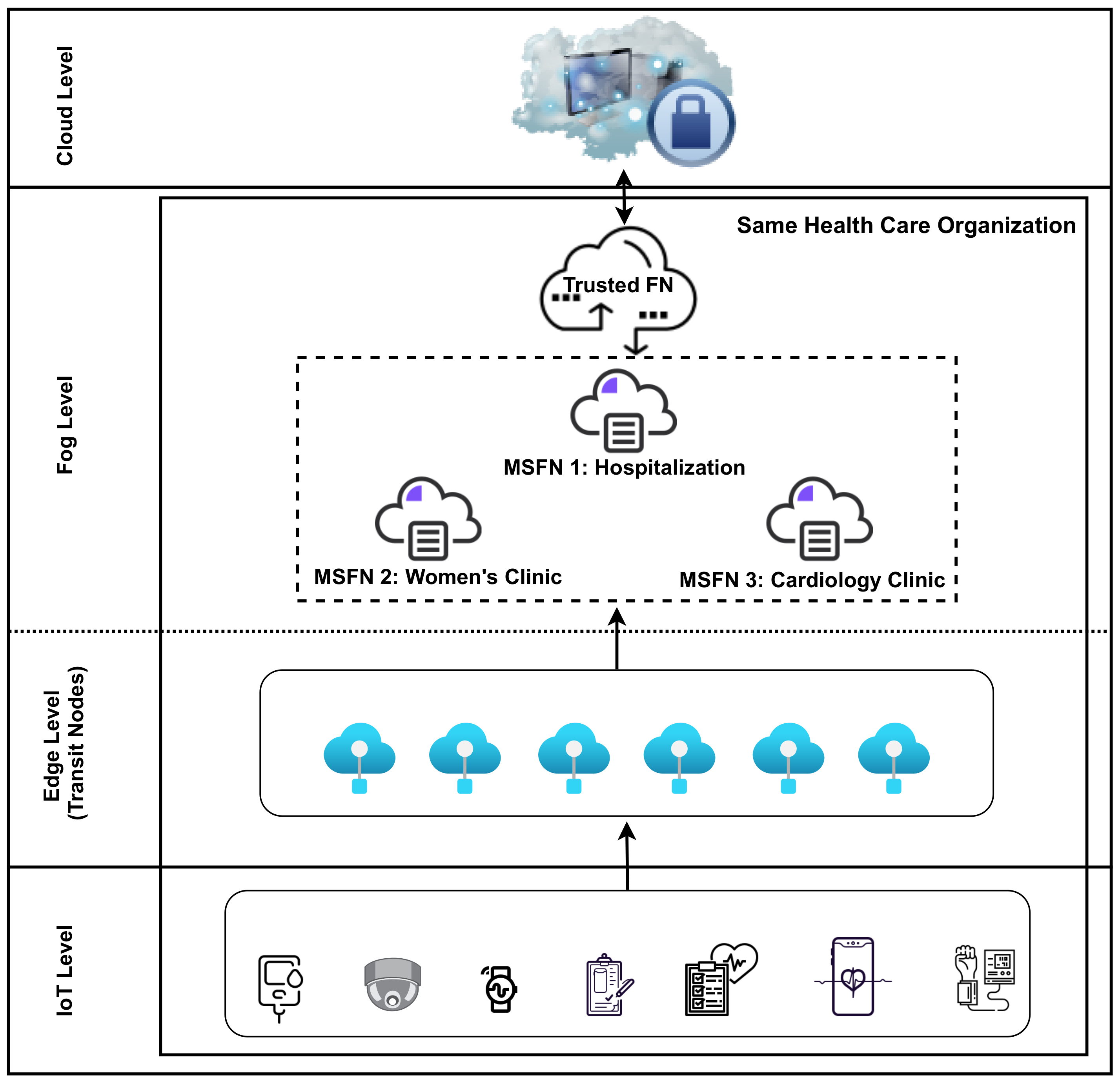
2.2. Fog Computing in Healthcare
2.3. Data Integrity in Fog Computing
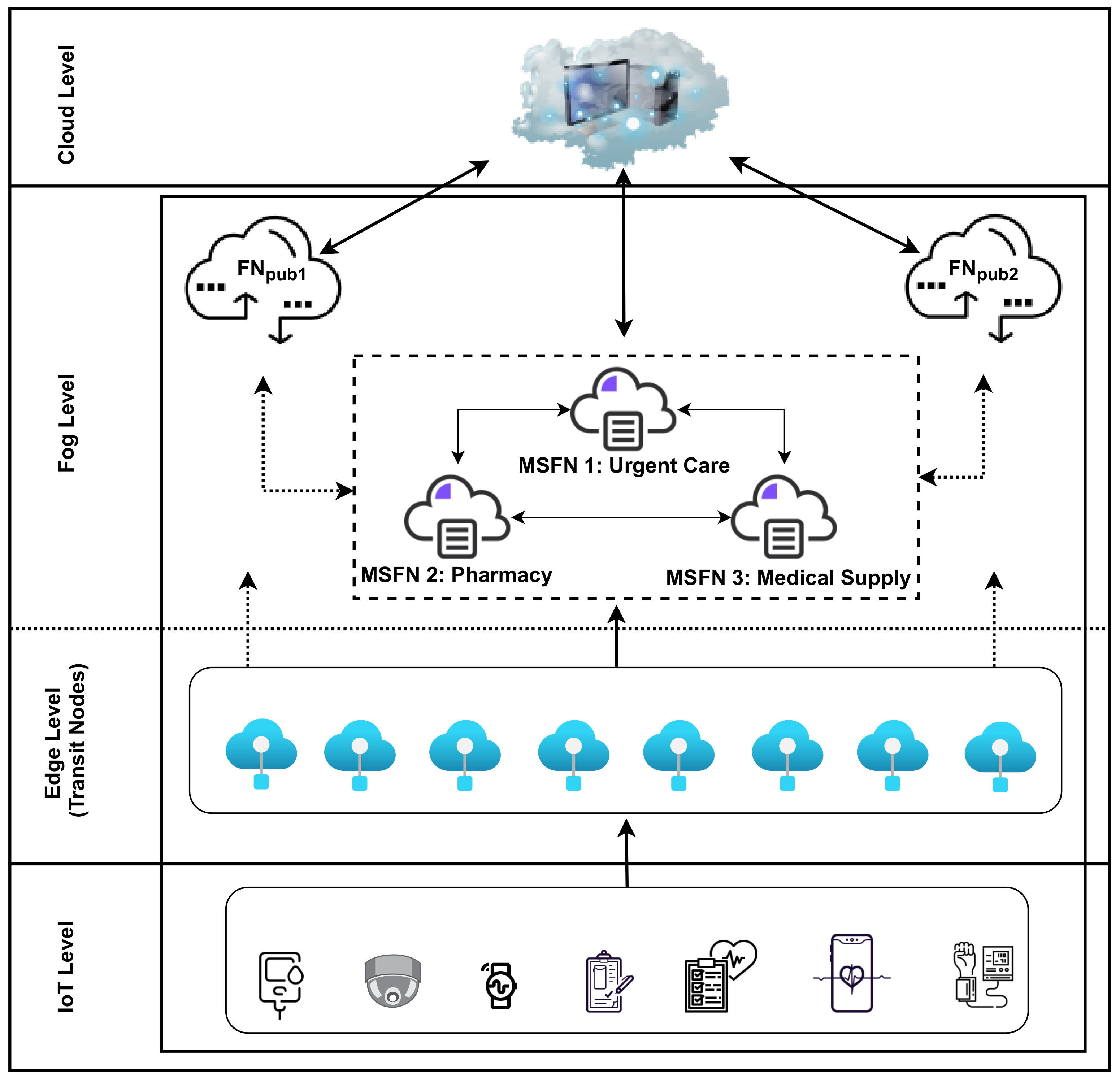
3. Proposed Scheme
3.1. Scheme Abbreviation Part
3.2. First Model
The Proposed Damage Assessment Algorithms
- Algorithm 1: building local graphs for private distributed fog computing:
| Algorithm 1 Building Local Graphs. |
| 1: Create a new Hash-table H and Initialize to null 2: Create a new Graph Representation T, and Initialize to null 3: When T is committed in the local DB then 4: for each operation O ∈ T do 5: if O is then 6: add a pair T to H 7: add Ti as a new vertex to G if it does not exist 8: else if O is then 9: if A∈ H then 10: add T as a new vertex to G if it does not exist 11: acquire the parents T ID from H 12: add edge from T to T 13: else if A ∈ foreign fog node then 14: call global graph algorithm (Algorithm 2) 15: end if 16: else if O is then 17: end if 18: end for |
- Algorithm 2: building global graphs on the trusted fog node:
- T, committed to the MSFN accesses data item A. The last transaction update for data item A was T on MSFN.
- A copy of the graph updating that last transaction’s data item A is sent to the global graph on the trusted fog node. The global graph includes all preceding vertices that could directly or indirectly affect T.
- Transaction T is added as a new child of T to the global graph and an edge is drawn from transaction T to T.
- Transaction T from MSFN continues updates to the global graph on the trusted fog node by copying and sending a copy of each subsequent transaction consigned locally at the MSFN (successor of T). This copy updates and is sent frequently.
| Algorithm 2 Building global graphs on the trusted fog node. |
| 1: Create a new Global Graph Representation G = (T, E) on trusted fog node and Initialize to null 2: (When T ∈ fog reads data item A ∈ fog) then 3: for each ∈ T do 4: acquire all predecessors of T from G 5: add Ti as a new vertex to G if it does not exist 6: add edge from MSFN.T to MSFN.T 7: end for 8: (When a new transaction T ∈ MSFN is committed where T is successor of T) then 9: add Tz as a new vertex to G if it does not exist 10: add edge from T to T |
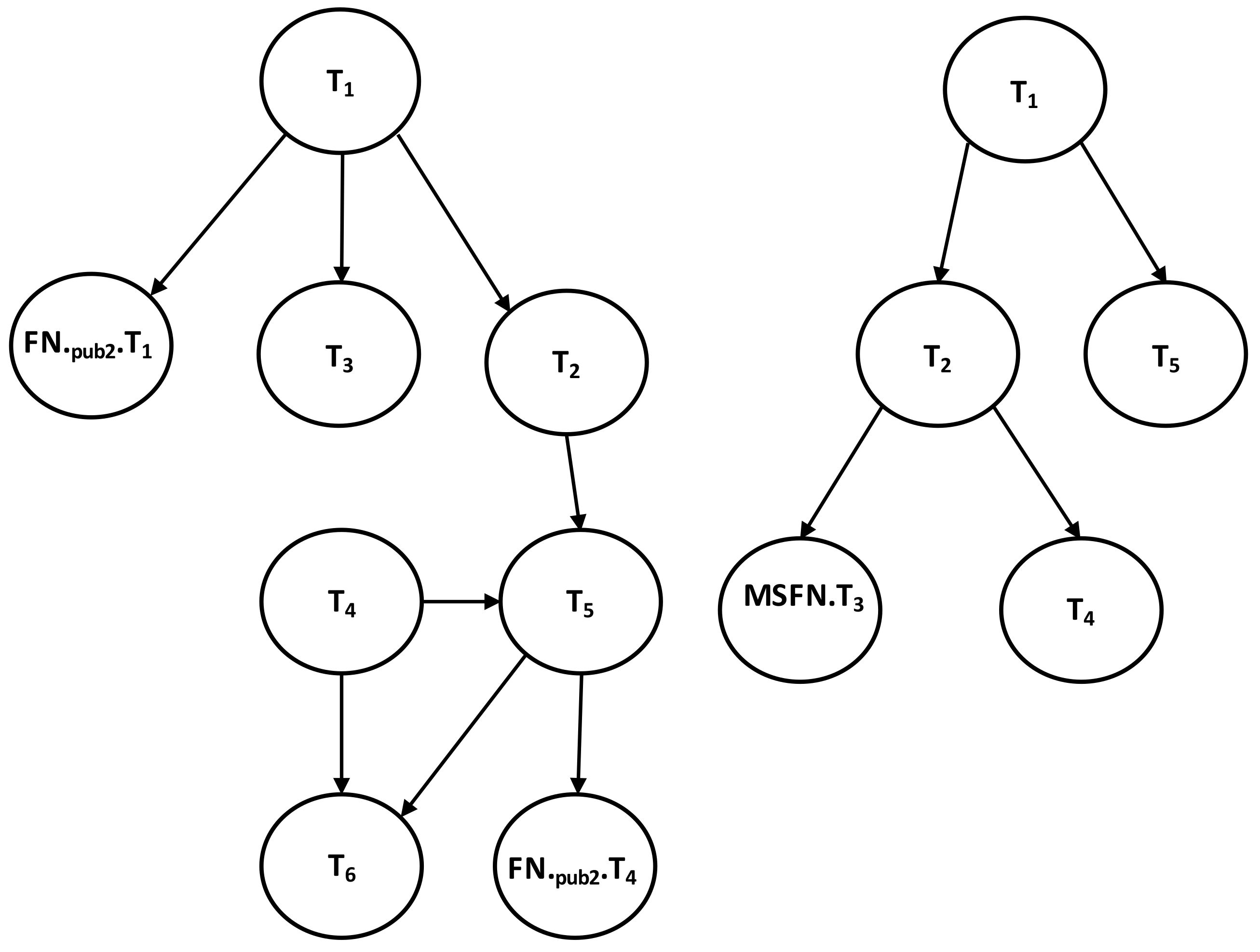
- In the log records of MSFN, T reads data item K from T. T is added as a new vertex in the local MSFN graph.
- An edge is drawn from T to T. The global graph is subsequently updated by adding T.
- And so, it continues: T reads item M from T and T reads item K from T. Hence, T and T are added as new vertices to the local MSFN graph. Edges are drawn from T to T and from T to T. Then T and T are added to the global graph. The MSFN will continue sending updated copies of T’s successor to the global graph upon commit operating at its local database. This copy, as indicated, is updated and sent frequently.
- Algorithm 3: damage assessment algorithms for private distributed fog computing:
| Algorithm 3 Damage assessment algorithm for private distributed fog computing. |
| 1: Once S{MSFN.T} is received from IDS 2: Classify S{MSFN.T} to multi-set {S{MSFN.T}..S{MSFN.T}} 3: Send each subset S{MSFN.T} to the (MSFN) 4: Send S{MSFN.T} to the trust fog node. 5: For the trust fog node and each other MSFN that receive S or S. 6: MDFS (G, T) 7: Create a new affected-transactions list Aff-Lfog and Initialize to null 8: Create a new Stack tranS and Initialize to null 9: add T to tranS 10: mark T as visited 11: while tranS is not empty do 12: T = tranS.pop 13: add T to Aff-Lfog 14: for each child T of T in G do 15: if T is not in then Aff-Lfog 16: add T to tranS 17: mark T as visited and add it to Aff-Lfog 18: end if 19: end for 20: end while |
3.3. Second Model
- Algorithm 4: building local graphs for public distributed fog nodes:
| Algorithm 4 Building local graphs for public distributed fog computing. |
| 1: Create a new Hash-table H and Initialize to null 2: Create a new Graph Representation T, and Initialize to null 3: When T is committed in the local DB then 4: for each operation O ∈ T do 5: if O is then 6: add a pair T to H 7: add T as a new vertex to G if it does not exist 8: else if O is && A ∈ H then 9: add T as a new vertex to G if it does not exist 10: acquire the parents T ID from H 11: add edge from T to T 12: else if T ∈ foreign fog node fog reads data item A that updated by T then 13: add fog.T as a new vertex to G if it does not exist 14: add edge from T to fog.T 15: end if 16: end for |
- Algorithm 5: damage assessment algorithms for public distributed fog nodes:
| Algorithm 5 Damage assessment algorithm for public distributed fog nodes. |
| 1: Once S{fog.T} is received from IDS 2: Assort S{fog.T} to multi-set S … S 3: Send S{fog.T} to the (fog) 4: For each fog that receive S 5: MDFS (G, T) 6: Establish a new list for affected transactions (Aff-Lfog) 7: Establish a new Stack 8: add T to 9: mark T as visited 10: while is not empty do 11: T = .pop 12: add T to Aff-Lfog 13: for each child T of T in G do 14: if T ∉ Aff-Lfog then 15: add T to 16: mark T as visited 17: add T to Aff-Lfog 18: if T is foreign transaction ∈ fog then 19: add T to sub-list Aff-Lfog 20: end if 21: end if 22: end for 23: end while 24: Send Aff-Lfog to fog to do further detection |
4. Implementation and Evaluation
4.1. Setup
4.2. Data-Set
4.2.1. Log Files
- r(345,669): is reading operation where r (data item, value)
- w(345,669,621): is writing operation where w (data item, old value, new value)
- c: The transaction 2 has been committed which means it is successfully completed.
4.2.2. Graphs
4.3. Experiments and Evaluation
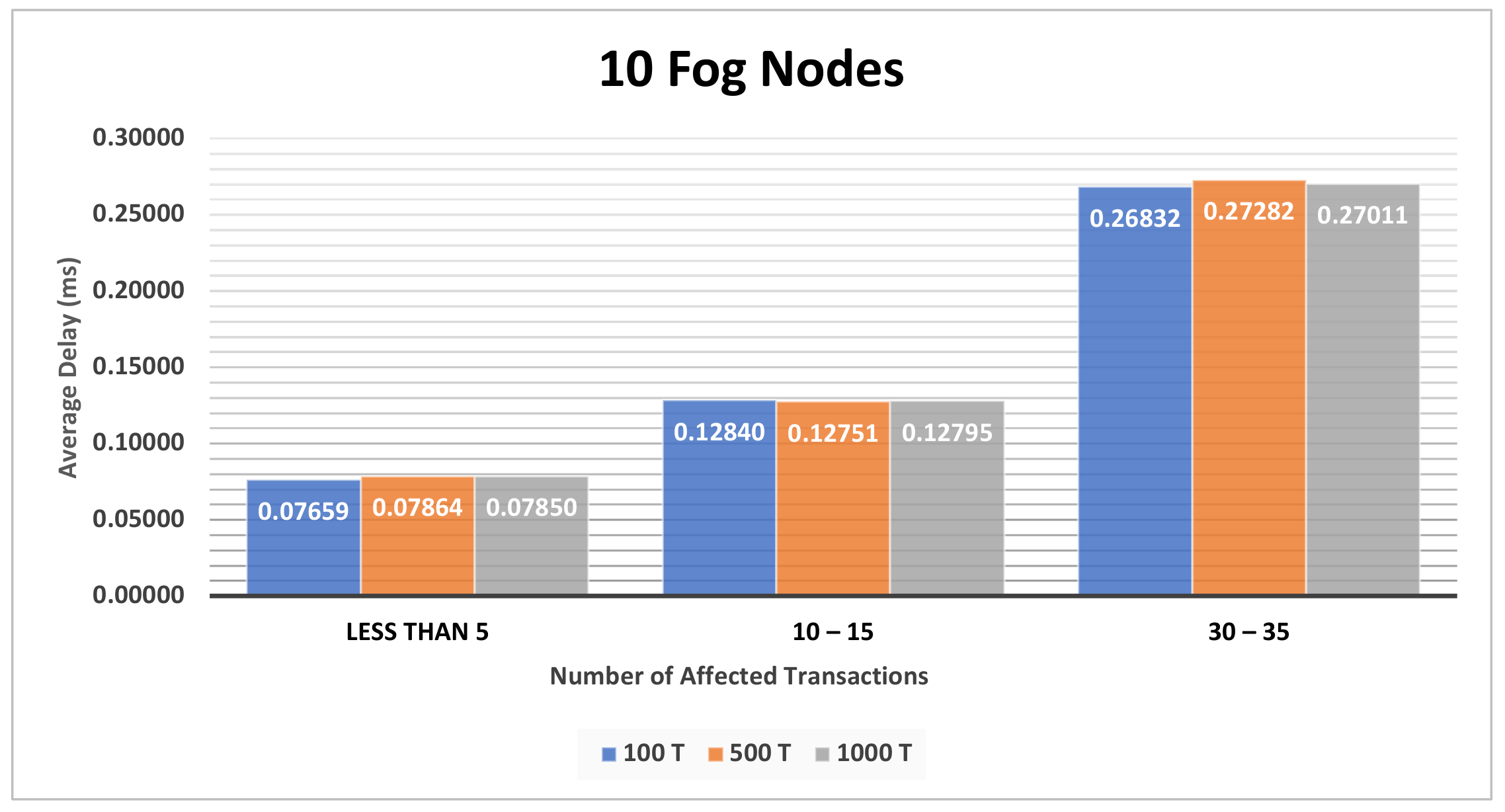
4.3.1. The Impact of the Different Sets of Affected Transactions on Various Fog Nodes Number on the First Model
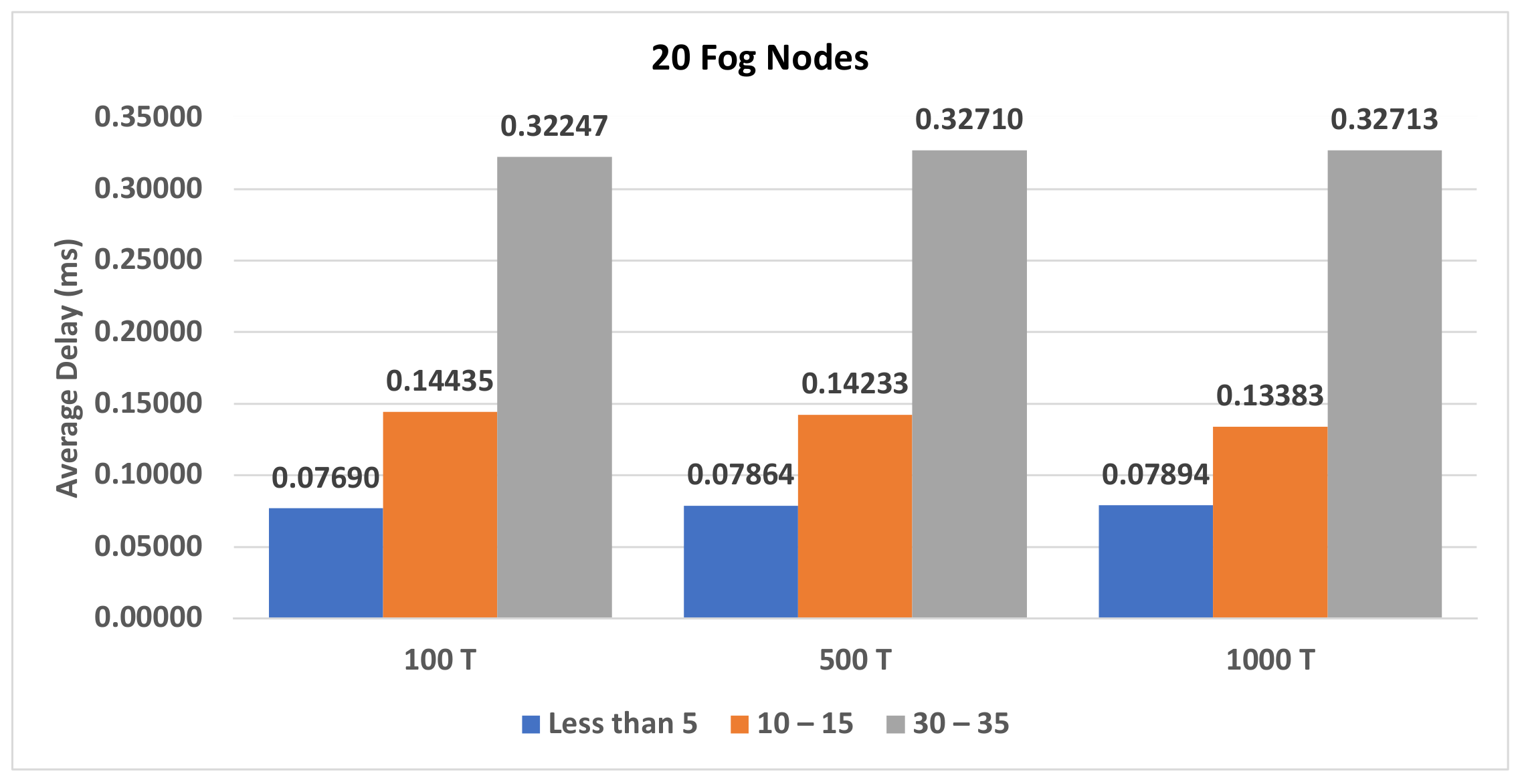
4.3.2. The Impact of Different Number of Transactions on Various Number of Fog Nodes on the First Model
4.3.3. The Impact of the Different Sets of Affected Transactions on Various Fog Nodes Number on the Second Model
4.3.4. The Impact of Different Number of Transactions on Various Number of Fog Nodes on the Second Model
4.3.5. Overall Comparison between the Two Models
4.3.6. Resource Requirement Cost
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Figures

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Figure | Section | Description |
|---|---|---|
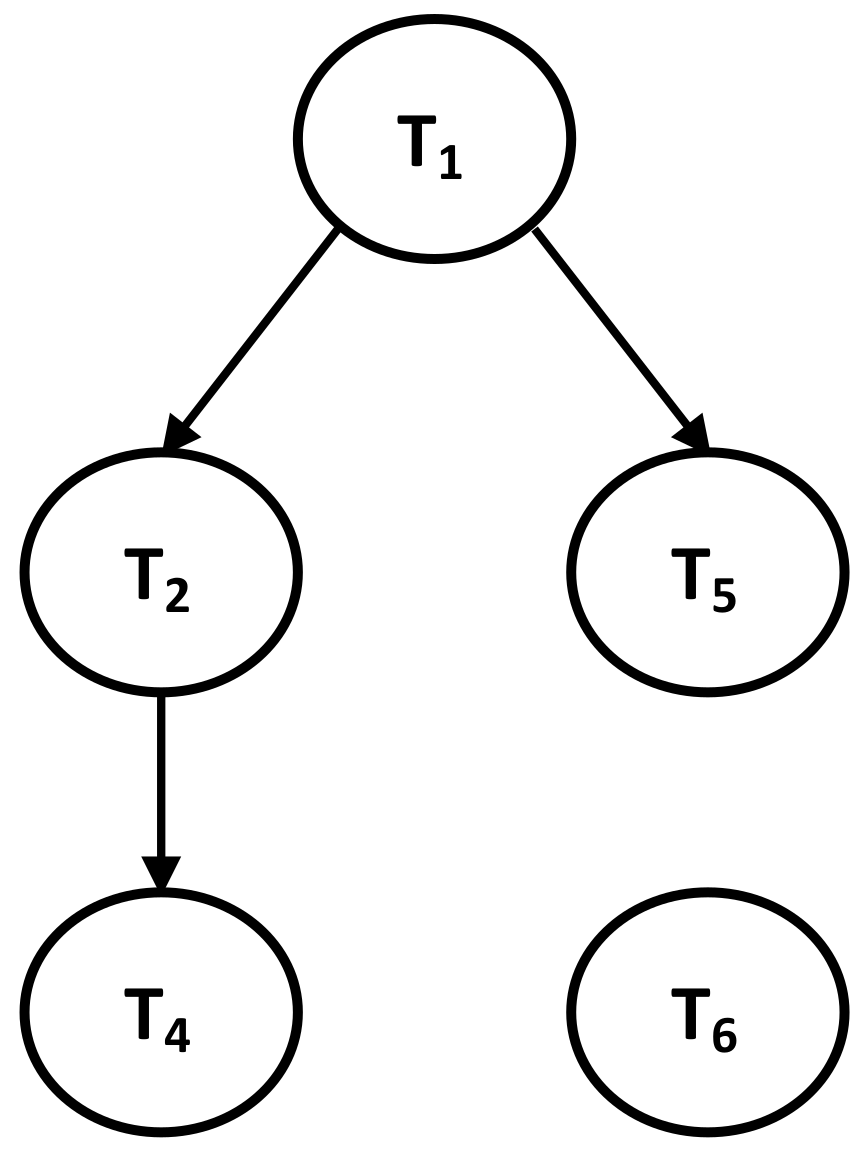
| Figure A1 | Section 3.2 | Described Local Dependency Graphs for MSFN. |
| Figure A2, Figure A3 and Figure A4 | Section 4.3.1 | The impact of the different sets of affected transactions on various fog nodes number on the first model. |
| Figure A5, Figure A6 and Figure A7 | Section 4.3.2 | The impact of different number of transactions on various number of fog nodes on the first model. |
| Figure A8, Figure A9 and Figure A10 | Section 4.3.3 | The impact of different number of transactions on various number of fog nodes on the second model. |
| Figure A11, Figure A12 and Figure A13 | Section 4.3.4 | The impact of different number of transactions on various number of fog nodes on the second model |










References
- Alazeb, A.; Panda, B. Ensuring Data Integrity in Fog Computing Based Health-Care Systems. In Proceedings of the International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, Atlanta, GA, USA, 14–17 July 2019; Springer: Atlanta, GA, USA, 2019. [Google Scholar] [CrossRef]
- Sanaa, K.; Haraty, R.; Masud, M. Tracking and Repairing Damaged Healthcare Databases Using the Matrix. Int. J. Distrib. Sens. Netw. 2015, 11. [Google Scholar] [CrossRef]
- Dos Anjos, J.; Gross, J.L.; Matteussi, K.J.; González, G.V.; Leithardt, V.R.; Geyer, C.F. An Algorithm to Minimize Energy Consumption and Elapsed Time for IoT Workloads in a Hybrid Architecture. Sensors 2021, 21, 2914. [Google Scholar] [CrossRef] [PubMed]
- Panda, B.; Kazi Asharful, H. Extended data dependency approach: A robust way of rebuilding database. In Proceedings of the 2002 ACM Symposium on Applied Computing, Madrid, Spain, 10–14 March 2002; pp. 446–452. [Google Scholar] [CrossRef]
- Mukherjee, M.; Matam, R.; Shu, L.; Maglaras, L.; Ferrag, M.A.; Choudhury, N.; Kumar, V. Security and Privacy in Fog Computing: Challenges. IEEE Access 2017, 5, 19293–19304. [Google Scholar] [CrossRef]
- Okay, F.; Ozdemir, S. A secure data aggregation protocol for fog computing based smart grids. In Proceedings of the 2018 IEEE 12th International Conference on Compatibility, Power Electronics and Power Engineering (CPE-POWERENG 2018), Doha, Qatar, 10–12 April 2018. [Google Scholar] [CrossRef]
- Khan, S.; Parkinson, S.; Qin, Y. Fog computing security: A review of current applications and security solutions. J. Cloud Comput. 2017, 6, 1–22. [Google Scholar] [CrossRef]
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A survey on internet of things: Architecture, enabling technologies, security and privacy, and applications. IEEE Internet Things J. 2017, 4, 1125–1142. [Google Scholar] [CrossRef]
- Wu, D.; Ansari, N. A Cooperative Computing Strategy for Blockchain-secured Fog Computing. IEEE Internet Things J. 2020, 7, 6603–6609. [Google Scholar] [CrossRef]
- Zhu, L.; Li, M.; Zhang, Z.; Xu, C.; Zhang, R.; Du, X.; Nadra, G. Privacy-Preserving Authentication and Data Aggregation for Fog-Based Smart Grid. IEEE Commun. Mag. 2019, 57, 80–85. [Google Scholar] [CrossRef]
- Lyu, L.; Nandakumar, K.; Rubinstein, B.; Jin, J.; Bedo, J.; Palaniswami, M. PPFA: Privacy preserving fog-enabled aggregation in smart grid. IEEE Trans. Ind. Inform. 2018, 14, 3733–3744. [Google Scholar] [CrossRef]
- Lu, R.; Heung, K.; Lashkari, A.H.; Ghorbani, A.A. A lightweight privacy-preserving data aggregation scheme for fog computing-enhanced IoT. IEEE Access 2017, 5, 3302–3312. [Google Scholar] [CrossRef]
- Aazam, M.; Zeadally, S.; Harras, K. Deploying fog computing in industrial internet of things and industry 4.0. IEEE Trans. Ind. Inform. 2018, 14, 4674–4682. [Google Scholar] [CrossRef]
- Alazeb, A.; Panda, B. Maintaining Data Integrity in Fog Computing Based Critical Infrastructure Systems. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence, Las Vegas, NV, USA, 5–7 December 2019. [Google Scholar] [CrossRef]
- OpenFog Consortium Architecture Working Group. OpenFog Reference Architecture for Fog Computing; Budapest University of Technology and Economics: Budapest, Hungary, 2017. [Google Scholar]
- Silva, L.A.; Leithardt, V.R.Q.; Rolim, C.O.; González, G.V.; Geyer, C.F.; Silva, J.S. PRISER: Managing notification in multiples devices with data privacy support. Sensors 2019, 19, 3098. [Google Scholar] [CrossRef] [Green Version]
- Azimi, I.; Anzanpour, A.; Rahmani, A.; Pahikkala, T.; Levorato, M.; Liljeberg, P.; Dutt, N. Hich: Hierarchical fog-assisted computing architecture for healthcare iot. ACM Trans. Embed. Comput. Syst. 2017, 16, 1–20. [Google Scholar] [CrossRef]
- Akrivopoulos, O.; Chatzigiannakis, I.; Tselios, C.; Antoniou, A. On the deployment of healthcare applications over fog computing infrastructure. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Dastjerdi, A.; Buyya, R. Fog Computing: Helping the Internet of things Realize Its Potential. Computer 2016, 49, 112–116. [Google Scholar] [CrossRef]
- Vora, J.; Tanwar, S.; Tyagi, S.; Kumar, N.; Rodrigues, J. FAAL: Fog computing-based patient monitoring system for ambient assisted living. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017. [Google Scholar] [CrossRef]
- Vijayakumar, V.; Malathi, D.; Subramaniyaswamy, V.; Saravanan, P.; Logesh, R. Fog computing-based intelligent healthcare system for the detection and prevention of mosquito-borne diseases. Comput. Hum. Behav. 2019, 100, 275–285. [Google Scholar] [CrossRef]
- Naranjo, P.; Pooranian, Z.; Shojafar, M.; Conti, M.; Buyya, R. FOCAN: A Fog-supported smart city network architecture for management of applications in the Internet of Everything environments. J. Parallel Distrib. Comput. 2019, 132, 274–283. [Google Scholar] [CrossRef] [Green Version]
- Tang, B.; Chen, Z.; Hefferman, G.; Wei, T.; He, H.; Yang, Q. A hierarchical distributed fog computing architecture for big data analysis in smart cities. Proc. Ase Bigdata Soc. 2015, 2015, 1–6. [Google Scholar] [CrossRef]
- Amaxilatis, D.; Chatzigiannakis, I.; Tselios, C.; Tsironis, N.; Niakas, N.; Papadogeorgos, S. A smart water metering deployment based on the fog computing paradigm. Appl. Sci. 2020, 10, 1965. [Google Scholar] [CrossRef] [Green Version]
- Froiz, M.; Fern, T.; Fraga-Lamas, P.; Castedo, L. Design, implementation and practical evaluation of an IoT home automation system for fog computing applications based on MQTT and ZigBee-WiFi sensor nodes. Sensors 2018, 8, 2660. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Liu, S.; Ye, F.; Chen, X. A fog-based architecture and programming model for iot applications in the smart grid. arXiv 2018, arXiv:1804.01239. [Google Scholar]
- Zuo, Y.; Panda, B. Distributed database damage assessment paradigm. Inf. Manag. Comput. Secur. 2006, 14, 116–139. [Google Scholar] [CrossRef]
- Peng, L.; Yu, M. Damage assessment and repair in attack resilient distributed database systems. Comput. Stand. Interfaces 2011, 33, 96–107. [Google Scholar] [CrossRef]
- Paul, A.; Sushil, J.; Peng, L. Recovery from malicious transactions. IEEE Trans. Knowl. Data Eng. 2002, 14, 1167–1185. [Google Scholar] [CrossRef]
- Anindya, C.; Arun K, M.; Shamik, S. A column dependency-based approach for static and dynamic recovery of databases from malicious transactions. Int. J. Inf. Secur. 2002, 9, 51–67. [Google Scholar] [CrossRef]
- Rao, U.; Patel, D. Incorporation of application specific information for recovery in database from malicious transactions. Inf. Secur. J. Glob. Perspect. 2013, 22, 35–45. [Google Scholar] [CrossRef]
- Haraty, R.; Sanaa, K.; Zekri, A. Transaction dependency based approach for database damage assessment using a matrix. Int. J. Semant. Web Inf. Syst. 2017, 13, 74–86. [Google Scholar] [CrossRef]
- Xie, M.; Zhu, H.; Feng, Y.; Hu, G. Tracking and repairing damaged databases using before image table. In Proceedings of the 2008 Japan-China Joint Workshop on Frontier of Computer Science and Technology, Nagasahi, Japan, 27–28 December 2007; pp. 36–41. [Google Scholar] [CrossRef]
- Panda, B.; Alazeb, A. Securing Database Integrity in Intelligent Government Systems that Employ Fog Computing Technology. In Proceedings of the 2020 International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 1–2 August 2020; IEEE: New York, NY, USA, 2020. ISBN 978-1-7281-7106-7. [Google Scholar] [CrossRef]
- Chang, C.; Narayana Srirama, S.; Buyya, R. Indie Fog: An Efficient Fog-Computing Infrastructure for the Internet of things. Computer 2017, 50, 92–98. [Google Scholar] [CrossRef]
- Kontopoulos, S.; Drakopoulos, G. A space efficient scheme for persistent graph representation. In Proceedings of the 2014 IEEE 26th International Conference on Tools with Artificial Intelligence, Limassol, Cyprus, 10–12 November 2014; pp. 299–303. [Google Scholar] [CrossRef]
- Cormen, T.; Leiserson, C.; Rivest, R.; Stein, C. Introduction to Algorithms, 3rd ed.; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]









| Type of Dependency | Space Requirement | Auxiliary Structure | Methodology | Drawback | |
|---|---|---|---|---|---|
| [27] | Transaction | NA | NA | Scan the entire log files. | Time consuming. |
| [2,32] | Data | Large Space | Matrix | Scan only the matrix. | Require a lot of space. |
| [33] | Data | Large Space | Tables | Refer to tables | Require space and Do unnecessary work. |
| [1] | Data | NA | NA | Scan the affected log files. | Continuous communication between all affected fog nodes. |
| [14] | Data | NA | NA | Scan the affected log files. | Continuous communication between all affected fog nodes. |
| The Proposed Scheme | Transaction | Small Space | Graphs | Scan only the affected graphs |
| Notation | Definition |
|---|---|
| FN | Public fog data service node on the system. |
| MSFN | The main medical service fog node. |
| S{fog.T} | The detected malicious transactions set done by IDS. |
| G(T, E) | Graph representation where T indicates the number of transactions in the node and E indicates the number of edges |
| Aff-Lfog | List of all affected transactions that have been identified by the proposed mechanism. |
| T | Transaction which is a single unit of logic in database and contains of multiple operations |
| A, X, or W | Data item which is the smallest element in the transaction. |
| The write operation of the transaction T; is the old value of the data item A, and is the new value of data item A after it is updated. | |
| The read operation of transaction T where A is the data item and v is the current value of A. | |
| The transaction T has been successfully committed to the database. | |
| O | Operation ∈ T (write, read, or committed). |
| is Big-O notation, which symbolizes upper bound of the space or running time. V is the set of vertices which in our models is the number of transactions in the log file T, and E is the set of edges which are the dependencies between two transactions. |
| Data Items | C | G | A | D |
| Last updated T | T | T | T | T |
| Data Items | C | G | A | D | B | E |
| Last updated T | T | T | T | T | T | T |
| No. of Fog Nodes | Storage Requirement In Bytes | |||||
|---|---|---|---|---|---|---|
| 100 Transactions | 500 Transactions | 1000 Transactions | ||||
| Global Graph | All Local Log Files | Global Graph | All Local Log Files | Global Graph | All Local Log Files | |
| 5 | 3857 | 29,535 | 38,423 | 177,345 | 90,978 | 370,110 |
| 10 | 7351 | 65,200 | 79,425 | 400,750 | 182,027 | 842,220 |
| 15 | 12,403 | 96,600 | 121,354 | 603,750 | 283,796 | 1,302,885 |
| 20 | 16,725 | 125,800 | 166,822 | 806,580 | 386,372 | 1,738,640 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alazeb, A.; Panda, B.; Almakdi, S.; Alshehri, M. Data Integrity Preservation Schemes in Smart Healthcare Systems That Use Fog Computing Distribution. Electronics 2021, 10, 1314. https://doi.org/10.3390/electronics10111314
Alazeb A, Panda B, Almakdi S, Alshehri M. Data Integrity Preservation Schemes in Smart Healthcare Systems That Use Fog Computing Distribution. Electronics. 2021; 10(11):1314. https://doi.org/10.3390/electronics10111314
Chicago/Turabian StyleAlazeb, Abdulwahab, Brajendra Panda, Sultan Almakdi, and Mohammed Alshehri. 2021. "Data Integrity Preservation Schemes in Smart Healthcare Systems That Use Fog Computing Distribution" Electronics 10, no. 11: 1314. https://doi.org/10.3390/electronics10111314
APA StyleAlazeb, A., Panda, B., Almakdi, S., & Alshehri, M. (2021). Data Integrity Preservation Schemes in Smart Healthcare Systems That Use Fog Computing Distribution. Electronics, 10(11), 1314. https://doi.org/10.3390/electronics10111314